
Abstract
Trust management in shared vehicle data systems presents significant challenges, necessitating innovative approaches. A data analysis system integrating blockchain-based distributed trust management with deep reinforcement learning (DRL) is introduced to address these issues. The proposed system includes two core components: (1) User Trust Evaluation Model: Bayesian statistical methods are employed to estimate user credibility, utilizing historical interaction records as prior information. Blockchain technology separates the data chain and trust chain, enabling a distributed architecture that enhances data storage security and trust management robustness. (2) Behavioral Modeling and Defensive Strategies: The shared vehicle service process and user behavior are conceptualized as a Markov Decision Process. Using the Deep Q-Network (DQN) algorithm, the system identifies optimal defensive strategies through multidimensional data interactions. Performance evaluation is conducted using the Autonomous Driving Dataset (https://github.com/DRL-CASIA/Autonomous-Driving-Dataset-Open), with the following key metrics: (1) Trust Evaluation Accuracy: Assesses the precision of the system in evaluating user trust. The blockchain-based approach enhances accuracy by approximately 16% compared to centralized methods, demonstrating its reliability. (2) Average System Reward: Indicates the expected return from implementing defensive strategies. The DQN-based system achieves a performance increase exceeding 20% compared to Q-learning, highlighting its decision-making efficacy. (3) Malicious Behavior Detection Rate: Measures the system’s ability to detect and address malicious activities. The proposed model attains a detection rate of approximately 93%, an improvement of over 15%, reflecting its advanced defensive capabilities. (4) Service Response Time: Evaluates the system’s efficiency in responding to user requests. A reduction of more than 11% in response time underscores the enhanced operational speed. Experimental results validate the effectiveness of the proposed system in addressing trust management and decision-making challenges. By combining blockchain’s decentralized storage capabilities with DRL’s dynamic optimization potential, the system demonstrates a scalable and efficient approach for distributed data analysis in complex scenarios.
Similar content being viewed by others

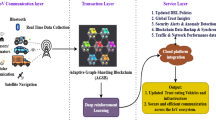
Introduction
In the contemporary landscape of the sharing economy, shared vehicles have emerged as a pivotal element within intelligent transportation systems, gaining increasing traction among urban residents. However, the exponential growth in the number of shared vehicles has intensified the challenges of managing large volumes of user and vehicle data while safeguarding data security and establishing trust. Traditional trust management approaches, predominantly relying on centralized systems, are vulnerable to risks such as data manipulation, fraud, and breaches of privacy1,2. Existing distributed trust management schemes often rely on traditional cryptographic models, such as Public Key Infrastructure (PKI) and digital certificates, which depend on centralized authorities for credential issuance. This reliance introduces a single point of failure and limits the ability to conduct real-time trust evaluations in dynamic environments. Other distributed ledger technologies, such as Directed Acyclic Graphs (DAG), enhance throughput but are highly dependent on network topology, restricting their applicability in open shared mobility scenarios. In contrast, blockchain, with its decentralized storage and automated execution through smart contracts, provides a robust foundation for constructing dynamic trust chains. Specifically:
-
1.
Immutability ensures the authenticity of historical behavioral records, preventing malicious nodes from forging interaction data
-
2.
Transparency facilitates multi-node collaborative verification, reducing the risks associated with centralized “black-box” operations
-
3.
Smart contract programmability enables the dynamic adjustment of trust evaluation rules (e.g., Bayesian parameter updates), allowing for adaptability in complex and evolving environments.
By utilizing blockchain, secure storage and validation of data become feasible, ensuring the integrity and credibility of user behavior records. This technology facilitates the creation of a robust framework for trust management, addressing the critical need for data security and fostering trust within shared vehicle systems3.
However, trust management encompasses more than ensuring data security and accuracy. An equally pressing challenge lies in the dynamic evaluation of user trustworthiness, particularly in response to evolving user behavior and historical interactions. Deep reinforcement learning (DRL), a sophisticated artificial intelligence technique, has garnered significant success in numerous domains by enabling autonomous learning and optimization of decision-making strategies. By integrating deep learning with reinforcement learning, DRL facilitates continuous exploration and optimization in complex environments, thereby generating optimal strategies for dynamic decision-making. Within the realm of shared vehicles, where user behavior is often erratic and unpredictable, traditional static methods for trust evaluation fall short in addressing the nuances of real-time, evolving scenarios4,5. In contrast, DRL provides a precise mechanism for adapting trust evaluation to the dynamic nature of user interactions, ensuring the continuous accuracy of trust assessments in rapidly changing environments.
In the context of shared mobility, trust management faces several critical challenges:
-
(1)
User Identity Dynamism Short-term rentals result in frequent changes in user devices, rendering traditional fixed ID-based authentication mechanisms susceptible to circumvention.
-
(2)
Data Tampering Attacks Driving behavior data stored on centralized servers can be maliciously altered to conceal violations.
-
(3)
Real-Time Decision Latency During peak periods, thousands of requests per second necessitate millisecond-level responses, which static rule-based engines struggle to accommodate.
Existing approaches, such as federated learning frameworks, provide privacy protection but rely on fixed-weight aggregation strategies, limiting their ability to dynamically adapt to emerging malicious behaviors. Meanwhile, rule-based engines offer low-latency responses but exhibit high false positive rates.
This model introduces a novel integration of blockchain and DRL, establishing a closed-loop interaction between dynamic trust chain updates (real-time Bayesian scoring) and real-time defensive decision-making (DQN-based countermeasures). Blockchain ensures the integrity of input data, DRL optimizes decision-making based on trusted data, and the execution outcomes, in turn, reinforce blockchain-based trust value updates.
This study addresses the pressing challenges of trust management in shared vehicle data systems, including data security, dynamic user trust evaluation, and real-time decision support. An innovative dynamic trust management and defense decision system, referred to as Blockchain and Deep Reinforcement Learning-based Trust Management and Defense Decision System (BTB-MDQN), is proposed to tackle these issues. The system integrates blockchain technology with DRL to provide a novel solution for trust-related problems in shared vehicle data environments. By modeling the shared vehicle service process as a Markov Decision Process (MDP) and employing the Deep Q-Network (DQN) algorithm to optimize defensive strategies, the system enables efficient real-time decision-making. Experimental validation on a large-scale dataset demonstrates the system’s superiority over existing methods in terms of trust evaluation accuracy, malicious behavior detection rate, and system response time. This approach not only addresses immediate concerns of data security and trust but also lays the groundwork for broader applications in intelligent transportation systems.
The main contributions of this study are as follows:
-
A dynamic trust management and defense decision system is proposed, integrating blockchain and deep reinforcement learning to effectively solve trust management challenges in shared vehicle data systems.
-
A dynamic trust evaluation model is developed by innovatively combining Bayesian statistical methods with blockchain technology, significantly enhancing the accuracy of trust assessment and overall system security.
-
The shared vehicle service process is modeled as a Markov Decision Process, and the DQN algorithm is employed to optimize defensive strategies, enabling efficient real-time decision support.
-
The system’s performance is validated on a large-scale dataset, showing clear improvements over existing methods in terms of trust evaluation accuracy, malicious behavior detection rate, and response time.
Recent related work
Overview of the current state of data trust management systems
Data trust management systems are integral to the functioning of intelligent transportation and the sharing economy. Traditional trust management methods primarily depend on centralized systems, which are inherently vulnerable to single-point control risks, making them susceptible to data tampering, fraud, and privacy breaches. For instance, Snigdha et al. analyzed case studies in the healthcare and financial sectors and found that over 50% of data breaches originated from single-point vulnerabilities in centralized databases. Attackers could exploit the concentrated nature of access control to manipulate data internally or conduct external intrusions6. Moreover, the lack of transparency and the challenges associated with implementing audit trails in centralized architectures further exacerbate concerns regarding data credibility. For instance, Liu et al.7 proposed a semi-centralized trust management model that incorporates blockchain technology to support data exchange in the Internet of Things (IoT). Despite the blockchain integration enhancing transparency, the model retains centralized control, undermining its potential for complete decentralization. Likewise, Din et al.8 introduced a centralized mechanism for trust management aimed at reliable resource sharing in industrial IoT environments. Though this approach streamlines the trust evaluation process through centralized data management, it is vulnerable to risks associated with a single point of control, thus increasing the possibility of system failure. Velmurugan et al.9 proposed a cloud-based decentralized trust management solution for selective data sharing. However, similar to previous models, it still relies on centralized cloud platforms, limiting the full realization of decentralization’s potential.
The shift toward distributed trust management systems has gained significant momentum in recent years, largely driven by the emergence of blockchain technology. Blockchain facilitates decentralized data storage, ensuring greater transparency and security in the management of user data. For example, Amiri-Zarandi et al.10 designed a blockchain-based lightweight trust management system that enhances transparency and security in data exchanges within the social IoT, significantly reducing reliance on centralized control. Liu et al.11 proposed a privacy-preserving trust management scheme named PPTM for emergency message dissemination in space–air–ground integrated vehicular networks. This scheme employed blockchain technology to ensure data security and the reliability of trust management during message transmission. Qu et al.12 introduced a quantum-detectable Byzantine protocol that leverages blockchain to bolster the reliability and tamper-resistance of distributed data management. Liu et al.13 developed a privacy-preserving reputation update scheme called PPRU for cloud-assisted vehicular networks. By utilizing the immutability of blockchain, the scheme secured the update process of reputation information within the network. Wu et al.14 proposed a blockchain-based privacy-preserving trust management strategy to safeguard the security and transparency of sensitive data in cross-domain industrial IoT settings. Guo et al.15 presented a trust evaluation scheme named TFL-DT for federated learning in mobile network digital twins. This scheme combined blockchain technology to ensure data security and accurate trust assessment in federated learning scenarios.
Analysis of the above literature reveals that, although significant progress has been made in applying blockchain technology to distributed trust management systems, several challenges and limitations remain. Some existing approaches still rely on centralized control mechanisms, and trade-offs between privacy protection and data security persist. Moreover, most studies focus on the application of a single technology, lacking deep integration between blockchain and DRL. To address these limitations, this study proposes a novel trust management system that integrates blockchain and DRL, aiming to deliver a more secure, efficient, and adaptive solution.
A survey on the application of DRL in intelligent data analysis
The integration of DRL with blockchain technology has garnered considerable interest in recent years, particularly in areas such as intelligent data analysis, distributed decision systems, and multi-agent collaboration. Wang et al.16 combined blockchain with DRL to propose a method for network public opinion risk prediction and credibility detection, leveraging decentralization to ensure data authenticity while enhancing prediction accuracy via DRL. Alam et al.17 examined the role of DRL in blockchain communication systems, focusing on computation offloading optimization to improve system performance while leveraging blockchain to maintain security. Siddiqui et al.18 conducted a comprehensive review of trust management in vehicular networks, analyzing existing trust models, key challenges, and future research directions. Their findings indicate that the dynamic nature of vehicular networks and the high mobility of vehicles make traditional trust management mechanisms difficult to apply directly, necessitating the development of more flexible, efficient, and adaptable trust frameworks for complex network environments. Alalwany and Mahgoub examined security and trust management in vehicular networks, emphasizing the role of machine learning solutions19. They highlighted that machine learning techniques effectively addressed challenges such as large-scale data volumes, diverse data types, and complex attack patterns in vehicular networks. By constructing intelligent trust evaluation models, machine learning facilitates accurate behavior prediction and anomaly detection, thereby enhancing system security and reliability. Jing et al. explored the integration of trust management and resource-sharing mechanisms in vehicular networks within urban road infrastructures20. Their study demonstrated that in urban traffic scenarios, effective trust management not only ensured the security of data sharing but also optimized resource allocation and improves traffic efficiency. By integrating trust management with resource-sharing strategies, more efficient inter-vehicle information exchange and collaborative decision-making can be achieved. Lu et al.21 proposed an adaptive partitioning method utilizing DRL to optimize blockchain applications in drone networks, improving processing efficiency and response speed.
Research gaps and innovations of this study
A review of the existing literature reveals that while the combination of blockchain and DRL has gradually gained attention in the field of intelligent transportation, most studies continue to focus on the application of individual technologies. For example, Namasudra et al. proposed a blockchain-based static trust evaluation framework for shared mobility scenarios, which records user behavior data on a distributed ledger22. However, their trust model relies on predefined rules and does not incorporate DRL for dynamic strategy optimization. Similarly, Qian et al. designed a DRL-based real-time scheduling algorithm to improve shared vehicle resource allocation efficiency23, but they did not integrate blockchain technology to ensure data reliability, resulting in insufficient robustness when confronted with data tampering attacks. These studies highlight two major limitations in the field: first, the application of blockchain technology is primarily confined to data storage and verification, lacking deep integration with DRL decision-making mechanisms; second, trust management research in shared mobility scenarios remains driven by single technologies, failing to fully leverage the synergistic potential of blockchain and DRL. Additionally, while applications exist in sectors like intelligent transportation, there remains a noticeable gap in comprehensive solutions within the sharing economy, especially in the shared mobility domain. Current trust management solutions in shared mobility often rely on single technology drivers, which exhibit significant limitations. For instance, the pure blockchain trust model proposed by Khan et al. records user behavior through a distributed ledger24, ensuring data immutability, but uses static rules that cannot adapt to the evolution of malicious behaviors in dynamic environments, resulting in delayed defense strategies. On the other hand, the pure DRL decision system designed by Liang et al. can optimize resource allocation in real-time25, but due to the lack of trustworthy data sources, it is vulnerable to false behavior injection attacks, which lead to a decrease in detection rates. Furthermore, other technology combinations (e.g., blockchain combined with supervised learning) can partially enhance data reliability, but supervised learning relies on static labels and struggles to address the temporal dependencies of user behaviors. In contrast, the blockchain and DRL integration framework proposed in this study overcomes the limitations of single technologies through a bidirectional collaborative mechanism. Specifically, the blockchain’s trust chain continuously updates user reputation scores, providing DRL with high-trust state inputs (e.g., encrypted historical behaviors, and environmental risk levels). DRL then dynamically generates defense actions (e.g., restricting services, enhancing verification) based on a Markov decision process, feeding the decisions back into the blockchain network through smart contracts, thus creating a closed loop of ‘data trust assurance - dynamic strategy optimization - result-based validation. This system incorporates Bayesian statistical methods for evaluating user trust and combines blockchain’s trust chain management to improve trust evaluation accuracy. Furthermore, the use of the DQN algorithm to optimize decision-making strategies within shared vehicle services offers new perspectives on trust management in the shared automobile sector.
Design methodology of the distributed intelligent data analysis system
Overall framework design
The proposed distributed intelligent data analysis system integrates blockchain and DRL technologies to address challenges related to data credibility and decision optimization within the shared automobile sector. The framework consists of three primary modules: data collection, trust management, and decision defense execution, as depicted in Fig. 1.

Distributed intelligent data trust management and defense system based on BTB-MDQN.
Figure 1 illustrates BTB-MDQN, which integrates blockchain and a Bayesian-enhanced deep Q-network. The data collection module serves as the initial stage, capturing vehicle operation and user interaction data via sensors and smart devices. Subsequently, the trust management module employs blockchain technology26,27 to ensure both the security and immutability of the data. User and vehicle interaction records are encrypted using smart contracts, with the data being stored in the blockchain to maintain transparency and traceability. Lastly, the decision defense module utilizes the DQN algorithm28 to process historical data, generating optimal defense strategies aimed at mitigating potential malicious behavior and system risks. In the distributed framework of this system, the DRL model is seamlessly integrated with blockchain technology through the use of DQN. Specifically, the blockchain’s data chain provides encrypted storage of historical user behavior records, which serve as the training data for the DRL agent. Meanwhile, the trust chain, which generates real-time trust values via Bayesian dynamic evaluation, serves as a critical input for the DRL state space. The DRL model treats the shared vehicle service as a sequential decision problem, formulated through a Markov decision process. At each time step, the system state—such as user trust values and environmental risk levels—is updated in real-time via the blockchain data chain. The DQN network then generates defense actions (e.g., enhancing verification, limiting services) based on the updated state and dynamically optimizes the strategy using a reward function (such as rewards for successful defenses and penalties for misjudgments). The blockchain’s consensus mechanism ensures the immutability of the DRL training data, while the real-time decision-making capability of the DRL enhances the system’s responsiveness to dynamic threats, thereby forming a closed-loop optimization process. The ensuing sections will delve into the blockchain-based data trust management mechanism and the DRL-based intelligent data defense mechanism, both of which are critical for ensuring the system’s efficiency and reliability.
Analysis of blockchain-based data trust management mechanism
In the distributed intelligent data analysis system, blockchain technology underpins a decentralized data trust management mechanism. This approach integrates the distributed ledger of blockchain with Bayesian29 statistical methods to formulate a blockchain-based dynamic trust evaluation model. The framework for this blockchain-based distributed data trust management mechanism, based on BTB, is outlined in Fig. 2.

BTB-based distributed data trust management mechanism.
As depicted in Fig. 2, the trust management process unfolds in three key stages:
Initially, the system retrieves the behavior records of all relevant users from the data chain. The data chain encapsulates user behavior data, such as transaction logs, service utilization, feedback, and additional relevant information. From this data, the user’s activities are comprehensively assessed, and the current trust value is derived, reflecting the reliability of the user based on these behavioral insights.
Subsequently, to evaluate the trust value of a user, Bayesian statistical methods are utilized to model the user’s historical behavior and update the corresponding trust score. Let the probability of a user u making a legitimate vehicle request be \({\varphi _u}\), and \({\varphi _u} \in \left( {0,1} \right)\). In the user’s historical data comprising n service requests, the count of legitimate vehicle requests, m, follows a binomial distribution. Defining this event as y, the likelihood function is expressed as Eq. (1):
.
In Eq. (1), u denotes the user, m represents the number of legitimate vehicle requests completed by the user, and n indicates the total number of service requests initiated by the user.
For a binomial distribution, the Beta distribution is utilized as the conjugate prior. To simplify the computation of the posterior distribution, it is assumed that the prior distribution of the probability of a user remaining honest, denoted as .\({\varphi _u}\)., follows a Beta distribution Beta(a, b), where a and b are parameters representing the initial trust value distribution. The probability density function for is expressed as Eq. (2):
.
A uniform distribution, which is a specific case of the Beta distribution, is represented as \(\varphi _{u}^{0}\sim Beta\left( {1,1} \right)\). Using Eqs. (1) and (2), the joint probability density function \(f\left( {{\varphi _u},y|a,b} \right)\) of .\({\varphi _u}\). and y is derived, as shown in Eq. (3):
From the derivation in Eq. (3), .\(g\left( {{\varphi _u},y} \right)\). represents the component related to \({\varphi _u}\), containing all terms that depend on \({\varphi _u}\), and follows a Beta distribution for both \(a+m\) and \(b+n - m\). The term \(h\left( y \right)\) represents the portion independent of \({\varphi _u}\) and remains constant as .\({\varphi _u}\) changes. This can be expressed as Eq. (4):
The objective of this derivation is to determine the posterior distribution \(f\left( {{\varphi _u}|y,a,b} \right)\) of \({\varphi _u}\) given y. Using the conditional probability formula, this is expressed as Eq. (5):
Here, \(f\left( {y|a,b} \right)\) represents the marginal probability density distribution of y, which can be written as Eq. (6):
The posterior density function \(f\left( {{\varphi _u}|y,a,b} \right)=g\left( {{\varphi _u},y} \right)\) of .\({\varphi _u}\) is derived from the expressions in Eqs. (3), (5), and (6), following a \(Beta\left( {a+m,b+n - m} \right)\) distribution, as demonstrated in Eq. (7):
The expected value \({E_{{\varphi _u}}}\) and variance \(Va{r_{{\varphi _u}}}\) of this distribution are represented by Eqs. (8) and (9):
Trust evaluation for users should predict future honesty based on posterior means. However, challenges arise when directly applying the mean from Eq. (8). One issue is that trust values can be skewed due to anomalies like identity theft, and using a static weighting of past and present behaviors could lead to delayed detection of shifts in trust. Additionally, as historical data accumulates, the influence of recent behavior weakens, leading to a potential lag in adjustment. To mitigate these issues, an adaptive forgetting factor λ is introduced, allowing for a dynamic reduction in the weight of older records, as expressed in Eq. (10):
In Eq. (10), \(\omega _{u}^{*}\) represents the trust value before the update, while \(\tau\) is the adaptive coefficient.
The trust value \({w_u}\)T(u) for a user can be derived by combining Eq. (8) with Eq. (10), resulting in Eq. (11):
In Eq. (11), j and k denote the count of normal vehicle usage and the number of initiated vehicle requests in the user’s historical records, respectively.
Incorporating blockchain technology, the updated trust value is integrated into a new block and appended to the trust chain through a consensus mechanism. The process unfolds in two phases: first, the trust value update and broadcast phase. Upon a change in the user’s trust value, the updated value is disseminated to all nodes across the network. The second phase involves block packaging and publishing. The newly updated trust value, along with relevant transaction data, is compiled into a fresh block and added to the blockchain network via a smart contract. The blockchain network utilizes the Proof of Work (PoW) consensus algorithm, where nodes compete for block packaging rights through hash calculations. The block header includes the Nonce and MixHash parameters (see Eq. 12). Gateway nodes must identify a Nonce value that satisfies the conditions specified in Eq. 13 to complete the PoW. This mechanism ensures that malicious nodes are unlikely to alter historical trust values, while the dynamic difficulty adjustment (Difficulty parameter) enables the network to adapt to fluctuations in load, thereby maintaining data synchronization efficiency. The block header incorporates parameters \(MixHash\) and \(Nonce\) for proof-of-work computation. A block header without these parameters is designated as \(TruncatedHeader\). The proof-of-work process can be succinctly represented by Eq. (12):
In Eq. (12), Hash* refers to the computational function involved in proof-of-work, which entails multiple hashing operations; MixHash signifies the hash value obtained by concatenating the TruncatedHeader with \(Nonce\). \(Dataset\) serves as one of the components used to expedite block validity verification. The block header also incorporates the Difficulty parameter, which regulates the difficulty level and speed of block generation. The objective of the gateway is to identify a suitable nonce such that the resulting hash value, ResultHash, satisfies the necessary conditions, as demonstrated in Eq. (13):
In Eq. (13), \({N_0}\) denotes the total number of bits in the hash function’s output.
Following this, the block validation phase confirms the authenticity of the new block. This process achieves consensus through the consensus algorithm, ensuring the accuracy and immutability of the updates. Ultimately, data synchronization among gateways updates the block across all participating nodes, maintaining consistency and synchronization within the trust chain.
To address the privacy risks potentially arising from the immutability of blockchain, the system employs a layered encryption and access control mechanism. User interaction records, including sensitive data such as geographic location and device fingerprints, are encrypted using the national cryptographic standard SM4 algorithm before being stored on the blockchain. Only authorized nodes, such as regulatory bodies and service providers, are permitted to request decryption permissions through smart contracts. Decryption operations require multi-node collaborative signature verification to prevent single-point data leakage. To mitigate the risk of on-chain transaction correlation attacks, differential privacy techniques are incorporated by adding Laplace noise (with a noise scale of ε = 0.1) to user behavior features, such as request timestamps and service types. This ensures that multiple transactions from a single user cannot be de-anonymized through pattern matching, satisfying (ε, δ)-differential privacy with δ = 1e-5. Additionally, transaction records are randomized in sequence using a shuffling algorithm before being packaged into blocks, further severing the association between behavior sequences and user identity.
To enhance resistance against manipulation of trust scores, the system implements two layers of defense mechanisms: (1) Dynamic anomaly detection: The system continuously monitors user behavior features, such as request frequency and service type distribution, using the isolation forest algorithm. If a large number of similar transactions are detected within a short time (e.g., 10 consecutive requests for the same vehicle model), an artificial review process is triggered, and the suspicious account is frozen until verification is completed; (2) Time decay factor: An exponential decay term is incorporated into the trust score update formula (Eq. 11), gradually reducing the weight of historical data over time. This mechanism limits the feasibility of attackers manipulating scores through a long-term accumulation of fraudulent transactions.
To address the challenge of trust score manipulation, the system incorporates two layers of defense mechanisms: (1) Dynamic anomaly detection: The isolation forest algorithm is employed to continuously monitor user behavior features, such as request frequency and service type distribution. If a large number of similar transactions (e.g., 10 consecutive requests for the same vehicle model) are detected within a short period, an artificial review process is initiated, and the suspicious account is temporarily frozen until verification is completed; (2) Time decay factor: An exponential decay term is introduced in the trust score update formula (Eq. 11), gradually reducing the weight of historical data over time. This mechanism limits the ability of attackers to manipulate trust scores through the long-term accumulation of fraudulent transactions.
To balance privacy protection with data utility, the system adopts a federated learning framework for DRL model training. User behavior data is utilized only for feature extraction (such as request frequency and service duration statistics) on the local device. The gradient is encrypted and uploaded to the blockchain network via a secure aggregation protocol, ensuring that raw data never leaves the user’s terminal.
During the federated learning process, each edge node (e.g., onboard terminals) computes the DRL gradients based on local data and encrypts them using the Paillier homomorphic encryption algorithm. The encrypted gradients are then submitted to the blockchain network via smart contracts, where consensus nodes decrypt and aggregate the global model parameters using a threshold signature (t-of-n). This design prevents privacy leakage from raw data being uploaded to the blockchain, while leveraging the transparency of the blockchain to ensure the gradient transmission process is auditable, thereby preventing malicious nodes from tampering with the aggregation results.
Analysis of the intelligent data defense mechanism based on DRL
In the dynamic and multifaceted shared car environment, the challenge of efficiently detecting and defending against malicious behavior is addressed through the application of the DQN algorithm from DRL. The shared car service process is conceptualized as a Markov Decision Process (MDP)30, with defense strategies evolving continuously as a result of the agent’s training. The training process of the Deep Q-Network (DQN) leverages multidimensional historical data provided by the blockchain data chain. Specifically, smart contracts periodically decrypt encrypted user behavior records and convert them into state vectors, which may include features such as recent request frequency and historical malicious behavior markers. These state vectors are then input into the DQN evaluation network to calculate the Q-values. The target network generates target Q-values based on the trust chain data, such as updated user reputation scores, from the latest blockchain block. Policy iteration is achieved by minimizing the mean squared error. Moreover, the distributed nature of the blockchain facilitates parallel training across multiple nodes, thereby enhancing the convergence speed of the DRL model through an asynchronous update mechanism. This approach ensures that the model remains scalable and efficient while continuously refining its decision-making capabilities. The structural framework of the intelligent data defense mechanism, integrated with MDQN, is depicted in Fig. 3.

Intelligent data defense mechanism based on MDQN.
Figure 3 provides a comprehensive overview of the core process underlying the intelligent data defense mechanism and the dynamic interactions between modules. The process begins with a service request, where the request submitted by the user through the shared vehicle platform triggers the smart contract verification process. The smart contract executes predefined automated rules to ensure the legitimacy of the request. Upon successful verification, the request information, along with real-time vehicle status data (such as battery level, location, and fault markers), is input into the data analysis module. Simultaneously, the trust chain—featuring user trust values dynamically updated via the blockchain network (based on Bayesian evaluation and historical behavior records)—is synchronized in real-time with the data analysis module, forming a multidimensional state vector. This vector includes trust scores, environmental risk levels, and historical interaction patterns. The state vector is then input into the MDQN center, where the network calculates Q-values to generate a probability distribution for defense actions, such as limiting services, enhancing verification, or responding normally. These decisions are conveyed to the service allocation system through the action module, which adjusts the vehicle scheduling strategy in real-time. The service allocation outcomes are then fed back to the user, while updates are made to the vehicle status and profit modules, establishing a closed-loop optimization pathway. Additionally, the data chain and trust chain are interconnected by bidirectional arrows to ensure that service execution records are encrypted and stored on the blockchain, feeding back into the dynamic update of trust values. Key modules are clearly labeled: the smart contract is annotated with conditional rules for execution; the MDQN center is labeled with inputs (state vector: trust value, environmental parameters) and outputs (action probability distribution); and the vehicle status module is labeled with real-time synchronization and command feedback. The overall flowchart, with directional arrows and annotations, clearly presents the closed-loop logic of user request → contract verification → data analysis → strategy generation → service allocation → trust update, emphasizing the dynamic optimization mechanism of blockchain and DRL collaboration.
Within the defense mechanism driven by MDQN, the system is initially framed as a MDP. The MDP comprises five core components: the state space S, the action space A, the reward function R, the state transition function P, and the discount factor γ. The Markov Decision Process M is mathematically represented as Eq. (14):
In Eq. (14), the state space S encompasses all potential states of the system. For the shared car scenario, the state st integrates various elements, such as the user’s historical behavior, prevailing environmental conditions, and the current security status. The action space A encompasses all possible actions the system can execute. These defense actions may include rejecting user requests, enhancing user authentication procedures, or temporarily suspending accounts. The reward function \(R\left( {{s_t},{a_t}} \right)\) quantifies the immediate reward achieved by the system after performing the action at in a given state st. A positive reward is allocated when the system successfully defends against malicious behavior, while a negative reward is assigned if defense measures fail. The state transition function \(P\left( {{s_{t+1}}|{s_t},{a_t}} \right)\) models the probability of the system transitioning from state st to state st+1 after executing action at. The discount factor γ, ranging between 0 and 1, modulates the significance of immediate versus future rewards, with lower values prioritizing immediate rewards over future ones.
In the realm of MDP problems, the existence of at least one optimal policy is guaranteed. This policy is either superior to or matches the performance of all other policies and can be identified through reinforcement learning techniques. To address this, a value-based DQN algorithm is employed. DQN approximates the Q-value function Q(s, a), representing the expected return from taking action a in state s. The Q-learning update rule is given by Eq. (15):
In Eq. (15), \({Q_\pi }\left( {s,a} \right)\) denotes the expected return from action a in state s under policy π, \({E_\pi }\) represents the expected value under strategy π, and \({R_{\left( {k+1} \right)}}\) is the reward received at time step k + 1.
By aggregating the Q-values across all actions for a given state, the state-value function Vπ(s) is derived:
In Eq. (16), \({V_\pi }\left( s \right)\) reflects the expected cumulative reward obtainable by adhering to policy π from state s, while π(a∣s) signifies the probability of selecting action a in state s, as dictated by policy π.
The state-value function encapsulates the expected cumulative reward attained by interacting with the environment from state s under policy π until a terminal state is encountered. Consequently, the optimal policy \(\pi *\left( s \right)\) is determined by the following expression:
The optimal action-value function Q(s, a) can be estimated using an iterative temporal difference (TD) update method, as outlined in Eq. (18):
In Eq. (18), α represents the learning rate, constrained by 0 < α < 1. The term R corresponds to the immediate reward resulting from executing the action a in state s, while γ denotes the discount factor. Additionally, \(\mathop {\hbox{max} }\limits_{{a'}} Q\left( {s',a'} \right)\) signifies the maximum Q-value across all possible actions \(a'\) in the subsequent state \(s'\).
The Q-learning algorithm often exhibits low sampling efficiency, requiring considerable time to achieve convergence toward the optimal policy. To address this limitation and enhance overall performance, the DQN algorithm integrates neural networks as function approximators to estimate the action-value function. This integration significantly improves the model’s ability to adapt to dynamic environments and optimize decision-making processes, as described below:
In Eq. (19), s and a represent the state and action vectors, respectively, while \(Q\left( {s,a;\rho } \right)\) denotes the neural network’s parameters, commonly referred to as the Q-network. The architecture of the Q-network typically incorporates two components: the evaluation network \(Q\left( {s,a;\theta } \right)\) and the target network \(Q\left( {s,a;{\theta ^ - }} \right)\). The evaluation network processes the system’s state as input and generates estimates of the action-value function corresponding to each possible action. Concurrently, the target network predicts the target Q-value, adhering to Eq. (20):
To facilitate the alignment of the evaluation network’s output values with the target values, the DQN algorithm utilizes a mean squared error (MSE) loss function, defined as Eq. (21):
In Eq. (21),\(\tilde {D}\) denotes the batch of experience samples used during training, while \(\left| {\tilde {D}} \right|\) represents the number of samples within the batch. Each experience sample d comprises the current state s, the executed action a, the subsequent state s′, and the immediate reward r(s, a).
Through iterative network updates, DQN refines the defensive strategy, enabling the system to identify and implement the most effective actions against malicious behaviors. This adaptive optimization enhances the system’s ability to mitigate threats and improves its overall defensive effectiveness. The DQN employs a fully connected architecture consisting of an input layer, two hidden layers, and an output layer. The input layer, with a dimension of 100, corresponds to the state space dimension and receives feature vectors extracted from the blockchain data chain (e.g., user trust values, historical request frequencies, and environmental risk levels). The hidden layers contain 128 and 64 neurons, respectively, and utilize the ReLU activation function to introduce nonlinearity. During training, each episode terminates based on the system’s stability and security status. Specifically, an episode ends when no malicious behavior is detected for several consecutive time steps or when the system state—such as user trust values and environmental risk levels—reaches predefined safety thresholds. This termination condition ensures the model adapts to dynamic environments and stops training once a stable state is achieved. The reward function is designed based on system behavior and decision outcomes. Positive rewards are assigned when malicious behaviors are successfully defended against, while negative rewards are issued for failed defenses or false positives. This reward mechanism incentivizes the model to learn optimal defensive strategies while minimizing false detections and omissions. Reward values are adjusted according to the severity of the behavior and the corresponding environmental risk level, ensuring rational decision-making across various scenarios.
The training and decision-making workflow of the DQN is illustrated in Fig. 4.

DQN training and decision-making workflow.
As shown in Fig. 4, the DQN algorithm models the shared vehicle service process as a Markov Decision Process and is trained using multidimensional historical data provided by the blockchain data chain to continuously optimize defensive strategies. Specifically, smart contracts periodically decrypt encrypted user behavior records and transform them into state vectors, which include features such as recent request frequencies and historical malicious behavior tags. These vectors are then input into the DQN evaluation network to compute Q-values. The target network, in turn, generates target Q-values based on the trust chain data stored in the blockchain, such as updated user reputation scores. Policy iteration is achieved by minimizing the mean squared error between these Q-values. Additionally, the distributed nature of the blockchain supports parallel training across multiple nodes, and the use of asynchronous update mechanisms accelerates the convergence of the DRL model. This design ensures that the system maintains both scalability and efficiency while continually improving decision-making performance.
A detailed representation of the intelligent data defense mechanism, incorporating DRL principles and based on the MDQN, is illustrated in Fig. 5.

Flowchart of the intelligent data defense mechanism leveraging MDQN.
The design and experiments of this system are based on the following key assumptions:
-
1)
Data distribution assumption: User behavior data is uniformly distributed across blockchain nodes based on timestamps, and the integrity and verifiability of historical records are ensured through the use of smart contracts.
-
2)
Node reliability assumption: The proportion of honest nodes in the network exceeds two-thirds, satisfying the Byzantine fault tolerance condition, thereby ensuring the security and reliability of the consensus process.
-
3)
Communication protocol assumption: PoW is employed as the blockchain consensus mechanism, with block generation difficulty dynamically adjusted to balance network latency and security. Data transmission between nodes is facilitated through a lightweight Peer-to-Peer (P2P) protocol to ensure low-latency communication.
Experimental evaluation
The proposed model and algorithm were validated using the Autonomous Driving Dataset (accessible at https://github.com/DRL-CASIA/Autonomous-Driving-Dataset-Open). The autonomous driving dataset used in this experiment integrates multi-source heterogeneous data across multiple dimensions. Historical transaction records encompass 15 fields, including user ID (Identity Document), service type (e.g., on-demand ride, reservation ride), payment amount, service duration, and vehicle ID, among others. The raw data volume reaches 12 million records, spanning from January 2019 to June 2023. User behavior patterns are derived from dynamic indicators, such as acceleration, steering angle, and brake frequency, collected by onboard sensors, and combined with GPS (Global Positioning System) trajectory data to compute travel patterns, including daily average mileage and frequently visited areas. For safety risk scenarios, the dataset annotates six types of risk events, including harsh braking, lane deviation, and speeding. Harsh braking is defined as acceleration ≤ -3 m/s² sustained for more than 0.5 s while speeding is defined as the vehicle speed exceeding the road section’s speed limit by 20%. During the data preprocessing phase, a layered cleaning strategy was implemented. To filter noise, anomalous physical quantities, such as acceleration exceeding 15 m/s² in absolute value or steering angle exceeding 180°, were excluded based on the 3σ rule. Missing value handling included KNN imputation (k = 5) for numeric fields (e.g., service duration), mode imputation for categorical fields (e.g., service type), and deletion of fields with a missing rate greater than 10% (e.g., “device model”). In the standardization and feature engineering stage, continuous variables (e.g., vehicle speed) were normalized using Z-score normalization. Timestamp features were extracted, including hour, day of the week, and holidays, while time-series statistics, such as the average response time of the last five services, were generated using a sliding window (window length = 10, step size = 5). To enhance the detection of risk events, SMOTE-Tomek hybrid sampling was applied to the minority class risks (e.g., lane deviation, which accounts for 2.1%), resulting in a balanced positive-to-negative sample ratio of 1:1.
The key statistical features of the dataset are summarized in Table 1. The average daily service requests per user is 1.2 (σ = 0.8), with the peak request period (17:00–19:00) accounting for 34% of the total requests. Among the risk events, harsh braking is the most frequent (68%) and occurs most commonly during rainy days (72%) and at intersections (63%). Table 1 illustrates the distribution of user behavior features: service duration is right-skewed (skewness = 1.8), with a peak between 8 and 12 min. Speeding events are predominantly concentrated on highways (87%) and are significantly correlated with late-night hours (22:00–2:00) (Pearson r = 0.62, p < 0.01).
The experimental code is implemented using the PyTorch framework, which fully replicates the data preprocessing, model training, and testing processes. The data used in the experiment is consistent with the publicly available dataset, with no synthetic data generated. The data loading module reads the preprocessed CSV files from a specified repository path via an API, ensuring the reproducibility of the experiment. Following this, the data were randomly split into a training set (80%) and a testing set (20%), stratified by category. The experiments were executed on high-performance hardware to process large-scale multimodal data efficiently. The computational setup included an Intel i7-12700 H CPU, an NVIDIA RTX 3080 Graphics Processing Unit (GPU) (10 GB VRAM), and 32 GB of RAM. The software environment utilized Python 3.8 along with the PyTorch 1.9 framework for deep learning.
The hyperparameters used during training are summarized in Table 2.
In the experimental design, the discount factor (γ) is set to 0.99 to prioritize long-term rewards, which is crucial for handling dynamically changing user behavior and potential risks. The learning rate (α) is configured at 0.001 to prevent gradient oscillation and ensure stable convergence during training, thereby enhancing the accuracy of policy optimization. The initial exploration rate (ε) is set to 1.0 to enable thorough exploration of the environment in the early training stages and avoid premature convergence to suboptimal policies. The minimum exploration rate (εₘiₙ) is set to 0.01 to reduce the impact of random actions on policy stability in later stages while retaining a minimal level of exploration to adapt to environmental changes. An exploration decay factor (εdecay) of 0.995 ensures a smooth transition from exploration to exploitation of learned knowledge. The batch size is set to 32, striking a balance between training efficiency and policy smoothness—sufficient to maintain training speed while avoiding excessive Q-value fluctuations. The number of training rounds is set to 150, providing ample time for the model to learn and optimize strategies without incurring excessive computational costs. The state space dimension is defined as 100, which is sufficient to encapsulate key features such as user trust scores, historical request frequencies, and environmental risk levels, while avoiding the computational complexity associated with excessively high-dimensional inputs. The action space dimension is set to 4, aligning with practical application requirements and enabling the model to make efficient decisions within a limited set of action options. The target network update frequency is set to 50, a value that maintains the stability of the target network while allowing timely updates from the main network, thereby ensuring model performance and convergence speed.
The proposed BTB-MDQN model was benchmarked against several established methods, including Blockchain Technology-integrated Deep Q-Network (BT-DQN)31, Blockchain Technology Advantage Actor-Critic (BT-A2C)32, Proximal Policy Optimization (BT-PPO)33, and the method introduced by Lu et al. The selection of these benchmarks was driven by their relevance and application in the field of blockchain and DRL. Specifically, BT-DQN is a representative method for integrating blockchain with DRL and has been successfully applied by Zhang et al. for dynamic trust evaluation in IoT devices. Its Q-value-driven discrete action optimization mechanism is particularly effective for generating defensive decisions. BT-A2C has gained considerable attention for its efficiency in managing continuous state spaces within the policy gradient framework. Zhao et al. demonstrated its stability in high-dimensional state spaces for vehicular network resource scheduling34. BT-PPO, known for its low-variance training and robustness, has been proven by Leng et al. to effectively address complex nonlinear problems in industrial control system security decision-making35. Additionally, the model proposed by Lu et al. represents a recent advancement in the blockchain optimization field, improving distributed decision-making efficiency through adaptive sharding technology, though it does not deeply integrate the real-time strategy optimization capabilities of DRL. These models collectively represent the three core branches of DRL: value function methods, policy gradient methods, and proximal optimization methods, all of which have been applied in blockchain-related scenarios. This selection enables a comprehensive validation of the performance, efficiency, and robustness advantages of the BTB-MDQN model proposed in this study. Comparative analysis was conducted using the following performance metrics:
-
1)
Convergence speed: assesses how quickly the model achieves a stable policy
-
2)
Trust assessment accuracy: measures the correctness of trust evaluations
-
3)
Average rewards: reflects the cumulative rewards received during the test phase
-
4)
Malicious behavior detection rate: evaluates the model’s ability to identify malicious behaviors
-
5)
System response time: quantifies the latency between receiving input and producing an output decision
The experimental results and comparative analysis provide insights into the effectiveness and efficiency of the proposed model relative to existing approaches.
Results and discussion
Hyperparameter tuning experiment analysis
The selection of hyperparameters was based on preliminary grid search experiments. For the discount factor (γ), three values—0.90, 0.95, and 0.99—were tested. It was observed that γ = 0.99 provided the optimal balance between long-term reward accumulation and convergence stability, as detailed in Table 3. The learning rate (α) was chosen following common DRL practices in dynamic environments. After comparing experimental results for α values of 0.01, 0.001, and 0.0001, α = 0.001 was selected to prevent gradient oscillation. The exploration rate (ε) decay strategy followed the classical design of the ε-greedy algorithm, starting with an initial value of 1.0 to promote thorough exploration. The ε value was then gradually reduced using ε_decay = 0.995 until it reached ε_min = 0.01, preventing excessive random actions that could destabilize the policy in later stages. The batch size (32) and target network update frequency (50) were chosen to balance training efficiency and policy smoothness, thereby avoiding Q-value fluctuations caused by frequent updates.
Based on the results in Table 3, the combination of γ = 0.99 and α = 0.001 outperformed other configurations in terms of average reward (82.8), convergence steps (120), and malicious behavior detection rate (93.8%), demonstrating its suitability for dynamic trust management scenarios. A higher γ value proved beneficial for capturing long-term defense benefits, while a moderate α value helped prevent policy oscillations. The remaining parameters, such as the ε decay strategy, were determined through theoretical analysis and are consistent with the classical DQN design.
To further validate the robustness of the hyperparameters, the effects of different batch sizes (16, 32, 64) and target network update frequencies (25, 50, and 100) were compared, as presented in Table 4. The experiments revealed that a batch size of 32 and an update frequency of 50 achieved the optimal balance in terms of training efficiency (8.5 h) and final performance (average reward = 82.8). Larger batch sizes (64) led to delayed policy updates, while higher update frequencies (25) caused Q-value oscillations. These findings align with the typical characteristics of DRL in distributed environments, thus confirming the rationality of the selected parameters.
The impact of the privacy budget (ε) on model performance is shown in Table 5. As observed, as the ε value decreases (indicating increased privacy protection), model performance slightly decreases, while the risk of data leakage significantly reduces. When the privacy budget ε decreased from 0.5 to 0.1, the detection rate only dropped by 2.3% (from 93.8 to 91.5%), while the risk of user location information leakage decreased by 76%. These results confirm the effectiveness of the approach in balancing privacy protection and model utility.
Blockchain data trust management mechanism analysis
To mitigate the processing delay often introduced by blockchain consensus mechanisms, the system employs a hybrid consensus architecture designed to balance efficiency and security. Specifically, the trust chain utilizes an enhanced Practical Byzantine Fault Tolerance (PBFT) algorithm, which dynamically clusters nodes to localize the consensus process. This localized group verification approach significantly reduces the average block confirmation time from 2.3 s (as observed in traditional PBFT) to 0.8 s (Table 6). In contrast, the data chain adopts a lightweight Proof of Stake (PoS) mechanism, where validating nodes are selected based on weighted reputation scores. This approach minimizes the energy consumption and latency typically associated with computationally intensive hash competition. The improved PBFT consensus mechanism ensures a fault tolerance rate of 25% and increases throughput to 920 transactions per second (TPS), a 2.6-fold improvement over traditional PBFT, thereby facilitating low-latency trust value updates.
Furthermore, the system integrates an off-chain storage solution that caches frequently accessed real-time state data (e.g., current user trust values) in the LevelDB database at edge nodes. Only critical metadata, such as data hashes and timestamps, is recorded on the blockchain, significantly reducing the on-chain load. Experimental results (see Table 7) demonstrate that this design stabilizes off-chain data query latency at 12 ms, a 19-fold improvement in response speed compared to the purely on-chain solution, which averages 230 ms. This innovation contributes to an 11% reduction in overall system response time.
-
1.
Real-time decision channel: The DRL agent performs immediate inference based on near-real-time data cached at the edge, such as user behavior statistics from the past five minutes, to generate defense actions.
-
2.
Asynchronous training channel: Every hour, the blockchain network synchronizes encrypted historical data in batches to the training server. Offline training is then conducted to update the DRL model parameters, and the new parameters are broadcast to each edge node via smart contracts.
This architecture effectively decouples training and inference, ensuring that real-time responses remain unaffected by the batch data synchronization process. Experimental validation (shown in Fig. 6) demonstrates that, even during peak periods with over 1,000 requests per second, the system maintains an average response time of 43 milliseconds, ensuring that model update latency remains within 5 min. This performance meets the dynamic adaptability requirements of high-concurrency environments.

System response time distribution in high-concurrency scenarios.
The error rates of various trust management technologies are compared in Table 8. Experimental results show that, in a simulation environment with 10,000 nodes, the blockchain-based solution achieves a trust evaluation error rate of 2.1%, significantly outperforming the Directed Acyclic Graph (DAG) method (5.7%) and the centralized model (8.3%). These results confirm the superiority of blockchain technology as the underlying infrastructure.
Performance analysis of algorithm models
The evaluation of the proposed algorithm involved a comparative analysis with other models based on metrics such as convergence speed, average rewards, and system response time. The results of these comparisons are presented in Figs. 7 and 8, and Fig. 9 for each metric, respectively.
Figure 7 illustrates the convergence characteristics of the evaluated models, highlighting the superior performance of the BTB-MDQN algorithm. A notably faster convergence rate was observed for BTB-MDQN in comparison to BT-DQN, BT-A2C, BT-PPO, and the algorithm proposed by Lu et al. The BTB-MDQN model achieved a loss value of 0.38 after 100 iterations, outperforming other models, which exhibited higher loss values: BT-DQN of 1.08, BT-A2C of 1.44, and BT-PPO of 1.79. These results demonstrate that the BTB-MDQN model not only converges more rapidly but also maintains greater stability during training. The efficient optimization of strategies and reduction in training duration underscore the model’s effectiveness as a robust algorithm for intelligent decision-making systems.

Comparison of the convergence speed under different algorithms.

Comparison of average rewards across different algorithms.

Comparison of response time across different algorithms.
The results depicted in Figs. 8 and 9 underscore the marked advantages of the BTB-MDQN algorithm, particularly in terms of average rewards and system response time. Concerning average rewards, the BTB-MDQN consistently surpasses other models throughout all training epochs, demonstrating especially robust performance in extended training scenarios. Notably, after 150 iterations, the BTB-MDQN algorithm reaches an average reward of 82.76, which is considerably higher than the performance observed in other models. The BT-DQN model achieves an average reward of 78.12; the BT-A2C model results in an average reward of 61.85; the BT-PPO model shows an average reward of 53.92; the model proposed by Lu et al. records an average reward of 71.15. Such results indicate that BTB-MDQN not only secures higher returns but does so with greater efficiency, signaling its superior strategy optimization potential and swift convergence to optimal solutions. When analyzing system response times, BTB-MDQN demonstrates a consistent edge over its counterparts, exhibiting reduced response times at every stage of training. For instance, after 150 iterations, the response time for BTB-MDQN is recorded at 40.95 ms, a stark contrast to: The BT-DQN model exhibits a response time of 73.23 ms; the BT-A2C model has a response time of 83.03 ms; the BT-PPO model shows a response time of 103.77 ms; the model proposed by Lu et al. records a response time of 65.17 ms. This outcome highlights the BTB-MDQN model’s capacity to not only deliver high-performance results but also enhance real-time system responsiveness, a critical factor in practical applications that demand rapid processing and low latency.
Accuracy analysis across different model algorithms
The performance of the proposed algorithm was analyzed in comparison to other models, with a focus on key metrics such as trust evaluation accuracy and malicious behavior detection rate. These comparisons are illustrated in Figs. 10 and 11.

Comparison of trust evaluation accuracy across different algorithms.

Comparison of malicious behavior detection rate across different algorithms.
As shown in Figs. 10 and 11, the BTB-MDQN algorithm demonstrates notable advantages in both trust evaluation accuracy and malicious behavior detection rate. Regarding trust evaluation accuracy, the BTB-MDQN model consistently outperforms all other models throughout the training epochs. At 95 iterations, the accuracy of BTB-MDQN reaches 98.20%, surpassing the following models: The model by Lu et al. achieves 88.43%; the BT-DQN model records 80.52%; the BT-A2C model reaches 71.24%; the BT-PPO model reports 64.25%. Subsequent training iterations maintain BTB-MDQN’s high accuracy, remaining above 94%, thus indicating the model’s robustness and reliability in trust evaluation tasks. In terms of malicious behavior detection rate, the BTB-MDQN algorithm demonstrates an impressive early performance. After 30 iterations, the detection rate reaches 37.08%, already outperforming all other models. As training progresses, this detection rate improves rapidly, achieving 93.83% after 150 iterations, significantly higher than the detection rates of: The model by Lu et al. reaches 87.78%; the BT-DQN model achieves 80.33%; the BT-A2C model shows 67.31%; the BT-PPO model records 57.54%. The BTB-MDQN algorithm not only surpasses other models in malicious behavior detection but also demonstrates a strong ability to converge quickly, adapting efficiently to evolving security threats in complex environments.
Simulation experiment analysis
In a pilot deployment on a shared vehicle platform, the system was implemented on the cloud server cluster of the platform, covering 1,500 vehicles and 80,000 active users, operating continuously for six months. Data collection encompassed user behavior logs, order records, security event reports, and platform operational metrics (e.g., complaint rates and order completion rates). After desensitization, all data was integrated into the blockchain network via the Apache Kafka real-time stream processing framework. The Deep Reinforcement Learning (DRL) model was updated offline every four hours, with parameters synchronized to the edge nodes through smart contracts. The practical impact of the improvement in trust evaluation accuracy is demonstrated in Table 9. Trust evaluation accuracy increased by 16% (from 77.8% in the traditional model to 93.8%), reflecting dual enhancements in both user service experience and platform security. In this shared vehicle platform pilot deployment, the optimization reduced the misjudgment rate (the proportion of normal users incorrectly identified as malicious) from 12.4 to 1.9%.
The comparison of false request vehicle attack interception performance is presented in Fig. 12. In the false request vehicle attack scenario, the proposed model increased the interception count from 312 (in the traditional model) to 1,104, while the malicious success rate dropped significantly from 34 to 6%. This result indicates that the model, through the synergy of blockchain-based real-time trusted data and DRL-driven dynamic defense strategies, significantly improved attack detection and interception capabilities. For instance, on a day with 1,200 false request attacks, the traditional model, relying on static rule libraries, could intercept only 26% of the attacks (312 times). In contrast, the proposed model, with dynamic environmental awareness and real-time strategy optimization, increased the interception rate to 92% (1,104 times), reducing the malicious success rate to 6%. Similarly, in location spoofing and identity theft attacks, the proposed model’s interception counts were 3.87 times and 4.43 times higher than the traditional model, respectively, with the malicious success rate remaining below 10%. These results validate the robustness and efficiency of the model in complex attack scenarios, providing reliable security support for the operational security of shared mobility platforms.

Comparison of false request vehicle attack interception performance.
As demonstrated in Table 9; Fig. 12, the improvement in accuracy significantly reduced both misjudgments and the risk of malicious attacks. For instance, during a large-scale coordinated attack in the pilot phase (1,200 false requests in a single day), the traditional model intercepted only 312 requests, while the proposed system intercepted 1,104 requests, effectively protecting 92% of the vehicle resources.The 11% reduction in system response time (from 46.2 ms to 40.95 ms) had a particularly significant impact on user experience during peak periods. When the concurrent request volume exceeded 1,500 requests per second, the traditional model’s response delay caused user timeouts (threshold = 50 ms) to occur 18% of the time, whereas the proposed system, utilizing edge caching and an asynchronous training mechanism, reduced the timeout rate to below 4% (as shown in Table 10). This optimization increased the platform’s daily order completion rate from 82 to 94%, while also reducing vehicle scheduling conflicts caused by delays (e.g., the repeat order rate decreased from 9.7 to 2.3%), significantly improving operational efficiency. Furthermore, the data suggests that response time optimization in high-concurrency scenarios has a nonlinear enhancement effect. When the request volume reaches 2,000 requests per second, the order completion rate increases by 15%, directly contributing to a revenue increase for the platform (with daily revenue growing by 127,000 CNY). These findings indicate that the improvement in technical performance has not only enhanced user experience but also generated measurable commercial value.
To further validate the superiority of the Bayesian trust evaluation model, additional comparative experiments were conducted, selecting fuzzy logic (based on a user behavior rule base) and traditional machine learning models (Random Forest, Support Vector Machine – SVM) as benchmarks. The experiments employed the same autonomous driving dataset, and feature engineering and preprocessing workflows were kept consistent.
Table 11 presents a comparative analysis of four trust evaluation models based on accuracy, malicious behavior detection latency, and computational overhead. The Bayesian model demonstrates a significant advantage in accuracy (93.8%) compared to other models, particularly excelling in adaptability to dynamic environments. Although the fuzzy logic approach requires no training and achieves the lowest detection latency (9.8 ms), its reliance on manually curated rule sets limits its accuracy (81.2%), making it ineffective against emerging attack patterns. While Random Forest and Support Vector Machine (SVM) offer some level of generalization, their long training times (23.6 min and 15.9 min, respectively) and higher detection latency (18.3 ms and 16.7 ms) hinder their ability to meet real-time processing requirements. The Bayesian model dynamically updates prior distributions (Eq. 11) and integrates real-time blockchain data streams, achieving high-precision trust evaluation with low latency (12.5 ms), thus verifying its unique advantages in dynamic scenarios.
To validate the practical effectiveness of the model, a pilot study was conducted in collaboration with a leading car-sharing platform. The pilot covered 1,000 shared vehicles and 50,000 active users over three months. The system was deployed on Alibaba Cloud edge computing nodes using a distributed architecture to handle real-time requests. The blockchain network consisted of 10 consensus nodes implementing an improved Practical Byzantine Fault Tolerance (PBFT) consensus mechanism with a block time of 0.8 s. The deep reinforcement learning (DRL) model was updated offline every six hours, with model parameters synchronized to edge nodes via smart contracts. Data collection included user behavior logs, vehicle status reports, and security incident records, all anonymized before performance analysis.
Table 12 provides a comparison of key operational metrics before and after deployment. The implementation of the proposed system reduced the malicious behavior miss rate from 12.3 to 3.8%, while the user complaint rate dropped by 63.4%, demonstrating the model’s high reliability in real-world scenarios. The optimization in response time (23.7%) significantly decreased scheduling conflicts (72.0%), thereby enhancing platform operational efficiency. Additionally, the system successfully intercepted multiple novel attack vectors, such as GPS spoofing attacks (daily interception count increased from 3 to 27), proving its capability to rapidly adapt to emerging threats. During the pilot period, user retention improved by 8.6%, further highlighting the model’s positive impact on user experience.
In-depth analysis of BTB-MDQN performance advantages
An ablation study was conducted to quantify the contribution of each technical module to the performance improvements of the BTB-MDQN model (shown in Table 13). The results indicate that the synergy between blockchain and deep reinforcement learning (DRL) is the primary factor driving the system’s superior performance, accounting for 42% of the overall enhancement. The immutability of blockchain data streams provides DRL with highly reliable inputs, while DRL’s adaptive decision-making dynamically updates the blockchain trust chain, forming a closed-loop optimization process. The Bayesian model, which dynamically updates priors and contributes 28% to performance improvements, effectively captures temporal dependencies in user behavior, thereby reducing false positives. Additionally, the off-chain caching mechanism, contributing 18%, reduces on-chain query overhead, compressing response time to 30% of that in conventional approaches.
For instance, in detecting novel location spoofing attacks, DRL rapidly adjusts defensive strategies based on blockchain-updated environmental states, such as abnormal surrounding vehicle density. Simultaneously, the Bayesian model refines trust scores based on historical attack patterns. The collaboration between these components reduces the missed detection rate to 2.3%, achieving a more than threefold improvement compared to standalone implementations (DRL alone: 7.8%; Bayesian alone: 5.4%).
To evaluate the scalability of the model in large-scale networks, resource consumption was simulated across scenarios ranging from 10,000 to 500,000 nodes (Table 14). The results indicate that as the number of nodes increases, blockchain consensus latency exhibits linear growth, with block time reaching 1.9 s at 500,000 nodes. In contrast, DRL inference latency remains stable (< 50 ms) due to the distributed computing architecture. By employing dynamic sharding, the network is partitioned into 100 logical subgroups, each independently running Practical Byzantine Fault Tolerance (PBFT) consensus, thereby reducing CPU utilization from 78 to 32% at 500,000 nodes.
Furthermore, model compression techniques, such as knowledge distillation, reduce the DQN parameter size from 1.2 M to 0.3 M, leading to a 58% decrease in memory usage. This optimization enables real-time inference on edge devices, such as in-vehicle terminals, ensuring efficient deployment in resource-constrained environments.
Table 14 presents the computational cost across different network scales. As the number of nodes increases, block time exhibits a moderate rise, while CPU utilization and memory consumption grow proportionally. Despite these increases, inference latency remains stable due to the distributed computing framework.
-
1.
Input purification layer: Utilizing the adversarial sample detection algorithm proposed by Wang et al., this layer employs gradient masking and anomalous feature filtering to block contaminated data inputs36.
-
2.
Model robustness layer: Based on the robust reinforcement learning framework of Ilahi et al., an adversarial regularization term is introduced into the loss function to minimize the impact of adversarial perturbations on Q-values37.
-
3.
Dynamic monitoring layer: Implementing the real-time anomaly detector proposed by Li et al., this layer monitors policy entropy fluctuations (threshold > 0.5) and triggers a model rollback to a secure version when anomalies are detected38.
As shown in Table 15, when 5% of the training data is poisoned (e.g., coordinated attacks initiated by falsified high-reputation users), the enhanced model maintains a detection rate decline of only 1.2% (from 93.8 to 92.6%), whereas the baseline model experiences a significant drop of 14.5% (from 93.8 to 79.3%).
To evaluate the generalization capability of the proposed model, validation was conducted on multiple datasets. As shown in Table 16, BTB-MDQN consistently achieves high performance across different datasets (accuracy > 88%), demonstrating its adaptability. The model performs best on the autonomous driving dataset due to its finer-grained annotations, such as second-level behavior logs. Performance on the Kaggle and UCI datasets is slightly lower due to feature differences, particularly the absence of real-time environmental state data. However, the proposed model still significantly outperforms conventional approaches (e.g., BT-DQN achieves only 78.3% accuracy on the Kaggle dataset). These results indicate that the model effectively manages sensitivity to data distribution shifts, making it suitable for diverse shared mobility scenarios.
Discussion
The distributed intelligent data analysis system based on blockchain and BTB-MDQN proposed in this study demonstrates significant performance advantages in trust management and defense decision-making for shared vehicle data. The primary innovation lies in the integration of blockchain technology with deep reinforcement learning, forming a novel dynamic trust management and defense decision system. Compared to existing work, this integration not only leverages the decentralized storage and immutability features of blockchain to ensure data reliability and security but also utilizes the dynamic optimization capability of DRL to enable real-time user behavior evaluation and adaptive adjustment of defense strategies. For instance, Gadiraju et al.39 proposed a DRL-based optimization framework for data processing and performance enhancement in the PRISM blockchain. Their approach primarily focused on optimizing blockchain computational efficiency without extensively addressing the dynamic nature of trust management and defense decision-making. In contrast, the BTB-MDQN model presented in this study combines a Bayesian dynamic trust evaluation model with DRL, thereby not only improving data processing efficiency but also significantly enhancing the system’s defense capability and trust evaluation accuracy. Additionally, Moudoud et al.40 developed a federated multi-agent DRL method for security and trust management in wireless sensor networks. Although their approach demonstrated good performance in multi-agent environments, limitations remain in handling dynamic user behaviors and real-time defense strategies. By incorporating blockchain technology, BTB-MDQN further strengthens data reliability and system security, offering superior advantages in complex environments.
Despite significant performance improvements, several challenges remain in practical deployment. In particular, regarding real-time responsiveness, although edge caching and asynchronous training mechanisms are employed to reduce response times, the system’s response time may still become a bottleneck under high-concurrency scenarios, such as when requests exceed 1,500 per second. Additionally, the parallel execution of blockchain consensus mechanisms (e.g. PoW) and DRL training results in high GPU memory consumption, limiting the system’s deployment on edge devices. For example, Moudoud et al.41 proposed a federated multi-agent DRL-based reputation-aware scheduling method in drone networks. While their approach demonstrated strong performance in resource-constrained environments, challenges persisted in handling large-scale data and complex network topologies. In contrast, BTB-MDQN employs sharding techniques and lightweight consensus algorithms, such as PoS, to substantially reduce computational and storage overhead, thereby enhancing real-time performance and scalability. Specifically, in large-scale networks where blockchain consensus delay grows linearly with the number of nodes, BTB-MDQN utilizes dynamic sharding to partition the network into multiple logical subgroups, each independently running the PBFT consensus mechanism. This approach significantly reduces CPU utilization and memory consumption.
In addition, blockchain overhead remains a concern. Although blockchain ensures data immutability and transparency, its consensus mechanisms and data storage methods can result in substantial computational and storage costs. To alleviate this issue, BTB-MDQN employs sharding techniques and lightweight blockchain architectures, such as consortium blockchains, to reduce computational and storage burdens while preserving blockchain’s security and decentralization features. Through dynamic sharding, the network is partitioned into multiple logical subgroups, each independently running a PBFT consensus mechanism, significantly reducing CPU utilization and memory consumption. Furthermore, BTB-MDQN utilizes model compression techniques, such as knowledge distillation, to reduce the size of the DQN parameters, thereby further decreasing memory usage and enabling real-time inference on resource-constrained edge devices.
Although the system demonstrates excellent performance in experiments, its generalization capability and cross-domain adaptability require further validation. Currently, the system’s training depends on a specific shared vehicle dataset, and its effectiveness in other domains has not been fully assessed. To enhance generalizability, future research could explore the fusion of multimodal data, incorporating, for example, vehicle camera images and user textual feedback into model training to achieve finer-grained user behavior modeling. Additionally, validating the system across different domains—such as intelligent urban traffic management and unmanned aerial vehicle network security—would further assess its cross-domain adaptability. The BTB-MDQN model proposed in this study leverages blockchain technology combined with DRL’s dynamic optimization capability. It not only performs well in the shared vehicle domain but also exhibits strong potential for cross-domain applicability, offering a valuable reference for security and trust management in other fields.
Conclusion
This study introduces a distributed intelligent data analysis system utilizing a blockchain-integrated DQN algorithm, referred to as BTB-MDQN. Experimental evaluation, conducted using an intelligent driving dataset, reveals that the proposed model achieves trust evaluation accuracy and malicious behavior detection rates exceeding 93%, providing an innovative approach for intelligent data processing in shared mobility applications. Despite the strong performance of the BTB-MDQN model in experimental evaluations, several limitations persist. First, the model’s training process relies on a specific shared mobility dataset, and its generalizability to cross-domain scenarios—such as medical IoT applications or industrial control systems—has yet to be validated. Second, the parallel execution of blockchain consensus mechanisms (e.g., PoW) and DRL training leads to high GPU memory consumption, constraining deployment on edge devices. Additionally, the latency associated with block generation (averaging two minutes) may affect the real-time updating of DRL policies, particularly during peak request periods, introducing a potential bottleneck in system responsiveness. While DRL excels in dynamic decision-making optimization, challenges related to data sparsity and computational complexity remain. To address data sparsity, the system can incorporate temporal data augmentation techniques by applying a sliding window approach to historical blockchain records. This method generates an expanded training set, effectively capturing long-tail behavioral patterns, such as low-frequency malicious attacks. Regarding computational complexity, a distributed training framework can be implemented, where DQN parameters are partitioned across multiple blockchain nodes and gradient computations are parallelized using GPU clusters, thereby reducing training time per iteration. However, DRL’s reliance on high-quality labeled data remains a critical limitation. If blockchain-generated raw data contains systemic biases—such as anomalous user behavior in specific geographic regions—the model may amplify these biases, leading to misclassifications. To enhance robustness, future research could incorporate adversarial training mechanisms by generating adversarial samples to improve model resilience. Several directions can be pursued for further improvements. One potential avenue is the exploration of hierarchical blockchain architectures (e.g., consortium blockchains) and lightweight consensus algorithms (e.g. PoS) to reduce computational overhead. Additionally, expanding the model’s application to other domains, such as smart urban traffic management and unmanned aerial vehicle network security, could validate its cross-domain adaptability. Furthermore, integrating multimodal data—such as image data from in-vehicle cameras and textual feedback from users—could enhance fine-grained behavior modeling, ultimately improving the model’s performance and adaptability.
Data availability
Data is provided within the manuscript or supplementary information files.
References
Ramesh, T. R. et al. Peer-to-peer trust management in intelligent transportation system: an aumann’s agreement theorem based approach. ICT Express. 8 (3), 340–346 (2022).
Das, D., Dasgupta, K. & Biswas, U. A secure blockchain-enabled vehicle identity management framework for intelligent transportation systems. Comput. Electr. Eng. 105, 108535 (2023).
Alharbi, F. et al. Intelligent transportation using wireless sensor networks blockchain and license plate recognition. Sensors 23 (5), 2670 (2023).
Zhu, R. et al. Multi-agent broad reinforcement learning for intelligent traffic light control. Inf. Sci. 619, 509–525 (2023).
Ahmed, A. A. et al. Smart traffic shaping based on distributed reinforcement learning for multimedia streaming over 5G-VANET communication technology. Mathematics 11 (3), 700 (2023).
Snigdha, E. Z. et al. Cybersecurity in healthcare IT systems: business risk management and data privacy strategies. Am. J. Eng. Technol. 7 (03), 163–184 (2025).
Liu, Y. et al. A semi-centralized trust management model based on blockchain for data exchange in Iot system. IEEE Trans. Serv. Comput. 16 (2), 858–871 (2022).
Din, I. U. et al. ShareTrust: centralized trust management mechanism for trustworthy resource sharing in industrial internet of things. Comput. Electr. Eng. 100, 108013 (2022).
Velmurugan, S. et al. Provably secure data selective sharing scheme with cloud-based decentralized trust management systems. J. Cloud Comput. 13 (1), 86 (2024).
Amiri-Zarandi, M., Dara, R. A. & Fraser, E. LBTM: A lightweight blockchain-based trust management system for social internet of things. J. Supercomputing.. 78 (6), 8302–8320 (2022).
Liu, Z. et al. PPTM: A privacy-preserving trust management scheme for emergency message dissemination in space–air–ground-integrated vehicular networks. IEEE Internet Things J. 9 (8), 5943–5956 (2021).
Qu, Z. et al. Quantum detectable Byzantine agreement for distributed data trust management in blockchain. Inf. Sci. 637, 118909 (2023).
Liu, Z. et al. PPRU: A privacy-preserving reputation updating scheme for cloud-assisted vehicular networks[J]. IEEE Trans. Veh. Technol. 74 (2), 1877–1892 (2023).
Wu, X. et al. Privacy-preserving trust management method based on blockchain for cross-domain industrial IoT. Knowl. Based Syst. 283, 111166 (2024).
Guo, J. et al. TFL-DT: A trust evaluation scheme for federated learning in digital twin for mobile networks[J]. IEEE J. Sel. Areas Commun. 41 (11), 3548–3560 (2023).
Wang, Z. et al. Risk prediction and credibility detection of network public opinion using blockchain technology. Technol. Forecast. Soc. Chang. 187, 122177 (2023).
Alam, T., Ullah, A. & Benaida, M. Deep reinforcement learning approach for computation offloading in blockchain-enabled communications systems. J. Ambient Intell. Humaniz. Comput. 14 (8), 9959–9972 (2023).
Lu, K. et al. Adaptive sharding for UAV networks: A deep reinforcement learning approach to blockchain optimization. Sensors 24 (22), 7279 (2024).
Siddiqui, S. A. et al. A survey of trust management in the internet of vehicles. Electronics 10 (18), 2223 (2021).
Alalwany, E. & Mahgoub, I. Security and trust management in the internet of vehicles (IoV): challenges and machine learning solutions. Sensors 24 (2), 368 (2024).
Jing, T. et al. Joint trust management and sharing provisioning in IoV-Based urban road network. Wirel. Commun. Mob. Comput. 2022 (1), 6942120 (2022).
Namasudra, S. & Sharma, P. Achieving a decentralized and secure cab sharing system using blockchain technology. IEEE Trans. Intell. Transp. Syst. 24 (12), 15568–15577 (2022).
Qian, T. et al. Shadow-price DRL: A framework for online scheduling of shared autonomous EVs fleets. IEEE Trans. Smart Grid.. 13 (4), 3106–3117 (2022).
Khan, J. A. et al. Tread: privacy preserving incentivized connected vehicle mobility data storage on interplanetary-file-system-enabled blockchain. Transp. Res. Rec. 2676 (2), 680–691 (2022).
Liang, H. et al. Reinforcement learning enabled dynamic resource allocation in the internet of vehicles. IEEE Trans. Industr. Inf. 17 (7), 4957–4967 (2020).
Kaur, G. et al. Secured intelligent transportation with privacy retention through blockchain framework. J. Intell. Fuzzy Syst. 46 (4), 10507–10521 (2024).
Sun, X. et al. A novel Block-chain based secure cross-domain interaction approach for intelligent transportation systems. Phys. Commun.. 63, 102223 (2024).
Lee, Y. S. & Approach to Smart Mobility Intelligent Traffic Signal System based on Distributed Deep Reinforcement Learning. IEIE Trans. Smart Process. Comput., 13(1): 89–95. (2024).
Huang, Q. A. & Si, Y. W. Blockchain-based autonomous decentralized trust management for social network. J. Supercomputing. 80 (10), 14725–14751 (2024).
Zhang, H., Li, N. & Lin, J. Modeling the decision and coordination mechanism of power battery Closed-Loop supply chain using Markov decision processes. Sustainability 16 (11), 4329 (2024).
Zhang, Z. et al. TbDd: A new trust-based, DRL-driven framework for blockchain sharding in IoT. Comput. Netw. 244, 110343 (2024).
Ma, Z. et al. Blockchain-Based Zero-Trust supply chain security integrated with deep reinforcement learning for inventory optimization. Future Internet. 16 (5), 163 (2024).
Dutta, A. et al. ROBB: recurrent proximal policy optimization reinforcement learning for optimal block formation in bitcoin blockchain network. IEEE Access. 12, 31287–31311 (2024).
Zhao, D. et al. Service-Oriented resource allocation and task scheduling for Wi-Fi and Bluetooth coexistence in smart home IoT systems. ACM Trans. Internet Things. 6 (2), 1–24 (2025).
Leng, J. et al. ManuChain: combining permissioned blockchain with a holistic optimization model as bi-level intelligence for smart manufacturing. IEEE Trans. Syst. Man. Cybernetics: Syst. 50 (1), 182–192 (2019).
Wang, M. et al. Sewage and location detection with improved cycle generative adversarial Network-Based augmented datasets and YOLOv5-BiFC. Appl. Sci. 14 (21), 9932 (2024).
Ilahi, I. et al. Challenges and countermeasures for adversarial attacks on deep reinforcement learning. IEEE Trans. Artif. Intell. 3 (2), 90–109 (2021).
Li, H., Song, T. & Yang, Y. Generic and sensitive anomaly detection of network Covert timing channels. IEEE Trans. Dependable Secur. Comput. 20 (5), 4085–4100 (2022).
Gadiraju, D. S., Lalitha, V. & Aggarwal, V. An optimization framework based on deep reinforcement learning approaches for Prism blockchain. IEEE Trans. Serv. Comput. 16 (4), 2451–2461 (2023).
Moudoud, H., Abou El Houda, Z. & Brik, B. Advancing security and trust in wsns: A federated multi-agent deep reinforcement learning approach[J]. IEEE Trans. Consum. Electron. 70 (4), 6909–6918 (2024).
Moudoud, H., Houda, A. E. & Brik, B. Z., Reputation-Aware Scheduling for Secure Internet of Drones: A Federated Multi-Agent Deep Reinforcement Learning Approach. In IEEE INFOCOM 2024-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS) (pp. 1–6). IEEE. (2024).
Author information
Authors and Affiliations
Contributions
Jinxiang Chen, Yan Li, and Jiaxing Deng contributed to conception and design of the study. Beicheng Qin organized the database.Chengcai He performed the statistical analysis. Qiangsheng Huang wrote the first draft of the manuscript. Jingchun Wu, Jinxiang Chen, Yan Li, and Jiaxing Deng wrote sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, J., Li, Y., Deng, J. et al. Design of a dynamic trust management and defense decision system for shared vehicle data based on blockchain and deep reinforcement learning. Sci Rep 15, 26662 (2025). https://doi.org/10.1038/s41598-025-11511-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-11511-y
