
Abstract
Grounded Situation Recognition (GSR) aims to generate structured image descriptions. For a given image, GSR needs to identify the key verb, the nouns corresponding to roles, and their bounding-box groundings. However, current GSR research demands numerous meticulously labeled images, which are labor-intensive and time-consuming, making it costly to expand detection categories. Our study enhances model accuracy in detecting and localizing under data scarcity, reducing dependency on large datasets and paving the way for broader detection capabilities. In this paper, we propose the Grounded Situation Recognition under Data Scarcity (GSRDS) model, which uses the CoFormer model as the baseline and optimizes three subtasks: image feature extraction, verb classification, and bounding-box localization, to better adapt to data-scarce scenarios. Specifically, we replace ResNet50 with EfficientNetV2-M for advanced image feature extraction. Additionally, we introduce the Transformer Combined with CLIP for Verb Classification (TCCV) module, utilizing features extracted by CLIP’s image encoder to enhance verb classification accuracy. Furthermore, we design the Multi-source Verb-Role Queries (Multi-VR Queries) and the Dual Parallel Decoders (DPD) modules to improve the accuracy of bounding-box localization. Through extensive comparative experiments and ablation studies, we demonstrate that our method achieves higher accuracy than mainstream approaches in data-scarce scenarios. Our code will be available at https://github.com/Zhou-maker-oss/GSRDS.
Similar content being viewed by others
Introduction
In recent years, research tasks in Computer Vision (CV) have evolved from traditional image recognition to understanding and interpreting the content of an image. For example, Image Captioning1,2,3,4 generates corresponding texts based on an input image. Visual Spatial Description (VSD)5,6 provides a comprehensive understanding of scenes by modeling spatial relationships. Human-Object Interaction (HOI) detection7,8 aims to detect people and objects with interaction relationships and their interaction actions in an image. In order to understand complex visual events, many studies9,10,11,12,13,14,15,16 investigate Grounded Situation Recognition (GSR), which is a task that requires the generation of structured descriptions of an image and encompasses several domains such as image classification, object detection, and image understanding. Specifically, for a given image, GSR first needs to identify the key verb depicted in the image. Guided by this verb and the associated roles, GSR then identifies the corresponding nouns and their bounding-box groundings. Taking the first example in Fig. 1 as an illustration, GSR task involves recognizing the verb ramming and identifying the nouns (wrestler, foot, adversary, \(wrestling\ ring\)) corresponding to roles (agent, \(ramming\ item\), victim, place), while also predicting the bounding-box groundings of these entities.
Currently, GSR is primarily studied using the SWiG dataset9, which comprises 126,102 meticulously annotated images categorized into 504 verb classes. Each category includes 150-350 images, and three workers annotate each image for nouns and bounding-box groundings to ensure accuracy. The high cost of constructing the SWiG dataset makes adding new categories very expensive, limiting the detection and application effectiveness of GSR in different scenarios. To address this challenge, our study investigates GSR under the condition of data scarcity for the first time. We employ random sampling strategies on the SWiG dataset to construct scaled-down datasets representing 1/2, 1/4, 1/8, 1/12, and 1/16 of the original size to simulate data scarcity scenarios. Importantly, we conduct random sampling separately for each of the 504 verb categories, ensuring that the resulting datasets still encompass all 504 categories. Studying GSR on scarce datasets can effectively reduce the model’s data requirements and subsequently lower annotation costs, facilitating the expansion of research into broader categories for GSR.

Four examples of GSR. GSR needs to correctly identify the verb ramming, as well as the nouns and bounding-box groundings corresponding to the roles associated with the verb.
In data-scarce scenarios, GSR research faces critical challenges: the model needs to extract as much comprehensive information as possible from limited data to accurately understand and infer the content of an image. We divide the research task into three steps: (1) extracting image features; (2) classifying the key verb in the image; (3) performing noun classification and bounding-box localization based on the detected verb. We use the CoFormer model as the baseline and implement corresponding improvements to each step to adapt to data-scarce scenarios, culminating in the proposal of the Grounded Situation Recognition under Data Scarcity (GSRDS) model.
In this study15, the authors pointed out that the ability of the backbone network to extract advanced image features greatly influences the overall performance of the CoFormer model. Inspired by this, we attempt to select a superior backbone network to extract image features. We note that the EfficientNet family17 offers advantages across three key aspects: classification accuracy, model size, and training speed. EfficientNetV1, introduced by Google in 2019, employs a straightforward yet efficient compound scaling method that uses a set of fixed scaling coefficients to uniformly scale network width, depth and resolution, resulting in improved performance. EfficientNetV218, an upgraded version of EfficientNetV1, enhances both training speed and parameter efficiency through a combination of training-aware neural architecture search and scaling. We choose EfficientNetV2-M as the backbone to replace ResNet5019, and experimental results demonstrate that this approach effectively improves all performance metrics.
After extracting image features, the next step is to classify the key verb in the image. As illustrated in the four examples in Fig. 1, the verb ramming can denote person-to-person, object-to-object, and person-to-object interactions. Therefore, achieving a deep semantic understanding of the image is crucial for accurately identifying the key verb. However, learning sufficient semantic features from limited samples to classify the key verb accurately under data scarcity poses a significant challenge for models. Recent studies have demonstrated that several deep learning models can learn rich feature representations through pre-training on large-scale datasets. The CLIP model20, released by OpenAI in 2021, stands out in this regard. Trained on 400 million image-text pairs using contrastive learning, CLIP has shown impressive capabilities in learning cross-modal representations. Inspired by the approach proposed by Jiang et al.14, we introduce the Transformer Combined with CLIP for Verb Classification (TCCV) module. TCCV integrates features extracted by CLIP’s image encoder with those from a Transformer encoder, which together serve as inputs to the verb classifier. This approach leverages the global features extracted by CLIP’s image encoder to compensate for potentially insufficient feature representation due to data scarcity. Consequently, it enhances the model’s ability to understand image semantics and maintains high accuracy in verb classification even under the condition of data scarcity.
Improving verb classification accuracy simultaneously enhances noun classification and bounding-box localization accuracy. Additionally, our study specifically focuses on enhancing the model’s ability in bounding-box localization. To achieve this, we design the Multi-source Verb-Role Queries (Multi-VR Queries) and the Dual Parallel Decoders (DPD) modules. Previous approaches10,11,12,13,15 typically incorporated only verb embedding vectors and their corresponding role embedding vectors within their semantic role queries module, overlooking the rich semantic information about each role present in the annotation files-specifically, the definition of each role relative to its corresponding verb. We consider this information crucial for object detection. Therefore, we utilize CLIP’s text encoder to encode role definitions and integrate them with the original semantic roles to form the Multi-VR Queries module. Additionally, drawing inspiration from conditional spatial queries in Conditional DETR21, we design the DPD module. The DPD module retains the Gaze-Step2 Transformer from CoFormer and introduces an additional parallel decoder that incorporates conditional spatial queries21. These queries assist in narrowing down the spatial scope for object classification and bounding-box regression, thereby reducing reliance on content embeddings and simplifying training. With these enhancements, our model demonstrates improved capability in the bounding-box localization task, effectively enhancing detection accuracy.
In summary, we randomly sample five small-scale datasets from the SWiG dataset based on verb categories to design the GSRDS model. This model uses CoFormer12 as the baseline and introduces improvements in image feature extraction, verb classification, and bounding-box localization to suit GSR task under the condition of data scarcity. Our contributions are outlined as follows:
-
Our work focuses for the first time on the high-quality requirement of labeled data for GSR and the high cost required for subsequent expansion of detection categories. We propose the GSRDS model to cope with GSR tasks in data-scarce scenarios, reducing the data volume requirement of GSR tasks and laying the foundation for future work on expanding the range of GSR detection categories;
-
The GSRDS model replaces ResNet50 with EfficientNetV2 for feature extraction and introduces the TCCV module for verb classification. Additionally, it incorporates the Multi-VR Queries and DPD modules for bounding-box localization. Experimental results demonstrate that GSRDS significantly improves on all metrics compared to other models under the condition of data scarcity;
-
We extract 1/2, 1/4, 1/8, 1/12, and 1/16 of the SWiG dataset to create five small-scale datasets simulating scenarios of data scarcity. Extensive experiments validate the effectiveness of our approach through comparative experiments and ablation studies.
The remainder of this paper is structured as follows: the Related Work section discusses related work in GSR. The Methods section provides a detailed introduction to the GSRDS model and its components. The Experimental Results and Discussion section details the experimental procedures, including comparative experiments and ablation studies to validate our approach. Finally, the Conclusions section presents the conclusions drawn from our work.
Related work
GSR builds upon the Situation Recognition (SR) task, which integrates tasks of inferring objects and actions to achieve a more complete and systematic understanding of images. In addition to SR, GSR introduces the localization of bounding-boxes. It expands the imSitu22 dataset by incorporating entity bounding-box labeling information, resulting in the SWiG dataset. Thus, GSR can be characterized as a multifaceted task that combines image understanding, object interaction recognition and object detection. Below, we provide an overview of related work on SR and GSR.
SR
In 2016, Yatskar et al.22 first proposed the SR task, where they constructed a triple correlation (verb, semantic roles, nouns) from FrameNet and WordNet, created the imSitu dataset, and devised a Conditional Random Field (CRF) model to co-predict verbs and nouns through structured learning. Subsequently, Yatskar et al.23 picked up the previous work and introduced a tensor composition function with semantic enhancement for sharing nouns across different roles, reducing the effect of semantic sparsity. Mallya et al.24 innovatively employed a fusion network25 to predict action verbs. They then used a Recurrent Neural Network (RNN)26 to predict noun roles in fixed sequences based on these verbs and visual features. Li et al.27 proposed a Graph Neural Network (GNN)28-based model to efficiently capture joint dependencies between roles. Cooray et al.29 approached semantic role prediction as a query-based visual reasoning challenge, introducing the first method to handle interdependent queries in this context. Suhail et al.30 devised a hybrid kernel attention GNN architecture that incorporates dynamic graph structures using graph attention mechanisms and context-aware interactions between role pairs during both training and inference phases.
GSR
In 2020, Pratt et al.9 expanded the imSitu dataset by incorporating 278,336 bounding-box groundings across its 11,538 entity classes, forming the SWiG dataset. They introduced the Independent Situation Localizer (ISL) and the Joint Situation Localizer (JSL), demonstrating through experiments that end-to-end joint prediction of situations and groundings outperforms independent training. Cho et al.10 were the first to apply Transformer architecture to the GSR task, proposing the Grounded Situation Recognition with Transformers (GSRTR) model. This model feeds image features into a Transformer encoder to capture rich semantic features crucial for accurate verb prediction, while a decoder handles noun predictions and bounding-box localizations. Wei et al.11 introduced the SituFormer model, which features a Coarse-to-Fine Verb Model (CFVM) and a Transformer-based Noun Model (TNM). CFVM enhances verb detection accuracy through a two-step prediction process, while TNM effectively utilizes the statistical dependencies among roles. Cho et al.12 proposed the Collaborative Glance-Gaze TransFormer (CoFormer), integrating interactive and complementary verb classification and entity estimation mechanisms. Cheng et al.13 developed the GSRFormer model, which exploits potential open semantic relations within verbs and nouns, iteratively updating their features to enhance flexibility and performance. Jiang et al.14 incorporated common-sense knowledge of objects depicted in images into a Transformer-based model, demonstrating improved performance by integrating knowledge about the prototypical functions of physical objects in the SR task. Liu et al.15 proposed the Open Scene Understanding (OpenSU) model, leveraging the Swin Transformer31 for advanced image feature extraction and GELU32 to expedite convergence. Roy et al.16 introduced the ClipSitu model, which employs CLIP embeddings of images in a simple multilayer perceptron (MLP) for verb prediction. Additionally, they developed a cross-attention-based Transformer that leverages CLIP visual tokens to model the relationship between textual roles and visual entities.
Methods
This section provides a detailed description of the study, including the task definition, an overview of the methodology, the design of each GSRDS module, and the calculation of loss.
Task definition
Given an image I, a set of verbs V, a set of semantic roles R, and a set of nouns N, the task of GSR is to identify a set of structured descriptions \(D=\{v_I, R_v, N_I, B_I\}\) for I. Here, \(v_I\) represents the key verb (each image corresponds to one verb), denoted by \(v_I=painting\) in Fig. 2. For each \(v_I\in V\), a corresponding frame from FrameNet is matched, providing a set of semantic roles \(R_v=\{r_1,r_2,\cdots ,r_m\}\subset R\) associated with that verb, represented in Fig. 2 as \(R_v=\{agent, item, tool, place\}\). The set of nouns corresponding to these semantic roles is denoted as \(N_I=\{n_1,n_2,\cdots ,n_m\}\subset N\), represented in Fig. 2 as \(N_I=\{man, picture, brush, outside\}\). The set of bounding-box coordinates corresponding to the semantic roles is denoted by \(B_I=\{b_1,b_2, \cdots ,b_m\}\), where each item \(b_i\in \mathbb {R}^4\). Note that not all semantic roles have corresponding nouns and bounding-boxes in I; hence, \(n_i\) and \(b_i\) can be \(\emptyset\). In Fig. 2, the GSR predictions are shown on the right. The colored boxes indicate the coordinates of the predicted bounding-boxes. Since place has no bounding-box, it is labeled \(\emptyset\).

GSRDS model architecture. The model extracts image features using EfficientNetV2-M and combines them with positional embeddings as input. The TCCV module classifies verbs using features extracted by both the Transformer encoder and CLIP’s image encoder. The Multi-VR Queries module integrates verbs, roles, and their definitions into object queries, which are input into the DPD module alongside aggregated image features from the Glance Transformer. The DPD module comprises the Gaze-Step2 Transformer and the Transformer Con-Decoder, which predict nouns and bounding-boxes corresponding to semantic roles. These predictions are averaged and then processed by three Feed-Forward Network (FFN) branches to generate the final predicted results.
Overview
We choose CoFormer as our baseline model and optimize it for image feature extraction, verb classification, and bounding-box localization. CoFormer, based on the DETR33 model, utilizes interactive and complementary mechanisms for verb classification and entity estimation. It introduces the Glance Transformer for verb classification and the Gaze Transformer for entity estimation. The Glance Transformer aggregates image features via self-attention to predict verbs. The Gaze Transformer operates in two stages: Gaze-Step1 Transformer estimates nouns for all candidate entities, aiding the Glance Transformer in making more precise verb predictions. Gaze-Step2 Transformer uses aggregated image features obtained by the Glance Transformer to predict the noun and bounding-box for each entity associated with the predicted verb.
We utilize EfficientNetV2-M as the backbone instead of ResNet50 to enhance the model’s capability for image feature extraction. Additionally, we employ CLIP’s image encoder for encoding images. The encoded features are then fused with those obtained from the Glance Transformer and the Gaze-Step1 Transformer, respectively, and concatenated as input to the verb classifier. This enhancement significantly improves the accuracy of verb classification.
Furthermore, our work strengthens the model’s ability in bounding-box localization. Specifically, we introduce the Multi-VR Queries module to integrate richer semantic information into the original semantic role queries. Additionally, the DPD module is developed to introduce conditional spatial queries in the Conditional DETR decoder. These two modules synergistically enhance the accuracy of bounding-box localization.
The architecture of the GSRDS model is depicted in Fig. 2. Detailed descriptions of each module of the GSRDS model and the computation of the loss function are provided below.
Image feature extraction
We select the backbone network based on criteria such as classification accuracy, model size and training speed, and the EfficientNetV2 family of networks emerges as the top choice. EfficientNetV2 integrates neural architecture search and scaling techniques, introducing an enhanced asymptotic learning method that performs notably well on the ImageNet ILSVRC2012 dataset34. After thorough consideration, we adopt EfficientNetV2-M as the backbone to replace ResNet50. For an input image \(I \in \mathbb {R}^{3 \times H \times W}\), where 3 represents the three channels of the RGB image, and H and W denote the image height and width respectively, the feature map obtained after extraction is denoted as \(X_F \in \mathbb {R}^{c \times h \times w}\). Here, c denotes the number of channels, and \(h \times w\) represents the resolution of the feature map. We select the final layer of the output feature map as it aggregates rich semantic information at a relatively low resolution. Subsequently, the channel dimension c is adjusted to d using a \(1 \times 1\) convolution, where d is a global hyperparameter. Finally, the spatial dimensions of \(X_F\) are flattened into one dimension and the dimensional order is rearranged. After these operations, the image features are represented as \(X_F \in \mathbb {R}^{hw \times d}\).
TCCV module
In CoFormer, the image features \(X_F\) are combined with their positional embeddings as input features. After passing through the Glance Transformer, aggregated image features \(X_A \in \mathbb {R}^{hw \times d}\) and IL token are obtained. Similarly, after passing through the Gaze-Step1 Transformer, aggregated role features \(R_A\in \mathbb {R}^{R\times d}\) and RL token are obtained. Among them, IL is Image-Looking, which captures basic features for verb prediction. RL is Role-Looking, which captures nouns and their relations from all role candidates. The IL token and RL token are concatenated and then input into the FFN for verb classification. However, in data-scarce scenarios, using only IL and RL tokens provides limited information.
Given the powerful feature extraction capabilities of CLIP, we consider utilizing its image encoder to encode the image, thereby obtaining the global features of the image. We then apply a linear transformation to adjust the number of channels to d, denoted as \(X_{CLIP\_F} \in \mathbb {R}^{1 \times d}\). Subsequently, \(X_{CLIP\_F}\) is added to IL and RL to obtain \(CLIP\_IL\) and \(CLIP\_RL\), respectively. Finally, \(CLIP\_IL\) and \(CLIP\_RL\) are concatenated and input into the verb classifier \({FFN}_{Verb}\), which is a simple MLP. The formulas are depicted in equations (1) and (2).
where \(\varphi _v \in \mathbb {R}^{|V|}\) represents the logits for each verb category, and \(\hat{v}\) is the predicted verb obtained through argmax.
Multi-VR queries module
In previous works10,11,12,13,15, each semantic role query \(w_{(v,r)}\in \mathbb {R}^d\) is typically constructed by concatenating or adding the verb embedding vector \(w_v \in \mathbb {R}^d\) with the corresponding role embedding vector \(w_r \in \mathbb {R}^d\). Here, \(r \in R_v\), where \(R_v\) denotes the roles associated with the verb v. This approach limits each semantic role query to capture only two-word information. We propose incorporating the definition of each role associated with a specific verb to enrich the semantic role queries. For instance, in Fig. 2, the verb painting includes four roles: \(\{agent, item, tool, place\}\), with their definitions detailed in the Role_Def section of Fig. 2. Utilizing CLIP’s text encoder, we encode the definition of each role within painting, resulting in encoded representations \(w_{CLIP\_r} \in \mathbb {R}^d\). Subsequently, we augment the original semantic role queries by adding this encoded information, forming the Multi-VR Queries \(Q_{multi} = {w_{(v, r, CLIP\_r)} \in \mathbb {R}^d}\).
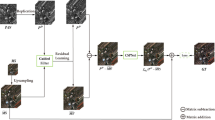
DPD module
To enhance accuracy in bounding-box localization for the GSR task under data scarcity, we introduce conditional spatial queries inspired by Conditional DETR. Specifically, we incorporate a Transformer Con-Decoder, positioned alongside the Gaze-Step2 Transformer to form the DPD module, as illustrated in Fig. 3. The gray box retains the conditional spatial queries similar to those in Conditional DETR, predicting jointly with learnable 2D coordinates s and the output of the previous decoder layer. Each decoder is a stack of three layers, with each layer composed of Multi-Head Self-Attention (MHSA), Multi-Head Cross-Attention (MHCA), and FFN blocks. They take aggregated image features \(X_A\), positional embeddings, and \(Q_{multi}\) as inputs. However, the Transformer Con-Decoder applies LayerNorm after each module, contrasting with the Gaze-Step2 Transformer, which applies it before. The Transformer Con-Decoder introduces conditional spatial embeddings as spatial queries in MHCA; the spatial query (key) and content query (key) are concatenated rather than added for combination. Both decoders capture nouns and their relationships with the associated verbs. Finally, features from both decoders are averaged and input into three classifiers for noun classification, bounding-box regression, and bounding-box existence prediction.

DPD module diagram. The module comprises the Gaze-Step2 Transformer and the Transformer Con-Decoder, which predict nouns and bounding-boxes corresponding to semantic roles. The gray box retains the conditional spatial queries similar to those in Conditional DETR.
Loss function
Similar to the works of Cho et al. 10,12, our loss function includes three components: verb classification loss, noun classification loss, and bounding-box prediction loss. Below, we explain each of these three types of losses.
Verb classification loss. As shown in equation (3), we compute the cross-entropy loss \(\mathcal {L}_{CE}\) between the predicted probability distribution \(p_{\hat{v}}\) of the verb \(\hat{v}\) and the true probability distribution \(p_{v}\) of the verb v, resulting in \(\mathcal {L}_{Verb}\).
Noun classification loss. We utilize three noun losses \(\mathcal {L}_{Noun}^1\), \(\mathcal {L}_{Noun}^2\), \(\mathcal {L}_{Noun}^3\) as employed in CoFormer. The computation of \(\mathcal {L}_{Noun}^1\) is depicted in equation (4), with the others computed similarly. Since the Transformer Con-Decoder and Gaze-Step2 Transformer are parallel, we compute \(\mathcal {L}_{Noun}^3\) by averaging the outputs from the noun classifier \({FFN}_{Noun}\). It’s important to note that during training, all three noun losses are employed, while during inference, only \(\mathcal {L}_{Noun}^3\) is required.
where \(|R_v|\) represents the number of roles associated with the ground-truth verb v. \(p_{\hat{n}_r}\) represents the predicted probability distribution of the noun corresponding to role r, and \(p_{n_r}\) represents the true probability distribution of the noun corresponding to role r. Note that we use the ground-truth verb during training, while we use the predicted verb during validation and inference.
Bounding-Box Prediction Loss. The bounding-box prediction loss comprises the bounding-box existence prediction loss and bounding-box regression loss. We take the output features of the Transformer Con-Decoder and Gaze-Step2 Transformer, pass them through \({FFN}_{BoxExist}\) and \({FFN}_{Box}\) respectively, and then average the results. The bounding-box existence prediction loss is computed as the cross-entropy loss between the predicted probability distribution \(p_{\hat{b}_r}\) of the bounding-box existence and the true probability distribution \(p_{b_r}\), as shown in equation (5).
where \(p_{{\hat{b}}_r}\in [0,1]\), \(p_{b_r}\in \{0,1\}\). The bounding-box regression loss consists of an L1 loss and a Generalized IoU (GIoU) loss35, denoted as \(\mathcal {L}_{L1}\) and \(\mathcal {L}_{GIoU}\) respectively. The calculations of these two losses are consistent with the work of Cho et al. 10.
Overall Loss. The overall loss \(\mathcal {L}_{Total}\) is shown in equation (6).
where \(\lambda _{Verb},\lambda _{Noun}^1,\lambda _{Noun}^2,\lambda _{Noun}^3,\lambda _{BoxExist},\lambda _{L1},\lambda _{GIoU}>0\), consistent with the hyperparameter settings in CoFormer.
Experimental results and discussion
This section introduces the experimental settings and presents the experimental results. The Experimental Settings subsection introduces the datasets, evaluation metrics, and parameter settings used in the experiments. The Experimental Results subsection presents comparative experiments, ablation studies, and qualitative model analyses.
Experimental settings
Datasets
Our data comes from the SWiG dataset, an extension of the imSitu dataset that includes bounding-box annotations for entities. SWiG comprises 126,102 images associated with 504 verbs and 190 semantic roles, with bounding-box annotations applied to 63.9% of non-empty entities. Each verb is associated with 1 to 6 semantic roles, with an average of 3.55. We partition the dataset into training/validation/test sets with sizes of 75K/25K/25K, following the methodology outlined in Pratt et al.9. To simulate data scarcity scenarios, we additionally sample subsets of 1/2, 1/4, 1/8, 1/12, and 1/16 of the original dataset based on verb categories for training. Notably, the sampled datasets maintain the same 504 verb categories. Table 1 shows the number of training, validation, and test samples for each verb under different sampling strategies. To ensure experimental accuracy and mitigate potential biases from data sampling, we conduct each experiment three times and average the results. During training, we use only the sampled training and validation sets, while the full dataset is used during inference.
Evaluation metrics
We adhere to the evaluation metrics outlined in Pratt et al. 9, encompassing five key aspects:
-
verb: Accuracy in verb classification;
-
value: Accuracy in predicting nouns for each semantic role;
-
value-all: Accuracy in predicting all nouns associated with the current verb;
-
grnd: Accuracy in predicting nouns and bounding-box groundings for each semantic role;
-
grnd-all: Accuracy in predicting all nouns and bounding-box groundings for all semantic roles associated with the current verb. Note that correct bounding-box grounding includes predicting the box’s existence and achieving an Intersection-over-Union (IoU) greater than 0.5 with the ground-truth box.
We report the above metrics across three verb settings: Top-1 Predicted Verb, Top-5 Predicted Verbs, and Ground-Truth Verb. In the Top-1 Predicted Verb setting, if the first predicted verb does not match the ground-truth verb, all metrics are considered prediction errors. In the Top-5 Predicted Verb setting, if any one of the top five predicted verbs matches the ground-truth verb, the verb prediction is considered correct, and the remaining metrics are computed based on the correct verb prediction. In the Ground-Truth Verb setting, the ground-truth verb is directly used as the known condition.
Parameter settings
We use EfficientNetV2-M pretrained on ImageNet as the backbone, extracting features from the final layer with dimensions \(h \times w \times c\), where \(h \times w = 22 \times 22\) and \(c = 512\). We employ CLIP ViT-B/32 to encode both the image features and textual features defining semantic roles. The embedding dimension d is set to 512, and reference points in the Transformer Con-Decoder are mapped to 512-dimensional sinusoidal positional embeddings. Other hyperparameters remain consistent with CoFormer. The model is trained on a single RTX 3090 GPU with a batch size of 4, over 40 epochs.
Experimental results
Comparative experiments
Our approach involves retraining and testing the GSRTR, CoFormer, and OpenSU models under data settings of 1/2, 1/4, 1/8, 1/12, and 1/16. We consider three criteria for selecting comparative models: (1) relevance to the GSR task; (2) utilization of the Transformer model architecture; (3) availability of publicly accessible model code and parameters.
GSRTR 10. In 2021, Cho et al. introduced the Transformer encoder-decoder architecture into the GSR task for the first time, proposing the GSRTR model. This model’s attention mechanism effectively captures advanced semantic features from images to accurately classify verbs and flexibly handles relationships between entities to improve noun classification and localization.
CoFormer 12. In 2022, Cho et al. focused on the interaction and complementarity between verb classification and entity estimation, proposing the CoFormer model. They designed the Glance Transformer for verb classification and the Gaze Transformer for entity estimation. The interaction between these two modules improved overall prediction accuracy. This model also serves as the baseline for the GSRDS model.
OpenSU 15. In 2023, Liu et al. introduced the OpenSU model, which utilizes the Swin Transformer instead of ResNet50 from CoFormer to extract image features for the GSR task. They employed GELU to shorten the convergence time. In this experiment, we use only the code corresponding to the GSR task, excluding its segmentation tasks.
To ensure fairness in training, we maintain all parameter settings unchanged from the original papers, except for standardizing the batch size to 4. The experimental results are presented in Table 2. They show that compared to OpenSU, our model achieves comprehensive improvements across all 14 metrics in the Top-1 Predicted Verb, Top-5 Predicted Verbs, and Ground-Truth Verb settings, especially in scenarios with data scarcity. Additionally, we observe minimal performance gaps between the test and validation sets, demonstrating the excellent generalization ability of GSRDS.
Taking the test experiment with 1/8 of the data as an example, compared to OpenSU, the GSRDS model shows notable improvements. Under the Top-1 Predicted Verb setting, verb accuracy increases by 8.17%, with value and value-all improving by 5.67% and 2.9%, respectively. Additionally, grnd value and grnd value-all rise by 4.54% and 1.75%, respectively. In the Top-5 Predicted Verbs setting, verb accuracy increases by 9.9%, with value and value-all improving by 6.81% and 3.02%, respectively, and grnd value and grnd value-all rise by 5.61% and 1.96%, respectively. These results demonstrate that the GSRDS model significantly enhances the performance of image feature extraction and greatly improves verb classification ability. This is attributed to the superior feature extraction capability of EfficientNetV2-M compared to ResNet50. Furthermore, incorporating features extracted by the CLIP’s image encoder in the verb prediction phase helps mitigate the issue of insufficient feature representation due to data scarcity, leading to excellent performance in verb classification. Since noun classification and bounding-box localization tasks rely on verb classification results, the improved verb prediction accuracy positively impacts noun classification and bounding-box localization. Under the Ground-Truth Verb setting, value and value-all improve by 0.41% and 0.43%, respectively, and grnd value and grnd value-all rise by 1.22% and 0.96%, respectively. The addition of the Multi-VR Queries module and DPD module enables the model to learn richer semantic information, resulting in substantial improvements in bounding-box localization performance compared to other models.
In Fig. 4(a), (b), and (c), we present the test experiment results of four models on the verb, value, and grnd value metrics under the Top-1 Predicted Verb setting, shown as line charts. It is evident that the GSRDS model demonstrates a significant advantage in this configuration. However, under the Ground-Truth Verb setting, as shown in Fig. 4(d) and (e), when the data volume exceeds 1/4 of the dataset, the performance of GSRDS is inferior to that of OpenSU, although it still outperforms CoFormer. We hypothesize that this is due to the superior feature extraction capabilities of the Swin Transformer used by OpenSU when the data volume increases.
To investigate this further, we conduct a series of related experiments using ResNet50, Swin Transformer, and EfficientNetV2-M as backbones, testing at data volumes of 1/2, 1/4, 1/8, 1/12, and 1/16. The results of these experiments are presented in Table 3. Our findings reveal that when data is relatively scarce, the EfficientNetV2-M model demonstrates favorable performance in extracting image features. This suggests that, under conditions of limited data availability, EfficientNetV2-M is particularly effective at leveraging the available information to generate meaningful feature representations. Conversely, as the data volume increases, the Swin Transformer exhibits superior performance in feature extraction. This shift indicates that with larger dataset sizes, the Swin Transformer’s architecture is better suited to capturing the complexities and variations inherent in the data, thereby enhancing its feature extraction capabilities. While our current investigation highlights these three models, it is important to acknowledge that other feature extraction models could potentially yield even more effective results. However, exploring these alternatives is beyond the scope of our study. Looking ahead, future work will delve into this aspect in greater detail, examining a wider array of feature extraction models and their performance across varying dataset sizes. This will provide a more comprehensive understanding of how different architectures respond to changes in data volume and inform the selection of models for specific applications in image feature extraction.

The first row of line graphs illustrates the test results for verb (a), value (b), and grnd value (c) metrics under the Top-1 Predicted Verb setting for four models. Additionally, the second row of line graphs showcases the results for value (d) and grnd value (e) metrics under the Ground-Truth Verb setting.
Ablation studies
We validate the impact of different modules on the model’s performance using the full validation set under data settings of 1/2, 1/4, 1/8, 1/12 and 1/16. Here, we only present the ablation studies results on the 1/8 dataset, as shown in Table 4. A total of five groups of experiments are conducted:
CoFormer baseline model.
Replacing ResNet50 in CoFormer with EfficientNetV2-M. As can be seen, EfficientNetV2-M exhibits superior capability in extracting advanced image features compared to ResNet50. Therefore, opting for a more advanced backbone can enhance overall accuracy.
Adding the TCCV module. From Table 4, it is evident that under the Top-1 Predicted Verb setting, the accuracy of verb increases by 6.14%. Due to the enhanced verb prediction capability, the model’s detection accuracy for value also improves by 4.55%. This demonstrates that features extracted by CLIP’s image encoder can effectively compensate for the lack of feature representation caused by data scarcity. Furthermore, the improvement in verb classification accuracy indirectly boosts the accuracy of noun classification and bounding-box localization, achieving a threefold benefit.
Adding the DPD module. After adding the DPD module, the accuracy of grnd value increases by 2.05% under the Ground-Truth Verb setting. This indicates that introducing conditional spatial queries in the decoder significantly enhances the accuracy of bounding-box localization.
Adding the Multi-VR Queries module. After adding the Multi-VR Queries module, the accuracy of grnd value increases by 1% under the Ground-Truth Verb setting. This demonstrates that incorporating richer semantic information is beneficial for guiding bounding-box localization.
Through these ablation studies, the effectiveness of the proposed modules is validated.

Qualitative comparisons of Ground-Truth, OpenSU, and GSRDS models in verb classification (a) and bounding-box groundings (b).
Qualitative analyses
We compare the qualitative results of GSRDS with the OpenSU model, as shown in Fig. 5. In Fig. 5(a), OpenSU incorrectly predicts the verb landing, resulting in all nouns being inaccurately predicted due to error propagation in verb prediction. In contrast, our model correctly predicts the verb and the corresponding nouns. Figure 5(b) illustrates a significant deviation in bounding-box localization for the agent role by OpenSU, whereas our model achieves more precise localization. This highlights the GSRDS model’s superior ability to classify verbs and accurately localize bounding-boxes under data scarcity scenarios.
Conclusions
In this study, we investigate the GSR task under the condition of data scarcity and propose the GSRDS model. Specifically, we replace ResNet50 with EfficientNetV2-M for extracting image features and introduce the TCCV module, which leverages features extracted by CLIP’s image encoder to achieve more accurate verb classification results. Additionally, we design the Multi-VR Queries and DPD modules to collectively enhance the precision of bounding-box groundings. Comparative experiments and ablation studies conducted under five different data volume settings validate our model’s superior performance in scenarios with limited data.
While the GSRDS model demonstrates significant accuracy improvements over other models under the condition of data scarcity, there remains a gap compared to models trained on full datasets. Future work could explore the following improvements:
-
More suitable feature extraction methods: Experimental results highlight the impact of advanced image features on overall GSR task performance, suggesting that future research could explore backbone networks more suitable for data-scarce scenarios;
-
More comprehensive feature learning methods: This study incorporates features extracted by the CLIP model to compensate for insufficient feature representations due to data scarcity. Future work could explore the advantages of pre-trained models to fully utilize data information and mitigate differences caused by data volume;
-
More advanced bounding-box localization models: Despite the improvements made by GSRDS in bounding-box prediction, there is still significant room for enhancement. Future research efforts could focus on improving noun classification accuracy and boosting object detection accuracy;
-
More extensive detection scope: This study primarily focuses on model improvements using data sampled from the SWiG dataset’s 504 categories. Future research can extend beyond the limitations of the SWiG dataset, encompassing a broader range of categories.
Data availability
The datasets used and/or analyzed during this study, including the human images, are available in the SWiG repository at https://github.com/allenai/swig (DOI: https://doi.org/10.1007/978-3-030-58548-8_19). The above website provides a usage license. Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files. Our study sampled from the SWiG dataset, and the sampled datasets can be obtained from the corresponding author upon reasonable request.
References
You, Q., Jin, H., Wang, Z., Fang, C. & Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4651–4659 (2016).
He, S. et al. Image captioning through image transformer. In Proceedings of the Asian conference on computer vision (2020).
Park, S. & Paik, J. Refcap: image captioning with referent objects attributes. Scientific Reports. 13, 21577 (2023).
Nguyen, T., Gadre, S. Y., Ilharco, G., Oh, S. & Schmidt, L. Improving multimodal datasets with image captioning. Advances in Neural Information Processing Systems. 36 (2024).
Zhao, Y. et al. Generating visual spatial description via holistic 3d scene understanding. arXiv preprint. arXiv:2305.11768 (2023).
Zhao, Y. et al. Visual spatial description: Controlled spatial-oriented image-to-text generation. arXiv preprint. arXiv:2210.11109 (2022).
Ning, S., Qiu, L., Liu, Y. & He, X. Hoiclip: Efficient knowledge transfer for hoi detection with vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 23507–23517 (2023).
Lim, J. et al. Ernet: An efficient and reliable human-object interaction detection network. IEEE Transactions on Image Processing. 32, 964–979 (2023).
Pratt, S., Yatskar, M., Weihs, L., Farhadi, A. & Kembhavi, A. Grounded situation recognition. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16, 314–332 (Springer, 2020).
Cho, J., Yoon, Y., Lee, H. & Kwak, S. Grounded situation recognition with transformers. arXiv preprint. arXiv:2111.10135 (2021).
Wei, M., Chen, L., Ji, W., Yue, X. & Chua, T.-S. Rethinking the two-stage framework for grounded situation recognition. In Proceedings of the AAAI Conference on Artificial Intelligence. 36, 2651–2658 (2022).
Cho, J., Yoon, Y. & Kwak, S. Collaborative transformers for grounded situation recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 19659–19668 (2022).
Cheng, Z.-Q., Dai, Q., Li, S., Mitamura, T. & Hauptmann, A. Gsrformer: Grounded situation recognition transformer with alternate semantic attention refinement. In Proceedings of the 30th ACM International Conference on Multimedia, 3272–3281 (2022).
Jiang, T. & Riloff, E. Exploiting commonsense knowledge about objects for visual activity recognition. In Findings of the Association for Computational Linguistics: ACL. 2023, 7277–7285 (2023).
Liu, R. et al. Open scene understanding: Grounded situation recognition meets segment anything for helping people with visual impairments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 1857–1867 (2023).
Roy, D., Verma, D. & Fernando, B. Clipsitu: Effectively leveraging clip for conditional predictions in situation recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 444–453 (2024).
Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, 6105–6114 (PMLR, 2019).
Tan, M. & Le, Q. Efficientnetv2: Smaller models and faster training. In International conference on machine learning, 10096–10106 (PMLR, 2021).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Radford, A. et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763 (PMLR, 2021).
Meng, D. et al. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF international conference on computer vision, 3651–3660 (2021).
Yatskar, M., Zettlemoyer, L. & Farhadi, A. Situation recognition: Visual semantic role labeling for image understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5534–5542 (2016).
Yatskar, M., Ordonez, V., Zettlemoyer, L. & Farhadi, A. Commonly uncommon: Semantic sparsity in situation recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7196–7205 (2017).
Mallya, A. & Lazebnik, S. Recurrent models for situation recognition. In Proceedings of the IEEE International Conference on Computer Vision, 455–463 (2017).
Mallya, A. & Lazebnik, S. Learning models for actions and person-object interactions with transfer to question answering. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, 414–428 (Springer, 2016).
Elman, J. L. Finding structure in time. Cognitive science. 14, 179–211 (1990).
Li, R. et al. Situation recognition with graph neural networks. In Proceedings of the IEEE international conference on computer vision, 4173–4182 (2017).
Scarselli, F., Gori, M., Tsoi, A. C., Hagenbuchner, M. & Monfardini, G. The graph neural network model. IEEE transactions on neural networks. 20, 61–80 (2008).
Cooray, T., Cheung, N.-M. & Lu, W. Attention-based context aware reasoning for situation recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4736–4745 (2020).
Suhail, M. & Sigal, L. Mixture-kernel graph attention network for situation recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10363–10372 (2019).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, 10012–10022 (2021).
Hendrycks, D. & Gimpel, K. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016).
Carion, N. et al. End-to-end object detection with transformers. In European conference on computer vision, 213–229 (Springer, 2020).
Russakovsky, O. et al. Imagenet large scale visual recognition challenge. International journal of computer vision. 115, 211–252 (2015).
Rezatofighi, H. et al. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 658–666 (2019).
Acknowledgements
This research is supported by National Natural Science Foundation of China (No. 61972414), National Key R&D Program of China (No. 2019YFC0312003) and Beijing Natural Science Foundation (No. 4202066).
Author information
Authors and Affiliations
Contributions
J.Z. designed the models, conducted the experiments, and wrote the manuscript; Z.L. and S.H. performed the validation experiments; X.L. collected and organized the data; Z.W. and Q.L. reviewed, guided, and supervised the work. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Code availability
The code for this paper is available in the GitHub repository at https://github.com/Zhou-maker-oss/GSRDS.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, J., Liu, Z., Hu, S. et al. Grounded situation recognition under data scarcity. Sci Rep 14, 25195 (2024). https://doi.org/10.1038/s41598-024-75823-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-75823-1
