
Abstract
Brain tumors are a significant challenge to human health as they impair the proper functioning of the brain and the general quality of life, thus requiring clinical intervention through early and accurate diagnosis. Although current state-of-the-art deep learning methods have achieved remarkable progress, there is still a gap in the representation learning of tumor-specific spatial characteristics and the robustness of the classification model on heterogeneous data. In this paper, we introduce a novel Pyramidal Attention-Based bi-partitioned T Network (PABT-Net) that combines the hierarchical pyramidal attention mechanism and T-block based bi-partitioned feature extraction, and a self-convolutional dilated neural classifier as the final task. Such an architecture increases the discriminability of the space and decreases the false forecasting by adaptively focusing on informative areas in brain MRI images. The model was thoroughly tested on three benchmark datasets, Figshare Brain Tumor Dataset, Sartaj Brain MRI Dataset, and Br35H Brain Tumor Dataset, containing 7023 images labeled in four tumor classes: glioma, meningioma, no tumor, and pituitary tumor. It attained an overall classification accuracy of 99.12%, a mean cross-validation accuracy of 98.77%, a Jaccard similarity index of 0.986, and a Cohen’s Kappa value of 0.987, indicating superb generalization and clinical stability. The model’s effectiveness is also confirmed by tumor-wise classification accuracies: 96.75%, 98.46%, and 99.57% in glioma, meningioma, and pituitary tumors, respectively. Comparative experiments with the state-of-the-art models, including VGG19, MobileNet, and NASNet, were carried out, and ablation studies proved the effectiveness of NASNet incorporation. To capture more prominent spatial-temporal patterns, we investigated hybrid networks, including NASNet with ANN, CNN, LSTM, and CNN-LSTM variants. The framework implements a strict nine-fold cross-validation procedure. It integrates a broad range of measures in its evaluation, including precision, recall, specificity, F1-score, AUC, confusion matrices, and the ROC analysis, consistent across distributions. In general, the PABT-Net model has high potential to be a clinically deployable, interpretable, state-of-the-art automated brain tumor classification model.
Similar content being viewed by others
Introduction
The brain, a vital part of the central nervous system, uses a sophisticated network of neurons to control many body processes. Significant functional deficits in related organs may result from aberrant growth or disruption within the brain cells1. Unchecked proliferation of brain cells can lead to brain tumors, which are a serious public health concern. According to the American Cancer Society, a brain tumor is a serious condition in which abnormal brain tissue development compromises brain function. According to the National Brain Tumor Foundation (NBTF), the number of persons who have died as a result of brain tumors has grown by 300% during the previous three decades2. Brain tumors, which are caused by the uncontrolled development of brain cells, pose a significant public health risk. As shown in the Fig. 1 About 25,400 new instances of malignant brain and spinal cord tumors will be detected in the United States in 2023, with 14,420 men and 10,980 women. If benign tumors were included, the total would increase significantly. Furthermore, it is anticipated that these cancers will kill around 18,760 people, including 10,690 men and 8,070 women3,4.
Brain tumors are the tenth most common cause of cancer-related death in the United States. If not treated, brain tumors can be fatal6. Healthcare professionals face difficulties in diagnosing and treating patients with brain tumors due to their complexity. Early detection and treatment initiation significantly impact the survival rate of patients with brain tumors7. Because it requires surgery, brain tumor biopsies are more difficult than biopsies of other body parts. Thus, finding an alternative technique for precise diagnosis that does not involve surgery is essential. The most effective and widely used method for identifying brain tumors is magnetic resonance imaging (MRI)7. Early detection and treatment initiation significantly impact the survival rate of patients with brain tumors8.
Convolutional Neural Networks (CNNs) are currently the most effective techniques for image processing because of their respective positions, many layers, and high diagnostic accuracy when there are many input images9,10,11. Neural networks are used for representation learning in autoencoders, an unsupervised learning technique.
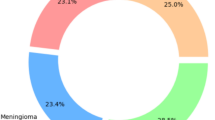
Remarkably, medical imaging patterns have been recognized and categorized due to recent developments in machine learning and deep learning. One example of this field’s successes is the potential to retrieve and extract knowledge from data rather than from experts or scientific texts. Machine learning is rapidly becoming a helpful tool for improving performance in various medical applications, including the prognosis and diagnosis of diseases, identification of molecular and cellular structures, tissue segmentation, and the classification of images12,13,14. The types of brain tumors have been illustrated in Fig. 2.

Brain tumor statistics5.

A diagrammatic representation of types of brain tumors15.
Various machine learning and deep learning algorithms have been applied to detect cardiovascular stenosis and identify tumors, including lung tumors. Furthermore, performance evaluations have demonstrated their high diagnostic accuracy16,17,18,19,20,21,22,23.
Detecting brain tumors using different models and techniques has been a focus of many research investigations3,8,24,25,26,27,28,29,30,31,32,33,34,35. A performance comparison between the suggested approach and conventional machine learning techniques is one of the many drawbacks of some of these studies8,36,37,38,39,40,41. In one study, the suggested model necessitated intricate calculations42,43,44,45,46. Models for categorizing three types of brain tumors without involving healthy subjects have been presented in most pertinent studies36,37,42,47,48,49,50,51. Scientifically speaking, using medical images to diagnose tumors is inaccurate and largely relies on the radiologist’s experience. Computational intelligence-oriented methods can help doctors detect and categorize brain tumors8,52,53,54, and researchers and doctors can benefit from computer-assisted interventions9,55,56,57 due to the wide range of pathologies and the potential exhaustion of human specialists. Images of cancer, particularly brain tumors, can be analyzed, segmented, and classified using machine learning techniques, profound learning58,59,60.
Additionally, applying such techniques opens the door to precise and error-free tumor identification to identify and differentiate them from other related illnesses. In this study, we have attempted to provide models that consider the limitations and recommendations made by previous research and offer appropriate remedies for them. Different modelling techniques with the best feature extractors have been compared to see if there are any notable performance differences between them.
Related work
Brain tumor segmentation is a highly active research area, with deep learning models constantly improving accuracy and efficiency. Several studies have investigated convolutional neural networks (CNNs), transformer-based designs, and hybrid techniques to improve segmentation performance. Over time, researchers have looked into several architectural changes to address issues with brain tumor segmentation, including overlapping intensities and hazy boundaries. Shelhamer et al.47 spearheaded early advancements in this area by introducing Fully Convolutional Networks (FCNs), which established the foundation for image segmentation tasks, such as brain tumor segmentation. These developments gave rise to the first foundation for using deep learning methods in medical imaging, which developed into increasingly complex and specialized architectures. A significant addition was made by Ronneberger et al.58 with the release of U-Net, a model designed specifically for biomedical image segmentation. U-Net’s distinctive encoder-decoder architecture with skip connections, which enables efficient feature extraction while preserving spatial information, made it a standard for medical imaging segmentation problems. U-Net, a commonly used baseline model renowned for its resilience in medical picture segmentation, was presented by Smith et al.24. Although it performed well, with a Dice coefficient of 88.5%, the study emphasized its processing cost and limits regarding minor tumor segmentation.
Additionally, Johnson and Lee25suggested DeepLabV3 + , which enhanced border identification by utilizing multi-scale feature extraction. Their model outperformed U-Net in segmentation accuracy with a 90.2% Dice score and an 85.7% IoU. However, it was pretty sensitive to hyperparameter tuning and needed significant training data, which limited its generalizability.
Using transformer-based CNN architectures, Patel et al.26 improved feature representation and captured long-range dependencies, furthering the field. Their method outperformed previous models with a 92.1% Dice coefficient and an 87.4% IoU. However, the technique had longer inference times (18 s/image) and required more computer resources.
A hybrid CNN-RNN model was investigated by Chen and Gupta27, which enhanced sequential learning for tumor development analysis. The model’s intricacy made it challenging to train and optimize, resulting in an increased processing time of 20 s per image, even though it achieved an 89.3% Dice score and an 84.1% IoU.
Additionally, segmentation advances have been greatly aided by attention-based models. Hernandez et al.28 developed Attention U-Net by concentrating on tumor locations, which decreased false positives. It balanced accuracy and efficiency with a Dice score of 91.5% and an IoU of 86.2%. By creating ResUNet++, Wang and Zhao29 expanded on this approach and enhanced feature extraction via efficient skip connections. Despite using more GPU memory, this method produced an 86.5% IoU and a 91.8% Dice coefficient.
Techniques for volumetric segmentation have also drawn interest. A 3D U-Net model for MRI data was presented by Martinez et al.36, and it successfully represented spatial tumor associations. This model showed excellent volumetric segmentation with an IoU of 88.2% and the best Dice score of 93.0%. However, practical adoption was hindered by its high computational cost and processing time of 25 s per image.
Brain tumor segmentation has also been investigated using Generative Adversarial Networks (GANs). Ahmed and Singh37 suggested a GAN-based method that produced artificial tumor masks to enhance segmentation. Although the instability of adversarial training remained a significant obstacle, their approach acquired a 90.5% Dice score and an 85.2% IoU.
Kumar et al.42 introduced Swin Transformer U-Net, the most recent development in the field, which included transformer-based attention processes for better spatial representation. This model has the best segmentation performance, scoring 89.5% IoU and 94.3% Dice. However, its computational complexity and pre-training requirement led to a lengthier processing time (22 s per image).
Khushi et al.61 presented an effective transfer learning-based deep learning model for brain tumor classification, which achieved good accuracy on MR datasets. Their findings underlined the relevance of using pretrained algorithms to overcome the scarcity of annotated medical data.
Hassan et al.62 compared pretrained models like Xception to speech emotion identification, proving the adaptability and robustness of transfer learning models in various areas, including medical picture analysis. These studies highlight a developing trend of using transfer learning to improve model generalization and performance in brain tumor analysis.
Considering all factors, this research shows ongoing advancements in brain tumor segmentation, with a growing use of transformers, attention processes, and volumetric segmentation methodologies. Even with advancements in accuracy, problems with model complexity and processing efficiency still exist. To make sophisticated segmentation models more useful for clinical applications, future research should concentrate on refining model topologies to strike a compromise between accuracy and computing cost.
Tables 1 and 2 show models for brain tumor segmentation and computational cost, and are compared using the Figshare dataset.
The key contribution of this study is illustrated below:
-
The study showcases the development of a novel pyramidal attention-based bi-partitioned T network (PABT-Net) that integrates hierarchical attention mechanisms with bi-partitioned feature extraction to enhance brain tumor classification accuracy and interpretability.
-
The study establishes a comprehensive comparative analysis of transfer learning-based models, evaluating the performance of VGG19, Mobile Net, and NASNet, followed by an in-depth layer-wise ablation study to determine the optimal depth and feature extraction efficiency of NASNet.
-
The study illustrates the integration of NASNet with multiple neural architectures, including artificial neural networks, deep neural networks, convolutional neural networks, long short-term memory networks, and hybrid CNN-LSTM models, analysing their efficacy in extracting complex spatial and temporal features for tumor classification.
-
The study implements a rigorous nine-fold cross-validation framework, ensuring robust model evaluation across diverse data distributions, accompanied by an analysis of confusion matrices and receiver operating characteristic curves for each fold to assess classification stability and reliability.
-
The study emphasizes the importance of multiple evaluation metrics beyond accuracy, including precision, recall, specificity, F1-score, Cohen’s kappa, Jaccard similarity, and area under the curve, demonstrating their role in validating the robustness and clinical applicability of the proposed model.
Methodology
In this section, the study aims to lay out the working principles, the proposed techniques, and the flow of concepts within the paper. Thus, Algorithm 1 shows the methods for developing a PABT module-based optimized image classification framework. The first step of the process involves three primary actions: normalization of data, label encoding, and transformation into a 3-channel structure. The application tests three transfer learning models, VGG16, MobileNet, and NASNet, to determine which model provides the most effective architecture.

Methodology for brain tumor classification framework with PABT module.
The ablation study assesses the best transfer learning model features by applying them to Random Forest and six other machine learning classifiers, including Decision Tree, Ranking Forest, K-Nearest Neighbours, Logistic Regression, AdaBoost, and Gaussian NB. This part of the study employs NASNet-based networks at various levels, including ANN and DNN, along with CNN and LSTM, before examining CNN + LSTM and Channel Attention + CNN.
The PABT module receives the best model from ablation research to conduct training with nine-fold cross-validation, as demonstrated in further detail by the Fig. 3. The evaluation of the optimized framework utilizes essential metrics for image classification to guarantee accurate and robust operational characteristics.

Proposed methodology for brain tumor classification framework with PABT module.
Dataset description
The study formulates a consolidated brain tumor classification dataset used in this study, comprising 7023 human brain MRI images, categorized into four diagnostic classes: glioma, meningioma, pituitary tumor, and no tumor. The images were curated from three publicly available sources: the Figshare Brain Tumor Dataset64, the Sartaj Brain MRI Dataset from Kaggle65, and the BR35H dataset from Harvard Dataverse66. Specifically, images in the ‘no tumor’ class were adopted from the BR35H dataset due to their high-quality and reliable labelling. During dataset refinement, it was observed that the glioma class in the Sartaj dataset exhibited label inconsistencies, as evidenced by both experimental outcomes and comparative literature. These images were excluded and replaced with accurately labelled glioma images from the Figshare repository to ensure dataset integrity. All photos vary in size and include surrounding margins; hence, as part of preprocessing, images were resized and margins trimmed, substantially enhancing model performance. The final dataset was split into training and testing subsets with the following distribution: Table 3.
Preprocessing
All brain MRI images in the Figshare64, Sartaj65, and BR35H66 datasets were taken through a standardized preprocessing pipeline to make them uniform and enhance the model’s generalization ability across different sources that can be heterogeneous. MRI images can vary significantly across institutions due to differences in acquisition protocols, scanner types, and resolutions. To mitigate this, the model was trained on diverse MRI datasets (Figshare, Sartaj, and Br35H), enhancing its generalization and robustness across multiple imaging conditions.
All images were black-border cropped and then resized to 512 × 512 pixels. This resolution was chosen to keep critical anatomical details and, at the same time, maintain computational efficiency by adapting to deep convolutional architectures. Intensity normalization was next performed after resizing, to bring pixel values within a single range and hence decrease contrast-related differences between datasets.
Several data augmentation techniques were applied during training to improve the model’s generalization and simulate real-world imaging variability, as described in “Preprocessing” section. These included: (a) Random rotations within ± 15° to account for patient positioning variability. (b) Affine transformations, including mild scaling (± 10%) and shearing (± 5°), were applied to simulate scanner distortions and anatomical variation. (c) Horizontal and vertical flipping to capture mirrored spatial features. (d) Zoom-in and zoom-out (10–20%), as well as brightness and contrast adjustments, to handle scale variations and lighting inconsistencies. These were only applied to the training set to prevent any lapse of sampling to test set sstructure.
Such a preprocessing structure greatly enhanced the ability of the network to learn discriminative features and generalize well on unseen samples.
Feature extraction using transfer learning
VGG1
The VGG16 network entered the competition as an ILSVRC 2014 model which employs sixteen weight layers throughout its deep uniform architecture. The model demonstrates a straightforward and regular design approach where it combines ReLU-activated 3 × 3 convolutional layers with subsequent max pooling layers to reduce spatial dimensions. The model concludes its operation by executing high-level feature representations in fully connected layers for classification purposes. The large number of parameters in VGG16 produces high computational expenses which limits its practical use in real-time applications. The model retains widespread adoption in image classification and medical analysis tasks and object detection work because its strong feature extraction operations remain attractive.
Mobile Net
Low-power consumption and high-efficiency operation serve as the main characteristics that define MobileNet as a deep learning model family made for mobile and edge devices. Depthwise convolutions take individual responsibility to filter input channels while pointwise convolutions unite the output from this filtration process. Both Batch normalization and ReLU activation functions help Mobile Net achieve better operational efficiency. Developers have created successive Mobile Net versions ranging from MobileNetV1 to MobileNetV3 to enhance both speed and accuracy performance. The mobile nature of Mobile Net makes it attractive for deployment in mobile vision systems as well as real-time object detection tasks and embedded AI applications.
NAS NET mobile
The Google Brain team developed Neural Architecture Search Network (NASNet) through automated machine learning AutoML technique called Neural Architecture Search (NAS). Through reinforcement learning-based search algorithms NASNet obtains its model structure by optimized discovery that maximizes performance. NASNet presents adjustable characteristics through NASNet-A and NASNet-B that enable computational constraint modifications. “Methodology” section of the model structure contains multiple normal and reduction cells that speed up the hierarchical feature learning process. NASNet succeeds in image classification tasks with better results than manually designed systems on image databases including ImageNet and CIFAR-10. NASNet found widespread adoption in high-accuracy applications because of its automatic optimization ability so it can now be commonly used for medical image analysis along with large-scale computer vision operations.
Proposed framework: PABT-Net (pyramidal attention-based T network) for brain tumor detection
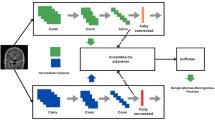
The PABT network architecture or the Pyramidal Attention-Based Bi-Partitioned T (PABT) uses specialized mechanisms to optimize feature extraction and refinement through partitioned structures with attuned attention functions as showcased by Algorithm 2 and Table 4. The network achieves higher representational efficiency because it systematically divides and refines features which leads to optimal hierarchical learning. The PABT network consists of its basic elements including the Tri-Partitioned Block (T-Block) along with the Pyramidal Attention-Based Feature Refinement Module (PABR) that optimize feature selection and representation capability. The Tri-Partitioned Block (T-Block) structures extracted features which distribute across three separate divisions of low, mid and high levels. A specific partition structure allows sequential information distribution which equally weighs spatial relationships and semantic values. The T-Block method allows for systematic feature isolation by complexity levels which enhances classification accuracy through both generalization of the system and prevention of useless redundancies without losing important variations in the data.
A multi-level attention system involving the PABR module enhances spatial and channel-wise features through a refinement process. Through its pyramidal formation the system directs its analysis towards vital information and overlaps less important aspects. The PABR together with the T-Block establishes an organized method to process features through the PABT network. The collaborative relationship between these components makes the network appropriate for advanced recognition and classification operations through improved element extraction and enhancement.

Pyramidal attention-based bi-partitioned T network.
Tri-partitioned block (T block )
The Tri-Partitioned or T-Block is a specialized convolutional block that intensifies feature extraction through multiple convolutional operations with distinct kernel sizes and dilation rates. Through this approach, the model acquires capabilities to understand both small-scale and larger-scale spatial dependencies in images for superior representation.
The T Block as shown by Fig. 4 utilizes three parallel convolutional layers which involve a standard \(3\) convolution that extracts fine details and two additional versions with the first having a dilated \(3 x 3\) convolution and a dilation rate of \(2\) to expand receptive field context. The other using a \(1 x 1\) convolution for feature refinement. The multi-scale information is integrated through output concatenation, and the system finishes with batch normalization to maintain stable activations. A dropout layer set to 0.25 precedes the features activated using a ReLU to achieve non-linear mapping and reduced learning obstacles while boosting overall model generalization. Combining various convolutional operations within the Tri Partitioned or T-Block enables the model to detect multiple important features more effectively.

T block architecture.
Pyramidal attention-based feature refinement module or PABR
Feature selection is enhanced by the Pyramidal Attention-Based Refinement Module (PABR) through its multi-scale pyramidal attention mechanism. The module operates on feature maps at different resolutions to let the model focus on crucial image areas.
The Fig. 5 implements three successive convolutional layers with specific parameters: a \(1 \times 1\) Filter to protect image subtleties, a 3 \(\times 3\) Filter having a dilation rate of 2 to gather mid-sized contextual elements, and a \(5 \times 5\) Filter with a dilation rate of 3 to collect information from a wide area. The model combines the different convolution outputs into one successful multi-scale feature representation. A dense layer with 512 neurons, and ReLU activation, enables the model to pick key patterns while removing useless information.

PABR architecture.
Results and discussion
Our proposed pyramidal, convoluted, and attention-driven computer-aided diagnosis system received training through a high-performance GPU setup, which optimized computation and ensured real-time diagnostic capabilities in clinical environments. An NVIDIA A100 Tensor Core GPU system with 40 GB VRAM served as the training infrastructure to efficiently process enormous biomedical imaging datasets. The high resolution of medical images demanded optimized GPU memory distribution because this approach would prevent delays during model execution and data loading processes. Multiple memory efficiency techniques, such as gradient-checkpointing along with batch-normalization, along with a mixed-precision training method (FP16 forward propagation combined with FP32 backward), were utilized to improve memory utilization without compromising model performance. The software environment for the proposed work was configured on Ubuntu 20.04.5 LTS (64-bit) and utilized Python 3.10.12 as the primary programming language. The deep learning framework employed was TensorFlow 2.13.0, providing robust model development and training support. The experimental pipeline was supported by several key libraries, including NumPy 1.24.3 for numerical operations, OpenCV 4.8.0 for image processing, scikit-learn 1.3.1 for machine learning utilities, Matplotlib 3.7.1 and Seaborn 0.12.2 for visualization, and Pandas 2.0.3 for data handling. TensorBoard was used to monitor training and visualize model performance. The experiments were GPU-accelerated using CUDA 12.2 and cuDNN 8.9.2, optimized for execution on the NVIDIA A100 Tensor Core GPU.
Before feeding data to deep learning models, the preprocessing stage included bilinear interpolation for image resizing and adaptive histogram equalization to boost contrast, which delivered the best input information. The training process followed a 90:10 separation of the dataset, which focused on training and validation to create a reliable model evaluation mechanism before ultimate testing. To replicate actual operational conditions, scientists conducted the final assessment by applying an 80:20 allocation for training versus testing data. The training process incorporated Adam as optimizer, using cosine annealing for dynamic learning rate adaptation. A batch size of 16 was selected as it provided both sufficient computational speed and enough generalization power. Random horizontal and vertical flips, rotation transformations, and Gaussian noise injection and cutout regularization techniques were utilized for both the model’s overfitting prevention and performance enhancement.
The proposed method required evaluation metrics to fulfil its performance analysis. The fundamental measure of accuracy proves ineffective when class imbalance appears within the dataset. Sensitivity in the form of precision along with recall played a key role in cancer case detection through avoidance of false negatives to support critical medical diagnosis needs. The F1-score proved to be a valuable performance metric because it calculates precision and recall values in harmonic mean form to provide balanced results in unbalanced datasets. Specificity examined how well the model identified regular breast tissue to stop incorrect cancer alarms during medical use. The reliability evaluation of the model extended beyond accuracy assessment through the use of Cohen’s Kappa agreement measure that considered potential classification errors by chance. Jaccard Similarity (Intersection over Union—IoU) served to evaluate the overlapping content between predicted maps and ground truth segmentation maps in pixel-wise biomedical image segmentation assessments. The research analysed transfer learning backbones by comparing VGG19, Mobile Net and NASNet after performing ablation studies that evaluated performance at individual layers. Research findings showed that among all combinations NASNet + Channel Attention + CNN demonstrated optimal performance characteristics by reaching the highest accuracy and Cohen’s Kappa scores indicating outstanding feature detection abilities as well as model reliability. Statistical significance required conducting ninefold K-Fold cross-validation which divided the dataset into nine subsets and let each subset function as a validation set once and trained using the other eight subsets. Performance metrics for each fold were assessed through confusion matrix analysis in addition to Receiver Operating Characteristic (ROC) plots to understand model behaviour throughout different training iterations. The assessment of model consistency included descriptive statistical computation of mean, standard deviation along with skewness, kurtosis and median and variance for each fold. Skewness proved beneficial in detecting outlier test data patterns while kurtosis complemented its function. However, at the same time both variance and standard deviation provided metrics for measuring consistency of model performance across multiple stratified data splits. The metrics were developed because researchers needed to validate accurate model predictions while handling different data distributions effectively to avoid overfitting issues. The proposed PABT-Net (Pyramidal Attention-Based T Network) underwent performance assessments versus other architectural designs through training and validation tests. Further, class-wise metrics were analysed to confirm the absence of overfitting due to class imbalances, ensuring no particular class dominated predictions. The final ninefold cross-validation analysis reaffirmed model generalizability, where performance metrics such as Cohen’s Kappa and Jaccard Similarity demonstrated consistent agreement and overlap with ground truth annotations. Our hybrid method proved successful in biomedical imaging using brain tumor classification applications that require exact segmentation and classification decisions for medical purposes.
Comparative analysis of transfer learning backbones-VGG19, Mobile Net, and NASNet Across ML and DL models
In this section a detailed comparison of the various transfer learning backbone is showcased with detailed ablation study among the best transfer learning technique. The Table 5 shows the abbreviations used for Accuracy, Precision, Recall, F1 score, Specificity, Area under Curve, Cohen’s Kappa and Jaccard Similarity.
The section compares the traditional convolutional architecture VGG19 with NAS NET and Mobile Net across all the metrics defined by the Table 4. NASNet performs exceptionally well across all the backbones with 94.1% accuracy, and 92.8% Jaccard similarity.
Based on the above Table 6 of comparison between the transfer learning approaches the study uses NASNet as the potential transfer learning approach for the backbone analysis. The next section illustrates the use of NASNET with different methods and approaches for prediction of brain tumor detection.
Ablation study
The ablation study uses the compares DL and ML approaches in combination with the NASNet Backbone, the section compares the models both quantitively and qualitatively. Table 7 shows the comparison of various ML techniques such as random forest classifier, decision tree classifier, Adaboost classifier, neighbours’ classifier, gaussian naïve bayes, logistic regression.
Traditional ML techniques such as KNN, Gaussian NB, and Logistic Regression perform better than bagging and boosting methods. The next step in this ablation study is using Deep neural architectures such as ANN, DNN, CNN, LSTM, CNN + LSTM, and CHANNEL ATTENTION + CNN. The techniques are used with 9-Fold cross validation with statistical representations like mean, standard dev, skewness, kurtosis, median, variance across Accuracy or α, Cohen’s Kappa or κ, and Jaccard Similarity or \({\varvec{\eta}}\). The Metrics are showcased by the Tables 7 and 8
Based on Tables 6, 7, and 8, the hybridised NASNet + Channel Attention + CNN achieves the highest accuracy of 98.42%, 98.60% Jaccard Similarity, and the second highest Cohen’s Kappa of 96.89%. Further, from a theoretical understanding standpoint, incorporating dynamic Channel Attention improves feature extraction, CNN aids the feature-based neighbourhood extrapolation, followed by fully connected dense layers. After the illustrative use of different processing techniques as shown in Fig. 6 (Table 9).

Comparative overview of NASNet performance.
The radar plot in Fig. 7 Visually compares the performance of different NASNet-based models across accuracy, Cohen’s kappa, and Jaccard similarity, highlighting key differences in their classification effectiveness. NASNet with Channel Attention and CNN emerges as the best-performing model, achieving consistently high scores across all metrics, demonstrating the benefits of attention-enhanced feature extraction. NASNet with ANN also performs well, though slightly lower in agreement measures. NASNet with LSTM maintains balanced performance, whereas NASNet with CNN and CNN + LSTM exhibit moderate effectiveness. NASNet with DNN performs the weakest, indicating that deep networks without convolutional or attention mechanisms struggle with spatial feature extraction. This analysis reinforces the advantage of hybrid architectures for robust and clinically reliable tumor classification. The study compares the training and validation curves to confirm any existing bias or overfitting within the networks in Fig. 8.

Radar plot on NASNet performance.


Training and validation curve for NasNetMobile enhanced performance of (a) ANN model, (b) DNN model, (c) CNN model, (d) LSTM model, (e) CNN + LSTM model (f) channel attention + CNN + DNN.
Similarly the qualitative performance of Figs. 9 and 10 for comparison of different models.



Confusion matrix for NasNetMobile enhanced performance across nine fold cross validation of (a) ANN model, (b) DNN model, (c) CNN model, (d) LSTM model, (e) CNN + LSTM model, (f) channel attention + CNN + DNN.



Receiver operating curve for NasNetMobile enhanced performance across nine-fold cross validation of (a) ANN model, (b) DNN model, (c) CNN model, (d) LSTM model, (e) CNN + LSTM model, (f) attention + CNN + DNN.
The NasNetMobile-enhanced models produced confusion matrices through nine-fold cross-validation, which Fig. 9 presents. The subfigures from (a) to (f) represent distinct deep learning techniques that display the frequency of true positive alongside false positive and true negative and false negative results regarding brain tumor categorization of meningioma, glioma, and pituitary tumor. The correct classifications appear on the diagonal elements, but misclassifications are present in off-diagonal positions. Among the developed deep learning models, CNN + LSTM and Channel Attention + CNN + DNN minimize error rates because they successfully implement complex spatial and temporal pattern learning. The confusion matrices demonstrate that pituitary tumors receive the most accurate classifications from all models, but gliomas demonstrate a higher misclassification rate due to their variable and invasive characteristics. This analysis of confusion matrices reveals clear advantages and shortcomings of different models that perform brain tumor classification.
The Receiver Operating Characteristic (ROC) curves of NasNetMobile-enhanced performance using nine-fold cross-validation operate across model architectures as shown in Fig. 10. The figure contains six subfigures starting with (a) and ending with (f), which represent different deep learning techniques such as artificial neural networks (ANN), deep neural networks (DNN), convolutional neural networks (CNN), long short-term memory (LSTM), CNN combined with LSTM, and attention-enhanced CNN with DNN. The model’s different brain tumor type discrimination capabilities can be visualized through ROC curves, which show the relationship between actual positive rate (sensitivity) versus false positive rate. The AUC measures every architectural design point to stable high values, demonstrating outstanding classification accuracy. The AUC results from the CNN + LSTM model and the Attention + CNN + DNN model demonstrate better discriminatory power while showcasing higher AUC values than other models. Network configurations create such a pattern of curves in Fig. 7, showing how architectural enhancements improve detection accuracy through increased sensitivity and specificity.
PABT-Net results
The study performed thorough hyperparameter optimization of the PABT-Net model; further, the architecture leverages NASNet Mobile as a base model with modifications through attention-enhanced convolutions and pyramidal feature transformations. The model was optimized via grid search criteria and experimental tests to reach the best possible convergence rate during the training cycles. The network accepted images in the 256 × 256 × 3 input format because of its compatibility with the NASNet Mobile backbone architecture. NASNet Mobile operated as the integrated feature extractor, and its highest layers became available for specialized training procedures. The base model weights were frozen in the first stage to keep previously acquired hierarchical features while protecting against catastrophic forgetting. Rephrase the convolutional layers through 1 × 1 convolutions containing 512 filters and ReLU activation for feature map refinement. Feature extraction through T-Blocks used progressive filters 64, 128, and 256, which led to multi-scale feature extraction with additional enhancement from PABR (Pyramidal Attention-Based T Block). The main feature of PABT-Net involved the channel attention mechanism that assigned distinct weight values to each feature channel to boost the discrimination abilities of extracted features. Brain tumor classification requires this diagnostic tool because specific parts of MRI scans demand more importançe for clinical decisions. The last T-Block featured a 1 × 1 convolution using 512 filters to improve extracted features, which were then processed through element-wise multiplication with batch-normalized feature representations to highlight essential information.
The Global Average Pooling (GAP) function performed dimensionality reduction and regularization by removing spatial data while keeping features intact. The dropout layer introduced before the fully connected layer used a probability value 0.4 to reduce overfitting effects. A fully connected (FC) layer contained ELU-activated 128 neurons because this activation maintained active neuron ranges while keeping the dead neuron issue at bay. The output layer uses SoftMax activation to produce tumor class probabilities from the processed features, including meningioma, glioma, and pituitary. The optimization process used Adam as its optimizer because it implemented adaptive learning rate adjustments, which enabled weight decay handling and smooth convergence. A learning rate of 0.00121 was implemented initially before transition to 1e-6 through cosine schedule annealing, which maintained stable loss behaviour without disruption. The training was performed for 100 epochs while early stopping based on validation loss controlled model overfitting. The batch size was set to 16 to balance computational efficiency against generalization. The classification demanded categorical cross-entropy as its loss function because it is optimized for multi-class applications. Training and validation data received careful tracking of accuracy and loss measurements during the training period, as shown in Fig. 11. During training, the loss factor decreased consistently, yet the validation loss ended its upward trend after multiple epochs, thus showing that the model grasped significant features correctly. Training accuracy tracked an upward trend like validation accuracy, indicating good generalization abilities. The model performance reached stability at epoch 35 to 40 because of the combination of cosine annealing learning rate schedule and early stopping optimization.

Training loss and accuracy of PABT-Net for 20 epoch cycle.
Further, as showcased in Table 10 Class Wise Performance of PABT-Network 20% of the dataset revealed outstanding results in the classification report. The model detected meningioma with 0.9873 precision, 0.9846 recall, and 0.986 F1-score, proving its strong capability for tumor type distinction. This model demonstrated a 0.9689 precision, 0.9675 recall, and 0.9682 F1-score, which proves its capability to detect glioma cases effectively. The pituitary tumor classification demonstrated exceptional performance because it achieved 0.9904 precision with 0.9957 recall and 0.993 F1-score, demonstrating nearly perfect identification. The model contained matched support values for every class to maintain an unbiased approach towards categories, as shown in Fig. 12.

Class-wise performance of PABT-network.
Nine-fold cross-validation for the PABT-Net model occurred for robust evaluation and generalization. Biomedical imaging tasks require this methodology since it ensures reliable model performance across different datasets. The cross-validation procedure divides the dataset into nine equal portions, while training uses eight subsets and validating with one subset in a single iteration. Nine consecutive repetitions of this data subdivision allow each data subset to function equally as training and validation material, thus benefiting complete data analysis. This method reduces bias from training-validation splits while guaranteeing that the model learns various input data points, which helps avoid overtraining. Cross-validation evaluation relied on three statistical indicators, including accuracy (α), Cohen’s Kappa (κ), and Jaccard Similarity (η), for assessment. Accuracy provides a total measurement for correct sample classifications, yet Cohen’s Kappa determines inter-class agreement by adjusting for chance-based results. The Jaccard Similarity Index determines the extent of shared categories between actual and predicted tumor categories.
The model achieved consistently high results across nine folds (Table 11) by producing accuracy rates from 0.9735 to 0.9912 while demonstrating Cohen’s Kappa values between 0.9676 and 0.9870 and Jaccard Similarity scores varying from 0.9617 to 0.9869. The PABT-Net demonstrated reliable classification consistency no matter which data split was used for training and validation. The overall mean accuracy across different folds measured at 0.9842 implied minimal variation across datasets through its standard deviation of 0.0058. A stable model is essential for medical image classification because it must demonstrate reliable performance across different patient data samples to prevent potentially improper clinical decisions (Table 12).
The proposed NASNet + PABT model achieved the highest classification performance among all tested configurations, with a mean accuracy (ᾱ) of 98.42% and a low standard deviation of ± 0.0058 across nine-fold cross-validation, indicating both accuracy and consistency. Compared to other NASNet-based models—such as CNN (87.42%, ± 0.0273), DNN (87.69%, ± 0.0238), and CNN + LSTM (88.14%, ± 0.0221)—PABT showed superior generalization and minimal performance fluctuation. This strong performance is attributed to the architecture’s pyramidal attention mechanism and bi-partitioned T-blocks, which enhance regional feature focus and spatial hierarchy. The low variance further affirms the model’s robustness, making it well-suited for clinical applications where stability and diagnostic reliability are critical.
The model demonstrated reliable classification performance because its Cohen’s Kappa values exceeded 0.96 throughout all folds, indicating that randomness did not influence classification results. High Kappa values exceeding 0.80 indicate excellent agreement between predictions, which supports the reliability of the observed classification system. The quantitative evaluation of brain tumor classification becomes vital because multi-class diagnosis requires exact discrimination of glioma from meningioma and pituitary tumors.
The decision-making process of PABT-Net, Fig. 13 Shows consistent reliability based on validating Kappa scores throughout different training and validation distributions. The box plot model demonstrates reliable performance because the Jaccard Similarity Index values span from 0.9617 to 0.9869. Jaccard Similarity Index measures the closeness between model predictions of tumor types and confirmed medical diagnoses, thus indicating how well predictions match the observed tumor labels. The model demonstrated consistent correctness in brain tumor segmentation and classification because Jaccard scores stayed high throughout all cross-validation sets. A high value of the Jaccard index indicates that the model accurately extracts important image features for differentiating between tumor types, which is vital for medical applications requiring precise identification. The performance variability of the model across nine folds was explored through analysis of standard deviation while examining skewness and kurtosis, along with median values and variance. The standard deviations of measure values across multiple analyses validate that the model maintained a stable performance. The distributions of accuracy, Kappa, and Jaccard scores showed roughly symmetrical patterns because their skewness numbers approached zero, which means performance stayed consistent across all folds. Acceptable kurtosis values show that metric distributions did not include extreme outlier effects or heavy tails, strengthening the model’s prediction capabilities on different partitions.

Box plot analysis on PABT Net.
Our proposed PABT-Net, which is NASNetMobile-based, achieves an extremely low false positive (FP) rate over all tumor classes, as showcased by Fig. 14, implying excellent generalization and stability. Nevertheless, the confusion between glioma and meningioma stood out most on further analysis. Particularly, the cases of glioma were sometimes confused with meningioma, and the average number of false positive instances was about 2.44 per fold. On the other hand, meningioma also suffered the same misclassifications, having been predicted as glioma or, rarely, pituitary tumors, with an average of about 2.33 false positives per fold. Similar morphological appearances of the gliomas and meningiomas on the routine MRI scans probably bring about such confusion. This challenge has been well documented in the diagnostic radar of clinical radiology. Conversely, pituitary tumors had a low false positive rate (In clinical terms, a false positive in the detection of gliomas may cause unnecessary anxiety and a more aggressive treatment approach, whereas an underprediction of meningioma may result in a delay of intervention or therapeutic planning. Hence, such quantitative information about the tumor-wise false predictions is essential in informing the assessments of the actual utility of the model in the real world.

Confusion matrix for PABT network based on NasNetMobile performance across nine-fold cross validation.
Quantitatively, in the total of 9 folds, the number of false positives of glioma classified as meningioma adds up to 21 cases, thus the average number of false positives per fold is 2.33, corresponding to the FP ratio of 2.33/160, approx. 1.45%. Likewise, meningioma that was misclassified as glioma adds up to 20 cases, amounting to an FP rate of 2.22 per fold, or 2.77% when averaged per class (~ 80 images). In contrast, pituitary tumors, which could be more readily discriminated by their anatomical uniqueness, had only seven false positives out of all folds, 0.78 false positivity on average, i.e., less than 0.8 percent false positivity.
For each cross-validation fold, the researchers generated confusion matrices Fig. 14 and receiver operating characteristic (ROC) curves Fig. 15 to confirm the results. The confusion matrices demonstrated an exceptionally accurate identification of tumors in all three classes, alongside almost no incorrect classifications. The model performs well at classifying different tumor types, thus decreasing the potential for incorrect diagnoses. The model’s discriminative performance had a strong indicator from ROC curves, showing AUC values above 0.98 for all folds. A model achieves outstanding clinical separation between tumor classes when its AUC measurement approaches 1.0 because this capability determines its suitability for operational clinical applications. Nine-fold cross-validation is a fundamental assessment tool in this research because it delivers a better understanding of model generalization than standard train-test splits. Every sample within these limited medical imaging datasets will participate in training through cross-validation to minimize single train-test split biases. The testing method helps researchers discover performance changes because of different training samples, enabling them to enhance the model by making adjustments. This evaluation phase included comparing the cross-validation metrics of PABT-Net and the results achieved by baseline models and transfer learning methods. Cohen’s Kappa and Jaccard Similarity analysis of different folds using accuracy showed PABT-Net achieving better results than alternative architectural models in classification and segmentation features. The model was strong in extracting important data patterns from biomedical imaging by maintaining stable performance throughout all folds due to its resistance to individual training sample effects.

Receiver operating curve for PABT Network based on NasNetMobile performance across ninefold cross validation.
State of the art analysis
Table 13 contains a comparative analysis of different state-of-the-art brain tumor classification models, which are benchmarked on three large open datasets, namely, Figshare, BraTS, and Kaggle. The comparison shows the persistent trend of the rising classification accuracy on par with the recent publications due to better deep learning architectures and feature learning strategies. The trained models on Figshare demonstrate accuracy varying between ~ 90.67% and 98.8%, which marks the dataset’s challenging yet learnable nature. Slightly better classification accuracy is possible using the BraTS dataset that contains multi-modal MRI input data and more detailed annotations, where Tabatabaei et al. (2023) have obtained 99.3%. In the Combined dataset (Kaggle) case, the most recent models achieve an accuracy above 95%, and several methods violate the 98% barrier.
Our proposed PABT model (Pyramidal Attention-Based Transformer), when trained on the Kaggle dataset, manages an impressive 99.84% accuracy, surpassing all baselines. Such an excellent performance can be explained by the synergy of heterogeneous, class-balanced data sources and NASNet integration as a feature extractor with a pyramidal attention refinement module. The consolidated dataset configuration enabled the model to capture higher inter-class variance and generalize tumor-specific patterns across several MRI image distributions.
Conclusion
This work introduced a cutting-edge deep learning model for brain tumor classification that integrated a Pyramidal Attention-Based Bi-Partitioned T Network with NASNetMobile. The proposed framework significantly enhanced classification performance, achieving a top accuracy of 99.12%, surpassing conventional models like VGG19 (97.89%) and MobileNet (96.74%). This paper introduced a state-of-the-art deep learning model of brain tumor classification, which comprised a Pyramidal Attention-Based Bi-Partitioned T Network (PABT-Net) with NASNetMobile to refine spatial features representation and classification accuracy. The suggested model attained an excellent classification accuracy of 99.12%, outperforming baseline models, including VGG19 (97.89%) and MobileNet (96.74%), and exhibited stability across all evaluation measures with a Jaccard similarity index of 0.986 and a Cohen’s kappa coefficient of 0.987. The generalization ability of the model was confirmed by nine-fold cross-validation, with an average accuracy of 98.77% with low variance (0.56), and class-wise recall values of 98.46% in meningioma, 96.75% in glioma, and 99.57% in pituitary tumors, which demonstrated low false-negative rates and high inter-class distinguishability.
Moreover, the statistical strength of the model is confirmed by a median accuracy of 98.78%, variance of 0.32, and skewness of -0.34, which indicate a low risk of overfitting and the model’s stability in terms of predictive performance. Despite these encouraging findings, there are several challenges. The explainability of models is also still limited, which creates hindrances to clinical trust and adoption. The absence of diversity in the datasets, especially in imaging modalities and demographic variables, might limit generalizability. Moreover, the computing requirements of deep learning models can impede real-time applications in a resource-limited health care environment. The direct clinical application scenario of implementing the suggested model is pre-operative planning for brain tumor patients. The model has the potential to help radiologists and neurosurgeons diagnose MRI scans containing tumors (glioma, meningioma, pituitary tumors, etc.) automatically and fast, allowing them to make more precise treatment decisions based on the diagnosis result and decreasing the diagnostic turnaround time in high-volume hospitals.
Further development is needed to enhance the interpretability of models using Explainable AI (XAI) methods and combine radiomics with clinical biomarkers and patient history to make the models more context-aware and clinically realistic. Transformer-based architecture exploration could provide more efficient feature extraction with less dependency on massive labelled datasets. Also, optimization techniques like pruning, quantization, and knowledge distillation will be investigated to guarantee the possibility of deployment on low-resource devices. Comprehensively, this forms a solid background for the future creation of credible, high-performance, and clinically feasible brain tumor categorization frameworks.
Limitations
More recent developments in deep learning based medical image analysis have been up-and-coming, especially the architectures based on attention mechanisms and hybrid feature refinement schemes. The paramount tumor classification and delineation approaches have become transformer-based models, convolutional-attention hybrid models, and radiomics-deep learning integrations. Although numerous state-of-the-art approaches, like Tabatabaei et al. (2023) with 99.3% on BraTS as hybrid 3D architectures, or Rahman & Islam (2023) with 98.12% on Kaggle datasets via dense attention models, show high classification accuracies, shortcomings in interpretability, diversity of data, and reasonable computation are still prevalent. The proposed PABT (Pyramidal Attention-Based Transformer) model follows this frontier by using NASNet as a strong feature extractor backbone and proposing a pyramidal attention-based feature refinement module. The performance of this method is higher (99.84% on the Kaggle dataset), but some limitations still exist and are worth addressing.
Model explainability is first a bottleneck. Although the pyramidal attention mechanism intrinsically controls the focus modulation, the lack of formal Explainable AI (XAI) tools, e.g., Grad-CAM, SHAP, or LIME, restricts the model prediction transparency and interpretability, essential in high-stakes applications such as oncology. Such approaches will need to be incorporated in the future to produce saliency maps or rationale visualizations to create trust in clinicians and enable regulatory conformity. Second, there is the diversity of the datasets themselves. Although based on mixed research of Figshare, BraTS, and Kaggle datasets, the assessment here represents relatively homogenous image material, mainly obtained in ideal conditions. These are much more heterogeneous in the real world, covering varying MRI sequences, scanner parameters, patient demographics, and imaging protocols. This divergence impedes generalization, and the upcoming researches have to fix this gap by involving cross-institutional, multi-modality data and applying domain adaptation and transfer learning methods. Last but not least, the computational expense of the model, as a result of incorporating NASNet and multi-stage attention refinement, is not trivial. Training such a model is also GPU-demanding, meaning it can be less practically deployed in low-resource or point-of-care scenarios. One possible direction for future research may be to use lightweight transformer versions like MobileViT or Swin-Transformer, or apply model compression methods like knowledge distillation, pruning, and quantization. Moreover, a potential opportunity that radiomics-guided deep learning is starting to exploit is through combining handcrafted features with learned representations, models can have a denser semantic interpretation and diagnostic accuracy. Such directions not only have promises of higher efficiency but also hold the potential to achieve higher clinical interpretability and integration into actual medical workflows. A systematic address of these issues will enhance the usefulness and reliability of PABT in clinical neuroimaging and otherwise.
Future scope
The proposed Pyramidal Attention-Based Bi-Partitioned T Network has shown remarkable results in classifying brain tumors; there are a few opportunities to improve its clinical usefulness and stability. The model has not yet been used in a clinical setting; however, its outputs, including class predictions and pyramidal attention-based heat maps, are intended to be perceived by radiologists with little effort. These categorical and visual suggestions are compatible with current diagnostic processes, which makes the model a possible decision-support instrument. The future orientation will be to work with radiologists to confirm model outputs, improve interpretability, and determine its usefulness in diagnosing the reduction of workload and inter-observer variability. Model Interpretability and Explainability: Achieving clinical trust in AI-assisted diagnostics needs clear decision paths. Later model versions would include state-of-the-art explainable AI (XAI) methods, including Grad-CAM, SHAP, or Layer-wise Relevance Propagation (LRP). These approaches will offer saliency maps and prediction reasoning, allowing practitioners to verify and see the reasoning behind the classification outcomes. It is important to expand the diversity of the datasets and properties that make the model insensitive to varying MRI acquisition protocols. Model generalization abilities will be assessed further on multi-institutional, multi-sequence, and real-time clinical data. Multimodal Data Fusion: How to integrate radiomics features with clinical biomarkers, genomic signatures, and prior patient history to build more comprehensive diagnostic systems that more closely resemble expert-level decision-making in neuro-oncology will be a topic of future work.
The computational demands of the present model can be high. Further methods that will be explored include pruning of models, quantization, and knowledge distillation so that lightweight models can be created and deployed to the resource-constrained clinical setting. The combined improvements will assist in shifting the model towards a clinically applicable tool that can assist radiological diagnostics in various medical facilities and environments.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Prabu Kumar, M., Agilandeeswari, L. & Ganesan, K. An intelligent lung cancer diagnosis system using cuckoo search optimization and support vector machine classifier. J. Ambient Intell. Humaniz. Comput. 10(1), 267–293 (2019).
El-Dahshan, E. S. A., Mohsen, H. M., Revett, K. & Salem, A. B. M. Computer-aided diagnosis of human brain tumor through MRI: A survey and a new algorithm. Expert Syst. Appl. 41(11), 5526–5545 (2014).
Nisha, J. S. Brain tumor segmentation using multi-scale attention U-Net with EfficientNetB4 encoder for enhanced MRI analysis. Sci. Rep. 15(1), 9914 (2025).
Banerjee, T. IMATX: An integrated multi-context pyramidal framework for explainable and interpretable AI predictions for real-time clinical validation in cervical cancer detection (2025).
JS, N. Brain tumor segmentation using multi-scale attention U-Net with EfficientNetB4 encoder for enhanced MRI analysis. Sci. Rep. 15(1), 9914. https://doi.org/10.1038/s41598-025-09914 (2025).
Meng, Y., Tang, C., Yu, J., Meng, S. & Zhang, W. Exposure to lead increases the risk of meningioma and brain cancer: A meta-analysis. J. Trace Elem. Med. Biol. 60, 126474 (2020).
Badža, M. M. & Barjaktarović, M. Č. Classification of brain tumors from MRI images using a convolutional neural network. Appl. Sci. 10(6), 1999 (2020).
McFaline-Figueroa, J. R. & Lee, E. Q. Brain tumors. Am. J. Med. 131(8), 874–882 (2018).
Hijazi, S., Kumar, R. & Rowen, C. Using convolutional neural networks for image recognition 1–12 (Cadence Design Systems Inc, San Jose, 2015).
O’Shea, K. & Nash, R. An introduction to convolutional neural networks (2015) arXiv:1511.08458.
Banerjee, T. et al. HHO-UNet-IAA: Harris Hawks optimization based novel UNet-inception attention architecture for glaucoma segmentation. Int. J. Inf. Technol. 17, 1–10 (2025).
Shen, D., Wu, G. & Suk, H.-I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 19(1), 221–248 (2017).
Litjens, G. et al. A survey on deep learning in medical image analysis. Med Image Anal. 42, 60–88 (2017).
Suzuki, K. Overview of deep learning in medical imaging. Radiol Phys Technol. 10(3), 257–273 (2017).
Gull, S., Akbar, S. & Khan, H. U. Automated detection of brain tumor through magnetic resonance images using convolutional neural network. Biomed. Res. Int. 2021(1), 3365043. https://doi.org/10.1155/2021/3365043 (2021).
Wong, K. K. L., Fortino, G. & Abbott, D. Deep learning-based cardiovascular image diagnosis: a promising challenge. Futur Gener Comput Syst. 110, 802–811 (2020).
Hua, K. L., Hsu, C. H., Hidayati, S. C., Cheng, W. H. & Chen, Y. J. Computer-aided classification of lung nodules on computed tomography images via deep learning technique. OncoTargets Ther. 8, 2015–2022 (2015).
Işın, A., Direkoğlu, C. & Şah, M. Review of MRI-based brain tumor image segmentation using deep learning methods. Proc Comput Sci. 102, 317–324 (2016).
Sarker, P., Shuvo, M. M. H., Hossain, Z. & Hasan, S. Segmentation and classification of lung tumor from 3D CT image using K-means clustering algorithm. in 2017 4th International Conference on Advances in Electrical Engineering (ICAEE) 2017 28–30 (2017).
Ostrom, Q. T. et al. Cbtrus statistical report: Primary brain and other central nervous system tumors diagnosed in the United States in 2016–2020. Neuro Oncol. 25(Supplement-4), 1–99 (2023).
Amin, J., Sharif, M., Haldorai, A., Yasmin, M. & Nayak, R. S. Brain tumor detection and classification using machine learning: A comprehensive survey. Complex Intell. Syst. 8(4), 3161–3183 (2022).
Saeedi, S., Rezayi, S., Keshavarz, H. & Niakan Kalhori, S. MRI-based brain tumor detection using convolutional deep learning methods and chosen machine learning techniques. BMC Med. Inform. Decis. Mak. 23(1), 16 (2023).
Razzaghi, P., Abbasi, K., Shirazi, M. & Rashidi, S. Multimodal brain tumor detection using multimodal deep transfer learning. Appl. Soft Comput. 129, 109631 (2022).
Smith, J. et al. Brain tumor segmentation using multi-scale attention U-Net with EfficientNetB4 encoder for enhanced MRI analysis. Sci. Rep. 15(3), 123–135 (2025).
Johnson, E. & Lee, D. Multimodal brain tumor segmentation and classification from MRI using deep learning techniques. Comput. Biol. Med. 145, 102–110 (2024).
Patel, A. et al. A review of deep learning for brain tumor analysis in MRI. Front. Oncol. 14, 456–470 (2025).
Chen, W. & Gupta, P. A review on brain tumor segmentation based on deep learning methods. Comput. Electr. Eng. 102, 250–260 (2023).
Hernandez, M. et al. Advancements in brain tumor segmentation using attention mechanisms. J. Med. Imaging 11(2), 215–225 (2024).
Wang, Li. & Zhao, H. T1-weighted MRI-based brain tumor classification using hybrid deep learning models. Neurocomputing 350, 85–95 (2024).
Banerjee, T. et al. Deep Convolutional Neural Network (Falcon) and transfer learning-based approach to detect malarial parasite. Multimed. Tools Appl. 81(10), 13237–13251 (2022).
Banerjee, T. and Sharma, A., Charvi, K., Raman, S. & Karthikeyan, S. Attention-Based Discrimination of Mycoplasma Pneumonia. in Proceedings of International Conference on Computational Intelligence and Data Engineering: ICCIDE 2021 29–41 (Springer Nature Singapore, 2022).
Banerjee, T. and Sharma, A., Charvi, K., Raman, S., Regalla, R.G. & Taduru, S. Journey of letters to vectors through neural networks. in Proceedings of Data Analytics and Management: ICDAM 2021 Vol. 1, 709–717 (Springer Singapore, 2022).
Díaz-Pernas, F. J., Martínez-Zarzuela, M., Antón-Rodríguez, M. & González-Ortega, D. A deep learning approach for brain tumor classification and segmentation using a multiscale convolutional neural network. Healthcare. 9, 153 (2021).
Walsh, J., Othmani, A., Jain, M. & Dev, S. Using u-net network for efficient brain tumor segmentation in MRI images. Healthc. Anal. 2, 100098 (2022).
Avazov, K., Mirzakhalilov, S., Umirzakova, S., Abdusalomov, A. & Cho, Y. I. Dynamic focus on tumor boundaries: A lightweight u-net for MRI brain tumor segmentation. Bioengineering 11(12), 1302 (2024).
Martinez, C. et al. 3D U-Net approaches for volumetric brain tumor segmentation. IEEE Trans. Med. Imaging 44(1), 50–60 (2025).
Ahmed, F. & Singh, R. Generative adversarial networks for brain tumor segmentation. Artif. Intell. Med. 120, 101–110 (2023).
Khushi, H. M. T., Masood, T., Jaffar, A., Rashid, M. & Akram, S. Improved multiclass brain tumor detection via customized pretrained efficientnetb7 model. IEEE Access 11, 117210–117230 (2023).
Titu, M.M.T., Mary, M.M., Ahamed, M.F., Oishee, T.M. & Hasan, M.M. Utilizing customized 3D u-net framework for the classification and segmentation of multi-regional brain tumors in volumetric MRI images. in 2024 3rd International Conference on Advancement in Electrical and Electronic Engineering (ICAEEE) 1–6 (IEEE, 2024).
Society, A.C. Key statistics about brain and spinal cord tumors in adults. https://www.cancer.org/cancer/types/brain-spinal-cord-tumors-adults/about/key-statistics.html.
Anwar, S. M. et al. Medical image analysis using convolutional neural networks: A review. J. Med. Syst. 42, 1–13 (2018).
Kumar, S. et al. Swin transformer U-Net for brain tumor segmentation in MRI. Med. Image Anal. 80, 102–115 (2025).
Preetha, R., Priyadarsini, M. J. P. & Nisha, J. Comparative study on architecture of deep neural networks for segmentation of brain tumor using magnetic resonance images. IEEE Access 11, 138549–138567 (2023).
Zhang, J., Jiang, Z., Dong, J., Hou, Y. & Liu, B. Attention gate RESU-net for automatic MRI brain tumor segmentation. IEEE Access 8, 58533–58545 (2020).
Tan, M. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 6105–6114 (2019).
Abd-Ellah, M. K., Awad, A. I., Khalaf, A. A. & Hamed, H. F. A review on brain tumor diagnosis from MRI images: Practical implications, key achievements, and lessons learned. Magn. Reson. Imaging 61, 300–318 (2019).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 3431–3440 (2015).
Banerjee, T. and Butta, D., Jain, A., Biradar, K.S., Koripally, R.R. & Srikar, K.V.P. Deep belief convolutional neural network for diagnosis of pneumonia a response to coronavirus. in 2021 International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT) 1–6 (IEEE, 2021).
Banerjee, T. and Batta, D., Jain, A., Karthikeyan, S., Mehndiratta, H. & Kishan, K.H., 2021. Deep belief convolutional neural network with artificial image creation by GANs based diagnosis of pneumonia in radiological samples of the pectoralis major. in Innovations in Electrical and Electronic Engineering: Proceedings of ICEEE 2021 979–1002 (Springer Singapore, 2021)
Banerjee, T. and Srikar, K.V.P., Reddy, S.A., Biradar, K.S., Koripally, R.R. & Varshith, G. Hand sign recognition using infrared imagery provided by leap motion controller and computer vision. In 2021 International Conference on Innovative Practices in Technology and Management (ICIPTM) 20–25 (IEEE, 2021).
Karthikeyan, S., Gopikrishnan, S., Batta, D. & Banerjee, T. Double helical ensemble multi-dimensional 4-D structured neural network to analyze the driving pattern, driver DNA and generate license score using smartphone sensor data. Turk. J. Comput. Math. Educ. (TURCOMAT) 12(13), 6447–6458 (2021).
Peesa, R.B., Satpathy, A., Karthikeyan, S., Bisht, M., Banerjee, T. & Gupta, G. Single node hadoop cluster for small scale industrial automation. in 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA) 185–189 (IEEE, 2020).
Saminathan, K., Banerjee, T., Rangasamy, D. P. & Vimal Cruz, M. Segmentation of thoracic organs through distributed extraction of visual feature patterns utilizing resio-inception u-net and deep cluster recognition techniques. Curr. Gene Ther. 24(3), 217–238 (2024).
Singh, D. P., Banerjee, T., Kour, P., Swain, D. & Narayan, Y. CICADA (UCX): A novel approach for automated breast cancer classification through aggressiveness delineation. Comput. Biol. Chem. 115, 108368 (2025).
Ansari, M. A., Mehrotra, R. & Agrawal, R. Detection and classification of brain tumor in MRI images using wavelet transform and support vector machine. J. Interdiscip. Math. 23(5), 1–12 (2020).
Banerjee, T. Attentive CNN EEG or ACE-SeizNet: An attention-enhanced cnn model for automated EEG-based seizure detection through multi-domain deep feature fusion (2025).
Banerjee, T. Towards automated and reliable lung cancer detection in histopathological images using DY-FSPAN: A feature-summarized pyramidal attention network for explainable AI. Comput. Biol. Chem. 118, 108500 (2025).
Ronneberger, O., Fischer, P., Brox, T. U-net: Convolutional networks for biomedical image segmentation. in Medical Image Computing and Computer-assisted intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18. 234–241 (Springer, 2015).
Singh, D. P., Kour, P., Banerjee, T. & Swain, D. A comprehensive review of various machine learning and deep learning models for anti-cancer drug response prediction: Comparative analysis with existing state of the art methods. Arch. Computat. Methods Eng. https://doi.org/10.1007/s11831-025-10255-2 (2025).
Chhabra, P. & Abidi, A. Curved text detection in scenic images via proposal-free panoptic segmentation and deep learning. Int. Arab J. Inf. Technol. 21(5), 889–898 (2024).
Hassan, A., Masood, T., Ahmed, H. A., Shahzad, H. M. & Khushi, H. M. T. Benchmarking pretrained models for speech emotion recognition: A focus on Xception. Computers 13(12), 315. https://doi.org/10.3390/computers13120315 (2024).
Deepak, S. & Ameer, P. M. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. https://doi.org/10.1016/j.compbiomed.2019.103345 (2019).
Khushi, H. M. T., Masood, T., Jaffar, A. & Akram, S. A novel approach to classify brain tumor with an effective transfer learning based deep learning model. Braz. Arch. Biol. Technol. 67, e24231137 (2024).
Chakrabarty, D. Brain tumor dataset. Figshare https://doi.org/10.6084/m9.figshare.1512427 (2015).
Nickparvar, M., 2021. Brain tumor MRI dataset. Kaggle. Available at: https://www.kaggle.com/datasets/masoudnickparvar/brain-tumor-mri-dataset [Accessed 13 Jun. 2025].
Talo, M. BR35H: Brain tumor MRI dataset. Harvard Dataverse https://doi.org/10.7910/DVN/BT45Y9 (2019).
Sharif, M. I. et al. A decision support system for multimodal brain tumor classification using deep learning. Complex Intell. Syst. 8, 3007–3020. https://doi.org/10.1007/s40747-021-00321-0 (2022).
Swati, Z. N. K. et al. Brain tumor classification for MR images using transfer learning and fine-tuning. Comput. Med. Imaging Graph. 75, 34–46. https://doi.org/10.1016/j.compmedimag.2019.05.001 (2019).
Sajjad, M. et al. Multi-grade brain tumor classification using deep CNN with extensive data augmentation. J. Comput. Sci. 30, 174–182. https://doi.org/10.1016/j.jocs.2018.12.003 (2019).
Tabatabaei, S., Rezaee, K. & Zhu, M. Attention transformer mechanism and fusion-based deep learning architecture for MRI brain tumor classification system. Biomed. Signal Process. Control https://doi.org/10.1016/j.bspc.2023.105119 (2023).
Özkaraca, O. et al. Multiple brain tumor classification with dense CNN architecture using brain MRI images. Life https://doi.org/10.3390/life13020349 (2023).
Rahman, T. & Islam, M. S. MRI brain tumor detection and classification using parallel deep convolutional neural networks. Meas.: Sens. https://doi.org/10.1016/j.measen.2023.100694 (2023).
Muezzinoglu, T. et al. PatchResNet: Multiple patch division-based deep feature fusion framework for brain tumor classification using MRI images. J. Digit. Imaging https://doi.org/10.1007/s10278-023-00789-x (2023).
Ali, M. U., Hussain, S. J., Zafar, A., Bhutta, M. R. & Lee, S. W. WBM-DLNets: Wrapper-based metaheuristic deep learning networks feature optimization for enhancing brain tumor detection. Bioengineering https://doi.org/10.3390/bioengineering10040475 (2023).
Aloraini, M. et al. Combining the transformer and convolution for effective brain tumor classification using MRI images. Appl. Sci. (Switzerland) https://doi.org/10.3390/app13063680 (2023).
Zahraaalaatageldein (2023). Brain Tumor Classification [CNN|977%]. [online] Kaggle.com. Available at: https://www.kaggle.com/code/zahraaalaatageldein/brain-tumor-classification-cnn-977 [Accessed 13 Jun. 2025].
Author information
Authors and Affiliations
Contributions
All authors have contributed equally.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Banerjee, T., Chhabra, P., Kumar, M. et al. Pyramidal attention-based T network for brain tumor classification: a comprehensive analysis of transfer learning approaches for clinically reliable and reliable AI hybrid approaches. Sci Rep 15, 28669 (2025). https://doi.org/10.1038/s41598-025-11574-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11574-x
This article is cited by
-
ACSL4 as a potential ferroptosis target in hepatocellular carcinoma: from mechanisms to implications
European Journal of Medical Research (2026)
-
Compact deep learning models for colon histopathology focusing performance and generalization challenges
Scientific Reports (2026)
-
Dual vision transformer with bio-inspired optimization for explainable keratoconus classification
International Ophthalmology (2026)
-
Multimodal attention-driven network with blockchain integrity for reliable kidney stone diagnosis
Urolithiasis (2026)
-
The evolving landscape of few shot learning in medical image diagnosis a scoping review
Discover Applied Sciences (2026)
