
Abstract
Computational tools, particularly electromagnetic (EM) solvers, are now commonplace in antenna design. While ensuring reliability, EM simulations are time-consuming, leading to high costs associated with EM-driven procedures like parametric optimization or statistical design. Various techniques have been developed to address this issue, with surrogate modeling methods garnering particular attention due to their potential advantages. One key benefit is the promise of unprecedented acceleration in handling design problems that require repetitive system evaluations. However, behavioral modeling of antennas is an intrinsic endeavor. Challenges include the curse of dimensionality and the high nonlinearity of antenna characteristics. Moreover, design utility necessitates that the models are defined across wide ranges of frequency, geometry dimensions, and material parameters, posing a significant bottleneck for existing modeling frameworks. This paper introduces an innovative approach to constructing design-ready behavioral surrogates for antenna structures. Our methodology involves a rapid global sensitivity analysis (GSA) algorithm developed to determine a set of parameter space directions that maximize antenna response variability. The latter are obtained from spectral analysis of the GSA-based sensitivity indicators, and employed to define a reduced-dimensionality domain of the metamodel. The dependability of the model constructed in such a domain is superior over conventional surrogates while being suitable for design purposes. These benefits have been conclusively showcased using several microstrip antennas and illustrated by a number of design scenarios involving antenna geometry optimization for a variety of performance specifications.
Similar content being viewed by others
Introduction
Over the years, the technical complexity of antenna systems has increased in response to industry demands for various functionalities, such as MIMO operation, tunability, circular polarization, and others1,2,3,4, as well as performance requirements imposed on electrical and field properties (gain5, broadband operation6, impedance matching7, axial ratio8, radiation pattern9) but also geometry itself (compact size10,11,12,13). Accurate assessment of complex geometric devices can be effectively conducted through EM simulation, as opposed to simpler models, which, if available, often overlook critical phenomena like mutual coupling14, feed radiation15, substrate anisotropy, or the effects of connectors16, radomes17, or proximity of environmental components (e.g., human body18). For the same reasons, EM simulation tools have become essential at all antenna design phases (architecture evolution19, parametric analysis20, geometry parameter adjustment21). Auxiliary representations, such as equivalent network models, are mainly used to explain antenna operation (having its geometry already established) rather than to support the design process itself22,23,24,25. Recently, the importance of EM-driven parameter adjustment using rigorous numerical optimization has grown enormously as a replacement of interactive methods, such as parametric studies governed by the designer’s insight. This is indispensable as only formal methods can simultaneously handle multiple parameters, objectives, and constraints, all instrumental in identifying truly optimum designs. Yet, simulation-based optimization is computationally expensive, the single most important factor that impedes its widespread employment by antenna designers. Typical search algorithms require anything from several dozen or hundreds (gradient-based26 or pattern search27 local methods), to many thousands of EM analyses (nature-inspired algorithms28,29,30,31,32, multi-criterial optimization33,34,35, statistical design36,37,38).
The cost-related bottleneck of EM-driven design fostered the development of accelerated techniques. Among a plethora available methods, one can mention utilization of adjoint sensitivities39,40 (as well as other approaches reducing the cost of sensitivity evaluation in gradient-based algorithms, e.g., sparse Jacobian updating schemes41,42,43, mesh deformation44), the employment of fast dedicated solvers45, response feature techniques46,47,48, cognition-driven design49, or dimensionality reduction methods50, etc. Recent years witnessed a growing interest in surrogate-assisted methods51,52,53,54,55 that find applications in both local56 and global57 parameter tuning, uncertainty quantification58,59, as well as multi-criterial design59,60,61. The underlying concept is to replace expensive EM evaluations by low-cost replacement models, which can be behavioral (e.g., kriging62, Gaussian process regression63, support vector machines64, radial basis functions65, neural networks66,67, polynomial chaos expansion68, etc.) or physics-based (space mapping69,70, response correction71,72,73). Physics-based methods construct the surrogate model by enhancing the lower-fidelity representation, such as a parameterized equivalent circuit. Surrogate models are often employed in iterative frameworks involving sequential sampling strategies74,75, where the prediction phase is followed by model refinement using the acquired EM data76. Procedures of this sort are often referred to as machine learning algorithms77,78,79.
Undoubtedly, replacing expensive computational models with fast surrogates is attractive. However, constructing design-ready metamodels that accurately represent system outputs across broad ranges of designable parameters (geometry and material) and frequencies presents significant challenges. The nonlinearity of antenna frequency responses and the curse of dimensionality80 make broad-range surrogate modeling impractical beyond simple structures parameterized using a few variables. Indeed, these challenges have driven the development of iterative procedures outlined in the previous paragraph. However, while machine-learning-type methods help alleviate cost-related issues by focusing on promising regions of the search space, they often compromise versatility. Changing design specifications necessitates repetitive algorithm executions and additional costs81. In some cases, general-purpose modeling can be enhanced by methods such as high-dimensional model representation (HDMR)82, least-angle regression83, or multi-fidelity approaches like two-stage Gaussian process regression (GPR)84 and co-kriging85. Another approach is performance-driven (or constrained) modeling86, addressing dimensionality-related issues by appropriately defining the model domain. The domain is set up in the areas encapsulating high-quality designs87. Several variations of domain-confined methods have been developed88,89,90, including nested kriging87, along with generalizations to variable-fidelity regimes91 and deep learning92. However, a performance-driven surrogate corresponds to a chosen set of performance figures and the associated optimality conditions86. Changing these necessitates rebuilding the model. Furthermore, defining the model domain requires a pre-optimized set of reference designs, which compromises the computational efficiency of model construction. However, this particular issue can be mitigated by the reference-design-free approaches93,94, or exploitation of sensitivity information95.
This paper presents an innovative method for constructing computationally-efficient design-ready surrogate models of antenna structures. Our approach entails a rapid global sensitivity analysis procedure, designed to identify parameter space directions associated with the maximum antenna response variability. A small subset of these directions, chosen to capture the majority (e.g., 90%) of response variability, defines the surrogate’s domain. By reducing dimensionality in this manner, it becomes feasible to establish an accurate behavioral model by utilizing a small subset of the points needed by traditional methods. At the same time, as the parameter ranges within the region of validity are not formally restricted (compared to full-dimensionality space), and the domain accounts for most antenna response changes, the surrogate can be effectively used for design purposes. These properties have been demonstrated using four microstrip antennas. Comparisons with the models set up is traditional (box-constrained domains) indicate significant predictive power improvement due to the implemented mechanisms. In contrast, application case studies (antenna optimization) corroborate design usefulness of the surrogates obtained using the proposed approach.
The novelty and the technical contributions of this study can be summarized as follows: (i) development of a novel rapid global sensitivity analysis (RGSA) strategy, (ii) development of a dimensionality reduction scheme based on sensitivity analysis, (iii) development of surrogate modeling procedure employing the aforementioned mechanisms, (iv) demonstrating superior reliability and remarkable computational savings achievable due to RGSA and dimensionality reduction, (v) demonstrating that computational savings are not detrimental to design utility of the surrogate. To the authors’ best knowledge, no modeling framework featuring similar characteristics has been proposed in the literature thus far.
Surrogate modelling by fast global sensitivity analysis and dimensionality restriction
In this part of the work we introduce the proposed modelling approach. It begins with the formulation of the modelling problem in Section "Modelling task formulation". Explanation of the rapid global sensitivity analysis (RGSA) procedure developed to derive an orthonormal set of directions associated with maximum antenna response variability is elucidated in Section "Rapid global sensitivity analysis". These directions are then applied to establish the surrogate model’s domain (Section "Model domain definition by means of RGSA"). The entire modelling workflow is summarized in Section "Modelling procedure".
Modelling task formulation
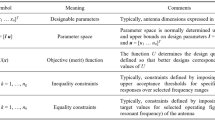
The modelling process aims at establishing a surrogate (replacement) model Rs(x). The model is to be valid within the region of interest, typically, a box-constrained parameter space X. We want to ensure that the surrogate-predicted antenna characteristics Rs(x) are well-aligned with those rendered by the high-resolution EM model Rf(x). Table 1 compiles the relevant notation. The predictive accuracy of the replacement model is evaluated through a suitable error metric. In this study, we utilize the relative root mean square (RMS) error, defined as ||Rs(x) – Rf(x)||/||Rf(x)||. The model accuracy will be estimated using the average error Eaver, computed for an independent set of testing points {xt(k)}k = 1, …, Nt, with
The relative error is convenient and intuitive as being independent of the actual values of the model outputs. In practical applications, a model error level of around five to eight percent is typically acceptable for design purposes. Further discussions on alternative error metrics are available in the literature (e.g.,96,97).
Rapid global sensitivity analysis
As previously mentioned, the primary challenge in surrogate modeling of antenna systems stems from a combination of factors, including the curse of dimensionality, excessive ranges of geometry and material parameters the model must accommodate to ensure its utility in design, and the nonlinearity of antenna characteristics, both concerning design variables and frequency. Among these challenges, dimensionality-related issues are particularly critical. Generally speaking, assuming the behavior of antenna responses is relatively consistent across the parameter space, the predictive accuracy of a data-driven surrogate improves as the average distance between training data samples decreases. This distance is influenced by both the number of samples N and the space dimensionality n, and is proportional to (1/N)1/n. This relation is an extremely unfavorable one from the modeling standpoint. For example, reducing the distance twice in three-dimensional space requires an eight-fold larger training set, whereas doing the same for n = 10 requires a set that is over 1000 times larger.
The aforementioned remarks indicate that reducing the dimensionality of the problem is instrumental in improving the feasibility of surrogate modeling of antenna systems. In the context of global or quasi-global modeling, one of the possible approaches is variable screening (e.g., the Morris method98, Pearson correlation coefficients99, partial correlation coefficients100) or global sensitivity analysis (GSA) (e.g., Sobol indices101, Jansen method102, regression-based methods103), which allows for determining the relative significance of particular parameters, and to potentially exclude those that are of minor importance. Unfortunately, most of these techniques are expensive to execute, i.e., require large amounts of samples to compute sensitivity indicators. In particular, sensitivity analysis uses many random observables and design perturbations around them. The latter is acquired to obtain local sensitivity data, further incorporated into global analysis schemes. Consequently, the overall number of observables required by conventional GSA methods is large per se (e.g., many hundreds or even thousands of samples). It grows quickly with the dimensionality of the parameter space.
The second disadvantage is that GSA techniques normally allow the assessment of the significance of individual variables (e.g., their effects on the system outputs). It eventually leads to the possibility of removing the least significant ones from the problem (whether it is optimization or modeling). On the other hand, for most antenna structures, excluding individual parameters is rarely an option because the vast majority of geometry (even more material) variables play a certain role in shaping antenna responses, often through interactions with other parameters.
To address these issues, an alternative technique for global sensitivity analysis is proposed in this work, which is specifically developed to fulfill the following prerequisites:
-
The CPU cost of GSA is low (e.g., not exceeding a hundred of antenna simulations);
-
The analysis is carried out to determine important parameter space directions rather than identify important variables (regarding their effects on antenna response variability).
The second property allows us to determine a low-dimensional subspace of the design variable space, which is the most important from the point of view of antenna response variability, and to set up the surrogate model in this very space. Dimensionality reduction is a fundamental factor from the perspective of improving the computational efficiency of the modeling process or, equivalently, improving the model predictive power while using a considerably smaller training dataset than setting the model in the complete (full-dimensional) parameter space.
The proposed GSA approach, called rapid global sensitivity analysis (RGSA) works as follows.
-
1.
Generate Ns random vectors xs(k) ∈ X, k = 1, …, Ns, preferably in a uniform manner. Here, we use modified Latin Hypercube Sampling (LHS)104;
-
2.
Acquire EM simulation data Rf(xs(k)), k = 1, …, Ns;
-
3.
For each k = 1, …, Ns, find xc(k) = xs(jmin) such that
$$j_{\min } = \arg \mathop {\min }\limits_{\substack{ 1 \le j \le N_{s} \\ j \ne k } } \left\| {{\mathbf{x}}_{s}^{(k)} - {\mathbf{x}}_{s}^{(j)} } \right\|$$(2)In other words, xc(k) is the vector closest to xs(k) in the norm sense;
-
4.
Compute (normalized) relocation vectors.
$${\varvec{v}}_{s}^{(k)} = \frac{{{\mathbf{x}}_{c}^{(k)} - {\mathbf{x}}_{s}^{(k)} }}{{\left\| {{\mathbf{x}}_{c}^{(k)} - {\mathbf{x}}_{s}^{(k)} } \right\|}}$$(3)and the corresponding (normalized) response variabilities
$$r_{s}^{(k)} = \frac{{{\mathbf{R}}_{f} ({\mathbf{x}}_{c}^{(k)} ) - {\mathbf{R}}_{f} ({\mathbf{x}}_{s}^{(k)} )}}{{\left\| {{\mathbf{x}}_{c}^{(k)} - {\mathbf{x}}_{s}^{(k)} } \right\|}}$$(4)for k = 1, …, Ns;
-
5.
Define a Ns × n relocation matrix S as
$${\mathbf{S}} = \left[ {\begin{array}{*{20}c} {r_{s}^{(1)} ({\mathbf{v}}_{s}^{(1)} )^{T} } \\ \vdots \\ {r_{s}^{{(N_{s} )}} ({\mathbf{v}}_{s}^{{(N_{s} )}} )^{T} } \\ \end{array} } \right]$$(5)The rows of S represent relocation vectors normalized with respect to their importance in terms of how they affect the antenna response in the norm sense;
-
6.
Perform spectral analysis of S105 in order to find its eigenvectors ej (principal components) and the corresponding eigenvalues λj, j = 1, …, n. The eigenvalues are ordered, so that λ1 ≥ λ2 ≥ … λn.
The principal components ej form an orthonormal basis and determine the parameter space directions that have a decreasing impact on the response variability. The underlying idea is to define a reduced-dimensionality domain of the metamodel, in particular, to span it using a few (most essential) principal vectors. The number Nd of domain-defining vectors is determined as the smallest integer Nd ∈ {1, 2, …, n}, such that
i.e., it is the smallest number of principal components for which the corresponding (joint) relative least-square variability is not smaller than the user-defined threshold Cmin. Here, we set Cmin = 0.9, meaning that the selected directions should account for at least ninety percent of the overall variability.
A comment should be made concerning the choice of the threshold factor Cmin. As mentioned earlier, the value 0.9 means that the number of principal components selected to span the surrogate model domain collectively accounts for ninety percent of antenna response variability. While the number is arbitrary, the 90% threshold is sufficiently significant: the response variability in the space orthogonal to that spanned by the selected vectors is only 10%. At the same time, it offers a sizable reduction of the modeling problem dimensionality, as illustrated in Section "Verification case studies".
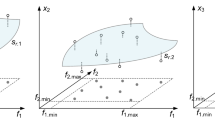
Let us consider a few examples. Figure 1 shows a linear function of two variables f(x) = f([x1 x2]T) = 3x1 – 2x2. Here, due to linearity, the function value only changes along the gradient vector g = [3–2]T, which is confirmed by the RGSA analysis based on twenty random points. Figure 2 shows a slightly more complex situation, with the function f(x) defined so that the direction corresponding to the largest variability can be readily identified visually (as the vector perpendicular to the function ‘ripples’). Again, RGSA, based on twenty random points, correctly identified this direction.

RGSA illustration using a linear function f(x) = f([x1 x2]T) = 3x1 – 2x2: (a) surface plot of the function (gray), twenty random observables xs(k) (circles), and relocation vectors xc(k) – xs(k) (line segments); (b) relocation matrix vectors rs(k)vs(k) (thin lines), the largest principal component e1 (thick solid line), and the normalized gradient g = [3–2]T/131/2 (thick dotted line). In this example, all function variability occurs along the gradient g (the function is constant in the direction orthogonal to g), which is well aligned with the vector e1, obtained using the proposed RGSA.

RGSA illustration using a nonlinear function of two variables: (a) surface plot of the function (gray), twenty random observables xs(k) (circles), and relocation vectors xc(k) – xs(k) (line segments), as well as the principal component e1 (thick arrow); (b) relocation matrix vectors rs(k)vs(k) (thin lines), and the largest principal component e1 (thick solid line). It can be noticed that the vector e1 obtained using RGSA visually corresponds to the direction of the largest variability of the function f(x).
Figure 3a illustrates an example of a dipole antenna parameterized with six independent variables x = [l1 l2 l3 w1 w2 w3]T. RGSA is executed based on fifty randomly allocated data points in this case.

RGSA illustration using a dual-band antenna: (a) parameterized geometry, (b) |S11| responses at a random parameter vector x and designs perturbed along the principal components, x + hek (here, h = 0.1) for the first four vectors (from top left to bottom right) obtained using RGSA, (c) normalized eigenvalues of the relocation matrix S obtained using RSGA based on fifty random samples, as well as average EM-simulated variability indicators dRj computed as in (7). It can be observed that response variability is gradually reduced for increasing k, which demonstrates that subsequent eigenvectors correspond to directions having less and less effect on antenna responses.
Figure 3b illustrates antenna’s |S11| at a random parameter vector x and designs perturbed along the principal components identified using RGSA, x + hek, k = 1, …, n. As expected, the response variability is gradually reduced for k, increasing from 1 to n. For this example, we also performed statistical analysis by generating Nr random vectors xr(k), k = 1, …., Nr (here, Nr = 20), along with their perturbations xr(k.j) = xr(k) + hej, j = 1, …, n. Upon acquiring EM simulation data Rf(xr(k)), k = 1, …, Nr, and Rf(xr(k.j)), k ∈ {1, …, Nr}, j ∈ {1, …, n}, the variability indicators have been computed as
for j = 1, …, n, which correspond to the average response variability in directions ej. Figure 3c compares the normalized eigenvalues λj and dRj. It should be noted that both are well aligned, which corroborates the relevance of RGSA.
Note that the CPU cost of RGSA is low. For many of the previously mentioned GSA methods (e.g., Sobol indices101, regression-based methods103) the typical number of samples required to obtain reliable sensitivity assessment is many hundreds to a few thousands for medium- to large-dimensionality problems. RGSA is executed using a few dozen random points (more specifically, fifty, in the verification experiments discussed in Section "Verification case studies"). Clearly, the sensitivity estimation may not be as accurate as for more expensive methods, yet sufficient for our purposes. Furthermore, RGSA yields principal directions that may be oriented in an arbitrary manner with respect to the coordinate system axes. Consequently, it does not eliminate any particular parameter but accounts for possible variable interactions.
Model domain definition by means of RGSA
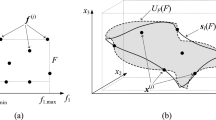
The eigenvectors generated using RGSA are used here to identify the model’s domain Xd. The latter is spanned by the first Nd vectors ej, j = 1, …, Nd. The number of directions is determined according to (5). Formally, we have
where xc = [l + u]/2 is the center of the original domain X (cf. Table 1), and aj, j = 1, …, Nd, are real numbers. Figure 4 shows a conceptual illustration of the set Xd.

Defining reduced-dimensionality model domain Xd. Here, the original parameter space is three dimensional, whereas Xd is established using two eigenvectors e1 and e2. Note that Xd is a set theory intersection of X and the affine subspace xc + Σj=1,2 ajej.
It is worth noting that while the dimensionality of Xd is lower than n, the domain incorporates the parameter space directions that are most critical for antenna response variability. This ensures that the surrogate model established within it is useful for design purposes.
After defining the domain, the surrogate model is established using kriging Interpolation106. However, the specific choice of modeling technique is of secondary importance, as our primary goal is to explore the computational benefits of dimensionality reduction achieved through RGSA.
Modelling procedure
The entire modeling procedure is encapsulated in Fig. 5 in the form of pseudocode, delineating three distinct stages: Stage I (rapid global sensitivity analysis, RGSA), Stage II (surrogate model domain definition), and Stage III (model identification). It should be emphasized that the only control parameter of the modeling process is the variability threshold Cmin, which, in Section "Verification case studies", is set to 0.9. For additional clarity, Fig. 6 illustrates the flow diagram of the modelling process. The number Ns of random observables employed to conduct the sensitivity analysis is typically set to 50 to ensure the computational efficiency of the RGSA process. Only for test cases with the parameter space dimensionality exceeding ten or so is it increased to 100. In general, Ns should increase with the number n of design variables, and setting Ns = 6n seems to be a reasonable rule of thumb.

Surrogate modelling of antenna structures using RGSA and reduced-dimensionality surrogates.

Operating flow of the suggested procedure for surrogate modeling of antennas using RGSA and reduced-dimensionality surrogates.
The number of training samples NB is normally selected based on the available computational budget (note that EM simulations are generally expensive, and it is not practical to acquire large training sets). Typically, a few hundred samples are what can be afforded. In this work, we construct the surrogate models using NB of various values, from 50 to 800, to investigate the scalability of the model’s predictive power as a function of the training dataset cardinality.
It should be noted that the last stage of the modeling process (Stage III) consists of three steps. The first one is allocating the training points, which is realized using Latin Hypercube Sampling to yield the normalized set of samples. These are further mapped into the dimensionality-reduced domain using an affine transformation defined using the domain-defining quantities, specifically, the center vector xc and the eigenvectors ej (cf. (8)). Subsequently, EM simulation is performed at the training designs and the kriging interpolation model is identified (through maximum likelihood estimation106).
Verification case studies
Here, we present numerical verification of the proposed modeling methodology. The analysis involves four microstrip structures comprising a ring-slot antenna, a dual-band uniplanar dipole, and two quasi-Yagi antennas. The modeled characteristics include reflection coefficients and realized gain as functions of frequency. We compare the reduced-domain approach to conventional modeling using factors such as reliability and the CPU cost of establishing the surrogate, and the scalability of the modeling error as a function of the training dataset size. Additionally, we showcase design applications of the models by conducting antenna optimization across various scenarios.
Test cases
The antennas used to demonstrate the proposed modeling procedure are shown in Fig. 7. There are four devices:
-
A ring-slot antenna (Antenna I), Fig. 7a,
-
A dual-band uniplanar dipole antenna (Antenna II), Fig. 7b,
-
A quasi-Yagi antenna with a parabolic reflector (Antenna III), Fig. 7c,
-
A quasi-Yagi antenna with integrated balun (Antenna IV), Fig. 7d.

Information about material parameters (substrate height and relative permittivity), design variables, and parameter spaces is included in Table 2. EM models of all antennas are evaluated in CST Microwave Studio (time-domain solver).
The considered modeling tasks are challenging. On the one hand, the parameter spaces are relatively high dimensional, from six parameters for Antenna II to fifteen for Antenna IV. Note that substrate permittivity is also included for three structures as a design parameter. On the other hand, the ranges of design variables are wide: the ratio between the upper and lower parameter bound is higher than three on average. Also, we are interested in modeling complex reflection responses and realized gain characteristics (for Antennas III and IV) all over broad ranges of frequencies as specified in Table 2, e.g., from 1 GHz to GHz for Antenna I or from 1 to 6 GHz for Antenna IV.
Experimental setup
The verification experiments are structured to address two primary inquiries: (i) the extent to which RGSA-based modeling enhances the predictive capability of the surrogate and (ii) whether dimensionality reduction, as proposed in Section "Surrogate modelling by fast global sensitivity analysis and dimensionality restriction", impacts the design utility of the model. The essence of the second question lies in determining whether reducing the number of dimensions in the domain maintains sufficient flexibility of the metamodel for effective design purposes. To answer the first question, we compare models built in the conventional parameter space X with those in the confined domain. Sensitivity analysis uses fifty samples distributed in X via Latin Hypercube Sampling104. The dimensionality of the restricted domain is adjusted with Cmin = 0.9 in (5), as discussed in Section "Rapid global sensitivity analysis", indicating that the domain should encompass at least ninety percent of antenna response variability. The surrogates are established using datasets of varying sizes, between 50 and 800 samples (with 1600 samples for Antenna IV, the most challenging case), allowing for an examination of model scalability. As for the second question, the RGSA-based surrogate models are utilized for antenna parameter tuning across different sets of design specifications. Given that the modeling process spans broad frequency ranges, the models can be applied to optimize antennas for various target operating bandwidths and different substrate materials (considering substrate permittivity as one of the design parameters, adjustable within a wide range from 2.0 to 5.0).
The surrogate is built using kriging interpolation with Gaussian correlation function and a trend function implemented utilizing a second-order polynomial. The model accuracy is estimated by means of a relative root mean square (RMS) error. The latter is defined as ||Rs(x) – Rf(x)||/||Rf(x)||, where Rs and Rf stand for the antenna responses predicted using the surrogate and EM analysis, respectively (cf. Section "Modelling task formulation", Eq. (1)). The error is computed using 100 randomly assigned testing vectors x.
Results
Table 3 encapsulates data on the eigenvalues λk obtained using the RGSA procedure of Section "Surrogate modelling by fast global sensitivity analysis and dimensionality restriction", and the surrogate model’s dimensionality Nd. As mentioned earlier, Nd has been determined using the condition (6) with Cmin = 0.9. An exception has been made for Antenna III, with Nd set to four and the variability factor equal to 0.89. It should be noted that the eigenvalues reduce quickly as the function of the index so that increasing the domain dimensionality by one (i.e., using Nd incremented by one as compared to that value obtained from (6)) does not change the antenna response variability significantly. For example, for Antenna I, the variability changes from 0.94 to 0.96 when increasing Nd from 4 to 5. For Antenna III, the figures are 0.89 (Nd = 4) and 0.92 (Nd = 5).
Table 4 indicates the modelling errors for the surrogates built within the original space X, and the RGSA-based domain Xd, for five training datasets of cardinalities 50, 100, 200, 400, and 800, respectively. As mentioned earlier, for Antenna IV, we also include a data set consisting of 1,600 samples. Antenna characteristics rendered using the metamodel and EM analysis at the chosen testing points are illustrated in Figs. 8, 9, 10, and 11 for Antennas I through IV, respectively.

Frequency characteristics of Antenna I at the selected test points: EM simulation (—), and the prediction of the proposed surrogate (o). The metamodel constructed for NB = 800.

Frequency characteristics of Antenna II at the selected test points: EM simulation (—), and the prediction of the proposed surrogate (o). The metamodel constructed for NB = 800.

Frequency characteristics of Antenna III at the selected test points: EM simulation (—), and the prediction of the proposed surrogate (o). The metamodel constructed for NB = 800.

Frequency characteristics of Antenna IV at the selected test points: EM simulation (—), and the prediction of the proposed surrogate (o). The metamodel constructed for NB = 1600.
The data in Table 4 unanimously demonstrate the computational benefits of the RGSA-based dimensionality reduction. To begin with, modeling in the original parameter space turns out to be extremely challenging. For Antenna II, the most straightforward case (six parameters), the conventional surrogate managed to secure a relative RMS error lower than ten percent, and only for the two largest datasets of 400 and 800 samples. The remaining structures’ error levels are between sixty percent (for the smallest datasets) and about thirty percent (for the largest datasets).
It should be noted that RGSA comes with some minor extra costs. As mentioned earlier, the purpose of developing RGSA was to ensure computational efficiency. The specific number of data samples utilized in our numerical experiments has been provided in the footnote of Table 4. These costs are 50 random observables for Antennas I, II, and III, and 100 observables for Antenna IV. It should be noted that Antenna IV is a complex case with 14-dimensional parameter space and broad parameter ranges therefore a larger number of RGSA samples were utilized. Nonetheless, these costs are almost negligible whenever the training dataset size exceeds 200. For example, the relative extra overhead for NB = 800 is only around six percent for Antennas I, II, and III, and around twelve percent for Antenna IV. These minor expenses are traded for a dramatic improvement of the modeling reliability, as shown in Table 4.
This predictive power is not sufficient when it comes to design applications of the models. On the other hand, the proposed approach allows for significant accuracy improvement. The relative errors are as low as a few percent, which makes the surrogates suitable for solving design tasks, as discussed in Section "Application case studies". Furthermore, reduced dimensionality of the domain greatly improves the scalability of the model, i.e., enlarging the training datasets greatly affects the model’s dependability, as opposed to the conventional approach.
At this point, it should be reiterated that the major factor enabling remarkable reliability of the proposed modeling procedure is the dimensionality reduction. As mentioned in Section II.B, parameter space dimensionality plays a fundamental role in constructing reliable data-driven models. Assuming comparable parameter ranges, the average distance between training points (which determines modeling accuracy) scales extremely poorly with the number of antenna parameters. This means that reducing the model domain dimensionality is of fundamental importance to improve the mentioned scalability and to observe the error reduction when increasing the number of training points. Now, constructing the surrogate model domain as a reduced-dimensionality subspace embedded in the original parameter space (cf. Fig. 4 and Eq. (8)) achieves exactly that: a dramatic reliability improvement without compromising the design utility. The latter is because the domain-defining parameter space directions correspond to the largest antenna response variability. Thus, all components of the proposed modeling approach work in synergy to enable both computational efficiency and design suitability.
In terms of scalability, it can be observed that the reduction of the modeling error for conventional models when increasing the dataset size from 50 to 800 is (in terms of multiplicative factor) between 1.4 for Antenna IV to 3.0 for Antenna II. At the same time, the error reduction is from 2.2 for Antenna IV to over 14 for Antenna I. The average improvement is around two for conventional models and over six for the proposed framework. On top of this, the overall error levels are much lower for our technique, even for the smallest dataset, as already discussed earlier.
Application case studies
Section "Results" unequivocally illustrated that reducing the domain’s dimensionality has a distinct and positive impact on the model’s predictive power and error scalability concerning the training dataset size. Here, we confirm that this reduction does not impair the model’s design utility. It is important to recall that dimensionality reduction is not aimed at eliminating specific antenna parameters; instead, it identifies directions most relevant to response variability. Therefore, the domain is expected to encompass regions that provide sufficient flexibility for shaping antenna characteristics following various design specifications imposed on the structure.
To validate this claim, our test antennas have been optimized in the sense explained in Table 5. For Antennas I and II, the primary goal is the improvement of impedance matching, whereas, for Antennas III and IV, it is the maximization of the average in-band realized gain; furthermore, a constraint is imposed on the in-band matching. Each antenna has been designed to meet four sets of specifications as specified in Tables 6, 7, 8, and 9. The same tables also contain the results regarding the geometry parameter values of the optimized antennas. Note that for Antennas I, III, and IV, substrate permittivity has been one of the design variables considered in the modeling process. This means that the same surrogate model can optimize the antenna for various substrates featuring permittivity within the prescribed range.
Figures 12, 13, 14, and 15 show the optimized responses of Antennas I through IV, obtained through surrogate model optimization. The same images depict the EM-simulated antenna responses across the respective designs. It is evident that all specifications have been consistently fulfilled, ensuring the intended operational bandwidths are maintained. Furthermore, the correlation between the antenna characteristics generated via the surrogate model and those acquired through EM analysis is deemed satisfactory. These demonstrate the proposed model’s practical utility, particularly its ability to design antennas over wide ranges of frequencies and material parameters (here, substrate permittivity).

Antenna I: model-predicted |S11| at the design found by optimizing the proposed metamodel (o), and EM-evaluated characteristic (—) at the same design; model constructed for NB = 800. The designs generated assuming the following specifications (bandwidth and substrate permittivity): (a) F = [4.3 4.7] GHz, εr = 3.5, (b) F = [2.9 3.1] GHz, εr = 4.4, (c) F = [3.45 3.75] GHz, εr = 2.5, (d) F = [5.7 6.1] GHz, εr = 2.5. Horizontal line marks the target operating bandwidth.

Antenna II: model-predicted |S11| at the design found by optimizing the proposed metamodel (o), and EM-evaluated characteristic (—) at the same design; model constructed for NB = 800. The designs generated assuming the following specifications (lower and upper operating frequency): (a) f1 = 2.0 GHz, f2 = 4.0 GHz, (b) f1 = 2.5 GHz, f2 = 5.3 GHz, (c) f1 = 3.0 GHz, f2 = 4.8 GHz, (d) f1 = 3.0 GHz, f2 = 6.0 GHz. Vertical lines mark the target operating frequencies.

Antenna III: model-predicted |S11| (black) and realized gain (gray) at the design found by optimizing the proposed metamodel (o), and EM-evaluated characteristic (—) at the same design; model constructed for NB = 800. The designs generated assuming the following specifications (lower and upper operating frequency): (a) F = [2.9 3.1] GHz, εr = 3.5, (b) F = [3.4 3.8] GHz, εr = 3.0, (c) F = [2.4 2.8] GHz, εr = 4.3, (d) F = [4.5 5.0] GHz, εr = 2.5. Vertical and horizontal lines mark the target operating band.

Antenna IV: model-predicted |S11| (black) and realized gain (gray) at the design found by optimizing the proposed metamodel (o), and EM-evaluated characteristic (—) at the same design; model constructed for NB = 800. The designs generated assuming the following specifications (lower and upper operating frequency): (a) F = [2.9 3.1] GHz, εr = 2.5, (b) F = [4.0 4.5] GHz, εr = 2.5, (c) F = [4.7 5.3] GHz, εr = 2.0, (d) F = [3.3 3.6] GHz, εr = 3.5. Vertical and horizontal lines mark the target operating band.
The discrepancy between surrogate model prediction and EM analysis is larger for Antennas III and IV than for the first two structures. This is because Antennas III and IV are extremely challenging test cases (eleven and fifteen parameters including substrate permittivity), much more complex than what is typically presented in the literature. Considering this, the accuracy of the surrogate models constructed using our approach is remarkably good (6.8% and 11.2% for Antenna III and IV, when using 800 and 1,600 training samples, respectively). The misalignment between model prediction and EM analysis for the mentioned error values is good and practically acceptable. At the same time, it should be stressed that conventional modeling methods (represented by models constructed in the original parameter space X, cf. Table 4) are dramatically worse (31.8% and 40.3% for Antenna III and IV, respectively, when using 800 and 1600 training samples), therefore entirely useless as design tools. Consequently, the results presented in Figs. 14 and 15 can be considered as highly successful.
Domain dimensionality analysis
The threshold parameter Cmin has been set to the value of 0.9 in this study, meaning that the surrogate domain is spanned directions that are collectively responsible for at least 90% of antenna response changes. Clearly, increasing the value of Cmin corresponds to a more strict condition, which would lead to increasing the domain dimensionality and, consequently, make the modeling process more challenging. Effectively, the model accuracy is expected to be reduced given the same number of training samples. When Cmin is reduced, so is the dimensionality of the domain. The result would improve the model predictive power (again, given the same number of training samples). This has been illustrated in Table 10 for Antenna I. Note that because the eigenvalues is a discrete set, the value of \({{\sqrt {\sum\nolimits_{j = 1}^{{N_{d} }} {\lambda_{j}^{2} } } } \mathord{\left/ {\vphantom {{\sqrt {\sum\nolimits_{j = 1}^{{N_{d} }} {\lambda_{j}^{2} } } } {\sqrt {\sum\nolimits_{j = 1}^{n} {\lambda_{j}^{2} } } }}} \right. \kern-0pt} {\sqrt {\sum\nolimits_{j = 1}^{n} {\lambda_{j}^{2} } } }}\) does not change continuously. The table considers three choices of the domain dimensionality, Nd = 3, 4, and 5, the middle one corresponding to what was presented in Tables 3 and 4. The first and the third values are smaller and larger than the dimensionality associated with Cmin = 0.9. As can be observed, reducing the dimensionality improves the surrogate’s predictive powers, whereas increasing it makes the RMS error larger. At this point, it should be noted, however, that reducing the dimensionality also reduces the domain volume, which is detrimental to the design utility of the surrogate. In particular, the optimum designs corresponding to particular specifications might not be allocated within the domain. On the other hand, increasing the dimensionality also compromises design utility, this time due to the inferior quality of the surrogate. This has been illustrated in Fig. 16 for one of the design scenarios considered in Section "Application case studies" (F = [4.3 4.7], εr = 3.5). Either increasing or decreasing the dimensionality leads to a slightly degraded optimization outcome. At the same time, it should be noted that the modeling process is relatively insensitive to the selection of Cmin. For example, for Antenna I, Nd = 4 is obtained for any Cmin within the range 0.88 to 0.97.

Optimization results of Antenna I for the first design scenario considered in Section "Application case studies" (F = [4.3 4.7], εr = 3.5). Note that the EM-simulated antenna responses obtained for Nd = 3 and Nd = 5 are noticeably worse than those obtained for Nd = 4.
An additional analysis is carried out for Antenna I concerning the number Ns of random observables utilized to carry out the sensitivity analysis (cf. Section "Rapid global sensitivity analysis"). The verification part of the paper was executed using Ns = 50. Table 11 shows the spectral analysis results of the relocation matrix S obtained using Ns = 100 and Ns = 200. As can be observed, the progression of the normalized eigenvalues is quite similar in all cases. This suggests that RGSA is relatively insensitive to the choice of Ns. Nonetheless, as mentioned in Section "Modelling procedure", it is generally recommended to increase Ns with the number of design variables, which is also suggested in the literature concerning GSA (e.g.98,99,100,101,102,103).
Conclusion
This article introduces an innovative approach to computationally efficient behavioral modeling of antennas. Our methodology leverages a rapid global sensitivity analysis (RGSA) procedure to identify the essential directions within the design variable space, significantly impacting antenna response variability. The surrogate model’s region of validity is then determined using a limited subset of these critical directions, determined through appropriate response variability indicators. This dimensionality reduction substantially enhances predictive power and enables achieving acceptable error levels even when using a restricted number of training points. Importantly, the surrogate maintains sufficient flexibility in representing antenna characteristics variability, ensuring that the model’s design utility remains intact. The efficiency of the introduced method has been comprehensively validated across four antenna structures, considering modeled responses such as reflection coefficient and realized gain over wide frequency ranges (typically between 1 and 7 GHz) and relative permittivity of the substrate (typically between 2.0 and 5.0). The RGSA-based domain definition results in remarkably accurate predictive power (relative RMS error within a few percent) despite challenging parameter space configurations where conventional modeling methods fail. Moreover, the proposed models are successfully employed for antenna optimization across various scenarios, including matching improvement over target frequency bands, gain maximization, and different combinations of target bands and substrate permittivity values. These findings suggest that the presented approach provides an attractive alternative to available modeling methods, especially for building low-cost, design-ready replacement models. The procedure is generic compared to some recently proposed methods, such as performance-driven modeling approaches, and is relatively straightforward to implement.
The proposed technique can be used to model input characteristics of array antennas such as microstrip patch arrays, MIMO antennas, and so on. From the perspective of the modeling process, the only difference is that the number of responses to be modeled would be larger (i.e., equal to the number of array excitation points), similarly as modeling of Antennas III and IV involved representing of the reflection and realized gain responses. This does not bring any fundamental limitations to the proposed methodology. At the same time, modeling of other types of responses is also possible (e.g., directivity as a function of array geometry parameters), although direct modeling of radiation patterns is a considerably more complex matter, which will be addressed in future work. It should be mentioned that although the proposed methodology has been applied to microstrip antennas, it is more generic. The reason is that none of the modeling steps (including sensitivity analysis, dimensionality reduction, surrogate model definition, or model identification) are related to the specific properties of antenna responses. Thus, the method can be applied to other types of high-frequency systems or even components/devices within other engineering disciplines. One of the topics of future work will be to demonstrate our approach’s applicability to other microwave and antenna structures classes.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Das, G., Sharma, A., Gangwar, R. K. & Sharawi, M. S. Performance improvement of multiband MIMO dielectric resonator antenna system with a partially reflecting surface. IEEE Ant. Wirel. Prop. Lett. 18(10), 2105–2109 (2019).
Shirazi, M., Li, T., Huang, J. & Gong, X. A reconfigurable dual-polarization slot-ring antenna element with wide bandwidth for array applications. IEEE Trans. Ant. Prop. 66(11), 5943–5954 (2018).
Feng, Y. et al. Cavity-backed broadband circularly polarized cross-dipole antenna. IEEE Ant. Wirel. Prop. Lett. 18(12), 2681–2685 (2019).
Karmokar, D. K., Esselle, K. P. & Bird, T. S. Wideband microstrip leaky-wave antennas with two symmetrical side beams for simultaneous dual-beam scanning. IEEE Trans. Ant. Prop. 64(4), 1262–1269 (2016).
Lehmensiek, R. & de Villiers, D. I. L. Optimization of log-periodic dipole array antennas for wideband omnidirectional radiation. IEEE Trans. Ant. Propag. 63(8), 3714–3718 (2015).
Cheng, T., Jiang, W., Gong, S. & Yu, Y. Broadband SIW cavity-backed modified dumbbell-shaped slot antenna. IEEE Ant. Wirel. Propag. Lett. 18(5), 936–940 (2019).
Tomasson, J. A., Pietrenko-Dabrowska, A. & Koziel, S. Expedited globalized antenna optimization by principal components and variable-fidelity EM simulations: application to microstrip antenna design. Electronics 9, 4 (2020).
Ullah, U., Koziel, S. & Mabrouk, I. B. A simple-topology compact broadband circularly polarized antenna with unidirectional radiation pattern. IEEE Ant. Wirel. Prop. Lett. 18(12), 2612–2616 (2019).
Zheng, T. et al. IWORMLF: Improved invasive weed optimization with random mutation and Lévy flight for beam pattern optimizations of linear and circular antenna arrays. IEEE Access 8, 19460–19478 (2020).
Haq, M. A., Koziel, S. & Cheng, Q. S. Miniaturization of wideband antennas by means of feed line topology alterations. IET Microw. Ant. Prop. 12(13), 2128–2134 (2018).
Wong, K., Chang, H., Wang, C. & Wang, S. Very-low-profile grounded coplanar waveguide-fed dual-band WLAN slot antenna for on-body antenna application. IEEE Ant. Wirel. Propag. Lett. 19(1), 213–217 (2020).
Tao, J. & Feng, Q. Compact ultrawideband MIMO antenna with half-slot structure. IEEE Ant. Wirel. Prop. Lett. 16, 792–795 (2017).
Qin, X. & Li, Y. Compact dual-polarized cross-slot antenna with colocated feeding. IEEE Trans. Ant. Propag. 67(11), 7139–7143 (2019).
Vishvaksenan, K. S., Mithra, K., Kalaiarasan, R. & Raj, K. S. Mutual coupling reduction in microstrip patch antenna arrays using parallel coupled-line resonators. IEEE Ant. Wirel. Prop. Lett. 16, 2146–2149 (2017).
Koziel, S. & Ogurtsov, S. Simulation-Based Optimization of Antenna Arrays (World Scientific, 2019).
Haq, M. A. & Koziel, S. Feedline alterations for optimization-based design of compact super wideband MIMO antennas in parallel configuration. IEEE Ant. Wirel. Prop. Lett. 18(10), 1986–1990 (2019).
Zhou, P., Zhang, Z. & He, M. Radiation pattern recovery of the impaired-radome-enclosed antenna array. IEEE Ant. Wirel. Prop. Lett. 19(9), 1639–1643 (2020).
Leduc, C. & Zhadobov, M. Impact of antenna topology and feeding technique on coupling with human body: Application to 60-GHz antenna arrays. IEEE Trans. Ant. Propag. 65(12), 6779–6787 (2017).
Ullah, U., Al-Hasan, M., Koziel, S. & Ben Mabrouk, I. Circular polarization diversity implementation for correlation reduction in wideband low-cost multiple-input-multiple-output antenna. IEEE Access 8(1), 95585–95593 (2020).
Wen, D., Hao, Y., Munoz, M. O., Wang, H. & Zhou, H. A compact and low-profile MIMO antenna using a miniature circular high-impedance surface for wearable applications. IEEE Trans. Ant. Propag. 66(1), 96–104 (2018).
Lei, S. et al. Power gain optimization method for wide-beam array antenna via convex optimization. IEEE Trans. Ant. Propag. 67(3), 1620–1629 (2019).
Kumar, S. et al. A bandwidth-enhanced sub-GHz wristwatch antenna using an optimized feed structure. IEEE Ant. Wireless Propag. Lett. 20(8), 1389–1393 (2021).
Chang, L.-C., Lin, Y.-H., Chen, S.-Y., Chou, H.-T. & Wang, H. A duplexing hybrid slot antenna design with high isolation for short-range radar detection and identification applications at 24 GHz band. IEEE Trans. Ant. Propag. 70(4), 2468–2479 (2022).
Cicchetti, R., Cicchetti, V., Faraone, A., Foged, L. & Testa, O. A compact high-gain wideband lens Vivaldi antenna for wireless communications and through-the-wall imaging. IEEE Trans. Ant. Propag. 69(6), 3177–3192 (2021).
Wang, Z., Dong, Y. & Itoh, T. Miniaturized wideband CP antenna based on metaresonator and CRLH-TLs for 5G new radio applications. IEEE Trans. Ant. Propag. 69(1), 74–83 (2021).
Koziel, S., Pietrenko-Dabrowska, A. & Al-Hasan, M. Frequency-based regularization for improved reliability optimization of antenna structures. IEEE Trans. Ant. Prop. 69(7), 4246–4251 (2020).
Kolda, T. G., Lewis, R. M. & Torczon, V. Optimization by direct search: New perspectives on some classical and modern methods. SIAM Rev. 45, 385–482 (2003).
Li, X. & Luk, K. M. The grey wolf optimizer and its applications in electromagnetics. IEEE Trans. Ant. Prop. 68(3), 2186–2197 (2020).
Luo, X., Yang, B. & Qian, H. J. Adaptive synthesis for resonator-coupled filters based on particle swarm optimization. IEEE Trans. Microw. Theory Technol. 67(2), 712–725 (2019).
Majumder, A., Chatterjee, S., Chatterjee, S., Sinha Chaudhari, S. & Poddar, D. R. Optimization of small-signal model of GaN HEMT by using evolutionary algorithms. IEEE Microw. Wirel. Comp. Lett. 27(4), 362–364 (2017).
Oyelade, O. N., Ezugwu, A.E.-S., Mohamed, T. I. A. & Abualigah, L. Ebola optimization search algorithm: A new nature-inspired metaheuristic optimization algorithm. IEEE Access 10, 16150–16177 (2022).
Milner, S., Davis, C., Zhang, H. & Llorca, J. Nature-inspired self-organization, control, and optimization in heterogeneous wireless networks. IEEE Trans. Mobile Comp. 11(7), 1207–1222 (2012).
Rayas-Sanchez, J. E., Koziel, S. & Bandler, J. W. Advanced RF and microwave design optimization: A journey and a vision of future trends. IEEE J. Microw. 1(1), 481–493 (2021).
Easum, J. A., Nagar, J., Werner, P. L. & Werner, D. H. Efficient multi-objective antenna optimization with tolerance analysis through the use of surrogate models. IEEE Trans. Ant. Prop. 66(12), 6706–6715 (2018).
Koziel, S. & Pietrenko-Dabrowska, A. Recent advances in accelerated multi-objective design of high-frequency structures using knowledge-based constrained modeling approach. Knowl. Based Syst. 214, 106726 (2021).
Du, J. & Roblin, C. Statistical modeling of disturbed antennas based on the polynomial chaos expansion. IEEE Ant. Wirel. Prop. Lett. 16, 1843–1847 (2017).
Pietrenko-Dabrowska, A., Koziel, S. & Al-Hasan, M. Expedited yield optimization of narrow- and multi-band antennas using performance-driven surrogates”. IEEE Access 1, 143104–143113 (2020).
Acikgoz, H. & Mittra, R. Stochastic polynomial chaos expansion analysis of a split-ring resonator at terahertz frequencies. IEEE Trans. Ant. Propag. 66(4), 2131–2134 (2018).
Hassan, E., Noreland, D., Augustine, R., Wadbro, E. & Berggren, M. Topology optimization of planar antennas for wideband near-field coupling. IEEE Trans. Ant. Prop. 63(9), 4208–4213 (2015).
Wang, J., Yang, X. S. & Wang, B. Z. Efficient gradient-based optimisation of pixel antenna with large-scale connections. IET Microw. Ant. Prop. 12(3), 385–389 (2018).
Koziel, S. & Pietrenko-Dabrowska, A. Reduced-cost electromagnetic-driven optimization of antenna structures by means of trust-region gradient-search with sparse Jacobian updates. IET Microw. Ant. Prop. 13(10), 1646–1652 (2019).
Koziel, S. & Pietrenko-Dabrowska, A. Variable-fidelity simulation models and sparse gradient updates for cost-efficient optimization of compact antenna input characteristics. Sensors 19(8), 1806 (2019).
Pietrenko-Dabrowska, A. & Koziel, S. Computationally-efficient design optimization of antennas by accelerated gradient search with sensitivity and design change monitoring. IET Microw. Ant. Prop. 14(2), 165–170 (2020).
Feng, F. et al. Coarse- and fine-mesh space mapping for EM optimization incorporating mesh deformation. IEEE Microw. Wirel. Comput. Lett. 29(8), 510–512 (2019).
Arndt, F. WASP-NET: recent advances in fast EM CAD and optimization of waveguide components, feeds and aperture antennas. in International Symposium on Antennas and Propagation, 1–2 (2012).
Koziel, S. Fast simulation-driven antenna design using response-feature surrogates. Int. J. RF & Micr. CAE 25(5), 394–402 (2015).
Koziel, S. & Pietrenko-Dabrowska, A. Expedited feature-based quasi-global optimization of multi-band antennas with Jacobian variability tracking. IEEE Access 8, 83907–83915 (2020).
Koziel, S. & Ogurtsov, S. Rapid design closure of linear microstrip antenna array apertures using response features. IEEE Antennas Wireless Prop. Lett. 17(4), 645–648 (2018).
Zhang, C., Feng, F., Gongal-Reddy, V., Zhang, Q. J. & Bandler, J. W. Cognition-driven formulation of space mapping for equal-ripple optimization of microwave filters. IEEE Trans. Microwave Theory Techn. 63(7), 2154–2165 (2015).
Pietrenko-Dabrowska, A. & Koziel, S. Reliable surrogate modeling of antenna input characteristics by means of domain confinement and principal components. Electronics 9(5), 1–16 (2020).
Cheng, Q. S., Rautio, J. C., Bandler, J. W. & Koziel, S. Progress in simulator-based tuning—the art of tuning space mapping. IEEE Microwave Magazine 11(4), 96–110 (2010).
A.K.S.O. Hassan, A.S. Etman, and E.A. Soliman, “Optimization of a novel nano antenna with two radiation modes using kriging surrogate models,” IEEE Photonic J., vol. 10, no. 4, art. no. 4800807, 2018.
Koziel, S., Bandler, J. W. & Madsen, K. Space-mapping based interpolation for engineering optimization. IEEE Trans. Microwave Theory and Tech. 54(6), 2410–2421 (2006).
Liu, B. et al. An efficient method for antenna design optimization based on evolutionary computation and machine learning techniques. IEEE Trans. Ant. Propag. 62(1), 7–18 (2014).
Feng, F. et al. Adaptive feature zero assisted surrogate-based EM optimization for microwave filter design. IEEE Microwave Wireless Comp. Lett. 29(1), 2–4 (2019).
Koziel, S., Bandler, J. W. & Madsen, K. Space-mapping based interpolation for engineering optimization. IEEE Trans. Microwave Theory and Tech. 54(6), 2410–2421 (2006).
Zhang, Z., Chen, H. C. & Cheng, Q. S. Surrogate-assisted quasi-newton enhanced global optimization of antennas based on a heuristic hypersphere sampling. IEEE Trans. Ant. Propag. 69(5), 2993–2998 (2021).
Li, Y., Ding, Y. & Zio, E. Random fuzzy extension of the universal generating function approach for the reliability assessment of multi-state systems under aleatory and epistemic uncertainties. IEEE Trans. Reliability 63(1), 13–25 (2014).
M. Rossi, A. Dierck, H. Rogier, and D. Vande Ginste, “A stochastic framework for the variability analysis of textile antennas,” IEEE Trans. Ant. Prop., vol. 62, no. 16, pp. 6510–6514, 2014.
B. Xia, Z. Ren, and C. S. Koh, “Utilizing kriging surrogate models for multi-objective robust optimization of electromagnetic devices,” IEEE Trans. Magn., vol. 50, no. 2, paper 7017104, Feb. 2014.
Xiao, S. et al. “Multi-objective Pareto optimization of electromagnetic devices exploiting kriging with Lipschitzian optimized expected improvement, “ IEEE Trans. Magn. 54(3), 7001704 (2018).
D.I.L. de Villiers, I. Couckuyt and T. Dhaene, “Multi-objective optimization of reflector antennas using kriging and probability of improvement,” Int. Symp. Ant. Prop., pp. 985–986, San Diego, USA, 2017.
Jacobs, J. P. Characterization by Gaussian processes of finite substrate size effects on gain patterns of microstrip antennas. IET Microw. Ant. Prop. 10(11), 1189–1195 (2016).
Cai, J., King, J., Yu, C., Liu, J. & Sun, L. Support vector regression-based behavioral modeling technique for RF power transistors. IEEE Microw. Wirel. Comput. Lett. 28(5), 428–430 (2018).
Zhou, Q. et al. An active learning radial basis function modeling method based on self-organization maps for simulation-based design problems. Knowl. Based Syst. 131, 10–27 (2017).
Dong, J., Qin, W. & Wang, M. “Fast multi-objective optimization of multi-parameter antenna structures based on improved BPNN surrogate model. IEEE Access 7, 77692–77701 (2019).
Koziel, S., Calik, N., Mahouti, P. & Belen, M. A. Accurate modeling of antenna structures by means of domain confinement and pyramidal deep neural networks. IEEE Trans. Ant. Prop. 70(3), 2174–2188 (2022).
Du, J. & Roblin, C. Stochastic surrogate models of deformable antennas based on vector spherical harmonics and polynomial chaos expansions: application to textile antennas. IEEE Trans. Ant. Prop. 66(7), 3610–3622 (2018).
Cervantes-González, J. C. et al. Space mapping optimization of handset antennas considering EM effects of mobile phone components and human body. Int. J. RF Microw. CAE 26(2), 121–128 (2016).
Koziel, S. & Bandler, J. W. A space-mapping approach to microwave device modeling exploiting fuzzy systems. IEEE Trans. Microw. Theory Technol. 55(12), 2539–2547 (2007).
Koziel, S. & Unnsteinsson, S. D. Expedited design closure of antennas by means of trust-region-based adaptive response scaling. IEEE Ant. Wirel. Propag. Lett. 17(6), 1099–1103 (2018).
Su, Y., Li, J., Fan, Z. & Chen, R. Shaping optimization of double reflector antenna based on manifold mapping. in International Applied Computational Electromagnetics Society ACES, 1–2 (2017).
Koziel, S. & Leifsson, L. Simulation-Driven Design by Knowledge-Based Response Correction Techniques (Springer, 2016).
Couckuyt, I., Declercq, F., Dhaene, T., Rogier, H. & Knockaert, L. Surrogate-based infill optimization applied to electromagnetic problems. Int. J. RF Microw. Comput. Aided Eng. 20(5), 492–501 (2010).
Chen, C., Liu, J. & Xu, P. Comparison of infill sampling criteria based on Kriging surrogate model. Sci. Rep. 12, 678 (2022).
Tak, J., Kantemur, A., Sharma, Y. & Xin, H. A 3-D-printed W-band slotted waveguide array antenna optimized using machine learning. IEEE Ant. Wirel. Prop. Lett. 17(11), 2008–2012 (2018).
Wu, Q., Wang, H. & Hong, W. Multistage collaborative machine learning and its application to antenna modeling and optimization. IEEE Trans. Ant. Propag. 68(5), 3397–3409 (2020).
Taran, N., Ionel, D. M. & Dorrell, D. G. Two-level surrogate-assisted differential evolution multi-objective optimization of electric machines using 3-D FEA. IEEE Trans. Magn. 54(11), 8107605 (2018).
Wu, Q., Chen, W., Yu, C., Wang, H. & Hong, W. Multilayer machine learning-assisted optimization-based robust design and its applications to antennas and arrays. IEEE Trans. Ant. Prop. (2021).
Pang, Y., Zhou, B. & Nie, F. Simultaneously learning neighborship and projection matrix for supervised dimensionality reduction. IEEE Trans Neural Netw. Learn. Syst. 30(9), 2779–2793 (2019).
Lv, Z., Wang, L., Han, Z., Zhao, J. & Wang, W. Surrogate-assisted particle swarm optimization algorithm with Pareto active learning for expensive multi-objective optimization. IEEE/CAA J. Autom. Sin. 6(3), 838–849 (2019).
Yücel, A. C., Bağcı, H. & Michielssen, E. An ME-PC enhanced HDMR method for efficient statistical analysis of multiconductor transmission line networks. IEEE Trans. Comput. Pack. Manuf. Technol. 5(5), 685–696 (2015).
Hu, R., Monebhurrun, V., Himeno, R., Yokota, H. & Costen, F. An adaptive least angle regression method for uncertainty quantification in FDTD computation. IEEE Trans. Ant. Prop. 66(12), 7188–7197 (2018).
Jacobs, J. P. & Koziel, S. Two-stage framework for efficient Gaussian process modeling of antenna input characteristics. IEEE Trans. Antennas Prop. 62(2), 706–713 (2014).
Kennedy, M. C. & O’Hagan, A. Predicting the output from complex computer code when fast approximations are available. Biometrika 87, 1–13 (2000).
Koziel, S. & Pietrenko-Dabrowska, A. Performance-Driven Surrogate Modeling of High-Frequency Structures (Springer, 2020).
Koziel, S. & Pietrenko-Dabrowska, A. Performance-based nested surrogate modeling of antenna input characteristics. IEEE Trans. Ant. Prop. 67(5), 2904–2912 (2019).
Koziel, S. Low-cost data-driven surrogate modeling of antenna structures by constrained sampling. IEEE Antennas Wirel. Prop. Lett. 16, 461–464 (2017).
Koziel, S. & Sigurdsson, A. T. Triangulation-based constrained surrogate modeling of antennas. IEEE Trans. Ant. Prop. 66(8), 4170–4179 (2018).
Pietrenko-Dabrowska, A. & Koziel, S. Nested kriging with variable domain thickness for rapid surrogate modeling and design optimization of antennas. Electronics 9(10), 1621 (2020).
Pietrenko-Dabrowska, A. & Koziel, S. Antenna modeling using variable-fidelity EM simulations and constrained co-kriging. IEEE Access 8(1), 91048–91056 (2020).
Koziel, S., Mahouti, P., Calik, N., Belen, M. A. & Szczepanski, S. Improved modeling of miniaturized microwave structures using performance-driven fully-connected regression surrogate. IEEE Access 9, 71470–71481 (2021).
Koziel, S. & Pietrenko-Dabrowska, A. Knowledge-based performance-driven modeling of antenna structures. Knowl. Based Syst. 1, 107698 (2021).
Koziel, S., Pietrenko-Dabrowska, A. & Ullah, U. Low-cost modeling of microwave components by means of two-stage inverse/forward surrogates and domain confinement. IEEE Trans. Microw. Theory Technol. 69(12), 5189–5202 (2021).
Pietrenko-Dabrowska, A., Koziel, S. & Al-Hasan, M. Cost-efficient bi-layer modeling of antenna input characteristics using gradient kriging surrogates. IEEE Access 8, 140831–140839 (2020).
Li, X. R. & Zhao, Z. Evaluation of estimation algorithms part I: Incomprehensive measures of performance. IEEE Trans. Aerosp. Electr. Syst. 42(4), 1340–1358 (2006).
Gorissen, D., Crombecq, K., Couckuyt, I., Dhaene, T. & Demeester, P. A surrogate modeling and adaptive sampling toolbox for computer based design. J. Mach. Learn. Res. 11, 2051–2055 (2010).
Morris, M. D. Factorial sampling plans for preliminary computational experiments. Technometrics 33, 161–174 (1991).
Iooss, B. & Lemaitre, P. A review on global sensitivity analysis methods. In Uncertainty Management in Simulation-Optimization of Complex Systems (eds Dellino, G. & Meloni, C.) 101–122 (Springer, 2015).
Tian, W. A review of sensitivity analysis methods in building energy analysis. Renew. Sustain. Energy Rev. 20, 411–419 (2013).
Saltelli, A. Making best use of model evaluations to compute sensitivity indices. Comput. Phys. Commun. 145, 280–297 (2002).
Jansen, M. J. W. Analysis of variance designs for model output. Comp. Phys. Commun. 117, 25–43 (1999).
Kovacs, I., Topa, M., Buzo, A., Rafaila, M. & Pelz, G. Comparison of sensitivity analysis methods in high-dimensional verification spaces. Acta Tecnica Napocensis. Electron. Telecommun. 57(3), 16–23 (2016).
Beachkofski, B. & Grandhi, R. Improved distributed hypercube sampling. in American Institute of Aeronautics and Astronautics, paper AIAA 2002–1274 (2002).
Jolliffe, I. T. Principal Component Analysis 2nd edn. (Springer, 2002).
Forrester, A. I. J. & Keane, A. J. Recent advances in surrogate-based optimization. Prog. Aerosp. Sci. 45, 50–79 (2009).
Koziel, S. & Pietrenko-Dabrowska, A. Design-oriented modeling of antenna structures by means of two-level kriging with explicit dimensionality reduction. AEU Int. J. Electron. Commun. 127, 1–12 (2020).
Chen, Y.-C. Dual-band slot dipole antenna fed by a coplanar waveguide. in International Symposium on Antennas and Propagation, 3589–3592 (2006).
Hua, Z. et al. A novel high-gain quasi-Yagi antenna with a parabolic reflector. in International Symposium on Antennas and Propagation Hobart, Australia (2015).
Farran, M. et al. Compact quasi-Yagi antenna with folded dipole fed by tapered integrated balun. Electron. Lett. 52(10), 789–790 (2016).
Acknowledgements
The authors would like to thank Dassault Systemes, France, for making CST Microwavw Studio available. This work is partially supported by the Icelandic Research Fund Grant 239858 and by National Science Centre of Poland Grant 2022/47/B/ST7/00072.
Author information
Authors and Affiliations
Contributions
Conceptualization, S.K., A.P.; methodology, S.K. and A.P.; data generation, S.K.; investigation, S.K. and A.P.; writing—original draft preparation, S.K. and A.P.; writing—review and editing, S.K.; visualization, S.K. and A.P.; supervision, S.K.; project administration, S.K. and A.P.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Koziel, S., Pietrenko-Dabrowska, A. Cost-efficient behavioral modeling of antennas by means of global sensitivity analysis and dimensionality reduction. Sci Rep 15, 3778 (2025). https://doi.org/10.1038/s41598-025-87465-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-87465-y
Keywords
This article is cited by
-
Cost-efficient variable-fidelity machine learning for globalized optimization of microwave structures
Scientific Reports (2025)
