
Abstract
The increasing impact of urban floods, driven by global climate change and the growing frequency of extreme weather events, poses significant threats to public safety, disrupts infrastructure, and hampers economic development. This paper presents a two-stage model for shortest path planning and dynamic dispatching of rescue forces (firefighters and fire engines) in response to urban floods caused by extreme rainfall. In the first stage, a path selection model for rescue vehicles is developed, supported by an efficient customized A* algorithm to determine worst-case travel times from fire stations to flood sites. A preference-based version of the algorithm is also introduced, incorporating driver preferences into path selection. In the second stage, rescue forces are dynamically allocated based on demand at flooded locations, which is estimated using population density and real-time flood depth data. The travel times derived in the first stage serve as inputs to a bi-objective dynamic dispatch model that utilizes real-time flood data to optimize emergency response. By integrating path planning with rescue force dispatching, this study provides essential support for effective flood response operations.
Similar content being viewed by others
Introduction
With the intensification of global climate change, the increasing frequency of extreme weather events and heavy rainfall has resulted in more frequent urban floods1. These floods pose significant threats to residents and have severe impacts on urban infrastructure, transportation systems, and economic development2. Across the globe, both developed and developing countries are experiencing an increase in the frequency and destructiveness of flooding disasters3. Reducing the losses caused by such disasters through effective emergency responses has become a critical issue for city managers and policymakers4. Furthermore, many cities’ drainage systems are vulnerable to heavy rainfall5. According to a report by the Ministry of Emergency Management of China6, over 3000 geological hazards were triggered by heavy rainfall and flooding during the first three quarters of 2023, with flood-related economic losses accounting for a large proportion of all natural disaster-related losses. In July 2021, a “once in a thousand years” rainfall in Henan Province led to more than 300 deaths, and in October of the same year, severe flooding in Shanxi Province caused direct economic losses exceeding 5 billion yuan7,8.
In recent years, there has been growing concern regarding emergency management research in response to urban floods, particularly in the post-flood response phase. When intense rainfall occurs suddenly and the effects of urban flood disasters become apparent, various actions–such as evacuation9, emergency logistics planning10, and others–must be taken to mitigate the adverse impacts of the flood. Among these tasks, the dispatch of rescue forces to affected areas is one of the most critical actions that must be executed11.
Firefighters, as the primary force in emergency rescue operations, play an indispensable role in flood rescue efforts. According to the London Fire Brigade12, “Firefighters have the responsibility to move people to safety, restore, and maintain order”. Additionally, the Chinese national document GA/T 1340-2016: Classification of Fire Alarms and Emergency Rescue Operations, issued by the Ministry of Public Security of the PRC13, designates firefighters as responsible for conducting emergency rescue operations during natural disasters such as floods. The primary duty of firefighters in urban flood rescue operations is to rescue individuals trapped by the flood and ensure their safety.
For emergency authorities, the strategies and decisions regarding the allocation of firefighters to flood-affected sites are crucial to ensuring the success and efficiency of rescue operations. Efficient firefighter dispatch can minimize casualties and property damage while avoiding the waste of rescue resources. In addition to the scheduling of firefighters, another key consideration is the selection of rescue routes from fire stations to flood sites. To carry out rescue operations, firefighters must be transported from fire stations to affected areas. However, the optimal rescue path and corresponding travel time from each fire station to each flood site may differ from those under normal traffic conditions. Due to the impact of intense rainfall and the disruption of roads by floods, the navigation of rescue vehicles must account for more complex conditions, thus raising higher demands for path planning in flood scenarios.
This paper aims to develop shortest path planning and dynamic rescue force dispatching strategies for addressing multiple urban floods caused by short-term heavy rainfall. A two-stage approach is proposed.
The first stage involves determining the worst-case optimal travel times from fire stations to local flood sites. Given the uncertainty of the disaster, the actual travel time is random and influenced by flood severity. In this stage, we focus on the worst-case travel times, assuming the lowest vehicle initial speeds based on historical data during previous heavy rainfall events. This robust approach is adopted due to the high unpredictability of traffic congestion and weather conditions during floods. We develop a path selection model for rescue vehicles (i.e., fire engines) affected by rainstorms and urban floods, and propose a customized A* algorithm that offers higher search efficiency compared to the time-varying modified Dijkstra algorithm presented in Yuan and Wang’s study14. Additionally, we design a preference-based customized A* algorithm to select paths that reflect users’ preferences for primary roads, providing an alternative option for users when selecting rescue routes for fire engines.
The second stage involves dynamically dispatching firefighters to local flood sites. The local population density and the real-time flood depths are used to estimate the demand for firefighters at each site across different stages. Given that the efficiency of rescue operations heavily depends on the timely arrival of rescue forces, and considering the limited availability of resources, we develop a bi-objective dynamic dispatching model. The first objective is to minimize the total transportation time, while the second objective aims to minimize the number of firefighters and fire engines dispatched. The transportation time from each fire station to each affected site is determined by solving the shortest path selection model using the customized A* algorithm developed in the first stage. The operational procedures for shortest path planning and dynamic rescue forces dispatching are depicted in Fig. 1.
To the best of our knowledge, no existing literature focuses on the dynamic scheduling of firefighters in response to urban flood disasters caused by short-term heavy rainfall. In this study, a bi-objective dynamic dispatching model is developed to address this issue. Additionally, in most literature related to emergency resource allocation or rescue team scheduling, the travel times from supply sides to demand sides are typically simplified15,16. In contrast, this study calculates transportation times using a shortest path selection model. Moreover, we propose a more efficient search algorithm for the path selection model, surpassing the time-varied modified Dijkstra algorithm introduced in Yuan and Wang’s work14. We also highlight that incorporating road preferences into path selection can potentially result in shorter arrival times in real-world scenarios.

Operational procedures for studying shortest path planning and dynamic rescue forces dispatching.
Literature review
Although the literature on emergency management, particularly disaster management, is extensive, we will not review all optimization and decision models in the disaster response phase. Instead, our focus will be on vehicle path selection during disasters and the scheduling of emergency resources, with particular emphasis on the dispatching of rescue forces after a disaster.
Path selection and route planning17 for rescue vehicles is a key area in emergency management research, significantly impacting the efficiency of rescue operations. By following optimal paths, emergency vehicles can reach disaster sites quickly, helping to mitigate the damage caused by catastrophes. Yuan and Wang developed a path selection model that considers the impact of disaster extension on travel speed, solving it using a modified Dijkstra algorithm. They also constructed a multi-objective path selection model that accounts for path complexity and solved it using an ant colony optimization algorithm, achieving a balance between travel time and path complexity14. Sun introduced a strategy to find the fastest route in a dynamic environment, incorporating the reliability level by converting real-time vehicle speed into reliability based on speed distribution. The numerical results confirmed the feasibility of this strategy, offering more reliable route options in dynamic traffic conditions18. Zhao et al. developed a two-stage dynamic path planning model for emergency vehicles, aiming to minimize transportation time and traffic congestion. They used a polyline-shaped speed function to model speed and proposed a hybrid algorithm combining the shuffled frog leaping algorithm and the K-paths algorithm to solve the model19. Meng et al. used a co-evolutionary path optimization method, which incorporated ripple diffusion processes and dynamic routing environment changes, to find optimal paths from emergency material storage points to distribution nodes in a dynamic setting20. Sang et al. proposed a directional search A* algorithm, which improves upon the traditional A* algorithm by introducing angle constraints for smoother turns, enhancing directional guidance to reduce the search space, and optimizing node count for greater efficiency21.
In the aftermath of natural disasters, efficiently delivering emergency resources to affected areas to meet urgent relief needs is crucial for the survival of victims22. Recently, there has been an increasing focus on emergency logistics research, particularly concerning the dispatch of relief goods or equipment to affected areas under uncertainty. Sheu proposed a method combining fuzzy clustering of affected areas and dynamic relief distribution within a three-layer emergency logistics network after large-scale natural disasters. The incorporation of feedback mechanisms for relief demand enhanced the robustness of the logistics system to changes23. Ahmadi et al. developed a multi-depot logistics model considering network failure. The model divided the relief chain into two parts to assist emergency authorities in decision-making. The objective was to minimize unsatisfied demand, ensuring that sufficient relief supplies reached the disaster sites15. Alem et al. made significant strides in the rapid supply of emergency resources to disaster victims by developing a stochastic network flow model. This model also incorporated insights from risk management, accounting for various risk attitudes in the decision-making process24. Zhang et al. proposed a three-stage multi-objective programming model to address resource allocation during primary and secondary disasters. They employed a fuzzy membership function approach to solve the problem25. Wei et al. developed an assignment system to help rescue vehicles deliver relief goods to affected sites. They built a location-routing model with soft time windows and designed an innovative ant colony optimization algorithm to approximate Pareto frontiers26.
In addition to emergency supplies, rescue teams, as a form of emergency human resources, play a critically significant role in disaster relief. The scheduling of rescue forces and teams after disasters has recently garnered significant attention from researchers. Rolland et al. presented a decision-support system for assigning rescue teams to disaster incidents and developed an efficient algorithm to solve the scheduling model under time pressure. The proposed system facilitated collaboration among different rescue organizations and set a strong example for coordinated rescue planning27. Zhang et al. emphasized the influence of potential secondary disasters on emergency rescue operations. They introduced a dynamic assignment model to address the disaster chain and applied NSGA-II, C-METRIC, and fuzzy logic methods to generate three scheduling strategies for solving the multistage model28. Rezapour et al. developed mathematical optimization models to identify the optimal strategy for scheduling medical and rescue units at disaster sites, aiming to minimize fatalities following sudden-onset disasters. This study highlighted the importance of coordination among various rescue activities in casualty management29. Rauchecker and Schryen built a binary linear model to plan rescue schedules for rescue teams, considering collaboration among rescue units. The problem was solved using a proposed branch-and-price algorithm, which enhanced the quality of scheduling strategies30. Tirkolaee et al. incorporated learning effects and developed a robust bi-objective programming model for allocating rescue units during the onset of disasters. They treated the scheduling problem as a combination of Unrelated Parallel Machine Scheduling and the Traveling Salesman Problem16. Sun et al. developed a robust optimization model with two objectives to optimize logistics under emergency conditions and the allocation of rescue vehicles and helicopters. The Injury Severity Score was introduced to describe injuries31. Some literature also focuses on the scheduling of firefighters specifically, rather than broader rescue teams or units. Alutaibi et al. studied the scheduling and allocation of firefighters using a decision support system that provides optimal strategies for dispatching firefighters to multiple fire incidents32. Rodriguez et al. proposed a simulation-based optimization approach to address the vehicle assignment problem for firefighters. The key innovation of their work was the improvement of emergency arrival accuracy by combining a Kernel Density Estimator and an NHNR arrival process33.
In the existing literature, the shortest path planning for rescue vehicles and the dynamic dispatching of firefighters during urban flood disasters caused by short-term, intensive rainfall have been largely overlooked. In this study, the worst-case optimal transportation times, derived from a shortest path selection model under flood conditions, are used to determine the dispatching scheme for firefighters and fire engines. For shortest path planning, we develop a customized A* algorithm. Building on this newly developed algorithm, we propose a preference-based path planning algorithm that incorporates user preferences into the selected path. Moreover, unlike existing literature where rescue force dispatching is typically team-based, our scheduling approach removes this restriction, offering a more flexible and cost-effective allocation strategy. This approach determines the precise number of firefighters and fire engines needed at each rescue stage.
Shortest path selection under flood
Notations and definitions
Various criteria can be used to define the cost of a path. In this paper, the cost of a path refers to the time cost rather than the distance. The notations used in the shortest path selection model and algorithms are described below.
Notations in the model
G(V, E) An undirected graph/network, where \(V=\{1,2,...n\}\) is the set of nodes and E denotes the set of arcs. If node i and node j are directly connected, then arc (i, j) \(\in\) E.
\(l_{i j}\) The length of the road section (i, j), i.e., the length of the arc between node i and node j.
\(v_{i j}^{0}\) The worse-case initial speed of an emergency vehicle on the road section (i, j), which can be estimated by the historical vehicle travel speed recordings when heavy rainfalls happened.
\(v_1,v_2\) The worse-case initial speed of an emergency vehicle on the primary and secondary roads. Here, we only consider the path planning on the primary and secondary roads (\(v_{i j}^{0}=v_1 \,\, \text {or} \,\, v_2\)).
\(v_{i j}(t)\) Speed function on the road section (i, j).
S, D The starting node and the ending node of the path to be planned.
\(t_{S},t_{D}\) The departure time and arrival time of an emergency vehicle.
\(t_{i},t_{j}\) The time when an emergency vehicle reaches the origin node i and the terminal node j of arc (i, j).
\(t_{i j}\) Travel time on arc (i, j), equivalent to \(t_{j}-t_{i}\).
\(\alpha _{i j}, \beta _{i j}\) The damping parameters that capture the decrease extent of \(v_{i j}(t)\) under the influence of urban floods.
\(\gamma _{i j}\) Road congestion parameter in normal traffic conditions without disaster.
\(x_{i j}\) A binary decision variable determining whether arc (i, j) is included in the path. If arc (i, j) is part of the selected path, then \(x_{i j}=1\), otherwise it equals to 0.
Notations in the algorithms
d(u, v) Geodesic distance (Euclidean distance) between u and v, where u, v are arbitrary two points in the network.
t(u, v) Actual time cost (minimum travel time) from u to v, where u, v are arbitrary two points in the network.
K(u, v) Estimated time cost from u to v, where u, v are arbitrary two points in the network.
g(n) Actual time cost from starting node S to node n.
\(\hat{g}(n)\) An estimate of g(n): the time cost from starting node S to node n calculated based on the path found by the algorithm so far.
h(n) Actual time cost from node n to destination node D.
\(\hat{h}(n)\) Estimated time cost from node n to destination node D.
Closed A list for storing nodes that have been explored.
Open A list for storing nodes to be explored.
C The current node under processing in the algorithm.
C.father Father node of the current node C.
Weight(a, b) The edge weight between two adjacent nodes a and b.
Path selection model for emergency vehicles
We select paths on an undirected road network G(V, E), where \(V=\{1,2,...n\}\) is the set of nodes and E denotes the set of arcs. If node i and node j are directly connected, then arc (i, j) \(\in\) E. Denote the starting point by S, with the initial time \(t_{S}=0\). The destination of the path is recorded as D and the time for reaching the terminal is \(t_{D}\). The path selection model is shown below.
The objective function (1) aims to find the shortest path from S to D considering the impact of rainstorms and urban flooding, where \(t_{i j}\) is the travel time on arc (i, j). The worst-case initial speeds of the emergency vehicles on primary and secondary roads are denoted as \(v_1\) and \(v_2\), respectively, as specified in constraint (2). Note that given the unpredictability of disasters, actual travel times vary and are influenced by flood severity. In this analysis, we consider worst-case scenarios by using the lowest initial vehicle speeds, derived from historical data during heavy rainfall periods. This robust approach is practical given the highly unpredictable traffic and weather conditions during floods. Constraints (3–5) represent the iterative expression of travel time along a path. Constraint (6) models the travel speed-dependent function for each road section in the context of floods, where \(\gamma _{i j}\) is the road congestion index of the arc (i, j) under normal traffic conditions (without disaster), and \(\alpha _{i j}\) and \(\beta _{i j}\) represent the spatial and temporal impacts of floods, respectively. These two damping parameters determine the extent to which \(v_{i j}(t)\) decreases as the flood extends both spatially and temporally. As stated by Yuan and Wang, \(\alpha _{i j}\) and \(\beta _{i j}\) can be estimated based on the distance between arc (i, j) and local flooding sites, the fragility of the arc, and the severity of the floods14. Constraint (7) ensures the feasibility of the path from S to D by restricting the value of \(x_{i j}\). The expression \(\sum _{j=1,j \ne i}^{n} x_{i j} - \sum _{j=1,j \ne i}^{n} x_{j i} = 1, -1, 0\) corresponds to the starting node, ending node, and intermediate node of the path, respectively. Constraint (8) guarantees that no cycles are present in the path. Additionally, as shown in constraint (9), certain rescue vehicles have size or weight restrictions, so roads with limited weight/height should be avoided to prevent blockages. Roads prone to water accumulation (i.e., ponding roads), which have a high probability of causing traffic disruptions, should also be avoided when selecting the shortest path to minimize prolonged stays in areas with heavy congestion. Finally, constraint (10) restricts the decision variable \(x_{i j}\) to be binary, indicating whether the arc (i, j) is part of the selected path. When the arc (i, j) is included in the path, \(x_{i j} = 1\); otherwise, \(x_{i j} = 0\).
Thus, if we denote the optimal path by \(p_0\longrightarrow p_1\longrightarrow ...\longrightarrow p_m\), where \(t_{p_0}=t_{S}\), \(t_{p_m}=t_{D}\), then the optimal travel time from S to D is \(t_{D}-t_{S}=\sum _{k=1}^m (t_{p_k}-t_{p_{k-1}})=\sum _{k=1}^m t_{p_{k-1}p_k}\).
Algorithms for solving the path selection model
Before introducing our new algorithm: A Customized A* Algorithm, we first have a brief review of the classical A* algorithm.
A brief review of the classical A* algorithm
A large body of literature focuses on solving point-to-point shortest path problems on static networks. The A* algorithm was first proposed by Hart et al.34, marking a milestone in selecting the shortest path using heuristics. Since then, various adaptations of the A* algorithm have emerged to address shortest path problems in different scenarios35,36,37.
The basic idea of the A* algorithm is to find the shortest path based on the node evaluation function \(\hat{f}(n) = \hat{g}(n) + \hat{h}(n)\), where \(\hat{g}(n)\) represents an estimate of the actual time cost from the starting node S to node n (denoted as g(n)), and \(\hat{h}(n)\) represents an estimate of the actual time cost from node n to the destination node D (denoted as h(n)). \(\hat{g}(n)\) is typically the time cost from the starting node S to node n, calculated based on the path found by the algorithm up to that point. In the classical A* algorithm for finding the shortest path, \(\hat{h}(n)\) is commonly approximated as \(\frac{d(n,D)}{ V }\), where d(n, D) is the Euclidean distance from node n to the destination node D, and \(V\) is the maximum travel speed38. The heuristic function \(\hat{h}(n)\) plays a key role in ensuring the efficiency of the algorithm, distinguishing A* from other search algorithms.
The A* algorithm explores the node with the smallest value of \(\hat{f}(n)\) in each iteration, selecting it as the current node C and simultaneously recording the father node of C: C.father. The algorithm terminates when the current node C reaches the destination node D, at which point the optimal path is formed by tracing back through the father nodes and reversing the path. The details of the classical A* algorithm are outlined below.

Classical A* Algorithm for finding the shortest path
Hart et al pointed out that the A* algorithm could find the optimal path when the heuristic function \(\hat{h}(n)\) can be controlled by the actual time cost h(n)34. Additionally, previous research has proved that the overall computational efforts can be largely reduced if \(\hat{h}(n)\) is a better lower approximation of h(n). Namely, if a node is searched by the A* algorithm with a larger \(\hat{h}(n)\), then this node will be searched by the A* algorithm with any smaller \(\hat{h}(n)\), as presented in Lemma 134,36.
Lemma 1
In the A* algorithm, if \(\hat{h}(n)\leqslant h(n)\), then A* is guaranteed to find the shortest path and the search efficiency can be improved if \(\hat{h}(n)\) is a better lower estimate of h(n).
Since the classical Dijkstra algorithm is a special case of the classical A* algorithm with the heuristic function \(\hat{h}(n)=0\)39. The time-varied modified Dijkstra algorithm proposed by Yuan and Wang can also be interpreted as a time-varied A* algorithm with the heuristic function \(\hat{h}(n)=0\)14. Thus, both the modified Dijkstra algorithm and the classical A* algorithm ensure the optimality of the selected path, as the heuristic functions of these two algorithms are always lower than the actual time cost, h(n). By Lemma 1, the paths selected by these two algorithms have the shortest travel times. However, the large gap between h(n) and \(\hat{h}(n)\) causes the algorithm to explore many redundant nodes when selecting the path, thereby increasing computational effort. That is to say, if \(\hat{h}(n)\) is a good enough approximation from below of the actual time cost h(n), the algorithm will explore considerably fewer nodes and efficiently accelerate the pace toward the destination node.
Under the influence of disaster extension, the shortest path model structure can be utilized to develop a more efficient algorithm based on the framework of the A* algorithm. In other words, we can customize a better path selection algorithm based on the model structure. We call the newly developed algorithm by “customized A* algorithm”.
A customized A* algorithm
Our proposed customized A* algorithm relies on a newly defined time cost function as a metric to build a heuristic. The estimated time cost function between two arbitrary points on the road network is defined as follows.
Definition 1
(The estimated time cost function between 2 points) Denote \(\alpha =\operatorname {Min} \alpha _{i j}\), \(\beta =\operatorname {Min} \beta _{i j}\), \(\gamma =\operatorname {Min} \gamma _{i j}\), and \(V =\operatorname {Max}v_{i j}(t)\). Let K(u, v) satisfy: \(V (1-\alpha -\gamma ) \int _{0}^{K(u,v)}\exp \left\{ -\beta t\right\} d t = d(u,v)\), where d(u, v) is the Geodesic distance (Euclidean distance) between u and v.
The definition of time cost function K(u, v) can also be written as \(K(u,v)=-\frac{1}{\beta }ln[1-\frac{\beta d(u,v)}{ V (1-\alpha -\gamma )}]\), which is constructed based on the Euclidean distance but involves more information such as the spatial and temporal effect of disaster and traffic congestion.
Based on the framework of the A* algorithm, the proposed customized A* algorithm has the following two improvements compared with the classical A* algorithm.
-
1.
The classical A* algorithm is only suitable for route planning in a static network. However, a disaster like heavy rainfall may affect the vehicle speed continuously, resulting in the decline of the vehicle speed with respect to time. Just as the model defined above, the travel time on arc (i, j), \(t_{i j}\), is determined by constraints (3) and (6). That is to say, \(t_{i j}\) is still affected by the time when the vehicle reaches the beginning node i of arc (i, j). Consequently, the travel time of the selected path needs to be obtained based on iterative calculation, in this sense, similar to the time-varied modified Dijkstra algorithm proposed by Yuan and Wang14.
-
2.
In the classical A* algorithm for solving the shortest path problem, the estimated cost function \(\hat{h}(n)\) is defined as \(\frac{d(n,D)}{ V }\)38, where D is the destination and \(V\) is the maximum travel speed on the road network . While using \(\hat{h}(n)=\frac{d(n,D)}{ V }\) guarantees that the path is optimal, as \(\frac{d(n,D)}{ V }\) is a lower bound of h(n), the large gap between \(\frac{d(n,D)}{ V }\) and the actual cost h(n) reduces the efficiency of the classical A* algorithm. However, in our customized A* algorithm, the estimated time cost function between 2 points is defined as K(u, v) rather than \(\frac{d(u,v)}{ V }\). Later we will prove that K(u, v) is a more precise estimate of the actual time cost from u to v.
Theorem 1
K(u, v) is a more precise lower estimate of the actual time cost from u to v than \(\frac{d(u,v)}{ V }\).
The proof of Theorem 1 is shown in Appendix. Now we can replace the heuristic function \(\frac{d(N,D)}{ V }\) in the classical A* algorithm by K(N, D). The details of the customized A* algorithm is listed below.

A customized A* algorithm
Theorem 2
The path selected by the customized A* is optimal and has higher search efficiency than the modified Dijkstra algorithm14 and the classical A* algorithm.
Proof
The theorem can be easily proven since, by Lemma 1, if the estimate \(\hat{h}(n)\) is made closer to h(n) from below, the algorithm will not only ensure optimality but also explore fewer nodes, thereby achieving higher search efficiency. For the modified Dijkstra algorithm14, \(\hat{h}(n)=0\); for the classical A* algorithm \(\hat{h}(n)=\frac{d(n,D)}{ V }\). By Theorem 1, K(u, v) is larger than \(\frac{d(n,D)}{ V }\), then large than 0 trivially. Thus, the path selected by the customized A* is optimal and has higher search efficiency than the classical A* algorithm and the modified Dijkstra algorithm. \(\square\)
Although the model proposed above provides a detailed description of vehicle routing during disasters, the complexity of real-world scenarios far exceeds what the model can represent. Therefore, incorporating habitual driving patterns or driver preferences allows for flexible adjustments to better adapt to actual road conditions. For example, Cunnington highlighted that drivers tend to prefer higher-speed roads unless there is significant traffic congestion40. Primary roads typically have higher speed limits, and their superior road conditions and driving environments reduce the likelihood of traffic congestion compared to secondary roads. As a result, when searching for the shortest path in an urban road network, many drivers prefer routes with more primary and trunk roads to enhance the driving experience and reduce travel time.
If we take people’s preference into account, the customized A* algorithm proposed above can be further extended to a preference-based customized A* algorithm.
A preference-based customized A* algorithm
In the customized A* algorithm presented earlier, the algorithm selects the next node to explore based on the smallest value of \(\hat{f}(n)\) in the open set Open. However, if there is a preference to prioritize primary roads when planning the route, the algorithm can be modified accordingly.
-
1.
In line 24 of algorithm 2, if N is not in Open, we also need to record the road rank of the arc between node N and the current node C.
-
2.
The selection criterion presented in line 31 of algorithm 2 is replaced by: Sort the nodes in Open according to the road rank as the first criterion and assign a new order in each rank group in terms of the value of \(\hat{f}(n)\), from the smallest to the largest. Then denote the first node on Open as M and set \(M.father=C, C=M\).
For example, suppose that \(Open=\{n_1,n_2,n_3,n_4\}\), the corresponding road ranks and \(\hat{f}(n)\) are \(\{1,2,1,2\}\) and \(\{10,12,9,8\}\) respectively, then Open is reordered as \(\{n_3,n_1,n_4,n_2\}\). We choose \(n_3\) as the next node to be explored.
The reason why the preference-based customized A* algorithm can ensure that as many primary roads as possible in the path are included is that the modified node selection criterion gives priority to searching those nodes which are connected to the primary road sections, increasing the probability of forming a path that contains more primary roads. Sometimes, the algorithm may deviate from the optimal path just for including as many primary roads as possible.
Despite that the preference-based customized A* algorithm can not guarantee the optimality of the selected path, it provides an alternative for the emergency authority for making a quick decision, especially when the path found by the preference-based customized A* algorithm is suboptimal but contains a larger proportion of primary roads in the path, which may lead to a shorter travel time in reality.
The optimal vehicle paths and the corresponding optimal travel times from fire stations to local flooding sites can be obtained by employing the model and algorithms described above, which then can be used as input in the following dynamic scheduling model.
Dynamic scheduling of emergency rescue forces
Once the optimal rescue path and corresponding minimal travel time from each fire station to each local flooding site are determined, the Emergency Management Bureau can efficiently plan the deployment of rescue forces to minimize the duration of rescue operations and reduce casualties and property damage caused by the disaster. The dynamic scheduling of rescue forces discussed in this paper addresses the challenge of managing multiple fire stations, local flooding sites, and multistage allocation during urban flood disasters triggered by short-term heavy rainfall. The emergency authority should allocate firefighters and fire engines to the affected flooding sites within a limited time frame at each stage to meet the rescue demands of the affected areas as effectively as possible, as shown in Fig. 2.

The diagram of dynamic rescue forces dispatching.
Model formulation
In addition to the notations introduced earlier, several new variables and notations are defined here for the dynamic dispatching model as follows.
Sets:
I Set of supply sites (fire stations), \(i \in I, I=\{1,2, \ldots , |I|\}\).
J Set of affected sites (local flooding sites), \(j \in J, J=\{1,2, \ldots , |J|\}\).
V Set of emergency vehicles (fire engines).
R Set of stages of rescue, \(r \in R, R=\{0,1,2, \ldots , |R|\}\), where |R| is the maximum number of stages.
Parameters:
\(y_{j}\) Risk value of the community where the affected site j locates computed based on the population density.
\(h_{j}^{r}\) flood depth (meters) at affected site j at the beginning of stage r.
\(\lambda\) A weight parameter that determines the relative importance of population density risk and the severity of local flooding.
\(d_{j}^{r}\) Demand for firefighters at \(j \in J\) at stage \(r \in R\).
\(m_{i}^{r}\) Available supply of firefighters at fire station i at stage \(r \in R\).
\(m_{a i}\) Number of firefighters at fire station i.
\(m_{d i}\) Number of firefighters on duty at fire station i.
\(v_{i}^{r}\) Available supply of fire engines at fire station i at stage \(r \in R\).
\(v_{a i}\) Number of fire engines at fire station i.
\(v_{d i}\) Number of fire engines on duty at fire station i.
TC Time limit for rescue dispatch.
\(t_{i j}^{r}\) Optimal transportation time from \(i \in I\) to \(j \in J\) at stage \(r \in R\), which is obtained based on the result of the proposed customized A* algorithm.
\(\eta\) Minimum satisfaction rate of firefighters demand.
Cap Capacity limit for firefighters in one fire engine.
Decision Variables:
\(s_{i j}^{r}\) A binary variable indicating whether the fire station \(i \in I\) allocates firefighters to the flooding site \(j \in J\) at stage \(r \in R\) or not. \(s_{i j}^{r}=1\) if there are firefighters allocated from \(i \in I\) to \(j \in J\) at stage \(r \in R\), otherwise it equals to 0.
\(m_{i j}^{r}\) Number of firefighters that are allocated from \(i \in I\) to \(j \in J\) at stage \(r \in R\).
\(v_{i j}^{r}\) Number of fire engines that are allocated from \(i \in I\) to \(j \in J\) at stage \(r \in R\).
Demand updating function
The criticality and severity of local flooding are highly influenced by population density and flood depth. Higher population densities often correlate with increased emergency service needs due to the greater number of individuals potentially affected. Real-time flood depth data provides insights into the severity and extent of flooding, which directly impacts the urgency and scale of required rescue operations41. By integrating these factors, emergency management agencies can more accurately allocate resources to areas with the greatest need, enhancing response efficiency and effectiveness. Therefore, population density data and real-time flood depth data are utilized to help predict the demand for firefighters at each rescue stage.
First, based on the document Standards for Local Flooding Prevention and Control System Planning published by the Department of Housing and Urban Construction42, and the risk evaluation method proposed by Cox et al.43, a risk mapping function is formulated as follows:
where 0-4 are flooding risk values, representing “no risk”, “low risk”,“medium risk”,“high risk” and “very high risk” respectively. Recall that \(h_{j}^{r}\) represents the flood depth at the affected site j at the start of stage r. A higher flood depth in a region indicates a more severe situation for citizens impacted by urban floods. Therefore, the risk mapping function connects the water depths with risk values, highlighting the urgency of rescue operations needed in a specific area at a given period.
Furthermore, according to the document GA/T 1340-2016 Classification of Fire Alarms and Emergency Rescue Operations published by the Ministry of Public Security of the PRC13, emergency rescue operations are classified into four grades: Blue (Grade 1), Yellow (Grade 2), Orange (Grade 3), and Red (Grade 4). In a given region, the total number of firefighters required for rescue at each grade can be estimated based on local emergency authority regulations.
Denote the firefighter demand estimate function by \(\mu (x)\), which maps the risk value to the total number of firefighters needed for rescue operations in a given area:
where \(a_0\), \(a_1\), \(a_2\), \(a_3\), and \(a_4\) represent the total number of firefighters needed under different risk levels. Up to now, a demand forecasting function at stage r can be devised as:
where \(g_j=\frac{y_j}{\sum _{j=1}^{|J|}y_j}\) and \(f_{j}^{r}=\frac{h_{j}^{r}}{\sum _{j=1}^{|J|}h_{j}^{r}}\) are the relative weight of the affected site j calculated based on the population density and real-time flood depth respectively. \((\lambda g_{j}+(1-\lambda )f_{j}^{r})\) measures the relative urgency of the rescue demand at stage r and \(\mu (\mathbbm {1}(h_{j}^{r}))\) represents how many firefighters need to be dispatched in total under the risk level corresponding to the current flood depth. \(\sum _{k=1}^{r-1}\sum _{i=1}^{|I|}m_{i j}^{k}\) is the total number of firefighters dispatched to affected site j in the past stages. If \(\lceil (\lambda g_{j}+(1-\lambda )f_{j}^{r})\mu (\mathbbm {1}(h_{j}^{r})) \rceil -\sum _{k=1}^{r-1}\sum _{i=1}^{|I|}m_{i j}^{k}\) is negative, it means that the firefighters allocated in the previous stages are sufficient to handle the rescue operation at the current stage. Thus, there is no need to dispatch more rescue forces to this site. And the reason why \(\lceil (\lambda g_{j}+(1-\lambda )f_{j}^{r})\mu (\mathbbm {1}(h_{j}^{r})) \rceil -\sum _{k=1}^{r-1}\sum _{i=1}^{|I|}m_{i j}^{k}=1\) leads to 0 allocation of firefighters is that it is too costly to send a single firefighter to the affected site by fire engine, which is also a waste of the vehicle resources.
Dynamic dispatching model
At the initial stage of the emergency rescue:
Equations (11) and (12) specify the number of vehicles and firefighters available for dispatch at each fire station at stage 0. The quantities of firefighters and fire engines ready for dispatch are equal to the total rescue forces available at each fire station, excluding those currently on duty. Equation (13) presents the estimated demand for firefighters at each affected site in the initial stage.
At stage r, a bi-objective nonlinear programming model can be formulated as follows.
The first objective (14) minimizes the total transportation time from supply sites to demand sites at stage r. The second objective (15) minimizes the total number of firefighters and fire engines allocated at stage r. Constraint (16) ensures that the number of firefighters allocated from fire station i does not exceed the available human resources. Similarly, constraint (17) ensures that the number of fire engines dispatched from fire station i is within the available range of vehicles. For each affected site, the demand is to be satisfied at a minimum level of \(\eta\) and at most 100 percent to avoid oversupply, as shown in constraint (18). The demand updating function is given in constraint (19). Constraint (20) is the capacity constraint that prevents vehicle overload. Constraint (21) requires that at least two firefighters be dispatched for each mission to avoid wasting vehicle resources. Additionally, the supply updating functions for firefighters and fire engines are provided in constraints (22) and (23). Constraint (24) ensures that the transportation time for each dispatch remains within a specified limit, thereby maintaining the efficiency of rescue operations at each stage. Finally, constraints (25) and (26) define the variable types of the decision variables.
Solution algorithm
The first objective in the model focuses on rescue efficiency, aiming to minimize the total travel time at each stage. The second objective aims to minimize the total number of firefighters and fire engines dispatched at each stage to avoid unnecessary waste of rescue forces. Since time has the highest priority in emergency management, objective 1 should be given more weight than objective 2 in the context of bi-objective programming. The lexicographic ordering method proposed by Fishburn and Peter44 is an appropriate approach for handling this bi-objective optimization problem, as it is well-suited for multi-objective programming problems with preferences. Additionally, Miettinen has proven that the solution obtained through this method is Pareto optimal45.
The procedures for dealing with the bi-objective programming model are listed below:
Step 1 Minimize the single objective function \(F_1\) over constraint (16)-constraint (26). Denote the optimal solution set by \(S_1\). Since only the decision variables \(s_{i j}^{r}\) are involved in \(F_1\), step 1 of the algorithm determines whether fire station \(i \in I\) allocates firefighters to the flooding site \(j \in J\) at stage \(r \in R\).
Step 2 Minimize the single objective function \(F_2\) over \(S_1\) and constraint (16)-constraint (26). The optimal solution for minimizing \(F_2\) is then the optimal solution for the bi-objective programming. Step 2 of the algorithm optimizes based on the optimal solution set \(S_1\) from step 1, calculating the exact number of firefighters and fire engines to be dispatched.
Case study
We present a case study to demonstrate the effectiveness of our approach in responding to short-term heavy rainfall and urban flood disasters46, showcasing its potential for practical application. The numerical experiment is based on a short-term heavy rainfall event that occurred in Futian District, Shenzhen, on April 11, 2019, known as the 411 Shenzhen Rainstorm. This sudden rainstorm resulted in eleven fatalities and severe flooding, with the maximum average precipitation over three hours reaching 65 millimeters47. Zhang et al. applied multi-source information fusion technology and conducted a hydrological analysis in Futian District, revealing that many drainage facilities in the area are vulnerable to intensive rainfall, leading to urban flood disasters48. Such extreme short-term heavy rainfall underscores the need for rapid and efficient rescue planning to minimize casualties and property damage.
Data collection and prepocessing
The road network of Futian District has been simplified in ArcMap 10.5, which consists of 176 nodes and 253 edges (road sections) in total, involving two-way 152 primary and 101 secondary road sections. The road grades, the initial travel speed \(v_{i j}^{0}\) on each arc (i, j), the length of each arc \(l_{i j}\), and the parameters \(\alpha _{i j}\), \(\beta _{i j}\), \(\gamma _{i j}\) of the 253 road sections are shown in Table 1 (See Appendix for full version parameters). The worst-case initial travel speeds on primary and secondary roads (\(v_1\) and \(v_2\)) are estimated based on historical traffic data from Futian District during heavy rainfall events (to maintain the confidentiality of data owned by the Shenzhen Urban Public Safety Institute, we choose not to disclose this information). The length of each road section is obtained using the “Calculate Geometry” function in ArcMap 10.5. The values of \(\alpha _{i j}\), \(\beta _{i j}\), and \(\gamma _{i j}\) are generated from uniform distributions.
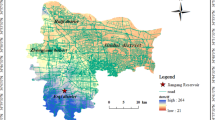
Futian District has 10 micro fire stations, each capable of accommodating two fire engines, along with 4 macro fire stations, forming the supply side of the emergency rescue forces. On the demand side, data gathered from the Shenzhen Municipal Government Data Open Platform49 identifies 4 local flooding areas to consider. The real-time flood depth data (from 21:45 to 22:45) for the 4 affected sites is presented in Table 2. Missing data has been supplemented using the ARIMA forecast model in time series analysis. The distribution of fire stations and affected sites is illustrated in Fig. 3.

Distribution of fire stations and local flooding sites in Futian District (Software: ArcMap 10.5; URL: www.arcgis.com).
Regional flooding risk in urban communities is closely related to population size and the real-time flood depth within local areas. Therefore, in this case study, we combine population density with real-time flood depth to calculate the estimated risk value. First, we apply the natural breaks method50 to rank the risk levels of communities based on population density. The natural breaks method is advantageous for identifying statistically significant breakpoints in sequences, which allows for classification into groups with similar properties. As shown in Table 3, we categorize the risk levels of communities by population density into six groups using the natural breaks method. The population densities of the communities where the affected sites are located are 1.61, 3.60, 9.50, and 0.30. Consequently, the corresponding risk values are \(y_1=1\), \(y_2=3\), \(y_3=5\), and \(y_4=1\), as detailed in Table 3. With the data collected from Shenzhen Urban Public Safety Institute, the number of firefighters and fire engines ready for dispatching is listed in Table 4. The number of firefighters needed in total at each grade can be estimated in the light of document51.
Short-term intensive rainfall can lead to rapid water accumulation, with the flood depth at affected site 2 rising by over 0.5 meters within just 10 minutes (from 21:50 onward), posing a significant threat to human safety. It is assumed that the emergency authority determines dispatch decisions for firefighters every 10 minutes. Therefore, during the rescue period (from 21:45 to 22:45), allocation strategies are dynamically determined across six rescue stages.
Numerical results
The numerical experiments are conducted on a computer system that consists of an Intel Core i7-6500U CPU at 2.50 GHz and 8 GB of RAM. For shortest path planning, Tables 5, 6, and 7 compare the performance of three algorithms–Modified Dijkstra Algorithm14, Customized A* Algorithm, and Preference-Based Customized A* Algorithm–in identifying routes from node 154 to node 26, node 155 to node 40, and node 58 to node 14, respectively. The optimal path from node 154 to node 26 is illustrated in Fig. 5.
In general, compared to the modified Dijkstra algorithm14, the customized A* algorithm explores fewer nodes and demonstrates better performance in terms of algorithm runtime, which aligns with our theoretical analysis. More importantly, both the modified Dijkstra algorithm and the customized A* algorithm consistently find optimal paths, as guaranteed by Theorem 2. Furthermore, it can be observed that the preference-based customized A* algorithm does not always guarantee the optimal path in terms of travel time. For instance, as shown in Table 6, the percentage of primary roads selected in the path increases by over 15%, resulting in an additional 11 minutes of vehicle travel time. However, the preference-based customized A* algorithm reliably provides an alternative path choice for emergency response planning when needed. For instance, as shown in Table 7, the path selected by the preference-based customized A* algorithm includes 100% primary roads, yet the vehicle travel time (21.25 minutes) is slightly higher than the optimal driving time obtained by the customized A* algorithm (17.31 minutes). Therefore, it is difficult to definitively determine which path would lead to an earlier arrival in real-world scenarios. In summary, the preference-based customized A* algorithm can accommodate the user’s preference for driving on primary roads, albeit at the cost of increased vehicle travel time.
Figure 4a and b illustrate the overall performance of three algorithms in finding paths from 14 fire stations to 4 flooding sites. The results reveal similar patterns, demonstrating that our proposed customized A* algorithm explores fewer nodes while ensuring path optimality. Moreover, the preference-based customized A* algorithm increases the average use of primary roads.

Comparison of three algorithms for routing from 14 fire stations to 4 flooding sites.
Since we consider worst-case vehicle travel times by using worst-case initial travel speeds, the final transportation times from fire stations to local flooding sites may exceed the actual vehicle travel times. Moreover, as the worst-case initial travel speeds are deterministic, the computed travel times remain constant across rescue stages. Therefore, using the optimal travel times from fire stations to local flooding sites, calculated based on the customized A* algorithm (as shown in Table 8), the dynamic scheduling model is solved according to our solution procedures. The lexicographic ordering and cutting plane methods embedded in Gurobi 9.0 are employed to solve the reformulated problem stage by stage. In the dynamic scheduling model, we set the standard relief time \(TC=22\) (min), the weight parameter \(\lambda =0.5\), the capacity limit \(Cap=6\), and the minimum satisfaction rate \(\eta =0.9\) to determine the allocation strategies of firefighters and fire engines at each stage. The number of fire engines and firefighters dispatched at each stage are provided in Tables 9 and 10.

Optimal path from node 154 to node 26 (Software: ArcMap 10.5; URL: www.arcgis.com).
Sensitive analysis

Firefighters allocation at affected site 2 with different \(\eta\) (\(\lambda =1/2\)).

Firefighters allocation at affected site 3 with different \(\eta\) (\(\lambda =1/2\)).

Firefighters allocation at affected sites 2 and 3 with different \(\lambda\) (\(\eta =0.90\)).
In this section, we investigate the optimal allocation strategy under varying minimum satisfaction rates (\(\eta\)) and the weight parameter (\(\lambda\)), which determines the relative importance of population density and local flood severity. Since the flooding at affected sites 1 and 4 poses minimal safety threats and no more than two firefighters are dispatched to either site, our sensitivity analysis focuses on sites 2 and 3.
As shown in Figs. 6 and 7, regardless of the minimum satisfaction rate \(\eta\), the allocation quantity increases from stage 0 to stage 1 and decreases from stage 2 onward. This phenomenon occurs because the rising rainfall intensity and increasing waterlogging levels at local flooding sites initially drive a surge in demand for firefighters during the early stages. However, as flood depths recede, the risk levels at affected sites diminish, leading to a reduced demand for firefighters in the later stages.
Furthermore, compared to allocation strategies with a lower minimum satisfaction rate, a higher \(\eta\) leads to more firefighters being dispatched in the early stages and fewer firefighters scheduled from stage 2 or 3 onward. As indicated by the demand updating function (19), allocating a larger number of firefighters at the early stages (driven by a higher \(\eta\)) often suffices to meet the rescue demand. Consequently, fewer firefighters are required in the later stages compared to the allocation based on a lower minimum satisfaction rate \(\eta\).
Figure 8 highlights the impact of the relative importance of population density versus flood severity on the dispatch of rescue forces. When less importance is placed on the severity of local flooding (i.e., when more importance is placed on population density), as \(\lambda\) increases from \(\frac{1}{2}\) to \(\frac{3}{4}\), the number of firefighters allocated to affected site 2 decreases before stage 3. However, the opposite trend is observed at affected site 3, where the number of firefighters allocated increases with \(\lambda\). This interesting phenomenon arises because increasing the weight parameter \(\lambda\) amplifies the significance of the risk value associated with population density. Compared to affected site 2, site 3 has a higher population density but lower flood depths. The increase in \(\lambda\) prompts the emergency authority to place greater emphasis on areas with dense population, increasing the criticality of emergency rescue at affected site 3 and leading to more rescue forces being allocated there. Therefore, the relative importance of population density versus flood severity significantly impacts the distribution of rescue forces over affected sites during urban floods.
It can also be observed that more firefighters are dispatched to affected site 2 during the initial stages (stage 0, stage 1), but the number decreases from stage 2 onward. A similar pattern is seen at affected site 3, with the key difference being that the maximum allocation occurs at stage 2 rather than stage 1. As a result, the allocation at affected site 3 surpasses that at site 2 from stage 2 onward. This aligns with the patterns of flood depth changes at the different affected sites over the stages.
Conclusions
This research investigates shortest path planning and dynamic rescue force dispatching in response to urban flood disasters. The study is divided into two phases. In the first phase, to determine the worst-case optimal travel times from fire stations to local flooding sites during floods, we develop a path selection model for rescue vehicles that incorporates more complex and realistic scenarios. A customized A* algorithm is designed to efficiently solve this model. In the second phase, using the worst-case optimal travel times derived from the customized A* algorithm as inputs, we formulate a bi-objective dynamic dispatch model for scheduling firefighters and fire engines. The lexicographic ordering method, combined with the cutting plane method embedded in the optimization solver, is used to solve the model and determine the optimal dispatch strategies at each rescue stage. We highlight the innovations and practical applications of our paper as follows:
-
1.
We demonstrate that the proposed customized A* algorithm offers higher search efficiency than the time-varied modified Dijkstra algorithm14. Additionally, a preference-based customized A* algorithm is designed to accommodate preferences for primary roads, selecting paths that feature a higher proportion of primary roads at the expense of increased vehicle travel time.
-
2.
For the demand forecast of firefighters at each stage, we innovatively incorporate two key factors related to flooding: population density and real-time flood depths. Unlike existing literature, where dispatching of rescue forces is typically based on teams, our scheduling approach removes this constraint, allowing for more flexible allocation strategies by determining the exact number of firefighters and fire engines dispatched at each stage.
-
3.
Our sensitivity analysis reveals that the allocation of firefighters and fire engines across stages corresponds with changes in the severity of local flooding. Moreover, a higher minimum satisfaction rate, \(\eta\), results in greater allocations during the early stages, followed by a more pronounced decline in later stages compared to an allocation strategy with a lower \(\eta\). When \(\eta\) is fixed, the weight parameter \(\lambda\) plays a crucial role in shaping the optimal allocation strategy. This is because \(\lambda\) adjusts the relative importance of population density risk and the severity of local flooding, influencing the urgency of rescue operations at different affected sites. Therefore, emergency authorities must exercise caution when determining dispatch strategies, ensuring a balanced consideration of both risks.
-
4.
Overall, this study develops a practical emergency rescue framework tailored for responding to urban floods caused by short-term intensive rainfall. Designed to support real-world emergency response planning, the framework integrates optimal path planning for emergency vehicles, accurate rescue demand forecasting, and dynamic dispatching of rescue forces at different stages. By addressing critical challenges in flood response operations, this framework provides actionable insights and tools for emergency authorities to enhance the efficiency and effectiveness of their rescue efforts.
We acknowledge several limitations of our study that point to fruitful directions for future research. First, our use of worst-case travel times based on historical data simplifies the uncertainty inherent in disaster scenarios. Relaxing this assumption and incorporating probabilistic or distributional travel time data would transform the model into a stochastic program, offering a more realistic yet computationally challenging formulation. Second, the dispatching model operates on a discretized time scale, which may not fully capture the continuous and time-sensitive nature of real-world rescue operations. Future research could explore continuous-time formulations to better support real-time decision-making. Third, while we focus on modeling the allocation of rescue forces, we do not consider behavioral responses of affected populations, such as spontaneous evacuations or panic behavior. Integrating such behavioral factors through agent-based modeling or empirical data could enhance the robustness of the model’s recommendations. In addition, the accuracy of rescue demand estimation could be improved by incorporating broader predictors, such as real-time weather, population density, and infrastructure conditions. Moreover, although the current dispatching model includes two objectives, it does not fully capture the range of trade-offs encountered in real-world disaster response, such as balancing efficiency, equity, and cost. Future work could adopt a more comprehensive multi-objective optimization framework, potentially using Pareto frontier analysis to better support complex decision-making. Lastly, the model currently focuses on a single type of rescue activity. Future work may consider the coordination of multiple specialized teams, which would require richer data and more complex modeling frameworks.
Data availability
All data generated or analysed during this study are included in this published article [and its supplementary information files].
References
Lin, J. et al. Predicting future urban waterlogging-prone areas by coupling the maximum entropy and flus model. Sustain. Cities Soc. 80, 103812 (2022).
Li, Z. et al. Gis-based risk assessment of flood disaster in the lijiang river basin. Sci. Rep. 13, 6160 (2023).
Vora, A., Sharma, P. J., Loliyana, V., Patel, P. & Timbadiya, P. Assessment and prioritization of flood protection levees along the lower tapi river, india. Nat. Hazard. Rev. 19, 05018009 (2018).
Al-Rawas, G. et al. Backward induction-based multi-layer approach for watershed flood management in arid regions. Sci. Total Environ. 957, 177762 (2024).
Sharma, P. J., Loliyana, V., Timbadiya, P. & Patel, P. Spatiotemporal trends in extreme rainfall and temperature indices over upper tapi basin, india. Theoret. Appl. Climatol. 134, 1329–1354 (2018).
Ministry of Emergency Management of China. National natural disasters in the first three quarters of 2021. https://www.mem.gov.cn/xw/yjglbgzdt/202110/t20211010_399762.shtml (2021). Accessed: 2022-12-27.
Hollingsworth, J. At least 15 dead after heavy rainfall and flooding in northern china. https://edition.cnn.com/2021/10/12/china/flooding-china-shanxi-ntl-hnk/index.html (2021). Accessed: 2023-06-21.
Gan, N. & Yeung, J. ’once in a thousand years’ rains devastated central china, but there is little talk of climate change. https://edition.cnn.com/2021/07/23/china/china-flood-climate-change-mic-intl-hnk/index.html (2021). Accessed: 2023-01-09.
Yang, L., Liu, Q., Yang, S. & Yu, D. Evacuation planning with flood inundation as inputs. In International Conference on Information Systems for Crisis Response and Management (2015).
Safaei, A. S., Farsad, S. & Paydar, M. M. Emergency logistics planning under supply risk and demand uncertainty. Oper. Res. Int. J. 20, 1437–1460 (2020).
Chen, H. Design of collaborative organization and on-site dispatching system for multiple water rescue forces. Highlights Sci. Eng. Technol. 15, 46–52 (2022).
London Fire Brigade. Flood response. https://www.london-fire.gov.uk/about-us/services-and-facilities/techniques-and-procedures/flood-response/ (2021). Accessed: 2022-06-25.
Ministry of Public Security of the PRC. GA/T 1340-2016 classification of fire alarms and emergency rescue operations. http://www.doc88.com/p-9922813877509.html (2016). Accessed: 2023-03-25.
Yuan, Y. & Wang, D. Path selection model and algorithm for emergency logistics management. Comput. Ind. Eng. 56, 1081–1094 (2009).
Ahmadi, M., Seifi, A. & Tootooni, B. A humanitarian logistics model for disaster relief operation considering network failure and standard relief time: A case study on san francisco district. Transp. Res. Part E 75, 145–163 (2015).
Tirkolaee, E. B., Aydin, N. S., Ranjbar-Bourani, M. & Weber, G.-W. A robust bi-objective mathematical model for disaster rescue units allocation and scheduling with learning effect. Comput. Ind. Eng. 149, 106790 (2020).
Wang, X. et al. Path planning of scenic spots based on improved A* algorithm. Sci. Rep. 12, 1320 (2022).
Sun, Y. A reliability-based approach of fastest routes planning in dynamic traffic network under emergency management situation. Int. J. Comput. Intel. Syst. 4, 1224 (2011).
Zhao, J., Guo, Y. & Duan, X. Dynamic path planning of emergency vehicles based on travel time prediction. J. Adv. Transp. 2017, 9184891 (2017).
Meng, X.-Z., Zhou, H. & Hu, X.-B. Many-to-many path planning for emergency material transportation in dynamic environment. IEEE Symposium Series on Computational Intelligence 276–280 (2020).
Sang, Y., Chen, X., Chen, Q., Tao, J. & Fan, Y. A route planning for oil sample transportation based on improved a* algorithm. Sci. Rep. 13, 22041 (2023).
Liang, J., Zhang, Z. & Zhi, Y. Multi-armed bandit approaches for location planning with dynamic relief supplies allocation under disaster uncertainty. Smart Cities 8, 5 (2024).
Sheu, J. B. An emergency logistics distribution approach for quick response to urgent relief demand in disasters. Transport. Res. Part E Log. Transport. Rev. 43, 687–709 (2007).
Alem, D., Clark, A. & Moreno, A. Stochastic network models for logistics planning in disaster relief. Eur. J. Oper. Res. 255, 187–206 (2016).
Zhang, J., Liu, H., Yu, G., Ruan, J. & Chan, F. T. A three-stage and multi-objective stochastic programming model to improve the sustainable rescue ability by considering secondary disasters in emergency logistics. Comput. Ind. Eng. 135, 1145–1154 (2019).
Wei, X. et al. An integrated location-routing problem with post-disaster relief distribution. Comput. Indus. Eng. 147, 106632 (2020).
Rolland, E., Patterson, R. A., Ward, K. & Dodin, B. Decision support for disaster management. Oper. Manag. Res. 3, 68–79 (2010).
Zhang, S., Guo, H., Zhu, K., Yu, S. & Li, J. Multistage assignment optimization for emergency rescue teams in the disaster chain. Knowl.-Based Syst. 137, 123–137 (2017).
Rezapour, S., Naderi, N., Morshedlou, N. & Rezapourbehnagh, S. Optimal deployment of emergency resources in sudden onset disasters. Int. J. Prod. Econ. 204, 365–382 (2018).
Rauchecker, G. & Schryen, G. An exact branch-and-price algorithm for scheduling rescue units during disaster response. Eur. J. Oper. Res. 272, 352–363 (2019).
Sun, H., Wang, Y. & Xue, Y. A bi-objective robust optimization model for disaster response planning under uncertainties. Comput. Ind. Eng. 155, 107213 (2021).
Alutaibi, K., Alsubaie, A. & Marti, J. Allocation and scheduling of firefighting units in large petrochemical complexes. In International Conference on Critical Infrastructure Protection (2015).
Rodriguez, S. A., Rodrigo, A. & Aguayo, M. M. A simulation-optimization approach for the facility location and vehicle assignment problem for firefighters using a loosely coupled spatio-temporal arrival process. Comput. Ind. Eng. 157, 107242 (2021).
Hart, P., Nilsson, N. & Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 4, 100–107 (1968).
Ikeda, T. et al. A fast algorithm for finding better routes by ai search techniques. In Proceedings of VNIS’94-1994 Vehicle Navigation and Information Systems Conference, 291–296 (1994).
Chabini, I. & Lan, S. Adaptations of the a* algorithm for the computation of fastest paths in deterministic discrete-time dynamic networks. Intel. Transport. Syst. IEEE Trans. 3, 60–74 (2002).
Nannicini, G., Delling, D., Schultes, D. & Liberti, L. Bidirectional a* search on time-dependent road networks. Netw. 59, 240–251 (2012).
Delling, D. & Nannicini, G. Core routing on dynamic time-dependent road networks. INFORMS J. Comput. 24, 187–201 (2012).
Magnanti, T., Ahuja, R. & Orlin, J. Network flows: theory, algorithms, and applications (PrenticeHall, Upper Saddle River, NJ, 1993).
Cunnington, D. A cognitive assistant for route selection using knowledge heuristics. In ACM Computer Science in Cars Symposium (2018).
Zhang, Z. et al. A multi-strategy-mode waterlogging-prediction framework for urban flood depth. Nat. Hazard. 22, 4139–4165 (2022).
Department of housing and urban construction. Standards for local flooding prevention and control system planning. https://www.docin.com/p-1009004947-f6.html (2014). Accessed: 2022-10-09.
Cox, R., Shand, T. & Blacka, M. Australian rainfall and runoff revision project 10: Appropriate safety criteria for people. Water Res. 978, 085825–9454 (2010).
Fishburn, & Peter, C. Exceptional paper-lexicographic orders, utilities and decision rules: A survey. Manage. Sci. 20, 1442–1471 (1974).
Miettinen, K. Nonlinear Multiobjective Optimization, vol. 12 (1999).
Hassani, M. R., Janbehsarayi, S. F. M., Niksokhan, M. H. & Sharma, A. Intersecting social welfare with resilience to streamline urban flood management. Sustain. Cities Soc. 116, 105927 (2024).
Xinhuanet. 11 people dead in shenzhen floods. http://en.people.cn/n3/2019/0414/c90000-9566570.html (2019). Accessed: 2023-06-20.
Zhang, Z., Zeng, Y., Huang, Z., Liu, J. & Yang, L. Multi-source data fusion and hydrodynamics for urban waterlogging risk identification. Int. J. Environ. Res. Public Health 20, 2528 (2023).
Shenzhen Municipal Government. Shenzhen municipal government data open platform. https://opendata.sz.gov.cn/data/dataSet/toDataDetails/29200_01403147 (2019). Accessed: 2022-10-26.
Chen, J., Yang, S. T., Li, H. W., Zhang, B. & Lv, J. R. Research on geographical environment unit division based on the method of natural breaks (jenks). ISPRS - Int. Arch. Photogrammetry, Remote Sens. Spatial Inform. Sci. XL–4/W3, 47–50 (2013).
Fire brigade command center. Dispatching standard of the fire receive-disposal alarm. https://wenku.baidu.com/view/b4a04598a66e58fafab069dc5022aaea998f418f.html (2018). Accessed: 2023-06-21.
Acknowledgements
This research is supported by the Educational Commission of Guangdong Province (Grant No. 2021ZDZX1069) and Key Laboratory of TechFin in SUSTech. This study was supported by the Central University Basic Research Business Expense Special Fund.
Author information
Authors and Affiliations
Contributions
J.L., Z.Z. and L.Y. participated in the literature review. J.L.and Z.Z. proposed the framework of the manuscript, J.L. and Z.Z. completed the construction of the emergency dispatch model, J.L. completed the solution of the optimization algorithm, Z.Z. completed the work of the flood risk assessment, L.Y. and M.L. revised the manuscript. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liang, J., Liu, M., Zhang, Z. et al. Shortest path planning and dynamic rescue forces dispatching for urban flood disasters. Sci Rep 15, 23643 (2025). https://doi.org/10.1038/s41598-025-06374-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-06374-2
