
Abstract
Recent advancements in applications such as natural language processing (NLP), applied linguistics, indexing, data mining, information retrieval, and machine translation have emphasized the need for robust datasets and corpora. While there exist many Arabic corpora, most are derived from social media platforms like X or news sources, leaving a significant gap in datasets tailored to academic research. To address this gap, the ARPD, Arabic Research Papers Dataset, is developed as a specialized resource for Arabic academic research papers. This paper explains the methodology used to construct the dataset, which consists of seven classes and is publicly available in several formats to benefit Arabic research. Experiments conducted on the ARPD dataset demonstrate its performance in classification and clustering tasks. The results show that most of the classical clustering algorithms achieve low performance compared to bio-inspiration algorithms such as Particle Swarm Optimization (PSO) and Gray Wolf Optimization (GWO) based on the Davies–Bouldin index measure. For classification, the Support Vector Machine (SVM) algorithm outperformed others, achieving the highest accuracy, with other classifiers ranging from 89% to 99%. These findings highlight the ARPD’s potential to enhance Arabic academic research and support advanced NLP applications.
Similar content being viewed by others

Introduction
Corpora are essential tools that provide the authentic texts and data required for a wide range of applications, including NLP, Applied Linguistics, Indexing, Data Mining, Information Retrieval, and Machine Translation. These areas and tools have experienced exponential growth worldwide since the 19th century1,2. However, the Arab world has not been able to derive maximum benefit from these tools because of the lack of specialist corpora and datasets for various domains and fields, particularly in academic areas. As noted by Eddakrouri2 and Mansour3. The lack of extensive resources is a significant challenge that hinders the advancement of Arabic language research.
It is a fact that the Arabic language is severely underrepresented in the available corpora based on Eddakrouri4 and Guellil5. This indicates that Arabic requires more attention, and some domains require particular datasets to help researchers provide valuable work and applications. Furthermore, most corpora developers were concerned with the language of the media (e.g., online newspapers, magazines, and news wire agencies) rather than other domains such as academic texts. Therefore, there is an urgent need to develop specialized corpora for many domains, especially academic fields, to meet the diverse needs of the Arab world. Such resources will enable researchers, linguists, and other researchers to conduct in-depth research, enhance their understanding of Arabic, and leverage technological advancements to achieve their goals.
In addition, the spread of Arabic documents in electronic form, especially academic papers, has increased significantly in recent years as noted by Eddakrouri2 and Sahmoudi et al.6. In the Middle East, the production of collective regional publications has grown significantly over the past four decades, from a mere 7,665 research papers in 1981 to 150,000 documents in 2019. A remarkable 20-fold increase was observed in the expansion of global production. Some of these papers are written in Arabic. This burgeoning academic production in the Arab world has sparked research and analytical interest, appropriately organizing and studying it in all aspects, especially in linguistics2.
Academic and scientific studies have unique characteristics. They are characterized by artistic quality, excellent production standards, and scientific levels2. Therefore, it is necessary to provide specialized data for academic papers to help researchers apply their application and algorithms that deal with academic papers with data having similar characteristics, instead of building their dataset from scratch, which is time-consuming. Researchers can benefit from public datasets or use them as a basis for any research.
This study addresses this gap by developing an open, free-source Arabic corpus designed for empirical research. The availability of an Arabic dataset for academic research papers is crucial to supporting the Arabic research community in improving quality, applying algorithms, and testing methodologies using Arabic academic datasets. Existing Arabic datasets from the literature focus on news or tweets. The ARPD dataset for academic Arabic research papers is proposed and built to improve the performance of text clusters, classification, or other NLP applications that deal with academic papers. This dataset will be used to enhance Arabic community research fields.
The ARPD dataset is a publicly available academic resource, specifically designed as a representative single-labeled Arabic dataset suitable for text classification, clustering, and other NLP tasks. It encompasses up to seven classes that have been appropriately selected to eliminate ambiguity and make it more robust for accurate text classification, clustering, or related NLP tasks. Additionally, the ARPD dataset caters to a wider range of research needs and consists of four distinct versions described in the Final Output section. Finally, the ARPD dataset provides extensive experimental results that evaluate and characterize clustering and classification performance.
The remainder of this paper is organized as follows. “Related work” section discusses related work that surveys existing Arabic corpora. “Methodology” section outlines the methodology used to construct the dataset. “ Dataset description” section describes the proposed dataset in detail. “Experiments” section outlines the experiments conducted to evaluate the dataset. “Result and discussion” section presents and discusses the experimental results. Finally, the “Conclusion” section concludes the paper.
Related work
Some Arabic datasets and corpses are available in bibliographic databases and references4, serving as valuable resources for researchers seeking to enhance their work. Detailed descriptions of these datasets are provided in the following paragraphs and summarized in Table 1. Several commonly used datasets are extracted from well-known news websites. One of such dataset is Khaleej-20047, which consists of articles and news as detailed by Abbas et al.8.
In addition, Saad et al.9 introduced three datasets: BBC, CNN, and OSAC. The BBC and CNN datasets were Arab News, collected from bbcarabic.com and cnnarabic.com, respectively. Both datasets are available in the text and ARFF file formats. Furthermore, Open-Source Arabic Corpora (OSAC)9 comprises news articles and serves as a freely accessible corpus aimed at supporting research in Arabic linguistics. OSAC is one of the most comprehensive open-source Arabic corpora, containing three datasets that span diverse genres and subject domains. The corpus is available in text file format.
The Arabic text corpus, known as the King Abdulaziz City of Science and Technology (KACST) Arabic corpus, is a substantial and diverse collection. Its design criteria were well-defined, and the corpus was carefully sampled. The content is classified according to various criteria: time, region, medium, domain, and topic. This enables users to search and explore a corpus easily10.
The TALAA corpus, introduced by Selab et al.11, is a collection of Arabic newspaper articles from various websites. Each category of the article is saved in a separate text file. A portion of the TALAA corpus was tagged to create an annotated Arabic corpus of approximately 7,000 tokens as parts of speech (POS). According to Guellil et al.5, the TALAA dataset is one of the most extensive Arabic corpora constructed from daily Arabic news articles. In addition, ANTCorpus12, short for Arabic News Texts Corpus, is a research project that gradually seeks to collect textual data from various web sources. The corpus files are formatted in XML.
Alalyani et al.13 proposed a new Arabic dataset called NADA, which is intended for text categorization. This corpus consists of two existing corpora, OSAC and Diab Dataset DAA14, and contains news articles. The new corpus was pre-processed and filtered using state-of-the-art methods. It was also organized based on the Dewey decimal classification scheme and the synthetic minority oversampling technique. Finally, the corpora consisted of three files: Attribute-Relation File Format (ARFF), classified text, and sample data files.
SANAD15 is an extensive dataset of Arabic news articles collected from three viral news portals: Al-Khaleej, Al-Arabiya, and Akhbarona. This single-labeled dataset has immense potential for use in various Arabic NLP tasks, including Text Classification and Word Embedding. Articles were gathered using Python scripts specifically designed for news portals. Once collected, the text files were saved in folders, each corresponding to a specific category. In 2023, Eddakrouri2 introduced the Arabic Corpus for Library and Information Science (ArCLIS), a specialized dataset in the field of Library and Information Science (LIS). This corpus contains 674 text files comprising scientific articles collected from various LIS journals. The files are available online.
In comparison to previous studies, the ARPD dataset contributes to the Arabic language field by providing a novel academic dataset that can be utilized for various applications, such as NLP models and text analysis. Unlike other datasets that focus on a single domain such as ArCLIS2, the ARPD dataset contains papers from seven scientific fields written in Arabic, including Arabic language, religion, art, law, education, business, and agriculture. The novelty of this research lies in several aspects. First, we created a new dataset for the academic literature consisting of seven classes for different fields of science. Second, our generated dataset had a significant size of 2011 documents. In addition, ARPD is published in different formats, such as PDF, text, and CSV to benefit Arabic research, as described in the “Final output” section. Finally, the dataset features are described in “ Dataset description” section.
Methodology
The dataset was built using a multiphase methodology, and the diagram shown in Figure 1 illustrates the main steps. This involves determining the number of classes, selecting suitable journals, and collecting PDF files from the chosen journals. The collected files were assessed against specific criteria, such as the whole file being written in the original Arabic language, which is Arabic, and not only having a title and abstract in Arabic. Additionally, the files should not be images scanned, and it is related to the dataset class by reading the abstract to ensure that it is related to the domain covered in the dataset. The accepted files were converted to text files to facilitate their use in the NLP process. Although many files were converted correctly, some errors could have been fixed manually. However, specific files were removed because they had issues that could not be resolved manually, such as text where all letters were connected without spaces or non-Arabic symbols. Consequently, only the correctly processed files were cleaned and prepared for further use. Finally, the processed files are saved in various formats. These phases are described in detail in the following subsections.

The steps followed to build the dataset.
Journals selection
The number of classes was initially selected on the basis of related studies. The agents searched for famous and publicly available journals in Arabic to select classes. Therefore, the average number of classes in the available datasets was seven. Based on this knowledge, seven classes were selected: Art, Law, Business, Religion, Agriculture, Arabic, and Education. These classes were selected based on significant colleges and reputable universities within high-ranking Arabic countries where the Arabic language is prominently taught. Further selection criteria included considering influential academic journals that regularly publish articles in Arabic and marking that the journals focus on topics related to these classes in most cases. We also ensured that the selected classes were distinct.
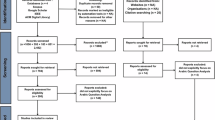
The journals included in this document collection are of great importance. They were carefully selected because of their high quality and dependability. This section follows the PRISMA framework as guidelines provided by Page et al. in17. Figure 2 shows a flowchart explaining the main processes applied in this study. A comprehensive list of the selected journals for each category is presented in Table 2.

The PRISMA model describing the identification of studies via database and registers.
The primary sources for the selected journals were affiliated with esteemed academic institutions in Saudi Arabia, Egypt, Jordan, Syria, Palestine, and the United Arab Emirates. The institutions included King Saud University, Egypt University, Jordan University, Syrian University, Palestinian University, Imam University, Umm Al-Qura University, and Sharjah University.
Finally, legal approval or consent to benefit from copyrighted papers from authors and researchers is not mandatory because the law allows access to journal papers without getting them back to their authors or even excusing them. In addition, all papers in this dataset are open-access and available online. Concerning copyright, all papers are available as original files as PDFs.
Moreover, based on the exceptions reported in copyright laws based on Geiger et al.18, some of which use the publication for purely educational purposes, similar to the ARPD dataset. In addition, a copy of the publication is created for non-commercial personal use. Finally, data mining of publications is performed to digitize and index their contents so that specialized software programs can process the texts.
Data collection
PDF files were manually obtained from the selected journals for each category with careful consideration, given that some journals were published in Arabic and English. In contrast, others published only the title and abstract in Arabic, and the remaining parts in English. It is imperative to ensure that the published versions are not scanned. Sometimes, all volumes or issues are published in a single file, making it necessary to split each study independently. We used the Love PDF tool, which is available online.
In addition, to ensure that the papers did not overlap and could be accurately classified, it was necessary to manually scrutinize their titles and abstracts. Finally, each PDF file was saved in the corresponding category on the drive, and the files were renamed with numbers starting from zero for each category. The number of papers collected from all journals that met the criteria is depicted in Figure 3 and Table 3.

Number of papers for each category that was collected from many Arabic journals.
Preprocessing steps
After collecting the PDF files based on Fig. 1, the next step was to convert the PDF files to text files through Python code using the PyPDF2 library to convert the PDF to a text file and save them in a separate folder. After this step, some files were converted correctly, whereas others were converted with errors. For this, the text files were checked manually, and it was decided whether the error or mistake could be corrected, or if it was impossible and the file needed to be removed because it was corrupted.
However, in some situations, after manual checking, the text file must be deleted because it cannot be corrected, and the related PDF file must be deleted. These errors are related to Unicode and are converted into unknown characters. In addition, some text files are converted into Arabic, but some letters are repeated many times and are difficult to fix. Moreover, most Arabic text files are converted to Faresi letters, and although the content can be understood, they are difficult or impossible to fix. Finally, some files were converted into Arabic without spaces. Table 4 lists the number of files deleted and removed after this step, while Table 5 lists the number of accepted files.
However, some errors can be fixed and corrected manually or by applying a tiny code script to the text file. In some files, the problem appeared only in the titles, abstracts, headings, or subheadings. The error was manually fixed by rewriting it based on the PDF file, as some of this problem was related to the font style and type used in this study. While some errors are related only to the order of some Arabic letters, so one needs to replace the wrong word with the correct one using the code script or manually, such as the ( اال ، األ ، اإل ، اآل، إال ، آال، أال ) convert to ( الا ). Moreover, some repeat letters in some files must be removed from the repeated letters manually or through Python code. Finally, after correction, all files were saved on the drive.
The final output
The dataset was built and made available online to help other researchers use and benefit from it. The dataset available in Zenodo and other materials will help researchers benefit from the academic dataset in their research, proposed applications, and algorithms. The dataset contains all PDF files classified into appropriate classes. In addition, it contains text files obtained after converting the PDF and processing.
Moreover, the dataset contains another text file as a new version after applying certain processing steps. The preprocessing step includes Arabic normalization for ALEF, TEH, and ligature using PyArabic in Python; it also removes tashkeel, harakat, tweel, and shadda. In addition, stop-word removal from Namly et al.19 and Alrefaie20 was applied as a preprocessing step.
Finally, the dataset is saved in a CSV file if the researcher requires it because the CSV file contains two columns: the first column of the paper and the second column, which includes the category (class) corresponding to the paper. Thus, there are two CSV files: one without preprocessing steps and the other containing preprocessed text. The dataset is publicly available in the Zenodo repository16.
Dataset description
The data were formatted as three folders as follows: one for PDF files was saved in each category in a deferred folder inside the PDF folder. The second folder is the same for text files converted from PDF files. Finally, the last folder contains text files after preprocessing, Arabic normalization, tashkeel and stop word removal. The dataset was saved as a CSV file in a Zenodo repository16.
The dataset contained seven main classes: law, business, religion, agriculture, Arabic, art, and education. Table 6 and Fig. 4 present the percentages of each category in the dataset. Figure 3 shows the total number of papers collected from these journals. In contrast, Fig. 5 indicates the number of papers accepted after the cleaning process and is used to build this dataset in each category. The dataset contained 2011 papers with different features. Table 7 lists the number of features for the various versions and situations ; the second value represents the number of unique terms (words or tokens) identified by the TF-IDF vectorizer across the entire document set. It illustrates the effect of preprocessing on the number of features and how feature reduction is achieved. This table provides valuable insight into the effectiveness and quality of the ARPD clean process when collecting data. Finally, Table 8, and Fig. 6 shows the word distribution for each category as total words, distinct words, most frequent words and their frequency, rare words, and average document length.

Percentage of papers for each category that was accepted based on the factor to filter the collected papers.

The Number of papers for each category that was accepted based on the factor to filter the collected papers.

Statistical distribution by category.
Experiments
The dataset was thoroughly tested and validated using various clustering algorithms and four distinct evaluation measures. In addition, several classifier algorithms were assessed and evaluated to demonstrate the performance of the proposed dataset. The following section provides a detailed explanation of the algorithms and evaluation measures used in the experiments, along with the primary settings for each algorithm.
Clustering algorithms
The dataset was evaluated and tested using several clustering algorithms, including traditional and bio-inspiration algorithms. Traditional algorithms include K-mean, density-based spatial clustering of applications with noise (DBSCAN), and mini-batch K-means algorithms. Recently, bio-inspired algorithms have attracted significant attention in this field of research. So, to evaluate the dataset, two algorithms were utilized: PSO and GWO.
The K-mean clustering algorithm is a widely used technique for clustering data. It partitions data points into k clusters based on their similarity distances. The algorithm is suitable for grouping circular data points. Furthermore, in order to implement and execute the K-mean algorithm, the value of k must be predetermined. The algorithm then assigns each data point to the nearest cluster center based on its similarity distance. The algorithm continues this process iteratively until it reaches an acceptable level of convergence where no further changes in the results are observed21.
Mini-batch K-means is a variant of the K-mean clustering technique that aims to improve computational efficiency. Unlike K-mean, which requires all data points in the dataset to be considered in every iteration of the clustering process, mini-batch K-means selects a random subset of data points (a “batch”) to perform distance calculations. This method begins with the empowering step of establishing the k and batch values in advance. This approach substantially reduces the time required for clustering and enhances the overall convergence rate. This method is effective in various scenarios, including large-scale datasets with millions of data points22.
DBSCAN is a clustering algorithm that effectively groups data points in high-dimensional, spatial, and nonspatial databases, even in noise. The fundamental principle of DBSCAN is to identify objects that belong to a cluster based on the proximity of nearby objects within a specified radius (Eps) and the minimum number of objects required to form a cluster (MinPts). This clustering approach suggests that objects nearby are likelier to belong to the same cluster than those farther apart. As a result, the algorithm efficiently clusters datasets with diverse shapes and structures, making it a valuable tool for various research and applications23.
PSO is a population-based stochastic search process inspired by the social behavior of bird flocks. In this evolutionary algorithm, a group of particles forms a swarm, and each particle attempts to find the best position. The main objective is to select the best particle and position. The algorithm maintains a population of particles, each representing a potential solution to an optimization problem. In PSO, a swarm refers to several possible solutions to the optimization problem, where each solution is called a particle. The goal of PSO is to determine the position of a particle leading to the best evaluation of a given fitness (objective) function. This algorithm has been used in various applications, such as data analysis and clustering24,25.
The GWO is a meta-heuristic algorithm that draws inspiration from the leadership behavior of gray wolves and their unique hunting mechanisms. This algorithm adopts a population-based approach and is motivated by the natural behavior of gray wolves during prey hunting. The GWO algorithm searches for prey, and the leader is influenced by the position of the prey, i.e., the current optimal solution for global exploration. On the other hand, followers perform full local exploration to balance the mining and exploration capabilities. It reduces the probability of falling into local optimal solutions since the GWO algorithm has a simple structure, few control parameters, and high convergence accuracy 26,27.
Clustering evaluation metrics
The cluster metrics and measures utilized to assess the results were the silhouette coefficient, the ARI, and Davies–Bouldin index.
The Silhouette coefficient28 is a valuable metric for evaluating the efficacy of the clustering techniques and can be used to determine the optimal separation between clusters. By measuring the proximity of each point within a cluster to points in neighboring clusters, the silhouette plot can provide insight into the distance between clusters. The resulting Silhouette score can range from -1 to 1, with a score of +1 indicating that the sample is significantly distant from its neighboring clusters. A score of zero indicates that the sample is in or close to the decision boundary between two neighboring clusters. In contrast, negative scores suggest that the sample may have been erroneously assigned to its cluster. The Silhouette Coefficient can be used with both Euclidean and cosine distance measures implemented in the experiment28. The equation for the silhouette coefficient is described in Eq. 1.
where \(a(i)\) is the average distance between \(i\) and all other points in the same cluster. While \(b(i)\) is the average distance between \(i\) and all points in the nearest neighboring cluster.
The Adjusted Rand Index (ARI)29 is a commonly used metric in cluster analysis that measures the degree to which two sets of data agree. It is a modified Rand index that is often used to compare two groups based on a given set of objects and is among the most widely employed similarity measures. This measure determines the similarity between two clusters by evaluating all pairs of samples and tallying pairs assigned to the same or different clusters in both the predicted and actual clustering. A higher value for this measure indicates a more substantial degree of similarity between the two clustering methods29. The equation for the ARI is described in Equation 2.
where \(n\) is total number of samples. \(n_{ij}\) is the number of points shared between the \(i\)-th predicted cluster and \(j\)-th true cluster. \(x(i)\) is the total number of points in the \(i\)-th predicted cluster. \(y(j)\) is the total number of points in the \(j\)-th true cluster.
The Davies-Bouldin index30, is a metric for evaluating clustering algorithms, it utilizes an internal evaluation scheme that verifies clustering quality by utilizing inherent quantities and features within the dataset. A lower value of this index indicated a higher degree of aggregation. This is another well-known metric based on the concept that groups should be segregated from each other with internal homogeneity and compactness within each group30. The equation for the Davies-Bouldin index is described in Eq.3.
where \(k\) is the number of clusters. \(\sigma _i\) is the average distance between each point in cluster \(i\) and the centroid of cluster \(i\) (intra-cluster scatter). \(d_{ij}\) is the distance between the centroids of clusters \(i\) and \(j\) (inter-cluster distance).
Classification algorithms
The main classification algorithms used to test the proposed dataset include a decision tree (DT), SVM, naive Bayes (NB), and random forest (RF).
DT is a technique used in text and data mining for classification. This algorithm has been successfully applied to a diverse range of fields. A decision tree is a hierarchical breakdown of a data space, with each level representing a classification. The main challenge with this technique is to determine which attributes or features should be placed at the parent and child levels. This was highlighted by Kowsari et al.31.
Another ensemble learning method used for text classification is the random forest, which utilizes decision trees. In this approach, multiple decision trees are randomly generated and the final classification is determined by the collective output of these trees. For more detailed information on this algorithm, refer to Wu et al.32 and Kowsari et al.31.
SVM is supervised learning models initially designed for binary classification tasks. These models are instrumental in solving significant high-dimensional classification problems. The SVM aims to determine the optimal hyperplane that separates two different classes of data that can be applied to document classification tasks31,33.
NB classifier is a family of simple probabilistic classifiers based on the common assumption that all the features are independent. The Naive Bayes method is theoretically based on the Bayes theorem formulated by Thomas Bayes. This approach has been widely used for document categorization31,34.
Classification evaluation metrics
The classification metrics and measures used to assess the results were accuracy, F-score, recall, and precision. Accuracy is one of the most commonly used measures of classification performance and is defined as the ratio of correctly classified samples to the total number of samples35. The recall represents the proportion of positive samples correctly classified to the total number of positive samples. However, precision represents the proportion of positive samples correctly classified to the total number of positively predicted samples, as indicated Tharwat35 and Ferri et al.36. The F-measure or F-score represents the harmonic mean of precision and recall. The F-measure value ranges from zero to one, with high values indicating high classification performance35.
Experiment setup
This experiment employed clustering and classification techniques in Python, implemented using Google Colab Pro+, to test and validate the proposed dataset. A series of experiments were conducted to evaluate the performance of these methods. One experiment excluded stopping words, specifically tashkeel, harakat, tweel, and shadda. In its preprocessed version, this dataset was referred to as Preprocessing 1, which aimed at a straightforward flow in a recent paper. The second set of preprocessing steps, known as Preprocessing 2, included Arabic normalization and removing tashkeel, harakat, tweel, and shadda. Additionally, it involved pruning terms that appeared fewer than three times and eliminating stop words. Preprocessing 3 included Arabic normalization, the removal of tashkeel, harakat, tweel, and shadda, stemming, pruning of terms appearing less than three times, and stop word removal. Finally, the results were converted into vectors in all scenarios using the term frequency-inverse document frequency (TF-IDF) method.
PyArabic and sci-kit-learn Python libraries were used to perform the preprocessing and stemming steps. The sklearn library in Python was used for clustering and classification. In addition, the Pyriad library in Python was used to run the bio-inspired algorithm for cal PSO and GWO. The experiments comprised the K-mean and mini-batch K-means methods, with varying k-cluster values ranging from 2-10. The DBSCSN method included a minimum sample size of five and tested five different settings for EPS: 0.3, 0.5, 0.7, 0.9, and 1. Finally, the PSO method utilizes a population of 30 iterations of 100, 50, and 30, and k values of 4, 6, and 5. The k values were selected based on the best results for the K-mean (k = 6), elbow experiment (k = 4), and silhouette score (k = 5).
Finally, to apply the classification experiment, it is paramount to have access to training and testing data. To achieve this, the entire dataset must be converted into a TF-IDF matrix. Data were divided into two partitions using the percentage method. The first partition consisted of training data, which comprised 70% of the dataset, whereas the second partition consisted of test data, which accounted for 30%. Notably, this step is crucial to ensure the accuracy and reliability of the classification experiment because it allows the model to be trained on a subset of the data and then tested on a separate subset to evaluate its effectiveness.
Results and discussion
Clustering results
The traditional cluster algorithm was applied with a specific implementation of preprocessing to the proposed dataset, stopping word removal and removing tashkeel, harakat, tweel, and shadda ( Preprocessing 1). The resulting data were converted into a TF-IDF matrix. Additionally, both the K-mean and DBSCAN algorithms were applied, and the results are tabulated for easy reference. The results of the K-mean algorithm are listed in Table 9, while the results of the DBSCAN algorithm are tabulated in Table 10. Finally, the mini-batch K-means algorithm was applied, and the results are presented in Table 11.
According to the Davies-Bouldin index, a lower value indicates better clustering because this metric serves as an internal measure for clusters. In this experiment, both DBSCAN (when eps = 0.7) and K-mean (k = 10) yielded the best value of 1.545 and 1.866 for the Davies-Bouldin index metric. Conversely, a less optimal value of 13.591 and 5.550 was obtained when applying DBSCAN (when eps = 1) K-mean with k = 6, respectively. In addition, the Silhouette Coefficient is an internal measure for assessing the clustering quality. This measure ranges from \(-1\) to 1, with a higher value indicating better clustering results. In our experiment, the K-mean algorithm with k = 7 produced the highest Silhouette Coefficient with cosine as a distance function value of 0.097. However, this value remains relatively small, indicating a weak cluster. Finally, DBSCAN yielded mostly negative scores for the Silhouette Coefficient, when the Euclidean distance except eps=0.7. Although the cosine distance has given positive results in most cases, the highest value was 0.032. External validation using the ARI is widely recognized as a reliable technique to measure the similarity between two clusters. The present study obtained a higher value (0.419) K-mean at k = 9, indicating significant agreement between the two clustering methods.
In the second scenario, additional preprocessing steps were applied ( Preprocessing 2). These steps included removing stop words, tashkeel, harakat, tweel, and shadda, and Arabic normalization for alef, teh, and ligature using PyArabic. The output is then tested using traditional algorithms. Finally, the results were converted into a TF-IDF matrix. The results of K-mean algorithm can be found in Table 12, the results of the DBSCAN algorithm are shown in Table 13, and Table 14 shows the results of the mini-batch K-means algorithm.
Based on internal measures of the Davies-Bouldin index, the best result was achieved by the mini-batch K-means algorithm in most K values with a score around 2.5 or above. However, the best and worst result was obtained by the DBSCAN algorithm when eps=0.7 and eps=1, with a score of 1.672 and 13.1, respectively. K-mean algorithm yields results between 3.5 and 5.5. Regarding the Silhouette Coefficient, the highest score was approximately 0.1 for K-mean when using cosine as a distance function for the Coefficient. However, DBSCAN mostly yielded negative scores when the Euclidean distance except eps=1. Although the cosine distance has given positive results in most cases, the highest value was 0.035.
Regarding the external measure, the ARI yielded the highest score of 0.49 K-mean when k = 9 or 10. For DBSCAN, the score was 0.009, and for mini-batch K-means, it was 0.3.
Several preprocessing steps were applied in the final experiment, including stop word removal, tashkeel, harakat, tweel, and shadda; and Arabic normalization for alef, teh, and ligature using PyArabic. The text was then stemmed using Arlstem and fine-tuned to exclude terms with fewer than three characters ( Preprocessing 3). The resulting text was converted into a TF-IDF matrix. For the K-mean algorithm, Table 15 shows the results, while Table 16 shows the results of the DBSCAN algorithm, and Table 17 shows the results for the mini-batch K-means algorithms, respectively. Additionally, PSO and GWO algorithms were applied because the number of features that are obtained after all these preprocesses makes them suitable to applied to these types of algorithms, as listed in Tables 18 and 19.
The results were obtained according to the internal measures used to test the quality of the cluster for this case, based on the Davies-Bouldin index and the explained Silhouette Coefficient. According to the Davies-Bouldin index, a lower value indicates better clustering. In this experiment, DBSCAN and mini-batch K-means yielded the best value of 1.6 and 2.2 for the Davies-Bouldin index metric. In addition, the K-means algorithm typically yields a value around 4 in most cases. Conversely, a lower optimal value of 8.6 was obtained when applying DBSCAN. Based on the experimental results, the bio-inspired GWO achieved the best results compared with the traditional algorithms because they scored around 1 and 2. In addition, the worst score obtained by bio-inspired algorithms was around 5 for PSO.
Moreover, the Silhouette Coefficient is an internal measure for cluster quality assessment. This measure ranges from \(-1\) to 1, with a higher value indicating better clustering results. In our experiment, the K-mean algorithm with k = 5 and k = 6 produced the highest Silhouette Coefficient (cosine ) value of 0.1. The highest result was obtained for the mini-batch K-means for k = 2 with value 0.09. However, this value remains relatively small, indicating a weak cluster. In addition, the PSO obtains a score for the Silhouette Coefficient around 0.04 and 0.05 when using cosine distance for k = 5, 6 and 4. The GWO received a negative score in most cases. Finally, DBSCAN yielded mostly negative scores for the Silhouette Coefficient, even when the Euclidean or cosine distance was used.
According to ARI measures, a higher ARI value indicates more substantial agreement between the clustering results. In this study, the K-mean clustering algorithm with k=9 produced the highest ARI of 0.5. By contrast, the mini-batch K-means clustering algorithm with k=10 resulted in an ARI value of 0.43. Notably, the DBSCAN clustering algorithm exhibited an ARI value of less than 0.016, indicating a complete dissimilarity between the two clustering algorithms. Furthermore, the GWO algorithm produced a low ARI value of less than 0.032, whereas the PSO algorithm produced a value of around 0.3 in most cases.
These results imply that the K-mean clustering algorithm with k = 7 was the most effective method for clustering the dataset used in this study. In contrast, the mini-batch K-means clustering algorithm with k = 5 and the DBSCAN clustering algorithm are unsuitable. Moreover, the GWO algorithm may not provide satisfactory results in this particular scenario. However, the PSO achieves better ARI and silhouette coefficients compared to GWO. These findings offer valuable insight into the performance of various clustering algorithms for this specific dataset and can aid in selecting an appropriate algorithm for similar datasets.
Classification results
The classification experiment for the first situation ( Preprocessing 1) when removed stop words and eliminated diacritics (such as tashkeel, harakat, tweel, and shadda). The data output was then transformed into a TF-IDF matrix. The output of the DT algorithm is presented in Table 20. The SVM and NB algorithm results are displayed in Tables 21 and 22, respectively. Finally, Table 23 lists the results of the RF result. The accuracy of all algorithms is generally above 92%. Our findings indicate that both SVM and RF demonstrated the highest accuracy rates, with SVM achieving an accuracy rate of 98% and RF achieving an accuracy rate of 97%. In contrast, DT and NB showed the lowest accuracy rates, with DT achieving an accuracy rate of 90% and NB achieving an accuracy rate of 92%.
Moreover, the RF yielded the best recall scores for the Arabic category. In contrast, SVM achieved the best recall score for the law category, with a perfect score of 100%. Additionally, the precision measure was more significant than or equal to 94% for all classes, indicating that the classifiers correctly identified the documents that belonged to each category of all those in that category. Finally, the F-score results showed that SVM outperformed all other algorithms, achieving an F-score of 99% for art, education, and law classes. Conversely, the lowest F-score was 84% for the Arabic category when running DT, indicating that the other algorithms performed better in terms of F-score.
In the second scenario, additional pre-processing steps were applied ( Preprocessing 2). These included removing stop words and addressing tashkeel, harakat, tweel, and shadda. Arabic normalization was also performed for alef, teh, and ligatures using PyArabic. The resulting output was then converted to a TF-IDF matrix. The DT algorithm results are listed in Table 24, and Table 25 displays the results of the SVM algorithm. Table 26 shows the results of the NB algorithm, and Table 27 shows the outcomes of the RF algorithm.
After conducting experiments, it was found that SVM and RF demonstrated the highest accuracy rates of 98% for both. In contrast, DT and NB exhibited the lowest accuracy rates of 90% and 91%, respectively. Furthermore, the best recall score was achieved with SVM for law class at 100%. In addition, SVM and RF for the agricultural and business classes had a perfect score of 99%.
The precision measure was greater than or equal to 83% for all classes. A high F-score of 99% was achieved when SVM was run for business, education, and law classes. The lowest score was 81% for the Arabic category when running DT. Finally, the precision measure was 100% for the education categories of SVM, and RF. Therefore, the education category correctly classifies positive samples in most classifiers. Moreover, the art of the class for SVM achieved 100%.
Finally, after applying several preprocessing steps ( Preprocessing 3), including stop word removal, tashkeel, harakat, tweel, shadda, and Arabic normalization for alef, teh, ligature using PyArabic, stemming using Arlstem, and term running that is less than three In, the result is converted to the TF-IDF matrix. For the DT algorithm, the results are shown in Table 28. Table 29 shows the results of the SVM algorithm, and Table 30 shows the results for the NB algorithm. Finally, Table 31 presents the results for RF.
Through experiments, SVM and RF demonstrated the highest accuracy rates of 99% and 98%, respectively. In contrast, NB and DT exhibited the lowest accuracy rates of 89% and 90% , respectively. Furthermore, SVM achieved the best recall score for art and education, with a perfect score of 100%. Additionally, RF received a score of 100% for the art class.
Moreover, the F-scores for the Art classes were 100% for SVM. In addition, the agriculture and education scores for both SVM and RT achieved 99%. DT recorded the top scores in the law category, achieving 97% and 96% for education of NB. Finally, the precision measure was 100% for the art categories in SVM and RF. Additionally, the SVM score was 100% for both the art and education categories, and art in RT also achieved 100%. In general, all the results of this experiment improve the classifier when more preprocessing is applied.
Discussion
The performance evaluation of the proposed dataset was conducted based on the outcomes of the cluster analysis and classification, as described in this section. These findings provide a basis for the key conclusions of this study. The SVM algorithm was suitable for the ARPD dataset for the classification dataset, achieving an overall accuracy of approximately 98% in all scenarios. In addition, the F-score, recall, and precision scores were approximately 98% for all situations and classes. The precision scores for the education category were exceptionally high, reaching 100% or above 90% in most classifiers in various experimental scenarios. This indicates that the education category accurately identifies true positives within the category, correctly classifying documents belonging to the education domain. Additionally, the SVM algorithm excelled in identifying law documents, achieving a recall of 100%, which reflects the algorithm’s ability to correctly retrieve all relevant documents for the law category. Similarly, the RF classifier performed effectively for the art category. The accuracy of the classifiers ranged between 89% and 99%, with precision consistently exceeding 83% across all scenarios. Furthermore, recall and F-score metrics were consistently around 97%, highlighting the strong overall performance of the classification algorithms.
The experimental analysis of clustering indicated weak performance based on the Silhouette Coefficient, with a maximum value of 0.1 or less. This low score due to the dimensionality of the data, achieving higher values becomes difficult because of the curse of dimensionality. The results indicate that the cluster separation quality is subpar, requiring further investigation to improve the clustering algorithm performance. The analysis also compared traditional clustering methods with bio-inspired algorithms. This shows that bio-inspired clustering methods are more effective than traditional methods based on the Davies-Bouldin index. The Davies-Bouldin index measures the separation between clusters and variation within clusters. Bio-inspired clustering methods GWO achieved the best results in the experiments, scoring between 1 and 2. In contrast, PSO performed poorly, scoring around 5. However, bio-inspired methods may not always be the best option because they may yield poor results for metrics such as the ARI and Silhouette Coefficient especially GWO. However, the PSO based on ARI consistently yields results around 0.3.
In the context of clustering, the optimal results were obtained when the value of k differed from 7, which is the number of categories present in the corpus. This discrepancy can be based on the characteristics of the dataset and the behavior of the clustering algorithm. Although the ARPD dataset is categorized into seven distinct domains, the clustering algorithms focus on the inherent features of the data. Consequently, they may identify patterns based on similarities within the feature space. This highlights the features extracted using clustering algorithms and their ability to uncover patterns within the data that align directly with the established categories.
In conclusion, our study offers valuable insight into the performance of clustering and classification algorithms for this specific dataset, which can help researchers select appropriate algorithms for similar datasets. In addition, this study provides evidence of the utility of ARPD in NLP applications, especially those focusing on academic datasets. The ARPD dataset is the first dataset that focuses on academic data with multiple classes.
Conclusion
This study introduced ARPD, a novel dataset for Arabic academic research papers. The dataset was meticulously crafted by gathering and refining research papers to make it accessible for researchers to utilize and reap benefits. Addressing the scarcity of academic datasets, ARPD aims to enhance the domain of Arabic academic clusters, classification, or any relevant NLP application.
The ARPD dataset comprises seven classes: Arabic, Law, Education, Religion, Art, Agriculture, and Business. It is provided in multiple versions and formats, including text files that have undergone preprocessing and filtering steps to reduce the efforts required by researchers to rebuild Arabic corpora. The dataset is publicly available on the Zenodo platform in three formats: CSV file, raw text, and PDF. Along with additional materials, this dataset assists researchers in utilizing academic resources to develop academic tools, propose applications, and design algorithms.
The dataset is rigorously assessed and validated using numerous cluster and classifier algorithms. Four evaluation measures for classification were also used for the cluster quality measures to effectively measure the classification quality. Simultaneously, the cluster experiment was evaluated using four measures to assess the internal and external qualities of the cluster. The experimental results indicated that the ARPD is a proficient dataset for Arabic classification purposes and can be exploited for cluster purposes. Moreover, the dataset can be expanded by adding new classes and documents to widen its applicability, particularly in Big Data and Deep Learning.
Data availability
The dataset generated and analyzed during the current study is publicly available in the Zenodo repository16. Link: https://doi.org/10.5281/zenodo.15547781
References
Arts, T., Belinkov, Y., Habash, N., Kilgarriff, A. & Suchomel, V. artenten: Arabic corpus and word sketches. J. King Saud Univ.-Comput. Inf. Sci. 26, 357–371 (2014).
Eddakrouri, A. Arabic corpus of library and information science: Design and construction. Egypt. J. Lang. Eng. 10, 1–9 (2023).
Mansour, M. A. The absence of Arabic corpus linguistics: A call for creating an Arabic national corpus. Int. J. Hum. Soc. Sci. 3, 81–90 (2013).
Ahmed, A. et al. Freely available Arabic corpora: A scoping review. Comput. Methods Prog. Biomed. Update 2, 100049 (2022).
Guellil, I., Saâdane, H., Azouaou, F., Gueni, B. & Nouvel, D. Arabic natural language processing: An overview. J. King Saud Univ.-Comput. Inf. Sci. 33, 497–507 (2021).
Sahmoudi, I. & Lachkar, A. Formal concept analysis for Arabic web search results clustering. J. King Saud Univ.-Comput. Inf. Sci. 29, 196–203 (2017).
Abbas, M. & Smaili, K. Comparison of topic identification methods for Arabic language. In Proceedings of International Conference on Recent Advances in Natural Language Processing, RANLP. 14–17 (2005).
Abbas, M. & Smaili, K. Comparison of topic identification methods for Arabic language. In Proceedings of International Conference on Recent Advances in Natural Language Processing, RANLP. 14–17 (2005).
Saad, M. K. & Ashour, W. Osac: Open source Arabic corpora. In 6th ArchEng International Symposiums, EEECS. Vol. 10. 55 (2010).
Al-Thubaity, A. O. A 700m+ Arabic corpus: Kacst Arabic corpus design and construction. Lang. Resour. Eval. 49, 721–751 (2015).
Selab, E. & Guessoum, A. Building Talaa, a free general and categorized Arabic corpus. ICAART 1, 284–291 (2015).
Chouigui, A., Khiroun, O. B. & Elayeb, B. Ant corpus: An Arabic news text collection for textual classification. In 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA). 135–142 (IEEE, 2017).
Alalyani, N. & Marie-Sainte, S. L. Nada: New Arabic dataset for text classification. Int. J. Adv. Comput. Sci. Appl. 9 (2018).
Abuaiadah, D., El Sana, J. & Abusalah, W. On the impact of dataset characteristics on Arabic document classification. Int. J. Comput. Appl. 101 (2014).
Einea, O., Elnagar, A. & Al Debsi, R. Sanad: Single-label Arabic news articles dataset for automatic text categorization. Data Brief 25, 104076 (2019).
Almutairi, T. Arpd: The academic Arabic research papers dataset (corpus). https://doi.org/10.5281/zenodo.15547781 (2025).
Page, M. J. et al. Prisma 2020 explanation and elaboration: Updated guidance and exemplars for reporting systematic reviews. BMJ 372 (2021).
Geiger, C., Frosio, G. & Bulayenko, O. Text and data mining in the proposed copyright reform: Making the EU ready for an age of big data?. IIC Int. Rev. Intellect. Property Competit. Law 49, 814–844. https://doi.org/10.1007/s40319-018-0722-2 (2018).
Namly, D., Bouzoubaa, K., Tajmout, R. & Laadimi, A. On Arabic stop-words: A comprehensive list and a dedicated morphological analyzer. In Arabic Language Processing: From Theory to Practice, Communications in Computer and Information Science (Smaïli, K. ed.) . 149–163. https://doi.org/10.1007/978-3-030-32959-4_11 (Springer, 2019).
Alrefaie, M. T. Mohataher/Arabic-stop-words (2024). Original-date: 2016-05-27T13:49:47Z.
Aggarwal, C. C. & Zhai, C. A survey of text clustering algorithms. Min. Text Data 77–128 (2012).
Wahyuningrum, T. et al. Improving clustering method performance using k-means, mini batch k-means, birch and spectral. In 2021 4th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI). 206–210 (IEEE, 2021).
Chen, Y. et al. Knn-block dbscan: Fast clustering for large-scale data. IEEE Trans. Syst. Man Cybern. Syst. 51, 3939–3953 (2019).
van der Merwe, D. & Engelbrecht, A. Data clustering using particle swarm optimization. In The 2003 Congress on Evolutionary Computation, 2003. CEC ’03. Vol. 1. 215–220. https://doi.org/10.1109/CEC.2003.1299577 (2003).
Rana, S., Jasola, S. & Kumar, R. A review on particle swarm optimization algorithms and their applications to data clustering. Artif. Intell. Rev. 35, 211–222 (2011).
Purushothaman, R., Rajagopalan, S. & Dhandapani, G. Hybridizing Gray Wolf Optimization (GWO) with Grasshopper Optimization Algorithm (GOA) for text feature selection and clustering. Appl. Soft Comput. 96, 106651. https://doi.org/10.1016/j.asoc.2020.106651 (2020).
Ahmadi, R., Ekbatanifard, G. & Bayat, P. A modified grey wolf optimizer based data clustering algorithm. Appl. Artif. Intell. 35, 63–79 (2021).
Ullmann, T., Hennig, C. & Boulesteix, A.-L. Validation of cluster analysis results on validation data: A systematic framework. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 12, e1444 (2022).
Chacón, J. E. & Rastrojo, A. I. Minimum adjusted rand index for two clusterings of a given size. Adv. Data Anal. Classif. 17, 125–133 (2023).
Zhao, Q. Cluster Validity in Clustering Methods. Ph.D. Thesis, Itä-Suomen yliopisto (2012).
Kowsari, K. et al. Text classification algorithms: A survey. Information 10, 150 (2019).
Wu, Q., Ye, Y., Zhang, H., Ng, M. K. & Ho, S.-S. Forestexter: An efficient random forest algorithm for imbalanced text categorization. Knowl. -Based Syst. 67, 105–116 (2014).
Goudjil, M., Koudil, M., Bedda, M. & Ghoggali, N. A novel active learning method using SVM for text classification. Int. J. Autom. Comput. 15, 290–298 (2018).
Xu, S. Bayesian naïve Bayes classifiers to text classification. J. Inf. Sci. 44, 48–59 (2018).
Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 17, 168–192 (2020).
Ferri, C., Hernández-Orallo, J. & Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 30, 27–38 (2009).
Funding
This Project was funded by the Deanship of Scientific Research (DSR) at King Abdulaziz University, Jeddah, under grant no.(GPIP: 148-612-2024). The authors, therefore, acknowledge with thanks DSR for technical and financial support.
Author information
Authors and Affiliations
Contributions
All authors conceptualized this study, curated the data, and reviewed the manuscript. T.M. and R.M. developed the Methodology. T.M. collected the dataset, conducted the experiments, analyzed the results, and prepared the original draft.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Almutairi, T.M., Saifuddin, S.R., Alotaibi, R.M. et al. Open source Arabic research paper dataset for natural language processing. Sci Rep 15, 31631 (2025). https://doi.org/10.1038/s41598-025-16647-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-16647-5
