
Abstract
When the coal gangue sorting robot sorts coal gangue, the position of the target coal gangue will change due to belt slippage, deviation, and speed fluctuations of the belt conveyor. This will cause the robotic to fail in grasping or miss grasping. We have developed a solution to this problem: the IMSSP-Net two-stage network gangue image fast matching method. This method will reacquire the target gangue position information and improve the robot’s grasping precision and efficiency. In the first stage, we use SuperPoint to guarantee the scene adaptability and credibility of feature point extraction. We have enhanced Superpoint’s ability to detect feature points further by using the improved Multi-scale Retinex with Color Restoration enhancement algorithm. In the second stage, we introduce SuperGlue for feature matching to improve the robustness of the matching network. We eliminated erroneous feature matching point pairs and improved the accuracy of image matching by adopting the PROSAC algorithm. We conducted image matching comparison experiments under different object distances, scales, rotation angles, and complex conditions. The experimental platform adopts the double-manipulator truss-type coal gangue sorting robot independently developed by the team. The matching precision, recall, and matching time of the method are 98.2%, 98.3%, and 84.6ms, respectively. The method can meet the requirements of efficient and accurate matching between coal gangue recognition images and sorting images.
Similar content being viewed by others


Introduction
At present, intelligent sorting robots for coal gangue have achieved sorting of different types of coal gangue to a certain extent. However, there are still some challenges in practical applications1,2,3,4. The coal gangue sorting robot recognizes the target coal gangue and obtains its pose information through the recognition system during the sorting process5,6,7. The robot control system combines pose information, belt speed, and time to calculate the real-time position of the target coal gangue, thereby achieving robot sorting. However, the actual working environment is complex. During the process of gangue moving from the recognition area to the grasping area, factors such as belt slippage, deviation, and speed fluctuations cause changes in the position and posture of the gangue. The existing methods are unable to achieve precise positioning of coal gangue, resulting in manipulator empty grasping, missed grasping, and even grasping failure. These all seriously affect the sorting efficiency of robots. To solve this problem, it is necessary to accurately locate the target coal gangue before the robot performs sorting actions. Therefore, by using visual methods to match the target coal gangue recognition image provided by the recognition system with the sorting image collected during sorting, precise positioning of the target coal gangue can be achieved. This method can further improve the sorting accuracy and efficiency of robots.
The research contributions of our work can be summarized as follows:
-
(1)
The coal gangue image matching method combining SuperPoint network and SuperGlue network was proposed. Applied to the intelligent sorting scenario of robot coal gangue, it has rich feature information and strong feature matching ability.
-
(2)
The improved MSRCR image enhancement algorithm is used to improve the stability and applicability of SuperPoint feature point detection in complex conditions.
-
(3)
The SuperGlue significantly enhances the feature representation and matching capabilities of the network. By utilizing PROSAC, the matching features are further refined and filtered, thereby ensuring the precision of image matching even under complex conditions.
Next, the relevant work on image matching in robot sorting scenarios is introduced in Section “Related work”. Section “Proposed method” introduces the proposed method framework. Section “Experiment” introduces the performance indicators and analysis of four image matching methods, and Section “Discussion and conclusion” presents the conclusions.
Related work
There introduces some related work on the application of image matching in sorting scenarios.
With the widespread application of machine vision in various industrial scenarios, scholars have also made certain progress in the research of image matching methods in sorting systems. Yang et al. proposed an improved edge feature template matching algorithm for the rapid sorting of multi-objective workpieces, which can achieve high real-time performance when combined with a pyramid layering strategy8. Yao et al. proposed a fast part matching method based on HU invariant moment features and improved Harris corner points to address the issues of long matching time and low precision in the process of part image matching. This method improves the speed of image matching, but the Harris corner detection operator performs relatively well only in fixed scale image detection9. Wang et al. proposed an improved ORB image matching algorithm for the fast recognition and sorting requirements of workpieces with complex texture features on the surface10. It replaces the Brief descriptor with the SURF feature sub-description, enhancing the robustness to lighting and image scale changes, and improving the matching accuracy of workpiece images under scale changes.
The above traditional image matching methods based on SIFT11,12, SURF13,14,15, BRIEF16,17, and ORB18,19,20 all rely on manually designed descriptors. Although they have certain effects, considering the on-site environment of the intelligent sorting robot for coal gangue, there are still some shortcomings. For example, for coal gangue images under complex lighting and scale changes, the above methods cannot effectively extract stable feature points or vectors from the images. Moreover, template based matching has relatively low efficiency, as deep learning can extract advanced semantic information from images.
To address above problems, DeTone et al. proposed SuperPoint network in 2018, which is an end-to-end learning approach that inputs images and outputs features of feature points and descriptors21. Among them, SuperPoint is not only accurate but also has a simple structure that can extract key points in real time. However, in the feature-matching stage, traditional methods often rely on minimizing or maximizing specific established metrics, such as squared differences and correlations. The typical Fast Approximation Neighbor Library (FLANN) matching method has poor robustness for matching image pairs lacking texture. SuperGlue: a graph neural network feature matching method provided a new idea for the matching problem22,23,24,25. The SuperGlue network is a mid-level matching network that needs to be combined with a feature extraction network to better leverage its performance.
The SuperPoint network extracts the most robust image feature points, while the SuperGlue network is completely robust to lighting changes, blurring, and scenes lacking texture. We have combined these two networks to achieve a significant improvement in the matching accuracy of complex images. We have also applied this combination to the sorting of coal gangue by robots in complex scenarios.
Proposed method
Motivation
We conducted research on coal gangue image matching under complex conditions by combining SuperPoint and Superglue networks. However, during the research process, based on the actual working conditions of coal gangue sorting, we believe that further optimization can be carried out in the following two aspects.
-
(1)
Due to the differences in object distance, scale, and rotation angle of sorting images acquired in different regions, it is difficult to detect enough key points for matching. In order to improve the ability to detect feature points, the sorting images are enhanced using the improved MSRCR algorithm.
-
(2)
The sorting process of coal gangue is complex. The presence of coal slag, water stains, and other factors on the belt can cause serious interference with the matching results. This will result in a decrease in the number of matching points and incorrect matching point pairs. Therefore, by optimizing the matching results through PROSAC, the matching accuracy can be improved.
Therefore, to solve the problem of image matching of coal gangue under complex conditions, we propose a more robust image matching network called IMSSP-Net.
Model construction
The coal gangue sorting robot obtains the recognition result of the target coal gangue from the recognition system as the recognition image. After the coal gangue enters the sorting area, a camera is used to capture the current image as the sorting image. Figure 1 illustrates the overall structure of our network. Firstly, the improved MSRCR algorithm enhances the two images separately. Then, the SuperPoint algorithm is used to extract feature points and their descriptors from the recognition image and sorting image. Next, it is used as input to perform feature matching between images using the SuperGlue algorithm. Finally, the obtained matching points are filtered using PROSAC to obtain the best matching point pair. The precise location of the target coal gangue is obtained by using the minimum bounding rectangle to frame the matching results.

Overview of the IMSSP-Net method. Figures 1 and 2 respectively represent the original recognition image and the original sorting image. Iretinex is the image enhanced by MSRCR. Equation (1) normalizes Iretinex and outputs Iout1. Equation (2) implements the power-law transformation of Iretinex, and outputs Iretinexγ. Normalize Iretinexγ using Eq. (1) to obtain Iout2. Equation (4) achieves brightness adjustment.
Improved MSRCR algorithm and feature extraction
To improve the ability of network to detect feature points in coal gangue images. Therefore, we use the improved MSRCR for image enhancement and then use the SuperPoint algorithm to detect the features of the image.
Improved MSRCR algorithm
The MSRCR is a commonly used image enhancement technique that enhances the details and contrast of images while preserving edge information. Its principle involves decomposing the image into different scales, followed by local contrast adjustment and enhancement. Finally, the enhanced image is reconstructed.The normalization formula is employed for intensity mapping, normalizing the Retinex components to scale the intensity range of the image.This achieves overall adjustment of image contrast and brightness. The relationship is expressed as follows:
In the equation, Iout1 and Iretinex represents the pixel values of the output image and enhanced image by the MSRCR algorithm. The max(Iretinex) represents the maximum pixel values of the image enhanced by the MSRCR algorithm, min(Iretinex) represents the minimum pixel values of the image enhanced by the MSRCR algorithm, and Lclip and Hclip respectively indicate the lower and upper limits of grayscale levels.
Power-law transformation is a non-linear image enhancement method that alters the pixel value distribution in order to highlight details and features in the image26. It is based on a simple mathematical principle, mapping original pixel values through an exponential function to anew pixel value range, thereby changing the shape of the original pixel value distribution. The relationship is expressed as follows:
In the equation, Iretinex represents the image enhanced by MSRCR. Iretinexγ represents the result of Iretinex power-law transformation. \(\:{\upgamma\:}\:\)is the exponent of the power-law transformation. When γ > 1, the pixel values of the output image become more concentrated, emphasizing details. When 0 < γ < 1 ,the pixel values become more dispersed, resulting in smoother details When γ = 1, the power-law transformation has no effect.
Integrating the power-law transformation Eq. (2) into the normalization formula of MSRCR Eq. (1) ,the improved MSRCR algorithm is as follows:
Then use the Eq. (4) to adjust the brightness level range of the output image.
In the equation, \(\:{\upbeta\:}\) represents the enhancement factor, used to adjust the brightness level range of the output image.Its expression is as follows:
The IMSRCR and MSRCR methods were used to enhance the recognition and sorting images respectively, and the results are shown in Fig. 2. The expression of Hclip and Lclip in Eq. (1) is general expression. In the experiment, Hclip and Lclip are set to 255 and 0, respectively.

The Visualization of feature point detection. (a) The original recognition image. (b) The MSRCR enhanced recognition image. (c) The IMSRCR enhanced recognition image. (d) The original sorting image. (e) The MSRCR enhanced sorting image. (f) The IMSRCR enhanced sorting image.
To evaluate the quality of the enhanced image, this article uses two widely used image quality evaluation metrics, Peak-Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM). The results are shown in Table 1.
It can be seen that compared with the MSRCR method, the improved method has significantly improved PSNR and SSIM. The IMSRCR image has a more balanced global grayscale, clearer contrast, and richer details.
Feature extraction
The SuperPoint algorithm is different from traditional feature detection algorithms, and its main feature is to simultaneously detect image key points and extract descriptors27. It utilizes a self-supervised convolutional neural network model and is implemented through the Encoder Decoder architecture. In the SuperPoint algorithm, the input image is first subjected to feature extraction through a VGG encoder to obtain a feature map. Then, decode two branches on the output feature map, one for key point detection and the other for descriptor extraction. The convolutional layer in SuperPoint network is shown in Table 2.
The key point detection branch adopts a sliding window approach to calculate the probability of being a key point pixel by pixel on the feature map. The size of each window is usually 8 × 8 pixels, and each pixel is evaluated for being a key point and a probability map of the key points is generated. This probability plot is a 3D tensor with a size of H/8 × W/8 × 65, where M and N are the height and width of the image, respectively, and each pixel block corresponds to an 8 × 8 area as the probability of key points. Determine the final key point position through threshold processing and connectivity analysis. Its structure is shown in Fig. 3.

The key point decoder.
The descriptor extraction branch is responsible for extracting descriptors for each key point from the feature map. This branch converts feature maps into three-dimensional tensors of H/8 × W/8 × D, where D is the dimension of the descriptor. Extract local features through a series of convolution and pooling operations. To obtain the final descriptor, it is necessary to perform different operations and normalization. The feature map is transformed into a three-dimensional tensor of H×W×D, representing the descriptor of each pixel. Its structure is shown in Fig. 4.

The descriptor decoder.
The SuperPoint network was used to extract feature points from the original image, MSRCR, and improved MSRCR images, as shown in Fig. 5. The colored dots in Fig. 5 represent the detected feature points. By comparison, the improved MSRCR method further enriches the color information of the image and extracts significantly more feature points compared to the other two methods. This will be more beneficial for subsequent matching.

The Visualization of feature point detection. (a) Feature detection in original recognition image. (b) Feature detection in the MSRCR enhanced recognition image. (c) Feature detection in the IMSRCR enhanced recognition image. (d) Feature detection in original sorting image. (e) Feature detection in the MSRCR enhanced sorting image. (f) Feature detection in the IMSRCR enhanced sorting image.
Feature matching and optimization
After completing the feature point extraction of coal gangue recognition images and sorting images, we need to match the feature points and optimize the matching results.
SuperGlue feature matching
After using SuperPoint to complete the feature detection of coal gangue recognition images and sorting images, it is necessary to match the feature points of the two images through feature matching methods to obtain the target coal gangue position. This article adopts the SuperGlue algorithm, which comprehensively considers the position information of feature points and visual appearance information to improve the accuracy and robustness of matching.
SuperGlue is a feature matching algorithm based on Graph Neural Network (GNN), which constructs the graph structure of feature points and utilizes Graph Convolutional Neural Network (GCN) for feature aggregation and matching. Figure 6 illustrates its network structure. It mainly consists of two parts: the first half combines self attention mechanism and cross attention mechanism, aiming to extract better matching descriptors. This part significantly improves the accuracy and robustness of feature matching by continuously strengthening the role of the (L = 7) vector f. The optimal matching layer in the latter half uses the inner product to obtain the score matrix and iteratively optimizes it using the Sinkhorn algorithm to achieve preliminary pose estimation optimization. Its structure is shown in Fig. 6.

The architecture of SuperGlue.
The first part of attention GNN is the key point encoder. Firstly, the feature points are dimensionally enhanced using a key point encoder. Each key point combines its position and score information and uses a multi-layer perceptron (MLP) to embed the position information of the key points into a high-dimensional vector. As shown in Eq. (5). Specifically, the input data is the key point p and its corresponding feature descriptor d extracted by the feature extraction network, which includes the coordinates and confidence information of the feature points. Firstly, feature points are converted into 256-dimensional data through 5 multi-layer perceptrons (fully connected layers), with channel numbers of 3, 32, 64, 128, and 256, respectively. As shown in Fig. 7.
Among them, di and pi are the i-th descriptor and feature point, respectively.

The Key point encoder.
The second part of attention GNN is the graph attention mechanism, which includes two undirected edges: Image edges εself and Cross edge εcross. The former connects the feature points inside the image, while the latter connects the feature points i of adjacent images (denoted as A and B), where t is the time corresponding to adjacent frames. The txiA represents the middle expression of the i-th element on image A in layer L. The information mε→i aggregates the {j:(i, j)∈ε} of all feature points, where ε∈{εself, εcross }. From this, all features i in image A transmit updated residual information.
Among them, [∙∥∙] represents concatenation operation, and MLP represents multi-layer perceptron. When the number of layers L is odd, ε = εcross, and when the number of layers L is even, ε = εself. By alternately updating between self mechanism and cross mechanism through mε, we simulate the process of humans repeatedly looking between two images until differences or similarities are discovered. The final feature description vector used for matching is shown in Eq. (7).
The above equation W represents weight, and b represents deviation.
The main function of the optimal matching layer is to generate a matching score matrix and output the final matching pair. After completing the feature description vectors fiA and fiB, the inner product is calculated to obtain the score matrix S∈RH×W, where M and N represent the number of feature points in the original image and the image to be matched, respectively. The inner product is calculated as follows:
Among them, <·,·> is the inner product. Expand the score matrix by one channel to obtain,‾S as shown in Eq. (9), and directly assign unmatched values to that channel. The score of newly added rows and columns is a fixed value, which can also be obtained through training.
Where S∈RH×W, represents the allocation matrix,‾S∈R(H+1)×(W+1) represents the augmented matching matrix, and each row represents the matching probability between a point and other points to be matched. Since each point can only have one matching point at most, the sum of values in each row of ‾S is 1. Finally, the Sinkhorn algorithm is used to solve for the maximum value of the ‾S allocation matrix, resulting in the optimal allocation result.
PROSAC optimization
Currently, traditional feature optimization methods often adopt the Random Sample Consensus (RANSAC) algorithm. However, since RANSAC selects data randomly without considering the difference in data quality, it may lead to difficulties in convergence under certain circumstances. To overcome this limitation, this paper introduces the PROSAC algorithm. The PROSAC algorithm adopts a semi-random approach. It evaluates the quality of matching point pairs, sorts them in descending order based on their quality, and gives priority to selecting high-quality point pairs. PROSAC can effectively reduce the computation time of the algorithm. Moreover, in cases where RANSAC fails to converge, its semi-random selection method can still ensure the convergence of the algorithm, thereby obtaining more accurate feature point-matching results. Figure 8 shows the results without optimization and the results further optimized with PROSAC. The matching relationship between the recognition image feature points and the sorting image feature points in the figure is connected by colored lines.

The match experiment.
From Fig. 8, we can see that there are some feature point pairs matching errors in Fig.(c), which leads to a deviation in the matching results indicated by the blue box in Fig.(e). However, after using the PROSAC algorithm for optimization, the mismatched feature point pairs were filtered out as shown in Fig.(d). The blue box in Fig.(e) outputs the correct result.
Experiment
Experimental environment and image acquisition
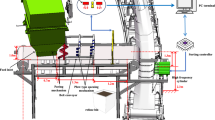
The experiment adopts the existing experimental platform of the coal gangue sorting robot of our team, and the experimental middling coal gangue sorting robot is a truss structure. The entire system consists of a belt conveyor, a coal gangue recognition system, a robotic arm sorting system, a robot control system, and a visual servo system. As shown in Fig. 9.

The coal gangue sorting robot system.
The experimental hardware environment is a PC with processor i7-10700, 16 GB of memory, NVIDIA GeForce RTX 2060 GPU, and MV-HS050GC Vickers camera. The industrial camera obtains 1000 images of coal and gangue from the gangue recognition system, including 500 images of coal and gangue respectively. The pixels of the coal gangue recognition image and sorting image are 455\(\:\times\:\)360 and 1440\(\:\times\:\)1080, respectively. We expanded the original samples to 10,000 by translating, rotating, and scaling the sample images, and constructed a coal gangue recognition sample library to ensure the rich diversity of the samples. Partial recognition images are shown in Fig. 10. The Gangue Dataset contains mixed images of coal gangue under scale object distance, rotation angle, and scale transformation.As shown in the Fig. 11, they are respectively referred to as GD-OT, GD-RT, and GD-ST datasets.

The recognition images.

The dataset images.
Experimental results and analysis
The eye in hand camera installation mode was used in the experiment. Due to differences in object distance, scale, rotation angle, and other factors, images captured in different regions may be affected. Therefore, matching experiments were conducted to verify the recognition images and sorting images under the above conditions. Precision (P), Recall (R), PR curve, and matching time (T) are used as evaluation indicators28.
NTP, NFP, and NP represent the numbers of true positive matching points, false positive matching points, and the total numbers of matching points, respectively.
The matching results of our algorithm under different conditions are shown in Figs. 12, 13, 14 and 15. The colored dots in the image are the detected feature points and matching points connected by colored lines.
Comparison experiment of matching different object distances
We set the scale of the image in our experiment to α .The rotation angle is 0°. To test the matching performance of the algorithm at different object distances, sorting images of different object distances were collected in the sorting area, where the vertical distances between the robotic manipulator and the belt were 80 cm, 70 cm, 60 cm, and 50 cm, respectively. Figure 12 shows the results of the matching experiment of our algorithm on coal gangue recognition images and sorting images with different object distances.

The Match results of different object distances.
From the matching results in Fig. 12, it can be seen that our method can correctly match the target coal gangue at different object distances. To further demonstrate the effectiveness of the algorithm proposed in this paper, the Descent-based Dense Feature Network (D2-Net) feature matching method29, MatchNet matching method30, Superpoint-Superglue (SP-SG) matching method31, LR-Superglue(LR-SG)matching method32, and DBSCAN-Superglue(DBSCAN-SG) matching method33 were used to match the coal gangue recognition image with the coal gangue sorting image.
Table 3 records the experimental data of matching rates and matching times for different methods, and takes the average value as the result.
The experimental results indicate that as the object distance increases, the matching rates of the six methods begin to decrease, and the matching time does not change significantly. Except for the method in this article, the matching rates of the other five methods have significantly decreased. Our method requires slightly longer time than SP-SG and DBSCAN-SG methods, but has higher matching accuracy. Our method maintains a matching rate of over 97% and a match time of less than 96ms.
Comparison experiment of matching different scales
We set the object distance of the coal gangue recognition image and sorting image to 50 cm, and the rotation angle is 0°. The scale factors are set to 0.3\(\:{\upalpha\:}\), 0.5\(\:{\upalpha\:}\), 0.7\(\:{\upalpha\:}\), and 0.9\(\:{\upalpha\:}\), respectively. Figure 13 demonstrates that our algorithm can match the target coal gangue under different scaling factors.

The Match results of different scales.
To further demonstrate the effectiveness of the algorithm proposed in this paper, the D2-Net feature matching method, MatchNet matching method, LR-SG matching method, DBSCAN-SG matching method and SP-SG matching method were used to match the coal gangue recognition image with the coal gangue sorting image. Table 4 records the experimental data of matching rates and matching times for different methods, and takes the average value as the result.
According to the results in Table 4, the following conclusions can be drawn. With the scale increases, the matching time of each method becomes longer, but the matching rate also gradually increases. Our method has significant advantages in speed and matching rate compared to other methods, such as D2-Net and MatchNet. The LR-SG method is more sensitive to scale transformations. The DBSCAN-SG method requires less time, but its matching accuracy performs poorly. Our method has a higher matching rate than the SP-SG algorithm and maintains a matching rate of around 98%.
Comparative experiments on different rotation angles
We set the object distance to 50 cm and the scale factor to \(\:{\upalpha\:}\). We only change the rotation angle, and other experimental conditions remain unchanged. We rotate at angles of -90°, -45°, 45°, and 90°, respectively. Under experimental conditions, obtain coal gangue sorting image samples with different rotation angles, where the clockwise rotation direction is positive. Using the algorithm proposed in this article, matching experiments were conducted on different rotation angles, as shown in Fig. 14.

The Match results of different rotation angles.
To further demonstrate the effectiveness of the algorithm proposed in this paper, the D2-Net feature matching method, MatchNet matching method, LR-SG matching method, DBSCAN-SG matching method and SP-SG matching method were used to match the coal gangue recognition image with the coal gangue sorting image. Table 5 records the experimental data of matching rates and matching times for different methods, and takes the average value as the result.
According to Table 5, when the rotation angle is between − 90° and 90°, the matching of the six methods first increases and then decreases, with the highest matching rate occurring at a rotation angle of 0°. In terms of matching time, the matching time of the six methods first decreases and then increases, with the shortest matching time occurring when the rotation angle is 0°. Our method still maintains a matching rate of over 98.1% and a matching time of less than 95ms, indicating significant advantages over other methods.
The matching results of complex conditions
The scene of coal gangue sorting is dynamically changing. There may be water stains, coal slag, and coal foreign objects on the belt. Therefore, algorithms were added for validation in these situations, and the results are shown in Fig. 15. The experiment includes matching results under different object distances, angles, and scales.

The comparison of matching results.
From the experimental results, it can be seen that although the matching environment is complex. But it can still perfectly match the target gangue. The Precision, Recall and matching time are 98.2%, 98.3%, and 84.6 ms, respectively. It has achieved good performance.
In summary, we have compiled the average matching results under different experimental conditions, as shown in Table 6. From the table, it can be seen that the average matching rate of this method for coal gangue recognition images and sorting images is 98.2%, with an average matching time of 84.6ms. It has the characteristics of a high matching rate, good real-time performance, and strong robustness. The performance advantage of our method can further improve the accuracy of coal gangue sorting robots.
In addition, the comparison results of our method with other matching performance are shown in Fig. 16. The larger the area of the envelope of the P-R curve (where P is precision and R is recall), the higher the precision.

P-R Curves.
Discussion and conclusion
In light of alterations in the pose of the target gangue during transmission, this paper puts forth an IMSSP-Net gangue image fast matching method to re-obtain the pose information of the target coal gangue. The proposed method will facilitate enhanced precision and efficiency in the robot’s grasping capabilities. Furthermore, to address the issue of the low matching rate of conventional methods in complex contexts, the SuperPoint and SuperGlue networks are combined to achieve precise and effective matching between gangue recognition and sorting images. To address the limited feature extraction capability of traditional methods, the improved MSRCR is adopted to enhance the feature point detection capability of the SuperPoint algorithm. For the matching results, the PROSAC method is used to refine and filter the matched features, thereby improving the matching precision. The experimental results demonstrate that the proposed IMSSP-Net Net method is more suitable for the research of coal gangue image matching. Compared with other algorithms, our algorithm can be applied to coal gangue sorting in complex environments. The average matching precision of the algorithm is 98.2%, and the time is 84.6ms. At present, the matching time and precision can meet the sorting tasks of coal gangue sorters well, but further research and improvement are needed to address the phenomenon of stacking in large coal throughput.
Data availability
The original contributions presented in the study are included in this article, further inquiries can be directed to the corresponding author.
References
Wang, G., Fan, J., Xu, Y. & Ren, H. Innovation process and prospect on key technologies of intelligent coal mining. J. Ind. Mine Autom. 44 (2), 5–12 (2018).
Wang, P. et al. A cooperative strategy of multi-arm coal gangue sorting robot based on immune dynamic workspace. Int. J. Coal Prep. Util. 43 (5), 794–814. https://doi.org/10.1080/19392699.2022.2078808 (2023).
Ma, H., Zhang, Y., Wang, P., Wei, X. & Zhou, W. Research on key generic technology of multi-arm intelligent coal gangue sorting robot. Coal Sci. Technol. 51 (01), 42736 (2023).
Zhang, Y. et al. Research on key technologies of intelligent gangue sorting robot.Journal of mine automation. Ind. Mine Autom. 48 (06), 69–76. https://doi.org/10.13272/j.issn.1671-251x.17931 (2022).
Zhang, N. et al. Precise detection of coal and gangue based on natural γ-ray. Sci. Rep. 14, 1276. https://doi.org/10.1038/s41598-024-51424-w (2024).
He, X. et al. Application of unmanned aerial vehicle (UAV) thermal infrared remote sensing to identify coal fires in the Huojitu coal mine in Shenmu city, China. Sci. Rep. 10, 13895. https://doi.org/10.1038/s41598-020-70964-5 (2020).
Zhang, L., Sui, Y., Wang, H., Hao, S. & Zhang, N. Image feature extraction and recognition model construction of coal and gangue based on image processing technology. Sci. Rep. 12, 20983. https://doi.org/10.1038/s41598-022-25496-5 (2022).
Yang, J., Yuan, Q., Liang, J. & Ye, K. Research of fast sorting method of Multi-objective Workpiece based on Linemod-2D and Otsu. Modular Mach. Tool. Autom. Manuf. Tech. 10 (10), 79–82. https://doi.org/10.13462/j.cnki.mmtamt.2022.10.017 (2022).
Yao, M., Zhang, X. & Xia L.Visual localization and classification of regular objects based on improved template matching. LASER J. 43 (05), 139–144. https://doi.org/10.14016/j.cnki.jgzz (2022).
Wang, J., Liu, L., Yao, T. & Zhang, R. Research on the application of Improved ORB Algorithm in RoboticSorting System. J. Huaiyin Inst. Technol. 31 (03), 53–58 (2022).
Wei, W., Zhang, X., Zhu, Y. & Improved SIFT Algorithm combined with Cosine Similarity for Face Matching. Comput. Eng. Appl. 56 (06), 207–212 (2020).
Zhao, Y., Zhai, Y., Dubois, E. & Wang, S. Image matching algorithm based on SIFT using color and exposure information. J. Syst. Eng. Electron. 27 (3), 691–699 (2016).
Chen, X. et al. Rail profile matching method based on stepped calibration plate and improved SURF algorithm. Eng. Res. Express. 5 (2). https://doi.org/10.1088/2631-8695/ACD98D (2023).
Gogan Taylor, B. & Jennifer, O. Julian. Image variability and face matching. Perception. 51(11), 804–819. https://doi.org/10.1177/03010066221119088 (2022).
Cui, J., Sun, C., Li, Y., Fu, L. & Wang, P. Animproved algorithm for fast image matching based on SURF. Chin. J. Sci. Instrum. 43 (08), 47–53. https://doi.org/10.19650/j.cnki.cjsi.J2209747 (2022).
Song, C., Xu, S., Yang, Y. & Hua, M. Binocular Vision Measurement Method using improved FAST and BRIEF. Laser Optoelectron. Progress. 59 (08), 173–180. https://doi.org/10.3788/LOP202259.0810013 (2022).
Zhou, L. & Jiang, F. Image matching algorithm based on FAST and BRIEF. J. Comput. Eng. Des. 36 (05), 1269–1273 (2015).
Zhong, P., Li, W. & Liu, J. Workpiece Image Reco-Gnition Method based on Improved ORB Algorithm. J. Mach.Tool Hydraul.. 48 (21), 12–16. https://doi.org/10.3969/j.issn.1001-3881.2020.21.003 (2020).
Liao, H., Wang, L., Sun, H. & Liu, Y. An improved ORB feature matching algorithm. J. Beijing Univ. Aeronaut. Astronaut. 47 (10), 2149–2154 (2021).
Wang, J., Liu, L., Yao, Tan, S. & Zhang Research on the application of Improved ORB Algorithm in RoboticSorting System. J. Huaiyin Inst. Technol. 31 (03), 53–58 (2022).
DeTone, D., Malisiewicz, T., Rabinovich, A. & Superpoint Selfsupervised interest point detection and description. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE. 224–236. (2018).
Liu, Y., Zhu, L., Yamada, M. & Yang, Y. Semanticcorrespondence asan optimal transport problem. J. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 4462-4471https://doi.org/10.1109/CVPR42600.2020.00452 (2020).
Liu, K. et al. A robust network for adaptive multisource image registration based on SuperGlue. J. Digit. Signal. Process. 140. https://doi.org/10.1016/J.DSP.2023.104128 (2023).
Sarlin, P. E., DeTone, D., Malisiewicz, T. & Rabinovich, A. Superglue: learning feature matchi-ng with graph neural networks. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle. 4938–4947. (2020). https://doi.org/10.1109/CVPR42600.2020.00499
Yuan, X., Jie, S., Jian, W., Jin, X. & Wei, L. Automated multispectral remote sensing image registration using local self-similarity. Acta Geodaetica Cartogr. Sin. https://doi.org/10.13485/j.cnki.11-2089.2014.0039 (2014).
Wang, Y., Liu, J., Saliency Object Detection Method Based on Power Law Transformation and Algorithm, I. G. L. C. Comput. Eng. Appl. 55(14):168–176. https://doi.org/10.3778/j.issn.1002-8331.1811-0300 (2019).
Li, K., Wang, L., Liu., Ran, Q., Xu, K. & Guo, Y. Decoupling makes weakly supervi-sed local feature better. arXive-prints. 15817–15827. https://doi.org/10.48550/arXiv.2201.02861 (2022).
Jian, F., Fan, L., Jian, H., Zhao, J. & He, Z. Infrared small dim target detection under maritime near sea-sky line based on regional-division local contrast measure. IEEE Geosci. Remote Sens. Lett. 1–5. https://doi.org/10.1109/LGRS.2023.3316272 (2023).
Zhao, J., Yang, D., Li, Y., Xiao, P. & Yang, J. Intelligent Matching Method for Heterogeneous Remote sensing images based on style transfer. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens.6723-6731https://doi.org/10.1109/JSTARS.2022.3197748 (2022).
Ye, Y., Teng, X., Yu, Q. & Li, Z. Optical-SAR image matching based on MatchNet and multi-point matching constraint. Acta Aeronautica et Astronaut. Sinica. 45 (10), 230–247. https://doi.org/10.7527/S1000-6893.2023.29162 (2024).
Li, S., Zhou, B., Yang, B., Ali, F. & Liang, Z. Feature tracking and matching for w-ide baseline images with closed-loop sequence. Comput. Electr. Eng. https://doi.org/10.1016/j.compeleceng.2023.108871 (2023).
Yuan, X., Chen, J., & Wang, X. Large aerial image Tie Point matching in real and difficult Survey areas via Deep Learning Method. Remote Sens. 14 (16), 3907–3907. https://doi.org/10.3390/rs14163907 (2022).
Hao, W., Wang, P., Ni, C., Zhang, G. & Huangfu, W. SuperGlue-based accurate feature matching via outlier filtering. VIsual Comput. 40, 3137–3150. https://doi.org/10.1007/s00371-023-03015-5 (2024).
Acknowledgements
Thanks to the National Natural Science Foundation of China (Grant No. 51975468) for the funding and all the authors of this article.
Funding
This work was supported by the National Natural Science Foundation of China (51975468), the program of Shaanxi Natural Science Foundation (2023-JC-YB-362) and the Natural Science Foundation of Shaanxi Provincial Department of Education (23JK0548).
Author information
Authors and Affiliations
Contributions
Y.Z. conceived the study. H.W.M., P.W. and W.J.Z. were the principal investigators; X.G.C. and M.Z.Z. directed the overall study design; Y.Z., H.W.M. and P.W. performed the experiments; X.G.C. and M.Z.Z. analyzed the data; Y.Z. wrote the manuscript. All authors discussed and interpreted the results.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ye, Z., Hongwei, M., Peng, W. et al. Research on efficient matching method of coal gangue recognition image and sorting image. Sci Rep 14, 25536 (2024). https://doi.org/10.1038/s41598-024-75654-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-75654-0
