
Abstract
Neighborhoods are frequently cited as impactful for social, economic, political, and health outcomes. Measuring neighborhoods, however, is challenging, as the definition of a neighborhood may change dramatically across places. Researchers lack widespread but locally-sourced data on neighborhoods, and instead often adopt widely available but arbitrary Census geographies as neighborhood proxies. Others invest in the collection of more precise definitions, but these types of data are hard to collect at scale. We address this tension between scale and precision by collecting, cleaning, and providing to researchers a new dataset of city-defined neighborhoods. Our data includes 206 of the largest cities in the United States, covering more than 77 million people. We combine these data with block-level Census demographic data and provide them along with open-source software to aid researchers in their use.
Similar content being viewed by others

Introduction
Neighborhoods are the basic unit of analysis for many areas of social science. Examples include research on the social benefits of connected life in neighborhoods and communities1,2, intergenerational mobility and socioeconomic inequality3,4,5, geographic and community sorting of individuals, crime6,7, the provision of public health and social services (e.g.8), racial context and racial attitudes9,10, attitudes towards redistribution11, and neighborhood effects on political behavior12,13,14,15.
Across this broad range of applications, measuring neighborhoods is a common research challenge. This measurement challenge arises because the term “neighborhood” has different meanings in different contexts. While neighborhoods are typically associated with particular geographic areas, neighborhoods are also “social constructions named and bounded differently by numerous and diverse individuals” structured by different perceptions between people (pg. 252)16 (quoted in17). More concretely, a Census Tract is a commonly deployed geographic unit representing a neighborhood in social science research. Yet, a 4,000 person (the target size for Census Tracts) tract in Manhattan may be more or less appropriate for capturing a Manhattan neighborhood than a 4,000 person Census Tract captures a neighborhood in Green Bay, Wisconsin. The extent to which neighborhoods form along different infrastructural or demographic boundaries likely varies across place as well. Complicating matters further, there may not be a common definition of neighborhoods even within the same city. Measurement and standardization concerns are recurring issues in the study of local politics more generally, given a lack of pre-existing centralized data on many subjects of interest for scholars18,19,20.
This measurement problem appears in the study of neighborhoods when scholars seek to study multiple cities at the same time. When examining individual cities with well-defined historical and social neighborhoods, scholars often turn to local city-defined boundaries. For example, Sampson uses locally-defined neighborhoods in his work on Chicago4. While local neighborhood definitions offer promising neighborhood definitions for place-based research that integrate local knowledge and context, local definitions are not centralized. Thus, researchers face a measurement problem when studying cities where neighborhoods are hard to find, or when studying multiple cities. Researchers generally address this measurement problem in one of two ways — (1) using administrative boundaries defined by the US Census Bureau, or (2) less commonly, by surveying subjective definitions of neighborhoods.
We argue these approaches both have limitations from a trade-off between scale and precision. The most common way to approximate neighborhoods relies on boundaries like Census Tracts, Census Block Groups, Census Voting Tabulation Districts (VTDs), and Postal Service ZIP Codes (ZIPs, ZCTAs). These layers are convenient for research at scale because they are universally defined by the Census Bureau and easy to download. However, they suffer from a lack of precision because they are defined for statistical reporting purposes, and do not necessarily correspond to the common meaning of a neighborhood as a local area of closely connected people, social activities, or economic activities. Alternatively, other research attempts to define neighborhoods using the subjective definitions that people provide when asked to draw, define, or otherwise describe their neighborhood17,21,22,23,24,25,26. This research is informative about the connectedness of local areas and may offer better precision than administrative units, but require costly surveys that are difficult to scale to provide a national picture of neighborhoods in the United States.
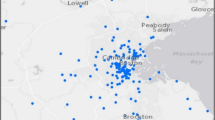
In this paper, we address this tension between scale and precision by collecting, cleaning, and analyzing a new dataset of neighborhoods as defined by city governments. Our sample includes 20,635 neighborhoods for 206 of the largest cities in the United States (shown in Fig. 1), encompassing more than 77,000,000 American residents. We attempted to acquire city-defined neighborhoods for each of the 336 cities in the United States with populations over 100,000 people as of 2022 through a combination of manual searches, direct contact with city officials, and open records requests. Our sampling frame thus includes the largest cities in the United States like New York, Los Angeles, and Chicago and more moderately sized cities like New Bedford, Massachusetts and Davenport, Iowa. By design, this means that one limitation of our approach is the omission of rural areas. We focus on cities with larger populations for two reasons: (1) first, we found that smaller cities were much less likely to report defining neighborhoods (see Supplementary Information Figure A1, and (2) existing research on rural settings finds that conceptualizations of neighborhoods differ in urban and rural areas27.

Neighborhoods Data Map. This figure shows a map of the cities in our neighborhoods data. Each city is visualized as a red point. We label several example cities. Our sample includes both large and mid-sized cities: bold labels indicate the city is among the top 25 cities by population (though, note that the labels shown here are not exhaustive of the large cities in our sample), while other cities are shown in regular font. Anchorage, AK and Honolulu, HI are both included in the sample, though not visualized here.
We find that many major cities in the United States define neighborhoods for internal or external purposes. Often, these neighborhoods serve as the base layer for administrative city functions ranging from planning to parking to policing to schools. Many are historically rooted sub-communities defined by geographic features within a city or dating to the original incorporation of an area into the city. The data we collected further demonstrate that neighborhoods vary substantially in characteristics like population, area, and racial/ethnic diversity, both within and across cities.
We release two files for each city in the City-Defined Neighborhood Dataset (CDND)28. First, we process and clean each neighborhood shapefile into a consistent format. Second, we combine these data on city-defined neighborhoods with 2020 Census Block demographic information. We demonstrate the utility of the CDND by comparing city-defined neighborhood definitions to commonly used proxies: Census Tracts, Block Groups, and Zip Codes. We use a series of comparisons and visualizations to demonstrate that city-defined neighborhoods are distinctive from these common neighborhood proxies. Comparisons of population and other demographics across and within cities further illustrate the potential for mismatch when relying on neighborhood proxies rather than our data. We anticipate the data provided in the CDND will be useful for a scholars studying a wide array of topics, including public opinion and political behavior9,12– 15, spatial disparities in public health29,30, legislative redistricting and communities of interest31,32, and school rezoning and student assignment policy33,34.
The rest of the article proceeds as follows. First, we describe the data collection process for building a dataset of city-defined neighborhoods. Second, we present examples and summary statistics from the CDND. Third, we compare our city-defined neighborhoods to alternative neighborhood measures. We conclude with information on accessing the full dataset.
Building a Dataset of Neighborhoods
We rely on the expertise of local governments to collect neighborhood definitions. Many city governments define their own neighborhood boundaries. These neighborhoods are defined and used for various purposes, like planning and development, statistical reporting on public dashboards, and defining roles for public input via neighborhood associations. Even in cases where city governments do not have a single pre-specified purpose for neighborhood definitions, they often maintain maps of the boundaries of the city’s neighborhoods to record what is commonly understood by city residents and officials as the distinctive areas of the city. Our data collection is thus motivated by asking cities directly to show us what are the neighborhoods in their municipalities, as this surveying is most likely to yield the best available data — locally sourced and officially maintained. This process means that we are capturing neighborhoods defined for official governmental purposes and often reflecting long-standing historical or sociological understandings that are meaningful to residents of the city. This process stands in contrast to alternative practices of overlaying Census or other geographies and assuming these reflect an underlying local reality.
For each city, we used a two-stage process to identify city-defined neighborhood boundaries. First, we searched websites of city and state offices for maps with designated neighborhoods. These searches included official websites of the city government or the cities’ Geographic Information Systems (GIS) office, which often contained data on neighborhood boundaries in the form of a shapefile for use in GIS software. For example, Miami, Florida maintains a neighborhoods shapefile on their public “City of Miami GIS Open Data” portal alongside other datasets like trash routes and parcel maps. Second, we contacted every city for which no map could be found in our initial searches. We started with an email or phone call and submitted formal records requests for cities that did not respond.
We differentiate between three different types of commonly available neighborhood definitions maintained by cities. First, we find boundaries of city-defined neighborhoods. These generally cover most or all land in the city and are the clearest representation of city-defined neighborhoods. Second, we find boundaries of neighborhood housing associations or neighborhood councils (NHAs). These are distinct from the first type in that they less frequently cover the entirety of the city, and are often for the specific use of citizen neighborhood engagement. However, we include NHAs as an alternative definition of neighborhoods, as local government officials often pointed to these as the most accurate neighborhood boundaries in the absence of city-defined neighborhoods. Therefore, in our data we include both of these types of boundaries as neighborhoods.
Third, we find boundaries of homeowner associations (HOAs), which are generally created by residential developers for real estate purposes. These boundaries are usually much smaller than neighborhoods or NHAs, and only cover select developments. In CDND, we also collect and release HOA data but note that these should be distinguished from city-defined neighborhoods. Table 1 contains counts of total neighborhood, neighborhood housing associations, and homeowner association shapefiles provided in our data, and city_list.csv in the data release contains a list of all cities with fields marking which shapefiles are available for which cities.
Descriptive neighborhood statistics across the United States
We identified some form of city-defined neighborhood (either a neighborhood shapefile or a neighborhood housing association shapefile) map for 206 of our cities, either through our own research or direct contact with a city representative. These 206 cities contain 20,635 neighborhoods and cover over 77 million people, about 23% of the over 331 million people reported in the 2020 Census. We release the geographic definition and demographic characteristics for each neighborhood (see below). 41 additional cities confirmed to us that they do not maintain any city-level definition of neighborhoods, but shared a shapefile of homeowners associations. The remaining 89 cities (out of the target 336 cities) either confirmed the city does not define neighborhoods in any capacity, or did not comply with our records request. Among the 89 that had no neighborhood definition, 22 never responded to our records request. The remaining 67 confirmed to us that they do not maintain official neighborhood definitions.
To better understand the purpose of the neighborhoods in our dataset, we collected information from city websites and analyzed the names of neighborhood shapefiles to investigate the purpose of these neighborhood definitions. For the most part, cities do not specify a purpose for neighborhood files, beyond preserving a common definition of local neighborhoods within the city. Other cities use these neighborhoods to guide planning and economic development, while a few neighborhoods use the neighborhood definitions to organize policing, tourism, or other functions of local governance.
Figure 1 plots the cities in the CDND. Our sample contains cities in 45 states, and also includes Washington, DC. Given the selection criteria (cities with populations over 100,000 people) the cities in our sample are concentrated in denser and larger population states, but we still have high coverage across regions such as the Northeast, the South, the Sun Belt, the Midwest, and Pacific Northwest. Figure 2 shows our sample neighborhoods vary widely in population, area, and racial/ethnic composition. Neighborhoods across our sample have a median population of 1,125, but the data include some very large neighborhoods like New York City’s Community Districts with more than 250,000 people. Similarly, the center histogram shows that most neighborhoods in the United States are less than a square mile in area.

Neighborhoods and Sample Descriptives. The histograms above demonstrate that our 25,213 sample neighborhoods vary widely across population, area, and racial composition. The left plot shows the total population in each neighborhood as reported by the 2020 Census, the middle column shows the number of square miles in each neighborhood, and the right column shows the proportion of the largest racial/ethnic group in each neighborhood (for neighborhoods with a total population of at least 500 Black, Hispanic, White, and Asian residents reported in the 2020 Census).
Neighborhoods also vary drastically in racial / ethnic diversity. In the right histogram of Fig. 2, we calculate a simple measure of racial diversity for each neighborhood in our sample. Specifically, we calculate the largest proportion of the neighborhood population represented by White, Black, Hispanic, or Asian residents by adding the group population for each Census block in the neighborhood. We calculate this by first performing a spatial merge between Census blocks and neighborhoods, and then aggregating Census block population counts for each racial group to the neighborhood level. Some neighborhoods primarily have residents from a single racial group: for example, Vine City in Atlanta, Georgia, borders Spelman and Morehouse Colleges and is over 85% Black. Other neighborhoods are more diverse.
Finally, we find that smaller cities are less likely than larger cities to define neighborhoods. Supplementary Information Figure A1 visualizes this pattern across all cities in our sample. The largest several dozen cities in the United States all define neighborhoods in some form. However, the probability of having a city defined neighborhood generally decreases with population size. In our data collection, smaller cities were, on the whole, more elusive, and many of them were contacted directly through phone calls, emails, and public records requests. In these cases, we are confident in most cases that there was no official neighborhood map for the city.
Figure 3 offers Philadelphia, PA as an example of our collection efforts. The Planning Commission in Philadelphia maintains a “neighborhood” shapefile on the city’s GIS site, shown in the map. These neighborhood units correspond to well-known areas in Philadelphia, like Fishtown, University City, and Germantown. Like many cities, Philadelphia’s city government does not define universal “official” neighborhood boundaries used for all scenarios, often due to local contention over precise boundaries, shifting populations, and active development. Instead, the Planning Commission neighborhoods are defined as “general boundaries that historically have been in place around the city. They fall along the lines of development patterns, historic references and known names.”

Philadelphia Neighborhoods and Sample Descriptives. The top map shows 148 Philadelphia neighborhoods as defined by the Planning Commission, with three notable neighborhood labeled. The white areas of the map are places within Census Place limits that are not assigned to a particular neighborhood, such as the Northeast Philadelphia Airport near the top of the map. The histograms demonstrate that Philadelphia’s 148 planning neighborhoods vary widely across the same dimensions shown in Fig. 2. The left column shows the total population in each neighborhood as reported by the 2020 Census, the middle column shows the number of square miles in each neighborhood, and the right column shows the proportion of the largest racial/ethnic group in each neighborhood, among the Black, Hispanic, White, and Asian populations.
Like our full sample, our data shows neighborhoods in Philadelphia vary in population, area, and racial / ethnic diversity. Philadelphia’s 148 planning neighborhoods are slightly larger than our sample average as shown in the left histogram of Fig. 3, with a median population of 8,304. Neighborhoods in Philadelphia are also generally less than 2 square miles. While Philadelphia neighborhoods are more racially/ethnically homogeneous than our sample average, some neighborhoods are quite diverse. For example, in Philadelphia’s Holmesburg neighborhood, the population is barely majority White; Black and Hispanic residents each comprise about 20% of the population, and nearly 5% of the population is Asian.
Data Records
The CDND28 is available at our Harvard Dataverse page: https://doi.org/10.7910/DVN/02NP1O. The CDND contains two types of data records. For each city, we release (1) a pre-processed shapefile including the neighborhood geometries and (2) a Census-block level dataset that includes spatially merged neighborhoods and 2020 Census demographics. Our pre-processing ensures that each neighborhood file includes valid neighborhood geometries. For example, several cities include neighborhoods in other cities in the neighborhood file they provided us, which we remove. Other cities often define a “no neighborhood” spatial layer, which we remove.
For each city, we also release a second file that includes neighborhood geometries merged to 2020 Census-block level data. We include the following Census geographic and demographic data using35: a set of Census identifiers (the block-level ‘GEOID`, identifiers for the state, county, place, and tract), population counts for both total population and voting age population (total population, and separately for White, Black, Hispanic, American Indian and Alaska Native (AIAN), Asian, Native Hawaiian and Other Pacific Islander (NHPI), two or more races, and Other).
Finally, when a city reported a homeowners association (HOA), we include the raw file. We release these separately, and do not merge HOAs into our block-level data, because HOAs are private organizations and not officially defined by the city government. Nonetheless, we include HOA shapefile data in CDND due to their potential for use in a wide variety of research questions36,37.
Technical Validation
Finally, we demonstrate the utility of our data by comparing our city-defined neighborhoods to other common proxies of neighborhoods: Census Block Groups, Census Tracts, and Zip Code Tabulation Areas. For Philadelphia, Fig. 4 shows that these four ways of operationalizing neighborhoods differ in several ways. First, they have vastly different scales: while tracts are one of the most commonly used neighborhood proxies, Philadelphia’s Planning Neighborhoods are generally larger. Second, Philadelphia’s Planning Neighborhoods make clear that not all areas of cities contain a neighborhood definition. For example, the Northeast Philadelphia Airport is not assigned to a neighborhood by the city government.

Four Ways to Define Neighborhoods in Philadelphia. This figure shows how four common ways to define neighborhoods can drastically differ. Here, we compare Philadelphia’s planning neighborhoods from our sample along with three different Census geographies commonly used by researchers and policymakers: tracts, block groups, and Zip Code Tabulation Areas (ZCTAs, a geographic approximation of postal ZIP codes created by the US Census).
This intuition that neighborhood proxies can produce different estimates of desired quantities holds across our entire sample. In Fig. 5, we compare aggregate statistics for logged population size (top panel), land area (middle panel), and percent Black population (bottom panel) for neighborhoods in the CDND against Census Tracts, Block Groups, and ZCTAs. The results show that even straightforward questions like “what is the average neighborhood population” in a given city can differ drastically depending on how neighborhoods are operationalized. Further, city-defined neighborhoods and Census geographies are only weakly correlated for area and total population. In general, the average land area of neighborhoods across cities is weakly correlated with average land area of other units across cities. Neighborhoods are on average larger than Census Block Groups, and similar in size to Census Tracts, but there is a lot of variation across cities. Neighborhoods are on average smaller in land area than ZCTAs.

Demographic comparisons of neighborhoods and Census geographies. Figure plots city-level averages of various statistics against city-level averages of the same statistics for Census geographies ZCTAs, Tracts, and Block Groups. We show comparisons for neighborhood population (top panel), land area in square miles (middle panel), and the proportion of the population that is White (bottom panel). Average population and land area are logged to remove skewness for visualization.
Code availability
All code for the CDND is available on our Harvard Dataverse page: https://doi.org/10.7910/DVN/02NP1O.
References
Aldrich, D. P.Building resilience: Social capital in post-disaster recovery (University of Chicago Press, 2012).
Hays, R. A. Neighborhood networks, social capital, and political participation: The relationships revisited. Journal of Urban Affairs 37, 122–143 (2015).
Chetty, R. & Hendren, N. The impacts of neighborhoods on intergenerational mobility i: Childhood exposure effects. The Quarterly Journal of Economics 133, 1107–1162 (2018).
Sampson, R. J.Great American city: Chicago and the enduring neighborhood effect (University of Chicago Press, 2012).
Chyn, E. Moved to opportunity: The long-run effects of public housing demolition on children. American Economic Review 108, 3028–56 (2018).
Hipp, J. R. A dynamic view of neighborhoods: The reciprocal relationship between crime and neighborhood structural characteristics. Social problems 57, 205–230 (2010).
Sampson, R. J. & Raudenbush, S. W. Disorder in urban neighborhoods: Does it lead to crime (US Department of Justice, Office of Justice Programs, National Institute of … , 2001).
Diez Roux, A. V. & Mair, C. Neighborhoods and health. Annals of the New York academy of sciences 1186, 125–145 (2010).
Enos, R. D.The Space Between Us: Social Geography and Politics (Cambridge University Press, New York, 2017).
Brown, J. R., Enos, R. D., Feigenbaum, J. & Mazumder, S. Childhood cross-ethnic exposure predicts political behavior seven decades later: Evidence from linked administrative data. Science Advances 7 (2021).
Sands, M. L. Exposure to inequality affects support for redistribution. Proceedings of the National Academy of Sciences 114, 663–668 (2017).
Barber, M. & Imai, K. Estimating neighborhood effects on turnout from geocoded voter registration records Working Paper, Princeton University (2014).
Chyn, E. & Haggag, K. Moved to vote: The long-run effects of neighborhoods on political participation. Tech. Rep., National Bureau of Economic Research (2019).
Brown, J. R. Partisan conversion through neighborhood influence: How voters adopt the partisanship of their neighbors. The Journal of Politics 0, https://doi.org/10.1086/732981 null (0).
Brown, J. R., Cantoni, E., Chinoy, S., Koenen, M. & Pons, V. The effect of childhood environment on political behavior: Evidence from young u.s. movers, 1992–2021. Working Paper 31759, National Bureau of Economic Research http://www.nber.org/papers/w31759 (2023).
Lee, B. A., Oropesa, R. S. & Kanan, J. W. Neighborhood context and residential mobility. Demography 31, 249–270 (1994).
Coulton, C. Defining neighborhoods for research and policy. Cityscape 231–236 (2012).
Marschall, M., Shah, P. & Ruhil, A. The study of local elections: Editors’ introduction: A looking glass into the future. PS: Political Science & Politics 44, 97–100 (2011).
Barari, S. & Simko, T. Localview, a database of public meetings for the study of local politics and policy-making in the united states. Scientific Data 10, 135 (2023).
Barari, S. & Simko, T. The promise of text, audio, and video data for the study of us local politics and federalism. Publius: The Journal of Federalism pjae046 (2024).
Milgram, S. & Jodelet, D.Psychological Maps of Paris (Holt, Rinehart and Winston, New York, 1976).
Wong, C., Bowers, J., Williams, T. & Drake, K. Bringing the person back in: Boundaries, perceptions, and the measurement of racial context. Journal of Politics 1, 1–18 (2012).
Wong, C., Bowers, J., Rubenson, D., Fredrickson, M. & Rundlett, A. Maps in people’s heads: Assessing a new measure of context. Political Science Research and Methods 8, 160–168, https://doi.org/10.1017/psrm.2018.51 (2020).
McCartan, C., Brown, J. R. & Imai, K. Measuring and modeling neighborhoods. American Political Science Review 1–20 (2024).
Guest, A. M. & Lee, B. A. How urbanites define their neighborhoods. Population and Environment 7, 32–56 (1984).
Coulton, C., Chan, T. & Mikelbank, K. Finding place in community change initiatives: Using gis to uncover resident perceptions of their neighborhoods. Journal of Community Practice 19, 10–28 (2011).
De Marco, A. & De Marco, M. Conceptualization and measurement of the neighborhood in rural settings: A systematic review of the literature. Journal of Community Psychology 38, 99–114 (2010).
Ansolabehere, S. et al. City-Defined Neighborhood Boundaries in the United States https://doi.org/10.7910/DVN/02NP1O (2025).
Osypuk, T. L. & Acevedo-Garcia, D. Beyond individual neighborhoods: a geography of opportunity perspective for understanding racial/ethnic health disparities. Health & place 16, 1113–1123 (2010).
Jackson, J. L. & Williams, J. S. Exploring and reducing the impact of neighborhoods on health disparities. JAMA Network Open 7, e2410206–e2410206 (2024).
Kenny, C. T., McCartan, C., Simko, T., Kuriwaki, S. & Imai, K. Widespread partisan gerrymandering mostly cancels nationally, but reduces electoral competition. Proceedings of the National Academy of Sciences 120, e2217322120 (2023).
Ternullo, S., Zorro-Medina, Á. & Vargas, R. How political dynasties concentrate advantage within cities: Evidence from crime and city services in chicago. Social Forces 102, 1310–1331 (2024).
Castro, A., Siegel-Hawley, G., Bridges, K. & Williams, S. E. Drawn into policy: A systematic review of school rezoning rationales, processes, and outcomes. Review of Educational Research 94, 539–583 (2024).
Simko, T. School desegregation by redrawing district boundaries. Scientific Reports 14, 22097 (2024).
Kenny, C. T. censable: Making Census Data More Usable https://christophertkenny.com/censable/. R package version 0.0.7, https://github.com/christopherkenny/censable (2024).
McKenzie, E.Privatopia: Homeowner associations and the rise of residential private government (Yale University Press, 1994).
Clarke, W. & Freedman, M. The rise and effects of homeowners associations. Journal of Urban Economics 112, 1–15 (2019).
Acknowledgements
We are grateful to June Park and Corey Kaulenas to excellent research assistance. We are also grateful to the many municipal employees across the country who shared data with us for this project.
Author information
Authors and Affiliations
Contributions
J.B., B.S., T.S., and D.S. collected all data. J.B., T.S., and D.S analyzed the data. All authors conceived the study, wrote the manuscript, and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ansolabehere, S., Brown, J.R., Enos, R.D. et al. City-Defined Neighborhood Boundaries in the United States. Sci Data 12, 1031 (2025). https://doi.org/10.1038/s41597-025-05329-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05329-6
