
Abstract
Parkinson’s disease is one of the most common and complex neurodegenerative diseases, characterized by remarkable motor and cognitive decline. As it is a highly heterogeneous disorder, i.e., the specific symptoms, their severity, and their progression rate manifest significant interpersonal variability, multiple progression subtypes can be defined. The identification and prediction of these subtypes is crucial for understanding the disease’s state and future trajectory, advancing prognostic accuracy and personalized treatment planning. At the same time, the ability to predict future MDS-UPDRS scores, provides an objective assessment of symptoms, supporting clinicians in tracking disease progression and evaluating treatment efficacy. To address both critical objectives, we introduce PDualNet, a novel dual-task framework that jointly models and predicts the disease progression and severity based on longitudinal clinical patient data. Our approach involves two key components: (i) an unsupervised module that maps the single-visit data of each patient, onto a “Single-Visit Embedding (SiVE) space”, and (ii) a supervised part, that utilizes the pre-trained SiVE embeddings to learn a compact representation of the longitudinal data of each patient, representing the “Disease State Embeddings (DiSE)”. These embeddings drive two parallel decoders: one predicting the progression subtype, and the other forecasting the future MDS-UPDRS I–III scores. After analysing patient visit data from up to six years after baseline, each consisting of 89 clinical features, we trained and evaluated PDualNet on 579 participants from the Parkinson’s Progression Markers Initiative. The resulting model, demonstrated remarkable performance on both classification and regression tasks, while additional validation on 490 participants from the Parkinson’s Disease Biomarkers Program cohort, confirmed its robust performance and strong generalization capabilities.
Similar content being viewed by others


Introduction
Affecting over 11 million people globally1, Parkinson’s disease (PD) is the second most prevalent neurodegenerative disorder2,3. According to recent studies4 the number of individuals affected is projected to reach 25.2 million by 2050, and in the absence of effective disease-modifying treatments capable of preventing or altering the disease’s progression, PD is expected to impose a considerable burden on public health systems worldwide. The main pathophysiology of the disease includes the progressive degeneration of dopaminergic neurons in the substantia nigra5,6, leading to motor symptoms such as bradykinesia, rigidity, resting tremor and gait problems7,8. Over time, non-motor symptoms also increase, including, among others, cognitive impairment, sleep disturbances, and mood swings9,10. It is worth noting, that PD displays substantial inter-individual variability in symptoms, severity, progression rate, medication responsiveness, and underlying pathophysiology11. This inherent and pervasive heterogeneity12,13, particularly evident in the early to middle stages poses significant challenges. Major issues include difficulties in designing clinical trials14 that accurately assess treatment efficacy, as well as in administering appropriate medication to patients with disease diverse trajectories.
To address these challenges, researchers have prioritized more personalized approaches, focusing on the identification and understanding of the different subtypes of PD progression, as it can help estimate the disease’s course and survival, providing a more accurate prognosis at the time of diagnosis15. Although early efforts at subtyping Parkinson’s disease mainly relied on motor symptoms16, more recent approaches lean toward integrating both motor and non-motor features12,17,18. These newer models are continually being refined through the inclusion of additional data modalities, offering potentially greater clinical utility19. Another notable difference is the employment of longitudinal data20,21, in place of single time-point predictions, which is crucial for capturing the disease dynamics and progression patterns over time. To achieve this effectively, many research works have extensively utilized Machine Learning (ML) and Artificial Intelligence (AI) methods22, for identification and prediction of PD subtypes, monitoring symptoms, and predicting outcomes. In particular, techniques such as unsupervised clustering, and deep learning-based trajectory modelling, offer distinct advantages by modeling nonlinear relationships, handling high-dimensional multimodal datasets, and incorporating longitudinal trajectories, thereby enabling more precise, data-driven stratification of PD patients and paving the way for personalized prognostic and therapeutic strategies.
More specifically, Su Chang et al.23 utilized multimodal data from de novo PD patients, to cluster them into three progression subtypes, namely the Inching Pace subtype (PD-I), the Moderate Pace subtype (PD-M) and the Rapid Pace subtype (PD-R). The authors further correlated these subtypes with biomarkers like CSF P-tau/a-synoclein and brain atrophy, while molecular analyses highlighted subtype-specific genes (e.g. STAT3, FYN) and revealed pathways such as neuroinflammation and oxidative stress driving rapid progression. Similarly, A. Dadu et al.24,25 performed dimensionality reduction via a non-negative matrix factorization approach along with a Gaussian Mixture Model, to cluster PD participants into the slower-progressors, moderate-progressors and fast-progressors, identifying serum neurofilament light as a significant indicator of fast disease progression among other key biomarkers of interest. For the supervised part, they used simple ML models for early subtype prediction after 60 months, on the three following input cases: (a) from BL clinical factors, (b) from BL and first year (after BL) clinical factors, and (c) from biological and genetics measurements. On the other hand, several works26,27 suggest clustering into two subtypes. For instance, Shakya et al.27 detected, using a K-Means clustering approach, the Severe Motor-Non-Motor Subtype (SMNS), characterized by older age at onset and more severe motor and non-motor symptoms, and the Mild Motor-Non-Motor Subtype (MMNS), with younger age at onset and milder symptoms. Imaging biomarkers supported these findings, showing greater neural damage in SMNS, while both subtypes suggest significantly different progression patterns in both motor and cognitive functions. Likewise, Hähnel et al.26 used a latent time joint mixed-effects model (LTJMM) in addition to a Variational Deep Embedding with Recurrence (VaDER)28, to derive two stable PD subtypes (fast and slow progressing) across three large cohorts. For the supervised classification stage, they examined several models including penalized Logistic Regression with L2 regularization, Random Forest, and eXtreme Gradient Boosting (XGBoost). The authors further demonstrated the cross-subtype differences in motor/non-motor progression, survival, treatment response, imaging and digital gait features. In order to deal with irregular time intervals that are common in longitudinal patient records, Baytas et al.29 proposed Time-Aware LSTM (T-LSTM), which was then integrated in an autoencoder to learn a powerful single representation suitable for patient subtyping. Similarly, a state-of-the-art recurrent neural network, namely Gated Recurrent Unit (GRU), was used for handling missing values in multivariate time series data30, leading to models achieving state-of-the-art performance for classification tasks.
Beyond identifying PD subtypes, it is also important to consider one of the most prevalent and widely used practices for assessing PD progression; the decline in motor symptoms, determined using the Movement Disorder Society Unified Parkinson’s Disease Rating Scale (MDS-UPDRS)31. Developing models capable of reliably predicting future MDS-UPDRS scores, can facilitate personalized treatment planning, enable more precise patient stratification, reduce variability in clinical trial cohorts, and yield valuable insights into disease mechanisms and progression. Building on these metrics, Sotirakis et al.32 employed wearable sensors and machine learning (notably Random Forest), to accurately predict MDS-UPDRS-III scores in PD patients over time. The developed model detected motor symptom progression within 15 months, outperforming traditional clinical scales, and proposed a Convolutional Neural Network (CNN) trained on baseline gait data, which accurately forecasts MDS-UPDRS III scores after 3 years, highlighting the potential of ML in assessing PD motor severity and supporting clinical management and decision-making. Tsolakis et al.33 developed the Ince-PD model, based on Inception architectures for time-series classification, demonstrating high accuracy in predicting MDS-UPDRS I & II scores using wearable data and surveys. Additionally, a Multi-Layer Perceptron model using temporal data from the AMP-PD dataset outperformed other algorithms in forecasting PD progression, with supervised data formatting significantly improving prediction accuracy, as shown by Chowdhury et al.34.
While the aforementioned approaches demonstrate promising results, showcasing that data-driven models can uncover early indicators of different motor and non-motor progression types, to this date, there is no explicit attempt to jointly characterize the individual disease trajectories’ subtype along with the future MDS-UPDRS scores; the two gold standards for assessing PD progression. Knowledge of both is considered crucial for a comprehensive understanding of the patient’s clinical status and disease progression. More specifically, the identification of the progression subtype, derived from diverse clinical features, e.g., demographics, motor assessment, MoCA score, medication, allows for a complete view of the disease’s state and its evolution, while the MDS-UPDRS I-III scores provide a robust, quantitative measure of the patient’s motor and non-motor symptoms, enabling clinicians to monitor disease progression and treatment response over time. To this end, in this paper we propose a novel dual-task framework, which models both progression subtype and severity, capturing their inherent interdependence and supporting a holistic and clinically meaningful assessment of the disease’s trajectory. More precisely, as a first step, using an unsupervised approach, we identify three progression subtypes of PD patients, unveiling rapid, moderate and slow progression pace. These subtype labels are then used to supervise the training of PDualNet; a novel multi-task Transformer-based architecture that integrates subtype classification with the prediction of future MDS-UPDRS I–III scores within a unified modeling framework. With a shared encoder for the two tasks, the model effectively learns a joint representation of each patient’s disease state (“Disease State Embedding”), while capturing the underlying latent dependencies between subtype classification and symptom progression. This ultimately yields to strong predictive performance and generalization capabilities across both objectives. The novelty of this work lies in the following contributions:
-
A novel deep learning framework is proposed that jointly predicts each participant’s progression subtype and future MDS-UPDRS I–III scores, based on a modelling approach that effectively transforms longitudinal clinical data from each patient, into meaningful representations, i.e., Disease State Embeddings (DiSE). This single-network architecture further enhances data efficiency and computational scalability, while addressing the dual-task objective. Moreover, based on representation learning, this approach enables generalization through cross-task regularization, capturing temporal dynamics that are relevant to both classification and regression tasks.
-
A single - unified DL model is introduced with autoregressive capabilities that allows the prediction of entire future trajectories of MDS-UPDRS I-III scores, irrespective of the number of clinical visits available per patient. The proposed model introduces flexibility in handling variable-length sequences and missing data, as well as the ability to monitor and observe long-term dependencies in disease progression.
-
The proposed methodology is validated on the large and most widely used cohort of the Parkinson’s Progression Markers Initiative (PPMI), as well as on the external validation cohort of Parkinson’s Disease Biomarkers Program (PDBP), showcasing its superior performance on both tasks over simpler baseline models and demonstrating strong generalization capabilities.
Methods
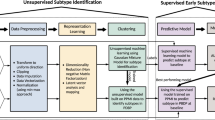
In this study, we propose an end-to-end methodology, starting from data preprocessing and identification of the PD progression subtypes, followed by the design and development of a Deep Learning (DL), Transformer-based framework, that addresses the dual task of predicting the progression subtype of each participant along with the future MDS-UPDRS I - III scores. More specifically, we extract different clinical motor and non-motor longitudinal data from large cohorts of PD participants as well as from Healthy Controls (HCs). The data is preprocessed, including cleaning, outlier detection and removal, normalization of specific features, and imputation of missing values. At the next stage of the proposed method, the progression subtypes are identified. This includes an unsupervised approach, which consists of an LSTM-based autoencoder, resulting in longitudinal data embeddings for each participant. The extracted representations, corresponding to PD patients are then clustered into the different progression subtypes of the PD patients: rapid - moderate - slow, while HCs are seen to form by default a separate cluster. The process continues with the PDualNet model, where we firstly train an Autoencoder for capturing the latent representation of each participant’s single-visit data, Single-Visit Embedding (SiVE) Space. The Encoder’s projection is then used as the embedding module for a Transformer encoder35, modelling the overall disease state representation of all the provided visit data per patient, Disease State Embeddings (DiSE). This learned representation is eventually fed into two separate decoders; a Subtype Decoder for the classification task and a MDS-UPDRS Decoder for addressing the regression task. The model is trained in a three-phase manner to effectively achieve the joint task objective.

Overview of the proposed methodology: Starting with data extraction and preprocessing, followed by the identification of the PD progression subtypes, and finally the modelling and joint prediction of the Parkinson’s Disease Progression & Severity, using the PDualNet framework.
The overview of the proposed methodology is illustrated in Fig. 1, while a detailed description of each step is provided in the following subsections.
Preprocessing
The first step consists of the data preprocessing. Initially, for each participant, p, its longitudinal data are extracted. This includes demographic information, patient history, and clinical features, such as MDS-UPDRS I-III score, MoCA assessment, UPSIT booklet, Schwab and England ADL (Activities of Daily Living) scale, EPWORTH Sleepiness Scale (ESS), and medication information, analytically described in future sections. These data, are organized in visits \(\{BL, V_1, V_2,...,V_n\}\), where BL is the Baseline visit and \(V_n\) is the last available visit of each patient. The visits are time-ordered, and quantified in 6-month intervals, starting from BL. As a result, for each patient, the longitudinal data of each participant p are represented as \(L_p = \{x_{BL}, x_1, x_2, \dots , x_n\}\), where \(x_i\) is the feature vector of the \(i^{th}\) visit.
While processing the data, feature selection is simultaneously being performed, as well as partial outlier detection and removal. In terms of the feature selection, there is a notable trade-off between the number of clinically significant features we want to include and the number of participants that have at least a single visit recording per feature. Thus, features that are available in very few participants are excluded from the analysis. Likewise, participants with sparse feature data are removed, thereby maximizing the cohort size with sufficient observations across the selected features. For the resulting sub-set of preserved participants \(P = \{p_i\}_{i=1}^{N_p}\) and features \(F = \{f_j\}_{j=1}^{N_f}\), the last step consists of data imputation as many participants contain feature vectors with missing values. This is performed using standard imputation techniques, including constant imputation (for static features, e.g. age, sex) and interpolation (for time-varying features, e.g., MDS-UPDRS scores), using least squares regression.
Progression subtypes extraction
After completing the data preprocessing step, we proceed with the identification of the PD progression subtypes. We first generate a single-vector representation of each participant’s extracted data, irrespective of the number of its available visits. For this purpose, as proposed in similar works23 an LSTM-based autoencoder is employed (Fig. 2a), which additionally serves the purpose of dimensionality reduction. The proposed autoencoder is trained using the reconstruction loss in Eq. 1.
Furthermore, the trained autoencoder is utilized for outlier detection and removal. More specifically, we define a threshold \(\mathcal {L}_{max}\) for the reconstruction loss. Then for each participant’s p longitudinal trajectory, we calculate its reconstruction loss \(\mathcal {L}_{rec}(p)\), and if \(\mathcal {L}_{rec}(p) > \mathcal {L}_{max}\), p is removed from the analysis. The intuition behind this is that the autoencoder learns the underlying distribution of the data points in the dataset, and thus, data points with significant difference from the norm, have a high reconstruction loss, indicating that they are outliers.
Moving forward, by preserving only the encoder part of the trained autoencoder, we extract longitudinal embeddings of each participant. Finally, using the embeddings corresponding to PD patients, we employ unsupervised clustering, namely K-Means, which uncovers the three progression subtypes.
PDualNet model
The extracted progression subtypes are used as labels for the next phase of the methodology, which is the design and training of the model. PDualNet consists of the following core components:
-
SiVE Autoencoder This network, illustrated in Fig. 2b, aims to capture the Single-Visit Embeddings (SiVE), \(z_i\), of each visit’s \(x_i\) feature vector. It is constructed using a Multi-Layer Perceptron (MLP) encoder and decoder. The latter is omitted after pre-training, whereas the former serves as the embedding module for the Transformer encoder. The rationale behind the use of this pre-trained module, as emerged from similar works36, lies on providing rich and meaningful initial representation of each visit’s data. Another significant advantage that comes with this modelling approach is the improved performance in terms of stability and training convergence37, especially when the available data is limited.
-
DiSE Transformer-Encoder A Transformer-based encoder that transforms longitudinal clinical data into informative unique Disease-State embeddings (DiSE). Using representation learning, this module contributes to generalization between tasks through shared temporal dynamics, allowing both classification and regression to be beneficial. The input to this module is the sequence of time-ordered SiVE embeddings for a single patient along with a CLS token at the beginning. The latter, is a special token38, often used in Transformer-based architectures, placed always at the beginning of the input and is responsible for capturing the representation of the input sequence. The resulting embedding vector \(d_p\) for each participant p is then provided as input to the two subsequent decoders.
-
Subtype decoder: A MLP decoder that generates an unnormalized logits vector \(s = [s_r, s_m, s_s, s_{HC}]\), assigning a single logit for each one of the classes (C): rapid, moderate, slow and HC respectively. The \(\displaystyle \arg \max _j s\) represents the predicted progression subtype of each participant, given their DiSE representation.
-
MDS-UPDRS decoder A framework consisting of a Transformer decoder, followed by a MLP is responsible for forecasting the future MDS-UPDRS I - III scores of each participant, given their DiSE representation and the previously computed MDS-UPDRS scores. It operates in an autoregressive manner: the MLP’s output, namely, a 3-d vector \(u = [u_I, u_{II}, u_{III}]\) of the predicted scores from the previous time-step, is passed through an embedding module and then used as input to the Transformer decoder, together with the DiSE representation.
The detailed architecture of PDualNet is illustrated in Fig. 2c

Overview of the subtype extraction and PDualNet architecture. (a) Unsupervised module for longitudinal embeddings extraction and clustering of PD progression subtypes into: rapid, moderate and slow. (b) Single-Visit Embedding (SiVE) space, where each visit’s feature vector is mapped to a reduced latent representation, using an Autoencoder. (c) the SiVE embeddings are used as input to a Transformer Encoder-Decoder based architecture, that models the Disease State of each participant (DiSE), and used this representation to jointly predict the progression subtype and the future MDS-UPDRS I-III scores.
Training of PDualNet
The final step is the training of the PDualNet network. Due to the model’s complexity and multi-objective training goal, the training is performed in three distinct phases, as depicted in Fig. 3. In the first phase, we train solely the SiVE Autoencoder, to learn the reduced latent representations \(z_i\) of each visit \(x_i\). This is achieved by minimizing the reconstruction loss in eq. 2.

Training phases of PDualNet. The first phase consists of training the SiVE Autoencoder, the second phase is the training of the DiSE Transformer Encoder, and the third phase is the joint training of both decoders.
Once, this first phase is complete, we preserve its encoder part and use it as the Transformer Encoder’s embedding module. In the second phase, we train the DiSE Transformer Encoder, with the single objective of subtype classification (i.e. the upper branch of PDualNet in Fig. 2c), while the lower branch of the model, consisting of the MDS-UPDRS Decoder remains frozen. For this part, we minimize the weighted cross-entropy loss \(\mathcal {L}_{subtype}\) in Eq. 3, where s is the vector of the predicted unnormalized logits, y is the ground truth subtype label, provided in the form of class indices in the range {0, ..., C}, C is the number of classes, and B is the batch size. To mitigate class imbalance and facilitate the convergence during the model’s training, we add class weights, w, in the subtype classification loss, ensuring that underrepresented or easily learned subtypes contribute proportionally during optimization.
The last training phase, also involves the MDS-UPDRS Decoder. The loss function consists of two components, namely, the cross-entropy loss as introduced above along with the MSE loss for the regression task, defined in eq. 4, below:
where \(\mathcal {L}_{MSE} = \alpha _1 \left\| u_I - \hat{u}_I \right\| _2^2 + \alpha _2 \left\| u_{II} - \hat{u}_{II} \right\| _2^2 + \alpha _3 \left\| u_{III} - \hat{u}_{III} \right\| _2^2\), with \(\hat{u}_I, \hat{u}_{II}, \hat{u}_{III}\) being the predicted MDS-UPDRS I, II and III scores respectively, and \(\alpha _1, \alpha _2, \alpha _3\) being the weights for each score. The weights \(w_1\) and \(w_2\) are used to balance the two components of the loss function. The exponential term is used for stability, when the weights are trainable parameters. Lastly, the threshold \(\mathcal {E}_{thres}\) acts as a “warm-up” phase, where the upper branch (i.e. SiVE Encoder, DiSE Transformer Encoder, and Subtype Decoder) of the model is frozen for same epochs, allowing the model to have a better initialization before the joint training phase. A point worth mentioning is that, since the MDS-UPDRS Decoder operates in an autoregressive manner, we use teacher forcing39 during training (i.e. the ground-truth MDS-UPDRS scores, \(u_I[t], u_{II}[t], u_{III}[t]\) are fed as input at each time step \(t + 1\)). In contrast, during inference, the model uses its own previously predicted scores \(\hat{u}_I[t], \hat{u}_{II}[t], \hat{u}_{III}[t]\) to forecast the next time step.
Lastly, to fully leverage the model’s capabilities, we perform a final data preparation step. More concretely, we split the dataset (i.e. the PPMI cohort) into a training and test set, containing \(q \%\) and \((100 - q) \%\) of the participants in the cohort respectively, to maintain consistent, non-overlapping samples for all training phases. Afterwards, using a sliding window approach, we create multiple, highly correlated training samples, as follows: for each participant’s longitudinal data \(L_p = \{x_{BL}, x_1, x_2, \dots , x_n\}\), given a window size \(W < |L_p|\), this yields \(|L_p| - W\) overlapping input sequences (i.e.\(\{x_{BL}, x_1, \dots , x_{W - 1}\}\), \(\{x_{1}, x_2, \dots , x_{W}\}\), ..., \(\{x_{|L_p| - W + 1}, x_{|L_p| - W + 2}, \dots , x_{n - 1}\}\)). Additionally, given that the model is designed to predict multiple future MDS-UPDRS scores, for each input sequence, e.g. \(\{x_i, \dots , x_{i + W - 1}\}\), there could be up to \(|L_p| - W - i\) different training samples, each corresponding to a different number of MDS-UPDRS scores to be predicted. It can be seen that there are \(N(p, W) = (|L_p| - W)(|L_p| - W + 1) / 2\), possible training samples per participant p and sliding window size W. The same procedure is applied to the test set as well. This acts not only as a form of data augmentation, increasing significantly the number of train and test instances, but also improves the model’s ability to generalize across varying input lengths and forecast horizons.
Datasets
In this work, two datasets were considered, the Parkinson’s Progression Markers Initiative (PPMI)40 used for both training and validation and the Parkinson’s Disease Biomarkers Program (PDBP)41 used as external validation for the proposed methodology, both extracted from the AMP-PDRD Knowledge Platform.

Summary of the utilized datasets. (a) Age distribution in both cohorts, over HC and PD participants. (b) Missing values over the extracted feature categories. (c) Total missing values percentage over the available visits in each cohort.
PPMI is a large, well-characterized cohort of thousands of individuals, with and without Parkinson’s Disease, aiming to identify critically needed biological markers of Parkinson’s onset and progression. In our analysis, after preprocessing, we considered 579 participants, comprising of (N= 391) PD patients (34% Male - 66% Female) and (N= 188) healthy controls (HC)(35.6% Male - 64.4%Female). We extracted their longitudinal data, accounting for a total of 89 clinical features, across the following categories:
-
Demographics Including age at BL, sex, race and years of education.
-
Patient History Including if the participant has a family member (e.g. parent or other relative) with PD.
-
MDS-UPDRS I The MDS-UPDRS Part I score, consisting of 13 features, assessing non-motor aspects of daily living.
-
MDS-UPDRS II The MDS-UPDRS Part II score, including 13 features, considering motor aspects of experiences in daily living.
-
MDS-UPDRS III The MDS-UPDRS Part III score, containing 18 distinct features, which is the clinically assessed motor examination.
-
Schwab and England ADL The Schwab and England ALD score42, which is a 100-point scale that addresses the capabilities of people with impaired mobility.
-
MoCA The Montreal Cognitive Assessment score43, which is designed as a rapid screening instrument for mild cognitive dysfunction. We utilize five relevant features, plus the total score.
-
UPSIT The University of Pennsylvania Smell Identification Test (UPSIT) booklet44, including 4 features (i.e. 4 different 10-page booklets), responsible for assessing the olfactory function of the participants.
-
ESS The Epworth Sleepiness Scale45, including eight features, responsible for assessing a person’s average sleep propensity, or how likely they are to fall asleep in various situations
-
Medication Includes three features, namely, whether the participants is on Levodopa, Dopamine Agonist or other PD medication.
The number of visits taken into account for the case of the PPMI cohort, ranges from 1 (BL) to 13 (\(V_{12}\)), positioned at fixed 6-month intervals. Intermediate 3-month visits were excluded, due to a higher proportion of missing values and their absence in the PDBP cohort.
On the other hand, regarding the PDBP cohort, we preserved 490 participants, consisting of (N= 280) PD patients (57.9 % Male - 42.1 % Female) and (N= 210) healthy controls (HC) (46.7 % Male - 53.3 %). For comparison purposes, the feature set was kept consistent with the PPMI cohort (89 features), and the number of available extracted visits ranges from 1 (BL) to 11 (\(V_{10}\)), all spaced at 6-month intervals.
Additional statistical information regarding the two cohorts is provided in Fig. 4. In particular, Fig. 4a
illustrates the age distribution of the participants in PPMI and PDBP, across the PD and HC groups. On the other hand, Fig. 4b
provides a missing values percentage distribution over the discrete feature categories, while Fig. 4c corresponds to the missing values percentage, over all features and participants, per visit. It can be observed that the PPMI cohort exhibits a higher percentage in missing values in most feature categories, while both cohorts show a similar trend in the missing values per visit, with yearly visits, i.e., \(BL, V_2, V_4\), having a decreased rate of absent values, compared to the intermediate visits, i.e., \(V_1, V_3,\) and so forth.
Method evaluation
This section demonstrates the effectiveness of the proposed methodology by presenting the imputation and clustering results and evaluating the performance of the PDualNet model. The model is assessed across both the PPMI and PDBP cohorts for each of the two tasks. Additionally, we compare the performance of PDualNet with three baseline models to highlight its advantages.
Imputation
For handling missing values, our approach combines constant imputation and linear regression, offering a balance between interpretability, computational efficiency, and temporal consistency. To evaluate our choice, we further conducted an analysis comparing the original imputation pipeline with two widely used alternative strategies, i.e. KNN imputation46 and Multivariate Imputation by Chained Equations (MICE)47. More specifically, we compared the mean and std. deviation of each feature, before and after each imputation technique was applied and report their respective differences in Table 1. Although all methods appear to preserve the initial feature distributions, we utilized the aforementioned imputation approach, as it achieves the lowest deviation across all three methods.
Clustering
The clustering procedure is performed on the PPMI cohort and the trained model (i.e. LSTM Autoencoder) as well as the determined cluster centroids are used to extract the labels for the PDBP cohort, as it represents our external validation set.
The LSTM Autoencoder, consisting of a single Layer in both the encoder and decoder part, with a hidden dimension (i.e., the embedding dimension) of 32, is trained for (N= 70) epochs, using the Adam optimizer with a learning rate of \(2 \times 10^{-3}\).
Upon completion of the training, K-Means clustering is performed for extracting the progression subtypes. For determining the number of clusters k, we examined the alternatives \(k=2\) and \(k=3\), as they represent the common practice in the latest literature23,26. We assessed their respective clustering performance using the silhouette score, the Davies-Bouldin index, and the Akaike Information Criterion (AIC), as summarized in Table 2. Since \(k=3\) produced the best results in two of the three cases and is also the most prevalent choice in related studies, we adopted \(k=3\) for subsequent analysis.
Thus, three clusters were formed, representing the distinct progression subtypes, i.e. rapid (with the faster progression pace), moderate (with an intermediate pace) and slow (with the milder symptom manifestation).
Specifically, for the PPMI cohort, the clustering unveiled (N= 145) rapid, (N= 152) moderate and (N=94) slow progression patients. The clustering result can be found in Fig. 5a, illustrating the 3 clusters (plus the HC participants). For visualization purposes, the projected 2D longitudinal embedding space is derived using Principal Component Analysis (PCA)48 on the latent representations of the participants. When it comes to the PDBP cohort, using the trained LSTM encoder to derive the latent representation embeddings, followed by the prediction of the cluster labels, based on the determined centroids, we detected (N= 112) rapid, (N= 128) moderate and (N = 40) slow PD patients. We additionally provide the mean distribution of certain feature categories, including the MDS-UPDRS I-III scores along with the Schwab and England ADL scores, which are of particular importance for our analysis, in Fig. 5b. Although the two cohorts exhibit differences - as expected, due to the heterogeneity of the disease and patients in each group - the progression subtypes appear to be consistent across the two.

Visualization of the clustering analysis results. (a) The projected 2D embedding space of the longitudinal latent representations of the participants in PPMI. The three clusters appear coloured in blue, yellow and green, representing the rapid, moderate and slow progression subtypes, respectively. For the sake of completeness, the HC participants are included, in red colour. (b) The progression plots of the three subtypes, in the PPMI cohort (continuous lines) and the PDBP cohort (dashed lines). The shaded areas represent the std. deviation from the mean value of each subtype.
PDualNet training and evaluation
Data preparation and baselines
For the training of PDualNet we split the cohort into training and test set, containing 75% and 25% of the participants respectively, stratified with respect to the progression subtypes (109/36 for rapid, 114/38 for moderate, 70/24 for slow and 141/47 for HC). Additionally, we further split the training set into 5 stratified subsets, to perform a 5-fold cross validation. To generate the input sequences, we use a sliding window for each participant, with sizes \(W = \{2, 3, 4, 5\}\), and for training we set the maximum number of future MDS-UPDRS scores to predict to 5.
For performance comparison, we use the same data split to train and test three baseline models. The first is a Temporal Convolutional Neural Network (TCN)49 -based model, consisting of a TCN encoder followed by two Multilayer Perceptron (MLP) decoders-one for classification and one for regression. Our second baseline shares the same encoder-decoder architecture, but with the encoder replaced by a Long Short-Term Memory (LSTM) module. Both aforementioned models were trained following a two-phase procedure analogous to that of our proposed model, ensuring clarity and fair comparison. Specifically, in the first phase, the models were trained on the classification task alone, with the regression decoders’ parameters kept frozen; in the second phase, both tasks were jointly optimized using the dual-task objective. The third baseline comprises two separate Random Forest (RF) models, each dedicated to classification and regression, respectively. However, since these baseline models do not support multi-length input/output sequences, we train different models for each sliding window size W, and set the number of future MDS-UPDRS scores to one, to ensure a fair comparison. Testing of all models (including PDualNet) is similarly conducted separately for each W, predicting a single future MDS-UPDRS I-III score.
Training and implementation details
The number of layers, hidden dimensions, and other hyperparameters of the PDualNet are summarized in Table 3, accounting for a total of 34,703 trainable parameters. The model is trained with batch sizes of 8, 64, 128 and a learning rates of \(10^{-3}\), \(3 \times 10^{-4}\) and \(3 \times 10^{-4}\) for each one of the three training phases, in that order. Regarding the baselines, the TCN-based model, consists of a two-layer TCN encoder with kernel size 2, dilation factors of 1 and 2, and a dropout rate of 0.2. It operates over 89 input channels (one for each input feature) and produces 16 latent feature maps per layer. The two task-specific decoder heads contain a single hidden layer of 16 units with ReLU activation and dropout of 0.1, followed by output layers of dimensions 3 and 4, respectively. In total, the model includes 6.615 trainable parameters. Regarding the LSTM-based model, its encoder contains a single LSTM layer with a hidden dimension of (N= 16) neurons, followed by two MLP decoders, identical to those used in the TCN model, yielding a total of 7511 trainable parameters. Both models are trained with batch sizes of 64 and 128 and a learning rate of \(5 \times 10^{-4}\) across the two different training phases. The RF models are trained with 50 and 300 estimators for the classification and regression tasks, respectively.
All experiments were conducted on a Linux server (AMD Ryzen 9 5950X CPU, 64GB RAM) with two Nvidia 3090Ti GPUs (24GB). The PDualNet training, including all three phases, was completed in approximately 4h, while the average inference time of a single test instance is 0.0062s.
Testing on PPMI cohort
We begin by evaluating the model’s performance on the PPMI cohort, using a 5-fold cross-validation approach, followed by testing the held-out test set. Figure 6 illustrates the cross-validation results, where the solid lines represent the mean performance for each model, while the shaded regions denote the range between minimum and maximum values across varying numbers of input visits. Notably, PDualNet consistently outperforms the baseline models in both tasks and exhibits a more stable performance across the different input sequence lengths. Furthermore, it exhibits low variability around the mean, indicating greater robustness to different training and testing conditions.

5-fold cross-validation results on the PPMI cohort.
For the held-out test set, we present the mean and standard deviation results for varying numbers of input visits (ranging from 2 to 5), across several evaluation metrics, which are summarized in Table 4. More specifically, considering the subtype classification task (Table 4a), PDualNet surpasses both baseline models, achieving the highest overall accuracy (82.87 ± 1.06), precision (83.48 ± 1.18), recall (81.68 ± 1.16) and F1 score (82.37 ± 1.16), retaining at the same time minimal standard deviation, indicating a stable and consistent performance. Another point worth mentioning is that PDualNet is the only model that achieves perfect accuracy for the HC participants, while it performs reliably across all PD subtypes. Lastly, since the task must meet rigorous performance standards, we underline the model’s ability to retain high precision, adding to model’s safety, reliability and effectiveness.
When it comes to the regression learning objective (Table 4b), our model demonstrates the lowest MSE (19.62 ± 0.19), RMSE (4.11 ± 0.01) and highest \(R^2\) (0.81 ± 0.01) for the MDS-UPDRS I-III scores. Seemingly, neither of the LSTM and \(RF_{reg}\) models can reliably predict all three sub-scores, while all baselines are constrained to a single-step prediction horizon, further highlighting the advantage of PDualNet’s more comprehensive and robust modeling capability.
When it comes to the model’s autoregressive capabilities, we evaluate the model’s performance on several future prediction horizons. The results, reported in Table 4c, indicate stable prediction performance, with controlled and gradual error increase for longer prediction horizons. Specifically, the mean RMSE rises from 4.72 (p.h. = 2) to 5.15 (p.h. = 4), indicating moderate degradation in multi-step forecasting accuracy. The RMSE values by prediction horizon exhibit similar trends, confirming that the PDualNet maintains consistent predictive behavior rather than experiencing abrupt degradation at any specific horizon.
To assess the statistical significance of the discussed performance differences between PDualNet and the baselines, we conducted paired Wilcoxon signed-rank tests, applied separately for both regression and classification metrics. For classification, we computed the error as \(1-p\), where p denotes the probability assigned by the model to the true class c. The results, present in Table 4d, indicate statistically significant improvements with all p-values below 0.05 in all comparisons.
External validation on PDBP
To put into the test the generalization capabilities of PDualNet, we evaluate its performance on the PDBP cohort. No further fine-tuning is applied to any of the models. The cluster labels derived in the earlier clustering step are used as ground truth, and the results are summarized in Table 5. To provide additional clarity and detail, we analytically present the classification report and regression performance in the form of confusion matrix and actual versus predicted scatter plots in Fig. 8, for the input sequence length of 2 visits (i.e., BL + 1 visit follow-up). Similar performance was observed for the other input sequence lengths, but we focus on the two-visit case for brevity and as this is the most challenging scenario, given the least amount of information available.
PDualNet maintains strong performance across both objectives, achieving an overall accuracy of 82.13 ± 0.80, precision of 78.70 ± 1.38, recall of 79.22 ± 1.17 and F1 score of 78.89 ± 1.31 for the subtype prediction task. Looking into the model’s regression performance, it achieves an overall MSE of 20.44 ± 0.96, RMSE of 4.28 ± 0.11 and \(R^2\) of 0.78 ± 0.00 for the MDS-UPDRS I-III scores. On the other hand, its autoregressive behavior further indicates that the model effectively captures longitudinal progression patterns while preserving reasonable accuracy for short- to mid-term forecasts. The aforementioned results closely align with those achieved in the internal test set of the PPMI cohort, showcasing PDualNet’s robustness and generalization capabilities across different datasets and varied input sequence lengths. Another observation is that the baseline models present biases towards certain subtypes. For instance, the \(RF_{clas}\) demonstrates a clear preference for the moderate subtypes, even in the PPMI test set, while producing erratic predictions for the remaining subtypes. When it comes to the LSTM model, it achieves significantly higher accuracy for the slow subtype, while the other two subtypes are predicted less reliably - a pattern not observed when tested on the PPMI data, suggesting the model’s difficulty to generalize across cohorts. Similar observations can be made for the TCN model as well, as a bias is observed toward predicting the rapid progression subtypes, with great variance in the model’s performance metrics for the moderate and slow subtype, compared to the PPMI case. These classification trends among the different subtypes for the two baseline models are also illustrated in the confusion matrices of Fig. 8. In contrast, PDualNet shows no such biases, and exhibits stable cross-cohort performance, further demonstrating its robustness.
To gain greater insight into the model’s generalization capabilities, we perform a stratified analysis across different demographic subgroups of the PDBP cohort. Specifically, we assessed PDualNet’s performance separately for male and female participants, as well as for younger (<60 years) and older (\(\ge\) 60 years) individuals, in both the classification and regression tasks. As illustrated in Fig. 7, across all subgroups, classification accuracy ranged from 0.805 to 0.834 and \(F_1\)-score from 0.703 to 0.801, indicating consistent model performance, and suggesting fairness and external generalization. Minor reductions, within accepted ranges, are observed in recall and MSE in older and male participants, which may reflect sample distribution or clinical heterogeneity rather than algorithmic bias.
Similarly to the PPMI case, we also provide the paired Wilcoxon signed-rank test results. The test statistics are consistently large in magnitude, and all corresponding p-values fall well below conventional significance thresholds (p < 0.005), indicating that the observed performance gains are highly unlikely to have occurred by chance. Even in the least significant comparison (regression PDualNet vs. TCN, were p = 0.0023 < 0.005), PDualNet still shows a statistically robust improvement.

Stratified analysis of PDualNet performance over different Demographic groups, including female, male, participants under 60 years (< 60) and those over 60 years (> 60). Similar performance is observed over all subgroups, indicating no significant algorithmic bias.

Actual vs Predicted values for the MDS-UPDRS I-III scores for the PDBP cohort for the three models, along with the confusion matrices for the subtype classification for number of input visits equal to 2. Colored dashed lines represent the least-squares fit for each MDS-UPDRS score and model, while the ± values indicate the \(95\%\) confidence intervals.
Model interpretability and forecasting
This section aims to shed light on the DiSE embeddings structure, which represent the key component for both learning objectives. In addition, we perform post-hoc explainability analysis using SHapley Additive exPlanations (SHAP)50 to extract feature contributions across progression subtypes. Finally, we demonstrate the model’s autoregressive predictive capabilities through representative examples.
Starting with the former aspect, we use a dimensionality reduction technique, namely, UMAP51, to project the DiSE embeddings into a 2D space, as shown in Fig. 9. The visualization unravels well-separated clusters between the four distinct subtypes. In more detail, the HC group is clearly isolated from the other three PD subtypes, accounting for the perfect accuracy achieved in the classification task. The remaining three classes also form separate regions with smooth transitions between them. Elaborating on the latter observation, the emerging continuity between the subtypes (\(slow \rightarrow moderate \rightarrow rapid\)), suggests that the model allows for gradual transitions between them. This is a significant remark, as it indicates that the model reflects clinical reality and captures the disease’s dynamic, as the progression subtypes are not rigid, phenotype snapshots, but rather time-informed evolving states.
Moreover, it is also observed that the greatest overlap occurs between the moderate region and its neighbouring subtypes. To some extent, this entanglement is anticipated, if we consider the greater permissive variability of the moderate subtype, compared to the other two. For instance, patients with extreme progression patterns, even when their disease course is substantially distinct from the class mean, are still observed closer to the rapid cluster, analogously to the very slow progression cases. Consistent with this, the embedding reflects patterns observed in the confusion matrix: rapid cases are misclassified only as moderate, and slow cases are similarly confused only with moderate, whereas misclassifications for the moderate subtype are distributed across both slow and rapid classes. Conclusively, although not a direct decision-level attribution, the above analysis suggests that the embedding space provides strong representation-level insights to the model’s decision-making process and underlying learned structure.

Visualization of disease state embeddings—DiSE space, using a 2D UMAP projection.
In order to provide a deeper understanding and transparency regarding the model’s decision-making process, we provide the SHAP values of the most significant features for each subtype. The results are illustrated in the form of a violin plot in Fig. 10, where positive (or negative) SHAP values indicate that the feature pushes the prediction closer to (or further from) the final output. The subplots reveal a clear, clinically interpretable structure in the model’s decision space: high-magnitude motor features, i.e., MDS-UPDRS-III items are the dominant drivers that push predictions toward pathological subtypes, whereas preserved global function and cognition (e.g., higher ADL/Modified Schwab & England, higher MoCA score) tend to push predictions away from rapid decline and toward slower courses or HC. Non-motor features (daytime sleepiness, EPWORTH score items, constipation, mood) contribute more subtly but consistently, enhancing the separation of moderate and slow subtypes from each other and from HC. Moreover, the participant’s age is considered in all subtypes, suggesting that younger patients experience slower disease progression, and vice versa. The color gradients in the summary plots show that higher values of motor-severity features produce positive SHAP contributions for identifying fast progressors, whereas higher cognitive/ADL scores produce negative contributions for those labels, while the exact opposite pattern is observed for the slow subtype. Overall, the SHAP-driven explainability is both informative and clinically meaningful, as it maps the model’s decisions onto familiar, domain-relevant measurements. It should be noted though, that SHAP describes the model’s associations, not causation, and further analysis should be made before clinical deployment.

Violin plot—SHAP values.
Since the model is trained to predict multiple future MDS-UPDRS scores, to demonstrate its autoregressive capabilities, in Fig. 11 we provide certain examples, where the model is tasked to predict multiple future scores, based on its previous predictions. We observe that the model is capable of capturing the underlying progression patterns, as the red dots (model’s predictions) generally follow the blue line (ground truth scores). Additionally, PDualNet respects patient-specific history and characteristics, generating smooth and realistic future predictions, without overshooting or undershooting compared to the expected values. This stable, and fully autoregressive performance, is a significant advantage compared to the baseline models, which are constrained to single-step predictions, and can be very beneficial for clinical decision-making, as it gives insight to clinicians regarding the disease’s future course. Furthermore, the model’s subtype predictions appear to reflect the patient’s current and future disease trajectory: clearer patterns of progression tend to yield more confident predictions for a specific subtype (see Fig. 11f), while more ambiguous patterns result in a more evenly distributed set of probabilities across multiple subtypes (see Fig. 11b).

Example of future MDS-UPDRS I-III score predictions for each subtypes. The blue line represents the future score (ground truth), while the red line indicates the model’s predictions. The green part corresponds to the visits used as input to the model.
Conclusions and future work
In this work, a novel end-to-end deep learning framework, PDualNet, is proposed to address the dual-problem of Parkinson’s Disease progression subtype classification and future MDS-UPDRS score prediction. The model exploits the longitudinal nature of the data on two levels: first, by encoding the single visit information into a latent representation (SiVE), and second, by identifying the hidden temporal patterns across all provided visits, through a Transformer-based architecture. This structure, combined with the three-phase training procedure, allows the model to learn a shared representation (DiSE), which essentially encodes the disease state in terms of progression, and thus being able to address both tasks simultaneously.
Furthermore, the model is trained on a large, broadly representative cohort, the PPMI, and evaluated on both an internal test and an external validation set, derived from the PDBP study. In addition to that, to benchmark performance, we compared PDualNet with three baseline models that are often used in the field to address the same tasks. The results demonstrated the model’s superior performance on both cohorts, highlighting its robustness and generalization capabilities. It is also worth mentioning that, compared to the baselines, PDualNet was able to achieve the highest accuracy, F1 score and lowest MSE for the regression task, all within a single-unified framework. This is a significant advantage over the baseline models, which are constrained to single-step predictions, and specific input sequence lengths. While PDualNet contains more parameters than its counterparts, it is important to highlight that baseline models were trained separately for each of the four input sequence lengths, resulting in comparable or even higher overall complexity and training effort when considering the total number of the required trained models. This further supports the efficiency and flexibility of PDualNet as a general-purpose forecasting framework.
Another limitation is that, although two large datasets were used, the study may not fully capture the diversity encountered in real-world clinical practice. The inevitable data heterogeneity (different quality or lack of data across different institutions) and/or possible inherent biases in training data may cause errors in predictions for underrepresented groups. Therefore, deeper analysis, including a wide spectrum of individual cases, is warranted before clinical deployment can be considered. Additionally, the use of latent representations of data leads inevitably to limited interpretability. Tools such as the SHAP values do address this limitation to a great extent by providing valuable insights regarding the model’s decision-making, as discussed above; however, they do not reflect causation. External validation and targeted causal and bias assessments are required in applications where interpretability is key.
In terms of future work, it would be interesting to integrate additional data sources, and modalities, such as wearable sensor data (e.g., accelerometer), imaging data (e.g. MRI, DaTscan) or genetic information, to further enhance the model’s generalization capabilities and deepen its disease encoding abilities. Multimodal fusion could help the model capture complementary information and disease signals that could lead to improved performance in downstream tasks. Exploring modality-specific encoders or cross-modal attention mechanisms that would enable the transformer to learn richer, clinically meaningful representations of Parkinson’s disease heterogeneity. This could also strengthen the model’s explainability. For instance, the integration of molecular biomarker or neuroimaging data (e.g., DAT-SPECT or MRI-derived features), could unveil stronger subtype-biomarker correlations, enhancing the clinical interpretability and diagnostic relevance of PDualNet. Another promising direction is to explore stacking-based ensemble learning models for combining results from different architectures. As recent studies52,53 have shown, such ensemble frameworks can enhance diagnostic accuracy and generalization. Similar models could be employed to fuse the predictions of PDualNet with complementary information from additional modality-specific modules (e.g., imaging, genetic, or sensor data), thereby leveraging their joint strengths to achieve more robust and clinically meaningful decision support. In the context of our work, similar models can be applied to fuse PDualNet results with data from modules processing additional modalities to combine their complementary strengths towards improved clinical decision support. Furthermore, extensions of PDualNet can be proposed by employing multi-modal federated learning for training models without direct access to the raw data held by different clients, thus facilitating clinical deployment and addressing important data privacy and security concerns. Another observation arising from the model’s generic structure is that the encoder component or the learned DiSE embeddings alone, can be employed independently in downstream tasks related to the disease (e.g. for predicting longitudinal trajectories of additional clinical scales such as MoCA, ESS, Schwab and England ADL score, etc.).
Data availability
Data used in the preparation of this article were obtained from the Accelerating Medicine Partnership\(^\circledR\) (AMP\(^\circledR\)) Parkinson’s Disease (AMP PD) Knowledge Platform. For up-to-date information on the study, visit https://www.amp-pd.org. “The AMP\(^\circledR\) PD program is a public-private partnership managed by the Foundation for the National Institutes of Health and funded by the National Institute of Neurological Disorders and Stroke (NINDS) in partnership with the Aligning Science Across Parkinson’s (ASAP) initiative; Celgene Corporation, a subsidiary of Bristol-Myers Squibb Company; GlaxoSmithKline plc (GSK); The Michael J. Fox Foundation for Parkinson’s Research ; Pfizer Inc.; Sanofi US Services Inc.; and Verily Life Sciences. “ACCELERATING MEDICINES PARTNERSHIP and AMP are registered service marks of the U.S. Department of Health and Human Services. More specifically, we obtained the clinical data corresponding to the MJFF Parkinson’s Progression Markers Initiative (PPMI) and the National Institute of Neurological Disorders and Stroke (NINDS) Parkinson’s Disease Biomarkers Program (PDBP) (AMP-PD, 2023 releases, v4 release).
PPMI–a public-private partnership–is funded by the Michael J. Fox Foundation for Parkinson’s Research and funding partners, including 4D Pharma, Abbvie, AcureX, Allergan,Amathus Therapeutics, Aligning Science Across Parkinson’s, AskBio, Avid Radiopharmaceuticals, BIAL, BioArctic, Biogen, Biohaven, BioLegend, BlueRock Therapeutics, Bristol-Myers Squibb, Calico Labs, Capsida Biotherapeutics, Celgene, Cerevel Therapeutics, Coave Therapeutics, DaCapo Brainscience, Denali, Edmond J. Safra Foundation, Eli Lilly, Gain Therapeutics, GE HealthCare, Genentech, GlaxoSmithKline plc (GSK), Golub Capital, Handl Therapeutics, Insitro, Janssen Neuroscience, Jazz Pharmaceuticals, Lundbeck, Merck, Meso Scale Discovery, Mission Therapeutics, Neurocrine Biosciences, Neuropore, Pfizer, Piramal, Prevail Therapeutics, Roche, Sanofi, Servier, Sun Pharma Advanced Research Company, Takeda, Teva, UCB, Vanqua Bio, Verily, Voyager Therapeutics, the Weston Family Foundation and Yumanity Therapeutics. The PPMI investigators have not participated in reviewing the data analysis or content of the manuscript. For up-to-date information on the study, visit https://www.ppmi-info.org.
PDBP is supported by the National Institute of Neurological Disorders and Stroke at the National Institutes of Health. Investigators include: Roger Albin,Roy Alcalay, Alberto Ascherio, Thomas Beach, Sarah Berman,Bradley Boeve, F. DuBois Bowman, Shu Chen, Alice Chen-Plotkin, William Dauer, Ted Dawson, Paula Desplats, Richard Dewey, Ray Dorsey, Jori Fleisher, Kirk Frey, Douglas Galasko, James Galvin, Dwight German, Lawrence Honig, Xuemei Huang, David Irwin, Kejal Kantarci, Anumantha Kanthasamy, Daniel Kaufer, James Leverenz, Carol Lippa, Irene Litvan, Oscar Lopez, Jian Ma, Lara Mangravite, Karen Marder, Laurie Orzelius, Vladislav Petyuk, Judith Potashkin, Liana Rosenthal, Rachel Saunders- Pullman, Clemens Scherzer, Michael Schwarzschild, Tanya Simuni, Andrew Singleton, David Standaert, Debby Tsuang, David Vaillancourt, David Walt, Andrew West, Cyrus Zabetian, Jing Zhang, and Wenquan Zou. The PDBP Investigators have not participated in reviewing the data analysis or content of the manuscript. For up-to-date information on the study, visit: https://pdbp.ninds.nih.gov.
References
Luo, Y. et al. Global, regional, national epidemiology and trends of parkinson’s disease from 1990 to 2021: findings from the global burden of disease study 2021. Front. Aging Neurosci. 16, 1498756. https://doi.org/10.3389/FNAGI.2024.1498756/BIBTEX (2024).
Bloem, B. R., Okun, M. S. & Klein, C. Parkinson’s disease. Lancet 397, 2284–2303. https://doi.org/10.1016/S0140-6736(21)00218-X (2021).
Mizuno, Y. Where do we stand in the treatment of parkinson’s disease?. J. Neurol. 254, 13–18. https://doi.org/10.1007/S00415-007-5003-9 (2007).
Li, M., Ye, X., Huang, Z., Ye, L. & Chen, C. Global burden of parkinson’s disease from 1990 to 2021: A population-based study. BMJ Open 15, e095610. https://doi.org/10.1136/BMJOPEN-2024-095610 (2025).
Ortiz, G. G. et al. Physiology and pathology of neuroimmunology: Role of inflammation in parkinson’s disease. Physiol. Pathol. Immunol. https://doi.org/10.5772/INTECHOPEN.70377 (2017).
Bonnet, A. M. & Houeto, J. L. Pathophysiology of parkinson’s disease. Biomed. Pharmacotherapy 53, 117–121. https://doi.org/10.1016/S0753-3322(99)80076-6 (1999).
Váradi, C. Clinical features of parkinson’s disease: The evolution of critical symptoms. Biology 2020, Vol. 9, Page 103 9, 103, https://doi.org/10.3390/BIOLOGY9050103 (2020).
Moustafa, A. A. et al. Motor symptoms in parkinson’s disease: A unified framework. Neurosci. Biobehavioral Rev. 68, 727–740. https://doi.org/10.1016/J.NEUBIOREV.2016.07.010 (2016).
Modugno, N. et al. A clinical overview of non-motor symptoms in parkinson’s disease. Archives Italiennes de Biologie https://doi.org/10.4449/AIB.V151I4.1564 (2013).
Poewe, W. Non-motor symptoms in parkinson’s disease. European J. Neurol. 15, 14–20. https://doi.org/10.1111/J.1468-1331.2008.02056.X (2008).
Wüllner, U. et al. The heterogeneity of parkinson’s disease. J. Neural Trans. 130, 827–838. https://doi.org/10.1007/S00702-023-02635-4 (2023).
Park, S.-M. H. et al. Parkinson’s disease subtyping using clinical features and biomarkers: Literature review and preliminary study of subtype clustering. Diagnostics 2022, Vol. 12, Page 112 12, 112, https://doi.org/10.3390/DIAGNOSTICS12010112 (2022).
Lewis, S. J. et al. Heterogeneity of parkinson’s disease in the early clinical stages using a data driven approach. J. Neurol., Neurosurg. Psychiatry 76, 343–348. https://doi.org/10.1136/JNNP.2003.033530 (2005).
Athauda, D. & Foltynie, T. Challenges in detecting disease modification in parkinson’s disease clinical trials. Parkinsonism Related Disorders 32, 1–11. https://doi.org/10.1016/J.PARKRELDIS.2016.07.019 (2016).
Rooden, S. M. V. et al. The identification of parkinson’s disease subtypes using cluster analysis: A systematic review. Movement Disorders 25, 969–978. https://doi.org/10.1002/MDS.23116 (2010).
Qian, E. & Huang, Y. Subtyping of parkinson’s disease - where are we up to?. Aging Disease 10, 1130–1139. https://doi.org/10.14336/AD.2019.0112 (2019).
Goldman, J. G. & Postuma, R. Premotor and nonmotor features of parkinson’s disease. Curr. Opinion Neurol. 27, 434–441. https://doi.org/10.1097/WCO.0000000000000112 (2014).
Gramotnev, G., Gramotnev, D. K. & Gramotnev, A. Parkinson’s disease prognostic scores for progression of cognitive decline. Scientific Rep. 2019 9:1 9, 1–13, https://doi.org/10.1038/s41598-019-54029-w (2019).
Fereshtehnejad, S. M., Zeighami, Y., Dagher, A. & Postuma, R. B. Clinical criteria for subtyping parkinson’s disease: Biomarkers and longitudinal progression. Brain 140, 1959–1976. https://doi.org/10.1093/BRAIN/AWX118 (2017).
Adeniyi, O. J., Ayankoya, F. Y., Kuyoro, S. O., Akwaronwu, B. G. & Abiodun, A. G. Machine learning models for predicting parkinson’s disease progression using longitudinal data: A systematic review. Asian J. Res. Comput. Sci. 18, 274–294. https://doi.org/10.9734/AJRCOS/2025/V18I3593 (2025).
Zhang, X. et al. Data-driven subtyping of parkinson’s disease using longitudinal clinical records: A cohort study. Scientific Rep. 9, 1–12 (2019).
Mohanakrishnan, S. S. Latest advanced artificial intelligence methods for machine learning model-based predictive parkinson’s disease identification. Int. Conference Contemporary Comput. 1103–1108, https://doi.org/10.1109/IC363308.2025.10956528 (2025).
Su, C. et al. Identification of parkinson’s disease pace subtypes and repurposing treatments through integrative analyses of multimodal data. npj Digital Med. 7, https://doi.org/10.1038/S41746-024-01175-9 (2024).
Dadu, A. Application of machine learning to the detection and prediction of Parkinson’s disease subtypes. Master’s thesis, University of Illinois at Urbana-Champaign (2021).
Dadu, A. et al. Identification and prediction of parkinson’s disease subtypes and progression using machine learning in two cohorts. npj Parkinson’s disease 8, https://doi.org/10.1038/S41531-022-00439-Z (2022).
Hähnel, T. et al. Progression subtypes in parkinson’s disease identified by a data-driven multi cohort analysis. npj Parkinson’s Disease 10, https://doi.org/10.1038/S41531-024-00712-3 (2024).
Shakya, S., Prevett, J., Hu, X. & Xiao, R. Characterization of parkinson’s disease subtypes and related attributes. Front. Neurol. 13, 810038. https://doi.org/10.3389/FNEUR.2022.810038/BIBTEX (2022).
de Jong, J. et al. Deep learning for clustering of multivariate clinical patient trajectories with missing values. GigaScience 8, giz134 (2019).
Baytas, I. M. et al. Patient subtyping via time-aware lstm networks. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 65–74 (2017).
Che, Z., Purushotham, S., Cho, K., Sontag, D. & Liu, Y. Recurrent neural networks for multivariate time series with missing values. Scientific Rep. 8, 6085 (2018).
Goetz, C. G. et al. Movement disorder society-sponsored revision of the unified parkinson’s disease rating scale (mds-updrs): Scale presentation and clinimetric testing results. Movement Disorders 23, 2129–2170. https://doi.org/10.1002/MDS.22340 (2008).
Sotirakis, C. et al. Identification of motor progression in parkinson’s disease using wearable sensors and machine learning. npj Parkinson’s Disease 9, https://doi.org/10.1038/S41531-023-00581-2 (2023).
Tsolakis, N., Maga-Nteve, C., Meditskos, G., Vrochidis, S. & Kompatsiaris, I. Ince-pd model for parkinson’s disease prediction using mds-updrs i & ii and pdq-8 score. Artificial Intelligence Applications and Innovations 675 IFIP, 267–278, https://doi.org/10.1007/978-3-031-34111-3_23 (2023).
Chowdhury, A. R., Ahuja, R. & Manroy, A. A machine learning driven approach for forecasting parkinson’s disease progression using temporal data. Int. Conf. Distributed Comput. Internet Technol. 14501, 266–281. https://doi.org/10.1007/978-3-031-50583-6_18 (2024).
Vaswani, A. et al. Attention is all you need. In Adv. Neural Inf. Proc. Syst.(NeurIPS), 5998–6008 (2017).
Shang, J., Ma, T., Xiao, C. & Sun, J. Pre-training of graph augmented transformers for medication recommendation. IJCAI International Joint Conference on Artificial Intelligence 2019-August, 5953–5959, https://doi.org/10.24963/IJCAI.2019/825 (2019).
Yao, Y., Yu, B., Gong, C. & Liu, T. Understanding how pretraining regularizes deep learning algorithms. IEEE Trans. Neural Netw. Learn. Syst. 34, 5828–5840. https://doi.org/10.1109/TNNLS.2021.3131377 (2023).
Devlin, J., Chang, M. W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL HLT 2019 - 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference 1, 4171–4186 (2018).
Sutton, R. S. Learning to predict by the methods of temporal differences. Machine Learning 1988 3:1 3, 9–44, https://doi.org/10.1007/BF00115009 (1988).
Marek, K. et al. The parkinson’s progression markers initiative (ppmi) – establishing a pd biomarker cohort. Annals Clin. Trans Neurol. 5, 1460. https://doi.org/10.1002/ACN3.644 (2018).
Ofori, E., Du, G., Babcock, D., Huang, X. & Vaillancourt, D. E. Parkinson’s disease biomarkers program brain imaging repository. NeuroImage 124, 1120. https://doi.org/10.1016/J.NEUROIMAGE.2015.05.005 (2015).
Siderowf, A. Schwab and england activities of daily living scale. Encyclopedia of Movement Disorders, Three-Volume Set 99–100, https://doi.org/10.1016/B978-0-12-374105-9.00070-8 (2010).
Nasreddine, Z. S. et al. The montreal cognitive assessment, moca: A brief screening tool for mild cognitive impairment. J. Am. Geriatrics Soc. 53, 695–699. https://doi.org/10.1111/J.1532-5415.2005.53221.X (2005).
Doty, R. L., Frye, R. E. & Agrawal, U. Internal consistency reliability of the fractionated and whole university of pennsylvania smell identification test. Perception Psychophys. 45, 381–384. https://doi.org/10.3758/BF03210709/METRICS (1989).
Johns, M. W. A new method for measuring daytime sleepiness: The epworth sleepiness scale. Sleep 14, 540–545. https://doi.org/10.1093/SLEEP/14.6.540 (1991).
Troyanskaya, O. et al. Missing value estimation methods for dna microarrays. Bioinformatics 17, 520–525. https://doi.org/10.1093/BIOINFORMATICS/17.6.520 (2001).
van Buuren, S. & Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in r. J. Statist. Softw. 45, 1–67. https://doi.org/10.18637/JSS.V045.I03 (2011).
F.R.S., K. P. Liii. on lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 2, 559–572, https://doi.org/10.1080/14786440109462720 (1901).
Lea, C., Flynn, M. D., Vidal, R., Reiter, A. & Hager, G. D. Temporal convolutional networks for action segmentation and detection. Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017 2017-January, 1003–1012, https://doi.org/10.1109/CVPR.2017.113 (2016).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, 4768–4777 (Curran Associates Inc., Red Hook, NY, USA, 2017).
McInnes, L., Healy, J., Saul, N. & Großberger, L. Umap: Uniform manifold approximation and projection. J. Open Sour. Softw. 3, 861. https://doi.org/10.21105/joss.00861 (2018).
Yanar, E., Hardalaç, F. & Ayturan, K. Celm: An ensemble deep learning model for early cardiomegaly diagnosis in chest radiography. Diagnostics 15, 1602 (2025).
Yanar, E., Hardalaç, F. & Ayturan, K. Pelm: A deep learning model for early detection of pneumonia in chest radiography. Appl. Sci. 15, 6487 (2025).
Funding
This work has been supported from EC under grant agreement 101080581 “AI-PROGNOSIS: Artificial intelligence based Parkinson’s disease risk assessment and prognosis”.
Author information
Authors and Affiliations
Contributions
V.R. and K.D. conceptualize the research work, V.R. developed the software and wrote the main manuscript text, V.R. and N.G. analyzed the results and P.D, and K.D. supervised the work. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rizou, V., Grammalidis, N., Daras, P. et al. PDualNet: a deep learning framework for joint prediction of Parkinson’s disease progression subtype and MDS-UPDRS scores. Sci Rep 15, 41931 (2025). https://doi.org/10.1038/s41598-025-25812-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-25812-9
