
Abstract
This paper proposes a hybridized model for air quality forecasting that combines the Support Vector Regression (SVR) method with Harris Hawks Optimization (HHO) called (HHO-SVR). The proposed HHO-SVR model utilizes five datasets from the environmental protection agency’s Downscaler Model (DS) to predict Particulate Matter (\(PM_{2.5}\)) levels. In order to assess the efficacy of the suggested HHO-SVR forecasting model, we employ metrics such as Mean Absolute Percentage Error (MAPE), Average, Standard Deviation (SD), Best Fit, Worst Fit, and CPU time. Additionally, we contrast our methodology with recently created models that have been published in the literature, such as the Grey Wolf Optimizer (GWO), Salp Swarm Algorithm (SSA), Henry Gas Solubility Optimization (HGSO), Barnacles Mating Optimizer (BMO), Whale Optimization Algorithm (WOA), and Manta Ray Foraging Optimization (MRFO). In particular, the proposed HHO-SVR model outperforms other approaches, establishing it as the optimal model based on its superior results.
Similar content being viewed by others

Introduction
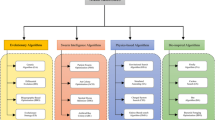
Over the past twenty years, meta-heuristic optimization approaches have gained immense popularity. Most of them, such as SSA1, EO2, HHO3, GWO4, BMO5, MRFO6, WOA7, AO8, AOA9, and HGSO10, are well acknowledged by scientists of multiple disciplines in addition to machine learning experts. These optimization approaches have been applied to a wide range of study topics and have been used to solve numerous optimization issues, including jobs that are non-linear, non-differentiable, or computationally demanding with many local minima. In addition, a substantial number of scientific papers have been conducted on these methodologies. The surprising popularity of metaheuristics can be attributed to four main factors: clarity, pliability, derivation-free processes, and the ability to avoid local optima4,11. Typically, these techniques can be categorized into four distinct groups12: evolution-based, physics-inspired, swarm-based13,14, and human-based algorithms.
Evolution-based models: integrate mechanisms such as chemical sensing and movement, reproductive processes, removal, distribution, and movement patterns.15. Among these, the Genetic Algorithm (GA) stands out as a common and powerful evolutionary technique16. In particular, GA does not require derivatives, unlike mathematical optimization methods. By emulating successful strategies, GA improves populations through efficient tactics such as escaping local optima. Over time, different approaches were suggested to improve the efficiency of GA. Furthermore, other evolutionary techniques have emerged based on the success of GA17, including Evolutionary Programming (EP)18, Differential Evolution (DE)19, Evolutionary Strategies (ES)20, and the Artificial Algae Algorithm (AAA)21.
Physics-based: simulate the physical rules governing our planet. One of the most recognized algorithms in this category is Simulated Annealing (SA)22. SA approximates physical material thermodynamics. The process of annealing, which involves cooling and crystallizing hot metals, is used to reduce electricity consumption. Additionally, several new physics-inspired algorithms, such as the Gravitational Search Algorithm (GSA)23. Lévy Flight Distribution (LFD)24, Archimedes optimization algorithm (AOA)25, have been established.
Swarm-based algorithms: strive to replicate the social tendencies observed in creatures, such as self-organizing mechanisms and the assignment of work duties.26. Two notable case studies in this domain are Particle Swarm Optimization (PSO)27 and Ant Colony Optimization (ACO)28. PSO, inspired by bird flocking activities, adjusts every agent based on both its best individual performance and the best global within the group. ACO, on the other hand, draws inspiration from ant swarms’ foraging habits and the diminishing strength of pheromones over time. Ants use this approach to find the most efficient path from their nest to a food source. In addition, other swarm-inspired techniques include Glowworm Swarm Optimization (GSO)29, Harris Hawks Optimization (HHO) , and cuckoo search (CS)30, as well as Artificial Ecosystem-based Optimization (AEO)31.
Human-based algorithms: mainly derived from human behavior where each individual has a unique way of accomplishing tasks that can impact their overall performance. Which becomes a motivation for researchers to improve the models32. The most well-known human-based algorithm is called Teaching-Learning-Based Optimization (TLBO), and it was developed to simulate the classroom interactions between the instructor and his students33. Human Mental Search (HMS)34 was designed by simulating human behavior versus online auction platforms. Doctor and Patient optimization algorithm (DPO)35 was designed with consideration for interactions between healthcare providers and patients, including illness prevention, examination, and therapy.
The No Free Lunch Theorem36 in optimization states that no single optimizer performs optimally across all optimization scenarios. Consequently, the pursuit of robust swarm-inspired optimizers has become a driving force for researchers aiming to tackle intricate real-world problems37,38 . In this study, we propose eight hybrid frameworks that incorporate modern metaheuristic techniques. These frameworks are specifically designed to fine-tune support vector regression parameters for forecasting the daily maximum concentration of Particulate Matter (\(PM_{2.5}\)).
According to the literature, various methods have been employed with different characterizations. Among these, optimization methods have proven their efficiency in solving \(PM_{2.5}\) forecasting problems compared to traditional approaches. However, SVR and optimization methods have been underutilized, despite their potential to provide more reliable solutions for forecasting. Existing search methods often face limitations in performance, model complexity, and time required to build and solve the problem. Consequently, realizing accurate calculation results can be challenging. Furthermore, as highlighted in39, a significant gap in this problem lies in the complex process of model establishment, which necessitates a comprehensive understanding of each variable’s impact on the target value. Unfortunately, some factors may be overlooked during implementation40. Although most current studies focus on non-linear models for \(PM_{2.5}\) forecasting, only a few have explored advanced machine learning and optimization techniques. This claim is reinforced by41, in which a cutting-edge optimization technique is utilized as a prediction system relying on unstructured data, leading to more accurate and coherent forecasts. In general, the consensus in the literature is that the \(PM_{2.5}\) forecasting problem is highly intricate and requires an efficient approach42.
This study compares the proposed HHO hybrid model with other recognized metaheuristic optimization techniques. These encompass GWO, WOA, SSA, BMO, HGSO, MRFO, and EO. Table 1 shows a summary of each of the algorithms, detailing their core principles, strengths, and limitations.
The paper presents the following contributions:
-
The study introduces a hybrid model that employs Support Vector Regression (SVR) with Harris Hawks Optimization (HHO) for the accurate prediction of \(PM_{2.5}\) concentrations.
-
The effectiveness of the suggested approach is evaluated by the Mean Absolute Percentage Error (MAPE), Average, Standard Deviation (SD), Best Fit, Worst Fit, and CPU time.
-
All models were trained with new real data from the Centers for Disease Control and Prevention’s National Environmental Public Health Tracking Network (1001, 1003, 1005, 1007, 1009) which is a governmental organization.
The paper is organized as follows: “Materials and methods” section provides an in-depth discussion of the general principles underlying the SVR model, along with an exploration of the HHO algorithm. In “The proposed HHO-SVR model” section, we delve into the proposed HHO-SVR model, detailing its configuration and settings. Moving on to “Experimental results analysis and discussion” section, we present the definition, analysis, and measurement criteria employed to assess precision, as well as an interpretation and thorough discussion of the obtained outcomes. Finally, “Conclusion and future directions” section offers the conclusion, summarizing the key findings and implications (Table 2).
Materials and methods
In the following section, the fundamental concepts of SVR along with HHO are addressed.
Support Vector Regression (SVR)
SVR is a data-driven approach that originated from Support Vector Machine (SVM). SVR is used for regression tasks by implementing the \(\varepsilon\)–insensitive loss function. For further information and a detailed description of support Vector Machine (SVM), you can refer to66. Suppose that the learning variables are assigned to \(D=\left\{ {\left( {{x_i},{y_i}}\right) }\right\}\), where the input is \({x_i}\in R\), and the output is \({y_i} \in R\) for \(i=1,2,3, \cdots , N\), and the sample number is N. The goal of SVR is to determine a functional relationship, denoted as f(x), that links the input variables \(x_{i}\) to the output variable \(y_{i}\). This is done without any prior knowledge of the joint distribution P of the variables (x, y). The formula in the linear case is \(f(x)= \langle {w, x}\rangle + b\), where w is the weight and b is the constant coefficient respectively. A non-linear mapping, denoted as (\(\Phi\)), is utilized to convert a hard non-linear task into a more feasible linear task. Regression function is presented in Eq. (1).
The f(x) tend to adjust the learning sets. with flexibility and aim for a minimal slope by reducing the standard value of w to avoid overfitting issues. In order to address constraints that would otherwise be impossible to overcome, introducing two slack variables, denoted as \(\xi\) and \({\xi }_{i}^{*}\). The feasibility of convex optimization in this context relies on the existence of a function that accurately adjust all pairs of data \(({x_i},{y_i})\) with a suitable accuracy level, denoted as \(\varepsilon\). The problem should be designed as a convex optimization job, as depicted in Eq. (2).
where C is the penalty factor constant, and \({{\xi _i},{\xi }_{i}^{*}}\) Denotes the difference between the anticipated and the intended values.
More easily, the matter of optimization in its dual forms can be solved. Using \(K\left( {{x_i},{x_j}} \right) = {\Phi ^T}\left( {{x_i}} \right) \Phi \left( {{x_j}} \right)\) as a direct substitute for the saddle point constraint instead of \(\Phi (.)\) explicitly, Eq.(3) yields the kernel version of the dual optimization problem by removing the dual variables \({{\eta }_i},\eta _{i}^{*}\). The kernel function that satisfies the mercer condition is denoted as \(K\left( {x,x'} \right)\)67.
Due to the fact that the Lagrange multipliers are \(\alpha _i\) and \(\alpha _{i}^{*}\), w is directly solved in Eq. (4) after resolving the two original optimization problems. Support Vectors (SVs) are denoted by the positive and non-zero samples \(\alpha _i\) and \(\alpha _{i}^{*}\). At the optimal solution, the product of two variables and the constraints should vanish, achieved through the use of Karush Kuhn Tucker (KKT) restrictions. These restrictions define the necessary and satisfactory conditions for achieving a global optimum. We determine the parameter b in Eq. (5). The function f(x) is modified in the support vector expansion shown in Eq. (6). A function complexity depends solely on the number of SVs and is independent of the size of the input space.
The SVR technique presents an intriguing topic on the seemingly random process of selecting a kernel for specific data patterns68,69. The gaussian RBF kernel is an implementation that works better than other kernel functions in terms of simplicity of use and effective mapping functionality. Therefore, in this article, \(K\left( {x,x'} \right) = \exp \left( { - \frac{{{{\left\| {x - x'} \right\| }^2}}}{{2{\sigma ^2}}}} \right)\) represents the gaussian function of the RBF kernel. Two parameters are involved in the SVR method.The trade-off between the complexity of the function and the frequency at which an error is allowed is controlled by the C parameter. The \(\sigma\) parameter controls the complexity of the model and shows the mapping of the translated input variables into feature space. As mentioned in70, it is consequently important to determine appropriate parameters and to choose the value of the \(\sigma\) parameter more carefully than C. SVR pseudo-code is displayed by Algorithm 1.

The pseudo-code of SVR model.
Harris Hawks Optimization (HHO)
Figure 1 shows all phases of HHO, which are described in the next subsections.

Different phases of HHO3.
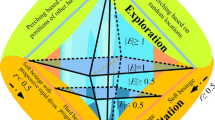
Exploration phase
In HHO, The Harris’ hawks exhibit a random perching behavior at various areas, employing two distinct strategies to detect and capture their prey.
where \(X(t+1)\) represent the position vector of the hawks in the next iteration t, \(X_{rabbit}(t)\) denote the position of the rabbit, and X(t) is the current position vector of hawks. Additionally, we have random numbers \(r_{1}\), \(r_{2}\), \(r_{3}\), \(r_{4}\), and q q, which are uniformly distributed between 0 and 1 and are updated in each iteration. The variables LB and UB represent the lower and upper bounds for the hawk positions. Furthermore, \(X_{rand}(t)\) corresponds to a randomly selected hawk from the current population, and \(X_{m}\) represents the average position of the current hawks population. The average position of hawks is attained using Eq. (8):
where \(X_{i}(t)\) represents the position of each hawk at iteration t, whereas N represents the total number of hawks.
Exploration to exploitation transition
To model this step, the energy of a rabbit is modeled as:
where E represents the amount of energy required for the prey to escape. The variable T represents the upper limit for the number of iterations, while \(E_{0}\) represents the initial energy state of the prey. The temporal dynamics of E are also illustrated in Fig. 2.

An illustration of the variable E during the execution of two runs and 500 rounds3.
Exploitation phase
In this phase, Harris’ hawks execute a surprise pounce on the prey identified in the preceding stage. Prey typically attempts to evade capture, resulting in diverse chasing behaviors in real-world scenarios. To model the attack phase, HHO incorporates four potential strategies based on the prey’s escape behaviors and the hawks’ pursuit tactics. The prey consistently strives to escape from threats, with the probability \(r\) representing the likelihood of successful evasion (\(r < 0.5\)) or failure (\(r \ge 0.5\)) before the pounce. Regardless of the prey’s actions, the hawks employ either a hard or soft besiege to capture it, encircling the prey from multiple directions based on its remaining energy. In natural settings, the hawks progressively close in on the prey, enhancing their cooperative hunting success via a surprise pounce. Over time, the escaping prey becomes increasingly fatigued, allowing the hawks to intensify their besiege and capture the exhausted prey with greater ease. To simulate this strategy within the HHO algorithm, the \(E\) parameter is utilized: a soft besiege occurs when \(|E| \ge 0.5\), while a hard besiege is employed when \(|E| < 0.5\).
Soft besiege The following rules are used to model this behavior:
where \(\Delta X(t)\) represents the difference between the position vector of the rabbit and its current location at iteration t, while \(r_{5}\) is a random number between 0 and 1. The variable J is defined as \(2(1-r_{5})\) and represents the random jump strength of the rabbit during the fleeing method, and its value undergoes random changes in each iteration to mimic the unpredictable nature of rabbit movements.
Hard besiege In this situation, the current positions are updated using Eq. (12):
A simple illustration of this step with one hawk is depicted in Fig. 3.

An illustration of all vectors in the context of hard besiege3.
Soft besiege with progressive rapid dives We assume that in order to execute a soft besiege, the hawks can assess (decide) their next step in accordance with the following rule in Eq. (13):
We assumed that they would use the following rule to dive based on the LF-based patterns:
where LF is the levy flight function, which is determined by applying Eq. (15), and D represents the problem’s dimension, while S is a random vector of size \(1\times D\).
where u and v represent random values between 0 and 1, and \(\beta\) denotes a default constant set to 1.5.
Therefore, Eq. (16) can be used as the final strategy for updating the positions of hawks during the soft besiege phase.
where Y and Z are obtained using Eqs. (13) and (14).
A simple illustration of this step for one hawk is demonstrated in Fig. 4.

A illustration of all vectors in the context of soft besiege with progressive rapid dives3.
Hard besiege with progressive rapid dives The following rule is performed in hard besiege condition:
where Y and Z are obtained using new rules in Eqs.(18) and (19).
where \(X_{m}(t)\) is obtained using Eq. (8).
A simple illustration of this step is demonstrated in Fig. 5.

An illustration of all vectors in the context of hard besiege with progressive rapid dives in 2-D and 3-D spaces.
The proposed HHO-SVR model
The HHO model combined with SVR for parameter tuning. Figure 6 represents The Workflow of the suggested HHO-SVR model, which illustrates the procedure into three main phases: (1) pre-processing, (2) parameter tuning, and (3) prediction and evaluation. Additionally, the pseudo-code for the HHO-SVR algorithm is provided in Algorithm 2.

The Workflow of the suggested HHO-SVR model.

Pseudo-code of HHO-SVR.
Objective function
To assess the efficacy of the proposed model, we subject the HHO solution to rigorous testing throughout the iterative process. The data is partitioned into training subset and testing subset during prediction. The MAPE serves as the objective function employed by HHO, acting as a statistical gauge of the precision of the prediction model. By excluding the minimum and maximum values and considering the average, MAPE provides a straightforward approach to addressing the problem. Its advantage lies in offering a clearer perspective on the actual prediction error, making it easily recognizable and quantifiable.
Computational complexity of HHO-SVR
To evaluate the computational complexity of the proposed HHO-SVR hybrid model, we analyze the time and space requirements. For the HHO, the complexity of each iteration is O(ND), where N is the population size and D is the problem dimension. The SVR model involves solving a quadratic optimization problem with complexity \(O(n^3)\), where n is the number of training samples. Thus, the overall complexity of HHO-SVR is:
where T is the number of iterations. This makes HHO-SVR computationally efficient for moderate data sizes.
Theoretical justification for the proposed HHO-SVR
The improved performance of the HHO-SVR model can be attributed to the synergistic integration of HHO and SVR. The key features include:
-
The exploration and exploitation mechanisms in HHO, such as soft and hard besiege strategies, enhance the search for optimal SVR parameters.
-
The use of Levy flight-based randomization allows HHO to escape local minima, ensuring robust convergence.
-
The regularization and kernelization capabilities of SVR improve model flexibility and generalization, leading to higher predictive accuracy.
The theoretical studies in3 and71 confirm that such hybridization can effectively mitigate overfitting and improve computational efficiency.
Experimental results analysis and discussion
To mitigate potential bias in the selection of testing and training sets, this study employs 10-fold cross-validation for SVR. The proposed model’s efficiency is evaluated by comparing it with seven other well-known algorithms. All algorithms are implemented using Matlab and thoroughly documented studies to produce results. Specifically, the comparative algorithms are combined with a well-established machine learning model, SVR. Five \(PM_{2.5}\) datasets are utilized to evaluate the proposed model’s effectiveness. Each comparative model is executed 10 times with 30 agents and 50 iterations.
The experiments are conducted on a machine with an Intel(R) Xeon(R) CPU E5-2698 v3 @ 2.30GHz (32 CPUs), 2.3GHz, 524288MB RAM, running Windows Server 2016 Datacenter, and MathWorks Matlab. The parameters for all evaluated approaches are defined as follows: 30 agents, a dimensionality of 2, 50 cycles, 10 independent trials, a minimum bound of 1, and a maximum bound of 1000. A selection of contemporary meta-heuristic algorithms, such as WOA, GWO, SSA, EO, HHO, HGSO, BMO, and MRFO, are considered for assessing the proposed technique. Each comparative algorithm employed an identical number of stochastic solutions. The objective function (fobj) is elaborated in earlier sections.
It is important to note that the parameter settings for all methods are summarized in Table 3. All tests were executed with an equivalent number of iterations (i.e., 50) and independent executions (i.e., 10).
Data description
The dataset includes values for particulate matter levels (\(PM_{2.5}\)) generated by the Environmental Protection Agency’s (EPA) Downscaler model. These data are used by the Centers for Disease Control and Prevention’s (CDC) National Environmental Public Health Tracking Network to calculate air quality metrics. The dataset provides county-level information from 2001 to 2014, including maximum, median, mean, and population-weighted mean concentrations of \(PM_{2.5}\). The Downscaler \(PM_{2.5}\) dataset is derived from a Bayesian downscaling fusion model, combining \(PM_{2.5}\) observations from the EPA’s Air Quality System with simulated data from the Models-3/Community Multiscale Air Quality (CMAQ) deterministic prediction model. Raw data processing involved extracting air quality monitoring data from the NAMS/SLAMS network, limited to Federal Reference Method (FRM) samplers. CMAQ data, from version 4.7.1 using the Carbon Bond Mechanism05 (CB-05), provides daily 24-hour average \(PM_{2.5}\) concentrations on a 12 km x 12 km grid for the continental U.S. Additional processing standardized variable names and expanded FIPS variables into statefips and countyfips. Daily maximum, mean, median, and population-weighted values were computed for each county based on census tract estimates and 2010 U.S. Census tract-level population data. The Downscaler model synthesizes monitoring data and estimated \(PM_{2.5}\) concentration surfaces from CMAQ to predict \(PM_{2.5}\) levels across space and time, using optimal linear relationships to derive predictions and associated standard errors. Data can be found here (https://data.cdc.gov/Environmental-Health-Toxicology/Daily-County-Level-PM2-5-Concentrations-2001-2014/qjju-smys/about_data).
The data utilized in this experiment are summarized in Table 4, and the descriptive statistics are summarized in Table 5. Potential limitations of the used dataset include:
-
Geographic bias: data do not represent all regions.
-
Temporal bias: Seasonal variations may affect model performance across years.
Future studies should incorporate more diverse datasets to improve model generalizability.
Data preprocessing
To improve forecasting results, we normalize the data using the minimal scale technique as described by72, following Eq. (22):
where \(\hat{x_{i}}\) represents the normalized value within the n samples at index i.
Evaluation metrics
The proposed approach is validated and assessed using the following metrics, based on the best objective value fobj achieved during run i:
-
Average value of the objective function achieved by running the method M times. The average objective function is computed using the Eq. (23).
$$\begin{aligned} Average = \frac{{\sum \nolimits _{i = 1}^M {fobj} }}{M} \end{aligned}$$(23) -
Standard Deviation (SD) is used to measure the variance of the objective function calculated from running the method M times. It indicates the integrity and robustness of the model. Large SD values suggest inconsistent results, whereas smaller values indicate convergence of the algorithm to similar results across runs. SD is calculated using Eq. (24).
$$\begin{aligned} SD = \sqrt{\frac{1}{{M - 1}}\sum \nolimits _{i = 1}^M {{{\left( {fobj - mean} \right) }^2}} } \end{aligned}$$(24) -
The best objective function corresponds to the minimum objective value achieved by the method over M runs. This value is computed using Eq. (25).
$$\begin{aligned} Best = \mathop {\min }\limits _{i = 1}^M \left( {fobj} \right) \end{aligned}$$(25) -
The worst objective function is the highest objective value obtained from running the algorithm M times. This value is calculated using Eq. (26).
$$\begin{aligned} Worst = \mathop {\max }\limits _{i = 1}^M \left( {fobj} \right) \end{aligned}$$(26) -
CPU Time refers to the total time the central processing unit (CPU) utilizes to run the model M times.
Results analysis and discussion
The empirical results of the HHO are compared with those of other hybrid approaches. Table 6 presents the results of the proposed model using Friedman’s ANOVA test in all data. The rank column indicates the algorithm’s ranking among the comparative methods based on Friedman’s ANOVA. The proposed approach demonstrated significant improvements, achieving the best results in three of the eight experiments.
The algorithms were ranked on the basis of their performance on several criteria: best, worst, average, standard deviation, and CPU time. The best performing algorithm is highlighted in boldface. Tables 7, 8, 9, 10, and 11 present the MAPE results, comparing the proposed approach with the seven recent approaches. The first column indicates the run number, while the subsequent columns represent the performed algorithms. Consequently, Tables 12, 13, 14, 15, and 16 exhibit the measured values for all methods, encompassing the best, worst, average, and standard deviation values, alongside CPU time, C value, and Alpha value.
In Table 9, it is evident that the hybrid SVR models achieved superior results with HHO compared to other comparative algorithms. The proposed approach displayed robust search capabilities, consistently nearing optimal solutions in various runs according to the MAPE metric. Similarly, Tables 7 and 10 underscore the consistent performance of the proposed hybrid approach in securing the best solution (Fig. 7).
Results varied across datasets. For instance, GWO demonstrated promising outcomes in the initial four runs, as depicted in Tables 7 and 8, whereas MRFO consistently outperformed other methods in all runs of dataset 1003. BMO closely followed HHO in achieving favorable results, as evident in Table 11, and exhibited superior performance in the initial six runs, as indicated in Table 10.
Figure 8 illustrates the accuracy of different algorithms in datasets, showcasing the accuracy for each run. HHO consistently outperformed all other methods in Fig. 8c, as well as in some runs depicted in Fig. 8a and d.
In addition, radar charts representing MAPE across all time horizons among different models are depicted in Fig. 7. These charts summarize the error of all selected models for each dataset. HHO consistently demonstrated superior performance across almost all datasets, while WOA produced inferior results for most runs, as indicated by the radar lines surrounding the counterparts.
Furthermore, Fig. 9 illustrates the convergence curves of various methods. As training iterations increase, the MAPE values calculated from different metaheuristics decrease. In Fig. 9a, WOA initially exhibited the highest MAPE results, while GWO outperformed other metaheuristic methods on the 1001 dataset in subsequent iterations. Similarly, in Fig. 9b, HHO initially showed the highest MAPE results, while EO outperformed other methods on dataset 1003 in subsequent iterations. Figure 9c–e also depict the convergence behaviour of different methods in the datasets 1005, 1007, and 1009, respectively.

MAPE values on the proposed datasets.

Accuracy on the proposed datasets.

Sample of convergence curves on the proposed datasets.
The HHO-SVR model exhibits enhanced performance relative to alternative optimization algorithms, attributed to its distinctive integration of HHO and SVR methodologies. The HHO algorithm efficiently balances exploration and exploitation in parameter tuning by employing mechanisms like soft and hard besiege strategies, along with Levy flight-based randomization. The mechanisms facilitate HHO’s exploration of various areas within the search space while concentrating the search on promising solutions, thereby ensuring effective optimization of SVR hyperparameters. The adaptability of HHO-SVR facilitates enhanced prediction accuracy, especially in high-dimensional parameter spaces where conventional optimization algorithms frequently encounter stagnation. HHO effectively addresses the complexities of the PM2.5 forecasting problem through dynamic adjustments of escape energy and jump strength.
The model’s performance undergoes further validation via statistical tests and supplementary metrics. Friedman’s ANOVA test indicates that HHO-SVR consistently achieves the highest predictive accuracy across various datasets, with statistically significant p-values (<0.01) noted in the majority of instances. The comparative analysis of convergence curves indicates that HHO-SVR demonstrates a faster convergence rate than alternative algorithms, reaching optimal solutions in fewer iterations. Furthermore, HHO-SVR exhibits enhanced robustness, characterized by diminished variability in MAPE across various iterations, signifying a reduction in overfitting and consistent performance. The findings, along with HHO-SVR’s superior performance in MAPE and CPU time metrics compared to competing algorithms, highlight its efficacy in air quality forecasting and its potential for wider environmental applications.
Conclusion and future directions
In this study, we introduced an innovative hybrid approach for predicting \(PM_{2.5}\) concentrations by combining Support Vector Regression (SVR) with the Harris Hawks Optimization (HHO) algorithm called the HHO-SVR model. Through experimentation and comparison with seven other optimization algorithms, the proposed HHO-SVR demonstrated promising performance in specific scenarios. Furthermore, the proposed HHO-SVR model consistently showed superior predictive accuracy, achieving the best results in three of the eight experiments in five distinct \(PM_{2.5}\) datasets. Statistical analysis using Friedman’s ANOVA test affirmed the robustness and high ranking of the HHO-SVR model, highlighting its effectiveness in diverse environmental contexts. However, the hybrid HHO-SVR model consistently outperformed competing approaches, demonstrating its potential for practical application in environmental monitoring and management. In conclusion, this study presented a promising avenue for improving prediction precision \(PM_{2.5}\) by using the synergistic benefits of SVR and HHO. The demonstrated superiority of the proposed HHO-SVR model underscores its potential to advance environmental forecasting capabilities, enabling informed decision making for sustainable environmental management. In future work, the proposed HHO-SVR model will be applied to solve another climate change issue, such as forecasting the increase in temperatures and other factors of climate change.
Data availibility
The data sets provided during the current study are available: https://data.cdc.gov/Environmental-Health-Toxicology/Daily-County-Level-PM2-5-Concentrations-2001-2014/qjju-smys/about_data.
References
Mirjalili, S., Gandomi, A. H., Mirjalili, S. Z., Saremi, S., Faris, H., & Mirjalili, S. M. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw..
Faramarzi, A., Heidarinejad, M., Stephens, B. & Mirjalili, S. Equilibrium optimizer: A novel optimization algorithm. Knowl.-Based Syst. 191, 105190 (2020).
Heidari, A. A. et al. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 97, 849–872 (2019).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014).
Sulaiman, M. H., Mustaffa, Z., Saari, M. M., Daniyal, H., Daud, M. R., Razali, S., & Mohamed, A. I. Barnacles mating optimizer: a bio-inspired algorithm for solving optimization problems. In 2018 19th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), 265–270 (IEEE, 2018).
Zhao, W., Zhang, Z. & Wang, L. Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications. Eng. Appl. Artif. Intell. 87, 103300 (2020).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016).
Abualigah, L. et al. Aquila optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 157, 107250 (2021).
Abualigah, L., Diabat, A., Mirjalili, S., Abd Elaziz, M. & Gandomi, A. H. The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 376, 113609 (2021).
Hashim, F. A., Houssein, E. H., Mabrouk, M. S., Al-Atabany, W. & Mirjalili, S. Henry gas solubility optimization: A novel physics-based algorithm. Futur. Gener. Comput. Syst. 101, 646–667 (2019).
Abualigah, L., Diabat, A., & Abd Elaziz, M. Intelligent workflow scheduling for big data applications in iot cloud computing environments. Cluster Comput. 1–20 (2021).
Mohamed, A. W., Hadi, A. A. & Mohamed, A. K. Gaining-sharing knowledge based algorithm for solving optimization problems: a novel nature-inspired algorithm. Int. J. Mach. Learn. Cybern. 11(7), 1501–1529 (2020).
Abualigah, L., & Diabat, A. A comprehensive survey of the grasshopper optimization algorithm: results, variants, and applications. Neural Comput. Appl., 1–24 (2020).
Abualigah, L. Group search optimizer: a nature-inspired meta-heuristic optimization algorithm with its results, variants, and applications. Neural Comput. Appl. 1–24 (2020).
De Falco, I., Della Cioppa, A., Maisto, D., Scafuri, U. & Tarantino, E. Biological invasion-inspired migration in distributed evolutionary algorithms. Inf. Sci. 207, 50–65 (2012).
Holland, J. H. et al. Adaptation in Natural and Artificial Systems: an Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence (MIT Press, 1992).
Rocca, P., Oliveri, G. & Massa, A. Differential evolution as applied to electromagnetics. IEEE Antennas Propag. Mag. 53(1), 38–49 (2011).
Yao, X., Liu, Y. & Lin, G. Evolutionary programming made faster. IEEE Trans. Evol. Comput. 3(2), 82–102 (1999).
Juste, K., Kita, H., Tanaka, E. & Hasegawa, J. An evolutionary programming solution to the unit commitment problem. IEEE Trans. Power Syst. 14(4), 1452–1459 (1999).
Beyer, H.-G. & Schwefel, H.-P. Evolution strategies-a comprehensive introduction. Nat. Comput. 1(1), 3–52 (2002).
Uymaz, S. A., Tezel, G. & Yel, E. Artificial algae algorithm (aaa) for nonlinear global optimization. Appl. Soft Comput. 31, 153–171 (2015).
Kirkpatrick, S., Gelatt, C. D. & Vecchi, M. P. Optimization by simulated annealing. Science 220(4598), 671–680 (1983).
Rashedi, E., Nezamabadi-Pour, H. & Saryazdi, S. Gsa: a gravitational search algorithm. Inf. Sci. 179(13), 2232–2248 (2009).
Houssein, E. H., Saad, M. R., Hashim, F. A., Shaban, H. & Hassaballah, M. Lévy flight distribution: A new metaheuristic algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. 94, 103731 (2020).
Hashim, F. A., Hussain, K., Houssein, E. H., Mabrouk, M. S. & Al-Atabany, W. Archimedes optimization algorithm: A new metaheuristic algorithm for solving optimization problems. Appl. Intell. 25(3), 263–282 (2020).
Ab Wahab, M. N., Nefti-Meziani, S. & Atyabi, A. A comprehensive review of swarm optimization algorithms. PLoS ONE 10(5), e0122827 (2015).
Kennedy, J., & Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95-International Conference on Neural Networks, vol. 4, 1942–1948 (IEEE, 1995).
Dorigo, M., Maniezzo, V. & Colorni, A. Ant system: optimization by a colony of cooperating agents. IEEE Trans. Syst. Man. Cybern. Part B (Cybern.) 26(1), 29–41 (1996).
Krishnanand, K. & Ghose, D. Glowworm swarm optimization for simultaneous capture of multiple local optima of multimodal functions. Swarm Intell. 3(2), 87–124 (2009).
Houssein, E. H. et al. Hybrid harris hawks optimization with cuckoo search for drug design and discovery in chemoinformatics. Sci. Rep. 10(1), 1–22 (2020).
Zhao, W., Wang, L., & Zhang, Z. Artificial ecosystem-based optimization: a novel nature-inspired meta-heuristic algorithm. Neural Comput. Appl. 1–43 (2019).
Agrawal, P., Abutarboush, H. F., Ganesh, T. & Mohamed, A. W. Metaheuristic algorithms on feature selection: A survey of one decade of research (2009–2019). IEEE Access 9, 26766–26791 (2021).
Rao, R. V., Savsani, V. J. & Vakharia, D. P. Teaching-learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput. Aided Des. 43(3), 303–315 (2011).
Mousavirad, S. J. & Ebrahimpour-Komleh, H. Human mental search: a new population-based metaheuristic optimization algorithm. Appl. Intell. 47, 850–887 (2017).
Dehghani, M. et al. A new “doctor and patient’’ optimization algorithm: An application to energy commitment problem. Appl. Sci. 10(17), 5791 (2020).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997).
Abualigah, L. Multi-verse optimizer algorithm: a comprehensive survey of its results, variants, and applications. Neural Comput. Appl. 1–21 (2020).
Abualigah, L., Diabat, A. & Geem, Z. W. A comprehensive survey of the harmony search algorithm in clustering applications. Appl. Sci. 10(11), 3827 (2020).
Yin, S., Liu, H. & Duan, Z. Hourly pm2. 5 concentration multi-step forecasting method based on extreme learning machine, boosting algorithm and error correction model. Digit. Signal Process. 118, 103221 (2021).
Feng, Y., Qin, Y., & Zhao, S. Correlation-split and recombination-sort interaction networks for air quality forecasting. Appl. Soft Comput. 110544 (2023).
Wang, J., Wang, R. & Li, Z. A combined forecasting system based on multi-objective optimization and feature extraction strategy for hourly pm2. 5 concentration. Appl. Soft Comput. 114, 108034 (2022).
Zhang, X. & Gan, H. Stf-net: An improved depth network based on spatio-temporal data fusion for pm2. 5 concentration prediction. Futur. Gener. Comput. Syst. 144, 37–49 (2023).
Maciag, P. S., Kasabov, N., Kryszkiewicz, M. & Bembenik, R. Air pollution prediction with clustering-based ensemble of evolving spiking neural networks and a case study for london area. Environ. Model. Softw. 118, 262–280 (2019).
Xi, T., Tian, Y., Li, X., Gao, H. & Wang, W. Pixel-wise depth based intelligent station for inferring fine-grained pm2. 5. Futur. Gener. Comput. Syst. 92, 84–92 (2019).
Yang, Q. et al. Mapping pm2. 5 concentration at a sub-km level resolution: A dual-scale retrieval approach. ISPRS J. Photogramm. Remote. Sens. 165, 140–151 (2020).
Li, T., Shen, H., Yuan, Q. & Zhang, L. Geographically and temporally weighted neural networks for satellite-based mapping of ground-level pm2. 5. ISPRS J. Photogramm. Remote. Sens. 167, 178–188 (2020).
Du, P., Wang, J., Hao, Y., Niu, T. & Yang, W. A novel hybrid model based on multi-objective harris hawks optimization algorithm for daily pm2. 5 and pm10 forecasting. Appl. Soft Comput. 96, 106620 (2020).
Bhardwaj, R. & Pruthi, D. Evolutionary techniques for optimizing air quality model. Procedia Comput. Sci. 167, 1872–1879 (2020).
Masood, A. & Ahmad, K. A model for particulate matter (pm2. 5) prediction for Delhi based on machine learning approaches. Procedia Comput. Sci. 167, 2101–2110 (2020).
Yang, H., Zhu, Z., Li, C. & Li, R. A novel combined forecasting system for air pollutants concentration based on fuzzy theory and optimization of aggregation weight. Appl. Soft Comput. 87, 105972 (2020).
Zhang, B., Zhang, H., Zhao, G. & Lian, J. Constructing a pm2. 5 concentration prediction model by combining auto-encoder with bi-lstm neural networks. Environ. Model. Softw. 124, 104600 (2020).
Harishkumar, K. et al. Forecasting air pollution particulate matter (pm2. 5) using machine learning regression models. Procedia Comput. Sci. 171, 2057–2066 (2020).
Zou, G., Zhang, B., Yong, R., Qin, D. & Zhao, Q. Fdn-learning: Urban pm2. 5-concentration spatial correlation prediction model based on fusion deep neural network. Big Data Res. 26, 100269 (2021).
Jiang, F., Zhang, C., Sun, S. & Sun, J. Forecasting hourly pm2. 5 based on deep temporal convolutional neural network and decomposition method. Appl. Soft Comput. 113, 107988 (2021).
Huang, Y., Ying, J.J.-C. & Tseng, V. S. Spatio-attention embedded recurrent neural network for air quality prediction. Knowl.-Based Syst. 233, 107416 (2021).
Zhang, L. et al. Spatiotemporal causal convolutional network for forecasting hourly pm2. 5 concentrations in Beijing, China. Comput. Geosci. 155, 104869 (2021).
Meena, K. et al. 5g narrow band-iot based air contamination prediction using recurrent neural network. Sustain. Comput. Inform. Syst. 33, 100619 (2022).
Wang, Z., Chen, H., Zhu, J. & Ding, Z. Daily pm2. 5 and pm10 forecasting using linear and nonlinear modeling framework based on robust local mean decomposition and moving window ensemble strategy. Appl. Soft Comput. 114, 108110 (2022).
Thongthammachart, T., Araki, S., Shimadera, H., Matsuo, T. & Kondo, A. Incorporating light gradient boosting machine to land use regression model for estimating no2 and pm2. 5 levels in kansai region, japan. Environ. Model. Softw. 155, 105447 (2022).
Bai, K., Li, K., Guo, J. & Chang, N.-B. Multiscale and multisource data fusion for full-coverage pm2. 5 concentration mapping: Can spatial pattern recognition come with modeling accuracy?. ISPRS J. Photogramm. Remote. Sens. 184, 31–44 (2022).
Wang, Z. et al. Predicting annual pm2. 5 in mainland China from 2014 to 2020 using multi temporal satellite product: An improved deep learning approach with spatial generalization ability. ISPRS J. Photogramm. Remote. Sens. 187, 141–158 (2022).
Hofman, J. et al. Spatiotemporal air quality inference of low-cost sensor data: Evidence from multiple sensor testbeds. Environ. Model. Softw. 149, 105306 (2022).
Cai, P., Zhang, C. & Chai, J. Forecasting hourly pm2. 5 concentrations based on decomposition-ensemble-reconstruction framework incorporating deep learning algorithms. Data Sci. Manag. 6(1), 46–54 (2023).
Dubey, A. & Rasool, A. Impact on air quality index of India due to lockdown. Procedia Comput. Sci. 218, 969–978 (2023).
Djarum, D. H., Ahmad, Z., & Zhang, J. Reduced Bayesian optimized stacked regressor (rbosr): A highly efficient stacked approach for improved air pollution prediction. Appl. Soft Comput. 110466 (2023).
Vapnik, V. The nature of statistical learning theory. (2000), There is no corresponding record for this reference.
Mercer, J. Xvi. functions of positive and negative type, and their connection the theory of integral equations. Philos. Trans. R. Soc. Lond. Ser. A containing papers of a mathematical or physical character 209(441–458), 415–446 (1909).
Mohammadi, K., Shamshirband, S., Anisi, M. H., Alam, K. A. & Petković, D. Support vector regression based prediction of global solar radiation on a horizontal surface. Energy Convers. Manag. 91, 433–441 (2015).
Shamshirband, S. et al. Support vector regression methodology for wind turbine reaction torque prediction with power-split hydrostatic continuous variable transmission. Energy 67, 623–630 (2014).
Schölkopf, B. et al. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond (MIT Press, 2002).
Schölkopf, B. Learning with kernels: support vector machines, regularization, optimization, and beyond (2002).
Liu, G. & Wang, X. A new metric for individual stock trend prediction. Eng. Appl. Artif. Intell. 82, 1–12 (2019).
Acknowledgements
Funding information is not available.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Essam H. Houssein: Supervision, Methodology, Software, Formal analysis, Writing - review & editing. Meran Mohamed: Methodology, Software, Data curation, Resources, Writing - original draft, Writing - review & editing. Eman M.G. Younis: Formal analysis, Investigation, Visualization, Validation, Writing - review & editing. Waleed M. Mohamed: Formal analysis, Investigation, Visualization, Validation, Writing - review & editing. All authors read and approved the final paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Houssein, E.H., Mohamed, M., Younis, E.M.G. et al. A hybrid Harris Hawks Optimization with Support Vector Regression for air quality forecasting. Sci Rep 15, 2275 (2025). https://doi.org/10.1038/s41598-025-86275-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-86275-6
Keywords
This article is cited by
-
FLSVR: Solving Lagrangian Support Vector Regression Using Functional Iterative Method
Neural Processing Letters (2025)
