
Abstract
Construction workers of long tunnel projects are confronted with numerous safety hazards such as fall from height (FFH) and object strike due to the harsh jobsite environment, limited space, and complex working conditions. And the absence of protective guardrails is identified as the primary cause of falling accidents from height. In order to automatically detect the safety protection status of working-at-high workers, a computer vision-based recognition method for working-at-high operation safety protection according to target detection and spatial relationship was proposed in this study. Firstly, the Cycle-consistent Generative Adversarial Networks (CycleGAN) was used to preprocess construction site images to enhance the image quality. Secondly, a YOLOv8 model integrated with the coordinate attention (CA) module was established to rapidly detect targets such as workers, trolleys, and guardrails in the tunnel. Furthermore, an identification method for working-at-high operation safety protection is proposed based on the detected targets and their spatial relationships. Finally, a case study was conducted, revealing that the model achieves an accuracy and recall rate of 95.89% and 97.22%, respectively, in identifying the safety protection status of working-at-high workers. The result indicates that the proposed method provides a new way for intelligent identification of working-at-high operation safety protection and assisting on-site management personnel to prevent the risk of FFH in the tunnel.
Similar content being viewed by others

Introduction
The construction industry frequently experiences accidents due to its complex construction environment, numerous safety hazards, high work intensity and insufficient management. Among these accidents, the fall from height (FFH) accident accounts for approximately 50% of all accidents, significantly surpassing the proportion of other accident types. During the construction process of tunnel projects, various factors such as complex and unpredictable geological conditions, confined spaces, and harsh construction environments often pose constraints. As a result, construction personnel are more susceptible to safety accidents such as FFH, object impacts, tunnel collapses, and mechanical collisions, leading to significant losses in terms of both lives and property1,2,3 .
The tunnel construction involves a multitude of coordinated procedures, among which manual drilling, loading explosives, supporting steel frame, and secondary lining procedures are all working-at-high operation. The unsafe behavior of workers and the lack of appropriate safety protection equipment are the main reasons for FFH accidents4. Therefore, it is necessary to ensure the safety of working-at-high operation from the perspectives of construction behavior monitoring of aerial workers and detection of passive protective equipment. At present, to reduce the occurrence of FFH accidents, construction units have formulated a series of safety management measures for working-at-high operation, such as active protective measures for regular safety training of construction personnel, and passive protective measures such as providing protective equipment like high-altitude guardrails and safety ropes. Both active and passive protective measures can reduce the occurrence of FFH accidents to a certain extent. However, due to subjective factors such as lack of concentration or a sense of invulnerability among workers, active protective measures may not entirely prevent such behaviors5, while passive protective measures such as guardrails are not affected by workers’ subjective factors. Therefore, ensuring the provision of passive protective equipment for working-at-high operation in tunnels is critical to reducing the fall risk of construction personnel6 .
The status of high-altitude protective equipment on the construction site is usually determined by manual inspection and analysis of video surveillance screens, which are often time-consuming, labor-intensive, and prone to delays in detection. With the advancement of sensor technology, computer vision, and other related technologies, automatic real-time detection of the safety status of working-at-high workers has become a reality. However, sensor-based method requires workers to wear additional sensing devices, which are costly and affect the normal operation of workers; the computer vision-based method is cost-effective and has minimal impact on workers, but it faces challenges such as poor lighting conditions in tunnels, complex image backgrounds, and detection of target size changes.
To address the aforementioned challenges, an identification method for working-at-high operation safety protection in the tunnel based on the improved YOLOv8 model incorporating target spatial relationship is proposed in this study. This method provides an end-to-end solution for the monitoring of working-at-high operation safety protection in the specific and complex actual application scenario of tunnel construction sites. Firstly, the Cycle-consistent Generative Adversarial Networks (CycleGAN) based image enhancement algorithm is used to preprocess the construction monitoring images in the tunnel, aiming to improve image quality. Then, based on the YOLOv8 model with the coordinate attention module, the targets such as workers, trolleys and guardrails are quickly detected. Subsequently, leveraging the detected targets and spatial relationships between the targets, the safety protection status of working-at-high workers is identified. Finally, an example analysis is conducted using the proposed method, which provides a novel approach for intelligent identification of working-at-high operation safety protection in the tunnel and assists on-site managers in preventing the risk of FFH.
The remaining sections of this paper are as follows: The second section reviews the related research work on the identification of working-at-high operation safety protection at the construction site. The third section introduces the methods of image preprocessing of tunnel construction based on CycleGAN, YOLOv8-CA model establishment, and identification of working-at-high operation safety protection. In the fourth section, the identification method of working-at-high operation safety protection in the tunnel is verified and applied. The fifth section discusses the limitations and conclusions of this study.
Literature review
Studies have shown that the unsafe behavior of workers and the unsafe status of protective equipment are likely to cause the risk of FFH. To address this issue, researchers have widely employed various methods for safety detection in working-at-high operation, primarily categorized into sensor-based and computer vision-based approaches.
Target detection based on deep learning algorithms
Target detection based on computer vision technology, owing to its advantages such as non-contact, flexibility, and real-time capabilities, has emerged as a primary research approach for construction safety management. In recent years, the development of target detection technology has undergone a paradigm transformation from traditional manual feature methods to a deep learning-based approach, resulting in a revolutionary improvement in its performance and application scope.
Early representative framework for deep learning-based target detection was the two-stage method. Girshick et al.7 proposed regions with convolutional neural networks (R-CNN) algorithm, which generated region proposals through selective search, and then independently performed CNN feature extraction and classification/regression on each proposed region. Girshick et al.8 proposed the Fast R-CNN algorithm, introducing the region of interest pooling technique. Ren et al.9 subsequently proposed the Faster R-CNN network architecture, an improvement upon Fast R-CNN, introducing a more efficient region proposal network (RPN) to replace the original selective search algorithm, significantly enhancing both detection speed and accuracy. Although the two-stage methods have been widely adopted in fields with high-precision detection requirements due to its high positioning accuracy, it has high computational cost and insufficient real-time performance. To address these limitations of two-stage methods, the single-stage target detection algorithms such as You Only Look Once (YOLO) emerged. These methods eliminate the need for pre-generating candidate regions; instead, they directly perform bounding box regression and classification on the feature maps at the output end. The accuracy is slightly lower but the inference speed is significantly improved. Since Redmon et al.10 introduced the YOLOv1 algorithm, the YOLO algorithm has undergone continuous iterations and has maintained a high detection speed while continuously improving the accuracy.
Target detection-based safety recognition of working-at-high operation
For the identification of working-at-high operation safety protection, the current research focus is mainly on monitoring the unsafe behavior of working-at-high workers and detecting working-at-high protective equipment based on computer vision technology4. Ding et al.11 developed a hybrid deep learning model based on CNN and LSTM algorithms to automatically recognize unsafe behaviors such as workers climbing ladders or other working-at-high operations. Khan et al.12 proposed an algorithm for detecting unsafe behaviors of workers based on Mask R-CNN, which is used to monitor workers’ working behaviors on mobile scaffolding. Chen et al.13 integrated the data of workers’ positions and poses collected by IMU with 3D skeleton extraction based on computer vision and UWB technology to develop a safety risk assessment framework for working-at-high operation. Piao et al.14 proposed a dynamic fall risk assessment framework by combining computer vision with dynamic Bayesian networks, which can classify and detect changes of workers’ construction height. Li et al.15 summarized the current application status of computer vision in monitoring the behaviors of construction workers, as well as the mainstream algorithms and their innovative integration methods. Fang et al.16 proposed a computer vision method based on Mask R-CNN and the overlapping detection module, which is used to automatically identify the dangerous behaviors of construction workers walking on the supports of high-altitude structures. Bonyani et al.17 proposed an adaptive spatiotemporal sampling and optimized attention network for construction workers’ unsafe behavior detection, achieving high accuracy with reduced computational costs. Park et al.18 proposed a real-time monitoring system based on the target marking method and the improved YOLOv5 model to detect unsafe behaviors of workers using portable multi-position ladders. Ding et al.19 proposed an unsupervised multi-anomaly GAN for construction worker unsafe behavior detection, which combines temporal information and multiple pseudo anomaly synthesizers.
In addition to the unsafe behavior of working-at-high workers, the failure of workers to wear personal protective equipment (PPE) safely is also a major cause of FFH accidents. Park et al.20 proposed a deep learning model–based multi-label risk factor recognition (MRFR) framework to recognize material and human risk factors at construction sites. Fang et al.21 developed a worker and safety harness recognition model based on Faster R-CNN and deep CNN, achieving safety monitoring on construction sites by automatically identifying whether working-at-high workers are wearing safety harnesses or not. Khan et al.22 developed an intelligent monitoring method for safety harness hooks based on computer vision and Internet of Things sensors, which can monitor the tightness of safety harnesses in real time to ensure the safety of working-at-high workers. Wu et al.23 constructed a safety helmet and harness monitoring and recognition system based on attribute knowledge modeling, which transforms the recognition of safety status into the semantic attribute recognition of images, thereby improving the robustness of the model in complex environments such as occlusion. Xu et al.24 proposed a lightweight target detection method based on Efficient-YOLOv5 to detect whether working-at-high workers wear harness. In addition, the guardrail is a passive protective measure to ensure the safety of working-at-high workers. The lack of guardrails is also likely to cause FFH accidents25. Mendes et al.26 collected and checked the installation of guardrails on the construction site through image recognition by unmanned aerial vehicle (UAV). Shanti et al.27 established YOLOv4 target detection model based on UAV aerial data to identify workers’ PPE, including safety harnesses, lifelines, and helmets. Gheisari et al.28 trained the UAV aerial data by cascade classifier and SVM classifier to identify the guardrail position of high-rise building sites. Kolar et al.6 used transfer learning and deep CNN models to detect guardrails from 2D images to prevent FFH accidents, and the detection accuracy of guardrails reached 96.5%. Chen et al.29 utilized OpenPose and YOLOv3 to achieve the identification of improper use of multiple types of PPE, ensuring real-time performance while accurately locating potential safety hazards in different construction areas. Fang et al.30 combined working-at-high operation scenario recognition with deep learning target detection to monitor in real time whether working-at-high workers are correctly using fall protection systems (PFAS) and safety helmets. Li et al.31 proposed a framework that integrates the target detection algorithm with the individual posture estimation algorithm to check the improper use of two types of PPE. Yang et al.32 proposed safe-wearing detection rules and a novel multi-targets and keypoints detection framework, accomplishing multiple classes of targets and keypoints detection simultaneously in one-stage. López et al.33 proposed an AI framework for automatically detecting PPE, which integrates worker detection, pose estimation, and PPE recognition.
Limitations of existing studies
The existing safety protection identification methods based on computer vision mainly utilize deep learning algorithms to detect unsafe behaviors or PPE in construction site videos or images. These studies provide reference and foundation for this research. However, tunnel environments often suffer from poor illumination and have abundant machinery or debris. The application of computer vision methods in tunnel scenarios faces problems such as low image quality, complex image backgrounds, and changes in the size of the detection targets. Furthermore, there is currently scant research specifically focused on safety protection recognition for high-altitude operations inside tunnel cavities. Thus, fewer previous studies were focusing on this field for above considerations. Therefore, it is necessary to further study the image preprocessing method and the identification method of working-at-high operation safety protection to reduce the risk of FFH.
Methodology
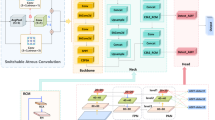
In this study, an image recognition method for working-at-high operation safety protection based on the improved YOLOv8 and target spatial relationship is proposed to detect the safety protection status of working-at-high workers in tunnels. Figure 1 shows the workflow of the proposed method, which mainly includes three steps: (1) Preprocessing of the images of tunnel construction; (2) Target detection model; (3) Identification of working-at-high operation safety protection.

Workflow of the proposed method.
Image preprocessing method based on cyclegan
Main steps of image preprocessing
Due to the poor light conditions in construction tunnels, the monitoring images are interfered by smoke and dust inside the tunnels, which are characterized by low illuminance and low clarity. CycleGAN is used to enhance the quality of monitoring images of tunnel construction to improve the accuracy of subsequent detection. CycleGAN is an unsupervised learning model34, which can transform image styles without using paired image training models, and has been widely used in data enhancement in various fields35,36,37,38. As shown in Fig. 2, CycleGAN consists of two generators, .\(G\). and \(F\), and two discriminators, \({D_{\text{x}}}\) and \({D_y}\), with constraints on each other. The function of generator .\(G\). is to generate clear tunnel image from the input low-light tunnel image, and the image generation direction of generator \(F\) is opposite to that of generator \(G\), that is, to generate low-light tunnel image from the clear tunnel image. The function of the discriminator in CycleGAN is to distinguish between the input image and the image generated by generator. \({D_{\text{x}}}\) is used to judge whether the input image is a real low-light tunnel image or a low-light tunnel image generated by generator \(F\), and \({D_y}\) is used to judge whether the input image is a real clear tunnel image or a clear tunnel image generated by generator \(G\). CycleGAN includes forward transformation and reverse transformation processes, and the two transformation processes are carried out at the same time. Take the forward transformation process as an example, its detailed steps are as follows:
(1) The discriminator \({D_{\text{x}}}\) is used to determine whether the input low-light tunnel image meets the features of images in the low illumination tunnel dataset, and output a probability value to represent the probability that the input image is a real low-light image.
(2) The input low-light tunnel image is input into the generator \(G\) to generate the normal illumination tunnel image, and then the generated image is inputted to discriminator \({D_y}\) to determine whether it meets the features of images in the normal illuminance tunnel dataset, and a probability value is output to represent the probability that the input image is a real normal illumination image.
(3) The normal illumination tunnel image generated in generator \(G\) is input into generator \(F\), where the low-light tunnel image is re-generated, so that the generated low-light tunnel image is as consistent as possible with the input low-light tunnel image, forming a cycle.
(4) The adversarial loss, cycle consistency loss and identity mapping loss in the process of image conversion are calculated. The optimizer is used to calculate and update the gradient value of the loss function and the parameter value of the generator and discriminator, and the gradient descent method is used to iterate until the total loss function reaches the minimum.

CycleGAN network architecture for image preprocessing of tunnel construction.
Loss function and objective optimization model
During the model training process, the target image data is subjected to constrained optimization by adversarial loss function, cycle consistency loss function and identity mapping loss function, so that the domain features of the original low-light image are maximally transformed into the domain features of the normal illumination image.
(1) Adversarial loss function.
The adversarial loss characterizes the competitive interaction between the generator and discriminator within an adversarial network framework. The generator seeks to produce images that effectively deceive the discriminator, while the discriminator aims to accurately differentiate between generated images and real ones. In the CycleGAN model, two adversarial losses are present. They are respectively the adversarial loss between the generator \(F\) and the discriminator \({D_y}\), and the loss between the generator \(F\) and the discriminator \({D_{\text{x}}}\).
For the generator \(G\) and the discriminator \({D_y}\), the loss function is as follows:
In this equation, \(X\) and \(Y\) respectively denote the low-light tunnel image domain and the clear tunnel image domain. \(x \in X\), \(y \in Y\), and \({P_{\operatorname{data} }}(x)\) represent the distribution of the dataset \(X\), \({\operatorname{E} _{x\sim {P_{\operatorname{data} }}(x)}}\) denotes the mean value of \(x\) when it follows the \({P_{\operatorname{data} }}(x)\) distribution. Additionally, \({P_{\operatorname{data} }}(y)\) represents the distribution of the dataset \(Y\), and \({\operatorname{E} _{y\sim {P_{\operatorname{data} }}(y)}}\) denotes the mean value of \(y\) when it follows the \({P_{\operatorname{data} }}(y)\) distribution.
The objective of the generator \(G\) is to minimize the adversarial loss function, whereas the objective of the discriminator \({D_y}\) is to maximize it. The optimization objective function for the adversarial loss is as follows:
Likewise, the loss function and the optimization objective function for the generator \(F\) and discriminator \({D_{\text{x}}}\) are as follows:
(2) Cycle consistency loss function.
The cycle consistency loss is the predominant loss function in CycleGAN. The role of this loss function is to ensure that the feature details of the original image prior to transformation can be retained after the transformed image is retransformed back, constraining and ensuring the consistency between the forward and backward image transformations. It can be represented as follows:
In this equation, \(F(G(x))\) denotes the cyclic image of the original low-light tunnel image \(x\), which facilitates the transformation of the generated output \(G(x)\) back to a low-light image. Correspondingly, \(G(F(y))\) denotes the cyclic image of the original clear tunnel image \(y\), which facilitates the transformation of the generated output \(F(y)\) back to a clear image. The objective of model training is to enhance the similarity between the original image and its corresponding cyclic counterpart.
(3) Identity mapping loss function.
The identity mapping loss is designed to preserve the style of images in the \(Y\) domain after they are processed by the generator \(G\). That is, it constrains the generator \(G\) from altering the color of the input image while ensuring that it generates images that closely resemble the style of images in the \(Y\) domain. The loss function is expressed as follows:
.
Consequently, the overall loss function of the CycleGAN model can be derived through the above-mentioned three parts of the loss functions. The expression of the overall loss function is presented as follows:
In this equation, \({\lambda _1}\) denotes the weight of the cyclic consistency loss, while \({\lambda _2}\) denotes the weight of the identity mapping loss.
The overall objective optimization function for the CycleGAN model is as follows:
Improved YOLOv8 model for target recognition of working-at-high operation
YOLOv8 target detection model enhanced with CA mechanism
The YOLOv8 algorithm was proposed by Ultralytics in 202339, which is characterized by compact size, rapid detection speed, and high accuracy, rendering it suited for target detection tasks across various complex environments. Meanwhile, YOLOv8 has undergone extensive industrial validation and boasts well-established community support. There exist five versions of YOLOv8, which can be categorized as YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x based on the depth and width of the network. To meet the dual requirements of real-time performance and accuracy for the detection tasks of trolleys, workers and guardrails in tunnel scenarios, the YOLOv8s, which demonstrates a favorable trade-off between inference speed and detection accuracy, is selected as the foundational target detection model. Although the YOLOv8 algorithm has exhibited commendable performance in target detection tasks within the COCO dataset40, when it comes to multi-scale targets such as construction workers, guardrails, and trolleys in the tunnel construction scenarios, the detection results frequently encounter issues such as low accuracy and high rate of missed detections.
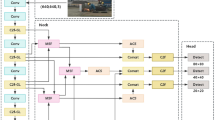
The coordinate attention (CA) mechanism41 effectively captures cross-channel relationships and encodes precise positional information through coordinate information embedding. This capability for location-aware feature enhancement is particularly critical for accurately detecting and localizing targets like trolleys, workers, and guardrails within the complex tunnel scenarios. Furthermore, CA maintains a lightweight design, aligning with the real-time requirements of the application. Therefore, to improve detection performance by leveraging both channel interdependencies and accurate spatial cues, this study integrates the CA mechanism into YOLOv8s, establishing the YOLOv8-CA model. YOLOv8-CA algorithm is comprised of four components: input layer, backbone network, neck network, and output layer, with its network structure illustrated in Fig. 3.

The network structure of YOLOv8-CA algorithm.
The input layer employs the Mosaic data augmentation technique to enhance the diversity of image feature information, which effectively improves the detection performance for small target categories including workers and guardrails in this study to a certain extent. The backbone network is designed to extract features from the input image, which consists of the CBS module, the C2f module, the SPPF module, and the CA layers sequentially added after each of them. The CBS module can perform downsampling, dimension increase/reduction, normalization, and nonlinear processing on input tunnel construction images. The C2f module can enhance the network’s depth and expand the receptive field size, thereby augmenting the model’s feature extraction capability. The SPPF module is a spatial pyramid pooling module, which can transform feature maps of varying scales into a uniform scale, thereby facilitating the convergence of the network and enhancing the model’s detection accuracy. The neck network utilizes an FPN + PAN feature pyramid architecture to facilitate multi-scale feature fusion in images. Among them, the FPN layer transmits robust semantic features from top to bottom, while the PAN layer conveys strong localization features from bottom to top. This integration of both types of features ensures accurate predictions across images of varying scales. The output layer employs three parallel decoupled heads to achieve classification and bounding box regression, with CIoU Loss and Distribution Focal Loss as the composite loss function.
The CA layer can integrate channel and location information more effectively, strengthening the network’s capacity for locating and recognizing target areas. The structure of CA mechanism is illustrated in Fig. 4, which operates on the principle of encoding precise positional information to capture attention across the width and height of images within the tunnel dataset. First, two pooling kernels with dimensions of (H, 1) and (1, W) are employed to conduct global pooling on the input feature map in the horizontal and vertical directions respectively, thereby yielding feature maps in these two directions. The corresponding formulas are presented as follows:
In this equation, \(H\) and \(W\) respectively denote the height and width of the input features. \(z_{c}^{h}(h)\) signifies the output value of the \(c\) channel at a height of \(h\), while \(z_{c}^{w}(w)\) denotes the output value of the \(c\) channel at a width of \(w\). \({{\mathbf{x}}_c}(h,i)\) represents the feature input from the \(i\) row, whereas \({{\mathbf{x}}_c}(j,w)\) indicates the feature input from the \(j\) column.
Second, the feature maps in the horizontal and vertical spatial directions are concatenated, followed by dimensionality reduction to \({C \mathord{\left/ {\vphantom {C r}} \right. \kern-0pt} r}\) using a 1 × 1 convolutional module. Subsequently, the feature map \(f\) is produced through activation by a nonlinear activation function, and it is then decomposed into a horizontal tensor of size \(C/{\text{r}} \times 1 \times H\) and a vertical tensor of size \(C/{\text{r}} \times 1 \times W\) based on the height and width of the input feature map. Finally, the feature matrix dimension is transformed to the same dimension as the input \(X\) through a 1 × 1 convolutional module, and then this transformed matrix undergoes activation and weighted fusion via the Sigmoid activation function. The expression for the final output is as follows:
In this equation, \({y_c}(i,j)\) denotes the final output of CA mechanism, while \({x_c}(i,j)\) indicates the input of CA mechanism.

The structure of the Coordinate Attention Module.
Performance evaluation for recognition model
(1) The accuracy of the target detection model.
Precision, recall, and average precision (AP) are utilized as evaluation metrics to assess the detection accuracy of workers, trolleys, and guardrails. The average precision (AP) is defined as the value of the area under the precision-recall curve. The definitions of precision and recall are articulated as follows respectively:
In this equation, \(precision\) and \(recall\) respectively denote precision and recall. True Positive (TP) refers to the count of correctly detected targets with an Intersection over Union (IoU) exceeding the specified threshold (typically set at 0.5). False Positive (FP) represents the number of actual non-targets that are incorrectly identified, while False Negative (FN) indicates the quantity of targets that remain undetected.
Utilizing the mean average precision (mAP) to assess the overall detection performance of the improved YOLOv8 model, mAP is defined as the average of the AP across all categories of detected targets, calculated as follows:
In this equation, \(c\) denotes the number of targets to be detected.
(2) The accuracy of the identification model of working-at-high operation safety protection.
The evaluation of identification of working-at-high operation scenario and working-at-high operation safety protection is contingent upon three fundamental definitions: True Positive (TP), False Positive (FP), and False Negative (FN). Taking the identification of working-at-high operation safety protection as an example: TP represents the quantity of samples correctly identified as in safety status, FP represents the quantity of samples erroneously identified as in safety status, and FN represents the quantity of samples erroneously identified as in unsafety status. Consequently, the identification model of working-at-high operation safety protection can be evaluated using precision (i.e., the ratio of TP to TP + FP) and recall (i.e., the ratio of TP to TP + FN).
Identification method of working-at-high operation scenario and safety protection based on target detection and Spatial relationship
To determine the protection status (safety/unsafety) of working-at-high workers in the tunnel, this study introduces an identification method of working-at-high operation scenario and safety protection based on the target detection results and the spatial relationships among identified targets.
Identification of working-at-high operation scenario
The excavation of the tunnel face encompasses a multitude of procedures. Among them, the majority of procedures and manual construction methods entail working-at-high operations on the trolley. Therefore, to monitor the safety protection status of working-at-high workers, it is essential to first identify working-at-high operation scenario. Based on the coordinates \(\left( {{x_{{\text{person\_min}}}},{y_{{\text{person\_min}}}},{x_{{\text{person\_max}}}},{y_{{\text{person\_max}}}}} \right)\) of the worker detection bounding box A and the coordinates \(\left( {{x_{{\text{trolley\_min}}}},{y_{{\text{trolley\_min}}}},{x_{{\text{trolley\_max}}}},{y_{{\text{trolley\_max}}}}} \right)\) of the trolley detection bounding box B identified by the improved YOLOv8 model, the spatial relationships between the two target categories’ bounding boxes (including containment, intersection, and dissociation) are acquired. Subsequently, taking Fig. 5 as an example, a comprehensive analysis of the spatial relationships between the trolley and worker detection bounding boxes is conducted to determine whether the scenario involves working-at-high operation.
(1) The relationship of containment, namely \(\operatorname{A} \subseteq B\).
In this case, the coordinates of the detection bounding boxes A and B satisfy the following equation:
In the equation, \(\left( {{x_{{\text{person\_min}}}},{y_{{\text{person\_min}}}}} \right)\) denotes the coordinates of the upper-left corner of the worker detection bounding box, \(\left( {{x_{{\text{person\_max}}}},{y_{{\text{person\_max}}}}} \right)\) denotes the coordinates of the lower-right corner of the worker detection bounding box, \(\left( {{x_{{\text{trolley\_min}}}},{y_{{\text{trolley\_min}}}}} \right)\) denotes the coordinates of the upper-left corner of the trolley detection bounding box, and \(\left( {{x_{{\text{trolley\_max}}}},{y_{{\text{trolley\_max}}}}} \right)\) denotes the coordinates of the lower-right corner of the trolley detection bounding box.
In this case, the worker detection bounding box A is encompassed by the trolley detection bounding box B. As illustrated in Fig. 5, the trolley and workers 2, 3, 4, 5, 6, 7, 8, and 9 are all respectively in the containment relationship. To facilitate comprehensive construction of the tunnel face, the dimensions of the trolley are typically comparable to those of the tunnel’s cross-section, so the spatial positions of working-at-high workers are encompassed within the trolley. In this case, the operation procedure is considered to be taking place in working-at-high operation scenario.
(2) The relationship of intersection, namely \(\operatorname{A} \cap \operatorname{B} >0\).
In this case, the coordinates of the detection bounding boxes A and B satisfy the following equation:
In this case, there is a partial intersection between the worker detection bounding box A and the trolley detection bounding box B. In Fig. 5, the trolley and worker 1 have an intersection relationship. This implies that spatial position intersections of workers and trolley may occur when workers carry out construction at the top of the trolley or on the ground, in which case the operation procedure can also be considered to be taking place in working-at-high operation scenario.
(3) The relationship of dissociation, namely \(\operatorname{A} \cap \operatorname{B} =0\).
In this case, the coordinates of the detection bounding boxes A and B satisfy \(\operatorname{A} \cap \operatorname{B} =0\). In cases where only the trolley is detected, where only the workers are detected, or where the workers and trolley are positioned at a considerable distance from one another (due to limitations in image perspective, situations in which both the worker and trolley coexist while being excessively distant do not occur), the dissociation relationship occurs between workers and trolley. In this case, it is not considered that the workers are in working-at-high operation scenario.

An example of spatial relationships between trolley and workers.
Identification of working-at-high operation safety protection
Building upon the identification of working-at-high operation scenario, the safety protection status of working-at-high workers is subsequently identified. Based on engineering experience and comprehensive consideration of the trolley size and the coverage area of surveillance camera on the waterproof membrane installation trolley, the image area above two-thirds (the value being contingent upon the size of the tunnel) of the trolley detection bounding box is regarded as working-at-high operation area. Then, in combination with the coordinates \(\left( {{x_{{\text{person\_min}}}},{y_{{\text{person\_min}}}},{x_{{\text{person\_max}}}},{y_{{\text{person\_max}}}}} \right)\) of the worker detection bounding box A and the coordinates \(\left( {{x_{{\text{guardrail\_min}}}},{y_{{\text{guardrail\_min}}}},{x_{{\text{guardrail\_max}}}},{y_{{\text{guardrail\_max}}}}} \right)\) of the guardrail detection bounding box C identified by the improved YOLOv8 model, the spatial relationships between the workers and the guardrails within the aforementioned area is analyzed, thereby identifying safety protection status of working-at-high workers.
(1) The relationship of containment, namely \(\operatorname{A} \subseteq \operatorname{C}\).
In this case, the coordinates of the detection bounding boxes A and C satisfy the following equation:
In the equation, \(\left( {{x_{{\text{guardrail\_min}}}},{y_{{\text{guardrail\_min}}}}} \right)\)denotes the coordinates of the upper-left corner of the guardrail detection bounding box, \(\left( {{x_{{\text{guardrail\_max}}}},{y_{{\text{guardrail\_max}}}}} \right)\)denotes the coordinates of the lower-right corner of the guardrail detection bounding box.
In this case, the worker detection bounding box A is encompassed by the guardrail detection bounding box C. As illustrated in Fig. 6, the guardrail and workers 1, 2, 3, and 4 are all respectively in the containment relationship. When workers are conducting working-at-high operations, the existence of guardrails around them can effectively prevent the occurrence of falling accidents. This spatial relationship indicates that workers are protected by guardrails while kneeling or bending to work, which is a safe operation status.
(2) The relationship of intersection, namely \(\operatorname{A} \cap \operatorname{C} >0\).
In this case, the coordinates of the detection bounding boxes A and C satisfy the following equation:
In this case, there is a partial intersection between the worker detection bounding box A and the guardrail detection bounding box C. In Fig. 6, the guardrail and worker 6 have an intersection relationship. This spatial relationship indicates that workers are protected by guardrails while standing upright, which is a safe operation status.
(3) The relationship of dissociation, namely \(\operatorname{A} \cap \operatorname{C} =0\).
In this case, the coordinates of the detection bounding boxes A and C satisfy\(\operatorname{A} \cap \operatorname{C} =0\). It indicates that the workers are conducting working-at-high operations without any nearby guardrails, and at this point, the workers are in an unsafe operation status.

An example of the spatial relationships between guardrails and workers.
Main steps of identification
By analyzing the spatial relationships between the trolley and the workers, it can be determined whether the operation procedures at the tunnel face are in working-at-high operation scenario. Further, by analyzing the spatial relationships between the workers and the guardrail, the safety protection status of working-at-high workers can be determined. The identification process is depicted in Fig. 7, which includes the following steps:
(1) Dataset Production. Prior to building the identification model for working-at-high operation safety protection, the corresponding dataset needs to be prepared. The images in the dataset are preprocessed by the CycleGAN algorithm before being annotated. This dataset encompasses targets of workers, guardrails, trolleys, etc., along with their annotation information, and is partitioned into a training set and a test set at a ratio of 4:1.
(2) Improved YOLOv8 model establishment. First, in accordance with the requirements of the detection task and the constraints of computational resources, YOLOv8s is chosen as the detection model, and CA mechanism is incorporated into this detection model for enhancing the detection accuracy. Subsequently, the YOLOv8-CA model was trained with the pre-partitioned training set. The training process encompassed inputting images into the model, optimizing the model parameters by employing the adaptive gradient optimization algorithm Adam. Through multiple iterations of training, the model’s network structure, loss function, and optimizer parameters were constantly adjusted to acquire the YOLOv8-CA detection model with the optimal parameters. Finally, the detection performance and generalization capacity of the model are evaluated based on the test set.
(3) Identification of working-at-high operation scenario. The working-at-high operation scenario is determined based on the spatial position relationship between the worker detection bounding box and the trolley detection bounding box. If the trolley detection bounding box encompasses or intersects with the worker detection bounding box, this scenario is judged as working-at-high operation. If only the trolley is detected, only the workers are detected, or both are detected and the trolley detection bounding box is disjoint from all the workers detection bounding boxes, the scenario is not judged as working-at-high operation.
(4) Identification of working-at-high operation safety protection. Following the identification of working-at-high operation scenario, an analysis is conducted on the spatial relationship between the detection bounding box of working-at-high worker and that of guardrail, thereby identifying the safety protection status of working-at-high operation. If the worker detection bounding box is disjoint from all the guardrails detection bounding boxes, it is determined that the workers are in an unsafe operation status with the absence of guardrails. Conversely, if any guardrail detection bounding box encompasses or intersects with the worker detection bounding box, it is determined that the workers are in a safe operation status.

The process of identification of working-at-high operation safety protection.
Case study
Dataset Preparation
Data collection
At present, owing to the absence of a comprehensive dataset concerning working-at-high workers in the tunnel, it is essential to develop a dedicated dataset for the training and test of YOLOv8 and YOLOv8-CA. To establish an image dataset for identification of working-at-high operation safety protection, monitoring images were obtained from tunnel construction surveillance videos through frame extraction. A total of 627 images of actual tunnel construction scenarios from various distances, angles, and locations were screened out. These images encompass instances such as trolleys, guardrails, workers conducting working-at-high operations such as drilling, charging and blasting, as well as those who are not engaged in working-at-high operations. Furthermore, to enrich the image dataset, 63 relevant tunnel images were selected through web searches utilizing keywords such as “tunnel construction”, “excavation trolley”, and “high altitude”. Eventually, a total of 690 images were collected as the image dataset for identification of working-at-high operation safety protection.
Data preprocess
To enhance the quality of images within the tunnel, the dataset images were preprocessed utilizing the method outlined in Sect. 3.1. CycleGAN is an unsupervised learning model which requires training with a source domain dataset and an unpaired target domain dataset. The source domain dataset comprises 690 images collected in the low-light environment of tunnels as mentioned previously, while the unpaired target domain dataset consists of 965 images captured near the tunnel entrance under normal illumination conditions. In this study, the GTX 1080ti GPU was employed for model training, with the CUDA version being 11.3. The model was implemented in Python programming language and based on the PyTorch deep learning framework. The parameters during the training process of CycleGAN are as follows: the batch size was configured as 2, the optimizer was selected as Adam, the epoch was set at 200, the learning rate for the first 100 epochs was set to 0.0002, and the learning rate for the subsequent 100 epochs was gradually reduced to 0 in a linear manner. Following the completion of model training, the preprocessing outcomes produced by the CycleGAN algorithm were compared with those generated by common image preprocessing algorithms, including dark channel prior algorithm and histogram equalization algorithm, as illustrated in Fig. 8.

Results comparison of image preprocess using different methods.
The comparison results indicate that the dark channel prior method effectively addresses the issue of smoky environments; however, its performance in processing low-light images is far from satisfactory, resulting in processed images that have diminished brightness. Following processing with the histogram equalization method, the luminance of the image is markedly enhanced, but the local details of the image are lost. The image preprocessing method based on CycleGAN effectively enhances the contrast and clarity of images while preserving local details, thereby rendering the images appear more natural. Additionally, the processing effects of the three image preprocessing methods were contrasted by computing brightness values, average gradient values, energy gradient values, and information entropy of their outcomes. The computational results are presented in Table 1. The computational results indicate that the image processed by the proposed method reveals distinct enhancements in all four indicators compared with the original image and the image processed by the dark channel prior method. In comparison to the image processed by the histogram equalization method, the image processed by the proposed method has a minor deficiency in brightness values and information entropy, but it shows manifested improved performance in average gradient values and energy gradient values. Moreover, the proposed image enhancement method in this study is a deep learning approach based on CycleGAN, characterized by its straightforward training process that does not require manual parameter tuning or image pairing, which exhibits significantly superior real-time performance compared to other algorithms, thereby satisfying the requirements of practical engineering applications. In conclusion, the comparison results demonstrate the effectiveness of the image preprocessing method based on CycleGAN proposed in this study, which not only enhances the overall brightness of the image but also improves the luminance of local regions while preserving intricate details, thereby yielding a processed image with superior visual quality.
Data annotation
A total of 690 images preprocessed using CycleGAN were used as the initial dataset for the object detection model. Among them, 531 images were randomly selected as the training set, while the remaining 159 images were used as the test set. To ensure labeling quality, two professionally trained annotators manually labeled workers, trolleys, and guardrails using the LabelImg annotation tool, with the labeling results verified by a third expert. The annotation includes both the label categories and the bounding box coordinates, with the label categories being “worker”, “trolley”, and “guardrail”. To further enhance the model’s robustness, data augmentation techniques were used to expand dataset. The expanded dataset consists of a total of 3450 images, among which the training set contains 2655 images and the test set contains 795 images. As shown in Fig. 9, the augmentation methods include horizontal flipping, translation, rotation, and scaling.

Image examples of dataset augmentation.
As illustrated in Fig. 10(a), the training set comprised 7649 instances of workers, 1445 instances of trolleys, and 4076 instances of guardrails, while the test set contained 1925 instances of workers, 365 instances of trolleys, and 1093 instances of guardrails. As shown in Fig. 10(b), the overall target distribution is relatively uniform, with a notable proportion of small targets present in the dataset.

Statistical results regarding the labeled targets in the dataset.
Results and analysis
Model training and parameter setting
The target detection model proposed in this study was trained on the Windows platform utilizing NVIDIA RTX A5000 GPU, employing Python 3.8 as the programming language and leveraging the open-source deep learning framework PyTorch to construct the model network. The running environment comprised dependent libraries such as OpenCV, PIL, and NumPy, and CUDA and cuDNN were employed to accelerate the network training.
In this study, both the YOLOv8 model and the improved YOLOv8-CA model were trained using identical hyperparameters, which are specified as follows: the input image size was configured to 640 × 640, the batch size for training data was set at 32, the initial learning rate was established at 0.001, the weight decay coefficient was defined as 0.0005, the training momentum was fixed at 0.937, the number of training epochs was designated as 400, and the optimizer was selected as Adam. Following the completion of parameter settings, the YOLOv8 and YOLOv8-CA models were trained respectively by inputting the training and test set, thereby obtaining the target detection model for workers, trolleys, and guardrails in the tunnel construction scenarios.
The mainstream two-stage target detection algorithm, Faster R-CNN, is chosen as the baseline for comparison. To enhance training performance, the training process of Faster R-CNN is divided into two stages: the freezing stage, during which the feature extraction backbone network is frozen and its weights remain unchanged, and the thawing stage, in which the backbone network’s weights are no longer fixed, allowing all parameters within the network to be updated. Considering the network architecture of Faster R-CNN and GPU memory limitations, the total number of training epochs is set to 500, with 50 epochs for the freezing stage (batch size = 32) and 450 epochs for the thawing stage (batch size = 16). All other hyperparameters are consistent with those used in the YOLOv8 and YOLOv8-CA models.
Model performance evaluation
The performance evaluation metrics of the three target detection models are presented in Table 2. The recall of Faster R-CNN is slightly higher than YOLOv8, but its precision and mAP are both lower than YOLOv8. Additionally, its FPS is 78% lower than YOLOv8, which means its detection speed is relatively slower and difficult to meet the practical deployment requirements. In the case where the FPS of YOLOv8-CA is nearly identical to that of YOLOv8, it outperforms YOLOv8 in all other metrics, demonstrating a significant improvement in model performance.
The performance evaluation metrics for each target category of the three models are shown in the Fig. 11. It can be observed that YOLOv8-CA performs the best across almost all metrics, with particularly outstanding recognition results for small-sized targets such as workers.

performance evaluation metrics for each target category of the three models.
The Precision-Recall (P-R) curve of YOLOv8-CA is shown in Fig. 12. The closer the inflection point of the curve approaches (1, 1), the more favorable the performance of the algorithm.

Precision-recall (P-R) curve of the YOLOv8-CA model.
Furthermore, as depicted in Fig. 13, the growth trajectory of performance metrics for the improved YOLOv8 algorithm during the trainidng process outperforms that of the original YOLOv8 algorithm. This indicates that the enhanced algorithm is more effective at feature extraction throughout the learning process and achieves superior performance within a shorter timeframe.

Comparison results of the trends of metrics during the training cycle before and after algorithm improvement.
The comparison of the detection performance between the improved and original YOLOv8 target detection algorithms is presented in Fig. 14. As depicted in the figure, due to issues such as device occlusion and shadows, the algorithm’s detection results may be subject to false negatives and false positives. The improved YOLOv8-CA algorithm can identify the targets that were previously undetected in the results of the original YOLOv8 algorithm, and the confidence of the detected targets is improved. It demonstrates greater accuracy in detecting small target entities such as workers and guardrails, thereby providing a foundational basis for subsequent identification and monitoring of working-at-high operation safety protection.

The comparison of detection performance before and after algorithm improvement. (Note: The yellow detection frames and the corresponding annotation contents denote the detection outcomes of workers, with “people” signifying workers. The pink detection frames and the related annotation contents indicate the detection results of trolleys, where “trolley” represents trolleys. The orange detection frames and the associated annotation contents represent the detection findings of guardrails, where “guardrail” represents guardrails.)
Figure 15 presents the confidence heatmaps of three types of identified targets in the same image for the YOLOv8 algorithm and the YOLOv8-CA algorithm. It can be observed that the detection capability for all three types of targets has been enhanced to a certain extent by the improved YOLOv8 algorithm.

The comparison of the confidence heatmaps before and after algorithm improvement.
Performance of working-at-high operation safety protection identification model
Based on the identification rules of working-at-high operation scenario and working-at-high operation safety protection that are established in the previous text, an identification model for working-at-high operation safety protection was built. A total of 87 tunnel images were randomly selected as the test set for model performance validation, among which 36 images belong to working-at-high operation scenario and 51 images belong to non-working-at-high operation scenario. The test set was input into the model, and the confusion matrix for identification of working-at-high operation scenario is depicted in Fig. 16(a). It can be observed that there are 33 images belonging to working-at-high operation scenario and 54 images belonging to non-working-at-high operation scenario. Specifically, the true positives (TP) amount to 32, false positives (FP) total 1, and false negatives (FN) count as 4. Consequently, the model’s precision and recall are calculated at 96.97% and 88.89%, respectively. Figure 17 illustrates instances where the real working-at-high operation scenario was not accurately identified, and non-working-at-high operation scenario was erroneously classified as working-at-high operation scenario. In Fig. 17(a), although trolley and workers are present, the working-at-high operation scenario was not recognized. This is a false negative (FN) sample, which is attributed to the incomplete details of the trolley resulting in the failure of the target detection model to identify it, thereby leading to a misjudgment. In Fig. 17(b), non-working-at-high operation scenario was misidentified as working-at-high operation scenario. This is a false positive (FP) sample, which is attributed to the imaging principle of near large and far small resulting in a significant disparity between the actual distance and the pixel distance in the image, thereby leading to a misjudgment. On the whole, the cause of errors lies in the inconsistency between the algorithmic judgment and the subjective human judgment. However, for the tunnel face camera with a limited shooting distance, under ideal shooting conditions, it can prevent issues related to misjudgments caused by incomplete images and distant scenes to a large extent. In conclusion, in general situations, the model can accurately identify the working-at-high operation scenario at the tunnel face.

Evaluation on the predictive performance of the identification model for working-at-high operation safety protection.

Example of misclassified samples.
After the image was determined as working-at-high operation scenario, a further determination of the safety protection status of working-at-high workers was carried out. Among the 32 true positive (TP) samples, there are a total of 267 worker instances, with 144 in a safe status and 123 in an unsafe status. According to the confusion matrix in Fig. 16(b), the model identified 146 workers as being in a safe status and 121 as being in an unsafe status, with true positives (TP) at 140, false positives (FP) at 6, and false negatives (FN) at 4. Consequently, the precision and recall of the model are calculated to be 95.89% and 97.22%, respectively. Figure 18 illustrates the partial recognition results of the model concerning the safety protection status of working-at-high workers, where the green detection bounding box indicates that the worker is in a safe status, and the red detection bounding box indicates that the worker is in an unsafe status. Based on the precision and recall of the model, it is evident that the model exhibits commendable performance in identifying safety protection status; however, issues related to false positives and false negatives remain. As illustrated in the lower right corner of Fig. 18, the model erroneously classified the safety workers on the ground as being in an unsafe status. The primary reason for this misclassification is that the workers are positioned too close to the camera, which results in inaccuracies during the transformation of images from 3D to 2D due to dimensional reduction and spatial overlap. Additionally, some misclassifications arise from discrepancies between the actual size of the trolley and its predetermined dimensions, failing to satisfy the rule that the image area above two-thirds of the trolley detection bounding box is regarded as the working-at-high operation area. Therefore, for trolleys of varying sizes, a specific ratio should be determined based on local conditions to establish the identification rules for working-at-high operation scenario, thereby enhancing the model’s recognition accuracy.

Identification results of the safety protection status of working-at-high workers.
Edge deployment
In this study, Jetson AGX Orin edge computer was selected to carry out the joint deployment of CycleGAN model, YOLOv8-CA model and working-at-high operation safety protection algorithm. The Jetson AGX Orin edge computer, equipped with a heterogeneous computing architecture that includes an Ampere architecture GPU and a 12-core ARM CPU, is capable of satisfying the real-time demands of model inference. The deployment process is as follows: First, the CycleGAN model and YOLOv8-CA model based on Pytorch architecture are exported into the common ONNX format, which is convenient for subsequent quantification operations; Then, TensorRT inference engine is used to carry out FP16 semi-precision quantization of the model. By compressing 32-bit floating-point weights to 16-bit floating-point format, the edge device resource occupation of the model is significantly reduced while maintaining a high degree of accuracy. Finally, a multi-level processing pipeline is constructed in Jetson AGX Orin edge computer to realize the three-level processing mechanism of “image enhancement → target detection → security decision” of video stream frame by frame. As shown in Fig. 19, the camera connected to the edge computer is located on the waterproof membrane installation trolley, its shooting range covers the tunnel face, and the edge computer is placed in an industrial waterproof protective box. The test shows that the inference delay of the three modules is controlled at 38ms, 8ms and 3ms respectively, and the overall processing frame rate reaches 20.4 FPS, which basically meets the requirements of real-time monitoring.

The on-site deployment situation of edge computer and camera.
Discussion and conclusions
To address the issue of the lack of research on working-at-high operation safety protection identification based on computer vision under conditions such as poor lighting conditions in tunnels, complex image backgrounds, and variable detection target sizes, this study proposed an identification method for working-at-high operation safety protection based on the improved YOLOv8, achieving real-time monitoring of the safety protection status of working-at-high workers at the tunnel face in complex tunnel environments. The validity of the method proposed in this study was verified through case analysis, and the following conclusions were obtained:
(1) The CycleGAN algorithm is employed for the preprocessing of tunnel images. The preprocessed images show remarkable enhancements in four metrics, namely brightness, average gradient, energy gradient, and information entropy, thereby improving the visual effect of the images. Moreover, this method holds a substantial advantage in image processing speed and is capable of achieving real-time processing.
(2) By introducing CA mechanism, the target detection model YOLOv8-CA was built, enabling the real-time detection of workers, trolleys, and guardrails in complex tunnel environments. This advancement enhances both detection accuracy and reliability, with the mean average precision (mAP) achieving 96.0%, representing an improvement of 1.05% over the original YOLOv8 algorithm, and reduces the missed detections and false detections of workers and guardrails.
(3) The identification model of working-at-high operation safety protection was built, achieving accurate recognition of working-at-high operation scenario and working-at-high operation safety protection. The accuracy can respectively reach 96.97% and 95.89%, while the recall can respectively amount to 88.89% and 97.22%, providing technical support for all-day, comprehensive, and efficient safety management in high-altitude edge area within the tunnel.
The method proposed in the study still exhibits certain limitations that require further study. Due to the absence of depth information in the images captured by the monocular camera, the recognition logic for safety protection status relies solely on bounding box overlap rules. This approach somewhat neglects the spatial attribute relationships between target objects, potentially causing the detection mechanism to fail under varying shooting angles. Additionally, the determination criteria for working-at-high operation area are based on engineering experience and specific perspectives. In future studies, for the determination of working-at-high operation area and safety protection status of working-at-high workers, depth cameras such as binocular cameras, structured light, and TOF can be utilized to collect the depth data of the targets, and a 3D spatial model can be built to determine the actual spatial coordinates of the targets, thus improving the accuracy of detecting the spatial relationships between the workers and the guardrails.
Data availability
The data presented in this study are available upon request from the corresponding author.
References
Yang, Y. et al. Factors affecting road tunnel construction accidents in China based on grounded theory and DEMATEL. Int. J. Environ. Res. Public Health. 19 (24), 16677 (2022).
Sousa, R. L. & Einstein, H. H. Lessons from accidents during tunnel construction. Tunn. Undergr. Space Technol. 113, 103916 (2021).
Zhu, Y. et al. Statistical analysis of major tunnel construction accidents in China from 2010 to 2020. Tunn. Undergr. Space Technol. 124, 104460 (2022).
Khan, M. et al. Risk factors and emerging technologies for preventing falls from heights at construction sites. Autom. Constr. 153, 104955 (2023).
Zhou, W., Whyte, J. & Sacks, R. Construction safety and digital design: A review. Autom. Constr. 22, 102–111 (2012).
Kolar, Z., Chen, H. & Luo, X. Transfer learning and deep convolutional neural networks for safety guardrail detection in 2D images. Autom. Constr. 89, 58–70 (2018).
Girshick, R. et al. Region-Based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 38 (1), 142–158 (2016).
Girshick, R. & Fast, R-C-N-N. in Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). : IEEE Computer Society. (2015).
Ren, S. et al. Towards Real-Time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39 (6), 1137–1149 (2017).
Redmon, J. & Farhadi, A. YOLO9000: Better, Faster, Stronger. in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2017).
Ding, L. et al. A deep hybrid learning model to detect unsafe behavior: integrating Convolution neural networks and long short-term memory. Autom. Constr. 86, 118–124 (2018).
Khan, N. et al. Utilizing safety rule correlation for mobile scaffolds monitoring leveraging deep Convolution neural networks. Comput. Ind. 129, 103448 (2021).
Chen, H. et al. A proactive workers’ safety risk evaluation framework based on position and posture data fusion. Autom. Constr. 98, 275–288 (2019).
Piao, Y. et al. Dynamic fall risk assessment framework for construction workers based on dynamic bayesian network and computer vision. J. Constr. Eng. Manag. 147 (12), 04021171 (2021).
Li, J. et al. A review of computer Vision-Based monitoring approaches for construction workers’ Work-Related behaviors. IEEE Access. 12, 7134–7155 (2024).
Fang, W. et al. A deep learning-based approach for mitigating falls from height with computer vision: convolutional neural network. Adv. Eng. Inform. 39, 170–177 (2019).
Bonyani, M., Soleymani, M. & Wang, C. Construction workers’ unsafe behavior detection through adaptive Spatiotemporal sampling and optimized attention based video monitoring. Autom. Constr. 165, 105508 (2024).
Park, M. et al. Real-time monitoring unsafe behaviors of portable multi-position ladder worker using deep learning based on vision data. J. Saf. Res. 87, 465–480 (2023).
Ding, C. et al. Identifying unsafe behaviors of construction workers through an unsupervised multi-anomaly GAN approach. Autom. Constr. 165, 105509 (2024).
Park, J. et al. Multi-label material and human risk factors recognition model for construction site safety management. J. Saf. Res. 91, 354–365 (2024).
Fang, W. et al. Falls from heights: A computer vision-based approach for safety Harness detection. Autom. Constr. 91, 53–61 (2018).
Khan, M. et al. Tag and IoT based safety Hook monitoring for prevention of falls from height. Autom. Constr. 136, 104153 (2022).
Wu, X. et al. A Remote-Vision-Based safety helmet and Harness monitoring system based on attribute knowledge modeling. Remote Sens., 15(2), 347 (2023).
Xu, Z., Huang, J. & Huang, K. A novel computer vision-based approach for monitoring safety Harness use in construction. IET Image Proc. 17 (4), 1071–1085 (2023).
Hatipkarasulu, Y. et al. Fatal Fall Accidents in Small Building Construction Projects. in 2014 ASEE annual conference. (2014).
Mendes, C. M. et al. Evaluating USA-image pattern recognition system application for safety guardrails inspection. (2018).
Shanti, M. Z. et al. Real-time monitoring of work-at-height safety hazards in construction sites using drones and deep learning. J. Saf. Res. 83, 364–370 (2022).
Gheisari, M., Rashidi, A. & Esmaeili, B. Using Unmanned Aerial Systems for Automated Fall Hazard Monitoring. In Construction Research Congress 2018: Safety and Disaster Management (Construction Research Congress, 2018).
Chen, S. & Demachi, K. Towards on-site hazards identification of improper use of personal protective equipment using deep learning-based geometric relationships and hierarchical scene graph. Autom. Constr. 125, 103619 (2021).
Fang, Q. et al. Computer vision aided inspection on falling prevention measures for steeplejacks in an aerial environment. Autom. Constr. 93, 148–164 (2018).
Li, J. et al. Standardized use inspection of workers’ personal protective equipment based on deep learning. Saf. Sci. 150, 105689 (2022).
Yang, B., Xiao, H. & Zhang, B. A unified object and keypoint detection framework for personal protective equipment use. Developments Built Environ. 20, 100559 (2024).
López, L. et al. Automated PPE compliance monitoring in industrial environments using deep learning-based detection and pose Estimation. Autom. Constr. 176, 106231 (2025).
Zhu, J. et al. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. in 2017 IEEE International Conference On Computer Vision (ICCV). 16th IEEE International Conference on Computer Vision (ICCV). (2017).
Park, J., Han, D. K. & Ko, H. Adaptive Weighted Multi-Discriminator CycleGAN for Underwater Image Enhancement. J. Mar. Sci. Eng. 7(7). (2019).
Bingnan, Y. et al. ADE-CycleGAN: A detail enhanced image dehazing cyclegan network. Sensors, 23(6), 3294 (2023).
Li, B. Q. et al. Turbid water image enhancement algorithm based on improved cyclegan. J. Electron. Inform. Technol. 44 (7), 2504–2511 (2022).
Du, R. et al. Unpaired underwater image enhancement based on cyclegan. INFORMATION, 13(1), 1 (2022).
H., M. YOLOv1 to v8: unveiling each Variant–A comprehensive review of YOLO. IEEE Access. 12, 42816–42833 (2024).
P., K. and K. V. Exploring the Frontier of Object Detection: A Deep Dive into YOLOv8 and the COCO Dataset. in 2023 IEEE International Conference on Computer Vision and Machine Intelligence (CVMI). (2023).
Hou, Q. et al. Coordinate Attention for Efficient Mobile Network Design. in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (2021).
Funding
This work was supported by China Three Gorges Corporation research project “Key Technologies and Applications of Knowledge-Driven Smart EPC Management and Control for Yangtze River Conservation” [grant numbers 202103551].
Author information
Authors and Affiliations
Contributions
D.L., K.W., Q.D. and R.Z. wrote the main manuscript text and prepared Figs. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18 and 19. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, D., Wang, K., Dai, Q. et al. Working-at-high operation safety protection recognition based on target detection and spatial relationship. Sci Rep 15, 35191 (2025). https://doi.org/10.1038/s41598-025-19048-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-19048-w
