
Abstract
Extreme event attribution assesses how climate change affected climate extremes, but typically focuses on single events1,2,3,4. Furthermore, these attributions rarely quantify the extent to which anthropogenic actors have contributed to these events5,6. Here we show that climate change made 213 historical heatwaves reported over 2000–2023 more likely and more intense, to which each of the 180 carbon majors (fossil fuel and cement producers) substantially contributed. This work relies on the expansion of a well-established event-based framework1. Owing to global warming since 1850–1900, the median of the heatwaves during 2000–2009 became about 20 times more likely, and about 200 times more likely during 2010–2019. Overall, one-quarter of these events were virtually impossible without climate change. The emissions of the carbon majors contribute to half the increase in heatwave intensity since 1850–1900. Depending on the carbon major, their individual contribution is high enough to enable the occurrence of 16–53 heatwaves that would have been virtually impossible in a preindustrial climate. We, therefore, establish that the influence of climate change on heatwaves has increased, and that all carbon majors, even the smaller ones, contributed substantially to the occurrence of heatwaves. Our results contribute to filling the evidentiary gap to establish accountability of historical climate extremes7,8.
Similar content being viewed by others
Main
Human-induced global warming not only causes long-term changes of state variables, energy and water fluxes in the Earth system but also manifests through climate extremes9. Every region of the world exhibits changes in intensity and frequency of extreme weather and climate events10,11, and events that were near impossible in the past are now occurring10,12. To assess the extent of contribution of climate change to these events, the field of extreme event attribution (EEA) has developed over the past years, through approaches promoted by the World Weather Attribution (WWA) initiative1 and other methods2,3,4.
These approaches have been used to study many individual extreme events13, often showing an important contribution of climate change. However, to our knowledge, there is no framework to systematically and collectively conduct attribution exercises on a set of events identified in past records14, implying that impactful extreme events may still not be assessed.
Moreover, EEA studies typically attribute events to climate change, but rarely to its causes5,6. Extending EEA to source attribution provides the quantification of the causal chain from emitters to climate extremes. It has been proven unambiguously that anthropogenic activities are largely responsible for climate change, and that combustion of fossil fuels is the main contributor15. Three categories of emitters may be used: countries5, individuals6 or businesses. In the first case, the source allocation of emissions can be based on the territorial origin of emissions produced within country borders16,17. Consumption-based allocations can be pursued, as well as approaches based on individual emission profiles6,18. Finally, emissions can also be allocated to businesses that directly profit from fossil fuel production or other high-emitting activities19,20,21,22,23,24. Businesses with particularly high emission profiles are referred as carbon majors, encompassing not only investor-owned companies (for example, ExxonMobil) but also state-owned companies (for example, Saudi Aramco) or nation-state producers (for example, the former Soviet Union)19.
Here, we address both issues: the lack of systematic attribution of extreme events and the absence of quantitative analysis establishing a causal chain from individual emitters to these events. We build on an existing and widely used EEA framework1, systematizing the approach. We assess how much climate change has contributed to 213 heatwaves reported in the international disaster database EM-DAT over 2000–2023, owing to their particularly significant impact, most of which were previously unattributed. Then, we build on existing approaches to assess contributions to climate change5,6, extending the attribution upstream to the emitters. We assess how much the emissions of the 180 biggest carbon majors19 contributed to global mean surface temperature and to the likelihood and severity of historical heatwaves.
Systematic attribution of heatwaves
In the EM-DAT database (www.emdat.be), 226 heatwaves are reported over 2000–2023, across 63 countries (Fig. 1a). These events were reported because of significant economic losses or casualties, a declaration of state of emergency or a call for international assistance. These societal impacts warrant their relevance for event attribution. Despite EM-DAT being the most widely used disaster database, the reporting of heatwaves across countries is highly uneven, with only nine heatwaves out of 226 reported over Africa, Latin America and the Caribbean, although these regions are also prone to heatwaves10. This known reporting bias in the EM-DAT database25 calls for more complete reporting to enable a more exhaustive analysis.

a, The number of heatwaves reported per country in EM-DAT (www.emdat.be) over 2000–2023. An EEA is performed for each of them, as shown for four examples with ERA5 (ref. 28) data. b, The 2021 Pacific Northwest heat dome. c, The 2003 heatwave in France. d, The 2022 Indian heatwave. e, The 2013 eastern China heatwave. For each example, the average temperatures during the event are mapped, with the outlines of the reported region (lime green contours). Moreover, the intensity (average temperature T (°C) during the period and the region of the event) and change in GMST (°C) are represented over 1950–2023 (black dots), with their conditional distribution represented through the median (red line) and ranges of the distribution (red shading). Finally, the change in intensity and change in return period (year) compared with the preindustrial reference period are shown for each example. Uncertainties inferred using bootstrapping are not shown here for the sake of clarity. Further details are provided in the Methods.
Each of these heatwaves is systematically characterized and analysed in a consistent framework, following the method promoted by the WWA initiative1. This method is shown with the Pacific Northwest heatwave of 2021 as reported for the United States (Fig. 1b), thus without British Columbia in Canada. This event was reported in Oregon, Washington, Northern California, Idaho and Western Nevada over 26–30 June 2021 (www.emdat.be). Usually, EEA defines the heatwave with a box surrounding the region1. Here the heatwave is defined using the exact spatial characterization in the EM-DAT database, as it represents how the disaster was experienced by the local populations1 (Fig. 1b). Daily temperatures are averaged over this period and region for every year of available observations. Although many indicators could be used to characterize the heatwave26, the choice of the average over the period is motivated by its relevance for the reported impact rather than its meteorological rarity (Methods). Following the method by WWA1 and justified by the extreme value theory27, a statistical relationship can be inferred that links the probability distribution of the event to the change in global mean surface temperature1 (GMST) (Fig. 1b). This relationship allows us to calculate the probability and the intensity of the heatwave, both under observed conditions with climate change and under the preindustrial climate of 1850–1900 without such perturbations (Fig. 1b). Using both observation-derived estimates (ERA5 (ref. 28) and BEST (ref. 29)) and Earth system models30, these results synthesize how climate change has affected the heatwave through a change in intensity and how many times more likely the event has become, which is called the probability ratio1. More details on the systematization of the WWA approach are provided in the Methods. Using only ERA528, the Pacific Northwest heatwave of 2021 over the United States had climate change increasing its intensity by 4.4 °C compared with that in 1850–1900, with a 95% confidence interval of 2.2–6.8 °C. Adding all other datasets29,30 relevant for the region decreases the influence of climate change to a change in intensity of the Pacific Northwest heatwave of 2021 over the United States of 3.1 °C (1.4–5.1 °C). The median estimate indicates that climate change has also increased the probability of heatwaves by more than 10,000, and at least seven times according to the lower bound of the confidence interval. This attribution is consistent with existing works on this heatwave: a previous work31 found a probability ratio of at least 150 and a change in intensity of 2.0 °C (1.2– 2.8 °C), whereas another analysis32 suggested a change in intensity of more than 2.9 °C. Although consistent, the results differ because of the characterization of the event and its very unlikely nature. The region and period are here determined through the reporting of the disaster for relevance to the impact rather than choices motivated by its meteorological rarity. Choosing the maximum temperature as an indicator over the period amplifies the extremeness of the event32,33. Very unlikely events such as the Pacific Northwest heatwave of 2021 are more difficult to investigate, increasing the dispersion across several analysis34. However, this increased dispersion does not lower the confidence in the conclusion, which is the strong influence of climate change on these unlikely events. The method described for this event is applied to the 226 heatwaves, with three other cases shown in Fig. 1c–e, with the results also consistent with available attribution studies.
Additional tests are conducted to assess the adequacy of the method for each event. The goodness of fit is assessed, validating 217 out of the 226 heatwaves, whereas the remaining nine are removed from the ensuing analysis. Furthermore, although there are strong physical justifications that GMST has a causal link to the heatwave1,10, this statistical model does not necessarily imply statistical causation. Thus, we also infer the non-linear Granger causality4. For 214 out of the 217 heatwaves, we prove with more than 95% certainty that GMST is a Granger-causing indicator of the heatwave. The three other events are removed from the ensuing analysis. Finally, another heatwave is removed because of the ensuing analysis related to the carbon majors. All details on these tests are provided in the Methods.
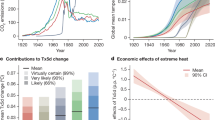
Our analysis shows that human-induced climate change has contributed to increasing the intensity of all 213 heatwaves analysed here (Fig. 2). With reference to 1850–1900, the median estimates for the changes in intensity range across events from +0.3 °C to +2.9 °C. The latter is the heatwave introduced in Fig. 1b, the Pacific Northwest heatwave of 2021 over the United States, whereas the heatwave with the mildest change in intensity occurred in Pakistan in June 2000. Over the study period, attributed heatwaves have become more and more intense (Fig. 2a–c). The median of the events shows that climate change has increased the intensity by 1.4 °C over 2000–2009, 1.7 °C over 2010–2019 and 2.2 °C over 2020–2023. This is consistent with GMST increasing by more than 0.2 °C per decade over the study period, and land warming faster35.

Each heatwave is allocated a category depending on its change in intensity (colour) and its probability ratio (vertical bars in per cent) with reference to 1850–1900. a–c, Events are categorized based on the year of the event: 78 heatwaves attributed over 2000–2009 (a), 54 heatwaves attributed over 2010–2019 (b) and 81 heatwaves attributed over 2020–2023 (c). Median results are shown here. Further details on the attribution of each heatwave event are provided in the Methods, and all results are provided in the Supplementary Information.
Apart from increasing the intensity, climate change has also increased the probability of all 213 heatwaves. The lowest probability ratio is observed for the heatwave of May 2006 in India, in which the event became only 22% more likely. However, the median estimates show that climate change has made 55 heatwaves out of 213 (26%) at least 10,000 times more likely, with a 95% confidence interval ranging from 7 to 158. This probability ratio is equivalent to saying that these heatwaves would have been virtually impossible without anthropogenic influence. Over the study period, the contribution of climate change to the likelihood of these events is also increasing (Fig. 2a–c). Figure 2 shows that the probability ratios of the heatwaves are shifting from low values to higher values, although this trend is highly affected by natural variability. The median probability ratios show that, with reference to 1850–1900, climate change made heatwaves about 20 times more likely over 2000–2009, and about 200 times more likely over 2010–2019. Overall, this systematic attribution of 213 heatwaves enhances the capacity of EEA for analyses across events, proving that climate change made all events more intense and more likely, and that this influence is increasing over time with increased global warming.
Attribution to emissions of carbon majors
EEA has been extensively used to quantify how human-induced climate change influences extreme events13. A growing literature has also investigated the contributions of anthropogenic actors to climate change16,18,21. However, the quantification of the causal chain from individual emitters to the extreme events has only been pursued in selected cases5,6. Here we build on established approaches while also introducing key methodological advancements in the decomposition (Methods) and developing the framework for simultaneous investigation over a large set of events. Unlike previous works that focus on emissions by countries5 or individuals6, we here investigate the attribution of emissions from businesses and specifically the carbon majors. Following established approaches20,21,22,23, we assign to each carbon major the emissions associated with the full value chain of their products, including all emissions in line with established accounting and reporting standards for corporates. This modelling choice aims at filling a gap in the scientific literature and does not preclude broader reflections on emission allocations and business responsibilities20.
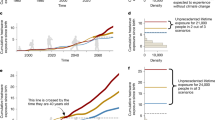
The emissions from carbon majors are estimated from company production records and associated emission factors19, leading to a dataset that provides CO2 and CH4 emissions for 180 carbon majors over 1854–2023 (Fig. 3a). Altogether, the emissions from these carbon majors represent 57% of the total cumulative anthropogenic CO2 emissions, including land use over the 1850–2023 period36. When considering only the emissions from fossil fuels and cement, the emissions from these carbon majors represent 75% of the cumulative CO2 emissions over 1850–2023 (ref. 36). The carbon majors have heterogeneous contributions to the CO2 emissions. The 14 top carbon majors (the former Soviet Union, People’s Republic of China for coal, Saudi Aramco, Gazprom, ExxonMobil, Chevron, National Iranian Oil Company, BP, Shell, India for coal, Pemex, CHN Energy, People’s Republic of China for cement) represent 30% of the total cumulative anthropogenic CO2 emissions, including land use, about as much as the 166 other carbon majors combined (27%). From a national perspective, 33 carbon majors are headquartered in the United States, accounting for 10% of the total CO2 emissions, and 33 carbon majors are headquartered in China (12% of the total CO2 emissions).

a,b, Contributions of the carbon majors to the cumulative CO2 emission since 1850 (all sectors) (a) as reported in the Carbon Majors database (https://carbonmajors.org/) and compared with the Global Carbon Budget36 and the ensuing GMST as simulated by the OSCAR model (b). The GMST of ERA528 and BEST29 have been rebased to 1850–1900 (ref. 9). c–q, Attribution of historical heatwaves to the emissions of carbon majors for 15 selected carbon majors. In each of these panels, the 213 heatwaves are allocated into categories of contributions of the carbon majors to the change in intensity (colours) and how many times the carbon major increased the likelihood of the heatwave compared to 1850–1900 (x-axis). The results are shown through the median, but all results are provided in the Supplementary Information.
Based on the CO2 and CH4 emissions of the carbon majors, we compute the contributions of these carbon majors to GMST. Climate models may be used to calculate climate change over the historical period, but also counterfactual worlds, such as a world in which a given carbon major would not have emitted. The difference informs how much this single actor has warmed the Earth over time. This method has already been applied to a former version of this database using a simple impulse-response model for CO2 (ref. 21). Here we use the reduced-complexity Earth system model OSCAR, for its non-linear representation of both the carbon cycle and the atmospheric chemistry of methane, as well as its capacity to integrate observational constraints to improve the robustness of the assessment37 (Methods).
Closely aligned with the estimates based on IPCC methodologies35, we estimate an increase in GMST of about 1.30 °C in 2023 with respect to 1850–1900 (ref. 28), of which 0.67 °C is due to the emissions of all carbon majors and 0.33 °C is due to the emissions of the 14 biggest carbon majors (Fig. 3b). The unattributed 0.63 °C is due to other actors responsible for unaccounted fossil fuel burning, agricultural and land-use activities, other industrial processes, as well as to non-attributed greenhouse gases (N2O and halogenated species) and short-lived climate forcers. For comparison, a former assessment associates 0.40 °C in 2010 with 90 carbon majors21, whereas we find 0.48 °C with 180 carbon majors in 2010.
Knowing the contributions of the carbon majors to GMST and knowing the relationship between GMST and the heatwaves from the event attribution, we subsequently compute how each carbon major has affected each heatwave (for details, see the Methods). For each heatwave, the total effect of climate change on the intensity and probability of the event is decomposed into the contributions from individual carbon majors and the combined effect of other unidentified contributors, anthropogenic and natural.
Contributions from carbon majors to the intensities of all heatwaves range from 0 °C to 0.18 °C (Fig. 3c–k). As expected, the higher the emissions from a carbon major, the higher its contributions to the intensities of the heatwaves. The median contributions to heatwaves from the 14 top carbon majors range from 0.01 °C to 0.09 °C. The other carbon majors have lower contributions, although the 166 of them combined have about the same importance as the biggest carbon majors. We calculate the influence of carbon majors on heatwaves reported over each decade of our dataset. With reference to 1850–1900, climate change has increased the median intensity of heatwaves by 1.36 °C over 2000–2009, of which 0.44 °C is traced back to the 14 top carbon majors and 0.22 °C to the 166 others. These contributions correspond, respectively, to 32% and 16% of the overall effect of climate change. Over 2010–2019, the influence of climate change increased to 1.68 °C, with 0.47 °C (28%) from the 14 top carbon majors and 0.38 °C (22%) from the 166 others. These results show that the emissions of carbon major contributed to about half of the increase in intensity of heatwaves since preindustrial times, and that this contribution is rising.
Apart from intensities, all the carbon majors have also increased the probability of all the heatwaves. For heatwaves that climate change made only slightly more likely, or for carbon majors with much lower emissions, the contributions are limited to an increase by 10% of the preindustrial probability. However, there are heatwaves that the carbon majors have made at least 10,000 times more likely compared with preindustrial levels, and which would have otherwise been virtually impossible without anthropogenic influence. Even relatively minor shares in total emissions lead to very substantial increases in the frequency of these events. Specifically, emissions associated with the biggest emitter, the former Soviet Union, have made 53 heatwaves (25%) at least 10,000 times more likely. For the smallest carbon major by emissions, Elgaugol, this is still the case for 16 heatwaves (8%). It means that the sole emissions of these carbon majors would have rendered possible these heatwaves otherwise virtually impossible.
Discussion
We have systematized the process of EEA, based on the widely used method promoted by the WWA initiative1. We achieve the analysis of 213 heatwaves, thus extending the coverage of existing event attribution studies. We validate the goodness of fit and the causality for each of these events. We show that climate change has increased the probability and intensity of all these heatwaves. Owing to the consistent protocol across all events, their meta-analysis over time shows that the extremeness of the heatwaves is rising more and more rapidly because of climate change, both in intensity and probability.
We also extend the attribution analysis upstream along the causal chain, providing a coherent attribution to individual emissions on the company level for 180 carbon majors. The contributions of the carbon majors are very heterogeneous, with 14 carbon majors (the former Soviet Union, People’s Republic of China for coal, Saudi Aramco, Gazprom, ExxonMobil, Chevron, National Iranian Oil Company, BP, Shell, India for coal, Pemex, CHN Energy, People’s Republic of China for cement) contributing as much as the 166 others. Considering all reporting heatwaves, we show that carbon majors represent about half of the change in intensity since 1850–1900 and that their contributions are rising, in particular the ones of the smaller carbon majors. The analysis of their contributions to the probabilities of the heatwaves shows that although the contributions scale well with their cumulative emissions, smaller carbon majors cannot be neglected. Depending on the carbon major, between 16 and 53 of these heatwaves are made possible with the sole contribution of the smaller carbon majors.
Although this assessment builds on well-established methods, there are still two limitations in this work. Although the EM-DAT is the most complete existing database for disasters, many heatwaves are still not reported, calling for a more exhaustive coverage of the events. Moreover, the contributions of the carbon majors remain incomplete. On the one hand, not all CO2 and CH4 emissions are covered in this database because of underreporting19. For instance, this database represents only 75% of the fossil fuel and cement CO2 emissions reported over 1850–2023 (ref. 36). The actual contributions of the carbon majors are thus expected to be higher if all the emissions from fossil fuel and cement producers are included. On the other hand, the burning of fossil fuels can release aerosols that would have a local effect on the climate. As a whole, the aerosols emitted by the fossil fuel sector reduce their contribution by approximately 10% (ref. 38). However, attributing aerosol climate effects to individual companies would be highly challenging. The effects of aerosols on climate are local to regional, yet fossil fuels are globally traded. Furthermore, aerosol emissions from fossil fuel combustion strongly depend on the use of filter technology, which differs between regions, sectors and combustion techniques. If these challenges are overcome, it would pave the way for attributing the aerosol health effects to individual emitters. Aerosols are also harmful air pollutants, with the emissions by the use of fossil fuel causing about 5 million excess deaths per year (ref. 39). Accounting for these effects remains beyond the scope of our analysis.
Our framework could be adapted to other physical hazards, such as ocean acidity22, sea-level rise40, fires41 or droughts42. Extending the attribution from physical hazards to societal impacts remains a challenge. We may use directly the fraction of attributable risk to deduce the fraction of the impact imputed to the actor6, but it neglects complex and non-linear aspects related to the vulnerability and the exposure to the hazard43. Nevertheless, this attribution framework may be extended to heat-related mortality44 or economic damages24. Finally, other top-down approaches can complement our findings45.
These results are relevant not only in the scientific community but also for climate policy, litigation and wider efforts concerning corporate accountability8. Climate-related legal proceedings are proliferating, with defendants seeking compensation for losses and damages or requiring more ambitious climate actions from corporations and nations8. However, the scientific evidence backing the claims is often lagging behind the state of the art in climate science, thus failing to adequately draw causality links7. Although this work aims at filling in scientific gaps, the results also fill in evidentiary gaps. This systematic attribution improves the coverage in extreme events, thus reinforcing the potential of attribution science for climate litigation7,43. Furthermore, if the fact that fossil fuels are the main driver of climate change has been unambiguously established15,36, as acknowledged by the carbon majors themselves46,47,48, proving and quantifying the causality from the emitters to the events provides important new resources to assess legal responsibilities. Further strengthening of the links between climate scientists, legal scholars and practitioners is beneficial to ensure that the overwhelming scientific literature is correctly accounted for49.
Methods
Definition of events
From the EM-DAT database, we select the events only after 2000, because the reporting is more complete after this date25,50, and since climate change has been shown to exert increasing influence on extremes over this period51.
The locations reported for the events in the EM-DAT database are names of cities, provinces, states or whole countries (for example, France). Geographical boundaries are necessary for the analysis, so the locations of EM-DAT are matched to spatial elements from GADM52 using the following algorithm.
-
1.
The reported ISO code is used to pre-select the spatial elements of GADM for the country and any attached disputed territories.
-
2.
The reported location is prepared: replacing spatial characters (accents, numbers and punctuation); removing extra spaces; lowercase letters for all characters; synthesizing specific sentences (for example, ‘Kadamjay district in Batken oblast’ becoming ‘Kadamjay’); correcting for any change in regional aggregation (for example, ‘Haute & Basse Normandie’ becoming ‘Normandie’); translating any region without its variant in GADM (for example, ‘Voreio Aigaio’ becoming ‘North Aegean’).
-
3.
Each preselected spatial element is compared with each element of the prepared reported location by applying a character matcher53 on its names and variants.
-
4.
Each retained spatial element is filtered using a prepared list of false positives. For instance, the location for the state of ‘Ohio’ triggers the identification of the county ‘Ohio’ in the states of Kentucky and West Virginia, which have not been reported.
-
5.
The list of spatial elements is compared with the initial reported location, checking whether it matches correctly. If not, the issue is implemented through the prepared lists of known issues in steps 2 and 4.
Another work, the dataset GDIS, is also used to match EM-DAT locations to geographical boundaries54. Both approaches have been developed independently. GDIS differs in that the locations of all categories of hazards are analysed, but only up to 2018. Here, only the hazards for heatwaves were analysed, but up to 2023. Moreover, GDIS uses GADM v.3.6, whereas our work uses GADM v.4.1.
In the EM-DAT database, the dates of the heatwaves are often reported with the starting and ending days. When both days are provided, we use the average of the daily average temperature over this exact period. Other indicators may be possible26, but the average aggregates the essential features of these heatwaves55. In particular, this choice is motivated by its relevance for the reported impact rather than its meteorological rarity. Heatwaves affect local populations not only through daily maximum temperatures but also through lack of cooling at night, which can be estimated using daily average temperatures. Sustaining high temperatures over time modifies the impact of a heatwave as well, justifying the use of averages over the period of the heatwave rather than its peak. The annual indicator is calculated first on each grid point, then averaged over the defined region to maximize the relevance of the indicator1,56. Furthermore, some events were reported without the starting and/or ending day(s). We observe that heatwaves reporting both days and lasting less than a month last on average for 8 days. Therefore, we use as an indicator for events with missing days the maximum of the 8 days running average over the reported month. In the case that several months were reported with missing starting and/or ending days, we lengthen the duration of the running average by 1 month for each supplementary month reported.
Training of conditional distributions
The statistical model of attribution studies is carefully chosen to model the frequencies and intensities of extreme events1,56. To capture possible trends and non-stationarities, the distribution depends on the parameters driven by explanatory variables. In this study, we opt for the generalized extreme value (GEV) distribution with a linear evolution of its location as outlined in equation (1). For every year y in the sample, the average temperature over the period and region of the event Ty is assumed to follow a GEV distribution of location μ, scale σ and shape ξ, whereas the location varies with the change in global mean surface temperature smoothed over the 3 previous years (GMST).
Although the statistical model in equation (1) is common for the EEA of heatwaves1,56, we have compared its performance with other potential models. Apart from this GEV model, we have tested three other distributions with linear and non-linear evolutions of the parameters: Gaussian, skew normal and generalized Pareto. Overall, our comparisons assessed through quantile–quantile plots indicate that the GEV performs the best among the four distributions, especially in terms of upper tail behaviours. We calculate the classical Bayesian information criteria (BIC) to compare their performances while reducing the risk of over-fitting57. We observe that for all heatwaves, a stationary GEV has the lowest BIC. We note that the linear model of equation (1) is not always the best distribution according to the BIC, although the gain in BIC from the linear model to the best solution is always marginal. More quantitatively, the improvement in BIC from the stationary GEV to the linear model represents between 88% and 100% of the improvement from the stationary model to the best solution over all heatwaves analysed, with an average of 98%. In other words, sophisticating further the statistical model would, on average, improve the performance by only 2%. This result confirms that this expression is the most appropriate for most heatwaves.
These fits are obtained by minimization of the negative log likelihood (NLL) of the training sample58. The first guess has its robustness improved using initial regression to approximate the coefficients42,59. The shape parameter is bounded between −0.4 and 0.4 (ref. 1). Moreover, the sample is weighted during minimization of the NLL, with weights equal to the inverse of the density of the GMST. This approach helps in providing equal performance over the full interval of GMST.
The choice of whether to include the event or not when estimating the statistical model has been extensively discussed, although no final consensus has been reached1,31,60. The results presented in this paper have been obtained by estimating the event, to prevent removing points from the observational record. To ensure numerical convergence, a minimum probability of 10−9 was set for each point of the full sample. It implies that the attributed events under factual conditions will not have return periods higher than a thousand million years, which we consider long enough.
Estimating return periods for unlikely events with relatively short observational records remains difficult34; thus, we append additional lines of evidence1,56. Conditional distributions are trained for ERA5, used as reference, but also with BEST29 (Extended Data Fig. 1) and simulations from Climate Model Intercomparison Phase 6 (CMIP6)30,61. The following Earth system models (ESMs) from CMIP6 are used: ACCESS-CM2, ACCESS-ESM1-5, AWI-CM-1-1-MR, BCC-CSM2-MR, CESM2, CESM2-WACCM, CMCC-CM2-SR5, CMCC-ESM2, CanESM5, EC-Earth3, EC-Earth3-CC, EC-Earth3-Veg, EC-Earth3-Veg-LR, FGOALS-g3, GFDL-CM4, GFDL-ESM4, INM-CM4-8, INM-CM5-0, IPSL-CM6A-LR, KACE-1-0-G, KIOST-ESM, MIROC6, MPI-ESM1-2-HR, MPI-ESM1-2-LR, MRI-ESM2-0, NESM3, NorESM2-LM, NorESM2-MM and TaiESM1. For every heatwave, only the ESMs with sufficient performance are used, as described in the next section. For ERA5 and BEST, we start the time series in 1950 for adequate spatial coverage over all regions62, and these time series finish in 2022 for BEST and 2023 for ERA5. For CMIP6, the time series is calculated over the historical (1850–2014) (ref. 63) and the SSP2-4.5 (2015–2100) (ref. 64). This scenario is chosen because its emissions are the closest to those observed over 2015-202 (ref. 36). Only runs with the initial conditions termed r1i1p1f1 are used, as it was run by most ESMs. Only one ensemble member is used to facilitate the comparison of the parameters and probabilities from ESMs to those based on observations.
Evaluation of the uncertainties
During the extreme event analysis, two sources of uncertainties are handled—namely, on the conditional distributions and on the handling of observations and simulations.
During the training of conditional distributions, the uncertainties on the parameters are obtained using an ensemble of 1,000 bootstrapped members, with replacements allowed during the resampling. The conditional distributions are then used to assess the probabilities and intensities of the event, under a factual climate and a counterfactual climate. The factual climate is defined as the GMST observed at the time of the event. The counterfactual climate is defined as the average of the GMST over 1850–1900.
ESMs exhibit different performance in reproducing local climates; thus, not all models may be useful for event attribution1. We calculate the seasonalities of ERA5 and each ESM over 1950–2020 in each grid point over the region. We then average their correlation. The most appropriate ESMs are the 10 most representative ESMs that maximize this average correlation.
Following the WWA approach, not all models are retained for further analysis1,65. The factual distributions at the time of the event are compared with those of ERA5. Both the scale and the shape parameters of ERA5 and the model must have their 95% confidence intervals overlapping. Otherwise, the model will be discarded. Thus, the overall selection process is to sort the ESMs by correlation with ERA5 seasonality, remove those with parameters inconsistent with ERA5 and select the 10 best ESMs in this list.
At this point, probability ratios and change in intensities are obtained for an ensemble of datasets, each with uncertainties. To synthesize over this large ensemble, equal weights are given to each bootstrap member of ERA5 and BEST, summarized into one distribution for observations. All kept ESMs are also given equal weights and summarized into one distribution for models. Finally, these distributions are averaged to deduce the median and 95% confidence intervals. We point out that synthesizing these lines of evidence could be conducted with other approaches1, although without affecting the main messages of this work.
Goodness of fit for the conditional distributions
Although using a non-stationary GEV with its location varying linearly with GMST is a well-established approach for EEA to statistically model extremes under global warming, this setup may not be well-suited in isolated cases66. To ensure that the GEV model represents the data adequately, the goodness of fit is verified for each conditional distribution used in this analysis with the method used in ref. 67.
For every heatwave, several datasets are used for analysis, from which conditional distributions are fitted. The location and scale of each of these fitted conditional distributions are used to transform the respective training sample onto a stationary GEV(0, 1, ξ) with the same shape as the fitted conditional distribution. This transformed sample has observed quantiles, which are compared with the theoretical quantiles of a GEV(0, 1, ξ) in a quantile–quantile plot. This quantile–quantile plot describes how well the GEV model describes the sample. The uncertainty in the GEV parameters determines a confidence band in the quantiles around the identity line, as shown in Extended Data Fig. 2.
The fraction of the sample out of the confidence band is deduced, estimated as a 95% confidence interval on the ensemble obtained from bootstrapping of the training of the conditional distribution. For each heatwave, the ensemble of conditional distributions is compared with an out-of-sample threshold at 5%. The results are shown in Extended Data Fig. 3. If the median out-of-sample fraction across the conditional distributions is below the threshold, the goodness of fit is confirmed, and the heatwave is kept for the ensuing analysis. As shown in Extended Data Fig. 3, 217 heatwaves are retained, and nine are removed from the ensuing analysis. These nine events removed from analysis are summarized in Extended Data Table 1.
Out of the nine events, eight occurred in India, and the last one occurred in Japan. In the 217 heatwaves kept for analysis, eight events occurred in India. Besides this apparent regional clustering, no discernible traits emerge with regard to the season or length of the heatwave. More research is required to investigate why these fits do not perform as well as elsewhere for these specific events, which lies beyond the scope of this study.
Causality using Granger causal inference
The well-established approach1 for EEA combines observations and simulations by using non-stationary distributions. These distributions correlate the evolution of the climate indicator T for the heatwave to GMST. Deducing causality, that climate change caused the event, using this correlation relies on the strong physics-based understanding5,6,31,41,65,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97 that increasing GMST tends to also increase regional temperatures, not only through its mean but also through the whole distribution inferred from natural variability, thus shifting the regional extremes as well. Yet, although there is a strong physical basis for this causality, we can also investigate the validity of this causality from a statistical perspective. Using Granger causal inference98, we may assess the predictive relationship between GMST and T, the climate indicator of the event4.
The common approach for Granger causality4,98 requires that the input variables are stationary to train vector auto-regressive models99. This is usually verified by differentiating the variables, in other words, taking the interannual variability. This method would then assess whether the interannual variability of GMST can predict the interannual variability of T, thus focusing on the predictability of short-term shocks. However, the trend contains a stronger signal compared with the interannual variability. To account for long-term trends in GMST and T, Granger causality can be generalized using the vector error correction model (VECM)100. It requires the search for an adequate VECM model based on the Akaike information criterion101 and a co-integration test, for instance, using a Johansen test99. Nevertheless, this method still fails to account for non-linear effects. An alternative is to use machine learning, such as Random Forest models trained to predict T with GMST through their lagged effects102. Permutation tests are conducted to assess the performance of Random Forest models trained on permuted lagged GMST, compared with the non-permuted version103. Applying this method accounts for the evolution of GMST and T, while also accounting for non-linear effects.
By using the latter method, only three events have a median value for the test above 0.05. As shown in Extended Data Fig. 4, for 214 events out of 217, we reject the null hypothesis, concluding that the evolution of GMST is Granger-causing the evolution of T. The three other events are listed in Extended Data Table 2. We notice that the median value for the Granger causality remains relatively low. Using IPCC terms, it is likely (>66%) that GMST Granger-caused the evolution of T for the event in the United States in 2011, whereas it is very likely (>90%) for all the others. These three events are removed from this analysis.
Contributions from the carbon majors to global warming
The contributions of emissions of the carbon majors to global mean surface temperature are assessed with the reduced-complexity Earth system model OSCARv3.3 (refs. 104,105). The model embeds an ensemble of modules that replicate the behaviour of models of higher complexity105. OSCAR features the ocean and land carbon cycles with a bookkeeping module for CO2 emissions from land use and land cover change, wetlands, permafrost, tropospheric and stratospheric chemistry, and global and regional climate responses to these forcers. It accounts for the effects of greenhouse gases (CO2, CH4, N2O and 37 halogenated compounds), short-lived climate forcers (stratospheric water vapour, tropospheric and stratospheric ozone, primary and secondary organic aerosols, nitrates, sulfates and black carbon), surface albedo change, volcanic activity, solar radiation and contrails37,105.
OSCAR is run over the historical period (1750–2023), following three sets of simulations: (1) The first set of simulations is driven by concentrations of greenhouse gases to ensure a match with the latest observations. (2) The second set is driven by emissions, using the compatible emissions from the first set obtained through mass balance106,107. This is a control run that confirms that the estimated compatible emissions lead to the observed atmospheric concentrations and is used as a reference for the following attribution runs. (3) In the third set of simulations, for each carbon major, the control run is repeated, but the CO2 and CH4 emissions of the major are subtracted from the compatible emissions. The difference in outcome (for example, global temperature) between the control and this simulation gives the contribution of the major. This approach is called a residual attribution method108.
In all simulations, the radiative forcings from species or forcers that are neither CO2 nor CH4 (that is, forcers that are not attributed in this study) are prescribed as global time series based on the latest version of the Indicators of Global Climate Change35. Global time series of atmospheric concentrations for the first set of simulations come from the same source. Emissions of short-lived species (that affect the atmospheric sink of CH4) are taken from the latest version of the CEDS dataset109,110 and the updated GFED4s dataset111 that extends the original CMIP6 emissions from biomass burning112. Land use and land cover change data are the same as in the latest Global Carbon Budget36, in which we use both an updated LUH2 dataset113 and the FAO-based dataset114.
OSCAR runs in a probabilistic framework to represent the uncertainty in the modelling of the Earth system. This uncertainty is sampled through a Monte Carlo approach with n = 2,400 elements. The uncertainty in the natural processes governing the atmospheric concentration of CO2 and CH4 comes from the available parametrizations of OSCAR105,115,116. The uncertainty in the input radiative forcing follows that of the IPCC AR6 (ref. 117) and is applied uniformly to the whole time series. The uncertainty in the input land use and land cover change is sampled by running one-half of the simulations with one dataset and the other half with the other dataset. There is no uncertainty in the input emissions. Finally, the raw uncertainty range from the Monte Carlo is constrained with observational data by weighting the elements of the ensemble based on their distance to the observations in the control simulations37,116. As constraining values, we use decadal CO2 emissions from fossil fuels and industry over 2012–2021 from the GCB36, decadal anthropogenic CH4 emissions over 2008–2017 from the AR6 (ref. 118) offset with their preindustrial value from PRIMAP third-party-based estimates119,120, and decadal global mean surface temperature change over 2011–2020 from the AR6 (ref. 9).
Contributions from the carbon majors to heatwaves
We assess whether the probability can be written as a sum of terms, with each term associated with contributions from anthropogenic actors or natural drivers.
We define a region in space S. Every year y, the temperature field over the region is averaged over a period p of the year, then over the region S, resulting in the temperature Ty. The heatwave is characterized by the exceedance of the heatwave level u by Ty, with u a real-valued scalar. Ty represents a real-valued continuous random variable (Borel σ-algebra on the reals). Given the heatwave level u, the target probability is a survival function P(Ty > u).
We assume that the probability of the heatwave is conditional on GMTy and that it follows the statistical model introduced in equation (1) and represented in equation (2). Every year, the temperature over the region and the period Ty is sampled from a non-stationary GEV distribution27. The parameters of this GEV distribution are the location μ, the scale σ and the shape ξ. The location varies linearly with a covariate, the change in GMSTy at the corresponding year.
With the analytical expression for the cumulative distribution function of the GEV that follows equation (3):
This well-established statistical model is widely used for EEA1,56 and has already been used extensively for heatwaves. We acknowledge that a more sophisticated model with additional covariates may further improve the performance121,122. However, this statistical model has been shown to have good performance for heatwaves in general13, and additional covariates can prevent the use of climate models as additional lines of evidence. The former section provides additional grounds for the choice of this model.
The causal theory applied to climate change justifies the decomposition of probabilities in a Gaussian case123,124. Given a statistical model built on a non-stationary Gaussian distribution linearly driven by GMST, if GMST can be split into a sum of contributions, then the probabilities can be approximated as a sum of their associated contributions123,124. However, the statistical model presented in equation (2) uses a GEV instead of a Gaussian. Even by attempting to write the decomposition using Bayes’s theorem and the inclusion–exclusion principle, the exact analytical form of each term remains challenging. This is mostly because the differences in probability when removing a contribution to GMST depend on the initial value of GMST. In other words, the non-linearity and the high number of terms lead to a solution that cannot be computed exactly.
Instead, we propose to approximate the solution and to investigate the quality of this approximation. The usual approach to calculate contributions to climate change is to run the statistical model with all contributors, then to run it again without one contributor, the difference corresponding to the contributor. This approach is thereafter called All-But-One (ABO). Thus, an emitter e with a contribution to global warming GMSTy,e would contribute to the probability of the event using this approach.
To account for non-linear effects in the decomposition of probabilities, this approach is complemented with a second approach that calculates the difference in GMSTy introduced by adding only the emitter (Add-One-to-None, AON). According to this approach, the emitter e would contribute to the probability of the heatwave as follows:
The approach based on the removal of a single entity (ABO) estimates the contribution of a state perturbed by all the other contributors. The approach based on the addition of a single entity (AON) evaluates the contribution in an unperturbed state, without the other contributors interfering. Given the non-linearity of the system, we expect the physical contribution to be between the two values. We choose to calculate both approaches and average them. This approach, calculated using equation (6), is called the combined ABU & AON (Extended Data Fig. 5).
For each event, the probability is calculated for all datasets for the region and averaged over the datasets. Its 95% confidence interval is calculated using bootstrapping. The total probability of the event is decomposed into contributions of each carbon major, other climate forcers and preindustrial probability. After decomposition, these terms are summed up for comparison with the total probability. The 95% confidence interval is shown for all events, and only one event (Cyprus, May–September 2022) does not reproduce the total probability. This event has been removed from the analysis of extreme events. As shown in Extended Data Fig. 5, the average of ABO and AON provides the best estimate, because it accounts for non-linear effects.
In EEA, probabilities are often communicated using probability ratios, quantifying how many times climate change has made the event more likely. It is calculated using the probability of the event in a preindustrial climate, thus with a GMST averaged over 1850–1900:
Because the contribution of the emitter e to the probability of the heatwave Py,e is a perturbation, the emitter multiplies the probability of the heatwave as in equation (8):
Discussing an alternative decomposition approach
Alternatively to the approach based on GMST, a basic approach would be to assess the contributions directly with the emissions. The fraction in the cumulative emissions at the time of the event would represent the share of responsibility of the carbon major in the causes of the event. This fraction can be used for the change in intensity and the change in probability of the event. This approach can be compared with the principle applied for the attributional life cycle assessments, taking the Earth system as a whole and using the shares in its inputs to trace the perturbation125,126, whereas the approach based on GMST traces the effects of the carbon majors through the Earth system. Therefore, GMST is more similar to the principle of the consequential life cycle assessment. However, the approach based on cumulative emissions has several drawbacks.
First, the carbon majors fuel climate change with CO2 and other compounds, such as CH4. As an approximation, it would still be possible to aggregate these compounds using a global warming potential for fossil CH4.
Then, the carbon cycle partially absorbs the emitted carbon over time. Thus, two companies with the same cumulated emissions may not share the same responsibility, if one has older emissions, thus with a lower contribution to the atmospheric concentration of CO2. Still, these old emissions contributed to warming up the Earth system and saturating the carbon sinks.
Finally, the attribution analysis may not respond linearly to changes in GMST. For our study, heatwaves are represented with a GEV with the location varying linearly with GMST. According to the Transient Climate Response to Emissions (TCRE), the GMST varies almost linearly with cumulative emissions. Thus, the approach based on cumulative emissions would lead to similar results to ours. However, for events for which the distributions do not vary linearly with GMST, as it may for extreme precipitations1,56, non-linearities would be introduced.
To conclude, the approach based on cumulative emissions is an approximation that relies on the linearity of the Earth system. However, this system is not entirely linear, and the TCRE is known as an approximation with its limits127. Under the assumptions that the linearity of the system would be respected, this simple approach would then lead to similar results as those based on the approach used in this work.
Data availability
The data that support the findings in this study are available through the following references: disaster database EM-DAT (https://public.emdat.be/), geographical boundaries database GADM (https://gadm.org/download_world.html), Carbon Majors database (https://carbonmajors.org/Downloads), ERA5 (https://cds.climate.copernicus.eu/datasets/reanalysis-era5-single-levels), BEST (https://berkeleyearth.org/data/), and CMIP6 on the Earth System Grid Federation data nodes (http://esgf-node.llnl.gov/search/cmip6/). Detailed data for the search query are as follows: Experiment ID (historical, ssp245), Variant Label (r1i1p1f1), Frequency (day) and Variable ID (tas). The outputs of this study are provided in the Supplementary Information.
Code availability
All the codes that support the findings in this study are available at Zenodo128 (https://doi.org/10.5281/zenodo.15569401). Moreover, the code for OSCARv3.3 can be accessed at Zenodo129 (https://doi.org/10.5281/zenodo.10548477).
References
Philip, S. et al. A protocol for probabilistic extreme event attribution analyses. Adv. Stat. Clim. Meteorol. Oceanogr. 6, 177–203 (2020).
Yiou, P. et al. A statistical framework for conditional extreme event attribution. Adv. Stat. Clim. Meteorol. Oceanogr. 3, 17–31 (2017).
Faranda, D. et al. ClimaMeter: contextualizing extreme weather in a changing climate. Weather Clim. Dyn. 5, 959–983 (2024).
Risser, M. D., Ombadi, M. & Wehner, M. F. Granger causal inference for climate change attribution. Environ. Res. Clim. 4, 022001 (2025).
Otto, F. E. L., Skeie, R. B., Fuglestvedt, J. S., Berntsen, T. & Allen, M. R. Assigning historic responsibility for extreme weather events. Nat. Clim. Change 7, 757–759 (2017).
Lott, F. C. et al. Quantifying the contribution of an individual to making extreme weather events more likely. Environ. Res. Lett. 16, 104040 (2021).
Stuart-Smith, R. F. et al. Filling the evidentiary gap in climate litigation. Nat. Clim. Change 11, 651–655 (2021).
Setzer, J. & Higham, C. Global Trends in Climate Change Litigation: 2025 Snapshot (Grantham Research Institute on Climate Change and the Environment, 2025).
Gulev, S. K. et al. in Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (eds Masson-Delmotte, V. et al.) 287–422 (Cambridge Univ. Press, 2021).
Seneviratne, S. I. et al. in Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (eds Masson-Delmotte, V. et al.) 1513–1766 (Cambridge Univ. Press, 2021).
AON. Weather, Climate and Catastrophe Insight 2023 (AON, 2023).
Fischer, E. M. & Knutti, R. Anthropogenic contribution to global occurrence of heavy-precipitation and high-temperature extremes. Nat. Clim. Change 5, 560–564 (2015).
Climate Signals. Science Sources: Detection and Attribution. https://www.climatesignals.org/reports/attribution (2025).
Perkins-Kirkpatrick, S. E. et al. Frontiers in attributing climate extremes and associated impacts. Front. Clim. 6, 1455023 (2024).
Canadell, J. G. et al. in Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (eds Masson-Delmotte, V. et al.) 673–816 (Cambridge Univ. Press, 2021).
Jones, M. W. et al. National contributions to climate change due to historical emissions of carbon dioxide, methane, and nitrous oxide since 1850. Sci. Data 10, 155 (2023).
Beusch, L. et al. Responsibility of major emitters for country-level warming and extreme hot years. Commun. Earth Environ. 3, 7 (2022).
Schöngart, S., Nicholls, Z., Hoffmann, R., Pelz, S. & Schleussner, C.-F. High-income groups disproportionately contribute to climate extremes worldwide. Nat. Clim. Change 15, 627–633 (2025).
Heede, R. Tracing anthropogenic carbon dioxide and methane emissions to fossil fuel and cement producers, 1854–2010. Clim. Change 122, 229–241 (2014).
Frumhoff, P. C., Heede, R. & Oreskes, N. The climate responsibilities of industrial carbon producers. Clim. Change 132, 157–171 (2015).
Ekwurzel, B. et al. The rise in global atmospheric CO2, surface temperature, and sea level from emissions traced to major carbon producers. Clim. Change 144, 579–590 (2017).
Licker, R. et al. Attributing ocean acidification to major carbon producers. Environ. Res. Lett. 14, 124060 (2019).
Dahl, K. A. et al. Quantifying the contribution of major carbon producers to increases in vapor pressure deficit and burned area in western US and southwestern Canadian forests. Environ. Res. Lett. 18, 064011 (2023).
Callahan, C. W. & Mankin, J. S. Carbon majors and the scientific case for climate liability. Nature 640, 893–901 (2025).
Jones, R. L., Kharb, A. & Tubeuf, S. The untold story of missing data in disaster research: a systematic review of the empirical literature utilising the Emergency Events Database (EM-DAT). Environ. Res. Lett. 18, 103006 (2023).
Russo, E. & Domeisen, D. I. V. Increasing intensity of extreme heatwaves: the crucial role of metrics. Geophys. Res. Lett. 50, e2023GL103540 (2023).
Coles, S. An Introduction to Statistical Modeling of Extreme Values (Springer, 2001).
Hersbach, H. et al. The ERA5 global reanalysis. Q. J. R. Meteorolog. Soc. 146, 1999–2049 (2020).
Rohde, R. A. & Hausfather, Z. The Berkeley Earth land/ocean temperature record. Earth Syst. Sci. Data 12, 3469–3479 (2020).
Tebaldi, C. et al. Climate model projections from the Scenario Model Intercomparison Project (ScenarioMIP) of CMIP6. Earth Syst. Dyn. 12, 253–293 (2021).
Philip, S. Y. et al. Rapid attribution analysis of the extraordinary heat wave on the Pacific coast of the US and Canada in June 2021. Earth Syst. Dyn. 13, 1689–1713 (2022).
Zeder, J. & Fischer, E. M. Quantifying the statistical dependence of mid-latitude heatwave intensity and likelihood on prevalent physical drivers and climate change. Adv. Stat. Clim. Meteorol. Oceanogr. 9, 83–102 (2023).
Pons, F. M. E., Yiou, P., Jézéquel, A. & Messori, G. Simulating the Western North America heatwave of 2021 with analogue importance sampling. Weather Clim. Extremes 43, 100651 (2024).
Zeder, J., Sippel, S., Pasche, O. C., Engelke, S. & Fischer, E. M. The effect of a short observational record on the statistics of temperature extremes. Geophys. Res. Lett. 50, e2023GL104090 (2023).
Forster, P. M. et al. Indicators of Global Climate Change 2024: annual update of key indicators of the state of the climate system and human influence. Earth Syst. Sci. Data 17, 2641–2680 (2025).
Friedlingstein, P. et al. Global Carbon Budget 2024. Earth Syst. Sci. Data 17, 965–1039 (2025).
Quilcaille, Y., Gasser, T., Ciais, P. & Boucher, O. CMIP6 simulations with the compact Earth system model OSCAR v3.1. Geosci. Model Dev. 16, 1129–1161 (2023).
Jiang, K. et al. Attributed radiative forcing of air pollutants from biomass and fossil burning emissions. Environ. Pollut. 306, 119378 (2022).
Lelieveld, J. et al. Air pollution deaths attributable to fossil fuels: observational and modelling study. BMJ 383, e077784 (2023).
Nauels, A. et al. Attributing long-term sea-level rise to Paris Agreement emission pledges. Proc. Natl Acad. Sci. USA 116, 23487–23492 (2019).
Liu, Z., Eden, J. M., Dieppois, B. & Blackett, M. A global view of observed changes in fire weather extremes: uncertainties and attribution to climate change. Clim. Change 173, 14 (2022).
Quilcaille, Y., Gudmundsson, L. & Seneviratne, S. I. Extending MESMER-X: a spatially resolved Earth system model emulator for fire weather and soil moisture. Earth Syst. Dynam. 14, 1333–1362 (2023).
Clarke, B., Otto, F., Stuart-Smith, R. & Harrington, L. Extreme weather impacts of climate change: an attribution perspective. Environ. Res. Clim. 1, 012001 (2022).
Vicedo-Cabrera, A. M. et al. The burden of heat-related mortality attributable to recent human-induced climate change. Nat. Clim. Change 11, 492–500 (2021).
Schleussner, C.-F. et al. Carbon Majors’ Trillion Dollar Damages (Climate Analytics, 2023).
Franta, B. Early oil industry knowledge of CO2 and global warming. Nat. Clim. Change 8, 1024–1025 (2018).
Bonneuil, C., Choquet, P.-L. & Franta, B. Early warnings and emerging accountability: total’s responses to global warming, 1971–2021. Global Environ. Change 71, 102386 (2021).
Supran, G., Rahmstorf, S. & Oreskes, N. Assessing ExxonMobil’s global warming projections. Science 379, eabk0063 (2023).
Blattner, C. E., Vicedo-Cabrera, A. M., Frölicher, T. L., Ingold, K., Raible, C. C. & Wyttenbach, J. How science bolstered a key European climate-change case. Nature 621, 255–257 (2023).
Jones, R. L., Guha-Sapir, D. & Tubeuf, S. Human and economic impacts of natural disasters: can we trust the global data? Sci. Data 9, 572 (2022).
Hawkins, E. et al. Observed emergence of the climate change signal: from the familiar to the unknown. Geophys. Res. Lett. 47, e2019GL086259 (2020).
GADM. Global administrative area data v.4.1. https://gadm.org/download_world.html (2022).
Python. difflib. SequenceMatcher from difflib. https://docs.python.org/3/library/difflib.html (2024).
Rosvold, E. L. & Buhaug, H. GDIS, a global dataset of geocoded disaster locations. Sci. Data 8, 61 (2021).
Xu, Z., Cheng, J., Hu, W. & Tong, S. Heatwave and health events: a systematic evaluation of different temperature indicators, heatwave intensities and durations. Sci. Total Environ. 630, 679–689 (2018).
van Oldenborgh, G. J. et al. Pathways and pitfalls in extreme event attribution. Clim. Change 166, 13 (2021).
Schwarz, G. Estimating the dimension of a model. Ann. Stat. 6, 461–464 (1978).
Naveau, P., Hannart, A. & Ribes, A. Statistical methods for extreme event attribution in climate science. Annu. Rev. Stat. Appl. 7, 89–110 (2020).
Quilcaille, Y., Gudmundsson, L., Beusch, L., Hauser, M. & Seneviratne, S. I. Showcasing MESMER-X: spatially resolved emulation of annual maximum temperatures of Earth system models. Geophys. Res. Lett. 49, e2022GL099012 (2022).
Miralles, O. & Davison, A. C. Timing and spatial selection bias in rapid extreme event attribution. Weather Clim. Extremes 41, 100584 (2023).
Fan, X., Duan, Q., Shen, C., Wu, Y. & Xing, C. Global surface air temperatures in CMIP6: historical performance and future changes. Environ. Res. Lett. 15, 104056 (2020).
Bell, B. et al. The ERA5 global reanalysis: preliminary extension to 1950. Q. J. R. Meteorolog. Soc. 147, 4186–4227 (2021).
Eyring, V. et al. Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geosci. Model Dev. 9, 1937–1958 (2016).
O’Neill, B. C. et al. The Scenario Model Intercomparison Project (ScenarioMIP) for CMIP6. Geosci. Model Dev. 9, 3461–3482 (2016).
Ciavarella, A. et al. Prolonged Siberian heat of 2020 almost impossible without human influence. Clim. Change 166, 9 (2021).
Bercos-Hickey, E. et al. Anthropogenic contributions to the 2021 Pacific Northwest heatwave. Geophys. Res. Lett. 49, e2022GL099396 (2022).
Risser, M. D., Zhang, L. & Wehner, M. F. Data-driven upper bounds and event attribution for unprecedented heatwaves. Weather Clim. Extremes 47, 100743 (2025).
Thompson, V. et al. The most at-risk regions in the world for high-impact heatwaves. Nat. Commun. 14, 2152 (2023).
Bartusek, S., Kornhuber, K. & Ting, M. 2021 North American heatwave amplified by climate change-driven nonlinear interactions. Nat. Clim. Change 12, 1143–1150 (2022).
Leach, N. J. et al. Heatwave attribution based on reliable operational weather forecasts. Nat. Commun. 15, 4530 (2024).
Ye, Y. et al. Attribution of a record-breaking cold event in the historically warmest year of 2023 and assessing future risks. npj Clim. Atmos. Sci. 8, 14 (2025).
Tradowsky, J. S. et al. Attribution of the heavy rainfall events leading to severe flooding in Western Europe during July 2021. Clim. Change 176, 90 (2023).
Arias, P. A. et al. Interplay between climate change and climate variability: the 2022 drought in Central South America. Clim. Change 177, 6 (2023).
Rivera, J. A. et al. 2022 early-summer heatwave in Southern South America: 60 times more likely due to climate change. Clim. Change 176, 102 (2023).
Li, S. & Otto, F. E. L. The role of human-induced climate change in heavy rainfall events such as the one associated with Typhoon Hagibis. Clim. Change 172, 7 (2022).
Luu, L. N. et al. Attribution of typhoon-induced torrential precipitation in Central Vietnam, October 2020. Clim. Change 169, 24 (2021).
Cael, B. B., Burger, F. A., Henson, S. A., Britten, G. L. & Frölicher, T. L. Historical and future maximum sea surface temperatures. Sci. Adv. 10, eadj5569 (2024).
Morim, J. et al. Understanding uncertainties in contemporary and future extreme wave events for broad-scale impact and adaptation planning. Sci. Adv. 9, eade3170 (2023).
Otto, F. E. L. et al. Climate change increased extreme monsoon rainfall, flooding highly vulnerable communities in Pakistan. Environ. Res. Clim. 2, 025001 (2023).
Philip, S. Y., Kew, S. F., van der Wiel, K., Wanders, N. & Jan van Oldenborgh, G. Regional differentiation in climate change induced drought trends in the Netherlands. Environ. Res. Lett. 15, 094081 (2020).
Qian, C. et al. Rapid attribution of the record-breaking heatwave event in North China in June 2023 and future risks. Environ. Res. Lett. 19, 014028 (2024).
Zachariah, M. et al. Attribution of 2022 early-spring heatwave in India and Pakistan to climate change: lessons in assessing vulnerability and preparedness in reducing impacts. Environ. Res. Clim. 2, 045005 (2023).
Harrington, L. J. et al. Limited role of climate change in extreme low rainfall associated with southern Madagascar food insecurity, 2019–21. Environ. Res. Clim. 1, 021003 (2022).
Dhasmana, M. K., Mondal, A. & Zachariah, M. On the role of climate change in the 2018 flooding event in Kerala. Environ. Res. Lett. 18, 084016 (2023).
Dunne, K. B. J., Dee, S. G., Reinders, J., Muñoz, S. E. & Nittrouer, J. A. Examining the impact of emissions scenario on lower Mississippi River flood hazard projections. Environ. Res. Commun. 4, 091001 (2022).
van Oldenborgh, G. J. et al. Attribution of the Australian bushfire risk to anthropogenic climate change. Nat. Hazards Earth Syst. Sci. 21, 941–960 (2021).
Rousi, E. et al. The extremely hot and dry 2018 summer in central and northern Europe from a multi-faceted weather and climate perspective. Nat. Hazards Earth Syst. Sci. 23, 1699–1718 (2023).
Sippel, S. et al. Could an extremely cold central European winter such as 1963 happen again despite climate change? Weather Clim. Dyn. 5, 943–957 (2024).
Kew, S. F. et al. Impact of precipitation and increasing temperatures on drought trends in eastern Africa. Earth Syst. Dyn. 12, 17–35 (2021).
Pietroiusti, R. et al. Possible role of anthropogenic climate change in the record-breaking 2020 Lake Victoria levels and floods. Earth Syst. Dyn. 15, 225–264 (2024).
Vautard, R. et al. Human influence on growing-period frosts like in early April 2021 in central France. Nat. Hazards Earth Syst. Sci. 23, 1045–1058 (2023).
Schumacher, D. L. et al. Detecting the human fingerprint in the summer 2022 western–central European soil drought. Earth Syst. Dyn. 15, 131–154 (2024).
Vautard, R. et al. Human influence on European winter wind storms such as those of January 2018. Earth Syst. Dyn. 10, 271–286 (2019).
Carrasco-Escaff, T., Garreaud, R., Bozkurt, D., Jacques-Coper, M. & Pauchard, A. The key role of extreme weather and climate change in the occurrence of exceptional fire seasons in south-central Chile. Weather Clim. Extremes 45, 100716 (2024).
Qian, C., Ye, Y., Bevacqua, E. & Zscheischler, J. Human influences on spatially compounding flooding and heatwave events in China and future increasing risks. Weather Clim. Extremes 42, 100616 (2023).
Kimutai, J., New, M., Wolski, P. & Otto, F. Attribution of the human influence on heavy rainfall associated with flooding events during the 2012, 2016, and 2018 March-April-May seasons in Kenya. Weather Clim. Extremes 38, 100529 (2022).
Zachariah, M., Kumari, S., Mondal, A., Haustein, K. & Otto, F. E. L. Attribution of the 2015 drought in Marathwada, India from a multivariate perspective. Weather Clim. Extremes 39, 100546 (2023).
Granger, C. W. J. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37, 424–438 (1969).
Lütkepohl, H. New Introduction to Multiple Time Series Analysis (Springer, 2005).
Granger, C. W. J. & Newbold, P. Spurious regressions in econometrics. J. Econ. 2, 111–120 (1974).
Akaike, H. in Selected Papers of Hirotugu Akaike. Springer Series in Statistics (eds Parzen, E. et al.) 199–213 (Springer, 1998).
Papagiannopoulou, C. et al. A non-linear Granger-causality framework to investigate climate–vegetation dynamics. Geosci. Model Dev. 10, 1945–1960 (2017).
Leng, S., Xu, Z. & Ma, H. Reconstructing directional causal networks with random forest: causality meeting machine learning. Chaos 29, 093130 (2019).
Gasser, T. & Fu, B. tgasser/OSCAR: v3.3 (v3.3). Zenodo https://doi.org/10.5281/zenodo.10548477 (2024).
Gasser, T. et al. The compact Earth system model OSCAR v2.2: description and first results. Geosci. Model Dev. 10, 271–319 (2017).
Jones, C. et al. Twenty-first-century compatible CO2 emissions and airborne fraction simulated by CMIP5 Earth system models under four representative concentration pathways. J. Clim. 26, 4398–4413 (2013).
Gasser, T., Guivarch, C., Tachiiri, K., Jones, C. D. & Ciais, P. Negative emissions physically needed to keep global warming below 2 °C. Nat. Commun. 6, 7958 (2015).
Trudinger, C. & Enting, I. Comparison of formalisms for attributing responsibility for climate change: non-linearities in the Brazilian Proposal approach. Clim. Change 68, 67–99 (2005).
Hoesly, R. M. et al. Historical (1750–2014) anthropogenic emissions of reactive gases and aerosols from the Community Emissions Data System (CEDS). Geosci. Model Dev. 11, 369–408 (2018).
Hoesly, R. & Smith, S. CEDS v_2024_04_01 Release Emission Data (v_2024_04_01). Zenodo https://doi.org/10.5281/zenodo.10904361 (2024).
Guido, R. et al. Global fire emissions estimates during 1997–2016. Earth System Science Data 9, 697–720 (2017).
Van Marle, M. J. E. et al. Historic global biomass burning emissions for CMIP6 (BB4CMIP) based on merging satellite observations with proxies and fire models (1750-2015). Geosci. Model Dev. 10, 3329–3357 (2017).
Hurtt, G. C. et al. Harmonization of global land use change and management for the period 850–2100 (LUH2) for CMIP6. Geosci. Model Dev. 13, 5425–5464 (2020).
Houghton, R. A. & Castanho, A. Annual emissions of carbon from land use, land-use change, and forestry from 1850 to 2020. Earth Syst. Sci. Data 15, 2025–2054 (2023).
Gasser, T. et al. Path-dependent reductions in CO2 emission budgets caused by permafrost carbon release. Nat. Geosci. 11, 830–835 (2018).
Gasser, T. et al. Historical CO2 emissions from land use and land cover change and their uncertainty. Biogeosciences 17, 4075–4101 (2020).
Forster, P. et al. in Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (eds Masson-Delmotte, V. et al.) 923–1054 (Cambridge Univ. Press, 2021).
Szopa, S. et al. in Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (eds Masson-Delmotte, V. et al.) 817–922 (Cambridge Univ. Press, 2021).
Gütschow, J. et al. The PRIMAP-hist national historical emissions time series. Earth Syst. Sci. Data 8, 571–603 (2016).
Gütschow, J., Pflüger, M. & Busch, D. The PRIMAP-hist national historical emissions time series (1750-2022) v2.5.1 (2.5.1). Zenodo https://doi.org/10.5281/zenodo.10705513 (2024).
Van Oldenborgh, G. J. et al. Attributing and projecting heatwaves is hard: we can do better. Earths Future 10, e2021EF002271 (2022).
Zhang, L., Risser, M. D., Wehner, M. F. & O’Brien, T. A. Leveraging extremal dependence to better characterize the 2021 Pacific Northwest heatwave. J. Agri. Biol. Environ. Stat. https://doi.org/10.1007/s13253-024-00636-8 (2024).
Hannart, A. & Naveau, P. Probabilities of causation of climate changes. J. Clim. 31, 5507–5524 (2018).
Hannart, A., Pearl, J., Otto, F. E. L., Naveau, P. & Ghil, M. Causal counterfactual theory for the attribution of weather and climate-related events. Bull. Am. Meteorol. Soc. 97, 99–110 (2016).
Weidema, B. P., Pizzol, M., Schmidt, J. & Thoma, G. Attributional or consequential life cycle assessment: a matter of social responsibility. J. Clean. Prod. 174, 305–314 (2018).
Brander, M., Burritt, R. L. & Christ, K. L. Coupling attributional and consequential life cycle assessment: a matter of social responsibility. J. Clean. Prod. 215, 514–521 (2019).
MacDougall, A. H. & Friedlingstein, P. The origin and limits of the near proportionality between climate warming and cumulative CO2 emissions. J. Clim. 28, 4217–4230 (2015).
Quilcaille, Y. Extension for extreme event analysis. Zenodo https://doi.org/10.5281/zenodo.15569401 (2025).
Gasser, T. & Fu, B. tgasser/OSCAR: v3.3 (v.3.3). Zenodo https://doi.org/10.5281/zenodo.10548477 (2024).
Acknowledgements
This work was supported by funding from the Horizon 2020 and Horizon Europe research and innovation programmes of the European Union (grant agreement nos. 101003687 (PROVIDE), 101081369 (SPARCCLE) and 101003469 (XAIDA)). T.G. also acknowledges support from the Horizon Europe research and innovation programme of the European Union (grant agreement no. 101056939 (RESCUE)). R.H. acknowledges funding from the Rockefeller Brothers Fund. We thank L. Pierini for verifying the equations for the decomposition of contributions. W.T. acknowledges funding from the European Research Council under the Horizon Framework research and innovation programme of the European Union (grant agreement no. 101124572 and European Research Council consolidator grant ‘LACRIMA’). Views and opinions expressed are, however, those of the authors only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency; neither the European Union nor the granting authority can be held responsible for them. We thank the referees for their careful review of the paper.
Funding
Open access funding provided by Swiss Federal Institute of Technology Zurich.
Author information
Authors and Affiliations
Contributions
Y.Q., L.G., D.L.S., T.G. and S.I.S. conceptualized the study. Y.Q. developed the software and carried out the analysis. R.H. provided guidance on the Carbon Majors database. T.G. conducted the analysis with OSCAR. P.N. revised the statistical decomposition. Y.Q. drafted the text, and Y.Q., L.G., D.L.S., T.G., R.H., C.H., Q.L., S.N., P.N., W.T., C.-F.S. and S.I.S. contributed to interpreting the results and refining the text.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Karsten Haustein, Mark Risser, Likun Zhang and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Besides ERA5, the contributions of climate change to each event are also assessed based on other datasets, such as BEST29.
a, Number of heatwaves reported per country in EM-DAT over 2000–2023. An extreme event attribution is performed for each of them, as illustrated for four examples with BEST29 data: b, the 2021 Pacific Northwest heat dome, c, the 2003 heatwave in France, d, the 2022 Indian heatwave, and e, the 2013 eastern China heatwave. For each example, the average temperatures during the event are mapped, with the outlines of the reported region (lime green contours). In addition, the intensity (average temperature T (°C) during the period and region of the event) and change in Global Mean Surface Temperature (GMST, °C) are represented over 1950–2023 (black dots), with their conditional distribution represented through the median (red line) and ranges of the distribution (red shading). Finally, the change in intensity and change in return period (year) compared to the pre-industrial reference period are shown for each example. Uncertainties inferred using bootstrapping are not shown here for the sake of clarity.
Extended Data Fig. 2 Illustration of the goodness-of-fit with the quantile-quantile plot for the heatwave Pacific North West 2021 using ERA528.
For a perfect fit, the quantiles of the sample (red dots) would be distributed over the identity line (black line). The uncertainties on the shape parameter provide a confidence band for the theoretical quantiles (grey shaded area), while the uncertainties on the location and scale provide a confidence band for the quantiles of the sample (red lines).
Extended Data Fig. 3 Out of the 226 analysed heatwaves, 217 events show sufficient goodness-of-fit.
For each of the heatwaves and datasets used for analysis, the fraction of sample outside confidence band is calculated (black circles). An event is rejected if the sample has a fraction higher than 5% out of the confidence band (red dashed line). For each heatwave, results are summarized over datasets in boxplots (black box) and the median (purple dot).
Extended Data Fig. 4 Out of the 217 analysed heatwaves, 214 events demonstrate a significant causality.
For each of the heatwaves and datasets used for analysis, the non-linear Granger causal inference is tested through comparisons of performance of Random Forest models (black circles). The hypothesis of non-causality is rejected if the p-value is lower than 0.05 (red dashed line). For each heatwave, results are summarized over datasets in boxplots (black box) and the median (purple dot).
Extended Data Fig. 5 To decompose probabilities, the method extends well-established approaches for higher performance, shown sufficient for 213 heatwaves out of 214 events.
Each heatwave attributed in this analysis is shown here (coloured dots). The total probability of each event is the result from the attribution analysis. The reconstructed probability results from the decomposition of the probabilities using the three approaches (ABU in yellow, AON in blue, combined in green), then all contributions are summed up to facilitate the comparison. The event in the red box in the upper right corner is the only event for which the decomposition fails. The 95% confidence interval is shown for the combined ABU & AON (green lines) only for the sake of clarity.
Supplementary information
Supplementary Table 1
Contributions of climate change and each carbon majors for each analysed heatwave. The results are ordered by geographical occurrence of the heatwaves and geographical headquarters of the carbon majors, and provide the contribution to the intensity and probability ratio, with median and 95% confidence intervals
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Quilcaille, Y., Gudmundsson, L., Schumacher, D.L. et al. Systematic attribution of heatwaves to the emissions of carbon majors. Nature 645, 392–398 (2025). https://doi.org/10.1038/s41586-025-09450-9
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-025-09450-9
This article is cited by
-
Exceeding 1.5 °C requires rethinking accountability in climate policy
Nature (2026)
-
Extreme weather event accountability
Nature Geoscience (2026)
-
Heatwaves linked to carbon emissions from specific companies
Nature (2025)
-
Ownership of power plants stranded by climate mitigation
Nature Sustainability (2025)
