
Abstract
The urgent demand for sustainable concrete has intensified as greenhouse gas emissions increasingly threaten global environmental stability. High-performance geopolymer concrete (HPGC) presents a promising sustainable alternative to traditional cement-based materials. The mix design of HPGC considering compressive strength, cost, and carbon emissions is crucial while hard to implement using traditional non-destructive methods. To resolve the issue, this study proposes an integrated framework combining automated machine learning (AutoML) modeling and multi-objective optimization (MOO) to balance compressive strength, cost, and carbon emissions in HPGC mix-design. Our research mainly includes three innovations: (1) We integrate ML-based predictive modeling with MOO framework for HPGC; (2) we establish an AutoML-Shapley Additive Explanations (SHAP) framework that harmonizes predictive accuracy with interpretability; and (3) we introduce the Pareto non-dominated sorting into MOO for HPGC. First, we employ an advanced AutoML algorithm to automatically develop a robust predictive model for HPGC compressive strength. Based on a database containing 295 mixes, the AutoML model demonstrated comparable accuracy compared to conventional ensemble learning methods, achieving a validation dataset determination coefficient (R2) of 0.9280, root mean squared error (RMSE) of 5.2954 MPa, mean absolute error (MAE) of 4.2307 MPa, mean absolute percentage error (MAPE) of 0.0724, and a20 index of 0.9677. Subsequently, the SHAP method is applied to identify critical factors influencing HPGC performance and enhance the interpretability of the AutoML model. Finally, a Pareto non-dominated sorting algorithm is integrated into MOO to generate solutions that minimize unit cost and carbon emissions while maintaining compressive strength. The optimization framework reduces CO₂ emissions by 23–60% and unit costs by 16–36%, confirming the method’s efficacy in balancing multiple objectives. This research advances eco-efficient concrete design methodologies and supports the broader adoption of green building technologies. It should be highlighted that the trained ML models are based on limited data, so the application of the models should be restricted to a certain range. The collected database will be expanded, which can resolve the ML limitations such as model generalizability.
Similar content being viewed by others

Introduction
Global warming has emerged as one of the most pressing challenges. Carbon dioxide (CO₂), a primary greenhouse gas, is a major contributor to climate change1. Cement production alone contributes 7–8% of global CO₂ output2. The environmental toll of cement manufacturing is overwhelming: for every ton of cement Manufactured, an estimated 0.9 tons of CO₂ are released into the atmosphere3. The construction industry has become a critical focus area for reducing carbon emissions and advancing sustainability goals. To combat climate change, the sector has increasingly adopted eco-friendly building technologies and materials4,5,6,7,8 as part of carbon neutrality initiatives. Among these innovations, geopolymer concrete (GC) has gained significant attention for demonstrating mechanical strengths surpassing those of conventional Portland cement (PC) concrete, alongside enhanced durability against chemical reactions9, corrosion10, and high-temperature exposure11. Unlike PC-based materials, GC is synthesized through alkaline activation solutions (such as silicates, alkali hydroxides, and carbonates) and industrial byproduct precursors, including blast furnace slag, fly ash, metakaolin, rice husk ash, and red mud. This substitution eliminates the energy-intensive clinker production required for PC, thereby enabling substantial reductions in lifecycle carbon emissions.
It should be noted that GC may suffer from low compressive strength and poor durability performance. Therefore, the development of high-performance geopolymer concrete (HPGC)—an advanced variant of GC with enhanced mechanical and durability properties—has attracted wide attention in infrastructure applications, including high-rise buildings and long-span bridges. However, HPGC optimization requires balancing competing objectives: compressive strength, cost, and carbon emissions. While compressive strength continues to dominate mix design criteria, cost and carbon emissions have emerged as equally critical constraints. Traditional laboratory trial-and-error approaches12 and non-destructive methods13,14,15,16 to optimize these multi-variable systems are excessively resource-intensive and inefficient. Consequently, there is an urgent need for computational frameworks capable of simultaneously maximizing compressive strength, minimizing costs, and reducing carbon emissions in HPGC production.
Machine learning (ML) becomes a powerful and alternative way to solve complicated nonlinear and high-dimensional problems17,18. It has demonstrated significant potential across diverse civil engineering applications, including structural health monitoring19, damage detection20, structural response prediction21,22,23, and strength prediction24,25,26,27,28,29,30,31,32,33,34. Notably, ML has been successfully employed to forecast compressive strength in GC35,36,37 and ultra-high-performance geopolymer concrete (UHPGC)38,39,40. Parallel advancements in multi-objective optimization (MOO) have explored trade-offs between strength, cost, and CO₂ emissions in GC41 and UHPGC42. However, to the authors’ knowledge, no prior study has integrated ML-based predictive modeling with MOO frameworks for HPGC—a gap this work seeks to bridge as its principal contribution.
Traditional ML workflows are highly complex, typically comprising five key stages: (1) Data Collection: Collecting relevant datasets refer to the research objective. (2) Data Preprocessing: Cleansing anomalies such as outliers and missing values, followed by partitioning the dataset into training, testing, and validation subsets. (3) Model Selection: Identifying suitable ML algorithms based on problem type (regression/classification), data characteristics, and performance criteria. (4) Hyperparameter Tuning: Optimizing model configurations via grid search or randomized methods to enhance predictive accuracy. (5) Model Evaluation: Quantifying performance on test data using metrics like the coefficient of determination (R²), root mean squared error (RMSE), and mean absolute error (MAE). This labor-intensive workflow presents significant barriers for non-specialists.
Motivated by advancing data science and the growing demand for democratized ML tools, Automated Machine Learning (AutoML)43,44 has emerged as a robust alternative. AutoML achieves predictive accuracy comparable to state-of-the-art ensemble models like XGBoost45 and LightGBM46, while automating iterative tasks. AutoML eliminates resource-intensive tasks such as hyperparameter optimization, thereby lowering technical entry barriers and enhancing accessibility for non-experts in using ML models. In this study, AutoML is deployed to predict the compressive strength of HPGC, benchmarked against conventional ensemble methods. However, while AutoML surpasses in performance, its “black-box” nature obscures interpretability.
To address this limitation, Shapley Additive Explanations (SHAP) methodology47,48 is integrated into the framework. SHAP quantifies the contribution of individual input variables to model predictions and ranks their relative importance, enabling actionable insights into HPGC strength determinants. Thus, the study’s secondary contribution lies in establishing an AutoML-SHAP framework that harmonizes predictive accuracy with interpretability, streamlining sustainable concrete design.
ML algorithms have proven effective for assessing the compressive strength of concrete; however, optimizing mix design requires the integration of advanced optimization techniques. Meta-heuristic optimization methods, inspired by natural phenomena such as predator-prey dynamics, are widely applied across disciplines, including mining49, materials science50, and civil engineering51. Common meta-heuristic algorithms include the genetic algorithm (GA)52, particle swarm optimization (PSO)53, simulated annealing (SA)54, and ant colony optimization (ACO)55. Recent applications demonstrate their effectiveness in concrete mix design. For instance, Zhang et al.56,57 utilized PSO and beetle antennae search (BAS) algorithms to optimize ML parameters and conduct multi-objective optimization (MOO) of concrete. Similarly, Huang et al.58 employed the firefly algorithm to optimize steel fiber-reinforced concrete (SFRC) mix ratios, achieving dual-objective minimization of cost while maximizing compressive strength.
However, prior research predominantly converted MOO into single-objective problems through weighted summation of competing objective. While this approach simplifies the optimization process, it may induce incorrect results by disproportionately emphasizing specific objectives, thereby constraining the solution space and neglecting critical trade-offs. To address these limitations, this study employs Pareto dominance criteria by integrating the non-dominated sorting algorithm59. This methodology enables a systematic exploration of the solution space, avoiding biases imposed by subjective weight assignments. The introduction of Pareto non-dominated sorting into MOO for HPGC constitutes the study’s third contribution, advancing the development of equitable, sustainable mix designs.
This study develops an explainable AutoML framework for predicting HPGC compressive strength, augmented by SHAP to elucidate model behavior. Subsequently, Pareto non-dominated sorting principles are applied to conduct MOO. The article structure is briefly summarized as follows: The research significance is articulated in the opening sections. This is followed by a detailed description of the integrated framework for interpretable AutoML prediction and MOO. Subsequent passages outline the development of the HPGC database and present key predictive and optimization results. The study concludes by summarizing the main findings and their implications.
Research significance
First, there is no existing studies integrated ML-based predictive models with MOO frameworks for HPGC. Therefore, our study develops AutoML-based predictive modelling with MOO for HPGC. This paper demonstrates that the AutoML model can achieve comparable prediction performance as other powerful ensemble learning models, but it is more user-friendly and does not require complicated processes such as hyperparameter tuning.
In addition, most conventional ML approaches are black-box models and cannot provide perceptions as mechanics-based or empirical regression-based models. Feature importance is a traditional way to explain ML models. However, feature importance is difficult to determine how a feature correlates to the outputs and cannot provide a quantitative influence of each feature on the predicted result of each sample. To overcome the issue, SHAP is adopted in this study to enhance the interpretability of the AutoML model. SHAP cannot only provide a global interpretation for whole sets like feature importance, but also provide a local interpretation for each sample.
Finally, most studies convert MOO into single-objective optimization problems. This simplified method restrains the solution space and omit critical trade-offs. To overcome this problem, the Pareto non-dominated sorting is introduced into MOO to avoid possible biases induced by subjective weight assignments. This approach improves the MOO results compared with the conventional MOO strategies.
Explainable automl and MOO framework
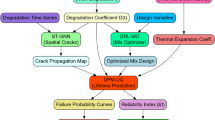
Figure 1 shows the research development flowchart, beginning with data collection and followed by evaluating the prediction performance of various ML models. The best ML model is subsequently integrated with a selected MOO algorithm to accomplish the optimization process.

Research development flowchart.
Figure 2 illustrates the workflow of the explainable AutoML prediction and MOO framework for HPGC. The framework comprises three phases: (1) AutoML Prediction: An AutoML model predicts the compressive strength of HPGC. Genetic programming optimizes hyperparameters through crossover and mutation operations. (2) Interpretability Analysis: SHAP interprets feature importance and predictions generated by the AutoML model. (3) Pareto-Optimized MOO: Leveraging the trained AutoML model, a Pareto dominance criterion guides MOO to balance compressive strength, cost, and carbon emissions. Traditional weighted-sum methods, while computationally simpler, fail to satisfy true Pareto optimality. Instead, solutions x1 and x2 are compared using dominance relationships defined in Eq. (1): x1 dominates x2 if if it outperforms x2 across all objectives without compromise. Non-dominated solutions, i.e., those not inferior to any other in all objectives, collectively form the Pareto front, enabling unbiased trade-off analysis.
where fi(x) and fj(x) denote the i-th and j-th objective function values for a candidate solution x.

Explainable AutoML and MOO framework for sustainable HPGC design.
Database construction
The HPGC database comprises 295 experimental datasets sourced from 19 peer-reviewed international journals60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78. In alignment with the CEB-FIP specification79, all mixes conform to a minimum compressive strength threshold of 50 MPa at 28 days. As recommended by previous studies38,41, ten input variables were selected, representing material constituents and curing conditions: fly ash (F), blast furnace slag (S), sodium hydroxide (SH), sodium silicate (SS), water (W), fine aggregate (FA), coarse aggregate (CA), curing temperature (T), relative humidity (RH), and curing age (Age). Compressive strength (CS), the primary performance metric, serves as the sole output variable. Detailed information for all variables is provided in Table 1.
Table 2 outlines six design constraints for HPGC, where Pi corresponds to the percentage composition of constituent i, and Wi indicates the unit weight of component i, as indicated in Table 1. The total concrete cost is derived from Eq. (2).
where Ui denotes the unit price of each constituent, as indicated in Table 1.
Figures 3 and 4 depict the frequency distributions and fitted curves for the input variables and output variable, respectively. These empirical results demonstrate comprehensive coverage of the designated parameter ranges, ensuring robust representation for model training. This range of data facilitates the ML algorithm in capturing complex, nonlinear relationships among input features and the target variable, thereby enhancing predictive accuracy. Furthermore, the ML model exhibits significant scalability, enabling seamless integration of novel data points as they become available. Such adaptability supports its application in optimizing HPGC mix designs, which necessitates identifying optimal combinations of input parameters under predefined constraints (Table 2) and cost objectives (Eq. 2).

Frequency distribution and fitting curve of input variables.

Frequency distribution and fitting curve of output variable.
Figure 5 presents a heatmap illustrating correlations between input variables and the output variable. This visualization enables researchers to quantify linear dependencies, identify redundant features (e.g., variables with correlation coefficients |r| ≥ 0.7), and iteratively refine feature selection to mitigate multicollinearity, thereby enhancing model interpretability and generalizability. Each cell in the heatmap displays the Spearman correlation coefficient (r) between two variables: positive values signify direct proportionality, while negative values indicate inverse relationships. Coefficients below |0.7| across all input pairs (Fig. 5) confirm the absence of multicollinearity, reducing overfitting risks during model training. Additionally, the heatmap reveals input-output linkages; for instance, fly ash (F) and coarse aggregate (CA) exhibit negative correlations with CS (r = − 0.1257 and r = − 0.2021, respectively), suggesting that optimizing aggregate proportions could improve compressive strength.

Heat map of input and output variables.
Prediction and optimization results
Prediction performance of ML models
Three ensemble learning algorithms—Random Forest (RF), XGBoost, and LightGBM—were implemented for comparison. Hyperparameters significantly influence the predictive accuracy of conventional ML algorithms. Systematic hyperparameter tuning enhances model performance by optimizing these variables. Grid search, a traditional hyperparameter tuning technique, follows three steps: (1) defining candidate parameter ranges, (2) exhaustively evaluating all combinations via cross-validation, and (3) selecting the configuration yielding the highest accuracy. However, grid search suffers from two critical limitations: (1) discretizing continuous hyperparameters may exclude optimal values, and (2) computational inefficiency in high-dimensional spaces due to exponentially increasing combinatorial complexity. In contrast, Bayesian optimization leverages probabilistic surrogate models to approximate the relationship between hyperparameters and performance, enabling efficient navigation of high-dimensional search spaces. Consequently, Bayesian optimization was employed for tuning three ensemble models. Conversely, AutoML eliminates manual hyperparameter adjustment through built-in optimization pipelines. It employs genetic algorithms to automatically optimize ML hyperparameters in candidate pipelines by simulating the biological evolutionary process of “selection-crossover-mutation,” ultimately retaining the best-performing solution.
No preprocessing like normalization80,81 or encoding was applied to input features or target variables during the training of ML models for predicting concrete compressive strength. This decision was driven by two primary considerations: (1) Compressive strength, as a critical engineering parameter, carries inherent physical significance and industry standards in its original units (MPa). Maintaining raw scale ensures model predictions are directly applicable to subsequent MOO algorithms; (2) It eliminates potential numerical precision loss and computational redundancy from inverse transformation steps, particularly when handling high-dimensional constrained optimization problems.
The dataset was partitioned into training, testing, and validation subsets with a 7:2:1 ratio. The predictive performance of the four ML models is plotted in Fig. 6. It can be seen from Fig. 6 that all ML models achieved excellent prediction performance.

Predicted data versus real data (experimental data) of different ML models.
To evaluate model performance, five widely recognized metrics—R2, RMSE, MAE, mean absolute percentage error (MAPE), a20 index82,83—were analyzed across all ML algorithms (Table 3). Validation results revealed R2 values exceeding 0.84 for all models, indicating their robust capacity to model nonlinear input-output relationships and deliver reliable predictions. Notably, the AutoML framework demonstrated comparable accuracy to the XGBoost and LightGBM models, achieving a R² of 0.9280 on the validation set. In contrast, the RF algorithm exhibited the lowest predictive accuracy among the evaluated models. The dataset comprises 295 samples, it substantially exceeds the fundamental requirement in ML for input parameter coverage (i.e., sample size ≥ 10× feature count)84,85. Models on validation datasets demonstrate R²>0.84 without error amplification at parameter boundaries, proving the dataset’s adequacy for reliable engineering decision-making.
The predictive accuracy of the four ML models is also compared via a Taylor diagram in Fig. 7. The diagram has two indices: correlation coefficient and standard deviation. It can be seen from Fig. 7 that the AutoML, LightGBM, and XGBoost exhibited very close predictive performance.

Taylor diagram for ML models.
Figure 8 displays the frequency distribution of the predicted-to-actual compressive strength (CS) ratios for HPGC. Compared to LightGBM, the XGBoost model exhibits a higher concentration of ratios near 1 on the testing dataset. The RF model demonstrates greater dispersion in its ratios, with a Markedly low frequency of values close to 1, indicating Limited generalization capability. In contrast, the AutoML framework achieved the most tightly clustered ratios around 1 among the four ML models on the validation set, signifying superior prediction stability.

Frequency distribution of ML predicted-to-actual compressive strength ratios for HPGC.
The 10-fold cross-validation was also conducted for the AutoML model to demonstrate the model’s robustness and avoid overfitting86,87. Figure 9 plots the 10-fold cross-validation results.

10-fold cross-validation results of the AutoML model.
It should be highlighted that the AutoML model does not require hyperparameter tuning. The key hyperparameters of three ensemble learning models are listed in Table 4.
Explainability of automl model
SHAP is an explanation method grounded in game theory. It quantifies the contribution of each feature to model predictions by computing Shapley values. This approach enables the visualization of both positive and negative feature impacts and additively decomposes prediction outcomes. Consequently, it assists researchers in identifying potential biases and enhances model interpretability. The SHAP method was applied to interpret the trained AutoML model. SHAP enables both local and global interpretation, including feature importance analysis. By calculating SHAP values, the method identifies each feature’s impact on model predictions and detects potential biases, thereby enhancing interpretability for researchers.
Figure 10 presents the SHAP values for the AutoML model, depicting feature importance in descending order. Age, Sodium Silicate, and Fine Aggregate are identified as the three most influential features, whereas Relative Humidity demonstrates the least impact on CS. A color gradient in Fig. 10 illustrates the directional influence of SHAP values on CS. For example, increased Age correlates positively with CS enhancement, while elevated Water and Coarse Aggregate levels exhibit negative correlations.

SHAP values of the AutoML model.
Figure 11 illustrates the SHAP diagrams for two representative prediction cases. In Fig. 11, the base value represents the mean model output across the entire training dataset, while f(x) denotes the model’s predicted output. Features marked in red drive the prediction above this baseline, while those in blue suppress the output below it. For example, in Fig. 11(a), the predicted value (f(x) = 74.98 MPa) exceeds the base value (60 MPa), indicating that contributions from red-region features outweigh those of the blue region. Notably, SH and W are the primary contributors to the blue-region effects. Similarly, in Fig. 11(b), elevated levels of FA, SS, S, and CA result in a reduced f(x) due to dominant blue-region influences.

SHAP diagram for two prediction cases.
Figure 12 presents the SHAP dependency plot for input parameters. Among these, SH demonstrates the strongest overall relevance and exhibits significant interactions with FA, W, and FA. Both low and high concrete age Levels yield elevated SHAP values, highlighting age as a critical determinant of CS. However, after 50 days, the compressive strength demonstrates only minimal enhancement as the concrete approaches its ultimate hardening state. The associated SHAP values consequently remain stable without obvious increase compared to earlier stages. Relative humidity (RH) exhibits SHAP values oscillating between 1 and − 4, reflecting its limited yet measurable impact on compressive strength development.

Dependency diagram for input variables.
Optimization results
Three objectives (CS, unit cost, and CO₂ emissions) were considered in the MOO. The Multi-Objective PSO (MOPSO) algorithm was employed for triple-objective optimization. MOPSO algorithm leverages particle memory and swarm collaboration (personal best + global best) to achieve superior computational efficiency over other algorithms, particularly for high-dimensional non-convex parameter spaces in concrete mix design. Its adaptive inertia weight dynamically balances exploration-exploitation, avoiding premature convergence. The emissions per cubic meter (m³) of HPGC were calculated via Eq. (3)41.
where Pi is the quantity of the variable i in 1 m3, ai is the emission factor of variable i:
The total computational time for AutoML prediction and optimization was approximately 563 s, achieved under the following configuration: PSO (200 particles × 300 iterations) executed on an engineering workstation with i7-12700 H CPU and 16GB RAM.
Figure 13 presents the non-dominated solutions and their fitted surface for the triple-objective optimization. The solutions exhibit a diagonal distribution from the lower left to upper right, reflecting the trade-off between increasing CS, unit cost, and CO₂ emissions. Specifically, higher CS correlates with elevated sodium silicate content, driving cost and emissions upward. A plateau in CO₂ emissions (~ 100 kg/m³) is observed for CS between 50 and 85 MPa, indicating minimal emission sensitivity to CS variations within this range. Beyond 85 MPa, emissions rise sharply, peaking at approximately 240 kg/m³ when CS is maximized.

Pareto front and its fitting surface of triple-objective optimization.
The cost-gain ratio (Eq. 4) was introduced to identify optimization points with high cost-effectiveness.
where CS, unit cost, and cost-gain ratio are expressed in MPa, $/m3, and MPa·m3/$, respectively.
Figure 14 presents the CS-cost projection and the cost-gain trend Line. Costs exhibit a positive correlation with CS. The triple-objective optimization lacks distinct cost-benefit Pareto optimal solutions. Instead, the cost-benefit ratio oscillates near 1.6. This may arise because the optimization algorithm prioritizes CS, unit cost, and CO2 emissions simultaneously, thereby diminishing the clarity of cost-benefit trade-offs.

CS-Cost projection diagram and cost-gain fitting curve.
Figure 15 illustrates the relationships between CS, CO2 emissions, and unit cost. As shown in Fig. 15(a), CO2 emissions exhibit a gradual nonlinear increase with CS, particularly within specific compressive strength ranges. For instance, growth rates remain stable between 50 and 85 MPa but accelerate significantly at 85–100 MPa. Emissions show minimal variation in low-to-medium CS ranges; however, beyond this threshold, higher CS necessitates increased sodium silicate content, leading to a substantial rise in CO2 emissions. Figure 15(b) reveals that when CO2 emissions approximate 100 kg/m³, the unit cost fluctuates between 40 and 50 $/m³. Beyond 120 kg/m³ of CO2 emissions, costs surge sharply.

CO2-CS projection diagram and CO2-Cost projection diagram.
Since the triple-objective functions exhibit inherent trade-offs, the target CS must be determined based on the project’s specific requirements. Table 5 presents two optimal mix proportions derived via triple-objective optimization. For comparison, Table 6 summarizes the CS, unit cost, and CO₂ emissions of database specimens with comparable CS to the optimized mixes. Based on Tables 5 and 6, the optimization framework reduces CO₂ emissions by 23–60% and unit costs by 16–36%, confirming the method’s efficacy in balancing competing objectives. These results underscore the viability of the proposed approach in achieving multi-objective sustainability goals.
Conclusion
This study leverages AutoML and MOO to identify optimal HPGC mix designs, ensuring a balanced compromise between CS, unit cost, and CO₂ emissions. Key findings include:
-
1)
The AutoML framework outperforms conventional ensemble learning models tuned via Bayesian optimization, yielding comparable predictive accuracy. Validation metrics confirm this advantage, with R², RMSE, MAE, MPAE, and a20 index of 0.9280, 5.2954 MPa, 4.2307 MPa, 0.0724, and 0.9677, respectively.
-
2)
SHAP analysis elucidates feature impacts on CS, enhancing model transparency. Curing age, sodium silicate, and fly ash are the three most influential factors, with curing age and sodium silicate content exerting positive effects, whereas water and coarse aggregate ratios demonstrate negative correlations.
-
3)
Triple-objective optimization (CS, cost, and CO₂) reduces emissions by 23–60% and unit costs by 16–36% relative to conventional mixes. This approach aligns material properties, economic viability, and sustainability objectives.
We must acknowledge the current study has certain limitations, especially on the ML model. The most important limitation lies in its sensitivity to data distribution and model generalizability. To resolve the issue, more experimental data will be collected from other resources to construct a more powerful and comprehensive database. After that, the well-trained ML tool will be more reasonable and accurate.
Data availability
All data generated or analysed during this study are included in this published article and its Supplementary Information files.
References
Sun, R. Y. et al. CO2 buildup drove global warming, the Marinoan deglaciation, and the genesis of the Ediacaran cap carbonates. Precambrian Res. 383, 106891 (2022).
Huang, Y. Y. et al. Utilization of the black tea powder as multifunctional admixture for the hemihydrate gypsum. J. Clean. Prod. 210, 231–237 (2019).
Hasanbeigi, A., Menke, C. & Price, L. The CO2 abatement cost curve for the Thailand cement industry. J. Clean. Prod. 18, 1509–1518 (2010).
Dong, J. F., Wang, Q. Y. & Guan, Z. W. Structural behaviour of RC beams externally strengthened with FRP sheets under fatigue and monotonic loading. Eng. Struct. 41, 24–33 (2012).
Dong, J. F., Wang, Q. Y. & Guan, Z. W. Material and structural response of steel tube confined recycled earthquake waste concrete subjected to axial compression. Mag Concr Res. 68, 271–282 (2015).
Dong, J. F. et al. High-temperature behaviour of basalt fibre reinforced concrete made with recycled aggregates from earthquake waste. J. Build. Eng. 48, 103895 (2022).
Dong, J. F., Xu, Y., Guan, Z. W. & Wang, Q. Y. Freeze-thaw behaviour of basalt fibre reinforced recycled aggregate concrete filled CFRP tube specimens. Eng. Struct. 273, 115088 (2022).
Liu, Y. et al. Variable fatigue loading effects on corrugated steel box girders with recycled concrete. J. Constr. Steel Res. 215, 108526 (2024).
Abdellatief, M., Elrahman, M. A., Abadel, A. A., Wasim, M. & Tahwia, A. Ultra-high performance concrete versus ultra-high performance geopolymer concrete: mechanical performance, microstructure, and ecological assessment. J. Build. Eng. 79, 107835 (2023).
Yang, W. et al. Effect of recycled coarse aggregate quality on the interfacial property and sulfuric acid resistance of geopolymer concrete at different acidity levels. Constr. Build. Mater. 375, 130919 (2023).
Amran, M., Murali, G., Makul, N., Tang, W. C. & Alluqmani, A. E. Sustainable development of eco-friendly ultra-high performance concrete (UHPC): cost, carbon emission, and structural ductility. Constr. Build. Mater. 398, 132477 (2023).
DeRousseau, M. A., Kasprzyk, J. R. & Srubar, W. V. Computational design optimization of concrete mixtures: A review. Cem. Concr Res. 109, 42–53 (2018).
Nobile, L. & Bonagura, M. Recent advances on non-destructive evaluation of concrete compression strength. Int. J. Microstruct. Mater Prop. 9, 413–421 (2014).
Nobile, L. Prediction of concrete compressive strength by combined non-destructive methods. Meccanica 50, 411–417 (2015).
Revilla-Cuesta, V., Shi, J. Y., Skaf, M., Ortega-López, V. & Manso, J. M. Non-destructive density-corrected Estimation of the elastic modulus of slag-cement self-compacting concrete containing recycled aggregate. Dev. Built Environ. 12, 100097 (2022).
Espinosa, A. B., Revilla-Cuesta, V., Skaf, M. & Faleschini, F. Ortega-López, V. Utility of ultrasonic pulse velocity for estimating the overall mechanical behavior of recycled aggregate self-compacting concrete. Appl. Sci. 13, 874 (2023).
Chen, D., Kang, F., Li, J., Zhu, S. & Liang, X. Enhancement of underwater dam crack images using multi-feature fusion. Autom. Constr. 167, 105727 (2024).
Asif, U., Khan, W. A., Naseem, K. A. & Rizvi, S. A. Enhancing the predictive accuracy of Marshall design tests using generative adversarial networks and advanced machine learning techniques. Mater. Today Commun. 45, 112379 (2025).
Luleci, F., Catbas, F. N. & Avci, O. CycleGAN for undamaged-to-damaged domain translation for structural health monitoring and damage detection. Mech. Syst. Signal. Process. 197, 110370 (2023).
Seventekidis, P. & Giagopoulos, D. Model error effects in supervised damage identification of structures with numerically trained classifiers. Mech. Syst. Signal. Process. 184, 109741 (2023).
Fu, B. & Wei, X. An intelligent analysis method for human-induced vibration of concrete footbridges. Int. J. Struct. Stab. Dyn. 21, 2150013 (2021).
Fu, B., Liu, X. & Chen, J. Machine learning-based hybrid optimization method for tuned mass damper considering seismic soil-structure interaction. J. Earthq. Eng. 28, 3410–3431 (2024).
Fu, B., Liu, X. & Chen, J. Ensemble learning-based seismic response prediction of isolated structure considering soil-structure interaction. Int. J. Struct. Stab. Dyn. 24, 2450081 (2024).
Feng, D. C. & Fu, B. Shear strength of internal reinforced concrete beam-column joints: intelligent modeling approach and sensitivity analysis. Adv. Civ. Eng. 8850417 (2020). (2020).
Asteris, P. G. & Mokos, V. G. Concrete compressive strength using artificial neural networks. Neural Comput. Applic. 32, 11807–11826 (2020).
Asteris, P. G., Lemonis, M. E., Nguyen, T. A., Le, H. V. & Pham, B. T. Soft computing-based Estimation of ultimate axial load of rectangular concrete-filled steel tubes. Steel Compos. Struct. 39, 471–491 (2021).
Fu, B. & Feng, D. C. A machine learning-based time-dependent shear strength model for corroded reinforced concrete beams. J. Build. Eng. 36, 102118 (2021).
Asteris, P. G., Skentou, A. D., Bardhan, A., Samui, P. & Lourenço, P. B. Soft computing techniques for the prediction of concrete compressive strength using Non-Destructive tests. Constr. Build. Mater. 303, 124450 (2021).
Fu, B., Chen, S. Z., Liu, X. R. & Feng, D. C. A probabilistic bond strength model for corroded reinforced concrete based on weighted averaging of non-fine-tuned machine learning models. Constr. Build. Mater. 318, 125767 (2022).
Mahmood, W., Mohammed, A. S., Asteris, P. G., Kurda, R. & Armaghani, D. J. Modeling flexural and compressive strengths behaviour of cement-grouted sands modified with water reducer polymer. Appl. Sci. 12, 1016 (2022).
Mahmood, W., Mohammed, A. S., Sihag, P., Asteris, P. G. & Ahmed, H. Interpreting the experimental results of compressive strength of hand-mixed cement-grouted sands using various mathematical approaches. Archiv Civ. Mech. Eng. 22, 19 (2022).
Zhang, H. et al. A generalized artificial intelligence model for estimating the friction angle of clays in evaluating slope stability using a deep neural network and Harris Hawks optimization algorithm. Eng. Comput. 38, 3901–3914 (2022).
Ashrafian, A., Panahi, E., Salehi, S., Karoglou, M. & Asteris, P. G. Mapping the strength of agro-ecological lightweight concrete containing oil palm by-product using artificial intelligence techniques. Structures 48, 1209–1229 (2023).
He, J., Liu, J., Li, N., Li, J. & Fu, B. Shear behavior of concrete beams reinforced with GFRP-steel hybrid stirrups. Constr. Build. Mater. 472, 140882 (2025).
Ahmad, A., Ahmad, W., Aslam, F. & Joyklad, P. Compressive strength prediction of fly ash-based geopolymer concrete via advanced machine learning techniques. Case Stud. Constr. Mat. 16, e00840 (2022).
Parhi, S. K. & Patro, S. K. Prediction of compressive strength of geopolymer concrete using a hybrid ensemble of grey Wolf optimized machine learning estimators. J. Build. Eng. 71, 106521 (2023).
Peng, Y. & Unluer, C. Analyzing the mechanical performance of fly ash-based geopolymer concrete with different machine learning techniques. Constr. Build. Mater. 316, 125785 (2022).
Mohamed, A., Hassan, Y. M. & Elnabwy, M. T. Investigation of machine learning models in predicting compressive strength for ultra-high-performance geopolymer concrete: a comparative study. Constr. Build. Mater. 436, 136884 (2024).
Katlav, M., Ergen, F. & Donmez, I. AI-driven design for the compressive strength of ultra-high performance geopolymer concrete (UHPGC): from explainable ensemble models to the graphical user interface. Mater. Today Commun. 40, 109915 (2024).
Nguyen, H. A. T. et al. Transfer learning framework for modelling the compressive strength of ultra-high performance geopolymer concrete. Constr. Build. Mater. 316, 139746 (2025).
Huang, Y. et al. Multi-objective optimization of fly ash-slag based geopolymer considering strength, cost and CO2 emission: a new framework based on tree-based ensemble models and NSGA-II. J. Build. Eng. 68, 106070 (2023).
Guo, P., Meng, W. & Bao, Y. Knowledge-guided data-driven design of ultra-high-performance geopolymer (UHPG). Cem. Concr Comp. 153, 105723 (2024).
Zhang, D. M., Shen, Y. M., Huang, Z. K. & Xie, X. C. Auto machine learning-based modelling and prediction of excavation-induced tunnel displacement. J. Rock. Mech. Geotech. Eng. 14, 1100–1114 (2022).
Long, W. J., Cheng, B. Y., Luo, S. Y., Li, L. X. & Mei, L. Interpretable auto-tune machine learning prediction of strength and flow properties for self-compacting concrete. Constr. Build. Mater. 393, 132101 (2023).
Feng, D. C., Wang, W. J., Mangalathu, S., Hu, G. & Wu, T. Implementing ensemble learning methods to predict the shear strength of RC deep beams with/without web reinforcements. Eng. Struct. 235, 111979 (2021).
Bian, L. K., Qin, X. E., Zhang, C. L., Guo, P. & Wu, H. Application, interpretability and prediction of machine learning method combined with LSTM and lightgbm: a case study for runoff simulation in an arid area. J. Hydrol. 625, 130091 (2023).
Wang, J. Y., Xu, P. C., Ji, X. B., Li, M. J. & Lu, W. C. MIC-SHAP: an ensemble feature selection method for materials machine learning. Mater. Today Commun. 37, 106910 (2023).
Cakiroglu, C. et al. Data-driven interpretable ensemble learning methods for the prediction of wind turbine power incorporating SHAP analysis. Expert Syst. Appl. 237, 121464 (2024).
Li, C. Q., Zhou, J., Du, K. & Dias, D. Stability prediction of hard rock pillar using support vector machine optimized by three metaheuristic algorithms. Int. J. Min. Sci. Technol. 33, 1019–1036 (2023).
Bouzateur, I. et al. Perovskite lattice constant prediction framework using optimized artificial neural network and fuzzy logic models by metaheuristic algorithms. Mater. Today Commun. 37, 107021 (2023).
Mei, X. C. et al. Application of metaheuristic optimization algorithms-based three strategies in predicting the energy absorption property of a novel aseismic concrete material. Soil. Dyn. Earthq. Eng. 173, 108085 (2023).
Tung, C. C., Lai, Y. Y., Chen, Y. Z., Lin, C. C. & Chen, P. Y. Optimization of mechanical properties of bio-inspired Voronoi structures by genetic algorithm. J. Mater. Res. Technol. 26, 3813–3829 (2023).
Hu, Q., Zhou, N. F., Chen, H. & Weng, S. Bayesian damage identification of an unsymmetrical frame structure with an improved PSO algorithm. Structures 57, 105119 (2023).
Ma, Z. C., He, X. H., Yan, P. C., Zhang, F. & Teng, Q. Z. A fast and flexible algorithm for microstructure reconstruction combining simulated annealing and deep learning. Comput. Geotech. 164, 105755 (2023).
Zhou, X. S. et al. Random following ant colony optimization: continuous and binary variants for global optimization and feature selection. Appl. Soft Comput. 144, 110513 (2023).
Zhang, J. F., Huang, Y. M., Wang, W. H. & Ma, G. W. Multi-objective optimization of concrete mixture proportions using machine learning and metaheuristic algorithms. Constr. Build. Mater. 253, 119208 (2020).
Zhang, J. F., Huang, Y. M., Ma, G. W. & Nener, B. Mixture optimization for environmental, economical and mechanical objectives in silica fume concrete: a novel framework based on machine learning and a new meta-heuristic algorithm. Resour. Conserv. Recycl. 167, 105395 (2021).
Huang, Y. M., Zhang, J. F., Ann, F. T. & Ma, G. W. Intelligent mixture design of steel fibre reinforced concrete using a support vector regression and firefly algorithm based multi-objective optimization model. Constr. Build. Mater. 260, 120457 (2020).
Shehata, M., Abdelnaeem, M. & Mokhiamar, O. Integrated multiple criteria decision-making framework for ranking Pareto optimal solutions of the multiobjective optimization problem of tuned mass dampers. Ocean. Eng. 278, 114440 (2023).
Bernal, S. A. et al. Effect of binder content on the performance of alkali-activated slag concretes. Cem. Concr Res. 41, 1–8 (2011).
Chi, M. Effects of dosage of alkali-activated solution and curing conditions on the properties and durability of alkali-activated slag concrete. Constr. Build. Mater. 35, 240–245 (2012).
Chi, M. & Huang, R. Binding mechanism and properties of alkali-activated fly ash/slag mortars. Constr. Build. Mater. 40, 291–298 (2013).
Ismail, I. et al. Influence of fly Ash on the water and chloride permeability of alkali-activated slag mortars and concretes. Constr. Build. Mater. 48, 1187–1201 (2013).
Deb, P. S., Nath, P. & Sarker, P. K. The effects of ground granulated blast-furnace slag blending with fly Ash and activator content on the workability and strength properties of geopolymer concrete cured at ambient temperature. Mater. Des. 62, 32–39 (2014).
Nath, P. & Sarker, P. K. Effect of GGBFS on setting, workability and early strength properties of fly Ash geopolymer concrete cured in ambient condition. Constr. Build. Mater. 66, 163–171 (2014).
Yuan, X., Chen, W., Lu, Z. & Chen, H. Shrinkage compensation of alkali-activated slag concrete and microstructural analysis. Constr. Build. Mater. 66, 422–428 (2014).
Ding, Y., Shi, C. J. & Li, N. Fracture properties of slag/fly ash-based geopolymer concrete cured in ambient temperature. Constr. Build. Mater. 190, 787–795 (2018).
Fang, G., Ho, W. K., Tu, W. & Zhang, M. Workability and mechanical properties of alkali-activated fly ash-slag concrete cured at ambient temperature. Constr. Build. Mater. 172, 476–487 (2018).
Nasr, D., Pakshir, A. H. & Ghayour, H. The influence of curing conditions and alkaline activator concentration on elevated temperature behavior of alkali activated slag (AAS) mortars. Constr. Build. Mater. 190, 108–119 (2018).
Taghvayi, H., Behfarnia, K. & Khalili, M. The effect of alkali concentration and sodium silicate modulus on the properties of alkali-activated slag concrete. J. Adv. Concr Technol. 16, 293–305 (2018).
Bondar, D., Basheer, M. & Nanukuttan, S. Suitability of alkali activated slag/fly Ash (AA-GGBS/FA) concretes for chloride environments: characterisation based on mix design and compliance testing. Constr. Build. Mater. 216, 612–621 (2019).
Cai, Y., Yu, L., Yang, Y., Gao, Y. & Yang, C. Effect of early age-curing methods on drying shrinkage of alkali-activated slag concrete. Materials 12, 1633 (2019).
You, N. et al. The influence of steel slag and ferronickel slag on the properties of alkali-activated slag mortar. Constr. Build. Mater. 227, 116614 (2019).
Zamanabadi, S. N., Zareei, S. A., Shoaei, P. & Ameri, F. Ambient-cured alkali-activated slag paste incorporating micro-silica as repair material: effects of alkali activator solution on physical and mechanical properties. Constr. Build. Mater. 229, 116911 (2019).
Fang, S., Lam, E. S. S., Li, B. & Wu, B. Effect of alkali contents, moduli and curing time on engineering properties of alkali activated slag. Constr. Build. Mater. 249, 118799 (2020).
Tuyan, M., Zhang, L. V. & Nehdi, M. L. Development of sustainable alkali-activated slag Grout for Preplaced aggregate concrete. J. Clean. Prod. 277, 123488 (2020).
Tuyan, M., Zhang, L. V. & Nehdi, M. L. Development of sustainable Preplaced aggregate concrete with alkali-activated slag Grout. Constr. Build. Mater. 263, 120227 (2020).
Xiang, J., He, Y., Liu, L., Zheng, H. & Cui, X. M. Exothermic behavior and drying shrinkage of alkali-activated slag concrete by low temperature-preparation method. Constr. Build. Mater. 262, 120056 (2020).
International Federation for Structural Concrete (fib). Fib Model Code for Concrete Structures 2010 (Ernst & Sohn, 2013).
Asteris, P. G. et al. On the metaheuristic models for the prediction of cement-metakaolin mortars compressive strength. Math. Comput. Appl. 25, 63 (2020).
Asteris, P. G. et al. Mapping and revealing the nature of masonry compressive strength using computational intelligence. Structures 78, 109189 (2025).
Le, T. T., Skentou, A. D., Mamou, A. & Asteris, P. G. Correlating the unconfined compressive strength of rock with the compressional wave velocity effective porosity and Schmidt hammer rebound number using artificial neural networks. Rock. Mech. Rock. Eng. 55, 6805–6840 (2022).
Asteris, P. G. et al. AI-powered GUI for prediction of axial compression capacity in concrete-filled steel tube columns. Neural Comput. Applic. 36, 22429–22459 (2024).
Zhou, J., Asteris, P. G., Armaghani, D. J. & Pham, B. T. Prediction of ground vibration induced by blasting operations through the use of the bayesian network and random forest models. Soil. Dyn. Earthq. Eng. 139, 106390 (2020).
Sarir, P., Chen, J., Asteris, P. G., Armaghani, D. J. & Tahir, M. M. Developing GEP tree-based, neuro-swarm, and Whale optimization models for evaluation of bearing capacity of concrete-filled steel tube columns. Eng. Comput. 37, 1–19 (2021).
Asteris, P. G., Skentou, A. D., Bardhan, A., Samui, P. & Pilakoutas, K. Predicting concrete compressive strength using hybrid ensembling of surrogate machine learning models. Cem. Concr Res. 145, 106449 (2021).
Armaghani, D.J., Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. & Applic. 33, 4501–4532 (2021).
Acknowledgements
The authors acknowledge the Fundamental Research Funds for the Central Universities, CHD (300102283201).
Author information
Authors and Affiliations
Contributions
Conceptualization, S.W. and B.F.; methodology, S.W., X.L., and B.F.; validation, X.L. and B.F.; formal analysis, S.W., X.L., and B.F.; writing-original draft preparation, S.W., X.L., and B.F.; writing-review and editing, S.W., X.L., and B.F.; funding acquisition, B.F.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, S., Liu, X. & Fu, B. Explainable automl and multi-objective optimization for sustainable high-performance geopolymer concrete. Sci Rep 15, 33027 (2025). https://doi.org/10.1038/s41598-025-18666-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18666-8
