
Abstract
Machine learning algorithms that integrate multiple biomarkers are increasingly used in disease detection, yet economic considerations are often overlooked. Medial vascular calcification (mVC), a pathology associated with elevated cardiovascular risk in chronic kidney disease (CKD), requires cost-effective diagnostic approaches. This pilot study evaluated the cost-effectiveness of machine learning models for mVC detection using traditional risk markers and circulating biomarkers in 152 CKD patients undergoing living donor kidney transplantation. Patients were classified as having no/minimal (n = 93) or moderate/extensive (n = 59) mVC. Five classification frameworks with automatic variable selection identified predictors of mVC. Age and copeptin were selected by all algorithms, while diabetes, male sex, choline, and osteoprotegerin were chosen by four methods. The number of features selected ranged from 5 to 21. Although accuracy differences among classifiers were limited to 3%, models using more features nearly tripled the procedure’s cost. By incorporating the incremental cost-effectiveness ratio, the study highlighted significant disparities in performance versus cost among classifiers. The present findings suggest that machine learning has the potential to complement imaging techniques for mVC detection and uncover novel biomarkers. However, modest performance improvements may not justify higher costs, underscoring the importance of considering cost-effectiveness when selecting classification models.
Similar content being viewed by others

Introduction
Medial vascular calcification (mVC) is a pathological condition, with estimated prevalence rates ranging from 27 to 80% in the chronic kidney disease (CKD) population1,2,3. The pathology contributes to the high cardiovascular morbidity and mortality in this group of patients4,5. Moreover, a recent study has revealed that it is associated with the progression of CKD6. While the pathogenesis of mVC is not fully understood and a causal therapy is not available as of today, new therapeutic possibilities are currently being studied7,8,9,10. Moreover, the feasibility of slowing down mVC progression in patients with CKD has been demonstrated11,12. Therefore, improved methods for mVC detection, especially at early stages, is highly warranted.
At present, there is a lack of a dedicated and reliable method of mVC assessment in clinical practice2,13,14. Invasive techniques such as artery biopsy15 or transcutaneous ultrasound16 are rarely performed and cannot be considered as screening procedures. Both direct semi-quantitative methods such as computed tomography, plain X-rays, or ultrasound13, and indirect methods such as measurement of pulse wave velocity that reflects increased arterial stiffness in calcified arteries17,18, are not always available and not easy to perform; therefore, the presence of mVC is likely underestimated. Moreover, currently used tools struggle to differentiate between the two types of vascular calcification: medial and intimal19,20,21; this is clinically significant, as these types have distinct implications and require different patient care strategies. Recently, a method enabling this differentiation, involving the identification of mVC patterns on PET-CT scans, has been introduced22. Nonetheless, the expense and limited availability of PET-CT scans highlight the need for an approach that can indicate the presence of mVC and readily determine which patients truly require this imaging technique.
Machine learning algorithms, which are designed to detect patterns in data, are thought to have the potential to radically improve our ability to diagnose and treat diseases. The large number of potential mVC markers complicates mVC diagnosis and statistical feature selection procedures may therefore play a crucial role in establishing future diagnostics. In previous studies, numerous biomarkers have been linked with vascular calcification including serum biomarkers23, vitamin-K dependent proteins24, various phenotypic features25,26 and risk factors such as high age, male sex, and diabetes mellitus20. While models for mVC detection have demonstrated promising performance quality25, the variability in their cost-effectiveness across different frameworks remains unexplored.
In a clinical setting, besides evaluating the statistical performance of the newly introduced methods, their overall applicability is a crucial consideration. This covers factors such as the procedure’s availability, safety, and the overall expense of the diagnostic procedure. One of the indicators that can characterize the latter is the incremental cost-effectiveness ratio (ICER) which provides insights into the method’s cost in relation to the potential benefits for patients27.
The objective of this pilot study was to investigate the cost-effectiveness of various machine learning frameworks for mVC detection in the chronic kidney disease population. For each of the tested models, in addition to conventional classification correctness metrics, ICER was calculated to incorporate both performance and cost considerations into evaluation. The most favorable model in terms of ICER was further investigated to showcase its possible clinical utility. Finally, we discussed possible pathophysiological associations between mVC and the variables selected by the applied algorithms.
Methods
Data investigation, model building process, and performance evaluation were implemented in R version 4.0.5 and Python version 3.7.
Patients and study design
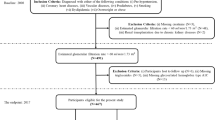
In this retrospective study, a cohort of patients with advanced CKD undergoing living donor kidney transplantation at Karolinska University Hospital was included. The study’s eligibility criteria aligned with those established for patients eligible for kidney transplantation. Exclusion criteria were age under 18 years and unwillingness to participate in the study. The clinical procedures and protocol of measurements were described previously28. The patients gave their informed consent for all performed procedures. The study was approved by the regional ethical review board in Stockholm and adhered to the Declaration of Helsinki.
The participants were classified into two groups according to the extent of medial calcification in inferior epigastric artery biopsies assessed by an experienced pathologist. ‘Group 0’ included patients with no and minimal signs of VC (n = 93), whereas patients having moderate and extensive signs of VC were classified into ‘Group 1’ (n = 59). The procedure of histological mVC examination was presented in detail in25,28.
The dataset consisted of 60 features in 152 patients. All 60 features were available in 71% of the patients; in total, 8.3% of the data were missing. The full data flow is described in25. The dataset included demographic and clinical data, circulating biomarkers, body composition and anthropometric measurements, and skin content of advanced glycation end products measured by autofluorescence. The investigated features are presented in Table 1.
Data preprocessing
First, we standardized the predictors proportionally within the range from 0 to 1. Missing values imputation was performed using the k-nearest neighbors algorithm with k = 3 and Euclidean distance measure between the patients. mVC, as an outcome variable, was not involved in the imputation process. The distributions of the imputed and non-imputed variables did not exhibit statistical differences (Kolmogorov-Smirnov and Chi-square test for continuous and discrete distributions, respectively). Feature selection and patient classification were performed on the complete, standardized set of variables, while the univariable analysis was performed on the raw data.
Data investigation
To choose the appropriate feature selection and classification algorithms, a preliminary data investigation was conducted. Firstly, the Spearman rank correlation coefficient was used to reveal interdependencies between the analyzed features. Categorical variables (sex, smoking, and diabetes mellitus) were excluded from the analysis. Secondly, logistic regression was carried out to assess the interrelationship between a single feature and mVC. To account for multiple comparisons, p-values were adjusted using Benjamini-Hochberg correction29.
Methods of feature selection and patient classification
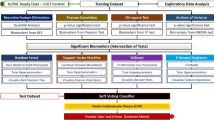
In the process of feature selection and patient classification, the following methods were applied: logistic regression with forward Akaike feature elimination process (LR)30, support vector machine with recursive feature elimination (SVM)31, random forest with permutation importance (RF)32, logistic regression with elastic net penalty (EN)33,34, and, less explored, relaxed linear separability method (RLS)35.
Each of the methods was applied in its standard configuration, with algorithm-specific hyperparameter optimization conducted where appropriate. For feature selection, we opted for well-established algorithms commonly used within the applied classification frameworks. A brief description of the chosen methods can be found in the supplementary material. LR, EN, RF and SVM models were built using R caret package, for training RLS we used our own MATLAB implementation.
Performance evaluation
All methods were validated in the leave-one-out cross-validation (LOOCV) process. In the algorithms where hyperparameter tuning was required, a nested 5-fold cross-validation was incorporated aiming to maximize accuracy as the primary optimization criterion. The metrics used to evaluate the predictions were accuracy, area under the receiver operating characteristic curve (AUC), precision, recall, and F-score, which are discussed in the supplementary material. Additionally, confidence intervals for the LOOCV AUC values were estimated using the bootstrap method with 1,000 resamples.
Incremental cost-effectiveness ratio
The incremental cost-effectiveness ratio (ICER)27,36 represents the additional cost incurred for achieving an additional unit of health outcome, usually measured in quality-adjusted life years (QALYs). It allows decision-makers to ensure that limited healthcare resources are directed towards treatments that provide the most substantial health benefits relative to their associated costs. Thus, the evaluation of ICER facilitates informed decisions about the adoption and funding of medical interventions. In our study, ICER was calculated as:
Where:
-
measure_cost – expense associated with evaluating the biomarkers. For certain biomarkers, their costs are considered hyperparameters (parameters with unknown true value) since they are not routinely measured - see Supplementary Table S2 for a list. For the biomarkers with unknown costs, where only the kit price is available, we introduce an additional factor called the unavailability weight which used to scale the kit prices accordingly.
-
prevalence – a hyperparameter indicating true prevalence of mVC among the advanced CKD population.
-
TPR – the rate of correctly identified true positive cases by the evaluated method.
-
FPR – the rate at which the evaluated method incorrectly identifies cases as positive when they are actually negative.
-
ct_price – the price of a PET-CT scan to confirm mVC presence; sourced from a polish laboratory in June 2023 and converted from PLN to USD at a rate of 0.23, was assumed to be 1127 USD.
-
years_gained – quality of life years gained due to mVC detection. A hyperparameter.
The pricing details for the biomarkers, sourced from Polish laboratories in June 2023 are presented in Table 2. The prices were converted from PLN to USD for clarity using an exchange rate of 0.23. Biomarkers denoted with an asterisk (*) represent hyperparameters. In addition, we performed a sensitivity analysis to assess how the assumed prices influence the results; see supplementary material. We decided to incorporate the cost of a PET-CT scan in the equation as we presume that, irrespective of how well the classifiers perform, cases with a certain likelihood of being positive would be additionally verified using a more direct method.
Results
Data investigation
Spearman correlation analysis revealed the presence of collinearity among certain feature pairs. Associations are presented as a heat map in Fig. S1.
Using a univariable logistic regression model, we identified age, male sex, angiopoietin 2, choline, copeptin, duMGP, hsCRP, IgM anti-PC, insulin-like growth factor 1, osteoprotegerin, sclerostin, troponin T, and body mass index as factors associated with mVC (Table 1). However, after adjusting for multiple comparisons, only age, male sex, copeptin, IGF1, osteoprotegerin, and BMI remained statistically significant (Table 1).
Classification frameworks
In a multivariable analysis, we applied five classification frameworks with appropriate variable selection methods. To fine-tune SVM, RF, and EN, we conducted hyperparameter optimization. Table S1 in the supplementary material presents the calculated optimal values and short parameter descriptions.
The algorithms applied to the data differed regarding features identified as being potentially associated with mVC (Table 2). Only age and copeptin were chosen by all five methods (Table 2). The number of selected features varied between the methods with 21 features being selected by SVM, 16 by RLS, 11 by EN, 6 by RF, and 5 features chosen by LR.
The classification ability of the applied methods was measured, among others, by the area under the receiver operating characteristic curve (AUC). In the cross-validation evaluation process, the highest AUC was achieved by LR (0.85 [0.78–0.90]), followed by RLS (0.84 [0.77–0.90]), EN (0.80 [0.72–0.87]), RF (0.80 [0.73–0.86]), and SVM (0.78 [0.70–0.85]) (Fig. 1). The values in square brackets represent bootstrapped 95% confidence intervals.

Receiver operating characteristic (ROC) curves with area under the curve (AUC) for elastic net (EN), logistic regression (LR), random forest (RF), relaxed linear separability method (RLS) and support vector machine (SVM).
All computed performance evaluation metrics are summarized in Table 3. None of the applied methods outperformed the others across all the assessed measures.
Incremental cost-effectiveness ratio
Figure 2 illustrates the Incremental Cost-Effectiveness ratio for the built models across three unknown parameters: unavailability weights (1, 10, 20, 30), reflecting the possible increase in procedure costs caused by the biomarkers with the unknown prices; true mVC prevalence in CKD population (0.4, 0.6, 0.8); and Quality Adjusted Life Years gained. In general, ICER decreases as QUALYs gained increase, indicating better cost-effectiveness with more QUALYs. Higher unavailability weights lead to higher ICER values for models relying on features with unknown costs (all except LR). Additionally, higher disease prevalence tends to result in lower ICER values suggesting better cost-effectiveness of the models. Moreover, the examination of the ICER indicate that irrespective of the model employed, the procedural costs remain notably low37 when compared with the potential gain in quality-adjusted life years (Fig. 2). Logistic Regression (LR), a model requiring only five input features, of which only one incurs a substantial cost, remains the cheapest procedure, while SVM, which takes 21 features as an input, remains the most expensive (Fig. 2). When sticking to the current state of knowledge about the prices, i.e., taking into account kit price for the features unavailable to examine in a laboratory, the order of ICER follows the order of the number of features. However, when considering the scenario where features not currently routinely measured are presumed to be significantly more expensive than the kit price, which is much more plausible, there is a shift in ICER outcomes among the methods evaluated. Averaged over prevalence, QUALYs, and unavailability weights, LR emerges as the most cost-effective option with mean ICER equal to $278, followed by RF ($412), RLS ($445), EN ($608), and SVM ($769). Sensitivity analysis revealed that the presented results are consistent regardless of the established feature prices. The only exception is sclerostin; assuming a 50% increase in its cost, RLS is favored over RF.

ICER plots with respect to mVC prevalence, quality of life years gained, and unavailability weight. (a) unavailability weight = 1, (b) unavailability weight = 10, (c) unavailability weight = 20, (d) unavailability weight = 30. The prices were converted from PLN to USD for clarity.
In the supplementary material we explored the LR model’s coefficients and showcase its possible clinical utility by calculating ICER for various probability thresholds.
Discussion
In our research, based on the data from 152 participants, we demonstrated the cost-effectiveness of five machine learning frameworks for detecting medial vascular calcification in CKD patients, a group susceptible to mVC. The algorithms were assessed in terms of statistical performance (Table 3) and cost-effectiveness assessed by the incremental cost-effectiveness ratio, ICER (Fig. 2).
Whereas the tested methods had similar predictive power with AUC values between 0.80 and 0.84 and most of them identified traditional risk factors including age, diabetes, male sex, and body mass index (BMI) as important predictors of mVC in patients with CKD, they yielded different results regarding mVC-related features (Table 2). However, the cost differs significantly between the frameworks with LR working on 5 features appearing as the most efficient option.
The accuracies of the models were not perfect, underscoring that there is still much to uncover regarding the biomarkers associated with mVC and that machine-learning-based algorithms cannot serve as a standalone method for assessing mVC presence in CKD patients. However, they can help reduce the frequency of performing unnecessary CT scans for individuals who are found to be less likely to have the pathology, based on the initial assessment of the biomarkers. This reduction can lead to significant savings in healthcare costs, limit radiation exposure, and decrease the time required for diagnostic procedures. In the supplementary material, we provide a detailed example using logistic regression to illustrate how model outputs can be translated into clinical decision-making. Lowering the cut-off threshold for recommending scans increases diagnostic accuracy but reduces potential savings from avoiding unnecessary imaging. The final choice of threshold should be guided by clinical context and resource availability, allowing practitioners to balance diagnostic performance with operational constraints.
In this pilot study, logistic regression emerged as the most effective method. Besides favorable cost-effectiveness, as well as simplicity, and interpretability of the coefficients, it offered another advantage over the other built classifiers: it required only 5 easily obtainable features (Table 2). This minimizes the likelihood of encountering missing values, a situation more common in complex models. However, this interpretation is possible only after looking at the models’ cost-effectiveness and the sets of their required features. Solely examining performance evaluation metrics (Table 3) makes determining the best of the built models much more complex.
Furthermore, examining a panel of different outcomes of the applied feature selection frameworks may provide valuable insights into biomarkers potentially related to mVC. A predictor that emerged as particularly important in our analysis is copeptin that was chosen by all utilized algorithms (Table 2). This confirms findings from a previous study on this topic38. Osteoprotegerin and sclerostin, chosen by 4 and 3 models, respectively, have also been demonstrated to be associated with mVC presence15,39. Hence, it would be worthwhile to perform a longitudinal study to assess whether it is justified to incorporate one or more of these three biomarkers into regular clinical practice.
Finally, we highlight some of the well-established or plausible underlying pathophysiological links between the selected variables and mVC (Table S4). This may reinforce the rationale for including some of the identified predictors when designing studies aiming at detecting mVC in future investigations.
In the context of applied biomedicine, it is increasingly recognized that the criteria for assessing a successful statistical model should extend beyond the predictive power of the classifiers; they ought to also be tailored to align with the medical facilities’ condition and capabilities. Thus, the cost of the procedure, the availability, and interpretability of the utilized features, should be also considered. Our findings demonstrated that, given certain conditions, a framework employing less expensive variables can outperform another that relies on fewer but costly ones. This was exemplified by RLS, which produced better results in terms of ICER when compared to EN despite utilizing 5 additional features (Fig. 2b–d) and obtaining far worse precision. Moreover, it produced equivalent results when compared to RF which employed 10 additional features (Fig. 2c, d). Although effective therapies specifically targeting mVC are currently lacking, there are interventions available that can slow its progression11,12. This supports the inclusion of years_gained in the ICER calculation, as early detection of mVC followed by appropriate clinical management may lead to gains in quality-adjusted life years. In the future, the development of therapies capable of reversing mVC would likely increase the expected years_gained, thereby reducing the relative cost of using biomarkers as a pre-screening tool, as illustrated in Fig. 2.
A major strength of our study is the comprehensiveness of the performed analysis and that it is based on a unique clinical material with histological identification of mVC in artery specimens. To the best of our knowledge, this represents one of the most extensive clinical datasets of arterial biopsies gathered from chronic kidney disease patients. The collected database includes, inter alia, an evaluation of several factors with documented involvement in the disturbed mineral metabolism in CKD and plausible involvement in the etiology of mVC such as sclerostin38 osteoprotegerin39, calciprotein particles40, FGF2341, klotho41, and parathyroid hormone42. We showed the interdependencies between features (Spearman rho, Fig. S1), univariable associations between mVC and each one of the 60 investigated features (Table 1) and performed a multivariable analysis that allowed us to select subsets of features associated with mVC, which entered classification models (Table 2). To the best of our knowledge, no previous studies on mVC detection analyzed ICER or any other price-related metrics of the evaluated procedures.
Our study has several limitations which should be considered when interpreting the results. First, the database includes missing values. Whereas their imputation can change the original dataset, including only complete cases may result in a considerable reduction of the number of included patients and features and therefore, a loss of statistical power. Additionally, many statistical tools and algorithms require a complete dataset; for this reason, and considering the relatively small sample size, we decided to fill in the missing data and ensured that the variable distribution did not alter significantly post-imputation. It should also be noted that imputation may interfere with the stability of feature selection. Furthermore, the lack of external validation is a key limitation, as it prevents us from fully assessing the generalizability and robustness of the developed models.
Moreover, due to the retrospective nature of this long-lasting study, some potentially relevant features were not analysed which may limit the comprehensiveness of our findings. Missing features include, for example, N-terminal pro b-type natriuretic peptide (NT-proBNP) and Gla-rich protein, a vitamin K dependent calcification inhibitor43,44.
Another issue is that the costs related to the measurements needed for ICER analysis can vary significantly between countries, laboratories, and over time. While the sensitivity analysis revealed the consistency of the presented results, it is important to emphasize that the conducted investigation is only a rough estimation of the potential costs associated with each procedure. Before implementation of such a detection method, medical facilities should estimate the costs based on their resources and capabilities.
Lastly, it is important to note that mVC distribution varies across different vascular beds45,46. In the past, mVC presence assessed in the inferior epigastric artery was linked with higher values of coronary artery calcification (CAC) score15, which altogether demonstrates the complexity and variability of the condition. However, further studies are needed to assess the impact of the selected features on calcification in different vascular beds, as the current findings may not be universally applicable.
Conclusion
Our findings showcase the importance of employing analysis that considers not only statistical accuracy but also economic implications of proposed machine learning frameworks. In the present study, the incremental cost-effectiveness ratio (ICER), was found to provide a suitable criterion for model selection, as analysis using ICER is where the difference between the models becomes evident. This highlights the importance of considering cost-effectiveness when selecting the final classifier, as a minor increase in model performance might not balance the costs related to measuring model-required inputs. While the findings from this pilot study warrant validation on a larger dataset, we believe that it may encourage other researchers using machine learning algorithms for detection of medial vascular calcification to seek optimal solutions that consider not only predictive capabilities but also the applicability of the implemented methods.
Data availability
The data that support the findings of this study are not openly available due to reasons of sensitivity and are available from the corresponding author upon reasonable request. Data are located in controlled access data storage at Karolinska Institutet.
References
London, G. M. et al. Arterial media calcification in end-stage renal disease: impact on all-cause and cardiovascular mortality. Nephrol. Dialysis Transplantation. https://doi.org/10.1093/ndt/gfg414 (2003).
Nelson, A. J. et al. Targeting vascular calcification in chronic kidney disease. JACC Basic. Transl Sci. https://doi.org/10.1016/j.jacbts.2020.02.002 (2020).
Duhn, V. et al. Breast arterial calcification: A marker of medial vascular calcification in chronic kidney disease. Clin. J. Am. Soc. Nephrol. https://doi.org/10.2215/CJN.07190810 (2011).
London, G. M. et al. Arterial media calcification in end-stage renal disease: impact on all-cause and cardiovascular mortality. Nephrol. Dialysis Transplantation. 18, 1731–1740. https://doi.org/10.1093/ndt/gfg414 (2003).
Erlandsson, H. et al. Scoring of medial arterial calcification predicts cardiovascular events and mortality after kidney transplantation. J. Intern. Med. 291, 813–823. https://doi.org/10.1111/joim.13459 (2022).
Park, S. et al. Vascular calcification as a novel risk factor for kidney function deterioration in the nonelderly. J. Am. Heart Assoc. https://doi.org/10.1161/JAHA.120.019300 (2021).
Lin, Y-L. & Hsu, B-G. Vitamin K and vascular calcification in chronic kidney disease: an update of current evidence. Tzu Chi Med. J. 35, 44. https://doi.org/10.4103/tcmj.tcmj_100_22 (2023).
Bao, W. H. et al. Relationship between gut microbiota and vascular calcification in Hemodialysis patients. Ren. Fail. https://doi.org/10.1080/0886022X.2022.2148538 (2023).
Düsing, P. et al. Vascular pathologies in chronic kidney disease: pathophysiological mechanisms and novel therapeutic approaches. J. Mol. Med. https://doi.org/10.1007/s00109-021-02037-7 (2021).
Xu, C., Smith, E. R., Tiong, M. K., Ruderman, I. & Toussaint, N. D. Interventions to attenuate vascular calcification progression in chronic kidney disease: A systematic review of clinical trials. J. Am. Soc. Nephrol. https://doi.org/10.1681/ASN.2021101327 (2022).
Raggi, P. et al. The ADVANCE study: A randomized study to evaluate the effects of Cinacalcet plus low-dose vitamin D on vascular calcification in patients on Hemodialysis. Nephrol. Dialysis Transplantation. https://doi.org/10.1093/ndt/gfq725 (2011).
Chen, N. C., Hsu, C. Y. & Chen, C. L. The strategy to prevent and regress the vascular calcification in dialysis patients. Biomed. Res. Int. https://doi.org/10.1155/2017/9035193 (2017).
Marreiros, C., Viegas, C. & Simes, D. Targeting a silent disease: vascular calcification in chronic kidney disease. Int. J. Mol. Sci. https://doi.org/10.3390/ijms232416114 (2022).
Raggi, P. & O’Neill, W. C. Imaging for vascular calcification. Semin Dial. https://doi.org/10.1111/sdi.12596 (2017).
Qureshi, A. R. et al. Increased circulating sclerostin levels in end-stage renal disease predict biopsy-verified vascular medial calcification and coronary artery calcification. Kidney Int. https://doi.org/10.1038/ki.2015.194 (2015).
Lanzer, P. et al. Medial arterial calcification: JACC state-of-the-art review. J. Am. Coll. Cardiol. https://doi.org/10.1016/j.jacc.2021.06.049 (2021).
Ren, S. C. et al. Vascular calcification in chronic kidney disease: an update and perspective. Aging Dis. 13, 673–697. https://doi.org/10.14336/AD.2021.1024 (2022).
Lanzer, P. et al. Medial vascular calcification revisited: review and perspectives. Eur. Heart J. 35, 1515–1525. https://doi.org/10.1093/eurheartj/ehu163 (2014).
Hjortnaes, J., New, S. E. P. & Aikawa, E. Visualizing novel concepts of cardiovascular calcification. Trends Cardiovasc. Med. https://doi.org/10.1016/j.tcm.2012.09.003 (2013).
Lanzer, P. et al. Medial vascular calcification revisited: review and perspectives. Eur. Heart J. https://doi.org/10.1093/eurheartj/ehu163 (2014).
Jinnouchi, H. et al. Intravascular imaging and histological correlates of medial and intimal calcification in peripheral artery disease. EuroIntervention. https://doi.org/10.4244/EIJ-D-20-01336 (2021).
Konijn, L. C. D. et al. CT calcification patterns of peripheral arteries in patients without known peripheral arterial disease. Eur. J. Radiol. https://doi.org/10.1016/j.ejrad.2020.108973 (2020).
Golüke, N. M. S. et al. Serum biomarkers for arterial calcification in humans: A systematic review. Bone Rep. https://doi.org/10.1016/j.bonr.2022.101599 (2022).
Wen, L., Chen, J., Duan, L. & Li, S. Vitamin K-dependent proteins involved in bone and cardiovascular health (Review). Mol. Med. Rep. https://doi.org/10.3892/mmr.2018.8940 (2018).
Dai, L. et al. Phenotypic features of vascular calcification in chronic kidney disease. J. Intern. Med. https://doi.org/10.1111/joim.13012 (2020).
Lyu, B. et al. Vascular calcification markers and hemodialysis vascular access complications. Am. J. Nephrol. https://doi.org/10.1159/000493549 (2018).
Bambha, K. & Kim, W. R. Cost-effectiveness analysis and incremental cost-effectiveness ratios: uses and pitfalls. Eur. J. Gastroenterol. Hepatol. 16, 519–526. https://doi.org/10.1097/00042737-200406000-00003 (2004).
Qureshi, A. R. et al. Increased circulating sclerostin levels in end-stage renal disease predict biopsy-verified vascular medial calcification and coronary artery calcification. Kidney Int. 88, 1356–1364. https://doi.org/10.1038/ki.2015.194 (2015).
Benjamini, Y. & Hochberg, Y. On the adaptive control of the false discovery rate in multiple testing with independent statistics. J. Educational Behav. Stat. 25, 60–83. https://doi.org/10.3102/10769986025001060 (2000).
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning Data Mining, Inference, and Prediction (12th printing). (2017).
Ben-Hur, A. & Weston, J. A user’s guide to support vector machines. Methods Mol. Biol. https://doi.org/10.1007/978-1-60327-241-4_13 (2010).
James, G., Witten, D., Hastie, T. & Tibshirani, R. An Introduction To Statistical Learning with Applications in R 8th edn https://doi.org/10.1201/9781315120256 (Springer, 2017).
Freijeiro-González, L., Febrero-Bande, M. & González-Manteiga, W. A critical review of LASSO and its derivatives for variable selection under dependence among covariates. Int. Stat. Rev. 90, 118–145. https://doi.org/10.1111/insr.12469 (2022).
Hastie, T., Tibshirani, R., James, G. & Witten, D. An introduction to statistical learning (2nd ed.). Springer Texts 102. (2021).
Bobrowski, L. et al. Selection of genetic and phenotypic features associated with inflammatory status of patients on dialysis using relaxed linear separability method. PLoS ONE. 9, e86630. https://doi.org/10.1371/journal.pone.0086630 (2014).
Weinstein, M. C. & Stason, W. B. Foundations of cost-effectiveness analysis for health and medical practices. N. Engl. J. Med. 296, 716–721. https://doi.org/10.1056/nejm197703312961304 (1977).
Appleby, J., Devlin, N. & Parkin, D. NICE’S cost effectiveness threshold. Br. Med. J. https://doi.org/10.1136/bmj.39308.560069.BE (2007).
Golembiewska, E. et al. Copeptin is independently associated with vascular calcification in chronic kidney disease stage 5. BMC Nephrol. https://doi.org/10.1186/s12882-020-1710-6 (2020).
Makarović, S., Makarović, Z., Steiner, R., Mihaljević, I. & Milas-Ahić, J. Osteoprotegerin and vascular calcification: clinical and prognostic relevance. Coll. Antropol. 39. (2015).
ter Braake, A. D. et al. Calciprotein particle Inhibition explains magnesium-mediated protection against vascular calcification. Nephrol. Dialysis Transplantation. https://doi.org/10.1093/ndt/gfz190 (2020).
Yamada, S. & Giachelli, C. M. Vascular calcification in CKD-MBD: roles for phosphate, FGF23, and Klotho. Bone 100, 87–93. https://doi.org/10.1016/j.bone.2016.11.012 (2017).
Fujii, H. Association between parathyroid hormone and cardiovascular disease. Therapeutic Apheresis Dialysis. https://doi.org/10.1111/1744-9987.12679 (2018).
Silva, A. P. et al. Gla-rich protein (GRP) as an early and novel marker of vascular calcification and kidney dysfunction in diabetic patients with CKD: A pilot cross-sectional study. J. Clin. Med. https://doi.org/10.3390/jcm9030635 (2020).
Jouni, H., Rodeheffer, R. J. & Kullo, I. J. Increased serum N-terminal pro-B-type natriuretic peptide levels in patients with medial arterial calcification and poorly compressible leg arteries. Arterioscler. Thromb. Vasc Biol. https://doi.org/10.1161/ATVBAHA.110.216770 (2011).
Sinha, S. & Santoro, M. M. New models to study vascular mural cell embryonic origin: implications in vascular diseases. Cardiovasc. Res. https://doi.org/10.1093/cvr/cvy005 (2018).
Muyor, K. et al. Vascular calcification in different arterial beds in ex vivo ring culture and in vivo rat model. Sci. Rep. https://doi.org/10.1038/s41598-022-15739-w (2022).
Funding
Baxter Novum is the result of a grant from Baxter Healthcare Corporation to Karolinska Institutet.
Author information
Authors and Affiliations
Contributions
UB – conceptualization, methodology, software, visualization, writing – original draft; MD – conceptualization, writing – review & editing; LD – data curation, writing – review & editing; AQ – data curation; LB – software; MS – supervision; BL – supervision, writing – review & editing; PS – supervision; TL – software; JP – conceptualization, supervision, writing – review & editing.
Corresponding author
Ethics declarations
Competing interests
Peter Stenvinkel has a support from Bayer for conducting a randomized trial on testosterone supplementation in dialysis patients, participates in scientific advisory boards: Astra Zeneca, Glaxo, Vifor, Baxter, Fresenius, Invizius, and has payment or honoraria for lectures, presentations, speakers bureaus, manuscript writing or educational events from Reata, Astra Zeneca, Baxter, Fresenius, Novo Nordisk, Astellas, Pfizer, Bayer; Magnus Soderberg is a full-time employee of AstraZeneca; Malgorzata Debowska has grant no 2018/31/D/ST7/03472 from National Science Center (Poland); Jan Poleszczuk has a grant grant No. 2018/31/D/ST7/03472 from National Science Center (Poland); Bengt Lindholm has a grant to Karolinska Institutet from Baxter Healthcare Corporation and was previously employed by Baxter Healthcare Corporation. He also has received stock or stock options from Baxter Healthcare Corporation; Urszula Bialonczyk – none; Lu Dai – none; Abdul Rashid Qureshi – none; Leon Bobrowski – none; Tomasz Lukaszuk – none.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bialonczyk, U., Debowska, M., Dai, L. et al. Balancing accuracy and cost in machine learning models for detecting medial vascular calcification in chronic kidney disease: a pilot study. Sci Rep 15, 17453 (2025). https://doi.org/10.1038/s41598-025-02457-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-02457-2
