
Abstract
In recent years, the prevalence of chronic diseases such as Ulcerative Colitis (UC) has increased, bringing a heavy burden to healthcare systems. Traditional Chinese Medicine (TCM) stands out for its cost-effective and efficient treatment modalities, providing unique advantages in healthcare. But syndrome differentiation of UC presents a longstanding challenge in TCM due to its chronic nature and varied manifestations. While existing research has primarily explored machine learning applications for diagnosis and prognosis prediction, the critical issue of explainability in syndrome differentiation remains underexamined. To bridge this gap, we propose an ensemble prediction model enhanced with SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) to improve interpretability and clinical utility. Our study utilizes a dataset of 8078 electronic medical records from Dongfang Hospital, Beijing University of Chinese Medicine, collected between 2006 and 2019. Comprehensive evaluations demonstrate that our ensemble models outperform individual deep learning approaches, with the Gradient Boosting (GB) model achieving 83% F1 in syndrome differentiation. Furthermore, SHAP and LIME reveal key features associated with different syndromes, such as frequent stool in spleen-kidney yang deficiency and lower abdominal coldness in spleen yang deficiency, offering valuable insights for intelligent syndrome differentiation. These findings hold significant promise for advancing TCM-based UC management, enhancing clinical decision-making, and improving patient outcomes.
Similar content being viewed by others
Introduction
Ulcerative colitis (UC) chronic immune-mediated inflammatory disorder of the colon (IBD). The global prevalence of ulcerative colitis (UC) is increasing, leading to significant health care and societal expenses due to its associated morbidity and mortality, with annual incidence rate 1.18/100 000, and the prevalence rate 11.6/100 000 in China1. Studies have estimated that annual direct and indirect costs related to UC range from €12.5 to €29.1 billion in Europe and $8.1 to $14.9 billion in the United States2. Long-term corticosteroid treatment is not well accepted in UC3, highlighting the need to explore alternative treatments like Traditional Chinese Medicine (TCM)4 for UC management. Despite advancements, treating UC remains challenging due to the complexity of TCM interventions.
This research addresses the difficulties faced by inexperienced TCM clinicians in diagnosing syndromes, considering the diverse conditions, symptoms, and disease progressions of UC patients. Our study investigates the use of machine learning techniques to improve syndrome differentiation in UC.
The motivation comes from the ability of machine learning to combine the strengths of multiple models, enhancing predictive accuracy and robustness, particularly useful for sparse datasets and previous research limitations5. Particularly, ensemble learning can outperform individual models by leveraging diverse algorithms and reducing overfitting, making it well-suited for pattern differentiation in UC.
This study aims to establish an interpretable syndrome prediction model based on ensemble learning, improve the accuracy and credibility, and provide support for accurate syndrome identification in TCM clinical practice.
Related work
Machine learning models
Previous studies have utilized not only traditional machine learning methods , such as SVM6, Decision Trees, Regression7 and XGBoost , but also deep learning methods8,9 for Inflammatory Bowel Disease (IBD) prediction on pathological diagnoses, endoscopic image classification and remission prediction, histological scoring and biologics efficacy evaluation.
Interpretability
Methods such as SHAP (SHapley Additive exPlanations)10 and LIME have been applied to visualize feature importance in medical diagnoses prediction, such as tissue morphologies in IBD11.
However, existing research has predominantly focused on the severity and prognosis prediction based on endoscopic images and biomedical indexes, neglecting syndrome differentiation and interpretability in UC, which is crucial in TCM treatment. This study fills this gap by developing models incorporating SHAP and LIME as interpretability methods for syndrome differentiation in UC.
Include recent advancements in machine learning for UC diagnosis and prognosis, such as applying the ANN model to identify crucial risk factors and comorbidities to predict major adverse cardiac and cerebrovascular events (MACCE) in IBD patients (Rahman et al. 2023) and Jin’s model developed by multivariate logistic regression which can assess the extent and severity based on several prevailing classifications, especially for patients who do not tolerate colonoscopy. (Liang et al. 2023).
Despite advances in machine learning for UC diagnosis, the specific challenge of syndrome differentiation in TCM remains underexplored. This study addresses this gap by leveraging ensemble learning combined with SHAP and LIME to enhance interpretability and clinical applicability.
Materials and methods
All methods were performed in accordance with the relevant guidelines and regulations.
Study design
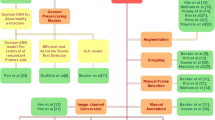
This study is approved by the < IRB of Dongfag Hospital Beijing University of Chincsc Medicinc > This study applies machine learning techniques in a retrospective data mining framework to analyze syndrome differentiation in ulcerative colitis (UC) using Traditional Chinese Medicine (TCM) records. 8,078 electronic medical records (EMRs) from Dongfang Hospital, Beijing University of Chinese Medicine, collected between 2006 and 2019 includes structured and semi-structured clinical variables relevant to Traditional Chinese Medicine (TCM) syndrome differentiation in ulcerative colitis (UC). Given the challenges of TCM diagnosis, we focused on syndrome-related symptoms, tongue and pulse characteristics, and laboratory test results.
The filtering strategy includes:
-
(i)
Patients with other gastrointestinal tumors were excluded.
-
(ii)
Patients with abnormal heart, lung, or hematopoietic functions, as well as those with diseases affecting blood coagulation, were excluded. Additionally, pregnant or lactating women were also excluded (see Fig. 1).

Technique route.
Methods
We have obtained informed consent from all the participants involved in this study. We declare that the research was conducted in accordance with ethical guidelines and that all participants were fully informed about the nature, purpose, and potential risks of the study. Their consent was voluntarily given, and their anonymity and confidentiality were ensured throughout the research process.
Dataset composition and partitioning
This study integrates tongue and pulse information, questionnaire-based symptom data, and medical examination results to comprehensively capture the clinical manifestations of ulcerative colitis (UC). The dataset consists of 8,078 electronic medical records (EMRs) collected from Dongfang Hospital, Beijing University of Chinese Medicine between 2006 and 2019 (shown in Table 1).
To ensure robust model training and evaluation, the dataset was randomly split into Training set (80%,6,469 cases) , Validation set (10%: 808 cases) for hyperparameter tuning, and Independent test set (10%808 cases): for final model evaluation.
Feature extraction and selection
The dataset contains structured medical records with 31 features, symptom-based features (n = 20),endoscopic examination features (n = 4)and demographic & medical history features (n = 7),which are shown in Table 2.
To improve model efficiency, we applied automated feature selection techniques Recursive Feature Elimination (RFE) with Support Vector Machines (SVM) and Least Absolute Shrinkage and Selection Operator (LASSO) to eliminates less relevant features by iteratively training models.
After iterative evaluations, 27 features were retained for model training (Table 2). Features with over 80% missing values were excluded to prevent bias.
Data standardization
To ensure model consistency, symptom descriptions were standardized using expert-defined rules, such as qualitative descriptions (adverbs) have been converted into quantitative values (labels) according to the comments of experts in Chinese medicine practitioners (Table 3). Standardized data helps the model learn patterns more effectively, especially when dealing with subjective or variable descriptions of symptoms.
Word2vec is used to embed tongue image and pulse texts to offer available corpus for computer processing. However, the original records have a large volume of incomplete information for coating and pulse features (7476 out of 8 078 in coating, 7486 out of 8078 in pulse).
Machine learning model development
To classify TCM syndromes, we implemented ensemble and boosting-based ML models, including: Random Forest (RF),Extra Trees (ET),XGBoost (XG),Gradient Boosting (GB),Decision Tree (DT),Stacking Model (meta-learning approach combining multiple classifiers).
To further enhance model performance and ensure robustness, additional hyperparameter tuning was conducted based on the validation set following the initial search. Specifically, cross-validation and GridSearchCV were employed to systematically fine-tune hyperparameters, thereby improving the generalization capability of the models.
Initially, a preliminary hyperparameter search was performed on the training set to identify a set of promising configurations. Subsequently, these hyperparameters were refined using the validation set to determine the optimal combination. For instance, in the Random Forest model, after selecting appropriate values for max_depth and n_estimators, further adjustments were made to min_samples_split and min_samples_leaf to mitigate overfitting.
For boosting-based algorithms, including AdaBoost, XGBoost, and Gradient Boosting, the hyperparameters learning_rate and n_estimators were further optimized on the validation set to achieve an optimal trade-off between model complexity and predictive performance. In XGBoost, additional tuning of gamma and subsample was performed alongside max_depth = 3 to enhance generalization. Similarly, in Gradient Boosting, different values of max_features were explored to optimize feature selection and improve model efficiency.
For the Stacking model, after determining the base classifiers, further optimization was conducted on the final_estimator using the validation set. Various meta-learners, including Logistic Regression, Random Forest, and XGBoost, were tested to identify the most effective aggregation strategy, ultimately improving the overall performance of the stacked model.
Finally, the optimized models were evaluated on the test set to assess the effectiveness of the hyperparameter tuning process. The refinements achieved through validation-based optimization resulted in further improvements in model performance, as detailed in Table 4.
Model evaluation and performance metrics
The optimized models were assessed on the test dataset using metrics such as accuracy (primary metric), Precision, Recall, and F1-score (for class imbalance evaluation) .The XGBoosting (XB) model achieved 82% accuracy, outperforming individual classifiers.
Model interpretability and feature importance analysis
SHAP (SHapley Additive exPlanations): Provides a breakdown of feature importance for model predictions.
LIME12 (Local Interpretable Model-agnostic Explanations): Focuses on local interpretability by approximating the behavior of the black-box model around a specific instance."
The Kendall’s Tau coefficient (τ\tauτ) was used to assess the rank correlation between the feature importance rankings obtained from SHAP and LIME.
Experimental results
Summary of findings
Our ensemble learning models significantly outperformed individual deep learning models, with Gradient Boosting achieving the highest F1 of 83% after feature selection. Key features identified include bloody purulent stool and lower abdominal symptoms, as highlighted by SHAP analysis.
Results with and without feature selection
To present a comprehensive comparison of performance in all algorithms, we put all results together and highlight the difference after feature selection with arrows. (Table 5).
Based on the table, GB outperformed in terms of accuracy, recall, and F1-score. Precision increased in all 7 algorithms after the feature selection. F1-score improved in 6, and recall improved in 5, which indicate that pattern selection is effective except Adaboost.
Class-wise prediction analysis
The details of every class prediction result can be shown in Table 6, which is beneficial to analyze their own performance on different classes.
From Table 6, XGboost achieves the highest performance in accuracy. It is evident that Class 2 exhibits the highest recall and F1-score in most algorithms, especially on Random Forest (RF) ,XGBoost (XG) and Gradient Boost (GB), underscoring the pivotal role of data volume in achieving optimal recall and F1 scores.
Class 3, with the least support cases, consistently underperforms in Random Forest (RF) and Extra Tree (ET) models, particularly in recall and F1 scores, despite high precision in AdaBoost (Ada) and Gradient Boost (GB). This paradox suggests that the distinctive symptom of polyposis, while algorithmically recognizable, is hampered by the class’s limited representation, impeding accurate recall.
Class 5, with 133 instances, paradoxically shows the lowest precision across Stack, Gradient Boost, XG Boost (XG), and Decision Tree (DT), contrasting with Class 1’s lowest precision in Ada. The complexity of symptoms in Class 5, such as acid regurgitation and emotion-linked manifestations, likely contributes to this precision decline.
Conversely, Class 0, despite its small sample size of 92 cases, achieves robust performance in RF, Gradient Boost, ET, and Stack, evidenced by strong recall and F1 scores. This outcome underscores that dataset size is not the exclusive predictor of model efficacy, indicating the potential for high-performing models even with limited data.
Deep learning classifiers
In this study, we have opted for the Transformer Vaswani et al. (2017) , Bidirectional Long Short-Term Memory (BiLSTM) + Attention and graph convolutional network (GCN)13 models as our baseline algorithms due to their proven efficacy in handling sequential data, while GCN has an excellent skill in processing the complex relation between symptoms and syndromes.
By leveraging these three robust architectures, we aim to establish a solid foundation for comparison against more sophisticated models that we will introduce in subsequent sections of this paper. The input of all models is all the symptoms, the output is the differentiation of syndromes. All results are shown in Table 7.
BiLSTM + attention
Performs better on smaller classes like class 1, with a precision of 0.22 and recall of 0.78. This indicates that sequence-based models (such as BiLSTM with attention mechanisms) may have an advantage when dealing with smaller datasets or more complex dependencies in the data, especially for text or sequential information.
Transformer
Has better performance across most classes compared to GCN, with significantly higher precision and recall, especially for class 2. Transformers are known to capture long-range dependencies in data and can process the global context more effectively than GCN, which might explain its better handling of different classes in this case.
GCN
Despite the use of class weights to adjust for imbalanced data, the results indicate that GCN’s performance is heavily skewed by the class distribution. Its poor performance in the minority classes and zero precision in some categories suggest that GCN might not be the most suitable method for handling highly imbalanced datasets where certain classes have fewer samples.
The results suggest that GCN faces challenges when dealing with class imbalance, even when class weights are used. This is likely because GCN models rely heavily on graph structures and local relationships between nodes (samples), and when classes have few samples, these relationships are harder to learn or may not exist in meaningful ways.
In contrast, ensemble learning methods such as Random Forest (RF), Adaptive Boosting (Ada), and eXtreme Gradient Boosting (XG), among others, exhibit significantly higher precision scores, especially on sparse data and classification with distinct features (class 3), surpassing baseline models. The ensemble methods’ superior performance underscores the potential benefits of combining multiple models to enhance predictive accuracy.
Interpretability analysis
While ensemble learning algorithms have demonstrated superior performance in syndrome prediction compared to pure deep learning approaches, their inherent robustness still underprivileged in interpretability, which is crucial for the credibility of syndrome prediction models in clinical decision support scenes.
To address this limitation, our study incorporates two distinct algorithms SHAP and LIME aimed at elucidating the internal mechanisms driving the predictions, thereby enhancing both the transparency and interpretability of our analytical framework.
Interpretation of SHAP in ensemble learning
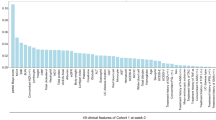
The use of SHAP allows us to understand the importance of each feature in our model’s predictions, which can not only help us understand the procedure of the models but also give us some instruction and inspiration in different syndromes identifications. The results can be shown in Fig. 2 and Table 8.

SHAP of ET, RF, GB, XG.
Overview of SHAP in ensemble learning
The SHAP analysis across various algorithms consistently highlights key features in syndrome prediction. For instance, in the Extra Tree (ET) model, the top 5 features include bloody purulent stool, lower abdominal distension/pain, stool frequency, dry stool, and lower abdomen cold, which are particularly vital in distinguishing between different syndromes, such as spleen-yang deficiency and damp-heat stasis syndrome.
Similarly, in the Random Forest (RF) model, lower abdominal distension/pain and stool frequency emerge as critical features, indicating underlying conditions like spleen-yang deficiency. Notably, dry stool shows high importance in class 4, which is a specific symptom manifested in the phlegm-heat stasis block and bowel qi failure syndrome.
Red tongue is identified as a chief factor in distinguishing certain syndromes in the XGboost (XG) and Gradient Boost (GB) model, underscoring the importance of tongue examination in diagnosis, even in a sparse data format.
In addition, factors such as emotional triggers and increased intestinal motility emerge as significant features in certain syndromes in GB model.
Across various algorithms, certain features consistently appear as crucial predictors in specific syndromes, such as stool frequency to class 0 , bloody purulent stool to classes 1 and 2, highlighting their significance in differentiating this syndrome regardless of algorithms.
In order to clearly show the top ten most important features of different algorithm models, Table 8 organized.
In this study, the top 10 SHAP values for each algorithm have been meticulously documented and listed, revealing a consistent important pattern across all employed models. Notably, the top seven features (underlined in Table 8) have emerged as pivotal in the classification process, regardless of algorithms.
In this study, the top 10 SHAP values for each algorithm have been meticulously documented and listed, revealing a consistent important pattern across all employed models. Notably, the top seven features (underlined in Table 8) have emerged as pivotal in the classification process, regardless of algorithms.
Furthermore, the feature ‘Fart’ is observed to be a recurring contributor in ET and RF models, while ‘Tongue’ is a significant factor in both the RF and XG models. Interestingly, ‘Unformed stool’ stands out as the sole feature that does not manifest in the RF model, suggesting a potential divergence in the algorithm’s sensitivity to this symptom.
In summary, the SHAP analysis, particularly for GB model, offers profound insights into the significance of specific features in syndrome differentiation. The analysis highlights the relevance of tongue appearance, characteristics of stool, and emotional factors, which are instrumental in the accurate classification of syndromes. These findings underscore the utility of SHAP in enhancing our understanding of model decision-making and in identifying the most informative features for TCM clinical decision support system.
SHAP value prediction in GB
To provide an example explanation specifically, we discuss the top 5 features for each class with the SHAP figure of GB.
In Class 0, the frequent occurrence of stools, particularly when exceeding 6 times per day, is indicative of compromised Spleen and Kidney Yang, a diagnosis highly probable according to Dr. Li’s clinical experience.
For Class 1, the quintessential features are lower abdomen cold, bloody purulent stool, lower abdominal distension/pain, stool frequency, and tenesmus. Lower abdomen cold is a prevalent symptom in Spleen-Yang deficiency syndrome, while the presence of bloody purulent stool, particularly when purulent, often signals Yang deficiency. Tenesmus, characterized by a sensation of incomplete bowel evacuation, is a hallmark symptom of UC and is also prominent in this syndrome.
Key symptoms of class 2 are indicative of a prevalent syndrome observed during the remission phase of Ulcerative Colitis (UC), associated with Spleen deficiency and damp-heat stagnation. Notably, dry stools, which are a hallmark of phlegm-heat stasis block and bowel qi failure syndrome, are identified as a significant predictor. This highlights the clinical relevance of stool characteristics in diagnosing UC. The disease’s influence is multifaceted, impacting not only stool consistency but also intestinal functionality and presenting with a range of symptoms. Class 3 is predominantly defined by polyposis as the paramount symptom, a critical finding in colonoscopy and indispensable for accurate syndrome differentiation. The red tongue, the second most influential feature, has been correlated with polyposis in recent research14, underscoring the interplay between tongue symptoms and polyposis.
In Class 4, dry stool reigns as a classic indicator of phlegm-heat stasis block and bowel qi failure syndrome. Bowel qi failure, indicative of weakened intestinal peristalsis, is a key contributor to the occurrence of dry stools.
Class 5 is marked by frequent flatulence and emotional factors as the most prevalent symptoms. Emotional perturbations can disrupt the flow of intestinal qi, leading to increased flatulence, upper abdominal distension, borborygmus and acid regurgitation.
The analysis of these cardinal symptoms for each syndrome class furnishes profound insights for learners of TCM and aids in the algorithmic comprehension., providing a roadmap and inspiration for the identification of distinct syndromes based on characteristic symptom patterns.
Interpretation of LIME in ensemble learning
LIME is focusing on local interpretable representation, which may excel in the single sample prediction explanation, expressing the positive and negative factors.
In order to more clearly understand the prediction of the model for each class, this study randomly selected a sample (correctly predicted) from each syndrome to draw the feature graph importance of LIME.
Overview of LIME explanations
Stool frequency emerges as a universally significant feature across all models (Extra Trees, Random Forest, XGBoost), underscoring its diagnostic relevance in TCM syndrome classification, particularly for yang deficiency and ulcerative colitis-related patterns.
Tongue characteristics (XGBoost) and lower abdominal cold (Random Forest, Gradient Boosting) align with TCM principles, aligning with SHAP results and TCM’s emphasis on tongue diagnosis.
Polyposis appears as a recurring predictor (Extra Trees, Random Forest, Gradient Boosting), though its theoretical linkage outside phlegm-heat stasis syndromes remains debated.
LIME for extra tree
Top 4 patterns looks like SHAP in Fig. 3, in which lower abdominal distension/pain is the most outstanding pattern in negative one. Frequence of stool is also the top 2 or 3 feature in all syndrome classification. Upper abdominal distension, as the second or third negative factor in all classes, which is also the main manifestation of spleen deficiency in UC, throughout the whole course.

LIME for extra tree.
Furthermore, polyposis in class3, dry stool in class 4, upper abdominal distension/pain, and fart often in class 5 are positive factors in prediction of each syndrome. In class 0, the presence of dry stools, often overlooked in the context of kidney deficiency patterns, is noteworthy. The underlying pathology is attributed to insufficient kidney yang, which fails to promote bowel movement effectively.
LIME for RF
Frequence of stool lists on top 2 patterns in class 0, 1, 2, which is considered the most important index to judge the severity and assess the syndrome type, especially on yang deficiency patterns(shown in Fig. 4). Lower abdomen cold in kidney yang deficiency pattern(class0), polyposis in phlegm-heat stasis (class4) ,belching in spleen deficiency and qi stagnation class 5),, which are completely in line with the rules of traditional Chinese medicine.

LIME for RF.
LIME for XG
Tongue ,frequence of stool and bloody purulent stool list the top three in all class samples(shown in Fig. 5), which exhibits a degree of homogeneity, indicating that the explanations provided by LIME are based on local data points and may not fully capture the model’s behavior on the overall dataset.

LIME for XG.
Noticeably, tongue as the most important positive feature is different from other algorithms, but the same to important pattern in XG with SHAP ,which may show a sensitivity in this feature.
Acid regurgitation shows a high negative effect in class 0, 1, 2, 4, and 5, indicated decreasing the likelihood of the instance being classified into the predicted class, which is explainable in class 0, 1, 2, 4, but confused in class 5, because acid regurgitation is a very significant symptom in spleen deficiency and qi stagnation pattern. In the training data set, the proportion of acid regurgitation in class5 is 13.39%, which is far higher than the overall 4.7%. However, the prediction accuracy of XG in class5 is the lowest, only 68% (Table 6). The algorithm’s low predictive accuracy stems from its failure to accurately capture the syndrome’s key features. In addition to the reason of small sample size, the model itself still needs to be improved.
LIME for GB
Figure 6 demonstrates that lower abdominal cold is listed as a negative factor five times across classes 0, 2, 3, 4, and 5, and is sensible in classes 2, 3, 4, and 5. However, it is inconsistent in the context of spleen-kidney yang deficiency syndrome. Interestingly, lower abdominal cold is highly significant in spleen-yang deficiency, which is crucial for syndrome differentiation. Similarly, borborygmus is notable in class 5, and polyposis is significant in class 4.

LIME for GB.
Polyposis are ranked in the top three positions in several samples (class 0,1,2,4,5), and all of them are positive factors. In addition to phlegm-heat stasis syndromes (class3,4), the others actually lack the support of traditional Chinese medicine theory. The possible reason is that the sample size is too small, or it is related to the characteristics of LIME itself.
Interpretation of Kendall’s Tau results
The Kendall’s Tau coefficient (τ\tauτ) was used to assess the rank correlation between the feature importance rankings obtained from SHAP and LIME in XGboost. Global Feature Ranking Consistency can be shown in Fig. 7.

Global feature ranking consistency.
As illustrated in Fig. 7 a scatter plot illustrating the global feature ranking consistency between SHAP and LIME, with a Kendall’s Tau coefficient of − 0.15. The negative Tau value indicates a weak negative correlation between the feature importance rankings assigned by the two methods. This suggests that SHAP and LIME yield notably different feature importance rankings, potentially due to differences in their underlying assumptions and interpretability approaches.
Figure 7 presents a scatter plot illustrating the global feature ranking consistency between SHAP and LIME, with a Kendall’s Tau coefficient of − 0.15. The negative Tau value indicates a weak negative correlation between the feature importance rankings assigned by the two methods. This suggests that SHAP and LIME yield notably different feature importance rankings, potentially due to differences in their underlying assumptions and interpretability approaches.
The scattered nature of the points around the red dashed line (indicating perfect agreement) further highlights the inconsistency in feature rankings. Several features exhibit significant ranking discrepancies, as reflected by the large vertical deviations from the diagonal. Such discrepancies may stem from LIME’s local approximation method, which can introduce variance across different samples, whereas SHAP provides a more globally consistent measure of feature importance by considering coalitional game theory principles.
The observed Kendall’s Tau of − 0.15 and the corresponding p-value of 0.30 suggest that the ranking disagreement is not statistically significant at conventional thresholds. However, the divergence in feature rankings warrants further investigation, particularly in scenarios where model explainability is critical. Future work may explore methods to align local and global interpretability metrics or leverage ensemble explainability techniques to mitigate inconsistencies.
Comparison of the two post-interpretation methods
As the comparative analysis of data and Chinese medicine theory above, SHAP has a better distinction degree especially in class 3, 4, and 5 classifications according to Table 9, while LIME shows indecipherable in some important feature representations that can not be explained by the Chinese medicine theory.
In addition, we can catch the importance of the top 20 features through SHAP, while 10 features in LIME. Furthermore, the bar graph can show the difference between different feature volumes, which can offer a more perspective and overall understanding.
Discussion
In this study, we employed SHAP analysis to systematically evaluate feature importance across multiple ensemble learning models for syndrome differentiation in Traditional Chinese Medicine (TCM), with results highlighting stool characteristics, lower abdominal distension/pain, and tongue appearance as critical diagnostic indicators. These findings align with TCM principles and prior research, reinforcing their clinical relevance for syndrome classification, particularly in yang deficiency and ulcerative colitis-related patterns15. In addition ,stool characteristics in this article means increased stool frequency and loose stool ,which contrasts with James16, who prioritized proximal constipation over diarrhea in ulcerative colitis.
The results demonstrated that certain features, such as stool characteristics, lower abdominal distension/pain, and tongue appearance, consistently emerged as pivotal indicators across different models, reinforcing their clinical relevance in syndrome classification. Notably, stool frequency emerged as a universally significant feature across all models (Extra Trees, Random Forest, XGBoost), underscoring its diagnostic relevance in TCM syndrome classification, particularly for yang deficiency and ulcerative colitis-related patterns. Additionally, tongue characteristics (XGBoost) and lower abdominal cold (Random Forest, Gradient Boosting) align with TCM principles, aligning with SHAP results and TCM’s emphasis on tongue diagnosis. Furthermore, polyposis appeared as a recurring predictor (Extra Trees, Random Forest, Gradient Boosting), though its theoretical linkage outside phlegm-heat stasis syndromes remains debated.
SHAP analysis also revealed that features like emotional triggers and increased intestinal motility played a significant role in the Gradient Boosting (GB) model, highlighting the importance of holistic symptom consideration in TCM diagnosis, which verifies the fact that patients with IBD often also exhibit extraintestinal manifestations (EIM)17
Our findings align with previous research highlighting the importance of stool characteristics and tongue appearance18 in TCM-based syndrome differentiation. The tongue’s coating, color, and shape are central to TCM diagnostics, where they are used to assess the condition of the internal organs, particularly the stomach and spleen (Li et al. 2025).
Interestingly, polyposis appeared as a recurring predictor across Extra Trees, Random Forest, and Gradient Boosting models. While its association with phlegm-heat stasis syndrome in TCM is well recognized, its theoretical linkage to other syndromes remains debated (Huang and Sun 2022). Future studies may further clarify this connection and its clinical relevance for early detection and syndrome classification in gastrointestinal diseases.
Moreover, the identification of emotional triggers and increased intestinal motility in the Gradient Boosting model emphasizes the holistic nature of TCM. Emotional factors are known to affect the spleen and liver in TCM, and their impact on gastrointestinal health is well-documented in clinical practice19. Increased intestinal motility, often linked to excess heat or yang, further emphasizes the role of both psychological and physiological factors in TCM diagnosis.
Prior studies have emphasized the role of machine learning in diagnosing TCM syndromes, but our integration of SHAP and LIME enhances interpretability and clinical usability. Notably, similar research has applied SHAP for identifying cardiovascular risk factors20, demonstrating its broad applicability.
To enhance model interpretability and reliability, we developed an ensemble syndrome differentiation framework integrating SHAP and LIME. While ensemble learning methods such as XGBoost21 and Random Forest have demonstrated strong predictive performance in disease diagnosis and risk stratification, their opacity remains a challenge in clinical applications. The incorporation of SHAP improved model transparency by quantifying global feature contributions, while LIME provided localized interpretability, offering complementary insights into model decision-making. LIME as a granular case-specific interpretability aids in validating diagnostic reasoning and enhances clinician trust in AI-assisted TCM syndrome differentiation. The dual-framework approach of combining SHAP’s systemic insights with LIME’s localized explanations enhances both the precision and trustworthiness of AI-driven diagnostic systems (Ribeiro et al., 2016).
While SHAP and LIME are widely advocated for demystifying model outputs—such as risk score nomograms22 and neural network-based predictors23—their synergistic use remains underexplored. Experts24 emphasize that combining SHAP’s global feature importance rankings with LIME’s granular, case-specific reasoning can yield complementary perspectives. This dual framework not only clarifies systemic model behavior but also contextualizes individual predictions, as exemplified in “Comparison of the two post-interpretation methods” section of our analysis.
Despite these advancements, our study has several limitations. First, the dataset was derived from 6462 medical records of ulcerative colitis treatments at Dongfang Hospital between 2006 and 2020. Although the sample size is relatively large, data sparsity and an imbalanced distribution of syndrome types may impact the model’s ability to generalize to unseen cases. Second, the manual effort required for feature extraction may reduce efficiency and scalability. Additionally, the observed discordance between SHAP and LIME rankings (τ = − 0.15) suggests methodological differences in feature importance quantification, with SHAP focusing on global contributions and LIME on local approximations.
Future research should explore techniques to mitigate data sparsity and imbalance while developing automated, data-driven approaches for feature engineering to enhance model robustness. Moreover, the integration of inherently interpretable models and human-centric interpretability frameworks could further improve the clinical applicability and explanatory power of AI-driven syndrome differentiation systems. These advancements will be essential in promoting the adoption of AI-based diagnostic tools in TCM and broader medical domains.
Conclusion
This study unequivocally demonstrates that ensemble learning algorithms outperform deep learning techniques, such as Transformer , BiLSTM and GCN, in the complex task of syndrome differentiation, underscoring the superior diagnostic capabilities of ensemble methods in intricate medical assessments. The integration of interpretability tools like SHAP and LIME further enhances the practicality and clinical credibility of these algorithms. By providing a comprehensive understanding of both the model’s predictions and the reasoning behind them, these tools help build clinician trust and facilitate the adoption of algorithmic recommendations in clinical practice.
Notably, the feature importance analysis using SHAP reveals key discriminative factors for syndrome differentiation: stool frequency in spleen-kidney yang deficiency (class 0), lower abdomen coldness in spleen yang deficiency (class 1), polyposis in phlegm-heat stasis (classes 3 and 4), and frequent flatulence and emotion-induced symptoms in spleen deficiency with qi stagnation (class 5). Notably, both SHAP and LIME consistently identified tongue features as the most influential positive predictor in the XGBoost model, suggesting high sensitivity and clinical relevance of this parameter.These findings not only contribute to the interpretability of the model but also hold significant implications for Chinese medicine education, clinical practice, and the development of intelligent Traditional Chinese Medicine (TCM) decision-support systems.
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request. All data generated or analyzed during this study are included in this published article and its supplementary information files.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Li, X. et al. The disease burden and clinical characteristics of inflammatory bowel disease in the Chinese population: A systematic review and meta-analysis. Int. J. Environ. Res. Public Health 14(3), 238 (2017).
Cohen, R. D. et al. Systematic review: The costs of ulcerative colitisin Western countries. Aliment. Pharmacol. Ther. 31, 693–707 (2010).
Kaur, R., Gulati, M. & Singh, S. K. Role of synbiotics in polysaccharide assisted colon targeted microspheres of mesalamine for the treatment of ulcerative colitis. Int. J. Biol. Macromol. 95, 438–450 (2017).
Shen, Z. et al. Traditional Chinese medicine for mild-to-moderate ulcerative colitis: Protocol for a network meta-analysis of randomized controlled trials. Medicine 98(33), e16881 (2019).
Ling, Z. et al. Research on ulcerative colitis syndrome prediction model based on convolutional neural network. China Digit. Med. 17(04), 49–55 (2012).
Dyer, E. et al. P264 Machine learning can accurately predict development of inflammatory bowel disease. J. Crohn’s Colitis 17(Supplement_1), i412–i414 (2023).
Chen, J. et al. Using supervised machine learning approach to predict treatment outcomes of vedolizumab in ulcerative colitis patients. J. Biopharm. Stat. 32(2), 330–345 (2022).
Turan, M. & Durmus, F. UC-NfNet: deep learning-enabled assessment of ulcerative colitis from colonoscopy images. Med. Image Anal. 82, 102587 (2022).
Luo, X. et al. Diagnosis of ulcerative colitis from endoscopic images based on deep learning. Biomed. Signal Process. Control 73, 103443 (2022).
Shapley, L. S. A value for n-person games 307–317 (1953).
Mokhtari, R., Hamidinekoo, A., Sutton, D. et al. Interpretable histopathology-based prediction of disease relevant features in Inflammatory Bowel Disease biopsies using weakly-supervised deep learning. arXiv preprint arXiv:2303.12095 (2023).
Ribeiro, M. T., Singh, S., Guestrin, C. Model-agnostic interpretability of machine learning. arXiv preprint arXiv:1606.05386 (2016).
Kipfand, T. N. & Welling, M. Semi-supervised classification with graph convolutional networks. in Proc. Int. Conf. Learn. Representations 1–10 (Toulon, France, 2017).
Liu, S. et al. The relationship between abnormal tongue features and non-malignant upper gastrointestinal disorders: A hospital-based cross-sectional study. Eur. J. Integr. Med. 47, 101379 (2021).
Song, Y. & Wang, H. A study on the treatment of ulcerative colitis of spleen and kidney yang deficiency type with modified Shao Yao Tang and Moxibustion J/OL. Liaoning J. Tradit. Chin. Med. 1–7 (2025).
James, S. L. et al. Characterization of ulcerative colitis-associated constipation syndrome (proximal constipation). JGH Open 2(5), 217–222 (2018).
Yangyang, R. Y. & Rodriguez, J. R. Clinical presentation of Crohn’s, ulcerative colitis, and indeterminate colitis: Symptoms, extraintestinal manifestations, and disease phenotypes[C]//Seminars in pediatric surgery. WB Saunders 26(6), 349–355 (2017).
Chenye, F. et al. Study on tongue image of ulcerative colitis patients with different syndromes based on image data processing. Chin. J. Integr. Tradit. West Med. Dig. 29(6), 406–410 (2021).
Chung, Y. K., Chen, J. & Ko, K. M. Spleen function and anxiety in Chinese medicine: a western medicine perspective. Chin. Med. 7(03), 110 (2016).
Sushmitha, G. L. N. D. & Utukuru, S. Age-based disease prediction and health monitoring: integrating explainable AI and deep learning techniques. Iran. J. Comput. Sci. https://doi.org/10.1007/s42044-024-00223-7 (2025).
Li, X. et al. Predictive models for endoscopic disease activity in patients with ulcerative colitis: practical machine learning-based modeling and interpretation. Front. Med. 9, 1043412 (2022).
Bu, Z. J. et al. Development and multiple visualization methods for the therapeutic effects prediction model of five-flavor Sophora Flavescens enteric-coated capsules in the treatment of active ulcerative colitis: A study on model development and result visualization. Eur. J. Integr. Med. 63, 102297 (2023).
Bhandari, M. et al. Exploring the capabilities of a lightweight CNN model in accurately identifying renal abnormalities: Cysts, stones, and tumors, using LIME and SHAP[J]. Appl. Sci. 13(5), 3125 (2023).
Kalusivalingam, A. K., Sharma, A., Patel, N. et al. Leveraging SHAP and LIME for enhanced explainability in AI-driven diagnostic systems. Int. J. AI ML 2(3) (2021).
Funding
The work is supported by grants from CACMS Innovation Fund CI2021A00510.
Author information
Authors and Affiliations
Contributions
L.Z.: Dr. Zhu played a pivotal role in conceptualizing the study, overseeing the project, and contributing to the interpretation of the ensemble learning models. She also provided critical insights into the application of these models within the context of ulcerative colitis syndrome. S.H.: S.H. was instrumental in preprocessing stages of the research. He was also responsible for the initial drafting of the manuscript and coordinating the revisions among the co-authors. W.Z.: W.Z. contributed significantly to the development and implementation of the ensemble learning models. She was also involved in the data collection and standardization. Y.T.: She is contributed to the data normalization of the study and the critical review of the manuscript. F.Y.: F.Y. played a key role in the design and writing of the project, ensuring that the predictive models were implemented efficiently. All authors have read and approved the final manuscript and agree with the submission to the journal.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhu, L., He, S., Zheng, W. et al. Predictive model of ulcerative colitis syndrome with ensemble learning and interpretability methods. Sci Rep 15, 21985 (2025). https://doi.org/10.1038/s41598-025-04824-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-04824-5
