
Abstract
The solution of large systems of nonlinear differential equations is essential for many applications in science and engineering. We present three improvements to existing quantum algorithms based on the Carleman linearisation technique. First, we use a high-precision method for solving the linearised system that yields logarithmic dependence on the error and near-linear dependence on time. Second, we introduce a rescaling strategy that significantly reduces the cost, which would otherwise scale exponentially with the Carleman order, thus limiting quantum speedups for PDEs. Third, we derive tighter error bounds for Carleman linearisation. We apply our results to a class of discretised reaction-diffusion equations using higher-order finite differences for spatial resolution. We also show that enforcing a stability criterion independent of the discretisation can conflict with rescaling due to the mismatch between the max-norm and the 2-norm. Nonetheless, efficient quantum solutions remain possible when the number of discretisation points is constrained, as enabled by higher-order schemes.
Similar content being viewed by others
Introduction
Many processes in nature exhibit nonlinear behaviour that is not sufficiently approximated by linear dynamics. Examples range from biological systems, chemical reactions, fluid flow, and population dynamics to problems in climate science. Because the Schrödinger equation is linear, quantum algorithms are more naturally designed for linear ordinary differential equations (ODEs), as in refs. 1,2,3,4,5,6,7,8,9. These algorithms are normally based on discretising time to encode the ODE in a system of linear equations, then using quantum linear system solvers10,11. Others are based on a time-marching strategy, solving the ODE using a linear combination of unitary dynamics8,9. The advantage of these quantum algorithms is that they naturally provide an exponential speedup in the dimension (number of simultaneous equations), similar to the simulation of quantum systems, with the caveat that the solution is encoded in the amplitudes of a quantum state.
The most natural way to approximate quantum solutions of partial differential equations (PDEs) is to first discretise the PDE to construct an ODE, which can then be solved using a quantum ODE algorithm. Although one might expect an exponential speedup in the number of discretisation points (which would give the dimension for the ODE), this is not realised. This approach to solve PDEs typically has a more modest polynomial speedup over classical methods due to the norm or condition number of the matrices resulting from the discretisation. Clader et al.12 suggested using preconditioners, though later work found that the preconditioners did not significantly reduce the condition number. Childs et al.13 approached this problem by using higher-order finite difference stencils as well as a pseudo-spectral method. Alternatively, one can use a wavelet-based preconditioner to achieve scaling independent of the condition number in some cases14. Jin et al.15,16 introduce a new method using a variable transformation which provides solutions of PDEs in an equivalent frame using quantum simulation techniques.
Quantum algorithms for nonlinear differential equations were addressed in early work which had very large complexity17. Later proposals were based on the nonlinear Schrödinger equation18, or an exact mapping of the nonlinear Hamilton–Jacobi PDE into a linear PDE19,20. Possibly the most promising approach for the solution of nonlinear ODEs is based on Carleman linearisation21, which involves transforming the nonlinear differential equation into a linear differential equation on multiple copies of the vector. This approach can be realised particularly easily for differential equations with polynomial nonlinearities and has been applied to quantum algorithms in the case of a quadratic function as the nonlinear part of the ODEs22, for a higher power of the function for a specific PDE23, and for the notorious Navier-Stokes equations24. The homotopy perturbation method to tackle quadratic nonlinear equations in ref. 25 leads to similar equations as Carleman linearisation.
However, most approaches to quantum Carleman linearisation22,23 applied to PDEs suffer from high error rates due to simple discretisation schemes for the underlying PDE in time and space. One work7 does use an improved discretisation in time via a truncated Taylor series2. Using a finer discretisation to achieve a given accuracy results in higher complexity, typically due to the complexity depending on the matrix condition number. That can result in the complexity being the same or worse than that for classical solution. Another difficulty in the use of Carleman linearisation in prior work is that the component with the solution may have low probability to be measured. In this study, we provide three improvements over prior work. First, we use higher-order methods in the time evolution as well as for the spatial discretisation for PDEs. Second, we use rescaling in order to eliminate the problem of the low probability of the component with the solution for an intrinsic system of ODEs. (Krovi7 mentioned a rescaling at one point, though their explanation is unclear and it is unclear if they are using it.) Third, we provide a tighter bound on the error in Carleman linearisation by explicitly bounding repeated integrals. In the case of a PDE, the appropriate stability condition is in terms of the max-norm. However, the interaction of the requirement of the rescaling with the Carleman linearisation and the stability requirement for the ODE solver means that a stronger stability criterion is needed to enable efficient solution.
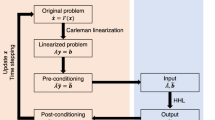
It is important to note that in the case of PDEs the factor that is exponential in N in prior work23 would give a large power in the number of grid points. Since a simple classical algorithm would have complexity linear in the number of grid points, the quantum speedup would be eliminated. Our work demonstrates that quantum computers can provide a sublinear complexity in the number of grid points for nonlinear PDEs, as well as establishing the limitations to this type of approach. We present an overview of the general solution procedure of nonlinear differential equations on quantum computers in relation to the present work in Fig. 1.

The PDE is approximated by a vectorial ODE via discretisation, u → u and we use a scaling \({\bf{u}}\mathop{\to }\limits^{1/\gamma }\widetilde{{\bf{u}}}\) as described in Definition 1.
Results
The main focus of this work is the treatment of nonlinear differential equations, when we have an arbitrary power M in the nonlinear ODE problem on quantum computers, that is
followed by its application to the nonlinear reaction-diffusion PDE,
We give a number of improvements to the solution of nonlinear ODEs and PDEs.
-
1.
We use a higher-order method for discretisation of the PDE, which will be required in practice because the stability of the solution will require that the number of points is not too large.
-
2.
We use rescaling of the components in the Carleman linearisation in order to ensure that the first component containing the solution can be obtained with high probability. We show that the amount of rescaling that can be used is closely related to the stability of the equations.
-
3.
We provide a much tighter analysis of the error due to the Carleman linearisation for ODEs, and extend this analysis to PDEs. This analysis is dependent on the stability and the discretisation of the PDE.
All these improvements are dependent on the stability of the equations, which is required for the quantum algorithm to give an efficient solution. The equations have a linear dissipative term and the nonlinear growth term. As the input is made larger, the nonlinear term will cause growth and make the solution unstable. Therefore, for the solution to be dissipative, the input needs to be sufficiently small that the dissipative term dominates. In the ODE case the input is a vector uin, and the stability criterion can be given in terms of the 2-norm of that vector. In the case of the PDE, it is more appropriate to give the stability criterion in terms of the max-norm, because the 2-norm will change depending on the number of discretisation points.
Giving the stability criterion in terms of the max-norm then makes the analysis of higher-order discretisations challenging. The reason is that, while the first-order discretisation of the Laplace operator is stable in terms of the max-norm, the higher-order discretisations no longer are. In the analysis of the Carleman linearisation error it is required that the equations are stable. For the ODE this stability in terms of the 2-norm enables the 2-norm of the error to be bounded. For the PDE, stability in terms of the max-norm enables the max-norm to be bounded, but the higher-order discretisation complicates the analysis and means slightly stronger stability is required.
The reason why rescaling is needed is that the Carleman method involves constructing a quantum state with a superposition of one copy of the initial vector, two copies, and so forth up to N copies. If the initial vector is not normalised, then this means that there can be an exponentially large weight on the largest number of copies, whereas the first part of the superposition with a single copy is needed for the solution. In order to ensure the probability for obtaining that component is not exponentially small, the Carleman vector needs to be rescaled by (at least) the 2-norm so that there is sufficient weight on that first component. Even if N is small, this feature means that rescaling is essential in order to obtain any speedup over classical algorithms for PDEs. Without the rescaling, the complexity is superlinear in the number of grid points.
In order to ensure that the same equations are being solved, the components of the matrix need a matching rescaling, which can increase the weight of the nonlinear part (causing growth) as compared to the linear dissipative part. In the case of an ODE, we show that if the original nonlinear equation is dissipative then the linear ODE obtained from Carleman linearisation is also stable. That stability is required for the quantum ODE solver to be efficient. If the ODE is not stable, then the condition number will be exponentially large (in time), which causes the linear equation solver to have exponential complexity.
Similarly for the discretised PDE, there needs to be rescaling by the 2-norm in order to ensure there is adequate weight on the first component of the solution. The key difference now is that the stability of the equations is given in terms of the max-norm, but the rescaling is by the 2-norm which is typically larger. That rescaling can give a linear ODE that is no longer stable, which in turn would mean an exponential complexity of the algorithm. That is perhaps surprising, because the original nonlinear equation is stable.
However, if the PDE is sufficiently dissipative, then the discretised equation will still satisfy the stability criterion in terms of the 2-norm, and there will still be an efficient quantum algorithm. Because the 2-norm will increase without limit with the number of discretisation points, it is then crucial to minimise the number of discretisation points used. That further motivates using the higher-order discretisation of the PDE, because that minimises the number of discretisation points.
We now summarise the problem description and solution strategy follow by the main results for Eqs. (1) and (2).
The ODE problem
Here, we present the problem of solving the nonlinear ODE, including the variable definitions and the dissipativity condition needed for an efficient quantum algorithm.
Problem 1
We consider the solution of a system of nonlinear (vectorial) dissipative ODEs of the form
with initial data
where \({\bf{u}}={({u}_{1}\cdots ,{u}_{n})}^{T}\in {{\mathbb{R}}}^{n}\) with time-dependent components uj = uj(t) for t ∈ [0, T] and j ∈ [n], using the notation [n] = {1, 2, …, n}. The matrices \({F}_{M}\in {{\mathbb{R}}}^{n\times {n}^{M}}\), \({F}_{1}\in {{\mathbb{R}}}^{n\times n}\) are time-independent. We denote the eigenvalues of \(({F}_{1}+{F}_{1}^{\dagger })/2\) by λj, and the dissipativity condition means that λj < 0. Denoting the maximum eigenvalue by λ0, we require that R < 1, where
The task is to output a state \(\left\vert {\bf{u}}\right\rangle\) encoding the solution to Eq. (3) at time T.
In the “Methods” section, we show that to solve Problem 1, we first map the finite-dimensional system of nonlinear differential equations in Eq. (3) to an infinite-dimensional, linear set of ODEs that can be truncated to some order N. This mapping is the Carleman linearisation technique21, which has previously been applied to quantum algorithms in refs. 7,22,23. Next, we show that by rescaling the linearised ODEs, we can reduce the complexity of the quantum algorithm. This is followed by improved error bounds due to Carleman linearisation for the rescaled variable and an estimate of the overall complexity for obtaining the solution of the truncated linearised ODE.
In contrast to refs. 7,22, we do not consider the driving term; on the other hand, we explore arbitrary nonlinear powers in the ODE problem rather than constrained to the quadratic case as in refs. 7,22. When we have an arbitrary power M in the nonlinear ODE it is more challenging to include the driving term F0, because F0 will produce characteristics of a more general polynomial of order M as opposed to just a single component. Therefore, to analyse the driving term we would also need to consider a general polynomial of order M for the nonlinear part of the ODE problem. We leave that considerably more complicated analysis to future work.
The solution of a linearised form of Problem 1 relies on oracles for F1, FM, and the initial vector. We show later in the “Methods” section, that the complexity of the solution in terms of calls to oracles for F1 and FM scales as
In this complexity, ε is the allowable error, and \({\lambda }_{{F}_{1}}\) is the λ-value for block encoding F1 (with an extra assumption on the efficiency of the block encoding of FM). An important quantity here is the Carleman order N, which can be chosen logarithmically in the allowable error provided R < 1. For the complexity in terms of calls to the preparation of the initial vector, there is an extra factor of N, but the final log factor can be omitted, so the overall complexity is similar. Without the rescaling, there would be an extra factor in the complexity \({\mathcal{O}}(\| {{\bf{u}}}_{{\rm{in}}}{\| }^{N})\) that is exponential in N. Even though N can be chosen logarithmic in the other parameters, that would still result in large complexity.
The result as given in ref. 23 has that problem. The complexity from ref. 23 is (using Eq. (4.2) of that work and replacing a in their notation with c in our notation)
where G denotes the average ℓ2 solution norm of the history state, and s is the maximum sparsity of F1, FM. The factor ∥uin∥2N exponential in N is due to the higher-order components of the Carleman vector without rescaling. They also have a factor of T2 rather than T, which is due to using a simple forward Euler scheme in time. We also give a further improvement in the polynomial factor of N, with our scaling being N in comparison to their N3.
Carleman solver for the reaction-diffusion equation
A large system of ODEs of the form in Eq. (3) may arise from discretisation of partial differential equations. Specifically, we can derive the nonlinear differential equation resulting from the discretisation of a nonlinear reaction-diffusion PDE similar to ref. 23,
This equation will be stable according to a criterion that depends on the max-norm of u(x, t), in contrast to the condition for the ODE that is based on the 2-norm. Discretising this PDE into an ODE, the stability condition R < 1 would be stronger and depend on the number of discretisation points. That condition is stronger than necessary for the PDE, but after we use Carleman linearisation to give a linear ODE it requires R < 1 for stability. This means that the stability condition needed for the quantum algorithm is stronger than that for the original PDE.
We explore techniques of finite-difference methods with higher-order approximations for the spatial discretisation of the PDEs. Our improved nonlinear ODE solver is then applied to the reaction-diffusion equation Eq. (8), with F1 resulting from the Laplacian discretisation and FM giving the non-linearity from the PDE. The overall procedure is illustrated in Fig. 1.
We then show in the “Methods” section, Corollary 6, that for this PDE, the overall cost for the solution in terms of calls to the oracles that block encode F1 and FM is
where we have used n gridpoints in total for the spatial discretisation of the d-dimensional PDE given in Eq. (8).
Classically, it is less useful to perform linearisation by the Carleman procedure, because the system size grows exponentially with the truncation number N making the simulation prohibitively costly. In general, explicit time-stepping methods like forward Euler or Runge–Kutta schemes do not rely on linearisation of the underlying differential equations. However, (semi-)implicit schemes which exhibit more favourable numerical stability rely on inversion of the system. This either requires linearisation (e.g., Carleman or Koopman–von-Neumann schemes) or methods to solve nonlinear systems, such as Newton–Raphson, which rely on a good initial guess and require inversion of a Jacobian matrix.
Discussion
In this study, we proposed a set of improvements to quantum algorithms for nonlinear differential equations via Carleman linearisation, eliminating some of the exponential scalings seen in prior work. We have examined both ODEs, and a class of nonlinear PDEs corresponding to reaction-diffusion equations23. These improvements include
-
rescaling the original dynamics,
-
a truncated Taylor series for the time evolution,
-
higher-order spatial discretisation of the PDEs, and
-
tighter bounds on the error of Carleman linearisation.
The rescaling boosts the success probability, needing exponentially fewer steps for the amplitude amplification to obtain the solution component of interest in the linearised ODE system. That is vital to enable the complexity of the PDE solver to be sublinear in the number of discretisation points. The solution approximation via the truncated Taylor method gives a near-linear dependence on T, the total evolution time. The higher-order spatial discretisation greatly improves the complexity of the quantum solution of PDEs, because it reduces the number of discretisation points needed, which is needed to avoid stability problems.
We show that the stability criterion for PDEs, rescaling, Carleman linearisation, and stability criterion for ODE solvers all interact in a way that makes the solution of PDEs more challenging than was appreciated in prior work. In particular, the stability criterion for PDEs is in terms of a max-norm, but rescaling by the 2-norm is required to obtain a reasonable probability for the correct component of the Carleman vector. But, rescaling by the 2-norm can make the resulting system of linearised equations unstable, which causes the ODE solver to have exponential complexity. If the discretised PDE is still stable in terms of the 2-norm, then the resulting quantum algorithm will still be efficient. Because the 2-norm increases as \(\sqrt{n}\) in the number of discretisation points, the number of those points should be made as small as possible, which is why it is crucial to use the higher-order discretisation.
In future work, one could devise a less restricted quantum algorithm for solving nonlinear PDEs via some other approach. The feature that the linearised equations can be unstable even though the nonlinear equation is stable suggests that an alternative linear equation solver may be efficient. The reason why the condition number is large (causing the inefficiency) is that the solution can grow exponentially over time, but for an initial vector that is not of the Carleman form. A solver that is able to take advantage of the restricted form of states could potentially be efficient.
Furthermore, there are a number of important generalisations that can be made to the type of differential equations. Instead of just including a nonlinear term of order M, one could include all nonlinear orders up to M. That could also be used to analyse the effect of driving because the method used for quadratic nonlinearities would produce nonlinearities at a range of orders. A further generalisation that could be considered is time-dependent differential equations. These generalisations can be made in a simple way in the quantum algorithm, but the analysis to bound the error would be considerably more complicated.
Methods
We begin by summarising the notation and key variables used throughout the manuscript. Table 1 defines the principal symbols, their roles, and the conventions adopted. This summary is intended to assist the reader in navigating the derivations and algorithmic steps that follow.
Quantum Carleman solver with rescaling and improved error bounds on Carleman truncation
Background on Carleman linearisation
We start with the Carleman linearisation for the initial value problem described by the n-dimensional equation with a nonlinearity of order M as given in Eq. (3). We recall the dissipativity assumption on F1, i.e., the eigenvalues of \(({F}_{1}+{F}_{1}^{\dagger })/2\) are purely negative. The quantity λ0, the eigenvalue closest to zero, thus gives the weakest amount of dissipation. This way, R in Eq. (5) can be used to quantify the strength of the nonlinearity of the problem. As shown in ref. 22, there exists a quantum algorithm that can solve Eq. (3) efficiently whenever R < 1. Furthermore, for \(R\ge \sqrt{2}\), the problem was shown to be intractable on quantum computers.
Next, we briefly outline the key idea of the Carleman linearisation. First, notice that
In particular, for M = 2, the Kronecker product gives
Now, define a new variable consisting of Kronecker powers of the solution vector
which we can summarise as a vector \({\bf{y}}={[{{\bf{y}}}_{1},{{\bf{y}}}_{2},\ldots ,{{\bf{y}}}_{N},\ldots ]}^{T}\). If we consider the time-derivative, we can identify the time-independent matrices \({F}_{M}\in {{\mathbb{R}}}^{n\times {n}^{M}}\) and \({F}_{1}\in {{\mathbb{R}}}^{n\times n}\) as follows,
We can write this in compact form,
where \({A}_{j+M-1}^{(M)}\in {{\mathbb{R}}}^{{n}^{j}\times {n}^{j+M-1}}\) and \({A}_{j}^{(1)}\in {{\mathbb{R}}}^{{n}^{j}\times {n}^{j}}\) with
where the \({\mathbb{I}}\) operation is the identity with the same domain as F1, i.e., \({{\mathbb{R}}}^{n\times n}\).
This results in an infinite-dimensional linear system, as there is no bound on the range of j. To make this computationally feasible, we restrict to j ∈ [N] for some \({\mathbb{N}}\ni N > M\). Further, we can see that N > M is a requirement in order to be able to capture any effects coming from a nonlinearity of order M. This allows one to write down a matrix form,
with
The matrix \({{\mathcal{A}}}_{N}\in {{\mathbb{R}}}^{{N}_{{\rm{tot}}}\times {N}_{{\rm{tot}}}}\) is called the Carleman matrix with truncation order N, where \({N}_{{\rm{tot}}}=\mathop{\sum }\nolimits_{j = 1}^{N}{n}^{j}=\frac{n({n}^{N}-1)}{n-1}\). The non-truncated, infinitely large matrix we call \({\mathcal{A}}\). As the dimensionality of the system is exponential in the order of Carleman truncation (see Fig. 2), this technique tends to be intractable for practical applications on classical computers.

Given the exponential increase in size, only a fraction of N = 4 is shown. The diagonal blocks correspond to linear terms of the ODE, the upper-diagonal blocks to a nonlinearity on the (M − 1)st off-diagonal.
The simple block structure of the matrix \({{\mathcal{A}}}_{N}\) enables us to obtain the upper bound for \(\parallel {{\mathcal{A}}}_{N}\parallel\) in terms of the norms of the submatrix of \({{\mathcal{A}}}_{N}\), that is
A similar relation holds for the λ-values, which is important for the estimation of the complexity of our quantum algorithm. In what follows, we present a lemma that allows us to quantify the total error involved in the Carleman truncation. Our lemma considers the error from the Carleman linearisation for the rescaled nonlinear ODE problem when we have an arbitrary power M for the function, as opposed to the quadratic case without the rescaling given in ref. 22. To that end, we will first present said rescaling.
A rescaled Carleman solver
We will motivate this rescaling by looking at the measurement probabilities of components in the vector \({\bf{y}}={[{\bf{u}},{{\bf{u}}}^{\otimes 2},\ldots ,{{\bf{u}}}^{\otimes N}]}^{T}\). Recall that the sole entry we are interested in measuring will be y1 ≡ u. The standard way to encode the solution u(t) in a computational basis \(\{\left\vert j\right\rangle \}\) is
Analogously, components \(\left\vert {{\bf{y}}}_{m}\right\rangle\) of y are written as a quantum state as
with
This follows the state encoding outlined in the Supplementary Information 3.C in ref. 22, where in each step up to the largest order N, extra dimensions are padded in the form of \(\left\vert 0\right\rangle\)’s to avoid the structure of a superposition over components of different size. The first register is set to m so we can distinguish the order by measurement of a subsystem. Then, we can write the full vector \(\left\vert {\bf{y}}(t)\right\rangle\) as follows:
For a normalised quantum state, the amplitudes \({u}_{{j}_{l}}(t)\) in Eq. (22) need to be normalised so that 〈y∣y〉 = 1. We then have to consider the normalisation factor \(1/\sqrt{{V}_{N}}\) where
Note that this formula does not work in the case that ∥u(t)∥ = 1. We therefore adopt the convention that wherever there appears a ratio of this form, for ∥u(t)∥ = 1 it takes the value in the limit ∥u(t)∥ → 1, so
The solution of the nonlinear ODE is given by the first component, where the probability is given by
From this equation, we see that as we increase the Carleman truncation order we also increase VN, which suppresses the probability of extracting the desired component. This brings an exponential cost in N for the algorithm due to the \({\mathcal{O}}\left(1/\sqrt{P({{\bf{y}}}_{1}(t))}\right)\) rounds of amplitude amplification needed at the end. To avoid this high cost in the algorithm, we propose the following rescaling, which can significantly reduce the cost of amplitude amplification.
Definition 1
(Rescaled Carleman problem). Consider a nonlinear ODE system of the form \(\frac{{\rm{d}}{\bf{u}}}{{\rm{d}}t}={F}_{1}{\bf{u}}+{{F}_{M}{\bf{u}}}^{\otimes M}\) as in Problem 1. Then, using a variable transformation in the form of a rescaling \(\widetilde{{\bf{u}}}={\bf{u}}/\gamma\) with γ > 0, we obtain another system in the rescaled variable
with \({\widetilde{F}}_{1}={F}_{1}\) and \({\widetilde{F}}_{M}={\gamma }^{M-1}{F}_{M}\).
This allows us to improve the measurement probability in the following sense.
Lemma 2
(Measurement probability of the rescaled Carleman problem). Using the rescaling in Definition 1, using a scaling factor γ ≥ ∥uin∥ and assuming dissipativity of the ODE, the probability to measure \(\widetilde{{\bf{u}}}={\widetilde{{\bf{y}}}}_{1}\) is given by
Proof.
Using the rescaling γ > 0, we obtain a new normalisation
with \(\|\widetilde{{\bf{u}}}(t)\| =\| {\bf{u}}(t)\| /\gamma\). Given dissipativity of the ODE, we have ∥u(t)∥ ≤ ∥uin∥, so \(\| \widetilde{{\bf{u}}}(t)\| \le 1\). In turn that implies
The measurement probability to obtain \({\widetilde{{\bf{y}}}}_{1}(t)\) is then
Therefore, using the parameter γ, we can adjust the probability to obtain \({\widetilde{{\bf{y}}}}_{1}\). Here we have taken γ ≥ ∥uin∥, though the first expression does not depend on this assumption. The probability is equal to 1/N if γ = ∥uin∥ = ∥u(t)∥, and otherwise for γ > ∥u(t)∥ the probability is even better. Thus the rescaling avoids the exponential (in N) suppression of the probability of obtaining the component of interest of the ODE problem, which occurs for ∥u(t)∥ > 1 without rescaling.
When we apply the rescaling above into Eq. (15) we obtain a linearised system in the rescaled solution vector with \({\widetilde{A}}_{j}^{(1)}={A}_{j}^{(1)}\) and \({\widetilde{A}}_{j+M-1}^{(M)}={\gamma }^{M-1}{A}_{j+M-1}^{(M)}\), and as a result we can write the rescaled Carleman linearisation as
where
We discuss the cost of implementing the rescaled dynamics when introducing the ODE solver.
Error bounds on rescaled solution
Next, we present error bounds on the global and component-wise errors due to Carleman linearisation in Lemma 3 and Lemma 4, where we make use of the rescaling technique outlined in the previous section. The first lemma provides a bound on the overall error in the Carleman vector. The error bounds we present here are based on the 2-norm.
Lemma 3
(Global rescaled Carleman error). Consider the ODE from Eq. (3) with its Carleman linearisation in Eq. (13) truncated at order N. Let F1 be dissipative, so that for λ0 < 0 with ∣λ0∣ > ∥uin∥M−1∥FM∥ and therefore \(\| {\widetilde{{\bf{u}}}}_{{\rm{in}}}\| \ge \|\widetilde{{\bf{u}}}(t)\|\) for t > 0. Then, the error in the rescaled solution as defined in Lemma 2 is given by \({\eta }_{j}={\widetilde{{\bf{u}}}}^{\otimes j}-{\widetilde{{\bf{y}}}}_{j}\) at order j ∈ [N] due to Carleman truncation N > M ≥ 2 and a scaling factor γ = ∥uin∥; \(\widetilde{{\bf{u}}}\) denotes the exact solution to the underlying ODE whereas \(\widetilde{{\bf{y}}}\) is the approximation due to Carleman truncation. Then, this error for any j ∈ [N] is upper bounded by the overall error vector,
The detailed proof is presented in Supplementary Section II of the Supplementary Information. Related results were given in ref. 22 and ref. 7. Neither included a general power for the nonlinearity, and were restricted to M = 2. Furthermore, we provide an exponential reduction in the Carleman order dependence due to the rescaling, i.e., ∥η∥ ∝ ∥uin∥M in opposed to ∥uin∥N. Although ref. 7 mentioned rescaling, it appears not to have been used in the error analysis. If the rescaled form was being used in that work, then it would imply that ∥uin∥ would be equal to 1, so \(\log (1/\| {{\bf{u}}}_{{\rm{in}}}\| )=0\) which results in N being infinite in Eq. (7.23) of ref. 7.
A problem with using this form is that it does not go down with the Carleman order. We aim to show that the error may be made arbitrarily small with higher-order Carleman approximations. We can provide tighter bounds when we consider the individual components of the Carleman vector, as in the following lemma.
Lemma 4
(Component-wise Carleman error). Under the same setting as in Lemma 3, and j ∈ [N], the Carleman error for each individual component of ηj satisfies
where
for \(k\in \{1,2,\cdots \,,\lceil \frac{N}{M-1}\rceil \}\) and k is determined so that for any j, we have k whenever j falls into the index set j ∈ Ωk with
In particular, for k = ⌈N/(M − 1)⌉ we have
The proof of Lemma 4 can be found in Supplementary Section II B of the Supplementary Information. The function fj,k,M(τ) is monotonically decreasing with k, and in particular fj,k,M(τ) ≤ fj,1,M(τ) = 1 − e−jτ (see Supplementary Section II B of the Supplementary Information). This result does not depend on the choice of rescaling γ. There is a factor of 1/γj in the definition of ηj, so the result is effectively independent of the choice of rescaling. Moreover, ∥η1(t)∥ gives the error in the desired component at the end, and shows that the error in u is proportional to ∥uin∥.
A similar result was provided in ref. 23 without using the rescaling, though that does not affect the result for the error. We give a significant improvement over the result in ref. 23 by evaluating the nested integrals to give the function fj,k,M(τ), whereas the result in ref. 23 just corresponds to replacing fj,k,M(τ) with its upper bound of 1.
We can use Lemma 4 to solve for a lower bound on N for a given allowable error. In practice, we are interested in the error in the solution relative to ∥uin∥ rather than γ, so we aim to bound ∥η1(t)∥γ/∥uin∥. Given a maximum allowable error ε, we then require
It is therefore sufficient to choose N as
or
We can also numerically solve for N, by using the exact expression for fj,k,M(τ) given in Eq. (35). That will give a tighter lower bound on N, but there is not a closed-form expression.
Solution of the linearised system of ordinary differential equations using a truncated Taylor series
Next, we describe how to solve the system of ODEs that results from the Carleman mapping applied onto the nonlinear system. The most simple way to solve the system of ODEs is to apply the first-order method for time discretisation known as the explicit Euler method. Upon application of the Euler method, there is a linear system of equations that can be solved. Here, this is a quantum linear system problem (QLSP), as the solution is encoded in a quantum state. In what follows, we aim to solve the linear system by a more sophisticated method than explicit Euler. The main drawback of the forward Euler method is low accuracy since it is a first-order method, meaning finer time discretisation is required to achieve a required precision. As a result, the dependence of the complexity for solving the QLSP is quadratic in the solution time, and there is a near-linear factor in the inverse error22,23.
Here, we follow the procedure outlined in ref. 3, which allows us to obtain an algorithm that has complexity near-linear in time and logarithmic in the inverse error. The solution of a time-independent ODE system
may be approximated by uK(t) = WK(t, t0)u(t0), with
This is a Taylor series truncated at order K. The error in the solution due to time propagation can be bounded as
We aim to solve Eq. (16) where the vector u(t) is mapped to a rescaled vector \(\widetilde{{\bf{y}}}(t)\) and A is the rescaled Carleman matrix \(U_{\tilde{A}_N}\) truncated at order N.
Following Theorem 2 in ref. 3, there exists a quantum algorithm that can provide an approximation \(\left\vert \hat{{\bf{y}}}\right\rangle\) of the solution \(\left\vert \widetilde{{\bf{y}}}(T)\right\rangle\) satisfying \(\left\Vert \left\vert \hat{{\bf{y}}}\right\rangle -\left\vert \widetilde{{\bf{y}}}(T)\right\rangle \right\Vert \le \varepsilon {y}_{\max }\). To do so, we require that \({{\mathcal{A}}}_{N}\) has non-positive logarithmic norm and we have the oracles Uy to prepare the initial state and block encoding of \({{\mathcal{A}}}_{N}\) via \({U}_{{\widetilde{{\mathcal{A}}}}_{N}}\) with \(\left\langle 0\right\vert {U}_{{\widetilde{{\mathcal{A}}}}_{N}}\left\vert 0\right\rangle ={\widetilde{{\mathcal{A}}}}_{N}/{\lambda }_{{\widetilde{{\mathcal{A}}}}_{N}}\). Then, to achieve the desired accuracy, the average number of calls to Uy and \({U}_{{\widetilde{{\mathcal{A}}}}_{N}}\) needed are
Furthermore, the number of additional elementary gates scales as
In these expressions
The stability requirement on the ODE to use the solver as in ref. 3 is that the logarithmic norm of the matrix is non-positive (similar to ref. 7). That norm is given by the eigenvalues of \(({\widetilde{{\mathcal{A}}}}_{N}+{\widetilde{{\mathcal{A}}}}_{N}^{\dagger })/2\). The eigenvalues of that matrix can be bounded via the block form of the Gershgorin circle theorem. That is equivalent to the usual Gershgorin circle theorem, except using the spectral norms of the off-diagonal blocks. For example, see Theorem 2 of ref. 26, or ref. 27.
For \(({\widetilde{{\mathcal{A}}}}_{N}+{\widetilde{{\mathcal{A}}}}_{N}^{\dagger })/2\) we obtain rows with \({A}_{j}^{(1)}\) and \({\gamma }^{M-1}{A}_{j}^{(M)}/2\) (for j ≥ M) and \({\gamma }^{M-1}{A}_{j+M-1}^{(M)}/2\) (for j + M − 1 ≤ N). Now \(\parallel {A}_{j+M-1}^{(M)}\parallel \le j\parallel {F}_{M}\parallel\), so the sum of the norms of the off-diagonal blocks is at most, for j ≥ M and j + M − 1 ≤ N,
In the case j < M but j + M − 1 ≤ N then we get j∥FM∥. If j + M − 1 > N but j ≥ M then we get (j − M + 1)∥FM∥. Now the maximum eigenvalue of \([{A}_{j}^{(1)}+{({A}_{j}^{(1)})}^{\dagger }]/2\) is jλ0. In that case the eigenvalues of \(({\widetilde{{\mathcal{A}}}}_{N}+{\widetilde{{\mathcal{A}}}}_{N}^{\dagger })/2\) can be at most
We can then see that the eigenvalues will be non-positive given all three inequalities
Provided N ≥ 2(M − 1) (as would normally be the case) the middle inequality would imply the other two. In all cases we can satisfy these inequalities using
or
where we used the definition of R from Eq. (5) in the equality above. Berry and Costa3 argue that for cases where the solution does not decay significantly, \({\mathcal{R}}\in {\mathcal{O}}(1)\). Here, we consider dissipative dynamics without driving, so \({\mathcal{R}}\) may be large. That is less of a problem for driven equations. We expect that our methods can be applied to driven equations as well, but the error analysis is considerably more complicated so we leave it as a problem for future work.
We can construct the block encoding of the Carleman matrix \({\widetilde{{\mathcal{A}}}}_{N}\) in terms of the block encoding of F1 and FM, as discussed in Supplementary Section VII of the Supplementary Information. Denoting the values of λ for F1 and FM by \({\lambda }_{{F}_{1}}\) and \({\lambda }_{{F}_{M}}\) respectively, the value of λ for \({\widetilde{{\mathcal{A}}}}_{N}\) is
This expression easily follows from expressing \({\widetilde{{\mathcal{A}}}}_{N}\) as a sum, and the value of λ being the sum of the values of λ in the sum. Since \({\widetilde{{\mathcal{A}}}}_{N}\) includes \({A}_{j}^{(1)}\) up to \({A}_{N}^{(1)}\), and \({A}_{N}^{(1)}\) is a sum of N operators with identity tensored with F1, we obtain the term \(N{\lambda }_{{F}_{1}}\) above. Similarly, we have \({\gamma }^{M-1}{A}_{j}^{(M)}\) up to \({\gamma }^{M-1}{A}_{N}^{(M)}\), and \({A}_{N}^{(M)}\) is a sum of N − M + 1 operators with with FM, giving the \((N-M+1){\gamma }^{M-1}{\lambda }_{{F}_{M}}\) term.
If we choose γM−1 = ∣λ0∣/∥FM∥ as above, then
In typical cases we would expect that \({\lambda }_{{F}_{1}}\propto \| {F}_{1}\|\) and \({\lambda }_{{F}_{M}}\propto \|{F}_{M}\|\). That would imply
Note that the scaling has not increased the value of λ by more than a constant factor. Note that this is assuming that the λ-values and norms in the block encoding are comparable, so it is possible it could be violated if the block encoding of FM is inefficient, so \({\lambda }_{{F}_{M}}\) is much larger than ∥FM∥.
Now for \({\mathcal{R}}\) we have \({y}_{\max }\) which considers the maximum norm that the vector can assume along the entire time evolution. Since we are working with a dissipative problem the maximum occurs at t = 0. First we consider the case without the scaling for comparison. To compute the norm ∥y(0)∥, note that it is the vector resulting from the Carleman mapping, i.e., \({\bf{y}}(0)={[{{\bf{u}}}_{{\rm{in}}},{{\bf{u}}}_{{\rm{in}}}^{\otimes 2},\ldots ,{{\bf{u}}}_{{\rm{in}}}^{\otimes N}]}^{T}\), so
as in Eq. (23). Similarly for the value of the norm at time T,
Therefore
Moreover, the above complexity is in order to obtain the full Carleman vector. The quantity \({\mathcal{R}}\) corresponds to an inverse amplitude for obtaining the state at the final time, so tells us how many steps of amplitude amplification are needed in the algorithm. In practice, we want only u(T) rather than the full vector. That implies a further factor in the complexity of ∥y(T)∥/∥u(T)∥, corresponding to the inverse amplitude for obtaining the component of the Carleman vector containing the solution. That gives a factor in the complexity of
From the equation above we can see how \({\mathcal{R}}\) grows exponentially in N for ∥uin∥ > 1.
Now with the rescaling, we simply divide each uin or u(T) by γ. That gives us
With the choice γM−1 = ∣λ0∣/∥FM∥, we obtain
We then can see that the amplitude amplification cost can be exponentially reduced when ∥uin∥ > 1. We could also use γ = ∥uin∥ to give
but that bound is looser for realistic parameters.
A further consideration is the relation between the relative error in the solution for \(\widetilde{{\bf{y}}}(T)\) and that for u(T). The complexity of the solution for the ODE solver is in terms of the former, whereas we need to bound the relative error in u(T). We have the error upper bounded by (with hats used to indicate results given by the linear equation solver)
In the second line we have assumed that the ODE solver has given the solution for y(T) to within error \(\varepsilon {y}_{\max }\). This shows that the relative error in u(T) is the same as that for \(\widetilde{{\bf{y}}}(T)\), up to a factor of \(1/\sqrt{1-{R}^{2/(M-1)}}\) which should be close to 1. We can also use the simpler but looser upper bound
which is obtained by noting that the expression in the square brackets in the third line of Eq. (66) is upper bounded by N.
We can now use the ODE solver given in ref. 3 in combination with our rescaling technique to provide our quantum algorithm for Problem 1.
Lemma 5
(Complexity of solving ODE) There is a algorithm to solve the nonlinear ODE from Eq. (3) i.e., to produce a quantum state \(\left\vert \hat{{\bf{u}}}(T)\right\rangle\) encoding the solution such that \(\|\hat{{\bf{u}}}(T)-{\bf{u}}(T)\| \le \varepsilon \| {{\bf{u}}}_{{\rm{in}}}\|\), using an average number
of calls to oracles for F1 and FM,
calls to oracles for preparation of uin, and
additional gates for dimension n, with
We require that R < 1 and assume that \({\lambda }_{{F}_{M}}/\| {F}_{M}\| ={\mathcal{O}}({\lambda }_{{F}_{1}}/\| {F}_{1}\| )\) for the block encodings of F1 and FM.
Proof.
The main step to derive our quantum algorithm is first to apply the Carleman linearisation in the rescaled nonlinear ODE problem, which is given in Eq. (26). We then have a linear ODE problem with the Carleman matrix of order N, denoted \({\widetilde{{\mathcal{A}}}}_{N}\). We can then apply the ODE solver given in ref. 3 to this equation.
There are then a number of considerations needed to give the overall complexity.
-
We need to multiply by a further factor of \(\parallel \widetilde{{\bf{y}}}(T)\parallel /\parallel \widetilde{{\bf{u}}}(T)\parallel\) to obtain the correct component of the solution containing the approximation of u(T). The product of that with \(\widetilde{{\mathcal{R}}}\) is given above in Eq. (64).
-
The value of \({\lambda }_{{\widetilde{{\mathcal{A}}}}_{N}}\) is given above in Eq. (58) under the assumption \({\lambda }_{{F}_{M}}/\| {F}_{M}\| ={\mathcal{O}}({\lambda }_{{F}_{1}}/\| {F}_{1}\| )\), which gives \({\lambda }_{{\widetilde{{\mathcal{A}}}}_{N}}={\mathcal{O}}(N{\lambda }_{{F}_{1}})\).
-
The matrix \({\widetilde{{\mathcal{A}}}}_{N}\) can be block encoded with \({\mathcal{O}}(1)\) calls to the oracles for F1, FM. There is an extra \({\mathcal{O}}(N)\) factor for the number of calls to uin. The implementation of the oracles is explained in the Supplementary Section VII of the Supplementary Information.
-
The choice of the Carleman order N in order to obtain a sufficiently accurate solution is given in Eq. (40). The error from the Carleman truncation can be chosen to be a fraction of the total allowable relative error ε here, which is accounted for using the order notation for N.
-
The solution for the ODE can be given to relative error \(\varepsilon /\sqrt{N}\). According to Eq. (67) that will ensure that the relative error in u(T) obtained is ε as required. It is for this reason that we have replaced the 1/ε in the complexity for the ODE solver with N/ε.
For the additional elementary gates, the block encoding is as in Supplementary Section VII of the Supplementary Information requires a factor of \({\mathcal{O}}(NM\log n)\) for swapping target registers into the appropriate location. That is a factor on the number of block encodings of \({\widetilde{{\mathcal{A}}}}_{N}\). Moreover, ref. 3 gives a log factor to account for the complexity of correctly giving the weighting in the Taylor series. For simplicity we give the product of these factors, but these factors are for different contributions to the complexity and we could instead give a more complicated expression with the maximum of \(NM\log n\) and the logarithm.
We can compare our quantum algorithm performance with what is given in Theorem 8 of ref. 7 for the case M = 2. The complexity given in that theorem can be simplified to the situation we consider by removing the driving term and replacing ∥A∥ with \({\lambda }_{{{\mathcal{A}}}_{N}}\). Then the complexity from ref. 7 is
The speedup is unclear because the complexity in that work is given in terms of poly factors. That work appears to be assuming a rescaling in order to avoid complexity exponential in N, but by assuming ∥uin∥ = 1. The problem is that they give a formula for N as
Using ∥uin∥ = 1 in that formula gives infinite N. In contrast, here we have given the rescaling explicitly and given a working formula for N.
Application to the quantum nonlinear PDE problem
Complexity of the quantum algorithm
We now demonstrate our techniques applied to the nonlinear PDE23
for some diffusion coefficient D ≥ 0 and constants \(c,b\in {\mathbb{R}}\). As a simple means of discretisation we consider finite differences with periodic boundary conditions, which leads to a vector-valued ODE that approximates the dynamics in Eq. (74). We go beyond the two-point stencil demonstrated in ref. 23 and apply higher-order finite differences similar to ref. 13 for the linear case.
We discretise a d-dimensional space in each direction with uniformly equidistant grid points. As a result, we obtain a nonlinear system of ODEs as in Eq. (3) with n grid points in total, or n1/d in each direction. Moreover, we consider the width of the simulation region to be 1 in each direction, so xj ∈ [0, 1], for simplicity.
The linear operator F1 resulting from the spatial discretisation of our PDE is given by
where \({\mathbb{I}}\) is the n1/d × n1/d identity matrix, and
The operator Lk,d above for the discretised Laplacian in dimension d is constructed from the sum of the discretised Laplacians in one dimension, Lk. Here, k is the order, so the truncation error scales as the inverse grid spacing to the power of 2k − 1, and 2k + 1 stencil points are used.
A Laplacian in one dimension with a kth order approximation and periodic boundary conditions can be expressed in terms of weights aj as (see ref. 13)
where S is a n1/d × n1/d matrix, where the entries are \({S}_{i,j}={\delta }_{i,j+1\mathrm{mod}\,{n}^{1/d}}\); S is also known as a circulant matrix. Note that for a total of n1/d grid points and a region size of 1 in each direction, the grid spacing is 1/n1/d. The method to obtain the coefficients aj for the Laplacian operator is given in Supplementary Section V of the Supplementary Information guarantees that
and we provide the coefficients for 1 ≤ k ≤ 5 in Table 2 (these are from ref. 28). Moreover, this procedure leads to a truncation error in the representation of the Laplacian operator which scales as (for the 2-norm)13,29
where C(u, k) is a constant depending on the (2k + 1)st spatial derivative in each direction
This expression is obtained from that in refs. 13,29 by adding the errors for derivatives in each direction.
We also have the matrix FM resulting from the spatial discretisation of the nonlinear part buM(x, t) that is a rectangular matrix FM,
operating on the vector u⊗M, as given in Eq. (10). Since we are only interested in the components \({u}_{i}^{M}\) from u⊗M, where i = 1, 2, ⋯ n, FM is a one sparse matrix with the non-zero components given by b. Hence \(\| {F}_{M}\| =\| {F}_{M}{\| }_{\max }=| b|\). In the case M = 2, where
we can express F2 as
Returning to the Laplacian operator with periodic boundary conditions, we see that Eq. (77) is a circulant matrix, so its eigenvalues are given by
where \(\omega ={e}^{i2\pi /{n}^{1/d}}\). Since the aj, with j = 0, 1, ⋯ , k, satisfy the condition in Eq. (78), we see that for ℓ = 0, λ0 = 0 gives the maximum eigenvalue and λℓ < 0 for ℓ ≠ 0. Moreover, using the triangle inequality in Eq. (77) we see that
By a simple application of Gershgorin’s circle theorem, one may obtain the asymptotic bound (Lemma 2 in ref. 13, Lemma 6 in ref. 29),
From the eigenvalues of Lk we can then determine the eigenvalues of F1 (which is symmetric so equal to \(({F}_{1}+{F}_{1}^{\dagger })/2\)) as defined in Eq. (75) as
As discussed above the maximum eigenvalue of Lk is 0 with periodic boundary conditions (it can be negative for non-periodic boundary conditions). For Carleman linearisation to be successful, we require R < 1 and, in particular, λ0 < 0. Since the maximum eigenvalue of F1 is c, we choose negative c such that the overall dynamics becomes dissipative and satisfies the stability condition R < 1. Moreover, we obtain the following bounds
The value of \({\lambda }_{{F}_{1}}\) for the block encoding of F1 can be determined in a similar way. The block encoding can be implemented by a linear combination of unitaries of the identity and powers of the circulant matrices S. The value of \({\lambda }_{{F}_{1}}\) is then exactly equal to the sum
Similarly, since FM is one-sparse it can be easily block encoded with a value of \({\lambda }_{{F}_{M}}\) equal to its norm of ∣b∣. We then obtain the value of λ for the complete block encoding as
The condition on the dissipativity of the ODE R < 1 implies that
Given these results for the discretisation of the PDE, we can use Lemma 5 to provide the following corollary.
Corollary 6
(Complexity of solving a dissipative reaction-diffusion PDE) There is a quantum algorithm to solve the nonlinear PDE in Eq. (74) i.e., to produce a quantum state \(\left\vert \hat{{\bf{u}}}(T)\right\rangle\) encoding the solution such that \(\|\hat{{\bf{u}}}(T)-{\bf{u}}(T)\| \le \varepsilon \| {{\bf{u}}}_{{\rm{in}}}\|\), using an average number
of calls to oracles for F1 and FM, as defined in Eq. (75) and Eq. (83) respectively,
calls to oracles for preparation of uin, and
additional gates, with
We require that R < 1, where R is computed from the discretised input vector uin.
Proof.
We first discretise the reaction-diffusion problem in Eq. (74) to the nonlinear ODE system with n discretisation points. We consider just the error in the solution of this ODE here, with the choice of n to accurately approximate the solution of the PDE described below. For this ODE we have an explicit bound for \({\lambda }_{{F}_{1}}\) given in Eq. (89), and can use it in the expressions in Lemma 5. For this simple FM the values of \({\lambda }_{{F}_{M}}\) and ∥FM∥ are equal, so the condition \({\lambda }_{{F}_{M}}/\| {F}_{M}\| ={\mathcal{O}}({\lambda }_{{F}_{1}}/\| {F}_{1}\| )\) is satisfied.
Note that for this result the oracles for F1 and FM can be easily implemented in terms of calls to elementary gates, with logarithmic complexity in n and linear complexity in M. Powers of the circulant matrices can be implemented with modular addition, and FM can be implemented via equality tests between the copies it acts upon. Note also that, apart from the R < 1 condition, this complexity scales as n2/d up to logarithmic factors. For d ≥ 3 this complexity is sublinear in n. This factor comes from the size of the discretised Laplacian, and is similar to that for quantum algorithms for linear PDEs. If we had the factor of ∥uin∥2N as in ref. 23, then because ∥uin∥2 ∝ n with the discretisation there would be a further factor of nN for the scaling with n, making the complexity far worse than that for a simple classical solver.
Stability and discretisation
Here we discuss conditions on nonlinear differential equations of the type in Eq. (74) so that numerical schemes based on Carleman linearisation are stable. Recall that for the ODE we have the stability condition R < 1 with
That condition is not ideal here, because the 2-norm of the solution increases with the number of discretisation points. Thus this condition for the stability depends not only on the underlying PDE and initial state but on its discretisation.
Ideally we would aim for a condition on the max-norm of the solution. That can then be used in order to guarantee stability of the solution as well as to bound error. For example, ref. 23 considers stability in their Lemma 2.1 and bounds error in their Theorem 3.3. A simple stability criterion can be given as
Before discretisation, the stability can be shown simply by considering the infinitesimal time interval dt and using
Now using the triangle inequality
Then if \((b/c)\,\|u({\bf{x}},t){\|}_{\max }^{M-1}\le 1\) this expression is upper bounded by \(\|u({\bf{x}},t){\|}_{\max }\).
Moreover, it is a standard result that \(\parallel {\mathbb{I}}+{\rm{d}}t\,D\Delta {\parallel }_{\infty }=1\). That is, the diffusion equation smooths out any peaks in the distribution. That expression also holds if we consider the discretised form, but only using the first-order discretisation. Then for spatial grid spacing h, the discretised form in one dimension has 1 − 2dt D/h2 on the diagonal, and dt D/h2 on the two off-diagonals. The sum of the absolute values along a row for this matrix is then exactly 1, giving an ∞-norm of 1. That means Eq. (98) implies \(\parallel u({\bf{x}},t){\parallel }_{\max }\) is non-increasing for the PDE given the stability criterion in Eq. (97).
This result for the ∞-norm no longer holds for the discretised PDE when using higher-order discretisations. For example, for the second-order discretisation, the −1/12 on the off-diagonals means that
That means that the max-norm is only upper bounded by the initial max-norm multiplied by a factor of \(\exp (D/(3{h}^{2}))\). In practice it is found that the max-norm is far better behaved. If we calculate the ∞-norm of \(\exp (tD{L}_{k})\), then we obtain the results shown in Fig. 3. For the second-order discretisation the initial slope is 1/3 as predicted using infinitesimal t, but the peak value is less than 1% above 1. For the higher-order discretisations this maximum increases, but it is still small for these orders. Therefore we find that if we consider the max-norm for just evolution under the discretised Laplacian then it is well-behaved, but that does not imply the result for the nonlinear discretised PDE.

The (induced) ∞-norm of the exponential of tDΔh when using a discretisation of the Laplacian of second order (blue), third order (red), and fourth order (orange).
To determine stability for the 2-norm, the equivalent of Eq. (98) gives
Therefore the 2-norm is non-increasing provided \((b/c)\,\| u({\bf{x}},t){\| }_{\max }^{M-1}\le 1\). In the discretised case the non-positive eigenvalues of the discretised Laplacian mean that the 2-norm is still stable given this condition, though as noted above it is possible for \(\parallel {\bf{u}}{\parallel }_{\max }\) to increase above its initial value.
However, for the purpose of solving the ODE using Carleman linearisation, what matters is not the stability of the nonlinear equation, but that of the linearised equation. That is because the stability of the linearised equation governs the condition number of the linear equations to solve, and in turn that is proportional to the complexity. For example, in ref. 23 their Problem 1 assumes that ∥FM∥≤∣λ0∣ (λ1 in the notation of that work) after some possible rescaling of the equation. Then Eq. (4.15) of that work gives \(\|{\mathbb{I}}+Ah\| \le 1\) (with h the time discretisation), using that condition from Problem 1. That is then used to provide the bound on the norm of ∥L−1∥ in Eq. (4.28) of that work, which is then used to give the bound on the condition number proportional to the number of time steps in Eq. (4.29) in ref. 23.
According to our analysis above, the stability of the linearised system will be satisfied provided γM−1≤∣λ0∣/∥FM∥. For the discretised PDE here we have λ0 = c and ∥FM∥ = b. That means if \(\gamma \le \|{{\bf{u}}}_{{\rm{in}}}{\|}_{\max }\), then the stability condition in Eq. (97) implies the stability of the matrix after Carleman linearisation. That condition is needed in order to be able to use the ODE solver of Ref. 3, but it will mean that the rescaling gives a smaller probability of success for obtaining the correct component of the Carleman vector than if we had the stability condition R < 1.
However, if we have sufficiently small b/∣c∣, then the condition R < 1 would be satisfied, so
Because ∥uin∥ increases with the number of discretisation points as \(\sqrt{n}\), this inequality can only be satisfied if the number of discretisation points is made as small as possible. This gives a strong motivation for using the higher-order spatial discretisation of the PDE. See Supplementary Section IV of the Supplementary Information for discussion of the number of points needed.
Error analysis
The overall error ε comes from three different parts,
-
the spatial discretisation error of the semi-discrete dynamics εdisc,
-
the error εCarl contributed by truncation in the Carleman linearisation as bounded in Lemma 4, and
-
the error in the time evolution εtime due to the Taylor series, as introduced earlier in the treatment of the linearised differential equation solver.
As usual in this type of analysis, we can simplify the discussion by taking the error to be ε for each of these contributions. In reality, the contribution to the error from each source would need to be taken to be a fraction of ε (e.g. ε/3), but because that fraction would at most give a constant factor to the complexity, it would not affect the complexities quoted using \({\mathcal{O}}\).
We have already considered εtime and εCarl above in Corollary 6. The time discretisation error will not be further considered here, but we will discuss how the Carleman error can be alternatively bounded in situations where the PDE is stable but R ≥ 1. Above we show that the ODE needs R < 1 for the quantum solution to be efficient, but this bound on the Carleman error will be useful if that limitation can be circumvented.
In the case of higher-order discretised Laplacians we obtain a somewhat worse bound as derived in Supplementary Section II C of the Supplementary Information,
where
The ≲ is because it is assuming that the max-norm of the solution is not increasing. We can use ≤ if \(\parallel {{\bf{u}}}_{{\rm{in}}}{\parallel }_{\max }\) is replaced with the maximum of \(\parallel {\bf{u}}{\parallel }_{\max }\) over time. The quantity Gκ is greater than 1 for higher-order discretised Laplacians, so this is a slightly larger upper bound than in the case of first-order discretised Laplacians. Nevertheless, the Carleman error may be made arbitrarily small with order provided
This condition is slightly stronger than the condition for stability of the PDE by the factor of \({G}_{\kappa }^{dM}\), but that will typically be close to 1. Typically this will be a much weaker requirement than the stability condition R < 1.
Next, we consider the bound on the error due to the spatial discretisation, which can be used to derive the appropriate number of discretisation points n to use. Using that in Corollary 6 then gives the complexity entirely in terms of the parameters of the problem instead of the value chosen for n. Our bound on the error is as given in the following Lemma, with the proof given in Supplementary Section III of the Supplementary material.
Lemma 7
(Nonlinear PDE solution error when discretising the Laplacian with higher-order finite differences). Using a higher-order finite difference discretisation with 2k + 1 stencil points in each direction, the solution of the PDE
at time T > 0 has error due to spatial discretisation when c < 0 and ∣c∣ > M∣b∣∥uin∥M−1 bounded as
where C(u, k) given in Eq. (80) is a constant depending on the (2k + 1)st spatial derivative of the solution assuming sufficient regularity, n is the number of grid points used, and d is the number of dimensions.
In this result, we are considering the continuous time evolution. Note that for the stability of the discretisation error we use the condition \(| c| > M| b| \|{{\bf{u}}}_{{\rm{in}}}{\|}_{\max }^{M-1}\), which is stronger than the condition \(| c| > | b| \|{{\bf{u}}}_{{\rm{in}}}{\|}_{\max }^{M-1}\) for PDE stability. This appears to be a fundamental condition due to the nonlinearity, because the derivative of the order-M nonlinearity produces a factor of M.
Next, if we take εdisc ∝ ε, then solving Eq. (107) for n gives
That is, this choice of n is sufficient to give εdisc as some set fraction of ε. In practice we would choose the minimum n needed to give the desired accuracy, so we would choose n proportional to the expression in Eq. (108). For simplicity of the solution for n, we have used
In Supplementary Section IV of the Supplementary Information we show how the discretisation error is reduced with the number of grid points with different orders of discretisation and a simple toy model.
The benefit of having fewer grid points comes with the drawback of having a less sparse operator. The block encoding of F1 is performed by a linear combination of unitaries over (2k + 1) basis states with amplitudes given by a table, and so has complexity in terms of elementary gates proportional to k. That is not immediately obvious from Corollary 6, because it gives complexity in terms of block encodings of F1 and FM. It is also possible for C(u, k) to increase with k. In a real implementation it would therefore be desirable to choose an optimal k to minimise the complexity, instead of taking k as large as possible.
Data availability
No datasets were generated or analysed during the current study.
References
Berry, D. W. High-order quantum algorithm for solving linear differential equations. J. Phys. A Math. Theor. 47, 105301 (2014).
Berry, D. W., Childs, A. M., Ostrander, A. & Wang, G. Quantum algorithm for linear differential equations with exponentially improved dependence on precision. Commun. Math. Phys. 356, 1057–1081 (2017).
Berry, D. W. & Costa, P. Quantum algorithm for time-dependent differential equations using Dyson series. Quantum 8, 1369 (2024).
Childs, A. M. & Liu, J.-P. Quantum spectral methods for differential equations. Commun. Math. Phys. 375, 1427–1457 (2020).
An, D., Liu, J.-P., Wang, D. & Zhao, Q. A theory of quantum differential equation solvers: limitations and fast-forwarding. Commun. Math. Phys. 406, 189 (2025).
Fang, D., Lin, L. & Tong, Y. Time-marching based quantum solvers for time-dependent linear differential equations. Quantum 7, 955 (2023).
Krovi, H. Improved quantum algorithms for linear and nonlinear differential equations. Quantum 7, 913 (2023).
An, D., Liu, J.-P. & Lin, L. Linear combination of hamiltonian simulation for nonunitary dynamics with optimal state preparation cost. Phys. Rev. Lett. 131, 150603 (2023).
An, D., Childs, A. M. & Lin, L. Quantum algorithm for linear non-unitary dynamics with near-optimal dependence on all parameters. Preprint at https://arxiv.org/abs/2312.03916 (2023).
Harrow, A. W., Hassidim, A. & Lloyd, S. Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 103, 150502 (2009).
Costa, P. C. et al. Optimal scaling quantum linear-systems solver via discrete adiabatic theorem. PRX Quantum 3, 040303 (2022).
Clader, B. D., Jacobs, B. C. & Sprouse, C. R. Preconditioned quantum linear system algorithm. Phys. Rev. Lett. 110, 250504 (2013).
Childs, A. M., Liu, J.-P. & Ostrander, A. High-precision quantum algorithms for partial differential equations. Quantum 5, 574 (2021).
Bagherimehrab, M., Nakaji, K., Wiebe, N. & Aspuru-Guzik, A. Fast quantum algorithm for differential equations. Preprint at https://arxiv.org/abs/2306.11802 (2023).
Jin, S., Liu, N. & Yu, Y. Quantum simulation of partial differential equations via Schrodingerisation. Phys. Rev. Lett. 133, 230602 (2024).
Jin, S., Liu, N. & Yu, Y. Quantum simulation of partial differential equations via Schrodingerisation: technical details. Phys. Rev. A 108, 032603 (2023).
Leyton, S. K. & Osborne, T. J. A quantum algorithm to solve nonlinear differential equations. Preprint at https://arxiv.org/abs/0812.4423 (2008).
Lloyd, S. et al. Quantum algorithm for nonlinear differential equations. Preprint at http://arxiv.org/abs/2011.06571 (2020).
Jin, S. & Liu, N. Quantum algorithms for computing observables of nonlinear partial differential equations. Bulletin des Sciences Mathematiques 194, 103457 (2024).
Jin, S., Liu, N. & Yu, Y. Time complexity analysis of quantum algorithms via linear representations for nonlinear ordinary and partial differential equations. J. Comput. Phys. 487, 112149 (2023).
Carleman, T. Application de la théorie des équations intégrales linéaires aux systèmes d’équations différentielles non linéaires. Acta Math. 59, 63–87 (1932).
Liu, J.-P. et al. Efficient quantum algorithm for dissipative nonlinear differential equations. Proc. Natl Acad. Sci. 118, e2026805118 (2021).
Liu, J.-P. et al. Efficient quantum algorithm for nonlinear reaction-diffusion equations and energy estimation. Commun. Math. Phys. 404, 963 (2023).
Li, X. et al. Potential quantum advantage for simulation of fluid dynamics. Phys. Rev. Res. 7, 013036 (2025).
Xue, C., Xu, X.-F., Wu, Y.-C. & Guo, G.-P. Quantum algorithm for solving a quadratic nonlinear system of equations. Phys. Rev. A 106, 032427 (2022).
Feingold, D. G. & Varga, R. S. Block diagonally dominant matrices and generalizations of the Gerschgorin circle theorem. Pac. J. Math 12, 1241–1250 (1962).
van der Sluis, A. Gershgorin domains for partitioned matrices. Linear Algebra Appl. 26, 265–280 (1979).
Costa, P. C., Jordan, S. & Ostrander, A. Quantum algorithm for simulating the wave equation. Phys. Rev. A 99, 012323 (2019).
Kivlichan, I. D., Wiebe, N., Babbush, R. & Aspuru-Guzik, A. Bounding the costs of quantum simulation of many-body physics in real space. J. Phys. A Math. Theor. 50, 305301 (2017).
Acknowledgements
M.E.S.M. and P.S. were supported by the Sydney Quantum Academy, Sydney, NSW, Australia. MESM was supported by the ARC Centre of Excellence for Quantum Computation and Communication Technology (CQC2T), project number CE170100012 and also supported by the Defense Advanced Research Projects Agency under Contract No.~HR001122C0074. D.W.B. worked on this project under a sponsored research agreement with Google Quantum AI. D.W.B. is also supported by Australian Research Council Discovery Projects DP190102633, DP210101367, and DP220101602.
Author information
Authors and Affiliations
Contributions
P.C.S.C. and D.W.B. jointly developed the algorithms, performed the complexity analysis, and co-wrote the manuscript. P.S. contributed to construction of the finite-difference coefficients and analysing sparsity of the Carleman matrix. M.E.S.M. wrote the section analysing the error with high-order finite difference discretisations. All authors participated in the discussion of results and writing and revision of the manuscript.
Corresponding author
Ethics declarations
Competing interests
D.W.B. is an Associate Editor for npj Quantum Information, but was not involved in the editorial review of, or the decision to publish this article. All other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Costa, P.C.S., Schleich, P., Morales, M.E.S. et al. Further improving quantum algorithms for nonlinear differential equations via higher-order methods and rescaling. npj Quantum Inf 11, 141 (2025). https://doi.org/10.1038/s41534-025-01084-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41534-025-01084-z
