
Abstract
This study aimed to develop a simple, interpretable model using routinely available data for predicting COVID-19 mortality at admission, addressing limitations of complex models, and to provide a statistically robust framework for controlled clinical use, managing model uncertainty for responsible healthcare application. Data from Belgium’s first COVID-19 wave (UZ Brussel, n = 252) were used for model development. External validation utilized data from unvaccinated patients during the late second and early third waves (AZ Delta, n = 175). Various machine learning methods were trained and compared for diagnostic performance after data preprocessing and feature selection. The final model, the M3-score, incorporated three features: age, white blood cell (WBC) count, and AI-derived total lung involvement (TOTALAI) quantified from CT scans using Icolung software. The M3-score demonstrated strong classification performance in the training cohort (AUC 0.903) and clinically useful performance in the external validation dataset (AUC 0.826), indicating generalizability potential. To enhance clinical utility and interpretability, predicted probabilities were categorized into actionable likelihood ratio (LR) intervals: highly unlikely (LR 0.0), unlikely (LR 0.13), gray zone (LR 0.85), more likely (LR 2.14), and likely (LR 8.19) based on the training cohort. External validation suggested temporal and geographical robustness, though some variability in AUC and LR performance was observed, as anticipated in real-world settings. The parsimonious M3-score, integrating AI-based CT quantification with clinical and laboratory data, offers an interpretable tool for predicting in-hospital COVID-19 mortality, showing robust training performance. Observed performance variations in external validation underscore the need for careful interpretation and further extensive validation across international cohorts to confirm wider applicability and robustness before widespread clinical adoption.
Similar content being viewed by others
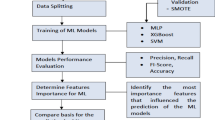

Introduction
The COVID-19 pandemic posed unprecedented challenges to global healthcare systems, exposing critical vulnerabilities in testing capacity, hospital beds, medical supplies, and personal protective equipment. Hospitals faced severe capacity constraints, and routine care was significantly disrupted. Policymakers responded with lockdowns to reduce viral transmission and manage ICU admissions, alleviating pressure on healthcare resources1,2,3,4.
Predictive models have since become essential for estimating clinical outcomes, such as in-hospital mortality, which serve as proxies for resource planning, including staffing, medical supplies, and ICU bed allocation. However, many existing models rely on complex machine-learning (ML) algorithms with numerous features that are often impractical for routine clinical use or integration into electronic health records. These models typically report metrics like AUC-ROC, which lack interpretability and are insufficient for patient-level decision-making5,6,7,8,9,10,11,12.
Belgium’s first three COVID-19 waves provided a unique opportunity to study the evolution of mortality risk, associated predictors, and treatment approaches in a pre-vaccination population, representing those at the highest risk of severe disease4.
This study aimed to develop an admission-based predictive model for in-hospital COVID-19 mortality using a limited set of well-defined, reproducible, and widely available features to enhance clinical applicability. These features included demographic, clinical, laboratory, and radiological data, with a particular focus on imaging metrics such as the CT severity score (CTSS)13 and an AI-driven lung involvement metric (Icolung, Icometrix)14,15. Notably, Icolung offers accurate quantitative lung parenchyma assessment with superior reproducibility, addressing a key limitation of traditional imaging metrics by minimizing interobserver variability.
To enhance clinical relevance, we prioritized interpretability by stratifying outcomes into multiple intervals with associated likelihood ratios16,17,18,19,20,21, rather than relying solely on AUC-ROC metrics. Temporal and spatial robustness of the model was assessed to address potential performance drift. Model development used data from the first Belgian wave (March 1–May 15, 2020, UZ Brussel, n = 252), while external validation was conducted using data from the late second and early third waves (AZ Delta, n = 175), exclusively in unvaccinated patients.
This study underscores the value of combining AI-derived imaging metrics with traditional predictors to improve the interpretability and actionability of machine learning models, ultimately aiding resource allocation and clinical decision-making during COVID-19 and future health crises by providing a practical and readily implementable AI tool for clinicians.
Materials and methods
Study population
This study retrospectively analysed data from a multi-center prospective trial. The study population comprised consecutive patients admitted to participating hospitals specifically for suspected COVID-19 pneumonia. Data were derived from two distinct periods: the first Belgian wave (March 1 - May 15, 2020) at Universitair Ziekenhuis Brussel (UZ Brussel, Dataset 1), and during the late second and early third waves (January 1 - March 22, 2021) at AZ Delta (Dataset 2). UZ Brussel, an academic hospital affiliated with Vrije Universiteit Brussel, serves as a hub for clinical care, education, and research, while AZ Delta is a supraregional secondary care center for a population of approximately 500,000.
Admission criteria for all patients mandated suspicion of COVID-19 pneumonia, according to hospital-approved triage protocols. All included patients underwent chest CT imaging and SARS-CoV-2 PCR testing within 24 h of admission, as part of standard diagnostic workup. Only patients with PCR-confirmed SARS-CoV-2 infection were included in this analysis. Exclusion criteria were limited to patients under 14 years of age, pregnant individuals, and those without symptoms of COVID-19 (due to the absence of routine admission chest CT imaging in asymptomatic suspected cases). Dataset 1 included 252 records, and Dataset 2 comprised 175 records. Critically, no patients included in this study had received COVID-19 vaccination.
The study received ethical approval from the Institutional Research Board Commissie Medische Ethiek (Medical Ethics Committee, IRB) of UZ Brussel (reference BUN 2020/106) and the Institutional Research Board Commissie Medische Ethiek (Medical Ethics Committee, IRB) of AZ Delta (Clinical Trial Number: IRB B1172020000008). Both committees waived the requirement for written informed consent due to the secondary use of anonymized data collected during standard care. Financial support was provided by the European Commission’s Horizon 2020 Research and Innovation program (grant agreement 101016131, ICOVID). All methods of the present study were performed in accordance with the relevant guidelines and regulations.
CT protocol
At UZ Brussel, all patients underwent CT imaging using the GE Apex Revolution CT system, featuring a slice thickness of 1-mm. The CT protocol employed a spiral acquisition method with a pitch of 1, a rotation time of 0.35 s, and an automated selection of kilovoltage peak (kVp) and tube current (mA), resulting in an average dose-length product (DLP) of 149 mGy·cm.
At AZ Delta, patients were scanned using multidetector computed tomography (MDCT) on one of the following systems: Siemens Somatom Force, Siemens Somatom AS (both utilizing a 1-mm slice thickness), or the GE Optima 660 scanner (with a 1.25-mm slice thickness). The scanning parameters included a tube voltage of 120 kVp and automatic tube current modulation ranging from 30 to 70 mA·s, with a median DLP of 520 mGy·cm (range: 310 to 906 mGy·cm), and a median estimated effective dose of 7.6 mSv (range: 4.2 to 11.2 mSv).
All imaging procedures were conducted without intravenous contrast administration, with patients positioned supine and instructed to perform end-inspiratory breath-holding.
Image evaluation
Two thoracic radiologists, each with over ten years of experience, retrospectively analyzed the computed tomography (CT) scans using PACS workstations— Agfa Impax 6.5.3 at UZ Brussel and Sectra IDS7 at AZ Delta. Multiplanar reconstruction tools were employed to evaluate the number of affected lobes and to calculate the CT severity score (CTSS)13, which quantifies the severity of pulmonary involvement. For each patient, the five lung lobes were visually scored based on the extent of lung abnormalities as follows: 0 (no involvement), 1 (< 5% involvement), 2 (5–25% involvement), 3 (26–49% involvement), 4 (50–75% involvement), and 5 (> 75% involvement). The CTSS was determined by summing the individual lobe scores, yielding a total score ranging from 0 to 25. Final scoring was achieved through consensus.
Software-based quantitative assessment of lung parenchyma involvement was performed using Icolung (version 0.7; URL: https://icovid.ai/) by Icometrix (Leuven, Belgium), a state-of-the-art, commercially available, cloud-based AI algorithm. Notably, Icolung holds the distinction of being among the first AI tools to receive CE marking for the quantification of lung pathology on chest CT scans. Icolung utilizes deep learning models, specifically convolutional neural networks (CNNs) based on 2D and 3D U-Net architectures. These models were trained on a substantial dataset of clinical CT scans with voxel-level delineations of lung abnormalities, meticulously annotated by experienced radiologists. The training dataset’s precise composition is detailed in the software’s technical documentation available from Icometrix. Icolung enables fully automated, quantitative analysis of lung pathology on non-contrast chest CT scans in patients with COVID-19, generating reports that offer objective evaluations of lung lesions (Fig. 1). These reports provide volumetric analysis by lobe and for the total lung, alongside quantification and classification of CT findings such as ground-glass opacities (GGOAI), crazy paving patterns (CPPAI), consolidations (COAI), and the total percentage of lung parenchyma affected (TOTALAI). Performance validation demonstrated robust classification performance in detecting COVID-19 pneumonia. Icolung was developed through a collaborative effort between Icometrix, University Hospital Brussels, VUB/ETRO, and KU Leuven14,15.

Structured report with analysis results. The report includes 2D visualizations of 3D segmentation masks of abnormalities in both axial and coronal views. It also features a table summarizing total lung involvement percentages and the specific involvement percentages for each type of lung abnormality—ground glass opacities (GGO), crazy paving patterns (CPP), and consolidations (CO). These values are provided for each lung lobe and the entire lungs.
Laboratory testing
COVID-19 detection for Dataset 1 (UZ Brussel) utilized real-time RT-PCR with the RealStar® SARS-CoV-2 RT-PCR Kit 1.0 (Altona Diagnostics, Germany), targeting the E-gene and S-gene. Hematological analyses (white blood cell (WBC), lymphocyte, and neutrophil counts) were performed using the CELL-DYN Sapphire analyzer (Abbott Diagnostics, USA), while clinical chemistry parameters (CRP and eGFR) were measured on the Cobas c501 module (Roche Diagnostics, Switzerland).
For Dataset 2 (AZ Delta), a multiplex RT-PCR assay (Allplex™ 2019-nCoV, Seegene Inc., Korea) targeting the E, N, and RdRP genes was used for COVID-19 detection. Hematological parameters were assessed with Sysmex XN analyzers (Sysmex Corporation, Japan), and clinical chemistry evaluations (CRP and eGFR) were performed on the Cobas c501 module (Roche Diagnostics, Switzerland).
The standardized testing ensured consistent and comparable data across both datasets.
Data preprocessing, characterization and feature selection
Before selecting informative features, both hospital datasets undergo preliminary preprocessing. This includes checks for potential duplicate records and addressing missing data. Missing values are handled through imputation, ensuring complete datasets. Imputation is favored over record removal to preserve data, given the relatively small dataset sizes.
Descriptive and comparative statistics were computed for both datasets. Pairwise comparisons of all features were conducted based on mortality outcomes within each dataset separately. Given that none of the continuous variables followed a normal distribution, the Mann-Whitney U test was employed for these comparisons. For dichotomous variables, proportions were analyzed using the Chi-squared test. Additionally, cohort-level comparisons were performed for the 13 shared features across both datasets, analyzing the complete patient populations and stratifying by mortality outcomes between the two cohorts.
Starting with the complete feature set of Dataset 1, collinearity was assessed by evaluating the Pearson correlation coefficient. Features exhibiting strong correlations (absolute values > 0.6) were removed. Following this, multicollinearity was examined using the Variance Inflation Factor (VIF). Features with a VIF exceeding 10 were iteratively excluded to ensure no remaining features exhibited significant multicollinearity.
Advanced feature selection methods (complete description in Supplementary Materials and Methods) were subsequently applied to the reduced feature set. These methods included wrapper techniques based on classification models (Sequential Feature Selectors and the Boruta method) as well as statistical scoring methods, such as Scikit-learn’s SelectKBest and the Minimum Redundancy Maximum Relevance (mRMR) method.
In total, 11 distinct feature selection techniques were implemented across 30 train-test splits (75%-25%) of Dataset 1. Feature rankings were determined by the frequency with which each feature was identified as most important during the selection process. The final feature set retained only those features consistently ranked as important across multiple methods and iterations.
Training of machine learning algorithms
Machine learning models were developed using Python (v3.11.4) with the Scikit-learn library (v1.2.2). Nine distinct algorithms were evaluated: Multiple Logistic Regression (MLR), Random Forest (RF), Support Vector Classifier with a Linear Kernel (SVC-Linear), Support Vector Classifier with a Radial Basis Function (RBF) Kernel (SVC-RBF), K-Nearest Neighbors (KNN), Gaussian Naive Bayes (GNB), Extreme Gradient Boosting (XGBoost), a Keras-based Neural Network (Keras NN), and an Ensemble Voting Classifier (EVC) that combines the outputs of all these models. The input features used in all models included age, white blood cell (WBC) count, and the total percentage of lung parenchyma affected (TOTALAI), as assessed by the Icolung algorithm.
Before initiating machine learning procedures, Dataset 1 was split stratified into an 80% training set and a 20% holdout set. Due to the class imbalance (15.5% positive samples), the Adaptive Synthetic Over-sampling Technique (ADASYN), based on SMOTE principles22,23,24,25, was applied to training folds to increase positive samples to 33.3%, with validation ensuring synthetic data remained within a controlled Euclidean distance of original data in feature space and minimizing bias. For each machine learning model, hyperparameter optimization was conducted using a grid search approach on the upsampled training set, employing stratified 5-fold cross-validation to reduce the risk of overfitting.
The ADASYN upsampling, implemented as part of the machine learning pipeline, was applied only to the training data within each cross-validation fold. This ensures the validation folds as well as the holdout set remain independent of any influence from the upsampling procedure, enabling an objective assessment of model performance.
Due to the small dataset size, a common challenge in medical research, the described method is sensitive to the specific split of Dataset 1 into training and holdout sets. This sensitivity can lead to machine learning performance metrics that are less reliable and not fully representative of real-world generalizability. To mitigate this limitation, we employed a robust statistical approach. The process was repeated 30 times, yielding 30 sets of optimized hyperparameters and corresponding performance metrics. The holdout AUC-ROC and F1-score values were averaged, and a final training and holdout split was determined. This was done by iteratively adjusting the split until the holdout ROC-AUC deviated by less than 0.02 from the average AUC-ROC across the 30 iterations. The final split was then used to train the ultimate estimator. A detailed explanation of this methodology is provided in the Supplementary Materials and Methods.
Performance evaluation
To assess the performance of the final estimators, Dataset 2, which is temporally and geographically distinct from Dataset 1, was used as a validation set. Each final estimator was applied to predict outcomes in Dataset 2, enabling the calculation of ROC-AUC values for each model. To statistically compare the ROC-AUCs of Dataset 1 and Dataset 2, the degree of overlap between their 95% confidence intervals was calculated following the methodology described by Cumming et al., 200526. At a significance level of 0.05, ROC-AUC differences are considered statistically significant if the proportion of overlap is 0.5 or less.
Categorization based on likelihood ratios
To enhance clinical interpretability and provide actionable insights16,17,18,19,20,21, the predicted probabilities for in-hospital mortality were categorized into clinically relevant groups based on increasing likelihood ratios (LRs): highly unlikely, unlikely, equivocal (gray zone), more likely, and likely. This categorization was derived using the UZ Brussel training set for the MLR model with the reduced feature set (“Age”, “TOTALAI”, and “WBC”), referred to as the “M3-score”.
The M3-scores for Dataset 2 were calculated and categorized according to the thresholds established in Dataset 1. For each category, LRs with corresponding 95% confidence intervals (CIs) were determined. To statistically compare the LRs from the UZ Brussel training set and the AZ Delta test set, two complementary approaches were used. First, the proportion of overlap between the 95% CIs was calculated following the method described by Cumming et al.., (2005)26. A significance threshold of 0.05 was applied, with statistical significance defined as a proportion overlap of 0.5 or less. Second, to further evaluate statistical differences in LRs between training and test sets, we applied the delta method27 to estimate confidence intervals and p-values for the ratio of likelihood ratios (RORs), using log-transformation for variance stabilization and Z-tests for significance, with a small value substitution in the lowest M3-score category (0.00-0.10) to accommodate zero likelihood ratios in the training set. A detailed explanation of this methodology is provided in the Supplementary Materials and Methods.
Statistical differences in the proportions of samples per LR category between the training set (dataset 1, UZ Brussel) and the test set (dataset 2, AZ Delta) were evaluated using the Chi-squared test.
Additionally, posttest probabilities were computed for all LR categories using Bayes’ theorem20, with the mortality prevalence serving as the pretest probability.
Results
Dataset description and data preprocessing
Dataset 1 contains 252 records (n = 213 alive, n = 39 deceased) with 18 features and a classification label (Table 1). Dataset 2 consists of 175 records (n = 152 alive, n = 23 deceased) with 13 features, which overlap with a subset of Dataset 1, and an identical classification label. The features “AHT”, “Diabetes”, “Renal Insufficiency”, “COPD”, and “Cardiac morbidity” are absent from Dataset 2 because they were not systematically recorded. Both datasets were verified to contain no duplicate entries. In Dataset 1, missing values for the features “Affected lobesRAD” (3 records), “CTSSRAD” (3 records), and “BMI” (9 records) were imputed using mean values calculated from the remaining data. In contrast, Dataset 2 had no missing values.
Descriptive statistics and p-values for intra- and inter-dataset comparisons are presented in Table 1. Statistically significant differences, defined as p-values < 0.05, are highlighted in bold.
Feature exploration and selection
Starting with the 18 features in Dataset 1, a collinearity analysis identified the features “COAI”, “CTSSAI”, “Neutrophils”, “Renal insufficiency”, and “eGFR” for removal due to high correlation. Following this, multicollinearity analysis resulted in the removal of “BMI” and “Affected lobesAI”. This process yielded a subset of 11 features, which were subjected to advanced feature selection methods.
A total of 11 feature selection algorithms were applied across 30 train/test splits using 5-fold cross-validation. Table S6 summarizes the results, highlighting how frequently each feature was ranked first by the algorithms. Notably, the top three features - “Age”, TOTALAI”, and “WBC” - were selected significantly more often than the remaining eight features. Considering the ROC-AUC results from sequential selector methods, there was no significant improvement in model performance when using more than these three features. Consequently, the feature set was reduced to “Age”, “TOTALAI”, and “WBC” for subsequent analysis.
Performance evaluation of machine learning models
Table 2 presents the AUC-ROC performance for supervised machine learning models trained using a reduced feature set (“Age”, “TOTALAI”, and “WBC”). Except for Gaussian Naive Bayes (GNB), which achieved an AUC (95% CI) of 0.674 (0.612–0.732), all models demonstrated robust to excellent classification, with AUC values (95% CI) between 0.830 (0.778–0.874) and 0.971 (0.941–0.988). External validation on the AZ Delta test set also showed acceptable AUC performance for most models, excluding GNB, suggesting some generalizability across time and location. Notably, while AUC values in the AZ Delta test set (AUC 0.826, 95% CI 0.762–0.879 for MLR) were lower compared to the UZ Brussel training set (AUC 0.903, 95% CI 0.859–0.936 for MLR), a difference that was statistically significant (proportional overlap < 0.50, Table 2), they still indicated clinically useful performance.
Categorization based on likelihood ratios
The MLR model, selected for its simplicity and robust AUC-ROC performance (Fig. 2A), was further employed to categorize predicted probabilities, treating these probabilities as an independent diagnostic test result for each individual. Table 3 details the regression coefficients and intercept used to derive these predicted probabilities, collectively referred to as the M3-score. All three model features—“Age”, “TOTALAI”, and “WBC” – exhibited positive regression coefficients that were statistically significant, underscoring their association with an elevated mortality risk.

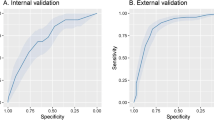
Diagnostic performance of M3-score in Training Set (n = 252, UZ Brussel, COVID-19 Wave 1, March 1 till May 15 2020). (A) Receiver Operating Characteristic (ROC) curve. (B) Violin plots of calculated M3-scores for 213 surviving patients and 39 deceased patients, with interpretative result intervals, associated likelihood ratios (LRs), and calculated posttest probabilities using mortality prevalence as the pretest probability. (C) Pie charts showing the proportion of samples categorized by LR group. (D) Posttest probability curves for mortality as a function of pretest probability and M3-score result intervals. Arrows indicate posttest probabilities calculated from mortality prevalence as the pretest probability.
AUC, area under the curve; CI, confidence interval; LR, likelihood ratio; PPRE, pretest probability; PPOST, posttest probability.
The distribution of M3-scores for survival and mortality groups within the UZ Brussel cohort is illustrated in Fig. 2B and summarized in Table 4. Five distinct probability categories were defined based on likelihood ratios (LRs) for mortality: “highly unlikely” (LR 0.00), “unlikely” (LR 0.13), “gray zone” (LR 0.85), “more likely” (LR 2.14), and “likely” (LR 8.19). Figure 2C shows the proportions of patients falling into these categories, which were 39.3%, 17.5%, 14.7%, 15.9%, and 12.6%, respectively. Posttest probabilities for these categories in the training set, based on the overall mortality prevalence of 15.5%, were 0.0%, 2.3%, 13.5%, 28.2%, and 60.0% respectively (Table 4; Fig. 2B, D).
Validation of these LR categories was performed using Dataset 2 (Table 4; Fig. 3). Assessment of the proportional overlap of 95% confidence intervals, according to Cumming’s method26, indicated substantial overlap for all M3-score categories, suggesting no statistically significant differences in LRs between the training and test sets based on this approach. Separately, the delta method27, when applied to the ratio of likelihood ratios (ROR), suggested a statistically significant difference for the lowest M3-score category (0.00-0.10, P = 0.0038). However, this specific finding should be interpreted with considerable caution, as the training set LR for this category was zero, necessitating the substitution of a small non-zero value for the delta method analysis (as detailed in Supplementary Table S9 and Supplementary Materials and Methods). Given these methodological considerations and the contrasting findings from the Cumming overlap method for all categories, the overall evidence does not strongly support a clinically meaningful difference in LR performance for this category.

Diagnostic performance of M3-score in Test Set (n = 175, AZ Delta, COVID-19 Wave 2–3, January 1 till March 22 2021). (A) Receiver Operating Characteristic (ROC) curve. (B) Violin plots of calculated M3-scores for 152 surviving patients and 23 deceased patients, with interpretative result intervals, associated likelihood ratios (LRs), and calculated posttest probabilities using mortality prevalence as the pretest probability. (C) Pie charts showing the proportion of samples categorized by LR group. Red stars indicate a statistically significant difference (p < 0.05, Chi-squared test) in patient proportions compared to Dataset 1 (UZ Brussel, Fig. 2). (D) Posttest probability curves for mortality as a function of pretest probability and M3-score result intervals. Arrows indicate posttest probabilities calculated from mortality prevalence as the pretest probability.
AUC, area under the curve; CI, confidence interval; LR, likelihood ratio; PPRE, pretest probability; PPOST, posttest probability.
Considering the robust findings from the proportional overlap method alongside the more conditional results from the delta method, the LR categories of the M3-score demonstrated overall consistency between the training and test datasets. This consistency, observed across different time periods (COVID-19 wave 1 vs. waves 2–3) and geographical locations (UZ Brussel vs. AZ Delta), indicates a degree of temporal and geographical robustness and generalizability of the M3-score model. However, it remains important to acknowledge that the proportions of patients in some categories differed significantly between datasets (Fig. 3C), and that interpretations for extreme M3-score categories, particularly the highest, should be made with caution due to the relatively small sample sizes of the mortality groups (n = 39 in training, n = 23 in test; Table 1) and wider confidence intervals inherent in these groups (Table 4).
Discussion
In this retrospective study, we developed the parsimonious M3-score, a multivariable logistic regression model predicting in-hospital COVID-19 mortality based on three readily accessible features: age, WBC count, and AI-derived CT quantification of total lung involvement (TOTALAI) at admission. While the model exhibited strong performance in the UZ Brussel training set, external validation on the geographically and temporally distinct AZ Delta dataset demonstrated its potential for broader application, while also highlighting the inherent challenges of maintaining identical predictive accuracy across diverse real-world settings. Validation on the AZ Delta dataset, while demonstrating some degree of temporal and geographical robustness, showed a statistically significant difference in AUC compared to the training set, and some expected variability in likelihood ratio performance. While one statistical approach (the delta method27, requiring specific assumptions for the lowest category) suggested a significant difference for that single category, the broader assessment using proportional CI overlap (Cumming’s method26 did not indicate significant differences across LR categories, pointing towards general consistency. Notably, mortality rates were slightly lower in the UZ Brussel cohort, potentially reflecting evolving management practices (e.g., corticosteroid use, high-flow oxygen therapy) and the emergence of the Alpha variant (lineage B.1.1.7) during the later waves4.
One key strength of the M3-score lies in its clinical interpretability and actionability, achieved through the categorization of predicted probabilities into likelihood ratio (LR) intervals, enhancing clinical utility beyond AUC-ROC metrics. LRs address a critical limitation of many ML models by providing clinically meaningful risk stratification. By leveraging the granularity of quantitative M3-scores and incorporating Bayesian principles, our LR categories offer clear shifts in post-test probability for in-hospital mortality, ranging from near exclusion (0.00% posttest probability, LR 0.00) in the “highly unlikely” category to substantial risk (60.0% posttest probability, LR 8.19) in the “likely” category within the training set. These extreme categories, encompassing over 50% of our cohort, offer clinically relevant stratification to guide triage, resource allocation, treatment decisions, and ICU bed anticipation – critical considerations during pandemic surges5,6,7,8,9,10,11,12. Even with some observed variability in LR performance in the validation dataset, the inherent clinical actionability of these categories remains a significant advantage of the M3-score in practical settings. The caution regarding wide confidence intervals, particularly for extreme LR categories, is relevant given the small sample sizes of the mortality groups, However, this variability, particularly the statistically nuanced difference observed for the lowest M3-score category in the external validation set when using the delta method, underscores that local validation and potentially cohort-specific calibration or adjustment of LR thresholds may be advisable before widespread clinical implementation to optimize local performance.
Compared to existing AI-based COVID-19 mortality prediction models, including parsimonious models like Yadaw et al.’s 3 F model5, our M3-score offers a distinct and clinically relevant form of parsimony. While Yadaw et al.’s 3 F model relies solely on non-imaging clinical features, our M3-score uniquely integrates AI-driven quantitative chest CT analysis, providing a more direct and standardized assessment of pulmonary involvement, a key pathophysiological feature of severe COVID-19. This imaging integration, coupled with the M3-score’s parsimony and likelihood ratio categorization, enhances both the robustness and clinical interpretability of our M3-score for early risk stratification at hospital admission. Furthermore, our study prioritized AI-based total lung involvement quantification via Icolung software14]– [15, ensuring reproducible, automated assessments consistent with radiologist evaluations. Paired with straightforward features like age and WBC count, our model supports seamless integration into EMR/LIS systems for real-time risk stratification at admission.
Older age is a well-established risk factor for adverse COVID-19 outcomes4,28,29, and consistent with this, our M3-score incorporates age as a key predictor. In our study, patients in the AZ Delta cohort were older than in the UZ Brussel cohort. However, among deceased patients, age differences between waves were non-significant.
The pivotal role of CT scans in COVID-19 management, particularly in resource-limited settings, is well-documented30,31,32,33,34. Indeed, chest CT severity score (CTSS), quantifying pulmonary involvement, is a validated prognostic marker for COVID-19 mortality35,36,37,38. Incorporating CTSS into ML algorithms demonstrably enhances predictive accuracy, as evidenced by studies like Zakariaee et al.12. However, many existing CT-based models rely on complex feature sets and AUC-ROC metrics, potentially limiting their practical applicability. Our M3-score, by integrating AI-driven CT-based lung involvement quantification (TOTALAI) with readily available clinical features, aims to bridge this gap, offering a more parsimonious and clinically actionable approach to CT-based risk stratification. This aligns with the broader trend in medical imaging where ensemble deep learning models are increasingly developed for specific radiological findings, such as cardiomegaly detection from chest radiographs, to enhance diagnostic accuracy39. While this study focused on the development and validation of the M3-score which integrates AI-driven CT quantification, a direct comparative performance analysis against the traditional radiologist-derived CTSS alone or other established multi-parameter clinical scores was not undertaken. Such comparisons would be a valuable focus for future research to further contextualize the M3-score’s utility relative to existing tools.
However, our study has inherent limitations that warrant careful consideration. External validation, while conducted in a geographically and temporally distinct setting, revealed a statistically significant difference in some performance metrics (e.g., AUC) compared to the training set, reinforcing the need for cautious interpretation when applying the M3-score in new environments. Critically, the absence of structured comorbidity data in the AZ Delta (validation) dataset introduces uncertainty regarding the generalizability of these findings. This data gap, as previously noted, limits our ability to fully disentangle potential confounding effects from unmeasured differences in comorbidity prevalence between cohorts. For instance, such unreported comorbidities or variations in patient demographics (e.g., the older age profile in the AZ Delta cohort) may have influenced the observed performance differences and could impact the model’s applicability without cohort-specific recalibration. Echoing De Paepe et al.’s findings4 on evolving comorbidity profiles across Belgian COVID-19 waves, this limitation warrants careful consideration. Furthermore, while missing data in Dataset 1 was minimal and handled by mean imputation for BMI (9 records) and CTSSRAD (3 records) to preserve sample size, this approach, though pragmatic for such small amounts of missingness, might theoretically introduce some bias compared to more sophisticated methods like multiple imputation. However, given the small proportion of imputed data, a substantial impact on the overall conclusions is less likely, though it remains a minor consideration for interpretation. Additionally, variations in CT acquisition protocols, including the documented differences in radiation dose between centers, existed. While the AI tool used for quantifying lung involvement is generally designed for robustness to typical variations in image quality, the specific impact of these dose differences on TOTALAI measurements was not formally assessed in this study; future technical investigations could explore this further. Consequently, future validation studies should prioritize comprehensive comorbidity data to rigorously assess model robustness across diverse patient populations. Furthermore, the current validation is confined to two Belgian centers. Broader external validation across diverse international cohorts—encompassing varied healthcare systems, patient populations (including vaccinated individuals), and evolving SARS-CoV-2 variants—is essential to confirm wider applicability and assess potential performance drift40, and should therefore form a key objective of future work on this M3-score. Similarly, while our study period encompassed the emergence of the Alpha variant, which potentially influenced mortality rates, incorporating specific viral variant information as a covariate was beyond the current scope due to data availability and our aim for a parsimonious model. However, this represents an important avenue for future research to refine predictive models across different pandemic phases where such data might be more systematically collected.
In conclusion, the parsimonious and interpretable M3-score offers a promising tool for in-hospital COVID-19 mortality risk prediction, demonstrating robust performance in the training cohort. However, while external validation in a geographically and temporally distinct Belgian cohort indicated potential utility, observed performance variations (such as a lower AUC and differences in LR performance as detailed in the Results) underscore that its generalizability cannot yet be fully established. These findings emphasize the need for careful interpretation of the M3-score in new settings and highlight that extensive further validation across diverse international cohorts, encompassing varied healthcare systems, patient populations (including vaccinated individuals), and evolving SARS-CoV-2 variants, is essential before widespread clinical adoption can be considered. Such validation is crucial to strengthen healthcare preparedness, improve patient outcomes, and support clinicians in prioritizing care for high-risk cases.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work the authors used ChatGPT (version GPT-4, OpenAI; URL: https://chat.openai.com) to improve language and readability. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Dong, E., Hongru, D. & Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 20, 533–534 (2020).
Guan, W. J. et al. Clinical characteristics of coronavirus disease 2019 in China. N Engl. J. Med. 382, 1708–1720 (2020).
Richardson, S. et al. Presenting characteristics, comorbidities, and outcomes among 5700 patients hospitalized with COVID-19 in the new York City area. JAMA 323, 2052–2059 (2020).
De Paepe, A. et al. COVID-19 in three waves in a tertiary referral hospital in belgium: a comparison of patient characteristics, management, and outcome. Virol. J. 21, 119. https://doi.org/10.1186/s12985-024-02360-8 (2024).
Yadaw, A. S. et al. Clinical features of COVID-19 mortality: development and validation of a clinical prediction model. Lancet Digit. Health. 2, 516–525 (2020).
Mamandipoor, B. et al. COVID-19 machine learning model predicts outcomes in older patients from various European countries,between pandemic waves, and in a cohort of asian, african, and American patients. PLoS Digit. Health. 1, 1–20 (2022).
Bertsimas, D. et al. COVID-19 mortality risk assessment: an international multi-center study. PLoS ONE. 15, 1–13 (2020).
Li, X., Liao, H. & Wen, Z. A consensus model to manage the non-cooperative behaviors of individuals in uncertain group decision making problems during the COVID-19 outbreak. Appl. Soft Comput. 99, 1–14 (2021).
Wynants, L. et al. Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal. BMJ 369, 1–22 (2020).
Wu, G. et al. Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: an international multicentre study. Eur. Respir J. 56, 1–11 (2020).
de Jong, V. M. T. et al. Clinical prediction models for mortality in patients with covid-19: external validation and individual participant data meta-analysis. BMJ 378, e069881. https://doi.org/10.1136/bmj-2021-069881 (2022).
Zakariaee, S. S., Naderi, N., Ebrahimi, M. & Kazemi-Arpanahi, H. Comparing machine learning algorithms to predict COVID–19 mortality using a dataset including chest computed tomography severity score data. Sci. Rep. 13, 11343. https://doi.org/10.1038/s41598-023-38133-6 (2023).
Li, K. et al. CT image visual quantitative evaluation and clinical classification of coronavirus disease (COVID-19). Eur. Radiol. 30, 4407–4416 (2020).
Esposito, G. et al. AI-Based chest CT analysis for rapid COVID-19 diagnosis and prognosis: A practical tool to flag High-Risk patients and lower healthcare costs. Diagnostics (Basel). 12, 1608. https://doi.org/10.3390/diagnostics12071608 (2022).
Nicolò, M. et al. Comparing visual and Software-Based quantitative assessment scores of lungs’ parenchymal involvement quantification in COVID-19 patients. Diagnostics (Basel). 14, 985. https://doi.org/10.3390/diagnostics14100985 (2024).
Simel, D. L., Samsa, G. P. & Matchar, D. B. Likelihood ratios with confidence: sample size Estimation for diagnostic test studies. J. Clin. Epidemiol. 44, 763–770 (1991).
Simel, D. L., Samsa, G. P. & Matchar, D. B. Likelihood ratios for continuous test results - making the clinicians’ job easier or harder? J. Clin. Epidemiol. 46, 85–93 (1993).
Pauker, S. G. & Kassirer, J. P. The threshold approach to clinical decision making. N Engl. J. Med. 302, 1109–1117 (1980).
Pauker, S. G. & Kopelman, R. I. Interpreting hoofbeats: can Bayes help clear the haze? N Engl. J. Med. 327, 1009–1013 (1992).
Fagan, T. J. Letter: nomogram for Bayes theorem. N Engl. J. Med. 293, 257 (1975).
Fierz, W. & Bossuyt, X. Likelihood ratio approach and clinical interpretation of laboratory tests. Front. Immunol. 12, 4523. https://doi.org/10.3389/fimmu.2021.655262 (2021).
Chawla, N. V., Bowyer, K. W., Hall, L. O. & Kegelmeyer, W. P. SMOTE: synthetic minority Over-sampling technique. JAIR 16, 321–357 (2002).
Gnip, P., Vokorokos, L. & Drotár, P. Selective oversampling approach for strongly imbalanced data. PeerJ Comput. Sci. 7, 1–17 (2021).
Dorn, M. et al. Comparison of machine learning techniques to handle imbalanced COVID-19 CBC datasets. Peer J. Comput. Sci. 7, 1–34 (2021).
Erol, G., Uzba, B., Yücelba, C. & Yücelbas, S. Analyzing the effect of data preprocessing techniques using machine learning algorithms on the diagnosis of COVID-19. Concurr Comput. 34, 1–16 (2022).
Cumming, G. & Finch, S. Inference by eye: confidence intervals and how to read pictures of data. Am. Psychol. 60, 170–180 (2005).
Casella, G. & Berger, R. L. Statistical inference. 2nd ed. Duxbury; (2002).
Wu, Z. & McGoogan, J. M. Characteristics of and important lessons from the coronavirus disease 2019 (COVID-19) outbreak in china: summary of a report of 72 314 cases from the Chinese center for disease control and prevention. JAMA 323, 1239–1242 (2020).
Mehra, M. R., Desai, S. S., Kuy, S., Henry, T. D. & Patel, A. N. Cardiovascular disease, drug therapy, and mortality in COVID-19. N Engl. J. Med. 382, 2582 (2020).
De Smet, K. et al. Diagnostic performance of chest CT for SARS-CoV-2 infection in individuals with or without COVID-19 symptoms. Radiology 298, E30–E37 (2021).
Revel, M-P. et al. COVID-19 patients and the radiology department - advice from the European society of radiology (ESR) and the European society of thoracic imaging (ESTI). Eur. Radiol. 30, 4903–4909 (2020).
Mir, M. et al. The role of computed tomography in the management of hospitalized patients with COVID-19. Cureus 15, e36821. https://doi.org/10.7759/cureus.36821 (2023).
Pontone, G. et al. Role of computed tomography in COVID-19. J. Cardiovasc. Comput. Tomogr. 15, 27–36 (2021).
Sverzellati, N. et al. Integrated radiologic algorithm for COVID-19 pandemic. J. Thorac. Imaging. 35, 228–233 (2020).
De Smet, D., De Smet, K., Herroelen, P., Gryspeerdt, S. & Martens, G. A. Serum 25(OH)D level on hospital admission associated with COVID-19 stage and mortality. Am. J. Clin. Pathol. 155, 381–388 (2021).
Zakariaee, S. S., Abdi, A. I., Naderi, N. & Babashahi, M. Prognostic significance of chest CT severity score in mortality prediction of COVID-19 patients, a machine learning study. Egypt. J. Radiol. Nucl. Med. 54, 1–9 (2023).
Zakariaee, S. S. & Abdi, A. I. Influence of threshold selection strategy on the prognostic accuracy of chest CT severity score for mortality prediction of COVID-19 patients. Heart Lung. 56, 74–75 (2022).
Zakariaee, S. S., Salmanipour, H., Naderi, N., Kazemi-Arpanahi, H. & Shanbehzadeh, M. Association of chest CT severity score with mortality of COVID-19 patients: a systematic review and meta-analysis. Clin. Transl Imaging. 10, 663–676 (2022).
Yanar, E., Hardalaç, F. & Ayturan, K. CELM: an ensemble deep learning model for early cardiomegaly diagnosis in chest radiography. Diagnostics 15 (13), 1602. https://doi.org/10.3390/diagnostics15131602 (2025).
Kore, A. et al. Empirical data drift detection experiments on real-world medical imaging data. Nat. Commun. 15, 1887. https://doi.org/10.1038/s41467-024-46142-w (2024).
Acknowledgements
The authors thank Youssed Amin Bahkani for helpful discussions concerning study design and methodology.
Author information
Authors and Affiliations
Contributions
K.D.S.: Writing – review & editing, Writing – original draft, Visualization, Validation, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. D.D.S.: Writing – review & editing, Writing – original draft, Visualization, Validation, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. P.D.J.: Data preprocessing, Feature exploration, Machine learning. J.D.: Writing – review & editing, Conceptualization. G.A.M.: Writing – review & editing, Methodology, Conceptualization. N.B.: Writing – review & editing, Methodology, Conceptualization. J.D.M: Writing – review & editing, Supervision, Resources, Methodology, Conceptualization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
De Smet, K., De Smet, D., De Jaeger, P. et al. AI-derived CT biomarker score for robust COVID-19 mortality prediction across multiple waves and regions using machine learning. Sci Rep 15, 28727 (2025). https://doi.org/10.1038/s41598-025-14667-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-14667-9
