
Abstract
Accurate energy system modelling of chemical separations is a critical component of technology selection to minimize operating costs, energy consumption and emissions. Here we report a hybrid modelling approach based on data-driven and mechanistic models to holistically compare chemical separation performance. Our model can be used to select the most suitable technology for a given chemical separation, such as membrane separation, evaporation, extraction or hybrid configurations, by training a machine learning model to predict solute rejection using an open-access membrane dataset. We estimated an average 40% reduction in energy consumption and carbon dioxide emissions for industrially relevant separations using our methodology. We predicted and analysed 7.1 million solute rejections across several industrial sectors. Pharmaceutical purification could realize carbon dioxide emissions reductions of up to 90% by selecting the most efficient technology. We mapped the reduction in carbon dioxide emissions and the reduction in operating costs globally, establishing parameter thresholds to facilitate corporate and governmental decision-making.
Similar content being viewed by others
Main
The global focus on energy demand and emissions reduction requires immediate exploration of alternative sources and efficiency improvements1,2. Membrane technology has been proposed as a promising separation technology with potential benefits to reduce energy and carbon dioxide emissions1. Nanofiltration is a pressure-driven membrane separation technology that distinguishes molecules and ions according to their physicochemical properties3. Nanofiltration offers advantages, such as energy efficiency, modularity, flexibility and scalability, due to its inherent non-thermal and continuous operation. The removal of impurities from solvents and water is crucial for sustainability and environmental conservation. In nanofiltration, a solute mixture is driven through a membrane, allowing for selective permeation of the components4. The pressure, temperature and concentration differences across the membrane induce a chemical potential difference that drives molecules through the membrane. The measure of molecules retained by the membrane is called solute rejection (R; Supplementary Methods), which is a critical process constant used for designing downstream purification systems. However, the vast chemical space encompassing small organic molecules, organic solvents and synthetic organic polymers poses a challenge as enumerating all possible membrane–solvent–solute combinations is beyond human capabilities5. The potential energy and emissions reduction capabilities of membranes compared with evaporation or extraction in various industrial contexts have been the subject of extensive debate and research1,6,7,8.
Optimization in hyperdimensional spaces has advanced through data-driven methods with the potential to bridge the gap between laboratory-scale nanofiltration experiments and industrial process design. These data-driven solutions hold the promise of addressing long-standing challenges in the natural sciences as they provide the means to address previously intractable problems using traditional analytical approaches9,10,11. For instance, machine learning models enable the estimation of parameters that were once unattainable through conventional analytical solutions, offering new possibilities for scientific exploration and process optimization12.
In this study, we focused on exploring the design space of separation processes and identifying the most suitable separation technology for specific applications. Nanofiltration process designs currently rely on solute rejection and selectivity values, impeding accurate technology selection and commercial decision-making. Here, we explored solutions for informed decision-making in the selection of separation technology. We found that accurate predictions of the rejection of small organic molecules, coupled with a comprehensive analysis of energy demand and carbon dioxide equivalent emissions, enable the environmentally conscious optimal selection of nanofiltration, evaporation, extraction and their respective hybrid technologies (Fig. 1a). We aimed to identify industrial sectors that can fully harness the advantages of nanofiltration. Through energy analysis and comparisons, we assessed nanofiltration alongside other solute–solute separation and concentration technology types, such as evaporation and extraction. Importantly, rather than comparing evaporation and extraction with nanofiltration, we explored which of these are the most suitable for a particular application. We used minimal metrics to assess the viability of nanofiltration. Our proposed methodology was further simplified by focusing on the carbon dioxide equivalent emissions or overall energy consumption, facilitating corporate and governmental decision-making processes. Finally, we explored in vitro how, and with what benefits, nanofiltration can be integrated into existing industrial separation processes (Fig. 1b).

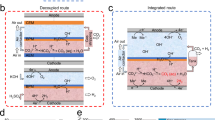
a, Schematic representation of this work: hybrid modelling for the chemical separation industry. The curated NF-10K dataset was used in the machine learning and energy models to forecast the applicability of nanofiltration in the untapped chemical space (that is, unexplored separations). The eight implications and results of the hybrid modelling are expected to aid industrial separation design and decision-making. Eevaporation, energy of evaporation; Enanofiltration, energy of nanofiltration; Eextraction, energy of extraction; S, solvent; R, rejection; logP, log partition coefficient. b, The three chemical separation technologies considered in this research: triple-effect continuous evaporator, continuous nanofiltration and liquid–liquid extraction. Details of assumptions and considerations are given in Supplementary Methods.
Predictive model for the chemical separation space
We compiled an extensive collection of nanofiltration measurements, focusing on commercially available membranes. This compilation of literature-based data, denoted the NF-10K dataset, includes 9,921 nanofiltration measurements (Fig. 1a) with rejection data for 1,089 small organic solutes across different solvents and membranes (Supplementary Methods). We compared the dataset with 124,010 organic compounds from various application datasets spanning domains from pharmaceuticals to pesticides (Supplementary Table 3).
To compare the molecular structures in the NF-10K dataset with those in the application datasets, we used a hybrid principal component analysis (PCA) coupled with t-distributed stochastic neighbour embedding (t-SNE) and generative topological mapping (GTM; Supplementary Methods). The hybrid PCA–t-SNE method (Fig. 2a) revealed that the NF-10K dataset is spread across the chemical space of the application datasets. The molecular weight and Crippen log partition coefficient (logP) distributions are similar across the datasets (Fig. 2b,c). The GTM landscape map (Fig. 2e) also indicates that the NF-10K dataset blends well into the chemical space of the application datasets. Comparison of the hybrid PCA–t-SNE and GTM results revealed that the NF-10K dataset is a good representation of the application domains with respect to chemical structure. Thus, the NF-10K dataset can be used to build predictive models, effectively representing industrial applications. Note that the NF-10K dataset is skewed to have high-rejection solutes because nanofiltration membrane development favours highly rejected solutes (Fig. 2d). While a balanced dataset is generally sought13, solutes with high rejection are critical in solute concentration and solvent purification applications.

a, Chemical space representation (PCA–t-SNE analysis) of the NF-10K dataset, the application datasets and the common nanofiltration markers. Similar molecules appear close to each other on the two-dimensional chemical space map due to their structural similarity. Overlapping points from the application datasets and markers indicate overlapping features in the NF-10K and application datasets. b,c, Molecular weight (b) and logP (c) distributions of the application datasets (red) and the NF-10K dataset (blue). d, Rejection distribution of the NF-10K dataset. e, GTM landscape map visualizing the chemical space of the NF-10K and application datasets. Components of the NF-10K dataset appear as dispersed clusters (yellow), indicating a high diversity of molecules. f, Training of the GNN downstream predictive model, showing validation of RMSE and R2 with increasing number of training steps and the test RMSE (green star). The GNN model inputs were solute chemical structures, solvents, membranes and process parameters. The output was the predicted rejection. Lower RMSE and higher R2 scores indicate better results. The results of the machine learning training and evaluation are presented in detail in Supplementary Note 1. Data are presented as moving average values; the shading represents the standard deviation.
Using the NF-10K dataset, we developed a downstream predictive model for solute rejection in nanofiltration using a message-passing graph neural network (GNN; Fig. 2f). The objective of the network was to predict solute rejection based on inputs from the NF-10K dataset, including molecular structure, solvent, membrane and process parameters. The trained GNN model achieved a root mean squared error (RMSE) of 0.1220 with an 89% coefficient of determination (R2) on the test set (Fig. 2f). The GNN model indicated minimal overfitting between the training and test sets (Supplementary Figs. 29–31), ensuring transferable performance to unseen data. The RMSE value of 0.1220 can be attributed to the inherent variability of the original nanofiltration measurements14 rather than the performance of the network itself. Therefore, this high variance is rooted in the missing standardization procedure for nanofiltration experiments, especially with organic solvents15.
The predictive model incorporates all major available parameters to predict rejection across various membranes, solvents and process parameters (Supplementary Methods). The expressiveness of the model enables the the rejection of organic compounds to be predicted using various input parameters. This variability enables us to search for the hypothetical best membrane–solvent pair. The current linear trial-and-error wet-laboratory measurements are expected to be replaced by streamlined, tailor-made, virtual search designs. These advances align with high-throughput methods, especially in the waste-heavy pharmaceutical industry, which is at the forefront of sustainable manufacturing design16,17.
Reducing energy demand, emissions and operating costs
We estimated the energy demand and emissions reductions enabled by the incorporation of nanofiltration into downstream processing. We used solute permeance and partition coefficients to build techno-economic models for energy demand assessments. The calculations and model assumptions, including the parametric examination of external heat integration, were designed to provide a conservative estimate of the average energy and carbon dioxide equivalent emissions savings (Supplementary Methods). We compared nanofiltration with conventional operations across a wide range of binary and ternary separation scenarios. Ternary solute separations were coupled with binary concentration steps to reach comparable product concentrations. This hybrid simulation ensured fair comparison between technology types. Figure 3 shows schematics of the three technologies considered in this work (Supplementary Methods).

a, Simplified process schemes of the three industrial separation types considered in this study: nanofiltration, evaporation and extraction. b, Preferred separation processes for solution concentration among nanofiltration, evaporation and their hybrid process. c, Rejection–energy correlation for nanofiltration and evaporation for solute concentration. The rejection threshold for nanofiltration is 0.6, while hybrid processes are generally preferred between 0.5 and 0.7 rejection. Evaporation or hybrid separation approaches are preferred for solutes having rejection lower than 0.6. The dotted and dashed lines represent average evaporation energy demand for no heat integration (integ.) and 75% heat integration, respectively. d, Distribution of preferred separation technologies and mean specific energy reduction (stars) for different solvents. 2-MeTHF, 2-methyltetrahydrofuran; DMF, N,N-dimethylformamide. The data in b and c are based on concentrating solutions from 1 g l−1 to 95% solubility or a maximum 100 g l−1.
The effectiveness of binary solvent–solute separations depends on maximizing the solute rejection in nanofiltration by increasing the solvent permeance or decreasing the solute permeance. Figure 3b,c indicates that, across all membranes and solvents included in the NF-10K dataset, an average energy reduction of 36% can be realized compared with pure evaporation when concentrating a solution from 1% to 95% solubility, or a maximum 100 g l−1 (Fig. 3c). Even with 75% heat integration, a mean energy demand reduction of 29% is attainable (Supplementary Note 4). In 38–43% of the cases, depending on heat integration, introducing nanofiltration either as a stand-alone operation or as a hybrid nanofiltration–evaporation system could result in a notable energy reduction. Evaporation is preferred in 57–62% of the cases in terms of energy consumption. Based on a wide array of simulations, we have proposed a threshold rejection value above which nanofiltration generally outperforms evaporation (Fig. 3c). This 0.6 rejection parameter boundary between nanofiltration and evaporation simplifies the technical decisions in process design. The threshold depends on the feed concentration, which was 1 g l−1 in our simulations and is valid between 0–50% external heat integration.
The results vary across solvents due to different enthalpy and rejection profiles (Fig. 3d). High boiling point solvents with high average solute rejections, such as water and N,N-dimethylformamide, can realize a substantial reduction in energy when nanofiltration is introduced into the downstream process. Nanofiltration for solvent recovery is advantageous in 11% of cases, with an average 10% energy reduction, assuming acceptable impurity levels of 0.01 g l−1. Therefore, high impurity rejection is essential for efficient solvent recovery. The results for binary separations are presented in detail in Supplementary Figs. 34–58.
Direct solute concentration is used in water treatment, catalyst recovery, solvent purification, natural product extraction, environmental mitigation and pharmaceutical purifications. In evaporation, the energy consumption is quasi-independent of the material characteristics of the impurities and the only governing factors are the evaporation enthalpy and boiling point of the solvent. In contrast, the applicability of nanofiltration is inherently dependent on the rejection of the impurity. Solute rejection can be fine-tuned by changing the membrane, solvent or process parameters, such as the pressure, to reach a desired rejection. This tuning capacity of membrane separations renders nanofiltration a highly and inherently adaptive operation.
Ternary solute–solute–solvent separations are performed to increase the relative purity of a mixture (Supplementary Methods), where relative purity is defined as the ratio of the concentrations of the two solutes. These ternary separation processes rely on maximizing the rejection selectivity (\(\varphi\); Supplementary Methods) between the two solutes. The rejection selectivity determines the upper bound for the attainable relative purity. Similar to binary applications, substantial energy reductions can be realized by replacing liquid–liquid extraction or subsequent evaporation in 74% of solute–solute separations with nanofiltration (Fig. 4a,b). Ternary nanofiltration is preferred over liquid–liquid extraction in 32% of the industrially relevant separation cases in the NF-10K dataset (Fig. 4a), even with 50% external heat integration in subsequent evaporation processes, considering a tenfold increase in relative purity in an equimolar feed. Compared with extraction combined with evaporation, an average energy reduction of 61% can be realized when using nanofiltration for solute–solute separation or for complementing the subsequent solute concentration, considering a tenfold increase in relative purity without heat integration (Fig. 4b). As the energy demand data span multiple orders of magnitude, in most individual separation cases, the energy reduction is close to 0% or 100%. External heat integration of 50% or increasing the target purity to 99% results in average specific energy demand reductions of 58% and 47%, respectively. Impurity removal operations, where only one solute is purified, can result in an average decrease of approximately 50% in specific energy demand, considering a tenfold increase in the relative purity of the product with up to 50% heat integration. Similar reductions can be achieved in purifications to 99%, assuming no external heat integration is applied. Further details regarding ternary separations using different membrane and solvent combinations are provided in Supplementary Figs. 59–76.

a, Preferred separation processes for solute–solute separations among nanofiltration and extraction, excluding solute concentration. b, Preferred solute concentration processes after solute–solute separation by nanofiltration and extraction. c, Parameter boundary (0% and 90% energy reduction) visualization of a kernel density estimation plot based on rejection selectivity (\(\varphi\)) and the difference in log partition coefficients (ΔlogP) for all solvents and membranes. The parameter boundaries create regions where either extraction or nanofiltration is preferred in terms of energy reduction. d, Scatter plot with a 90% energy reduction parameter boundary for a polyamide membrane in acetonitrile. e, Average energy reductions realized with nanofiltration compared with extraction and subsequent evaporation for different membranes in different solvents. The absence of values indicates no available data. f,g, Maps of carbon dioxide equivalent emissions reduction (f) and operating cost reduction (g) for solute separation. The data in a and b are based on a tenfold relative purity increase. For detailed specifications of feed and target compositions, see Supplementary Methods.
Using the rejection selectivity and partition coefficients of the solutes, a parameter boundary can be established with preferred regions for nanofiltration and extraction (Fig. 4c,d). The parameter boundary displays considerable variance across applications, solvents and membranes (Supplementary Tables 13–18), similar to the reduction in overall energy demand (Fig. 4e).
We used energy analysis to estimate both carbon dioxide equivalent emissions reductions and operating cost reductions globally (Fig. 4f,g, Supplementary Figs. 77–80 and Supplementary Table 19). Our calculations indicate that introducing nanofiltration into industrial separation processes is more environmentally beneficial in countries where electrical energy is generated primarily from renewable resources with a lower carbon footprint. As membrane separations use electrical power instead of heat, the difference in the emissions data associated with the two energy types has a notable effect on the attainable reduction in carbon dioxide equivalent emissions. Operating cost reductions vary among the examined countries owing to the differences in natural gas and electricity prices. Nevertheless, the high cost of commercially available membranes can decrease the commercial viability of nanofiltration. The final cost must be assessed case by case before decision-making. Optimization is needed due to a conflict in design parameters, such as pressure and membrane area.
Our simulations and analysis have collectively demonstrated the substantial potential of nanofiltration in energy-conscious manufacturing. Compared with evaporation and extraction processes, nanofiltration offers an average energy reduction of 40% for the concentration of dilute solutions and separation of ternary mixtures. In industrial applications, the established rejection thresholds and parameter boundaries aid decision-making to reduce specific energy demand, waste generation and, potentially, the operating costs of separation processes, with the compelling possibility of geographical differentiation. Coupling parameter thresholds with the predictive capabilities of our machine learning models allows the virtual design and techno-economic assessment of nanofiltration systems without the explicit need to conduct trial-and-error wet-laboratory measurements.
High-throughput virtual screening
Using the predictive models, we explored the chemical space across application datasets. We estimated 7.1 million rejection values for solutes across membranes, solvents, pressures and temperatures. We used a high-throughput virtual search and inverse design approach to explore and identify potential new applications for nanofiltration in an industrial context based on data science10,11. The application datasets were divided into products (for example, pharmaceuticals and catalysts) and impurities (for example, pollutants and surfactants; Supplementary Table 3). An estimated 59% of solutes have a rejection value higher than 0.6. Therefore, these solutes can be efficiently concentrated using nanofiltration (Fig. 5a), depending on the solubility of the solute in the solvent. In specific membrane–solvent combinations, this figure could even reach as high as 86% (polyamide–acetone; Supplementary Fig. 83). Furthermore, this finding suggests that a sizable proportion of the solvents commonly used in industrial processes could be efficiently regenerated using nanofiltration. We estimated a 74% energy reduction in 59% of solute concentration cases, considering membranes and solvents with higher than 20% mean energy reduction potential (Figs. 3c and 5a and Supplementary Fig. 36).

a, Rejection distribution of separable and inseparable molecules for solute concentration with a separable threshold of 0.6 rejections, considering a concentration increase from 1 g l−1 (all membranes, solvents and solutes). The region highlighted in blue covers the majority of separations, with 59% of the total cases. b, Main panel: mass solubility versus predicted rejection for each solvent–solute pair (~1.18 million examples were considered on all membranes). Deeper blue represents higher density regions; the red boxes represent distinct areas, that is, rejections of 0.6 and 0.8 and solubilities of 10 and 100 g l−1. The numbers linked to the boxes denote the respective numbers of examples within the boxes. Side panel: marginal distribution of the log mass solubility of the solvents. c, Product (blue) and impurity (red) separation distributions with the 0.6 rejection threshold. Higher density values represent more solute–membrane–solvent triplets at the corresponding rejection value. d, Density distribution of the rejection selectivity for the products and impurities in the application datasets. The blue area starts at the threshold where nanofiltration is applicable (\({\log }_{10}\varphi > 0.3\)). e, Overall separability (%) of solutes S1–S3 in binary separation by solvent in the application datasets. The chemical substructures represent solutes with the highest average rejection predicted. The number at the base of each bar is the average predicted rejection for solutes featuring the substructure in the given solvent. f, Normal and conservative estimates of the separable molecules (%) for cases where the solubility (c) is higher than 10 g l−1 and the rejection is greater than 0.6, 0.8 or 0.98. PPPs, plant protection products dataset (Supplementary Table 3). Conservative estimates are standard deviation corrected normal values (Supplementary Table 32 and Supplementary Note 10).
Compound solubility could limit the number of solutes that can be subjected to concentration applications. We calculated the solubility of 1.18 million solute–solvent pairs using the best available model18. Over 42.5% and 27.8% of solutes show rejection values above 0.6 with solubilities of 10 and 100 g l−1, respectively (Fig. 5b). Supplementary Table 31 highlights a disparity between solubility in different solvents, with the lowest solubility observed in water. Surprisingly, different application datasets show a large variance in the solubility–rejection values (Supplementary Table 32) and 1–14% of them could be subjected to single-stage nanofiltration for solute or solvent recovery by having a rejection of at least 0.98 with a solubility of 100 g l−1.
Figure 5c shows a disparity in solute rejection distribution between impurities and products. This substantial difference in distribution results in a high separation factor (Supplementary Methods). A higher separation factor across solute–solute pairs indicates a higher increase in relative purity in single-stage nanofiltration (Fig. 3a). The predicted rejection (R′) range for impurities and products covers considerable chemical diversity. High predicted rejections were noted for solutes with large and non-polar structures, while polar and small solutes exhibited lower rejections.
We estimated that approximately 65% of the product–impurity pairs have an absolute rejection selectivity higher than 0.3 \(({\log }_{10}\varphi )\) in ternary solute–solute separations (Fig. 5d). This indicates that the relative purity can increase by at least twofold in 65% of the cases. The overall high rejection selectivity values, coupled with the energy, cost and carbon dioxide equivalent emissions reductions, suggest that a technological shift towards nanofiltration in chemical separations could be advantageous from economic and sustainability perspectives in the relevant cases. The log rejection selectivity data also reveal that in 17% and 4% of the cases, a 10- and 50-fold increase in relative purity can be achieved, respectively (Fig. 5d). Moreover, across the various product and impurity datasets, the ternary solute–solute 50-fold increase in relative purity can be realized in 5–70% of the cases (Supplementary Figs. 84–97). These results underscore the potential of nanofiltration in ternary separations to substantially enhance the purity of products across industrial applications. The integration of nanofiltration into high-purity product manufacturing (for example, in the pharmaceutical and food industries) holds great potential.
Certain solute substructures uniquely influence rejection values across different solvents and membranes (Fig. 5e). For instance, β-lactam (S2) and quinuclidine (S3) rings are primarily found in large antibiotics and catalysts, respectively (Fig. 5e). Solute substructures with the lowest molecular polarity tend to have the highest rejection values. For example, with polyimide membranes, the non-polar decahydronaphthalene (S7) substructure has the highest rejection (Supplementary Fig. 138). There is a correlation between Fig. 5c and Fig. 5f, highlighting that important products such as catalysts, natural molecules and pharmaceuticals have high potential in concentration applications. In contrast, genotoxins and pollutants have lower concentration potential in binary separations. While this difference between impurities and products is beneficial in ternary solute–solute separations, it is undesired in purification applications.
Analysis of molecular structures highlighted high- and low-rejection regions in the chemical space (Fig. 6a), which also displayed differences in the average occurrence of various solute substructures.

a, Visualization of the chemical space for application datasets with rejections and their change (ΔR′) for a DuraMem 300 polyimide membrane in acetonitrile. The dashed boxes represent high- and low-rejection areas, where the average rejection is lower (red) or higher (blue) than the overall rejection. The percentage values represent the relative change compared to the overall rejection. The substructures with the greatest deviation from the average rejection within the dashed boxes are shown above. The latent variables were determined by the PCA–t-SNE method (Supplementary Methods). b, Visualization of the chemical space for products and impurities with four example solutes highlighted. The membrane was non-crosslinked polybenzimidazole in acetonitrile.
The solutes populating the low-rejection region in Fig. 5a are less suitable for solute concentration applications with nanofiltration than solutes in the high-rejection region. In the chemical space in Fig. 6a, two solutes with high structural similarity have a small difference between their latent variables; thus, they are spatially close to each other. However, spatial difference in the chemical space on its own cannot always explain solute rejection. For example, impurities and products are positioned separately in the chemical space in Fig. 6b. Solutes celecoxib (S9), an anti-inflammatory drug, herbicide metabolite S10, abiraterone acetate (S11) and possible abiraterone precursor S12 are positioned across the presented chemical space. Although S9 and S10 display similarly high predicted rejections, there is a difference of 0.83 in the rejection of S11 and S12. Thus, binary separations of S9 and S10 (concentration or solvent recovery) would be less challenging than their ternary separation (separating S9 from S10). In contrast, S11 and S12 are better suited to ternary separation (purifying S12 from S11), although the downstream removal of S12 by nanofiltration would be challenging due to its low rejection.
Membranes with a high resolution for structurally similar solutes would broaden the applicability of nanofiltration, especially in the fine chemical industry, where products and their substrates often have high chemical similarity. We propose that future research on membrane materials should focus more on exploring solutes that exhibit both high and low rejection within a given membrane–solvent system. Current membrane material design often aims to maximize the rejection of individual solutes and solvent permeance, but not the separation factor. Aligning the research focus with maximizing rejection selectivity could realize a broader range of applications. Selective membranes could be developed to highly retain pharmaceuticals while allowing the permeation of genotoxic impurities. The lower chemical diversity of genotoxic impurities compared with pharmaceuticals presents an opportunity to design membranes specifically for genotoxin removal (Supplementary Figs. 24 and 25). Figure 5f shows separable cases in binary concentration systems with respect to each application dataset.
Performance characterization should prioritize solute diversity and maximize rejection selectivity. The high- and low-rejection regions of a membrane must be identified because they correspond to specific molecules with distinct physicochemical parameters where critical industrial solutes can reside. Our results highlight that 91% of pharmaceuticals can be removed from wastewater using nanofiltration (Supplementary Fig. 82). Moreover, genotoxic impurities, plant protection products, surfactants and dyes are also highly retained by nanofiltration in water (Fig. 5f). The purifications of various reaction mixtures by ternary solute–solute separation are presented in Supplementary Figs. 84–97. These examples are in line with the design for separation and design for energy efficiency points of the 12 principles of green engineering and green chemistry.
Validation through industrial case studies
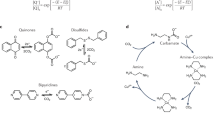
Nanofiltration is used for the purification of high-value solutes in iterative syntheses, known as nanostar sieving19,20. Oligonucleotides, peptides and polymers are grown on a hub, forming a nanostar, and nanofiltration removes impurities while retaining the nanostars (Fig. 7a). The resulting peptides have higher purity than that achieved by conventional methods at similar costs19,20.

a,b, Process schematic (a) and original versus proposed chemical structures (b). Predicted rejections (R′) were estimated using the weighted average of the machine learning-predicted rejections on DMF–DuraMem 300 and MeTHF–polybenzimidazole (PBI). Fmoc, fluoren-9-ylmethyloxycarbonyl. c, PCA–t-SNE chemical space visualization with the solutes S13–S22 highlighted. d, log rejection selectivity (\(\log \varphi\), where \(\varphi\) = (1 − Rimpurity)/(1 − Rnanostar)) between nanostars S13–S15 and impurities S16–S18 (left y axis). Measured nanostar rejection in NMP–THF (NMP, N-methyl-2-pyrrolidone; THF, tetrahydrofuran; 65:35, v/v%) with a crosslinked PBI membrane at 20 bar and 20 °C in a cross-flow configuration (right y axis). Measured rejections are denoted with R. Structures of S19–S22 are detailed in Fig. 8.
However, recent studies have highlighted that low-rejection selectivity between impurities and nanostars could undermine the advantages of nanofiltration. The low rejection of nanostars (0.75–0.90)19 is due to the flexible ether arms of the hub (S13). With the help of the proposed GNN model, we engineered hypothetical hubs to maximize rejection selectivity (Supplementary Methods). Replacing flexible S13 with rigid amides S14 and S15 increased nanostar rejection to 0.987 and 0.9999 (Fig. 7b and Supplementary Tables 28 and 29). This led to a 7- and 810-fold increase in the rejection selectivity between the nanostars and impurity S17, respectively (Fig. 7d). Replacement of the hydroxybenzotriazole (S16) coupling agent with azabenzotriazole (S17) led to a decrease in the rejection from –0.04 to –0.130 (Supplementary Table 30). These two changes result in a ‘no-loss diafiltration’ scenario, where the nanostar is wholly retained. Structural changes in the nanostar can increase solubility21 and capacity and reduce the size, cost and carbon footprint.
We also considered the separation of two pharmaceuticals, namely, apixaban (S19) and metoprolol (S22), in the final step of their synthesis. In 2022, apixaban was the sixth top-selling pharmaceutical22 and metoprolol was the most prescribed beta-blocker in the United States23. In the patented last reaction step in the synthesis of apixaban24, an ammonia–methanol mixture is distilled under vacuum (Fig. 8a). Replacing evaporation with nanofiltration could reduce energy demand by 95% and the carbon footprint by 88–95% (Fig. 8b and Supplementary Fig. 81). Cost reduction is hindered by the high cost of the membrane. In the examined cases, cost reduction can most easily be achieved in the European Union. The threshold membrane prices presented in Fig. 8b demonstrate the yearly membrane cost below which nanofiltration becomes an economically more advantageous process, as far as operating costs are concerned. The predictive model indicates that nanofiltration can achieve a rejection of above 0.963 for apixaban (methanol and DuraMem 300), ensuring its high retention while allowing ammonia to pass through the membrane easily. We successfully demonstrated apixaban separation with a measured rejection of 0.989 (Supplementary Table 26). Figure 8c illustrates that a separation score of 25.1 (rejection selectivity of 90.0; Supplementary Methods) could be achieved between apixaban and ammonia.

a, Final synthesis step of apixaban with the predicted (R′) and measured (R) rejection values. b, Estimated energy demand and carbon dioxide equivalent (equiv.) emissions reductions achieved by introducing nanofiltration into the final synthetic step of apixaban. c, Stage cut (Θ)–impurity rejection–separation score plots for S19 and ammonia. The surface represents S19 and the red line represents ammonia. d, Final synthesis step of metoprolol with the predicted and measured rejection values. e, Estimated energy demand and carbon dioxide equivalent emissions reductions achieved by introducing nanofiltration into the final synthetic step of metoprolol. f, Stage-cut (Θ)–impurity rejection–separation score plots for S20–S22. The surface represents S22 and the red lines represent S20 and S21. In b and e, threshold membrane prices are also presented, below which it is economically beneficial to switch to nanofiltration, based on the operating costs. For details of the procedure, work-up and characterization, see Supplementary Methods. Rejection values highlighted in blue show the highest value between the measured and predicted rejections.
Figure 8d shows the final patented reaction step for metoprolol25. Using DuraMem 300 in methanol, the predicted and measured rejections for metoprolol (S22) were 1.000 and 0.991, respectively, while the predicted and measured rejections for 2-aminopropane (S21) were 0.209 and 0.279, respectively, and the predicted and measured rejections of the metoprolol precursor S20 were 0.917 and 0.888 (Supplementary Table 27), respectively. The separation score for the S21–S22 solute pair was as high as 24.0 (rejection selectivity of 80.1; Fig. 8f). Replacing vacuum distillation and extraction with nanofiltration could reduce energy demand by 61% and carbon emissions by 60%, but with no cost reduction (Fig. 8e and Supplementary Methods). Figure 8e highlights that, based on current heat and electricity prices, a drastic yearly membrane price reduction is needed to make nanofiltration an economically viable option for metoprolol synthesis. In the case of apixaban, more realistic US$170–721 yr−1 m−2 prices would suffice (Fig. 8b) to make nanofiltration a viable option. This shows that further efforts might be necessary to lower membrane costs or increase membrane lifetime for certain applications. The emissions reductions in Fig. 8b,e show that electricity sources also affect the sustainability of nanofiltration. The success of nanofiltration depends on cleaner electricity, linking sustainable energy with energy-efficient technologies.
These examples demonstrate that hybrid predictive modelling could be coupled with a virtual search to improve existing industrial separations or design new chemical manufacturing routes with effective separations. The proposed hybrid modelling methodology enables the search for reactions where nanofiltration is more efficient than conventional separation processes. Moreover, the molecular level design of nanostars applied in iterative synthesis with organic solvent nanofiltration could be tailored to specific applications, solvents and membranes. Our methodology addresses the seventh and twelfth United Nations Sustainable Development Goals, the sixth green chemistry principle and the fourth green engineering principle.
Conclusion
We curated the NF-10K nanofiltration dataset comprising chemical and process parameters. The comprehensive analysis and predictive models based on the NF-10K dataset revealed that nanofiltration is not limited to niche applications, but has the potential to replace or supplement traditional separation technologies, such as evaporation and extraction, realizing substantial energy reductions in up to 74% of industrially relevant liquid-phase separations. We identified membranes and solvents that offer the highest energy reductions for these processes. We introduced three types of parameter threshold that offer simple rule-of-thumb solutions for industrial and governmental decision-making. Through the proposed virtual screening approach, we predicted approximately 7.1 million solute rejection values in 11 industrial domains. Complementing or replacing conventional separations with nanofiltration is energetically and environmentally favourable in an estimated 38–43% of binary solute–solvent separation cases and in 60–70% of ternary solute–solute separation cases across all industries.
The current limitations of our methodology include imprecise rejection predictions for out-of-chemical space solutes, semi-ideal industrial parameters and the lack of a case-by-case optimization for techno-economic comparisons. The energy and carbon dioxide equivalent reduction capabilities vary widely depending on feed and target concentrations, with considerable variability in specific energy reduction outcomes. A more representative dataset and the inclusion of complete life cycle assessments are needed for improved generalization and to directly compare the cost and energy demand of the technologies. Despite these limitations, our results expand expectations for membrane and nanofiltration applications.
Finally, we have experimentally demonstrated the effectiveness of the proposed data-driven methodology through three industrial case studies on 14 solutes. Our proposed amide nanostars have up to 810 times higher rejection selectivity for liquid-phase peptide syntheses than the previous oligo-ether nanostars. Furthermore, we have demonstrated that nanofiltration could result in energy reductions of 95% and 61% during the final synthesis step of two trending pharmaceuticals.
Methods
Dataset curation
The NF-10K dataset comprises 9,921 data points curated from literature containing commercially available membranes. Detailed information about the NF-10K dataset is provided in Supplementary Methods.
Machine learning
The best-performing machine learning model was a directed message-passing GNN based on Chemprop26,27,28. This network uses both molecular and process parameters from the NF-10K dataset to minimize the error between the predicted (R′) and measured rejections (R). The evaluation metric is the RMSE between measured and predicted rejections. More details about the model are provided in Supplementary Note 1 and Supplementary Methods. The model was deployed to an open-access website and can be accessed at www.osndatabase.com/gnn_predictor.
Application datasets
The application datasets cover the following industrial domains: fine chemical synthesis, catalyst recovery and removal, genotoxic impurity removal, organic dye removal, natural product extraction, plant protection products, organic micropollutants and surfactant removal. The total number of studied application molecules was 124,010. More details regarding the application datasets are provided in Supplementary Methods.
Solubility calculation
The solubility of each solute–solvent combination (~1.18 million examples) was estimated using Solprop18. A detailed description of how Solprop operates can be found in Supplementary Methods.
Energy and carbon dioxide equivalent emissions calculations
Energy and carbon dioxide equivalent emissions calculations were conducted as detailed in Supplementary Methods and Supplementary Notes 2 and 4. In summary, binary solvent–solute and ternary solute–solute separation performances were examined using mechanistic models of continuous nanofiltration, counter-current and batch extraction, and triple-effect evaporation (Supplementary Methods). Ternary separation processes can be further categorized as impurity removal and solute–solute separation problems, depending on whether we separate and concentrate only one or both solutes to a target purity and concentration (Supplementary Methods). Another assumption was made, that in solvent purification applications, the many-solute system can be reduced to binary separation if we only consider the solute with the highest rejection to be the limiting factor. Assumptions for model simplification were chosen to provide a conservative, not optimal, estimate of the energy reduction potential of incorporating nanofiltration into separation processes. Greenhouse gas emissions from operating the examined technologies are expressed in carbon dioxide equivalents, determined by the global warming impact of the individual compounds. We used the carbon dioxide equivalent emissions data for electrical and heat energy to calculate emissions reductions for countries worldwide. Similar assessments were made for cost reductions. The abbreviations and symbols used throughout the paper can be found in Supplementary Table 1. Binary and ternary separation technology selectors can be accessed via www.osndatabase.com/binary_energy and www.osndatabase.com/ternary_energy, respectively.
Chemical space visualizations
Chemical space visualization and comparisons were conducted using PCA and t-SNE on the 1,024 bit fingerprints of each molecule. This 1,024-dimensional system was projected onto a two-dimensional space with axes of two latent variables. The spatial distribution of molecules in this two-dimensional space reflects chemical similarities across molecules: molecules that are spatially close have a high chemical fingerprint similarity (Supplementary Methods). The 1,024-sized fingerprints showed excellent chemical space separation and reduced computational time compared with fingerprints of 32 and 4,096 bits (Supplementary Note 11 and Supplementary Fig. 139). Chemical fingerprints are hashed-like bit vectors containing information on the chemical structures of molecules.
Chemical structure engineering
Human-expert nanofiltration experience was used to generate hypothetical structures for the core-hub solute. A suitable and chemically feasible structure was selected and synthesized to evaluate its rejection on crosslinked PBI in a MeTHF–N-methyl-2-pyrrolidone solvent mixture to mimic the industrial example.
Nanofiltration measurements
Nanofiltration experiments were performed in a cross-flow filtration set-up, similarly to previous work29,30. After conditioning the membrane for 48 h, a solute was introduced at a concentration of 0.05 M into the feed tank and left to reach a steady-state concentration in the system. The permeate and retentate streams were sampled and the samples were subjected to high-performance liquid chromatography ultraviolet mass spectrometric analysis. Rejection was determined from the relative change in the concentration of the solute in the retentate and permeate. The DuraMem 300 membrane was purchased from Evonik and soaked and washed in solvent for 24 h before measurement. Crosslinked PBI membranes were fabricated by casting 18% and 19% dope solutions into water at 22.5 °C with 56% relative humidity on an Elcometer automatic film applicator. The wet thickness of the PBI film was set to 200 μm. The cast membranes were crosslinked using 1,4-bis(bromomethyl)benzene in acetonitrile at 60 °C for 12 h. The membranes were cut and stored in water–acetonitrile (98:2 volume%) at 20 °C. For more information on the nanofiltration experiments, see Supplementary Methods.
Chemical synthesis of solutes
Solutes S14, S18 and S20 were synthesized using conventional organic chemistry synthesis methods to obtain the pure compounds, but not to replicate the patent. The energy demand for the separation of the synthesized solutes was calculated on the basis of the patent description using the rejections obtained from the nanofiltration experiments. More details of the chemical synthesis are presented in Supplementary Methods.
Data availability
The authors declare that all data supporting the findings of this study are available within the paper and its Supplementary Information. The NF-10K data and the predictions for the application datasets are available from www.osndatabase.com/datasets under the section NF-10K.
Code availability
The code used in this work is available at https://github.com/ignaczgerg/nf10k. The energy calculations can be reproduced from https://github.com/aronbeke/meprom-tea.
References
Sholl, D. S. & Lively, R. P. Seven chemical separations to change the world. Nature 532, 435–437 (2016).
Zhou, S. et al. Electrochemical synthesis of continuous metal–organic framework membranes for separation of hydrocarbons. Nat. Energy 6, 882–891 (2021).
Marchetti, P., Jimenez Solomon, M. F., Szekely, G. & Livingston, A. G. Molecular separation with organic solvent nanofiltration: a critical review. Chem. Rev. 114, 10735–10806 (2014).
Baker, R. W. Membrane Technology and Applications (Wiley, 2012).
Reymond, J.-L. The chemical space project. Acc. Chem. Res. 48, 722–730 (2015).
Chavez Velasco, J. A., Tawarmalani, M. & Agrawal, R. Systematic analysis reveals thermal separations are not necessarily most energy intensive. Joule 5, 330–343 (2021).
Chavez Velasco, J. A., Tawarmalani, M. & Agrawal, R. Which separation scenarios are advantageous for membranes or distillations? AlChE J. 68, e17839 (2022).
Koros, W. J. Evolving beyond the thermal age of separation processes: membranes can lead the way. AlChE J. 50, 2326–2334 (2004).
Zunger, A. Inverse design in search of materials with target functionalities. Nat. Rev. Chem. 2, 0121 (2018).
Sanchez-Lengeling, B. & Aspuru-Guzik, A. Inverse molecular design using machine learning: generative models for matter engineering. Science 361, 360–365 (2018).
Zhou, M., Vassallo, A. & Wu, J. Toward the inverse design of MOF membranes for efficient D2/H2 separation by combination of physics-based and data-driven modeling. J. Membr. Sci. 598, 117675 (2020).
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021).
Artrith, N. et al. Best practices in machine learning for chemistry. Nat. Chem. 13, 505–508 (2021).
Böcking, A. et al. Can the variance in membrane performance influence the design of organic solvent nanofiltration processes? J. Membr. Sci. 575, 217–228 (2019).
Le Phuong, H. A., Blanford, C. F. & Szekely, G. Reporting the unreported: the reliability and comparability of the literature on organic solvent nanofiltration. Green Chem. 22, 3397–3409 (2020).
Sheldon, R. A. Metrics of green chemistry and sustainability: past, present, and future. ACS Sustain. Chem. Eng. 6, 32–48 (2018).
Milanesi, M., Runfola, A. & Guercini, S. Pharmaceutical industry riding the wave of sustainability: review and opportunities for future research. J. Clean. Prod. 261, 121204 (2020).
Vermeire, F. H., Chung, Y. & Green, W. H. Predicting solubility limits of organic solutes for a wide range of solvents and temperatures. J. Am. Chem. Soc. 144, 10785–10797 (2022).
Yeo, J. et al. Liquid phase peptide synthesis via one‐pot nanostar sieving (PEPSTAR). Angew. Chem. 133, 7865–7874 (2021).
Sharma, A., Kumar, A., de la Torre, B. G. & Albericio, F. Liquid-phase peptide synthesis (LPPS): a third wave for the preparation of peptides. Chem. Rev. 122, 13516–13546 (2022).
Chang, C.-W., Liou, G.-S. & Hsiao, S.-H. Highly stable anodic green electrochromic aromatic polyamides: synthesis and electrochromic properties. J. Mater. Chem. 17, 1007–1015 (2007).
Brown, A. Top product forecasts for 2023. Nat. Rev. Drug Discov. 22, 8 (2022).
Witowski, N. Most common beta blockers in 2023. Definitive Healthcare https://www.definitivehc.com/blog/beta-blocker-prescription-patterns (2023).
Vladiskovic, C., Attolino, E., Lombardo, A. & Tambini, S. Apixaban preparation process. World patent WO2012168364A1 (2012).
Aguilar, C. A. & Llado, J. B. I. Synthesis and preparations of metoprolol and its salts. US patent US20090247642A1 (2006).
Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O. & Dahl, G. E. Neural message passing for quantum chemistry. Preprint at https://arxiv.org/abs/1704.01212 (2017).
Yang, K. et al. Analyzing learned molecular representations for property prediction. J. Chem. Inf. Model. 59, 3370–3388 (2019).
Heid, E. et al. Chemprop: a machine learning package for chemical property prediction. J. Chem. Inf. Model. 64, 9–17 (2023).
Ignacz, G., Alqadhi, N. & Szekely, G. Explainable machine learning for unraveling solvent effects in polyimide organic solvent nanofiltration membranes. Adv. Membr. 3, 100061 (2023).
Ignacz, G., Yang, C. & Szekely, G. Diversity matters: widening the chemical space in organic solvent nanofiltration. J. Membr. Sci. 641, 119929 (2022).
Acknowledgements
The research reported in this publication was supported by funding from King Abdullah University of Science and Technology (KAUST). The funder had no role in study design, data collection and analysis, decision to publish or preparation of the paper.
Author information
Authors and Affiliations
Contributions
G.I., A.K.B. and G.S. co-wrote the paper. G.I. conceptualized the research, curated the dataset, performed the machine learning, chemical space and high-throughput studies, designed the nanofiltration experiments and molecules, performed rejection measurements and analysed the wet-laboratory data. A.K.B. designed and performed the energy, carbon dioxide emissions and cost reduction calculations and analysed the results. V.T. synthesized and purified the chemicals, characterized all of the new molecules and performed the rejection measurements. G.S. conceptualized, supervised and administered the research and provided resources and funding.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Energy thanks Eric Favre, Michael Tsapatsis and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Discussion, Methods 1–13, Notes 1–11, Figs. 1–139, Tables 1–34 and references.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ignacz, G., Beke, A.K., Toth, V. et al. A hybrid modelling approach to compare chemical separation technologies in terms of energy consumption and carbon dioxide emissions. Nat Energy 10, 308–317 (2025). https://doi.org/10.1038/s41560-024-01668-7
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41560-024-01668-7
This article is cited by
-
Advanced oxidation processes for sustainable wastewater treatment
Journal of Materials Science (2026)
-
Chemical processes and the energy system
Nature Energy (2025)
-
Facilitating decision making
Nature Energy (2025)
-
Forecasting Chinese CO\(_2\) emissions using a novel unbiased fractional nonlinear grey Bernoulli model with unified fractional grey generation operator
Environment, Development and Sustainability (2025)
