
Abstract
Access to real data is a challenge for research and professional analysis in the insurance sector, especially since such access is often restricted due to confidentiality and competitive issues, particularly in health insurance. This paper introduces a new dataset from a Spanish health insurance portfolio, covering the years 2017 to 2019 with over 70 thousand unique insured and more than 225 thousand rows of data. The dataset contains 42 variables, of which 27 are directly sourced from the insurer and the rest are derived to include area-based contextual information obtained from publicly available sources. The data are anonymized to ensure privacy while maintaining the integrity required for robust professional analysis. Researchers can use the dataset to explore health insurance dynamics, from product design to contextual effects and risk management. Moreover, it supports academic applications for students and educators where they can use real-world data for exercises in data cleaning, statistical analysis and machine learning models.
Similar content being viewed by others

Background & Summary
Access to quality data in the insurance sector has long been a recurring challenge for researchers and professionals, particularly in lines of business like health insurance, where privacy regulations and market competitiveness significantly limit data availability1. Insurers, aware of the strategic value of their data, are reluctant to share information that could reveal vulnerabilities in their business models or risk management strategies2. Several studies have attempted to address the lack of real data in the insurance sector.
An anonymized car insurance dataset has been developed to facilitate access to real-world data without compromising policyholder confidentiality3. However, the specific nature of this dataset limits its applicability to other types of insurance, such as health insurance. Similarly, there is a life insurance dataset with detailed policyholder information4 although the authors point out the difficulties of including sensitive data.
Three out of four insurers face difficulties in applying individualized pricing due to a lack of detailed data about their policyholders5. Thus, insurers that can access and utilize relevant data gain a significant competitive advantage by improving accuracy in risk assessment and customizing products to meet clients’ needs. Moreover, data access in the health insurance sector is particularly restrictive due to confidentiality regulations that protect insureds’ medical information.
In the specific field of health insurance, the issue of data access has been the subject of numerous studies6,7,8. Evidence from the U.S. National Medical Expenditure Survey highlights the presence of asymmetric information in health insurance markets, showing how a lack of precise data can limit the development of products that accurately reflect the risks assumed by insurers6. Other research has identified the challenges insurers face in pricing or designing products without complete and accurate data, which leads to reduced efficiency in the health insurance market7. More recently, studies have analyzed the effects of health insurance price regulation on resource allocation, demonstrating that restrictions on access to detailed data on policyholders’ behavior can reduce insurers’ ability to tailor their products to market needs, with negative implications for efficiency and equity in health insurance distribution8. All of these contributions share a common point: the lack of real data.
The lack of access to quality data in the insurance sector, particularly in health insurance, remains a significant challenge for research and innovation. Despite efforts to generate synthetic9 or anonymized datasets, the available information remains insufficient to comprehensively address the sector’s needs. This study aims to contribute to this field by providing a static health insurance dataset that addresses these gaps, making a structured dataset available that can be used for researchers and professionals in the insurance sector. The next sections describe in greater detail the characteristics of this dataset.
In this context, we present a static dataset related to health insurance, provided by a Spanish insurance company. This dataset was processed and consolidated after numerous discussions with the company’s representatives, with the aim of offering the academic and professional community a comprehensive set of variables while ensuring the privacy of the insured individuals so that no one could be identified from the included data. As a result, after an important process of treatment and cleaning of data, we present a dataset in an open format: https://doi.org/10.17632/386vmj2tbk.
This dataset corresponds to a health insurance product and includes the insured individuals recorded in the dataset. It contains more than 70,000 unique insured with a total of more than 225,000 rows for the years 2017 to 2019 and a total of 42 variables. Of these, 27 are provided directly by the insurance company while the remainder was derived from relationships with the original variables. Among these (original) variables is a georeferenced code, specifically the postal code, which identifies each individual’s place of residence. While this code cannot be shared, it enables us to include variables related to the socioeconomic context of each person based on freely available data from Spanish National Statistics Institute, as well as the integration of climatic information provided by the Spanish Meteorological Agency (AEMET) corresponding to the individual’s location. As a result, we incorporate new variables such as income levels, regional policy penetration relative to the total number of policies in the portfolio, the size of the municipality’s population, education levels and even regional climatic indicators. Almost all these variables are categorized by level, allowing the ordering and measurement of the intensity of each variable.
The dataset can be employed in various research and analytical contexts, including studies of product design, socioeconomic context analysis, customer segmentation and even risk management, particularly within the context of the Solvency II framework. Moreover, the database can also be utilized in academic settings, where it can be integrated into the educational processes, such as practical assignments or classroom analyses. To facilitate this usage, the authors provide a single, fully curated dataset, which has been cleaned and prepared for analysis and constitutes the only version released for public use.
Methods
The construction of the dataset begins at the time of policy issuance and initial interaction with the customer. The insurance company operates through three distribution channels: (i) company-owned commercial offices (agency), (ii) direct sales through online and telephone (direct business) and (iii) insurance intermediaries and brokers. Regardless of the channel, applicants complete a standardized underwriting form that collects the information required for two purposes: (a) to assess the risk profile, including any relevant medical history that may lead to exclusions and (b) to determine the premium according to the applicant’s characteristics and the selected coverage. Once the applicant meets the health requirements and accepts the proposed premium and policy conditions, the policy is issued. At that point, all the collected information is automatically integrated into the insurer’s internal information system, with each new policyholder generating a unique record that constitutes the basis of the raw dataset used in this study.
Access to these data was possible through formal knowledge-transfer agreements between the insurer and members of the author team. Periodically, and particularly at the end of each calendar year, the Information Technology Department extracts a structured copy of this internal (raw) database and passes it to the technical departments for actuarial analysis and reporting purposes. This periodic extraction serves as the starting point for the dataset used in this study. This extraction is subsequently subjected to a data cleaning and processing procedure, which is described in greater detail in the Technical Validation section.
Once the net dataset containing the individual-level variables is defined (see Table 1), contextual variables are incorporated. The insurer dataset includes the postal code of residence for each policyholder, while the contextual socioeconomic and demographic information (e.g., average income per consumption unit and distribution of educational attainment) is provided by the National Statistics Institute (INE) at the census-section level. However, in Spain, postal codes and census sections are two different geographic segmentation systems that do not share a one-to-one spatial correspondence. A postal code may overlap several census sections, and conversely, a census section may intersect more than one postal code. This prevents a direct merge and would lead to biased estimates if a simple spatial join were applied.
To resolve this issue, we employ the sc2sc R package10, which implements a population-weighted areal interpolation method specifically designed to transfer variables between non-coincident spatial units. It first identifies the geometric intersections between census sections and postal codes, then reallocates values based on both spatial overlap and population distribution. More precisely, the procedure estimates the proportion of each census section contributing to each postal code and distributes the contextual variables accordingly, ensuring that aggregate totals are preserved. This approach refines traditional areal weighting by incorporating population density into the weighting scheme, assigning greater influence to more densely populated areas within each overlap11. As a result, distortions associated with area-only weighting are avoided, yielding a more accurate and representative spatial allocation. The sc2sc R package is open-source, documented and applicable in demographic and regional-analysis contexts.
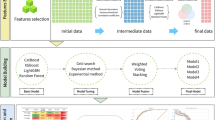
Through this process, the individual records are enriched with area-based contextual information linked to each policyholder’s residence, including income level percentiles, educational attainment indicators and insurance penetration. This integration would not be feasible using postal codes alone, as the INE does not publish socioeconomic statistics at that spatial resolution. The resulting contextual variables are detailed in the Data Records section and in the data repository. Figure 1 provides a schematic overview of the integration workflow, showing how the individual-level insurance records and the contextual INE variables are combined into a unified dataset.

Data integration flowchart between postal codes and census sections.
The first set of contextual variables relates to population size and settlement structure. Using official statistics from INE, under the section “Demografía y población/Cifras de población y Censos demográficos/Censos de Población y Viviendas. Resultados”, the resident population of each municipality across Spain can be obtained. To classify postal codes by population size, we leverage the resident population data available at the census section level from INE and use the sc2cp function (using the “counts” parameter) from the sc2sc R package10. This function allow us to spatially aggregate population counts from census sections to postal codes, aligning each postal code with a cumulative population value based on its overlapping census sections. Each insured is categorized according to habitat size, defined as the resident population within each geographical segment (municipality).
The second contextual block concerns economic conditions, in which we incorporate income-related indicators derived from official INE sources. Specifically, we obtained data from the INE on average income per unit of consumption under the section “Nivel y condiciones de vida (IPC)/Condiciones de vida/Atlas de distribución de renta de los hogares. Resultados”. This measure reflects the net income per consumption unit of a household, which is then applied to each household member to determine income per consumption unit for the entire population12. The calculation follows the modified OECD scale, a standard used across the European Union to evaluate household consumption units. According to this scale, the first adult in a household is assigned a weight of 1, each additional person over the age of 13 a weight of 0.5 and children under 14 a weight of 0.3. This system adjusts for the varying financial needs of adults and children. This variable is available by census section.
Once income levels for all census sections in the general population are obtained, the data are mapped from census sections (sscc) to postal codes using the sc2sc R package10. Subsequently, the income values are organized in ascending order to establish 100 income percentiles (the values of percentiles 25, 50 and 75 can be found in data repository). Each census section in Spain is then assigned an income level percentile.
The third contextual block concerns educational attainment. Educational levels for each census section were obtained from the INE through the section “Cifras de población y Censos demográficos/Demografía y Población/Censo de Población y Viviendas/Censo anual de población (Educación y Relación con la actividad) 2021-2022/Resultados por sección censal”. Although the data are only available for 2021, we assumed that the educational levels within each census section have remained relatively consistent compared to the 2017-2019 dataset13. In other words, a census section positioned at a particular percentile in 2021 is considered to have experienced minimal change compared to the rest of Spain in the period 2017-2019.
The INE provides four educational levels: (i) primary education and below, (ii) first stage of secondary education and similar, (iii) second stage of secondary education and post-secondary non-higher education and (iv) higher education. Given the similarity between levels (ii) and (iii), we combine these into a single category. Therefore, for our purposes, we categorize the levels as primary education (P), secondary education (S) and higher (tertiary) education (T). The INE reports the number of people within each census section who have attained these educational levels. The values are not cumulative, which it means that the individuals listed under higher (tertiary) education are not included in the previous categories. The total population of each census section corresponds to the sum of these values which allows us to calculate the percentage of the population with each educational level. In this context, a high percentage in the higher (tertiary) education category indicates that a significant portion of the population has completed higher levels of education. Conversely, a high percentage in the primary education (P) category suggests that a large portion of the population has only basic education or none at all.
Lastly, we incorporate a climatic contextual block that captures the characteristics of the local climate. Climatic information is provided by the Spanish Meteorological Agency (AEMET) as point data in geographic coordinates (latitude and longitude). The climate variable was developed following the methodology proposed by14, using daily meteorological data collected over 11 years from weather stations across the country and accessed via the climaemet R package15. Although the original dataset spans 2010-202113, we restrict our analysis to 2017-2019. The dataset includes temperature, precipitation, wind, UV index and atmospheric pressure, among other variables; however, the data are initially limited to discrete observation points16.
To extend this information to census-section level, we apply kriging interpolation17, a geostatistical method for predicting values at unsampled locations using spatial correlations. Based on observations from weather stations, climatic values are interpolated at the centroids of census sections, which serve as the spatial reference units in this study. This approach accounts for both spatial distance and variability in the data, producing continuous climate surfaces across the country and addressing gaps due to uneven station distribution.
From the interpolated information, descriptive measures (e.g., means, minima, maxima, ranges, standard deviations) are computed for each climate variable and census section per year to facilitate data processing. The K-means clustering algorithm18 is then applied to the set of climate variables19,20, identifying six primary climate clusters.
While the incorporation of contextual indicators broadens the analytical possibilities, it also raises considerations for interpretation. These area-based contextual indicators are derived from area-level estimates (in this case, postal codes) rather than from individual records. This inevitably assumes a degree of homogeneity within each geographic unit–particularly with respect to income–and cannot fully capture intra-area heterogeneity.
Even with this limitation, the inclusion of contextual information allows analyses that would not be possible otherwise. Area-level measures such as average household income, educational attainment or regional environmental patterns provide an approximation that avoids relying on self-reported values, which in the insurance sector are often declarative and rarely verified against official documentation. Moreover, income and other socioeconomic characteristics tend to show spatial clustering, making residential location a meaningful proxy for individual circumstances. This is consistent with well-established practices in economics21, demography22 and actuarial science, where contextual data are routinely employed for segmentation, pricing and risk assessment.
Data Records
Insurance company
The dataset is available at Mendeley Data in https://doi.org/10.17632/386vmj2tbk13. It consists of an anonymized and static dataset sourced from a Spanish insurance company specializing in health insurance. The dataset is provided in spreadsheet format, specifically as an .xlsx extension file in a structured wide table format. It covers the primary operations of the company over a period of three full years, from January 1, 2017, to December 31, 2019. The dataset, referred to as the insurance portfolio, includes a wide range of information related to health insurance policy characteristics. Specifically, it contains data on effective date and lapse date, details about each insured individual (such as age and gender) and attributes related to the insurance provider including distribution channel and product types. Additionally, it includes standard economic indicators, such as premium amounts and claims amounts.
The final dataset13 consists of a total of 228,711 rows, where each row represents an insured / year and includes a total of 42 columns. Individually, there are over 70,000 unique (insured) policies in each of the three analyzed years: 2017, 2018 and 2019. Each insured contract is tacitly renewed every year unless the insured decides to cancel it or the insurance company ends the contract due to non-payment, both denoted as lapse. Each policy may be associated with a single insured person or a group/collective, depending on the type of insurance (individual or collective).
The dataset13 is organized into two groups of variables. Although presented together, these groups differ in both origin and nature. First, from the total of 42 variables, Table 1 provides a brief description of the 27 original individual variables supplied directly by the insurance company. These original variables are classified into four sub categories based on their characteristics: (i) ID variables, which serve as identifier; (ii) date variables, related to different time periods; (iii) insured-insurer variables, which include information specific to both the insured individuals and the insurance company and (iv) economic variables, taking into account key financial metrics like premiums and claims amounts. All these variables are described in greater detail in the column “Expanded description” in Descriptive of the variables.xlsx file of the data repository.
ID variables
The first block of variables is designed to uniquely identify each insured individual using an identification code. While the company provided its internal codes, these were modified by the authors to ensure consistency and confidentiality. This set of ID variables serves only to uniquely label each entry in the database13. Individually, there are over 70,000 unique insured policies in each of the three analyzed years: 78,459, 73,970 and 76,282 for the year 2017, 2018 and 2019 respectively.
The variable ID concatenates the ID_policy and ID_insured variables. ID_policy represents the generic policy number, which is identified as an integer, while ID_insured, also an integer, refers to the unique identifier of the insured policy. Within the generic policy, there can be multiple ID_insured entries, specifically when the policy_type refers to a collective. It is important to note that, for example, a family unit consisting of two adults and one or more children is considered an individual (generic) policy.
Time variables
Time variables represent specific points in time and provide information about events or periods in the company’s database13. These variables enable temporal analyses, such as calculating age or seniority, tracking event frequency and identifying trends over time.
The variables date_effect_insured, date_lapse_insured, date_effect_policy and date_lapse_policy correspond to the start (denoted as date effect) and end (denoted as date lapse) dates of the insured policy and the generic policy, respectively. The first two variables refer to the insured policy while the last two refer to the generic policy. All dates are formatted as DD/MM/YYYY where YYYY represents the year, MM the month and DD the day. date_effect_insured and date_lapse_insured indicate the start and end of the insured individual’s coverage period with the company. The relationship is considered terminated if date_lapse_insured has data; otherwise, the insured policy remains recorded as active within the portfolio. Similarly, date_effect_policy and date_lapse_policy represent the start and end of the generic policy’s validity. In the same way, the generic policy is still considered active at the closed portfolio if date_lapse_policy is empty. In total, there were 14,972, 14,137 and 12,331 insured lapses recorded in 2017, 2018 and 2019, respectively. In percentage terms, this represents 19.08%, 19.11% and 16.16%, referred to as the lapse rate, for the entire portfolio in each respective year.
The variables year_effect_insured, year_lapse_insured, year_effect_policy and year_lapse_policy are in integer format and represent the year for each of the four previous date variables. Although the variables can be easily derived from the previous ones, their inclusion by the company is intended to facilitate data processing. The variable exposure_time refers to the time the policyholder is exposed to the risk. This variable allows the risk associated with each policyholder to be evaluated based on the time they were covered by the policy during the analysis period. The exposure can take a value of 1, indicating full coverage throughout the year or be fractional if the coverage was partial due to an insured policy lapse.
In the insurance sector, many products such as car or home insurance have an annual term, which is why they are called renewable annual term insurance. For instance, if an individual wants to ensure an asset like a car, they might purchase an insurance policy on April 3 that provides coverage against any risks. This insurance starts (effective date) on April 3 of year t at 00:00 and ends exactly one year later, on April 2 of year t + 1 at 23:59. However, certain health insurance policies do not follow this model due to factors such as outdated IT systems, contract negotiations with hospitals and specialists and management needs. In these cases, regardless of the policy start date, the expiration date is set to December 31 of the same year. After that, unless there is non-payment, the policy is automatically renewed with the premium terms established by the insurance company. Consequently, for insured policies that start after January 1, the variable exposure_time for that initial year will be less than 1. In relation to this important scenario, the variable lapse uses a code to indicate the policy’s status in the company’s portfolio: 1 if the policy lapsed before expiration (12/31/YYYY), 2 if the insured policy remains active and 3 if the insured policy terminated coverage as of 12/31/YYYY.
Lastly, seniority_insured represents the number of years an insured has been with the insurance company. It reflects the insured’s tenure or length of association with the company. seniority_policy represents the same variable, but in relation to the generic policy. When a new insured has no direct family members or does not belong to a collective insured, both variables will coincide. Both variables were calculated as of December 31 of each year.
Insured-insurer variables
The variables in this block provide information about the characteristics insured and the generic policy, both from the perspective of the insured and the insurance company. These variables allow the insured’s profile, coverage conditions and the types of products contracted to be analyzed. This group includes data on the policy type, distribution channel, gender and age.
The variable type_policy classifies policies into two main categories: Individual (I) and Collective (C) with approximately 64% and 36% of insured policies respectively. Individual policies refer to either a single member or a family unit, while collective policies refer to groups of individuals united by a legal entity such as a company. Meanwhile, type_policy_dg breaks down this classification further by the nature of the collectives, specifying options such as Self-employed (S), which refers to self-employed workers, Individual (I) and various Collective categories (Collective 1 = C1, Collective 2 = C2, Collective 3 = C3 and Collective 4 = C4). Although the specific details of each collective cannot be determined due to the anonymization, conclusions can still be made, for example, about the economic profitability of the collectives.
The variable type_product describes the policy type. The type_product (D) provides coverage mainly for dental services, with treatments subject to predefined deductibles. The standard type (S) provides basic coverage and offers a standard network of hospitals and medical specialists. The premium type (P) provides broader coverage, including access to an extended network of hospitals and medical specialists. Lastly, the international type (I) is designed for individuals who frequently travel abroad for professional reasons. This variable is complemented by the reimbursement type, which refers to the option of freely choosing a hospital and specialist. In this case, the policyholder pays for medical services upfront and the insurance company reimburses a portion of the expense, typically covering between 70% and 80% of the health price.
The variable new_business indicates whether the policy is newly created in the company’s portfolio, assigning the value yes if true and no if the policyholder was already part of the portfolio at the beginning of the year. Even though there are insured policies with high maturity values, more than 10% of the portfolio consists of newly issued policies. The variable distribution_channel specifies the channel through which the policy was processed. This can be: Agencial (A), referring to the establishment or company where an agent performs their mediation functions; Direct (D), referring to premiums obtained through direct contracting, mainly via digital channels such as the internet or mobile apps; or Insurance Intermediary (M), which refers to a person or legal entity that legally acts as an insurance mediator, meeting the requirements to provide accurate information, safeguard premiums and compensation received and complying with advertising regulations.
Finally, regarding the characteristics of the insured, the variable gender identifies their gender, with male (M) and female (F) as possible values, where women account for nearly 55% of the insured policies. The variable age indicates the insured’s age in the year defined by the period variable.
Economic variables
The Economic variables refer to the financial aspects involved in the exchange of capital between the insured and the insurance company. At the effective date of coverage, the insured pays a premium to the insurer, thereby transferring the associated risk while the insurer receives the monetary amount in exchange for covering the medical services included in the healthcare network.
In this context, the variable premium represents the cost that the insured pays to the insurance company for health coverage, which the company records as revenue. This amount may vary depending on factors such as the type of policy, the number of medical services used by the insured in previous periods, the insured’s age, offered coverage and specific contract conditions. Thus, the premium reflects the financial consideration paid by the insured for protection. The company has chosen not to disclose its specific pricing policy to protect its marketing strategy. The variable cost_claims_year refers to the expense incurred by the insurance company for the medical services used by the insured. This represents an accounting expense and accounts for the majority of cash outflows.
The variables premium and cost_claims_year provide metrics commonly used to evaluate business performance in the insurance sector. Their relationship with other variables could be further explored in future research.
Finally, the number of claims is an economic variable in the insurance industry, also in health insurance. In other branches of insurance, such as car or home insurance, a claim typically refers to an unexpected event that causes material, financial or personal losses. However, discussions with the insurance company revealed that the number of health insurance claims is not tracked in the same way. Instead, the number of n_medical_services provided is recorded. For example, if a person visits a doctor and, during the visit, undergoes a specialist consultation, a radiological exam and a blood test, each service could be recorded as separate medical acts. In fact, certain procedures, like a thorough blood test, may be counted as multiple medical services, as each parameter evaluated (for instance, glucose, cholesterol, etc.) is considered an individual medical act. Although this approach is a valid alternative for measurement, the considerably higher values in this variable may lead to confusion among specialists, such as risk managers and actuaries, who are more accustomed to working with the traditional claims metric.
In addition, it should be noted that the dataset13 does not include detailed clinical information such as diagnoses or reasons for claims. While such data could provide additional granularity, its disclosure is legally restricted given its classification as highly sensitive personal health information under frameworks such as the European Union’s General Data Protection Regulation23. The absence of this type of variable represents a limitation, but it also reflects a necessary balance between research utility and the protection of privacy.
New variables: socioeconomic and demographic environment
In Table 2 details the new variables added to the dataset13, along with their respective descriptions and specifications. Of the total individual policies, 13,219 (5.08% of the total) either did not have a postal code or had an incorrect one. These policies were kept as they contain all the original (initial) variables. Policies with these issues are marked as empty with all variables in Table 2. In the following subsections, each variable is examined in detail and readers can find additional information in the third column “Expanded description” in Descriptive of the variables.xlsx file of the data repository.
Insurance penetration, population density and habitat size
This block begins with the variables related to insurance penetration, population density and habitat size. The first three variables in Table 2 facilitate an analysis of the distribution and concentration of health insurance policyholders relative to the population at different geographic scales, specifically by postal code, by municipality and by province, per period. The variables n_insured_pc, n_insured_mun and n_insured_prov capture the count of insured individuals per postal code, municipality and per province, respectively.
More specifically, we include two additional (variables) indices that measure policy concentration per 1,000 inhabitants at both the municipality and provincial levels. On the one hand, IICIMUN (Insurance Insured Concentration Index per 1,000 inhabitants at the municipality level) measures insured concentration in each postal municipally and period; this is calculated by dividing the number of unique insured recorded within the municipality code and period by its (general) population and multiplying the result by 1,000. This indicator helps to identify areas with higher insurance penetration and to analyze how insurance distribution aligns with population density in each postal code. Similarly, IICIPROV (Insurance Insured Concentration Index per 1,000 inhabitants at the provincial level) is presented. This index is calculated for each province by dividing the number of insured by the population, multiplied by 1,000.
The previous variables analyze the concentration of insured individuals within a specific region. The next variable, C_H, represents the habitat size of each insured residence. This variable is structured into six levels based on the INE’s categorization for municipalities: (i) up to 1,000 inhabitants (C1); (ii) between 1,001 and 10,000 inhabitants (C2); (iii) between 10,001 and 25,000 inhabitants (C3); (iv) between 25,001 and 50,000 inhabitants (C4); (v) between 50,001 and 100,000 inhabitants (C5) and (vi) more than 100,000 inhabitants (C6).
Economic environment
While the previous subsection focused on insurance penetration and population-based characteristics, this subsection introduces the economic environment associated with each policyholder’s area of residence. The variable C_GI reflects the categorization of the general population by postal code and income level. Specifically, this variable expresses the percentile position of the insured person’s postal code within the national income distribution. For instance, a value of 75 indicates that the insured individual resides in a postal code area where the average income is higher than 75% of postal codes in Spain. Given the typically high cost of health insurance, it is expected that such insurance policies are more commonly chosen by individuals in the higher income percentiles. Note that, for instance, an income level of 1 spans the 0% to 1% range, while an income level of 100 covers the 99% to 100% range.
In parallel, we calculate the variable C_II using the same statistical method as above to define 100 income levels based on percentiles (see the quartiles in data repository). Once these monetary values are assign, we proceed to compute the 100 income levels, but specifically within the insurance portfolio. Therefore, this variable represents the percentile position of the insured person’s postal code within the income distribution of the insured population. Unlike C_GI, this indicator focuses on the income structure within the insurance portfolio itself.
The distinction between C_GI and C_II lies in their respective bases: the first calculates percentiles based on the income levels of the general population, while the second calculates percentiles based on the income distribution within the insurance portfolio. As a result, the average population value for C_II will be centered around 50%, whereas C_GI is likely to yield a higher average since health insurance tends to be purchased more frequently by individuals in higher income brackets.
Educational environment
This subsection introduces six educational variables that facilitate the analysis of educational attainment across the geographic level by postal code. These variables serve as a basis for exploring the link between education and health insurance coverage, and for identifying regions with varying educational characteristics.
As detailed in the Methods section, the educational levels considered and the procedure used to obtain the percentage values are fully described. The percentage values for each educational level across all of Spain (general population) are ordered, following the mapping from census sections to postal codes, from lowest to highest and assigned their corresponding percentiles see the quartiles in data repository). In line with the previous variables, we use the R package sc2sc. As a result of this process, the variables C_GE_P, C_GE_S and C_GE_T are created for primary education, secondary education and higher (tertiary) education, respectively. Each of these variables expresses the percentile position of a postal code within the national distribution of educational attainment. For instance, a value of 75 in C_GE_T indicates that the insured person lives in a postal code where the share of residents with tertiary education is higher than in 75% of postal codes across Spain. Conversely, a high value in C_GE_P suggests that the area has a relatively greater proportion of residents with only primary education.
Finally, the same process described earlier is applied, but instead of using the general population of Spain, it is conducted only on the insurance portfolio. As a result, the variables C_IE_P, C_IE_S and C_IE_T are obtained, corresponding to primary education, secondary education and higher (tertiary) education, respectively, within the insurance portfolio. These indicators are constructed analogously to the previous ones but reflect the educational distribution among insured individuals rather than the general population.
Climatic environment
Climate is a factor in public health, directly influencing the prevalence of specific diseases and conditions across various regions. Climate variations also impact healthcare access and resource availability, as certain illnesses can be seasonal or closely linked to regional environmental conditions. This link between climate and health is relevant for evaluating insurance coverage and setting premiums within the industry. In this context, we prioritize the creation of a climate-based variable capable of categorizing the climate zones of the country where the insurance provider operates. This classification allows the integration of climate data to uncover potential relationships between climate patterns and insured-insurer variables, as shown in Table 1.
The climate variable was developed following the methodology described in the Methods section, resulting in six clearly differentiated clusters: C1: central plateau (Central-continental); C2: Canary Islands; C3: Mediterranean coast and southern Atlantic coast (Mediterranean); C4: northern plateau and Iberian mountain system (North-continental); C5: southern plateau and Iberian mountain system (South-continental) and C6: Galician and Cantabrian Atlantic coast (Oceanic). The aggregation of various census sections to the postal codes is conducted using the sc2sc R package10. Additionally, the file “Descriptive of the variables.xlsx” in data repository includes the Autonomous Community(ies) associated with each climatological cluster and the file Division of Spanish regions into homogeneous climatological areas.pdf contains a map showing the geographical boundaries of these areas. Finally, to facilitate understanding of the climate clusters and their structure, the repository includes the file "Centroid values of the climate clusters.xlsx", which provides the centroid scores for each climatic variable in each cluster, along with a brief description of each variable.
Technical Validation
From the initial reception to the final presentation, the dataset13 underwent a multi-stage quality control process to ensure its reliability and consistency. This process includes identifying and addressing missing, duplicate or erroneous data, as well as correcting null values related to the absolute frequency of each variable.
The workflow for data extraction and validation follows a sequence of well-defined stages. The first phase involves tasks such as cleaning, preparing and thoroughly reviewing the dataset13 to confirm its integrity and adequacy. Variable creation or transformation is also carried out, with particular emphasis on those based on georeferenced postal codes, as well as standardizing formats, including unifying dates under the ISO 8601 standard24 and defining categorical variables as factors.
The dataset13 was subjected to exploratory data analysis (EDA) to assess its statistical integrity. Distributions of continuous variables were inspected to verify normality and qualitative variable categories were reviewed to avoid redundancies or inconsistencies. The dataset13 is divided into two major groups: Individual variables and area-based contextual variables.
Individual variables
The original (individual) variables include subgroups such as ID Variables, Time Variables, Insured-Insurer Variables, and Economic Variables. For identification variables, the uniqueness of IDs was verified, with duplicates or incorrect values removed, considering that some identifiers may repeat across periods due to the longitudinal structure of the dataset13. For example, the variables ID_policy and ID_insured were merged to create a unique identifier.
Regarding Time Variables, dates were standardized to the ISO 8601 format and validated to ensure temporal consistency. It was verified that start dates always preceded end dates and that policyholders’ enrollment dates adhered to the logical order concerning policy creation dates. Missing values in end dates were interpreted as active policies or insured individuals. Variables like exposure_time and seniority_insured were also reviewed to ensure consistency, to confirm that their values were reasonable and within expected ranges.
The Insured-Insurer Variables were checked to ensure that categorical assignments were correct, such as in type_policy, where group policies and their corresponding subcategories were verified as properly classified. For variables like age and gender, ranges and values were reviewed to prevent entry errors, such as negative ages or invalid values. Lastly, in the economic variable subgroup, it was ensured that no monetary variables had negative values and that metrics for medical services (n_medical_services) were consistent with established parameters.
Area-based contextual variables
The area-based contextual variables group includes four main subgroups: (i) Insurance Penetration, Population Density and Habitat Size, (ii) Economic Environment, (iii) Educational Environment and (iv) Climatic Environment. These variables were derived using georeferenced postal codes, which were validated against the official geographic boundaries provided by the INE. Invalid postal codes (e.g. 99999 or 00000) were excluded from the process of deriving the new area-based contextual variables to ensure data quality. However, the original (individual) variables were preserved in their entirety, including entries with invalid postal codes, for potential reference or future analysis.
In the first subgroup (Insurance Penetration, Population Density and Habitat Size), variables such as n_insured_pc and n_insured_prov were checked to confirm that municipal-level totals did not exceed those of their respective provinces. Furthermore, concentration indices (IICIMUN and IICIPROV) were checked to ensure that there were no negative values.
For variables in the Economic Environment and Educational Environment subgroups, correct percentile assignments between [1-100] were ensured, based on population data by postal code. For example, educational variables such as C_IE_P and C_GE_S were calculated using disaggregated educational population data by postal code and any inconsistencies in values were corrected.
Finally, Climatic variables were classified into groups based on postal codes. Erroneous postal codes were not assigned to any climatic category, thereby preserving the integrity of this variable subgroup.
Usage Notes
The database13 described in this document, which includes both general initial individual variables and an expanded set of area-based contextual variables (economic, demographic, educational and climatic), offers opportunities for multiple lines of research and professional-level studies.
The first set of studies could focus on the financial analysis of traditional variables (see Table 1). A key performance indicator (KPI) in the insurance sector, the loss ratio, can be defined and utilized. This ratio indicates the percentage of premiums consumed by claims, allowing for the segmentation of the portfolio by policy type, product type, gender, age group, distribution channel and the other factors. The aim of this analysis is to identify the most profitable segments and target these groups with customized marketing actions. All these analyses can be efficiently performed using an interactive dashboard, enabling dynamic data visualization and segmentation.
Another area of study could focus on situating the dataset13 within a socioeconomic context. This approach could explore whether policies are more often purchased in larger habitats or if they are associated with higher income levels and advanced educational attainment. For income and education levels, the dataset13 allows for both categorical and numerical analysis, given that each policy is ranked within income and education percentiles for both the general Spanish population and the insurance company’s own portfolio. Additionally, the loss ratio KPI can be applied here to assess claim severity across different area-based contextual socioeconomic percentiles. The used of percentiles allows quartiles or broader groupings to be easily obtained, such as dividing the population into four major segments in order to identify trends and patterns across larger demographic clusters.
The climate context has become an increasingly relevant variable and is closely linked to healthcare expenditure levels25. In our study, we divide the dataset13 into six regions, providing a more granular breakdown of territorial characteristics than classic studies such as those based on Köppen-Geiger maps26, which focus on larger territorial scales. This regional division allows us to explore potential climate-based relationships between each climatological zone and any variable of interest.
All variables described in this document, whether numerical or categorical, are open to various statistical analyses. Variables such as claims or premium amounts can be analyzed in relation to other factors. For these explorations, traditional models like linear and logistic regression are applicable, alongside more complex techniques such as decision trees, support vector machines and artificial neural networks. This dataset13 can serve as a teaching resource for actuarial and economics students, allowing them to explore and compare different pricing strategies. It also offers trainers a tool for designing practical challenges to evaluate students’ proficiency in managing health insurance operations, especially by segmenting the data for targeted case studies.
The study blocks are designed not only for research analysis but also for practical and professional application. This dataset13 can be utilized by an insurance company aiming to enter the health sector but lacking historical data to establish a pricing policy. Assuming that their future insured population will exhibit similar behaviors to those in our dataset13, a company could begin its operations with these data as a baseline. Over time, by gradually incorporating its own claims experience and potentially using credibility theory, the company could refine its pricing model year by year.
Lastly, in addition to the analytical applications described above, the dataset13 also enables specific operational and longitudinal analyses. First, the stable encrypted identifier allows the same individual to be followed across different policy renewals and claim events over the 2017-2019 period. This makes it possible to determine whether a policyholder generated claims in multiple years or only once, or whether characteristics such as product type or risk category changed over time. Second, lapse behavior can be analyzed by comparing the portfolio composition at the beginning of each year, allowing the computation of lapse rates across different population segments. Third, the dataset supports segmentation strategies based on clustering methods (e.g., k-means or hierarchical clustering) that combine individual-level attributes and area-based contextual variables to form groups with similar characteristics for pricing, retention or targeting purposes.
Although the dataset13 offers multiple research and professional applications, it is not without limitations. One such limitation concerns the temporal scope: the dataset13 only spans a relatively short period (2017-2019). However, this horizon is consistent with, and in many cases exceeds, the temporal scope of similar contributions in the insurance literature. For example, automobile insurance has been used covering a three-year period3, while other studies work with a single year of automobile insurance data27 or a one-year life insurance dataset that does not include area-based contextual variables4. In the health insurance field, recent studies employ datasets of even shorter duration, such as 18 months28 or a single-year29,30,31.
A second limitation concerns the dataset’s geographic scope, which is restricted to a single insurer operating in Spain. This focus is, however, fully aligned with established practice in insurance research, where data are almost always country- and company-specific due to differences in regulation, underwriting frameworks and market structures. Comparable datasets are drawn from a single national context, whether in Spain3,27, the United States29,30 or Brazil28. However, this limitation, it does not preclude the dataset’s relevance for international research. Insurance risks often display broadly comparable patterns across markets, making single-country datasets widely useful to the academic community.
Data availability
The dataset is available at Mendeley Data in https://doi.org/10.17632/386vmj2tbk13.
Code availability
The code used to perform the matching between census sections and postal codes was implemented in R (v4.4.2) using the sc2sc package (v0.0.1-14). Some illustrative examples of the code can be provided by the authors upon request.
References
Rothschild, M. & Stiglitz, J. Equilibrium in competitive insurance markets: an essay on the economics of imperfect information, 257–280, https://doi.org/10.1016/B978-0-12-214850-7.50024-3 (Academic Press, 1978).
Scanlon, D. P., Chernew, M., Swaminathan, S. & Lee, W. Competition in health insurance markets: Limitations of current measures for policy analysis. Medical Care Research and Review 63, 37–55, https://doi.org/10.1177/1077558706293834 (2006).
Segura-Gisbert, J., Lledó, J. & Pavía, J. M. Dataset of an actual motor vehicle insurance portfolio. European Actuarial Journal 1–13, https://doi.org/10.1007/s13385-024-00398-0 (2025).
Lledó, J. & Pavía, J. M. Dataset of an actual life-risk insurance portfolio. Data in Brief 45, 108655, https://doi.org/10.1016/j.dib.2022.108655 (2022).
Capgemini World property and casualty insurance report 2024. Tech. Rep., Capgemini Research Institute (2024).
Cardon, J. H. & Hendel, I. Asymmetric information in health insurance: evidence from the national medical expenditure survey. The RAND Journal of Economics 32, https://doi.org/10.2307/2696362 (2001).
Chiappori, P. & Salanie, B. Testing for asymmetric information in insurance markets. Journal of Political Economy 108, https://doi.org/10.1086/262111 (2000).
Valdez, S. Revisiting early structural findings of asymmetric information’s non-existence in health insurance. Economic Letters 207, 110016, https://doi.org/10.1016/j.econlet.2021.110016 (2021).
So, B., Boucher, J.-P. & Valdez, E. A. Synthetic dataset generation of driver telematics. Risks 9, 58, https://doi.org/10.3390/risks9040058 (2021).
Pérez, V. & Pavía, J. M. sc2sc: Spatial Transfer of Statistics among Spanish Census Sections, R package version 0.0.1-18, https://doi.org/10.32614/CRAN.package.sc2sc (2025).
Pérez, V. & Pavía, J. M. Automating the transfer of data between census sections and postal codes areas over time. an application to spain. Journal of Regional Research https://doi.org/10.38191/iirr-jorr.24.057 (2024).
INE. Instituto nacional de estadística. Atlas de distribución de renta de los hogares (ADRH), Accessed: 2024-11-20, https://www.ine.es/metodologia/metodologia_adrh.pdf (2024).
Lledó, J., Espinosa, P. & Pérez, V. Dataset of health insurance portfolio. Mendeley Data, https://doi.org/10.17632/386vmj2tbk (2025).
Espinosa, P. & Pavía, J. M. A partitioning of spain into climate areas at the census section level: assessing temporal dynamics and spatial coherence. Under-review (2025).
Pizarro, M., Hernangómez, D. & Fernández-Avilés, G. climaemet: Climate AEMET Tools, https://doi.org/10.5281/zenodo.5205573 (2021).
Royé, D. & Serrano, R. Introducción a los SIG con R (Prensas de la Universidad de Zaragoza, 2019).
Bilonick, R. An introduction to applied geostatistics. Technometrics 33, 483–485, https://doi.org/10.1080/00401706.1991.10484886 (1991).
Chong, B. K-means clustering algorithm: a brief review. Academic Journal of Computing & Information Science 4, 37–40, https://doi.org/10.25236/AJCIS.2021.040506 (2021).
Briggs, W. Statistical methods in the atmospheric sciences. Journal of the American Statistical Association 102, 380–380, https://doi.org/10.1198/jasa.2007.s163 (2007).
Wilks, D. S. Statistical methods in the atmospheric sciences (Academic Press, 2011).
Lledó, J., Pavía, J. M. & Espinosa, P. Impact of income level on life insurance pricing and reserving: evidence from spain. Applied Economics Letters 0, 1–5, https://doi.org/10.1080/13504851.2025.2534509 (2025).
Timonin, S., Adair, T., Welsh, J. & Canudas-Romo, V. Socioeconomic inequalities in life expectancy in australia, 2013–22: an ecological study of trends and contributions of causes of death. The Lancet Public Health 10, e599–e608, https://doi.org/10.1016/S2468-2667(25)00138-0 (2025).
Regulation (eu) 2016/679 of the european parliament and of the council of 27 april 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing directive 95/46/ec (general data protection regulation). Official Journal of the European Union, L 119, 4 May 2016, pp. 1–88, https://eur-lex.europa.eu/eli/reg/2016/679/oj (2016).
Iso 8601: Data elements and interchange formats – information interchange – representation of dates and times. Tech. Rep., International Organization for Standardization, Geneva, Switzerland (2019).
Vilhelmsson, A. Navigating the climate-health nexus: linking health data with climate data to advance public health interventions. BMC Global Public Health 2, https://doi.org/10.1186/s44263-024-00109-7 (2024).
Peel, M. C., Finlayson, B. L. & McMahon, T. A. Updated world map of the Köppen-Geiger climate classification. Hydrology and Earth System Sciences 11, 1633–1644, https://doi.org/10.5194/hess-11-1633-2007 (2007).
Ayuso, M., Guillen, M. & Nielsen, J. P. Improving automobile insurance ratemaking using telematics: incorporating mileage and driver behaviour data. Transportation 46, 735–752, https://doi.org/10.1007/s11116-018-9890-7 (2019).
Figueredo, V., Appel, A. P., Moyano, L. G., Ito, M. & Santos, C. Revealing physicians referrals from health insurance claims data. Big Data Research 13, 3–10, https://doi.org/10.1016/j.bdr.2018.03.002 (2018).
Dahlen, A. & Charu, V. Analysis of sampling bias in large health care claims databases. JAMA Network Open 6, e2249804, https://doi.org/10.1001/jamanetworkopen.2022.49804 (2023).
Baser, O., Samayoa, G., Yapar, N., Baser, E. & Mete, F. Use of open claims vs closed claims in health outcomes research. Journal of Health Economics and Outcomes Research 10, 44–52, https://doi.org/10.36469/001c.87538 (2023).
Lopez Cruz, B., Rosales, D., Chuang, J., Cruz, R. & Huang, J. Cross-sectional evaluation of health insurance knowledge and self-efficacy in adolescents and young adults with inflammatory bowel disease. The Journal of Pediatrics 275, 114244, https://doi.org/10.1016/j.jpeds.2024.114244 (2024).
Acknowledgements
This study was supported by Generalitat Valenciana (CIGE/2023/7 and CIACO/2023/031, Conselleria de Educación, Cultura, Universidades y Empleo) and Ministerio de Ciencia e Innovación (grant PID2021-128228NB-I00). We would like to express our special thanks to the editor and the anonymous reviewers for their comments and suggestions, which have greatly contributed to improving this paper.
Author information
Authors and Affiliations
Contributions
Conceptualization, J.L. and P.E.; methodology, P.E. and V.P.; software, P.E. and V.P.; validation, J.L. and P.E.; formal analysis, J.L. and P.E.; investigation, J.L. and V.P.; resources, J.L. and V.P.; data curation, P.E.; writing–original draft preparation, V.P. and P.E.; writing–review and editing, J.L. and V.P.; visualization, V.P.; supervision, J.L. and V.P.; project administration, J.L. and P.E.; funding acquisition, J.L. and V.P. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lledó, J., Espinosa, P. & Pérez, V. A dataset for health insurance analysis: Integrating individual and area-based contextual variables. Sci Data 13, 54 (2026). https://doi.org/10.1038/s41597-025-06372-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-06372-z
