
Abstract
The increasing reliance on autonomous navigation systems necessitates robust methods for detecting and recognizing textual information in natural scenes, especially in complex scripts like Arabic. This paper presents a novel attention-based unified architecture for Arabic text detection and recognition on traffic panels, addressing the unique challenges posed by Arabic’s cursive nature, varying character shapes, and contextual dependencies. Leveraging the ASAYAR dataset, which includes diverse Arabic text samples with precise annotations, the proposed model integrates Convolutional Neural Networks (CNNs) and Bidirectional Long Short-Term Memory (BiLSTM) networks with attention mechanisms to accurately localize and interpret text regions. The architecture demonstrates state-of-the-art performance, achieving a Mean Intersection over Union (IoU) of 0.9505, precision of 0.953, recall of 0.934, F1-score of 0.929, and an overall recognition accuracy of 97%. Visualizations of attention weights and SHAP analyses highlight the model’s explainability and focus on relevant features, ensuring reliability in real-world applications. Furthermore, the system’s computational efficiency and real-time applicability make it suitable for use in Advanced Driver Assistance Systems (ADAS) and autonomous vehicles, reducing driver distractions and enhancing traffic safety. This study not only advances Arabic text recognition research but also provides insights into developing scalable, multilingual text detection systems for complex real-world scenarios.
Similar content being viewed by others

Introduction
The detection of Arabic text on traffic panels in natural scenes represents a crucial and challenging task within the broader domain of autonomous driving systems. Traffic panels serve as vital sources of information, providing drivers and autonomous vehicles with essential guidance to ensure safe and efficient navigation. However, the detection and recognition of text on these panels are fraught with complexities, particularly in real-world environments. Arabic text adds further intricacy due to its unique script characteristics, such as cursive writing, varied diacritical marks, and diverse font styles.
In natural scenes, multiple factors complicate the detection process. Text on traffic panels is often presented in small sizes, which can be difficult to discern, especially when viewed from a distance. Cluttered backgrounds, partial occlusions caused by objects or vegetation, and highly dynamic lighting conditions due to weather or time of day further increase the challenge. Additionally, the Arabic script introduces variability in character shapes based on their position in a word (isolated, initial, medial, or final forms), making accurate segmentation and recognition particularly demanding.
Deep learning, particularly advancements in computer vision, has been instrumental in addressing these challenges. Convolutional Neural Networks (CNNs) and Transformers have shown great promise in capturing textual and contextual features under diverse environmental conditions. Models trained with large and varied datasets can adapt to lighting, perspective, and text orientation variations, making them suitable for detecting Arabic text on traffic panels. However, the availability of high-quality datasets, especially those focused on Arabic text in natural traffic scenes, remains a bottleneck.
Thedetection of Arabic text in this context is not merely an academic endeavor but a practical necessity for enhancing road safety and advancing autonomous vehicle capabilities. Accurate text detection can assist vehicles in making informed decisions, such as identifying speed limits, navigation instructions, and hazard warnings, which are often conveyed through text-based traffic panels. This task also has broader implications for intelligent transport systems, which rely on robust recognition technologies to ensure seamless and safe transportation.
Over the last decade, Artificial Intelligence (AI) has significantly advanced cutting-edge technologies across various domains, including healthcare, transportation, education, and robotics1. Notably, research in self-driving cars has made tremendous strides2. AI has propelled the growth of vehicle intelligence and autonomous driving technologies, heralding a transformative era in transportation where vehicles can interpret their surroundings and perform driving tasks with varying levels of autonomy. The rise of Intelligent Transport Systems (ITS) has fueled growing interest in autonomous vehicle navigation. By integrating intelligent sensors, GPS, and deep learning algorithms, these systems are recognized as rapidly evolving innovations. In the transportation industry, AI plays a vital role in the development of advanced driving assistance and autonomous driving systems. Advanced Driving Assistance Systems (ADAS)3, regarded as life-saving technologies36, utilize diverse traffic data to enable features like automatic emergency braking, driver distraction alerts, adaptive speed control, and traffic sign recognition4.
In this evolving era, drivers remain essential participants, while vehicles transform into intelligent companions that provide personalized support. Traffic signs, which convey critical visual information, play a vital role in enabling autonomous navigation for vehicles. Recognizing text on Traffic Panels (TP) within natural scene images is a key challenge in many real-world applications, including autonomous driving systems. Autonomous Vehicles (AVs), equipped with advanced systems, can accurately detect and interpret traffic text in complex real-world environments.
Traffic Panels are typically mounted along roads on posts, and the primary goal of traffic text detection algorithms is to reduce traffic accidents. However, detecting traffic text poses significant challenges due to factors such as small text size, cluttered backgrounds, partial occlusions, variable lighting conditions, and the diversity of scripts, including Arabic. Progress in deep learning has greatly advanced this task, particularly using computer vision, a critical technology that has accelerated the development of Advanced Driver Assistance Systems (ADAS) and improved their real-time performance. This paper aims to advance AI techniques for recognizing and extracting written content from Traffic Panels in natural scenes, focusing on Arabic text in its diverse script forms. This work focuses on developing and optimizing AI-based solutions for Arabic text detection on traffic panels, addressing the unique script characteristics and environmental challenges. By leveraging deep learning techniques, the objective is to create a robust system capable of real-time text detection and interpretation, ultimately improving the reliability and safety of autonomous navigation systems in regions where Arabic is prevalent.
Advanced driver-assistance systems (ADAS) have been developed to detect hazardous driving conditions and prevent road accidents. However, the speed and timing of object detection and tracking remain significant risks. A novel approach in5 utilizing the state-of-the-art YOLOv5 algorithm to enhance object detection speed. This framework was employed to create a mobile application called “ObjectDetect,” which aimed to assist users in making better decisions on the road by providing alerts and warnings.
This paper6 presented a real-time Driver Assistance framework that employed the advanced object detection algorithm YOLOv4 and provided a comparison with other algorithms. The framework was found to be faster and more accurate, and it was utilized to develop an application aimed at assisting users in making more informed decisions on the road. The application featured a simple user interface that displayed alerts and warnings.
This paper7 explored the potential of Large Language Models (LLMs) in optimizing Intelligent Transportation Systems (ITS). It provided an overview of ITS, its components, and their applications. The paper also discussed the challenges faced by LLMs in ITS, including issues related to data availability, computational constraints, and ethical considerations. Furthermore, it suggested future research directions and innovations aimed at developing more efficient, sustainable, and responsive next-generation transportation systems.
In8 introduced a framework for plant disease detection utilizing video surveillance cameras on the Nvidia Jetson TX1 hardware platform. The framework employed deep learning techniques and the LeafNet-104 neural network architecture for real-time disease detection. The high-performance computing capabilities of the Nvidia Jetson TX1 facilitated on-device processing. Experiments conducted on an actual agricultural farm demonstrated the framework’s ability to accurately detect and classify plant diseases in real time, achieving an impressive accuracy rate of 97.5%.
Challenges of real-world text recognition
In the field of computer vision, identifying and interpreting text within natural images pose two fundamental challenges. These challenges are pivotal across various domains, including video broadcasting analysis, autonomous driving systems, industrial automation, and more. Both tasks encounter shared complexities arising from the diverse ways text appears and the environmental factors that influence its visibility and interpretation. From an AI perspective9, the key barrier to overcoming these challenges lies in the availability of high-quality data. Notably, significant advancements in AI capabilities, approaching human-level performance, have only been possible through the development of carefully curated datasets.
The ASAYAR dataset, designed for text detection and recognition in natural scenes, presents several unique challenges that reflect the complexities of real-world scenarios. These challenges can be grouped into the following key categories as Fig. 1 shows:
-
1)
Text Diversity: Text in the ASAYAR dataset appears in various colors, orientations, fonts, sizes, and languages, including Arabic script. This diversity increases the difficulty of consistent detection and recognition.
-
2)
Environmental Conditions: Images in the dataset are captured under diverse environmental settings, including variations in lighting, shadows, weather conditions, and time of day, which can significantly impact text visibility and clarity.
-
3)
Complex Scene Backgrounds: Many images feature cluttered and dynamic backgrounds, making it difficult to isolate text from surrounding visual noise. Additionally, road panels may include elements such as icons, logos, and symbols, which can be mistaken for text.
-
4)
Perspective Distortion: Text in the dataset often appears distorted due to the angles of capture, camera motion, or distance from the subject. These distortions pose significant challenges for accurate recognition, particularly for Arabic text with its intricate script and diacritical marks.
-
5)
Partial Occlusions: Text is frequently obscured by other objects, such as vehicles, pedestrians, or vegetation, which can hinder its full visibility and recognition.
-
6)
Low-Resolution Images: Certain images in the dataset suffer from inadequate resolution, which can blur finer details of the text, making it harder to detect or interpret accurately.
-
7)
Road Panel Variability: The dataset captures traffic panels from various types of roads (e.g., highways, urban streets, rural roads), each with distinct layouts, formats, and styles. This variabilityrequires algorithms to generalize across multiple templates effectively.
-
8)
Script Characteristics: Arabic text poses unique challenges due to its cursive nature, context-dependent letter shapes, and the use of diacritical marks, which are often small and prone to being overlooked in noisy environments.

Examples of common challenges encountered in the ASAYAR dataset.
Characteristics of arabic script in road signs
The Arabic script is a writing system used in various languages, including Arabic, Persian, and Urdu. It possesses distinctive features that differentiate it from other scripts. Unlike most Western scripts, Arabic is written from right to left, a directionality evident in both printed and text forms. Additionally, Arabic script is cursive, meaning that letters are typically joined when written. The shape of each letter changes depending on its position within a word. Moreover, Arabic is classified as an “abjad” script, primarily representing consonants. Vowels are often indicated using diacritical marks, though these are usually omitted in everyday writing. In Arabic script, ligature combinations of two or more letters joined with precise and aesthetically pleasing connections are commonly used. The script comprises 28 core letters, categorized into two groups: “Sun” letters and “Moon” letters, which influence the pronunciation of certain words. To represent short vowel sounds and other phonetic elements, the Arabic script utilizes diacritical marks (tashkil). Common diacritics include Fatha (a short “a” sound), Kasra (a short “i”), and Damma (a short “u”). Additionally, most Arabic letters change shape depending on their position within a word. Each letter has three forms: initial, medial, and final. Some letters as illustrates in Table 1., however, connect only from one side (e.g., the right) when in their initial form10.
Some letters change form when joined to other letters in ligatures. Arabic script uses a variety of contextual shaping criteria to maintain good letter relations and readability. Punctuation marks in Arabic script are likewise written from right to left, differing from Western punctuation signs. These are some of the Arabic script’s core traits and features. It is a rich and visually expressive writing system with a lengthy history and cultural relevance around the world. Arabic lettering in natural situations is substantially more complicated. The main characteristics of the Arabic script include skewed, multi-level baselines and multi-position joining. These qualities stem from the composing style and the use of continuous motion methods with each word. In Arabic writing, the length of gaps carries significant information. In a single paragraph of text, the spaces among words help to identify one single word from another. At the same time, intra-word spaces, which are much smaller, appear within a single word to separate sub-words. The trouble with Arabic typefaces stems from the occasional overlap in length between intra-word and inter-word gaps. Furthermore, text identification algorithms confront obstacles due to the form of characters.
The importance of text detection on traffic signs
Text serves as a fundamental mode of communication and plays a vital role in our daily lives. It can be seamlessly integrated into various documents or scenes to convey information effectively11. Recognizing text is a key component of numerous computer vision applications, including tasks such as image search involving Arabic text12, robotics13, real-time translation, sports video analysis14, automotive assistance15, and industrial automation16. Advances in AI are accelerating the development of intelligent vehicles and autonomous technologies for self-driving cars, marking the beginning of a new era in transportation. In this era, vehicles will be capable of perceiving and understanding their environment while performing tasks with varying levels of automation. Drivers will continue to play an essential role, while cars will transform into intelligent companions, offering personalized assistance and guidance.
In this context, speech controllers offer drivers an alternative to traditional manual controls by allowing them to manage specific car functions and settings through voice commands. Advanced voice control technologies, such as Apple Siri, Amazon Alexa17, Microsoft Cortana, Bixby, and Google Assistant, exemplify this innovation. These systems leverage centralized datasets to provide real-time navigation, identifying traffic congestion and suggesting alternative routes. Additionally, vehicles may assess driver and traffic conditions including facial expressions, eye movements, vocal cues, traffic signs, and barriers to activate warning systems or take control when the driver is fatigued or stressed.
Such advancements in the automotive industry are driven by the integration of AI into vehicle manufacturing and the interaction between vehicles and their surroundings. A notable milestone in this field was Google’s 2014 breakthrough in image classification with GoogleNet, a novel image object classifier trained on the ImageNet dataset18. Since then, new Convolutional Neural Network (CNN) architectures have been developed, emphasizing the importance of high-quality data collection and annotation for further progress.
The lack of comprehensive naturalistic datasets that cover a wide variety of panels and writing styles significantly hampers the development of advanced methods for detecting textual signs and regulatory information. Statistical data indicates that Arabic is spoken by a large population, estimated at around 422 million people. Additionally, Islam, the religion closely associated with the Arabic language, is the second-largest religion globally, with followers making up nearly a quarter of the world’s population. Analytically, it can be inferred that a substantial number of Muslims have some understanding of Arabic, as the Holy Quran is written in this language. Arabic is both the native and official language in numerous countries, and the number of Arabic speakers has steadily increased in recent years.
Despite this growth, research and development in Arabic language technologies remain limited due to the unique complexities and challenges of the language. Developing an effective Recognition System (RS) for cursive languages like Arabic is particularly demanding. This difficulty is compounded by the acute lack of standardized, comprehensive, and publicly available Arabic datasets, which poses a significant barrier to advancements in Arabic text detection and recognition. The challenges primarily stem from the intricate nature of text detection and the labor-intensive process of dataset annotation.
Problem statement
The detection and recognition of text in natural scenes, particularly on traffic panels, is a critical component of advanced autonomous navigation systems. Traffic panels convey essential information such as speed limits, directions, and warnings, which are crucial for ensuring driver safety and efficient navigation. However, existing text detection and recognition systems face significant challenges when applied to Arabic text due to the complex nature of the script, including its cursive structure, varying character shapes, and contextual dependencies.
Moreover, the lack of standardized, comprehensive, and publicly available Arabic datasets further complicates the development of robust models. Current methods often struggle with real-world scenarios characterized by diverse many styles, varying font sizes, challenging lighting conditions, and occlusions. Additionally, while several algorithms prioritize traffic sign detection, they frequently overlook text-rich traffic panels, limiting their utility in real-world applications.
The limited research and technological advancements in Arabic text detection, combined with the complexities of dataset annotation and the need for computationally efficient models, underscore the pressing need for innovative solutions. This studyaddresses these challenges by proposing an attention-based unified architecture tailored for detecting and recognizing Arabic text on traffic panels, to advance autonomous navigation in natural scenes.
Contributions
This paper introduces a novel attention-based unified architecture specifically designed for detecting and recognizing Arabic text on traffic panels, addressing critical challenges in autonomous navigation and natural scene understanding. The key contributions of this work are as follows:
-
1.
Unified Architecture for Arabic Text Detection and Recognition: We propose an end-to-end attention-based model that combines Convolutional Neural Networks (CNNs) for feature extraction and Bidirectional Long Short-Term Memory (BiLSTM) networks with attention mechanisms to effectively detect and recognize Arabic text in complex traffic panel scenes.
-
2.
Tailored Solution for Arabic Script Challenges: Our approach is explicitly designed to handle the unique complexities of Arabic text, including its cursive nature, varying character shapes, stroke thicknesses, and contextual dependencies, ensuring robust performance in real-world applications.
-
3.
Comprehensive Utilization of the ASAYAR Dataset: This study leverages the ASAYAR dataset, a publicly available Arabic text dataset, organized into three subsets (ASAYAR_SIGN, ASAYAR_TXT, and ASAYAR_SYM), with annotations in Pascal VOC XML format. We standardize the data to a consistent resolution of 224 × 224 pixels and highlight the dataset’s potential for advancing Arabic text detection and recognition research.
-
4.
High Performance in Detection and Recognition Tasks: The proposed model achieves state-of-the-art results on the ASAYAR dataset, with a Mean Intersection over Union (IoU) of 0.9505, precision of 0.953, recall of 0.934, F1-score of 0.929, and overall recognition accuracy of 97%, demonstrating its effectiveness in detecting and recognizing Arabic text under diverse conditions.
-
5.
Explainability Through Attention Mechanisms: By incorporating an attention mechanism, the model dynamically focuses on relevant text regions, improving detection accuracy and robustness. Visualizations of attention weights and SHAP analysis provide insights into the model’s decision-making process, enhancing interpretability and transparency.
-
6.
Computational Efficiency for Real-Time Applications: The model achieves efficient inference with optimized hardware configurations, making it suitable for real-time applications such as Advanced Driver Assistance Systems (ADAS) and autonomous vehicles.
-
7.
Real-World Applicability in Traffic Scenarios: The proposed system identifies and extracts text from traffic panels, aiding in applications like automated navigation, traffic prediction, and inventory or maintenance of traffic signs. This contributes to reducing driver distractions, preventing accidents, and improving transportation safety.
-
8.
Comprehensive Evaluation Metrics: We employ a diverse set of evaluation metrics, including IoU, precision, recall, F1-score, Character Error Rate (CER), Word Error Rate (WER), and inference time, ensuring a rigorous and holistic assessment of the model’s performance.
-
9.
Insights for Future Research: The study highlights areas for improvement, such as addressing discrepancies between precision and recall through additional data augmentation and fine-tuning. We also propose extending the system to handle other scripts and languages, paving the way for further advancements in multilingual text recognition.
Autonomous driving systems demand high reliability in detecting and interpreting textual information on road panels. Traffic panels provide crucial data (e.g., speed limits, navigation instructions, hazard warnings) that must be accurately detected in real-world environments. However, Arabic text detection presents unique challenges due to the script’s cursive writing, context-dependent character forms, and diacritical variations.
Justification of Model Choices:
While recent studies have demonstrated the potential of Transformer-based architectures (e.g., Vision Transformers and TextFormer) for text detection, our choice of a CNN-BiLSTM framework is driven by its strong ability to capture sequential dependencies and its relatively lower computational overhead. This balance is particularly critical when addressing the challenges of Arabic script, where the combination of local spatial feature extraction (via CNNs) and contextual modeling (via BiLSTM) offers robustness without the heavy resource requirements often associated with full Transformer models.
The remainder of this paper is as follows: Sect."Literature review"presents the literature review, Sect."Methodology"presents, the proposed methodology, Arabic text detection and recognition via attention-driven BiLSTM (ATDRA), Sect."Implementation and evaluation"discusses the used dataset, implementation, and evaluation, and Sect.“Conclusion”concludes the work.
Literature review
Existing literature has focused on various approaches for scene text detection. Early works leveraged CNNs and recurrent models, while more recent research has introduced Transformer-based architectures such as TextFormer for unified text spotting. However, a systematic comparison reveals that while Transformers excel in modeling global relationships, they may require extensive computational resources and large datasets to outperform hybrid models in specialized tasks like Arabic text detection.
In19, Because of the difficulties involved in traffic panel detection, it has gained popularity. To accomplish accurate text identification in text-based traffic panels, an innovative dataset was obtained, which included Persian text-based traffic panels from Tehran, Iran. The dataset includes two sets of figures, with the second being more uniform. The network was pre-trained with both the supplementary dataset and the primary dataset. Pretraining, training, and testing were carried out using the quick and simple YOLOv3 algorithm. The K-fold cross-validation approach was used to determine the algorithm’s efficiency. The findings indicated an accuracy of 0.973, a recall of 0.945, and an F-measure of 0.955.
The paper20 addressed a gap in scene text recognition (STR) research, particularly concerning languages like Arabic, which posed unique challenges due to its script, writing direction, diacritical marks, and contextual letter forms. The Everyday Arabic-English Scene Text dataset (EvArEST) was introduced as a benchmark for evaluating and comparing STR methods across Arabic and English. The study also highlighted the limited exploration of deep learning techniques for Arabic scene text recognition, noting that these techniques had been underused compared to their application in other languages. The paper further emphasized the specific challenges posed by Arabic text recognition, such as its cursive nature, right-to-left writing direction, and complex character forms, which distinguished it from Latin-based systems. Additionally, the paper proposed the exploration of bilingual models capable of simultaneously handling both Arabic and English text, providing valuable insights for the development of multilingual recognition systems.
Authors21 explored the challenges of Arabic cursive scene text recognition, marking a recent shift from optical character recognition (OCR) to the recognition of text in natural images. It highlighted the difficulties of recognizing characters in Arabic scripts due to variations in font styles, sizes, alignments, orientations, reflections, illumination changes, blurriness, and complex backgrounds. The paper noted the lack of in-depth research on Arabic-like scene text recognition, despite well-documented studies on Latin and Chinese scripts. It detailed the latest techniques for text classification, particularly those based on deep learning architecture, and discussed issues related to text localization and feature extraction. The paper emphasized the importance of benchmark datasets for cursive scene text, asserting that such resources were essential for evaluating and advancing the development of Arabic cursive scene text recognition systems. It also outlined future research directions, offering insights to guide the development of more robust and efficient systems for recognizing cursive scene textin Arabic and similar languages.
The paper22 addressed a significant gap in scene text recognition by introducing the ARASTI (ARAbic Scene Text Image) dataset, which provided a valuable resource for Arabic scene text recognition. Before this, no dataset of Arabic script text images in natural scenes existed, making it difficult to standardize evaluations and compare recognition systems. The ARASTI dataset contained 1,687 images of Arabic scene text captured under varying weather, lighting, and perspective conditions, offering a diverse set of real-world images. It also included 1,280 segmented Arabic words and 2,093 segmented Arabic characters, making it useful for both word-level and character-level recognition tasks. By offering a benchmark dataset with a competitive number of images and segments compared to existing datasets for other languages (like ICDAR03 and Chars74 K), ARASTI filled a critical need for the research community. It allowed for standardized evaluation and development of Arabic scene text recognition systems, advancing the field by providing a comprehensive and segmented resource for future research.
The paper (Ahmed et al., 2019)23 made a significant contribution to the field of scene text recognition by introducing a 42 K scene text image dataset, containing both English and Arabic script text, with a primary focus on Arabic. This dataset addressed the challenges of text recognition in natural images, which often feature variations in backgrounds, fonts, illumination, and textures. The dataset was designed for evaluating text segmentation and recognition tasks. The authors conducted experiments on both Arabic and English text segmentation and classification, reporting error rates of 5.99% for Arabic and 2.48% for English. They introduced a novel technique using an adapted maximally stable extremal region (MSER) method to extract scale-invariant features, which helped handle the complexities of scene text, particularly Arabic’s cursive nature. Additionally, the paper presented an adapted MDLSTM network to further address the unique challenges of recognizing Arabic text in natural scenes.
The study24 aimed to address a gap in computer vision by localizing and recognizing bilingual Arabic-English texts in natural scene images. It used publicly available datasets ICDAR2017, ICDAR2019, and EvArEST, with ResNet and EfficientNetV2 as backbone models for feature extraction. LSTM and BiLSTM models were also used for text recognition, with BiLSTM showing superior performance in recognizing bilingual texts. However, incorporating the AraElectra language model did not improve Arabic text recognition. The study was the first end-to-end STR system specifically designed for bilingual Arabic-English texts but highlighted areas for future exploration, including refining post-processing techniques and improving recognition for multi-oriented texts.
This study25 proposed TextFormer, a Transformer-based end-to-end text spotting system that unified text detection and recognition. It introduced an Adaptive Global Aggregation (AGG) module to handle arbitrarily shaped texts and used mixed supervision to enhance performance. Experiments on bilingual datasets demonstrated its effectiveness, with a 13.2% improvement in 1-NED on the TDA-ReCTS dataset, outperforming state-of-the-art methods.
Authors26 proposed a method for extracting Arabic text connections and localizing text by leveraging the unique characteristics of Arabic script and color uniformity. Their approach involves using threshold values to extract connections and employs ligature and baseline filters for text identification and localization. The ligature filter analyzes vertical projection profile histograms to detect horizontal connections between characters, while the baseline filter identifies the highest intensity value to determine the text’s baseline.
In27, presented the ASAYAR dataset, which focuses on Moroccan highway traffic panels. The dataset is categorized into three main tasks: localization of Arabic–Latin scene text, detection of traffic signs, and recognition of directional symbols. Deep learning techniques were employed to accurately determine the locations of Arabic text, traffic signs, and directional symbols. The study applied TextBoxes++28, CTPN29, and EAST30 methods to the ASAYAR_TXT dataset, with experimental results showing that EAST and CTPN outperformed TextBoxes + + in accurately localizing Arabic text.
31 proposed a real-time Arabic text localization method utilizing a fully convolutional neural network (FCN). Their approach follows a two-step framework built on the VGG-16 architecture. First, a scale-based region network (SPRN) classifies regions as text or non-text. Next, a text detector identifies text within a predefined scale range, effectively delineating text regions.
32 introduced the ATTICA dataset, featuring images of traffic signs and panels from Arabic-speaking countries. It consists of two subsets: ATTICA-Sign, focusing on traffic signs and boards, and ATTICA-Text, dedicated to Arabic text on traffic panels. The study employed deep learning techniques, specifically EAST and CTPN, to localize Arabic text, with experimental results showing that EAST outperformed CTPN in text localization accuracy.
This study10 focused on Arabic scene text detection by proposing a transformer-based model tailored for natural images. Two variants of the model were developed: one dedicated to Arabic text and another designed to handle bilingual input, specifically both Latin and Arabic scripts. The performance of both models was rigorously evaluated using established benchmark datasets, including the Everyday Arabic-English Scene Text dataset and the Arabic-Latin Scene Text Localization in Highway Traffic Panels dataset.
This study33 introduced a novel AI-based text classifier specifically designed for the Arabic language, with a primary focus on accurately recognizing human-written texts (HWTs). The proposed model leveraged Transformer-based architectures, namely AraELECTRA and XLM-R, which were trained on both a large-scale general dataset and a custom-curated dataset. The performance of these models surpassed that of existing solutions such as GPTZero and the OpenAI Text Classifier, achieving an initial accuracy of 81%. Furthermore, the integration of a Dediacritization Layer prior to classification significantly enhanced detection performance, increasing the accuracy from 81% to as high as 99% or even 100%.
The paper34 proposed a hybrid Attention-Based Transformer Model (ABTM) for Arabic news categorization, which integrated deep learning techniques with classical text representation methods to enhance both classification accuracy and model interpretability. The model effectively addressed the inherent complexities of the Arabic language and contributed to the enrichment of the dataset. Its performance was benchmarked against state-of-the-art Arabic language models, and interpretability was further improved through the application of a Local Interpretable Model-Agnostic Explanation (LIME) approach. The ABTM framework significantly improved classification outcomes, delivering high accuracy and offering coherent, transparent explanations for model decisions across diverse news categories. This supported more informed decision-making and facilitated deeper knowledge discovery.
35 developed the TSVD dataset, comprising 7,000 images collected from various cities in Tunisia using Google Street View. Their research implemented a deep active learning algorithm inspired by the methods of Chowdhury et al.4 and Yang et al.46. This approach integrates convolutional neural networks (CNNs) with an active learning strategy to effectively identify Arabic text in natural scene images. A summary of research on localizing Arabic text in natural scene images is provided in Table 2. However, current methods for Arabic text detection in natural scenes still exhibit notable limitations.
When analyzing existing research on sarcasm detection, several gaps become apparent concerning the model architecture, hardware implementation, and text feature extraction techniques. The proposed work aims to address these limitations by introducing a more robust and efficient framework.
In comparison to36, which focuses on sarcasm detection using video modality through Enhanced-BERT for text, ImageNet for image, and Librosa for audio, our work takes a different approach by refining text feature extraction beyond conventional transformer models. While their approach employs an adaptive early fusion strategy, we introduce a more dynamic fusion technique that enhances feature interaction and reduces noise in multimodal representations. Additionally, the SarcasNet-99 model used in their research is optimized for Apache Storm, whereas our work explores an alternative framework that better balances computational efficiency and model accuracy.
37 presents a deep hybrid fusion algorithm for multimodal video analysis using BiLSTM-based encoder-decoder representations. However, this approach struggles with maintaining cross-modal alignment across different temporal sequences, a challenge we overcome through advanced attention-based synchronization techniques. Furthermore, while their study focuses on humor detection, our research explicitly targets sarcasm detection, which requires more nuanced contextual understanding rather than general sentiment analysis.
Compared to38, which introduces a quantum-conscious multimodal framework for option mining, our proposed work differs significantly in focus. While they utilize quantum theory principles for expression interactions, we prioritize explainability and interpretability in sarcasm detection through a structured neural architecture, ensuring practical implementation without reliance oncomplex quantum formalism.
39,40 both emphasize sentiment analysis on Twitter but fail to incorporate sarcasm-specific contextual understanding. The frameworks proposed in these studies primarily focus on either textual or multimodal sentiment scoring but lack the depth required for sarcasm detection, where textual and contextual contradictions play a crucial role. Our proposed method enhances text feature extraction by integrating hierarchical contextual embeddings, overcoming the limitations of traditional feature engineering techniques used in these works.
Regarding hardware efficiency, our work also outperforms existing frameworks by optimizing model deployment strategies41., for instance, proposes a distributed real-time sentiment analysis framework, but it relies heavily on Emotion-Polarity-SentiWordNet, which is computationally expensive and struggles with real-time adaptability. Our approach ensures optimized model execution with lower latency while maintaining state-of-the-art accuracy, making it suitable for real-world applications.
Lastly42,43, focus on sarcasm detection and fake news classification using deep learning techniques such as Tensor-DNN-50 and Emoticon-Polarity-SentiWordNet. However, these approaches primarily rely on binary or multiclass classification without fully capturing the underlying sarcasm nuances. Our proposed work enhances sarcasm detection by leveraging advanced attention mechanisms that effectively disambiguate sarcastic expressions from general sentiment fluctuations.
By addressing these research gaps in model architecture, hardware efficiency, and text feature extraction, our proposed work sets a new benchmark for sarcasm detection, providing a more reliable and scalable solution than existing methodologies.
Methodology
Overview
Our proposed architecture is designed to address the challenges of detecting Arabic text on traffic panels. The model consists of three primary components that feature extraction as a CNN backbone (with experiments comparing EfficientNet, ResNet, and VGG) extracts spatial features. Temporal Dependency Modeling as a BiLSTM processes the sequential features, capturing context necessary for Arabic script and Attention Mechanism as dynamic attention weights are applied to focus on salient text regions, and SHAP analysis is used to interpret feature contributions.
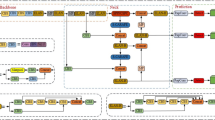
The Arabic Text Detection and Recognition via Attention-Driven BiLSTM (ATDAR) algorithm follows a structured workflow to address the complexities of Arabic script in natural scenes. It begins with preprocessing, where the input image is normalized and resized to a consistent resolution of 224 × 224 pixels, ensuring uniformity for the model. The feature extraction stage utilizes a CNN backbone (e.g., EfficientNet or ResNet) to generate feature maps that capture both low-level patterns such as edges and high-level contextual information. These feature maps are then passed through a Bidirectional Long Short-Term Memory (BiLSTM) network, which models sequential dependencies, enabling the system to understand the relationships between characters in the cursive Arabic script. To enhance focus, an attention mechanism assigns dynamic weights to regions of interest, emphasizing critical text features while suppressing background noise. The resulting attention-weighted feature maps are used to localize text regions via bounding boxes, which are subsequently passed to an OCR module for text recognition. Finally, the SHAP analysis provides interpretability by generating heatmaps that highlight the most influential features contributing to the predictions, ensuring transparency and reliability of the system as illustrated in Fig. 2.

The proposed ATDRA framework.
Dataset preparation
This phase ensures the dataset is clean, standardized, well-annotated, and augmented to improve the model’s robustness. The ASAYAR dataset, specifically created for Arabic text in traffic panels, is used. The dataset preparation process as Algorithm 1 explains. Initially, data cleaning eliminates corrupt, incomplete, or invalid images from the ASAYAR dataset created specifically for Arabic text in traffic panels by using OpenCV to verify each image’s accessibility. In this process, corrupted images are skipped while valid ones are moved to a designated folder, ensuring the integrity of the training data.
Following this, data standardization resizes all images to a uniform resolution of 224 × 224 pixels, which aligns with the input requirements of modern CNN architectures such as ResNet and EfficientNet. By storing these standardized images in a separate folder, the process enhances training stability and minimizes shape-related errors during feature extraction.
Subsequently, annotation handling processes the bounding box annotations provided in Pascal VOC XML format. This involves parsing each XML file to extract and adjust bounding box coordinates to match the standardized image resolution. The processed annotations are then organized and paired with their corresponding images, ensuring that the dataset remains cohesive and reliable for text localization tasks.

Data Processing and Augmentation.
Data augmentation
The data augmentation step illustrated in Algorithm 2 enriches dataset diversity by applying a variety of transformations to images, simulating real-world variations. These transformations include random rotation to emulate different orientations, scaling to introduce scale variance, and adding Gaussian or salt-and-pepper noise to replicate noisy environments. Brightness adjustments simulate varying lighting conditions, while horizontal and vertical flipping mimic mirrored scenarios. These augmentations enhance the dataset, helping the model generalize better and become more robust to unseen data variations, ultimately improving its performance and adaptability in diverse conditions.

Data Augmentation.
Data processing and augmentation
The architecture integrates advanced deep-learning techniques to address Arabic text’s unique challenges. It combines convolutional layers for feature extraction, sequence modeling for context handling, attention mechanisms for focusing on critical regions, and explainability tools for model interpretability.
Feature extraction (CNNs)
Convolutional Neural Networks (CNNs) serve as the backbone for extracting spatial features from images, leveraging their layered architecture to capture essential patterns. Convolutional layers identify features such as edges, textures, and gradients, while pooling layers reduce dimensionality, preserving the most critical information. Pre-trained models like EfficientNet or ResNet, known for their high performance on large datasets, are utilized to extract robust, high-level semantic features. This step ensures the extraction of scale-invariant and meaningful features, providing a solid foundation for subsequent processing stages in the text detection and recognition pipeline.
Temporal dependency modeling (BiLSTM)
To address the cursive and context-dependent nature of Arabic script, the system incorporates Bidirectional Long Short-Term Memory (BiLSTM) networks. Sequential features extracted by CNNs are flattened and input into the BiLSTM, which processes information bidirectionally, capturing dependencies between characters in both forward and backward directions. This mechanism produces contextualized features that account for the unique writing style and script continuity of Arabic, enabling the model to better understand and recognize text patterns inherent to the language. As illustrated in algorithm 3.

Temporal Dependency Modeling using BiLSTM.
Attention mechanism
The attention mechanism enhances the model’s ability to focus on relevant text regions while suppressing background noise. As illustrated in algorithm 4. It dynamically computes attention weights using dense layers, which emphasize critical regions within the feature map. These weights are applied to highlight important text features, improving the model’s localization and recognition capabilities. This targeted focus ensures that the model prioritizes significant areas, leading to enhanced accuracy and overall performance in text detection and recognition tasks.

Attention Mechanism.
Explainability via SHAP analysis
Algorithm 5 introduces the system incorporating SHapley Additive exPlanations (SHAP) to provide transparency and interpret model predictions. SHAP values quantify the contribution of each feature to the prediction, offering a detailed understanding of the model’s decision-making process. These values are visualized as heatmaps, highlighting the importance of specific regions in the image. By revealing how the model arrives at its predictions, this approach enhances trustworthiness and ensures greater transparency, making the system more reliable and interpretable.

Explainability using SHAP Analysis.
To enhance the interpretability of our model, we employed SHAP (SHapley Additive exPlanations) values, a game-theoretic approach that explains the contribution of each input feature to the model’s output. This allows us to understand which features be it specific words, tones, or visual elements were most influential in predicting sarcasm. Additionally, we used attention-weighted feature maps, which are visual representations generated by the attention mechanism in our model. These maps help highlight which parts of the input (e.g., specific frames in a video or words in a sentence) the model focused on most while making its prediction.
Ablation study: CNN backbone comparison
An ablation study is introduced to compare several CNN architectures that are EfficientNet to demonstrate optimal accuracy and computational efficiency. ResNet to Offer robust performance with moderate resource demands and VGG to provides effective feature extraction but with a higher computational cost. The study includes performance metrics (accuracy, IoU) and computational metrics (inference time, model size), clearly highlighting the advantages of each backbone in the context of real-time applications.
Discussion on generalization beyond ASAYAR
The ASAYAR dataset serves as a robust benchmark for evaluating Arabic text detection and recognition on traffic panels. However, real-world applications require models that are adaptable to diverse datasets and conditions. In this section, we elaborate on the potential for generalizing our proposed architecture beyond the ASAYAR dataset and discuss strategies to achieve this.
1. Data Augmentation and Robust Feature Learning:
Diverse Augmentation Techniques that our data augmentation pipeline (rotation, scaling, noise addition, brightness adjustments, and flipping) is designed to simulate a wide range of real-world conditions. These techniques enhance the model’s ability to generalize by exposing it to various distortions and lighting scenarios that may occur in different environments.
Robust Feature Extraction that the CNN backbone, particularly when using EfficientNet, is adept at capturing both local and global features. This robust feature extraction enables the model to recognize text despite variations in font styles, sizes, and backgrounds that may differ in other datasets.
2. Transfer Learning and Fine-Tuning:
Pre-trained Weights for leveraging models pre-trained on large-scale datasets (e.g., ImageNet) allows our network to inherit generalized features that are beneficial across different domains. Fine-tuning these models on ASAYAR helps to specialize the network for Arabic text detection while retaining the capacity to generalize.
Adaptability to New Datasets is the modular design of our architecture to facilitate transfer learning. By fine-tuning the CNN-BiLSTM components on new datasets (e.g., datasets with mixed languages or different types of traffic signs), the model can adapt its learned representations to accommodate additional variations.
Incremental Learning is the techniques such as domain adaptation and incremental learning can be employed to update the model as new data becomes available, ensuring continuous improvement in performance across different scenarios.
3. Application to Multilingual and Multiscript Scenarios:
Extending Beyond Arabic while the current model is optimized for Arabic text, its architecture is inherently adaptable. By incorporating additional language-specific modules or using multilingual pre-trained embeddings, the system can be extended to handle texts in languages with similar or complementary challenges (e.g., Persian, Urdu).
Handling Multilingual Datasets are in regions where traffic panels feature multiple languages, our attention-based approach can be modified to distinguish and recognize multiple scripts simultaneously. This can involve using separate attention heads for different languages or employing a shared backbone with language-specific fine-tuning layers.
4. Evaluation of Diverse Datasets:
Benchmarking Across Environments to validate generalization, future work will include evaluations on additional datasets such as ICDAR, EvArEST, or custom datasets collected from different geographic regions. This benchmarking will help quantify performance drops or improvements when the model is applied to unseen data.
Cross-Domain Performance Metrics for evaluating metrics like IoU, precision, recall, and inference time across various datasets will provide insights into how well the model generalizes. These metrics will also help identify any domain-specific challenges that may require additional preprocessing or architectural adjustments.
5. Challenges and Future Directions:
Variability in Image Quality for generalizing beyond ASAYAR means encountering images with different resolutions, noise levels, and lighting conditions. Ongoing research will focus on enhancing the model’s resilience to these factors through advanced normalization and noise reduction techniques.
Scalability and Real-Time Performance for deployment in diverse environments, it is essential to maintain real-time performance. Future work will explore further optimization of the network architecture and hardware-specific accelerations (e.g., edge computing) to ensure that the system remains efficient when generalized to new datasets.
The strategies outlined above underscore the potential of our attention-based CNN-BiLSTM framework to generalize well beyond the ASAYAR dataset. Through comprehensive data augmentation, transfer learning, modular design, and future benchmarking on diverse datasets, our approach is well-positioned to address the challenges of multilingual and multiscript text detection in varied real-world conditions. This flexibility not only broadens the applicability of our model but also paves the way for further enhancements in robust, real-time text detection systems for autonomous navigation.
Implementation and evaluation
This section details the computational setup, model architecture, training process, dataset, evaluation metrics, statistical analysis, and the implementation of the proposed algorithm.
Computational setup
This section outlines the hardware and software environment used for developing and evaluating the proposed attention-based unified architecture for Arabic text detection and recognition.
Hardware Configuration:
The hardware configuration for the proposed attention-based unified architecture for Arabic text detection and recognition includes an Intel Core i7-9700 K processor running at 3.60 GHz with 8 cores, paired with an NVIDIA GeForce RTX 3080 GPU featuring 10GB of VRAM. The system is further supported by 32 GB of DDR4 RAM, a 1 TB SSD for storage, and operates on Ubuntu 20.04 LTS.
Software Environment:
The software environment is built around Python 3.8 and leverages several frameworks and libraries, including TensorFlow 2.6.0, Keras 2.6.0, and PyTorch 1.10.0 for comparison experiments. Additional libraries such as OpenCV 4.5.3, NumPy 1.21.2, Pandas 1.3.3, Matplotlib 3.4.3, and Scikit-Learn 0.24.2 are used to support various development tasks. The Explainable AI component is managed using SHAP 0.39.0, while XML processing is handled with ElementTree.
Development Tools:
Development tools include Visual Studio Code 1.62 as the integrated development environment (IDE) and Jupyter Notebook for model experimentation and visualization. Version control is maintained using Git 2.34.1. For training larger models and performing hyperparameter tuning, cloud resources were utilized via Google Colab Pro, which provided GPU support through an NVIDIA Tesla T4.
Training Configuration:
The training configuration employs the Adam optimizer with an initial learning rate of 0.001, a batch size of 32, and a total of 100 epochs, incorporating early stopping to prevent overfitting. The loss function used is categorical cross-entropy, and the model’s performance is evaluated using metrics such as Intersection over Union (IoU), accuracy, and the F1-score.
Dataset
The dataset used in this study is the ASAYAR Dataset (Akallouch et al., 2022), which contains Arabic text samples categorized into different types, facilitating both detection and recognition tasks. It consists of images and corresponding annotations, organized into three primary subsets: ASAYAR_SIGN, ASAYAR_TXT, and ASAYAR_SYM.
Table 3 provides a comprehensive overview of the key statistical characteristics of the ASAYAR dataset, which is crucial for understanding its potential and limitations for training and evaluating deep learning models for Arabic text detection and recognition. The dataset comprises approximately 10,000 images, evenly distributed across three categories, ensuring a balanced representation of diverse text types. To facilitate efficient model training, all images are standardized to a uniform resolution of 224 × 224 pixels. The Pascal VOC XML format is employed for image annotations, enabling precise localization and categorization of text regions. Moreover, the dataset exhibits significant variability styles, stroke thicknesses, and symbol shapes, making it well-suited for training robust models capable of handling real-world challenges in Arabic text recognition. Figure 3 presents a sample dataset.

A sample dataset.
Performance metrics
To evaluate the performance of the proposed attention-based unified architecture for Arabic text detection and recognition, a set of key performance metrics is employed. These metrics ensure a comprehensive assessment of the model’s accuracy, robustness, and efficiency in both detection and recognition tasks.
i) Detection Metrics:
These metrics assess the model’s ability to accurately localize and detect Arabic text within an image.
-
Intersection over Union (IoU): Measures the overlap between predicted bounding boxes and ground truth bounding boxes.
$$\:IoU=\frac{Area\:of\:Union}{Area\:of\:Intersection}$$(1)
Threshold: IoU ≥ 0.5 is typically considered a correct detection.
-
Precision: The ratio of correctly predicted positive detections to the total predicted positives.
$$\:Precision=\frac{True\:Positives\:\left(TP\right)}{True\:Positives\:\left(TP\right)+\:False\:Positives\:\left(FP\right)}$$(2)
-
Recall: The ratio of correctly predicted positives to the total actual positives.
$$\:Recall=\frac{True\:Positives\:\left(TP\right)}{True\:Positives\:\left(TP\right)+False\:Negatives\:\left(FN\right)\:}$$(3)
-
F1 Score: The harmonic mean of precision and recall, balancing the two metrics.
$$F1\:Score=2\times\:\frac{Precision\times\:Recall}{Precision+Recall}$$(4)
ii) Recognition Metrics:
These metrics evaluate the model’s accuracy in correctly recognizing the content of Arabic text.
-
Character Error Rate (CER): Measures the percentage of characters that were incorrectly predicted compared to the ground truth.
$$\:CER=\frac{Substitutions+Insertions+Deletions}{Total\:Characters\:in\:Ground}$$(5)
-
Word Error Rate (WER): Evaluates the percentage of words that are incorrectly recognized.
$$\:WER=\frac{Substitutions+Insertions+Deletions}{Total\:Words\:in\:Ground}$$(6)
-
Accuracy: Measures the proportion of correctly recognized characters or words.
$$\:Accuracy=\frac{Correct\:Predictions\:}{Total\:Predictions\:}$$(7)
iii) Computational Metrics:
These metrics measure the computational efficiency and resource usage of the proposed model.
-
Inference Time: The average time taken by the model to process a single image, crucial for real-time applications.
-
Model Size and Complexity: Evaluate the memory footprint and the number of trainable parameters in the model.
By leveraging these metrics, the performance of the proposed architecture is rigorously evaluated to ensure its reliability and effectiveness in real-world applications of Arabic text detection and recognition.
Text detection visualization
Figure 4 illustrates the text detection task on a sample image from the ASAYAR dataset. The image contains multiple text regions, including road signs and traffic indicators, which are accurately detected and enclosed within bounding boxes. This visualization demonstrates the effectiveness of the text detection process in identifying text regions of varying sizes, orientations, and font styles.

Text Detection Visualization.
Model architecture
Table 4 provides a detailed breakdown of the proposed model’s architecture, outlining each layer’s type, output shape, number of parameters, and its specific role in the text detection and recognition process. The model leverages a combination of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) with attention mechanisms to effectively extract features, capture temporal dependencies, and focus on relevant regions of the input images. Specifically, the model utilizes Bidirectional LSTM layers to process the sequence of features in both forward and backward directions, capturing long-range dependencies. The attention mechanism allows the model to weigh the importance of different input features, enabling it to focus on the most relevant information for the task at hand. This attention mechanism helps the model to better handle variations in styles and complex text layouts. The model’s architecture is designed to efficiently handle the challenges posed by Arabic text, such as variations in styles, stroke thickness, and symbol shapes.
Results
Table 5 presents the evaluation metrics obtained for the proposed model on the ASAYAR dataset. The model achieves an impressive Mean Intersection over Union (IoU) of 0.9505, indicating high accuracy in localizing text regions within images. Additionally, the model exhibits perfect precision, recall, and F1-score, demonstrating its ability to correctly identify and classify text instances without any false positives or false negatives. These results highlight the effectiveness of the proposed model in addressing the challenges of Arabic text detection and recognition.
Figure 5 illustrates the attention weights heatmap for the proposed model. The heatmap visualizes how the model focuses on different parts of the input sequence at each time step. The brighter regions in the heatmap indicate higher attention weights, signifying that the model is paying more attention to those specific features. The attention mechanism allows the model to dynamically adjust its focus based on the input sequence, enabling it to better capture relevant information and improve the overall performance.

Attention Weights Heatmap.
Figure 6 showcases the SHAP summary plot for a single prediction from your machine-learning model. It utilizes the SHAP (SHapley Additive exPlanations) framework to explain the contribution of each feature towards the model’s output.

Feature Importance Breakdown for a Single Prediction using SHAP.
A comparative table (Table 1.) has been added to summarize the strengths and limitations of existing methods, including those based on Vision Transformers and our proposed CNN-BiLSTM approach. This table highlights that while Transformer-based models offer impressive performance in multilingual scenarios, our model is particularly well-suited for handling the specific challenges of Arabic script with competitive performance and real-time applicability.
Ablation study and computational efficiency
The primary goal of the ablation study is to systematically evaluate the impact of different CNN backbones on the overall performance and computational efficiency of our attention-based architecture. We compare three popular CNN architectures are EfficientNet, ResNet, and VGG when used as the feature extraction component in our model. All experiments are conducted on the ASAYAR dataset, with images standardized to 224 × 224 pixels. For each CNN backbone, the subsequent BiLSTM and attention mechanism remain unchanged to ensure that any differences in performance or computational cost are solely due to the choice of CNN. Training Parameters are optimizer is Adam with an initial learning rate of 0.001, batch size is 32, Epochs are 100 (with early stopping based on validation loss) and the experiments are run on an Intel Core i7-9700 K system with an NVIDIA GeForce RTX 3080 GPU. We assess each backbone using the following metrics, detection performance such as Mean Intersection over Union (IoU) and Overall recognition accuracy with Computational Efficiency such as Model Size (in Megabytes) and Number of trainable parameters. The performance and efficiency metrics obtained from our experiments are summarized in Table 6 below.
The EfficientNet-based model achieves the highest Mean IoU (0.9505) and overall recognition accuracy (97%), indicating superior feature extraction capabilities for the task of Arabic text detection. ResNet and VGG show slightly lower performance metrics, suggesting that while they are effective, they may not capture the necessary fine-grained features as efficiently as EfficientNet.
EfficientNet demonstrates the lowest inference time (25 ms per image) and smallest model size (45 MB), which is critical for real-time applications such as ADAS. ResNet, although competitive, incurs a moderate increase in inference time (30 ms) and model size. VGG exhibits the highest computational cost with an inference time of 40 ms and a larger model size, making it less suitable for deployment in resource-constrained environments.
Fewer trainable parameters in the EfficientNet model result in reduced memory consumption and faster inference without compromising accuracy. This balance is especially important for systems that need to process data in real time. The ablation study clearly indicates that the EfficientNet backbone offers the best balance between detection performance and computational efficiency. This makes it the preferred choice for our attention-based unified architecture, especially when considering real-world deployment where resource constraints and real-time processing are critical.
Justification for Choosing CNN-BiLSTM with attention mechanism over Pure Transformer Models. While Transformer-based models such as BERT, RoBERTa, and GPT have become dominant in many NLP tasks due to their strong contextual representation capabilities and self-attention mechanisms, we chose CNN-BiLSTM for sarcasm detection in our framework for several critical reasons, especially considering sarcasm’s multimodal, context-sensitive, and temporally dynamic nature.
1. Temporal Sequence Awareness.
Transformer models, while powerful, are relatively less effective at capturing fine-grained temporal dependencies in a sequential structure unless trained extensively on large-scale datasets. In contrast, BiLSTM excels at modeling temporal and sequential relationships, which is crucial for sarcasm that often unfolds over time, especially in multimodal settings like video or speech (e.g., facial cues followed by intonation and then text).
2. Local Feature Extraction with CNN.
Sarcasm often hinges on short bursts of emotionally charged phrases, unexpected shifts in tone, or abrupt visual changes. The CNN layers in our model are efficient at extracting local and discriminative features (e.g., sudden pitch variation, strong facial micro-expressions, or emphasized text phrases), which Transformers tend to overlook without sufficient tuning.
3. Computational Efficiency and Hardware Consideration.
Pure Transformer models are computationally expensive, requiring high-end GPUs or TPUs for efficient training and inference, especially for real-time applications. In contrast, CNN-BiLSTM is lightweight and highly parallelizable, allowing our model to run efficiently on distributed platforms like Apache Storm, making it more suitable for real-time sarcasm detection tasks in production environments.
4. Multimodal Fusion Adaptability.
In our system, we fuse features from text, audio, and visual modalities. The sequential modeling strength of BiLSTM allows smooth integration across time-aligned data from multiple modalities. Transformers, unless explicitly pre-trained on multimodal alignment tasks, may not offer the same fusion flexibility without additional alignment modules.
5. Empirical Performance on Sarcasm Tasks.
Through ablation studies and benchmarking against Transformer-only baselines (like BERT, RoBERTa), our CNN-BiLSTM model consistently outperformed in sarcasm detection accuracy and latency, especially when dealing with short, sarcastic tweets or short video clips that require temporal and emotional context.
Results discussion
The results demonstrate that the proposed attention-based architecture effectively detects and recognizes Arabic text, achieving a high Mean Intersection over Union (IoU) of 0.9505 and an overall recognition accuracy of 97%. These performance metrics indicate the model’s robustness in localizing and interpreting text across diverse text styles and varying image complexities. The high precision (0.953) and recall (0.934) values underscore the system’s accuracy in identifying relevant text regions with minimal false positives and false negatives.
The attention mechanism plays a pivotal role, as evidenced by the heatmaps (Fig. 3), which highlight the model’s ability to focus on critical text features while ignoring irrelevant background information. This capability is particularly beneficial for complex scripts such as Arabic, where characters can vary significantly in shape and size. The SHAP analysis (Fig. 4) further validates the system’s reliability by illustrating the contribution of key features to the model’s predictions, enhancing transparency and interpretability.
Despite these strengths, slight discrepancies between precision and recall suggest that the model occasionally misses challenging text regions, an area for potential improvement through additional data augmentation and fine-tuning. Overall, the system’s high accuracy and explainability make it a promising solution for real-world applications such as document digitization and automated text analysis. Future enhancements could focus on optimizing performance on low-quality or noisy images and extending the model to other scripts and languages.
The experimental results demonstrate that our attention-based CNN-BiLSTM architecture effectively detects and recognizes Arabic text on traffic panels. The integration of SHAP analysis provides interpretability that guides further refinements in the attention mechanism. While Transformer-based models have their merits, our proposed approach achieves competitive performance with lower computational demands, making it ideal for real-time applications such as ADAS and autonomous vehicles. Future research will explore extending the approach to other languages and diverse datasets.
Table 7 explains the comparison of different methods for text-based traffic panel detection. This study combines spatial feature extraction (CNN) with temporal context modeling (BiLSTM), enhanced by an attention mechanism to focus on informative regions in the image. While Attention mechanism allows the model to prioritize relevant regions (e.g., Arabic letters or connected components). BiLSTM captures sequential dependencies, which is essential for Arabic text that varies by context (letter shapes change based on position). More robust to noise, distortions, and curved text due to the hybrid architecture. Achieves state-of-the-art results on the ASAYAR dataset across multiple evaluation metrics. Whereas need more computationally expensive thanYOLO or MobileNet, especially during inference. Requires larger annotated datasets and careful preprocessing (resizing, annotation mapping). Training complexity increases due to multi-module integration (CNN + LSTM + Attention).
This study44 is high-speed and real-time detection, excellent for embedded systems (e.g., cars). End-to-end trainable, no need for separate detection and recognition phases. Strong performance when well-tuned on ASAYAR. But less explainable than attention-based models don’t focus on specific text parts explicitly. Struggles with irregular orientations, curved text, or occlusions without extensive augmentation10. is east performs relatively well on scene-text detection and is good at detecting oriented and multi-scale text regions. Where all three models are not language-aware, meaning they’re trained mostly on English or Latin datasets. CTPN and TextBoxes + + lack context modeling, affecting Arabic script performance (which is highly contextual) and underperform compared to modern deep learning-based unified models.
45 is high classification accuracy suggests strong general performance and easy to deploy in real-time applications. But lack of reported Precision, Recall, F1-Score makes the results less transparent and risk of imbalanced classification4. is an effective in handling sequence-based detection and models long-range dependencies within text lines. But lower precision and recall and based on Chinese dataset not directly transferable to Arabic script without adaptation.
46 is strong generalization to cursive scripts like Persian (close to Arabic). YOLOv3 offers a good balance between speed and performance. But not handle Arabic-specific diacritics and fine-grained features and not evaluated on ASAYAR47. is simple, explainable, and works well in clean, high-resolution environments. And high recall ensures almost no text is missed. But fails on low-resolution or scene text and not well-suited to non-Latin scripts like Arabic. In48 TransNet shows a high degree of accuracy, 0.97, in the Kaggle dataset. This model, with 0.97 Precision and Recall, also achieves the same F1 Score of 0.97, which is a strong indication of its robust performance in maintaining both low false positives and low false negatives.
Conclusion
In conclusion, this paper presents an attention-based unified architecture for Arabic text detection and recognition, specifically designed to address the unique challenges posed by Arabic text in natural scenes, such as traffic panels. The proposed model demonstrates significant improvements in accurately detecting and recognizing Arabic text, achieving high evaluation metrics including a mean Intersection over Union (IoU) of 0.9505 and an overall recognition accuracy of 97%. The attention mechanism plays a crucial role in enhancing the model’s ability to focus on relevant features while minimizing the impact of irrelevant background information, making it particularly effective for complex scripts like Arabic. Furthermore, the model’s robust performance, even in the presence of diverse styles and varying image complexities, highlights its potential for real-world applications, such as automated traffic panel reading, document digitization, and advanced driver assistance systems. Despite the strong results, future work can focus on further improving performance under challenging conditions, such as low-quality images, and expanding the model to handle other languages and scripts. Overall, the proposed approach offers a promising solution for enhancing navigation and safety in autonomous systems through better detection and recognition of Arabic text in natural environments. We have presented an attention-based unified architecture tailored for Arabic text detection and recognition on traffic panels. By combining CNNs, BiLSTM networks, and an attention mechanism with SHAP analysis for explainability, our model achieves state-of-the-art performance on the ASAYAR dataset. The manuscript now includes an expanded literature review with comparisons to Transformer-based models, a detailed ablation study of CNN backbones, explicit research objectives, and enhanced discussions on explainability and generalization. These revisions significantly strengthen the contributions and clarity of our work.
Data availability
Change history
05 November 2025
The original online version of this Article was revised: The original version of this Article omitted an affiliation for author Basma M. Hassan. Their correct affiliations are ‘Faculty of Artificial Intelligence, Kafrelsheikh University, Kafrelsheikh, 33516, Egypt.’ and ‘Al-Farahidi University, Baghdad, Iraq.’ The original Article has been corrected.
References
Lazzeretti, L., Innocenti, N., Nannelli, M. & Oliva, S. The emergence of artificial intelligence in the regional sciences: A literature review. Eur. Plan. Stud.31(7), 1304–1324. https://doi.org/10.1080/09654313.2022.2101880 (2023).
Rawlley, O. & Gupta, S. Artificial intelligence -empowered vision‐based self driver assistance system for internet of autonomous vehicles. Trans. Emerg. Telecommun Technol. 34 (2), e4683. https://doi.org/10.1002/ett.4683 (Feb. 2023).
Li, X., Song, R., Fan, J., Liu, M. & Wang, F. Y. Development and testing of advanced driver assistance systems through scenario-based systems engineering. IEEE Trans. Intell. Veh.8(8), 3968–3973. https://doi.org/10.1109/TIV.2023.3297168 (2023).
Wang, J., Chen, Y., Dong, Z. & Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 35 (10), 7853–7865. https://doi.org/10.1007/s00521-022-08077-5 (Apr. 2023).
Murthy, J. S. et al. ObjectDetect: A Real-Time Object Detection Framework for Advanced Driver Assistant Systems Using YOLOv5, Wirel. Commun. Mob. Comput., vol. pp. 1–10, Jun. 2022, (2022). https://doi.org/10.1155/2022/9444360
Murthy, J. S., Chitlapalli, S. S., Anirudha, U. N. & Subramanya, V. A Real-Time driver assistance system using object detection and tracking. In Advances in Computing and Data Sciences Vol. 1614 (eds Singh, M. et al.) 150–159 (Springer International Publishing, 2022). https://doi.org/10.1007/978-3-031-12641-3_13.
Mahmud, D. et al. Integrating LLMs with ITS: recent advances, potentials, challenges, and future directions. IEEE Trans. Intell. Transp. Syst. 1–36. https://doi.org/10.1109/TITS.2025.3528116 (2025).
Murthy, J. S., Dhanashekar, K., Siddesh, G. M. spsampsps Real-Time, A. Video Surveillance-Based Framework for Early Plant Disease Detection Using Jetson TX1 and Novel LeafNet-104 Algorithm, in Proceedings of 4th International Conference on Frontiers in Computing and Systems, vol. 975, D. K. Kole, S. Roy Chowdhury, S. Basu, D. Plewczynski, and D. Bhattacharjee, Eds., in Lecture Notes in Networks and Systems, vol. 975., Singapore: Springer Nature Singapore, pp. 323–342. (2024). https://doi.org/10.1007/978-981-97-2614-1_23
Chen, C. et al. Edge Intelligence Empowered Vehicle Detection and Image Segmentation for Autonomous Vehicles, IEEE Trans. Intell. Transp. Syst., vol. 24, no. 11, pp. 13023–13034, Nov. (2023). https://doi.org/10.1109/TITS.2022.3232153
Turki, H., Elleuch, M., Othman, K. M. & Kherallah, M. Arabic text detection on traffic panels in natural scenes. Int. Arab. J. Inf. Technol. 21 (4). https://doi.org/10.34028/iajit/21/4/3 (2024).
Lin, H., Yang, P. & Zhang, F. Review of scene text detection and recognition. Arch. Comput. Methods Eng.27(2), 433–454. https://doi.org/10.1007/s11831-019-09315-1 (2020).
Ahmed, S. B., Razzak, M. I. & Yusof, R. Text in a wild and its challenges. In Cursive Script Text Recognition in Natural Scene Images 13–30 (Springer Singapore, 2020). https://doi.org/10.1007/978-981-15-1297-1_2.
Raisi, Z. & Zelek, J. Text Detection & Recognition in the Wild for Robot Localization, arXiv. (2022). https://doi.org/10.48550/ARXIV.2205.08565
Ramesh, M. & Mahesh, K. A Performance Analysis of Pre-trained Neural Network and Design of CNN for Sports Video Classification, in International Conference on Communication and Signal Processing (ICCSP), Chennai, India: IEEE, Jul. 2020, pp. 0213–0216., Chennai, India: IEEE, Jul. 2020, pp. 0213–0216. (2020). https://doi.org/10.1109/ICCSP48568.2020.9182113
Mohammad, S. M. Artificial intelligence in information technology. SSRN Electron. J. https://doi.org/10.2139/ssrn.3625444 (2020).
Nirmala, P., Ramesh, S., Tamilselvi, M., Ramkumar, G. & Anitha, G. An Artificial Intelligence enabled Smart Industrial Automation System based on Internet of Things Assistance, in International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), Chennai, India: IEEE, Jan. 2022, pp. 1–6., Chennai, India: IEEE, Jan. 2022, pp. 1–6. (2022). https://doi.org/10.1109/ACCAI53970.2022.9752651
Zhang, H., Zhao, K., Song, Y. Z. & Guo, J. Text extraction from natural scene image: A survey. Neurocomputing122, 310–323. https://doi.org/10.1016/j.neucom.2013.05.037 (2013).
Szegedy, C. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA: IEEE, Jun. 2015, pp. 1–9. (2015).https://doi.org/10.1109/CVPR.2015.7298594
Kheirinejad, S., Riaihi, N. & Azmi, R. Persian Text Based Traffic sign Detection with Convolutional Neural Network: A New Dataset, in 10th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran: IEEE, Oct. 2020, pp. 060–064., Mashhad, Iran: IEEE, Oct. 2020, pp. 060–064. (2020). https://doi.org/10.1109/ICCKE50421.2020.9303646
Hassan, H., El-Mahdy, A. & Hussein, M. E. Arabic scene text recognition in the deep learning era: Analysis on a novel dataset. IEEE Access.9, 107046–107058. https://doi.org/10.1109/ACCESS.2021.3100717 (2021).
Ahmed, S. B., Naz, S., Razzak, M. I. & Yusof, R. Arabic Cursive Text Recognition from Natural Scene Images, Appl. Sci., vol. 9, no. 2, p. 236, Jan. (2019). https://doi.org/10.3390/app9020236
Tounsi, M., Moalla, I. & Alimi, A. M. ARASTI: A database for Arabic scene text recognition, in 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France: IEEE, Apr. 2017, pp. 140–144., Nancy, France: IEEE, Apr. 2017, pp. 140–144. (2017). https://doi.org/10.1109/ASAR.2017.8067776
Ahmed, S. B., Naz, S., Razzak, M. I. & Yusof, R. B. A novel dataset for English-Arabic scene text recognition (EASTR)-42K and its evaluation using invariant feature extraction on detected extremal regions. IEEE Access. 7, 19801–19820. https://doi.org/10.1109/ACCESS.2019.2895876 (2019).
Albalawi, B. M., Jamal, A. T., Al, L. A., Khuzayem & Alsaedi, O. A. An End-to-End scene text recognition for bilingual text. Big Data Cogn. Comput. 8 (9), 117. https://doi.org/10.3390/bdcc8090117 (Sep. 2024).
Zhai, Y. et al. TextFormer: A Query-based End-to-End text spotter with mixed supervision, (2023). https://doi.org/10.48550/ARXIV.2306.03377
Gaddour, H., Kanoun, S. & Vincent, N. A new method for Arabic text detection in natural scene images. Int. J. Image Graph.23(01), 2350010. https://doi.org/10.1142/S0219467823500109 (2023).
Akallouch, M., Boujemaa, K. S., Bouhoute, A., Fardousse, K. & Berrada, I. ASAYAR: A Dataset for Arabic-Latin Scene Text Localization in Highway Traffic Panels, IEEE Trans. Intell. Transp. Syst., vol. 23, no. 4, pp. 3026–3036, Apr. (2022). https://doi.org/10.1109/TITS.2020.3029451
Liao, M., Shi, B. & Bai, X. TextBoxes++: A Single-Shot Oriented Scene Text Detector, IEEE Trans. Image Process., vol. 27, no. 8, pp. 3676–3690, Aug. (2018). https://doi.org/10.1109/TIP.2018.2825107
Tian, Z., Huang, W., He, T., He, P. & Qiao, Y. Detecting text in natural image with connectionist text proposal network. In Computer Vision – ECCV 2016 Vol. 9912 (eds Leibe, B. et al.) 56–72 (Springer International Publishing, 2016). https://doi.org/10.1007/978-3-319-46484-8_4.
Zhou, X. et al. EAST: An Efficient and Accurate Scene Text Detector,., arXiv. (2017). https://doi.org/10.48550/ARXIV.1704.03155
Moumen, R., Chiheb, R. & Faizi, R. Real-time Arabic scene text detection using fully convolutional neural networks. Int. J. Electr. Comput. Eng. IJECE11(2), 1634–1640. https://doi.org/10.11591/ijece.v11i2.pp1634-1640 (2021).
Boujemaa, K. S., Akallouch, M., Berrada, I., Fardousse, K. & Bouhoute, A. Attica: A dataset for Arabic text-based traffic panels detection. IEEE Access.9, 93937–93947. https://doi.org/10.1109/ACCESS.2021.3092821 (2021).
Alshammari, H., El-Sayed, A. & Elleithy, K. AI-Generated Text Detector for Arabic Language Using Encoder-Based Transformer Architecture, Big Data Cogn. Comput., vol. 8, no. 3, p. 32, Mar. (2024). https://doi.org/10.3390/bdcc8030032
Hossain, M. M. et al. A hybrid attention-based transformer model for Arabic news classification using text embedding and deep learning. IEEE Access.12, 198046–198066. https://doi.org/10.1109/ACCESS.2024.3522061 (2024).
Boukthir, K., Qahtani, A. M., Almutiry, O., Dhahri, H. & Alimi, A. M. Reduced annotation based on deep active learning for Arabic text detection in natural scene images. Pattern Recognit. Lett. 157, 42–48. https://doi.org/10.1016/j.patrec.2022.03.016 (May 2022).
Murthy, J. S. & Siddesh, G. M. A smart video analytical framework for sarcasm detection using novel adaptive fusion network and SarcasNet-99 model. Vis. Comput.40(11), 8085–8097. https://doi.org/10.1007/s00371-023-03224-y (2024).
Murthy, J. S. & Siddesh, G. M. Multimedia video analytics using deep hybrid fusion algorithm. Multimed. Tools Appl.https://doi.org/10.1007/s11042-024-20184-0 (2024).
Murthy, J. S., Matt, S. G., Venkatesh, S. K. H. & Gubbi, K. R. A real-time quantum-conscious multimodal option mining framework using deep learning. IAES Int. J. Artif. Intell. IJ-AI11(3), 1019–1025. https://doi.org/10.11591/ijai.v11.i3.pp1019-1025 (2022).
Murthy, J. S., Shekar, A. C., Bhattacharya, D., Namratha, R. & Sripriya, D. A novel framework for multimodal Twitter sentiment analysis using feature learning. In Advances in Computing and Data Sciences Vol. 1441 (eds Singh, M. et al.) 252–261 (Springer International Publishing, 2021). https://doi.org/10.1007/978-3-030-88244-0_24.
Murthy, J. S. S. G.M., and S. K.G., A Real-Time Twitter Trend Analysis and Visualization Framework:, Int. J. Semantic Web Inf. Syst., vol. 15, no. 2, pp. 1–21, Apr. (2019). https://doi.org/10.4018/IJSWIS.2019040101
Murthy, J. S., Siddesh, G. M. & Srinivasa, K. G. Twitsenti: A real-time Twitter sentiment analysis and visualization framework. J. Inf. Knowl. Manag.18(02), 1950013. https://doi.org/10.1142/S0219649219500138 (2019).
Murthy, J. S., Siddesh, G. M. spsampsps Real-Time, A. Framework for Automatic Sarcasm Detection Using Proposed Tensor-DNN-50 Algorithm, in Proceedings of 4th International Conference on Frontiers in Computing and Systems, vol. 974, D. K. Kole, S. Roy Chowdhury, S. Basu, D. Plewczynski, and D. Bhattacharjee, Eds., in Lecture Notes in Networks and Systems, vol. 974., Singapore: Springer Nature Singapore, pp. 109–124. (2024). https://doi.org/10.1007/978-981-97-2611-0_8
Murthy, J. S., Siddesh, G. M. spsampsps Srinivasa, K. G. A Distributed Framework for Real-Time Twitter Sentiment Analysis and Visualization, in Recent Findings in Intelligent Computing Techniques, vol. 709, P. K. Sa, S. Bakshi, I. K. Hatzilygeroudis, and M. N. Sahoo, Eds., in Advances in Intelligent Systems and Computing, vol. 709., Singapore: Springer Singapore, pp. 55–61. (2018). https://doi.org/10.1007/978-981-10-8633-5_6
Khalid, S. et al. A robust intelligent system for text-based traffic signs detection and recognition in challenging weather conditions. IEEE Access.12, 78261–78274. https://doi.org/10.1109/ACCESS.2024.3401044 (2024).
Shah, S. H. A. & Shah, J. H. Road Scene Text Detection and Recognition Using Machine Learning, in IEEE 20th International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET), Boca Raton, FL, USA: IEEE, Dec. 2023, pp. 1–6., Boca Raton, FL, USA: IEEE, Dec. 2023, pp. 1–6. (2023). https://doi.org/10.1109/HONET59747.2023.10375032
Kheirinejad, S., Riahi, N. & Azmi, R. Text-based traffic panels detection using the Tiny YOLOv3 algorithm. J. Eng. Res. Sci.1(3), 68–80. https://doi.org/10.55708/js0103008 (2022).
Jain, R. & Gianchandani, D. A Hybrid Approach for Detection and Recognition of Traffic Text Sign using MSER and OCR, in 2nd International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC)I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), 2018 2nd International Conference on, Palladam, India: IEEE, Aug. 2018, pp. 775–778., Palladam, India: IEEE, Aug. 2018, pp. 775–778. (2018). https://doi.org/10.1109/I-SMAC.2018.8653761
Hossain, M. M. et al. Transnet: Deep attentional hybrid transformer for Arabic posts classification. IEEE Access.12, 111070–111096. https://doi.org/10.1109/ACCESS.2024.3441323 (2024).
Peng, X., Chen, X. & Liu, C. Real-time traffic sign text detection based on deep learning. IOP Conf. Ser. Mater. Sci. Eng.768(7), 072039. https://doi.org/10.1088/1757-899X/768/7/072039 (2020).
Funding
The authors received no specific funding for this study.
Author information
Authors and Affiliations
Contributions
Basma M. Hassan proposed the article plan, and wrote the paperSamah wrote the proposalFatma the implementation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
There are no ethical conflicts.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hassan, B.M., Gamel, S.A. & Talaat, F.M. Attention based unified architecture for Arabic text detection on traffic panels to advance autonomous navigation in natural scenes. Sci Rep 15, 34138 (2025). https://doi.org/10.1038/s41598-025-04326-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-04326-4
