
Abstract
Steel defect detection is a crucial aspect of steel production and quality control. Therefore, focusing on small-scale defects in complex production environments remains a critical challenge. To address this issue, we propose an innovative perception-efficient network designed for the fast and accurate detection of multi-scale surface defects. First, we introduce the Defect Capture Path Aggregation Network, which enhances the feature fusion network’s ability to learn multi-scale representations. Second, we design a Perception-Efficient Head (PEHead) to effectively mitigate local aliasing issues, thereby reducing the occurrence of missed detections. Finally, we propose the Receptive Field Extension Module (RFEM) to strengthen the backbone network’s ability to capture global features and address extreme aspect ratio variations. These three modules can be seamlessly integrated into the YOLO framework. The proposed method is evaluated on three public steel defect datasets: NEU-DET, GC10-DET, and Severstal. Compared to the original YOLOv8n model, PEYOLO achieves mAP50 improvements of 3.5%, 9.1%, and 3.3% on these datasets, respectively. While maintaining similar detection accuracy, PEYOLO retains a high inference speed, making it suitable for real-time applications. Experimental results demonstrate that the proposed PEYOLO can be effectively applied to real-time steel defect detection.
Similar content being viewed by others

Introduction
Steel materials are widely used in various fields, including construction, bridges, automobiles, aerospace, and energy. Its quality directly impacts production efficiency. During the manufacturing process, various surface defects may occur in steel products, such as cracks, inclusions, scratches, and corrosion1. These defects not only affect the performance of the products but may also pose potential threats to the quality and safety of downstream products. As an indispensable part of steel production, defect detection plays a crucial role in improving product quality, enhancing production efficiency, and ensuring product safety.
Fast and accurate defect detection faces multiple challenges. First, as shown in Fig. 1, steel surface defects are diverse and complex, and different types of defects may coexist on the same product, increasing the difficulty of detection. Second, the steel production environment often involves uneven lighting, background noise interference, and steel plate vibrations, all of which can affect the performance of defect detection equipment. If defects on steel surfaces are not detected and addressed in a timely manner, they may lead to reprocessing or even scrapping of entire batches of products as the manufacturing process progresses.

The NEU-DET dataset includes six types of defects.
Steel surface defect detection can be broadly categorized into three approaches: manual inspection, machine vision-based detection, and deep learning-based detection. The accuracy of manual visual inspection is highly dependent on the experience and vision of the inspectors, making it inefficient. Although traditional machine vision-based detection methods improve inspection efficiency, manually extracting defect features and designing corresponding algorithms significantly increase the workload2,3. Additionally, non-end-to-end learning approaches may lead to error accumulation. Recently, deep learning has achieved remarkable success in various fields. Deep learning-based object detection methods have demonstrated advantages in real-time performance and accuracy for surface defect detection across different industrial products. Traditional CNN-based detectors, such as Faster R-CNN, Single Shot MultiBox Detector (SSD), Fully Convolutional One-Stage Object Detection (FCOS), Efficient Detection (EfficientDet), and You Only Look Once (YOLO)4,5,6,7,8,9,10,11,12,13, play a crucial role in capturing fine-grained features. However, the inductive bias of convolution restricts non-local feature extraction14, limiting the detector’s ability to obtain global semantic information of defects. Transformer-based detectors, such as DEtection TRansformer (DETR) and Real-Time Detection Transformer (RT-DETR), are able to model long-range dependencies in local features, thus addressing the issue of insufficient visual features for defects15,16. However, the dot-product operations in Vision Transformer (ViT) lead to high memory consumption17, restricting its widespread deployment on resource-limited platforms. Mamba-based detectors, such as Mamba-YOLO, through their unique architectural design, significantly enhance the detector’s capability to capture both local and global features while being more computationally efficient18. Existing studies have shown that large-kernel attention can significantly increase the receptive field of detectors, and detectors with larger receptive fields can more effectively model the global features of foreground objects19. We consider whether it is possible to retain the detailed feature perception and low memory consumption of YOLO models while expanding their receptive field to achieve global modeling capabilities similar to ViT or Mamba architectures. Multi-branch components can aggregate diverse gradient flows, facilitating the model’s learning of multi-scale features20. Based on these findings, we design a receptive field extension module to enhance the backbone network’s ability to perceive global features, enabling the detector to accurately focus on steel defects in complex background noise. The feature fusion network can combine and correlate global features and fine-grained features from different levels21,22. However, compared to objects in natural scenes, the visual features of steel defects are limited and small in scale. During the forward propagation process, the detailed features of defects gradually fade, leading to a widening semantic gap between features at different levels. Specifically, feature maps from the high levels of the backbone network must undergo several upsampling and downsampling operations before being passed to the high levels of the Path Aggregation Network (PAN), which amplifies the impact of information bottlenecks23. Therefore, we design an advanced semantic fusion module and embed it in the upper layers of the PAN, forming the defect capture path aggregation network. DcPAN can fully aggregate multi-scale features, reducing the semantic gap between different levels and solving the multi-scale defect problem. In practical production, due to lighting and manufacturing process factors, defects on the steel surface are often obscured by shadows or other defects, resulting in incomplete defect features. To tackle this problem, we propose a perception-efficient head to solve problems related to local aliasing and shadow occlusion. Additionally, the three magnetic heads of PEHead enhance the detector’s robustness to multi-scale defects.
In conclusion, the main contributions of this paper are summarized as follows:
-
(1)
A perception-efficient detection head is proposed, which boosts the detector’s robustness to multi-scale objects and addresses the issue of local aliasing between defects.
-
(2)
A receptive field extension module is proposed, which boosts the backbone’s capability to extract global features and improves the detector’s accuracy in detecting defects with extreme aspect ratios.
-
(3)
An advanced semantic fusion module is proposed to optimize the existing PAN, leading to the introduction of a defect capture path aggregation network. This method reduces the semantic gap between different levels and enhances the detector’s sensitivity to multi-scale information.
The structure of the subsequent section of the paper is as described below: Section II outlines the related work on tiny defect detection, multi-scale feature extraction and background noise removal for industrial defect images. Section III describes the proposed PEYOLO and its associated improvement strategies. Section IV details the implementation process and presents an analysis of the experimental results. Section V concludes with a summary and suggests possible avenues for future research.
Related work
Defect detection is a key research focus in the field of target detection. In this paper, we will review the related work from three perspectives: tiny defect detection, multi-scale feature extraction, and background noise removal.
Tiny defect detection
The small scale of defects is one of the challenges in defect detection. Existing research has proposed several effective methods to improve the detection performance of small defects, but certain limitations still exist. The first approach is to expand the receptive field of the detector to extract global defect features more comprehensively. For example, Zhou et al.24 employed the ASPP module to extend the receptive field of the feature extraction network, enabling the model to extract defect information more effectively within an appropriate receptive field. However, this method may introduce irrelevant information in complex backgrounds, reducing detection accuracy. The second approach is to minimize the loss of detailed features, which helps to more accurately retain information about small defects. Yu et al.25 proposed a multi-dimensional data feature fusion method to adaptively focus on local features. Liu et al.26 introduced the MPFF module, which preserves more small defect features as the network deepens. Yuan et al.27 optimized the detection head adaptively for enhancing the recognition capability of small detection heads for tiny defects. Wu et al.28 optimized the upsampling module by introducing the CARAFE component, which enhanced the detector’s ability to retain small defect features. However, these methods still rely on feature fusion strategies, which may lead to information mismatches under drastic multi-scale variations. The third approach is to incorporate attention mechanisms to enhance the detector’s focus on small defects. For example, Zhu et al.29 introduced an attention mechanism at each feature extraction stage to better retain small object information. However, excessive reliance on attention mechanisms may increase computational overhead, affecting real-time performance.
In summary, while existing methods have improved small defect detection to some extent, they still face challenges such as multi-scale feature loss, background noise interference, and increased computational complexity. To address these issues, this paper proposes an optimized detection head—PEHead. PEHead enhances the model’s perception of small defects while mitigating the impact of shadow occlusion. Experimental results demonstrate that PEHead achieves higher detection accuracy and greater robustness in complex steel defect detection tasks. Therefore, optimizing the feature extraction capability of detectors and enhancing their focus on small targets are crucial directions for improving defect detection performance.
Multi-scale feature extraction
Traditional feature fusion networks achieve the interaction of multi-scale features by aggregating gradient flows from different levels. However, due to multiple downsampling operations during the feed-forward process, the semantic gap between features at different levels gradually increases, which affects the effective fusion of features. Zhang et al.30 introduced the DsPAN component to narrow the semantic gap between the Feature Pyramid Network (FPN) and PAN, thus improving the fusion of multi-scale information. However, this method still does not fully address the issue of insufficient visualization feature in steel defect detection tasks. Su et al.31 reduced the impact of defects at different scales by combining important information with background information in the feature map, but they did not completely solve the problem of background noise interference. The adaptive feature fusion method proposed by Yeung et al.32 enhanced the detector’s ability to recognize defects at different scales, but it still has limitations when dealing with defects with extreme aspect ratios. Peng et al.33 added skip connections between the encoder and decoder, enabling the model to effectively capture multi-scale features of images. However, this method mainly relies on direct feature transfer and does not fully consider the hierarchical differences between features at different scales, which may lead to insufficient fusion of global information and local details. Song et al.34 improved the detector’s performance in detecting complex-shaped defects by combining deformable convolution and region-of-interest (ROI) alignment techniques, but their feature alignment mechanism still faces the risk of information loss in multi-scale scenarios. Yu et al.35 combined the advantages of CNN and Transformer to achieve the fusion of global and local feature extraction, enhancing the model’s ability to represent multi-scale features. However, this method has a high computational complexity, making it difficult to deploy in resource-constrained industrial environments.
To address these issues, this paper proposes an optimized multi-scale feature fusion method. DcPAN improves the detector’s sensitivity to small targets by merging information flows from different receptive fields through a parallel branch structure. Experimental results show that the introduction of DcPAN significantly improves the detection performance of multi-scale defects. In particular, when dealing with small-scale defects, complex backgrounds, and extreme aspect ratios, DcPAN can effectively reduce the false detection rate and improve the overall detection accuracy of the model. Therefore, optimizing feature fusion strategies is an effective approach to solving the multi-scale variation problem in steel defect detection.
Background noise removal
Due to poor lighting conditions and the high similarity between steel defects and the background, the detector is easily affected by background noise interference. Existing research has proposed various methods to reduce the impact of background noise, but there are still certain limitations. Liu et al.36 treated channels and their relationships as a fully connected graph and enhanced the model’s understanding of global information through graph-based channel reasoning, enabling the detector to better focus on the foreground target. However, this method primarily focuses on feature relationship modeling and does not fully address the dynamic interference from background noise. Dong et al.37 adopted attention mechanisms and dilated convolutions to effectively improve the model’s ability to extract key features from complex backgrounds, but this approach has high computational complexity, which may affect the real-time performance of detection. Chen et al.38 selected MobileNet as the backbone extractor and replaced traditional convolutions with multi-scale depthwise separable convolutions to expand the receptive field and enhance the model’s robustness against complex background noise. However, the lightweight nature of the MobileNet structure may limit the ability to extract high-level semantic information. Zhou et al.39 introduced a bidirectional fusion strategy to enhance the integration of semantic information, thereby improving the contrast between defects and background, but detection accuracy may still decrease under complex lighting conditions. Tie et al.40 optimized feature representation of the detection head through attention components, enabling the detector to accurately learn the relationship between steel defects and the background. However, this method primarily focuses on feature representation optimization and does not provide stable detection performance in noisy and complex environments.
In conclusion, although existing methods have reduced the impact of background noise to some extent, they still face challenges such as insufficient global information modeling, high computational overhead, and decreased detection accuracy in complex environments. To address these challenges, this paper proposes an optimized receptive field expansion module. RFEM utilizes depthwise separable convolutions and dilated convolutions to expand the receptive field, thereby enhancing the detector’s adaptability to complex background noise. Experimental results show that RFEM can effectively focus on foreground targets in complex industrial environments, improving detection accuracy and reducing the false detection rate. Therefore, optimizing the receptive field of the detector can effectively eliminate noise interference in the steel defect detection process.
Methods
This paper proposes the PEYOLO model based on YOLOv8n to address the challenges of 2D detection of steel surface defects. The innovations of PEYOLO mainly include three aspects: DcPAN, PEHead, and RFEM. The primary function of DcPAN is to capture multi-scale defects. PEHead further represents multi-scale defects and effectively addresses occlusion issues in the defect detection process. RFEM enhances the detector’s receptive field while maintaining sensitivity to small defect targets and detailed information.
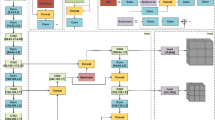
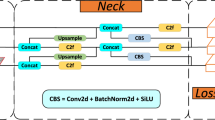
Apart from these improvements, the rest of PEYOLO retains the network structure of YOLOv8n. The C2f module fully utilizes information from different levels, enabling the detector to acquire both rich non-local and fine-grained information simultaneously, thereby improving its adaptability to complex scenes. The CBS module transforms features to better represent defects. The detailed network architecture of PEYOLO is shown in Fig. 2.

General framework of PEYOLO proposed.
Defect capture PAN
The size, shape, and aspect ratio of steel defects vary significantly. Multi-scale feature fusion helps the detector capture subtle features at different resolutions, which is crucial for improving the detection capability of small defects. The effectiveness of feature fusion networks in multi-scale feature extraction has been widely validated. FPN propagates global information from deep feature maps layer by layer through upsampling and fuses it with shallow feature maps of corresponding scales, which enriches the details of the entire feature layer. However, since FPN primarily employs a unidirectional information flow, small defect information may be lost during feature transmission. PAN builds upon FPN by introducing a bottom-up path, enabling multi-level multi-scale information interaction and improving the detector’s response to small objects.
Compared to natural scenes, steel defect detection involves more complex multi-scale objects and background noise interference. Therefore, we optimized the PAN structure by replacing its top-layer C2f module with ASFM and proposed DcPAN. Unlike other PAN variants, such as the Bidirectional Feature Pyramid Network (BiFPN), which relies on denser hierarchical connections to capture scale information41, DcPAN effectively integrates information flows from different receptive fields through the ASFM module, which improves the detector’s sensitivity to small defects.
The motivation behind ASFM’s design is to enhance the distinguishability of small defects. Small defects may appear differently at various feature scales, and without establishing effective connections between low-level and high-level features, their edge details may be lost or blurred during transmission. ASFM employs multiple parallel branches to extract different types of features and process images from various perspectives. This design strengthens the detector’s ability to capture image details, allowing the detector to learn multi-scale and multi-view information. By fusing these features, the detector can extract more comprehensive representations, improving its recognition ability for complex patterns, textures, and small defects.
As the core encoder module of ASFM, the Multi-Scale Block (MSBlock) allows adaptive selection of branch numbers and convolution kernel sizes based on task requirements, which reduces the semantic gap between different feature levels. This enables better integration of low-level and high-level features, preventing excessive compression of small defect details42. Specifically, MSBlock replaces standard 3 × 3 convolutions with inverted bottleneck layers, significantly improving parameter efficiency while retaining detailed information within a larger receptive field. Experimental results show that incorporating the ASFM module increases detection accuracy for small defects such as crazing and inclusion by 5.3% and 4%, respectively. Figure 3 illustrates the detailed structure of the ASFM module.

Architecture of the advanced semantic fusion module.
Let \({X}_{a}\in {\mathbb{R}}^{H\times W\times C}\) be the input feature map of the ASFM module, where \(H\) and \(W\) represent the height and width of the feature map, respectively, and \(C\) denotes the number of input channels. First, \({X}_{a}\) is fed into the CBS module, transforming the feature map size to \(H\times W\times C\_out\). Next, the feature map is evenly split into two parts, which are then fed into the main branch and the identity mapping branch separately. The main branch is further divided into an identity mapping branch and a MSBlock branch, where the feature maps in both branches have the same size of \(H\times W\times {C}_{out}/2\). The MSBlock branch consists of three sub-branches. The first sub-branch is an identity mapping branch. The remaining two sub-branches are composed of cascaded 1 × 1 convolution, 9 × 9 convolution, and another 1 × 1 convolution. At this stage, the feature maps in all three sub-branches of the MSBlock branch are of size \(H\times W\times {C}_{out}/6\). Then, the feature maps from the main branch and the identity mapping branch are concatenated, resulting in a feature map of size \(H\times W\times {3(C}_{out}/2)\). Finally, the concatenated feature map is passed through the CBS module to obtain the output feature map of the ASFM module, denoted as \({X}_{a}{\prime}\in {\mathbb{R}}^{H\times W\times C\_out}\). Notably, each CBS module consists of a cascaded 3 × 3 convolution module, a batch normalization layer, and a SiLU activation function.
The primary function of the 3 × 3 convolution is features transformation and channel reduction, thereby reducing computational cost.
Here, \({W}_{conv}\) is a 3 × 3 convolution kernel used to extract local features from the input feature map \(X\).
Batch normalization helps improve training stability and reduces the problem of internal covariate shift.
Here, \(BN(\cdot )\) represents normalization applied to each channel, where \({\mu }_{X}\) and \({\sigma }_{X}\) are the mean and standard deviation of each channel, and \(\gamma\) and \(\beta\) are the learned scaling and bias parameters.
SiLU activation function provides a smoother nonlinear transformation. Compared to ReLU, SiLU ensures more stable gradient propagation.
Here, \(\sigma (\cdot )\) represents the SiLU activation function, which enhances the network’s expressive capability by introducing nonlinear operations.
Channel-wise division splits the feature map into multiple sub-feature maps, allowing the model to process different channel groups in parallel, thereby increasing the network’s diversity.
Here, \(Split(\cdot )\) represents dividing the feature map \(X\) into \(n\) equal parts along the channel dimension.
With different convolution kernels, feature maps capture varying local or global semantics. By concatenating different feature maps, the network can learn more diverse feature representations, thereby enhancing the model’s expressiveness.
Here, \(Concat(\cdot )\) represents the concatenation of feature maps along the channel dimension after different pooling and convolution operations, enabling the fusion of multi-scale and multi-channel information.
The parallel branches in MSBlock enhance the network’s sensitivity to defects of different scales, and its working principle is as follows:
Here, \({Y}_{n}\) represents the output feature map of each branch in the MSBlock module; \(I{B}_{k\times k}(\cdot )\) denotes the cascaded 1 × 1 convolution, \(k\times k\) convolution, and 1 × 1 convolution. Here, \(k\) = 9 and \(n\) = 3.
Perception-efficient head
Steel surface defects often exhibit multi-scale variations, local aliasing, and shadow occlusion, making it difficult for detectors to accurately focus on them. As a key component of the detector, the detection head is directly responsible for predicting defect categories and locations. Therefore, the detection head must be robust to multi-scale defects and sensitive to occluded defect features. Based on this, we designed the PEHead.
PEHead consists of three heads with different resolutions: 80 × 80, 40 × 40, and 20 × 20. The low-resolution head can quickly locate large defects, the medium-resolution head further refines medium-sized defects, and the high-resolution head focuses on accurately detecting small defects. By combining heads of different sizes, PEHead can effectively perceive variations in defect scale, enabling it to handle multi-scale defect detection tasks efficiently.
To address local aliasing and shadow occlusion issues, PEHead incorporates specific designs to enhance its perception of occluded areas. Local aliasing refers to the visual overlap or similarity between defects, which may cause the detector to misidentify them. Shadow occlusion occurs when part of a defect is covered by shadows or other objects, leading to the loss of critical feature information. To mitigate these challenges, PEHead introduces the Semantic Enhancement Attention Module (SEAM)43. Similar to the approach used to address occlusion in face recognition, the SEAM module learns the relationship between occluded and non-occluded defects, allowing the model to supplement key feature information of the defect in the occluded areas. Specifically, SEAM utilizes depthwise separable convolution to efficiently extract local features from each channel, ensuring that even under partial occlusion or feature loss, sufficient information can still be captured. Following the depthwise separable convolution, the SEAM module applies a 1 × 1 convolution to fuse information across channels. The 1 × 1 convolution learns the importance of each channel, weighting and integrating different feature channels, allowing SEAM to restore occluded defect features using contextual information. Figure 4 illustrates the detailed structure of PEHead.

Architecture of the perception-efficient detection head.
PEHead consists of a cascade of CBS modules, the SEAM module, and 1 × 1 convolutional modules. The SEAM module is composed of two residual branches and a main branch. The output feature map from the first residual branch is element-wise added to the output feature map of the CSMM module. The output feature map from the second residual branch is multiplied with the output feature map from the main branch to obtain the output feature map of the SEAM module. The main branch of the SEAM module consists of the CSMM module, an average pooling layer, and linear layers. The CSMM module is divided into two parts. The first part consists of the main branch and the identity mapping branch. The main branch consists of 3 × 3 depthwise separable convolutions, GELU activation functions, and batch normalization layers. The second part consists of a cascade of 1 × 1 convolutions, GELU activation functions, and batch normalization layers.
Let \({H}_{p}\in {\mathbb{R}}^{H\times W\times C\_in}\) represent the input feature map of the SEAM module, where \(H\) and \(W\) are the height and width of the feature map, and \(C\_in\) is the number of input channels. \({H}_{p}\) is fed into the first part of the CSMM module to obtain the feature map \({H}_{0}\in {\mathbb{R}}^{H\times W\times C\_in}\). \({H}_{0}\) is then input into the second part of the CSMM module to obtain the output feature map \({H}_{1}\in {\mathbb{R}}^{H\times W\times C\_in}\). The feature map undergoes an adaptive average pooling operation. Adaptive average pooling dynamically adjusts the pooled size according to the size of the input feature map, extracting global information and avoiding size mismatch issues caused by input size variations. At this point, the feature map size is \(1\times 1\times C\_in\). The feature map is input into a cascade of linear layers, ReLU activation functions, linear layers, and Sigmoid activation functions to obtain \({H}_{2}\in {\mathbb{R}}^{1\times 1\times C\_in}\). The exponential operation with base e is applied to \({H}_{2}\), and the result is element-wise multiplied with \({H}_{p}\) to obtain the output feature map of the SEAM module \({H}_{3}\in {\mathbb{R}}^{H\times W\times C\_in}\).
Receptive field extension module
The challenge in steel defect detection lies in the limited visual features of defects and interference from background noise. Increasing the receptive field allows the detector to extract global features of the defects, which helps the detector learn the relationship between the background and defects, thereby accurately identifying and locating defects. Detectors based on ViT architectures like DETR expand the global receptive field by calculating the cosine similarity between each pixel, but this approach has two main problems: high computational overhead and neglecting small defects. Large Kernel Attention (LKA) combined with vision detectors achieves satisfactory receptive fields with lower computational cost, but its memory usage and kernel size still exhibit an exponential relationship44. Large Separable Kernel Attention (LSKA) decomposes the rectangular convolution kernel into cascaded horizontal and vertical strip convolution kernels, which reduces the memory usage of the detector further on top of LKA45.
Steel surfaces often have many elongated scratch defects, which have simple features and extreme aspect ratios. The receptive field of traditional 2D convolution components is small and unable to capture complete feature information for such defects. The strip convolution kernels of LSKA can effectively match the features of such strip-like defects. At the same time, LSKA achieves a larger receptive field by cascading deep convolution and dilated convolution, allowing the detector to capture the complete features of strip-like defects. However, a larger receptive field may smooth out subtle spatial changes, sacrificing the detector’s sensitivity to small defects and local details.
To address this issue, we introduce a multi-scale feature fusion strategy based on the LSKA component and propose the RFEM component. RFEM effectively improves detection accuracy for defects of different sizes by combining features at different scales. Specifically, the 1D convolution module in RFEM performs convolution along the elongated direction of the defect, which better captures the vertical features of strip-like defects while avoiding the local information loss problem that traditional 2D kernels may produce. Compared to traditional 2D convolution, 1D kernels retain better vertical texture information when processing such strip-like structures, while reducing interference from irrelevant horizontal information. Therefore, RFEM effectively captures the features of strip-like defects through 1D convolution and enhances sensitivity to small defects. Figure 5 shows the detailed structure of the RFEM component.

Architecture of the receptive field extension module.
Assume \({X}_{r}\in {\mathbb{R}}^{H\times W\times C}\) is the input feature map of the RFEM component, where \(H\) and \(W\) are the height and width of the feature map, respectively, and \(C\) is the number of channels. The first part of the RFEM component is a 1 × 1 convolution module, which is used to adjust the number of channels in the feature map while effectively reducing computational complexity through weight sharing.
Here, \(Conv\) represents the 1 × 1 convolution, and \(W\) is the 1 × 1 convolution kernel applied to the input feature map \({X}_{r}\) to extract local features. \({X}_{1}\in {\mathbb{R}}^{H\times W\times C\_out}\) is the output feature map.
The pooling window reduces the computational complexity and extracts important spatial information by retaining the maximum features within the local region. The cascaded pooling layers increase the receptive field, thereby enhancing the network’s ability to perceive global context.
Here, \({MaxPool}_{5\times 5}(\cdot )\) represents a 5 × 5 max pooling layer, and \({X}_{2}, {X}_{3},{X}_{4}\in {\mathbb{R}}^{H\times W\times C\_out/2}\), \({X}_{m}\in {\mathbb{R}}^{H\times W\times 4(C\_out/2)}\).
Compared to traditional convolutions, depthwise separable convolutions can significantly improve efficiency. Dilated depthwise separable convolutions expand the receptive field by increasing the spacing between convolutional kernel elements, which helps capture features from greater distances within the image. By cascading depthwise separable convolutions with dilated depthwise separable convolutions, the background noise interference to the detector is reduced, and the detector’s sensitivity to small defects is enhanced.
Here, \({DW}_{1\times 3}(\cdot )\) and \({DW}_{3\times 1}(\cdot )\) represent depthwise separable convolutions of size 1 × 3 and 3 × 1, respectively; \({D}_{1\times 5}(\cdot )\) and \({D}_{5\times 1}(\cdot )\) represent dilated depthwise separable convolutions of size 1 × 5 and 5 × 1, respectively, with dilation = 2. \({X}_{L}\in {\mathbb{R}}^{H\times W\times 4(C\_out/2)}\) and \({X}_{o}\in {\mathbb{R}}^{H\times W\times C\_out}\) represent the output feature maps of the RFEM module.
Experiments and analysis
This section introduces three publicly available steel surface defect detection datasets: NEU-DET, GC10-DET, and Severstal. In addition, this paper also introduces the publicly available PCB-DET dataset. For relevant information, please refer to Table 1. Then, it explains the experimental metrics and environment. Next, it selects the baseline model of PEYOLO and compares its detection results with other methods on the NEU-DET, GC10-DET, Severstal and PCB-DET datasets, demonstrating the performance advantages of PEYOLO. In addition, through ablation experiments, the effectiveness of the proposed improvement strategies is validated and the generalization validation of the proposed DcPAN, PEHead, and RFEM structures is conducted, using the YOLOv5 framework. Finally, it replaces the Backbone, Neck, and Head of the baseline model separately and compares the modified detectors with PEYOLO. The experimental results further confirm the superiority of PEYOLO.
Dataset description
To evaluate the effectiveness of the proposed method in steel surface defect detection, this study conducted extensive experiments using three publicly available steel surface defect benchmark datasets: NEU-DET, GC10-DET, and Severstal. Furthermore, the PCB-DET dataset is utilized in this study to conduct cross-domain experiments. The following provides relevant information about NEU-DET, GC10-DET, and Severstal.
-
(1)
NEU-DET: The NEU-DET dataset was released by Northeastern University (NEU) to provide academia and industry with a tool for studying and analyzing steel surface defects. It includes six common surface defects found in hot-rolled steel strips: pitted surfaces, inclusion, patches, crazing, scratches, and rolled-in scale.
-
(2)
GC10-DET: The GC10-DET dataset is a surface defect dataset collected in real industrial environments, designed to help researchers and engineers develop more accurate industrial inspection models for targeted inspection tasks. It includes ten types of defects: water spots, punched hole, weld lines, oil stains, inclusions, crescent gaps, silk spots, rolled pits, waist folds, and creases.
-
(3)
Severstal: This is a publicly available dataset provided by the Russian steel manufacturer Severstal. It includes four types of defects: pitting, scratch, inclusion, and other.
-
(4)
PCB-DET: This is a printed circuit board defect detection dataset released by Peking University. It includes six types of defects: mouse bite (Mb), short (Sh), spur (Sp), spurious copper (Spc), missing hole (Mh), and open circuit (Oc). The dataset contains a total of 693 images. In our experiments, we split the dataset into 560 training images, 63 validation images, and 70 test images.
The surface defects in these four types of datasets exhibit characteristics such as background noise interference, significant variations in lighting, a limited number of training samples, and diverse scale variations. As shown in Figs. 6, 7, 8 and 9, these factors pose significant challenges for real-time and accurate defect detection.

Defects annotated in the NEU-DET dataset.

Defects annotated in the GC10-DET dataset.

Defects annotated in Severstal dataset.

Defects annotated in PCB-DET dataset.
Evaluation metrics
To comprehensively evaluate the accuracy and real-time performance of the model, the following key performance metrics are adopted: Precision(P), Recal(R), Average Precision (AP), Mean Average Precision (mAP), F1 Score, and Frames Per Second (FPS). These metrics assess the overall performance of the detector in object detection tasks, including detection accuracy, recognition capability, overall detection performance, and inference speed.
-
(1)
Precision and Recall: Precision represents the proportion of predicted positive samples that are actually positive, measuring the accuracy of the detector in positive class detection. Recall indicates the proportion of actual positive samples correctly predicted by the model, reflecting the detector’s ability to identify targets. The definitions of precision and recall are as follows:
$$Precision=\frac{TP}{TP+FP}$$(15)$$Recall=\frac{TP}{TP+FN}$$(16)where TP (True Positive) represents correctly detected targets, FP (False Positive) denotes background regions mistakenly identified as targets, and FN (False Negative) refers to targets that the detector failed to identify, incorrectly treating them as background.
-
(2)
Average Precision: In object detection tasks, AP is a key metric for evaluating model performance. It quantifies the balance between precision and recall for a specific class by computing the area under the precision-recall curve. The formula for AP is defined as follows:
$${AP}_{n}={\int }_{0}^{1}P(r)dr$$(17)where \(n\) represents the number of classes, \(P(r)\) denotes the precision-recall curve, and the computed integral represents the AP value for the corresponding class.
-
(3)
Mean Average Precision: To comprehensively assess the model’s performance across all classes, the mAP is utilized. It represents the average of the AP values for each class in the dataset, providing an overall evaluation of the detector’s effectiveness. Specifically, mAP50 refers to the mAP value calculated when the Intersection over Union (IoU) threshold between the predicted and ground truth bounding boxes is set to 0.5. The formula for calculating mAP is as follows:
$$mAP=\frac{1}{N}\sum_{n=1}^{N}A{P}_{n}$$(18)where \(N\) is the total number of classes, and \(A{P}_{n}\) is the Average Precision for class \(n\).
-
(4)
F1 Score: To balance both precision and recall, the F1 score is introduced as the harmonic mean of these two metrics. The F1 score provides a more comprehensive assessment of the detection model’s performance. The formula for calculating the F1 score is:
$$F1 score=2\times \frac{Precision\times Recall}{Precision+Recall}$$(19) -
(5)
FPS: To evaluate the real-time performance of the detector, FPS is used as a key metric. FPS indicates the number of images the detector can process per second, providing an assessment of its inference speed. A higher FPS value signifies improved real-time performance of the detector.
$$FPS=\frac{1}{{T}_{m}}$$(20)where \({T}_{m}\) denotes the time taken by the detector to process a single defect image.
Training strategies and implementation details
To ensure the reproducibility of the experimental results, all experiments were conducted on the same high-performance deep learning server. The server configuration includes an Intel i9-13900K 3.00 GHz CPU, an NVIDIA GeForce RTX 3090 GPU, and the Windows 10 operating system. The deep learning framework used is Python 3.10.14, CUDA 11.8, and PyTorch 2.2.2. During model training, the image size was set to 640 × 640. This resolution achieved a good balance between image detail and computational load while ensuring high detection accuracy and efficiency across multiple experiments.
The initial learning rate was determined through a series of tuning experiments, where different values were tested to evaluate their impact on model convergence speed and stability. Experimental results indicated that a learning rate of 0.001 achieved the optimal balance between convergence speed and stability. A smaller learning rate resulted in slower training, whereas a larger one led to rapid gradient updates, potentially causing instability. Therefore, setting the learning rate to 0.001 effectively mitigated both extremes, ensuring a smooth and efficient training process.
Multiple experiments and tuning processes were conducted to determine the optimal weight decay. After evaluating different values, 5e−4 was identified as the most suitable choice. As a regularization term in the loss function, weight decay helps suppress overfitting. An excessively high weight decay value may oversimplify model parameters, compromising expressive capability, while an excessively low value may fail to effectively prevent overfitting, reducing generalization performance on the test set. Experimental results demonstrated that a weight decay of 5e−4 effectively mitigates overfitting while preserving the model’s expressive power, thereby enhancing generalization during training.
The choice of the learning rate decay strategy directly affects model training performance. The cosine annealing strategy gradually decreases the learning rate in a smooth manner, preventing it from dropping too quickly in the early stages of training. This allows the model to continue fine-tuning at a lower learning rate during later training stages, improving convergence and generalization. Experiments confirmed that cosine annealing not only maintained training stability but also helped the model fine-tune parameters when approaching the optimal solution, thereby enhancing overall performance.
The Close mosaic parameter controls the effect of data augmentation during training, particularly by introducing image patching to increase data diversity. Experiments showed that setting Close mosaic to 10 provided a good balance between data diversity and training stability, thereby improving the model’s generalization ability while avoiding the negative effects of excessive augmentation.
The performance of SGD and Adam optimizers was compared, with experimental results indicating that Adam outperformed SGD in both convergence speed and final model accuracy, particularly in avoiding local minima and accelerating convergence. Consequently, Adam was selected as the optimizer. To further enhance its performance, a momentum mechanism was incorporated, utilizing a weighted average of past gradients to accelerate updates and reduce oscillations. After tuning, the momentum value was set to 0.937, which effectively improved convergence speed while maintaining training stability.
Considering hardware limitations and efficiency requirements, a batch size of 8 was selected to enable efficient training without excessive memory consumption. This setting ensured stable training without memory overflow while maintaining a reasonable training speed.
Additionally, FPS measurements were conducted on an NVIDIA GeForce RTX 4050, with input image resolution set to 640 × 640 pixels to balance detection accuracy and inference speed. While different resolutions affect FPS, this resolution aligns with the standard input size used in YOLO models, ensuring fair comparisons with existing methods and meeting real-world requirements for speed and accuracy. All FPS measurements were performed with a batch size of 1, meaning that each inference processed a single image at a time. This setup is particularly relevant for real-time applications such as video surveillance and autonomous driving, where each frame must be processed individually and efficiently.
The hyperparameters used in the proposed model are listed in Table 2.
Results on NEU-DET and GC10-DET dataset
Baseline model selection
To find a suitable baseline model, the proposed components were combined with three representative lightweight detectors: YOLOv8n, YOLOv9t, and YOLOv10n. Systematic experiments were conducted on the NEU-DET dataset. Table 3 summarizes the performance variations after incorporating each module into the different baseline models.
Experimental results show that although YOLOv9t exhibits strong original performance, its performance generally degrades after integrating the proposed modules. For example, with the introduction of RFEM, the mAP50 drops from 77.0% to 73.4%, accompanied by significant declines in inference speed and precision. This may be attributed to the highly sensitivity of YOLOv9t’s architecture to lightweight design; structural incompatibilities or redundant features between YOLOv9t and the proposed modules likely led to suboptimal fusion results.
In contrast, YOLOv10n demonstrates relatively better adaptability to the proposed modules. Notably, incorporating PEHead leads to a substantial increase in mAP50 from 69.4% to 75.7%. However, the original performance of YOLOv10n is generally lower than that of YOLOv8n, and even after module integration, its final performance does not surpass the optimal configuration of YOLOv8n. Therefore, it is not considered a suitable baseline.
YOLOv8n exhibits a good balance between accuracy, speed, and parameter efficiency after module integration. For instance, with DcPAN, the mAP50 improves to 75.8% while the parameter count decreases to 3.06 M, indicating strong compatibility and enhancement potential. In addition, YOLOv8n achieves the highest inference speed, satisfying real-time requirements for industrial deployment. As a result, we selected YOLOv8n as the baseline model for our improved detection framework, PEYOLO.
Comparison of PEYOLO with YOLOv8, YOLOv9, and YOLOv10 series
To validate the performance advantage of PEYOLO in the steel defect image object detection task, a quantitative analysis was conducted on the NEU-DET validation set. The results are shown in Table 4. On the NEU-DET dataset, PEYOLO achieved an accuracy of 70.9%, a recall of 74.5%, an mAP50 of 78.1%, and an F1 score of 72.0%. Compared to YOLOv8n, PEYOLO’s FPS decreased by 72.7. Preliminary analysis suggests that the complex parallel structure in the ASFM component and the fully connected layers in PEHead are the main factors contributing to the decrease in inference speed. These complex modules increased the computational load and memory overhead, which improved detection accuracy but sacrificed inference speed. However, compared to YOLOv8l, which has a detection accuracy similar to that of PEYOLO, its FPS is 82.7 lower than that of PEYOLO. This indicates that despite the added complexity in PEYOLO, a good balance between detection accuracy and inference speed was still achieved.
To further optimize the inference speed of PEYOLO, several optimization techniques can be applied to alleviate the decline in FPS. First, the parallel computation structure of the ASFM component can be optimized. For instance, replacing some regular convolutions with more efficient depthwise separable convolutions can reduce the computational burden. In addition, the fully connected layers in PEHead can be replaced with more efficient global pooling layers, further reducing the computational overhead of the model. Additionally, hardware acceleration can significantly improve inference speed, especially when running on hardware platforms that support higher parallelism, which can effectively enhance inference efficiency. In practical applications, there is an undeniable trade-off between model accuracy and inference speed. If the application scenario requires high inference speed, optimizations such as simplifying the model structure and using efficient hardware to improve FPS can be considered. In contrast, in scenarios with higher accuracy requirements, sacrificing some inference speed to ensure better detection accuracy may be preferred. For different application needs, an appropriate configuration should be selected based on the requirements for accuracy and speed to ensure that the model performance is maintained while meeting real-time demands.
In addition, PEYOLO was compared with the YOLOv9 and YOLOv10 series, with the experimental results presented in Tables 5 and 6. These results further validate the effectiveness of the proposed improvement strategy. Figure 10 shows the performance comparison between PEYOLO, the YOLOv8 series, YOLOv9 series, and YOLOv10 series on the NEU-DET dataset, clearly highlighting the performance advantages of PEYOLO.

Performance of PEYOLO and YOLOv8, YOLOv9, YOLOv10 series on NEU-DET dataset.
Comparison with the latest techniques
To comprehensively evaluate the superiority of PEYOLO in the steel defect detection task, a comparison was made with 15 state-of-the-art object detection methods on the NEU-DET and GC10-DET benchmark datasets. The methods include Faster R-CNN, EfficientDet-d1, SSD, FCOS, RT-DETR, YOLOv8n-ghost, YOLOv8n-world, YOLOv8n-worldv2, YOLOv3-Tiny, YOLOv4-csp, YOLOv5n, YOLOv6n, YOLOv8n, YOLOv9c, and YOLOv10n. Tables 7 and 8 present the performance of these methods on the NEU-DET and GC10-DET validation datasets, while Table 9 records the detection results of the RT-DETR series on the NEU-DET dataset.
As a classic two-stage object detection model, Faster R-CNN serves as a valuable reference for detection tasks involving complex scenes. EfficientDet is a lightweight and efficient object detection model that offers high computational efficiency. As an anchor-free detection method, FCOS achieves high detection accuracy with low computational resources. The YOLO model’s high accuracy and real-time performance provide significant advantages in object detection tasks. As a Transformer-based object detection model, RT-DETR provides real-time detection capabilities. By introducing RT-DETR, the performance differences between the Transformer architecture and the YOLO architecture in steel surface defect detection tasks can be analyzed.
The experimental results on the NEU-DET dataset show that, compared to other advanced object detectors, PEYOLO leads in recall rate, mAP50, and F1 score, achieving 74.5%, 78.1%, and 72%, respectively. Among these, PEYOLO’s mAP50 reached 78.1%, significantly outperforming other methods. For instance, YOLOv8-world and YOLOv8-worldv2 achieved mAP50 values of 76.8% and 75.2%, while RT-DETR only achieved a mAP50 of 69.5%, which is much lower than PEYOLO. This result indicates that many detectors designed for natural scenes are not suitable for steel surface defect detection tasks. A deeper analysis reveals that although the ViT structure in RT-DETR enhances global feature modeling, the increased model complexity raises training difficulty, leading to poor performance in small defect detection. The experimental results on the GC10-DET dataset are similar to those on NEU-DET. PEYOLO achieved precision, mAP50, and F1 scores of 64.3%, 62.3%, and 61%, respectively, significantly outperforming other methods. This result further demonstrates that PEYOLO maintains good detection capability and robustness even in complex backgrounds.
As shown in Table 7, the FPS of YOLOv3-Tiny and YOLOv6n are almost the same, but YOLOv6n has a higher mAP50. This is because YOLOv3-Tiny uses a lightweight backbone network and only two scales of prediction heads for object detection, ensuring higher inference speed. However, this design has certain limitations in feature extraction, leading to lower detection accuracy. In contrast, YOLOv6n uses EfficientRep as the backbone network and applies structural reparameterization techniques to convert the multi-branch structure into a single-branch 3 × 3 convolution during the inference stage, improving detection accuracy while maintaining efficiency. YOLOv8-world has a mAP50 of 76.8%, slightly higher than YOLOv8-ghost’s 76.4%, but with a significant drop in FPS. This indicates that although YOLOv8-world shows improvement in accuracy, its increased computational complexity results in a decrease in inference speed.
The improvement of PEYOLO in mAP50 indicates its better feature extraction capability for small object detection. Compared to YOLOv8-world, PEYOLO shows a significant improvement in recall, demonstrating its robustness in detecting minute defects. PEYOLO outperforms traditional YOLO models in detecting large-area defects (such as Pitted_surface) and elongated defects (such as Scratches), thanks to its enhanced modeling capability for features at different scales. Additionally, as shown in Table 4, PEYOLO’s mAP50 is similar to that of YOLOv8l, but PEYOLO’s parameter size is only 7% of YOLOv8l. At the same time, PEYOLO’s FPS is 82.7 higher than that of YOLOv8l, indicating that PEYOLO achieves a good balance between parameter size and inference speed. On the GC10-DET dataset, PEYOLO still maintains high mAP50 and F1 scores, further demonstrating its strong detection robustness in complex industrial scenarios.
The FPS of PEYOLO is significantly lower than that of YOLOv6n, indicating that YOLOv6n may be more suitable for applications with ultra-high real-time requirements. Although the parameter size of PEYOLO is comparable to that of YOLOv8n, its FPS is considerably lower, suggesting that PEYOLO has not achieved an optimal balance between lightweight design and speed.
To provide a more intuitive presentation of the quantitative analysis results for each method, scatter plots are used for visualization, as shown in Fig. 11. Furthermore, Figs. 12 and 13 illustrate the inference results of PEYOLO compared to SOTA models on the NEU-DET and GC10-DET datasets. In conclusion, PEYOLO outperforms all other detectors on both the NEU-DET and GC10-DET datasets. The advantages of PEYOLO are primarily demonstrated in small object detection, robustness in complex backgrounds, and adaptability to multi-scale defects, making it an ideal choice for steel defect detection tasks.

Scatterplot of experimental results for each method on the NEU-DET dataset.

Results of YOLO detector on the NEU-DET.

Results of YOLO detector on the GC10-DET.
Inference experiment
In the actual environment of steel production, various defects may occur simultaneously, which puts higher demands on the detector’s detection performance. Consequently, we concatenated images of different defect types and fed them into the model to simulate potential scenarios in real-world detection processes. As shown in Fig. 14, PEYOLO is able to accurately predict the types and locations of various defects, demonstrating that PEYOLO possesses the capability for real-world detection.

Results of PEYOLO on the spliced pictures with different defects.
Results on severstal dataset
To evaluate the robustness and generalization ability of PEYOLO in real-world steel production environments, comparative experiments were conducted on the Severstal dataset. The models included in the comparison are YOLOv5n, YOLOv7-tiny, YOLOv8n, GELAN-t, YOLOv10n, YOLO11n, and Hyper-YOLO. As shown in Table 10, PEYOLO demonstrates outstanding performance across multiple key metrics, particularly showcasing significant advantages in balancing detection accuracy and inference speed.
In terms of mAP50, PEYOLO achieves 49.7%, which is on par with GELAN-t and Hyper-YOLO, and only slightly lower than YOLOv7-tiny. However, PEYOLO significantly outperforms YOLOv5n, YOLOv8n, and YOLO11n. This result indicates that PEYOLO has stronger object recognition capabilities in industrial defect detection tasks, especially in complex steel surface environments where it can still effectively detect defect targets. Additionally, PEYOLO reaches 23.1% on the mAP50-95 metric, matching Hyper-YOLO, and significantly outperforming YOLOv5n, YOLOv8n, and YOLOv7-tiny. This further demonstrates the stability and robustness of PEYOLO in detecting defects at different scales, enabling better adaptation to the diverse defect patterns on steel surfaces. Specifically, PEYOLO performs exceptionally well in detecting defects such as Pitting and Scratch. As shown in Fig. 15a, PEYOLO accurately locates the position of the Scratch defect. As shown in Fig. 15b, PEYOLO accurately frames the location of elongated defects. In contrast, YOLOv8n fails to frame the entire shape of the defect, and YOLOv7-tiny even misses the detection. This is because such defects often have smaller object areas or fuzzy boundaries, while PEYOLO, through feature fusion enhancement via DcPAN, enables the detector to more effectively capture defects at various scales. Furthermore, the introduction of RFEM enhances PEYOLO’s detection ability for elongated defects, surpassing traditional YOLO models. This global receptive field expansion capability is crucial for steel defect detection, as many defects tend to exhibit elongated structures that may be difficult for conventional convolutional neural networks to capture in their entirety.

Results of YOLO detector on Severstal.
In terms of precision and recall, PEYOLO achieves 57.8% precision and 45.1% recall, significantly outperforming YOLOv8n and YOLO11n. This indicates that PEYOLO maintains high detection accuracy while also demonstrating good recall ability, helping to reduce missed detections. This is mainly due to the optimization of the PEHead, which enhances both object classification and localization capabilities, enabling the model to maintain high recognition accuracy even in high-noise industrial environments. This can also be observed in Fig. 15c, where, apart from PEYOLO, other detectors all suffer from false detections.
However, compared to Hyper-YOLO, PEYOLO still has room for improvement in recall. This phenomenon may be related to PEYOLO’s receptive field design and feature extraction approach. Since PEYOLO focuses more on balancing local and global information during feature extraction, it might fall short in detecting extremely small defects, which affects recall. Therefore, future improvements could focus on optimizing the receptive field design to better handle tasks involving very small defects or low-contrast detections.
In terms of inference speed, PEYOLO achieves a good balance with an inference speed of 117.8 FPS among lightweight models. PEYOLO’s FPS is significantly higher than that of GELAN-t and Hyper-YOLO, indicating that PEYOLO has strong real-time detection capabilities while maintaining high detection accuracy, meeting the real-time detection requirements for defect detection in steel production lines. However, it is worth noting that PEYOLO’s FPS is still lower than YOLOv5n and YOLOv7-tiny, indicating that further optimization is needed for extremely high real-time applications. This reduction in inference speed mainly comes from the increased computational complexity of the PEHead and RFEM modules. In the future, more efficient attention mechanisms or lightweight convolution strategies could be explored to further optimize inference efficiency. In terms of computational complexity, PEYOLO’s GFLOPS is only 7.2, which is comparable to YOLOv8n and YOLOv10n, but it achieves superior performance in detection accuracy, demonstrating its efficient network design. In contrast, although YOLOv5n has a faster inference speed, its simplified network architecture results in significantly lower detection accuracy compared to PEYOLO.
Overall, PEYOLO, by incorporating the DcPAN, PEHead, and RFEM modules, outperforms existing lightweight object detectors in detection accuracy, recall, and multi-scale object detection capabilities. It also achieves a good balance between computational complexity and inference speed. Compared to traditional YOLO models, PEYOLO excels in small object detection, elongated defect detection, and detection in high-noise environments, making it particularly suitable for industrial steel defect detection tasks.
Cross-domain experiments on PCB-DET dataset
To further validate the generalization capability and cross-domain robustness of PEYOLO, cross-domain experiments were conducted on the PCB-DET dataset. This dataset differs significantly from NEU-DET in terms of visual style and represents defect types from different industrial scenarios. The objective of this experiment is to evaluate PEYOLO’s detection performance across domains and conduct a comprehensive comparison with mainstream lightweight detectors in terms of detection accuracy, inference speed, model parameters, and computational efficiency.
As shown in Table 11, PEYOLO outperforms all comparison methods, achieving an mAP50 of 88.1%, an F1 score of 88.0%, a precision of 94.3%, and a recall of 82.8%. Compared to the widely used YOLOv5n, PEYOLO improves mAP50 by 1.9% while maintaining a comparable parameter size. Although the inference speed of PEYOLO is slightly lower, it still meets the real-time requirements for industrial applications.
Notably, in comparison with the high-accuracy model YOLOv9t, PEYOLO achieves superior precision and F1 score while offering a 2.5 × increase in inference speed. This demonstrates PEYOLO’s excellent balance between detection performance and deployment efficiency. Furthermore, even when compared to ultra-lightweight models such as YOLOv8n-ghost, PEYOLO maintains significant advantages in detection accuracy and robustness, further verifying the effectiveness of the proposed architecture in lightweight scenarios.
In terms of the precision-recall trade-off, PEYOLO achieves the highest precision, which is crucial for reducing false positives in real-world industrial inspection. At the same time, the recall of 82.8% indicates strong sensitivity and coverage in cross-domain environments.
In summary, PEYOLO not only delivers state-of-the-art detection performance in steel defect detection but also demonstrates superior adaptability and generalization on the PCB-DET dataset, a novel target domain. The DcPAN, PEHead, and RFEM modules consistently exhibit stable performance under varying defect characteristics and image conditions, further validating the cross-domain robustness and practical value of the proposed approach. Detection results of PEYOLO on the PCB-DET dataset are illustrated in Fig. 16.

Results of YOLO detector on PCB-DET.
Ablation analysis
To verify the effectiveness of the improvement strategies in PEYOLO, ablation experiments were conducted. Table 12 presents the detection performance of the baseline model with different components on the NEU-DET validation set. Each improvement component contributes to a certain extent in enhancing detection accuracy. Specifically, the introduction of DcPAN increases the recall and mAP50 by 1.2% compared to the baseline. The addition of PEHead improves precision by 2.5% and mAP50 by 0.7%. Furthermore, RFEM further enhances recall and mAP50 by 3.4% and 1.6%, respectively. Ultimately, compared to the baseline method, PEYOLO achieves an improvement of 3.5% in recall, 3.5% in mAP50, and 4.1% in precision. The following sections provide a detailed experimental analysis of each improvement strategy in PEYOLO, including DcPAN, PEHead, and RFEM.
Effectiveness of DcPAN
DcPAN utilizes a multi-branch structure to extract multi-scale features with different receptive fields, effectively reducing the semantic gap between different levels. This enables efficient fusion of high-level semantic information in both the backbone and neck networks, allowing the model to focus on foreground objects. To verify the effectiveness of DcPAN, this paper analyzes its impact on various types of defects. The results are shown in Table 13.
For Inclusion defects, the mAP50 increased by 4%, demonstrating its ability to enhance detection accuracy for such defects. Since Crazing and Inclusion defects often have colors and textures similar to the background, making them susceptible to background noise interference. DcPAN effectively suppresses noise through multi-scale feature fusion, thereby improving detection capability. Specifically, the mAP50 for Crazing and Inclusion increases by 5.3% and 4%, respectively, indicating that DcPAN effectively focuses on defect regions.
For Scratches defects, which exhibit significant scale variations, traditional methods struggle to effectively handle it. DcPAN, through its multi-branch parallel structure, enhances the model’s sensitivity to scale variations. As a result, the detection performance for Scratches improves significantly, with an increase of 5.3% in mAP50. This highlights the advantage of DcPAN in multi-scale feature extraction, particularly in handling defects with large scale variations.
However, for Patches and Pitted_surface defects, the detection performance declines. These defect types have relatively larger scales and may require a broader receptive field for effective detection. Analysis suggests that DcPAN has certain limitations in handling these defects, and further optimization of the receptive field or the incorporation of more powerful background modeling techniques may be needed to enhance its detection capability for large-scale defects.
To further validate the advantages of DcPAN, we compared it with other feature fusion networks. As shown in Table 14, compared to the original FPN, DcPAN significantly improves precision, recall, mAP50, and F1-score by 0.9%, 8.8%, 10.8%, and 11.3%, respectively. Furthermore, DcPAN demonstrates clear advantages over advanced architectures such as BiFPN, BiFPN-SDI46, and MAFPN47. As illustrated in Fig. 17, the baseline model with DcPAN significantly outperforms other FPN architectures in addressing challenges related to defect scale variations and complex background interference.

Visual analysis of heat maps on NEU-DET dataset for baseline models with different feature fusion networks.
Effectiveness of PEHead
PEHead is designed to address the challenges of multi-scale variations and local occlusions in steel defect detection. To verify its effectiveness, experiments were conducted on the NEU-DET dataset, and the impact of PEHead on different defect types was analyzed, as shown in Table 13.
Specifically, PEHead exhibits varying detection performance across different defect types. For Pitted_surface and Scratches defects, which have significant size differences, traditional detectors often struggle to extract features across different scales. By adopting a three-head configuration, PEHead demonstrates superior multi-scale feature extraction capabilities, leading to an mAP50 improvement of 6.5% for Pitted_surface and 2.1% for Scratches. These results indicate that PEHead effectively enhances adaptability of the detector to scale variations.
In real-world industrial environments, Inclusion-type defects are often occluded by shadows or other large-scale defects, making traditional detection methods prone to missed detections. By introducing the SEAM module, PEHead learns the relationships between occluded and non-occluded regions, achieving accurate classification and localization of occluded defects. For Inclusion defects, the mAP50 increased by 2.7%, significantly reducing missed detections caused by occlusions and enhancing robustness of the detector in complex environments.
However, for Patches and Rolled-in_scale defects, detection performance did not exhibit a significant improvement and even showed a slight decline. This phenomenon may be attributed to the unique shapes and blurred boundaries of these defect types, which pose challenges for the existing feature extraction mechanisms in achieving precise classification. Future improvements could involve optimizing feature selection strategies or incorporating stronger contextual information to enhance detection capabilities.
To comprehensively evaluate the performance of PEHead, comparisons were made with other mainstream detection heads on the NEU-DET validation set. As shown in Table 15, compared to detection head of YOLOv8, detection head of RT-DETR, and Efficient Head of YOLOv6, PEHead demonstrated superior performance in both mAP50 and recall. Specifically, when using the detection head of baseline model (YOLOv8n), the mAP50 was 74.6%, recall was 71%, and the parameter count was 3.15 M. After integrating PEHead, the mAP50 increased by 1.1%, recall improved by 2.3% and the parameter count was 2.91 M, achieving a balanced trade-off between accuracy and computational efficiency.
Additionally, to visually demonstrate the effectiveness of PEHead, visual analyses were performed. As shown in Fig. 18, PEHead demonstrates significant advantages in addressing false positives and missed detections, providing an efficient and robust solution for practical industrial inspection applications.

Visual analysis of confusion matrices for baseline models with different detection heads.
Effectiveness of RFEM
RFEM is designed to enhance the receptive field to mitigate the issue of insufficient visual information in steel defect detection. To verify the effectiveness of RFEM, experiments were conducted on the NEU-DET dataset, and the impact of RFEM on different defect types was analyzed, as shown in Table 13.
Specifically, RFEM exhibits varying degrees of influence on different defect types. For Scratches, which are characterized by extreme aspect ratios, traditional 2D convolutions have limitations in feature extraction for elongated defects. The introduction of 1D convolution in RFEM improves detection performance for such objects, resulting in a 2.8% increase in mAP50. This demonstrates that RFEM effectively captures the edge information of elongated defects, thereby enhancing detection accuracy.
Pitted_surface defects typically cover a larger area. It is difficult for traditional methods to capture all of its features. RFEM effectively expands the receptive field, leading to a 4.3% increase in mAP50 for this defect type. This improvement confirms the effectiveness of RFEM in enhancing global feature extraction.
However, for Rolled-in_scale defects, the mAP50 decreased by 3.4%. Analysis suggests that although a larger receptive field helps capture macroscopic features, it may introduce unnecessary contextual information when detecting small-scale defects, thereby reducing attention to fine details. Future improvements could involve incorporating more refined feature selection mechanisms to achieve better detection performance across different scales.
To further validate the superiority of the RFEM, backbone replacement experiments were conducted, as shown in Table 16. The models involved in the experiment include MobileNetV448, EfficientViT49, Fasternet50, StarNet51, and LSKNet52. For fairness, each model uses the same neck and head. Experimental results indicate that the backbone with RFEM outperforms other backbone networks in improving model performance, further demonstrating the effectiveness of RFEM.
Additionally, visual analyses were conducted. As shown in Fig. 19, green regions represent the receptive field coverage of the backbone network. The backbone with RFEM has a significantly larger receptive field than other backbone networks, indicating that RFEM effectively expands the perception range and enhances global defect detection capabilities.

Visual analysis of receptive fields for baseline models with different backbone networks. (a) EfficientViT, (b) Fasternet, (c) LSKNet, (d) Mobilenetv4, (e) Startnet, (f) PEYOLO.
In summary, RFEM exhibits significant advantages in receptive field and detection accuracy, particularly for elongated and large-area defects. Although detection performance for certain small-scale defects declined, further optimization of feature extraction strategies is expected to achieve a better balance in multi-scale defect detection.
Generalization verification
To test the robustness and generalization ability of the module, the proposed module was embedded into YOLOv5. As shown in Table 17, compared to the original YOLOv5 model, the introduction of RFEM resulted in a 0.4% increase in precision and a 0.8% increase in mAP50. After incorporating PEHead, precision increased by 6.1% and mAP50 improved by 1.8%. With the introduction of DcPAN, precision increased by 6.3% and mAP50 improved by 3.3%. The experimental results demonstrate that the proposed module exhibits superior compatibility with the YOLO frameworks.
Conclusion
This study proposes PEYOLO, an efficient perceptual deep learning framework for multi-scale surface defect detection. To address the challenges of small-scale defects, background noise interference, and limited visual feature representation, three innovative modules were designed.
Advantage
DcPAN enhances the cross-scale feature fusion capability of the detector, effectively bridging the semantic gap between features at different levels. By optimizing the gradient information flow between the backbone network and the neck, DcPAN captures fine-grained defect features with high precision while preserving global context information, significantly improving the detection accuracy of small-scale and complex defects. This provides a superior feature fusion strategy for small object detection in industrial vision tasks. PEHead effectively alleviates the issues of local occlusion and feature overlap, ensuring accurate localization of densely distributed defects. With a multi-scale feature expression strategy, PEHead enhances the detector’s adaptability to variations in defect size and shape, offering new insights for handling overlapping defects in high-noise environments. The RFEM adopts a novel large-kernel separable convolution strategy, which expands the detector’s receptive field without adding excessive computational overhead. This design is particularly suitable for detecting elongated defects with extreme aspect ratios while maintaining high sensitivity to small-scale defects, laying the foundation for future receptive field optimization research.
Experimental results on three benchmark datasets demonstrate that PEYOLO achieves state-of-the-art detection performance, excelling in key metrics such as mAP50 and F1 score, while maintaining high inference speed. Notably, PEYOLO’s generalization ability across different defect types and industrial application scenarios showcases its potential as a universal solution for steel defect detection.
Limitation
Although PEYOLO demonstrates outstanding detection performance and strong generalization across multiple benchmark datasets and various defect types, it still exhibits certain limitations under specific conditions that warrant further optimization:
First, DcPAN shows a degree of disadvantage when handling large-scale defects. This may be attributed to its multi-branch structure, which primarily focuses on the fusion of multi-scale features with small receptive fields, thereby limiting its ability to model contextual information in large-scale regions. Future work may consider integrating larger receptive fields or incorporating global context modeling mechanisms to enhance its adaptability to large-scale defects. Second, PEHead offers limited improvements when dealing with morphologically blurred or poorly defined defects, and even exhibits slight performance degradation in certain categories. This suggests that the current multi-head structure and attention mechanism still face bottlenecks in feature representation. Future research could explore enhanced feature extraction or more effective attention-guided mechanisms to improve the recognition accuracy of complex-shaped defects. Lastly, while RFEM significantly expands the receptive field and improves detection of elongated and large-area defects, it tends to introduce excessive redundant information when processing fine-grained defects, potentially diminishing attention to local details. This highlights a trade-off between receptive field design and feature selection. Future directions may involve exploring dynamic receptive field regulation strategies or incorporating multi-scale feature reweighting mechanisms to achieve a better synergy between global perception and detail preservation.
In summary, although PEYOLO has achieved excellent performance in surface defect detection for steel, there remains room for further improvement—particularly in extreme scenarios characterized by scale imbalance, complex morphology, and cluttered backgrounds. Future work will focus on architectural optimization, dynamic feature selection, and adaptive receptive field adjustment to promote broader application of PEYOLO in intelligent industrial visual inspection.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding authors upon reasonable request.
References
Lu, J. et al. Steel strip surface defect detection method based on improved YOLOv5s. Biomimetics 9, 28 (2024).
Ghorai, S. et al. Automatic defect detection on hot-rolled flat steel products. IEEE Trans. Instrum. Meas. 62, 612–621 (2012).
Pernkopf, F. Detection of surface defects on raw steel blocks using Bayesian network classifiers. Pattern Anal. Appl. 7, 333–342 (2004).
Ren, S. et al. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
Liu, W., Anguelov, D., Erhan, D. et al. SSD: Single shot multibox detector. In Presented at 14th Euro. Conf. Amsterdam, The Netherlands, October, 11–14 (2016).
Tian, Z. et al. FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 44, 1922–1933 (2020).
Tan, M., Pang, R., Le, Q. V. Efficientdet: Scalable and efficient object detection. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10781–10790 (2020).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Li, C., Li, L., & Jiang, H. et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976 (2022).
Wang, C. Y., Bochkovskiy, A., Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7464–7475 (2023).
Wang, C. Y., Yeh, I. H., & Liao, H. Y. M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv preprint arXiv:2402.13616 (2024).
Wang, A., Chen, H., & Liu, L. et al. Yolov10: Real-time end-to-end object detection. arXiv preprint arXiv:2405.14458 (2024).
LeCun, Y., Bengio, Y. Convolutional networks for images, speech, and time series. In The handbook of brain theory and neural networks, 3361 (1995).
Zhu, X., Su, W., & Lu, L. et al. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020).
Zhao, Y., Lv, W., & Xu, S. et al. Detrs beat yolos on real-time object detection. in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 16965–16974 (2024).
Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Wang, Z., Li, C., & Xu, H. et al. Mamba YOLO: SSMs-Based YOLO for object detection. arXiv preprint arXiv:2406.05835 (2024).
Ding, X., Zhang, X., & Han, J. et al. Scaling up your kernels to 31x31: Revisiting large kernel design in CNNs. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11963–11975 (2022).
Wang, C. Y., Liao, H. Y. M. & Wu, Y. H. et al. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 390–391 (2020).
Lin, T. Y., Dollár, P. & Girshick, R. et al. Feature pyramid networks for object detection. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2117–2125 (2017).
Liu, S,, Qi, L. & Qin, H. et al. Path aggregation network for instance segmentation. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8759–8768 (2018).
Tishby, N., & Zaslavsky, N. Deep learning and the information bottleneck principle. In IEEE Information Theory Workshop (ITW), 1–5 (2015).
Zhou, S. et al. Surface defect detection of steel plate based on SKS-YOLO. IEEE Access 12, 91499 (2024).
Yu, B. et al. YOLO-MPAM: Efficient real-time neural networks based on multi-channel feature fusion. Expert Syst. Appl. 252, 124282 (2024).
Liu, Q. et al. A real-time anchor-free defect detector with global and local feature enhancement for surface defect detection. Expert Syst. Appl. 246, 123199 (2024).
Yuan, M. et al. YOLO-HMC: An improved method for PCB surface defect detection. IEEE Trans. Instrum. Meas. 73, 1 (2024).
Wu, Y. et al. SDD-YOLO: A lightweight, high-generalization methodology for real-time detection of strip surface defects. Metals 14, 650 (2024).
Zhu, X. et al. High-speed and accurate cascade detection method for chip surface defects. IEEE Trans. Instrum. Meas. 73, 1 (2024).
Zhang, Y. et al. DsP-YOLO: An anchor-free network with DsPAN for small object detection of multiscale defects. Expert Syst. Appl. 241, 122669 (2024).
Su, P. et al. MOD-YOLO: Rethinking the YOLO architecture at the level of feature information and applying it to crack detection. Expert Syst. Appl. 237, 121346 (2024).
Yeung, C. C. & Lam, K. M. “Efficient fused-attention model for steel surface defect detection. IEEE Trans. Instrum. Meas. 71, 1–11 (2022).
Peng, J. et al. Industrial surface defect detection and localization using multi-scale information focusing and enhancement GANomaly. Expert Syst. Appl. 238, 122361 (2024).
Song, C. et al. Steel surface defect detection via deformable convolution and background suppression. IEEE Trans. Instrum. Meas. 72, 1–9 (2023).
Yu, T. et al. CRGF-YOLO: An optimized multi-scale feature fusion model based on YOLOv5 for detection of steel surface defects. Int. J. Comput. Intell. Syst. 17, 154 (2024).
Liu, Q. et al. A real-time anchor-free defect detector with global and local feature enhancement for surface defect detection. Expert Syst. Appl. 246, 123199 (2024).
Dong, C. et al. EL-Net: An efficient and lightweight optimized network for object detection in remote sensing images. Expert Syst. Appl. 255, 124661 (2024).
Chen, J. et al. Multiscale attention networks for pavement defect detection. IEEE Trans. Instrum. Meas. 72, 1–12 (2023).
Zhou, Q. & Wang, H. CABF-YOLO: A precise and efficient deep learning method for defect detection on strip steel surface. Pattern Anal. Appl. 27, 36 (2024).
Tie, J. et al. LSKA-YOLOv8: A lightweight steel surface defect detection algorithm based on YOLOv8 improvement. Alex. Eng. J. 109, 201–212 (2024).
Tan, M., Pang, R. & Le, Q. V. Efficientdet: Scalable and efficient object detection. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10781–10790 (2020).
Chen, Y., Yuan, X. & Wu, R. et al. Yolo-ms: Rethinking multi-scale representation learning for real-time object detection. arXiv preprint arXiv:2308.05480 (2023).
Yu, Z., Huang, H. & Chen, W. et al. Yolo-facev2: A scale and occlusion aware face detector. arXiv 2022. arXiv preprint arXiv:2208.0 (2019).
Guo, M. H. et al. Visual attention network. Comput. Vis. Med. 9, 733 (2023).
Lau, K. W., Po, L. M. & Rehman, Y. A. U. Large separable kernel attention: Rethinking the large kernel attention design in CNN. Expert Syst. Appl. 236, 121352 (2024).
Peng, Y., Sonka, M., Chen, D. Z. U-Net v2: Rethinking the skip connections of U-Net for medical image segmentation. arXiv preprint arXiv:2311.17791.
Xue, Y. et al. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 118, 103906 (2021).
Qin, D., Leichner, C. & Delakis, M. et al. MobileNetV4-universal models for the mobile ecosystem. arXiv preprint arXiv:2404.10518 (2024).
Liu, X., Peng, H. & Zheng, N. et al. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 14420–14430 (2023).
Chen, J., Kao, S. & He, H. et al. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12021–12031 (2023).
Ma, X., Dai, X. & Bai, Y. et al. Rewrite the stars. In Proceediings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5694–5703 (2024).
Li, Y., Hou, Q. & Zheng, Z. et al. Large selective kernel network for remote sensing object detection. In Proceedings IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 16794–16805 (2023).
Funding
This research was funded by Natural Science Basic Research Plan in Shaanxi Province of China (No. 2024JC-YBMS-342) , the Natural Science Foundation of Shaanxi Province (2021JM-537), the KeyProgram of the National Social Science Foundation of China (NSSFC,23AGL039) the Shaanxi Provincial Science and Technology Plan Project (2024GX-YBXM-114).
Author information
Authors and Affiliations
Contributions
X.L. and Y.Z. wrote the main manuscript text; X.J. performed data analysis; Q.M. and Z.G. conducted the experiments; R.Y. and Y.Y. processed the figures; B.Y. supervised the experimental design and revised the manuscript. All authors reviewed and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, X., Zhao, Y., Jiao, X. et al. PEYOLO a perception efficient network for multiscale surface defects detection. Sci Rep 15, 28804 (2025). https://doi.org/10.1038/s41598-025-05574-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-05574-0
Keywords
This article is cited by
-
An improved steel defect detection model using multi-scale feature fusion based on YOLO-MFD
Scientific Reports (2025)
