
Abstract
Internal threats are becoming more common in today’s cybersecurity landscape. This is mainly because internal personnel often have privileged access, which can be exploited for malicious purposes. Traditional detection methods frequently fail due to data imbalance and the difficulty of detecting hidden malicious activities, especially when attackers conceal their intentions over extended periods. Most existing internal threat detection systems are designed to identify malicious users after they have acted. They model the behavior of normal employees to spot anomalies. However, detection should shift from targeting users to focusing on discrete work sessions. Relying on post hoc identification is unacceptable for businesses and organizations, as it detects malicious users only after completing their activities and leaving. Detecting threats based on daily sessions has two main advantages: it enables timely intervention before damage escalates and captures context-relevant risk factors. Our research introduces a novel detection framework for single-day employee behavior detection to address these issues. This framework combines the strengths of Temporal Convolutional Networks (TCNs) and the Transformer architecture. The integrated model uses sliding window technology to segment user logs into time series for model input. The TCN component employs causal and dilated convolutions to maintain temporal order and expand the receptive field, enhancing the detection of long-term patterns. The Transformer models global dependencies in sequences, improving the detection of complex long-term behaviors. The model detects anomalies at each time step and achieves a recall rate of \(95\%\) with a sequence length of 30 days. Experimental results show that this method can accurately detect malicious behavior daily, promptly identify such actions, and effectively mitigate internal threats in complex environments.
Similar content being viewed by others

Introduction
In today’s organizational landscape, safeguarding information against intentional and unintentional insider threats has become paramount1. Typically, the most threatening cyber attacks originate not from external malicious actors but from trusted insiders. These threats often stem from individual members, current or former employees, accessing sensitive information. Inside threats usually result from these individuals’ improper or malicious handling of the organization’s resources, data, networks, and systems. They result in 20 times more severe damage than that caused by external actors, with an average breach cost of $4.5 million per breach2. The 2023 Insider Threat Report3 reveals that a higher percentage of organizations, precisely \(74\%\), now acknowledge an increase in the frequency of insider attacks.
Insider threats can cause significant economic, reputational, and asset damage to companies and organizations. Companies have deployed detection systems and confidentiality measures to manage internal security risks. Protecting against insider threats necessitates the implementation of robust detection mechanisms within organizations4. In the current research landscape, insider threat detection is predominantly framed as a user-classification problem5,6,7,8,9. Systems determine whether to label individuals as malicious explicitly. This approach has two key limitations: (a) detection is delayed until sufficient evidence accumulates, and (b) it cannot distinguish between accidental and intentional abuse by the same user. This renders it ineffective for malicious employees who leave immediately after carrying out harmful actions. A few researchers have shifted from post-hoc to instance-based detection. For example, Dongyang Li et al. achieved AUC scores of \(89.36\%\) (instance-based) and \(94.56\%\) (user-based) with their MAITD10. Similarly, Xiangrui Cai et al., using Transformer + GCN on the CERT R4.2 dataset, obtained AUC scores of \(90.86\%\) (instance-based) and \(93.06\%\) (post-hoc), with DR values of \(82.17\%\) and \(89.34\%\), respectively11. This indicates that instance-based detection is more challenging than post-hoc user-based detection. We propose a novel approach that combines temporal convolutional networks (TCNs) and transformers for per-time-step employee classification. Converting user logs into sliding window sequences captures behavior patterns over time and detects anomalies at each step. This enables timely identification of malicious employees before significant damage occurs and achieves a higher detection rate.
Regarding feature learning, TCNs capture local patterns and short-term dependencies in time series data through multi-layer dilated convolutions12. For example, certain anomalous behaviors may only manifest over a few consecutive time steps, and TCNs are adept at identifying these short-term features13. Meanwhile, global dependencies–relationships between any two-time steps within a sequence–are equally important. Combining both allows anomalous behavior to be linked with earlier events in the sequence at a specific time step. Transformers allow the model to simultaneously consider information from all other time steps when processing each step, thereby understanding the overall context. Through the self-attention mechanism, Transformers can capture relationships between any two-time steps in the input sequence, enhancing the richness and expressiveness of feature representations14,15. A more comprehensive feature representation is formed by effectively merging the local features derived from TCNs with the global dependency information provided by Transformers. This enriched representation strengthens subsequent classifiers’ support, improving overall detection performance. Combining these two architectures enhances the model’s feature representation capabilities and classification accuracy16. Experiments showed that the model achieved a recall of \(95\%\) with a sequence length of 30.
Contributions of this Paper:
-
Innovative hybrid model for insider threat detection: We propose an anomaly detection model that integrates a TCN with a Transformer. It detects malicious behavior by identifying actions in a sliding time-series window that deviate from preceding and succeeding time steps via learning patterns of user actions in these windows.
-
Based on single-day malicious detection: Our model performs daily detection within the window, enabling the timely discovery of employee anomalies. This allows organizations and businesses to detect and address issues early, offering greater practical value than post-hoc user detection.
Related work
The method of integration
Kotb, H.M. et al. proposed a novel Deep Synthesis Insider Intrusion Detection (DS-IID) model. This model leverages deep feature synthesis techniques to generate detailed user profiles from event data automatically and employs binary deep learning for precise threat identification. When tested on the CERT Insider Threat dataset, the DS-IID model achieved an accuracy of \(97\%\) and an AUC value of 0.99. The high accuracy of the DS-IID model indicates its potential as a valuable tool in real-world cybersecurity applications.17
Research by Parveen and McDaniel N. et al. demonstrated that ensemble stream mining techniques outperform traditional single-model approaches. This method effectively identifies inside threats that attempt to conceal their activities through time-evolving behaviors by combining the robustness of single-class Support Vector Machines (SVMs) with the adaptability of stream mining. It achieves effective and practical inside threat detection for unlimited, continuously changing data streams. They selected to use the Radial Basis Function (RBF) kernel for Support Vector Machines (SVM) to test their dataset, achieving excellent results5.
Kim J., Park M., and others, based on user log data, constructed three types of datasets (user daily activity summaries, email content topic distributions, and users’ weekly email communication histories) and then applied four anomaly detection algorithms (Gauss, Parzen, PCA, and KMC) and their combinations to detect malicious activities. The results indicate that this framework is well-suited for imbalanced datasets. However, this method uses models based on specific time units and cannot achieve real-time detection6.
Le D.C. et al. employed four machine learning methods with different fundamental concepts (Autoencoder (AE), Isolation Forest (IF), Lightweight Online Detector of Anomalies (LODA), and Local Outlier Factor (LOF)), highlighting abnormal user behaviors by studying different representations of temporal information data. They demonstrated the robustness of LODA, which can be used for online learning and prediction under extreme conditions with low time complexity; autoencoders that represent data using percentiles are the best combination for anomaly detection; and voting-based anomaly detection ensembles can improve detection performance and robustness7.
Bartoszewski F.W. created a flexible and modular experimental pipeline, applying multiple models (LOF, One-Class SVM (OCSVM), Hidden Markov Models (HMM), and Isolation Forest (IF)) to analyze real and synthetic data, evaluate the strengths and weaknesses of the models, and compare them in the context of inside threat detection problems8.
Lo O., Buchanan W.J., and colleagues applied Hidden Markov Models and analyzed distance vector methods (Damerau-Levenshtein distance, cosine distance, and Jaccard distance), finding that all three are capable of detecting inside threats in the CERT r4.2 dataset and operates faster than machine learning-based detection. The combined total detection rate using all three techniques was 0.8, but this method generates many false positives for benign users9.
Addressing the data imbalance problem
Taher Al-Shehari et al. integrated Convolutional Neural Networks (CNN) with three popular data imbalance addressing techniques: Synthetic Minority Oversampling Technique (SMOTE), Borderline-SMOTE, and Adaptive Synthetic Sampling (ADASYN). They achieved AUC values of 0.64, 0.89, and 0.96, respectively. Their work emphasized the effectiveness of ADASYN in enhancing detection accuracy for imbalanced datasets.18
X. R. Cai, Y. Wang, S. H. Xu, H. Li, Y. Zhang, Z. L. Liu, and X. J. Yuan researched real-time insider threat detection, proposing a fine-grained LAN framework and introducing a new hybrid prediction loss to mitigate data imbalance issues. LAN simultaneously learns temporal dependencies within activity sequences and the relationships between activities across sequences through graph structure learning. Experimental results demonstrate that LAN achieves AUC scores of \(9.92\%\) and \(6.35\%\) higher than nine state-of-the-art baselines on the CERT r4.2 and CERT r5.2 datasets, respectively11.
Pal P. et al. observed that few methods simultaneously utilize multiple deep learning-based feature extraction models. Few adequately address data imbalance issues, especially the uneven ratio of threat instance categories. To address this, they proposed a model based on stacked Long Short-Term Memory (LSTM) and stacked Gated Recurrent Unit (GRU), trained using fixed-length one-hot embedding vectors generated from activity sequences with corresponding labels. They also introduced a new EWRS sampling technique to balance the overall distribution of different threat patterns, effectively addressing the data imbalance problem19.
Mohammed Nasser Al-Mhiqani, Rabiah Ahmed, and Zainal Abidin integrated ADASYN and DNN to develop the AD-DNN model. They utilize ADASYN to address the issue of imbalanced data and they employ DNN to detect insider threats. Experimental results demonstrate that the proposed integrated model exhibits excellent overall detection performance for insider threats on the CERT dataset20.
As the model’s input is user time-series data, conventional oversampling methods struggle to generate synthetic user time-series data. Meanwhile, time-series-based GANs are hard to implement for this study. Thus, this paper tackles data imbalance via phased training and a Focal loss function. The model is first trained on the original dataset to learn general patterns. Then, the Focal loss function adjusts the learning process by focusing on hard-to-classify instances, improving the model’s ability to handle data imbalance and enhancing its performance in detecting malicious behavior.
Other methods
R. G. Gayathri, Atul Sajjanhar, and Yong Xiang proposed a Generative Adversarial Network (GAN) based on linear manifold learning, termed SPCAGAN. This model generates high-quality data that closely mirrors the original distribution by leveraging heterogeneous data sources. By integrating a deep learning-based hybrid model, the SPCAGAN effectively overcomes the mode collapse issue and achieves faster convergence than previous GAN models. However, the computational cost remains high due to the sampling or variational inference stages21.
T. A. Al-Shehari, D. Rosaci, M. Al-Razgan, T. Alfakih, M. Kadrie, H. Afzal, and R. Nawaz introduced an innovative density-based Local Outlier Factor detection algorithm, DBLOF. The algorithm achieved excellent results on the CERTr4.2 dataset with an F1_score of \(98.9\%\). However, the experimental results are limited to the CERTr4.2 dataset, and the model lacks interpretability and has untested scalability22.
Y. R. Gong, S. S. Cui, S. Liu, B. Jiang, C. Dong, and Z. G. Lu discovered that models with higher information content perform better than those with less. They provided a framework and taxonomy based on the detection process, categorizing existing works into three aspects: data collection, graph construction, and graph anomaly detection. They summarized six types of graph anomaly detection methods, offering new insights for the development of novel approaches23.
Zhang J. et al. discovered that employing deep learning models with multiple hidden layers can thoroughly learn the behavioral characteristics of insiders, thereby enhancing the detection rate of inside threats. Specifically, in the adaptive optimization of the Deep Belief Network (DBN) algorithm, the golden section adaptive optimization method outperforms the bisection method, increasing the DBN model’s threat detection rate to \(97.872\%\)24.
Kan X. and colleagues designed a novel Data Adjustment (DA) strategy to enhance the utilization of two-stage classification methods. They also used an Enhanced Random Particle Swarm Optimization (ERPSO) algorithm to search for parameters of the Extreme Gradient Boosting (XGBoost) model, thereby accurately and swiftly detecting malicious behaviors25.
Happa J. et al. proposed two new methods: one that uses Gaussian Mixture Models to model employees’ normal behaviors for anomaly detection and another that integrates security experts’ knowledge to design sensitivity profiles, showing significant potential26.
Hu T. and others designed a blockchain traceability system that considers data structure, transaction structure, block structure, consensus algorithms, data storage algorithms, and query algorithms while employing differential privacy to protect user privacy. Experimental results demonstrate that it can reduce inside threats, though it has several limitations, as network latency, time interval values, and nodes can all affect the system27.
Charlie Soh et al., based on the premise that “insiders typically undergo an emotional transition stage before committing actions,” conducted sentiment analysis on various aspects combined with deep learning techniques. They utilized the Aspect-Based Sentiment Analysis (ABSA) module within the Employee Social Communication-based Identification Framework (ASEP) to classify sentiments of aspect-based sentences extracted from emails. The employee profiling module leverages ABSA results and network information, employing a jump graph algorithm to understand each employee’s profile, thereby establishing a temporal emotional profile for anomaly detection28.
Elmrabit et al. constructed a framework from the perspectives of technology, organization, and human factors, using Bayesian networks for modeling and implementation. However, this approach requires prior probability distributions based on judgments and literature reviews and is limited to authorized employees with access to organizational assets according to human resource records29.
Methodology
Data preprocessing
Data collection and preprocessing are critical in inside threat detection and cybersecurity tasks. The CERT dataset contains five behavioral log types, each containing substantial data. The following procedure integrates these data:
-
First, iterate through each unique user identifier (id).
-
Second, filter records that contain the specific user identifier from the five types of logs.
-
Finally, these records will be sorted based on the temporal information in the date field.
In the CERT dataset, data collection predominantly relies on sensors, which results in a certain degree of data missingness. This missing data could impact the normal functioning of algorithms. The process addresses this issue by imputing missing values and calculating the estimated means for the relevant features. This step is crucial for ensuring the dataset’s integrity and the algorithms’ effectiveness. Adopting this approach mitigates the problem of missing data, providing a robust data foundation for subsequent inside threat detection and cybersecurity analysis.
Based on the characteristic that insiders typically exhibit behavior similar to regular employees before engaging in malicious activities, this study applies a temporal data representation approach that integrates the time dimension. This method emphasizes capturing trends in user behavior over time to identify potential malicious behavior dynamics. Specifically, the approach involves concatenating data points within consecutive time segments or comparing the behavioral patterns of the same user across adjacent periods. This strategy effectively reveals potential shifts in behavior, facilitating the detection of underlying behavioral transitions indicative of malicious intent.
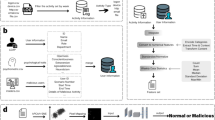
The CERT dataset comprises five categories of behavioral log data from 1,000 employees over 18 months, including HTTP accesses, email send/receive activities, login/logout events, device operations, and file operations. This results in an enormous volume of data. For feature extraction for each employee, the daily unit records each user’s behavioral characteristics within a single day. Figure 1 illustrates the feature extraction process.

Data Processing and Feature Extraction. Step 1: Aggregate all behavioral logs daily and save them to a pickle file. Step 2: Obtain comprehensive user information, including roles, teams, psychological assessments, etc., and integrate this information into a data frame. Step 3: Extract statistical and frequency-based features daily. Step 4: Save the features by date to a CSV file.
The feature extraction process involves the following steps:
Step 1: Daily Data Aggregation Consolidate all activity files (device, email, file, HTTP, logon) daily. This aggregation process consolidates the data into daily segments, resulting in pickle files categorized by day. This approach facilitates the creation of time series using daily behavioral features to capture user behavior patterns, thereby reducing the complexity of handling data fluctuations.
Step 2: User Information Retrieval Comprehensive user information, including relevant features and malicious user labels, is obtained from multiple CSV files within the LDAP directory. These files contain essential user attributes such as username, role, department, and team. After numerically processing the psychological test information, integrate it into the employee database. The insiders.csv file provides detailed information on the malicious activities of users, including their activities’ start and end times and scenario identifiers. The result is a Pandas data frame encompassing all user features, providing a holistic view of each employee’s profile.
Step 3: Daily Behavioral Feature Extraction Transform the daily behavioral data recorded in the DataFrame into statistical and frequency features. In addition to the provided psychometric and role-based attributes, various statistical and frequency-based behavioral characteristics of employees are required. These include but are not limited to, the number of activities performed, login frequency, the number of file operations, the volume of emails sent, the number of HTTP requests, the duration of activities, the lengths of emails/files, and specific category behaviors.
Step 4: Extract the Features and Save Them as CSV Files.
Data windowing
First, dimensionality reduction is performed on the raw feature data using Linear Discriminant Analysis (LDA) to reduce the dimensionality of the extracted features, selecting the directions that maximize the discrimination between normal users and the three scenario-based categories30. After LDA filtering, a 104-dimensional feature set is obtained, excluding employee information. At this stage, the feature data comprises a mixture of 1,000 users. However, the model needs to learn the behavioral patterns of users to identify malicious users who intentionally conceal their activities. Therefore, sliding window processing of the feature data is also required. Partition and sort each user’s data chronologically. Process the time series as in Fig. 2: set the window size to w = [20,25,30,35,40,45] and the sliding step to s = 131. The reason for choosing the window size w in this way is that the normal working hours of the employees in the dataset correspond to a typical weekly working pattern (five days a week). In Scenario 2, the employee tries to cover up malicious behaviour by a long-term behaviour that lasts for about two months. Since the time series cannot be too short, the length of the input series to the model increases from the number of working days in a month to about 20 to 25 days. The window size increases by five working days (one week) at a time, eventually reaching two months of working days, or 40 to 45 days.

Data Windowing and Model Input. Intercept window data for w time steps on each user’s timeline. Move back one time step (s = 1) for each window acquired until the end of the timeline.
Additionally, continuous window inputs can better capture the relationships between time steps. However, the extensive overlap in the data may lead to information redundancy and overfitting. Dropout integrates into each structure layer to address this issue, while early stopping and validation strategies help prevent overfitting.
The npz file saves each user’s set of windows, with each window containing all features of w time steps and their corresponding classification labels. Windowed data stored in npz files are loaded before training begins. The data is organized in terms of users (user) and the model inputs all windowed data for each user in turn (after completing all windowed data inputs for one user, then start inputting data for the next user). Each window consists of:
Model
This model aims to construct a fine-grained temporal analysis system tailored for each user, integrating local behavioral features with global contextual semantics to achieve precise threat detection daily. Unlike traditional user-level detection methods, our architecture can determine whether a user’s single-day behavior is anomalous, even if the user’s long-term behavioral pattern is normal. S. Bai and colleagues have highlighted that traditional Recurrent Neural Network (RNN) approaches are becoming increasingly outdated, with Convolutional Neural Networks (CNNs) emerging as the primary method for handling sequence data. Their research demonstrates that CNNs outperform RNNs across various tasks and circumvent common RNN issues such as vanishing or exploding gradients and limited memory capacity. They introduced Temporal Convolutional Networks (TCN), which surpass RNNs and Long Short-Term Memory (LSTM) networks in managing longer temporal spans within convolutional prediction and residual layer modules32. This design integrates multiple best practice methodologies, such as Fully Convolutional Networks, dilated convolutions, residual connections, and causal convolutions33.
TCNs expand the network’s receptive field and capture a broader range of historical information. Our approach uses TCN’s multi-layer dilated convolutions to effectively capture local patterns and short-term dependencies in time series data, specifically focusing on the relationships between adjacent time steps. Furthermore, Transformers empower the model to simultaneously consider information from all other time steps when processing each step, thereby comprehending the overall context. The self-attention mechanism inherent to Transformers enables the capture of relationships between any two-time steps within the input sequence, enriching the feature representations’ complexity and expressiveness. The model establishes a more robust feature representation, enhancing support for the classifier by integrating TCN with Transformers. The model processes input time series obtained from the CERT dataset, segmented by the user, and derived using a sliding window method along the timeline. The architecture comprises four TCN Blocks and two Transformer Layers, culminating in a Classifier output. Figure 3 illustrates the model structure. Algorithm 1 describes the process of using a time series for insider threat detection with the model.

Model Architecture. The model takes window-based data as input, with w \(\times\) 104, where w represents the number of time steps, and 104 is the feature dimension. After passing through four layers of TCNBlock, the data is fed into two layers of Transformer. The final output shape is w \(\times\) 1, corresponding to predictions for each time step.

Temporal Learning.
Temporal Convolutional Networks (TCN)
Causal convolution
Causal Convolution is a specialized convolutional method within convolutional neural networks, primarily utilized for processing time series data. Its distinguishing feature is that the convolution operation exclusively considers inputs from the current and preceding time steps, deliberately excluding any future data. This design ensures the model’s causality, effectively preventing the “leakage” of future information and thereby preserving the temporal order characteristics inherent in time series data, as illustrated in Fig. 4.

Causal Convolution. Causal Convolution ensures that the output at any time point t depends only on the inputs at time point t and before, without relying on future inputs. Moreover, the receptive field of the model can be expanded by stacking multiple convolutional layers, enabling the model to capture dependencies over a longer period.
Here,\(y_t\) represents the output at the current time step t, \(x_{t-d_i}\) is the time step data from the input sequence adjusted according to the dilation rate \(d_i\), \(w_i\) denotes the convolution kernel weights.
Dilated convolution
Dilated convolution is a technique that increases the receptive field of convolutional layers by introducing gaps (dilations) within the convolution operation, enabling exponential growth of the receptive field. In standard convolution, each element of the convolution kernel interacts with consecutive elements of the input data. In contrast, dilated convolution expands the kernel’s field of view by inserting gaps between its elements, allowing the model to capture broader temporal dependencies, as illustrated in Fig. 5.

Dilated Convolution. Dilated convolution expands the receptive field by inserting gaps (determined by the dilation rate) between the elements of the convolutional kernel, allowing the kernel to cover a larger spatial range.
Here,\(x\in R^{N}\) represents the input of a one-dimensional sequence,f denotes the convolution kernel, and s is an element within the sequence.
The formula for calculating the receptive field of dilated convolution is:
Therefore, to increase the receptive field, one can adjust the convolution kernel size k or enlarge the dilation factor \(d_i\). However, as the network depth increases, this strategy also increases computational costs, gradient explosion, and gradient vanishing.
Residual connections
Residual connections address these issues. They facilitate network training by skipping specific layers and directly adding the inputs of these layers to their outputs, as demonstrated in Fig. 6. Residual connections can alleviate common problems in deep neural networks, such as vanishing or exploding gradients, and accelerate the training process. They enable the network to learn identity mappings more efficiently, simplifying optimization.

Residual Connections. Residual connections, inspired by the Residual Networks (ResNet) concept, are an important design mechanism. Their primary function is to mitigate deep networks’ vanishing and exploding gradient problems while enhancing the model’s learning capacity.
x represents the input and F(x) denotes the result after processing through several layers. The formula for calculating the receptive field in residual layers is as follows:
TCNBlock
4 TCNBlocks constitute the TCN component of the model, each of which includes the following structure:
-
1.
Causal Conv1D: Causal Conv1D is employed to capture temporal dependencies.
-
filters refer to the number of output feature dimensions.
-
\(kernel_{size}\) denotes the size of the convolutional kernel.
-
\(dilation_{rate}\) is used to expand the receptive field of the convolutional kernel.
-
ReLU serves as the activation function.
-
2.
Dropout: Randomly setting a portion of neuron outputs to zero to prevent overfitting.
-
3.
Layer Normalization: Performing normalization to maintain stable activation values across each layer.
-
4.
Residual Connection: Adding the input directly to the convolution result.
Figure 7 illustrates the structure of the TCNBlock. When stacked TCNBlocks are used to implement dilated convolutions, the receptive field expands exponentially as the number of layers increases.

TCNBlock.
Transformer
PositionalEncoding
The output of the TCN is passed to the position encoding module to inject positional information into the sequence, as both convolution and the Transformer itself are insensitive to positional information. The model integrates positional information into each time step by adding extra positional data (without changing the dimensionality) to strengthen the temporal order34. Position encoding uses sine and cosine functions to calculate. For each input position t and dimension k, the position encoding PE(t,k) is the following formula:
-
Sine functions apply to even indices:
-
Cosine functions apply to odd indices:
d denotes the feature dimension.
-
Addition of Position Encoding:
PE represents a predefined position embedding matrix. Consequently, positional information is incorporated into each time step of the input data.
MultiHeadSelfAttention
The input undergoes linear transformations to generate the Query (), Key (), and Value () matrices:
\(W_Q\),\(W_K\), and \(W_V\) are trainable weight matrices.
-
Calculation of Attention Weights:
\(d_k\) denotes the dimension of the Key vectors, and Attention(Q, K, V) represents the attention weights.
-
Attention Output:
-
After Residual Connection and Layer Normalization:
-
Multiple independent attention heads compute the MultiHead attention, and then the outputs of each head are concatenated together:
h is the number of attention heads, \(W_O\) is the output projection matrix, Q, K, and V represent the Query, Key, and Value matrices, respectively, and \(d_k\) denotes the dimension of the Key vectors.
Feed-ForwardLayer
In the Transformer encoder, the feature at each time step is processed through a feedforward neural network comprising two fully connected layers. The first fully connected layer performs an affine transformation using the weight matrix and bias, followed by a ReLU activation function. The second fully connected layer takes the output from the first layer and applies another affine transformation using \(W_2\) and \(b_2\). Dropout applies to the multi-head attention and feedforward network layers before applying residual connections and layer normalization.
\(W_1\), \(W_2\), \(b_1\), \(b_2\) are trainable parameters.
TransformerLayer
Figure 8 depicts the structure of the TransformerLayer.

TansformerLayer. The output from the TCN is first processed with positional encoding and then fed into the multi-head attention mechanism. Subsequently, dropout is applied to prevent over-fitting, followed by Layer Normalization (Layer Norm). The result is then passed through the Feed-Forward network, after which dropout and Layer Norm are applied once more before the final output.
Classifier
Perform prediction and classification for each time step in the input sequence.
Experiment setting and evaluation
Dataset
In this study, we utilized the CERTr4.2 Insider Threat dataset. The CERT dataset is generated by the CERT Insider Threat Center at Carnegie Mellon University (CMU). Under the sponsorship of the Defense Advanced Research Projects Agency (DARPA), the center collaborates with ExactData to collect data from real-world enterprise environments. The dataset is designed to simulate the behavior of malicious insiders in real-world settings, encompassing various attack behaviors such as system sabotage, information theft, and internal fraud35. The dataset consists of seven types of CSV files, as detailed in Table 1. The CERTr4.2 dataset records behavioral logs of 1,000 employees over 18 months, with only 70 identified as malicious insiders, leading to a significant data imbalance. Figure 9(a) displays the proportion of employees. After assigning daily classification labels for all users, Fig. 9(b) illustrates the number of normal days to malicious days. Hence, data preprocessing is a critical task.

Degree of Dataset Imbalance. (a) The proportion of Normal Users and Malicious Users. Malicious users account for \(93\%\) of the dataset, while normal users constitute \(7\%\). (b) Number of Normal Days and Malicious Days. The number of days with malicious activities is 966, while the number of days with normal activities is 330,452.
Inside threat scenarios
Different versions of the CERT dataset encompass various scenarios. The http.csv is the most significant component of the dataset. CERTr4.2 reveals that malicious employee behaviors manifest in three distinct scenarios.
Scenario 1: Data Uploading During Non-Working Hours
Users log into devices during non-working hours and upload sensitive company data to malicious websites, like wikileaks.org. These activities typically occur after office hours and are characterized by abnormal login patterns, file operations, and network activities.
Scenario 2: Data Theft Prior to Resignation
Users browse recruitment websites in preparation for switching jobs, decide to join a competitor, and steal data. The data theft method usually involves copying files to external storage devices like USB drives. This scenario’s behaviors tend to persist over an extended period (averaging approximately two months)to minimize the risk of detection. Specific features include USB activity, file operations, and network access.
Scenario 3: File Leakage to Personal Email Accounts
Users log in from multiple inside machines, search for confidential files, and send them to personal email accounts. The behaviors in this scenario include cross-device file operations, search activities, and email sending-actions.
Experiment setting
Due to the significantly smaller number of malicious daily samples than normal daily samples, the experiment adopts a staged training approach. In the first stage, the model utilizes windowed data from normal users to learn their normal behavioral patterns. In the second stage, \(80\%\) of the malicious user window data from three scenarios are used as training samples, while the remaining \(20\%\) serves as the test set. Additionally, a similar number of normal user samples are randomly selected to constitute the normal training and test sets, thereby mitigating the issue of data imbalance. There are a total of 70 malicious users and 930 normal users. In the first stage of training, 860 normal users are randomly selected to learn their features. In the second stage, \(80\%\)(i.e., 56) of the remaining 70 normal and 70 malicious users are randomly chosen as the training set, while the remaining \(20\%\)(i.e., 14) are used for testing. The specific process is illustrated in Fig. 10. After conducting multiple experiments and fine-tuning, we selected the hyperparameter configuration shown in Table 2 for model training.

Experimental Workflow Diagram. First, features are extracted and saved to a CSV file. Subsequently, Linear Discriminant Analysis (LDA) is applied to reduce the dimensionality of the data. The dimensionality-reduced data are then processed through windowing. The dataset is divided according to users for phased training. In the first phase, 860 normal users are selected to learn the normal behavior patterns. In the second phase, 56 malicious and 56 normal users are chosen to adjust the model weights. Finally, 14 malicious and 14 normal users are left as the test set. After model training, classification is performed using a classifier.
Experimental results
Each sequence length underwent three experiments, and Table 3 shows the results. The evaluation focuses on precision, recall, and F1_score, specifically for the malicious samples, as the three metrics for normal samples remain consistently high, ranging from \(98\%\) to \(99\%\). Our primary focus is on analyzing the detection performance of the malicious samples. The experimental results showed that the model achieved the highest recall rate of \(95\%\) for daily malicious information detection when the sequence length was set to 30 days, as depicted in Table 3(a). The recall rates for the other two experiments were \(91\%\) and \(93\%\), respectively. Experimental results indicate that a sequence length of 30 days is an appropriate choice. It is important to note that the recall = 0.95 mentioned in this paper refers specifically to the detection results of malicious samples. The recall rate for normal samples fluctuates between 0.98 and 0.99. However, due to the overwhelming number of normal time steps, we use the recall rate of malicious detection as the evaluation metric. For specific data, please refer to Fig. 19.
Figure 11(a), (b), and (c) present the AUC values from the three experiments. Figure 11(d) displays the ROC curve corresponding to the highest AUC, which was achieved in the same experiment where the recall rate reached \(95\%\).

Comparison of AUC for Different Window Sizes Across Three Experiments. (a), (b) and (c) present the AUC values for the six window sizes across the three experiments in the same order as shown in Table 3. In the experiment with w = 30 and Recall = 0.95, the AUC also reaches its highest value of 0.984, and (d) displays the corresponding ROC curve.
Comparison with TCN and transformer
Moreover, we conducted relevant experiments to elucidate the rationale behind integrating TCN and Transformer. As illustrated in Table 4, the experimental results demonstrate that pure TCN and Transformer perform poorly in single-day malicious detection and fail to achieve effective single-day malicious classification. However, both TCN and Transformer demonstrated efficacy in user-level classification. After incorporating Positional Encoding, the Transformer outperforms the pure Transformer. Our proposed method, TCN + Transformer, achieves effective detection of malicious single-day activities. It outperforms the individual user-based classification methods using TCN or Transformer alone in terms of recall and AUC.
When using Transformer alone, its attention mechanism encounters two fundamental limitations in the single-day detection scenario:(a) Lack of positional sensitivity: It cannot distinguish between “yesterday abnormal + today normal” and “today abnormal + yesterday normal.”(b) Over-smoothing: It dilutes sudden anomalies across the entire historical sequence.
By incorporating positional encoding into the Transformer for user-level detection, we observed an improvement in classification performance. The Transformer excels at extracting long-term user behavior profiles, which is why it is effective in user-based detection. However, the attention mechanism’s over-smoothing of anomaly signals in short sequences leads to its failure in single-day detection.
As illustrated in Fig. 12 and Fig. 13, we obtained the filter visualization images for pure TCN in user-based and single-day classification. The color variations in the figures represent changes in activation levels, with red dashed lines indicating high sensitivity to the current time-step data, which is crucial for anomaly detection. In Fig. 13, it is evident that there are no time steps where TCN shows high sensitivity. Moreover, the flat activation levels of most filters in response to single-day inputs suggest that an isolated time point (single-day behavior) is insufficient for malicious detection using pure TCN alone. However, Fig. 12 also indicates that TCN fails to identify all malicious time steps at the user-level classification, merely completing the classification of the user, which is inadequate.

TCN-user Temporal Response Graph. The figure illustrates the filter activation levels of TCN during user-level detection, and the time steps to which the model is highly sensitive (indicated by red dashed lines). Only three red dashed lines in the figure indicate that not all malicious time steps have been identified.

TCN-day Temporal Response Graph. The figure displays the filter activation levels of TCN for single-day detection. The absence of red dashed lines in the figure indicates that TCN has not focused on any malicious single-day instances, which also serves as evidence of TCN’s failure in single-day detection.
Figure 14 and Fig. 15 present the malicious user response graphs for pure Transformer in user-based and single-day detection. The red dashed lines in the figures denote the true classification of users. The vertical axis represents the predicted probability, while the horizontal axis indicates the total number of time steps associated with the user. It is clear that, whether for user-based or single-day detection, the Transformer misclassifies a large number of normal single-day behaviors as malicious, with more false positives in single-day detection.

Transformer–User Malicious User Response Graph. The figure illustrates the temporal response of the Transformer to malicious detection by users. The number of time steps predicted as malicious by the model significantly exceeds the number of malicious time steps, resulting in many false positives.

Transformer-Day Malicious User Response Graph. The figure illustrates the temporal response of the Transformer for single-day malicious detection, where nearly all time steps are predicted as malicious.
The experimental results indicate that neither TCN nor Transformer alone is capable of performing single-day malicious detection. TCN excels at capturing temporal dependencies in data. However, single-day data is essentially an isolated time point, lacking associations with other time points. Under such circumstances, TCN cannot leverage its strengths, as it struggles to establish practical spatiotemporal features simultaneously. Meanwhile, Transformer is adept at modeling global dependencies but has weaker capabilities in capturing local features. TCN, through causal Convolution and dilated Convolution, can effectively capture local patterns and short-term dependencies in time-series data. Specifically, causal Convolution ensures temporal causality, meaning the model can only use past information when predicting the current time step, thereby avoiding information leakage. Dilated Convolution expands the receptive field through interval sampling, enabling TCN to capture local features over an extended period.
On the other hand, the Transformer can simultaneously consider information from all time steps in a sequence through its self-attention mechanism, thus modeling global dependencies. This is highly effective for understanding long-term patterns and contextual information in user behavior.By integrating TCN and Transformer and obtaining time series data through a sliding window, we obtained the TCN filter activation images, as shown in Fig. 16. The model exhibits high sensitivity to a greater number of time steps, which demonstrates the effectiveness of our model in single-day malicious detection.

TCN+Transformer Temporal Response Graph. The figure displays the temporal activation levels of the filters and the highly sensitive time steps for our integrated model. It can be seen that a greater number of time steps are highly focused on, which is essential for detecting malicious single-day activities. This demonstrates the high potential of our integrated model for malicious single-day detection.
Figure 17 presents an enlarged comparison of the visualizations from our model and TCN, clearly revealing the significant enhancement in sensitivity to key time steps after integrating the two models.

Comparison of TCN + Transformer with TCN-User and TCN-Day. By zooming in on the local regions of the three filter activation images, it is evident that the integrated model exhibits heightened attention (indicated by red dashed lines) to a greater number of suspicious time steps.
Comparison with other methods
In addition, we compared our method with those of other researchers who conducted real-time monitoring experiments on the CERTr4.2 dataset, as shown in Table 5.
The majority of existing papers focus on user-level detection. Table 6 presents the classification performance of various models on the CERTr4.2 dataset.
Comparison of training and prediction time
Our method performs best at a window size of w = 30. Taking w = 30 as an example, Fig. 18 compares training and prediction times between our model and other methods48. Our method is highly efficient during the training phase, with a significantly shorter training time than other approaches. The training time is directly proportional to the window size w. In the prediction phase, the average prediction time per time step in the window for our method is slower than that of the Autoencoder (AE) and Isolation Forest (IF) methods, which is an area where our method can be improved.

Training and prediction time.
Experimental evaluation
Our method achieves the highest recall rate of \(95\%\) at a window size of w = 30, as demonstrated in the results presented above. Additionally, a sequence length of 40 days also exhibits satisfactory performance, with recall rates consistently exceeding \(90\%\) across three experiments. As shown in Table 3, when the sequence length is 35 or 45 days, the recall rate shows noticeable fluctuations, yet the lowest point remains above approximately \(85\%\). Compared with other methods, our model outperforms existing models in detecting malicious activities on a single-day basis. Moreover, the model’s training efficiency is significantly higher, with much shorter training times than those of the models mentioned. However, our method performs poorly in terms of precision and F1_score across all sequence lengths. This is because the number of normal user time steps far exceeds that of malicious user time steps, resulting in a significantly larger number of normal user time windows in the test set compared to malicious user time windows. The model conducts detection at each time step of the input sequence. Given the sliding step size of s = 1, there is substantial overlap between prediction classifications. Consequently, when the model misclassifies one or a few time steps of a normal user as malicious, this extensive overlap naturally leads to many false positives. Therefore, most false positives are due to repeated misclassifications of a small number of time steps. Since the number of normal user windows is much larger than that of malicious user windows, 10 to 15 false positives from normal single-day instances can surpass the total number of malicious single-day instances. This is the reason for the poor performance in precision and F1_score. As illustrated in Fig. 19, misclassification of normal time steps is common across all sequence lengths. Moreover, the model’s ability to detect malicious time steps daily is inconsistent, showing significant fluctuations. When the sequence length is 20 days, the performance is unstable, with precision fluctuating between \(66\%\) and \(52\%\). As shown in Fig. 19, when precision reaches \(66\%\), the model has the fewest misclassifications of normal time steps, with 2,101 misclassified instances. However, in experiments with sequence lengths of 25, 30, 35, and 40 days, when precision is at \(52\%\), up to 3,882 time steps are misclassified as malicious, resulting in two significantly different false-positive (FP) outcomes.

Results of three experiments with six window sizes.
In the experiments with window sizes w = [35,45], the decline in recall rate is attributed to the uneven distribution of malicious time steps among malicious users. The data in Fig. 19 shows that each increase in sequence length corresponds to an approximate increase of 35,000 normal time steps. The rise in false positives is attributed to the overall increase in time steps, as the repetition of false positives within the same time step also increases accordingly. However, the increase in malicious time steps is relatively slower. In the dataset, normal users typically have around 500 days of time steps. Scenario 1 and Scenario 2 each have 30 malicious users, while Scenario 3 has only 10. Among the 30 users in Scenario 1, 15 have malicious time steps lasting only 1 to 5 days, as shown in Fig. 20(a). In Scenario 2, 19 out of 30 users have malicious time steps lasting only 1 to 4 days, as shown in Fig. 20(b). In Scenario 3, 6 out of 10 users have malicious time steps lasting only 1 to 4 days, as shown in Fig. 20(c). This results in a minimal number of available malicious samples. When the second-phase training set randomly includes malicious users with fewer malicious time steps, the model fails to capture the normal behavior patterns of users, and the detection performance for malicious time steps naturally declines, leading to fluctuations in the recall rate.

The Number of Malicious Time Steps in Three Scenarios. (a) tallies the malicious time steps for 30 malicious users in Scenario 1. (b) does the same for 30 malicious users in Scenario 2. (c) covers 10 malicious users in Scenario 3.
The main reason is that our two-phase training and the Focal loss function have not effectively addressed the data imbalance issue. The model’s detection performance deteriorates when the number of malicious samples in the divided dataset is small.
Conclusion
In this paper, we integrate TCN and Transformer to capture both local features and global dependencies in user time-series data. By employing a sliding-window approach, we extracted time-series data of six different lengths as inputs to the model. Additionally, we adopted a two-phase training method to mitigate the issue of data imbalance. The model achieved the best detection performance at a time-series length of 30 days, with a recall rate of 0.95 and an AUC of 0.984. However, given that the number of normal user time steps far exceeds that of malicious time steps, we do not consider AUC the evaluation criterion. The limitations of this study are as follows: The current experiments focus solely on specific time-series lengths (up to a maximum of 45 days), and the model’s performance on significantly longer sequences or other scenarios remains unexplored. Due to the scarcity of malicious time steps, the model’s detection performance exhibits considerable fluctuations. Moreover, detecting malicious users in Scenario 2 remains challenging and critical.
Our approach to handling data imbalance is relatively simplistic. However, we employed two-phase training to alleviate the data imbalance issue. The scarcity of malicious time steps still impacts the model’s ability to learn features effectively. In the future, we plan to use Conditional TimeGAN to generate new malicious time-series samples that closely align with the patterns of actual data based on the time-series data of malicious users. The model is anticipated to perform better on the new dataset.
Data availability
The datasets used and/or analysed during the current study are available in the Carnegie Mellon University KiltHub repository under the title “Insider Threat Test Dataset” and can be accessed via the following persistent URL: https://kilthub.cmu.edu/articles/dataset/Insider_Threat_Test_Dataset/12841247. This dataset is publicly available under the repository’s terms of use and does not contain personally identifiable information requiring de-identification.
References
Aggarwal, A. & Srivastava, S. K. Synthesizing information security policy compliance and non-compliance: A comprehensive study and unified framework. J. Organ. Comput. Electron. Commer. 34, 338–369 (2024).
Alzaabi, F. R. & Mehmood, A. A review of recent advances, challenges, and opportunities in malicious insider threat detection using machine learning methods. IEEE Access 12, 30907–30927 (2024).
Schulze, H. 2023 insider threat report. (2024).
Al-Mhiqani, M. N. et al. Insider threat detection in cyber-physical systems: a systematic literature review. Comput. Electr.Eng. 119, 109489 (2024).
Parveen, P. et al. Evolving insider threat detection stream mining perspective. Int. J. on Artif. Intell. Tools 22, 1360013 (2013).
Kim, J., Park, M., Kim, H., Cho, S. & Kang, P. Insider threat detection based on user behavior modeling and anomaly detection algorithms. Appl. Sci. 9, 4018 (2019).
Le, D. C. & Zincir-Heywood, N. Anomaly detection for insider threats using unsupervised ensembles. IEEE Trans. Netw. Serv. Manag. 18, 1152–1164 (2021).
Bartoszewski, F. W. Machine learning and anomaly detection for insider threat detection. Ph.D. thesis, Heriot-Watt University (2022).
Lo, O., Buchanan, W. J., Griffiths, P. & Macfarlane, R. Distance measurement methods for improved insider threat detection. Secur. Commun. Networks 2018, 5906368 (2018).
Li, D., Yang, L., Zhang, H., Wang, X. & Ma, L. Memory-augmented insider threat detection with temporal-spatial fusion. Secur. Commun. Networks 2022, https://doi.org/10.1155/2022/6418420 (2022).
Cai, X. et al. Lan: Learning adaptive neighbors for real-time insider threat detection. IEEE Trans. Infor. Foren. Secu. 19, 10157–10172. https://doi.org/10.1109/TIFS.2024.3488527 (2024).
Wei, H., Zhang, Q. & Gu, Y. Remaining useful life prediction of bearings based on self-attention mechanism, multi-scale dilated causal convolution, and temporal convolution network. Meas. Sci. Technol. 34, 045107 (2023).
Raihan, A. S. Prediction of Anomalous Events with Data Augmentation and Hybrid Deep Learning Approach. Master’s thesis, West Virginia University (2024).
Han, K. et al. Transformer in transformer. Adv. Neural Inf. Process. Syst. 34, 15908–15919 (2021).
Ahmed, S. et al. Transformers in time-series analysis: A tutorial. Circuits Syst. Signal Process. 42, 7433–7466 (2023).
Zhang, Z., Gong, S., Liu, Z. & Chen, D. A novel hybrid framework based on temporal convolution network and transformer for network traffic prediction. Plos one 18, e0288935 (2023).
Kotb, H. M., Gaber, T., Aljanah, S., Zawbaa, H. M. & Alkhathami, M. A novel deep synthesis-based insider intrusion detection (ds-iid) model for malicious insiders and ai-generated threats. Sci. Rep. 15, https://doi.org/10.1038/s41598-024-84673-w (2025).
Al-Shehari, T. et al. Comparative evaluation of data imbalance addressing techniques for cnn-based insider threat detection. Sci. Rep. 14, https://doi.org/10.1038/s41598-024-73510-9 (2024).
Pal, P., Chattopadhyay, P. & Swarnkar, M. Temporal feature aggregation with attention for insider threat detection from activity logs. Expert Syst. Appl. 224, 119925 (2023).
Al-Mhiqani, M. N., Ahmed, R., Abidin, Z. Z. & Isnin, S. An integrated imbalanced learning and deep neural network model for insider threat detection. Int. J. Adv. Comput. Sci. Appl. 12 (2021).
Gayathri, R., Sajjanhar, A. & Xiang, Y. Hybrid deep learning model using spcagan augmentation for insider threat analysis. Expert. Syst. with Appl. 249, 123533 (2024).
Al-Shehari, T. et al. Enhancing insider threat detection in imbalanced cybersecurity settings using the density-based local outlier factor algorithm. IEEE Access (2024).
Gong, Y. et al. Graph-based insider threat detection: A survey. Comput. Networks 254, 110757 (2024).
Zhang, J., Chen, Y. & Ju, A. Insider threat detection of adaptive optimization dbn for behavior logs. Turkish J. Electr. Eng.Comput. Sci. 26, 792–802 (2018).
Kan, X. et al. Data adjusting strategy and optimized xgboost algorithm for novel insider threat detection model. J. Franklin Inst. 360, 11414–11443. https://doi.org/10.1016/j.jfranklin.2023.09.004 (2023).
Happa, J. et al. Insider-threat detection using gaussian mixture models and sensitivity profiles. Comput. Secur. 77, 838–859 (2018).
Hu, T. et al. Tracking the insider attacker: A blockchain traceability system for insider threats. Sensors 20, https://doi.org/10.3390/s20185297 (2020).
Soh, C., Yu, S., Narayanan, A., Duraisamy, S. & Chen, L. Employee profiling via aspect-based sentiment and network for insider threats detection. Expert Syst. Appl. 135, 351–361 (2019).
Elmrabit, N., Yang, S.-H., Yang, L. & Zhou, H. Insider threat risk prediction based on bayesian network. Comput. Secur. 96, 101908 (2020).
Li, X. & Wang, H. On mean-optimal robust linear discriminant analysis. ACM Trans. Knowl. Discov. Data. 18, 1–27 (2024).
Tao, X. et al. User behavior threat detection based on adaptive sliding window gan. IEEE Trans. Netw. Serv.Manag. (2024).
Bai, S., Kolter, J. Z. & Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271 (2018).
Hu, C., Cheng, F., Ma, L. & Li, B. State of charge estimation for lithium-ion batteries based on tcn-lstm neural networks. J. Electrochem. Soc. 169, 030544 (2022).
Huynh, V., Lee, G.-S., Yang, H.-J. & Kim, S.-H. Temporal convolution networks with positional encoding for evoked expression estimation. arXiv preprint arXiv:2106.08596 (2021).
Glasser, J. & Lindauer, B. Bridging the gap: A pragmatic approach to generating insider threat data. In 2013 IEEE Security and Privacy Workshops, 98–104, https://doi.org/10.1109/SPW.2013.37 (2013).
Anju, A. & Krishnamurthy, M. M-eos: modified-equilibrium optimization-based stacked cnn for insider threat detection. Wirel. Networks 30, 2819–2838. https://doi.org/10.1007/s11276-024-03678-5 (2024).
Fang, L. et al. A practical model based on anomaly detection for protecting medical iot control services against external attacks. IEEE Trans. Industr. Inform. 17, 4260–4269. https://doi.org/10.1109/TII.2020.3011444 (2021).
Villarreal-Vasquez, M., Modelo-Howard, G., Dube, S. & Bhargava, B. Hunting for insider threats using lstm-based anomaly detection. IEEE Trans. Dependable Secure Comput. 20, 451–462. https://doi.org/10.1109/TDSC.2021.3135639 (2023).
Le, D. C., Zincir-Heywood, N. & Heywood, M. I. Analyzing data granularity levels for insider threat detection using machine learning. IEEE Trans. Netw. Serv. Manag. 17, 30–44. https://doi.org/10.1109/TNSM.2020.2967721 (2020).
Yu, K. et al. Securing critical infrastructures: Deep-learning-based threat detection in iiot. IEEE Commun. Mag. 59, 76–82. https://doi.org/10.1109/MCOM.101.2001126 (2021).
Li, W., Tug, S., Meng, W. & Wang, Y. Designing collaborative blockchained signature-based intrusion detection in iot environments. Futur. Gener. Comput. Syst. 96, 481–489. https://doi.org/10.1016/j.future.2019.02.064 (2019).
Chattopadhyay, P., Wang, L. & Tan, Y.-P. Scenario-based insider threat detection from cyber activities. IEEE Trans. Comput. Soc. Syst. 5, 660–675. https://doi.org/10.1109/TCSS.2018.2857473 (2018).
Pal, P., Chattopadhyay, P. & Swarnkar, M. Temporal feature aggregation with attention for insider threat detection from activity logs. Expert. Syst. with Appl. 224, 119925. https://doi.org/10.1016/j.eswa.2023.119925 (2023).
AlSlaiman, M., Salman, M. I., Saleh, M. M. & Wang, B. Enhancing false negative and positive rates for efficient insider threat detection. Comput. Secur. 126, 103066. https://doi.org/10.1016/j.cose.2022.103066 (2023).
Racherache, B., Shirani, P., Soeanu, A. & Debbabi, M. Cpid: Insider threat detection using profiling and cyber-persona identification. Comput. Secur. 132, 103350. https://doi.org/10.1016/j.cose.2023.103350 (2023).
Mehnaz, S. & Bertino, E. A fine-grained approach for anomaly detection in file system accesses with enhanced temporal user profiles. IEEE Trans. Dependable Secur. Comput. 18, 2535–2550. https://doi.org/10.1109/TDSC.2019.2954507 (2021).
Wang, Z. Q. & El Saddik, A. Dtitd: An intelligent insider threat detection framework based on digital twin and self-attention based deep learning models. IEEE Access 11, 114013–114030. https://doi.org/10.1109/ACCESS.2023.3324371 (2023).
Le, D. C. & Zincir-Heywood, N. Anomaly detection for insider threats using unsupervised ensembles. IEEE Trans. Netw. Serv. Manag. 18, 1152–1164. https://doi.org/10.1109/TNSM.2021.3071928 (2021).
Author information
Authors and Affiliations
Contributions
X.Y. and H.C. contributed equally to conceptualization, methodology, software development, validation, and writing the original draft. F.L., J.W., and X.X. performed data preprocessing, formal analysis, and implementation of experiments. W.Z. (School of Business) contributed to resources, dataset interpretation, and project supervision. J.Y. and W.Z. (School of Information and Control Engineering) conducted investigation, visualization, and result validation. All authors reviewed, edited, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ye, X., Cui, H., Luo, F. et al. Daily insider threat detection with hybrid TCN transformer architecture. Sci Rep 15, 28590 (2025). https://doi.org/10.1038/s41598-025-12063-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-12063-x
