
Abstract
Living kidney donors typically experience approximately a 30% reduction in kidney function after donation, although the degree of reduction varies among individuals. This study aimed to develop a machine learning (ML) model to predict serum creatinine (Cre) levels at one year post-donation using preoperative clinical data, including kidney-, fat-, and muscle-volumetry values from computed tomography. A total of 204 living kidney donors were included. Symbolic regression via genetic programming was employed to create an ML-based Cre prediction model using preoperative clinical variables. Validation was conducted using a 7:3 training-to-test data split. The ML model demonstrated a median absolute error of 0.079 mg/dL for predicting Cre. In the validation cohort, it outperformed conventional methods (which assume post-donation eGFR to be 70% of the preoperative value) with higher R2 (0.58 vs. 0.27), lower root mean squared error (5.27 vs. 6.89), and lower mean absolute error (3.92 vs. 5.8). Key predictive variables included preoperative Cre and remnant kidney volume. The model was deployed as a web application for clinical use. The ML model offers accurate predictions of post-donation kidney function and may assist in monitoring donor outcomes, enhancing personalized care after kidney donation.
Similar content being viewed by others

Introduction
Careful screening of living donor candidates is critical to minimizing the risk of end-stage kidney disease (ESKD) and ensuring ongoing monitoring of renal function post-donation. Although rigorously screened living kidney donors were traditionally thought to have comparable risks of mortality and ESKD to the general population1, they may face a higher risk of ESKD compared to matched healthy non-donors2 Additionally, selection criteria for living donors have broadened to include medically complex individuals, such as those with advanced age, hypertension, obesity, or lower estimated glomerular filtration rate (eGFR)3 These evolving trends underscore the urgent need for more precise and individualized prediction models to assess and monitor postoperative renal function in this population.
Post-donation eGFRs are typically reach approximately 60–70% of the pre-donation levels, attributed to compensatory hypertrophy of the remaining kidney4 Grams et al. developed an online risk tool to estimate the long-term risk of ESKD for living kidney donor candidates, using meta-analyzed risk associations from seven general population cohorts5 Several reports have proposed predictive factors for post-donation kidney function that included donor age, sex, race, body mass index (BMI) and preoperative computed tomography (CT) volumetry of kidney6,7,8,9 These were based on observational study and traditional statistics which aims to identify significant risk factors among explanatory variables through model-driven regression using linear models10.
Traditional regression models that fit data to pre-defined models are directly meaningful to clinicians, though it relies on liner predefined models and are constrained by strict assumptions. In contrast, symbolic regression (SR) via genetic programming (GP) is a machine learning (ML) algorithm where the goal is discovering an explicit mathematical formula that best describes a given dataset from the vast function space, enabling it to uncover complex, non-linear interactions directly from the data11 Genetic programming (GP) explores both the structure of the model and its parameters. This evolutionary methodology is based on the principles of mutation and natural selection, mirroring the way organisms evolve and adapt to their environments. In SR via GP, innumerable mathematical formulas evolve to fit the given dataset, progressively yielding better ones that can predict the target value from the explanatory variables. In the previous study, Ueno et al. utilized SR via GP to evaluate pathological factors associated with the development of glomerular hypertrophy (GH)12 From a set of 60 variables, the SR model identified key factors such as inflammation, vascular damage, and obesity as significant predictors, while eGFR was ranked low (46th out of 60). This finding highlights the ability of SR to distinguish morbid GH from adaptive hypertrophy due to nephron loss. Collectively, these results suggest that SR can evaluate variables in an unbiased manner, providing valuable insights into the underlying mechanisms.
The objective of this study was to develop a machine learning model for more accurate and personalized prediction of post-donation kidney function. We employed an SR model to predict post-donation creatinine (Cre) values using preoperative variables, including CT volumetry data for excised and non-excised kidney volumes. Given that excess visceral fat and reduced skeletal muscle mass—characteristic of sarcopenia—are recognized risk factors for the development of chronic kidney disease (CKD)13,14,15, we also implemented CT volumetry for visceral fat and skeletal muscle. The resulting model was integrated into a user-friendly interface to facilitate clinical application and improve decision-making in transplant practice.
Results
Patient’s background
The clinical characteristics and laboratory data of the patients in the study cohorts are summarized in Table 1. All the participants were Asian. The mean donor age was 59.9 years, and 35% were male. The median baseline Cre level before donation was 0.7 mg/dl. There were no significant differences in the variables between the training and the validation cohort.
CT volumetry data
There were no significant differences in CT volumetry data between training cohort and validation cohort (Table 1). The correlation between CT volumetry data and preoperative Cre level was investigated using Pearson’s correlation coefficient (r). The analysis revealed moderate positive correlations between area of psoas muscle/skeletal muscle/visceral fat and pre-operative Cre level (Supplementary table 1A). Significant positive correlations were observed between CT volumetry data and pre-operative body weight (Supplementary table 1B).
Correlation between explanatory variables and post-donation cre level
All correlation coefficients between preoperative data and Cre level at 1 year post-donation are presented in Supplemental Fig. 1. Additionally, the point-biserial correlation coefficients (r values) for the top 10 variables with the strongest positive correlations are summarized in Table 2. As with the pre-operative Cre level, the Cre level at 1 year post-donation demonstrated a positive correlation with preoperative skeletal muscle volume (r = 0.62, p < 0.001), along with weak positive correlations with the psoas muscle and visceral fat volumes.
Analysis of predictive variables for Cre level post-donation using ML
By using 34 explanatory variables, Data Modeler automatically generated 1123 models that calculate Cre level at 1-year post-donation. Figure 1 show their distribution in the function space. We selected 98 models with lower complexities and lower 1-R2 in each epoch to limit the number of models to 9% of all generated models. We ranked the frequencies of all explanatory variables that were used in the selected models (Fig. 2). The selected factors for generating models included age, male, BW, the history of CVD, BUN, Cre, HbA1C, and the volume of the non-excised kidney.

Distribution of functions generated using symbolic regression via genetic programming within the function space. This figure illustrates the distribution of complexities and errors of generated models in a function space. The horizontal axis represents complexity, while the vertical axis indicates error. Each dot corresponds to a single generated model. Red dots represent models on the Pareto Front, and the green dot marks the model positioned at the uppermost and rightmost edge of a rectangle used to select appropriate models that strike a balance between underfitting and overfitting.

Frequently of variables utilized in the selected models. The frequency of variables used in the selected models is shown in descending order. The horizontal axis represents the frequency of appearance. Cre, creatinine; Bw, body weight; BUN, blood urea nitrogen; CVD, cardiovascular disease; HbA1C, hemoglobinA1C; UA, uric acid; HL, hyperlipidemia (lipid-lowering agents); K, potassium; CRP, C-reactive protein; HTN, hypertension; Na sodium; Ht, height; AST, aspartate aminotransferase; ALT, alanine aminotransferase; SBP, systolic blood pressure; DBP, Diastolic blood pressure; HU, hyper uricemia (uric acid lowering agents); TP, total protein; TC, total cholesterol;
Creating a predictive model for Cre level at 1-year
To establish an optimized model for predicting Cre levels 1 year post-donation, ensemble learning was performed using the bagging method, which calculates the trimmed means of the selected models. The formula for the optimized DKF model, incorporating key variables extracted from the developed models, is provided in Supplemental Document 1. The R2, RMSE, and MAE values between the predicted Cre levels generated by the optimized DKF model and the measured values were 0.72, 0.1, 0.073 mg/dl mg/dL in the training cohort (Fig. 3A) and 0.69, 0.1, and 0.079 mg/dl in the validation cohort (Fig. 3B), respectively.

Relationship between calculated and measured creatinine values in (A) training cohort and (B) validation cohort. Red dots represent the calculated creatinine values obtained from the optimized DKF model. Blue dots represent the measured creatinine values at 1 year post-donation. Arrows indicate the discrepancies between the calculated and measured values.
The impact of each variable in the generated formula
We investigated factors that were used in the generated formula to determine which factors had higher impact on the target. A simulation was performed by changing each variable within its range, while the influence of all other variables was averaged out. Table 3 lists the 8 most significant driver variables that influenced the result. Pre-Cre level and the volume of the non-excised kidney were the most influential factors for Cre levels at 1 year, with high partial dependence estimate. Supplementary Fig. 2 illustrates the extent to which the target Cre value changes as the top 3 driver variables are varied.
The development of a sparse model
Based on the above analysis, several valuables incorporated in the model have small impact on the estimated eGFR. To enhance user-friendliness in clinical settings, we developed a simplified prediction formula (referred to as the sparse DKF model), where variables with partial dependent estimate smaller than 0.1 were replaced with their median values. Specifically, age, BUN and HbA1C were fixed at their median values, while the history of CVD was set to its mode, which was 0. The key driving factors for this simplified model included sex (male), body weight (BW), Pre-Cre, and the volume of the non-excised kidney. The developed model has been uploaded to GitHub and implemented as a web application for convenient calculations, accessible at the following address: [https://donorcrcalculatoren-89wgze554kd9n2yjkcyubb.streamlit.app/].
Verification of accuracy of developed models
To assess the accuracy of the developed models, we calculated the R2, RMSE, and MAE for the values predicted by the optimized DKF model, the sparse DKF model, and the conventional DKF model, comparing them to the measured eGFR values in the validation cohort (N = 61). (Table 4) The optimized DKF model achieved the highest R2 and the lowest RMSE and MAE, indicating minimal prediction error and high predictive accuracy. The sparse DKF model, designed with clinical practicality in mind, also demonstrated significantly better predictive accuracy compared to the conventional DKF model. Consequently, both the optimized DKF model and the sparse DKF model showed superior data fit and can be considered more reliable than the conventional DKF model.
Next, we analyzed the correlation between the predicted values from the optimized DKF model and the measured eGFR values (Fig. 4A), as well as the predicted values from the conventional DKF model and the measured eGFR values (Fig. 4B). Three cases with |Z| ≥ 2 were identified, and these cases completely overlapped between the optimized DKF model and the conventional DKF model. Supplementary Table 2 compares the patient characteristics among inliers (-2 < Z < 2), high outliers (Z > 2), and low outliers (Z < -2) in the prediction of Cre at 1 year post-donation. Although the small sample size limits statistical interpretation, cases with higher preoperative Cre levels appeared more likely to be classified as outliers in both the optimized DKF model and the conventional DKF model.

The correlation graphs with Z-score between observed eGFR and estimated eGFR. The plots show the observed eGFR at 1 year post-donation (Y-axis) versus the estimated eGFR (X-axis) using the optimized DKF model (A) and the conventional DKF model (B). The color scale represents the Z-score. The green dashed line indicates the 75th percentile, while the orange dashed line indicates the 25th percentile.
Discussion
In the present study, we generated a predictive model for Cre level at 1-year post-donation, using the SR via GP technique, which is one of the ML techniques. The developed model, referred to “the optimized DKF model” by ML was found to have higher accuracy, demonstrating higher R2 values and lower RMSE and MAE, compared to the conventional DKF model which assumed eGFR post-donation was 70% of the preoperative value. Preoperative Cre level and the volume of the non-excised kidney were identified as the most influential predictive factors for Cre levels at 1 year post-donation. Predicting the kidney function post-donation will facilitate more rigorous management and help achieve optimal post-transplant outcomes.
Statistical analysis revealed that there was a moderate correlation between the skeletal muscle volume and Cre levels at 1 year, as well as between the visceral fat volume and Cre levels at 1 year. The volume of non-excised kidney was not corelated to Cre level post-donation. Approximately 95% of the human body’s total creatine is located in skeletal muscle and serum Cre can be served as a surrogate marker of skeletal muscle mass even in CKD patients16 The previous study revealed that visceral adipose tissue detected by CT scan was associated with CKD when defined using cystatin C estimating equations but not when using a Cre-based estimating Eq. 17 On the other hand, area of skeletal muscle and area of visceral fat were not identified as influential factors in the ML analysis. Volume of non-excised kidney was found to be a factor affecting Cre level at 1-year. The larger the volume of the non-excised kidney, the lower the Cre levels at 1 year tended to be. (Supplementary Fig. 2A) Shimada et al. demonstrated that body surface area-adjusted preserved kidney volume calculated by the 3D reconstructed image was an independent risk factor for > 30% reduction of eGFR at 1-year post-donation (odds ratio, 0.93)9, which aligned with our findings. It is well known that adaptive hyperfiltration after donor nephrectomy is attributable to hyper perfusion and hypertrophy of the remaining glomeruli18 The increases in single-kidney renal plasma flow, cortical volume, and GFR continue through to the late post-donation period18 From the perspective of donor outcomes, it is suggested to determine which side of kidney to be excised based on the volume of the remaining kidney.
As previously mentioned, the post-donation eGFRs are approximately 60–70% of the pre-donation values based on past reports4 To assess the generated model’s goodness-of-fit, we compared its R2, RMSE, and MAE values to those of the conventional prediction method. The optimized DKF model showed higher explanatory power and accuracy for predicting Cre level at 1 year compared to the conventional method. The eGFR was reported to increase by + 0.35 ml/min/ 1.73 m2 per year from 6 weeks post-donation onward, with this increase leveling off by the fifth year19 It is reported that increase in GFR can begin as early as 8 h post-donation, however, this acute compensation is less efficient in older donors20 Thus, predicting Cre levels at 1-year by ML may be more beneficial than the conventional prediction method in clinical practice. However, outliers also exist in the optimized DKF model. Since the cases with pre-operative Cre values deviating from the median were likely to become outliers, the prediction may not be applied in the cases with extreme Cre level before the donation.
Then, how should this model be applied in clinical practice? While the rate of ESKD development among living donors is exceedingly low, it is well known that kidney donors had an increased risk of ESKD, compared with matched healthy nondonors2 Massie et al. measured eGFR at 6 months post-donation to estimate the 15-year cumulative incidence of ESKD, using data from 71,468 living kidney donors21After adjusting for age, race, sex, BMI, and biological relationship, each 10 mL/min/1.73 m² decrease in eGFR at 6 months post-donation was associated with a 28% higher risk of ESKD21 Longitudinal monitoring of post donation kidney function is expected to enhance risk assessment in living kidney donors. Thus, kidney function at 1-year post donation may serve as a surrogate marker for long-term risk of ESKD in living kidney donors. Ensuring the safety of living kidney donation is a top priority, and transplant physicians have a responsibility to provide careful post-nephrectomy monitoring, even when donors fully understand and accept the associated risks. It is meaningful to predict Cre levels at 1-year post-donation, to determine the follow-up intervals and management strategy. Additionally, this model is also valuable during pre-donation discussion with prospective living donors, as it provides an individualized estimate of kidney function at 1-year post-donation, thereby helping candidates to better visualize and understand their expected outcomes. Therefore, predicting kidney function at 1-year post donation is critically important for pre-donation counseling, and helps tailor post-donation monitoring strategies.
This model was developed by analyzing the characteristics of donors who were ultimately selected for kidney donation, excluding those who did not meet the criteria for a living kidney donor. Therefore, it is essential to note that even if a good Cre level was expected by the generated model, it does not guarantee the safety of prognosis for cases which don’t meet the criteria for a living kidney donor. It is important to adhere to the guidelines for evaluating eligibility for a living kidney donor. How to approach to donor selection has been discussed nowadays. While the Kidney Disease Improving Global Outcomes Guideline recommends the use of fixed cutoffs22, age and sex- based GFR cutoffs are commonly used in the British Transplantation Society, the European Renal Best Practice, and the Canadian Society of Transplantation, considering kidney function decline with healthy aging23,24,25 It is challenging to judge whether older candidates’ kidney function is appropriate for their age because they tend to be more medically complex. In such cases, which include so-called marginal donors, the prediction of kidney function post-donation by the generated model might be useful in planning follow-up. In cases where a donor is acceptable for kidney donation but is predicted to have poor post-donation kidney function, careful follow-up should be warranted after donation. Additionally, as non-excised kidney volume was an influential factor for predicting Cre level at 1-year, it is possible to simulate the impact on kidney function based on CT imaging data. It can be used as a reference to consider the impact on kidney function depending on which kidney will be donated. Overall, although the optimized DKF model/the sparse DKF model cannot be used directly for donor selection, it might be helpful as a reference for donor selection, for simulating kidney function post-donation, and for planning follow-up.
We acknowledge there are limitations in our study. First, this model was generated by data set from a single institution with a small sample size. According to the report by Guyon et al.26, even with only a few dozen samples, having a lot of features can make it possible to separate the training data perfectly with a linear classifier. We increased the feature dimensionality by adding variables, including CT volumetry, to address the small sample size. There might be more other factors affecting kidney function after donation beyond our dataset, however, increasing the number of features also increase the risk of overfitting and data noise26 Therefore, data validation using external data set is mandatory in the future study. Second, the formula developed in this study was designed solely to predict post‑donation kidney function, not to determine which kidney to remove. In fact, CT volumetry was not used for evaluating split renal function in this cohort. Habbous et al. performed a meta‑analysis of 19 studies (n = 1,479) and found that CT volumetry shows a moderate correlation with split renal function by nuclear renography (pooled Pearson’s r = 0.74; 95% CI, 0.61–0.82), yet its ability to detect a clinically meaningful between‑kidney function difference of ≥ 10% is limited: sensitivity 35%, specificity 88%, overall agreement 78%, and a false‑negative rate of approximately 14%.27 Although selection bias may have influenced these findings (since renography was often only performed in donors with marked size asymmetry), CT volumetry measures kidney volume alone and does not account for factors affecting true renal function—such as nephron density, scarring, or other underlying pathology. Therefore, when a significant split renal function disparity is suspected, nuclear renography remains the recommended evaluation method.
Finally, strictly speaking, the model can only be applied at the time a candidate presents for donation, because the blood pressure data used in the process of making model, was taken on the day of admission for donor nephrectomy. All other clinical factors, including CT findings, were obtained during the donor evaluation. However, in both the optimized DKF model and the sparse DKF model (a simplified model), blood pressure was not selected as a factor. Therefore, it may still serve as a useful reference during donation discussions with prospective living donors.
In conclusion, the ML model achieved an effective predictive performance for predicting Cre level post-donation. It is meaningful for transplant physicians to pay sufficient attention to the care for donors after donation. Applying ML techniques to the clinical field has the potential to lead to better healthcare for patients.
Materials and methods
Patients and data collection
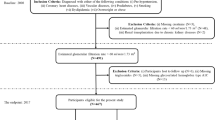
We identified 204 patients who underwent enhanced CT prior to donor nephrectomy for living kidney transplantation at Tokyo Women’s Medical University Hospital between January 2012 and December 2016. Patients who were lost to follow-up after discharge or whose follow-up period after nephrectomy was less than one year were excluded. This study was approved by the Institutional Review Board of the Tokyo Women’s Medical University Hospital (#2021 − 0122). Since this is a retrospective study, informed consent was waived by the Institutional Review Board of the Tokyo Women’s Medical University Hospital. All methods of research procedures were performed in accordance with the Declaration of Helsinki.
Basic information about the patients was obtained from donor medical records within 3 months before donation, including age, sex, medications for hypertension, hyperlipidemia, and hyperuricemia, smoking habits, systolic/diastolic blood pressure, body mass index, and laboratory data. The laboratory data comprised white blood cell (WBC) count, hemoglobin (Hb), platelets, AST (aspartate aminotransferase), ALT (alanine aminotransferase), blood urea nitrogen (BUN), serum creatinine (Cre), estimated glomerular filtration rate (eGFR), sodium (Na), potassium (K), total protein (TP), C-reactive protein (CRP), uric acid (UA), hemoglobin A1c (HbA1c), total cholesterol (T. Chol), urinary protein, and urinary occult blood as qualitative tests. Blood pressure was measured with a brachial sphygmomanometer.
Donor selection
Our donor selection is conducted in accordance with the Japanese criteria for living donor kidney transplantation. (Japanese donor guideline written in Japanese, https://cdn.jsn.or.jp/guideeline/pdf/Donor-guidelines.pdf, Supplementary Table 3A) For the marginal donor in our facility, who do not meet the Japanese standard criteria, we adopted our own marginal donor criteria. (Supplementary Table 3B)28 In our facility, donor candidates diagnosed with diabetes mellitus or suspected diabetes mellitus are excluded. (Criteria: fasting blood sugar ≤ 126 mg/dl and HbA1C < 6.2%, oral hypoglycemic agent is not allowed.)
For surgical assessment for determining which kidney to remove, CT volumetry was not used in the actual donor selection; it was performed retrospectively. If there was a clear difference in kidney size on CT, a renogram was performed. If the renogram showed no functional issues in either kidney, the decision on which kidney to donate was made based on the number and anatomical structure of the blood vessels.
CT volumetry
Preoperative dynamic CT was performed using 64-,80- or 320-multidetector CT scanners (Aquilion 64, Aquilion Prime SP, Aquilion ONE; Canon Medical Systems Corporation, Otawara, Tochigi, Japan). Iodinated contrast media (Iohexol, Omnipaque 300; GE Healthcare Pharmaceutical Diagnostics, Tokyo, Japan) was injected using a power injector following an unenhanced CT scan. The nephrographic phase images were transferred and analyzed retrospectively using dedicated software (SYNAPSE VINCENT; FUJIFILM Corporation Tokyo, Japan). The software semi-automatically generated a 3D model of the kidney by stacking 1-mm axial slices and calculated the kidney’s volume (Supplementary Fig. 3A, B). Whole-body skeletal muscle mass was estimated from the trunk muscle area at the L3-4 level which is known to be highly correlated with the total body skeletal muscle volume (Supplementary Fig. 3C)29 As for the visceral fat area at the naval level, a single axial slice at the L3-L4 intervertebral space was chosen for analysis, as it is frequently used as a surrogate for abdominal adiposity (Supplementary Fig. 3C)30.
Evaluation of renal function
Renal function, measured by serum Cre levels, was evaluated pre-donation and at 1-year post-donation. The pre-donation serum Cre level was defined as the most recent result obtained within 3 months before donation. Serum Cre level at 1-year post-donation was employed as the primary outcome for this study. The eGFR was calculated using a formula specific to Japanese patients with CKD (eGFR [mL/min/1.73 m2] = 194 x Serum creatinine(-1.094) × Age(-0.287) × 0.739 [if female])31.
Statistical analysis
Continuous data were described as mean ± standard deviation or median (interquartile range). Unpaired t-test or Mann–Whitney U test was used to compare continuous variables. The chi-square test or Fisher’s exact test was used to compare the categorical variables. A Pearson’s correlation test was performed on correlation between clinical factors and Cre level at 1-year post donation. A Pearson’s correlation test was also performed to evaluate the correlation between the eGFR predicted by the generated/conventional model and the observed eGFR measured in practice. Values for which p was less than 0.05 were inferred as significant.
Model generation
The data were randomly divided into a training and a validation data in a 7:3 ratio. By using training data, we conducted SR via GP to construct machine learning models for predicting Cre levels at 1-year post-donation using Data Modeler version 9.3 (Evolved Analytics LLC, Rancho Santa Fe, CA, USA) which runs on Mathematica version 12.1 (Wolfram Research Incorporated, Champaign, IL, USA). The explanatory variables included 34 pre-operative variables (Supplementary Table 4) such as gender, age, height, body weight, blood pressure, smoking history, disease history, laboratory data, and CT volumetry data. DataModeler was executed with 8 independent evolutions and 6 min modeling time. During the evolution, SR via GP automatically discards less important variables and selects more important ones, effectively performing dimensionality reduction. Then it generates hundreds of predictive models, selects a few to a few dozen of simpler and less erroneous models, and uses their trimmed mean as the optimized predictive model, just like a bagging method used in random forest. The optimized model created through the process is referred to as “optimized donor’s kidney function (DKF) model” in this paper.
We also explored the driver variables in the optimized DKF model and their impact on the overall model, illustrating their effects on the target using a partial dependence estimate, based on the approach suggested by Friedman32 A partial dependence estimate calculates the average prediction of a model by fixing a feature at a specific value while averaging over the other features. This gives an estimate of how the feature of interest affects the model’s output. By holding the other features constant, we can understand the marginal effect of just the one feature.
We developed a simplified prediction formula from the optimized DKF model to enhance user-friendliness in clinical settings, where variables with smaller effects on the target were fixed at a representative value (median or mode). This model is referred to as the “sparse DKF model.”
As a conventional method for estimating renal function post-donation, a formula 0.7 × [eGFR at pre-donation] was used and is referred to as the “conventional DKF model”. This assumption is based on the previous report that post-donation eGFRs are typically reach approximately 60–70% of the pre-donation levels4.
Verification of accuracy of developed models
To compare the accuracy among the optimized DKF model, the sparse DKF model, and the conventional DKF model, metrics such as R2, root mean squared error (RMSE), mean absolute error (MAE), and Pearson’s correlation coefficient between each predicted value and measured eGFR were utilized.
Additionally, outliers in the optimized DKF model were identified using Z-scores, which represent the distance of a data point from the mean in terms of standard deviations. The standard cutoff values for defining outliers were Z-scores of ± 2 or more extreme. Based on the Z-scores, the validation cohort was divided into three groups: inliers (-2 < Z < 2), high outliers (Z > 2), and low outliers (Z < -2). This classification was used to investigate preoperative factors that are likely to contribute to outliers.
Data availability
The data which support the findings of this study are available from the corresponding author, [T.H.], upon reasonable request. The generated model by machine learning was published in GitHub (https://github.com/thirai-0813/Donor_Cr_Calculator_EN.git).
References
Ibrahim, H. N. et al. Long-term consequences of kidney donation. N Engl. J. Med Jan. 29 (5), 459–469. https://doi.org/10.1056/NEJMoa0804883 (2009).
Muzaale, A. D. et al. Risk of end-stage renal disease following live kidney donation. Jama. Feb 12. ;311(6):579 – 86. (2014). https://doi.org/10.1001/jama.2013.285141
Textor, S. C. Medically complex living kidney donors: where are we now?? Kidney Int. Rep. 1, 4–6 (2020).
Mueller, T. F. & Luyckx, V. A. The natural history of residual renal function in transplant donors. J Am. Soc. Nephrol Sep. 23 (9), 1462–1466. https://doi.org/10.1681/asn.2011111080 (2012).
Grams, M. E. et al. Kidney-Failure risk projection for the living Kidney-Donor candidate. N Engl. J. Med Feb. 4 (5), 411–421. https://doi.org/10.1056/NEJMoa1510491 (2016).
Augustine, J. J., Arrigain, S., Mandelbrot, D. A., Schold, J. D. & Poggio, E. D. Factors associated with residual kidney function and proteinuria after living kidney donation in the united States. Transplantation Feb. 1 (2), 372–381. https://doi.org/10.1097/tp.0000000000003210 (2021).
Locke, J. E. et al. Obesity increases the risk of end-stage renal disease among living kidney donors. Kidney Int Mar. 91 (3), 699–703. https://doi.org/10.1016/j.kint.2016.10.014 (2017).
Lentine, K. L. & Patel, A. Risks and outcomes of living donation. Adv Chronic Kidney Dis Jul. 19 (4), 220–228. https://doi.org/10.1053/j.ackd.2011.09.005 (2012).
Shinoda, K. et al. Pre-donation BMI and preserved kidney volume can predict the cohort with unfavorable renal functional compensation at 1-year after kidney donation. BMC Nephrol Feb. 8 (1), 46. https://doi.org/10.1186/s12882-019-1242-0 (2019).
Bzdok, D., Altman, N. & Krzywinski, M. Statistics versus machine learning. Nat Methods Apr. 15 (4), 233–234. https://doi.org/10.1038/nmeth.4642 (2018).
Schmidt, M. & Lipson, H. Distilling free-form natural laws from experimental data. Science. Apr 3. ;324(5923):81 – 5. (2009). https://doi.org/10.1126/science.1165893
Ushio, Y. et al. Machine learning for morbid glomerular hypertrophy. Sci Rep Nov. 9 (1), 19155. https://doi.org/10.1038/s41598-022-23882-7 (2022).
Madero, M. et al. Comparison between different measures of body fat with kidney function decline and incident CKD. Clin J. Am. Soc. Nephrol Jun. 7 (6), 893–903. https://doi.org/10.2215/cjn.07010716 (2017).
Tagliafico, A. S., Bignotti, B., Torri, L. & Rossi, F. Sarcopenia: how to measure, when and why. Radiol. Med. 127 (3), 228–237. https://doi.org/10.1007/s11547-022-01450-3 (Mar 2022).
Wilkinson, T. J. et al. Association of sarcopenia with mortality and end-stage renal disease in those with chronic kidney disease: a UK biobank study. J Cachexia Sarcopenia Muscle Jun. 12 (3), 586–598. https://doi.org/10.1002/jcsm.12705 (2021).
Patel, S. S. et al. Serum creatinine as a marker of muscle mass in chronic kidney disease: results of a cross-sectional study and review of literature. J Cachexia Sarcopenia Muscle Mar. 4 (1), 19–29. https://doi.org/10.1007/s13539-012-0079-1 (2013).
Young, J. A. et al. Association of visceral and subcutaneous adiposity with kidney function. Clin J. Am. Soc. Nephrol Nov. 3 (6), 1786–1791. https://doi.org/10.2215/cjn.02490508 (2008).
Lenihan, C. R. et al. Longitudinal study of living kidney donor glomerular dynamics after nephrectomy. J Clin. Invest Mar. 2 (3), 1311–1318. https://doi.org/10.1172/jci78885 (2015).
Lam, N. N. et al. Changes in kidney function follow living donor nephrectomy. Kidney Int Jul. 98 (1), 176–186. https://doi.org/10.1016/j.kint.2020.03.034 (2020).
Delanaye, P. et al. Outcome of the living kidney donor. Nephrol Dial Transplant Jan. 27 (1), 41–50. https://doi.org/10.1093/ndt/gfr669 (2012).
Massie, A. B. et al. Association of early postdonation renal function with subsequent risk of End-Stage renal disease in living kidney donors. JAMA Surg Mar. 1 (3), e195472. https://doi.org/10.1001/jamasurg.2019.5472 (2020).
Lentine, K. L. et al. KDIGO clinical practice guideline on the evaluation and care of living kidney donors. Transplantation Aug. 101 (8S Suppl 1), S1–s109. https://doi.org/10.1097/tp.0000000000001769 (2017).
Andrews, P. A., Burnapp, L. & British Transplantation Society / Renal Association UK Guidelines for Living Donor Kidney Transplantation 2018. Summary of updated guidance. Transplantation Jul. 102 (7), e307. https://doi.org/10.1097/tp.0000000000002253 (2018).
ERBP Guideline on the Management and Evaluation of the Kidney Donor and Recipient. Nephrol Dial Transplant Aug ;28 Suppl 2:ii1–71. doi:https://doi.org/10.1093/ndt/gft218 (2013).
Richardson, R. et al. Kidney paired donation protocol for participating donors 2014. Transplantation Oct. 99 (10 Suppl 1), S1–s88. https://doi.org/10.1097/tp.0000000000000918 (2015).
Guyon, I., Weston, J., Barnhill, S. & Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines.
Habbous, S., Garcia-Ochoa, C., Brahm, G., Nguan, C. & Garg, A. X. Can split renal volume assessment by computed tomography replace nuclear split renal function in living kidney donor evaluations?? A systematic review and Meta-Analysis. Can. J. Kidney Health Dis. 6, 2054358119875459. https://doi.org/10.1177/2054358119875459 (2019).
Oki, R. Renal Outcome of Living Kidney Donors Aged More than 70 Years (Clinical and Experimental Nephrology., 2024).
Shen, W. et al. Total body skeletal muscle and adipose tissue volumes: estimation from a single abdominal cross-sectional image. J Appl Physiol (). Dec 2004;97(6):2333-8.). Dec 2004;97(6):2333-8. (1985). https://doi.org/10.1152/japplphysiol.00744.2004
Srikumar, T. et al. Semiautomated measure of abdominal adiposity using computed tomography scan analysis. J Surg. Res May. 237, 12–21. https://doi.org/10.1016/j.jss.2018.11.027 (2019).
Matsuo, S. et al. Revised equations for estimated GFR from serum creatinine in Japan. Am J. Kidney Dis Jun. 53 (6), 982–992. https://doi.org/10.1053/j.ajkd.2008.12.034 (2009).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Annals Stat. 29 (5), 1189–1232 (2001).
Funding
This work was supported by Funds for the Development of Human Resources in Science and Technology, Initiative for Realizing Diversity in the Research Environment, Tokyo Women’s Medical University.
Author information
Authors and Affiliations
Contributions
RO, TH, and KI conceived the idea of the study. RO, TH, KI and YK developed and conducted the statistical analysis and machine learning. TB, KU, KO, TS, JH, TT, and HI contributed to the interpretation of the results. RO drafted the original manuscript and TH revised it. TH, KI and YK supervised the conduct of this study. All authors reviewed the manuscript draft and revised it critically on intellectual content. All authors approved the final version of the manuscript to be published.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Disclosure
The authors declare that they have no competing financial or other interest or personal relationship that could have influenced this paper or the study it describes.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Oki, R., Hirai, T., Iwadoh, K. et al. Personalized prediction model generated with machine learning for kidney function one year after living kidney donation. Sci Rep 15, 20752 (2025). https://doi.org/10.1038/s41598-025-02879-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-02879-y
