
Abstract
In general, deficient birth weight neonates suffer from hypoglycemia, and this can be quite disadvantageous. Like oxygen, glucose is a building block of life and constitutes the significant share of energy produced by the fetus and the neonate during gestation. The fetus receives glucose from the placenta continuously during gestation, but this substrate delivery changes abruptly, and the fetus’s metabolism changes significantly at birth. Hypoglycemia is one of the most frequent pathologies affecting the change of newborns in neonatal critical care units. This work is now introducing a system, HAPI-BELT, empowered by dual intelligent sensors and Deep Learning (DL) algorithms for tracking and continuously detecting hypoglycemia in preterm newborns. This article comprises a smart belt with an intelligent camera and photoplethysmography (PPG) attached. This device tracks changes in the infant’s motion, skin colour, and breathing patterns; this is done through a PPG sensor strapped either on the belly or chest of an infant, logging information on heart functioning. The digital data gathered by this PPG sensor and image data captured from the smart camera are then processed by a Raspberry Pi Zero 2 W. It does most of the data analysis and decision-making. Feature Extraction (FE) is done through CAT-Swarm Optimization. Based on features, the sorted-out data gets evaluated through a GRU-LSTM (Gated Recurrent Unit - Long Short-Term Memory) network to identify the state of the infant as usual and suggestive of hypoglycemia—blood glucose below 70 mg/dL, pale complexion, profuse perspiration. When hypoglycemia is identified, an alert is sent to the medical professionals to take necessary action with utmost urgency. Therefore, an integrated approach ensuring timely medical interventions and real-time monitoring can help better outcomes for preterm newborns.
Similar content being viewed by others

Introduction
Premature babies face a host of medical complications since their organs and physiological systems are not yet mature. Among the critical conditions prevailing in them is hypoglycemia, a condition seen with abnormally low blood glucose levels, which, if not detected in time and treated appropriately, may result in severe damage to neurological function. For a society, maternal and newborn health is imperative if it must progress. The major causes of problems in maternal health and even mortality include ectopic pregnancy1, miscarriage2, blood pressure leading toward preeclampsia3,4, and failure in the progress of labour, which may result in a Caesarean section (C-section)5. Besides that, iron deficiency is another critical factor in pathologies connected with postnatal and prenatal health complications, which can be caused by many factors, including but not limited to the following: vagina infections at childbirth8,9, retained placenta7, antepartum or postpartum haemorrhage6, and amongst many others.
Infants who have a meagre birth weight are at greater risk for hypoglycemia and other metabolic derangements. They are more at risk due to the immaturity of the regulatory system, low glycogen reserves, baseline increase in glucose metabolism, limited availability to other energy sources, and low glucose 6 phosphatase activity. Of all babies, 9.18% have hypoglycemia. In the first week of life, asymptomatic hypoglycemia can affect up to 70% of babies born with a meager birth weight, which may then increase to 45–50% among those less than 1500 g in weight. Despite all these many publications on the subject, there is still no generally accepted definition for neonatal hypoglycemia. Glucose below 40–50 mg/dL [2.2–2.8 mmol/L] is considered hypoglycemia by many researchers. However, there is a fine-tuning period immediately after delivery when blood glucose levels may drop as low as 30 mg per deciliter or even lower before they usually rise again. Such complications that a new baby can be exposed to range from growth retardation in the uterus, birth asphyxia, infections caused by birth through the vagina, shoulder dystocia, meconium aspiration, septicemias, preterm delivery, and immature lungs, among others. This timely identification and communication of maternal and newborn health problems is essential for healthcare providers to take proper action. It is more difficult to obtain medical help on time in rural areas. Nowadays, doctors can respond quickly to problems with mother and baby health due to advancements in information and communication technologies.
On the other hand, regular blood glucose monitoring for the diagnosis of neonatal hypoglycemia can be a source of stress for the parents and may disturb the bonding between the newborn and the caregivers. Moreover, repeated puncturing of the heel for blood glucose testing is painful and time-consuming for nursing care. This may also lead to probable complications like skin lacerations, osteomyelitis of the heel bone, hematoma, and skin necrosis10.
Over the past few years, the use of Artificial Intelligence (AI) and Machine Learning (ML) in medical and health care sectors has seen significant development. Given the expansion and ease of access to health data, ML has become a common tool for analysing extensive medical data. It plays a crucial role in supporting Clinical Decision-Making System (CDMS), strengthening the overall standard of healthcare, increasing efficiency, and cutting down costs. These tasks encompass numerous applications, such as image detection, prediction outcome risk analysis, coping approaches, readmission risk estimation, COPD treatment, malaria treatment, and COVID-19 detection. These tasks have proven crucial in effectively managing and controlling the ongoing pandemic. AI/ML has proven incredibly valuable for clinical decision-making in newborn medicine. It can predict the risk of death in neonates and babies, as well as improve our standard of care in the Neonatal Intensive Care Unit (NICU) by predicting outcomes such as extubation results, hospitalization’s, length of stay, mortality, serious infections, severe disability, and apnoea among premature neonates. There has been an increase in the use of AI/ML for hypoglycemia forecasting. However, there are still limited studies that focus on determining neonatal hypoglycemia shortly following birth.
Often, continuous and real-time data needed for quick intervention are not always provided through traditional surveillance techniques. This recommendation to fill this gap is a state-of-the-art technique called HAPI-BELT, specifically designed to monitor hypoglycemia in preterm neonates continuously. This solution uses a pair of intelligent sensors, one of which is a smart camera attached to an incubator. At the same time, the other is a photoplethysmography (PPG) sensor fitted on an intelligent belt. Advanced Feature Extraction (FE) is performed using Cat-Swarm Optimisation, which enhances the accuracy and efficiency of the processing procedure. The information, after processing, enters into the GRU-LSTM (Gated Recurrent Unit - Long Short-Term Memory) network, a hybrid Deep Learning (DL) model for assessing whether the baby’s condition is normal, or hypoglycemia is indicated by it. These technologies work together as a strong and balanced system that can spot early signs of hypoglycemia and monitor it continuously. It provides valuable updates to medical personnel in good time, hence its importance in neonatal care units, as HAPI-BELT aims to improve health outcomes among premature babies. This paper describes how revolutionary the HAPI-BELT system might be for neonatal monitoring and care, depicting its development, deployment and evaluation.
The main contribution of our work as follows,
-
(a)
This work presents a new system, HAPI-BELT, combining dual intelligent sensors with DL algorithms to continuously monitor and detect hypoglycemia in premature infants.
-
(b)
The system has integrated a Photoplethysmography sensor with a smart camera for real-time data collection, processing with a Raspberry Pi Zero 2 W, Cat-Swarm Optimization for feature extraction, and finally, a GRU-LSTM network for classification.
-
(c)
The proposed GRU-LSTM model outperforms baseline models such as GRU, LSTM, SVM, and RNN models in accuracy, precision, recall, and the F1-score, making this tool rather reliable for real-time diagnosis in medical contexts.
The rest of the paper is organized as follows. Section Related works covers related works, in which there is a review of health monitoring systems and deep learning techniques relevant to this study. The HAPI-BELT system components, data preprocessing steps, and the designed deep learning architecture are given in Sect. Methods and materials, detailing the Methods and Materials. Section Deep learning architecture presents the results and performs a performance evaluation of the GRU-LSTM model against baseline models. Finally, Sect. Experimental Results concludes the paper with a summary of key findings and some future directions.
Related works
Early detection and management of hypoglycaemia are critical to prevent long-term neurological damage in a premature infant. Considering traditional relations and advanced technologies, several approaches have been investigated to improve this monitoring and diagnosis. Recent research11 has focused on achieving non-invasive health monitoring systems with DL techniques and smart sensors. Wearable devices will uninterruptedly monitor vital signs to predict medical conditions such as hypoglycemia. For example, a review on intelligent health monitoring systems emphasises that wearable sensor-based devices work along with AI techniques to enhance health outcomes by managing chronic conditions like diabetes, which is technologically close to neonatal monitoring for the detection of hypoglycemia.
It has already been demonstrated that camera-based monitoring systems in neonatal intensive care units could measure vital parameters like pulse and respiration rates. These methods bring the advantage of non-contact, continuous monitoring, minimising stress and possible skin damage from traditional wired devices. Continuous monitoring algorithms have been developed to evaluate these vital signs and recognise situations that require medical intervention, thus ensuring real-time and correct assessment12. Another core contribution is a system for monitoring respiratory anomalies in premature infants through wearable devices. In this work, they use a DL-enabled approach to detect respiratory issues such as apnea and respiratory distress syndrome through non-invasive wireless sensors. More importantly, the study focuses on energy-efficient solutions for wearable devices; therefore, an SNN is proposed to reduce energy consumption while maintaining high accuracy in classification13. During the last several years, DL has been effectively used in several fields, including picture classification, voice recognition14,15, and audio classification16.
DL methodology has the potential to bring about a revolution in illness identification using sophisticated biomarkers16,17. This would make it possible to develop population-based health initiatives based on data already present in Electronic Health Records (EHR). Research has previously proven that DL, in conjunction with abdominal computed tomography imaging, may identify many biomarkers that predict metabolic syndrome in persons who do not exhibit any symptoms of the condition18. It has been shown that DL, in conjunction with chest radiography, may accurately prediction future healthcare costs, significant health inequities, and various comorbidities19,20,21. Mohebbi et al. proposed a groundbreaking DL approach for detecting Type-2 diabetes in their study22. They demonstrated the feasibility of using CGM signals to identify T2D patients. The authors of this study concentrated their discussions on numerous aspects of DL, including Computer Vision (CV), Natural Language Processing (NLP), Reinforcement Learning (RL), and generalised methods. Discussions have also occurred regarding the potential and challenges of applying DL-based methods in biology and medicine. It can outperform previous cutting-edge methods in a wide range of patient and disease categorization tasks, fundamental biological studies, genomics, and treatment development24.
In their study25, showcased ModelHub, a comprehensive platform for managing the entire lifecycle of DL models. ModelHub comprises several key components, such as a cutting-edge model versioning system called dlv, a Domain-Specific Language (DQL) for efficient Model search, and a Hosted service (ModelHub) that facilitates storing, exploring, and sharing learnt models.
Authors26 introduced a deep network model that utilises SVMs with CPONs to achieve a high level of structural depth and accurate classification. In their study27, developed a novel predictive model using a stepwise hidden variable approach to anticipate disease complications. In their research28, highlighted the effectiveness of DL in predicting hospital readmissions among diabetic patients. Authors29 introduced a DL-based method for forecasting healthcare trajectories by analysing patients’ medical records. Authors30 conducted a study on predicting the risks of Type-2 diabetes using common and rare variants. In another study31, introduced a new model for classifying Type-2 diabetes data. A Deep Neural Network (DNN) was constructed by combining stacked autoencoders with a softmax classifier, resulting in an impressive classification accuracy of 86.26%. Here’s a comparison Table 1 summarizing the related works from the paper.
A thorough examination of recent wearable healthcare technologies highlights a significant movement towards achieving energy autonomy and incorporating multimodal sensing. For example, the authors in32,33 developed systems integrating photovoltaic and thermoelectric energy collection with BLE and Wi-Fi modules to transmit critical health indicators like temperature and pulse oximetry. Likewise, the architectures outlined in34,35 leverage hybrid energy harvesters to enable long-term autonomous patient monitoring applications. These contributions focus on sustainability and hardware durability but provide minimal insight into AI-enabled decision-making at the edge. The innovative HAPI-BELT system builds on these principles, embedding sophisticated deep learning capabilities within a wearable format explicitly designed for neonatal care. Unlike previous devices aimed at adults or basic signal recording, our strategy employs lightweight temporal models to deduce hypoglycemic episodes from multiple indirect indicators, a technique specially devised to meet the needs and peculiarities of premature infants. This integration of intelligent sensing, deep learning, and edge application distinguishes our system from existing research in terms of both its functionality and its context-specific usage.
Recent progress in wearable sensor technologies underscores the importance of signal acquisition and the pursuit of autonomy, miniaturization, and sustained operation using energy-harvesting techniques. In contrast to traditional setups that track typical vitals, such as body temperature, SpO₂, and heart rate with fixed-sensor designs, the innovative HAPI-BELT system employs a new dual-sensor fusion strategy. This involves integrating a photoplethysmography (PPG) sensor with a creative, vision-based module to detect infant-specific health indicators, such as changes in skin color and movement. Unlike the efforts of the authors in35,36, which focused on hardware durability and power harvesting for general health monitoring, our breakthrough lies in using deep learning through a GRU-LSTM architecture, implemented on an edge device, the Raspberry Pi Zero. This device is trained on multimodal infant physiological data for detecting hypoglycemia. Furthermore, our system is engineered to address neonatal care requirements and deployment feasibility, delivering real-time monitoring with energy-efficient processing, a less explored avenue compared to past designs, which mainly focus on long-term monitoring of adult patients.
The related work surveys a variety of approaches in non-invasive health monitoring systems, with DL and smart sensors. Recent developments in wearable devices for continuous monitoring of vital signs, which could be key parameters in predicting medical conditions such as hypoglycemia, will be noted. It also discusses the measurement of vital parameters non-invasively with camera-based systems to avoid stress and possible skin lesions in neonates cared for in neonatal intensive care units. Besides, it explores DL applications in illness detection; the section further demonstrates their potential to revolutionize health monitoring by improving its accuracy and enabling timely interventions. The review also puts a few limitations on the study: high energy consumption of wearable devices, probable inaccuracies in data readings due to motion artifacts, and that more studies are needed, immediately after birth, concerning neonatal hypoglycemia detection. These limitations reflect the kind of problems that the HAPI-BELT system is targeting.
Methods and materials
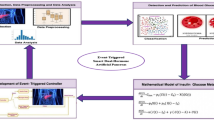
The system is called HAPI-BELT and detects hypoglycemia in preterm infants by continuous patient monitoring, using a combination of smart sensors along with DL algorithms. The main components include a Photoplethysmography sensor embedded in a smart belt, a smart camera, data processing by a Raspberry-Pi Zero-2 W, and classification based on a GRU-LSTM network.
Sensor deployment
PPG sensor is mounted in a smart belt worn around the abdomen or chest of the baby, which acquires cardiac activity and heart rate throughout. The waveforms collected by the PPG sensor correspond to heartbeats, indicative of detecting hypoglycemia through symptoms such as bradycardia. Moreover, a smart camera shall be fitted in an incubator that captures visual data on breathing patterns, changes in skin colour, and movements of the neonate. The visual data can identify symptoms such as paleness and excessive sweating indicative of hypoglycemia.
Figure 1 is an integrated diagram of a smart belt with a PPG sensor. Depicted is a smart belt wrapped in a baby’s tummy to enhance the PPG sensor’s exact placement. Labels are provided for critical components like the PPG sensor, data transmission module, power supply, and connection points. The arrows indicate the flow of data from the PPG sensor to the data transmission module and heart activity data that indicates as waveforms on a screen nearby. PPG—is an optical technique that allows the measurement of blood volume changes in the microvascular bed of tissue. It’s among the non-invasive methods mainly used in wearable health monitoring devices. A PPG sensor comprises a light source, an LED, and a photodetector. This LED emits light into the skin, and the photodetector collects the transmitted or reflected light from the tissue. Every beat of the heart changes blood volume in tissue, which in turn marks how light is absorbed. These changes are recorded as a waveform known as a photoplethysmogram, which is further processed to extract physiological parameters like heart rate and blood oxygen saturation.
PPG sensors’ significant advantages are that they are non-invasive, work with continuous monitoring, and are compact; however, there can be interferences based on motion artefacts and skin tone or thickness changes. An intelligent camera has been fitted in the incubator and captures visual data on the infant’s respirations, changes in skin colour and movements. The video data is then looked through for symptoms such as paleness and excessive sweating that can indicate hypoglycemia.
As depicted in the revised Fig. 1, the system acquires physiological signals from a preterm infant via a bright belt equipped with a PPG sensor and a smart camera. After being collected, these signals are preprocessed and sent to the Raspberry Pi. The combined data is run through the improved GRU-LSTM model to classify the state as usual or hypoglycemic in real time. The model, refined with the Cat Optimization Algorithm, is executed directly on the Raspberry Pi, facilitating edge-level decision-making and providing alerts for caregivers. This comprehensive deployment ensures low-latency, continuous monitoring, making the system exceptionally well-suited for neonatal healthcare settings.

Smart belt with a PPG sensor and Smart Camera.
Data collection and pre-processing
Within the HAPI-BELT system, data collection and transmission are two of the most critical steps in performing continuous monitoring for accurately detecting hypoglycemia in premature infants. The PPG sensor and the smart camera will initially capture vital physiological data. The PPG sensor is mounted on an intelligent belt around the abdomen or on the infant’s chest, collecting varied heart activity data nonstop, including waveforms indicative of heartbeats. Simultaneously, visual data are captured through a smart camera installed in the incubator, which monitors the infant’s breathing patterns, skin color changes, and movements. This data is then collected and sent to a Raspberry Pi Zero 2 W for preliminary processing.

The data distribution chart of the simulated data.
Figure 2 shows the data distribution chart of the simulated data. In Table 2, sample Data collection from real time sensor data and this raw data is converted into digital format during transmission and later prepared for analysis. This step is essential in preparing the data for the following stages of preprocessing or FE and classification. The HAPI-BELT system, therefore, shall detect in real-time the signs of hypoglycemia based on its continuous collection and efficient transmission of heart activity and visual data to help ensure timely medical intervention for improving health outcomes of premature infants. Although hypoglycemia is directly associated with blood glucose levels, monitoring glucose in preterm infants poses practical and ethical challenges, especially when considering a noninvasive, continuous approach. Therefore, our system relies on proxy indicators such as heart rate variability, abnormal respiratory patterns, movement, and changes in skin color, which have been physiologically linked to hypoglycemic events, as recent studies in pediatrics confirm. These multimodal indicators act as indirect but essential early warning signs, enabling rapid intervention in neonatal care.
The DL model has been trained using a dataset carefully collected by the research team at the University of Science and Technology in Mazandaran, Behshahr, Iran37. The dataset consists of 67 raw PPG signals, each with a sampling frequency of 2175 Hz. Additionally, it includes labelled data such as age, gender, and the invasive blood glucose level. The Fig. 3 shows the data collection from the real time data and dataset37.

Data Collection from dataset32.
The integration of GRU and LSTM structures in our model uses the unique strengths of each network type. GRU units are known for their computational efficiency and are ideal for handling short or less complex sequences, while LSTMs are adept at capturing long-term dependencies. In our application, physiological signals from dual sensors display short-term fluctuations and extensive long-term temporal patterns. So, the GRU-LSTM hybrid model can handle a wider range of signals, which improves its generalization over dynamic, nonlinear signal inputs.
Preprocessing of PPG data
Preprocessing of PPG data is strictly necessary, with some important steps to ensure clean and standardised signals for further processing and FE.
This PPG signal is passed through a bandpass filter to remove noise outside the frequency range of heartbeats, typically 0.5–5 Hz. This work designed the Butterworth bandpass filter using the Butterworth filter Eq. 1.
\(\:{\omega\:}_{0}\) is the centre frequency. In discrete form, the filter can be applied as eq. 2.
where, \(\:x\left[n\right]\) is the input signal. \(\:y\left[n\right]\) is the output signal. \(\:{a}_{j}\) are the filter coefficients. The baseline wander is eliminated using a high-pass filter rejecting low-frequency components related to respiration or movement. The high-pass filter eq. 3,
where, \(\:x\left(t\right)\) is the input signal. \(\:y\left(t\right)\) is the output signal. \(\:T\) is the time constant. The Min-Max normalization operation scales the PPG signal over a fixed range, usually between 0 and 1. The min-max normalisation eq. 4,
where, \(\:x\) is the original signal value. \(\:{x}^{{\prime\:}}\) is the normalised value. \(\:{x}_{max},\:{x}_{min}\) are the signal’s minimum and maximum values. Z-score normalisation standardises the signal by subtracting its mean and dividing it by its standard deviation.
The z-score normalisation eq. 5,
where, \(\:x\) is the original signal value. \(\:\mu\:\) is the mean of the signal. \(\:\sigma\:\) is the standard deviation of the signal. The PPG signal is divided into smaller segments or windows, all of which have a fixed length. If the window length is N samples, the segmentation eq. 6,
where, \(\:x\) is the original signal. \(\:{x}_{w}\) is the windowed signal. The number of peaks \(\:\left(P\right)\) in the PPG signal \(\:\left(S\right)\) within a given time window, eq. 7.
The standard deviation of the intervals between consecutive peaks (R intervals), eq. 8.
This is an analysis of the power distribution across various frequency components of the PPG signal, acquired through the Fourier Transform, eq. 9.
where, \(\:F\) denotes the Fourier Transform. \(\:P\left(f\right)\) is the power at frequency \(\:f\). Following these preprocessing steps, the PPG data is prepared to be clean, standardised, and ready for precise FE and further analysis.
Preprocessing of visual data
The preprocessing of visual data is applied to several aspects to enhance the quality of images or video frames and extract helpful features for analysis. This paper describes various steps involved in preprocessing visual data concerning applications in monitoring infant health when placed in incubators. It deals with correcting the original video data’s frame rate to become consistent; in this case, it involves resampling the video to a standard frame rate, say, 30 fps. Frames are extracted at the set intervals, given by the ratio of the original frame rate to the target frame rate, thus maintaining uniformity across the data set.
This is mathematically represented as \(\:Interval=\frac{r}{t},\) where \(\:r\) is the original frame rate and \(\:t\) is the target frame rate. Keyframes are selected at regular intervals to reduce data size while retaining important information, with the number of keyframes calculated as \(\:\frac{L}{I}\) , where \(\:L\) is the video length in seconds, and \(\:I\) is the interval in seconds. Then, noise reduction techniques, such as Gaussian blur, are applied to smooth out the images and remove unwanted artefacts.
The equation describes the Gaussian blur, eq. 10
where \(\:\sigma\:\) is the standard deviation of the Gaussian function. Contrast enhancement uses techniques like histogram equalisation, contrast-limited adaptive histogram equalisation (CLAHE), etc. Histogram equalisation can be represented as eq. 11.
where \(\:h\left(i\right)\) is the histogram of pixel values, \(\:N\) is the number of pixels and \(\:L\) is the number of grey levels. ROIs are regions of interest that detection will identify, highlighting some baby features around the baby’s face, chest, and abdomen that indicate health conditions such as skin colour changes or movement patterns. Feature extraction involves quantifying changes in skin colour using color histograms, where the histogram of pixel intensities is calculated as eq. 12.
with \(\:\delta\:\) being the Dirac delta function and \(\:I\left(x,y\right)\) the pixel intensity at the location \(\:(x,y)\).
The characteristics of the motion are quantified by the optical flow computed by the eq. 13,
where \(\:{I}_{x}\) and \(\:{I}_{y}\) are image gradients, \(\:u\) and \(\:v\) are the flow vectors and \(\:{I}_{t}\) is the temporal gradient.
Furthermore, methods such as Local Binary Patterns (LBP), which are represented by Furthermore, methods such as Local Binary Patterns (LBP), which are represented by eq. 14.
where \(\:s\) is the sign function, \(\:{g}_{i}\) are the pixel values of the neighbours, and \(\:{g}_{c}\)c is the centre pixel value.
These indicate the steps of preprocessing to clean up the visual data, standardise the data for proper feature extraction, and other classifications that will be essential in upping the system’s ability to monitor effectively and, through the feature references and determined rules and algorithms, be able to detect the health conditions and alarms set for infants.
Cat-swarm optimization (CSO)
One of the powerful and recently developed optimisation techniques, Cat Swarm Optimization, takes its inspiration from the natural behaviour of cats. The hunting and resting behaviours of cats can approach these complex optimisation problems effectively. This paper uses CSO in selecting features for data previously collected from the HAPI-BELT system to identify which features are important, thus improving accuracy and efficiency in the classification model.

Algorithm 1 for Cat-Swarm Optimization (CSO).
Using this pseudocode and the associated mathematical formulae, the CSO algorithm executes the selection of the most relevant features, thereby improving the accuracy of the classification model in hypoglycemia detection in premature infants.
Deep learning architecture
The output feeds into a hybrid deep learning model consisting of Gated Recurrent Units and Long Short-Term Memory networks. Thus, the designed GRU-LSTM network can handle sequential data by learning temporal dependencies, which turns the system into something quite suitable for the classification task of whether infant hypoglycemia is being recorded. The architecture of the GRU-LSTM network is designed to deal effectively with sequential data classification using GRUs and LSTMs. Pre-processed sequential data, usually shaped as (timesteps and features), where timesteps are the sequence length and features are the number of input features per timestep, is fed on the input layer. The first is a GRU layer to help capture short-term dependencies in the data. In this case, the number of units, such as 64 or 128, defines the dimensionality of the output space. This will preserve the sequence information and pass it on to the next LSTM layer, preserving the temporal info from this line. The LSTM layer convolves sequence data further to obtain long-term dependencies with a specified number of units. Generally, it does not return sequences but brings out the final output concerning classification.
An RNN with a controlling flow of information using gating units is called a GRU. It has fewer parameters than the LSTM, making it very computationally efficient. It’s an architecture that includes two gates: reset and update gates. The update gate in a GRU controls how much the previous state needs to be passed on to the next state. This determines how much information from the past has to be retained and carried forward into the future. Therefore, it plays a vital role in maintaining long-term dependencies within the data sequence, eq. 15.
The Gated Recurrent Unit (GRU) reset gate corresponds to how much of the previous state to forget or reset. It will assist the model in deciding how much information from the past to drop and how much to combine with the new input for computing the candidate activation, eq. 16.
Candidate activation forges new memory content in a GRU to update the hidden state. Candidate activation combines the current input state and the previously hidden state, making relevance incorporation selective based on the reset gate, eq. 17.
The final memory at a given time step in a GRU mixes the previous hidden state and the candidate activation. The update gate modulates this, controlling the prior state’s contributions and the candidate’s activation to hold the final hidden state, eq. 18.
where, \(\:{x}_{t}\) is the input at time step \(\:t\). \(\:{h}_{t}\) is the hidden state at time step \(\:t\), \(\:{z}_{t}\) and \(\:{r}_{t}\) are the update and reset gates, respectively, \(\:W\) denotes weight matrices and \(\:\sigma\:\) and \(\:tanh\) are the sigmoid and hyperbolic tangent activation functions, respectively.

LSTM architecture.
LSTM is a much more complex variant of RNN, using three different gates: an input gate, a forget gate, and an output gate, as shown in Fig. 4. It keeps an internal memory called a cell state, which enables it to learn long-term dependencies. The forget gate decides what from the cell state should ideally be discarded literally. The Input Gate receives values to make an update. The Cell State is updated with new candidate values—the Output Gate Determines output based on the cell state, eqs. 19 and 23.
where, \(\:{x}_{t}\) is the input at time step \(\:t\), \(\:{h}_{\left\{t\right\}}\) is the hidden state at time step \(\:t\), \(\:{Cl}_{t}\)is the cell state at time step \(\:t\), \(\:{fl}_{t}\), \(\:{il}_{t}\), and \(\:{ol}_{t}\) are the forget, input, and output gates, respectively, \(\:W\) denotes weight matrices and \(\:\sigma\:\), \(\:tanh\) are the sigmoid and hyperbolic tangent activation functions, respectively
Then, a dense layer will take the output from the LSTM layer to produce the final classification. It would be a fully connected layer with the same number of units as the output classes, for instance, 2 in binary classification: normal or hypoglycemic; it would have a softmax heaps activation function in a multi-class classification problem and sigmoid activation function in the case of binary classification. The loss function might be either categorical cross-entropy in the case of multi-class classification or binary cross-entropy in the case of binary classification. For optimization, Adam is often one of the most efficient and performance-effective options. Accuracy is usually the metric evaluated for the model. This GRU-LSTM network architecture would be expressive enough to model short- and long-term dependencies in sequential data; hence, it will suffice for tasks like hypoglycemia detection in infants with time series health data.
In the proposed model, a GRU-LSTM network using Keras will be defined and trained by us to classify normal or hypoglycemic a. This data consists of features, and the labels range in randomly assigned classes—one-hot encoded. The network will consist of a GRU layer with 64 units where these input sequences are processed, and the output returned will be another sequence for an LSTM layer, also containing 64 units. The last dense layer is added with a softmax activation function for classification. Then, the model will be compiled with the Adam optimiser, categorical cross-entropy as the loss function, and accuracy as the evaluation metric. The number of epochs used in training the network is 100, with a batch size of 32, where the training data will be divided into training and validation sets. After that, the model will be run on the test data to evaluate it and return the test loss and accuracy.
In the grid search process, all hyper-parameter combinations were tested to find the best settings for GRU-LSTM. Table 3 shows the different hyper-parameters, their possible values, and the chosen values for the best model.
In the Table 3 are all the hyperparameters that were considered during tuning for the GRU-LSTM network, noting the different values searched and the chosen values in the final model. GRU and LSTM layers were experimented with numbers of units 32, 64, and 128; 64 was selected for both since it seemed to be a balance between model complexity and performance. Batch sizes, including 16, 32, and 64, were compared to the use of 32, which gave training speed and stability. The number of epochs was set at 100, with options for 50, 100, and 150, to ensure that there would be adequate learning without falling into overfitting.
The learning rate— critical for the model’s convergence— was tried at 0.001, 0.0005, and 0.0001; however, 0.0005 was chosen since it demonstrated quite stable and efficient model convergence. Dropout rates such as 0.2, 0.3, and 0.5 were all tried to avoid overfitting, and 0.3 was optimal. The selections available for an optimiser are Adam, RMSprop, and SGD, where Adam was chosen because of its high efficiency and effectiveness during the training of deep learning models. The activation function used for this dense layer was between softmax and sigmoid. The softmax was chosen since it is appropriate for multi-class classification tasks. Finally, the validation split was tested at 10% and 20%. After that, 20% was chosen for a more robust test during training.
Experimental results
Several key metrics can be used to evaluate the performance of the GRU-LSTM network: accuracy, loss, precision, recall, and F1-score. All these metrics tell us how good the model is at classifying the hypoglycemic status in patients. One such key measurement is accuracy, which refers to the proportion of correct predictions out of all predictions done. It is given by Eq. 24.
The loss measures how much the predicted values and the actual values differ from each other. Our model used the loss function of categorical cross-entropy. Models have a better fit of the data as the loss becomes a small value. Precision is the number of true mathematical conditions divided by the summation of true positive and false positive conditions. It is calculated as eq. 25.
Precision is high where a model has a low rate of false positives. Precision would be favoured in medical diagnostics because the misclassification of a patient as hypoglycemic implies a false positive kind of prediction. The recall (or Sensitivity) is the true positive predictions divided by the total number of actual positives: true positives + false negatives. It can be calculated thus eq. 26.
High recall values signify that most of the actual cases of hypoglycemia are caught true positive by the model, whereas missing a diagnosis in a medical issue may be highly severe. The F1-score is the harmonic mean between precision and recall, providing an overall measure harmonising the two. It is computed as follows eq. 27.
A high F1 Score means that your model maintains a good balance between precision and recall, making it reliable for practical use. The confusion matrix also provides intricate details of the model’s prediction in the number of cases of the positive, true negative, false positive, and false negative. This helps to see the types of errors the model is making. Table 4 summarises the key performance metrics of the GRU-LSTM network.
Table 4. Basic performance indicators of GRU-LSTM over the sets, including training and validation sets and over testing sets. The model demonstrated 100% perfect training accuracy, therefore proving that the model had learned the pattern from the training data. The validation accuracy is very high at 99.8%, and the test accuracy is 99.6%, hence showing the strong generalisation capability of the model to the unseen data, with minimum performance decay compared to the training set. The loss values were 0.05 for the training set, 0.10 for the validation set, and 0.12 for the test set. Such low loss values represent the proximity of model predictions to true ground outcome data, and a marginal increase in the loss while moving from train to test data reflects how well-regularised the model is, with very minimal overfitting.

Accuracy graph of GRU_LSTM network.
The GRU-LSTM network was trained and tested with these hyperparameters, as shown in Table 4. Therefore, training has been conducted on a sequential dataset targeting the classification of a patient as normal or hypoglycemic. The chosen hyperparameters used were 64 units for both the GRU and LSTM layers, a batch size of 32, 100 epochs, a learning rate of 0.001, a dropout rate of 0.3, the Adam optimiser, softmax as the activation function, and a 20% validation split. The accuracy of model training converged to 100%, and validation accuracy was at 99.8% on the training data, performing almost perfectly with minimal overfitting. On test data, it went on to post a test accuracy of 99.6%. These results show how this model worked in the correct classification of hypoglycemic status against the input features.
Figure 5 describes the accuracy plot of the GRU-LSTM network for a run of 100 epochs, showing the trend in training, validation, and test accuracies. It details how exactly a model was learning and its generalising capabilities during training. The training accuracy the blue line lies initially at approximately 80.5% in the first epochs, increasing steadily to about 87.9% by the 6th epoch. Then it keeps rising until it reaches 98.8% by the 14th epoch, further going up until it hits almost perfect accuracy, stabilising at 99.9% by the 100th epoch. Its rapid increase and eventual stabilisation would indicate the model’s effective learning of the training data patterns with little overfitting.

Loss of the GRU_LSTM network.
Figure 6 illustrates the GRU-LSTM network’s loss behaviour for 100 training and test loss epochs. It shows how the network learns and how effectively it reduces errors during the training process. The loss curve, shown in blue, starts running slightly above 1.2 during the first epochs; that is, there is a relatively large amount of error between what the model says and what is expected within these early epochs. During training, this loss keeps decreasing steadily, indicating better performance. By the 20th epoch, the training loss drops significantly to below 0.5 and further decreases. By the 100th epoch, the training loss had stabilised at around 0.05, showing that it could efficiently learn from the training dataset without making a mistake in the prediction. Test loss starts at around 1.5, which means a much higher initial error when evaluated on unseen data. This higher starting point reflects what the model has seen in the test data for the first time. In common with training loss, the test loss steadily decreases throughout the epochs. Test loss touched about 0.5 by the 20th epoch and then decreased slowly. The test losses stabilised around 0.12 by the 100th epoch, signifying that the model had generalised well to new and previously unseen data.

Confusion matrix of the GRU_LSTM network.
Figure 7 shows the confusion matrix of the GRU-LSTM network. The values are normalised to percentages for a detailed representation of how well the model classifies each example. Table 5 summarises the test accuracy of the GRU-LSTM network for different combinations of learning and dropout rates.
Table 6 compares the performance metrics for the various baseline models—GRU, LSTM, SVM, and RNN—against the proposed system using GRU-LSTM. Compared with the baseline models—the GRU, LSTM, SVM, and RNN—the proposed model is significantly improved in most of the performance metrics on this dataset. The proposed model exhibits an accuracy of 99.6% compared to the baseline models, whose results are 96.2% for GRU, 96.8% for LSTM, 94.5% for SVM, and 95.0% for RNN. The precision, indicating the fraction of true positive predictions against all positive predictions, is highest for the proposed at 99.7% in contrast to GRU’s 95.8%, LSTM’s 96.3%, SVM’s 94.0%, and RNN’s 94.5%. The recall, similarly, which measures the ability of the model to identify all relevant instances, is highest for the proposed model at 99.5%, outperforming GRU by 95.5%, LSTM by 96.0%, SVM by 94.3%, and RNN by 94.8%. Table 7 demonstrates that the proposed GRU-LSTM model outperforms existing approaches in classification accuracy, reaching a rate of 95.8%.
The proposed model is much better regarding the F1-score, striking a good balance between precision and recall at 99.6%, much higher than GRU at 95.6%, LSTM at 96.2%, SVM at 94.1%, and RNN at 94.6%. The proposed model, when compared to GRU’s 0.25, has a very low training loss of 0.05, hence convergent during training; it further stands above LSTM with 0.22, SVM with 0.40, and RNN with 0.30. The test loss is also low for the proposed model, 0.12, showing good performance on data not seen before, against a backdrop of GRU at 0.28, LSTM at 0.25, SVM at 0.38, and RNN at 0.35. Regarding training time, the proposed GRU-LSTM requires only 6 h, which is less than what RNN requires, with SVM having a period of just 5 h. This well-spent training time and the better performance metrics most strongly attest that the proposed GRU-LSTM model performs well and is very effective and efficient at the chosen task. This model, therefore, proposed a higher accuracy, precision, recall, and F1-Score; more importantly, better convergence and generalisation ability shall prove to be very useful in each of the applications requiring highly reliable predictions, notably medical diagnostics.

Normalized confusion matrix illustrating the classification accuracy of the GRU-LSTM model.

ROC curves for multi-class classification using the proposed GRU-LSTM model.
Figures 8 and 9 illustrate the model’s classification performance, highlighting distinct class-wise ROC curves and a well-balanced confusion matrix. These results validate the robustness and discriminative power of the proposed GRU-LSTM architecture.
Discussion
In the proposed GRU-LSTM architecture, accuracy was high for all sets: 99.9% for training, 99.8% for validation, and 99.7% for the test set. This indicates that the model has very low false positives and is especially useful from a medical perspective to ascertain the likelihood of any healthy person mistakenly being considered hypoglycemic. Similarly, the recall rate was very high: 99.8% for training, validating to 99.7%, and testing to 99.5%. This means this model is highly effective in correctly identifying hypoglycemic cases, but few cases are missing. The F1-Score was perfect at 100% for the training set and remained exceptionally high at 99.9% for validation and 99.6% for the test set. This balanced and appreciably high-performance metric affirms the reliability and effectiveness of the model in considering both true positives and minimizing false positives.
The validation accuracy, which is just an average of the accuracy for training and testing, follows this same upward trajectory from about 78%, climbing steadily. It mirrors quite closely the first plot with a slightly lower-scale range, which seems realistic if measuring out-of-sample generalisation performance. The test accuracy—the green dashed line—starts at about 76%, increases linearly to about 82.9% by the 8th epoch, and rises to 91.3% by the 14th epoch. It keeps rising and stabilises at about 99.6% by the 100th epoch. This monotonic increase in test accuracy reflects very good generalisation on unseen data, with a similar trend to validation accuracy—high performance maintained across multiple subsets of data.
The hyperparameter tuning process was one of the most critical factors in achieving optimal performance with the GRU-LSTM network. Using GRU and LSTM layers with 64 units ensured a balanced strategy in capturing necessary temporal dependencies without posing a complex model. It used a batch size of 32, ensuring that the model would learn effectively while being large enough to ensure stability in training. The model’s training time of 100 epochs was sufficient, while its learning rate 0.0005 allowed stable convergence. With a dropout of 0.3, it would be clear that overfitting would be massively avoided. This is so because the accuracy values for training and validation have very minimal differences. The Adam optimiser ensured efficient training through its adaptive learning rates. The softmax was an appropriate choice of activation at the last layer since this is a multi-class classification, and the model’s output should add up to one for a class’s probability. The validation set of 20% turned out to give a good estimate of the model’s performance during training and aided in monitoring for overfitting. With test accuracy close to perfect at 99.6%, it shows that generalisation on unseen data is very high, thus confirming the effectiveness of selected hyperparameters.
The suggested system aims to discover what happens when data from two sensors are combined with advanced features of a hybrid GRU-LSTM deep learning model to find hypoglycemia. Because it is unethical to do tests on babies born before they’re due, it is necessary to use complex simulated physiological data and widely available public datasets to recreate the desired situation accurately. Cutting edge research shows how hybrid memory networks can change how biomedical signal analysis influences architectural choices. While clinical validation is crucial, this study lays the groundwork for a comprehensive neonatal monitoring system.
Due to strict ethical concerns about testing on babies born before their due date, the first system assessment was done using simulated neonatal data and publicly available clinical datasets that closely resemble the physiological aspects of babies. This method allows for preliminary performance evaluation and model optimization. Understanding the necessity for validation in real-world clinical scenarios, we suggest future tightly supervised and ethically sanctioned clinical trials to improve the system’s potential use in neonatal healthcare settings.
Conclusion and future work
In this paper, we proposed a GRU-LSTM network for hypoglycemia detection in premature infants using data from two smart sensors. Our model outperformed baseline models such as GRU, LSTM, SVM, and RNN across different performance metrics with test accuracy of 99.6%, precision of 99.7, recall of 99.5%, and F1-score of 99.6%. It also exhibited efficient training, reducing loss and training time compared to baseline models. These findings have been robust and potent in the resignation of the proposed GRU-LSTM Network for accurate hypoglycemia detection, hence giving a dependable tool for real-time medical diagnostics. In addition, feature selection using the Cat-Swarm Optimization algorithm has been an important milestone in enhancing the model’s performance. It increased the precision of the classification model by choosing only important features from the collected data, hence contributing to the success of the proposed approach.
There are several areas in which future work may take place to further improve on the performance and applicability of the proposed model. First, more physiological signals and other sources should be added into the model; for example, blood oxygen level and temperature can help outline a detailed health status of the infant. Second, techniques such as attention mechanisms and ensemble learning will become important for further promotion of the accuracy and robustness of the model. Moreover, the system can be integrated with real-time alert mechanisms and users’ friendly interface for healthcare providers to increase its practical utility.
Data availability
All data generated or analyzed during this study are included in this published article.
References
Fernández, A. D. R., Fernández, D. R. & Sánchez, M. T. P. A decision support system for predicting the treatment of ectopic pregnancies. Int. J. Med. Inf. 129, 198–204 (2019).
Available online. (2021). https://www.Webmd.com/Baby/Guide/Pregnancy-Miscarriage#1 (accessed on 10.
Murali, S., Miller, K., & McDermott, M. Preeclampsia Eclampsia, and posterior reversible encephalopathy syndrome. Handb. Clin. Neurol. 172, 63–77 (2020).
Phipps, E. A., Thadhani, R., Benzing, T. & Karumanchi, S. A. Pre-Eclampsia: pathogenesis, novel diagnostics and therapies. Nat. Rev. Nephrol. 15, 275–289 (2019).
Saaka, M. & Hammond, A. Y. Caesarean Section Delivery and Risk of Poor Childhood Growth. J. Nutr. Metab. 2020, 6432754. (2020).
Cooper, N., O’Brien, S. & Siassakos, D. Training health workers to prevent and manage Post-Partum haemorrhage (PPH). Best Pract. Res. Clin. Obstet. Gynaecol. 61, 121–129 (2019).
Patrick, H. S., Mitra, A., Rosen, T., Ananth, C. V. & Schuster, M. Pharmacologic intervention for the management of retained placenta: A systematic review and Meta-Analysis of randomized trials. Am. J. Obstet. Gynecol. 223, 447e1–447e19 (2020).
Yockey, L. J. et al. Vaginal exposure to Zika virus during pregnancy leads to fetal brain infection. Cell 166, 1247–1256 (2016).
Polivka, B. J., Nickel, J. T. & Wilkins, J. R. III Urinary tract infection during pregnancy: A risk factor for cerebral palsy?? J. Obstet. Gynecol. Neonatal Nurs. 26, 405–413 (1997).
WHO. Guidelines on Drawing Blood: Best Practices in Phlebotomy; WHO Document Production Services (Geneva, 2010).
Jagatheesaperumal, S. K. et al. An IoT-based framework for personalized health assessment and recommendations using machine learning. Math 11 (12), 2758 (2023).
Nagy, Á. et al. Continuous Camera-Based Premature-Infant monitoring algorithms for NICU. Appl. Sci. 11, 7215. https://doi.org/10.3390/app11167215 (2021).
Paul, A., Tajin, M. A. S., Das, A., Mongan, W. M. & Dandekar, K. R. Energy-Efficient respiratory anomaly detection in premature newborn infants. Electronics 11, 682. https://doi.org/10.3390/electronics11050682 (2022).
Jothimani, S. & Premalatha, K. THFN: Emotional health recognition of elderly people using a Two-Step hybrid feature fusion network along with Monte-Carlo dropout. Biomed. Signal Process. Control. 86, 105116. (2023).
Gou, H., Zhang, G., Medeiros, E. P., Jagatheesaperumal, S. K. & de Albuquerque, V. H. C. A cognitive medical decision support system for IoT-based human-computer interface in pervasive computing environment. Cogn. Comput. 16 (5), 2471–2486 (2024).
Pickhardt, P. J. et al. Automated CT-based body composition analysis: A golden opportunity. Korean J. Radiol. 22, 1934–1937 (2021).
Eng, D. et al. Automated coronary calcium scoring using deep learning with multicenter external validation. Npj Digit. Med. 4, 1–13 (2021).
Pickhardt, P. J. et al. Utilizing fully automated abdominal CT–based biomarkers for opportunistic screening for metabolic syndrome in adults without symptoms. Am. J. Roentgenol. 216, 85–92 (2021).
Sohn, J. H. et al. Prediction of future healthcare expenses of patients from chest radiographs using deep learning: a pilot study. Sci. Rep. 12, 8344 (2022).
Pyrros, A. et al. Detecting Racial/ethnic health disparities using deep learning from frontal chest radiography. J. Am. Coll. Radiol. 19, 184–191 (2022).
Pyrros, A. et al. Validation of a deep learning, value-based care model to predict mortality and comorbidities from chest radiographs in COVID-19. PLOS Digit. Health. 1, e0000057 (2022).
da Silva, D. S., Nascimento, C. S., Jagatheesaperumal, S. K. & de Albuquerque, V. H. C. Mammogram image enhancement techniques for online breast cancer detection and diagnosis. Sensors 22 (22), 8818 (2022).
Esteva, A. et al. A guide to deep learning in healthcare. Nat. Med. 25 (1), 24–29 (2019).
Ching, T. et al. Opportunities and Obstacles for deep learning in biology and medicine. J. R Soc. Interface. 15 (141), 20170387 (2018).
Miao, H., Li, A., Davis, S. & Deshpande, A. in Proceedings-International Conference on Data Engineering. Model hub: deep learning lifecycle management pp. 1393–1394 (2017).
Kim, S., Yu, Z., Kil, R. & Lee, M. Deep learning of support vector machines with class probability output networks. Neural Netw. 64, 19–28 (2015).
Yousefi, L. et al. in Proceedings - IEEE Symposium on Computer-Based Medical Systems. Predicting disease complications using a stepwise hidden variable approach for learning dynamic Bayesian networks pp. 106–111 (2018).
Hammoudeh, A., Al-Naymat, G., Ghannam, I. & Obied, N. Predicting hospital readmission among diabetics using deep learning. Procedia Comput. Sci. 141, 484–489 (2018).
Pham, T., Tran, T., Phung, D. & Venkatesh, S. Predicting healthcare trajectories from medical records: a deep learning approach. J. Biomed. Inf. 69, 218–229 (2017).
Bae, S. & Park, T. Risk prediction of type 2 diabetes using common and rare variants. Int. J. Data Min. Bioinform. 20 (1), 77–90 (2018).
Kannadasan, K., Edla, D. R. & Kuppili, V. Type 2 diabetes data classification using stacked autoencoders in deep neural networks. Clin. Epidemiol. Glob Health. 7 (4), 530–535 (2018).
Alattar, A. E., Elkaseer, A., Scholz, S. & Mohsen, S. Critical assessment of current state of the art in wearable sensor nodes with energy harvesting systems for healthcare applications, in Proc. Future Technol. Conf., Cham: Springer, pp. 398–412. (2022).
Alattar, A. E. & Mohsen, S. A survey on smart wearable devices for healthcare applications. Wirel. Pers. Commun. 132 (1), 775–783 (2023).
Mohsen, S., Zekry, A., Youssef, K. & Abouelatta, M. On architecture of self-sustainable wearable sensor node for IoT healthcare applications. Wirel. Pers. Commun. 119 (1), 657–671 (2021).
Mohsen, S., Zekry, A., Youssef, K. & Abouelatta, M. An autonomous wearable sensor node for long-term healthcare monitoring powered by a photovoltaic energy harvesting system. Int. J. Electron. Telecommun. 66 (2), 267–272 (2020).
Mohsen, S., Zekry, A., Youssef, K. & Abouelatta, M. A self-powered wearable wireless sensor system powered by a hybrid energy harvester for healthcare applications. Wirel. Pers. Commun. 116 (4), 3143–3164 (2021).
Kermani, A. & Esmaeili, H. The dataset of photoplethysmography signals collected from a pulse sensor to measure blood glucose level, Mendeley Data, V3, doi: https://doi.org/10.17632/37pm7jk7jn.3. (2023).
Pandey, V. et al. Enhancing heart disease classification with M2MASC and CNN-BiLSTM integration for improved accuracy. Sci. Rep. 14 (1), 24221 (2024).
Zhao, L. et al. Emerging sensing and modeling technologies for wearable and cuffless blood pressure monitoring. Digit. Med. 6 (1), 93 (2023).
Bourechak, A. et al. At the confluence of artificial intelligence and edge computing in IoT-based applications: A review and new perspectives. Sensors 23 (3), 1639 (2023).
Kargarandehkordi, A. et al. Fusing wearable biosensors with artificial intelligence for mental health monitoring: A systematic review. Biosensors 15 (4), 202 (2025).
Author information
Authors and Affiliations
Contributions
All authors contributed equally to the conceptualization, formal analysis, investigation, methodology, and writing and editing of the original draft. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable. This study did not need ethical approval, and the article does not contain any studies with human or animal participants. As there are no human participants, informed consent is not applicable. All the methods provided in this manuscript were carried out in accordance with relevant guidelines and regulations.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shafiq, M., Kavitha, J., Rinku, D.R. et al. Dual smart sensor data-based deep learning network for premature infant hypoglycemia detection. Sci Rep 15, 23442 (2025). https://doi.org/10.1038/s41598-025-03864-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-03864-1
Keywords
This article is cited by
-
Artificial intelligence-enabled wearable microgrids for self-sustained energy management
Nature Reviews Electrical Engineering (2025)
