
Abstract
This article describes a dataset on nut allergy extracted from Spanish clinical records provided by the Hospital Universitario Fundación de Alcorcón (HUFA) in Madrid, Spain, in collaboration with its Allergology Unit and Information Systems and Technologies Department. There are few publicly available clinical texts in Spanish and having more is essential as a valuable resource to train and test information extraction systems. In total, 828 clinical notes in Spanish were employed and several experts participated in the annotation process by categorizing the annotated entities into medical semantic groups related to allergies. To evaluate inter-annotator agreement, a triple annotation was performed on 8% of the texts. The guidelines followed to create the corpus are also provided. To determine the validation of the corpus and introduce a real use case, we performed some experiments using this resource in the context of a supervised named entity recognition (NER) task by fine-tuning encoder-based transformers. In these experiments, an average F-measure of 86.2% was achieved. These results indicate that the corpus used is suitable for training and testing approaches to NER related to the field of allergology.
Similar content being viewed by others

Background & Summary
Tree nut allergy poses a challenge in the field of allergology due to the adverse reactions that a patient may suffer from, such as anaphylaxis. These reactions are a consequence of the immune system’s actions on specific proteins present in nuts. Their severity can vary from mild symptoms, like itching and hives, to more severe manifestations that affect the respiratory and cardiovascular systems. Anaphylaxis is a severe and potentially life-threatening immune system response. Its main characteristics include symptoms of difficulty breathing, swelling of the airways, a drop in blood pressure, and anaphylactic shock. Therefore, this serious reaction is a cause for concern in the medical community, as it requires urgent medical intervention in cases of rapid progression. Nut allergies can behave as hidden allergens, and small amounts of these foods can produce severe reactions. In addition, they are a cause of cross-reactivity and co-sensitization between various nuts or with other plant foods (fruits, seeds, etc.), making their clinical management and diagnosis difficult and constituting a health problem.
In this work, a corpus of clinical progress notes annotated by allergists is introduced. This corpus is a valuable resource to train and test systems to process Spanish clinical texts. Spanish is the fourth most spoken language in the world1; compared to English, Spanish is a highly inflectional language with a richer morphology; morphemes signify many syntactic, semantic, and grammatical aspects of words (such as gender, number, etc.). From a syntactic perspective, Spanish texts feature more subordinate clauses and lengthy sentences with a high degree of word order flexibility; for example, the subject is not restricted to appearing solely before the verb in a sentence. This means that Spanish clinical texts have particularities that require specific language resources to train and test language processors.
Regarding the creation of corpora in the health domain, different efforts have been made by the scientific community in the field of clinical texts in Spanish. In2, the authors introduce the first iteration of the NUBes corpus (Negation and Uncertainty annotations in Biomedical texts in Spanish). As part of an ongoing study, 29,682 sentences from anonymized health records, annotated with negation and uncertainty, comprise the corpus. The research offers the primary annotation and design choices and a thorough comparison with comparable Spanish corpora. The authors present that NUBes is the biggest negation corpus available to the general public in Spanish and the first to include annotations for speculative cues, scopes, and events. Another approach was presented in3, where the authors describe an open-source corpus for section identification in Spanish health records. A corpus of unstructured clinical records, in this case, progress notes written in Spanish, was annotated with seven major section types. As a result of this research, an annotated corpus was defined, and the designed new evaluation script and a baseline model were freely available to the community. In4, the authors defined a process for the identification and extraction of relevant symptom-related data within the medical notes written in Spanish. In this case, a corpus of 98 electronic medical records of patients diagnosed with the new coronavirus SARS-CoV-2 (COVID) was used. With the collaboration of three experts, each medical note from the COVID-19 patient corpus was manually labelled. Moreover, a systematic review of clinical texts in languages other than English performed in5 highlights the research of6 for Spanish. The definition of a gold standard corpus of adverse drug reactions, known as IxaMed-GS, is one of the primary contributions of this research. A team of physicians and pharmacists who worked in pharmacology and pharmacovigilance in a Spanish hospital took a year to annotate the corpus manually. The goal of the corpus annotation was to identify adverse drug reactions in discharge reports5.
Related to the use of Large Language Models (LLM) to process Spanish clinical narrative, in this work we used encoder-based transformers to validate the corpus in a Named Entity Recognition (NER) task on Spanish clinical texts. Previous works described in7 and8 reported results using bidirectional encoder representations for transformers (BERT-based architectures) and Bi-LSTM-CRF models (a bidirectional long short-term memory plus Conditional Random Fields layer) on Spanish clinical cases, achieving an F-score of 88.8% on entity identification and classification. Additionally9, addressed the identification of negation and speculation, two relevant phenomena analyzing clinical documentation, integrating deep learning architectures. It was evaluated for English and Spanish languages on biomedical corpora, particularly with BioScope and IULA, with F-measures of 86.6% (BioScope) and 85.0% (IULA).
The field of Natural Language Processing (NLP) is essential for improving access to relevant clinical information, where standard corpora are needed to refine and optimize information extraction systems from unstructured data. This work aims to obtain a corpus on allergology from Spanish clinical notes about patients suffering from nut allergies. To determine the validity of the dataset some experiments for NER in the medical field were conducted to address the issue of information accessibility for future applications. Therefore, to the best of our knowledge, no open-source corpus has been defined in Spanish containing information related to clinical notes focused on allergy processes.
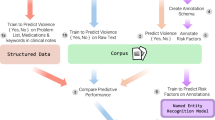
In this section, the methodology to collect and create the corpus and the experiments done to test the validity of the corpus are described. As illustrated in Fig. 1, the overall methodology comprises different phases encompassing the steps of (1) Data collection, (2) Data pre-annotation, (3) Data annotation, and (4) Validation of the corpus. Firstly, a preliminary set of annotation guidelines based on using medical dictionaries are defined. These dictionaries are created by obtaining terms for the different semantic groups from SNOMED-CT10 complemented with terms provided by the doctors of the Allergology Unit at Hospital Universitario Fundación Alcorcón (HUFA), a public health institution of the Madrid Health Service. This allows to pre-annotate the clinical notes, generating an initial dataset. Subsequently, the clinical notes are preprocessed, and a specific dataset is selected for manual revision and annotation. An annotation environment is set up with the Doccano tool11, allowing physicians to manually annotate the pre-annotated dataset following the established guidelines. The physicians review and annotate the pre-annotated dataset to generate a high-quality annotated dataset where disagreements are discussed and annotation guidelines are refined. This labelled dataset is prepared for training and testing an encoder-based transformer NER model.

Methodology in the creation and validation the corpus. The upper part reflects the Corpus Creation phase with three steps: Data collection, Pre-annotation and Annotation. The bottom part concerns the Corpus Validation phase where the RoBERTa encoder-based transformers are fine tuned in a NER task and then tested using the corpus created.
This research has obtained the approval from the Ethical Committee for Research with Medicines, Hospital Universitario Fundación Alcorcón. 2nd June 2020. Reference number: 20/97.
Text sources
The HUFA has provided 1,333,678 fully anonymized medical records from the Allergology Unit and Emergency Department, covering the period from 1998 to 2021. These medical records are associated with patients presenting symptoms or clinical pictures related to allergic reactions. From these texts, a subset of 235,040 records related to nut allergies was used. Finally, medical experts selected 828 highly relevant records that included cases of anaphylaxis in patients, assessing a dataset with a vocabulary size of 8,430 unique tokens. Physicians selected the notes from among those available for patients with varying degrees of severity of nut allergies and anaphylaxis. What they were looking for was to locate clinical progress notes of adequate length (with different templates as is shown in Table 2) detailing diagnoses and tests for allergy and anaphylaxis to build a rich resource for NLP.
The collection of texts has a total of 70,272 words and 3,938 sentences, with an average of 85 words and five sentences per note. The maximum number of words in a text is 533, and 50 sentences. The notes contain medical terms that pose a complex comprehension challenge for non-medical professionals. Clinical notes follow a different structure depending on the template used to collect patient information. The types of templates are anamnesis, personal and family history, physical examination, medical-evolution, diagnostic tests, summary of the situation, diagnosis, medical treatment, and recommendations.
The texts are written in informal clinical writing where typos, abbreviations, and incomplete sentences are found. Some clinical notes may contain results of analyses or skin tests performed on the patient. There are typographical errors caused by rushed medical care, tokenization errors, and words that should not be anonymized. As for the anonymization of non-sensitive information, the cases where this occurs are very few and are due to the strict anonymization rules previously implemented in the hospital.
Text selection
Concerning the methodology used in the selection of clinical notes, first, texts that integrate only one character, symbol, or letter are eliminated. In this work, a text is a clinical note that contains a unique identifier (note ID generated by the hospital system) and that integrates information about the patients collected by doctors. Secondly, a subset of 10,176 patients with 235,040 notes was selected, where the information contained in the patient texts is related to nut allergies. For this purpose, the medical staff creates a nut allergy dictionary with relevant terms to search the notes. It comprises seven semantic groups (Comorbidities, Manifestations, Allergy, Nut allergy, Cofactors, Proteins, and Treatments) with terms extracted from SNOMED CT12 and some terms collected by HUFA. Table 1 presents the characteristics of the dictionary.
The medical staff manually selected 828 texts related to 197 patients from two databases; one collected patients allergic to nuts, and the other collected patients who had had anaphylaxis due to nuts. Table 2 displays the total number of each template in the 828 notes. Two clinical notes extracted from the corpus with the translation to English has been included at Zenodo repository13.
Annotation scheme
The entities or semantic groups the physicians participating in the corpus creation decided to annotate are described below:
-
Comorbidity entities describe disorders or diseases occurring in the same person. It implies an interaction between diseases that may worsen the course of both. One example of this case could be:
-
Original sentence in Spanish: “Durante la primavera síntomas de asma incrementados”.
-
English translation: “During spring, increased asthma symptoms”.
-
Annotated original sentence: “Durante la primavera síntomas de [asma] COMORBIDITY incrementados”.
-
-
Manifestation refers to an indication or sign of an organic disturbance or illness. In pathology, it denotes the perceptible expression of a disease to the observer, which, once assessed, becomes a diagnostic factor. One example of this case could be:
-
Original sentence in Spanish: Destacando la aparición de edemas.
-
English translation: “Highlighting the appearance of edemas”.
-
Annotated original sentence: “Destacando la aparición de [edemas] MANIFESTATION.
-
-
Allergy refers to entities that encompass allergies and the allergens that cause them. Distinctions should be made regarding nut allergies. One example of this case could be:
-
Original sentence in Spanish:“El paciente presenta alergias alimentarias”.
-
English translation: “The patient has food allergies”.
-
Annotated original sentence: “El paciente presenta [alergias alimentarias] ALLERGY”.
-
-
Nut allergy entity pertains to nuts and the reactions they cause in some patients, often associated with cutaneous and/or serum sensitization. One example of this case could be:
-
Original sentence in Spanish: the sentence “No comerá pistachos”.
-
English translation: “He will not eat pistachios”.
-
Annotated original sentence: “No comerá [pistacho] NUT ALLERGY”.
-
-
Cofactors are factors that might contribute to the severity of a reaction independently of allergen exposure. One example of this case could be:
-
Original sentence in Spanish: “El paciente presenta un cuadro de estrés”.
-
English translation: “The patient has a stress syndrome”.
-
Annotated original sentence: “El paciente presenta un cuadro de [estrés] COFACTOR”.
-
-
Protein refers to proteins that are present in different allergen sources and may be responsible for genuine sensitization and/or cross-reactivity between them. One example of this case could be:
-
Original sentence in Spanish: “Los alimentos que más cantidad de LTP suelen tener”.
-
English translation: “Foods that tend to have a higher amount of LTP”.
-
Annotated original sentence: “Los alimentos que más cantidad de [LTP] PROTEIN suelen tener”.
-
-
Treatments are measures implemented to improve, alleviate, or cure an allergy in the patient. One example of this case could be:
-
Original sentence in Spanish: “Se le suministra adrenalina intramuscular”.
-
English translation: “Intramuscular adrenaline is administered”.
-
Annotated original sentence: “Se le suministra [adrenalina intramuscular] TREATMENT”.
-
Table 3 shows the semantic groups with their semantic types and examples. All entity types are annotated, including negated contexts. For example, edema (‘oedema’) is annotated in no presenta edema (‘no edema’). Conversely, discontinuous entities, that is, text fragments where an entity is split up into non-adjacent sections within the text but is still regarded as a single entity, are not annotated. However, nested entities (entities that contain other entities) are annotated. Nested entities are rarely annotated in corpora14 and including them in this corpus is an important contribution.
Pre-annotation process
The texts are annotated according to the annotation schema described in this manuscript. Before starting the annotation process, a pre-annotation of entities is performed to expedite labelling. Previous research has shown that a pre-annotation phase does not interfere with obtaining good results15,16. A NER system is used, which involves the creation of dictionaries by medical staff, and the use of the SpaCy library17. This system is based on dictionaries where a module is used for normalization, tokenization, lemmatization, and matching of terms contained in the dictionaries. It automatically identifies and labels entities in a text using dictionaries previously created by medical practitioners before initiating the annotation task.
Annotation process
Once the pre-annotation is completed, the annotation phase begins using the Doccano tool version 1.8.411 as a supporting environment to facilitate doctors the annotation task. Doccano is an open-source annotation tool that allows intuitive text data labelling through a web-based graphical interface. Doccano facilitates text classification and named entity tagging, generating structured datasets ready for training machine learning models. Installation was performed using Docker to deploy the service in a container. Once annotation was completed, the data was exported in JSON format, which was directly integrated into the project’s natural language processing pipeline.
Annotation guidelines are developed in conjunction with doctors and are available in a separate document at Zenodo repository13. The guidelines consist of rules used for labelling training data. It should be noted that nested entities are annotated; e.g. the phrase f420 rPru p 3 LTP Melocotón would be annotated as “f420 [rPru p 3 LTP [Melocotón] ALLERGY] PROTEIN”, inside the protein entity annotation, there is the annotation of melocotón (“peach”) as an allergy. Figure 2 displays more examples of nested annotations.

Example of an excerpt from a clinical note related to a blood test containing nested entities: (1) “rPru p 3 LTP Melocotón” is a PROTEIN entity containing “Melocotón” ALLERGY entity, (2) “rAra h 9 LTP Cacahuete” is a PROTEIN entity containing “Cacahuete” NUTALLERGY entity and (3) “rJuq r1 Nuez” is a PROTEIN entity containing “Nuez” NUTALLERGY entity.
In the data collection phase (see Fig. 1), the first version of the annotation guidelines was created and then, in the annotation phase, this set of guidelines is refined; Three medical practitioners from the HUFA participated in the annotation process using the Doccano tool performing a triple annotation on the same 60 texts. This triple annotation allowed the annotators to become familiar with the task, discuss, and adjust the annotation criteria. After reaching an agreement on the criteria and modifying the guidelines, the same 60 texts were reviewed again by the annotators to calculate the inter-annotation agreement. During this stage, the final guidelines were updated and established. Once the final guidelines were established, the remaining 768 notes were divided in a stratified manner, assigning 256 notes to each physician for annotation.
The inter-annotation agreement (IIA) was calculated for 60 texts (approximately 8% of the corpus) to measure the quality of the annotations. Previous works showed conclusive IAAs using a similar percentage of their initial datasets18. The IAA is calculated using two metrics, the raw inter-annotator agreement calculation and the Jaccard index19. Metrics based on percentage agreement or corrective metrics have not been used because they are not suitable for tasks where the number of items to be annotated is not previously known19.
Table 4 shows the number of annotated entities in each semantic group. The semantic group with the fewest annotated entities is ‘cofactors’ because most patients do not present factors that can worsen allergic reactions. The second semantic group with the fewest annotated entities is ‘comorbidities’. Therefore, most patients do not have disorders or diseases that may interact with allergies. ‘Nut allergy’ and ‘allergy’ entities outnumber the rest of the entity types. A total of 5.81% of the annotations are nested.
The results of the inter-annotator agreement are measured using both the raw inter-annotator agreement calculation and the Jaccard index.
Table 5 shows the results of inter-annotator agreement calculated using the “raw agreement” method. This method measures the consistency of annotations by identifying how many specific entities were identically labelled by all three annotators. To obtain this measure, the number of entities that all three annotators marked the same is counted, meaning they all agreed to identify that entity in the same way and in the same context. This number of identical entities is then divided by the total number of entities that must be annotated in the dataset. This raw agreement method measures the level of consensus without considering partial similarity; that is, agreement is only counted when the annotations are identical. The total inter-annotator agreement is 72.2%.
Table 6 shows the results of inter-annotator agreement calculated using the Jaccard index, a metric that evaluates the degree of similarity between two sets of annotations. This index is defined as the size of the intersection divided by the size of the union of the two sets, which is interpreted as a measure of how much the annotators’ labels agree in comparison to the total number of labels made. In this context, for each pair of annotators, the set of entities labelled by both annotators is compared with the set of all entities labelled by either of the two annotators. The “intersection” refers to the number of entities that both annotators labelled similarly, while the “union” represents the total number of entities annotated by either of the two, regardless of whether they matched or not. The Jaccard index is thus the result of dividing the number of matches (intersection) by the total number of labels present in at least one of the sets (union). This index ranges from 0 to 1, where a value close to 1 indicates high similarity in annotations (meaning the annotators agreed on almost all labels), while a value close to 0 indicates low similarity (few or no matches). Unlike the raw agreement calculation, the Jaccard index captures partial matches between two annotators, which is useful in cases where annotation criteria may be interpreted differently or when categories are complex and difficult to identify consistently.
Table 5 shows the agreement values per entity type, while Table 6 shows the agreement values per pair of annotators. In the assessment, most disagreement is observed in the category of ‘cofactors’, followed by ‘comorbidities’. This may be because these are the two minority groups and the most difficult categories to identify.
Data Records
The corpus is available at Zenodo13, following the JSON Lines (JSONL) format, contains detailed records of allergology clinical notes for individuals. Each entry includes a unique identifier, a descriptive text providing information about the patient, a list for additional comments, and a list of tags specifying different types of allergies and reactions. The labels cover semantic groups. This structure enables detailed analysis and effective clinical monitoring of allergies in patients, facilitating accurate documentation and categorization of relevant medical information. Additionally, the annotation guidelines are included.
Technical Validation
Several experiments using the resources in the context of NER are presented to test the validity of the corpus created and show a practical use case. The aim is to formalize a first baseline with the corpus of clinical notes using a discriminative large language model (LLM). Next, we describe the employed bidirectional encoder representations from transformers (BERT), along with the methodology and evaluation metrics.
We use a framework based on LLMs such as BERT20, and contextualized embeddings. It employs a bidirectional strategy, which allows it to effectively capture the semantic relationships and dependencies between words in a text by considering the context both before and after each word. This model is trained with self-attention layers of encoders, Next Sentence Prediction (NSP), and a Masked Language Model (MLM), which randomly replaces 15% of the input tokens. The fundamental aim of the training is to predict the original word that was substituted, which enables the model to be trained in both left and right contexts, using the UNK (“Unknown”) token to replace out-of-vocabulary words and WordPiece embeddings. The training process of the model is divided into two fundamental stages, an initial phase of unsupervised training and a subsequent fine-tuning of pre-trained representations for supervised tasks. The result of this training is an internal language representation that captures complex patterns and relationships between words and sentences, and these representations can be used as fundamental features in other natural language processing tasks, such as named entity recognition. We tested a Robustly Optimized BERT Pretraining Approach (RoBERTa)21 in different variants with general and other specific training in the clinical setting in Spanish. Two available models were tested, (1) PlanTL-GOB-ES ROBERTA Large-BNE model22 trained on 570 GB of clean text from the Spanish National Library and (2) PlanTL-GOB-ES ROBERTA Base-biomedical-clinical-es23 trained on a real-world clinical corpus as well as a number of biomedical corpora in Spanish gathered via publically accessible corpora and crawlers. In addition, (3) XLM model ROBERTA Base24 is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages and was pre-trained on raw texts only, without any human tagging in any way with an automatic process to generate entries and tags from those texts.
Experimental setup
The annotated texts of the corpus were transformed into a BIO (Beginning, Inside, Outside) schema to label and represent the entities in the text in a structured and hierarchical way. The effects of various segment representations in the NER task with a machine learning approach have been analysed in the literature25. The BIO format is a common tagging format for tagging tokens in a chunking task in computational linguistics26.
The models were then trained using a randomly selected subset of 662 texts, which constitute 80% of the total corpus, while the remaining 166 texts were reserved for model validation, representing the remaining 20% of the corpus.
In the fine-tuning phase, we plugged a layer for named entity recognition (without conditional random fields) on top of the Spanish models. We implemented it in PyTorch with the Transformers library. The whole implementation was completed using jupyter notebook, and an NVIDIA GeForce RTX 3060 12GB was used to train the NER models. The GPU facilitates asynchronous data loading and multiprocessing.
The PlanTL-GOB-ES ROBERTA Large-BNE (RL-BNE) model was trained with 24 layers, a hidden size of 1024, and 16 attention heads. In the fine-tuning, a layer was added for named entity recognition. We trained it for six epochs with a maximum length of 512 tokens for the inputs to the transformer model.
The PlanTL-GOB-ES ROBERTA Base-biomedical-clinical-es (BIO-CLI) model was trained with 12 layers, a hidden size of 768, and 12 attention heads. We used Adam’s optimizer with a learning rate of 0.0005 and an effective batch size of 2048 sentences. In the fine-tuning stage, a layer for named entity recognition was added. We trained it for four epochs with a maximum length of 512 tokens for the inputs to the transformer model.
The XLM ROBERTA Base (XRB) model was trained with 12 layers, a hidden size of 768, and 12 attention heads. Then, in the fine-tuning process, a layer was added for named entity recognition. It was trained for four epochs with a maximum length of 512 tokens for the inputs to the transformer model
Table 7 shows the hyperparameters of the models. Additionally, to prevent overfitting during the fine-tuning process in the named entity recognition (NER) task, several regularization techniques were applied through training parameters. A low learning rate was used to reduce the impact of each weight update, thus preventing the model from excessively fitting the training data. Likewise, “weight decay” was implemented as a penalty that encourages smaller weights and reduces the risk of overfitting by penalizing high parameter values. Early stopping was also employed to interrupt training if no improvement was observed on the validation set for several consecutive steps, helping to stop the process before the model began to overfit. Finally, the “load best model at end” option was activated, which automatically loads the model with the best performance on the validation set at the end of the training, ensuring that the final selected model has the highest generalization ability according to the validation metric.
Results
We report the average precision, recall, accuracy, and the F-measure with their standard deviation. We ran five experimental rounds with different random initializations of the training set for the NER models.
The models are trained using 80% of the corpus for training and 20% for testing. Table 8 shows the distribution by the semantic group in each partition. In the five experimental rounds, the language models are trained for eight epochs. Table 9 displays the results obtained in the models, including precision, recall, F-measure (strict match), and accuracy, along with their respective standard deviations. Strict match refers to identifying entities in text with exact boundaries of entities as opposed to partial matching which considers as a true positive any text subset of the entity.
We can observe the results of the benchmark. BIO-CLI obtains the best results, but there is no significant difference from the other models. In the manuscript a statistical analysis of the results is detailed in order to check this point.
No substantial improvements are achieved from the fourth epoch onwards in any of the models. The training is conducted with more epochs, but the different checkpoints are stored to save the model when it achieves better results to avoid overfitting.
An error analysis is conducted to understand the performance of models in the task. Model predictions are examined to identify errors. There are 1388 tokens with a frequency of 1 in the training set, and 685 out-of-vocabulary (OOV) tokens in the test set. Some errors arise from medications infrequently mentioned in the texts, such as the ‘Emerade’ drug, which refers to ‘adrenaline’. Entities that appear rarely or not at all in the texts often lead to errors in their prediction.
In the partitioned dataset, three duplicate records were found in the training set (662 records) but none in the test set (166 records). Additionally, seven duplicate records were identified that are present in both partitions (training and test). These findings suggest that, whilst most of the data is properly divided, some identical records exist in both sets. This could influence the model evaluation, as information from the training set leaks into the test set. This situation may result from the common practice among doctors of copying information from previous notes to contextualize the current patient consultation.
Figure 3 shows the confusion matrix, revealing an overall positive performance. Most of the labels have a high number of correct predictions. However, some confusions are observed, especially with the label “O” (Others), which has many correct predictions but is also the category with the most confusion coming from other labels. In Table 10, the F-measure by semantic groups for BIO-CLI model is showed.

Confusion matrix of the NER model (BIO-CLI).
Labels such as B-Cofactor, I-Treatment, and I-Cofactor have a low number of correct predictions. This is because “cofactor” is the minority semantic group and there are few cases in the training set, just like the number of treatments consisting of more than one word. With a higher number of labels in these semantic groups in the training set, the model’s effectiveness and accuracy would increase.
In ambiguous contexts, there are also prediction errors, such as ‘cefaleas’ (headaches). Models label it as a manifestation when it should be identified as a comorbidity. Another example is ‘catarro de repetición’ (recurrent colds), which is a comorbidity, but the model predicts it as a manifestation. All models used made prediction errors in certain contexts. Some text features, such as hyphens with no space between the words, cause prediction errors. For example, ‘-reacción cutánea’ (skin reaction) is not correctly identified by the model when the hyphen is placed next to ‘reaction’. These errors occur because hyphens can lead to issues related to the tokenization of entities.
Table 11 displays examples of errors and predictions for each model. The first row includes an error related to punctuation marks (hyphen between two words), the second row shows an error related to a lack of understanding of the context (in this case unable to distinguish between comorbidity and manifestation) and the third row concerns a false negative because of infrequent terms (“increased physical activity”).
Statistical Analysis
In any empirical scientific study, repeating an experiment under identical conditions often results in some variability in the outcomes. This is known as experimental error. Therefore, in any scientific experimental study, it is crucial to compare and evaluate the characteristics of the different sets of samples and the results obtained. In this research, and following the steps defined in27, the validity of the results has been validated from a statistical standpoint, thereby reducing the appearance of experimental errors or the appearance of possible randomness.
Figure 4 includes the scatter-plot (top left), residual plot (top right), box-plot (bottom left) and analysis of means (bottom right) associated with the results.

Scatter and box plots (left) and Residuals and analysis of means plot (right).
The models included in this analysis are again RL-BNE, BIO-CLI and XRB. The scatter plot describes the behaviour of the set of samples obtained for each classifier through a point cloud. The box plot allows, through a simple visual inspection, to have an approximate idea of the central tendency (through the median), the dispersion (through the interquartile range), the symmetry of the distribution (through the symmetry of the plot) and the possible outliers of each classifier. The central line within the box describes the location of the sample median, and the mean is represented by a cross. The graph also includes a notch for the median, the width of which roughly indicates the 95% confidence interval. In the analysis of the means plot, all the models are compared together with the overall mean and the 95% decision limits. In all models, there are not samples outside the decision limits, so no model is significantly different from the overall mean. Finally, the residual plot shows the residuals obtained for each alternative. The residuals are equal to the values of the percentage correct minus the mean value for the group from which they come and show that the variability within each alternative is approximately the same. In the box plot, the different boxes show symmetry in the sample distribution. In this case, the widths of the median notches, for a 95% confidence interval, are quite similar. This suggests no statistically significant difference between the medians at this confidence level.
Hence, to be able to compare different models, it is necessary to ensure no significant differences between the variances of the populations. Therefore, a variance check for the accuracy of the models has been performed. The three statistics displayed in Table 12 test the null hypothesis that the standard deviations of the results within each of the three levels of models are the same. Since the smaller of the p-values is greater than or equal to 0.05, there is no statistically significant difference between the standard deviations at a 95.0% confidence level.
This point agrees with one of the important assumptions underlying the analysis of variance or ANOVA analysis. Therefore, as the conditions for applying the ANOVA method are fulfilled, it has been decided to include this method in the statistical parametric study to determine a ratio between the observed differences and to test different hypotheses based on the t-test. This analysis will indicate whether there are significant differences between the different means, and the Multiple Range Test (MRT) will identify the differences between different groups of results.
The analysis of variance or ANOVA analysis is shown in Table 13, and it decomposes the Accuracy variance into two components: a between-group component and a within-group component. The F-ratio, equal to 2.04099, is the ratio of the between-group estimate to the within-group estimate. Since the p-value of the F-test is greater than or equal to 0.05, so again, there is no statistically significant difference between the mean Accuracy from one Model level to another at 95.0
An MRT test, shown in Table 14, has been carried out to determine the significantly different means. This test applies a multiple comparison procedure to determine which means differ significantly. Table 14 shows the estimated difference between each pair of means. In the column ‘Difference’, an asterisk should be placed next to any model pair for showing statistically significant differences at the 95.0% confidence level. The column ‘ ± Limits’ defines the width of the confidence intervals for each mean difference of each model so that these intervals will be defined as Difference ± Limits. In summary, according to the MRT test, no statistically significant differences exist between any pair of means at a confidence level of 95.0%.
Table 15 identifies one homogeneous group using columns of ✓. Within each column, the levels containing ✓ form a group of means within which there are no statistically significant differences. In this case, all models have the same level for the symbol ✓, so only one homogeneous group has been detected. The method currently being used to discriminate between the means is Fisher’s least significant difference (LSD) procedure. With this method, there is a 5.0% risk of calling each pair of means significantly different when the actual difference equals 0.
Code availability
Custom code for this research is available at https://github.com/hulat/NER-Clinical-Notes.
References
Eberhard, D. M., Simons, G. F. & Fennig, C. D.Ethnologue: Languages of the World (SIL International, Dallas, 2023), 26 edn.
Lima, S., Perez, N., Cuadros, M. & Rigau, G. Nubes: A corpus of negation and uncertainty in spanish clinical texts. LREC 2020 - 12th International Conference on Language Resources and Evaluation, Conference Proceedings5772-5781 (2020).
de la Iglesia, I. et al. An open source corpus and automatic tool for section identification in spanish health records. Journal of Biomedical Informatics 145, 104461, https://doi.org/10.1016/J.JBI.2023.104461 (2023).
Cruz-Aguirre, D., Gómez-Adorno, H. & Rios-Lastiri, A. Extracción de síntomas en notas médicas escritas en español. Research in Computing Science 150, 269–280 (2021).
Alshuweihi, M., Salloum, S. A. & Shaalan, K. Biomedical corpora and natural language processing on clinical text in languages other than english: A systematic review. Studies in Systems, Decision and Control 295, 491–509, https://doi.org/10.1007/978-3-030-47411-9_27/TABLES/8 (2021).
Oronoz, M., Gojenola, K., Pérez, A., de Ilarraza, A. D. & Casillas, A. On the creation of a clinical gold standard corpus in spanish: Mining adverse drug reactions. Journal of Biomedical Informatics 56, 318–332, https://doi.org/10.1016/J.JBI.2015.06.016 (2015).
Akhtyamova, L., Martínez, P., Verspoor, K. & Cardiff, J. testing contextualized word embeddings to improve ner in spanish clinical case narratives. IEEE Access 8, 164717–164726 (2020).
Rivera-Zavala, R. M. & Martínez, P. Analyzing transfer learning impact in biomedical cross-lingual named entity recognition and normalization. BMC bioinformatics 22, 1–23 (2021).
Zavala, R. R. & Martinez, P. et al. The impact of pretrained language models on negation and speculation detection in cross-lingual medical text: comparative study. JMIR Medical Informatics 8, e18953 (2020).
International Health Terminology Standards Development Organisation (IHTSDO). SNOMED CT: Systematized Nomenclature of Medicine – Clinical Terms (2023).
Nakayama, H., Kubo, T., Kamura, J., Taniguchi, Y. & Liang, X. doccano: Text annotation tool for human (2018). Software available from https://github.com/doccano/doccano.
College of American Pathologists. Software and tools (2007).
Universidad Carlos III de Madrid & Hospital Universitario Fundación Alcorcón. Nut allergy corpus, https://doi.org/10.5281/zenodo.12724183 (2024).
Wang, Y., Tong, H., Zhu, Z. & Li, Y. Nested named entity recognition: a survey. ACM Transactions on Knowledge Discovery from Data (TKDD) 16, 1–29 (2022).
Lingren, T. et al. Evaluating the impact of pre-annotation on annotation speed and potential bias: natural language processing gold standard development for clinical named entity recognition in clinical trial announcements. Journal of the American Medical Informatics Association 21, 406–413 (2014).
Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. & Moreno-Sandoval, A. A clinical trials corpus annotated with umls entities to enhance the access to evidence-based medicine. BMC medical informatics and decision making 21, 1–19 (2021).
Honnibal, M. spaCy: Industrial-strength natural language processing in python (2015).
Gonzalez-Agirre, A. et al. Pharmaconer: Pharmacological substances, compounds and proteins named entity recognition track. In Proceedings of The 5th Workshop on BioNLP Open Shared Tasks, 1–10 (2019).
Aldama, N., Guerrero, M., Montoro, H. & Samy, D. Anotación de corpus lingüísticos: metodología utilizada en el instituto de ingeniería del conocimiento (iic) (2021). White paper.
Kenton, J. D. M. W. C., & Toutanova, L. K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of naacL-HLT (Vol. 1, No. 2) (June, 2019).
Liu, Y. et al. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
Fandiño, A. G. et al. Maria: Spanish language models. Procesamiento del Lenguaje Natural 68, https://doi.org/10.26342/2022-68-3 (2022).
Carrino, C. P. et al. Biomedical and clinical language models for spanish: On the benefits of domain-specific pretraining in a mid-resource scenario (2021). 2109.03570.
Conneau, A. et al. Unsupervised cross-lingual representation learning at scale. CoRR abs/1911.02116 (2019). 1911.02116.
Konkol, M. & Konopík, M. Segment representations in named entity recognition. In International conference on text, speech, and dialogue, 61-70 (Springer, 2015).
Khandelwal, A., Kar, A., Chikka, V. R. & Karlapalem, K. Biomedical ner using novel schema and distant supervision. In Proceedings of the 21st Workshop on Biomedical Language Processing, 155-160 (2022).
Gonzalez-Carrasco, I., Garcia-Crespo, A., Ruiz-Mezcua, B., Lopez-Cuadrado, J. L. & Colomo-Palacios, R. Towards a framework for multiple artificial neural network topologies validation by means of statistics. Expert Systems 31, 20–36 (2014).
Acknowledgements
This work was supported by grants PID2023-148577OB-C21 and PID2020-116527RB-I0 funded by MICIU/AEI/ 10.13039/501100011033 and by ERDF/UE.
Author information
Authors and Affiliations
Contributions
A.G.M defined and provided the collection of medical records and performed the annotation process, A.R.G defined the annotation scheme, conducted the experiment(s) and analysed the results, I.G.C conceived the experiments and analysed the results, M.D.A defined and provided the collection of medical records and performed the annotation process, B.S.G, A.M.S and A.B.P defined and provided the collection of medical records and performed the annotation process, B.G.P, P.M and M.A.T conceived the experiments and analysed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
González-Moreno, A., Ramos-González, A., González-Carrasco, I. et al. A clinical narrative corpus on nut allergy: annotation schema, guidelines and use case. Sci Data 12, 173 (2025). https://doi.org/10.1038/s41597-025-04503-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04503-0
