
Abstract
This paper reports the Wave 2 expansion of the Multilingual Eye-Movement Corpus (MECO), a collaborative multi-lab project collecting eye-tracking data on text reading in a variety of languages. The present expansion comes with new eye-tracking data of N = 654 from 13 languages, collected in 16 labs over 15 countries, including in several languages that have little to no representation in current eye-tracking studies on reading. MECO also contains demographic, language use, and other individual differences data. This paper makes available the first-language reading data of MECO Wave 2 and incorporates reliability estimates of all tests at the participant and item level, as well as other methods of data validation. It also reports the descriptive statistics on all languages, including comparisons with prior similar data, and outlines directions for potential reuse.
Similar content being viewed by others

Background & Summary
A central goal of language research is to develop theoretical and computational accounts of linguistic structure, function, and behaviour that can generalize over the astounding diversity of world languages. However, research into language acquisition and use demonstrably suffers from a bias towards and an over-reliance on data from speakers of Indo-European languages in general and English in particular1,2. Among the sub-fields of cognitive sciences where such bias is salient is the study of reading3,4. Our focus is on reading research that uses eye-tracking as the experimental paradigm, since eye movements have been shown to be reliable and valid indices of real-time cognitive processes unfolding during reading5. For instance, Siegelman et al.6 bibliometric analysis of eye-tracking studies of reading between 2000 and 2018 revealed that this literature only addresses 28 unique languages out of roughly 4,000 written languages that exist in the world (https://www.ethnologue.com/). Over 50% of those papers have the English language as their subject, and there is a strong overall bias towards alphabetic and Indo-European languages (see also7). There is an even greater deficit of studies dedicated to direct cross-linguistic comparisons of two or more languages. Thus, the progress of research into reading is undermined by paucity of high-quality data that represent multiple languages and uses comparable text stimuli, participants, and equipment. Such data can enable researchers to move beyond the idiosyncrasies of a specific language or population both in their theorizing and computational modelling (notably, leading models of eye movement control in reading are based on either Chinese, English, or German, see8).
A recent step towards addressing the deficit in required empirical data is the Multilingual Eye Movement Corpus (MECO6,9). MECO is a coordinated international effort of eye-tracking labs and researchers dedicated to creating a database of text reading behaviour across languages. Participants in the MECO study read texts in their first language (L1) and in English as the second (or additional) language (L2) while their eye movements are recorded using an eye-tracker, an infrared video-based tracking system. Participants further complete a questionnaire collecting demographic information and language background and use, go through a brief non-verbal intelligence assessment, and complete additional tests of component skills of reading in both their L1 and L2. The MECO project makes use of highly comparable texts in different languages, participants of generally similar skill level in their L1 (university students), and similar equipment (EyeLink eye-trackers) and procedures.
Recently, the first wave of the MECO project was released, making publicly available data from 13 countries and languages. Two papers present the Wave 1 MECO data: One paper including the L1 eye-tracking reading data and relevant participant-level measures6 and a second paper with the L2 (i.e., English) eye-tracking reading data with associated English skill assessments9. Participants’ languages included in MECO’s Wave 1 represent substantial improvement in terms of linguistic diversity compared to typical studies in the field: The 13 languages in MECO’s Wave 1 span five language families (Indo-European, Koreanic, Semitic, Turkic, and Uralic) and three types of writing systems (alphabetic, e.g., English; abjad, e.g., Hebrew; and hangul, Korean). The open-source datasets made available gave a substantial boost to cross-linguistic research on oculomotor control in reading, first and second language acquisition, and computational models of text processing (for examples of studies making secondary use of the MECO Wave 1 see10,11).
However, it is important to keep in mind that Wave 1 of the MECO project is still highly limited in terms of cross-linguistic coverage: While the availability of data from 13 languages is a vast improvement compared to typical studies in the field (see above and Siegelman et al.6), this number still pales in comparison to the vast number of the world’s languages. The present paper therefore reports data from a new wave of the MECO project – MECO Wave 2, which includes new data from a total of 654 participants from 16 participant samples. Specifically, it makes available the eye-tracking record of reading in L1, along with the supplementary questionnaires and tests of component skills of L1 reading. Wave 2 of MECO follows the same procedures and recruitment practices as Wave 1.
Importantly, MECO’s Wave 2 features seven new languages and eight new written languages (Basque, Mandarin Chinese – with separate samples for the traditional and simplified scripts, Danish, Hindi, Icelandic, Brazilian Portuguese, and Serbian). This substantially expands the overall coverage of the MECO project to an unprecedented set of 21 languages overall. It is worth noticing that – with the exception of Chinese – all new languages added in MECO Wave 2 have had little to no coverage in the recent eye-tracking literature according to recent bibliometric analyses by Siegelman et al.6 and Angele and Duñabeitia7. Besides the mere increase in the number of languages, additional languages also include two new types of writing systems not represented in MECO’s Wave 1: logographic (Chinese) and abugida (Hindi). This expansion further enhances the coverage of languages and writing systems that is necessary for generalizable theories and models of reading.
Another important feature of MECO’s Wave 2 is the introduction of several “replication” samples, i.e., multiple datasets from the same language collected in different labs and, in some cases, different countries. With the new Wave 2 data, the MECO project now includes multiple samples in five languages – English, German, Hindi, Russian, and Spanish. This replication is methodologically important. Multiple within-language samples can represent regional varieties or differences in educational or social backgrounds of readers and differences in the entry requirements that different universities impose on students within a country. Replication samples can also help estimate inevitable uncontrollable factors that may lead to differences in data quality within a language, such as a given lab’s assistant training, equipment, etc. With multiple samples representing a given language, researchers can begin to dissociate behaviours characteristic of all readers of the language from behaviours characteristic of a specific university sample.
A final goal of MECO Wave 2 is to complement some of the language samples reported earlier as part of Wave 1. The data collection phase of MECO Wave 1 was interrupted by the COVID-19 pandemic and lab closures. For this reason, several sites did not reach the recommended sample size of 45–50 participants per site. The present update of the project adds data to two language samples from MECO Wave 1 (Norwegian and Turkish), bringing them up to and beyond the recommended sample size. To clarify, the supplement data from these sites are not meant to be used in isolation but rather in combination with data from MECO Wave 16 from the same sites.
The present paper presents the L1 (first language) component of Wave 2 of the MECO project, describes in detail all relevant procedures and data, and establishes the data reliability, to ensure that it is appropriate for data mining by the research community. Details on how to access the publicly available MECO data are also provided.
Methods
Testing sites and investigated languages
Data were collected at 16 testing sites in 15 countries, representing 13 unique L1s. Table 1 presents information about the location of the testing sites included in the current release and the L1 investigated in each site. Following Siegelman et al.6, Table 1 further includes an estimate of the prevalence of each investigated language in eye-movement studies of reading, based on the bibliometric analysis of eye-movement research literature in 2000–2018. The estimated prevalence of 9 out of 13 languages included in the current MECO release was very low (<1%), suggesting that much of the new data comes from languages under-represented in research in the field. Table 2 includes information about each L1’s language family and branch, script, morphological type, and orthographic transparency (as classified in past studies12,13,14).
Participants
Overall, the present Wave 2 release of MECO-L1 includes valid data from N = 654 participants (this number only includes participants that were included after data cleaning, see below). Table 3 includes information about the number of participants in each site and compensation information. Table 4 contains basic demographic information (age and years of education) along with participants’ self-rated levels of proficiency in their L1 (in speaking, oral comprehension, and reading; the demographic and self-ratings of proficiency were collected using a language background questionnaire, see Additional Questionnaires and Tests, below). Full demographic information for all participants is available at the project’s OSF page (see Data Records). Table 3 also provides designations for the status of each language sample in the MECO project. As noted above, eight new samples of languages and writing systems were added to the MECO project by nine participating sites. Five additional sites added replication samples for four languages, i.e., languages that were included in MECO Wave 16: All these sites were different from the sites of data collection for Wave 1. Two more sites provided supplement samples, i.e., continued data collection initiated and reported in Wave 1 to bring their sample sizes to the expected sample size (combined with Wave 1 data, the total sample size for the Turkish and Norwegian sites is N = 45 and N = 61, respectively). Table 5 shows the main features of the current (i.e., second) Wave of MECO-L1 and how it compares to the previous Wave 1 of the project in Siegelman et al.6. To clarify, in the current release we make available new eye-movement data on L1 reading along with accompanying measures of individual differences in L1 and thus expand the scope of the MECO-L1 dataset considerably (see Data Records for details).
The project obtained a general ethics approval by the McMaster University’s Ethics Review Board protocol #1892. Ethics clearance was further obtained by the following local ethics research boards: Ethics Committee at Basque Center on Cognition Brain and Language (approval number: 070521MK); Research Ethics Committee for Human Subjects at the Federal University of Ceará (CEP/UFC; approval number: 5.360.941, CAAE 56014522.6.0000.5054); Research Ethics Committee, National Taiwan Normal University (approval number: 202104HS001), University of Southampton Ethics Committee (submission number: 55085); Institutional Ethics Committee, Indian Institute of Technology Kanpur (approval number: IITK/IEC/2022-23/I/2); Institute Review Board, International Institute of Information Technology, Hyderabad (proposal number: IIITH-IRB-PRO-2024-01); the Institutional Review Board of the National Research University Higher School of Economics (HSE IRB; dated: 11/10/2020); Departmental Ethics Committee of the Department of Psychology, Faculty of Philosophy, University of Novi Sad (submission number: 202211062255_rbqs); Bioethics and Biosafety Committee of Pontificia Universidad Católica de Valparaíso (BIOEPUCV-H 335–2020); and the Human Research Ethics Committee of Middle East Technical University, Ankara, Turkey. In all other data collection sites (University of Science and Technology Beijing; Aalborg University; University of Potsdam; University of Zurich; University of Iceland; and University of Oslo), the research was declared exempt by the local ethics board given local guidelines. Participants in all sites provided informed consent for participation and for sharing of their deidentified data.
Materials
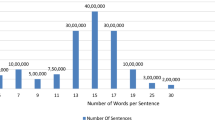
The core data in the MECO project comes from the passage reading task, during which the participants’ eye movements are recorded. The task was identical to MECO Wave 16, and its reading materials in each language were created using an identical procedure. Participants in all sites read 12 texts in their respective L1 while their eye-movement were recorded: Texts were encyclopaedic (Wikipedia-like) entries on topics such as historical figures, events, and natural or social phenomena, with topics chosen to minimize the effect of specific academic knowledge and cultural biases. As in MECO’s Wave 1, we used the 12 texts in English as our starting point. Five of the 12 texts were translated closely into the L1 of each site (these five texts are henceforth labelled as “matched texts”), through an iterative process of (human) back-translation from the target L1 to English and introduction of changes as needed. The remaining seven texts were created by the research team in each site: These texts were on the same topics as the English originals and used the same encyclopaedic genre, similar length, and a roughly similar level of difficulty (e.g., they all avoided uncommon grammatical constructions). However, they were not matched on their semantic content (we label these seven texts as “non-matched texts”). The main rationale behind including both semantically matched and non-matched texts is to enable testing which cross-linguistic similarities and differences in eye-movements are found regardless of whether texts are semantically similar or not (see6 for details). Each of the 12 texts was followed by four yes/no comprehension questions: Simple questions that tapped into factual knowledge obtained from the read materials and served as attention checks. The comprehension questions were similar across languages in matched texts but naturally differed for non-matched texts. Table 6 details the number of words and sentences in each text in each language.
To evaluate the quality of translations for matched texts, we ran computational analyses of the meaning and textual features of the back-translations provided by different research teams (we used the back-translations, rather than the original texts written in the different L1s, because validated computational tools for textual analyses across many languages are still limited). First, to ensure that matched texts were indeed similar in their meaning across sites, we quantified the text-wise cosine semantic similarity between back-translations and the English originals using pre-trained Latent Semantic Analysis (LSA) vectors15. As expected, back-translations of matched texts were highly similar to the English originals (mean cosine = 0.89), significantly more than the similarity of non-matched texts to the original non-matched texts (mean cosine = 0.64, p < 0.001). The similarity of matched back-translated texts was on par with similarity estimates in MECO’s Wave 16 (with mean cosine = 0.88) and a seminal cross-language eye-movement study that used back-translated matched texts16 (with mean cosine = 0.93). Second, to examine potential differences in textual content more broadly, we computed 10 complexity and readability measures for the back-translations using Coh-Metrix17,18. As readability measures, we included Flesch-Kincaid readability and the more psycholinguistically informed L2 readability score19. For text complexity, we used eight Text Easability Principal Component Scores, which quantify the contribution of linguistic characteristics to text difficulty17: Narrativity, simplicity, concreteness, cohesion, deep cohesion, verb cohesion, connectivity and temporality (see detailed documentation at www.cohmetrix.com). We found that the properties of matched texts were highly similar across languages: A regression analysis predicting each readability/complexity metric from “language” (a dummy-coded variable) showed no significant effect on any of the 10 complexity/readability dependent variables (see Table 7). In non-matched texts, there were some differences in readability/complexity (significant differences in 2 out of 10 readability/complexity dependent measures after Bonferroni correction). Tables 8, 9 further reports means and SDs of all readability/complexity measures by language for matched and non-matched texts, respectively, and the project’s repository includes estimates of all 10 complexity and readability measures for all texts in all languages. Future users of the MECO data can use this information both to examine how complexity/readability impacts eye-movements, and to control for these text-level properties when examining cross-linguistic effects that may be impacted by the differences found in the readability/complexity of non-matched texts.
Additional questionnaires and tests
In addition to the main passage reading eye-tracking task, participants in all sites completed two identical instruments: (1) The non-verbal IQ test from the Culture Fair Test-3 (CFT20, Subset 3 Matrices, short version, Form A, timed at 3 minutes20), and (2) an abridged version of the Language Experience and Proficiency Questionnaire (LEAP-Q21). The CFT20 aimed at providing a comparable measure of non-verbal intelligence across all sites (due to copyright restrictions, however, it was not available in 2 out of 16 sites: Brazil and Serbia). The LEAP-Q aimed at collecting basic demographic and linguistic information about participants. These two instruments were identical to MECO’s Wave 16. Researchers at various sites were also encouraged to include additional (non-eye-tracking) measures of individual differences in L1 reading and language proficiency, with the goal of enabling within-site analyses of the correlations between individual differences in language skills and oculomotor reading behaviour. Note that these measures were not shared across sites, given differences in the availability of measures in different languages. Common L1 individual differences tests included measures of vocabulary, word and pseudoword naming, phonological awareness, and other component skills of reading. The full individual-differences data from each site are available at the project’s OSF page (see Data Records).
Procedure
The order of task administration was fixed in all sites: Participants started by filling out the LEAP-Q questionnaire, followed by the main reading task in their first language during which their eye movements were recorded, and then the individual-differences battery (including the CFT-20 and any L1 individual-differences tests). The entire procedure lasted no more than an hour, and breaks were provided as needed. At the conclusion of the experimental session, participants in all samples proceeded to participate in an English-language eye-tracking study (the “MECO-L2” component of the project). The goal of that study was to create an additional eye-tracking corpus of reading in English as a non-dominant language. This additional study is beyond the scope of this paper and is reported elsewhere22. However, participant identifiers are shared between the data releases of MECO’s components, to enable within-participant analyses of reading patterns in L1 and L2 (see9).
Eye-tracking task: apparatus and procedure
To register eye-movements during the reading task, all sites used an EyeLink eye-tracker (SR Research, Kanata, Ontario, Canada). The exact model in each lab varied (with labs using either the Portable Duo, EyeLink II, 1000 or 1000+ models). Sampling rate was set at 1000 Hz, with the exception of one lab which used the EyeLink II model with the sampling rate of 500 Hz. All sites used the same experimental task template programmed in the Experiment Builder software (SR Research). A chin and a forehead rest were used to minimize head movements. Before the beginning of the task, a 9-point calibration was performed (i.e., with nine targets distributed around the display), followed by a 9-point accuracy test for validation. Experimenters were also encouraged to perform re-calibrations whenever deemed necessary during the reading task. Stimuli were viewed binocularly but eye-movements were analysed from the self-reported dominant eye only. Before each trial (i.e., passage), a drift correction was performed, via a dot appearing slightly to the left of the first word in the passage. Once the participant had fixated on it, the trial began. Calibration was monitored by the experimenter throughout the task and was redone if necessary. Each of the 12 passages appeared on a separate screen, with participants instructed to read them silently for comprehension and press the space bar when finished. Each text was then followed by the four yes/no comprehension questions, appearing one after the other on separate screens, with participants instructed to provide their answer using the 1 (“yes”) and 0 (“no”) keys –the comprehension accuracy data are made available as part of the data release. Texts were presented in a mono-spaced font, except in Serbia (due to technical issues and experimenter error) and in India (because mono-spaced fonts are unavailable for Devanagari script). Different sites used font settings to maximize the readability of texts given their local setup (i.e., screen size and resolution). Table 10 summarizes the specifications of the apparatus and presentation settings in each participating site. The project’s OSF site further includes image files with the presented texts from all sites (i.e., bitmap images as used by the experiment presentation software).
Data processing and cleaning
As in all other components of the MECO project, the popEye software23 (implemented in R, version 0.8.3) was used to pre-process the eye-tracking data. During this pre-processing process, fixations are automatically corrected on the vertical axis and assigned to lines. In the current Wave 2 of MECO, the “slice” algorithm was used, because it was shown to substantially improve assignment accuracy compared to the baseline algorithm used for Wave 124. However, in the two supplement samples (i.e., in Turkey and Norway) the “chain” algorithm was used to maintain consistency across MECO waves within a site. Following the automatic fixation alignment procedure by popEye, members of the research team inspected the output of the software and assessed the quality of the resulting data. Further, when processing data in simplified and traditional Chinese, members of the research team used the “interactive” mode of popEye to correct cases of misalignment, when possible, because inspection of the software’s output revealed cases that could be easily fixed by that mode. Texts in which fixations and text lines were misaligned after processing (e.g., due to poor calibration or software error) were removed from the data pool. Additionally, as in other MECO components, participants with fewer than 5 (out of 12) usable texts were removed altogether from the database (see Table 3 above for percent of remaining texts and word tokens after data cleaning).
Data Records
As with previous releases of MECO6,9,22, the data of the current Wave 2 release of MECO L1 is made fully available via the Open Science Foundation (OSF) website25, at: https://osf.io/3527a/.
This OSF repository includes word-level reports from usable participants and trials, as well as passage- and sentence-level reports. Two of the scripts in the present MECO release are written without spaces: simplified and traditional Chinese. We identified words in these scripts based on the segmentation provided by linguist experts in Mandarin. We also make available fixation and saccade reports, information about participants’ reading rate (at the passage- and subject-level), and comprehension accuracy (at the word-, text- and subject-level). Note that variable names in these reports are identical and thus backward compatible with variables in other releases of the MECO project6,9,22. The participant identifiers in the current release are compatible with those used in the MECO L2 Wave 2 release22, to enable within-participant analyses of L1-L2 eye-movement data. Also included on OSF are full data from individual differences tests in L2, the non-verbal IQ test, and the background questionnaire. The OSF page also includes auxiliary data tables (e.g., detailed descriptive statistics for different eye-movement measures by sample), and the analysis code for the validation analyses that follow. Please refer to the readme files in the OSF repository for detailed information regarding files and data structures.
To clarify, the new data being released as part of the current paper is the data on L1 reading in the 16 Wave 2 testing sites, along with the accompanying individual differences data. The data that is unique to the current release includes therefore all files on the project’s OSF page under release 2.0/version 2.0/wave 2. As noted above, these new data include word- sentence- and passage-reports from the eye-movement record (on OSF, under: release 2.0/version 2.0/wave 2/primary data/eye tracking data) and full accompanying individual differences data (under: release 2.0/version 2.0/wave 2/primary data/individual differences data). The same OSF project includes also parallel Wave 1 data from MECO L1, reported in Siegelman et al.6 (under: release 2.0/version 2.0/wave 1). New data versions, within release 2.0, will be made available as needed (e.g., to reflect improvements in data processing pipelines). A separate OSF project includes data from MECO L2, that is, eye-movement English-as-L2 reading data and separate tests of individual differences (https://osf.io/q9h43/). This latter OSF project includes both the Wave 1 MECO L2 data (reported in9), and the Wave 2 MECO L2 data (reported in22), which can be merged with the respective Wave of MECO L1 data, given the shared participant identifiers.
Technical Validation
As means of validation, we used two sets of analyses, also used in earlier MECO releases6,9. The first examines the reliability of the resulting data, via estimates of the stability of basic measures commonly used in eye-movement research, computed both at the item- and participant-level. This analysis is meant to ensure that the data have reasonable levels of measurement error that allow for secondary data usage and hypothesis testing. The second analysis provides basic descriptive information for eye-movement measures and accompanying measures such as comprehension accuracy.
In validation analyses, we focus on several basic eye-movement variables that are considered as fundamental measures of reading fluency. Word-level variables include skipping (a binary index of whether the word was not fixated even once during the entire text reading, labeled as skip); and, for words that were fixated at least once: first fixation duration (the duration of the first fixation landing on the word, firstfix.dur); gaze duration (the summed duration of fixations on the word in the first pass, i.e., before the gaze leaves it for the first time, firstrun.dur); total fixation duration (the summed duration of all fixations on the word, dur); number of fixations on the word (nfix); refixation (a binary index of whether a word elicited more than one fixation in the first pass, refix); regression-in (a binary index of whether the gaze returned to the word after inspecting further textual material; reg.in); and re-reading (a binary index of whether the word elicited fixations after the first pass, i.e., after the gaze left the word for the first time, reread). A detailed discussion of these variables is provided in previous studies5,26,27. At the text- and participant-level, we further define the following measures: reading rate (in words per minute, rate), and comprehension accuracy (the percent of correct responses in comprehension questions) computed for all passages (acc) and for matched texts only (acc_matched). Prior to analyses in this section, we further cleaned the data by removing data points that showed unrealistically short (<80 msec) first fixations, which are unlikely to provide sufficient time to complete visual uptake28, or very long total fixation times (top 1% of the participant-specific distribution, all exceeding 3 s on the word).
Reliability estimates
We computed two types of reliability estimates: At the participant-level and at the word token-level (see also6,9). Both were estimated mainly using a split-half procedure. Participant-level reliability for a given dependent variable examines how stable that measure is given inter-participant variation. Using a split-half procedure, it is computed as the correlation between mean values for ‘odd’ and ‘even’ words within a participant (e.g., computing, say, mean gaze duration for words tokens 1, 3, 5, etc. and words 2, 4, 6, etc. for each participant, and examining the correlation between the two sets of values). This split-half procedure was used for all dependent variables, with the exception of reading rate where it was estimated using an Intra-class Correlation Coefficient (ICC), measuring the degree of agreement in reading rate across the 12 texts. Word-level reliability was done at the word token-level, and is of interest mainly for studies of the effect that word properties have on eye movements. For each word token in the database, mean values were computed for each eye-movement measure for “odd” and “even” participants separately. Then, the correlation across word tokens between these two sets of values form a reliability estimate at the word token-level.
Tables 11, 12 provide reliability estimates for the different dependent variables in each site, at the participant- and word token-level, respectively. As can be seen, reliability at the participant level was very high (r’s > 0.9 in all sites for all measures after Spearman-Brown correction for attenuation). This is in line with parallel previous estimates in the MECO project6,9,22, and elsewhere29 and is expected given the general stability of basic eye-movement measures at the individual level and the large number of words read by each participant. We also computed participant-level reliability estimates for comprehension accuracy (both for all texts and matched texts only, computed across languages). In line with Siegelman et al., 2022, reliability for comprehension accuracy were generally lower (r = 0.53 and r = 0.50 for all texts and matched texts, respectively). This is expected: MECO-L1 comprehension questions are meant to serve as attention checks, not as sensitive measures of individual differences6. Future users should be mindful when using these metrics in correlational analyses.
Reliability at the word token-level was somewhat lower than parallel estimates at the participant-level, again in line with similar previous estimates6,9,30. In particular, there were inevitably lower reliability estimates for sites with a smaller number of participants (e.g., Supplement samples in Norwegian and Turkish), and for measures that were previously shown to be less stable at the word-level (e.g., re-reading, first fixation duration6,9,22). Still, reliability levels found in the Wave 2 data were high on average across sites and measures (mean r = 0.71, median 0.73; values after Spearman-Brown correction), and again comparable to those in MECO’s Wave 16 as well as the GECO database30.
Descriptive statistics
As another validation of the new data, we examined the inter-relations among the basic eye-movement measures, as well as their correlation with the measure of non-verbal intelligence (CFT). As shown in Table 13, the resulting patterns of correlation between these variables is highly consistent with similar previous estimates6,9,30. Specifically, we observe (1) substantial correlations between the various eye-movement measures; and (2) conversely, low correlations between CFT scores and eye-movement measures (|r| ≤ 0.15). These expected correlational patterns and their similarity with the MECO’s Wave 1 data further validate the new data.
Lastly, we calculated for each site the means and standard errors for all eye-movement measures and comprehension accuracy (in matched and all texts). These estimates were calculated over respective average values computed per participant. The descriptive by-site statistics, shown in Fig. 1, can be used for the purposes of both validation and comparison. In terms of validation, the ranges of means across sites resemble those in MECO’s Wave 1. For example, comprehension accuracy for matched texts in the present data ranges between 0.7 and 0.9 in 15/16 sites, a range that included mean comprehension accuracy in 12/13 sites in MECO’s Wave 1. The same is true for cumulative measures of eye-movements (e.g., first fixation duration generally ranges from 200 to 250 msec; gaze durations from 250 to 300; reading rate from 150 to 350 words/minute: All ranges are comparable to the ones observed in the samples in MECO’s Wave 16). At the same time, there are clearly noticeable cross-linguistic and inter-site differences in the data. For instance, some language samples show longer fixations and larger number of fixations per word on average: see in particular patterns observed among readers of Basque (an agglutinative language) and Hindi (a morphologically rich language with a visually complex abugida writing system). Furthermore, readers of simplified and traditional Chinese demonstrate higher skipping and regression rates than readers of other languages: This is likely due to the extremely small number of (visually complex) characters that make words in written Chinese. Further variation across sites is found in essentially all dependent variables of eye-movement behaviour. Such variation is both expected and desirable. Properties of the language, the writing system, and participants in each site are expected to contribute to variation in oculomotor behaviour. Future research can therefore mine the new data to examine what constitutes systematic patterns of cross-linguistic differences and similarities and reveal the sources behind them.

Means of eye-movement measures, comprehension accuracy, and CFT scores, across testing sites. Error bars stand for ± 1 SE. skip: skipping rate; firstfix.dur: first fixation duration (in msec); firstrun.dur: gaze duration (in msec); dur: total fixation time (in msec); nfix: number of fixations; rate: reading rate (words per minute); refix: likelihood of second fixation on the word; reg.in: regression rate; reread: likelihood of second pass; accuracy: comprehension accuracy; accuracyMatched: percent answers correct in matched texts; cft: score in the CFT test. ba: Basque; bp – Brazilian Portuguese; ch_s – Chinese simplified; ch_t – Chinese traditional; da – Danish; en_uk – English (UK sample); ge_po - German (Potsdam sample); ge_zu - German (Zurich sample); hi_iiith - Hindi (Hyderabad sample); hi_iitk - Hindi (Kanpur sample); ic – Icelandic; no – Norwegian; ru_mo – Russian (Moscow sample); se – Serbian; sp_ch – Spanish (Chile sample); tr - Turkish.
Limitations
MECO is an international collaboration that uses existing setups in different sites worldwide to collect cross-linguistic data on eye-movements during reading. The use of existing setups led to inevitable variability in parameters related to data acquisition, including the physical size of the texts as read by the participants, as determined by cross-site variation in screen size, resolution, and participants’ distance from screen (see information regarding presentation parameters in each site, and in particular the number of characters per visual angle, in Table 10). Analyses that require stricter control of these parameters may require more targeted experimental manipulations; however, for the many effects that are presumably not contingent on the physical size of the orthographic characters, this variance may be either less relevant or even an opportunity to examine whether cross-linguistic differences are present even when controlling for these differences. Similarly, different MECO sites use available student populations from their local university pool, which leads to a general reliance of the project on educated populations, and sometimes further leads to cross-site variation in participants’ demographics and educational background. We do make available information about demographics and language and educational background, which can be considered in future analyses, but we admit that in some cases a stricter control is again needed. Another limitation of MECO is the variation of sample size across sites. In this second wave of data collection we have attempted to bring the sample size in each site to a minimum of 45 participants: Indeed, across the two data collection waves, 18 out of 27 sites now reach this number (also with the help of the current supplement samples), and another 7 sites have a sample size between N = 38 and N = 44 participants. Still, the variation in sample sizes should be considered and data from sites with smaller samples should be interpreted with caution.
More broadly, we wish to highlight that analyses on MECO can and should be supplemented with both targeted manipulations and with analyses of data from language-specific eye-movement corpora, which have recently become increasingly common31,32,33. We can envision multiple scenarios where MECO can first provide insights about cross-linguistic trends, with data from language-specific corpora or experimentation then used to validate the findings and dig deeper into the observed pattern within a language or a set of languages. We also highlight that the MECO project is continuously involving to include more sites and languages and to increase the sample sizes of existing data samples via additional supplement samples. As the MECO network continues to grow, we hope to converge on a dataset that further achieves cross-linguistic coverage as well as a high statistical power for both between- and within-site analyses.
Code availability
The code used for the validation analyses is available via the project’s OSF repository – see Data Records.
References
Blasi, D. E., Henrich, J., Adamou, E., Kemmerer, D. & Majid, A. Over-reliance on English hinders cognitive science. Trends Cogn Sci 26, 1153–1170 (2022).
Kidd, E. & Garcia, R. How diverse is child language acquisition research? First Lang 42, 703–735 (2022).
Share, D. L. On the Anglocentricities of current reading research and practice: the perils of overreliance on an ‘outlier’ orthography. Psychol Bull 134, 584–615 (2008).
Share, D. L. Alphabetism in reading science. Front Psychol 5, 752 (2014).
Rayner, K. Eye Movements in Reading and Information Processing: 20 Years of Research. Psychol Bull 124, 372–422 (1998).
Siegelman, N. et al. Expanding horizons of cross-linguistic research on reading: The Multilingual Eye-movement Corpus (MECO). Behav Res Methods 10, 1–21 (2022).
Angele, B. & Duñabeitia, J. A. Closing the eye-tracking gap in reading research. Front Psychol 15, (2024).
Reichle, E. D. Computational Models of Reading: A Handbook. (Oxford University Press, 2021).
Kuperman, V. et al. Text reading in English as a second language: Evidence from the Multilingual Eye-Movements Corpus. Stud Second Lang Acquis 45, 3–37 (2023).
Wilcox, E. G., Pimentel, T., Meister, C., Cotterell, R. & Levy, R. P. Testing the Predictions of Surprisal Theory in 11 Languages. Trans Assoc Comput Linguist 11, 1451–1470 (2023).
de Varda, A. & Marelli, M. Scaling in Cognitive Modelling: a Multilingual Approach to Human Reading Times. in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) 139–149, https://doi.org/10.18653/v1/2023.acl-short.14 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2023).
Dryer, M. S. & Haspelmath, M. The World Atlas of Language Structures Online. https://doi.org/10.5281/zenodo.13950591 (Max Planck Institute for Evolutionary Anthropology, Leipzig, 2013).
Seymour, P. H. K. et al. Foundation literacy acquisition in European orthographies. British Journal of Psychology 94, 143–174 (2003).
Verhoeven, L. T. W. & Perfetti, C. A. Learning to Read across Languages and Writing Systems. https://doi.org/10.1017/9781316155752 (Cambridge University Press, 2017).
Günther, F., Dudschig, C. & Kaup, B. LSAfun - An R package for computations based on Latent Semantic Analysis. Behav Res Methods 47, 930–944 (2014).
Liversedge, S. P. et al. Universality in eye movements and reading: A trilingual investigation. Cognition 147 (2016).
Graesser, A. C., McNamara, D. S. & Kulikowich, J. M. Coh-Metrix: Providing Multilevel Analyses of Text Characteristics. Educational Researcher 40, 223–234 (2011).
Graesser, A. C., McNamara, D. S., Louwerse, M. M. & Cai, Z. Coh-Metrix: Analysis of text on cohesion and language. Behavior Research Methods, Instruments, & Computers 36, 193–202 (2004).
Crossley, S. A., Allen, D. B. & McNamara, D. S. Text readability and intuitive simplification: A comparison of readability formulas. Reading in a Foreign Language 23, 84–101 (2011).
Weiß, R. H. Grundintelligenzskala 2 Mit Wortschatztest and Zahlenfolgetest [Basic Intelligence Scale 2 with Vocabulary Knowledge Test and Sequential Number Test]. (Hogrefe, Göttingen, Germany, 2006).
Marian, V., Blumenfeld, H. K. & Kaushanskaya, M. The Language Experience and Proficiency Questionnaire (LEAP-Q): assessing language profiles in bilinguals and multilinguals. J Speech Lang Hear Res 50, 940–967 (2007).
Kuperman, V. et al. New data on text reading in English as a second language. Stud Second Lang Acquis 1–19, https://doi.org/10.1017/S0272263125000105 (2025).
Schroeder, S. popEye-An integrated R package to analyse eye movement data from reading experiments. J Eye Mov Res 12, 92 (2019).
Glandorf, D. & Schroeder, S. Slice: an algorithm to assign fixations in multi-line texts. Procedia Comput Sci 192, 2971–2979 (2021).
Siegelman, N. & Kuperman, V. OSF | MECO L1: The Multilingual Eye-movement COrpus, L1 releases. https://doi.org/10.17605/OSF.IO/3527A.
Inhoff, A. W. & Radach, R. Definition and Computation of Oculomotor Measures in the Study of Cognitive Processes. in Eye Guidance in Reading and Scene Perception 29–53, https://doi.org/10.1016/B978-008043361-5/50003-1 (Elsevier, 1998).
Godfroid, A. Eye Tracking in Second Language Acquisition and Bilingualism. https://doi.org/10.4324/9781315775616 (Routledge, 2019).
Warren, T., White, S. J. & Reichle, E. D. Investigating the causes of wrap-up effects: Evidence from eye movements and E–Z Reader. Cognition 111, 132–137 (2009).
Staub, A. How reliable are individual differences in eye movements in reading? J Mem Lang 116, 104190 (2021).
Cop, U., Dirix, N., Drieghe, D. & Duyck, W. Presenting GECO: An eyetracking corpus of monolingual and bilingual sentence reading. Behav Res Methods 49, 602–615 (2017).
Acartürk, C., Özkan, A., Pekçetin, T. N., Ormanoğlu, Z. & Kırkıcı, B. TURead: An eye movement dataset of Turkish reading. Behav Res Methods 56, 1793–1816 (2023).
Berzak, Y. et al. CELER: A 365-Participant Corpus of Eye Movements in L1 and L2 English Reading. Open Mind 6, 41–50 (2022).
Yan, M., Pan, J. & Kliegl, R. The Beijing Sentence Corpus II: A cross-script comparison between traditional and simplified Chinese sentence reading. Behav Res Methods 57, 60 (2025).
Acknowledgements
Research reported in this publication was supported by the following grants: The Social Sciences and Humanities Research Council of Canada Partnered Research Training Grant, 895-2016-1008 (PI: G. Libben); the Social Sciences and Humanities Research Council of Canada (SSHRC) Insight Grant, 435-2021-0657 (PI: V. Kuperman); the Canada Research Chair (Tier 2; PI: V. Kuperman); German Federal Ministry of Education and Research, grant number 01IS20043 (PI: L. A. Jäger); the National Council for Scientific and Technological Development of Brazil (CNPq) Project 316036/2021-8 (PI: R. Rothe-Neves); the Obel Family Foundation, Research Equipment Grant to Aalborg University; Project Fondecyt Regular by the National Research and Development Agency (ANID-CHILE), 1240550; The Featured Areas Research Center Program within the framework of the Higher Education Sprout Project by the Ministry of Education (MOE) in Taiwan (PI: Y. T. Sung); the Basic Research Program at the National Research University Higher School of Economics (HSE University); the Ministry of Science, Technological Development and Innovation of the Republic of Serbia; The Research Council of Norway, Centres of Excellence, 331640; the Israel Science Foundation (ISF) Grant, project 1034/23 (PI: N. Siegelman), and by an Azrieli Early Career Faculty Fellowship (PI: N. Siegelman). We wish to thank the following individuals: Itziar Basterra, Isidora Damjanović, Nevena Dimitrijević, Ainhoa Eguiguren, Amets Esnal, Jordan Gallant, Chia En Hsieh, Marija Jožić, Damjan Kopilović, Petra Kovačević, Nadia Lana, Aleksa Luburić, Nevena Marković, Lucy Thomas, Tanja Vidović.
Author information
Authors and Affiliations
Contributions
Victor Kuperman and Noam Siegelman are the co-leaders of the MECO project. They designed the study, coordinated data collection and data cleaning efforts worldwide, and curated the published dataset. They also ran the technical validation presented and wrote the original draft of the manuscript. Sascha Schroeder is the person in charge of data pre-processing in MECO. He wrote and ran all analysis scripts related to pre-processing of eye-movement data. Yaqian (Borogjoon) Bao participated in data curation, validation, and project administration. All other co-authors participated or led data acquisition efforts in their respective sites, as well as obtained local funding for these efforts. All co-authors also reviewed, commented, and approved a draft of this paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Siegelman, N., Schroeder, S., Bao, Y.B. et al. Wave 2 of the Multilingual Eye-Movement Corpus (MECO): New text reading data across languages. Sci Data 12, 1183 (2025). https://doi.org/10.1038/s41597-025-05453-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05453-3
