
Abstract
Conventional multi-label classification methods often fail to capture the dynamic relationships and relative intensity shifts between labels, treating them as independent entities. This limitation is particularly detrimental in tasks like sentiment analysis where emotions co-occur in nuanced proportions. To address this, we introduce a novel Weighted Difference Loss (WDL) framework. WDL operates on three core principles: (1) transforming labels into a normalized distribution to model their relative proportions; (2) computing learnable, weighted differences across this distribution to explicitly capture inter-label dynamics and trends; and (3) employing a label-shuffling augmentation to ensure the model learns intrinsic, order-invariant relationships. Our framework not only achieves state-of-the-art performance on four public benchmarks, but more importantly, it substantially improves the recognition of minority classes. This demonstrates the framework’s ability to learn from sparse data by effectively leveraging the underlying label structure, offering a robust, loss-driven alternative to complex architectural modifications.
Similar content being viewed by others
Introduction
Multi-label sentiment classification (MLSC) is a critical task for understanding the nuanced and often complex emotions expressed in text, with applications ranging from market research to public opinion analysis1,2,3,4. Unlike single-label tasks, MLSC acknowledges that a single text can convey multiple sentiments simultaneously5. However, this task is impeded by two persistent challenges: severe class imbalance, where minority emotions are poorly learned6, and the flawed label independence assumption inherent in standard fine-tuning approaches. Pre-trained models like BERT7, despite their power, often inherit this limitation by using loss functions like Binary Cross-Entropy (BCE), which by design treats each label as a separate binary problem, thus failing to model the rich interdependencies between them5,8.
This failure to model label relationships is not merely a statistical issue; it represents a fundamental misunderstanding of sentiment. Emotions are not independent events but exist in a structured, dynamic relationship9. For instance, an increase in ’joy’ often corresponds to a decrease in ’sadness’10, and the co-occurrence of ’joy’ and ’surprise’ has a different proportional intensity than ’anger’ and ’disgust’. To overcome these limitations, we argue for a paradigm shift: from predicting independent label probabilities to modeling a structured label distribution11. Our core hypothesis is that by supervising not only the presence of labels but also their relative proportions and their rates of change (differences), a model can learn the underlying structure of the label space without requiring external knowledge graphs or complex architectural changes12,13.
To operationalize this paradigm shift, we propose the Weighted Difference Loss (WDL) framework. This paper makes the following primary contributions:
-
We introduce a novel ratio-to-difference mechanism that normalizes label values into a distribution of relative proportions and then computes higher-order differences to explicitly model the dynamic trends and interdependencies between labels.
-
We design a learnable weighting scheme that allows the model to adaptively balance the supervisory signals from the base classification loss, the ratio-matching loss, and the multi-order difference losses, thereby optimizing the learning process.
-
We incorporate a label-shuffling augmentation strategy during training, which forces the model to learn intrinsic, order-invariant relationships between emotions, significantly enhancing its robustness and generalization capabilities.
-
We empirically demonstrate through extensive experiments on four public benchmarks that our WDL framework achieves state-of-the-art performance and, most critically, substantially improves the recognition of minority classes, evidenced by a 0.90 absolute F1-score gain for the ’grief’ category on the GoEmotions dataset.
The remainder of this paper is organized as follows: Section "Related work" reviews related work. Section "The WDL framework" details the proposed WDL framework. Section "Experimental analysis" presents the experimental setup and results. Section "Ablation study and discussion" provides ablation studies and discussion. Finally, Section "Conclusion" concludes the paper.
Related work
Sentiment analysis aims to automatically extract subjective information from text14,15. Multi-label sentiment classification (MLSC), a subfield, addresses the realistic scenario where a text expresses multiple, intertwined emotions16,17. The evolution of MLSC methods reflects a continuous effort to better capture textual context and label relationships.
Evolution and persistent challenges in MLSC
Early approaches relied on traditional feature engineering (e.g., N-grams, TF-IDF), which required significant manual effort and lacked deep contextual understanding18,19. The advent of deep learning models like CNNs and RNNs automated feature extraction but often struggled with long-range dependencies and implicitly assumed label independence20,21.
The introduction of Transformer-based Pre-trained Language Models (PLMs), particularly BERT7, revolutionized the field with powerful contextual representations22. However, even when fine-tuned, PLMs still face two core MLSC challenges: (1) Class Imbalance, where models become biased towards frequent emotions23, and (2) the Label Independence Assumption, where standard loss functions like BCE neglect the rich, natural correlations between emotions24.
Modern strategies for enhanced MLSC
Contemporary research has explored various strategies to overcome these limitations, as summarized in Table 1. Our work primarily contributes to the “Loss Function Modification” category, but its prompt-based input formulation also connects it to “Advanced Representation” techniques.
Innovations in loss functions directly steer model training. Focal Loss25 and ASL26 address class imbalance by re-weighting examples. LDL27 learns a probability distribution over labels, implicitly modeling relationships. While effective, these methods may not fully capture the relative proportional strength or dynamic shifts between co-occurring emotions.
Explicit modeling of label dependencies directly represents label relationships. GNNs31 are a dominant paradigm, constructing a label graph (from co-occurrence statistics or external knowledge) and propagating information to learn correlation-aware predictions. While powerful, GNN-based methods introduce significant overheads: they require the pre-construction of a label graph, which may be suboptimal or unavailable, and add notable computational complexity35. To circumvent these issues, we propose an alternative, loss-driven approach. Instead of encoding label relationships into a fixed graph structure, our method forces the model to learn these relationships dynamically from the data itself, guided purely by the loss function.
Advanced representation learning techniques, such as contrastive learning33 and prompt-based learning34, aim to improve the underlying features. Contrastive methods learn more discriminative embeddings by pushing dissimilar samples apart in the feature space. Prompting reformulates the task to better align with the PLM’s pre-training objectives. Our work incorporates a prompt-inspired input formulation but focuses its core innovation on the loss function, making it complementary to these representation-focused methods.
Motivation for weighted difference loss
Existing approaches often specialize in either class imbalance or label dependency, introduce significant architectural complexity, or fail to model the nuanced, relative proportional strengths of emotions. Our proposed WDL offers a unified, lightweight solution that operates directly on the model’s output distribution. By focusing on the learnable, weighted differences in normalized label proportions, WDL provides a computationally tractable method to simultaneously mitigate class imbalance and model label interdependencies, aiming to improve performance, particularly for minority classes.
The WDL framework
Framework overview
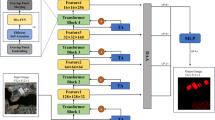
The WDL framework enhances a standard BERT model by introducing a multi-component loss function that supervises the model on label presence, relative proportions, and inter-label trends. Figure 1 illustrates the overall workflow. Given an input text and a set of labels, the framework proceeds in three steps: 1. Prediction: A prompt-based BERT model with a feature refinement module generates predicted logits \(\hat{\textbf{y}}_l\) for each label. 2. Transformation: Both predicted logits and true labels \(\textbf{y}\) are transformed into normalized ratio vectors, \(\hat{\textbf{r}}\) and \(\textbf{r}\), respectively. Higher-order differences (\(\Delta ^d\hat{\textbf{r}}, \Delta ^d\textbf{r}\)) are then computed from these ratio vectors. 3. Weighted Loss Calculation: A final loss, \(\mathcal {L}_{\text {WDL}}\), is computed as a dynamically weighted sum of the binary classification loss, the ratio-matching loss, and the difference losses.
The complete loss function is defined as:
where \(\textbf{w} = [w_l, w_0, \dots , w_D]\) are learnable weights, \(\hat{\textbf{y}}_l\) are the predicted logits, \(\textbf{y}_{\text {bin}}\) are the true binary labels, and \(\Delta ^d\hat{\textbf{r}}\) and \(\Delta ^d\textbf{r}\) are the d-th order differences of the predicted and true ratios, respectively.

The Bert-WDL architecture. An input text is prepended with emotion-guided [MASK] prompts. BERT generates representations, which are refined by a Self-Attention Network (SAN) module. The final logits are supervised by the multi-component WDL, which includes losses on labels, ratios, and their differences (2nd-order shown).
Prompt-based input and feature refinement
Inspired by prompt-based learning36, we construct inputs by prepending emotion labels with [MASK] tokens to the text: "\(e_1\)[MASK]…\(e_M\)[MASK]. ti". After extracting the final-layer representations for each [MASK] token from BERT, we hypothesize that these initial representations can be further refined to be more discriminative. To this end, we employ a Self-Attention Network (SAN) module to act as a feature refiner. Each [MASK] token’s representation is independently processed by the SAN to enhance its contextual features before being passed to the classifiers. As our ablation study confirms (Section Component effectiveness analysis), this refinement step creates a higher-quality substrate for the WDL and is crucial for overall performance.
Ratio and difference formulation
From a theoretical standpoint, we posit that the set of co-occurring emotions in a text can be viewed as a discrete signal over the label space. The value at each point corresponds to the intensity of an emotion. The first-order difference (\(\Delta ^1\)) of this signal approximates its derivative-the rate of change in intensity from one emotion to the next. The second-order difference (\(\Delta ^2\)) approximates the second derivative, or the “acceleration” of this change. By supervising these derivatives, we compel the model to learn not just the static presence of emotions (the “position” of the signal), but also their dynamic relationships and trends (the “velocity” and “acceleration”).
To operationalize this, we first transform both true labels and predicted logits into ratio vectors. For a given instance with a multi-hot true label vector \(\textbf{y}_{\text {bin}} \in \{0, 1\}^M\), the true ratio vector \(\textbf{r}\) is computed by L1 normalization:
If an instance has no positive labels (\(||\textbf{y}_{\text {bin}}||_1 = 0\)), \(\textbf{r}\) is a zero vector. The predicted logits \(\hat{\textbf{y}}_l\) are passed through a softmax activation to produce a probability distribution \(\hat{\textbf{r}}\), ensuring it is also L1-normalized.
To explicitly model label dependencies, we then compute the d-th order forward difference \(\Delta ^d \textbf{r}\) recursively:
where \(\Delta ^0 \textbf{r} \triangleq \textbf{r}\). The 1st-order difference captures intensity transitions between adjacent labels, while higher orders encode more complex, non-local dependencies.
Order-invariant learning via label shuffling
Since the difference calculation is sensitive to label order, we introduce a crucial augmentation step. During each training iteration, the original batch is expanded by creating K random permutations of the emotion label sequence for each sample. The input prompts, true labels, and true ratios are re-constructed according to these permutations, forming an augmented batch of size \(K \times \text {batch}\_\text {size}\). The WDL loss is computed over this entire augmented batch in a single forward and backward pass. This procedure forces the model to learn true semantic correlations between emotions (e.g., ’joy’ and ’excitement’) rather than spurious positional artifacts (e.g., ’the 5th label is always higher than the 4th’), thereby improving model robustness and generalization. During inference, predictions from shuffled sequences are re-ordered back to their original label sequence before evaluation.
Learnable multi-component loss
The final WDL (Eq. 1) combines the losses from the binary classification task (BCE) and \(D+1\) orders of ratio/difference matching (MSE). The weights \(\textbf{w}\) are not fixed hyperparameters but are learned dynamically. They are parameterized by a vector of logits \(\textbf{u} \in \mathbb {R}^{D+2}\), such that \(\textbf{w} = \text {softmax}(\textbf{u})\). Both the model parameters \(\theta\) and the weight logits \(\textbf{u}\) are updated via gradient descent, allowing the framework to adaptively determine the importance of each loss component. The complete training process is detailed in Algorithm 1.

Training the WDL framework.
Implementation details
Our framework was implemented in PyTorch 2.0.0 and run on an Ubuntu 20.04 system with a 48GB vGPU. We fine-tuned bert-base-uncased and bert-base-chinese models from Hugging Face. The architecture includes a single-layer SAN for feature refinement and employs a dedicated SGD optimizer for the loss weight logits. All experiments were conducted using the comprehensive set of hyperparameters detailed in Table 2, with early stopping based on validation loss to prevent overfitting.
Experimental analysis
Datasets
We evaluated our method on four public multi-label emotion datasets: two Chinese (NLPCC 2018 Task 1 with 5 emotion labels and Ren-CECPs with 8 labels) and two English (GoEmotions with 28 labels and SemEval 2018 Task 1, E-c with 11 labels). For NLPCC, GoEmotions, and SemEval, we used the official train/validation/test splits. For datasets lacking official splits, such as Ren-CECPs, we randomly partitioned the data into training (70%), validation (15%), and test (15%) sets. To ensure reproducibility, all random partitioning was performed using a fixed random seed (42).
Evaluation metrics
We use a comprehensive suite of metrics: Macro-F1 (MF1) and Micro-F1 (mF1) to assess classification performance, with MF1 being particularly sensitive to minority class performance. We also report Average Precision (AP), Hamming Loss (HL), Coverage Error (CE), and Ranking Loss (RL). Arrows (\(\uparrow /\downarrow\)) indicate the desired direction for each metric.
Baseline methods
We compare Bert-WDL against state-of-the-art models including prompt-based (PC-MTED37), capsule network (CapsLDM38), neural architecture (MEDA-FS39, LEM40, EduEmo41), and hybrid methods (Hybrid HEF-DLF42, Seq2Emo43). All baseline results are sourced from their original publications. In the following tables, a dash (-) indicates that a specific metric was not provided in the source paper.
Experimental results
Cross-dataset performance
Table 3 and Table 4 show that the WDL framework consistently delivers top-tier performance across all four datasets, demonstrating its robustness and generalizability. Unlike baseline methods that excel on one dataset but falter on another, WDL variants consistently rank among the top performers. For example, WDL2 achieves the best MF1 and mF1 on NLPCC, while WDL1 is highly competitive on Ren-CECPs and SemEval, and secures the best MF1 and mF1 on GoEmotions. This stability highlights the effectiveness of modeling label dynamics as a general principle.
Effectiveness on minority classes
The primary strength of WDL lies in its ability to mitigate class imbalance. The heatmap in Fig. 2 provides a clear visual proof of this effect on the 28-category GoEmotions dataset. In the figure, emotions are sorted by their training sample count, from the least frequent at the top to the most frequent at the bottom. This arrangement vividly illustrates that the most significant performance gains, indicated in green, occur on minority classes.
The exceptional performance on ’grief’ (F1-score of 0.91 vs. a baseline of 0.01), despite only 6 training samples, strongly validates our core hypothesis. A standard BCE loss struggles with such extreme sparsity. However, WDL forces the model to consider ’grief’ in relation to other emotions. By learning the difference patterns-how the presence of ’grief’ alters the proportions of ’sadness’ or ’disappointment’-the model can effectively infer its presence even from minimal direct evidence. This pattern of significant gains is consistent across most low-to-mid frequency emotions. While some high-frequency emotions like ’gratitude’ and ’remorse’ show a trade-off, indicated in red, the overall 17.4% improvement in MF1 (0.46-0.54) confirms a more balanced and robust predictive capability across the entire emotion spectrum. This is further detailed in Table 5.

Heatmap illustrating the F1-score gain of Bert-WDL1 over the baseline on the GoEmotions dataset. Emotions are sorted by their training sample count (from lowest to highest) to visualize the strong performance gains on minority classes (green) and the trade-offs on some majority classes (red).
Comparison of loss functions
To isolate the effect of our loss design, we compared WDL1 against standard multi-label loss functions on GoEmotions, keeping the model architecture fixed. As shown in Table 6 and the conceptual gain plot in Fig. 3, WDL1 consistently outperforms BCE, ASL, and Focal Loss in terms of both MF1 and mF1. While ASL achieves higher recall and Focal Loss higher precision, WDL1 provides the best balance, validating that explicitly modeling label dynamics is more effective than only re-weighting for class imbalance. Wasserstein loss performed poorly, suggesting it is ill-suited for this classification task without significant tuning.

Bar chart showing the relative percentage improvement in Macro-F1 score of WDL1 compared to other loss functions (BCE, ASL, Focal) on the GoEmotions dataset.
Computational cost analysis
To assess the practical viability of our framework, we analyze its computational cost relative to a standard BERT baseline on the GoEmotions dataset (Table 7). Our Bert-WDL model introduces a modest increase in parameters (from 110M to 112.4M) due to the SAN module. The primary overhead comes from the label shuffling strategy (\(K=3\)), which triples the number of forward passes per batch. This results in a reduction in training throughput (from 158.4 to 53.1 samples/sec) and a corresponding increase in training time per epoch. However, this is a direct and worthwhile trade-off for the substantial gains in minority class recognition and overall robustness. In contrast, the inference cost remains comparable to a standard BERT model, as shuffling is not required during evaluation. The theoretical complexity is dominated by the Transformer’s \(O(NL^2D)\), with the WDL component adding a negligible \(O(NKD_{diff})\) term.
Ablation study and discussion
Component effectiveness analysis
We conducted extensive ablation studies on the GoEmotions dataset to dissect the WDL framework and validate the contribution of each component. The results, detailed in Table 8, systematically compare variants by removing or altering key elements: the SAN for feature refinement, the learnable weights (WDL vs. D series), and the difference order. The base ‘Bert‘ model (BERT-base with a simple classifier) serves as the fundamental baseline.
The results reveal a clear synergistic effect. First, comparing the learnable weight models (e.g., ‘WDL1‘) against their unweighted counterparts (‘D1‘) shows that the adaptive weighting is critical. ‘WDL1‘ (MF1=52.18%) outperforms ‘D1‘ (MF1=50.27%) by 1.91 absolute points, demonstrating that allowing the model to balance loss components is superior to a fixed combination.
Second, the SAN module for feature refinement provides a significant boost. ‘SAN + WDL1‘ (MF1=53.55%) outperforms ‘WDL1‘ without the SAN (MF1=52.18%) by 1.37 absolute MF1 points. This supports our hypothesis that the SAN creates richer, more discriminative emotion representations, which in turn provides a higher-quality substrate for the WDL to operate on. Without well-defined features, calculating differences might be noisy; the SAN sharpens these features, allowing the difference loss to capture meaningful trends more effectively. The full model (‘SAN + WDL1‘) achieves the best Macro F1, showcasing the importance of both feature refinement and learnable difference loss.
Impact of backbone model scale
To assess the scalability of our WDL framework and understand its interaction with more powerful encoders, we conducted an additional set of experiments replacing the bert-base-uncased backbone with its larger counterpart, bert-large-uncased. The results, presented in Fig. 4, reveal a nuanced relationship between model scale and performance, rather than a simple monotonic improvement.

Performance comparison of Bert-WDL using BERT-Base (orange line) and BERT-Large (blue line) backbones. The plots show mF1 and MF1 scores across different WDL difference orders (0 to 3 on the x-axis) for the GoEmotions (top row) and SemEval (bottom row) datasets.
As shown in Fig. 4, employing BERT-Large can lead to a higher peak performance. For instance, on the SemEval dataset, the BERT-Large model achieves a significantly higher peak MF1 score (approx. 59.1%) compared to the relatively flat performance of the BERT-Base model. This suggests that a larger model has the capacity to better leverage the WDL framework to capture more complex label dynamics under certain configurations.
However, the performance gains are not consistent. On the SemEval mF1 metric, the BERT-Base model consistently outperforms BERT-Large in three out of four configurations. Similarly, on the GoEmotions MF1 metric, the performance of BERT-Large is more volatile and is surpassed by BERT-Base at one of the configuration points. This indicates that simply increasing the model size does not guarantee superior performance and may even introduce instability, possibly due to overfitting or a more challenging optimization landscape.
This analysis underscores an important trade-off: while a larger backbone offers the potential for higher peak performance, it comes at a significant computational cost and without a guarantee of consistent improvement across all metrics and datasets. The choice of backbone model should therefore be considered in the context of the specific application’s requirements for both performance and efficiency. This finding suggests that the primary benefits observed in our study stem from the WDL framework itself, which proves effective on both base and large model scales, rather than from simply using a larger model.
Weight dynamics and order effects
Figure 5 visualizes the learned weight distributions, revealing two key patterns. First, the weight for the ’label’ component remains remarkably stable across all configurations, acting as a prediction anchor. Second, our weight parameterization scheme is designed to impose a structural prior where weights for higher-order differences decay monotonically. This design choice reflects the hypothesis that lower-order differences (e.g., ’d1’) contain the most valuable signal for capturing label dynamics, while complex, higher-order interactions are progressively down-weighted to prevent the amplification of noise. As Fig. 5 confirms, the first-order difference (’d1’) in the WDL1 model consequently receives a significant weight, which correlates with its strong performance on several benchmarks.

Weight distribution across difference orders.
Analysis of performance trade-offs and limitations
Despite its strong performance, particularly on minority classes, our analysis reveals an important performance trade-off. As seen in Table 5, while WDL significantly boosts F1 scores for rare emotions like ’grief’, it can lead to a performance decrease for some high-frequency, semantically distinct emotions like ’gratitude’ and ’remorse’. We posit that this is a consequence of WDL’s implicit attention re-allocation. By forcing the model to learn the relationships and relative proportions across all labels, WDL effectively redistributes the model’s capacity from “over-learned” majority classes to under-represented minority classes. This is beneficial for overall balanced accuracy (MF1) but can come at the cost of peak performance on specific, well-represented labels. This trade-off highlights a key challenge for future work: developing more dynamic weighting schemes that can adapt at an instance level.
Furthermore, our experiments indicate a performance plateau or even degradation with higher-order differences (\(D>2\)). We hypothesize this is due to two factors: 1) a noise amplification effect, where higher-order derivatives become overly sensitive to small perturbations in the predicted ratios, and 2) semantic sparsity, where meaningful third-order or higher emotional dependencies are rare in natural language and thus difficult to learn from limited data. This suggests that simply increasing the order is not a viable path for improvement. Future research could explore adaptive order selection mechanisms or apply regularization techniques to stabilize the learning of higher-order differences.
Extensibility and future work
The WDL framework is designed as a model-agnostic loss function. Although this paper implements it on BERT, its principles can be extended to other architectures. For instance, in a GNN-based model, WDL could be applied to the final node-level predictions to further refine label relationships beyond what is captured by the graph structure. However, extending WDL to new domains requires careful consideration.
In Extreme Multi-Label Classification (XMLC), where the number of labels can be in the thousands, the direct application of WDL with prompt-based inputs becomes computationally infeasible. A potential solution is a two-stage approach: first, use a candidate-sampling model to retrieve a smaller, relevant subset of labels, then apply WDL to this subset for fine-grained ranking and classification. This would leverage WDL’s strength in modeling local dependencies without incurring prohibitive costs.
In Hierarchical Multi-Label Classification (HMLC), the difference calculation could be adapted to respect the hierarchy. For example, differences could be computed primarily among sibling nodes at each level, and perhaps between parent-child nodes, rather than across a flat list. This would allow WDL to model dependencies that are consistent with the predefined label structure. These adaptations, while promising, require substantial future work to validate and implement effectively.
Conclusion
This research introduces the WDL, a novel framework that fundamentally reframes the multi-label classification task from predicting independent probabilities to modeling a dynamic label distribution. By supervising not only label presence but also their relative proportions and rates of change, WDL effectively captures inter-label dependencies without requiring complex architectural modifications or external knowledge graphs.
Our extensive experiments across four diverse datasets demonstrate three key advantages of the WDL framework:
-
1.
Dynamic Relationship Modeling: WDL successfully captures the nuanced, dynamic trends between emotion labels, leading to more robust and accurate predictions, especially in complex scenarios.
-
2.
Implicit Minority Class Boosting: The focus on relative proportions naturally re-allocates model attention to under-represented classes, yielding substantial improvements in minority class F1-scores and overall balanced accuracy.
-
3.
Architecture-Agnostic Simplicity: As a loss-driven innovation, WDL is a lightweight, plug-and-play module that can be easily integrated with various pre-trained models to enhance their performance with minimal overhead.
Our analysis also shows that while the WDL framework can leverage larger backbone models like BERT-Large for potential peak performance gains, this does not guarantee consistent improvement, highlighting that the core benefits stem from the loss design itself. Despite these strengths, our work also highlights areas for future research, including the development of instance-level adaptive weighting to manage performance trade-offs on high-frequency classes and exploring regularization techniques for stable high-order difference learning. The promising results presented here establish WDL as a potent and flexible tool for a wide range of multi-label classification tasks, paving the way for future explorations into more sophisticated dynamic label modeling.
Data availability
The datasets analyzed during the current study are publicly available and can be accessed as described below: \(\bullet\) GoEmotions Dataset: Available at: https://huggingface.co/datasets/google-research-datasets/go_emotions/tree/main/simplified\(\bullet\) NLPCC 2018 Task 1 Dataset: Available at: http://tcci.ccf.org.cn/conference/2018/taskdata.php\(\bullet\) SemEval Task E-c Dataset: Available at: https://competitions.codalab.org/competitions/17751\(\bullet\) Ren-CECPS Dataset: Access to the Ren-CECPS dataset requires contacting the author, Dr. Kang-Xin, at kang-xin@is.tokushima-u.ac.jp.
References
Saleema, J.S., Sairam, B., Naveen, S.D., Yuvaraj, K. & Patnaik, L.M. Prominent label identification and multi-label classification for cancer prognosis prediction. In: TENCON 2012 IEEE Region 10 Conference, pp. 1–6 (2012). https://doi.org/10.1109/TENCON.2012.6412321
Huang, S. et al. Application of label correlation in multi-label classification: A survey. Appl. Sci. 14(19), 9034 (2024).
Tsai, C.-P. & Lee, H.-Y. Order-free learning alleviating exposure bias in multi-label classification. Proc. AAAI Conf. Artif. Intell. 34(04), 6038–6045. https://doi.org/10.1609/aaai.v34i04.6066 (2020).
Huang, Y., Giledereli, B., Köksal, A., Özgür, A. & Ozkirimli, E. Balancing methods for multi-label text classification with long-tailed class distribution. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics https://doi.org/10.18653/v1/2021.emnlp-main.643 (2021).
Pal, A., Selvakumar, M. & Sankarasubbu, M. Magnet: Multi-label text classification using attention-based graph neural network. In: Proceedings of the 12th International Conference on Agents and Artificial Intelligence. SCITEPRESS - Science and Technology Publications, https://doi.org/10.5220/0008940304940505 (2020).
Lango, M. Tackling the problem of class imbalance in multi-class sentiment classification: An experimental study. Foundations of Computing and Decision Sciences 44(2), 151–178. https://doi.org/10.2478/fcds-2019-0009 (2019).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
Durand, T., Mehrasa, N. & Mori, G. Learning a deep convnet for multi-label classification with partial labels. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 647-657 https://doi.org/10.1109/cvpr.2019.00074 (2019).
Gao, W., Li, S., Lee, S.Y.M., Zhou, G. & Huang, C.-R. Joint learning on sentiment and emotion classification. In: Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. CIKM13, pp. 1505–1508. ACM, (https://doi.org/10.1145/2505515.2507830 2013).
Chong, J. J. Q. & Aryadoust, V. Investigating the effect of multimodality and sentiments on speaking assessments: a facial emotional analysis. Educ. Inf. Technol. 28(6), 7413–7436. https://doi.org/10.1007/s10639-022-11478-7 (2022).
Alsheikh, S.S., Shaalan, K. & Meziane, F. Exploring the effects of consumers’ trust: A predictive model for satisfying buyers’ expectations based on sellers’ behavior in the marketplace. IEEE Access 7, 73357–73372 (2019) https://doi.org/10.1109/access.2019.2917999
Maharani, W. & Effendy, V. Big five personality prediction based in indonesian tweets using machine learning methods. International Journal of Electrical and Computer Engineering (IJECE) 12(2), 1973 https://doi.org/10.11591/ijece.v12i2.pp1973-1981 (2022).
Liao, L. & Wu, Z. Untangling the relationship between work pressure and emotions in social media: auantitative empirical study of construction industry. Engineering, Construction and Architectural Management 31(2), 767–788. https://doi.org/10.1108/ecam-01-2022-0062 (2022).
Al Shamsi, A.A. & Abdallah, S. A systematic review for sentiment analysis of arabic dialect texts researches. In: Proceedings of International Conference on Emerging Technologies and Intelligent Systems: ICETIS 2021 Volume 2, pp. 291–309 (2022). Springer
Hsieh, Y.-H. & Zeng, X.-P. Sentiment analysis: An ernie-bilstm approach to bullet screen comments. Sensors 22(14), 5223. https://doi.org/10.3390/s22145223 (2022).
Wang, S., Wang, J., Wang, Z. & Ji, Q. Multiple emotion tagging for multimedia data by exploiting high-order dependencies among emotions. IEEE Trans. Multimedia 17(12), 2185–2197. https://doi.org/10.1109/tmm.2015.2484966 (2015).
Park, H.-M. & Kim, J.-H. Stepwise multi-task learning model for holder extraction in aspect-based sentiment analysis. Appl. Sci. 12(13), 6777. https://doi.org/10.3390/app12136777 (2022).
Shu, H., Peng, W., Li, J. & Lee, D. Sentiment and topic analysis on social media. Proceedings of the 5th Annual ACM Web Science Conference, 172–181 (2013) https://doi.org/10.1145/2464464.2464512
Zhang, Y. & Xie, Y. Emotion analysis system based on skep model. Business Intelligence and Information Technology, 632–642 https://doi.org/10.1007/978-3-030-92632-8_59 (2021).
Wang, C., Yang, X. & Ding, L. Deep learning sentiment classification based on weak tagging information. IEEE Access 9, 66509–66518 https://doi.org/10.1109/access.2021.3077059 (2021).
He, H. & Xia, R. Joint binary neural network for multi-label learning with applications to emotion classification. In: Zhang, M., Ng, V., Zhao, D., Li, S., Zan, H. (eds.) Natural Language Processing and Chinese Computing, pp. 250–259. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-99495-6_21 .
Bai, W., Wang, J. & Zhang, X. YNU-HPCC at SemEval-2022 task 4: Finetuning pretrained language models for patronizing and condescending language detection. In: Emerson, G., Schluter, N., Stanovsky, G., Kumar, R., Palmer, A., Schneider, N., Singh, S., Ratan, S. (eds.) Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), pp. 454–458. Association for Computational Linguistics, Seattle, United States (2022). https://doi.org/10.18653/v1/2022.semeval-1.61 .
Chen, M., Wang, G., Xue, J.-H., Ding, Z. & Sun, L. Enhance via decoupling: Improving multi-label classifiers with variational feature augmentation. In: 2021 IEEE International Conference on Image Processing (ICIP), pp. 1329–1333 (2021). Institute of Electrical and Electronics Engineers (IEEE)
Tang, T., Tang, X. & Yuan, T. Fine-tuning bert for multi-label sentiment analysis in unbalanced code-switching text. IEEE Access 8, 193248–193256 (2020).
Lin, T. Focal loss for dense object detection. arXiv preprint arXiv:1708.02002 (2017)
Ridnik, T., Ben-Baruch, E., Zamir, N., Noy, A., Friedman, I., Protter, M. & Zelnik-Manor, L. Asymmetric loss for multi-label classification. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 82–91 (2021)
Geng, X. Label distribution learning. IEEE Trans. Knowl. Data. Eng. 28(7), 1734–1748 (2016).
Ghosh, S., R. Menon, R. & Srivastava, S. Lasque: Improved zero-shot classification from explanations through quantifier modeling and curriculum learning. In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 7403–7419. Association for Computational Linguistics, 7403–7419 (2023). https://doi.org/10.18653/v1/2023.findings-acl.467 .
Lafferty, J., McCallum, A. & Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In: Icml, vol. 1, p. 3 (2001). Williamstown, MA
Li, Y. & Yang, Y. Label embedding for multi-label classification via dependence maximization. Neural Processing Letters 52(2), 1651–1674 (2020).
Zhang, M., Cui, Z., Neumann, M. & Chen, Y. An end-to-end deep learning architecture for graph classification. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32 (2018)
Ma, Q., Yuan, C., Zhou, W. & Hu, S. Label-specific dual graph neural network for multi-label text classification. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, (2021). https://doi.org/10.18653/v1/2021.acl-long.298 .
Inoue, S., Komachi, M., Ogiso, T., Takamura, H. & Mochihashi, D. Infinite scan: An infinite model of diachronic semantic change. In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 1605–1616. Association for Computational Linguistics, (2022). https://doi.org/10.18653/v1/2022.emnlp-main.104 .
Wei, X., Cui, X., Cheng, N., Wang, X., Zhang, X., Huang, S., Xie, P., Xu, J., Chen, Y., Zhang, M., Jiang, Y. & Han, W. ChatIE: Zero-Shot Information Extraction via Chatting with ChatGPT. arXiv https://doi.org/10.48550/ARXIV.2302.10205 (2023).
He, Z.-F., Zhang, C.-H., Liu, B. & Li, B. Label recovery and label correlation co-learning for multi-view multi-label classification with incomplete labels. Applied Intelligence 53(8), 9444–9462. https://doi.org/10.1007/s10489-022-03945-y (2022).
Wang, Y., Deng, J., Wang, T., Zheng, B., Hu, S., Liu, X. & Meng, H. Exploiting prompt learning with pre-trained language models for alzheimer’s disease detection. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE pp. 1–5 (2023).
Zhou, Y., Kang, X. & Ren, F. Prompt consistency for multi-label textual emotion detection. IEEE Trans. Affect. Comput. 15(1), 121–129 (2023).
Ruan, Y. & Li, T. Capsule network with label dependency modeling for multi-label emotion classification. Frontiers in Artificial Intelligence and Applications https://doi.org/10.3233/faia230494 (2023).
Deng, J. & Ren, F. Multi-label emotion detection via emotion-specified feature extraction and emotion correlation learning. IEEE Trans. Affect. Comput. 14(1), 475–486 (2020).
Fei, H., Zhang, Y., Ren, Y. & Ji, D. Latent emotion memory for multi-label emotion classification. Proc. AAAI Conf. Artif. Intell. 34, 7692–7699 (2020).
Zhu, Y. & Wu, O. Elementary discourse units with sparse attention for multi-label emotion classification. Knowledge-Based Systems 240, 108114 (2022).
Ahanin, Z., Ismail, M. A., Singh, N. S. S. & AL-Ashmori, A. Hybrid feature extraction for multi-label emotion classification in english text messages. Sustainability 15(16), 12539 (2023).
Huang, C., Trabelsi, A., Qin, X., Farruque, N., Mou, L. & Zaiane, O.R. Seq2emo: A sequence to multi-label emotion classification model. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4717–4724 (2021).
Demszky, D., Movshovitz-Attias, D., Ko, J., Cowen, A., Nemade, G. & Ravi, S. Goemotions: A dataset of fine-grained emotions. arXiv preprint arXiv:2005.00547 (2020)
Funding
This work was supported by the Natural Science Foundation of the Jiangsu Higher Education Institutions of China (Grant No. 1020240051) and the Geran Putra (Grant No. GP-IPS/2023/9773800).
Author information
Authors and Affiliations
Contributions
Q.H. and M.A.A.M. conceptualized the research and conducted the experiments. A.B.A. performed the data analysis and N.A.N. implemented the algorithms. All authors contributed to the writing and editing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hu, Q., Azrifah Azmi Murad, M., Azman, A.B. et al. A weighted difference loss approach for enhancing multi-label classification. Sci Rep 15, 25052 (2025). https://doi.org/10.1038/s41598-025-09883-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-09883-2
