
Abstract
Gliomas are known to have different sub-regions within the tumor, including the edema, necrotic, and active tumor regions. Segmenting of these regions is very important for glioma treatment decisions and management. This paper aims to demonstrate the application of U-Net and pre-trained U-Net backbone networks in glioma semantic segmentation, utilizing different magnetic resonance imaging (MRI) image weights. The data used in this study for network training, validation, and testing is the Multimodal Brain Tumor Segmentation (BraTS) 2021 challenge. In this study, we applied the U-Net and different pre-trained Backbone U-Net for the semantic segmentation of glioma regions. The ResNet, Inception, and VGG networks, which are pre-trained using the ImageNet dataset, have been used as the Backbone in the U-Net architecture. The Accuracy (ACC) and Intersection over Union (IoU) were employed to assess the performance of the networks. The most prominent finding to emerge from this study is that trained ResNet-U-Net with T1 post-contrast enhancement (T1Gd) has the highest ACC and IoU for the necrotic and active tumor regions semantic segmentation in glioma. It was also demonstrated that a trained ResNet-U-Net with T2 Fluid-Attenuated Inversion Recovery (T2-FLAIR) is a suitable combination for edema segmentation in glioma. Our study further validates that the proposed framework’s architecture and modules are scientifically grounded and practical, enabling the extraction and aggregation of valuable semantic information to enhance glioma semantic segmentation capability. It demonstrates how useful the ResNet-U-Net will be for physicians to extract glioma regions automatically.
Similar content being viewed by others

Introduction
Glioma tumors represent a formidable challenge in oncology, characterized by their aggressive nature and diverse clinical manifestations. These kinds of tumors originate from glial cells, which function as supportive cells within the brain and spinal cord. Glioma tumors exhibit distinct spatial heterogeneity, characterized by identifiable regions, including edema, necrosis, and active tumor proliferation1,2,3. Each of these particular areas in glioma possesses specific features that have significant implications for therapeutic strategies and biological understanding.
The edema region refers to the swelling caused by the abnormal accumulation of fluid around the tumor, which can lead to severe neurological symptoms1. The necrotic region represents areas of dead or dying tumor cells, which often create serpentine patterns and are surrounded by tumor cells forming pseudopalisades4,5. The active tumor region comprises proliferating and invasive tumor cells that contribute to the malignant nature of gliomas6. Therefore, segmentation and detection of these regions are a crucial stage in glioma treatment and play a vital role in its management.
Magnetic Resonance Imaging (MRI) is a primary imaging modality for visualizing these regions. Peritumoral brain edema (PTBE) appears as high intensity on T2-weighted images2 and contains scattered invasive tumor cells and reactive cells (astrocytes and activated microglia)7. Necrotic regions exhibit T2 hyperintensity and gadolinium enhancement, which can be similar to radiation-induced necrosis8. Active tumor regions are identified by a high choline-containing compound-N-acetylaspartate index (CNI) on MRI spectroscopy (MRS), indicative of metabolic activity9. They also exhibit high amino acid uptake, dense cellularity, and reduced apparent diffusion coefficient (ADC) values on diffusion-weighted imaging (DWI)9. Post-gadolinium contrast-enhanced regions in glioblastomas, often with spherical and symmetric shapes, suggest tumor progression10.
Hence, precise segmentation of different glioma regions in MRI scans is essential for accurate diagnosis, effective treatment planning, and monitoring the progression of the disease. Manual segmentation by expert radiologists is time-consuming, subjective, and prone to inter-rater variability11,12. Therefore, the development of automated and robust glioma segmentation methods has been an active area of research in the field of medical image analysis.
In recent years, the advent of deep learning techniques has significantly advanced the field of glioma segmentation. Convolutional Neural Networks (CNNs) and their variants, such as U-Net13, have demonstrated state-of-the-art performance in segmenting different tumor subregions, including the enhancing tumor, tumor core, and the entire tumor12,14,15. These methods leverage the inherent spatial and contextual information present in multimodal MRI data, including T1, T2, post-contrast enhanced T1 (T1Gd), and fluid-attenuated inversion recovery (FLAIR) MRI images weights.
However, several challenges remain in glioma segmentation using U-Net and CNN, including the high degree of intra- and inter-tumor heterogeneity, the presence of ambiguous tumor boundaries, and the limited availability of large-scale, annotated datasets, especially from diverse patient populations. Many attempts have been made to improve the performance of U-Net and CNNs architectures for glioma tumor semantic segmentation. To address these challenges, recent research has focused on developing advanced deep-learning architectures, such as Backbone U-Net16,17 and modifications of CNN architectures18. Yadav et al.17 developed EfficientNetB7 as the encoder part of the U-Net + + network for whole-tumor segmentation of LGG tumors using FLAIR MRI image weights. Backbone U-Net models are a variation of the classic U-Net architecture, specifically designed for image segmentation tasks. The critical distinction is that the encoder part of the U-Net, also known as the backbone, employs a pre-trained model from a more extensive network such as ResNet19, Inception20, or VGG21. By leveraging these pre-trained backbones, the model can benefit from the rich and discriminative features learned on large-scale datasets, which can improve the performance of the target task, especially when the training dataset is relatively small. Alongside performance improvements in CNNs, there’s growing interest in using different MRI image-weights as CNN inputs to enhance glioma semantic segmentation performance. The primary purpose of this study is to develop an understanding of the benefits of Backbone U-Net for the semantic segmentation of different regions of glioma tumors in comparison with the U-Net architecture. This paper aims to demonstrate the impact of different backbones on the U-Net architecture’s performance in glioma semantic segmentation. Additionally, this research investigates the emerging role of MRI image weight input during the training phase in the context of glioma semantic segmentation, utilizing the backbone U-Net architectures.
Materials and methods
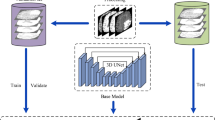
To illustrate the overall workflow of the study, Fig. 1 presents a visual representation. The study began with the preparation of the Multimodal Brain Tumor Segmentation (BraTS) dataset, which involved creating training, testing, and validation datasets. This data was then used to train, test, and validate U-Net and different Backbone U-Net networks. Finally, these findings were evaluated to clearly convey the study’s methodology, results, and conclusions. Additionally, the research ethics committee at Isfahan University of Medical Sciences, Isfahan, Iran, approved the study with ID: IR.MUI.DHMT.REC.1403.143.

Schematic flow of proposed work including Image Dataset, Data preparation (Data splitting), Model training, Model prediction, and Model evaluation stages.
Image data set and data Preparation
The BraTS dataset22,23,24 was used in this study for the glioma semantic segmentation task. The BraTS dataset provides an extensive collection of pre-operative multimodal MRI scans of subjects with glioblastoma (high-grade, GBM/HGG) and lower-grade glioma (LGG), all of which have pathologically confirmed diagnoses. Through the use of the BraTS dataset, we were able to access different MRI image weights for each subject, such as T1, T1Gd, T2, and T2-FLAIR. All the subject images in the BraTS dataset have been manually segmented by one to four specialists, following experienced neuro-radiologists who approved the annotations. Each image in the dataset was annotated with four distinct labels: the background, the active region, the necrotic and non-enhancing tumor core, and the peritumoral edema. Skull-stripping, co-registration to the same anatomical template, and interpolation to the exact resolution (1 mm3) are critical steps in BraTS preprocessing. The data used in this study is consistent with the BraTS 2021 challenge.
U-Net and backbone U-Net architecture
In this study, we applied the U-Net architecture for the semantic segmentation of glioma regions. The U-Net, illustrated in Fig. 2, consists of nineteen convolution layers with a kernel size of 3 × 3 and Rectified Linear Unit (ReLU) as activation function. We maintained consistent padding and used the ‘he_normal’ kernel initializer. Moreover, the architecture consists of four max-pooling layers with a 2 × 2 kernel size, four up-convolution layers of the same size, four concatenate layers, and a final convolution layer with a 1 × 1 kernel size and a ‘Sigmoid’ activation function. The details regarding image size and the number of filters in each layer are shown in Fig. 2. To compile the U-Net model, ‘categorical cross-entropy’ loss function, ‘Adam’ optimizer, and ‘accuracy’ as the evaluation metric were used. The total number of trainable parameters in our U-Net architecture amounts to 1,940,868. We implemented the U-Net architecture using TensorFlow and the Keras library in Python. We conducted multiple runs of the U-Net model to determine the optimal number of epochs for training and evaluate the network’s accuracy. To create a test dataset during training, we utilized a train-test split of 0.8/0.2 from the data, and the model training was conducted on a GPU (NVIDIA GeForce RTX-3090 with 24 GB memory). Due to our GPU memory and computational capabilities, it was decided that the images would be resized to 128 × 128 for this investigation.

The U-Net architecture and parameters utilized in this study are depicted in detail. Each box in the architectural diagram corresponds to a multichannel feature map, with the number of channels indicated above each box. The feature map size is also displayed on the lower side of each box. The arrows, distinguished by various colors, symbolize distinct operations within the architecture such as Convolution, Maxpooling, Up-Convolution, and Concatenation.
The Backbone U-Net is a popular variant of the original U-Net architecture that leverages pre-trained CNN models as the encoder, or backbone, of the network. This approach aims to benefit from the rich feature representations learned by these pre-trained backbones and enhance the overall performance of the U-Net model for image segmentation tasks. In this study, the Backbone U-Net builds upon the standard U-Net by replacing the encoder part with a pre-trained CNN model, such as VGG, ResNet, and Inception. These pre-trained models have been trained on ImageNet, a large-scale dataset.
The U-Net architecture employed for glioma segmentation incorporates the ResNet-50 model as its backbone. The encoder segment of the ResNet-U-Net leverages the ResNet architecture, well-known for its robust deep residual learning framework. Each ResNet block within the backbone comprises three convolutional layers, a batch normalization layer, a ReLU activation layer, and a max pooling layer (Fig. 3). The decoder consists of four blocks, each featuring a transposed convolution layer, concatenation with the corresponding encoder feature maps, and two convolutional layers with batch normalization and ReLU activation. The architecture culminates in a convolutional layer with a 1 × 1 kernel size, utilizing a ‘Sigmoid’ activation function to generate the final segmentation map delineating the glioma regions. The ResNet-U-Net model is compiled using a ‘categorical cross-entropy’ loss function and the ‘Adam’ optimizer, with ‘accuracy’ serving as the performance metric. The total number of trainable parameters in the ResNet-U-Net architecture amounts to 24,439,239. Further details of the ResNet-U-Net architecture are illustrated in Fig. 3.

The ResNet-U-Net architecture and parameters utilized in this study are detailed. The architecture integrates the robust feature extraction capabilities of the Residual Network (ResNet) with the U-Net’s efficient segmentation framework. The ResNet serves as the backbone, employing residual blocks that allow the training of deeper networks by mitigating the vanishing gradient problem. The U-Net structure, with its characteristic skip connections, ensures the preservation of spatial details essential for accurate segmentation.
The Inception-U-Net architecture (Fig. 4) leverages the strengths of the Inception V3 modules, known for their efficiency in handling multi-scale information, with the robustness of the U-Net framework for semantic segmentation. The encoder of our Inception-U-Net is built upon the Inception model, which consists of multiple Inception blocks. Each block contains parallel convolutional layers with varying kernel sizes (1 × 1, 3 × 3, 5 × 5) and a 2 × 2 max-pooling layer, all concatenated to capture features at different scales. This multi-path design allows the network to adapt to the diverse shapes and sizes of glioma regions within MRI images. The Inception-U-Net’s decoder part mirrors the traditional U-Net’s expansive path. It includes up-convolution layers that increase the resolution of the feature maps, followed by concatenation with the corresponding feature maps from the encoder via skip connections. These connections help preserve spatial information, which is crucial for accurate segmentation. The architecture culminates in a convolutional layer with a 1 × 1 kernel size, employing a ‘Sigmoid’ activation function to generate the final segmentation map, delineating the glioma regions with precision. Our Inception-U-Net model is compiled with a ‘categorical cross-entropy’ loss function and an ‘Adam’ optimizer. The performance metric used is ‘accuracy’, ensuring that the model’s predictions are closely aligned with the ground truth annotations. The total count of trainable parameters in the Inception-U-Net architecture amounts to 29,897,124.

Detailed architecture of the Inception-U-Net for glioma semantic segmentation. The architecture is depicted in two main sections: the encoder, which utilizes Inception blocks for multi-scale feature extraction, and the decoder, which employs up-convolution layers for precise localization. Skip connections between corresponding layers in the encoder and decoder facilitate the integration of contextual information at various resolutions. The final output layer uses a sigmoid activation function to produce the segmented image.
In this study, we adapted the VGG-16 architecture to resemble the U-Net architecture. We achieved this by introducing an expansive layer at the end of the VGG16, which includes multiple upsampling layers and convolutional layers. The resulting model architecture becomes symmetrical, resembling the shape of the letter “U.” Specifically, the VGG-U-Net model (Fig. 5) comprises the original contracting layer (VGG-16) and an expansion layer that we add subsequently. The encoder, or contracting path, of the VGG-U-Net consists of five down-sampling layers, each containing two convolutional layers, a batch normalization layer, and a ReLU activation layer. The decoder, or expansive path, comprises four up-sampling layers, each with a transposed convolution layer, a concatenation with the corresponding feature maps from the encoder, and two convolutional layers with batch normalization and ReLU activation. The total count of trainable parameters in the VGG-U-Net architecture amounts to 23,748,676.

VGG-U-Net architecture for glioma segmentation. This figure illustrates the VGG-U-Net, a hybrid model that combines the VGG-16 backbone with the U-Net architecture. The VGG-16 serves as the encoder, extracting high-level features from glioma MRI scans. The U-Net decoder reconstructs the segmented glioma regions, preserving spatial information through skip connections. The final output layer produces precise tumor segmentations.
To address potential bias and improve model performance in the presence of class imbalance, we implemented class weighting during model training. Specifically, we assigned higher weights to the minority class, inversely proportional to its frequency in the training set. It is important to bear in mind in this study for network training, we employed 5-fold cross-validation to rigorously evaluate the performance and generalizability of our models.
Performance evaluation
In this research, we utilized two key metrics to evaluate the performance of the U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net models: Accuracy (ACC) and Intersection over Union (IoU). Accuracy is the ratio of accurately predicted pixels ((True Positive) + (True Negative)) to the total pixel count ((True Positive) + (True Negative) + (False Positive) + (False Negative)), which comprehensively assesses the model’s classification accuracy.
The IoU (Eq. 1), on the other hand, quantifies the overlap between the predicted segmentation and the ground truth, serving as a crucial indicator of the model’s segmentation precision.
Meanwhile, IoU calculates the overlap between the predicted segmentation and ground truth (original) masks, quantifying their spatial agreement.
To comprehensively evaluate the performance of different DNN architectures for glioma semantic segmentation, we calculated four distinct IoU metrics corresponding to the different regions of interest within the glioma tumor:
-
1.
Necrotic region IoU (N-IoU): This metric quantifies the overlap between the predicted segmentation and the ground truth annotation for the necrotic regions of the glioma.
-
2.
Active Tumor IoU (AT-IoU): This metric assessed the model’s accuracy in delineating the glioma’s active, proliferating tumor areas.
-
3.
Edema IoU (E-IoU): This metric evaluates the model’s ability to segment the regions of fluid accumulation, or edema, surrounding the glioma.
-
4.
Background IoU (B-IoU): This metric assessed the model’s performance in segmenting the background tissue or non-tumoral regions.
Our study examines how these metrics offer a dual perspective on the model’s efficacy: accuracy highlights the precision of pixel-wise classification, while IoU assesses the quality of semantic segmentation by measuring the spatial congruence with the annotations.
Statistical analysis
For statistical analysis, the SPSS 26.0 software (IBM Corp., Armonk, NY, USA) was used. Normality test was done in order to assess the normal distribution of the data. For this purpose, a student’s t-test was used for binary variables (U-Net Vs. Backbone U-Nets) and an analysis of variance (ANOVA) for those with more than two groups (impact of MRI image-weight)25. In this study, P < 0.05 was indicated to be statistically significant.
Result
Trained U-Net and Backbone U-Net models have been evaluated with T1, T2, T1Gd, and T2-FLAIR MRI image weights, and the semantic segmentation results were comprehensively evaluated. Figure 6 presents the evaluation of the semantic segmentation results obtained from the trained U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net models using different MRI image weights on a subset of test data. The results of the semantic segmentation of regions in glioma, including edema, necrotic, and active tumor regions, with trained models, are presented in Fig. 6. Table 1 summarizes the performance of U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net in segmenting glioma regions across various MRI image weights, including T1, T1Gd, T2, and T2-FLAIR. It is apparent from this table that an essential aspect of our evaluation involved comparing the mean IoU scores between the U-Net network and the Backbone U-Net for glioma semantic segmentation tasks. While the U-Net network demonstrated faster runtime due to its smaller trainable parameter size, it is noteworthy that the Backbone U-Net (ResNet-U-Net, Inception-U-Net, and VGG-U-Net) consistently achieved significantly higher mean IoU scores for glioma semantic segmentation. What is interesting in this table is that, among the backbone U-Net architectures evaluated in this study, the ResNet-U-Net network trained with T1Gd images emerged as the top performer in terms of mean IoU values for glioma semantic segmentation. Incorporating the ResNet architecture into the U-Net framework has proven beneficial for accurate boundary detection and object localization in glioma segmentation.

This figure presents the semantic segmentation results obtained from training various U-Net models, including the standard U-Net as well as its ResNet-U-Net, Inception-U-Net, and VGG-U-Net variants, using different MRI image weights such as T1, T2, T1Gd, and T2-FLAIR.1 Each row in the figure corresponds to a specific MRI image modality, while each column represents a different U-Net architecture. The segmentation outputs demonstrate the models’ ability to accurately delineate regions of interest, including edema, Necrotic, and active tumor regions, across diverse MRI image weights and U-Net models.
To gain further insights into the performance of different MRI image weights and U-Net and Backbone U-Net architectures in segmenting various glioma regions, such as the necrotic region, edema, and active tumor regions, we generated a heatmap illustrating the IoU values for each combination. As depicted in the heat map (Fig. 8), different MRI image weights, including T1, T2, T2-FLAIR, and T1Gd, were evaluated in conjunction with different U-Net architectures, such as U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net.
From the necrotic IoU (N-IoU) heat map (Fig. 7), it is evident that certain combinations consistently outperformed others in terms of necrotic region segmentation. For instance, the ResNet-U-Net architecture trained with T1Gd images consistently demonstrated the significant highest N-IoU values, indicating its superior performance in accurately delineating the necrotic region in glioma. A key observation in our study was that all the backbone U-Net architectures, ResNet-U-Net, Inception-U-Net, and VGG-U-Net, consistently outperformed the standard U-Net architecture in necrotic region segmentation. This finding highlights the positive impact of incorporating a backbone network within the U-Net framework, improving segmentation accuracy.

Necrotic region IoU (N-IoU) heat map for glioma region segmentation using T1Gd, T1, T2, and FLAIR MRI image weights by U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net networks. The mean N-IoU values in test data are presented.
Similarly, we evaluated the performance of different MRI image weights and U-Net and Backbone U-Net architectures for edema segmentation, and the results are presented as a heat map in Fig. 8. Notably, the ResNet-U-Net architecture trained with T2-FLAIR images consistently exhibited the highest E-IoU values and outperformed other configurations regarding edema region segmentation accuracy in glioma. According to Fig. 8, interestingly, the Inception-U-Net architecture yielded results that were very close to those obtained with the ResNet-U-Net for edema segmentation using T2-FLAIR images, demonstrating a similar level of E-IoU for edema segmentation in glioma tumors.

Edema IoU (E-IoU) heat map for glioma region segmentation using T1Gd, T1, T2, and T2-FLAIR MRI image weights by U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net networks. The mean E-IoU values in test data are presented.
Regarding the glioma active tumor region segmentation, our analysis revealed that the ResNet-U-Net trained with T1Gd images exhibited the highest performance (Fig. 9). This finding, evident from the AT-IoU heat map analysis, underscores the effectiveness of utilizing the ResNet-U-Net architecture in combination with T1Gd images for precise delineation of the active tumor region.

Active tumor IoU (AT-IoU) heat map for glioma region segmentation using T1Gd, T1, T2, and FLAIR MRI image weights by U-Net, ResNet-U-Net, Inception-U-Net, and VGG-U-Net networks. The mean AT-IoU values in test data are presented.
Discussion
Gliomas are known to have distinct regions within the tumor, including the edema region, necrotic region, and active tumor region. Edema is commonly observed around glioma tumors, and histopathological analysis reveals that the edema area contains scattered invasive tumor cells, reactive cells (astrocytes and activated microglia), and various blood vessel patterns. The necrotic region in gliomas exhibits histological features associated with poor prognosis. Metabolically active tumor regions indicate the active tumor regions in gliomas. As mentioned in the literature, segmenting different regions in glioma is essential for treatment and decision-making processes. Manual segmentation of glioma regions is a time-consuming method due to the labor-intensive nature of the task. Recent developments in computer science have led to the introduction of different automatic segmentation methods for glioma semantic segmentation. This study aimed to assess the importance of pre-trained Backbone U-Net networks in glioma semantic segmentation tasks using different MRI image weights.
The results of this study show that all pre-trained Backbone U-Net models (ResNet-U-Net, Inception-U-Net, and VGG-U-Net) have higher mean IoU values for glioma semantic segmentation compared to the standard U-Net architecture. In accordance with the present results, previous studies have demonstrated that the Backbone U-Net architecture exhibits superior performance in segmenting LGG tumors17,26,27. In the current study, a notable difference in runtime was observed between the U-Net and pre-trained Backbone U-Net networks, with the U-Net network demonstrating significantly faster training times for each epoch. The U-Net network exhibits a smaller parameter count for training than the Backbone U-Net, reducing computational requirements during training stages. The higher mean IoU values achieved by the Backbone U-Net demonstrate its superior ability to delineate accurately and segment objects of interest within the given images. Despite the increased computational requirements associated with the more significant number of trainable parameters in the Backbone U-Net, the improved semantic segmentation performance is crucial in applications where precise boundary detection and object localization are paramount.
Our study examined the performance of various backbone U-Net architectures and MRI image weights in segmenting necrotic regions, tumor-active regions, and edema regions within glioma tumors. Our findings indicated that a trained ResNet-U-Net architecture with FLAIR resulted in the highest IoU and performance compared to other architectures and MRI image weights for peritumoral edema segmentation in gliomas. Additionally, our findings showed that training the ResNet-U-Net architecture with T1Gd images yielded the highest IoU and performance compared to other architectures and image weights for segmenting necrotic and tumor-active regions in glioma tumors. In the current study, comparing the performance of different backbone U-Net architectures for glioma different region segmentation showed that the ResNet-U-Net outperformed the Inception-U-Net and VGG-U-Net. This study yields results that corroborate the findings of a great deal of previous work in various scientific fields28,29,30. There are several possible explanations for these results. ResNet introduces residual connections that allow the model to learn residual mappings instead of directly approximating the underlying mapping31. This helps address the vanishing gradient problem, enabling the model to learn more effective representations31. The residual connections also facilitate the flow of gradients during backpropagation, allowing for better network optimization. ResNet is recognized for its robust feature extraction capabilities32. The deep architecture enables it to capture intricate details and hierarchical features, which are crucial for accurately segmenting gliomas. The network’s ability to learn complex representations may allow it to capture fine-grained patterns, edges, and textures related to gliomas, resulting in improved segmentation performance compared to other networks.
It is encouraging to compare the results of this study with the top-ranking models from the BraTS 2021 challenge. In their groundbreaking paper on the BraTS 2021 challenge winner, Futrega et al.33 utilized an optimized U-Net for glioma tumor segmentation, reporting a mean DICE coefficient of 0.8855 for whole-tumor segmentation. This value matches and is comparable to those observed in our study. In another top-ranking model, Siddiquee and Myronenko34 developed a new model, named SegResNet, for glioma segmentation, showing that the mean DICE coefficient was 0.8847 for enhancing tumor region segmentation. These data must be interpreted with caution because both studies33,34 used a stacked tensor of four MRI image-weights (T1, T2, T1Gd, and FLAIR. Input tensor is in the (C, H, W, D) format, where C-MRI image weights, H- image height, W-image width and D-image depth) for model training while in our study we trained our models with each MRI image-weights separately for evaluation the impact of MRI image-weights as image input on segmentation result.
Furthermore, our research emphasized the importance of selecting appropriate MRI image weights for training U-Net and backbone U-Net for accurate semantic segmentation of different regions of gliomas. The results of this study show that, by focusing on FLAIR as the input image for the training phase, we leveraged its unique characteristics to enhance the performance of ResNet-U-Net for edema region segmentation in glioma tumors. This result may be explained by the fact that the different MRI image contrasts are based on distinct physiological data and processes35,36,37. FLAIR images are sensitive to edematous tissues, providing valuable information about the extent of the peritumoral edema. These findings further support the use of FLAIR for edema segmentation in glioma tumors using the ResNet-U-Net architecture.
By specifically focusing on T1Gd images as the primary input during training, our ResNet-U-Net model achieved superior performance in accurately delineating the necrotic and tumor active regions in glioma tumors. T1Gd images, which capture the contrast enhancement after gadolinium injection, offer valuable insights into the presence and intensity of these regions. Following the present results, previous studies have demonstrated that T1Gd images provide better visualization and delineation of active tumor regions in gliomas in comparison with T2, T1, and FLAIR due to the enhancement of contrast agent uptake, which highlights areas of increased vascularity and tumor activity38,39 and higher signal-to-background contrast40. Several studies have reported that T1Gd images provide superior accuracy and sensitivity in detecting necrotic regions within gliomas, as the contrast enhancement facilitates the differentiation of necrotic areas from viable tumor tissue, edema, or other non-enhancing structures41,42,43. The current investigation was limited by the MRI image weights in the BraTS dataset. As you know, MRI images can have different weights with different image contrast and data, such as DWI, Susceptibility-weighted imaging (SWI), functional MRI (fMRI), etc. Future research can further explore the benefits of incorporating other advanced architectures or alternative MRI image weight combinations to improve semantic segmentation accuracy and advance the understanding of glioma tumor characteristics. In this study we used original ResNet, Inception, and VGG blocks as backbones in the U-Net architecture without change and optimization the block layers. Future works should focus on using fine-tunning of these backbones for enhancing the model performance for glioma semantic segmentation. Data imbalance is a major limitation of the BraTS dataset, arising from variations in tumor-to-healthy tissue ratios, LGG/HGG distributions, and tumor sub-region sizes. While we used image class weighting to mitigate data imbalance in this study, other research, such as44, has investigated novel methods for this issue. Future work could explore these alternative approaches. Also, it is recommended that further research be undertaken to compare the performance of Backbone U-Net’s with new shape-scale co-awareness network45 and hybrid CNN-transformer networks46 in future works on same data and same purpose. While this study employed categorical cross-entropy loss to maintain consistency with standard segmentation benchmarks, future work could explore specialized loss functions (e.g., Dice, Tversky, or focal loss) to further improve performance, particularly for class-imbalanced medical imaging datasets. While our 5-fold cross-validation on BraTS 2021 demonstrates consistent performance, the generalizability of our approach to other datasets (e.g., acquired with different scanners or protocols) remains to be verified. Future work should include multi-center studies and external validation to further strengthen clinical relevance.
Conclusion
This study aimed to evaluate the impact of various pre-trained backbone U-Net architectures and MRI image weights on glioma semantic segmentation. Overall, the combination of ResNet’s deep residual learning, strong feature extraction capabilities, potential transfer learning benefits, the effectiveness of skip connections in U-Net, and the dataset characteristics could collectively contribute to the ResNet-U-Net model achieving the highest performance in the glioma semantic segmentation task. Our findings highlight the importance of considering both the architectural choices and the selection of MRI image weights when developing segmentation models for glioma tumors. The superior performance for glioma edema segmentation achieved by the trained ResNet-U-Net architecture with FLAIR MRI weights has significant implications for clinical practice. It was also shown that the ResNet-U-Net model trained with T1Gd images achieved the highest performance in segmenting both active tumor and necrotic regions in glioma tumors.
Data availability
The datasets utilized in this study are available at (brats@cbica.upenn.edu, http://braintumorsegmentation.org) and analyzed data and models are available from the corresponding author upon reasonable request.
References
Lin, Z-X. Glioma-related edema: new insight into molecular mechanisms and their clinical implications. Chin. J. Cancer. 32, 49 (2013).
Ohmura, K., Tomita, H. & Hara, A. Peritumoral edema in gliomas: a review of mechanisms and management. Biomedicines 11, 2731 (2023).
Lee, E. J. et al. Diagnostic value of peritumoral minimum apparent diffusion coefficient for differentiation of glioblastoma multiforme from solitary metastatic lesions. Am. J. Roentgenol. 196, 71–76 (2011).
Hambardzumyan, D. & Bergers, G. Glioblastoma: defining tumor niches. Trends Cancer. 1, 252–265 (2015).
Liu, S. et al. Relationship between necrotic patterns in glioblastoma and patient survival: fractal dimension and lacunarity analyses using magnetic resonance imaging. Sci. Rep. 7, 8302 (2017).
Manini, I. et al. Heterogeneity matters: different regions of glioblastoma are characterized by distinctive tumor-supporting pathways. Cancers (Basel). 12, 2960 (2020).
Wang, X. et al. Histopathological findings in the peritumoral edema area of human glioma (2015).
Raimbault, A. et al. Radionecrosis of malignant glioma and cerebral metastasis: a diagnostic challenge in MRI. Diagn. Interv Imaging. 95, 985–1000 (2014).
McKnight, T. R. et al. Histopathological validation of a three-dimensional magnetic resonance spectroscopy index as a predictor of tumor presence. J. Neurosurg. 97, 794–802 (2002).
Upadhyay, N. & Waldman, A. Conventional MRI evaluation of gliomas. Br. J. Radiol. 84, S107–S111 (2011).
Xiong, F., Shen, C. & Wang, X. Generalized knowledge distillation for unimodal glioma segmentation from multimodal models. Electronics 12, 1516 (2023).
Khorasani, A., Kafieh, R., Saboori, M. & Tavakoli, M. B. Glioma segmentation with DWI weighted images, conventional anatomical images, and post-contrast enhancement magnetic resonance imaging images by U-Net. Phys. Eng. Sci. Med. 45, 925–934 (2022).
Ronneberger, O., Fischer, P., Brox, T. & Munich U-net: Convolutional networks for biomedical image segmentation. In Med. image Comput. Comput. Interv. 18th Int. Conf. Ger. Oct. 5–9, 2015, proceedings, part III 18 234–241 (Springer, 2015).
Shi, X. et al. Cross-modality attention adapter: a glioma segmentation Fine-tuning method for SAM using multimodal brain MR images. ArXiv Prepr ArXiv230701124 (2023).
Vafaeikia, P. et al. MRI-based end-to-end pediatric low-grade glioma segmentation and classification. Can. Assoc. Radiol. J. 75, 153–160 (2024).
Sharma, N. et al. U-Net model with transfer learning model as a backbone for segmentation of Gastrointestinal tract. Bioengineering 10, 119 (2023).
Yadav, A. C. et al. EffUNet++: a novel architecture for brain tumor segmentation using FLAIR MRI images. IEEE Access. (2024).
Yadav, A. C., Kolekar, M. H. & Zope, M. K. Modified recurrent residual attention U-Net model for MRI-based brain tumor segmentation. Biomed. Signal. Process. Control. 102, 107220 (2025).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. IEEE Conf. Comput. Vis. pattern Recognit. 770–778 (2016).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. In Proc. IEEE Conf. Comput. Vis. pattern Recognit. 2818–2826 (2016).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. ArXiv Prepr ArXiv 14091556 (2014).
Baid, U. et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. ArXiv Prepr ArXiv210702314 (2021).
Bakas, S. et al. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data. 4, 1–13 (2017).
Menze, B. H. et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging. 34, 1993–2024 (2014).
Beser-Robles, M. et al. Deep learning automatic semantic segmentation of glioblastoma multiforme regions on multimodal magnetic resonance images. Int. J. Comput. Assist. Radiol. Surg. 19, 1743–1751 (2024).
Kunjumon, A., Jacob, C. & Resmi, R. An efficient U-Net based model for low grade glioma segmentation in MRI images. In 2024 second int. Conf. Emerg. Trends Inf. Technol. Eng. 1–5 (IEEE, 2024).
Sabharwal, M., Sinha, A., Gupta, D. & Malik, P. Impact Of backbone architectures and loss functions on U-Net models For brain tumor segmentation: a comparative analysis. In Proc. 2023 Fifteenth Int. Conf. Contemp. Comput. 484–492 (2023).
Jain, J., Kubadia, M., Mangla, M. & Tawde, P. Comparison of transfer learning techniques to classify brain tumours using MRI images. Eng. Proc. 59, 144 (2024).
Klontzas, M. E. et al. Deep learning for the differential diagnosis between transient osteoporosis and avascular necrosis of the hip. Diagnostics 12, 1870 (2022).
Shah, S. R. et al. Comparing inception V3, VGG 16, VGG 19, CNN, and ResNet 50: a case study on early detection of a rice disease. Agronomy 13, 1633 (2023).
Borawar, L., Kaur, R. & ResNet Solving vanishing gradient in deep networks. In Proc. Int. Conf. Recent Trends Comput. ICRTC 235–247 (Springer, 2022).
Wahid, J. A. et al. A hybrid ResNet-ViT approach to Bridge the global and local features for myocardial infarction detection. Sci. Rep. 14, 4359 (2024).
Futrega, M., Milesi, A., Marcinkiewicz, M. & Ribalta, P. Optimized U-Net for brain tumor segmentation. In MICCAI brainlesion Work 15–29 (Springer, 2021).
Rahman Siddiquee, M. M. & Myronenko, A. Redundancy reduction in semantic segmentation of 3d brain tumor mris. In MICCAI Brainlesion Work 163–172 (Springer, 2021).
Khorasani, A., Dadashi serej, N., Jalilian, M., Shayganfar, A. & Tavakoli, M. B. Performance comparison of different medical image fusion algorithms for clinical glioma grade classification with advanced magnetic resonance imaging (MRI). Sci. Rep. 13, 17646 (2023).
Tavakoli, M. B., Khorasani, A. & Jalilian, M. Improvement grading brain glioma using T2 relaxation times and susceptibility-weighted images in MRI. Inf. Med. Unlocked. 37, 101201 (2023).
Khorasani, A. & Tavakoli, M. B. Multiparametric study for glioma grading with FLAIR, ADC map, eADC map, T1 map, and SWI images. Magn. Reson. Imaging. 96, 93–101 (2023).
Carrete, L. R., Young, J. S. & Cha, S. Advanced imaging techniques for newly diagnosed and recurrent gliomas. Front. Neurosci. 16, 787755 (2022).
Yamashiro, H., Teramoto, A., Saito, K. & Fujita, H. Development of a fully automated glioma-grading pipeline using post-contrast T1-weighted images combined with cloud-based 3D convolutional neural network. Appl. Sci. 11, 5118 (2021).
Gad, M., Elsorogy, L. G. & Moustafa, S. A. F. Diagnostic utility of contrast-enhanced FLAIR MRI in imaging of demyelinating and infectious brain lesions. Egypt. J. Radiol. Nucl. Med. 54, 104 (2023).
Markwell, S. M., Ross, J. L., Olson, C. L. & Brat, D. J. Necrotic reshaping of the glioma microenvironment drives disease progression. Acta Neuropathol. 143, 291–310 (2022).
Verma, N., Cowperthwaite, M. C., Burnett, M. G. & Markey, M. K. Differentiating tumor recurrence from treatment necrosis: a review of neuro-oncologic imaging strategies. Neuro Oncol. 15, 515–534 (2013).
Fan, H. et al. Artificial intelligence-based MRI radiomics and radiogenomics in glioma. Cancer Imaging. 24, 36 (2024).
Ghosal, P. et al. Compound attention embedded dual channel encoder-decoder for Ms lesion segmentation from brain MRI. Multimed Tools Appl. 2024, 1–33 (2024).
Zhou, L., Jiang, Y., Li, W., Hu, J. & Zheng, S. Shape-scale co-awareness network for 3d brain tumor segmentation. IEEE Trans. Med. Imaging (2024).
Liu, Y., Ma, Y., Zhu, Z., Cheng, J. & Chen, X. TransSea: hybrid CNN-transformer with semantic awareness for 3D brain tumor segmentation. IEEE Trans. Instrum. Meas. (2024).
Acknowledgements
The authors express their gratitude to Isfahan University of Medical Sciences for providing the financial support for this work.
Funding
This study was supported by Isfahan University of Medical Sciences, Isfahan, I.R. Iran (grant number 2403179).
Author information
Authors and Affiliations
Contributions
Conceptualization, A.K.; Methodology, A.K.; Validation, A.K.; Investigation, A.K.; Resources, A.K.; Data Curation, A.K.; Writing—Original Draft Preparation, A.K.; Writing—Review and Editing, A.K.; Supervision, A.K.; Project Administration, A.K.; Funding Acquisition, A.K., All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Khorasani, A. Enhanced glioma semantic segmentation using U-net and pre-trained backbone U-net architectures. Sci Rep 15, 31821 (2025). https://doi.org/10.1038/s41598-025-17895-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17895-1
Keywords
This article is cited by
-
Modeling Ischemic Stroke Pathological Dynamics via Continuous Fields and Vector Flow
npj Digital Medicine (2026)
