
Abstract
Control of vehicle platoon can effectively reduce the traffic accidents caused by fatigue driving and misoperation, reduce air resistance by eliminating the inter-vehicle gap which will effectively reduce fuel consumption and exhaust emissions. A hierarchical control scheme for vehicle platoons is proposed in this paper. Considering safety, consistency, and passengers’ comfort, a synchronous distributed model predictive controller is designed as an upper-level controller, in which a constraint guaranteeing string stability is introduced into the involved local optimization problem so as to guarantee that the inter-vehicle gap error gradually attenuates as it propagates downstream. A terminal equality constraint is added to guarantee asymptotic consensus of vehicle platoons. By constructing the vehicle inverse longitudinal dynamics model, a lower-level control scheme with feedforward and feedback controllers is designed to adjust the throttle angle and brake pressure of vehicles. A PID is used as the feedback controller to eliminate the influence of unmodeled dynamics and uncertainties. Finally, the performance of longitudinal tracking with the proposed control scheme is validated by joint simulations with PreScan, CarSim, and Simulink.
Similar content being viewed by others
Introduction
Control of vehicle platoon has significant social and economic value for improving vehicle driving safety, energy-saving, and emission reduction. It can reduce the labor intensity of drivers, avoid traffic accidents caused by drivers’ misoperation or illegal operation1. Control of vehicle platoon can effectively reduce the inter-vehicle gap, so that the following vehicles will enter the wake region under the barrier of the leader vehicle. That is, vehicle platoon can reduce the air resistance of the vehicle at a high speed, and reduce fuel consumption and exhaust emissions2.
A hierarchical control strategies for vehicle platoon is proposed in3,4, in which the upper-level control method plans the motion and path, and the lower-level control method executes the commands of upper-level control method. In5, a hierarchical control structure for vehicle platoon is proposed, where the upper-level control method performs distributed control, and the lower-level control method adopts the feedback linearization technology to achieve drive and brake control. In6, a hierarchical control structure is adopted for vehicle platoons with actuator delays and non-ideal communication conditions. The upper-level distributed proportional controller guarantees string stability, and the lower-level adopts the inverse model-based feedforward control to regulate the driving and braking of vehicles. In7, the upper-level utilizes model predictive control (MPC), in which a multi-vehicle collision avoidance system is proposed to minimize the risk of collision. In8, considering the complexity of network-connected vehicle platoon, a simplified model of vehicles is utilized to design the upper-level controller to achieve string stability, reduce fuel consumption, and collision avoidance, etc. In the lower-level, an adaptive control strategy is implemented to regulate engine torque and switching gears. In9, an adaptive sliding mode control method is chosen as the lower-level controller so as to guarantee tracking performance in the case of disturbances. In10, a hierarchical personalized adaptive cruise controller is proposed, where the upper-level controller adopts MPC, and the lower-level controller adopts the combination of feedforward and feedback. Currently, the research on hierarchical control structure of vehicle platoons mainly focuses on exploring the upper-level strategies, such as the influence of vehicle platoon model, inter-vehicle gap strategy, communication topology, communication time delay, and string stability, etc11. However, the research on the lower-level control strategies of vehicle platoons is still relatively limited. The lower-level controllers are designed often utilizing simple models and inverse engine characteristic maps to “control” the vehicle throttle angle and brake pressure12. In this paper, a lower-level controller with the feedforward and feedback control strategies is proposed, where the feedforward controller is designed as well based on an inverse longitudinal dynamics model of vehicles, and the feedback controller eliminates the influence of model uncertainties and unmodeled dynamics by adopting a PID controller.
Model predictive control is widely applied to Advanced Driver-Assistance Systems since it can generally provide better performances than standard control methods13. Distributed model predictive control (DMPC) is a kind of model predictive control, which can predict the future control sequence as the future estimate of each vehicle to improve the control effect of vehicle platoons14. In-depth research on distributed mode predictive control has been conducted to design corresponding coordination strategies according to different performance requirements, which involves coupling constraints of the system, stability, security, and feasibility analysis, etc15. In general, DMPC converts the control problem into an optimization problem so as to obtain control actions accordingly. In16, a DMPC algorithm based on Nash optimality is proposed, which achieves better performance by exchanging information (communication) during the optimization process. In17, a distributed economic MPC strategy is constructed to minimize the fuel consumption of vehicle platoons. In18, a DMPC method is desigen for the vehicle platoon under unidirectional communication topologies. In19, a DMPC algorithm is adopted for the vehicle platoon under switching communication topologies. To ensure asymptotic stability, a terminal equality constraint is added, which enforces the terminal state of each vehicle to be equal to the average state of its neighbours18,19,20,21,22. Note that some investigations also use the terminal inequality constraint to analyze the asymptotic stability of DMPC23,24,25,26. Though the terminal inequality constraint is easier to implement numerically compared to the terminal equality constraint, there are many highly efficient methods for solving optimization problem with terminal equality constraints27.
String stability of vehicle platoons must also be considered28. Recently, research on string stability of vehicle platoons is mainly focused on the frequency domain29,30. However, DMPC algorithm of vehicle platoons is difficult to guarantee the constraint satisfaction in the frequency domain; moreover, converting the frequency domain analysis of string stability into the time domain is difficult in general31. String stability of a platoon of vehicles with nonlinear dynamics by using the DMPC method is first proposed in27, which transforms string stability requirement into an inequality constraint. And sufficient conditions are given to ensure string stability for both leader−follower communication topology and predecessor−follower communication topology. In32, a new DMPC scheme is designed for the heterogeneous vehicle platoon with input and state constraints to ensure the closed-loop stability and \(\gamma \)-gain string stability (a new string stability concept). A distributed economic MPC algorithm is proposed in33 to ensure asymptotic stability, and to achieve \(\gamma \)-gain string stability simultaneously.
This paper proposes a synchronous DMPC algorithm with guaranteed string stability as the upper-level controller for vehicle platoons. Each vehicle constructs a local optimization problem based on communication topology, and solves its local optimization problem synchronously to obtain a feasible solution. Combining with the proposed lower-level control strategy, the string stability and consensus of vehicle platoons are verified by the joint simulation with PreScan, CarSim and Simulink. The main highlights of this paper are listed below:
-
1)
In this paper, a synchronous DMPC algorithm of a vehicle platoon is proposed, and the string stability with predecessor-leader following (PLF) communication topology is investigated. By adding an inequality constraint to the optimization problem, the string stability of vehicle platoons is guaranteed. In addition, a terminal equality constraint is added to guarantee the asymptotic consensus of vehicle platoons.
-
2)
Considering the real scenarios of the vehicle platoon, the desired control input determined by the upper-level DMPC cannot be directly implemented on the real vehicle. Therefore, a feedforward and feedback control strategy is designed. The feedforward controller is based on the vehicle inverse longitudinal dynamics model, which transforms the desired control input into throttle angle and brake pressure, and the feedback controller is designed to eliminate the influence of model uncertainties and unmodeled dynamics.
The remainder of the paper is structured below. Section II sets up the problem, including communication topology, vehicle dynamics, vehicle platoon modeling, control objective. Section III presents the hierarchical control structure for the vehicle platoon, which includes an upper-level distributed model predictive control, and a lower-level feedforward and feedback control strategies. Section IV is the joint simulation with PreScan, CarSim and Simulink. Section V ends the paper with conclusions.
Notation: Denote \({N_{\left[ {{k_1},\,{k_2}} \right] }} = \left\{ {{k_1},\,{k_1} + 1,\,\cdots ,\;{k_2}} \right\} \), both \({k_1}\) and \({k_2}\) are integer, \({k_2} > {k_1}\). Define \({\left\| {\vartheta (t)} \right\| _2}\) as the 2-norm of the function \({\vartheta (t)}\), i.e., \(\mathop {\mathrm{{lim}}}\limits _{t \rightarrow \infty } \,\vartheta (t) = 0\).
Vehicle platoon and problem setup
This section first introduces the PLF communication topology, then the vehicle and vehicle platoon models. Since the focus of the paper is the longitudinal control of a platoon, the vehicle dynamics model is simplified below:
-
1)
Only the longitudinal motion of vehicles is studied, i.e., the lateral and vertical motion of vehicles are ignored.
-
2)
Neither the slippery roads nor vehicle tires slipping are taken into account.
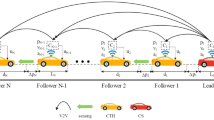
Communication topology
The vehicle in the platoon needs to know itself, and its neighbouring vehicles’ information. The vehicle obtains its status information such as position, velocity, etc., through onboard sensors or state estimation. Through V2V communication, a connection is established with neighbouring vehicles in the platoon.
A vehicle platoon with one leader vehicle and M following vehicles, which is driving in a straight line. The PLF communication topology is employed, a vehicle platoon under the PLF communication topology is illustrated in Fig. 1.

The structure of the PLF communication topology.
Vehicle dynamics
The ith vehicle’s longitudinal dynamics is formulated by a \(3^{rd}\) model34
where \(i \in {N_{\left[ {1,\,M} \right] }} \), \({q_i}\) is the position of the \( ith \) vehicle; \({q_i}\) is the velocity of the \( ith \) vehicle; \({{T_i}}\) and \({{T_{des,i}}}\) represent the actual and desired drive/braking torque, respectively; \({C_{d,i}}\) is the aerodynamic drag coefficient; \(\mu _i\) is the ambient air density; \({m_i}\) is the vehicle mass; \({{\bar{A}}_i}\) is the frontal area; \({{{\sigma } _i}}\) is the time constants of longitudinal dynamics; \({{\eta _{T,i}}}\) is the mechanical efficiency of driveline; \({{r_{eff,i}}}\) is the effective rolling radius; \(f_{i}\) is the rolling resistance coefficient; g is the gravity acceleration.
Assume that the aforementioned parameters are known, then the nonlinear control law28,35 is designed accordingly
Combining (1) and (2), the linear vehicle model can be obtained
where \({a_i}\) is the acceleration; \( {{a_{des,i}}}\) the desired acceleration, i.e., the control input.
For simplicity, the following assumptions are made in the paper.
Assumption 1
For any vehicle \(i,\,i \in {N_{\left[ {1,\,M} \right] }}\), its position \(q_i\), velocity \(v_i\), and acceleration \(a_i\) can be measured instantaneously.
Assumption 2
Only the longitudinal motion of the vehicle is studied, i.e., the lateral and vertical motion of the vehicle are ignored.
Assumption 3
Each vehicle shares a synchronized clock, i.e., the onboard controllers are synchronized.
Remark 1
Since the knowledge of states and parameters plays a crucial role in the controller design of vehicles36, state estimation and sensor fusion of vehicles in the platoon will be our future research direction.
Vehicle platoon modeling
Suppose that the leader vehicle is uncontrolled, cf., its position and velocity are given as \(\left( {{q_0}(t),{v_0}(t)} \right) \). For following vehicle i, \(i \in 1,\,2,\, \cdots ,\,M,\) describe its position and velocity as \(\left( {q_i}(t),{v_i}(t)\right) \), and define the reference position and velocity are
where \({q_ {{{des}}}} \) is the desired inter-vehicle gap.
In this paper, the constant distance policy37 is adopted
with \(q_0>0\).
According to the current position and reference position of the vehicle, the state error is denoted as
Define \({\zeta _i} = {{[{\Delta q_{i}}\quad {\Delta v_{i}}\quad {a_i}]}^T}\), \(u_i=a_{des,i}\), the system state space equation is
where
Remark 2
The leader vehicle’s acceleration of \({a_0}(t)\) is a sort of “reference” for the vehicle \(i \ge 1\) since the value of \({a_0}\) is already known a priori by vehicle to vehicle communication.
Objective of vehicle platoon control
Definition 1
27 (Predecessor-leader following string stability): Assume that at some time instant t, if the desired velocity of the leader vehicle changes, the state of (5) asymptotically converges to its equilibrium, and the inter-vehicle gap error of following vehicles satisfies accordingly
and
Note that for any vehicle \(i\,\), if there exists a constant \({\lambda _i} \in (0,1)\), such that (7) and (8) are satisfied, then the vehicle platoon is string stable as shown in Fig. 2.

Vehicle platoons with string stability.
The objectives of the control of a platoon are summarized as follows:
The inter-vehicle gap should maintain a desired safe distance, and the velocity of the vehicles should keep the same:
Furthermore, to guarantee that the vehicle platoon maintains steady formation driving, the following constraints should be satisfied.
-
(1)
Minimum safety distance: The distance between any front and rear vehicles should maintain a minimum safe distance to avoid collisions,
$$\begin{aligned} {\Delta q_{i,\textrm{mi}}} \le {\Delta q_{i}}(t)\le {\Delta q_{i,\textrm{ma}}},\quad \forall t \ge 0 \end{aligned}$$(10)where \({\Delta q_{i,\textrm{ma}}}\) and \({\Delta q_{i,\textrm{mi}}}\) are the maximum and minimum inter-vehicle gap error.
-
(2)
Consistency: The relative velocity deviation of vehicles has to be satisfied,
$$\begin{aligned} {\Delta v_{i,\textrm{mi}}} \le {\Delta v_{i}}(t)\le {\Delta v_{i,\textrm{ma}}},\quad \forall t \ge 0 \end{aligned}$$(11)where \({\Delta v_{i,\textrm{mi}}}\) and \({\Delta v_{i,\textrm{ma}}}\) are the minimum and maximum velocity errors.
-
(3)
Passenger comfort: During acceleration or deceleration, the control input needs to be within an admissible region:
$$\begin{aligned} {u_{i,\textrm{mi}}} \le {u_i}(t) \le {u_{i,\textrm{ma}}},\quad \forall t \ge 0 \end{aligned}$$(12)where \(u_{i,\textrm{mi}}\) and \(u_{i,\textrm{ma}}\) are the allowed minimum and maximum control input.
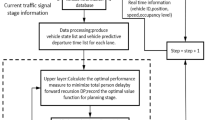
Controller design
A hierarchical control framework is employed to achieve the vehicle platoon driving. The hierarchical control framework is illustrated in Fig. 3, where an upper-level DMPC is designed to achieve vehicle platoon control. A feedforward controller in the lower-level controller adopts feedback linearization technology to realize the adjustment of the driving and braking, and a PID controller to eliminate the influence of unmodeled dynamics and uncertainties. In Fig. 3\(q_j\) is the position of adjacent vehicles; \(v_j\) is the velocity of adjacent vehicles; \(p_{bdes,i}\) is the desired brake pressure; \(\alpha _{des,i}\) is the desired throttle angle.

The framework of hierarchical control of the \(i^{th}\) vehicle.
DMPC algorithm with guaranteed string stability
Denote the prediction horizon as \(N_p\), sampling time \(T_s > 0\). The updated time for each vehicle is denoted as
where \(\delta \in {N_{ {\left[ {0,\,\infty } \right] }}}\).
For \(p \in {N_{ {\left[ {0,\,{N_p} - 1} \right] } }}\), define three types of control inputs sequences:
-
\(u_i^p\left( {p;{t_\delta }} \right) \): the predicted control input sequence;
-
\(u_i^*\left( {p;{t_\delta }} \right) \): the optimal control input sequence;
-
\({{{\hat{u}}}_i}\left( {p;{t_\delta }} \right) \): the assumed control input sequence;
Accordingly, define three types of output sequences:
-
\(y_i^p\left( {p;{t_\delta }} \right) \): the predicted output sequence;
-
\(y_i^*\left( {p;{t_\delta }} \right) \): the optimal output sequence;
-
\({{{\hat{y}}}_i}\left( {p;{t_\delta }} \right) \): the assumed output sequence, which is transmitted to neighboring vehicles through communication.
At time instant \({t_\delta }\), the maximum position deviation in the prediction horizon and the maximum position deviation within one sampling instant are defined as:
At time instant \({t_{\delta + 1}}\), the assumed control input sequence is:
For each vehicle \(i\ge 1\), the sequence of control inputs is defined at time instant \(t_\delta \)
First, a local optimization problem at time instant \({t_0}\) is designed.
Problem 0
where
For any \({t_\delta }>{t_0}\), a new optimization problem is constructed
Problem 1
where
and \({Q_i}\), \({F_i}\), \({G_i}\), \({R_i}\) and \({W_i}\) are weighting matrices. Note that \(\Vert x_i\Vert _{P_i}^2 = {x_i^T{P_i}{x_i}}\) with \({P_i}\in {\mathbb {R}^{n\times n}}\) and \({P_i}>0\) for a vector \(x_i\in {\mathbb {R}^n}\). Since the leader vehicle is uncontrolled, the term \({G_1}=0\). The term \({\Vert {( {y_i^p( {p;{t_\delta }} ) - {{{\hat{y}}}_i}( {p;{t_\delta }})} )} \Vert _{{F_i}}^2}\) is the penalty of the error of the sequence of the \(i^{th}\) vehicle and its assumed output sequence; the term \({\Vert {( {y_i^p ( {p;{t_\delta }} ) - {{{\hat{y}}}_{i - 1}}( {p;{t_\delta }})} )} \Vert _{{G_i}}^2}\) is the penalty between the predicted and the assumed output sequence from the communication vehicle; the terms \({\varepsilon _i}, {c_i}, {\rho _i}\in (0,1)\) and \({\varpi _i}(\delta )\) are the parameters to be determined to ensure string stability of vehicle platoons.
Constraints (17d), (17e), together with (18d) will guarantee string stability; (17f), (17g), (18e), (18f), (17h) and (18g) are the constraints; (17i) and (18h) are the terminal equality constraint to ensure asymptotic consensus.
The distributed model predictive control scheme to ensure string stability is as Algorithm 1.

Remark 3
A synchronous distributed model prediction controller is presented for the vehicle platoon, where the following vehicle solves its optimization problem synchronously. Since each vehicle does not know the predicted output sequence of other vehicles, the assumed output sequences are used to replace the actual predicted output sequences in the optimization problems.
Remark 4
A qualitative analysis of the performance of longitudinal tracking with the proposed control scheme is performed in this paper, whereas other important issues including communication delay and packet loss, parameter uncertainty, and measurement noise of sensors will be our future research direction.
Asymptotic consensus of DMPC
Theorem 1
For Algorithm 1, if weight values of Problem 1 satisfy
with \({G_1}=0\). Then, a vehicle platoon under Algorithm 1 is asymptotic consensus.
Proof
Define the sum of objective function as a candidate Lyapunov function
At the time instant \({t_\delta }\), the sum of objective function is
Similarly, at the time instant \({t_{\delta + 1}}\), the sum of the objective function is
At the time instant \({t_{\delta + 1}}\), since \(u_i^p\left( {p;{t_{\delta + 1}}} \right) = {{{\hat{u}}}_i}\left( {p;{t_{\delta + 1}}} \right) \) is a feasible control sequence (but suboptimal) for Problem 1, the sum of objective function is bounded
According to (16) and (19), one has
In terms of (24) and (27), the following inequality is yielded
where
Due to the triangle inequality,
Due to \(G_1 = 0\), (29) is bounded by
Since \({F_i} > {G_{i + 1}}\),
Therefore, the asymptotic consensus of Algorithm 1 is guaranteed38. \(\square \)
String stability
Remark 5
If a vehicle platoon’s communication network is exactly reliable, i.e. there is no communication delay and no data packet loss, string stability with the leader-follower (LF) communication topology is examined. Suppose there exists a velocity change for the leader vehicle, according to (6), if all vehicles are homogeneous, i.e., \({{\tilde{A}}_1} = {{\tilde{A}}_2} = \cdots = {{\tilde{A}}_M}\), \({{\tilde{B}}_1} = {{\tilde{B}}_2} = \cdots = {{\tilde{B}}_M}\), then the inter-vehicle gap error \({\Delta q_{i}}\) will not change as it propagates downstream. Otherwise, if all vehicles are heterogeneous, the inter-vehicle gap error \({\Delta q_{i}}\) might change as it propagates downstream.
Lemma 1
Suppose that (17d) is satisfied at the initial time instant \({t_0}\), then,
where
Proof
The position deviation of the \(i -1\) and i vehicles is given by solving Problem 0 at the initial time instant, i.e.,
and
where \(p \in {N_{ {\left[ {0,\,{N_p} - 1} \right] }}}\), then (31) holds by applying the lower bound on \({\left| {\Delta q_{i-1}^*\left( {p;{t_0}} \right) } \right| }\), and the upper bound on \({\left| {\Delta q_{i}^*\left( {p ;{t_0}} \right) } \right| }\). \(\square \)
Theorem 2
At the initial time instant, if the local optimization problem of the following vehicle has a feasible solution, and the parameters satisfy:
where \(i \in {N_{ {\left[ {{2},\,{M}} \right] }}}\), then string stability of vehicle platoons with the predecessor-follower communication topology is guaranteed.
Proof
At the time instant \({t_1}\), by using the triangular inequality, the position deviation of adjacent vehicles satisfies
According to the string stability constraint (18d), one has
Then, the following inequality can be concluded
Similarly, by using the triangular inequality, the \({(i-1)}^{th}\) vehicle satisfies
According to the definition of the assumed trajectory, and (31), the following inequality is yielded
Combining (38), (39) and (40), the position deviation of adjacent vehicles at the time instant \({t_1}\) can be obtained
In terms of \({\left| {\Delta q_{i}^*\left( {p;{t_1}} \right) } \right| _{\infty ,T_s }} \le {\left| {\Delta q_{i}^*\left( {p ;{t_1}} \right) } \right| _\infty }\), (41) can be rewritten as
In terms of (38) and (39), for each vehicle i at the time instant \({t_2}\),
Combining constraints (18d), (20) and (41),
Similarly to (42), the position deviation of adjacent vehicles at time instant \({t_2}\) can be obtained as
Base on inductive reasoning, the position deviation at the time instant \({t_\delta }\) is
To guarantee string stability with the predecessor-follower communication topology, i.e.,
the parameters can be chosen such that
Setting \({{\varpi _i}(\hbar )}={\varpi _i}\), \({{\varpi _i}} \in {(0,1)}\), using Taylor’s formula, (48) can be rewritten as
That is, the string stability of vehicle platoons is guaranteed, if
The values of \(\left\{ {{\rho _i},\,{\varpi _{i}},\,{\varpi _{i-1}}} \right\} \) that satisfy (50) are shown in Fig. 4. \(\square \)

The selection of parameter values \(\left\{ {{\rho _i},\,{\varpi _{i}},\,{\varpi _{i-1}}} \right\} \).
Corollary 1
At the initial time instant, if the local optimization problem of the following vehicle has a feasible solution, and the parameters satisfy:
where \(i \in {N_{ {\left[ {{2},\,{M}} \right] }}} \), then string stability of vehicle platoons with the LF communication topology is guaranteed.
Since the proof of Corollary 1 is similar to the proof of Theorem 2, it is omitted.
Theorem 3
Under Algorithm 1, if the local optimization problem of the following vehicle has a feasible solution at the initial time instant, and the parameters satisfy (35) and (51) simultaneously, then string stability of vehicle platoons with the PLF communication topology is guaranteed.
The proof of Theorem 3 is omitted since it can be obtained directly by using Theorem 2 and Corollary 1.
The lower-level controller
The lower-level feedforward and feedback control strategy first transforms desired acceleration into the desired throttle angle and brake pressure through an inverse longitudinal dynamics model of vehicles, and then eliminates the influence of unmodeled dynamics and uncertainties by a PID controller. The diagram of the lower-level feedforward and feedback control strategy is illustrated in Fig. 5.

The diagram of the lower-level controller of the \(i^{th}\) vehicle.
1) In the process of acceleration: The desired acceleration is calculated39, i.e.,
where \({F_{x,i}}\) is the driving force of vehicles.
The engine provides a longitudinal force for the driving wheels, i.e.,
where \({i_{g,i}}\) is the transmission gear ratio, and \({i_{o,i}}\) is the ratio of final gear.
Considering (52) and (53), the desired engine torque can be calculated
According to the engine torque \({T_{des,i}}\), the engine torque characteristic map of the F-Class vehicle from CarSim software shown in Fig. 6, and the engine speed \({w_{e,i}}\), the desired throttle angle can be obtained by the inverse look-up table method10, i.e.,
and the term \(f_i^{-1} :( {{T_{des,i}}} ) \times ( {{w_{e,i}}} ) \rightarrow ( {{\alpha _{des,i}}} )\) represents a mapping of the \(i^{th}\) vehicle.

Engine torque map of the ith vehicle.
2) In the process of braking: The vehicle dynamics in the process of braking is as follows39:
where \({F_{b,i}}\) represents the braking force of the vehicle. The desired braking force satisfy40,
where \({K_{s,i}}\) is the braking coefficient, and
the term \({p_{b,i}}\) is the braking pressure, \({T_{bf,i}}\) and \({T_{br,i}}\) are the braking torques of the front and rear wheels, respectively.
According to (57), the relationship between braking pressure and acceleration is
After obtaining the current desired throttle angle and braking pressure, a PID controller is used to correct the error, i.e.,
where \({K_{P}}\), \({K_{I}}\), and \({K_{D}}\) are parameters of the PID controller.
3) Throttle-brake switching logic: To improve fuel economy and passenger comfort, and to avoid the frequent switching of drive and brake, a threshold-based throttle switching strategy is implemented in this paper10. First, the vehicle velocity \(v_{i,{(0)}}\) and maximum acceleration \(a_{i,{(0)}}\) without throttle angle and brake pressure are calibrated, which is shown in Table 1.
A throttle-brake switching logic is designed according to Table 1, which is shown in Fig. 7 as well. Set the transition belt with the width of 2h, where \(h = 0.1\)41.
-
(i)
When the desired acceleration \({a_{des,i}}\) is above upper switching line, i.e., \({a_{des,i}} \ge {a_{i{(0)}}} + h\), the throttle control is triggered;
-
(ii)
When the desired acceleration \({a_{des,i}}\) is below lower switching line, i.e., \({a_{des,i}} \le {a_{i,{(0)}}} - h\), the brake control is launched;
-
(iii)
When the desired acceleration \({a_{des,i}}\) is inside the transition belt, i.e., \({a_{i,{(0)}}} - h \le {a_{des,i}} \le {a_{i,{(0)}}} + h\), neither throttle control nor brake control is carried out.

Coasting simulation curve of the ith vehicle.
Remark 6
The vehicle driving equation (52) and the brake equation (56) are consistent according to (1).
Simulation and result analysis
A vehicle platoon consists of five vehicles, i.e., one leader vehicle, and four following vehicles. A joint simulation platform with PreScan, CarSim, and Simulink is constructed shown in Fig. 8, where Prescan provides the road environment information, CarSim provides the vehicle dynamics, and Simulink is employed to design and implement of the controller. All vehicle parameters in the joint simulation are the same except for the vehicle mass \({m _i} \), i.e., \({{C_{d,i}}}={C_{d}}\), \(\mu _i=\mu \), \({{\bar{A}}_i}={\bar{A}}\), \({{\sigma }_i} = {\sigma } \), \({\eta _{T,i}} = {\eta _{T}}\), \({r_{eff,i}}={r_{eff}}\), \(f_{i}=f\), \({i_{o,i}}={i_{o}}\), \({i_{g,i}}={i_{g}}\). In the joint simulation, the vehicle employs an eight-speed automatic transmission. Set \({m _0}=1820\,\textrm{kg}\), \({m _1}=1984\,\textrm{kg}\), \({m_2}=1942\,\textrm{kg}\), \({m _3}=1898\,\textrm{kg}\), \({m _4}=1865\,\textrm{kg}\). The parameter values of the F-Class vehicle from CarSim software are defined in Table 2, and the parameter values of the controller are provided in Table 3. The sampling time is chosen as \(T_s=0.2s\), and the prediction horizon is set as \(N_p=6\). In addition, choose the parameters of \(c_i =\varpi _i^{}\), \({\varepsilon _2}\mathrm{{ = }}{\rho _2}/\left( {1 + {c_2}} \right) \), \({\varepsilon _i} = ({\rho _i}*{\varepsilon _{i - 1}})/\left( {\left( {1 + {c_i}} \right) /\left( {1 - {c_{i - 1}}} \right) } \right) , i\in {N_{ {\left[ {{3},\,{M}} \right] }}}\).

The framework of the joint simulation platform.
In the joint simulation, a platoon with five vehicles is interconnected by the LF communication topology and PLF communication topology, respectively. A constant distance strategy is employed, i.e., \({q_{des}} = 15\textrm{m}\). The leader vehicle in the platoon is running along a given straight road. Set the initial feasible state of the vehicles as \([{\Delta q_{i}}\;{\Delta v_{i}}] = [0\;\,0]\), \(i=1,2,3,4\), respectively. When the leader vehicle accelerates, set the initial state of the leader vehicle as \({q_0}(t) = 100\textrm{m}\), \({v_0}(t) = 15\mathrm {m/s}\) and the desired velocity trajectory is given by
When the leader vehicle decelerates, set the initial state of the leader vehicle as \({q_0}(t) = 100\textrm{m}\), \({v_0}(t) = 20\mathrm {m/s}\) and the desired velocity trajectory is given by
The proposed DMPC algorithm with string stability constraints is implemented in Matlab. The joint simulation performance with the LF communication topology is shown in Figs. 9, 10, 11, 12, 13 and 14. For the PLF communication topology, the acceleration performance is shown in Figs. 15, 16, 17, 18 and 19, and deceleration performance is shown in Figs. 20, 21, 22, 23 and24.

Inter-vehicle gap errors for homogeneous vehicles under LF topology.

Velocity errors for homogeneous vehicles under LF topology.

Inter-vehicle gap errors for heterogeneous vehicles under LF topology.

Velocity errors for heterogeneous vehicles under LF topology.

Inter-vehicle gap errors with string stability constraints under LF topology.

Velocity errors with string stability constraints under LF topology.
For the LF communication topology, Figs. 9-10 show the inter-vehicle gap errors and velocity errors of homogeneous vehicle platoons. Figs. 11-12 show the inter-vehicle gap errors and velocity errors of heterogeneous vehicle platoons. It can be found that when the leader vehicle’s velocity changes, if all vehicles in the platoon are homogeneous, the inter-vehicle gap errors will not be amplified as it propagates downstream; while if all vehicles are heterogeneous, the inter-vehicle gap error will be amplified as it propagates downstream. Figs. 13-14 show that the inter-vehicle gap errors and velocity errors are gradually attenuated as they propagate downstream by adopting the proposed algorithm for the heterogeneous vehicle platoon.
For the PLF communication topology, Fig. 15 shows that the leader vehicle accelerates, and the following vehicles can track the leader vehicle and maintain consistency with the velocity of the leader vehicle. Figs. 16-17 show the inter-vehicle gap errors and velocity errors of vehicles platoons. It can be found that the inter-vehicle gap error is attenuated as it propagates downstream with the proposed DMPC algorithm. As a comparison, a DMPC without string stability constraints, and with the same controller parameters is implemented, and the results of the joint simulation are shown in Figs. 18-19. It can be seen that the inter-vehicle gap error is amplified as it propagates downstream.
Figs. 20, 21, 22, 23 and 24 show the joint simulation results when the leader vehicle decelerates. Figs. 20 shows that when the leader vehicle decelerates, the following vehicle can quickly track and keep the consistent velocity with the leader vehicle. Figs. 21-22 show that when the leader vehicle decelerates, the inter-vehicle gap error is attenuated as it propagates downstream. From the joint simulation results in Figs. 23-24, it can be found that the inter-vehicle gap error of vehicle platoons adopting the DMPC algorithm without string stability constraint is increasing.

Vehicle velocities with string stability constraints under PLF topology (accelerates case).

Inter-vehicle gap errors with string stability constraints under PLF topology (accelerates case).

Velocity errors with string stability constraints under PLF topology (accelerates case).

Inter-vehicle gap errors without string stability constraints under PLF topology (accelerates case).

Velocity errors without string stability constraints under PLF topology (accelerates case).

Vehicle velocities with string stability constraints under PLF topology (decelerates case).

Inter-vehicle gap errors with string stability constraints under PLF topology (decelerates case).

Velocity errors with string stability constraints under PLF topology (decelerates case).

Inter-vehicle gap errors without string stability constraints under PLF topology (decelerates case).

Velocity errors without string stability constraints under PLF topology (decelerates case).
Remark 7
Note that the performance of the proposed control scheme should be assessed by high-fidelity tests42. However, the current experimental conditions of the Hardware-in-the-loop or small-scale vehicle are not yet available, and we will consider the experiment with Hardware-in-the-loop or small-scale vehicles in the future.
Conclusion
In this paper, a hierarchical control structure was designed for communication vehicles in the platoon. Firstly, a synchronous DMPC algorithm was proposed as the upper-level controller, in which each vehicle in the platoon solves its local optimization problem synchronously to obtain the control sequence, and then transmits its assumed output sequence to neighbouring vehicles. By introducing the assumed output sequence instead of the actual predicted output sequence, the computational efficiency is improved. By adding string stability constraints and terminal equality constraints in the local optimization problem, thereby both the asymptotic consensus and string stability of vehicle platoons are guaranteed. Additionally, the sufficient condition that guarantees asymptotic consensus and string stability of vehicle platoons were given, respectively. Then, a lower-level controller was designed, where the desired control input determined by the upper-level DMPC was first transformed into the desired throttle angle and brake pressure through an inverse longitudinal dynamics model of vehicles. A PID feedback controller was employed to eliminate the influence of unmodeled dynamics and uncertainties so as to achieve the desired control performance. Finally, performance was verified by a joint simulation platform based on PreScan, CarSim and Simulink.
Data availability
Due to space limitation, this paper only shows partial results. The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Li, S. E., Zheng, Y., Li, K. & Wang, J. An overview of vehicular platoon control under the four-component framework. Proc. Intell. Veh. Symp. 4, 286–291 (2015).
Alam, A., Bsselink, B., Turri, Martensson, V. J. & Johansson, K. H. Heavy-duty vehicle platooning for sustainable freight transportation: A cooperative method to enhance safety and efficiency. IEEE Control Syst. 35, 5–27 (2015).
Rajamani, R. et al. Design and experimental implementation of longitudinal control for a platoon of automated vehicles. J. Dyn. Syst. Meas. Control. 122, 470–476 (2000).
Li, S. E., Qin, X., Li, K., Wang, J. & Xie, B. Robustness analysis and controller synthesis of homogeneous vehicular platoons with bounded parameter uncertainty. IEEE/ASME Trans. Mech. 22, 1014–1025 (2017).
Li, S. E. et al. Distributed platoon control under topologies with complex eigenvalues: Stability analysis and controller synthesis. IEEE Trans. Control Syst. Technol. 27, 206–220 (2019).
Ma, F., Wang, J., Zhu, S., Gelbal, S. Y. & Guvenc, L. Distributed control of cooperative vehicular platoon with nonideal communication condition. IEEE Trans. Veh. Technol. 69, 8207–8220 (2020).
Yu, G. K., Wong, P. K., Zhao, J., Mei, X. T. & Xie, Z. C. Design of an acceleration redistribution cooperative strategy for collision avoidance system based on dynamic weighted multi-objective model predictive controller. IEEE Trans. Intell. Transp. Syst.https://doi.org/10.1109/TITS.2020.3045758 (2021).
Zhang, L., He, C., Sun, J., & Orosz, G. Hierarchical design for connected cruise control. in Proc. ASME Dyn. Syst. Control Conf. V001T17A005 (2015).
Zhang, L., Sun, J. & Orosz, G. Hierarchical design of connected cruise control in the presence of information delays and uncertain vehicle dynamics. IEEE Trans. Control Syst. Technol. 26, 139–150 (2018).
Gao, B., Cai, K., Qu, T., Hu, Y. & Chen, H. Personalized adaptive cruise control based on online driving style recognition technology and model predictive control. IEEE Trans. Veh. Technol. 69, 12482–12496 (2020).
Li, S. E., Feng, G., Cao, D. P. & Li, K. Multiple-model switching control of vehicle longitudinal dynamics for platoon-level automation. IEEE Trans. Veh. Technol. 65, 4480–4492 (2016).
Ma, F. et al. Stability design for the homogeneous platoon with communication time delay. Autom. Innov. 3, 101–110 (2020).
Musa, A. et al. A review of model predictive controls applied to advanced driver-assistance systems. Energies 14, 7974 (2021).
Negenborn, R. R. & Maestre, J. M. Distributed model predictive control: An overview and roadmap of future research opportunities. IEEE Control Syst. 34, 87–97 (2014).
Giselsson, P. & Rantzer, A. On feasibility, stability and performance in distributed model predictive control. IEEE Trans. Autom. Control. 59, 1031–1036 (2014).
Yu, S. et al. Nash optimality based distributed modelpredictive control for vehicle platoon. IFAC-PapersOnLine. 53, 6610–6615 (2021).
Bian, Y. et al. Fuel economy optimization for platooning vehicle swarms via distributed economic model predictive control. IEEE Trans. Autom. Sci. Eng.https://doi.org/10.1109/TASE.2021.3128920 (2021).
Zheng, Y., Li, K., Borrelli, F. & Hedrick, J. K. Distributed model predictive control for heterogeneous vehicle platoons under unidirectional topologies. IEEE Trans. Control Syst. Technol. 25, 899–910 (2017).
Li, K., Bian, Y., Li, S. E., Xu, B., & Wang, J. Distributed model predictive control of multi-vehicle systems with switching communication topologies. Transp. Res. C Emerg. Technol. 118, (2020).
Luo, Q. Y., Nguyen, A. T., Fleming, J. & Zhang, H. Unknown input observer based approach for distributed tube-based model predictive control of heterogeneous vehicle platoons. IEEE Trans. Veh. Technol. 70, 2930–2944 (2021).
Basiri, M. H., Azad, N. L., & Fischmeister, S. Attack resilient heterogeneous vehicle platooning using secure distributed nonlinear model predictive control. in Proc. Mediterr. Conf. Control Autom. 15-18 (2020).
Tapli, T., & Akar, M. Cooperative adaptive cruise control algorithms for vehicular platoons based on distributed model predictive control. in Proc. IEEE 16th Int. Workshop Adv. Motion Control (AMC). 305-310 (2020).
Yan, M., Ma, W., Zuo, L. & Yang, P. Dual-mode distributed model predictive control for platooning of connected vehicles with nonlinear dynamics. Int. J. Control Automat. Syst. 17, 3091–3101 (2019).
Dunbar, W. B. & Caveney, D. S. Distributed receding horizon control for multi-vehicle formation stabilization. Automatica. 42, 549–558 (2006).
Wang, P. & Ding, B. Distributed RHC for tracking and formation of nonholonomic multi-vehicle systems. IEEE Trans. Autom. Control. 59, 1439–1453 (2014).
Yan, M. D., Ma, W. R., Zuo, L. & Yang, P. P. Distributed model predictive control for platooning of heterogeneous vehicles with multiple constraints and communication delays. J. Adv. Transp.https://doi.org/10.1155/2020/4657584 (2020).
Dunbar, W. B. & Caveney, D. S. Distributed receding horizon control of vehicle platoons: stability and string stability. IEEE Trans. Autom. Control. 57, 620–633 (2012).
Xiao, L. & Gao, F. Practical string stability of platoon of adaptive cruise control vehicles. IEEE Trans. Intell. Transp. Syst. 12, 1184–1194 (2011).
Kianfar, R. et al. Design and experimental validation of a cooperative driving system in the grand cooperative driving challenge. IEEE Trans. Intell. Transp. Syst. 13, 994–1007 (2012).
Wang, Q., Guo, G. & Cai, B. B. Distributed receding horizon control for fuel-efficient and safe vehicle platooning. Sci. China Technol. Sci. 59, 1953–1962 (2016).
Kianfar, R., Falcone, P. & Fredriksson, J. A control matching-based predictive approach to string stable vehicle platooning. IFAC Proc. Vol. 47, 10700–10705 (2014).
Li, H., Shi, Y. & Yang, W. Distributed receding horizon control of constrained nonlinear vehicle formations with guaranteed \(\gamma \)-gain stability. Automatica. 68, 148–154 (2016).
Lu, L. Y., Song, X. l., He, D. F., & Chen, Q. X. Stability and fuel economy of nonlinear vehicle platoons: A distributed economic MPC approach. in Proc. the 37th Chinese Control Conf. 7678-7683 (2018).
Bian, Y. G. et al. Behavioral harmonization of a cyclic vehicular platoon in a closed road network. IEEE Trans. Intell. Veh. 6, 559–570 (2021).
Ghasemi, A., Kazemi, R. & Azadi, S. Stable decentralized control of a platoon of vehicles with heterogeneous information feedback. IEEE Trans. Veh. Technol. 62, 4299–4308 (2013).
Battistini, S., Brancati, R., Lui, D. G., & Tufano, F. Enhancing ADS and ADAS under critical road conditions through vehicle sideslip angle estimation via unscented kalman filter-based interacting multiple model approach. in Proc. 4st Int. Conf. Italy (IFToMM), in Mechanisms and Machine Science, 450–460 (2022).
He, D., Qiu, T. & Luo, R. Fuel efficiency-oriented platooning control of connected nonlinear vehicles: A distributed economic MPC approach. Asian J. Control. 22, 1628–1638 (2020).
Rawlings, J. B. & Mayne, D. Q. Model predictive control: Theory and design (Nob Hi, Madison, WI, 2009).
Guo, J. H., Li, W. C., Wang, J. Y., Luo, Y. G. & Li, K. Safe and energy-efficient car-following control strategy for intelligent electric vehicles considering regenerative braking. IEEE Trans. Intell. Transp. Syst.https://doi.org/10.1109/TITS.2021.3066611 (2021).
Luu, D. L., Lupu, C., Alshareefi, H., & Pham, H. T. Coordinated throttle and brake control for adaptive cruise control strategy design. in Proc. 23st Int. Conf. Control Syst, Control Comput. 9-14 (2021).
Wu, W. G., Zou, D. B., Ou, J. & Hu, L. Adaptive cruise control strategy design with optimized active braking control algorithm. Math. Probl. Eng. 2020, 1–10 (2020).
Petrillo, A., Prati, M. V., Santini, S. & Tufano, F. Improving the \(NO_x\) reduction performance of an Euro VI d SCR System in real-world condition via nonlinear model predictive control. Int. J. Engine Res. 24, 823–842 (2022).
Acknowledgements
This work is supported by the National Natural Science Foundation of China (No.U1964202), the Natural Science Foundation of Jilin Province (No.YDZJ202101ZYTS169), the Foundation of Key Laboratory of Industrial Internet of Things and Networked Control (No.2019FF01), and the New Energy Vehicle Power System Key Laboratory in Jiangsu Province (No.JKLNEVPS201901).
Author information
Authors and Affiliations
Contributions
Design and conduct of the research (Y.Y.F., S.Y., Ha.C); performed the experiments and acquired the data (Y.Y.F., Ha.C); writing-original draft (Y.Y.F); writing-review and editing (S.Y., Y.Y.F., H.C); supervision (Y.L., S.M.S., J.H.Y., H.C); All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Feng, Y., Yu, S., Chen, H. et al. Distributed MPC of vehicle platoons with guaranteed consensus and string stability. Sci Rep 13, 10396 (2023). https://doi.org/10.1038/s41598-023-36898-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-36898-4
This article is cited by
-
Steer-by-wire control algorithm using a dual-layer closed-loop model
Scientific Reports (2024)
-
Distributed Cooperative Neural Control for Nonlinear Heterogeneous Platoon Systems with Unknown Uncertainties
Arabian Journal for Science and Engineering (2024)
