
Abstract
Hand gesture recognition based on sparse multichannel surface electromyography (sEMG) still poses a significant challenge to deployment as a muscle–computer interface. Many researchers have been working to develop an sEMG-based hand gesture recognition system. However, the existing system still faces challenges in achieving satisfactory performance due to ineffective feature enhancement, so the prediction is erratic and unstable. To comprehensively tackle these challenges, we introduce a novel approach: a lightweight sEMG-based hand gesture recognition system using a 4-stream deep learning architecture. Each stream strategically combines Temporal Convolutional Network (TCN)-based time-varying features with Convolutional Neural Network (CNN)-based frame-wise features. In the first stream, we harness the power of the TCN module to extract nuanced time-varying temporal features. The second stream integrates a hybrid Long short-term memory (LSTM)-TCN module. This stream extracts temporal features using LSTM and seamlessly enhances them with TCN to effectively capture intricate long-range temporal relations. The third stream adopts a spatio-temporal strategy, merging the CNN and TCN modules. This integration facilitates concurrent comprehension of both spatial and temporal features, enriching the model’s understanding of the underlying dynamics of the data. The fourth stream uses a skip connection mechanism to alleviate potential problems of data loss, ensuring a robust information flow throughout the network and concatenating the 4 stream features, yielding a comprehensive and effective final feature representation. We employ a channel attention-based feature selection module to select the most effective features, aiming to reduce the computational complexity and feed them into the classification module. The proposed model achieves an average accuracy of 94.31% and 98.96% on the Ninapro DB1 and DB9 datasets, respectively. This high-performance accuracy proves the superiority of the proposed model, and its implications extend to enhancing the quality of life for individuals using prosthetic limbs and advancing control systems in the field of robotic human–machine interfaces.
Similar content being viewed by others
Introduction
Recognizing hand gestures using surface electromyography (sEMG) signals is important for various applications, such as human–computer interaction1,2,3,4, controlling prostheses3, and engaging in rehabilitation gaming5. Deciphering muscle activity and hand motion are recorded by the sEMG signals mainly from the forearm, and serve as a valuable source of information for these purposes. As there are numerous applications for hand gestures, sEMG is an effective way to collect muscle activity for hand gesture recognition. Many researchers have employed machine learning (ML)-based classification to recognize hand motion and gestures from sEMG datasets. For gesture recognition using sEMG, electrodes affixed to the arm and/or forearm capture the sEMG signals. The extracted features, including RMS, variance, zero crossings, and frequency coefficients, serve as inputs to classifiers such as k-nearest neighbour (kNN), Support vector machine (SVM), Multilayer perception (MLP), and Random Forest (RF)6.
There is a gap in myoelectric control, which faces several challenges, such as training time and variability in sEMG signal characteristics1. The variability of the sEMG signal is the most challenging because of the time dependent state of the muscle, the dynamics and kinematics of the takes, and variations in the neural control of different users. In addition, signal variability arises from the placement of the electrodes. Since sEMG signals are time-series, the size of the dataset poses challenges to ML-based algorithms, making it difficult to achieve good accuracy7,8,9,10,11,12.
In this situation, researchers started to apply an approach based on deep learing (DL) to achieve good performance with efficiency by taking advantage of experience in other domains. Atzori et al. employed a simple CNN architecture and evaluated their model on the Ninapro DB1 +DB2 dataset; they reported that the average classification accuracy was 60.27%–7.7%12. In contrast, the average classification accuracy achieved by classical methods on the same dataset is 60.28%±6.51%. Much effort has been directed towards developing advanced DNN architectures. Notably, recent work10,11 has achieved an average classification accuracy of 82.95% on the DB1 dataset, a performance superior to existing methods. However, it is essential to recognize that DNNs typically require extensive training data to attain high accuracy. While this is manageable in controlled laboratory conditions, it poses challenges for practical applications, particularly in the real-life use of prostheses. Tsinganos et al. employed a TCN-based model to recognize hand gestures using sEMG13. They mainly used various configurations with a TCN module and achieved 5% higher accuracy than the existing system. More recently, Joseph et al. also employed a TCN module to extract the muscle activity pattern to improve the classification2. As we know, temporal features are very crucial in classifying sEMG-based hand gesture signals; however, existing systems with TCN modules still face challenges in achieving high-performance accuracy. Recently, researchers in various domains have integrated CNN with TCN and LSTM with TCN to enhance the extraction of temporal features. But no one has integrated the TCN with CNN14 or TCN with LSTM15 to recognize hand gestures based on sEMG. However, improving the performance of sEMG signal-based hand gesture recognition is very crucial for real-time deployment and to achieve a generalised hand gesture recognition system. To overcome these challenges, we propose an effective time-varying feature enhancement module for an sEMG-based classification and recognition of hand gestures. We developed this time-varying enhancement module using TCN with three aspects, including TCN16 features, CNN integrated with TCN, LSTM integrated with TCN, and a skip connection feature. The key contributions of our proposed model are outlined in the following.
-
Multifaceted architectural innovation: The proposed model introduces a pioneering 4-stream architecture comprising 4 streams, each incorporating specialized modules. The innovative architectural design allows the model to leverage diverse feature extraction techniques, addressing the complexities of sEMG data.
-
Efficient sequential learning with TCN: The inclusion of a TCN module in the first stream facilitates leveraging the myoelectric signal’s history to discover contextual temporal features that aid in capturing temporal patterns in muscle activity effectively.
-
Spatial-temporal understanding with CNN-TCN integration: The third stream integrates CNN and TCN modules, enabling simultaneous understanding of spatial and temporal features in the sEMG data and enhancing the model’s discriminative power.
-
Hybrid LSTM-TCN for complex temporal relations and skip connection: The second stream integrates a hybrid LSTM and TCN module, capitalizing on the strengths of both architectures to capture intricate temporal relationships in the data. The fourth stream introduces a skip connection mechanism to address issues of data loss, facilitating a robust flow of information and enhancing the model’s resilience. Features from all 4 streams are concatenated to produce a comprehensive final representation.
-
Feature selection, classification module and evaluation: We concatenated the 4 stream features and produced hierarchical extensive features. Then, we employed a channel attention module to select the potential features. The selected final feature is fed into the classification module to generate a probabilistic map and classification. The proposed model achieves remarkable results in extensive experiments: 94.31% and 98.96% for DB1 and DB9, respectively. These results outperform some recent studies and demonstrate the model’s effectiveness in recognizing hand gestures, due to its effectiveness over a broad range of features.
The structure of the paper is outlined as follows: Section Related work offers an overview of related approaches to gesture recognition. The section “Proposed Method” included the TCN-based proposed model. The Section “Experimental analysis and results” included the presentation of the results and discussion. Lastly, the “Conclusions and future directions” section summarizes the conclusions and outlines potential avenues for future work.
Related work
In recent years, gesture recognition using sEMG data has attracted attention in many fields, including medicine, exercise science, engineering, and prosthetic limb control3. The advances in ML, DL, and advances in rehabilitation technology are also reasons for the increased interest. Traditional ML techniques, such as Linear discriminant analysis (LDA)5,6 and SVM5,6, were used to recognize hand gestures acquired from sEMG signals. Although myoelectric control using classical pattern recognition techniques has been widely studied in the academic disciplines in the past, in general, advanced methods have tended not to be used in commercial examples. This is because there is a gap16 between real-world challenges and existing methods. The reasons for this include training time and variability in the characteristics of the sEMG signals.
A prevalent strategy adopted in recent studies for hand gesture recognition involves the use of Deep Neural Networks (DNN)17,18,19,20, with a specific emphasis on enhancing the classification performance of hand gestures, particularly in scenarios involving never-seen-before repetitions. Numerous state-of-the-art works, as documented in7,8,9,10,11,12,21,22,23, predominantly employ the Ninapro database24,25,26. This public dataset provides kinematic and sEMG signals associated with 52 finger, hand, and wrist movements. Notably, the Ninapro database mirrors data collected under real-world conditions, enabling the development of advanced DNN-based recognition frameworks. The prevailing method in recent research7,8,9,10,11,12,21,22,23, aligning with the guidelines outlined by the Ninapro database, involves training Deep Neural Network (DNN)-based models on a training set that encompasses around 2/3 of the gesture trials for each subject. Subsequently, an assessment is conducted on the remaining trials, forming the test set. Despite the commendable performance of existing DNN techniques on ‘never-seen-before repetitions’, they exhibit limitations when confronted with repetitions that have not been extensively explored27,28,29. As an illustration,30 presents the average accuracy across the 10 subjects of the Ninapro DB5 for different numbers of training repetitions (where one repetition corresponds to 5 seconds of data). Notably, the accuracy experiences a decline, and the model encounters challenges in functioning optimally when the repetition is not thoroughly explored. To elucidate, the accuracies for one to four training repetitions are reported to be 49.41% ± 5.82%, 60.12% ± 4.79%, 65.16% ± 4.46%, and 68.98% ± 4.46%, respectively. Chattopadhyay et al. introduced a domain adaptation technique aimed at aligning the original and target data into a shared domain while preserving the probability distribution topology of the input data31. To improve the accuracy, Transfer Learning (TL) was employed to assimilate a pre-trained model and exploit the knowledge gained from various subjects, expediting the training process for new users. Notably, in works such as30, the authors introduced TL-based algorithms that use CNN to transfer knowledge across diverse subjects in the context of sEMG-based hand gesture recognition. The researchers in30 used the Myo armband for gathering sEMG signals, focusing on the fifth Ninapro database. This particular database comprises data from 10 intact-limb subjects, and a good accuracy was achieved. Pizzolato et al. also employed TL-based transfer learning and used their model with the DB5 dataset. They achieved a good accuracy shows in6.
These recognition methods still face challenges in achieving good accuracy, due to the lack of temporal contextual enhancement. To overcome this, Tsinganos et al. employed a TCN-based model to recognize sEMG-based hand gestures. They used various stages of the TCN and achieved a performance 5% higher than existing systems13, an enhancement of the TCN used by2. However, existing systems with TCN modules still face challenges in achieving high-performance accuracy. Recently, some researchers in various domains have integrated CNN with LSTM and TCN to enhance the recognition of temporal features14,15. We have not find any research combining these features to recognize sEMG-based hand gesture signals. To overcome these challenges, we propose an effective time-varying feature enhancement module to classify sEMG-based hand gestures. We developed this time-varying enhancement module using TCN with three aspects including TCN16, CNN integrated with TCN, LSTM integrated with TCN, and a skip connection feature.
Proposed method
In the present study, we propose an innovative sEMG signal-based hand gesture recognition system to address the existing challenges. It uses a 4-streams DL module, which is shown in Fig. 1. This advanced architecture comprises 4 distinct streams, each meticulously designed to address specific challenges and enhance the overall performance. We were inspired by1, where they used a multistage design: TCN with a combination of attention and another module. We have produces a comprehensive and effective system to improve the accuracy while keeping the computational complexity stable. To increase its effectiveness, we extract features from 4 streams, where each stream produces a feature distinct from those of the other streams. This has the aim of enhancing the short-range and long-range dependency integration. The first stream leverages TCN’s efficiency in capturing long-range dependencies in sequential data, ensuring that intricate temporal patterns are effectively captured for accurate predictions. The second stream combines LSTM’s proficiency in capturing complex temporal relations with TCN’s parallelizability and scalability, adapting to diverse data patterns. The third stream integrates CNN and TCN modules to understand both spatial and temporal aspects of the input data, comprehensively understanding complex data structures and enhancing generalization across diverse datasets. The fourth stream introduces a skip connection mechanism to mitigate the potential for data loss, facilitating information flow from the earlier layers to the later layers, enhancing gradient flow, and contributing to a more robust and adaptive learning process. Collectively, these 4 streams create a holistic and synergistic DL architecture tailored for tasks requiring joint learning of temporal and spatial features, enhancing the model’s ability to capture a wide range of temporal and spatial features in the input data. In the next section, we will describe the dataset in 3.1, the preprocessing 3.2, the 4-stream feature extraction module in 3.3, the feature concatenation 3.4 and the classification in 3.6. Algorithm 1 shows the algorithm of the proposed model.

The structure of our proposed model.
Dataset
We used two benchmark datasets, Ninapro DB1 and Ninapro DB9, recorded using Cybergloves technology. Detailed information on these datasets is provided below.
NinaPro DB1 sEMG dataset
The Ninapro DB1 dataset includes sEMG signals and hand gesture data from 27 subjects (20 males, 7 females; 25 right-handed, 2 left-handed) with an average age of 28.0 years (SD = 3.4 years)32,33,34. This dataset captures 52 different hand movements using 10 sEMG electrodes, with each subject performing 10 repetitions per gesture. It includes three exercises focusing on various hand movements, from basic finger motions to complex grasping actions. Data entries encompass subject IDs, exercise details, sEMG and glove signals, stimulus labels, and repetition indicators. Table 1 shows information about the DB1 dataset.
NinaPro DB9 kinematic dataset
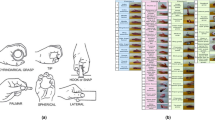
The Ninapro DB9 dataset consists of data from 77 subjects, which mainly included the subjects from Ninapro DB1, DB2, and DB535. It features calibrated kinematic data, addressing sensor nonlinearities to ensure accuracy and reliability. This dataset includes 40 different movements, each repeated multiple times, making it the largest available kinematic dataset. It uses a Cyberglove-II with 22 sensors and includes two main exercises: basic finger movements and grasping/functional movements. Information about this dataset and its gestures is shown in Table 1. Fig. 2 shows some examples of images and label names of this dataset.

Sample images of the DB9 dataset.

Algorithm of proposed sEMG-based hand gesture recognition system.
Data preprocessing
Adhering to the preprocessing methodology outlined in earlier investigations12,23,24, a first-order low-pass Butterworth filter was employed to dampen the electrical activity data of the muscles. Additionally, we implemented a \(\mu\)-law transformation to amplify the output of sensors with smaller magnitudes logarithmically while maintaining the scale of sensors with larger values over time. The \(\mu\)-law transformation method is traditionally used for the purpose of quantisation in the fields of speech and telecommunication. We used this method as a pre-processing tool to scale the sEMG signals. The \(\mu\)-law transformation was executed using the following formulation:
In this formulation, where \(t \ge 1\) is the time index, \(x_{t}\) represents the input to be scaled, and the parameter \(\mu\) defines the new range. Specifically, \(\mu = 2,048\) was employed, resulting in the scaled data points being distributed between 0 and 2, 048. Subsequently, we subjected the scaled sEMG signals to Minmax normalization. Our prior investigation8 revealed through empirical observation that normalizing the scaled sEMG signals yields better results compared to non-scaled sEMG signals.

Workflow of the TCN module.
Multi-stream feature extraction approach
After completing the pre-processing system, we fed the preprocessed sEMG information into our DL module, which consists of 4 streams. The details of each stream are given below.
Stream-1: TCN for sequential learning
TCNs fall under a category of sequential prediction models designed specifically to uncover hidden temporal dependencies within input sequences. The inclusion of TCN streams enhances the model’s ability to learn sequential patterns in the data. TCN is known for its efficiency in capturing long-range dependencies in sequential data. A time-distributed, fully-connected classification layer follows a single layer of convolutional filters2,36. Fig. 3 demonstrated the working diagram of the TCN module.
In the convolutional layer, a set of \(M=64\) convolutional filters \(W in Rd \times F\), where d denotes the duration of the filter, and \(F=10\) denotes the number of input features, carry out convolutions along the temporal dimension of the input sequence \(X \in RF \times T\), where T is the number of time-steps in the sequence. This process yields temporal feature maps \(E \in RM \times T\); here, \(E_{i}=f(w_{i} \times X+b_{i})\) where \(i=1,2,...,M\) ReLU functions are applied to each element as an activation function; in the fully connected layer, the softmax activation function is also used to generate C class probabilities for the current time t. In this experiment, we used a TCN from keras-tcn. The TCN model used in this research is composed of a single layer of convolutional filters. Within the convolution layer, there are 64 convolutional filters. The kernel size is 3, and return_sequence was set to True.
Stream-2: CNN-TCN fusion for spatio-temporal feature enhancement
The second stream incorporates a fusion of CNN and TCN, enabling the model to enhance the relationship of both spatial and temporal aspects simultaneously. This fusion is beneficial for tasks where features in both the spatial and temporal domains are crucial. In this experiment, we use a Conv1D layer with 32 filters; the filter size is 3 to enhance the detection of the spatial features of the time series14. Let X be the input sequence and K be the filter; the formula can be expressed below.
Here, m is the size of the filter, which is 3. This operation is applied iteratively to produce the entire output sequence. The structure of the following TCN layer is also the same as that of stream 1.
Stream-3: LSTM-TCN hybrid module for complex temporal relations
The second stream combines LSTM and TCN, leveraging the strengths of both architectures14,15. LSTM is effective in capturing complex temporal relations, while TCN provides parallelizability and scalability. LSTM is a kind of recurrent neural network (RNN). Its architecture solves the problems of vanishing gradients and vanishing weights by changing the structure of the hidden layers from other RNNs. It is particularly effective in handling sequences and has been widely used in tasks such as natural language processing and time series analysis. In this experiment, we used an LSTM layer with 64 units, and return_sequence was set to True. The structure of the following TCN layer is the same as stream 1.
Stream-4: data loss mitigation through skip connection
The fourth stream, using a skip connection, addresses the problems related to data loss that can occur in deep networks. Skip connections facilitate the flow of information from earlier layers to later layers, aiding in better gradient flow and mitigating the vanishing gradient problem.
Feature concatenation
In this section, we describe the process of concatenating the features from different streams to enhance the model’s performance in classifying hand gestures employing sEMG signals. By combining the outputs from multiple streams, we leverage the strengths of each module to improve the overall accuracy and reliability of our model. The output of each TCN stream can be described by the following equation:
Here, F(x) denotes the output of the dilated convolutional layers, x denotes the original input value (or the value from the skip connection), and O denotes the final output of the TCN-based stream after applying the activation function. By concatenating the outputs from the TCN, CNN-TCN, LSTM-TCN, and the original skip connection using a concatenate layer, we create a comprehensive feature set that leverages the strengths of each module. The following equation represents the concatenation process:
This combination allows the architecture to jointly learn both temporal and spatial features, making it well-suited for tasks that require this dual understanding.
This innovative concatenation process enhances the model’s resilience to noise and improves its capacity to capture subtle nuances in the data. The fusion of these features maximizes the model’s discriminative power, enabling it to make accurate and reliable predictions across various hand gesture recognition tasks. Furthermore, after this concatenation, we add a dropout layer with a rate set at 0.2 to prevent overfitting and ensure robust model performance.
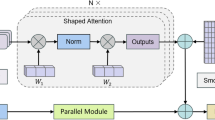
Feature selection using channel attention (CA)
The integration of the TCN model with various other modules is capable of extracting strong temporal dependency features that vary from one sample to another based on the filters and layers used. However, it has been demonstrated that incorporating an attention module following the extraction of temporal contextual features significantly enhances the identification of critical features in classification tasks37,38. Our approach employs a channel attention (CA) mechanism to refine the feature maps. The CA module enhances the feature maps by passing them through a global average pooling, which computes the average value for each channel, effectively summarizing the channel’s feature information. After this global average pooling, each channel passes through a series of fully connected (FC) layers, followed by the performance of batch normalization and ReLU activation. This results in the generation of either positive values or zeros, ensuring that only the most significant features are retained. The feature vector is obtained by multiplying the activation outputs, where the module assigns positive values to the significant features and zeros to the less significant ones. This multiplication isolates crucial features from the concatenated feature set, transforming unimportant features into zeros, thereby effectively filtering out noise and irrelevant information39. Figure 4(a) illustrates the architecture of the CA module. The global average pooling layer receives input from N channels and produces a condensed feature representation. We then use a dense layer with a size of N/8, followed by batch normalization, to mitigate internal covariate shifts and prevent excessively small gradients. A ReLU activation is applied, followed by another FC layer of size N, followed by another ReLU activation. ReLU is preferred because its computational complexity is lower than that of the sigmoid function. The CA module prioritizes significant features while suppressing less significant ones, leading to a more focused and effective feature set for classification. By assigning zeros to unimportant features, the CA mechanism reduces noise, while improving the model’s robustness and accuracy. Refining the feature set this way enhances the model’s ability to distinguish between different classes, leading to better classification. Using ReLU activation functions ensures lower computational complexity, making the feature selection process efficient without compromising its effectiveness.

(a) Outline of the channel attention approach (b) Classification module.
Classification
Finally, we add a fully connected layer. We use a dense layer. The number of unit is same as the number of gestures. The softmax function is used as the activation function. Fig. 4(b) shows the details of this layer of the classification module.
Experimental analysis and results
After evaluating its performance on both the DB1 and DB9 sEMG-based datasets, we will describe the proposed model’s accuracy.
Experimental setup
The proposed model was implemented using Python 3.8, and tested using TensorFlow 2.4.1, pandas 1.2.3, NumPy 1.1.9.5, and sci-kit-learn 0.24.1, on a machine equipped with an Intel Core i7-9700K processor, 16 GB RAM, and Ubuntu 20.04 LTS. The datasets were divided in accordance with the recommendations in the Ninapro-DB manual: Ninapro DB1 and DB9 were split into 70% training, 15% validation, and 15% testing sets, ensuring balanced distributions of the hand gestures. Preprocessing included normalization of the sEMG signals to a [0, 1] range and data augmentation through random cropping and flipping. The model was trained with a learning rate of 0.000125, a batch size of 1 for test, and 128 epochs for DB1, 16 epochs for DB9 using the Adam optimizer. The model architecture comprises 4 streams: a TCN module for the time-varying features, a hybrid LSTM-TCN module for long-range temporal dependencies, a CNN-TCN module for the spatio-temporal features, and a skip connection mechanism to provide a robust flow of the information. A feature selection module based on CA was applied before the classification to reduce the computational complexity. This section provides sufficient details about the setup to ensure the reproducibility of our experimental setup and results.
We have carefully selected and optimized the hyperparameters to ensure the best performance. The number of units in the LSTM layers is set to 64, balancing the model’s ability to capture temporal dependencies while avoiding overfitting. We use 32 filters with a kernel size of 3 in the CNN layers, effectively capturing the spatial features in the data. For all layers of the TCN, we set the number of filters to 64, the number of residual blocks stacked to 1, and the kernel size to 3, balancing the ability to capture local patterns with computational efficiency. These hyperparameters were optimized through extensive experimentation and cross-validation to ensure the optimal performance and computational efficiency of the model.
Ablation study of the proposal
Table 2 examines the impact of varying the configuration (of the number of TCNs and the presence of residual connections) on the accuracy on two different datasets, namely DB1 and DB9. This ablation study systematically evaluates these configurations to understand their influence on the model’s effectiveness.
This ablation study reveals that certain modifications, such as increasing the number of TCNs without a residual connection, adversely affect the performance. However, the proposed configuration, incorporating two streams and a residual connection, leads to notable improvements in accuracy for both datasets. This suggests the importance of specific architectural choices in optimizing the model’s performance for the given task.
Accuracy on the DB1 Dataset
Table 3 shows the accuracy on the DB1 dataset. We achieved an average classification accuracy of 93.45% for the proposed model without including the channel attention module and 94.31% accuracy without including the channel attention module.
The table presents detailed results for the accuracy across the 27 subjects in the dataset, both with and without the channel attention module. Comparing these two conditions, it is evident that integrating the channel attention mechanism leads to improvements in accuracy for the majority of subjects. For instance, on subject 2, there is an increase in the accuracy from 92.45% without channel attention to 95.60% with it. Similarly, on subject 6, there is an increase from 93.71% to 94.34%. On subject 8, the accuracy is consistently 96.86% both with and without the channel attention. However, there are cases where the channel attention module does not result in significant improvements, it can even slightly reduce the accuracy. For example, with subject 16, there is a decrease in accuracy from 88.68% without channel attention to 87.42% with it. The average accuracy across all subjects highlights the efficacy of the proposed approach, reaching 93.45% and 93.71% with and without the channel attention module, indicating a substantial improvement when integrating the channel attention module. Table 4 shows the precision-recall and F1 score for the DB1 datasets. The information provided by the average precision, recall and F1-score are almost the same as that provided by the accuracy.
Accuracy with DB9 dataset
The accuracy of the proposed model on the NinaPro DB9 dataset is shown in Table 5. The average accuracy is 93.37% and 98.96% for the 77 subjects with and without the channel attention model, respectively.
The evaluation of the performance of the proposed hand gesture recognition model on the NinaPro DB9 dataset, comprising 77 subjects, provides valuable insights into the efficacy of incorporating a channel attention mechanism. Table 5 presents the results of an assessment of the model’s accuracy both with and without the channel attention module, across the diverse set of subjects. Among these subjects, for subjects 4 and 11 there are considerable enhancements in the performance with the inclusion of CA module, achieving accuracies of 96.88% and 100.00%, respectively, compared to 94.88% and 99.96% without the CA module. With subject 39, the method enjoys an increase in accuracy from 92.80% without channel attention to 100.00% with it.
Comparison with the state of the art
The proposed model stands out prominently when compared to state-of-the-art methods in hand gesture recognition, as shown in Table 6. Notably, the model achieves exceptional accuracy on both the DB1 and DB9 datasets, surpassing the results of previous methods by a significant margin.
Table 6 compares the performance of various models on the DB1 and DB9 datasets. For DB1, performance metrics such as accuracy, precision, recall, and F1-score are provided for all models, whereas for DB9, only the proposed model’s performance is provided, due to the lack of comparable research on this new dataset. The main reason behind this is that DB9 is a new dataset, and no research results have been found with which to make this comparison. The models included in Table are LS-SVM (IAV+MAV+RMS+WL)1, LDA(IAV(or MAV)+ CC)1, RF2, RNN with weight loss40, LSTM+MLP41, Attention-based hybrid CNN-RNN11, RCNN42, and CFF-RCNN42, which will now be described separately. LS-SVM (IAV+MAV+RMS+WL)1 combines various features, such as Integrated Absolute Value (IAV), Mean Absolute Value (MAV), Root Mean Square (RMS), and Waveform Length (WL). It achieves an accuracy of 85.19% on DB1. LDA(IAV(or MAV)+ CC)1 uses Linear Discriminant Analysis (LDA) with features like IAV or MAV and Cross-Covariance (CC); this method achieves an accuracy of 84.23% on DB1. RF2 achieves an accuracy of 75.32% on DB1. RNN with weight loss40 integrates an RNN with a weight loss mechanism, and achieves an accuracy of 79.30% on DB1. LSTM+MLP41 combines LSTM and Multi-Layer Perceptron (MLP); this method achieves an accuracy of 75.45% on DB1. Attention-based hybrid CNN-RNN11 incorporates an attention mechanisms within a hybrid CNN-RNN architecture, achieving an accuracy of 87.00% on DB1. The RCNN42 method achieves an accuracy of 87.34% on DB1 in 2022. Xu et al. developed a hybrid model by integrating a contextual feature fusion (CFF) within RCNN42, achieving the highest accuracy of 88.87% on DB1.
Our proposed model achieves significant improvements over these methods. The detailed results are as follows: For DB1, the proposed model achieves an accuracy of 94.31%, precision of 95.60%, recall of 94.31%, and F1-score of 94.08%. For DB9, the proposed model achieves an accuracy of 98.96%, precision of 98.50%, recall of 98.96%, and F1-score of 98.60%. This substantial improvement highlights the effectiveness of the multi-stream-based time-varying feature enhancement approach, coupled with the use of channel attention, in capturing and leveraging crucial information within the sEMG signals for accurate hand gesture recognition. The model’s superior performance on both the DB1 and DB9 datasets underscores its robustness and reliability in handling diverse hand gesture patterns across different subjects.
Discussion
The proposed model constitutes a groundbreaking approach to hand gesture recognition, offering both exceptional performance and several innovative features that set it apart from existing methods. At the core of its novelty lies a multi-stream-based time-varying feature enhancement approach, which combines the strengths of TCNs, CNNs, and LSTM networks. This fusion enables the model to capture both spatial and temporal dependencies within electromyography (EMG) signals, providing a more comprehensive representation of hand gestures. Moreover, the inclusion of a channel attention mechanism further enhances the model’s capabilities by allowing it to focus on salient features, thereby improving the accuracy and interpretability of the classification by highlighting the most significant aspects of the input signals. One of the key advantages of the proposed model is its remarkable performance across multiple datasets, including NinaPro DB1 and DB9, where it outperforms state-of-the-art methods by a significant margin. Table 6 presents a comparison of the proposed model with the state-of-the-art. Traditional methods, such as LS-SVM (IAV+MAV+RMS+WL)1 and LDA (IAV(or MAV)+CC)1 have achieved accuracies of 85.19% and 84.23% on the DB1 dataset, respectively, while our model achieved an accuracy of 94.31%, precision of 95.60%, recall of 94.31%, and F1-score of 94.08%. On the DB9 dataset, where limited comparable results are available, our model set a new benchmark with an accuracy of 98.96%, precision of 98.50%, recall of 98.96%, and F1-score of 98.60%. Compared to other state-of-the-art methods, our model shows significant improvements. For instance, RF2 achieves an accuracy of 75.32% on DB1, while RNN with weight loss40 and LSTM+MLP41 achieve accuracies of 79.30% and 75.45%, respectively. The Attention-based hybrid CNN-RNN11 method achieves an accuracy of 87.00%, and the RCNN42 and CFF-RCNN42 methods achieve accuracies of 87.34% and 88.87%, respectively. Our model’s superior performance in terms of all these metrics highlights its robustness and adaptability to diverse datasets and subject populations, making it well-suited for a wide range of real-world applications, from healthcare to human–computer interaction. The practical advantages of our proposed model include its scalability, adaptability, and interpretability. Its ability to handle variability in user characteristics and environmental conditions makes it suitable for deployment in various contexts. Additionally, the interpretability of the model facilitates understanding and trusting its decisions, which is crucial for applications in assistive technology and human–robot interfaces. Our model sets a new standard in hand gesture recognition by addressing the complexity of sEMG data through a comprehensive and innovative approach. The high accuracy achieved demonstrates our method’s potential to significantly improve the functionality of prosthetic limbs, offering users more natural and precise control. Based on the discussion we can say that, the proposed model significantly contributes to hand gesture recognition by achieving state-of-the-art performance by combining advanced deep learning techniques with attention mechanisms. Its innovative features, high accuracy, and practical advantages make it a promising solution for many applications, with potential implications for improving human–computer interaction, assistive technology, and beyond. This positions our research as a significant step forward in developing advanced prosthetic limb control systems and human-robot interfaces.
Conclusions and future directions
In this study, we introduced a novel system for processing surface electromyography (sEMG) signals in order to recognize hand gestures. It uses a 4-stream deep learning module. Each stream includes specialized modules to capture both the temporal and spatial features inherent in sEMG data. Specifically, we fused time-varying features extracted by temporal convolutional networks (TCNs), complex temporal relations extracted by a long short-term memory (LSTM)-TCN module, spatio-temporal features extracted by a module that integrates convolutional neuronal network (CNN) and TCN modules, and a skip connection mechanism. This multifaceted approach not only enhances the effectiveness of the extraction of features from the sEMG data, but also improves the robustness and stability of the predictions. Our model demonstrated high performance, achieving superior accuracy on the benchmark Ninapro DB1 and DB9 datasets, with average accuracies of 94.31% and 98.96%, respectively. This level of accuracy is a significant improvement over existing systems, showcasing the robustness of our approach in handling the complexity of sEMG signals. The integration of TCN, LSTM-TCN, and CNN-TCN modules provides a comprehensive feature extraction mechanism that captures the intricate temporal and spatial patterns in sEMG data. The use of residual connections ensures robust information flow, mitigating potential data loss and enhancing the stability of the predictions. Additionally, our channel attention-based feature selection module effectively reduces the computational complexity while maintaining high accuracy, making the system more efficient and practical for real-world applications. This superior performance represents a significant breakthrough in improving the natural movement and control capabilities of prosthetic limb users. The ability to accurately interpret individualized sEMG data has promising implications for enhancing the quality of life for individuals relying on prosthetic limbs. Additionally, the advances demonstrated in control systems have broader applications, particularly in the domain of robot-human interfaces. By leveraging these advanced deep learning techniques, our research paves the way for future innovations in assistive technologies and human-computer interactions, offering the possibility of precise control and interaction. These findings underscore the potential of our approach in contributing to significant improvements in both prosthetic technologies and robotic control systems, setting a new benchmark in the field of sEMG-based hand gesture recognition.
Data availability
NinaPro DB1 sEMG Dataset Original Source: https://ninapro.hevs.ch/instructions/DB1.html. NinaPro DB1 sEMG Dataset Kaggle Source: https://www.kaggle.com/datasets/mansibmursalin/ninapro-db1-full-dataset. NinaPro DB9 kinematic Dataset: https://ninapro.hevs.ch/instructions/DB9.html.
References
Rahimian, E. et al. FS-HGR: Few-shot learning for hand gesture recognition via electromyography. IEEE Transactions on Neural Systems and Rehabilitation Engineering29, 1004–1015. https://doi.org/10.1109/TNSRE.2021.3077413 (2021).
Betthauser, J. L., Krall, J. T., Kaliki, R. R., Fifer, M. S. & Thakor, N. V. Stable electromyographic sequence prediction during movement transitions using temporal convolutional networks. In 2019 9th International IEEE/EMBS Conference on Neural Engineering, 1046–1049 (IEEE, 2019).
Jiang, N., Dosen, S., Muller, K. R. & Farina, D. Myoelectric control of artificial limbs—Is there a need to change focus. IEEE Signal Processing Magazine29, 150–152 (2012).
Miah, A. S. M., Shin, J. & Hasan, M. A. Effective features extraction and selection for hand gesture recognition using sEMG signal. Multimedia Tools and Applications 1–25 (2024).
Esposito, D. et al. A piezoresistive array armband with reduced number of sensors for hand gesture recognition. Frontiers Neurorobotics13, 114 (2020).
Pizzolato, S. et al. Comparison of six electromyography acquisition setups on hand movement classification tasks. PLoS ONE12, 1–7 (2017).
Rahimian, E., Zabihi, S., Atashzar, S. F., Asif, A. & Mohammadi, A. XceptionTime: Independent time-window xceptiontime architecture for hand gesture classification. In Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 1304–1308 (2020).
Rahimian, E., Zabihi, S., Atashzar, S. F., Asif, A. & Mohammadi, A. sEMG-based hand gesture recognition via dilated convolutional neural networks. In Proc. IEEE Global Conf. Signal Inf. Process., 1–5 (2019).
Chen, L., Fu, J., Wu, Y., Li, H. & Zheng, B. Hand gesture recognition using compact CNN via surface electromyography signals. Sensors20, 672 (2020).
Wei, W. et al. Surface-electromyography-based gesture recognition by multi-view deep learning. IEEE Trans. Biomed. Eng.66, 2964–2973 (2019).
Hu, Y. et al. A novel attention-based hybrid CNN-RNN architecture for sEMG-based gesture recognition. PLoS ONE13, e0206049 (2018).
Atzori, M., Cognolato, M. & Müller, H. Deep learning with convolutional neural networks applied to electromyography data: A resource for the classification of movements for prosthetic hands. Frontiers Neurorobot.10, 9 (2016).
Tsinganos, P., Cornelis, B., Cornelis, J., Jansen, B. & Skodras, A. Improved Gesture Recognition Based on sEMG Signals and TCN. In ICASSP 2019 – 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, 1169–1173, https://doi.org/10.1109/ICASSP.2019.8683239 (IEEE, Brighton, UK, 2019).
He, S. et al. A per-unit curve rotated decoupling method for CNN-TCN based day-ahead load forecasting. IET Generation, Transmission and Distribution15, https://doi.org/10.1049/gtd2.12214 (2021).
Xing, Z. & Liu, K. Estimated off-block time based on LSTM-TCN network. In Kannan, H. & Hemanth, J. (eds.) Third International Conference on Sensors and Information Technology (ICSI 2023), 126990V, https://doi.org/10.1117/12.2679159. International Society for Optics and Photonics (SPIE, 2023).
Castellini, C. et al. Proceedings of the first workshop on peripheral machine interfaces: Going beyond traditional surface electromyography. Frontiers Neurorobotics8, 22 (2014).
Miah, A. S. M., Shin, J., Hasan, M. A., Okuyama, Y. & Nobuyoshi, A. Dynamic hand gesture recognition using effective feature extraction and attention based deep neural network. In 2023 IEEE 16th International Symposium on Embedded Multicore/Many-core Systems-on-Chip, 241–247 (IEEE, 2023).
Miah, A. S. M., Hasan, M. A., Tomioka, Y. & Shin, J. Hand gesture recognition for multi-culture sign language using graph and general deep learning network. IEEE Open Journal of the Computer Society (2024).
Miah, A. S. M., Hasan, M. A. M., Okuyama, Y., Tomioka, Y. & Shin, J. Spatial-temporal attention with graph and general neural network-based sign language recognition. Pattern Analysis and Applications27, 37 (2024).
Miah, A. S. M., Hasan, M. A. M., Nishimura, S. & Shin, J. Sign language recognition using graph and general deep neural network based on large scale dataset. IEEE Access (2024).
Ding, Z. et al. SEMG-based gesture recognition with convolution neural networks. Sustainability10, 1865 (2018).
Zhai, X., Jelfs, B., Chan, R. H. M. & Tin, C. Self-recalibrating surface EMG pattern recognition for neuroprosthesis control based on convolutional neural network. Frontiers Neurosci.11, 379 (2017).
Geng, W. et al. Gesture recognition by instantaneous surface EMG images. Sci. Rep.6, 36571 (2016).
Atzori, M. et al. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data1, 1–13 (2014).
Gijsberts, A., Atzori, M., Castellini, C., Muller, H. & Caputo, B. Movement error rate for evaluation of machine learning methods for sEMG-based hand movement classification. IEEE Trans. Neural Syst. Rehabil. Eng.22, 735–744 (2014).
Atzori, M. et al. Characterization of a benchmark database for myoelectric movement classification. IEEE Trans. Neural Syst. Rehabil. Eng.23, 73–83 (2015).
Mishra, N., Rohaninejad, M., Chen, X. & Abbeel, P. A simple neural attentive meta-learner. arXiv preprint arXiv:1707.03141 (2017).
Srinivasan, A., Bharadwaj, A., Sathyan, M. & Natarajan, S. Optimization of image embeddings for few shot learning. In Proc. 10th Int. Conf. Pattern Recognit. Appl. Methods, 1–4 (2021).
Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proc. 34th Int. Conf. Mach. Learn., vol. 100, 1126–1135 (2017).
Cãtãllard, U. et al. Deep learning for electromyographic hand gesture signal classification using transfer learning. IEEE Trans. Neural Syst. Rehabil. Eng.27, 760–771 (2019).
Chattopadhyay, R., Krishnan, N. C. & Panchanathan, S. Topology preserving domain adaptation for addressing subject based variability in SEMG signal. In Proc. AAAI Spring Symp., Comput. Physiol., 4–9 (2011).
Atzori, M. et al. Characterization of a benchmark database for myoelectric movement classification. IEEE Transactions on Neural Systems and Rehabilitation Engineering23, 73–83. https://doi.org/10.1109/TNSRE.2014.2328495 (2015).
Atzori, M. et al. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Scientific Data1, 1–13 (2014).
Atzori, M. et al. Building the Ninapro database: A resource for the biorobotics community. In 2012 4th IEEE RAS & EMBS International Conference on Biomedical Robotics and Biomechatronics, 1258–1265 (IEEE, 2012).
Jarque-Bou, N. J., Atzori, M. & Müller, H. A large calibrated database of hand movements and grasps kinematics. Scientific Data7, 12 (2020).
Remy, P. Temporal convolutional networks for keras (2020).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7132–7141, https://doi.org/10.1109/CVPR.2018.00745 (2018).
Zhang, Y. e. a. Image super-resolution using very deep residual channel attention networks. In Ferrari, V. e. a. (ed.) Computer Vision – ECCV 2018, 294–310 (Springer-Verlag, Berlin, 2018).
Li, H. et al. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters18, 905–909. https://doi.org/10.1109/LGRS.2020.2988294 (2021).
Koch, P. et al. Recurrent neural networks with weighting loss for early prediction of hand movements. In 2018 26th European Signal Processing Conference, 1152–1156 (IEEE, 2018).
He, Y., Fukuda, O., Bu, N., Okumura, H. & Yamaguchi, N. Surface EMG pattern recognition using long short-term memory combined with multilayer perceptron. In 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 5636–5639 (IEEE, 2018).
Xu, P., Li, F. & Wang, H. A novel concatenate feature fusion RCNN architecture for sEMG-based hand gesture recognition. PloS one17, e0262810 (2022).
Author information
Authors and Affiliations
Contributions
Conceptualization, Abu Saleh Musa Miah, Jungpil Shin, Sota Konnai, and Itsuki Takahashi; Methodology, Abu Saleh Musa Miah, Jungpil Shin, Sota Konnai, Itsuki Takahashi, and Koki Hirooka; Investigation, Abu Saleh Musa Miah, Sota Konnai, Itsuki Takahashi, and Koki Hirooka; Data Curation, Abu Saleh Musa Miah, Sota Konnai, and Itsuki Takahashi; Writing-Original Draft Preparation, Abu Saleh Musa Miah, Jungpil Shin, and Sota Konnai; Writing-Review and Editing, Jungpil Shin, Abu Saleh Musa Miah, and Itsuki Takahashi; Visualization, Abu Saleh Musa Miah, and Sota Konnai; Supervision, Jungpil Shin; Funding Acquisition, Jungpil Shin. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shin, J., Miah, A.S.M., Konnai, S. et al. Hand gesture recognition using sEMG signals with a multi-stream time-varying feature enhancement approach. Sci Rep 14, 22061 (2024). https://doi.org/10.1038/s41598-024-72996-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-72996-7
Keywords
This article is cited by
-
Contactless biometric verification from in-air signatures using deep siamese networks
Scientific Reports (2026)
-
Advanced biomimetic robotic hand with EMG lifelong learning and recognition
Scientific Reports (2025)
-
A lightweight and efficient gesture recognizer for traffic police commands using spatiotemporal feature fusion
Scientific Reports (2025)
-
Optimization of deep learning architecture based on multi-path convolutional neural network algorithm
Scientific Reports (2025)
-
Bewegungsanalyse in der orthopädietechnischen Forschung
Die Unfallchirurgie (2025)
