
Abstract
While classical shadows can efficiently predict key quantum state properties, their suitability for certified quantum state tomography remains uncertain. In this paper, we address this challenge by introducing a projected classical shadow (PCS) that extends the standard classical shadow by incorporating a projection step onto the target subspace. For a general quantum state consisting of n qubits, our method requires a minimum of O(4n) total state copies to achieve a bounded recovery error in the Frobenius norm between the reconstructed and true density matrices, reducing to O(2nr) for states of rank r < 2n—meeting information-theoretic optimal bounds in both cases. For matrix product operator states, we demonstrate that the PCS can recover the ground-truth state with O(n2) total state copies, improving upon the previously established Haar-random bound of O(n3). Numerical simulations validate our scaling results and demonstrate the practical accuracy of the proposed PCS method.
Similar content being viewed by others
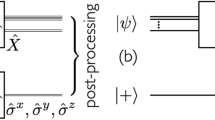

Introduction
Quantum state tomography (QST) is widely used for estimating quantum states1,2,3,4,5. To reconstruct the density matrix with high accuracy, measurements should be performed on a large number of identical copies; specifically, for single-copy (i.e., non-collective) measurements, a minimum of O(4n) total copies is required to estimate the density matrix of an n-qubit system with a bounded recovery error, as defined by the Frobenius norm between the reconstructed and true density matrices6. Various methods have been proposed to achieve efficient and accurate QST. Classical computational approaches include linear inversion7, maximum likelihood estimation4,5,8, Bayesian inference9,10,11, region estimation12,13, classical machine learning14, and least squares estimators15,16,17. In contrast, quantum machine learning methods encompass algorithms such as variational quantum circuits18,19, quantum principal component analysis20, and quantum variational algorithms combined with classical statistics21.
A significant reduction in the number of required state copies can be achieved by assuming two common low-dimensional structures: low-rankness and matrix product operators (MPOs). (i) Low-rank density matrices frequently emerge in quantum systems with pure or nearly pure states that exhibit low entropy6,16,22,23,24, and low-rank assumptions are employed in various state estimation procedures, with a range of associated measurement processes, including 4-designs22, Pauli strings23,25, Clifford gates16, and Haar-random projective measurements24. When the density matrix has rank r, the required number of total state copies can be reduced to O(2nr)6,16, yet this remains exponential in n, posing challenges for current quantum computers exceeding 100 qubits. (ii) MPOs, on the other hand, offer a more scalable alternative for certain quantum systems, including one-dimensional spatial systems26, Hamiltonians with decaying long-range interactions27, and states generated by noisy quantum devices28. When employing Haar-random projective measurements29 or specific classes of informationally complete positive operator-valued measures (IC-POVMs)30, the required number of total state copies can be reduced to polynomial scaling—either O(n3) or O(n), respectively—while ensuring bounded recovery error for MPO states.
While algorithms with low-rank assumptions or low-dimensional structures can enable significantly improved scaling, they still face considerable computational complexity, which in existing approaches can be attributed to four potential operations: (i) the calculation of the inverse; (ii) repeated inner product operations between matrices that grow exponentially with n; (iii) multiple projection steps onto the target subspace; and (iv) additional matrix multiplications introduced by iterative algorithms to enforce low-rankness or MPO representations. Recently, an efficient and experimentally feasible approach, known as classical shadow (CS) estimation, was introduced by ref. 31 to infer limited sets of state properties like fidelity, entanglement measures, and correlations. By exploiting efficient computational and storage capabilities on classical hardware, all necessary processing to predict these properties can be carried out via classical computations. This has sparked a series of studies leveraging the CS method32,33,34,35,36. Meanwhile, CS has also been utilized for full quantum state reconstruction37,38, and integrated with projection techniques to recover physical quantum states in39,40. Yet to the best of our knowledge, no existing theoretical analysis of the sampling complexity for the CS-based method addresses the reconstruction of other structured quantum states, above and beyond simply enforcing physicality. Thus, a theoretical understanding of whether the CS-based method can be effectively extended to the full state (i.e., QST) with provable performance guarantees remains absent.
In this paper, we derive performance guarantees for QST using a method we term projected classical shadow (PCS), which projects CS estimators onto target subspaces of the Hilbert space, as illustrated in Fig. 1. Given that the original CS density matrix is Hermitian but not in general positive semidefinite (PSD), our method involves projecting its eigenvalues onto the simplex41. We demonstrate that this approach requires O(4n) total state copies to sufficiently achieve a bounded recovery error in the Frobenius norm. For low-rank states, we further leverage (truncated) low-rank eigenvalue decomposition and show that the required number of total state copies can be reduced to O(2nr) for the same accuracy. Finally, for MPO states, we employ a quasi-optimal MPO projection—tensor-train singular value decomposition (TT-SVD)42 with a simplex projection—to form the PCS step, demonstrating that with O(n2) total state copies, the method reliably recovers the ground-truth state. While suboptimal relative to the degrees of freedom for MPO states, this approach improves upon the theoretical O(n3) scaling in ref. 29. PCS also offers a framework for incorporating prior knowledge about the target state form into the CS approach.

Given an initial CS estimate ρCS lying in the space of Hermitian and unit-trace matrices (not necessarily PSD), we compute the closest state ρPCS in the physical space of interest–either the space of all possible states (left) or a subspace possessing a desired structure (right).
Notation
We use bold capital letters (e.g., X) to denote matrices, bold lowercase letters (e.g., x) to denote column vectors, and italic letters (e.g., x) to denote scalar quantities. Matrix elements are denoted in parentheses. For example, X(i1, i2) denotes the element in position (i1, i2) of the matrix X. The superscripts (⋅)⊤ and (⋅)† denote the transpose and Hermitian transpose, respectively. For two matrices A, B of the same size, \(\left\langle {\boldsymbol{A}},{\boldsymbol{B}}\right\rangle =\mathrm{trace}\,({{\boldsymbol{A}}}^{\dagger }{\boldsymbol{B}})\) denotes the inner product. ∥X∥, ∥X∥1, and ∥X∥F respectively represent the spectral, trace, and Frobenius norm of X. For two positive quantities \(a,b\in {{\mathbb{R}}}^{+}\), the inequality b ≲ a or b = O(a) implies b ≤ ca for some universal constant c; likewise, b ≳ a or b = Ω(a) represents b ≥ ca for some universal constant c.
Results
Classical shadows
Quantum information science harnesses quantum states for information processing43. The state of an n-qubit system can be described by the density operator \({\boldsymbol{\rho }}\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}\), which is PSD (ρ ≽ 0) and has unit-trace (trace(ρ) = 1). In order to estimate this state, measurements can be performed on a collection of copies.
Projective measurements
Within the most general quantum measurement framework of positive operator valued measures (POVMs) (Specifically, a POVM is characterized as a set of PSD matrices: \(\{{{\boldsymbol{A}}}_{1},\ldots ,{{\boldsymbol{A}}}_{K}\}\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}},\,\,s.\; t.\,\mathop{\sum}\nolimits_{k = 1}^{K}{{\boldsymbol{A}}}_{k}={{\bf{I}}}_{{2}^{n}}\). Each POVM element Ak corresponds to a potential outcome of a quantum measurement with the special case of projective measurements corresponding to the case where all Ak are pairwise orthogonal projection operators, meaning they satisfy \({{\boldsymbol{A}}}_{k}^{2}={{\boldsymbol{A}}}_{k}\) and AkAj = 0 for k ≠ j.), the special case of projective measurements is often employed, where the measurement outcomes are associated with an orthonormal eigenbasis of the system. To implement such a measurement defined by an arbitrary orthonormal basis \(\{{{\boldsymbol{\phi }}}_{k}:{{\boldsymbol{\phi }}}_{k}^{\dagger }{{\boldsymbol{\phi }}}_{l}={\delta }_{kl}\}\), we can introduce a unitary matrix \({\boldsymbol{U}}=\left[\begin{array}{ccc}{{\boldsymbol{\phi }}}_{1}&\cdots \,&{{\boldsymbol{\phi }}}_{{2}^{n}}\end{array}\right]\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}\) and apply U† to the state ρ before conducting a projective measurement in the computational basis {ek}, where Uek = ϕk. The probability of observing the k-th outcome is given by:
However, a single projective measurement, even if repeated infinitely many times, provides only partial information on ρ, so multiple projective measurements must be conducted in various bases. In the subsequent discussion, we denote the number of distinct measurement bases by M, and the measurement operators for the m-th projective measurement by \(\{{{\boldsymbol{\phi }}}_{m,1}{{\boldsymbol{\phi }}}_{m,1}^{\dagger },\ldots ,{{\boldsymbol{\phi }}}_{m,{2}^{n}}{{\boldsymbol{\phi }}}_{m,{2}^{n}}^{\dagger }\}\).
Classical shadow (CS)
Consider the original CS proposal with single-shot Haar-random projective measurements. Given an unknown n-qubit ground truth ρ⋆, we repeatedly execute the measurement procedure above Eq. (1) in which U is chosen randomly from the Haar distribution and each measurement is performed on only one copy (i.e., a new U is selected for each copy measured). The specific result \({{\boldsymbol{e}}}_{{j}_{m}}\) yields a snapshot, or “shadow,” of the underlying quantum state, which for Haar-distributed unitaries can be expressed as31:
By construction, this snapshot equals the ground truth in expectation (over both unitaries and measurement outcomes): \({\mathbb{E}}[{{\boldsymbol{\rho }}}_{m}]={{\boldsymbol{\rho }}}^{\star }\). Executing this process M times produces an array of M independent classical snapshots for the total CS estimator:
CS for Tomography?
Although CS estimators can efficiently predict observables of ρ⋆, to our knowledge, there exist no theoretical results concerning the recovery error of the full state. Following the detailed derivation in the section “Methods”, we find the expectation of the mean squared error:
Given that \(\Vert{{\boldsymbol{\rho}}}^{\star }{\Vert}_{F}^{2}\le {\left[{\mathrm{trace}}\,({{\boldsymbol{\rho }}}^{\star })\right]}^{2}=1\), it follows that Eq. (4) can be simplified to
for large n. Eq. (5) demonstrates that stable recovery of the full state can be achieved only when M scales proportionally to 4n, aligning with the optimal M required in QST for general states6.
A comparison between CS and traditional QST returns several key observations of relevance to this study:
-
1.
CS yields an unbiased estimate (\({\mathbb{E}}[{{\boldsymbol{\rho }}}_{{\rm{CS}}}]={{\boldsymbol{\rho }}}^{\star }\)), whereas the solution from QST is often biased44, due to the fact that most QST methods involve physical constraints, such as positivity and unit trace.
-
2.
While the CS estimator is typically unphysical (not PSD), leading QST methods like maximum likelihood estimation (MLE)5, projected least squares45, and Bayesian inference9 enforce physicality by construction.
-
3.
CS boasts significantly lower computational complexity compared to standard QST methods, such as MLE using the fixed-point (FP) algorithm46,47, MLE using gradient descent (GD)48, least squares (LS) using GD29, and the one-step LS method17. The number of iterations required for convergence in iterative methods [e.g., MLE (FP), MLE (GD), and LS (GD)] significantly increases computational complexity. Moreover, the requirement of a suitable initialization further imposes a strong and often nontrivial condition for successful recovery. Although the one-step LS method17 avoids iterations, it does not incorporate any constraint and still involves matrix inversion and multiple matrix multiplications, resulting in substantial computational cost. In contrast, the CS method offers the lowest computational complexity, as it is also a one-step approach whose primary cost arises from computing the outer product of two vectors.
-
4.
For M ≪ 2n, CS outperforms QST in predicting certain linear observables, not in predicting the entire state17,49.
-
5.
Including prior information about state structure allows for a reduction in scaling in QST (see Tables 1 and 2). Apart from specialized CS methods tailored for states generated by shallow circuits and Hamiltonian dynamics50,51, which aim to improve the accuracy of predicting quantum state properties, there currently exists no known approach that similarly reduces the sample complexity of CS for full quantum state reconstruction. In other words, CS requires O(4n) measurements for estimating the full state, as demonstrated in Eq. (5).
In the next section we investigate methods for incorporating prior information about state structure into CS to reduce the scaling shown in Eq. (5).
Projected Classical Shadow (PCS) for QST
In this section, we will study the application of CS for the task of describing the full quantum state and show that, with a simple projection step, CS estimators are also effective for QST and achieve (nearly) information-theoretically optimal bounds for broad classes of states. Let \({\mathbb{X}}\) denote the class of states of interest, and assume that the underlying ground truth \({{\boldsymbol{\rho }}}^{\star }\in {\mathbb{X}}\). For instance, \({\mathbb{X}}\) could contain all physical states (PSD and unit-trace) or be restricted to a specific structure with compact representations, such as low-rank or MPO states. Because of the availability of previous sample complexity results based on the Frobenius norm, we choose to define ρPCS as the projection of ρCS on the set \({\mathbb{X}}\) that minimizes Frobenius error, i.e.,
To provide a unified and general analysis of Eq. (6), we enlist tools from ϵ-net and covering number29,52 to capture the complexity of the classes of states within the set \({\mathbb{X}}\). First, consider the set \({\mathcal{N}}=\left\{\frac{{\boldsymbol{\rho }}}{\parallel {\boldsymbol{\rho }}{\parallel }_{F}}:{\boldsymbol{\rho }}\in {\mathbb{X}}\right\}\) scaled to unit Frobenius norm. For ϵ > 0, the set \({{\mathcal{N}}}_{\epsilon }\subset {\mathcal{N}}\) is said to be an ϵ-net (or an ϵ-cover) over \({\mathcal{N}}\) if for all \(\frac{{\boldsymbol{\rho }}}{\parallel {\boldsymbol{\rho }}{\parallel }_{F}}\in {\mathcal{N}}\), there exists \(\frac{{{\boldsymbol{\rho }}}^{{\prime} }}{\parallel {{\boldsymbol{\rho }}}^{{\prime} }{\parallel }_{F}}\in {{\mathcal{N}}}_{\epsilon }\) such that \({\left\Vert \frac{{\boldsymbol{\rho }}}{\parallel {\boldsymbol{\rho }}{\parallel }_{F}}-\frac{{{\boldsymbol{\rho }}}^{{\prime} }}{\parallel {{\boldsymbol{\rho }}}^{{\prime} }{\parallel }_{F}}\right\Vert }_{F}\le \epsilon\). The size of an ϵ-net with the smallest cardinality is called the covering number of \({\mathbb{X}}\), denoted by \({N}_{\epsilon }({\mathbb{X}})\). Intuitively speaking, a covering number is the minimum number of balls of a specified radius ϵ to cover a given set entirely. Coverings are useful for managing the complexity of a large set: instead of directly analyzing the behavior of an uncountable number of points in \({\mathcal{N}}\), we can analyze the finite number of points in \({{\mathcal{N}}}_{\epsilon }\). The behavior of all points in \({\mathcal{N}}\) is similar to that of the points in \({{\mathcal{N}}}_{\epsilon }\), as each point in \({\mathcal{N}}\) is close to some point in the covering.
Instead of the covering number \({N}_{\epsilon }({\mathbb{X}})\), our analysis will rely on the covering number of the set \(\overline{{\mathbb{X}}}\) formed by the differences between the elements in \({\mathbb{X}}\):
In many cases, the covering number \({N}_{\epsilon }(\overline{{\mathbb{X}}})\) can be upper-bounded by \({N}_{\epsilon }^{2}({\mathbb{X}})\). Here we use \(\overline{{\mathbb{X}}}\) for convenience in the following.
The covering number when \({\mathbb{X}}\) comprises all physical quantum states can be computed as \(\log {N}_{\epsilon }(\overline{{\mathbb{X}}})=O({4}^{n}\log \frac{9}{\epsilon })\). By comparison, for quantum states with rank at most r, this reduces to \(\log {N}_{\epsilon }(\overline{{\mathbb{X}}})=O({2}^{n}r\log \frac{9}{\epsilon })\); when the density matrices are represented by MPOs with bond dimension D, the covering number can be further reduced to \(\log {N}_{\epsilon }(\overline{{\mathbb{X}}})=O\left(4n{D}^{2}\log \frac{4n+\epsilon }{\epsilon }\right)\), as discussed in the next part.
Theorem 1
For a given \({{\boldsymbol{\rho }}}^{\star }\in {\mathbb{X}}\), let ρPCS be the projected CS in Eq. (6). Then with probability at least \(1-{e}^{-\Omega (\log {N}_{1/2}(\overline{{\mathbb{X}}}))}\),
The proof is given in the section “Methods”. Here, the set \({\mathbb{X}}\subset \{{\boldsymbol{\rho }}\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}:{\boldsymbol{\rho }}={{\boldsymbol{\rho }}}^{\dagger },\mathrm{trace}\,({\boldsymbol{\rho }})=1\}\) is any subspace of Hermitian, trace-one matrices (tan space in Fig. 1. The set \({\mathbb{X}}\) will be specialized to PSD matrices only (blue space in Fig. 1) in Corollary 1 and low-dimensional structures (green space in Fig. 1) in Theorems 3 and 4. Theorem 1 guarantees a stable recovery of the ground-truth ρ⋆ with ξ-closeness in the Frobenius norm, provided \(M=O(\log {N}_{1/2}({\mathbb{X}})/{\xi }^{2})\) number of Haar-random projective measurements, which scales linearly with the logarithm of the covering number. For structured sets \({\mathbb{X}}\) that are nonconvex, such as MPO states, computing the optimal projection \({{\mathcal{P}}}_{{\mathbb{X}}}\) might be difficult or even NP-hard. For these cases, we can use numerical methods to compute an approximate projection \({\widetilde{{\mathcal{P}}}}_{{\mathbb{X}}}\) that we assume is α-approximately optimal (α ≥ 1), satisfying
for any ρ. As will be explained in the next sections, there exist efficient methods to find approximation projections for low-rank and MPO states. Denote by \({\widetilde{{\boldsymbol{\rho }}}}_{{\rm{PCS}}}={\widetilde{{\mathcal{P}}}}_{{\mathbb{X}}}({{\boldsymbol{\rho }}}_{{\rm{CS}}})\) the PCS estimator obtained with this approximate projection. The following extends the results in Theorem 1 to \({\widetilde{{\boldsymbol{\rho }}}}_{{\rm{PCS}}}\).
Theorem 2
For a given \({{\boldsymbol{\rho }}}^{\star }\in {\mathbb{X}}\), let \({\widetilde{{\boldsymbol{\rho }}}}_{{\rm{PCS}}}\) be the approximate PCS estimator in Eq. (9). Then with probability at least \(1-{e}^{-\Omega (\log {N}_{1/2}(\overline{{\mathbb{X}}}))}\),
General physical states
We first specialize \({\mathbb{X}}\) to all physical quantum states (We chose the label “simplex” for this set since the eigenvalues {λk} of all physical states define a standard simplex, i.e., λk ≥ 0 and ∑kλk = 1.):
For \({{\mathbb{X}}}_{{\rm{simplex}}}\), the PCS projection in Eq. (6) can be implemented by performing an eigenvalue decomposition, followed by projecting the eigenvalues onto the simplex \(\{{\boldsymbol{x}}\in {{\mathbb{R}}}^{{2}^{n}}:{x}_{i}\ge 0,\mathop{\sum}\nolimits_{i = 1}^{{2}^{n}}{x}_{i}=1\}\) using the algorithm proposed in Refs. 41,45, while keeping the eigenvectors unchanged. This approach has also been employed in Refs. 39,40 to ensure the physical structure of the reconstructed state. The computational complexity of the projection step is \(O(a\log a)\), where a denotes the number of nonzero eigenvalues.
Since the corresponding set \(\overline{{\mathbb{X}}}\) has covering number \(\log {N}_{\epsilon }(\overline{{\mathbb{X}}})=O({4}^{n}\log \frac{9}{\epsilon })\), we can plug this information into Theorem 1 to obtain recovery guarantee for \({{\mathcal{P}}}_{{\rm{simplex}}}({{\boldsymbol{\rho }}}_{{\rm{CS}}})\).
Corollary 1
For a given physical state \({{\boldsymbol{\rho }}}^{\star }\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}\), we perform M projective measurements to obtain the CS estimate ρCS. Then with probability at least \(1-{e}^{-\Omega ({4}^{n})}\), the projected classical shadow \({{\mathcal{P}}}_{{\rm{simplex}}}({{\boldsymbol{\rho }}}_{{\rm{CS}}})\) satisfies
Low-rank states
We next explore the structure of pure or nearly pure quantum states characterized by low entropy and represented as low-rank density matrices. Assuming ρ⋆ has rank r ≤ 2n, we can refine our attention to the set \({{\mathbb{X}}}_{r}=\{{\boldsymbol{\rho }}\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}:{\boldsymbol{\rho }}\succcurlyeq {\boldsymbol{0}},\mathrm{trace}\,({\boldsymbol{\rho }})=1,\,\text{rank}\,({\boldsymbol{\rho }})=r\}\). Denote \({{\mathcal{P}}}_{{{\mathbb{X}}}_{r}}(\cdot )\) as the optimal projection satisfying Eq. (6). It follows from Theorem 1 and the covering number of the corresponding set \(\log {N}_{\epsilon }(\overline{{\mathbb{X}}})=O({2}^{n}r\log \frac{9}{\epsilon })\) that \(\Vert{{\mathcal{P}}}_{{{\mathbb{X}}}_{r}}({{\boldsymbol{\rho}}}_{{\rm{CS}}})-{{\boldsymbol{\rho }}}^{\star }{\Vert }_{F}\,\le\, O(\sqrt{{2}^{n}r/M})\).
However, since we are unaware of an algorithm to perform the ideal projection \({{\mathcal{P}}}_{{{\mathbb{X}}}_{r}}(\cdot )\), we instead consider a two-step alternative to obtain the low-rank projected classical shadow (LR-PCS):
where \({{\mathcal{P}}}_{\text{rank-}r\text{}}(\cdot )\) denotes the rank-r projection obtained by setting all eigenvalues beyond the r-th largest eigenvalue to zero. We can show that ρLR-PCS shares a similar guarantee as \({{\mathcal{P}}}_{{{\mathbb{X}}}_{r}}({{\boldsymbol{\rho }}}_{{\rm{CS}}})\).
Theorem 3
Given M Haar-random projective measurements on physical state \({{\boldsymbol{\rho }}}^{\star }\in {{\mathbb{X}}}_{r}\), with probability \(1-{e}^{-\Omega ({2}^{n}r)}\,{{\boldsymbol{\rho }}}_{{\rm{LR-PCS}}}\), defined in Eq. (13), satisfies
The detailed proof appears in the section “Methods”. This theoretical recovery error is optimal, given that the degrees of freedom for the ground truth ρ⋆ are O(2nr). This highlights that LR-PCS can achieve the optimal solution in QST using independent measurements, without requiring multiple iterations of optimization algorithms.
To compare LR-PCS with prior results, we convert the result of Theorem 3 to trace norm leveraging the inequality between the Frobenius and the trace norms6, namely \(\Vert{{\boldsymbol{\rho }}}_{{\rm{LR}}{\mbox{-}}{\rm{PCS}}}-{{\boldsymbol{\rho }}}^{\star }{\Vert}_{1}\le \sqrt{2r}\Vert{{\boldsymbol{\rho}}}_{{\rm{LR}}{\mbox{-}}{\rm{PCS}}}-{{\boldsymbol{\rho }}}^{\star }{\Vert}_{F}\le O(\sqrt{{2}^{n}{r}^{2}/M})\), which matches the optimal guarantee (up to small log terms) with independent measurements according to ref. 6. We have summarized the comparison in Table 1. We note that the sufficient condition for PCS in the general setting matches the necessary condition established in ref. 6. Similarly, the sufficient condition for PCS in the low-rank setting is also close to the corresponding necessary condition in ref. 6, up to logarithmic factors.
MPO states
While the computational and storage requirements for low-rank density matrices are significantly smaller compared to general ones, they still grow exponentially in the number of qubits n. Moreover, the assumption of high purity on which the low-rank approximation is based becomes increasingly tenuous in practice for existing processors in the noisy intermediate-scale quantum (NISQ) era. For this reason, reducing parameter count through alternative assumptions is worth pursuing. Examples such as ground states of many quantum systems with short-range interactions and states generated by such systems within a finite duration26 often possess entanglement localized to subsystems of the entire quantum computer. Consequently, they can be compactly represented using MPOs, whose degrees of freedom scale only polynomially in n. To assist in the development of an MPO-PCS method, we will first establish their connection to tensor train (TT) decompositions42, a technique widely utilized in signal processing and machine learning.
For a n-qubit density matrix \({{\boldsymbol{\rho }}}^{\star }\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}\), we employ a single index array i1 ⋯ in (j1 ⋯ jn) to denote the row (column) indices, where i1, …, in ∈ {1, 2} (Specifically, i1 ⋯ in represents the \(({i}_{1}+\mathop{\sum}\nolimits_{\ell = 2}^{n}{2}^{\ell -1}({i}_{\ell }-1))\)-th row.). We designate ρ⋆ as an MPO if we can represent its (i1 ⋯ in, j1 ⋯ jn)-th element using the following matrix product53:
where \({{\boldsymbol{X}}}_{\ell }^{{i}_{\ell },{j}_{\ell }}\in {{\mathbb{C}}}^{D\times D}\) for ℓ ∈ {2, …, n − 1}, \({{\boldsymbol{X}}}_{1}^{{i}_{1},{j}_{1}}\in {{\mathbb{C}}}^{1\times D}\), \({{\boldsymbol{X}}}_{n}^{{i}_{n},{j}_{n}}\in {{\mathbb{C}}}^{D\times 1}\), and D is the bond dimension, and thus we can introduce the set of physical MPO states with bond dimension D as
Here, the corresponding difference set \(\overline{{\mathbb{X}}}\) has a covering number \(\log {N}_{\epsilon }(\overline{{\mathbb{X}}})=O\left(4n{D}^{2}\log \frac{4n+\epsilon }{\epsilon }\right)\), which is proportional to the degrees of freedom O(4nD2) in the MPO states. Given the optimal projection \({{\mathcal{P}}}_{{{\mathbb{X}}}_{D}}(\cdot )\), it follows from Theorem 1 that \(\Vert{{\mathcal{P}}}_{{{\mathbb{X}}}_{D}}\left({{\boldsymbol{\rho }}}_{{\rm{CS}}}\right)-{{\boldsymbol{\rho }}}^{\star }{\Vert}_{F}\,\le\,O(\sqrt{n{D}^{2}\log n/M})\).
However, we have been unable to implement the optimal \({{\mathcal{P}}}_{{{\mathbb{X}}}_{D}}(\cdot )\) due to the difficulty in satisfying both the MPO and simplex conditions simultaneously. Therefore, we introduce a quasi-optimal projection based on a sequential singular value decomposition (SVD) algorithm, commonly referred to as tensor train SVD (TT-SVD)42. Based on tensor-matrix equivalence, we can design a two-step MPO PCS method:
where \({\,\text{SVD}\,}_{D}^{tt}(\cdot )\) denotes the TT-SVD operation. It is worth noting that the bond dimension of ρMPO-PCS may differ slightly from D due to the simplex projection, but the recovery error still depends on D. We analyze the recovery error of Eq. (17) as follows:
Theorem 4
Consider an MPO state \({{\boldsymbol{\rho }}}^{\star }\in {{\mathbb{X}}}_{D}\), measured M times with Haar-random projections. With ρMPO-PCS defined as in Eq. (17), with probability \(1-{e}^{-\Omega (n{D}^{2}\log n)}\) we have
The proof can be found in the section “Methods”. Note that due to the quasi-optimality of the TT-SVD, the upper bound of Eq. (18) is not optimal when considering the degrees of freedom O(4nD2) in ρ⋆. To our knowledge, there exists no method that can guarantee both MPO and PSD constraints simultaneously. Should such an optimal MPO projection be found, however, we could potentially remove one factor of n in the numerator of Eq. (18), thus ensuring exact MPO rank. In Table 2, we summarize the total number of state copies required for MPO-PCS compared to existing QST methods. It is important to highlight that all QST results represent sufficient, rather than necessary, conditions. Compared to the constrained LS method using Haar measurements in ref. 29, MPO-PCS exhibits better sample complexity. While the result30 based on constrained least squares with spherical 3-design POVMs—which are informationally complete—could potentially outperform PCS in terms of sample complexity (but PCS achieves the same complexity given an optimal projection), attaining the bound in ref. 30 requires solving a highly nonconvex optimization problem to global optimality. Table 3. However, there is currently a lack of practical algorithms capable of achieving this bound. The gradient-based iterative algorithm proposed in ref. 30 provides only a suboptimal guarantee and is initialization-dependent—which may limit its practical applicability. Additionally, spherical 3-designs are not known to have efficient implementations using current local quantum circuits, whereas Haar measurements are generally more feasible in experimental settings.
Simulation results
In this section, we conduct numerical QST experiments with Haar-random projective measurements to compare CS, LR-PCS, and MPO-PCS methods. For each configuration, we conduct 10 Monte Carlo tomographic experiments in which each Haar measurement and result are sampled at random; then we take the average over all 10 trials to report the results. For the random state cases (Figs. 2, 3), each trial corresponds to a different randomly chosen ground truth, whereas for the tailored state cases (Figs. 4, 5), each trial in a given average is performed on the same ground truth. Furthermore, since the magnitude of ∥ρ⋆∥F differs across quantum states with different ranks or bond dimensions, we apply the normalized Frobenius norm to enable fair comparisons and provide a consistent metric for reconstruction accuracy.

Mean squared error as a function of state copies M, averaged over trials on ten randomly chosen ground truth states of rank r = 1 (a), r = 4 (b), and r = 16 (c). The horizontal axes span M = 250 to M = 10000. Uncertainty is defined as the sample standard deviation.

Mean squared error as a function of state copies M, where each point is the average over trials on ten randomly chosen ground truth states for bond dimension D = 1 (a) and D = 4 (b). Uncertainty is defined as the sample standard deviation.

Mean squared error as a function of the number of state copies M for (a) thermal state (T = 0.2), (b) thermal state (T = 2), and (c) GHZ state. Comparison between different methods for (a) thermal state (T = 0.2), (b) thermal state (T = 2), and (c) GHZ state. All figures have M = 100 as the starting point.
In the first set of tests, we compare CS and LR-PCS for a specific rank r as a function of measurements M. We generate random ground-truth density matrices \({{\boldsymbol{\rho }}}^{\star }={{\boldsymbol{F}}}^{\star }{{{\boldsymbol{F}}}^{\star }}^{\dagger }\in {{\mathbb{C}}}^{16\times 16}\) (n = 4 qubits), where \({{\boldsymbol{F}}}^{\star }=\frac{{{\boldsymbol{A}}}^{\star }+{\rm{i}}{{\boldsymbol{B}}}^{\star }}{\parallel {{\boldsymbol{A}}}^{\star }+{\rm{i}}{{\boldsymbol{B}}}^{\star }{\parallel }_{F}}\in {{\mathbb{C}}}^{16\times r}\), and the entries of A⋆ and B⋆ are independent and identically distributed (i.i.d.) samples drawn from the standard normal distribution. Notably, when r = 16, LR-PCS reduces to projection onto the set of general physical states defined in Eq. (11). The results in Fig. 2 for rank r ∈ {1, 4, 16} reveal two key observations: (i) as the rank r decreases and the number of measurements M increases, the recovery error across all methods consistently reduces, with the squared error quantitatively scaling as expected (4n/M for CS and 2nr/M for LR-PCS); (ii) for any r and M, LR-PCS outperforms standard CS (even at full rank), as it preserves physicality under any rank constraints; and (iii) in Fig. 2c, since r = 16 (i.e., ρ⋆ is full rank), LR-PCS provides only the additional PSD constraint compared to CS. As M increases, the performance gap between LR-PCS and CS narrows, as the PSD constraint alone has limited impact on reducing the recovery error.
In the second set of trials, we test CS and MPO-PCS across varying numbers of measurements M and bond dimension D. We consider n = 7-qubit matrix product states (MPSs, pure state special cases of MPOs) of the form \({{\boldsymbol{\rho }}}^{\star }={{\boldsymbol{u}}}^{\star }{{{\boldsymbol{u}}}^{\star }}^{\dagger }\in {{\mathbb{C}}}^{128\times 128}\), where \({{\boldsymbol{u}}}^{\star }\in {{\mathbb{C}}}^{128\times 1}\) satisfies ∥u⋆∥2 = 1 and its (i1 ⋯ i7)-element can be represented in the matrix product form: \({{\boldsymbol{u}}}^{\star }({i}_{1}\cdots {i}_{7})={{{\boldsymbol{U}}}_{1}^{\star }}^{{i}_{1}}\cdots {{{\boldsymbol{U}}}_{7}^{\star }}^{{i}_{7}}\). Here, each matrix \({{{\boldsymbol{U}}}_{\ell }^{\star }}^{{i}_{\ell }}\) has size d × d, except for \({{{\boldsymbol{U}}}_{1}^{\star }}^{{i}_{1}}\) and \({{{\boldsymbol{U}}}_{7}^{\star }}^{{i}_{7}}\) of dimensions of 1 × d and d × 1, respectively.
To generate each MPS u⋆, we draw a length-128 complex vector with i.i.d. standard normal elements, apply TT-SVD42 to truncate it to an MPS, and then normalize the result to unit length. As a result, entry ρ⋆(i1 ⋯ i7, j1 ⋯ j7) can be expressed as \({{\boldsymbol{\rho }}}^{\star }({i}_{1}\cdots {i}_{7},{j}_{1}\cdots {j}_{7})=({{{\boldsymbol{U}}}_{1}^{\star }}^{{i}_{1}}\otimes {{{{\boldsymbol{U}}}_{1}^{\star }}^{{j}_{1}}}^{\dagger })\cdots ({{{\boldsymbol{U}}}_{7}^{\star }}^{{i}_{7}}\otimes {{{{\boldsymbol{U}}}_{7}^{\star }}^{{j}_{7}}}^{\dagger })={{{\boldsymbol{X}}}_{1}^{\star }}^{{i}_{1},{j}_{1}}\cdots {{{\boldsymbol{X}}}_{7}^{\star }}^{{i}_{7},{j}_{7}}\), where ⊗ denotes the Kronecker product. Thus, \({{\boldsymbol{\rho }}}^{\star }={{\boldsymbol{u}}}^{\star }{{{\boldsymbol{u}}}^{\star }}^{\dagger }\) is also an MPO with bond dimension D = d2 (equal for all qubits). As shown in Fig. 3, MPO-PCS attains significantly lower error than CS, as it leverages knowledge about the underlying MPO structure. And the recovery error of MPO-PCS increases with higher MPO bond dimension (in line with Table 2), whereas that of CS remains the same regardless of D.
In the third set of trials, we simulate measurements on 7-qubit density matrices: (i) thermal state (The thermal state is generated from the 1D quantum Ising model \(H=\mathop{\sum}\nolimits_{j = 1}^{n-1}{\sigma }_{j}^{z}{\sigma }_{j+1}^{z}+\mathop{\sum}\nolimits_{j = 1}^{n}{\sigma }_{j}^{x}\) with \({\sigma }_{j}^{a}={{\bf{I}}}_{{2}^{j-1}}\otimes {\sigma }^{a}\otimes {{\bf{I}}}_{{2}^{n-j}}\in {{\mathbb{R}}}^{{2}^{n}\times {2}^{n}},a=x,z\) and \({\sigma }^{x}=\left[\begin{array}{cc}0&1\\ 1&0\end{array}\right],{\sigma }^{z}=\left[\begin{array}{cc}1&0\\ 0&-1\end{array}\right]\). The thermal state is then defined as \({{\boldsymbol{\rho }}}^{\star }=\frac{{e}^{-H/T}}{\mathrm{trace}\,({e}^{-H/T})}\),) with temperature T = 0.2 (a relatively low temperature close to the ground state); (ii) thermal state with temperature T = 2 (corresponding to a relatively high temperature); and (iii) Greenberger–Horne–Zeilinger (GHZ) state (The GHZ state is constructed as ρ⋆ = gg† where \({\boldsymbol{g}}={\left[\begin{array}{ccccc}\frac{1}{\sqrt{2}}&0&\cdots &0&\frac{1}{\sqrt{2}}\end{array}\right]}^{\top }\in {{\mathbb{R}}}^{{2}^{n}\times 1}\).). It is worth noting that the low-temperature thermal state (i) and the GHZ state (iii) simultaneously exhibit low-rank and MPO structures16,48,54, making them well-suited for demonstrating the advantages of exploiting structured subspaces. We impose a rank constraint r ∈ {4, 24, 1} for the estimator on each state, respectively. For the T = 0.2 thermal state, the ground-truth density matrix has rank of approximately 4, while for the high-temperature case (T = 2), it is full-rank; for LR-PCS r = 24 is selected, somewhat arbitrarily, which is sufficient to encompass 80% of the sum of the eigenvalues of the ground-truth density matrix. In addition, we apply TT-SVD on the CS estimator to adaptively select the bond dimensions using the error tolerance 10−14. To facilitate a comprehensive comparison between the PCS-based methods and MLE, we introduce the low-rank MLE (LR-MLE) and matrix product operator MLE (MPO-MLE) algorithms, as detailed in the section “Methods”. For LR-MLE and MPO-MLE, we adopt random initialization (We generate a density matrix \({{\boldsymbol{\rho }}}_{0}={{\boldsymbol{F}}}_{0}{{{\boldsymbol{F}}}_{0}}^{\dagger }\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}\), where \({{\boldsymbol{F}}}_{0}=\frac{{{\boldsymbol{A}}}_{0}+i\cdot {{\boldsymbol{B}}}_{0}}{\parallel {{\boldsymbol{A}}}_{0}+i\cdot {{\boldsymbol{B}}}_{0}{\parallel }_{F}}\in {{\mathbb{C}}}^{{2}^{n}\times r}\), with the entries of A0 and B0 independently drawn from the standard normal distribution.) and spectral initialization30, respectively. The step sizes are set to 0.5, 0.05, and 0.1 for LR-MLE, and 0.3, 0.05, and 0.1 for MPO-MLE across the three set of quantum states mentioned above; the number of iterations is fixed at 500 to guarantee convergence for all cases. Given that the variance error in reconstructing the thermal state and GHZ state is less than 10% of the mean error, we exclude this error from the figure to preserve its clarity. Fig. 4 shows that the proposed LR-PCS and MPO-PCS methods outperform standard CS, as quantified by the Frobenius norm. Furthermore, MPO-PCS demonstrates superior performance compared to LR-PCS, which can be attributed to the lower degrees of freedom in the MPO structure relative to the low-rank structure [cf. Eqs. (14),(18))]. In addition, LR-PCS achieves performance comparable to that of LR-MLE, as it attains the information-theoretically optimal error bound. In contrast, the performance of MPO-PCS is slightly inferior to that of MPO-MLE, primarily due to its suboptimal recovery error bound, which contains a factor of n2 rather than n. Nevertheless, according to Table 3, we note that CS-based methods are significantly more computationally efficient than MLE-based methods (more than 100 × faster in the cases considered), as the latter require iterative optimization procedures.
In the final test, we examine how the recovery error scales with qubit number n, using parameter settings of r = 4 for T = 0.2, r = 4(n − 1) for T = 2, r = 1 for GHZ state and an error tolerance of 10−14 for determining bond dimension D. As highlighted in Fig. 5, both LR-PCS and MPO-PCS effectively attenuate the growth in recovery error as the system size n increases, in contrast to the standard CS method. This improvement is attributed to the utilization of the low-dimensional structure in these methods. Additionally, the recovery error of MPO-PCS scales polynomially with n, as indicated in Eq. (18), rather than exponentially as in Eq. (14) of LR-PCS; hence, MPO-PCS outperforms LR-PCS in terms of recovery error.

Mean squared error as a function of the total qubit number with M = 3000 for (a) thermal state (T = 0.2), (b) thermal state (T = 2), and (c) GHZ state.
Discussion
This paper has introduced the projected classical shadow (PCS) method to address the computational challenges of quantum state tomography (QST) in large Hilbert spaces by leveraging the classical shadow (CS) framework combined with a physical projection step. The method provides guaranteed performance under Haar-random measurements. Theoretical results show that the PCS method achieves high accuracy in reconstructing general and low-rank quantum states while minimizing the number of state copies, meeting information-theoretically optimal bounds. Moreover, the PCS method reduces the number of state copies required for matrix product operator (MPO) states compared to existing results using Haar random measurements. Numerical validation further demonstrates the practicality and computational efficiency of PCS for large-scale quantum state reconstruction.
More broadly, our formalism points to a promising new general direction for CS methods. Although originally introduced for the estimation of state properties rather than the state per se31, CS nevertheless relies on an estimator ρCS of the full density matrix. As our results reveal, this generally unphysical estimator can be projected onto a physical space of interest—whether the entire Hilbert space or some subset thereof (Fig. 1)—with performance guarantees that attain information-theoretic bounds (for the case of arbitrary and low-rank states) or improve upon previous scaling results (for MPO states). Therefore in merging the conceptual simplicity of CS with the scaling improvements possible in structured quantum systems, our results suggest a compelling role for PCS in traditional quantum state estimation, with exciting opportunities for future exploration in even more types of subspaces tailored to specific physical conditions or prior knowledge, such as projected entangled pair operator (PEPO)55 and multiscale entanglement renormalization ansatz (MERA)56 constructions.
Another promising direction is to analyze the PCS method under local measurements. Although global measurements—characterized by joint operations across all qubits—are theoretically advantageous, their implementation using practical quantum circuits poses substantial challenges. In contrast, local measurements—whether taken from the Haar measure16, the Pauli set23, or local informationally complete POVMs48—are significantly more compatible with current quantum architectures and can be implemented with greater experimental efficiency. While the projection-based framework employed in this work could, in principle, be directly adapted to local measurement scenarios, the theoretical machinery developed herein does not extend to such cases, as the concentration inequality in Eq. (27) [see section “Methods”] cannot be established under local measurements. Addressing this gap necessitates the development of new analytical tools tailored to the locality constraints, which we leave as an important direction for future investigation.
Methods
This section provides detailed proofs and a comprehensive description of the MLE-based methods (LR-MLE and MPO-MLE) introduced in the last section.
Proof of Equation 4
Proof
We expand \({\mathbb{E}}{\Vert{{\boldsymbol{\rho }}}_{{\rm{CS}}}-{{\boldsymbol{\rho }}}^{\star }\Vert}_{F}^{2}\) as follows:
where the third line follows from \({\mathbb{E}}[{{\boldsymbol{\rho }}}_{m}]={{\boldsymbol{\rho }}}^{\star }\), the fourth from the equivalence under expectation of all measurements m, and the last from the normalization \(\langle {{\boldsymbol{\phi }}}_{1,{j}_{1}}{{\boldsymbol{\phi }}}_{1,{j}_{1}}^{\dagger },{{\boldsymbol{\phi }}}_{1,{j}_{1}}{{\boldsymbol{\phi }}}_{1,{j}_{1}}^{\dagger }\rangle =\langle {{\boldsymbol{\phi }}}_{1,{j}_{1}}{{\boldsymbol{\phi }}}_{1,{j}_{1}}^{\dagger },{{\bf{I}}}_{{2}^{n}}\rangle =1\).
Proof of Theorem 1
Proof
We define a restricted Frobenius norm as
where \(\widehat{{\mathbb{X}}}=\{{\boldsymbol{\rho }}\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}:\mathrm{trace}\,({\boldsymbol{\rho }})=0,{\boldsymbol{\rho }}={{\boldsymbol{\rho }}}^{\dagger },\parallel\!\!{\boldsymbol{\rho }}{\parallel }_{F}\le 1\}\). By the definition of the restricted Frobenius norm in Eq. (20), we can further analyze
where the inequality follows from the assumption that the physical projection \({{\mathcal{P}}}_{{\mathbb{X}}}(\cdot )\) is optimal and therefore satisfies nonexpansiveness. Next, we bound \(\frac{1}{M}\mathop{\sum}\nolimits_{m = 1}^{M}[({2}^{n}+1){{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger }-{{\bf{I}}}_{{2}^{n}}]-{{\boldsymbol{\rho }}}^{\star }\) using the covering argument. According to the assumption, we initially construct an ϵ-net \(\{{{\boldsymbol{\rho }}}^{(1)},\ldots ,{{\boldsymbol{\rho }}}^{({N}_{\epsilon }(\widetilde{{\mathbb{X}}}))}\}\in \widetilde{{\mathbb{X}}}\subset \widehat{{\mathbb{X}}}\), where the size of \(\widetilde{{\mathbb{X}}}\) is denoted by \({N}_{\epsilon }(\widetilde{{\mathbb{X}}})\) such that
In addition, we denote \({{\boldsymbol{B}}}_{m}=\frac{1}{M}(({2}^{n}+1){{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger }-{{\bf{I}}}_{{2}^{n}}-{{\boldsymbol{\rho }}}^{\star })\) and derive
By setting ϵ = 0.5 and moving the second term on the right-hand side to the left, we get
Then we need to build the concentration inequality for the right-hand side of Eq. (23). First, we define
and due to \({\mathbb{E}}[({2}^{n}+1){{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger }-{{\bf{I}}}_{{2}^{n}}-{{\boldsymbol{\rho }}}^{\star }]={\bf{0}}\), we have \({\mathbb{E}}[{s}_{m}]=0\). Moreover, we rewrite sm as
where the second line follows from \({\mathrm{trace}}\,({{\boldsymbol{\rho }}}^{(p)})=\langle {{\bf{I}}}_{{2}^{n}},{{\boldsymbol{\rho }}}^{(p)}\rangle =0\). We can further compute
where \(| {\boldsymbol{D}}| =\sqrt{{{\boldsymbol{D}}}^{2}}={\boldsymbol{U}}\sqrt{{\boldsymbol{\Sigma }}}{{\boldsymbol{V}}}^{\dagger }\) denotes the absolute value of the matrix D with its compact SVD D2 = UΣV† and \({\boldsymbol{A}}^{{\otimes}a} = \underbrace{{\boldsymbol{A}}\otimes \cdots \otimes {\boldsymbol{A}}}_{{a}}\) holds for any matrix A. Given that the unitary Haar measure conforms to any unitary p-design, as exemplified in [ref. 57, Example 51], we can deduce the third line, with PSym representing an orthogonal projector onto the symmetric subspace. The second inequality follows from [ref. 58, Lemma 7] and \(\Vert| {\boldsymbol{D}}| {\parallel }_{F}^{\otimes a}=\Vert | {\boldsymbol{D}}{| }^{\otimes a}{\Vert }_{F}\) due to the positive semidefiniteness of ∣D∣⊗a and the orthogonal projection. In the last line, we utilize \(\Vert | {\boldsymbol{D}}| {\Vert }_{F}\le \Vert {{\boldsymbol{\rho }}}^{(p)}{\Vert }_{F}+\Vert \frac{\langle {{\boldsymbol{\rho }}}^{\star },{{\boldsymbol{\rho }}}^{(p)}\rangle }{{2}^{n}+1}{{\bf{I}}}_{{2}^{n}}{\Vert}_{F}\le 1+\frac{{2}^{n}}{{2}^{n}+1}\Vert {{\boldsymbol{\rho }}}^{(p)}{\Vert }_{F}\Vert {{\boldsymbol{\rho }}}^{\star }{\Vert }_{F}\le 2\), ∥PSym∥≤1 and \(\frac{{({2}^{n}+1)}^{a}}{{C}_{{2}^{n}+a-1}^{a}}\le \frac{3}{2}a!\).
Based on Lemma 1 with \({\mathbb{E}}[{s}_{m}]=0\) and \({\mathbb{E}}[| {s}_{m}{| }^{a}]\le 6\times {2}^{a-2}a!\), for any t ∈ [0, 1], we have the probability
Combining Eqs. (23), (27), there exists an ϵ-net \(\widetilde{{\mathbb{X}}}\) of \(\widehat{{\mathbb{X}}}\) such that
We opt for \(t=O\left(\sqrt{\frac{\log {N}_{\epsilon }(\widetilde{{\mathbb{X}}})}{M}}\right)\), and subsequently, with probability \(1-{e}^{-\Omega (\log {N}_{\epsilon }(\widetilde{{\mathbb{X}}}))}\), we derive
Proof of Theorem 3
Proof
We define a restricted Frobenius norm as following:
where the set \({\widehat{{\mathbb{X}}}}_{r}\) is defined as follows:
By the definition of the restricted Frobenius norm in Eq. (30), we can further analyze
where the first two inequalities respectively follow the nonexpansiveness property of the projection and the quasi-optimality property of eigenvalue decomposition (ED) projection42. Next, we need to bound the first term in the last line of Eq. (32) using the covering argument. According to [ref. 59, Lemma 3.1], we initially construct an ϵ-net \(\{{{\boldsymbol{\rho }}}^{(1)},\ldots ,{{\boldsymbol{\rho }}}^{{N}_{\epsilon }({\widetilde{{\mathbb{X}}}}_{2r})}\}\in {\widetilde{{\mathbb{X}}}}_{2r}\subset {\widehat{{\mathbb{X}}}}_{2r}\) in which the size of \({\widetilde{{\mathbb{X}}}}_{2r}\) is denoted by \({N}_{\epsilon }({\widetilde{{\mathbb{X}}}}_{2r})\le {(\frac{9}{\epsilon })}^{({2}^{n+2}+2)r}\) such that
Combining Eqs. (23), (27), there exists an ϵ-net \({\widetilde{{\mathbb{X}}}}_{2r}\) of \({\widehat{{\mathbb{X}}}}_{2r}\) such that
where we set \(\epsilon =\frac{1}{2}\) and C is a positive constant. We opt for \(t=O\left(\sqrt{\frac{{2}^{n}r}{M}}\right)\) and subsequently, with probability \(1-{e}^{-\Omega ({2}^{n}r)}\), derive
Proof of Theorem 4
Proof
We define a restricted Frobenius norm as follows:
where we denote by \({\widehat{{\mathbb{X}}}}_{D}\) the normalized set of MPOs with bond dimension D:
Note that the presence of additional orthonormal structures arises from the fact that, according to ref. 60, any TT form is equivalent to a left-orthogonal TT form42.
We define \({{\mathcal{P}}}_{\mathrm{trace}\,}(\cdot )\) as a projection onto a convex set \(\{{\boldsymbol{\rho }}\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}:\mathrm{trace}\,({\boldsymbol{\rho }})=1\}\). By the definition of the restricted Frobenius norm (36), we can derive
where the first two inequalities respectively follow from the nonexpansiveness property of the projection onto the convex set, while the third inequality is a consequence of the quasi-optimality property of TT-SVD projection42. Additionally, we denote
Based on ∥ρ∥F = ∥L(Xn)∥F ≤ 1 for a left-orthogonal TT form using [ref. 61, Eq.(44)], we obtain the last line.
Next, we will apply the covering argument to bound (38). For any fixed value of \(\widetilde{{\boldsymbol{\rho }}}\in {\widetilde{{\mathbb{X}}}}_{2D}\subset {\widehat{{\mathbb{X}}}}_{2D}\), using Eq. (23), concentration inequality in Eq. (27) and Lemma 3, there exists an ϵ-net \({\widetilde{{\mathbb{X}}}}_{2D}\) of \({\widehat{{\mathbb{X}}}}_{2D}\) such that
where we set \(\epsilon =\frac{1}{2}\) and C is a positive constant. We opt for \(t=O\left(\sqrt{\frac{n{D}^{2}\log n}{M}}\right)\) and subsequently, with probability \(1-{e}^{-\Omega (n{D}^{2}\log n)}\), derive
Maximum Likelihood Estimation for Low-rank States and MPO states Maximum likelihood estimation (MLE) is a widely used technique for quantum state reconstruction. Under single-shot measurements, the MLE loss function can be formulated as follows47,62,63,64,65,66:
However, the objective function in (42) does not leverage the structural properties inherent in quantum states. To address this limitation, we propose two MLE methods tailored for (1) low-rank states and (2) MPO states.
Low-rank MLE
When the density matrix is low-rank, we adopt a Riemannian gradient descent (RGD) algorithm on the unit Frobenius norm sphere. Specifically, for a quantum state \({{\boldsymbol{\rho }}}^{\star }\in {{\mathbb{C}}}^{{2}^{n}\times {2}^{n}}\) satisfying trace(ρ⋆) = 1 and ρ⋆ ≽ 0, we can factorize it as \({{\boldsymbol{\rho }}}^{\star }={{\boldsymbol{F}}}^{\star }{{{\boldsymbol{F}}}^{\star }}^{\dagger },{{\boldsymbol{F}}}^{\star }\in {{\mathbb{C}}}^{{2}^{n}\times r}\) with ∥F⋆∥F = 1. This leads to the reformulated MLE objective:
The corresponding Riemannian gradient descent update reads:
where the Euclidean gradient is \({\nabla }_{{\boldsymbol{F}}}{f}_{1}({\boldsymbol{F}})=-\frac{1}{M}\mathop{\sum}\nolimits_{m = 1}^{M}\frac{{{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger }}{\langle {{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger },{\boldsymbol{F}}{{\boldsymbol{F}}}^{\dagger }\rangle }{\boldsymbol{F}}\) and \({{\mathcal{P}}}_{{T}_{{\boldsymbol{F}}}\text{Sp}}({\boldsymbol{V}})={\boldsymbol{V}}-\langle {\boldsymbol{F}},{\boldsymbol{V}}\rangle {\boldsymbol{F}}\) denotes the projection onto the tangent space TFSp = {F: ∥F∥F = 1}. Here, μ is the step size.
MPO-based MLE
When the density matrix admits an MPO representation with bond dimension D, we consider the constrained optimization problem:
We solve (43) using a projected gradient descent (PGD) scheme:
where \({\nabla }_{{\boldsymbol{\rho }}}{f}_{2}({\boldsymbol{\rho }})=-\frac{1}{M}\sum\limits_{m = 1}^{M}\frac{{{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger }}{\langle {{\boldsymbol{\phi }}}_{m,{j}_{m}}{{\boldsymbol{\phi }}}_{m,{j}_{m}}^{\dagger },{\boldsymbol{\rho }}\rangle }\), and μ is the step size.
Materials
Lemma 1
(Classical Bernstein’s inequality23, Theorem 6) Let \({s}_{1},\ldots ,{s}_{n}\in {\mathbb{R}}\) denote i.i.d. copies of a mean-zero random variable s that obeys \({\mathbb{E}}[| s{| }^{p}]\le p!{R}^{p-2}{\sigma }^{2}/2\) for all integers p≥2, where R, σ2 > 0 are constants. Then, for all t > 0,
Lemma 2
(ref. 29, Lemma 10) For any \({{\boldsymbol{A}}}_{i},{{\boldsymbol{A}}}_{i}^{\star }\in {{\mathbb{R}}}^{{r}_{i-1}\times {r}_{i}},i\in \{1,\ldots ,N\}\), we have
Lemma 3
There exists an ϵ-net \({\widetilde{{\mathbb{X}}}}_{D}\) for \({\widehat{{\mathbb{X}}}}_{D}\) in Eq. (39) under the Frobenius norm, i.e., ∥ρ − ρ(p)∥F ≤ ϵ for \({{\boldsymbol{\rho }}}^{(p)}\in {\widetilde{{\mathbb{X}}}}_{D}\), obeying
where \({N}_{\epsilon }({\widetilde{{\mathbb{X}}}}_{D})\) denotes the number of elements in the set \({\widetilde{{\mathbb{X}}}}_{D}\).
Proof
For each set of matrices \(\{L({{\boldsymbol{X}}}_{\ell })\in {{\mathbb{R}}}^{4D\times D}:\parallel L({{\boldsymbol{X}}}_{\ell })\parallel \le 1\}\), according to ref. 67, we can construct an ξ-net \(\{L({{\boldsymbol{X}}}_{\ell }^{(1)}),\ldots ,L({{\boldsymbol{X}}}_{\ell }^{({N}_{\ell })})\}\) with the covering number \({N}_{\ell }\le {(\frac{4+\xi }{\xi })}^{4{D}^{2}}\) such that
for all ℓ ∈ {1, …, n − 1}. Also, we can construct an ξ-net \(\{L({{\boldsymbol{X}}}_{n}^{(1)}),\ldots ,L({{\boldsymbol{X}}}_{n}^{({N}_{n})})\}\) for \(\{L({{\boldsymbol{X}}}_{n})\in {{\mathbb{R}}}^{4D\times 1}:\parallel L({{\boldsymbol{X}}}_{n}){\parallel }_{F}\le 1\}\) such that
with the covering number \({N}_{n}\le {(\frac{2+\xi }{\xi })}^{4D}\).
Therefore, we can construct a ξ-net \(\{[{{\boldsymbol{X}}}_{1}^{(1)},\ldots ,{{\boldsymbol{X}}}_{n}^{(1)}],\ldots ,[{{\boldsymbol{X}}}_{1}^{({N}_{1})},\ldots ,{{\boldsymbol{X}}}_{n}^{({N}_{n})}]\}\) with covering number
for any MPO ρ = [X1, …, Xn] with bond dimension D. Then we expand ∥ρ − ρ(p)∥F as follows:
where the second line and the second inequality respectively follow Lemma 2 and29, Eq.(47). In addition, we choose \(\xi =\frac{\epsilon }{n}\) in the last line. Ultimately, we can construct an ϵ-net \(\{{{\boldsymbol{\rho }}}^{(1)},\ldots ,{{\boldsymbol{\rho }}}^{{N}_{1}\cdots {N}_{n}}\}\) with covering number
for any MPO \({\boldsymbol{\rho }}\in {\widehat{{\mathbb{X}}}}_{D}.\)
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Code availability
The code used in this study is available from the corresponding author upon reasonable request.
References
Bertrand, J. & Bertrand, P. A tomographic approach to Wigner’s function. Found. Phys. 17, 397–405 (1987).
Vogel, K. & Risken, H. Determination of quasiprobability distributions in terms of probability distributions for the rotated quadrature phase. Phys. Rev. A 40, 2847 (1989).
Leonhardt, U. Quantum-state tomography and discrete wigner function. Phys. Rev. Lett. 74, 4101 (1995).
Hradil, Z. Quantum-state estimation. Phys. Rev. A 55, R1561 (1997).
James, D. F. V., Kwiat, P. G., Munro, W. J. & White, A. G. Measurement of qubits. Phys. Rev. A 64, 052312 (2001).
Haah, J., Harrow, A., Ji, Z., Wu, X. & Yu, N. Sample-optimal tomography of quantum states. IEEE Trans. Inf. Theory 63, 5628–5641 (2017).
Fano, U. Description of states in quantum mechanics by density matrix and operator techniques. Rev. Mod. Phys. 29, 74 (1957).
Reháček, J., Hradil, Z. & Ježek, M. Iterative algorithm for reconstruction of entangled states. Phys. Rev. A 63, 040303 (2001).
Blume-Kohout, R. Optimal, reliable estimation of quantum states. N. J. Phys. 12, 043034 (2010).
Granade, C., Combes, J. & Cory, D. Practical Bayesian tomography. N. J. Phys. 18, 033024 (2016).
Lukens, J. M., Law, K. J. H., Jasra, A. & Lougovski, P. A practical and efficient approach for Bayesian quantum state estimation. N. J. Phys. 22, 063038 (2020).
Blume-Kohout, R. Robust error bars for quantum tomography. arXiv:1202.5270 (2012).
Faist, P. & Renner, R. Practical and reliable error bars in quantum tomography. Phys. Rev. Lett. 117, 010404 (2016).
Lohani, S., Kirby, B. T., Brodsky, M., Danaci, O. & Glasser, R. T. Machine learning assisted quantum state estimation. Mach. Learn. Sci. Technol. 1, 035007 (2020).
Kyrillidis, A. et al. Provable compressed sensing quantum state tomography via non-convex methods. npj Quantum Inf. 4, 36 (2018).
Brandão, F. G., Kueng, R. & França, D. S. Fast and robust quantum state tomography from few basis measurements. arXiv:2009.08216 (2020).
Zhu, Z., Lukens, J. M. & Kirby, B. T. On the connection between least squares, regularization, and classical shadows. Quantum 8, 1455 (2024).
Sen, P., Bhatia, A. S., Bhangu, K. S. & Elbeltagi, A. Variational quantum classifiers through the lens of the Hessian. Plos one 17, e0262346 (2022).
Liu, Y. et al. Variational quantum circuits for quantum state tomography. Phys. Rev. A 101, 052316 (2020).
Lloyd, S., Mohseni, M. & Rebentrost, P. Quantum principal component analysis. Nat. Phys. 10, 631–633 (2014).
Kurmapu, M. K. Machine learning assisted quantum state tomography (2020).
Kueng, R., Rauhut, H. & Terstiege, U. Low rank matrix recovery from rank one measurements. Appl. Comput. Harmon. Anal. 41, 88–116 (2017).
Guţă, M., Kahn, J., Kueng, R. & Tropp, J. A. Fast state tomography with optimal error bounds. J. Phys. A: Math. Theor. 53, 204001 (2020).
Voroninski, V. Quantum tomography from few full-rank observables. arXiv:1309.7669 (2013).
Liu, Y.-K. Universal low-rank matrix recovery from Pauli measurements.Adv. Neural Inf. Process Syst 24, 1–9 (2011).
Eisert, J., Cramer, M. & Plenio, M. B. Colloquium: Area laws for the entanglement entropy. Rev. Mod. Phys. 82, 277–306 (2010).
Pirvu, B., Murg, V., Cirac, J. I. & Verstraete, F. Matrix product operator representations. N. J. Phys. 12, 025012 (2010).
Noh, K., Jiang, L. & Fefferman, B. Efficient classical simulation of noisy random quantum circuits in one dimension. Quantum 4, 318 (2020).
Qin, Z., Jameson, C., Gong, Z., Wakin, M. B. & Zhu, Z. Quantum state tomography for matrix product density operators. IEEE Trans. Inf. Theory 70, 5030–5056 (2024).
Qin, Z. et al. Sample-optimal quantum state tomography for structured quantum states in one dimension. arXiv:2410.02583 (2024).
Huang, H.-Y., Kueng, R. & Preskill, J. Predicting many properties of a quantum system from very few measurements. Nat. Phys. 16, 1050–1057 (2020).
Acharya, A., Saha, S. & Sengupta, A. M. Shadow tomography based on informationally complete positive operator-valued measure. Phys. Rev. A 104, 052418 (2021).
Akhtar, A. A., Hu, H.-Y. & You, Y.-Z. Scalable and flexible classical shadow tomography with tensor networks. Quantum 7, 1026 (2023).
Grier, D., Pashayan, H. & Schaeffer, L. Sample-optimal classical shadows for pure states. Quantum 8, 1373 (2024).
Ippoliti, M. Classical shadows based on locally-entangled measurements. Quantum 8, 1293 (2024).
Becker, S., Datta, N., Lami, L. & Rouz, C. Classical shadow tomography for continuous variables quantum systems. IEEE Trans. Inf. Theory 70, 3427–3452 (2024).
Huang, H.-Y., Preskill, J. & Soleimanifar, M. Certifying almost all quantum states with few single-qubit measurements. 1202–1206 (IEEE, 2024).
Wei, V., Coish, W., Ronagh, P. & Muschik, C. A. Neural-shadow quantum state tomography. Phys. Rev. Res. 6, 023250 (2024).
Struchalin, G., Zagorovskii, Y. A., Kovlakov, E., Straupe, S. & Kulik, S. Experimental estimation of quantum state properties from classical shadows. PRX Quantum 2, 010307 (2021).
Kokaew, W., Kulchytskyy, B., Matsuura, S. & Ronagh, P. Bootstrapping classical shadows for neural quantum state tomography. arXiv:2405.06864 (2024).
Chen, Y. & Ye, X. Projection onto a simplex. arXiv:1101.6081 (2011).
Oseledets, I. Tensor-train decomposition. SIAM J. Sci. Comput. 33, 2295–2317 (2011).
Nielsen, M. A. & Chuang, I. L. Quantum computation and quantum information. (Cambridge university press, 2000).
Schwemmer, C. et al. Systematic errors in current quantum state tomography tools. Phys. Rev. Lett. 114, 080403 (2015).
Smolin, J. A., Gambetta, J. M. & Smith, G. Efficient method for computing the maximum-likelihood quantum state from measurements with additive gaussian noise. Phys. Rev. Lett. 108, 070502 (2012).
Lvovsky, A. I. Iterative maximum-likelihood reconstruction in quantum homodyne tomography. J. Opt. B: Quantum Semiclass. Opt. 6, S556 (2004).
Baumgratz, T., Nüeler, A., Cramer, M. & Plenio, M. B. A scalable maximum likelihood method for quantum state tomography. N. J. Phys. 15, 125004 (2013).
Jameson, C. et al. Optimal quantum state tomography with local informationally complete measurements. arXiv:2408.07115 (2024).
Lukens, J. M., Law, K. J. & Bennink, R. S. A Bayesian analysis of classical shadows. npj Quantum Inf. 7, 113 (2021).
Hu, H.-Y. & You, Y.-Z. Hamiltonian-driven shadow tomography of quantum states. Phys. Rev. Res. 4, 013054 (2022).
Hu, H.-Y., Choi, S. & You, Y.-Z. Classical shadow tomography with locally scrambled quantum dynamics. Phys. Rev. Res. 5, 023027 (2023).
Candes, E. J. & Plan, Y. Tight oracle inequalities for low-rank matrix recovery from a minimal number of noisy random measurements. IEEE Trans. Inf. Theory 57, 2342–2359 (2011).
Werner, A. H. et al. Positive tensor network approach for simulating open quantum many-body systems. Phys. Rev. Lett. 116, 237201 (2016).
Cramer, M. et al. Efficient quantum state tomography. Nat. Commun. 1, 1–7 (2010).
Cirac, J. I., Perez-Garcia, D., Schuch, N. & Verstraete, F. Matrix product states and projected entangled pair states: Concepts, symmetries, theorems. Rev. Mod. Phys. 93, 045003 (2021).
Haegeman, J., Osborne, T. J., Verschelde, H. & Verstraete, F. Entanglement renormalization for quantum fields in real space. Phys. Rev. Lett. 110, 100402 (2013).
Mele, A. A. Introduction to Haar measure tools in quantum information: A beginner’s tutorial. arXiv:2307.08956 (2023).
Zhu, Z., Li, Q., Tang, G. & Wakin, M. B. The global optimization geometry of low-rank matrix optimization. IEEE Trans. Inf. Theory 67, 1308–1331 (2021).
Candès, E. J., Li, X., Ma, Y. & Wright, J. Robust principal component analysis? J. ACM 58, 1–37 (2011).
Holtz, S., Rohwedder, T. & Schneider, R. On manifolds of tensors of fixed tt-rank. Numer. Math. 120, 701–731 (2012).
Qin, Z., Wakin, M. B. & Zhu, Z. Guaranteed nonconvex factorization approach for tensor train recovery. arXiv:2401.02592 (2024).
Hradil, Z., Řeháček, J., Fiurášek, J. & Ježek, M. 3 maximum-likelihood methods in quantum mechanics. Quantum State Estimation 59–112 (2004).
Gonçalves, D. S., Gomes-Ruggiero, M. A., Lavor, C., Farias, O. J. & Ribeiro, P. S. Local solutions of maximum likelihood estimation in quantum state tomography. Quantum Inf. Comput. 12, 775–790 (2012).
Silva, G., Glancy, S. & Vasconcelos, H. M. Investigating bias in maximum-likelihood quantum-state tomography. Phys. Rev. A 95, 022107 (2017).
Shang, J., Zhang, Z. & Ng, H. K. Superfast maximum-likelihood reconstruction for quantum tomography. Phys. Rev. A 95, 062336 (2017).
Scholten, T. L. & Blume-Kohout, R. Behavior of the maximum likelihood in quantum state tomography. N. J. Phys. 20, 023050 (2018).
Zhang, A. & Xia, D. Tensor SVD: Statistical and computational limits. IEEE Trans. Inf. Theory 64, 7311–7338 (2018).
Acknowledgements
We acknowledge funding support from the National Science Foundation (CCF-2241298, EECS-2409701) and the U.S. Department of Energy (ERKJ432, DE-SC0024257). We thank the Ohio Supercomputer Center for providing the computational resources and the Quantum Collaborative led by Arizona State University for providing valuable expertise and resources. A portion of this work was performed at Oak Ridge National Laboratory, operated by UT-Battelle for the U.S. Department of Energy under Contract No. DE-AC05-00OR22725.
Author information
Authors and Affiliations
Contributions
Z.Q. led the conceptualization, developed the methodology, implemented the software, and drafted the manuscript. J.M.L. and B.K. contributed to the conceptual design, methodological development, and manuscript revision. Z.Z. supervised the project and contributed to the conceptual design, methodological development, and manuscript revision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qin, Z., Lukens, J.M., Kirby, B.T. et al. Enhancing quantum state reconstruction with structured classical shadows. npj Quantum Inf 11, 147 (2025). https://doi.org/10.1038/s41534-025-01101-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-025-01101-1
