
Abstract
The universal demand for the development and deployment of responsive medical infrastructure and damage control techniques, including the application of technology, is the foremost necessity that emerged immediately in the post-pandemic era. Numerous technologies, such as artificial intelligence (AI)-aided decision-making and the Internet of Things (IoT), have been rendered indispensable for such applications. Federated learning (FL) is a popular approach used to enhance AI-driven decision support systems and maintain decentralized learning. As part of a bio-safety norms observance setup, IoT, edge computing, and FL tools can be configured to monitor social distance norms, face-mask use, contact tracing, and cyber-attacks. The design of a pandemic-compliant mechanism for keeping an eye on protocol observance of virus-triggered infectious disease and contact tracing is the subject of this study. The mechanism is based on edge computing, FL frameworks, and a variety of sensors that are connected via IoT. We employ a variety of deep learning pre-trained models (DPTM) as benchmark techniques to compare the performance of the proposed YOLOv4 and SENet attention layer combination. This combination is deployed on a FL framework that is executed using a server and Grove AI-Raspberry Pi 4 blocks act as nodes as part of a human residential premises. The models include the RESNET-50, MobileNetV2, and SocialdistancingNet-19. In particular, the integration of the YoloV4 and SENET attention layer as part of a FL framework delivers dependable performance while addressing facemask detection (94.6%), incorrect facemask detection (98%), facemask classification (95.4%), social distance (96.1%), contact tracing (95.2%) and cyber attack detection (94.2%) while performing tasks like correct and incorrect, proper and improper facemask wearing, monitoring social distancing norms observance, and contact tracing.
Similar content being viewed by others

Introduction
Even though COVID-19 virus infections have decreased considerably globally, these will continue to exist and have had a significant impact on contemporary lifestyles. According to researchers, disease and other influenza-like ailments have always been and will forever be part of human existence1. Consequently, it has become imperative that frameworks for the continuous vigilance and monitoring of the observance of the relevant protocols released by the World Health Organization (WHO)2 are developed and deployed. This is true despite the fact that vaccination campaigns have been implemented throughout the world. Simultaneously, there have been numerous reports of novel COVID-19-like viruses exhibiting a variety of unfamiliar symptoms3,4,5. The accessibility of technological solutions available to monitor adherence to social distance standards (1 m distance between individuals as prescribed by the WHO2), facemask use, and contact tracing are documented in numerous works6,7. One example of a popular and reliable technology relevant to such applications is the Internet of Things (IoT)8, which, as an integration and connection framework, utilizes a variety of sensors in conjunction with wireless networking. Further, the escalation and evolution of the IoT have been facilitated by recent advances in Artificial Intelligence (AI) technologies such as deep learning (DL)7, deep transfer learning (DTL)9, and edge computing10. These mechanisms are now emerging as trustworthy aids and have been accepted to be suitable for deployment in the healthcare sector, particularly in the context of virus infections and pandemics. In the aftermath of the COVID-19 outbreak (2020-22), which is expected to occur in the near future, these advancements have established AI-aided IoT devices to be indispensable in the fight against any lethal influenza strain. The implementation and study of IoT technologies in health management systems have encompassed the following areas: automatic data sensing11, authentication, analytics12, diagnostic decision support13, and effective tracking of agents (patients, medical staff and medical resources)14. Most of these approaches have adopted a centralized mrthodology of data processing and know-how generation for AI- based techniques. However, constraints and privacy issues have been reported by such works15,16.
Recently, federated learning (FL)17 has emerged as a reliable and secure method for providing AI-assisted decision support in a distributed setting18. FL is an AI technique that undertakes decentralized training on data stored on numerous devices or servers19, similar to a model that is thriving on millions of smartphones. This ensures that the device operates efficiently without compromising the identity or location of the participating phones. FL has many benefits, including improved scalability and cost-efficiency, increased adaptability, greater data accuracy and diversity, quicker training with fewer computational resources, distributed data storage, concurrent model tuning, and many more20,21.
The IoT, edge computing (EC), FL, and a set of AI tools provide opportunities to create frameworks for efficient monitoring of social distance norms, mask use, and contact tracing in the context of any of the dreaded influenza-type virus attacks, including COVID-19 that can cause outbreaks and threaten human life. Programmable hardware devices are necessary for the flexibility in the development, deployment, and configuration of IoT set-ups11,22, especially for critical infrastructure design that places greater priority on reliability, cost-cutting, and ease of handling of a range of applications. Certain programmable hardware (Grove AI HAT and Raspberry Pi 4) enables smooth integration of sensors with AI tools, which can be tailor-made for deployment as part of FL frameworks. These are effective for the design of pandemic-compliant infrastructure, even for human residential complexes. Among the class of AI techniques, You Look Only Once (YOLO) networks are fast, reliable, and effective for computer vision and related applications23. Further, transformer networks and attention layers have been found to enhance the effectiveness of DL models, especially while executing region-specific detection and identification24. By combining an attention layer with the YOLO, we can obtain better object detection performance and extract a real-time response under diverse and continuously varying conditions15. With FL , decentralized learning and scalability are likely to enhance the effectiveness of the YOLO- attention layer combination.
As noted above, reliable and secured computing paradigms like FL thrieve on distributed process and efficiency increases in diversity of data and content of processing25. Together with YOLOv4 assisted by an attention layer, DL systems deployed on Raspberry Pi4 and Grove AI Hat edge nodes processing diverse data at varied locations are expected to enhance the effectiveness of the framework. Such a framework is expected to exceed the efficiency of centralize processing paradigms. In this description, we present the design of a pandemic-compliant mechanism configured to monitor the adherence of influenza-type viral disease protocols, including COVID-19, as a part of a residential premise. This mechanism has been implemented using the Grove AI HAT and Raspberry Pi 4 combination, configured to run a YOLOv4 and SENet attention layer mix on an FL framework for facemask detection, proper facemask wearing recognition, classification of facemask, social distancing, contact tracing and cyber-attack detection. While tasks like facemask detection, proper facemask wearing recognition, classification of facemask, social distancing, and contact tracing are related to pandemic-time or viral infection-related bio-safety protocol observance, detection of cyber-attacks is a necessary feature as the proposed system is intended to work in an online mode with frequent updates of records as part of a human habitat complex. Further, we compare the performance of the proposed YOLOv4 and SENet attention layer combination with that obtained from several deep learning pre-trained models (DPTM), such as RESNET-50, MobileNetV2, and SocialdistancingNet-19. These models serve as benchmarks for extensive evaluation, fine-tuning, and ascertaining the levels of accuracy obtained during training. The system made up of edge nodes connected to a cloud server (hosting the FL setup), links up a variety of sensors and cameras deployed at a few numbers of entrances to a human habitat. The evaluation results and outcomes of this Internet of Intelligent Infrastructure Things (IoIIT) framework, provide evidence that the proposed strategy is effective in monitoring of observance of bio-safety norms related to virus-triggered infectious disease.
The key contributions of the work are:
-
1.
Design of an edge computing set-up with Grove AI HAT and Raspberry Pi 4 combination configured for FL processing as part of a pandemic-compliant infrastructure intended for deployment in human residential premises.
-
2.
Implementation of a YOLOV4-SENet combination in a FL framework for performing a series of tasks like facemask detection, proper facemask wearing recognition, classification of facemasks, social distancing, contact tracing, and cyber-attack detection in a distributed and diversity driven setup as part of an automated critical healthcare setting.
-
3.
Training, validating, and testing a series of pre-trained DL models as benchmarks to ascertain the performance of the proposed YOLOV4-SENet combination in a FL framework for the identified application areas.
The rest of the discussion is distributed in the following sections. In section “Related Works”, some of the recent works related to the present description is highlighted. The experimental details including the composition of data, DPTMs, blocks and sub-blocks etc. are presented in Section “Methods and materials”. Results and discussion are highlighted in section “Results and discussion”. Section “Conclusion” concludes the discussion.
Related work and challenges of application of FL in critical healthcare
Here in this section, we discuss some of the recent works that are related to the application of DTL, DPTM and IoT with centralized and decentralized frameworks for medical healthcare applications. Further, we highlight some of the challenges associated with the application of FL in critical healthcare.
Related works
The term FL refers to a distributed and privacy-preserving method of training machine learning (ML) or DL models without allowing others access to sensitive data. It was originally used by McMahan et al.11.
As already mentioned, FL is a revolutionary approach that has recently evolved as a mechanism for offering AI-assisted decision support in a decentralized environment18. In22, the topic of FL, the fundamental privacy ideas, and relevant research and applications are thoroughly introduced. Data privacy is an important topic in healthcare as it involves many hospitals (adopting regulations like General Data Protection Regulation (GDPR) (May 2018)23. This is due to the fact that FL offers a privacy-preserving solution, and it has already been demonstrated to function well with publicly available medical datasets. The small number of clients (2–100), who are hospitals or doctors, and the comparatively high degree of trust among them make the medical environment of FL unique. Kairouz et al. have dubbed this phenomenon “cross siloFL”24. Certain works adopted electronic health records (EHR) or data from intensive care units (ICUs). This is mainly tabular data describing patients’ previous treatments, medication intake, genomic data and so on15. The Virtual Topologies Generalization in OpenFlow networks (VeRTIGO) algorithm for vertically distributed data by Li et al.25 evolved around the attempts to solve the problem of binary prediction of mortality based on genome data for breast cancer patients, EHR data for myocardial infarction, or ICU data from the popular database MIMIC-II25. Another work is26 where again the authors used their algorithm LoAdaBoost for predicting patient survival status based on the MIMIC-III database. Similarly, in16 there is a discussion that describes an optimal model selection process for different genome datasets. In contrast to most other FL literature, Lee et al.12 attempt to solve an unsupervised ML task in the form of a k-nearest neighbour (k-NN) model based on hashed EHRs. Similarly, Huang and Liu27 perform patient clustering, but with the goal of training multiple, more powerful and specialized Deep Neural Networks (DNNs) instead of one global one. Liu et al.13 suggest a Federated-Autonomous Deep Learning (FADL) approach. This follows the observation of Chen et al.28 that evaluate shallow and deep layers for binary mortality prediction task based on the e-ICU Collaborative Research Database29. These are a few reported works related to the application of FL methods for data security and privacy preservation.
A few applications of the FL are summarized in Table 1.
Another set of works have reported the use of FL approaches for data clustering, detection, classification, etc38, Brisimi et al. solved a binary classification problem for predicting hospitalizations from EHRs. A previously discussed method for a human activity recognition (HAR) dataset can be found in39. Here, the authors use federated regression models and artificial neural networks (ANNs). Also, Sanyal et al.40 investigated a federated filtering framework for a public multivariate, time-series IoHT dataset of patients performing 12 physical activities (MHEALTH)41. Another study simulated a Least Mean Square (LMS) filter42 on each device and used a fog server to combine the individual prediction models.
FL has also been used for human activity recognition, computer vision applications, etc. A sensor-data-related work configured for classification and recognition using FL frameworks is43,44,45 in which a human activity recognition (HAR) task is solved using YOLOv3 and inertial measurement unit (IMU) data (accelerometer, gyroscope) from smart phones. In contrast to13, the work43,46 adopts federated transfer learning (FTL) to personalize the model for individuals. In another set of studies, authors have evaluated supervised ML/ DL models, IoMT, Edge AI etc for COVID-19-related challenges47,48.
Recent studies have reported the use of specially trained DNNs like U-nets. The U-Net design of a convolutional neural network (CNN) has been developed for segmenting images, specifically for the purpose of medical applications like distinguishing organs, tumors, and other anatomical components49. The U-Net architecture is suited for integration with other DNNs as part of FL50,51 set-ups. In a similar vein, \(U-Net++\) is an improved version of the original U-Net architecture that has been designed for image segmentation, image labeling, and other jobs that require a high level of precision52. Attention \(U-Net++\) is an extension of the \(U-Net\) architecture that uses self-attention, especially in order to improve the performance of a range of computer vision tasks53 like image segmentation and image-to-image translation. The Squeeze-and-Excitation Networks (SENet)54,55,56 is a prominent example of a typical channel attention mechanism that provides performance enhancements when combined with other DNNs. Further, programmable hardware is crucial for the design of secured IoT set-ups57,58. A few more pieces of literature have been shown in Table 2.
From the above, it is obvious that no reported works have explored the adoption of a YOLOv4 and SENET attention layer on edge nodes and several DPTMs on a FL framework to develop a pandemic-compliant architecture to perform facemask detection, determine correct facemask wearing, conduct contact tracing, and figure out cyber-attacks. The key contributions of the work have already been highlighted above in the section “Introduction”.
Challenges of FL in critical healthcare
Since FL is known to be more concerned with privacy20,21,59, it offers a fresh paradigm for working without much control from a central regulator. Such training algorithms have historically relied on centralized architectures20,21,59,60. Similarly, FL provides a novel way to decentralizing solutions that yield higher efficiency and performance on massive data volumes61,62. FL thrives well in situations where the edge devices are trained by a decentralized learning algorithm, which only shares the necessary and pertinent data63 and the updated version of the network architecture without much regard to the data source location, whether the edge devices are continuously in operation or not, charging or connected to Wi-Fi communication access point and feed time of the content.
A few of the recent works that addresses challenges of applications of FL in critical healthcare are64,65,66,67,68. These are mentioned in Table 2.
The details of optimal performance of the proposed FL system and other benchmark methods deployed for performing the identified tasks have been discussed in details in section “Methods and materials” and summarized in Tables 11 and 12 respectively. Discussion regarding challenges faced by the proposed approach and the mechanism adopted to address these challenges, have been highlighted in the last two paragraphs of section “Results and discussion”.
Methods and materials
In this section, we discuss the different aspects related to the design of the proposed approach. Further, before discussing the working of the proposed approach, a brief description of the related background is included below:
Data set and deep pre-trained models (DPTM)
Kaggle data sets are adopted for the design of the system for protocol observance detection. The data set contains faces with and without facemasks. The primary data set consists of around 10500 images, of which 6450 depict people wearing facemasks and 4050 depict people without them. With variations in colour, illumination, size, etc., these are grouped into several sets to enhance the diversity of samples required during training and testing. There are two groupings made out of these datasets. The training set, which has roughly 8400 photos (80%), is one of them. Both the validation set and the testing data set contain 2100 photos (20%). Additionally, the images come in a variety of sizes, colours, backdrops, brightness levels, and contrast levels to suit any circumstance, as already indicated. This adds to the overall augmentation of the data available for training and testing. For developing the ability of the system to detect cyber-attacks, a total of 30,190 samples are taken, of which 70% are used for training and 30% are used for testing. We have used several DPTMs as benchmark methods to ascertain the performance of our proposed approach. A few are discussed below:
-
RESNET-50 - When it comes to computer vision tasks like image categorization, object detection, and recognition, the RESNET-50 (Residual Network 50) CNN architecture is a popular option69. It belongs to the Microsoft Research-created ResNet family of DL networks. The 50 convolutional and fully linked layers in ResNet-50 give it a distinctively deep architecture. To train DNNs without encountering vanishing gradient difficulties, ResNet architectures make use of residual connections, also known as skip connections. When used in the training of DNNs, these skip connections facilitate the smooth transfer of data throughout the network50. In this work, we have used RESNET-50 for facemask detection, improper facemask wearing, facemask classification, social distancing, contact tracing, and detection of cyber attacks. This is mentioned in Table 10.
-
MobileNetV2- For effective on-device vision applications, especially on mobile and embedded devices, MobileNetV2 is a popular option. Lightweight and efficient, it is an improvement of the original MobileNet architecture created by Google70. For image recognition and classification activities that need to be performed in real-time on mobile devices and embedded systems, MobileNetV2 has become a preferred option. Applications with limited computational resources can benefit from its efficient design because it allows for faster inference with minimal compromise in accuracy71. In this work, we have used MobileNetV2 for facemask detection, improper facemask wearing, facemask classification, social distancing, contact tracing, and detection of cyber attacks as mentioned in Table 10.
-
SocialdistancingNet-19- It is designed especially for dealing with the task of finding social distance between persons affected by pandemic situations. It works around computer vision principles using DNN architecture72. In this work we have uses SocialdistancingNet-19 for social distancing (Table)10.
-
VGG-16- The Visual Geometry Group (VGG) at the University of Oxford devised the VGG-16 CNN architecture. Several different computer vision applications have made use of VGG-16 as a foundational model for transfer learning and further fine-tuning in the form of versions such as VGG-19 which has additional layers73. In this work, we have adopted VGG-16 for contact tracing and detection of cyber attacks (Table 10). Further, we have used several special-purpose architectures for fine-tuning the proposed attention layer. These are briefly discussed below:
-
U-Net- The U-Net architecture of a CNN has been designed primarily for segmenting images into their components. U-Net has proven particularly useful for medical picture segmentation tasks like separating organs, tumors, and other anatomical components74. It is well-suited for these uses because of its capacity to capture both fine features and geographical context. To improve the U-Net’s performance and tailor it to different tasks, researchers have built several variants of the original design75.
-
U-Net++- U-Net++, is an enhanced version of the original U-Net architecture developed specifically for picture segmentation. U-Net++ excels at image segmentation tasks where it is important to both capture fine details and maintain spatial relationships. U-Net++’s robust architecture, comprised of nested skip routes and dense convolution blocks, makes it ideal for image labeling jobs that necessitate high precision52,76.
-
Attention UNet- To better perform while used with a variety of computer vision tasks, such as image segmentation and image-to-image translation, the “Attention U-Net” serves as an extension of the U-Net architecture that integrates attention mechanisms, specifically self-attention77. In circumstances where long-range dependencies or context are crucial, attention mechanisms can help the network zero in on the most significant bits of the input material52,77,78.
-
Grove AI Hat-The Grove Artificial Intelligence Hardware attached on Top (AI HAT) is a hardware adapter that work in concert with the Raspberry Pi. The Grove AI HAT is intended for the smooth integration of AI and ML/ DL capabilities into a Raspberry Pi and facilitate a range of expandable capabilities71,79.
SENet attention layer
The attention mechanism has been widely used in DL networks. It adjusts the weight of each channel information, assigns different weights to each channel information, and then filters the channel information according to the weight, which can effectively reduce the influence of interference information. The Squeeze-and-Excitation Networks (SENet)71,80,81 is a typical representative of the channel attention mechanism. The channel attention mechanism can be expressed as
For the SENet expression (1), f(.) is a convolutional function and the g(x) function can be written as

Functioning of the SENet attention mechanism.
Here, GAP is Global Average Pooling function, x represent input features, g(x) generates attention, Sigmoid() is a sigmoidal function, and MLP is a Multi-Layer Perception layer. Further, g(x) is used to generate attention corresponding to the discriminative regions. Next, f(g(x), x) means processing input x based on the attention g(x) which is consistent with processing critical regions and getting information. Figure 1 summarizes, the working of the SENet layer. Here, the input feature map X has C channels \((C = 1, 2, 3, \ldots , n)\), the space size of each channel is \(h \times w\), and the global average pooling is performed on each channel. The calculation of the channel weight Z is done as follows:
where \(F_{sq}(.)\) is a Squeeze Layer, \(X_{c}(.)\) is channel attention, h is the height and w is the weight of the input and \(F_{scale}(.)\) is a convolution (scaling) function. The output Z is a one-dimensional array of length C, which represents the weight obtained by the compression channel. The activation function needs to be used to model the correlation degree of each channel weight. The expression for correlation degree is given as
where \(F_{ex}(.)\) is an excitation layer, \(\sigma (.)\) is a sigmoid function, \(w_{1}\) is the weight of channel 1, \(w_{2}\) is the weight of channel 2 and S is an activation function.
The dimension of \(S_{c}\) is \(1 \times 1 \times C\). The channel attention weights need to be obtained through operations such as fully connected layers and nonlinear learning. The dimension of \(w_{1}\) is \(C/r \times C\), the dimension of \(w_{2}\) is \(C \times C/r\), and r is the scaling factor. Finally, the input channel is weighted and adjusted, and the channel attention weighting formula is expressed as
where \(\circledast\) represents the multiplication of elements, \(X_{c}(.)\) represents channel attention, \(S_{c}(.)\) represents spatial constrained convolution and \(X_{c}(.)\) represents the result after attention network processing. Some of the critical benefits derived from the SENet attention layer are52,53:
-
Model Accuracy: SENet’s attention layers train the network to identify which features are most salient, leading to increased model accuracy. This can especially be useful in situations where some features are more relevant than others, as it helps to increase the model’s accuracy by focusing on the most informative channels82.
-
Awareness of Context on a Global Scale: The attention layers of SENets provide better awareness of the context on a global scale by taking into account the relationships between channels throughout the entire feature map. This helps the model learn the structure of the input data and ultimately perform in tasks that demand awareness of context30.
-
Generalization through Enhanced Adaptability: By allowing the model to learn and adapt to the relevance of different characteristics during training, SENet attention can assist improve the model’s generalization capabilities. Because of this flexibility, the model may be less sensitive to changes in the input data31.
-
Lower over fitting: SENet generates less over fitting due to its adaptive re-calibration of feature maps. It helps the network better prioritize information. This results in models that are more adaptable to novel inputs32.
-
Reduced Model Size and Training Complexity: The attention layers in SENet are computationally efficient and increase the network’s parameters by a negligible amount33.
-
Enhanced Compatibility: The attention layers of SENets can be included into many different types of DNN topologies. This adaptability has been exploited to integrate SENet attention layers into pre-existing designs34.
Proposed YOLOV4 and SENet attention combination
The real-time object detection system YOLOV4 has contents connected to its predecessor, YOLOv355,72 with certain advanced features. The YOLO approach has been developed as an enhancement to it predecessors. It predicts bounding boxes and class probabilities for items in each grid cell by first splitting a picture into a grid and carrying out the subsequent processing. Its reputation for quickness and precision have made it a popular option for a wide range of computer vision tasks. The backbone network in YOLOv4 is a CNN and Backbone for Object Detection (CSPDarknet53) architecture, which allows for improved feature extraction and overall performance. With the YOLOv4, the Path Aggregation Network (PANet) has been included in the neck block to aid the feature fusion process and scale-up object management. The training and detection capabilities of YOLOv4 have been enhanced by the use of multiple data augmentation approaches, including mosaic and mix-up data methods. Improved object detection is obtained from a redesign of the detection head’s architecture72,73. The YOLOv4’s flexibility and ease of integration into diverse applications stem from its ability to interact with different back ends like OpenCV, ONNX, Tensor Flow, and PyTorch.
YOLOv4’s backbone network based CSPDarknet53 functions with Cross-Stage-Partial (CSP) connections to boost feature extraction. The neck of the YOLOv4 contains PANet, which uses feature maps at multiple scales to handle objects of varied sizes. The detecting head generates bounding boxes, class scores, and objectness scores with anchor boxes and prediction layers. YOLOv4 uses Intersection over Union (IoU) losses to improve localization and confidence forecasts.
As indicated, SENet uses “squeeze” and “excitation” procedures. The channel-wise average pool is used to “squeeze” global information from feature maps into a \(1 \times 1\) spatial dimension tensor. Fully connected layers teach the “excitation” operation how to prioritize channels. It results in the generation of channel-wise scaling factors47,73.
YOLOv4 and SENet can be combined in many ways. SENet can be added to YOLOv4’s backbone. Modeling channel-wise dependencies with these pieces improves feature maps. The “squeeze” and “excitation” procedures in SENet blocks collect channel-wise dependencies and scale feature maps according to relevance and improving efficiency74,83. The merged model must be correctly trained when joining the two networks17,72.
The integration of YOLOv4 with SENet has various benefits, most notably in the area of object detection, which is one of the key strengths that serves as the core processing block of our present research. YOLOv4 is a real-time object identification model, while SENet is a network architecture that has been developed with the objective of improving feature representation. In SENet, attention algorithms are included that dynamically recalibrate channel-wise feature responses based on the relevance of the features. This can result in a more accurate depiction of the object’s properties, which makes it simpler for the detector to differentiate between different objects, particularly while operating in difficult conditions. Next, the attention processes found in SENet can assist YOLOv4 in concentrating its efforts on the most important aspects, hence minimizing the influence of less informative or noisy features30,48. This can contribute to enhanced accuracy in object detection, particularly in situations in which the items to be detected are small, obscured, or have backgrounds that are complicated. Additionally, combining YOLOv4 and SENet can boost the model’s ability to generalize to a wide variety of object classes and datasets, which is a significant benefit. The attention mechanisms have the potential to assist the model in better capturing discriminative characteristics across a diverse set of items54,84. In this work we have use SENet Attention for facemask detections, improper facemask wearing, facemask classification, social distancing, contact tracing and detection of cyber attack.This is mentioned in Table 10.
Additionally, YOLOv4+SENet is helpful in reducing the number of false positives that occur during object detection activities. The model can grow with a more selective approach in its detection of objects by highlighting significant properties and suppressing less relevant ones35. This results in fewer false detection of the objects being studied. In addition, the use of YOLOv4 and SENet together has the potential to make the object detector more resilient to changes in illumination, position, scale, and other characteristics, which is an essential quality for real world applications36. As a consequence of this, the YOLOv4 is well-known for the real-time object recognition capabilities it possesses, and the incorporation of SENet does not significantly impair the speed of the model. This is critical for applications like autonomous operation and surveillance systems, as intended to be incorporated into the present work. Such a requirement necessitates accurate object detection with lower latency. Combining the precise and efficient YOLOv4 object identification model with SENet’s attention mechanisms has the potential to push the performance bounds even further, making it a viable option for a variety of computer vision workloads, including while deploying as part of distributed processing frameworks like the FL for protocol observance monitoring and cyber-attack detection as required in the present context37,85.
In our work, we have applied the SENet attention layer in the backbone and neck regions of the YOLOV4 as shown in Figure 2. When it is essential to take into account long-range dependencies or the context of the situation, attention mechanisms could assist the network in concentrating on the most important aspects of the input data. The features obtained by the preceding network are given more or less weight based on the SENet attention mechanism. Because of this, important elements may be distinguished regardless of input format, size, distance, lighting, or background, colour, frame, gender etc variations. When it comes to dealing with protocol observance in the face of a pandemic or mass scale infection of a virus attack and detecting cyber-attacks, the YOLOV4’s SENet layer emphasizes these capacities to zero in on certain aspects while still allowing for sound decision-making despite the presence of a wide variety of variants67,68,86.

YOLOv4 and SENet attention layer configured for the proposed approach.

Block diagram showing different attributes and components of the proposed approach.
Configuring the edge nodes
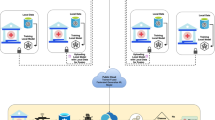
An IoT and edge computing (Fig. 3)-based method for monitoring face mask wearing, social distance norms, contact tracing, and detecting cyber-attacks using FL is the main focus of the proposed work. Grove AI HAT71,87,88 and Raspberry Pi 4 (model B) form the edge computing node. An IoT pack consisting of a camera, IR thermometer, ultrasonic sensor, and proximity sensor can be connected to the edge node. The Grove AI HAT connects to the camera that monitors physical distance. While entering the premises, an infrared thermometer detects each person’s temperature without touching them. An ultrasonic sensor detects anyone who passes through the gates without being checked. The Raspberry Pi processes data and tracks visitors. Displays for temperature, social distance, observance state, etc. can be integrated. A 24-pin serial connector connects the Grove AI HAT to the camera and display89. Encrypted Wi-Fi links connect the Raspberry Pi, the Grove AI HAT, ultrasonic and infrared temperature sensors and cloud server90. The edge node is an IoT pack featuring sensors, an AI tool, a processor, and the encrypted Wi-Fi connection. Multiple-sensor IoT pickup devices convey edge computing platform requirements (location-specific). Second, edge computing calculates sensor data for a person during scan while processing. Next, the edge computing platform selects a sensor node by location and edits the cloud server’s record based on the sensor feeds which derive decision during AI-based decision suport executing multitasking.
Finally, IoT-AI-Wi-Fi access completes data gathering, processing, local decision-making, record update, and status notification. We positioned four edge-computing nodes in the entryway of a residential complex in our trials supported by FL (Fig. 4). When someone enters, each sensor sends a reading to the edge-computing node. The edge node decides what to do, such as monitoring face mask wearing and social distance norms and then tracing contacts, updates information in the cloud server and a database. The cloud server, where dedicated DNNs are placed, helps the edge node make executable decisions for each activity. DNNs learn end-to-end and then manage face mask wearing detection, social distance norms observance monitoring, and contact tracing. The decision derived at the node level is shared with the learning accumulated by the cloud server and the know-how is shared with each of the nodes associated with the framework. The next section describes how each DNN type has been configured for the purpose. The Wi-Fi access has 50 Mbps data rates and 1 Gbps optical fibre back-haul. Setup delay matters. After testing the system with three Wi-Fi setups (50 Mbps, 40 Mbps, and 30 Mbps), 4G (10 Mbps), and 3G (1 Mbps), we observed latency variation between 3 and 100 milliseconds (mS).

FL-aided pandemic protocol observance monitoring system for a residential apartment.

Proposed IoHT based on FL designed for pandemic compliant infrastructure.
Design of a FL aided pandemic protocol observance monitoring system
As already indicated, FL enables training on a group of decentralized edge devices without requiring to move or store the raw data on a central server, adopting an iterative process on a variety of devices or centralized processors28,45,91. In our case, the edge nodes provide the decentralized basis of training using images and sensor data, which updates the learning through each iteration and holds the latest versions of the training in a central processor. Figure 5 depicts the proposed approach.
As shown in Fig. 5, the proposed FL system comprises three phases: data collection, data preparation, and FL. Usually in case of medical information processing, patient data maintained by many centres for disease control (CDCs) is gathered to effectively train the YOLOV4 and SENet combination, which is deployed at the edge nodes. Interpolation is a technique used in the data preparation stage to recover and eliminate missing and incorrect data. The three-sigma rule80,92,93 of thumb method is applied to data interpolation in this study. Additionally, by creating synthetic data during the pre-processing stage, the issue of data imbalance is resolved. The edge nodes obtain the global model from the server during the FL phase, compute the local gradient, and send the local model back to the server. The latter is in charge of computing and disseminating the global model to the clients, as well as receiving models from the clients and aggregating local models. In the proposed work, the YOLOV4-SENet combination is trained using facemask data (section “Proposed YOLOV4 and SENet attention combination”) and sensor/ camera inputs received at the four entrances where the edge nodes are deployed.
The training of the FL framework is summarized by Algorithm 1. The local model is tuned in synchronization with the global framework. The process starts with initial global and local weights, which are updated continuously. The local weights are conveyed to the central server, which produces an aggregate weight and is shared with the local nodes during each cycle. The communication link is encrypted, and the system is trained for unbalanced and independently but identically distributed data. The configuration and specification of the edge nodes and the DL mechanisms are summarized in Table 3.

Federated learning-based process logic for training nodes and the cloud server
Along with the proposed YOLOv4-SENet combination used for protocol observance monitoring and cyber-attack detection, a few benchmark models namely RESNET-50, MobileNet, VGG-16, SocialDistanceNet-19 etc are trained for the purpose. The four-layered IoT architecture designed for this function consists of a “perception” layer, “transport” layer, “processing” layer, and an “application” layer. A camera, infrared thermometer, ultrasonic sensor, and proximity sensor make up the perception layer. These are stationed at the respective entrances. The nodes and the cloud server talk to one another over the transport layer, and this is often accomplished via Wi-Fi access (XLT240170) with a maximum range of 150 m and fiber back-haul support. The edge nodes constitute the processing layer along with the central processor. The application layer is confined to the use of the system as part of a residential property.
Detection of cyber-attack
When a computer-driven system is connected to a wider network through the use of the internet, the possibility of a cyber-attack is always present and cannot be ignored. In this section, the cyber-attack detection capacity of the composite system is discussed. This ability is required to continually monitor the data traffic in a network-based environment for the purpose of differentiating between authorized and unauthorized access and friendly and hostile activity. There are two stages that can be reached during a cyber-attack:
-
1.
The training phase, and
-
2.
The testing phase.
There are various common forms of cyber-attacks that can be launched against computers, connected devices, and IoT-based systems. These are known as phishing, log access, social engineering, and brute force attacks (on passwords) which are the four main types of cyber-attacks82. Moreover, there are such as data tampering, denial-of-service (DoS) attacks, or unauthorized access, anomaly detection, intrusion detection and secure authentication types.
Identifying cyberthreats can be accomplished using a variety of approaches. In this scenario, the FL set-up running the YOLOv4 - SENet combination is trained to detect the cyber-attack. Further, ResNet-50 and MobilenetV2 are put to work as classifiers in order to identify malicious cyber-activity, along with Linear Regression (LR) and VGG-16 classifiers, which are used as benchmark methods for determining the capabilities of DPTMs. In order to accomplish this, a total of 30,190 samples are collected, of which 70 % are utilized for training purposes and 30 % are utilized for testing purposes.
Results and discussion
A series of experiments are performed to establish the effectiveness of the proposed method. The SENet attention layer is selected for the experimental purpose after a series of simulations involving U-Net, U-Net++, Attention U-Net and SENet attention layers. The results for protocol observance monitoring derived using the YOLOv4 along with the above mentioned attention layers is shown in Table 4. The results clearly indicate the effectiveness of the SENet attention layer when used with the YOLOv4. The SENet attention layer improves the performance of the model, as well as its adaptability and generalization, while preserving its computational economy. In order to extract features, the SENet employs a separate channel network and a specialized attention mechanism and provides support to the YOLOv4 detector to demonstrate enhanced discrimination capability. The combination while executing its processing the FL framework is able to learn and alter the importance of various attributes of the inputs, modify and enhance the content of the important segments, share and update the decision making within the network, which is a contributing factor to the efficiency of the framework.
For the YOLOv4-SENet combination, the specifications of the networks deployed in the edge nodes and the central processor are shown in Table 5. Various activities which are handled by the FL framework are summarized in Table 6. Figures 6 and 7 show images of people wearing and not wearing masks, respectively. As already mentioned, these are used to train and test DL models for facemask detection. Figure 8 shows the datasets of improper wearing of facemasks. Medical facemasks are typically made of materials such as cloth, non-woven fabric, or disposable paper. Some examples of datasets of normal masks and medical facemasks are shown in Fig. 9a and b, respectively. Additionally, the images come in a variety of sizes, colours, backdrops, brightness levels, and contrast levels to suit any prevailing circumstance around a human residenctial block. There are several groupings of these datasets including male and female classes under a range of variations, including resolution. In order to prevent over-fitting, we utilized dropout rates as a component of multi modal factorized bilinear pooling (MFBP)49 with ResNet-50 and MobileNet after the training cycles are complete. After that, in order to evaluate testing and contrast performance before and after training, we have used the mean square error (MSE) as the cost function and vary the learning rate by employing the adaptive moment estimation optimizer technique. This allows us to compare performance before and after training. The performance of the YOLOv4-SENet combination is found to be superior.
Recalibration of feature responses across channels is made possible by the SENet’s explicit modeling of channel relationships and combining that with the YOLOv4’s excellent object recognition capability.

Examples of face masks datasets with masks.

Examples of face masks datasets without mask.

Examples of face masks datasets incorrect face mask.

Datasets of (a) NG facemasks and (b) medical facemask.
A separation calculation based on the pixel values of an image or video stream is utilized to identify the observance of social distance. The presence of a cough, sneeze, or both can be taken as evidence of an infection along with the physiological vitals captured by the senors at the entrance. Along with this, the presence of an infected individual is also considered as probable source of virus transmission. As soon as a situation of this kind is identified, the system alerts the decision support system, edge nodes, and the local population, and it also initiates a number of actions connected to the social distancing standards. At first, the algorithm identifies masks that are being worn by individuals. The identification of a person can be completed by determining whether or not they are wearing a mask on their face. It is therefore necessary to carry out a pixel-to-spatial separation conversion in order to ascertain the distance that exists between two such individuals. After that, the identity of the infringing individuals can be determined by utilizing facial recognition; a record is made, and a message is communicated to the stakeholder groups, including the person or persons who are concerned. While the system is busy extracting, storing, and sharing the first features from the image or footage captured by the camera at one of the edge node levels, the higher-level inputs are shared with the cloud-resident FL setup, which continues training utilizing inputs from all of the remaining feed points, updates the learning and again shares back the current form of the training with the edge nodes. Figures 10 and 11 show the training and validation loss and accuracy of the \(YOLOV4+SENet\) combination while executing protocol observance monitoring. The proposed FL-based approach is evaluated alongside seven other architectures, including VGG-16, ResNet-50, MobileNetV2, SVM, Decision Tree (DT), K-Nearest Neighbor (KNN), and Logistic Regression (LR), in a battery of tests designed to evaluate the effectiveness of the network and the degrees of trustworthiness required to carry out contact tracing from within a cloud-resident framework in concert with intelligent edge nodes. Incoming data are evaluated in an attempt to locate a person or a group that may have been the source of the infection and to determine whether or not they are responsible for its spread. The procedure of forward tracing can start if all of the steps have been completed successfully. Forward tracing entails isolating the patient and initiating treatment in the event that an infection is proven. In the meantime, another system detects the onset of symptoms while the patient is in quarantine and continues treatment. Those who come into contact with the isolated individuals are investigated, and if they test positive for the illness, their symptoms are graded according to the condition in which they are : mild, moderate, or severe. Those who may have come into contact with the infected individual may be subjected to testing and treatment while the infected person’s whereabouts are being investigated. Quarantine measures may also be implemented. The database is regularly updated with new information, while in the background, there are systems running to ensure that social distance requirements are being adhered to. Table 7 summarizes the best possible reliability of the multi-node edge and FL computing setup provided for a home environment.

Accuracy performance recorded by federated learning v/s centralized learning.

Average training and validation accuracy of the YOLOV4-SENet combination while executing protocol observance monitoring.
Multiple jobs being handled by a single node, frequently changing sample kinds, variable network types, and synchronization problems all contribute to the discrepancies. However, the system’s dependability is limited by issues with Wi-Fi connectivity and the efficiency of pickup devices. The node and server each have their own error thresholds. Error occurs at the beginning when a person who normally uses the same gate on a given day presents at a different gate, but learning and decision-making at the node level are shared with the server. In such situations, the server produces a genuine negative choice that, in the long run, tends to stabilize towards the desired reliability margin. The FL arrangement minimizes the error in subsequent iterations of training. Table 8 provides a summary of a detailed examination of the effectiveness of various strategies used in the proposed system and tested in residential settings over a six-month period.

Accuracy performance recorded by federated learning v/s centralized learning.

Federated learning accuracy with facemask recognition while node numbers.
The post-validation and deployment (Table 7) phases show response speeds (in milliseconds (mS)) that make the system appropriate for real-world conditions, despite the lengthy training and testing time frames (in seconds (S)). Individually, each of the three parts demonstrates dependability, which is what gives the system its effectiveness. Such a system can operate continuous COVID-related behavioural monitoring as a part of an intelligent infrastructure that complies with pandemic regulations. Repeating the above with people results in involvement that is tiresome, dangerous, and inaccurate. In light of the aforementioned, the proposed system becomes pertinent for the creation of intelligent human environments. Figure 12 shows the advantage of using the FL compared to centralized learning.
Using a data set of over 21000 samples (facemask) two sets of 10500 samples taken from kaggle with four edge nodes, the FL provides atleast 1% better accuracy at lesser response times, which despite variation in node numbers doesn’t change much (Fig. 13). Initially, there are some miss-hits. An error is made at the beginning of the classification process whenever a person who regularly uses the same gate on a given day presents themselves at a different gate. However, learning and decision-making at the node level are shared with the server. In these kinds of circumstances, the server will make a truly undesirable decision, which, over time, demonstrates a tendency to stabilize in the desired direction. The FL layout reduces the amount of error that occurs during future training repetitions. Further, the capability of the FL design to demonstrate detailed and distributed learning is exemplified by the fact that in situations where one class becomes the majority and the other minority, the performance doesn’t change much as shown in Table 9. The tests are carried out for two separate cases. First, the number of female samples are very less while in the other case the count of male faces are disproportionately less. In the first case the accuracy difference is 0.4% while in the second this variation is 0.7%. This establishes an advantage provided by FL due to the fact that if the network is fully trained once despite variation in class-count, the performances don’t show wide deviations. Similarly, it has been observed for the ’not properly wearing’ case that though the count of male and female samples shows a 22% difference, the accuracy performance varies by less than 3%. This is a clear case of advantage of the FL mechanism extending the leaning to the edge nodes with extensive feature capture taking place. We have compared the results with certain previously reported works related to FL even though these works are not exactly aligned with the reported approach. Yet, due to the adoption of FL platforms for the present work and the previously reported works, certain comparisons are done. For the not wearing case, the work84 scores a \(3\%\) better results, but the present work uses imbalanced data distribution, and test data are captured in real-time and applied with pre-trained networks. Such clarity is not reported in84. Similarly, for the wearing case, the proposed approach performs marginally better than84 despite the use of imbalanced data sets during training and on-field data while testing. For the not properly wearing case, the present work marginally falls behind84 because the proposed approach generates erroneous responses in the case of persons with beards. Beards are taken as improper wearing of masks. This aspect will show improvement as the system is subjected to more testing and training with updated data sets, especially with those captured by on-field cameras.
The performance of the proposed FL model has been compared with that reported in44. The work in44 is related to lung cancer detection and reports an accuracy of 99.6%. We have implemented the approach reported in44 with our dataset and experimental setup in data balanced and imbalanced situations. The accuracy levels fall by 5% and 6.5% respectively. The performance is expected to suffer further if network traffic variability conditions and other constraints are taken into consideration. It shows that the present approach has a clear advantage. The combination of Yolov4 and SENet in FL configuration proposed in this work is versatile and is able to perform multi task discrimination as discussed above.
Table 10 provides the specifications of the various networks used for the above tasks. Table 11 provides the summarized accuracy of each of the tasks undertaken by the proposed FL approach with the YOLOV4+SENET architecture compared to a few benchmark methods and previously reported works. It also includes error margins obtained from confidence interval tests considered at two different intervals (85% and 95%) and carried out with the benchmark models, proposed model, and previously reported works. Further, we have performed Friedman and Wilcoxon tests for six different tasks involving the implemented benchmark methods and the proposed model83. The results also highlight the efficiency of the proposed approach in detecting a class of cyber-threats as mentioned in section “Configuring the edge nodes”. The summary results are shown in Table 12. The tests have been performed using different datasets for three different accuracy levels. The advantage of the proposed approach is obvious.
FL completed its task regardless of whether the edge devices were in operation, charging, or linked via WiFi. Thus, the end-user is relieved of their concern over data loss and battery64.
Several applications utilizing FL are shown in Table 1. A comparison between the proposed model’s accuracy and loss derived using COVID-19 data is shown in Table 13. It is observed that the proposed FL (trained with scaled conjugate gradient descent (SGD)) has better model accuracy and loss performance though it takes more training time. From Table 13, it is obvious that the FL model is suitable for critical medical care and data analytics where multi-modal data is applied through multiple nodes95.
The performance of the system suffers from network latency as shown in Table 8. Similarly, there might be a processing bottleneck if the number of connections or persons rises all of a sudden beyond the limits to which the system has been tested. Moreover, the reliability of the sensors and the continuously evolving decision-making process are other notable limitations of the system.
Conclusion
Here, we have presented the design of a pandemic-compliant mechanism to monitor the observance of influenza-type virus protocols, including COVID-19, as part of a residential premise. This mechanism has been designed using the Grove AI HAT and Raspberry Pi 4 as edge nodes working in concert with a server running YOLOV4 and SENet in a specially configured FL framework. In addition to this, the system is able to perform the detection of cyber-attacks. The system has been designed to be a part of critical care health monitoring system. The system has been extensive tested for accuracy, and response time under different load conditions. Further, we have highlighted the advantage of the FL approach v/s centralized system, ability of the FL to sustain reliable performance under processing node number variation and with load imbalance conditions. We have compared the performance of the proposed YOLOv4 and SENet attention layer combination with that obtained from a number of DPTMs, such as RESNET-50, MobileNetV2, and SocialdistancingNet-19. From the experimental results, we observe that the proposed approach provides effective and robust performance, which is superior to previously reported works. In an extended form, the proposed approach can be effectively used as part of a pandemic-compliant intelligent infrastructure.
Data availability
This research did not involve animal or human studies and did not inflict damage on any living organism. The dataset is taken from Kaggle and it is an open source resource. The images are already publicly shared. The dataset is available in the following links: https://www.kaggle.com/mrviswamitrakaushik/facedatahybrid.
References
Lefringhausen, C. T. Covid-19 vaccines-an australian review. J. Clin. Exp. Immunol. 7(3), 491–508 (2022).
Haleem, A., Javaid, M. & Vaishya, R. Effects of covid-19 pandemic in daily life. Curr. Med. Res. Pract. 10, 78 (2020).
WHO. Bulletin of who at https://www.who.int/publications/m/item/covid-19-epidemiological-update-edition-167 (WHO, 2020).
Article. Reports of european centre for disease prevention and control at. https://www.ecdc.europa.eu/en/covid-19/variants-concern (2024).
https://www.unmc.edu/healthsecurity/transmission/2023/12/19/4-big-covid-predictions-for-2024 (2024).
Ellis, R. Who changes stance, says public should wear masks. webmd (2020).
Qin, B. & Li, D. Identifying facemask-wearing condition using image super-resolution with classification network to prevent covid-19. Sensors 20, 5236 (2020).
Feng, S. et al. Rational use of face masks in the covid-19 pandemic. Lancet Respir. Med. 8, 434–436 (2020).
Ejaz, S. E. A. & Islam, R. Implementation of principal component analysis on masked and non-masked face recognition. In 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT) 1–5 (IEEE, 2019).
Prajapati, A. C. et al. A hospital based cross sectional study to find out factors associated with disease severity and length of hospital stay in covid-19 patients in tertiary care hospital of ahmedabad city. Indian J. Community Health 33, 256–259 (2021).
Shadesh, N. H. Enhancing public health: a better approach for face mask detection using transfer learning to prevent airborne disease. Ph.D. thesis, Sonargaon University (SU) (2023).
Lv, W. et al. Towards large-scale and privacy-preserving contact tracing in covid-19 pandemic: a blockchain perspective. IEEE Trans. Netw. Sci. Eng. 9, 282–298 (2020).
Desai, F. et al. Health cloud: a system for monitoring health status of heart patients using machine learning and cloud computing. IEEE Internet Things J. 17, 1–35 (2021).
Wu, T., Wu, F., Qiu, C., Redouté, J.-M. & Yuce, M. R. A rigid-flex wearable health monitoring sensor patch for iot-connected healthcare applications. IEEE Internet Things J. 7, 6932–6945 (2020).
Leung, N. H. et al. Respiratory virus shedding in exhaled breath and efficacy of face masks. Nat. Med. 26, 676–680 (2020).
Christa, G. H., Jesica, J., Anisha, K. & Sagayam, K. M. Cnn-based mask detection system using opencv and mobilenetv2. In 2021 3rd International Conference on Signal Processing and Communication (ICPSC) 115–119 (IEEE, 2021).
Rocha, A. et al. Edge ai for internet of medical things: a literature review. Comput. Electr. Eng. 116, 109202 (2024).
Vinuesa, R. et al. The role of artificial intelligence in achieving the sustainable development goals. Nat. Commun. 11, 1–10 (2020).
Joshi, M., P, A. & S, M. Federated learning for healthcare domain - pipeline, applications and challenges. ACM Trans. Computi. Healthcare3, 1–36 (2022).
Peiyuan, J. et al. A review of yolo algorithm developments. Procedia Comput. Sci. 199, 1066–1073. https://doi.org/10.1016/j.procs.2022.01.135 (2022).
Li, Li, et al. Deepcovid-xr: An artificial intelligence algorithm to detect covid-19 on chest radiographs trained and tested on a large us clinical dataset. Radiology. https://pubs.rsna.org/doi/10.1148/radiol.2020203511 (2021).
Habibzadeh, H. et al. A survey of healthcare internet of things (hiot): a clinical perspective. IEEE Internet Things J. 7, 53–71 (2019).
Chigada, J. & Madzinga, R. Cyberattacks and threats during covid-19: a systematic literature review. South Afr. J. Inf. Manage. 23, 1–11 (2021).
Park Jisu, E. S., Jinman, Jung & Sun, Y. Y. Ui elements identification for mobile applications based on deep learning using symbol marker. J. Inst. Internet Broadcast. Commun. 20, 89–95 (2020).
Li Chong, L. J., Wang Rong & Linyu, F. Face detection based on yolov3. In Recent Trends in Intelligent Computing, Communication and Devices: Proceedings of ICCD 2018 277–284 (Springer, 2020).
Ray, P. P., Thapa, N., Dash, D. & De, D. Novel implementation of iot based non-invasive sensor system for real-time monitoring of intravenous fluid level for assistive e-healthcare. Circ. World 45, 109–123 (2019).
Habibzadeh, H. et al. A survey of healthcare internet of things (hiot): a clinical perspective. IEEE Internet Things J. 7, 53–71 (2019).
Yang Q, Liu Y, et al. Federated machine learning: concept and applications. arXiv (Cornell University). arXiv:1902.04885v1 (2019).
Ahmed, I., J, G., & Ahmad, I. M. Social distance monitoring framework using deep learning architecture to control infection transmission of covid-19 pandemic. Sustain. Cities Soc.69, 102777 (2021).
Dubey, P., Dubey, P., Iwendi, C., Biamba, C. N. & Rao, D. D. Enhanced iot-based face mask detection framework using optimized deep learning models: a hybrid approach with adaptive algorithms. IEEE Access (2025).
Chen, S., Xue, D., Chuai, G., Yang, Q. & Liu, Q. Fl-qsar: a federated learning-based qsar prototype for collaborative drug discovery. Bioinformatics 36, 5492–5498 (2020).
Nishio, T. & Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In ICC 2019-2019 IEEE International Conference on Communications (ICC) 1–7 (IEEE, 2019).
Ammad-Ud-Din, M. et al. Federated collaborative filtering for privacy-preserving personalized recommendation system. arXiv preprint arXiv:1901.09888 (2019).
Solanki, T., Rai, B. K. & Sharma, S. Federated learning using tensor flow. In Federated Learning for IoT Applications 157–167 (Springer, 2022).
Alawida, M., Omolara, A. E., Abiodun, O. I. & Al-Rajab, M. A deeper look into cybersecurity issues in the wake of covid-19: a survey. J. King Saud Univ.-Comput. Inf. Sci. 34, 8176–8206 (2022).
Huang, L. et al. Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J. Biomed. Inform. 99, 103291 (2019).
Ge, S. et al. Fedner: Privacy-preserving medical named entity recognition with federated learning. arXiv preprint arXiv:2003.09288 (2020).
Stuart, R. M., Abeysuriya, R. G. et al. Role of masks, testing and contact tracing in preventing covid-19 resurgences: a case study from new south wales, australia. In BMJ Open 1–8 (IEEE, 2021).
Hussain, S. et al. Iot and deep learning based approach for rapid screening and face mask detection for infection spread control of covid-19. Appl. Sci. 2021, 3495 (2021).
Sanyal S, W. D. & B, N. A federated filtering framework for internet of medical things. In ICC 2019–2019 IEEE International Conference on Communications (ICC) 1–6. https://doi.org/10.1109/ICC.2019.8761381 (2019).
Teo, Z. L. et al. Federated machine learning in healthcare: a systematic review on clinical applications and technical architecture. Cell Rep. Med. 5, 56 (2024).
P, B. D. & G, B. B. Implementation of least mean square adaptive algorithm on covid-19 prediction. In JUITA: JurnalInformatika, e-ISSN: 2579-8901 1–11. https://doi.org/10.1007/s13748-012-0035-5 (2022).
Li Chong, L. J., Wang Rong & Linyu, F. Face detection based on yolov3. In Recent Trends in Intelligent Computing, Communication and Devices: Proceedings of ICCD 2018 277–284 (Springer, 2020).
Heidari, A. et al. A new lung cancer detection method based on the chest ct images using federated learning and blockchain systems. Artif. Intell. Med. 141, 102572 (2023).
Amiri, Z., Heidari, A., Navimipour, N. J., Esmaeilpour, M. & Yazdani, Y. The deep learning applications in iot-based bio-and medical informatics: a systematic literature review. Neural Comput. Appl. 36, 5757–5797 (2024).
Amiri, Z., Heidari, A., Navimipour, N. J. & Unal, M. Resilient and dependability management in distributed environments: a systematic and comprehensive literature review. Clust. Comput. 26, 1565–1600 (2023).
Z, W. Use of supervised machine learning to detect abuse of covid-19 related domain names. Comput. Electr. Eng. 100, 107864 (2022).
Sadeghi, Z., Alizadehsani, R., et al. A review of explainable artificial intelligence in healthcare. Comput. Electri. Engi. 118, 109370 (2024).
Din Nizam Ud, B. S., Kamran, Javed & Juneho, Y. A novel gan-based network for unmasking of masked face. IEEE Access 8, 44276–44287 (2020).
Goodfellow, I. Deep learning (2016).
Heidari, A., Jamali, M. A. J. & Navimipour, N. J. Fuzzy logic multicriteria decision-making for broadcast storm resolution in vehicular ad hoc networks. Int. J. Commun. Syst. 38, e6034 (2025).
Wang, R., Lei, T, et al. Medical image segmentation using deep learning: a survey. IET image Process. 16, 1243–1267 (2022).
Wang Yi, G. G., Xiao, Song & Ni, L. A multi-scale feature extraction-based normalized attention neural network for image denoising. Electronics 10, 319 (2021).
Tedeschi, S., Emmanouilidis, C., Mehnen, J. & Roy, R. A design approach to iot endpoint security for production machinery monitoring. Sensors 19, 2355 (2019).
Mondal, S. & Mitra, P. The role of emerging technologies to fight against covid-19 pandemic: an exploratory review. Trans. Indian Natl. Acad. Eng. 7, 157–174 (2022).
Heidari, A., Amiri, Z., Jamali, M. A. J. & Navimipour, N. J. Enhancing solar convection analysis with multi-core processors and gpus. Eng. Rep. 7, e13050 (2025).
Jain, R., T, S., Gupta, M. & J, H. D. Deep learning based detection and analysis of covid-19 on chest x-ray images. Appl. Intell.51, 1690–1700 (2021).
Toumaj, S., Heidari, A., Shahhosseini, R. & Jafari Navimipour, N. Applications of deep learning in alzheimer’s disease: a systematic literature review of current trends, methodologies, challenges, innovations, and future directions. Artif. Intell. Rev. 58, 44 (2024).
M, B. The risk to population health equity posed by automated decision systems-a narrative review. ArXiv200106615 Cs Jan. 2020. Accessed Nov 21 2020. (2020).
M Seif, R. T. & Li, M. Wireless federated learning with local differential privacy,. ArXiv200205151 Cs Math, Feb. 2020, Accessed: Nov. 21, 2020. (2020).
Lyu, L, Yu, H, et al. Threats to federated learning-a survey,. ArXiv200302133 Cs Stat, Mar. 2020, Accessed: Nov. 21, 2020. (2020).
Liu, Y, Ma, Z, et al. Boosting privately-privacy-preserving federated extreme boosting for mobile crowdsensing,. ArXiv190710218 Cs, Apr. 2020, Accessed: Nov. 21, 2020. (2020).
Yao, X., Huang, T., Wu, C., Zhang, R. & Sun, L. Towards faster and better federated learning: a feature fusion approach. 2019 IEEE International Conference on Image Processing (ICIP) 175–179 (2019).
Mansour, Y., Mohri, M., Ro, J. & Suresh, A. T. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619 (2020).
Abdul Salam, M., Taha, S. & Ramadan, M. Covid-19 detection using federated machine learning. PLoS ONE 16, e0252573 (2021).
Kandati, D. R. & Gadekallu, T. R. Genetic clustered federated learning for covid-19 detection. Electronics 11, 2714 (2022).
Rahman, A. et al. Federated learning-based ai approaches in smart healthcare: concepts, taxonomies, challenges and open issues. Clust. Comput. 26, 2271–2311 (2023).
Shahin Ali, M. et al. Federated learning in healthcare: model misconducts, security, challenges, applications, and future research directions–a systematic review. arXiv e-prints arXiv–2405 (2024).
Keniya, R. & Mehendale, N. Real-time social distancing detector using socialdistancingnet-19 deep learning network. Available at SSRN 3669311 (2020).
Wang, L., Lin, Z. Q. & Wong, A. Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Sci. Rep. 10, 19549 (2020).
Loke, C. H. et al. Physical distancing device with edge computing for covid-19 (paddie-c19). Sensors 22, 279 (2021).
Li, J. & Wu, Z. The application of yolov4 and a new pedestrian clustering algorithm to implement social distance monitoring during the covid-19 pandemic. In Journal of Physics: Conference Series, vol. 1865 042019 (IOP Publishing, 2021).
Shareef, A. A. A., Yannawar, P. L., Abdul-Qawy, A. S. H. & Ahmed, Z. A. Yolov4-based monitoring model for covid-19 social distancing control. In Smart Systems: Innovations in Computing: Proceedings of SSIC 2021 333–346 (Springer, 2022).
Elbachir, Y. M., Makhlouf, D., Mohamed, G., Bouhamed, M. M. & Abdellah, K. Federated learning for multi-institutional on 3d brain tumor segmentation. In 2024 6th International Conference on Pattern Analysis and Intelligent Systems (PAIS) 1–8 (IEEE, 2024).
Rahman, A. et al. Federated learning-based ai approaches in smart healthcare: concepts, taxonomies, challenges and open issues. Clust. Comput. 26, 2271–2311 (2023).
Rauniyar, A. et al. Federated learning for medical applications: a taxonomy, current trends, challenges, and future research directions. IEEE Internet Things J. 11, 7374–7398 (2023).
Dhade, P. & Shirke, P. Federated learning for healthcare: a comprehensive review. Eng. Proc. 59, 230 (2024).
Mahmoud, M., Kasem, M. S. & Kang, H.-S. A comprehensive survey of masked faces: recognition, detection, and unmasking. arXiv preprint arXiv:2405.05900 (2024).
Seresirikachorn, K. et al. Investigating public behavior with artificial intelligence-assisted detection of face mask wearing during the covid-19 pandemic. PLoS ONE 18, e0281841 (2023).
Al-Rakhami, M. S. & Al-Amri, A. M. Lies kill, facts save: detecting covid-19 misinformation in twitter. Ieee Access 8, 155961–155970 (2020).
Verma, S. et al. An automated face mask detection system using transfer learning based neural network to preventing viral infection. Expert. Syst. 41, e13507 (2024).
AlZubi, A. A., Al-Maitah, M. & Alarifi, A. Cyber-attack detection in healthcare using cyber-physical system and machine learning techniques. Soft. Comput. 25, 12319–12332 (2021).
M, S. & S, K. A. K. The power of deep learning for intelligent tumor classification systems: a review. Comput. Electri. Eng.106, 107586 (2023).
Nguyen, T. et al. A novel decentralized federated learning approach to train on globally distributed, poor quality, and protected private medical data. Sci. Rep. 12, 8888 (2022).
Amiri, Z., Heidari, A. & Navimipour, N. J. Comprehensive survey of artificial intelligence techniques and strategies for climate change mitigation. Energy 132827 (2024).
Asadi, M., Jamali, M. A. J., Heidari, A. & Navimipour, N. J. Botnets unveiled: a comprehensive survey on evolving threats and defense strategies. Trans. Emerg. Telecommun. Technol. 35, e5056 (2024).
Heidari, A., Amiri, Z., Jamali, M. A. J. & Jafari, N. Assessment of reliability and availability of wireless sensor networks in industrial applications by considering permanent faults. Concurr. Comput. Pract. Exp. 36, e8252 (2024).
Amiri, Z., Heidari, A., Zavvar, M., Navimipour, N. J. & Esmaeilpour, M. The applications of nature-inspired algorithms in internet of things-based healthcare service: a systematic literature review. Trans. Emerg. Telecommun. Technol. 35, e4969 (2024).
Zanbouri, K. et al. A gso-based multi-objective technique for performance optimization of blockchain-based industrial internet of things. Int. J. Commun. Syst. 37, e5886 (2024).
Heidari, A., Navimipour, N. J., Zeadally, S. & Chamola, V. Everything you wanted to know about chatgpt: components, capabilities, applications, and opportunities. Internet Technol. Lett. 7, e530 (2024).
Vakili, A. et al. A new service composition method in the cloud-based internet of things environment using a grey wolf optimization algorithm and mapreduce framework. Concurr. Comput. Pract. Exp. 36, e8091 (2024).
Heidari, A., Shishehlou, H., Darbandi, M., Navimipour, N. J. & Yalcin, S. A reliable method for data aggregation on the industrial internet of things using a hybrid optimization algorithm and density correlation degree. Clust. Comput. 27, 7521–7539 (2024).
Heidari, A., Navimipour, N. J. & Unal, M. A secure intrusion detection platform using blockchain and radial basis function neural networks for internet of drones. IEEE Internet Things J. 10, 8445–8454 (2023).
Aggarwal, D., Zhou, J. & Jain, A. K. Fedface: collaborative learning of face recognition model. In 2021 IEEE International Joint Conference on Biometrics (IJCB) 1–8 (IEEE, 2021).
Zhang, J. et al. A review on face mask recognition. Sensors25, https://doi.org/10.3390/s25020387 (2025).
Acknowledgements
This research was funded by the Ministry of Science and Higher Education of the Russian Federation (Project “Goszadanie” No. 075-00003-24-02, FSEE-2024-0003). This work is supported by SERB, DST, Government of India, under the project reference no. SUR/2022/001704.
Author information
Authors and Affiliations
Contributions
Conceptualization, Atlanta Choudhury, and Kandarpa Kumar Sarma; investigation, Vyacheslav Gulvanskii and Atlanta Choudhury; methodology, Kandarpa Kumar Sarma and Dmitrii Kaplun; project administration, Kandarpa Kumar Sarma and Dmitrii Kaplun; resources, Dmitrii Kaplun; software, Vyacheslav Gulvanskii and Atlanta Choudhury; supervision, Kandarpa Kumar Sarma and Dmitrii Kaplun; writing-original draft preparation, Atlanta Choudhury; writing-review and editing, Kandarpa Kumar Sarma, Vyacheslav Gulvanskii, Dmitrii Kaplun and Lachit Dutta. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Choudhury, A., Sarma, K.K., Gulvanskii, V. et al. Leveraging federated learning and edge computing for pandemic-resilient healthcare. Sci Rep 15, 20497 (2025). https://doi.org/10.1038/s41598-025-00199-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-00199-9
