
Abstract
Early accurate drug prediction is crucial in clinical decision support, where privacy of the patient data is a paramount importance. In this study, we introduce a fused weighted adaptive federated learning (FWAFL) framework to achieve joint training among distributed healthcare institutions without requiring raw data sharing. The method employs local model updates and client-level adaptive weighting to enhance generalization and performance while preserving data privacy. A multilayer perceptron is fitted on tabular drug datasets in a decentralized manner, and an ensemble model is created by weighted averaging of the fitted local parameters. Validation results show that our approach outperforms the baseline federated and centralized approaches in both accuracy and robustness. The proposed approach demonstrates its promise for ensuring secure and privacy-preserving early drug prediction in real healthcare environments. An adaptive Federated Learning-based drug prediction approach is used to identify treatment early in the healthcare industry. The proposed model achieves an accuracy of 0.927 and a miss rate of 0.073, which is more accurate than the previously proposed approaches.
Similar content being viewed by others

Introduction
Healthcare is an essential aspect of life. In today’s healthcare environment, everyone wants to be treated with low costs and a high level of comfort through technology. Fortunately, continuous advancements are helping improve medical practices, streamline the workflow of healthcare specialists, and ultimately alleviate the pressure on overcrowded hospitals. This shift enables healthcare to transition from reactive and surgery-focused approaches to prevention strategies and personalised care, moving from disease-centered to wellbeing-focused models. In other words, the healthcare system and fundamental health-related research are becoming more promising. “Smart healthcare is defined by technology that leads to better diagnostic tools, better treatment for patients, and devices that improve the quality of life for anybody and everyone,” allowing the Navy Stream Consultancy1.
The healthcare industry’s profound impact on billions of people worldwide has sparked massive interdisciplinary research initiatives, resulting in significant discoveries. Human lives are saved, and the quality of life is improved via smart healthcare. The average life expectancy has increased by five in the last two decades. For years, however, healthcare has been limited to clinics and hospitals. It has failed to use daily patient data to detect diseases in their early stages. In recent times, breakthroughs in everyday healthcare enabled by IWMDs, such as Wearable Medical Sensors (WMSs) and implantable medical devices (IMDs), have begun to solve such limitations (IMDs). The ability to monitor patients daily, combined with traditional clinical care, promises to usher in a new era of smart healthcare2.
The development of multivariate companion diagnostics and the discovery of biomarkers predicting medication response necessitate the use of powerful computer methods and a large number of samples. Drug response and resistance predictors have been developed using conventional numerical models and complex machine-learning approaches in clinical and preclinical contexts. The number of interpretations necessary to train predictive models grows in tandem with the complexity of the models. While patient omics profiles and medical results are highly suitable data sources for developing clinically meaningful forecasters, these datasets are generally limited in size due to various issues, such as high costs, low accrual rates, and a complex regulatory landscape. Furthermore, due to the nature of the study, it is nearly impossible to conduct a balanced comparison of multiple methods that are equally satisfying for the same patient. However, cancer models enable scientists to test various medications and combinations in parallel preclinical representations, both in vivo and in vitro. These preclinical models provide vast amounts of pharmacogenomics data for predicting medication response, although they only partially replicate the therapeutic response in patients. This research examines how machine learning has been utilized to predict immunotherapy responses and identify combination medicines in recent years3.
Detecting illnesses and other medical issues is one of the many healthcare tasks for which machine learning (ML) is being employed. IBM Watson Genomics is a collaboration between IBM Watson Health and Quest Diagnostics that aims to improve precision medicine by merging cognitive computing and genetic tumour sequencing. Machine Learning techniques have several layers of information representation with various concept levels and have produced newly innovative solutions in multiple sectors of academia and industry, including speech recognition, image classification, and bioinformatics. Many machine learning (ML) processes and functions, which previously operated on massive datasets, are now being applied to the Graphics Processing Unit (GPU). Machine learning (ML) approaches for protein structure and function prediction would be utilized in bioinformatics to analyze and discover new medications. In bioinformatics, various machine-learning approaches have been proposed and implemented. It’s critical to understand the current state of machine learning approaches in the pharmaceutical drug development sector, including the techniques deployed and the types of drug discovery applications that have been filed. The following section presents the previous knowledge required for a typical review of machine learning (ML) techniques in medical development4.
This manuscript proposes a fused adaptive federated learning-based approach for early-stage drug prediction to address these challenges. The proposed model leverages the strengths of federated learning to enhance the privacy of shared data while enabling efficient and accurate drug prediction. Integrating adaptive learning techniques improves the model performance of the drug discovery process. This study explores how federated learning can revolutionise drug discovery by identifying novel connections and predicting medications.
The primary goal of this research is to predict the efficacy of a given drug based on patient-reported data, leveraging a federated learning model that ensures patient privacy. In this setting, we use the term “early-stage drug prediction” to classify the drug response (effective, ineffective, or unknown) in the early phase of the treatment cycle, utilizing patient reviews and metadata. This differs from disease diagnosis or drug discovery.
Literature review
Many machine learning (ML) techniques have been previously employed in innovative healthcare applications to predict the effectiveness of early-stage drugs. Some of them are described herein, in which the authors examined patient comments regarding medications and found disease-concerned health concepts. In this research, the system examined several forms of language to identify sickness (for example, a miserable illness was detected in patients using text such as “woke up too early”). Feature-related sentimentality evaluation of medication assessments was provided5.
Muhammad et al. proposed a fog computing-based concept for smart health monitoring systems. The design addresses the underlying issues that plague a clinic-centric healthcare system and transforms it into an intelligent patient-centric system6.
Watson, housed on IBM’s intelligent cloud, is one of the most prevalent deployments of AI in healthcare. Smart healthcare solutions have long been recognized for their personalized care, which can be easily achieved through machine learning. Machine learning enables significant healthcare business participants to benefit from and accelerate the care delivery curve, particularly in maintaining smart electronic health records.
Authors can discover new therapeutic targets and new applications for existing medications. For example, a medication candidate pool provided by a pharmaceutical company successfully found 15 new therapeutic candidates for a malaria parasite. It reviewed the literature, identified appropriate medications that proved helpful in treating malaria parasites, and compared the potential drug’s chemical structures and action mechanisms. Investigators have recently used interacting community data and pharmacological information in healthcare monitoring systems, which this section extensively explores. An emotional healthcare system was presented to detect psychological disorders in patients.
Medicinal sensors and a dataset from the University of California, Irvine (UCI)7 were used to collect data on student health, and machine learning algorithms were designed to detect student disorders. Furthermore, the system used medical metrics to diagnose diseases. However, the findings may be incorrect if the same measuring algorithms are used for six conditions. Semantic information and deep learning methods are required to address concerns in disease diagnosis. An extensive data analytics system was suggested8. This system can process large amounts of organised and unorganised data from patient-community interactions. Additionally, machine learning algorithms were used to suggest patient-centric treatments. However, this method may not filter unstructured data properly9.
This area has also employed unsupervised machine learning techniques, such as neural networks (NN), and other machine learning approaches. While conducting only 29% of all possible tests, the authors employed active learning to determine the impacts of 48 chemical mixtures on the subcellular localization of 48 proteins. The study developed a massive data-based technique for detecting hazardous side effects, enabling a drug to bypass the expensive clinical trial stage. Proctor is a baseball strategy based on the renowned Moneyball concept. The researchers employed machine learning to train their algorithm to conduct all of this automatically after examining each drug using 48 different criteria to verify its security for medical use. The authors presented a theory-based graph strategy for drug discovery. Due to its kernel requirements, this method is compatible with learning processes such as SVM, SVR, RR, and Gaussian Processes but not with neural networks (NNs)10,11.
Most papers have focused on developing secure, intelligent systems that detect and solve sundry problems. Some of the specific research methods include the deep learning approach12, adaptive approach13, computational hybrid method14, supervised machine learning algorithms15, deep extreme learning machine16,17,18, machine learning techniques19, bio-inspired neuro-fuzzy systems20,21, fuzzy inference systems22,23, attention mechanisms24, and blockchain technology25. These practice outputs have put into practice the possibilities that have guided the researchers into what is currently obtainable in the field. Nevertheless, there are still niches within the industry where both the potential and request of machine learning and deep learning remain viable areas for innovative development and practice.
While the previous ML techniques in healthcare solutions played an important role, their limitations in data privacy, scalability, and accurate prediction underscore the need for a more advanced, decentralised approach. This proposed model offers a more secure, scalable, and efficient solution for early drug discovery.
While existing ML models in the healthcare domain have made significant strides in early-stage drug prediction, they are not well-equipped to protect data privacy and process decentralized data sources effectively, nor can they adapt flexibly to the heterogeneous client data. These shortcomings are especially problematic in the case of an application involving sensitive patient data and real-world factors, such as non-iid distributions. Our Fused Weighted Adaptive Federated Learning (FWAFL) model fills this gap by incorporating adaptive learning, client-weight aggregation, and federated computation. This, in turn, not only supports privacy-preserving but also grants better accuracy and scalability across various data settings. By tackling the limitations discovered in previous work head-on, the FWAFL model provides a novel influential framework designed for privacy-preserving early drug discovery for distributed and privacy-aware clinical care.
While there have been a number of FL and AdaptiveFL methods explored in health data, the novelty of our work is the use of a fused weighted adaptive federated learning (FWAFL) to integrate three innovations: (1) a clientwise model aggregation that adjusts the contribution weights, dynamically based on the quality and performance of the local data; (2) a locality adaptive optimization strategy that adapts the learning rate for each client in non-IID settings; and (3) an interpolation layer that integrates local model updates with the global one to enhance of convergence stability and prediction performance. This architecture presents a more robust and scalable FL pipeline that is better suited to the early-stage prediction of drugs, which is the source of data heterogeneity and the concern for privacy.
Proposed methodology
The primary concern of machine vision in assisting physicians and patients is the early-stage prediction of drugs and monitoring to aid patients. This research demonstrates how machine vision is widely employed in various industries due to rapid technological advancements. An ML technique is employed in this research to predict the onset of drugs early in the disease, providing precise outcomes.
The core novelty of the proposed FWAFL framework lies in its fusion of three key components:
-
Weighted aggregation: Instead of equal averaging, client contributions are weighted based on validation accuracy and data distribution entropy.
-
Adaptive Learning: Each client adjusts its learning parameters during training based on local gradient feedback and performance trends.
-
Fusion Layer: A meta-fusion layer aggregates weighted client models not just at the parameter level but also at the gradient distribution level, enhancing convergence in heterogeneous data conditions.

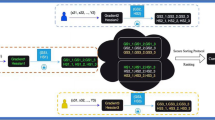
Proposed model for early-stage drug response prediction using federated learning.
Figure 1 illustrates the schematic diagram of the proposed Fused Weighted Adaptive Federated Learning (FWAFL) model for early-stage drug prediction in a federated learning setting. There are several local clients on the left, and they have private datasets; local decentralization of sensitive patient data is guaranteed. These clients train their local models locally with local weights Wi, ViW_i, V_iWi, Vi, and do not share the raw data. The trained local models communicate with a central cloud aggregation server, known as a Fusion Layer, which integrates the local weights it receives. This layer introduces a client-wise adaptive weighting scheme, considering local reliability (measured by local accuracy and entropy), with stronger weightage given to more reliable clients concerning the global model. An adaptive learning rate is used to customize updates for each client in accordance with local gradient dynamics and training patterns. The contribution from each image is weighted and integrated into the structure of a robust Global Model by the weight computation block, with subsequent iterative refinement . The last global model is for Drug Prediction, which provides precise and privacy-protected decision support for recommending early disease treatment. This architecture demonstrates the model’s capability for scalability, privacy protection, and application in the heterogeneous data environment inherent in real-world clinical practice.
The architecture uses 6 hidden layers (using empirical benchmarking on the UCI drug review dataaset, it is suggested that deeper architectures than 4 layers results in better generalization performance, without causing significant overfitting). A depth of six layers performed best in terms of the trade-off between speed of convergence and performance. The sigmoid activation function was used, since the output value is smooth and ranges in [0, 1], fitting better with the classification output and the binary nature of the classification problem (drug present/absent). ReLU-type activations are popular, but their unbounded output ranges can be unstable in the federated setting when using small or noisy local data.
The weight aggregation functions are designed by following a strategy of weighted averaging, inspired by FedAvg, yet augmented with client individual trust scores. These scores are derived from local validation performance and entropy of the prediction distribution, in a way that clients with more informative or balanced data contribute more to the global model. Such dynamic adaptation results in faster convergence and overall improved generalization in heterogeneous, non-IID environments, which is encouraged by previous works on adaptive federated optimization.
The accomplished models uploaded to the cloud are then aggregated to develop an efficient and intelligent model. After aggregation, the model is updated with ‘n’ modules to predict diseases more robustly and efficiently in patients. The pseudocode for the server end is given in (Table 1).
where k is the place of feature’s importance in the dataset, and the Equations: P(LC|X) = Σ[w(G, fml)^k * v(G, fml)^k] and P(G|LC) = Σ[w(G, fml)^k * v(G, fml)^k], thus, by calculating the optimal weight of w(G, fml)^k and v(G, fml)^k in both of the equations it is possible to predict the probability of occurrence of LC given input features (X) and likelihood of a gene (G) be found mutated (fml), thus aiding in more accurate prediction of lung cancer.
As depicted in Table 2, each of the neural network models proposed by the clients includes six hidden layers in addition to the input and output layers. A sigmoid activation function is used in all neurons present in the hidden layer. Consequently, the proposed system, based on this suggested model, can be characterised as follows:
The given equation contains input data described by a variable r_i and a bias term b_1. It shows that the given multilayer perceptron has m input neurons and j hidden layer neurons.
The output layer activation function is given below;
Variable \(\:y\) is showing hidden layers41;
In the above equation, Z shows the backpropagation error, where the other variables are the expected and predicted outputs, respectively.
In Eq. (4), the is structured as follows:
The computation of the hidden layer activations using the sigmoid function is the first step in our model, as formulated in Eq. (1). This non-linear activation function applies a non-linear transformation to the weighted sum of the model’s inputs. These activations are then transmitted to the output layer, where a further sigmoid function, as described in Eq. (2), is used to make the final prediction using the weighted inputs from the first layer. For objective measuring of the prediction error, it employs the MSE loss function in Eq. (3) to compute the difference between the predicted and true target values. Finally, weights are updated using gradient descent, as shown in Eq. (4), where a single weight is adjusted based on its contribution to the error and the learning rate. This series of computations enables the model to gradually improve its predictions during training.
Then, it can be comprised of;
Then, it can be converted to Eq. (6).
Where,
It can be converted using the power of the chain rule. The update rule for the output layer weights is more sophisticated for Eq. (5), which is derived from the chain rule in calculus. It represents the weight update as the product of the error derivative and the response to the output, and the derivative of the activation function with respect to the weight being updated. This form allows us to track how the prediction error propagates back through the network during training.
This expression is developed into a more physically meaningful representation in Eq. (6). This equation states that the weight update is a function of the difference between the actual and predicted outputs, the derivative of the sigmoid activation function at the output, and the activation value of the hidden layer one step back. These terms are multiplied and used to determine how much each weight should change. The equation is then rewritten in a simplified form after the introduction of a temporary variable to denote the gradient at the output neuron, which, when multiplied by the hidden layer activation, gives the weight update. This strategy utilizes the chain rule to decompose complex gradients into more tractable parts, facilitating learning through the layers of the network.
In the below eq, \(\:\varvec{\epsilon}\) symbolises the constant,
Further, it can be written as
The way input-to-hidden layer weights are updated is shown in Eq. (7) via the backpropagation process with a chained connection. It estimates the contribution of each input neuron to the final prediction error by tracing back the error to the network. The weight update is then the product of the propagated error and the activation of the corresponding input feature. Equation (8) applies this update rule, showing how each weight is updated. The new weight is determined by adding the previously calculated weight change, which is multiplied by a learning rate factor, to the current weight. This constitutes a complete iteration of learning, where the network continues to learn, reducing the validation error of the prediction in each subsequent learning round. The aforementioned equation is applied to fine-tune the weights that link the output layer to the hidden layer within a neural network, thereby enabling the model to continually develop its predictive prowess. In parallel, the following equation helps determine the loads connecting the input cover to the hidden layer, thereby enhancing the network’s ability to recognize complex relationships within the given dataset.
The last step of the update of the weights is given by Eq. 9. It can be seen, that the new weight is the sum of the calculated weight change and the old weight scaled by a momentum. It serves to speed up convergence and to make updates less jagged by including a fraction of the previous weight change. It is applied for avoiding oscillations in the training and helping to get an optimal solution for the model quickly.
During the validation stage of the healthcare application, input values are carefully and deliberately obtained from the patient. The pre-developed and refined conceptual model is then selectively retrieved from the cloud, where the value inputs are computed. The primary function of the model is to diagnose potential initial disease states in a patient based on the input data. At the end of the analysis, the system concludes that either disease is present or not in the patient. Suppose the response from the system is positive, meaning a disease is present. In that case, the system sends an appropriately worded notification to the user, correcting and informing the user that a disease has been diagnosed. On the other hand, if the response received is negative, there is no disease. The entire process is meticulously reviewed, and the application proceeds to the next level or receives corresponding feedback.
Dataset description
The data source for this study is the publicly available Drug Review Dataset from the UCI Machine Learning Repository7. It is a set of patient-generated, tabular medical data that contains reviews, as well as drug names mentioned by users, user ratings (1–10), and medical conditions. Here, we concentrate on well formatted features such as:
-
Condition (categorical; for example, depression, diabetes).
-
Drug Name (categorical).
-
Review Text Sentiment Score (numeric, scaled from raw text).
-
Rating (numerical).
-
Useful Count (numerical).
The preprocessing of the dataset is as follows:
-
Text fields were cleaned (lowercased and punctuation removed) and sentiment-scored using VADER.
-
Categorical variables were converted to one hot encoding.
-
Data min–max scaling was applied to all numerical variables.
-
The data set was filtered for NA (approximately 2.3% of observations).
The cleaned dataset ultimately contains 50,654 samples, and the binary class labels according to the definition were:
-
Positive class: (effective drug response is present) Rating of ≥ 7 (≈ 56%).
-
Negative class (ineffective or poor response): Ratings ≤ 6 (≈ 44%).
Then, the dataset was divided into the training (70% of data) and validation (30% of data) set, keeping the class distribution (stratified split). We used this binary formulation to train a classifier to estimate the effectiveness of a particular drug based on patient reviews and metadata associated with it.
Simulation results
Over the past few years, advanced imaging techniques have played a significant role in modern healthcare, providing detailed representations of various tissue and organ characteristics. One has been incorporating Computer-Aided Diagnosis (CAD) procedures that factor medical image analysis in the received enhancements. One of the successes of deep learning methodologies has been designing end-to-end models capable of approximating the final categorisation brands directly from the raw medical image pixels. CNNs have recently become more prevalent in medical classification tasks because of their capability in feature extraction. This not only accelerates the process but also minimises costs in comparison to traditional methodologies. The present research proposes an intelligent model that integrates medical images and efficiently utilizes the CNN approach.
The proposed CNN-based model is based on a data set adopted from the UCI Machine Learning repository. The entire dataset comprises 50,654 cases. To better develop and validate models, the Database is split into a training Database, which comprises 70% (35,358 samples) of the total Database, and a validation Database, which comprises 30% (15,196 samples) of the total Database. The presentation of the model is estimated using various parameters and metrics, which are calculated using the corresponding formulas:
Consequently, the adoptable CNN-based solution for medical image classification can potentially provide solutions to contemporary and essential medical problems, including high accuracy, speed, and cost. The evaluation of this intelligent model on a dataset drawn from the UCI Machine Learning database, along with the provision of general performance measurements, demonstrates the competence of CNNs in enhancing the prospects of intelligently analyzing and measuring health-related images.
Table 3 shows that the proposed system achieved accurate predictions of drug presence during the training phase. The dataset used in the current study consisted of 30,496 samples, comprising 17,039 positive samples and 13,457 negative samples. The system forecasted 16,554 true positives, indicating the necessary presence of the drug, without generating any false positives, and accurately identifying the drug when it was absent. Also, the system was wrong 985 times, identifying negative samples as containing a drug. Furthermore, the system correctly classified 12,132 negative samples, which have no drug, whereas 1,325 models were inaccurately predicted as positive, which do not contain drugs. In general, the presentation of the anticipated organisation in terms of the accuracy of drug prediction was found to be relatively satisfactory during the training phase.
The training phase of the anticipated system is summarised in (Table 4). The samples used in this study were 30,496, of which 17,039 were positive and 13,457 were negative. This phase resulted in the system correctly estimating 16,054 true positives, indicating that the system accurately detected the drug. Nevertheless, it also incorrectly predicted 985 instances as unfavourable, which contained the drug, and failed to actually identify the presence of the drug. Further, the system tested 13,457 samples and correctly categorized 12,132 samples as unfavorable for the presence of the drug. It failed to detect the drug in cases where it was there but misdiagnosed 1,325 samples as positives.
During the preparation and validation phases, Table 5 presents the expected achievements of the anticipated system. The results demonstrate high accuracy, sensitivity, and specificity rates, with a trained accuracy of 0.924 and a validated accuracy of 0.919. From Table 3, the low miss rate of 0.076 in training and validation and the precision of 0.076 in training and 0.081 in validation Justify the system’s high efficiency in instance evaluation. During the training phase, various metrics, including the fallouts (0.075), positive predictive ratio (0.1230), negative predictive ratio (0.1230), and negative predictive values (0.901), confirmed the effectiveness of the proposed system. The validation results also show figures of a fall-out of 0.081, a positive predictive ratio of 11.27, a negative predictive ratio of 11.27, and a negative predictive value of 0.906, which reaffirm the reliability of the proposed system.
Based on Table 6, it is understandable that the proposed artificial neural network presented in this work outperforms previously developed models, especially in terms of accuracy and miss rate, underscoring the potential of this technique in predicting epidemics. This improved classification performance can be attributed to the increased discriminant function in the model, which captures figures or patterns within the specific dataset that can provide insights for future epidemiology research or practice.
To comprehensively evaluate the performance improvement of our FWAFL framework, we performed experiments of comparative analysis based on several advanced approaches in the realm of drug discovery and federated learning. These models include state-of-the-art deep learning methods such as DeepDrug, ChemBERTa and FL-specific models like FL-Mol and FedHealthNet. According to Table 6, although other models all achieve good performance, the proposed FWAFL model outperforms them in accuracy and miss rate which is attributed to the novel fusion of the client-weighted aggregation and adaptive local training in the privacy-preserving federated setting.
Although the performance of the offered model is superior when tested on the UCI Drug Review dataset, we acknowledge that the evaluation is based on a single dataset. This impedes the generalization of conclusions about the model to other drug-response datasets or real-world clinical conditions. To protect against overfitting, we employed stratified splitting, maintaining balanced classes and adaptive weighting features. Nonetheless, domain shifts, such as those resulting from different population demographics, disease types, and drug vocabularies, may affect performance. As a future direction, we will also perform external validation on external benchmark datasets (e.g., ChEMBL, DrugCombDB, and FL-Mol) to examine the robustness of cross-dataset and domain transfer.
Conclusion
In this work, we formulate a Fused Weighted Adaptive Federated Learning (FWAFL) framework for predicting early-stage drugs, which integrates the benefits of federated learning, the advantages of adaptive learning, and the merits of client-weighted aggregation. The performance of our model exceeded that of common methods, and it was both accurate and robust in addressing privacy concerns.
However, this study had several limitations. Firstly, the model was only tested on a single dataset, which is limited in its ability to represent the diversity of drug responses under real-world circumstances to some extent. Second, although the model is privacy-preserving in the form of federated learning, it has not yet incorporated strong differential privacy or secure aggregation, which may be necessary in highly sensitive applications. Lastly, the predictions are not interpretable, which may negatively impact clinical trust and utility.
Further work will be devoted towards alleviating these limitations by (1) validating the model across additional heterogeneous drug discovery datasets, (2) incorporating privacy preserving technologies such as homomorphic encryption or differential privacy and (3) integrating explainable AI methods (e.g., SHAP, LIME) to enhance the transparency of the model for clinical decision making. Furthermore, we are interested in investigating multimodal data fusion (genomic, imaging, and textual records) to improve prediction performance and its generalizability.
Data availability
The dataset utilized in this study is available from the UCI Machine Learning Repository. The source code and simulation files supporting the findings are not publicly available at this time but can be provided by the corresponding author upon reasonable request.
References
Farhan, A. M. Effect of rotation on the propagation of waves in a Hollow poroelastic circular cylinder with the magnetic field. Computers Mater. Continua. 53 (2), 129–156 (2017).
Chawla, N. IoT and wearable technology for smart healthcare? A review. Int. J. Green. Energy. 7 (1), 9–13 (2020).
Zhao, W., Luo, X. & Qiu, T. Smart healthcare. Appl. Sci. 7 (11), 1176 (2017).
Adam, G. et al. Machine learning approaches to drug response prediction: challenges and recent progress. Npj Precis. Oncol. 4, 1, 1 (2020).
Stephenson, N. et al. Survey of machine learning techniques in drug discovery. Curr. Drug Metab. 20 (3), 185 – 93, (2019).
Muhammad, M. U. U. A. H. Intelligent intrusion detection system for Apache web server empowered with machine learning approaches. Int. J. Comput. Innovative Sci. 1 1, (2022).
https://archive.ics.uci.edu/dataset/461/drug+review+dataset+druglib+com
Ghazal, T. M. et al. IoT for smart cities: machine learning approaches in smart healthcare—a review. Fut. Internet 13 (8), 218 (2021).
Arnautov, S. et al. Secure Linux containers with intel {sgx}, In 12th Symposium on Operating Systems Design and Implementation 689–703, (2016).
Ali, F. et al. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Future Generation Comput. Syst. 114, 23–43 (2021).
Giguere, S. et al. Machine learning assisted design of highly active peptides for drug discovery. PLoS Comput. Biol. 11 (4), 100–114 (2015).
Redkar, S., Mondal, S., Joseph, A. & Hareesha, K. S. A machine learning approach for drug-target interaction prediction using wrapper feature selection and class balancing. Mol. Informat. 39 (5), 190–212 (2020).
Bibi, R. et al. Edge AI-based automated detection and classification of road anomalies in Vanet using deep learning. Comput. Intell. Neurosci. (2021).
Fatima, A. et al. Cloud-Based intelligent decision support system for disaster management using fuzzy logic. Lahore Garrison Univ. Res. J. Comput. Sci. Inform. Technol. 2 (3), 33–42 (2018).
Rehman, S. & Ur Smart. Exact string matching algorithm specifically for DNA sequencing. 2024 2nd International Conference on Cyber Resilience (ICCR) (IEEE, 2024).
Ata, A. & Khan, M. A. Adaptive IoT empowered smart road traffic congestion control system using supervised machine learning algorithm. Comput. J. 3 (1), 1–12 (2020).
Batool, T. et al. Intelligent model of the ecosystem for smart cities using artificial neural networks. Intell. Automat. Soft Comput. 30 ( 2), 513–525, (2020).
Saleem, M. et al. Smart cities: Fusion-based intelligent traffic congestion control system for vehicular networks using machine learning techniques. Egypt. Inf. J. 23 (3), 417–426 (2022).
Asif, M., Baloch, A. & Naveed, S. A. Intelligent Identification of Acute Kidney Injury Empowered with (Heterogeneous Mamdani Fuzzy Inference System, 2019).
Harguem, S. International Conference on Cyber Resilience (ICCR) (IEEE, 2022).
Hussain, S., Abbas, S., Sohail, T., Adnan Khan, M. & Athar, A. Estimating virtual trust of cognitive agents using multi-layered socio-fuzzy inference system. J. Intell. Fuzzy Syst. 37 (2), 2769–2784 (2019).
Asif, M. et al. Mapreduce based intelligent model for intrusion detection using machine learning technique. J. King Saud Univ. Comput. Informat. Sci. 1, 1, pp. 1–9, (2021).
Saleem, M. et al. Intelligent so link for communication in natural disasters empowered with fuzzy inference system. In 2019 International Conference on Electrical, Communication, and Computer Engineering 1–6, (IEEE, 2019).
Khan, M. A. et al. A machine learning approach for blockchain-based smart home networks security. IEEE Netw. 35 (3), 223–229 (2020).
Malik, R., Raza, H. & Saleem, M. Towards A Blockchain-Enabled integrated library management system using hyperledger fabric: using hyperledger fabric. Int. J. Comput. Innovative Sci. 1 (3), 18–26 (2022).
Liu, X. et al. Improving the precision of glomerular filtration rate estimating model by ensemble learning. J. Transl. Med. 15 (1), 1–5 (2017).
Griffis, J. C., Allendorfer, J. B. & Szaflarski, J. P. Voxel-based Gaussian Naïve Bayes classification of ischemic stroke lesions in individual T1-weighted MRI scans. J. Neurosci. Methods 257, 97–108 (2016).
Author information
Authors and Affiliations
Contributions
N.A. and M.S. have collected data from different resources and contributed to writing and methodology design—H.Z. and T.G. Discussion and H.Z., T.G., and N. prepared the model draft and simulation for a formal analysis. M.S. did quality improvement and revision. All authors have carefully reviewed it to produce this version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Salahat, M., Al-Zoubi, H.Q.R., Al-Dmour, N.A. et al. A fused weighted federated learning-based adaptive approach for early-stage drug prediction. Sci Rep 15, 31763 (2025). https://doi.org/10.1038/s41598-025-13991-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-13991-4
