
Abstract
Advances in optical microscopy scanning have significantly contributed to computational pathology (CPath) by converting traditional histopathological slides into whole slide images (WSIs). This development enables comprehensive digital reviews by pathologists and accelerates AI-driven diagnostic support for WSI analysis. Recent advances in foundational pathology models have increased the need for benchmarking tasks. The Camelyon series is one of the most widely used open-source datasets in computational pathology. However, the quality, accessibility, and clinical relevance of the labels have not been comprehensively evaluated.In this study, we reprocessed 1,399 WSIs and labels from the Camelyon-16 and Camelyon-17 datasets, removing low-quality slides, correcting erroneous labels, and providing expert pixel annotations for tumor regions in the previously unreleased test set. Based on the sizes of re-annotated tumor regions, we upgraded the binary cancer screening task to a four-class task: negative, micro-metastasis, macro-metastasis, and Isolated Tumor Cells (ITC). We reevaluated pre-trained pathology feature extractors and multiple instance learning (MIL) methods using the cleaned dataset, providing a benchmark that advances AI development in histopathology.
Similar content being viewed by others
Background & Summary
The efficient utilization of digital pathology and computational resources has led to the rapid rise of AI-based computational pathology1,2. In recent years, general foundational models for pathology, pre-trained on large-scale data, have garnered significant attention3,4,5,6,7. These models have demonstrated strong feature extraction capabilities for pathological images, as evidenced by evaluations across a series of whole-slide image-level downstream tasks8,9,10. For example, CTranspath6 uses a Semantically-Relevant Contrastive Learning (SRCL) framework to pre-train a CNN-Transformer hybrid feature extractor on 150 million patches, with its effectiveness validated across five downstream tasks. UNI4 employed the self-supervised DINO-v211 method to train a robust general pathology visual encoder on one billion patches from approximately 100,000 whole slide images (WSIs). Gigapath5 utilized 1.3 billion patches to pre-train a visual encoder based on VIT-Gaint12 architecture and adopted LongNet13 to scale itself to a slide-level foundation model for slide-level representation learning. Virchow14 is a pathology foundation model based on the ViT-Huge architecture, trained using the DINOv2 approach on a dataset constructed from 1,488,550 whole slide images (WSIs), enabling clinical-grade diagnosis and rare disease identification. Pathorchestra15 trained a VIT-Large encoder on 300,000 WSIs and conducted extensive evaluation across 112 downstream tasks, achieving over 95% accuracy on 47 of them. These pathology-pre-trained models have demonstrated superior performance in downstream tasks including tumor classification, survival analysis, and lesion segmentation. PLIP3, pre-trained on approximately 200,000 pathology image-text pairs collected from medical Twitter, developed a multimodal pathology foundational model using contrastive learning16, capable of both image and text comprehension. CONCH7 employs CoCa17 for self-supervised pre-training on 1.17 million image-caption pairs and has been extensively evaluated across 14 downstream benchmarks, demonstrating its outstanding performance. In addition to patch-level encoders, some studies have focused on developing pretrained slide-level encoders, which are built upon patch encoders. For example, CHIEF18 constructs a slide encoder with an ABMIL19 architecture through vision-language joint training based on CTranspath6, using 60,530 WSIs. Prism20 is a Transformer-based slide encoder trained on 587,196 WSIs, built upon patch embeddings from Virchow. Titan21 is a slide-level encoder trained via slide-level vision-language contrastive learning, based on CONCH-V1.521, an upgraded version of the CONCH model. Slide-level encoders eliminate the need to retrain aggregators by directly generating WSI-level representations through inference, enabling downstream slide-level tasks such as classification, survival analysis, and report generation.
Acquiring finely annotated large-scale pathology image datasets remains challenging due to the extremely high resolution of pathology images and the specialized expertise required for annotations. Nonetheless, the continued development of foundational models and downstream tasks in computational pathology makes high-quality pathology image datasets increasingly essential.
The Camelyon series22,23 (http://gigadb.org/dataset/100439), a publicly available pathology dataset focused on detecting breast cancer lymph node metastasis, is widely used for evaluating multiple instance Learning (MIL) methods. However, as shown in Fig. 1, some images in the Camelyon series are of poor quality, exhibit treatment-related artifacts, and contain errors in slide-level labeling. The Camelyon-1622 dataset includes only tumor and negative labels, making it incompatible with Camelyon-1723 labels. Many pixel-level annotations are inaccurate, and some slides lack pixel-level annotations entirely. These issues hinder the accurate evaluation of deep learning methods in downstream pathology tasks.

Examples of issues in the Camelyon-16 and Camelyon-17 datasets. (a) The WSI shows a therapeutic response characterized by tissue fibrosis. (b) The WSI exhibits a blurred histiocyte-cancer boundary (left) and poor staining quality (right). (c) The cancerous region is missed in the annotation. (d) The WSI shows a therapeutic response with tissue necrosis.
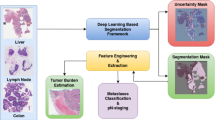
In this paper, we filtered out and removed slides from the Camelyon dataset that were blurred, poorly stained, exhibited treatment-related artifacts, or were ambiguous in terms of positivity. Furthermore, we expanded the binary classification labels in Camelyon-1622 to a four-class system to facilitate the merging of the Camelyon-16 and Camelyon-1723 datasets. Finally, we corrected the pixel-level annotations in the Camelyon dataset and added pixel-level annotations to positive slides that previously lacked them. Using the corrected dataset, we reevaluated 12 main MIL methods, including ABMIL19, TransMIL24 and CLAM25, etc. in two pre-trained natural image feature encoders, ResNet-5026 and VIT-S12, as well as ten pathology-specific pre-trained feature encoders, PILP3, CONCH7, UNI4, Gigapath5, CONCH-V1.521, TITAN21, Virchow14, Prism20, Ctranspath6 and Chief18.
Technical Validation
Dataset Overview
The official Camelyon-1622 dataset contains 399 WSIs, split into 270 for training and 129 for testing. The training set includes 111 tumor slides and 259 negative slides, while the test set includes 49 tumor slides and 80 negative slides. The official Camelyon-1723 dataset consists of 1000 WSIs, evenly divided into 500 for training and 500 for testing. The training set consists of 318 negative slides, 59 micro-metastasis slides, 87 macro-metastasis slides, and 36 Isolated Tumor Cells (ITC) slides. The test set labels are not publicly available. After data cleaning by professional pathologists, the Camelyon-16 dataset consists of 386 WSIs: 238 negative, 71 micro-metastasis, 69 macro-metastasis, and 8 ITC WSIs. The Camelyon-17 dataset consists of 964 WSIs: 633 negative, 103 micro-metastasis, 182 macro-metastasis, and 46 ITC WSIs. We combined the updated Camelyon-16 and Camelyon-17 datasets to form the Camelyon+ dataset. Figure 2 shows the dataset overvire. It consists of 1,350 WSIs: 871 negative, 174 micro-metastasis, 251 macro-metastasis, and 54 ITC WSIs.

Data characteristics and metastasis categories in Camelyon datasets. (a) Distribution of WSIs across different metastasis categories (Negative, Micro, Macro, and ITC) in three datasets: Camelyon-16-Refine22, Camelyon-17-Refine23, and Camelyon+27. (b) Representative histopathological examples for each category: Negative, Micro, Macro, and ITC.
Exclusion Criteria
We excluded certain WSIs based on the following criteria: focal blurriness, poor staining quality, difficulty distinguishing positive foci, and the presence of treatment-related artifacts. Of the 49 slides we remove, 26 show therapeutic response, 3 have staining issues, 12 exhibit focal blurring, 4 are of poor quality, and 4 contain suspicious cancerous regions. The verification of WSI labels and the annotation work were performed in the ASAP pathology annotation software (https://computationalpathologygroup.github.io/ASAP) by a mid-level pathologist, in accordance with the 8th edition of the American Joint Committee on Cancer (AJCC), and consistency checks were conducted by a senior pathologist. The presence of treatment response may interfere with model construction. In pathology, tumor treatment response refers to the histological changes in tumors following treatments such as surgery, chemotherapy, radiotherapy, targeted therapy, or immunotherapy, and the corresponding reaction to these treatments. Pathological analysis can assess histological indicators such as tumor cell necrosis, proliferation, and apoptosis, thereby evaluating treatment efficacy. Two typical treatment responses are tissue necrosis and fibrosis. Necrosis refers to areas of dead tissue formed after tumor cells die following treatment. Fibrosis refers to the scar tissue formed as a result of the self-repair of the tumor after damage. Necrotic and fibrotic areas can affect the representation of the characteristics of tumor regions in computational pathology, thereby affecting the performance of downstream tasks.
Data Records
The Camelyon+27 dataset is available via ScienceDB: (https://doi.org/10.57760/sciencedb.16442). The original WSI data can be downloaded from the official dataset repository (http://gigadb.org/dataset/100439), so it has not been uploaded to the database. The Camelyon+ dataset is structured into several directories, each serving a specific function in supporting downstream computational pathology tasks. The directory structure includes the following main components: slide-labels/, name-convert/, pixel-annotations/, feature-files/, and h5py-files/.
-
slide-labels/: This directory stores slide-level classification annotations in Excel format. We provide two XLSX files: camelyon+(2-classes).xlsx and camelyon+(4-classes).xlsx, which correspond to binary classification (negative vs. tumor) and four-class classification (negative, micro, macro, ITC), respectively. Each file contains two columns: slide (the WSI ID) and label (the assigned class). These labels are derived from corrected and unified versions of the Camelyon-16 and Camelyon-17 datasets, supporting various supervised learning scenarios.
-
name-convert/: To eliminate annotation bias, all original WSI file names from the Camelyon-16 training set that contain diagnostic hints such as “tumor” or “normal” have been renamed. The name-convert.xlsx file in this directory provides a mapping between the original and new file names through two columns: Origin Name and New Name. This enables accurate cross-referencing during label alignment or post-hoc analysis.
-
pixel-annotations/: For positive WSIs, pixel-level tumor region annotations are provided in XML format. Polygonal coordinates of positive regions are stored in the XML files and can be visualized on whole-slide images using ASAP. These files include detailed boundary information and can be used for tasks such as semantic segmentation or weakly supervised learning.
-
feature-files/: To facilitate fair and reproducible benchmarking across various visual encoders, this directory contains patch-level features extracted at 20 × magnification using a diverse set of backbone models, including ResNet-5026, VIT-S12, PLIP3, CONCH7, CONCH-V1.521, Ctranspath6, UNI4, GigaPath5, Virchow14, Chief18, Prism20, and Titan21. All features are stored in .pt format, which is natively compatible with the PyTorch library and supports efficient loading during training and inference.
-
h5py-files/: This optional directory offers an alternative representation of extracted features in .h5 format, enabling high-speed access and batch-wise loading for large-scale training workflows.
This modular organization of Camelyon+27 supports a broad spectrum of tasks, including classification, segmentation, and representation learning, and provides a standardized testbed for developing and evaluating pathology foundation models.
Methods
Methodology
The objective of our designed benchmark is to utilize slide-level labels to predict metastasis types. The commonly used approach is to adopt a deep learning strategy based on MIL, which has been recognized in recent studies for its strong capability to represent slide-level features28,29,30,31,32. MIL is a weakly supervised approach where a single WSI is treated as a bag, and each patch within the WSI is considered an instance. If any instance is cancerous, the entire WSI is labeled as cancerous, while a WSI is classified as normal only if all instances are normal.
With the advancement of deep neural networks, embedding-based MIL has become the dominant approach for WSI analysis. In embedding-based MIL, a pre-trained feature extractor first extracts features from the WSI, followed by an aggregator that pools the features for downstream classification tasks. Mean-MIL and Max-MIL aggregate features using mean pooling and max pooling, respectively, though the pooling mechanism inevitably results in information loss. ABMIL19 introduces the attention mechanism into MIL, dynamically assigning weights to each instance based on attention scores. CLAM25 further enhances this by incorporating instance-level clustering mechanisms to introduce domain knowledge, providing additional supervision alongside attention-based weight assignments. TransMIL24 leverages self-attention within the MIL aggregator to capture relationships between different instances, thereby improving global modeling capabilities. AMD-MIL33 introduces an agent mechanism into the MIL aggregator and employs threshold filtering for feature selection, improving MIL performance. DSMIL34 models instance relationships directly using a dual-stream architecture and a trainable distance measurement module. DTFD35 addresses the issue of limited WSIs by creating pseudo-bags. WiKG36 treats WSIs as knowledge graphs, dynamically constructing neighboring nodes and directed edges based on relationships between instances, and then updates the head node using knowledge-aware attention. FR-MIL37 introduces a distribution re-calibration approach that adjusts the feature distribution of a WSI bag (instances) based on the statistics of the max-instance (key) feature.
Data Preprocessing
For all datasets, we crop non-overlapping 256 × 256 patches at 20 × magnification. We then use twelve feature extractors ResNet-5026, VIT-S12, PILP3, CONCH7, UNI4, Gigapath5, CONCH-V1.521, TITAN21, Virchow14, Prism20, Ctranspath6 and Chief18 to extract features from the WSIs. Subsequently, we conducted two sets of experiments. The first set is a comparative experiment on the Camelyon-1723 dataset before and after label correction. The Camelyon-17-Origin dataset follows the official split, with 500 WSIs for training and 500 WSIs for testing. The Camelyon-17-Refine dataset also maintains the official split but excludes slides that fall under exclusion criteria. The Camelyon-17-Refine training set contains 492 slides, while the test set includes 472 slides. This comparative experiment evaluates the impact of dataset quality on MIL models. Since the original version of Camelyon-1622 does not have four-class labels, we do not perform similar experiments on it. The next set is the benchmark experiments on Camelyon+27. We evaluate using five-fold cross-validation, with each fold employing stratified sampling to maintain a fixed proportion of different classes. Since each patient has multiple slides in the Camelyon-17 dataset, in order to prevent data leakage, we ensure that slides of the same label of the same patient do not appear in the training set and the validation set at the same time.
Camelyon-17 Comparative Experiment
In the comparative experiments before and after correction on the Camelyon-1723 dataset, we primarily evaluated three pathology pre-trained feature extractors: PLIP3, UNI4, and Gigapath5. The learning rate was set to 2e-4, using the Adam optimizer with a weight decay of 1e-5. We repeated the experiments with random seeds of 2023, 2024, and 2025, and reported the mean and standard deviation of the evaluation metrics as shown in Table 1 and Table 2. All experiments were conducted on a workstation equipped with 4 NVIDIA RTX 3090 GPUs. Due to the significant class imbalance in the Camelyon-17 four-class dataset, our analysis concentrated on two key evaluation metrics: AUC and F1-score. Figure 3 presents a visualization of these metrics for a single MIL model across different feature extractors, using bar charts for both the Camelyon-17-Origin and Camelyon-17-Refine datasets. This visualization effectively illustrates how these metrics vary as the dataset undergoes refinement. Our results indicate that both AUC and F1-score exhibited notable changes following the dataset’s adjustment. Figure 4 further visualizes the F1-score, AUC, and their combined values, highlighting the top three models to assess the impact of dataset refinement on the performance ranking of the models. While the overall model rankings shifted to some extent after the dataset refinement, the CLAM-MB25 model consistently maintained its top-ranked position, indicating its robustness. In summary, dataset refinement enhanced the accuracy of model evaluation metrics and improved the fairness of model rankings, establishing a more solid foundation for future research.

Performance comparison between Camelyon-17-Origin23 and Camelyon-17-Refine across different MIL models and feature encoders. (a–c) AUC comparison using three feature encoders: (a) PLIP3, (b) UNI4, and (c) Gigapath5. (d–f) F1-score comparison using three feature encoders: (d) PLIP, (e) UNI, and (f) Gigapath.

Radar chart analysis of MIL models across different encoders and dataset versions. Each subplot shows the performance of multiple MIL models on the Camelyon-17-Origin23 and Camelyon-17-Refine datasets using three feature encoders: (a,e) PLIP3, (b,f) UNI4, and (c,g) Gigapath5. The outermost yellow line represents the average of AUC and F1-score, green represents AUC, and blue represents F1-score. (d,h) summarize the total ranking across all encoders for each dataset. Top-3 ranked models are highlighted with dashed boxes.
Camelyon+ Benchmark Experiment
In the Benchmark Experiment on Camelyon+27, we maintained the same hyperparameter settings as in the comparative experiments on Camelyon-1723. On the merged Camelyon+ dataset, we evaluated the MIL approach using feature extractors from two pre-trained natural image models, ResNet-5026 and VIT-S12, and twelve pre-trained pathology image models, Ctranspath, PLIP3, CONCH7, CONCH-V1.521, UNI4, Gigapath5, Virchow14, Chief18, Prism20 and Titan21. We classify these feature extractors into four main categories: ResNet-50 and ViT-S fall under the domain of natural image pre-training; PLIP, CONCH and CONCH-V1.5 fall under the domain of image-text contrastive learning pre-training; Ctranspath, UNI, GigaPath and Virchow belong to the category of pathology-specific visual pre-training; Chief, Prsim, and Titan are slide-level encoders that can represent a slide as an embedding. We report the mean and standard deviation of model performance in Tables 3–12 which can serve as baselines and references for future work based on the Camelyon+ dataset. As shown in Fig. 5, we present a heatmap of the distribution of AUC and F1-score across different MIL models under various feature extractors. It can be observed that pathology-pretrained feature extractors significantly enhance the performance of MIL. Notably, the CONCH model, which uses a VIT-Base architecture with image-text contrastive learning, achieves performance comparable to the UNI and Gigapath models, which utilize VIT-Large and VIT-Giant architectures, respectively. Moreover, both UNI and Gigapath leverage larger training datasets. This suggests that image-text contrastive pretraining may hold greater potential than pure visual pretraining in the pathology domain. While the PLIP model is also pretrained using image-text contrastive learning, its performance does not match that of CONCH, likely due to its smaller dataset and the lower quality of data sourced from Twitter. Slide-level encoders have recently emerged as a popular direction in computational pathology pretraining, aiming to produce holistic representations for entire WSI. However, due to the extremely large resolution of WSIs, the current generation of slide-level encoders still exhibits limited representational capacity. As shown in Table 12, we report the linear probing performance of three representative slide encoders-Chief, Prism, and Titan-and compare them against patch-level encoders (namely Ctranspath, Virchow, and CONCH-V1.5) used for precomputing features in three state-of-the-art MIL frameworks. Among the slide-level encoders, Chief achieved the highest performance, yet still fell significantly short compared to MIL models trained on patch-level features extracted by Ctranspath. This highlights the current limitations of slide-level encoders in capturing the complex pathological patterns required for downstream clinical tasks.

Benchmark comparison of MIL models with various feature encoders. (a) Mean AUC scores across 12 MIL models and 9 feature encoders, including ResNet-5026, ViT-S12, Ctranspath6, PLIP3, CONCH7, CONCH-V1.521, UNI4, Gigapath5, and Virchow14. (b) Mean F1-score under the same evaluation setup. Each cell represents the averaged performance across datasets. Warmer colors denote higher values. CLAM-MB25, TransMIL24, and AMD-MIL33 exhibit consistently strong performance across multiple encoders, while newer foundation models such as UNI, Gigapath, and Virchow lead to higher AUC and F1-scores than conventional encoders.
Figure 6 further presents few-shot learning results using slide encoders under various N-way, K-shot settings, ranging from 1 to 32 shots. The observed performance consistently improves with increasing shot number, suggesting that expanding annotated datasets for tasks such as lymph node metastasis detection could meaningfully enhance the clinical utility of slide-level foundation models.

Few-shot classification performance on the Camelyon+27. Benchmark. Boxplots show the performance of three models (Titan21, Prism20, Chief18) under 2-way, 3-way, and 4-way classification settings, with varying numbers of shots (1, 2, 4, 8, 16, 32). (a–c) Accuracy, (d–f) Recall, and (g–i) F1-score across increasing few-shot levels. Each box represents model performance distribution over multiple test episodes. Titan and Chief generally outperform Prism in low-shot regimes, and the performance gap narrows with increasing shot numbers.
In the Camelyon+27 dataset, noisy samples were initially removed to construct a clean benchmark. To assess the impact of noisy data, we conducted comparative experiments by reintroducing the noisy subset into either the training set or the test set of Camelyon+. As shown in Fig. 7, we evaluated the performance under 9 patch-level encoders and 3 state-of-the-art MIL methods. We observed that, in most cases, adding noisy data to the training set while keeping the test set clean resulted in performance comparable to the original benchmark. In contrast, when the test set was augmented with noisy data while keeping the training set unchanged, the performance on the test set dropped significantly compared to the benchmark. These results suggest that while incorporating noisy data during training may improve robustness without harming performance, the presence of noise in the evaluation set substantially undermines the reliability of performance estimation. This highlights the importance of clean and well-curated test data when benchmarking and deploying pathology AI systems.

Impact of noisy data on model performance across different feature encoders. Bar plots show the AUC and F1-score of three MIL models (a) CLAM-MB25, (b) AMD-MIL33, and (c) FR-MIL37-when noisy data is added either to the training set or to the test set. Each group of bars compares the performance across multiple feature encoders, including ResNet-5026, ViT-S12, PLIP3, CONCH7, CONCH-V1.521, Ctranspath6, Gigapath5, UNI4, and Virchow14. Models exhibit more robust performance degradation when noise is added to the test set, while training set noise leads to more varied effects depending on the encoder.
In the benchmark results, while the model demonstrates relatively strong performance in terms of accuracy and AUC, the F1-score, recall, and precision are notably low. As illustrated in Fig. 8, we visualized the confusion matrices for the CLAM-MB25 and FR-MIL37 models. The results show that the models perform relatively well in classifying the negative, micro, and macro categories, but perform poorly in the ITC category. We used macro-averaging to calculate the F1-score, recall, and precision, and the model’s poor performance on the ITC category significantly lowered the overall performance metrics. To investigate this issue further, we analyzed the model’s difficulty in identifying ITC cases. One major factor is the severe class imbalance in the Camelyon+27 dataset. As shown in Fig. 2, the head class, negative, contains 871 slides, while the tail class, ITC, contains only 54 slides, resulting in an imbalance ratio of approximately 16.1. This imbalance classifies the dataset as having a moderately long-tailed distribution. Such imbalance highlights a key challenge in pathology image analysis: how to achieve balanced model performance on long-tailed datasets like Camelyon+, particularly since real-world pathological data naturally follow a long-tailed distribution. Furthermore, we identified a fundamental difference between the four-class classification task in Camelyon+ and typical cancer subtyping tasks. The ITC, micro, and macro categories in Camelyon+ are primarily distinguished by the size of metastatic regions, whereas MIL is generally better suited for binary classification tasks, such as detecting the presence or absence of cancer. This explains why models achieve high performance on binary tasks like those in Camelyon-1622 or Camelyon-1723. Consequently, Camelyon+ raises an important question about whether the MIL approach the most suitable paradigm for clinical classification tasks like Camelyon+, where categories are defined by the size of metastatic regions rather than distinct subtypes of cancer.

Confusion matrices of MIL models on the four-class metastasis classification task. Each subfigure presents the confusion matrix of a model-encoder pair on the Camelyon+27 benchmark. Rows indicate the ground truth labels and columns indicate the predicted labels. (a–d) show results for AMD-MIL33 combined with PLIP3, CONCH7, UNI4, and Gigapath5 encoders, respectively. (e–h) show results for FR-MIL37, and (i–l) for CLAM-MB25 under the same set of encoders.
Evaluation metrics
In the comparative experiments on the Camelyon-1723 dataset and in the benchmark evaluations, we used accuracy, AUC, F1-score, recall, precision, and Cohen’s kappa coefficient to assess classification performance. The kappa coefficient is a statistical metric used to evaluate the level of agreement between predicted and true labels. It is particularly useful for assessing the performance of classification models in multi-class settings, as it accounts for agreement that may occur by chance.
Usage Notes
The Camelyon+27 Dataset is publicly available under the Creative Commons Zero (CC0) license. However, please note that this dataset is not intended for developing diagnosis-focused algorithms or models, and should not be used as the sole basis for clinical evaluations in classification tasks.
Code availability
The code related to dataset partitioning strategies, hyperparameter configurations, integration of MIL methods, and evaluation metric calculations is available at: https://github.com/lingxitong/MIL_BASELINE.
References
Song, A. H. et al. Artificial intelligence for digital and computational pathology. Nature Reviews Bioengineering 1, 930–949 (2023).
Van der Laak, J., Litjens, G. & Ciompi, F. Deep learning in histopathology: the path to the clinic. Nature medicine 27, 775–784 (2021).
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical twitter. Nature medicine 29, 2307–2316 (2023).
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nature Medicine 30, 850–862 (2024).
Xu, H. et al. A whole-slide foundation model for digital pathology from real-world data. Nature 1–8 (2024).
Wang, X. et al. Transformer-based unsupervised contrastive learning for histopathological image classification. Medical image analysis 81, 102559 (2022).
Lu, M. Y. et al. A visual-language foundation model for computational pathology. Nature Medicine 30, 863–874 (2024).
Kather, J. N. et al. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS medicine 16, e1002730 (2019).
Pataki, B. Á. et al. Huncrc: annotated pathological slides to enhance deep learning applications in colorectal cancer screening. Scientific Data 9, 370 (2022).
Barbano, C. A. et al. Unitopatho, a labeled histopathological dataset for colorectal polyps classification and adenoma dysplasia grading. In 2021 IEEE International Conference on Image Processing (ICIP), 76–80 (IEEE, 2021).
Oquab, M. et al. DINOv2: Learning robust visual features without supervision. Transact. Mach. Learn. Res. oquab2024dinov (2023).
Dosovitskiy, A. et al. An image is worth 16×16 words: transformers for image recognition at scale. In International Conference on Learning Representations (2021).
Ding, J. et al. Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv preprint arXiv:2307.02486 (2023).
Vorontsov, E. et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nature medicine 30, 2924–2935 (2024).
Yan, F. et al. Pathorchestra: A comprehensive foundation model for computational pathology with over 100 diverse clinical-grade tasks. arXiv preprint arXiv:2503.24345 (2025).
Radford, A. et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763 (PMLR, 2021).
Yu, J. et al. CoCa: contrastive captioners are image–text foundation models. Trans. Mach. Learn. Artif. Intell. https://openreview.net/forum?id=Ee277P3AYC (2022).
Wang, X. et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature 634, 970–978 (2024).
Ilse, M., Tomczak, J. & Welling, M. Attention-based deep multiple instance learning. In International conference on machine learning, 2127–2136 (PMLR, 2018).
Shaikovski, G. et al. Prism: A multi-modal generative foundation model for slide-level histopathology. arXiv preprint arXiv:2405.10254 (2024).
Ding, T. et al. Multimodal whole slide foundation model for pathology. arXiv preprint arXiv:2411.19666 (2024).
Bejnordi, B. E. et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. Jama 318, 2199–2210 (2017).
Bandi, P. et al. From detection of individual metastases to classification of lymph node status at the patient level: the camelyon17 challenge. IEEE transactions on medical imaging 38, 550–560 (2018).
Shao, Z. et al. Transmil: Transformer based correlated multiple instance learning for whole slide image classification. Advances in neural information processing systems 34, 2136–2147 (2021).
Lu, M. Y. et al. Data-efficient and weakly supervised computational pathology on whole-slide images. Nature biomedical engineering 5, 555–570 (2021).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Xitong, L. et al. Comprehensive benchmark dataset for pathological lymph node metastasis in breast cancer sections, https://doi.org/10.57760/sciencedb.16442 (2025).
Yan, R. et al. Shapley values-enabled progressive pseudo bag augmentation for whole-slide image classification. IEEE Transactions on Medical Imaging (2024).
Ouyang, M. et al. Mergeup-augmented semi-weakly supervised learning for wsi classification. arXiv preprint arXiv:2408.12825 (2024).
Chu, H. et al. Retmil: Retentive multiple instance learning for histopathological whole slide image classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 437–447 (Springer, 2024).
Qiehe, S. et al. Nciemil: Rethinking decoupled multiple instance learning framework for histopathological slide classification. In Medical Imaging with Deep Learning (2024).
Yang, S., Wang, Y. & Chen, H. Mambamil: Enhancing long sequence modeling with sequence reordering in computational pathology. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 296–306 (Springer, 2024).
Ling, Xitong, et al. Agent aggregator with mask denoise mechanism for histopathology whole slide image analysis. Proceedings of the 32nd ACM International Conference on Multimedia (2024).
Li, B., Li, Y. & Eliceiri, K. W. Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 14318–14328 (2021).
Zhang, H. et al. Dtfd-mil: Double-tier feature distillation multiple instance learning for histopathology whole slide image classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 18802–18812 (2022).
Li, J. et al. Dynamic graph representation with knowledge-aware attention for histopathology whole slide image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11323–11332 (2024).
Chikontwe, P. et al. Fr-mil: Distribution re-calibration based multiple instance learning with transformer for whole slide image classification. IEEE Transactions on Medical Imaging 1–1, https://doi.org/10.1109/TMI.2024.3446716 (2024).
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255 (Ieee, 2009).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (NSFC) under Grant No. 82430062. We also gratefully acknowledge the support from the Shenzhen Engineering Research Centre (Grant No. XMHT20230115004) and the Shenzhen Science and Technology Innovation Commission (Grant No. KCXFZ20201221173207022). This work was also supported by the Shenzhen High-level Hospital Construction Fund. Additionally, we thank the Jilin FuyuanGuan Food Group Co., Ltd. for their collaboration.
Author information
Authors and Affiliations
Contributions
X.L. and J.L. conceptualized the study, designed the experiments, and conducted the specific experiments. Y.L., J.C., and W.H. were responsible for dataset correction and construction. T.G., J.G., and Y.H. contributed to the manuscript writing and provided insights into the development of the manuscript structure. All authors read and approved the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ling, X., Lei, Y., Li, J. et al. Comprehensive Benchmark Dataset for Pathological Lymph Node Metastasis in Breast Cancer Sections. Sci Data 12, 1381 (2025). https://doi.org/10.1038/s41597-025-05586-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05586-5
