
Abstract
Generative Learning enables the generation of unseen data by learning the patterns from existing data. Text-to-Image generation (T2I) is one of the growing areas of generative learning that mainly focuses on creating realistic images from natural language descriptions. Although many models are available for generating images from text, there is a significant gap in regional languages as input, which restricts the capacity to produce realistic visuals based on regional textual descriptions. This paper proposes a semantic mapping of Hindi T2I generation using the Generative Adversarial Network (GAN). The regional T2I generation model, specifically trained on region-specific data, such as a Hindi language dataset, is prepared, pre-processed, and fed to the model. The study utilizes the Caltech-UCSD Birds 200 (CUB) dataset as its primary source. The experiments indicate that the model delivers well and produces robust images. Our model boosts the existing result significantly with an Inception score of 4.65, FID score of 37.17, and a first-of-kind semantic Alignment in Hindi text-image using R-precision score of 75.12.
Similar content being viewed by others
Introduction
Humans can think, imagine, and respond according to the information they see through their eyes—the ability to think, machine-like, human research has evolved rapidly in recent years. The evolution of artificial intelligence makes machines think, imagine, and generate images from a single prompt, from basic probabilistic models to sophisticated deep generative frameworks. The development of generative learning has rapidly increased over the recent years. The Generative model, such as Variational Autoencoders (VAE) and GAN, can generate high-quality images. Adopting LLM models accelerated the development of generative models across diverse domains. The transformer-based architectures like GPT and BERT has demonstrated that LLM gains the ability to generate human-like text. Integrating the generative capabilities with the LLM has tremendous applications extending beyond text generation to multimodal applications, including T2I, image-to-text, and even video generation1,2,3.
To produce quality visuals based on textual representation, a ground-breaking application of a generative model translates descriptive text into accurate images. The recent advancements in image generation have introduced powerful models such as GAN, VAE, and diffusion models. These models are trained with a huge text-image pair datasets to learn the patterns associated with the language and visual concepts. The image synthesis by these models is more realistic and semantically aligned with the input prompt. The applications of these models are diverse in disciplines such as design, education, healthcare, and entertainment. DALL·E, Imagen, and Stable Diffusion are major cutting-edge models for T2I generation.
The regional T2I generation model is a framework explicitly designed to generate images based on the specific regional language as the input textual description. The models, such as the IndicNLP corpus4,5,6 mainly build an Indic language corpus for the regional languages of the Indic Languages (Indian Languages). The region-specific models are trained from scratch with the region’s dataset, including local language captions and corresponding images. This regional adaptation enhances the model’s semantic understanding and visual relevance, making it suitable for localized applications such as cultural preservation, regional design automation, educational tools, and heritage documentation. It becomes a powerful tool for generating localized content that resonates with native users and reflects India’s multicultural identity.
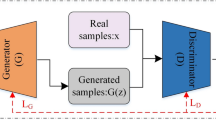
The study proposed a T2I GAN-based model using Hindi text as input, using CUB bird data. GAN works with two neural network architectures consisting of a generator and a discriminator; both modules play significant roles, the visual creation by combination of random noise by the generator and the classification task between real or fake by the discriminator simultaneously. It mainly focuses on textual input description to ensure the image matches the description well. BERT allows the model to process input Hindi text. The GAN generator then uses the encoded text features to produce images semantically aligned with region-specific content. Using BERT further enhances the model’s capability to understand and create culturally relevant visuals based on regional language input. The significant contributions of the study are as follows:
-
1.
Regionally Enriched Hindi Text-Image Dataset Preparation for Semantic Alignment.
-
2.
Data Translation and Semantic Verification Pipeline by Hindi Language experts.
-
3.
Semantic Mapping for Hindi Text-to-Image Generation via Regional Language Embedding Fusion.
-
4.
Comprehensive Evaluation through Quantitative and Qualitative Analysis for the Caltech-UCSD Birds-200-2011 dataset.
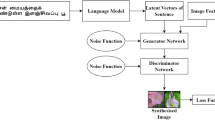
The arrangement of the work is as follows: the existing literature of the T2I is presented in Sect. 2, the detailed methodology is explained in Sect. 3, the empirical evaluation, both qualitative and quantitative, is presented in Sect. 4, and the conclusion, as well as future scope, is described in Sect. 5. Fig. 1
Background survey
T2I generation is the most emerging area of generative learning, enabling the model to produce images from the textual input. Various studies proposed methods for T2I generation using different approaches. This section examines the existing studies on the T2I generation approaches.
Jaiprakash and Prakash7 explain the insights of T2I generation growth and existing image generation approaches. The study demonstrates the key models such as VAE, GAN, Conditional GAN, StackGAN, Transformers, and diffusion models. It further describes various T2I applications, like entertainment, education, and e-commerce. The study also discusses commonly used metrics to assess the fidelity of the model-produced visuals and the challenges faced by the methods used.
Chen and Zhao8 proposed an Efficient Multilayer Fusion GAN. The study gradually integrates contextual details into the feature maps by fusing a multilayer fusion and an efficient multi-scale attention module. Experimental findings suggested the model considerably enhances performance on the COCO (FID from 19.32 to 16.86) and CUB (FID from 14.81 to 10.74) datasets.
Mudiraj and Singh9 demonstrated the dataset collected to build the T2I generation model for the Indian scenario. The study explains the diverse and disparate collection of text image pairs across the parts of India with different environments to make a robust system. Experimentally, the results show that the manual data sets perform better than online and crowdsourced data, with training losses of 0.38 and validation losses of 1.30. Further, it explains the annotation methods and challenges during the data collection.
Mishra et al.10 use the well-known MSCOCO dataset. The study explains how it was manually translated from English to Hindi to create a dataset for Hindi-based image captioning. It describes the transformer model of sequential dependency, which uses an attention-based mechanism approach. Experimental results show that the models significantly perform well and have attained the BLEU-1 score 62.9, the BLEU-2 score 43.3, the BLEU-3 score 29.1, and the BLEU-4 score 19.0.
Mishra et al.11 created the Hindi-language Visual content annotation model. The major contribution of the work is to build an image labelling dataset by translating the widely recognized COCO dataset from English to Hindi. The research further investigates multiple attention-based architectures to effectively produce the text in Hindi. Experimental results indicate the model achieves superior performance compared to several baseline models regarding BLEU scores, with Baseline 1 on BLUE-1 63.3, on BLUE-2 44.6, on BLUE-3 30.9, and on BLUE-4 20.4.
Nwoye et al.12 demonstrated a design to improve the training convergence using an instrument-aware balancing technique to improve training stability amid class imbalances. The study proposed Surgical Imagen, a model that uses triplet-based textual prompts to produce realistic and semantically matched surgical images. Evaluation measures show that the model is effective, as evidenced by its 3.7 FID and 26.8% CLIP scores.
Jin et al.13 propose a generation model framework to control the human pose and texture images with input text. The proposed framework first generates a pose network map from the given prompt description. This pose map is then converted into a parsing map using the corresponding shape details. Finally, the complete image is synthesized based on the textual description of clothing texture, further refined by a quality enhancement network after extensive experimental findings show that the model produces realistic human body visuals based on the input text.
Bahani et al.14 explain the DF-GAN by combining a T2I framework and the AraBERT model. The study uses the DeepL Translator to translate English captions to Arabic to match the Arabic text-visual creation task. Secondly, with AraBERT trained on many Arabic words, it is reduced to a vector dimension to the DF-GAN shape. Finally, the minimized embedding is sent to the UPBlock, and then the data is trained. The datasets used in the study are CUB and Oxford-102 flowers, which are open-source datasets. The experimental results of the Inception score in CUB were 3.51, and the FID score was 55.96; the Inception score on the Oxford-102 text-driven human image generation score was 3.06, and the FID score was 59.45.
Zhang et al.15 introduced the StackGAN, a two-level generative model capable of producing 256 × 256 realistic visuals from the input text. The study breaks down the complex problem into a sub-problem through sketch refinement. At the first level, it generates the simple shapes and colors of the object. At the second level, it inputs the previous level and refines it into high-resolution images with accurate details. The model also introduces Conditioning Augmentation to enhance diversity and training stability. CUB, Oxford-102, and COCO datasets serve as the primary source of the study. The experimental result of the model shows an inception score of CUB 3.70. FID score 51.89, Oxford IS score 3.20, FID score 55.28, The COCO dataset IS score 8.45, and FID score 74.05.
Zhang et al.16 proposed the two-stage GAN architecture. StackGAN-v1 at stage 1 creates low-quality images capturing basic shapes and colors. Furthermore, Stage 2 enhances them into high-quality images with realistic details. Furthermore, StackGAN-v2 extends this concept to enhance the generative efficiency by employing multiple generators and discriminators organized in a tree structure to handle conditional and unconditional tasks.StackGAN-v2 exhibits stability in training with various values within the dataset. The model assessments on benchmark datasets: CUB, Oxford-102, and COCO. The experimental values of Inception’s CUB 4.04, FID score 15.30, Oxford IS score 3.26, FID score 48.68, the COCO dataset IS score 8.30, and FID score 81.59.
Qiao et al.17 propose a novel text-to-image-to-text framework to ensure Contextual alignment between input text and generated visuals through a redescription process called MirrorGAN. IT has three key modules: STEM, to create word and sentence-level text embeddings; GLAM, a global-local attention-based cascaded generator that uses both word- and sentence-level attention to refine images from coarse to satisfactory resolution, and STREAM, which attempts to recreate the original text from the image synthesis to preserve semantic alignment. CUB and COCO datasets are used in the study. The result shows inception core 4.56 and R-precision 60.42 (k = 3) for the CUB dataset. Inception score for coco is 26.47 and R-0 precision is 80.21(k = 3).
Tian and Lu18 proposed rdAttnGAN to generate fine images with the multi-pair generator and discriminators. The study is more important in generating representative and diverse images than conventional models. IT further explains the method of semantic enhancing, an optimal similarity computing approach for better image generation with their textual descriptions. Efficiency is assessed using benchmark datasets such as COCO and CUB. The IS of the rdAttnGAN is 4.39.
Tao et al.19 introduce the DCFGAN, a generative model that accurately fuses the semantics and visual content features using the Dynamic Convolutional Fusion Block. It adapts the convolutional parameters using different text descriptions, and the model can generate images that better match the given text. This fusion helps to improve the semantic and visual content features in the generator network—the model uses the two benchmark datasets CUB and Oxford-102. The experimental results show the Incidence score on CUB is 4.58, and Oxford’s 102 is 3.80.
Li et al.20 proposed a GAN based on cross-modal global and local semantic phrases (CGL-GAN) to address the training difficulties of the GAN, consisting of the global representation results and a fine-grained information horizon in generating images. The study uses a generator for image synthesis using text input and a discriminator to authenticate the produced images to match the input text. The discriminator maps semantic and feature-level visual features onto corresponding global and local linguistic information to enhance cross-modal understanding. COCO and CUB datasets are employed to measure the effectiveness of the approach. The model shows that the Inception score on CUB is 3.67, the MS-COCO data Inception score is 13.62, and the FIS score is 37.12.
Ruan et al.21 introduced the Dynamic Aspect-aware GAN to display the text details at various sentence components. The study constructed an Aspect-aware Dynamic Re-drawer for visual improvement. It has two modules. The AGR module uses word-level embeddings to improve the overall image. The ALR module refines the minute details of the images of aspect-level embeddings. The study further sets the loss function to ensure the semantic matching between the prompt and visuals across these levels. The CUB-200 and COCO datasets are employed in the model evaluation for performance assessment. The inception score in CUB is 4.42, and the FID score is 15.19. R-precision 85.45. The inception score of the COCO dataset is 35.08, the FID score is 28.12, and the R-precision is 92.61.
Zhang et al.22 demonstrated that the up-sampling mechanism helps interact efficiently during training between the object and background generators. This study aims to clarify the use of an asymmetric information flow scheme, allowing each generator to handle distinct synthesis tasks using only the semantic details provided. The effective dual generator can generate fine-grained details of the targeted object based on the attention mechanism. Experiments on CUB, and Oxford-102 datasets show the results regarding IS with CUB showing 4.45, and R-precision is 62.45. In Oxford-102, the score is 3.48.
Kumar et al.23 created a dataset specific to the Indian context, consisting of 3974 images collected manually and 1726 images accessed from internet resources. Deep learning models like the VGG16 model are for analysis and classification. The collected data includes various categories, including transportation, household, clothing, natural elements, and reading materials. The evaluation results show that accuracy on online data collections varied from 11.9 to 93% and for manual data collection, from 50 to 90% for various categories.
Table 1 explains the existing work in T2I generation. Most of the work is done in English as input to the model. Bahani et al.14 use the Deep Fusion GAN for Arabic T2I generation. The study uses the publicly available CUB and Oxford-102 flowers and uses DeepLTranslator to translate to Arabic. Didn’t provide verification step for the converted language authentication; it achieves an IS score in CUB of 3.51, and a FID score of 55.96; the Inception score on the Oxford-102 text-driven human image generation was 3.06, and the FID score was 59.45. The inference of the works states that the model still requires improvement for performance. Nwoye et al.12 and Jin et al.13 models mainly focus on domain-specific tasks, such as surgical image generation and specific tasks like pose generation, with preprocessing of manually annotated skeleton maps. They are not designed to generate content from region-specific prompts, which limits their use in diverse, real-world scenarios. Zhang et al.15 model struggles with the limitation of mismatches between text and generated images in complex regional descriptions. Further, Qiao et al.17 work is significant for contextual alignment, evaluated using R-precision of 57.67. Still, it is limited to English and does not explain the diversity of the Images, and a further limitation is the struggle to generalize to regional languages. However, several models available in the text-to-image generation were mainly used with English text as input. It is limited and has no support for regional languages.
The proposed model helps mitigate the limitations of the existing approaches, especially in systematically preparing Hindi text data, which an expert verifies through a semi-automated approach, and by building semantic mapping for the Hindi T2I generation by using a BERT-based encoder for Hindi linguistic embeddings. Further, Quantitative and Qualitative results and semantic alignment evaluation of Hindi text-image using R-precision show the effectiveness of the proposed model. It enables robust and semantically accurate image generation from prompts in regional languages.
Methodology
This section explains the step-by-step method of developing the proposed Hindi T2I generation model. The process includes data collection and preparation, data translation and expert verification, text encoding, Hindi text-to-image model building, and training pipeline with hyper parameter tuning.
Figure 2 shows the overview of the constructed approach.

Hindi text-to-image generation.

Block diagram of the designed framework.
Data collection and preparation
The Caltech-UCSD Birds-200-2011 (CUB-200-2011) dataset24 is collected from publicly available sources to train and evaluate the proposed Hindi T2I generation model. Figure 3 shows the small snapshot of the bird’s data. It covers a diverse dataset of 200 bird species with different shapes, sizes, and colors. Each image was further processed from the annotated images for translation with a short Hindi caption that accurately describes its visual content. This dataset aims to capture linguistic diversity, enabling the model to learn meaningful relations between regional language input and corresponding visual content.

Snapshot images from CUB dataset24.
Data translation and expert verification
The cub data has bird images and an annotation field. The annotation data is further processed to transform the English textual description into Hindi. The fundamental components of building an efficient model are its quality and accuracy, which are key factors that influence the AI model’s performance. To enhance the dataset and support regional language, a subset of captions written initially in English was translated into Hindi using automated tools and manual correction. At first, from the collected data, each image in the dataset was annotated with 10 unique Hindi captions to provide diverse textual descriptions capturing different aspects of the visual content. The textual description is prepared in English and then translated into Hindi using translation models25. Hindi language experts further review and refine all the translated text descriptions to ensure grammatical accuracy and semantic corrections. This is the key that helps to maintain the consistency and richness of the language, which helps to accurately translate the text that will convey the visual details of each image. The translated text is added to the manual annotated zone to improve the dataset’s diversity and size.
Figure 4 shows the translation of English to Hindi text and verified text. The data quality is tested to ensure that the collected and annotated data meet the model-building requirements. To evaluate the dataset’s quality, verifying that the English textual descriptions are accurately translated into the required Hindi language is necessary. It is verified by the set of translated texts given to the groups, and the translated language textual description verifies each group.

English to Hindi translated text with verification.
Text encoding
BERT is a transformer-based architecture to learn deep bidirectional representations by simultaneously considering the context from a word’s left and right sides26. BERT is excellent at understanding the semantics of the text because it captures the entire context of a sentence, unlike standard models that read material sequentially. A transformer-based language model for Indian languages that has already been trained and is used to process the Hindi text input. A BERT will convert the sentence into dense semantic embeddings to capture the contextual meanings and structure of the input. These embeddings will help in the image generation process as they serve as a condition vector for the generator in the GAN architecture. The role of the BERT is to enable the model to effectively understand complex phrases and ensure the model can create visuals that are closely matches with the input prompts.
Hindi text-to-image model building
The study develops a GAN-based model to produce images from Hindi text. The architecture is composed of two major parts: a generator that creates images and a discriminator that evaluates their realism, trained to improve image quality and text relevance. —Trained together to improve image quality in the minmax game27.
Generator
It is the key module in the process, takes the semantic embedding of the Hindi language text as input, along with a random noise vector, which introduces variability in the produced images. The model accurately captures overall layout and detailed features, resulting in realistic and accurate images that reflect the regional context of the input text.
Discriminator
The module evaluates the clarity and contextual accuracy of images produced. The primary job of the discriminator is to identify the generated and original visuals created by the generator. Providing feedback while training guides the generator in making more realistic and contextually accurate images, especially when working with regional language inputs.
The process begins with the processed text description, such as Hindi, given as input to the model. The BERT encodes the input prompt, which converts the sentence into a meaningful feature vector that captures the semantic content. The generator network receives this encoded text along with a random noise vector. At first, the generator will use the combined input order to generate the low-resolution image. Later, it was refined using multiple layers to produce a high-quality output. The discriminator network assesses the image produced to check whether it is realistic and matches the original text. Through this adversarial training loop, the model learns to create visually realistic images semantically aligned with the input regional language text.
Training pipeline
Ensuring the effective learning of the model involves several stages of training. The GAN training process involves the two core modules, the generator and the discriminator. The generator part is for image synthesis on text embeddings extracted from Hindi descriptions using the BERT model, and simultaneously, the discriminator part is to classify actual images paired with their accurate text captions and fake images created by the model. The training is carried out over 700 epochs, during which the generator continuously improves its ability to create high-quality visuals that align with the semantic content of the input text. Regular monitoring of validation loss and early stopping was employed to prevent over-fitting and improve generalization.
Figure 5 illustrates the image generated by the GAN model while training with 600 epochs, which is the optimal and realistic image produced by the model. It considers the training parameters of the batch size 32. The output shows the diverse birds of different colours, textures, and sizes, showing the model learning effectively.

Hindi GAN model training epoch at 600.
Table 2 presents the key hyperparameters that train the proposed T2I GAN model. K. Kumar et al.28 presented a table for effective tuning hyperparameters. In the proposed work, various values were tested for each parameter to determine the optimal configuration that yields the best image quality and text-image alignment. The best-performing values, highlighted in the table, were selected based on empirical performance measured through quantitative metrics (IS, FID) and qualitative observations.
Semantic mapping from text to visuals
Text-image mapping indicates that the alignment of textual input with respect to visual content will make the generated content accurately reflect the semantics of the input text. To evaluate this alignment, the commonly used metric R-precision measures the accuracy of the image within the top-rated results for the given text. The semantic consistency between the text and the produced visuals is stronger when the R-precision is higher.
Figure 6 shows the detailed process of mapping. At first, the input text is encoded to semantic embeddings, and the produced visuals are mapped to the same feature space as the image encoder. Then the similarity between these embeddings is compared. And retrieval checks whether the accurate image that lies in the top-R ranked result with respect to the text. Finally, the R-precision score is calculated with Eq. 1, showing the strength of the semantic alignment of text and visuals.

Semantic flow for T2I mapping.
Where, R is total number of relevant ground truth item from the given text input.
Experimental results
Experimental setting
The Hindi T2I generation model is trained and evaluated with a custom preprocessed dataset of Hindi text descriptions paired with relevant images. The experimental setup for the training model is conducted on a workstation equipped with an Ubuntu operating system with an NVIDIA GPU (24 GB) to support accelerated training. The model’s training is carried out up to 700 epochs with a batch size 32. All hyperparameters were tuned based on validation performance. The optimized learning rate for the generator is 0.0003, and the discriminator is 0.0001.
Evaluation metrics
The proposed GAN approach was evaluated by conducting experiments on the CUB dataset. Qualitative and quantitative metrics are applied to check the model’s efficiency. For quantitative measurements, the metrics include Inception score (IS) and Frechet Inception Distance (FID) scores.
Inception score
The metric measures the realism and variety of the images the model produces. A pre-trained Inception v3 model is the foundation for IS to predict the class label distribution p(y∣x) for an Image created x29. The score is computed as follows in Eq. 2.
Working principle
The Inception Score (IS) evaluates generated images by passing them through a pretrained Inception-v3 classifier. It measures how accurately the model assigns a class label to each image, and how diverse the overall set of images is across different classes. Each image has a clear and confident prediction (low entropy), across the dataset, predictions are diverse (high entropy over all images).
Interpretation
A strong IS indicates that the high-quality visual content has a broad range of visually convincing images. This helps evaluate how well the model generates explicit and varied content. However, IS is limited — it does not compare the model-generated images to real images, so it cannot directly assess how close the outputs are to real-world data. Therefore, IS is often combined with Fréchet Inception Distance (FID), which provides such a comparison, to give a more complete evaluation of image generation quality.
Frechet inception distance
The metric will assess how closely the distributions of the actual and T2I model-generated images resemble each other. IS focuses on individual image recognition and diversity, but FID focuses on the feature level realism and distribution of the similarity as mentioned in Eq. 330.
Working principle
The FID uses a pretrained Inception-v3 network to compare the feature distributions of actual and produced visual content. It calculates the FID between these features by modelling them as multivariate Gaussians. FID is a valid metric for assessing generative models because a lower score suggests that the visuals produced are better and more varied than the originals.
Interpretation
High-quality and realistically generated visuals are indicated by lower FID scores, which also show that the distribution of produced images is more similar to that of genuine images. FID calculates the distance between feature representations of actual and produced images using a pretrained Inception network. It is particularly valuable because it is sensitive to image fidelity and diversity (output variety). This makes FID a more robust and reliable metric than others, focusing on only one aspect.
Quantitative results
The study conducted a qualitative evaluation using standardized metrics such as IS and FID. Table 3 shows the result of the proposed work with the comparison of existing models. AttnGAN, Stack++, and DFGAN. Ref AttnGAN uses the attention mechanism to better align image regions with textual descriptions. It achieves a nearby IS score of 4.36 and a FID score slightly better than the proposed model, with 23.98. Stack + + uses a multi-stage architecture for refining image generation with an IS score of 3.70 and a FID score with a large margin of 51.89. DFGAN is a one-stage design with a deep fusion block for efficient and high-quality image generation. IT is an Arabic regional text-to-image goal that will result in an IS score of 3.51 and an FID score of 55.96. The model’s overall performance with the CUB dataset shows a better result, outperforming the base model, with an improvement in the result, with an IS of 4.65 and FID score of 37.17.
Table 3 shows the quantitative evaluation using IS and FID, demonstrating the improved performance of the proposed approach over existing models. A higher IS value indicates improved image diversity and object recognizability, while a lower FID reflects closer alignment to the distribution of real images. The inference of the Table 4 result shows that the developed model achieves an IS of 4.65, outperforming the base models, such as the AttnGAN(4.36), stackGAN(3.70), and StackGAN++ (4.04). Also, FID score ATTnGAN(23.98), stackGAN(51.86), StackGAN++ (15.30). This shows the significance of the realistic and diverse image generation. Some existing models achieve competitive IS values, but their FID score varies.
In contrast, our approach strikes a balanced improvement in both metrics, suggesting superior alignment between produced images and text semantics. Although the models like Chen and Zhao8, Zhang et al.16, and Ruan et al.21 achieve FID scores of 10.74, 15.30, and 15.19, the inception score of the model is less than that of the proposed model. The models are based on the English language as an input model to generate images. Further, DFGAN takes the input as Arabic text and creates the images, and its results show IS 3.51 and FID 55.96.
Table 4 shows the R-precision score of existing approaches concerning the current study. Qiao et al.17 achieve the 57.67 with the least alignment and less diversity of the generated content, and Xu et al.31 and Zhang et al.12 achieve improvement in the semantic consistency with the 67.82 and 62.45, respectively, with better results than the previous work. The languages used for this model are in English, and the proposed approach is the first of its kind, which achieves a reasonable score of 75.12 in Hindi text-image semantic alignment and produces efficient results. The achieved score quantifies how accurately the generated visuals align with the given text in the shared embedding space. It confirms that our model maintains fine-grained control over generated content and surpasses existing methods through enhanced data preparation, translation, and expert verification. It enables more accurate text–image semantic alignment to achieve better IS and FID scores even in linguistically diverse input scenarios.
Qualitative results
To further evaluate the model’s effectiveness, the study presents qualitative results of the generated images from the Hindi textural description. Figure 7 shows the proposed model generated images from the Hindi text as input. Hindi text is a description in the first column, and the second column shows the generated image. The model generates the three outputs for each prompt, semantically meaningful images that closely match the input prompts. The result shows the model’s ability to create visually realistic photos. The generated images can generate essential descriptions in the text, such as the object, color, body part, and size. This shows the model can understand Hindi language inputs and generate. It further indicates the model will not generate the same images to maintain the diversity of the model; it creates different positions of images based on the input prompt. The overall results show that the model can match the semantics of the input to the generated image.

Generated Images using proposed Hindi text-to-image model
Figure 7 further shows the specificity of the pictures produced. In column 1, the textual details aligned with the visuals presented in column 2. For example, the colors काली चोंच, हरा पक्षी, काला, shape and body parts सफेद पेट,मोटी भारी चोंच,पंख are some of the text attributes that appear in model-created images in column 2. That is accurately visible in the visuals produced by the model, as represented in the text, which shows that the model aligns, has high efficiency, and can understand the text semantically to match the visuals.
Implication of the work
The research provides the introduction of a manually verified, linguistically grounded Hindi caption dataset sets a new precedent for benchmarking T2I models in multilingual contexts. The proposed methodology can be adapted to critical sectors such as regional education, cultural heritage preservation, medical imaging, and localized content generation, where semantic fidelity to regional input is vital. By showing the effectiveness of regional embeddings in GAN-based pipelines, this work encourages further exploration into language-conditioned generation frameworks, including cross-lingual transfer learning and code-mixed text synthesis. This research lays the groundwork for building scalable generative architectures for low-resource languages.
Limitations
The current work focuses on the CUB dataset within a single task scenario, making the developed GAN model a consistent and controlled environmental setting to validate. It helps to produce high-quality, fine-grained bird images, but its evaluation is limited to this specific domain. Extending the study to multiple datasets and broader application scenarios would further strengthen the evidence of generalizability, and we identify this as a promising direction for future work.
Conclusion and future work
This paper proposed a semantic mapping of a Hindi text-to-image GAN-based framework, incorporating a Hindi language understanding model using the CUB dataset. The model is specifically trained on Hindi textual descriptions. Firstly, in this study, the data preparation and pre-processing of the Hindi textual description are done by semi-automated tools, annotated with diverse captions, and manually verified by native language experts, ensuring relevance and linguistic quality. Secondly, the study uses BERT for text encoding and a GAN-based architecture for image synthesis. The processed text is fed to a GAN-based model for training, and the model successfully generates semantically meaningful and visually realistic images. Thirdly, a Comprehensive Evaluation was performed through Quantitative and Qualitative Analysis; the experimental results show that quantitative and qualitative metrics (IS and FID) show that the proposed model gives better results. The model generates robust images, showing a better result than the existing model with an IS of 4.65 and an FID score of 37.17.
In Future work, we will expand to other regional languages, improve image resolution, and incorporate diffusion-based techniques for enhanced realism. A diverse dataset of the regional languages with various images is considered for training the GAN model in future work32. Further, the ALAP Experience Replay algorithm will be adopted to regulate the importance of sampling weights and eliminate the estimation error caused by PER33. DALAP is an extension of work to compensate for errors more accurately and to identify the range of data distribution that has shifted by using a parallel self-attention network34.
Data availability
The dataset used in this study is the publicly available Caltech-UCSD Birds-200 (CUB) dataset, accessible at [http://www.vision.caltech.edu/datasets/cub\_200\_2011/](http:/www.vision.caltech.edu/datasets/cub_200_2011). No proprietary or restricted data were used.
Code Availability
The code is available at the following link: https://github.com/srinivasmudhiraj/-Hindi-T2I-generation-.
References
Raiaan, M. K. et al. A review on large Language models: architectures, applications, taxonomies, open issues and challenges. IEEE Access. 12, 26839–26874. https://doi.org/10.1109/access.2024.3365742 (2024).
B, S. The Evolution of Large Language Model: Models, Applications and Challenges (IEEE, 2024). https://doi.org/10.1109/icctac61556.2024.10581180.
Ozkaya, I. Application of large Language models to software engineering tasks: Opportunities, risks, and implications. IEEE Softw. 40 (3), 4–8. https://doi.org/10.1109/ms.2023.3248401 (2023).
Kunchukuttan, A. et al. AI4Bharat-INDiCNLP corpus: monolingual corpora and word embeddings for indic languages. ArXiv (Cornell University). https://doi.org/10.48550/arxiv.2005.00085 (2020).
Goswami, D., Malviya, S., Mishra, R. & Tiwary, U. S. Analysis of word-level embeddings for InDic Languages on AI4Bharat-IndicNLP Corpora. 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), 1–4. (2021). https://doi.org/10.1109/upcon52273.2021.9667615
Deode, S., Gadre, J., Kajale, A., Joshi, A. & Joshi, R. L3Cube-IndicSBERT: A simple approach for learning cross-lingual sentence representations using multilingual BERT. ArXiv (Cornell University). https://doi.org/10.48550/arxiv.2304.11434 (2023).
Jaiprakash, S. P. & Prakash, C. S. Exploring text-to-image generation models: applications and cloud resource utilization. Comput. Electr. Eng. 123, 110194. https://doi.org/10.1016/j.compeleceng.2025.110194 (2025).
Chen, W. & Zhao, H. EMF-GAN:Efficient Multilayer Fusion GAN for text-to-image synthesis. Comput. Gr. https://doi.org/10.1016/j.cag.2025.104219 (2025).
Mudiraj, N. S. & Singh, S. Hindi Text-to-Image Generation: A Diverse Data Collection Methods, Annotation Approaches and Challenges (IEEE, 2024). https://doi.org/10.1109/icacctech65084.2024.00019.
Mishra, S. K., Dhir, R., Saha, S. & Bhattacharyya, P. A Hindi image caption generation framework using deep learning. ACM Trans. Asian Low-Resource Lang. Inform. Process. 20 (2), 1–19. https://doi.org/10.1145/3432246 (2021).
Mishra, S. K., Dhir, R., Saha, S., Bhattacharyya, P. & Singh, A. K. Image captioning in Hindi Language using transformer networks. Comput. Electr. Eng. 92, 107114. https://doi.org/10.1016/j.compeleceng.2021.107114 (2021).
Nwoye, C. I. et al. Surgical text-to-image generation. Pattern Recognit. Lett. https://doi.org/10.1016/j.patrec.2025.02.002 (2025).
Jin, Z. et al. Text-driven human image generation with texture and pose control. Neurocomputing https://doi.org/10.1016/j.neucom.2025.129813 (2025).
Bahani, M., Ouaazizi, A. E. & Maalmi, K. AraBERT and DF-GAN fusion for Arabic text-to-image generation. Array 16, 100260. https://doi.org/10.1016/j.array.2022.100260 (2022).
Zhang, H. et al. StackGAN: text to Photo-Realistic image synthesis with stacked generative adversarial networks. IEEE https://doi.org/10.1109/iccv.2017.629 (2017).
Zhang, H. et al. StackGAN++: realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 41 (8), 1947–1962. https://doi.org/10.1109/tpami.2018.2856256 (2018).
Qiao, T., Zhang, J., Xu, D. & Tao, D. MirrorGAN: learning Text-To-Image generation by redescription. 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR). https://doi.org/10.1109/cvpr.2019.00160 (2019).
Tian, A. & Lu, L. Attentional generative adversarial networks with representativeness and diversity for generating text to realistic image. IEEE Access. 8, 9587–9596. https://doi.org/10.1109/access.2020.2964946 (2020).
Tao, M., Wu, S., Zhang, X. & Wang, C. DCFGAN: Dynamic Convolutional Fusion Generative Adversarial Network for Text-to-Image Synthesis (IEEE, 2020). https://doi.org/10.1109/iciba50161.2020.9277299.
Li, R., Wang, N., Feng, F., Zhang, G. & Wang, X. Exploring global and local linguistic representations for Text-to-Image synthesis. IEEE Trans. Multimedia. 22 (12), 3075–3087. https://doi.org/10.1109/tmm.2020.2972856 (2020).
Ruan, S. et al. DAE-GAN: Dynamic Aspect-Aware GAN for Text-to-Image synthesis. 2021 IEEE/CVF International Conference on Computer Vision (ICCV).https://doi.org/10.1109/iccv48922.2021.01370(2021).
Zhang, H., Zhu, H., Yang, S. & Li, W. DGATTGAN: cooperative Up-Sampling based dual generator attentional GAN on Text-to-Image synthesis. IEEE Access. 9, 29584–29598. https://doi.org/10.1109/access.2021.3058674 (2021).
Kumar, M., Mittal, M. & Singh, S. Development and classification of image dataset for Text-to Image Generation. J. Institution Eng. (India) Ser. B, 105(4), 787–796. https://doi.org/10.1007/s40031-024-01013-2 (2024).
Wah, C., Branson, S., Welinder, P., Perona, P. & Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset. In Computation & Neural Systems Technical Report.http://www.vision.caltech.edu/datasets/cub_200_2011(2011).
Li, J., Li, D., Xiong, C. & Hoi, S. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. arXiv (Cornell University) https://doi.org/10.48550/arxiv.2201.12086 (2022).
Devlin, J., Chang, M., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional Transformers for Language Understanding. ArXiv (Cornell University). https://doi.org/10.48550/arxiv.1810.04805 (2018).
Goodfellow, I. et al. GAN(Generative adversarial Nets). J. Japan Soc. Fuzzy Theory Intell. Inf. 29 (5), 177. https://doi.org/10.3156/jsoft.29.5_177_2 (2017).
Kumar, K., Mudiraj, N. S., Mittal, M. & Singh, S. Fine-tuned convolutional neural networks for feature extraction and classification of scanned document images using semi-automatic labelling approach. Int. J. Intell. Eng. Inf. 12 (1), 103–134. https://doi.org/10.1504/ijiei.2024.137711 (2024).
Barratt, S. (ed Sharma, R.) A note on the inception score. ArXiv (Cornell University) https://doi.org/10.48550/arxiv.1801.01973 (2018).
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B. & Hochreiter, S. GANs trained by a two Time-Scale update rule converge to a local Nash equilibrium. ArXiv (Cornell University). 30, 6626–6637 (2017). https://arxiv.org/pdf/1706.08500
Xu, T. et al. AttnGAN: Fine-Grained text to image generation with attentional generative adversarial networks. Ieee https://doi.org/10.1109/cvpr.2018.00143 (2018).
Mudiraj, N. S., Kumar, M., Mittal, M. & Singh, S. Building a diverse Text-to-Image generation dataset. Mendeley Data. https://doi.org/10.17632/b4cg3kyygs.1 (2024).
Chen, Z., Li, H. & Wang, R. Attention loss adjusted prioritized experience replay. ArXiv (Cornell University). https://doi.org/10.48550/arxiv.2309.06684 (2023).
Chen, Z., Li, H. & Wang, Z. Directly attention loss adjusted prioritized experience replay. Complex. Intell. Syst. https://doi.org/10.1007/s40747-025-01852-6 (2025).
Author information
Authors and Affiliations
Contributions
Nakkala Srinivas Mudiraj: Contributed to the conceptualization, data preparation, model development, and manuscript drafting.Satwinder singh: Results Analysis, Supervision, and Manuscript Review.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mudiraj, N.S., Singh, S. Semantic mapping of Hindi text-to-image generation using CUB dataset. Sci Rep 15, 36632 (2025). https://doi.org/10.1038/s41598-025-20537-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-20537-1
