
Abstract
Due to the similar features of different diseases and insufficient semantic information of small area diseases in the surface disease image of concrete bridges, the existing semantic segmentation models for identifying surface diseases in concrete bridges suffer from problems such as large number of parameters, insufficient feature extraction, and low segmentation accuracy. Therefore, this paper proposed a lightweight semantic segmentation method for concrete bridge surface diseases based on improved DeeplabV3+. Firstly, the lightweight improved MobileNetV3 was used as the backbone network to reduce the computational complexity of the model. Secondly, the CSF-ASPP (cross scale fusion atrous spatial pyramid pooling) module was designed to expand the receptive field, enable the model to capture more contextual information at different scales and improve its anti-interference ability. Finally, the focal loss function was used to solve the problem of sample imbalance. The experimental results show that the mean intersection over union (mIoU) and mean pixel accuracy (mPA) of the improved DeeplabV3 + reached 75.24% and 84.68%, respectively, which were 3.73% and 4.21% higher than those of DeeplabV3+. The segmentation accuracy for four diseases of spalling, exposed reinforcement rebar, efflorescence, and crack was better than that of DeeplabV3+, and it also achieved better segmentation results compared to other semantic segmentation models. The improved DeeplabV3 + model achieves a parameter size of 6.97 × 106 and an inference speed of 52.64 FPS, demonstrating 90.33% reduction in parameters and 36.22 improvement in FPS compared to the DeeplabV3+. These advancements significantly enhance its suitability for real-time deployment on edge detection devices while maintaining high segmentation accuracy.
Similar content being viewed by others

Introduction
With the continuous development of infrastructure construction and transportation in China, the scale of concrete bridge construction has been progressively expanding. By the end of 2023, the total number of highway bridges in China reached 1.0793 million, with a total extension of 95.2882 million meters1. With the increase of operation years, concrete bridges may suffer from various diseases, which not only affect the durability and reliability of the bridge, but may even lead to bridge collapse accidents. Therefore, timely detection of diseases and corresponding reinforcement measures are crucial for ensuring the safety of concrete bridges. The traditional bridge inspection method mainly relies on manual inspection, which has the disadvantages of strong subjectivity, high risk, heavy workload, and low efficiency. Surface inspection of bridges can be achieved through technology such as drones and wall climbing robots, but manual disease recognition of the photos collected by the machines is still required, which is still inefficient.
The use of image processing method can replace manual recognition and realize automatic identification of diseases in images to some extent. Perry et al.2 used the Canny edge detection operator to segment cracks in digital images containing concrete cracks. Scholars Liu et al.3, Humpe et al.4, Wang et al.5, and Jiang et al.6 respectively used the Otsu threshold segmentation method and its variants to segment cracks on the surface of bridge structures. In addition, Morgenthal et al.7 used the multi-scale centerline detection method to extract cracks from bridge inspection images. Peng et al.8 used the maximum entropy method to achieve pixel level segmentation of concrete cracks. The implementation difficulty of the above methods is relatively low, with clear physical meanings, but they are easily affected by noise in the image and are only suitable for detecting diseases with clear edges (such as cracks), their applicability to area diseases and other complex diseases is poor.
In recent years, deep learning has been widely applied in bridge surface disease detection due to its high performance and strong flexibility. Lin et al.9 integrated FPN10 structure based on Fast-RCNN network framework, achieving object detection of multiple diseases including concrete crack, spalling, efflorescence, corrosion stains, and exposed reinforcement rebar. Yang et al.11 introduced the atrous spatial pyramid pooling (ASPP) module into YOLOv3 and adopted the transfer learning training strategy to identify concrete bridge surface diseases, achieving an increase of 1.3% in mPA. Mu et al.12 proposed a adaptive cropping shallow attention network based on the YOLOv5 object detection framework, which effectively improved the detection accuracy of steel structure surface diseases and bolt diseases. Wan et al.13 proposed a BR-DETR model for bridge surface diseases based on object detection transformers, which introduced modules such as deformable convolution and convolutional project attention, effectively improving the accuracy of disease detection.
The above methods can quickly detect surface diseases of bridges, but cannot provide more detailed information such as area. To obtain quantitative parameters such as the area of bridge surface diseases, semantic segmentation technology has been applied in the field of bridge surface disease identification. Rubio et al.14 proposed a pixel level identification method for concrete bridge delamination and rebar exposure based on FCN, using pre-trained VGG as the feature extractor to improve the average accuracy of delamination and rebar exposure. Li et al.15 proposed a pixel level crack segmentation network SCCDNet based on CNN, the network uses a depthwise separable convolution to improve the accuracy of crack segmentation and reduce the complexity of the model. Ding et al.16 proposed an independent boundary refinement transformer for crack segmentation in drone captured images based on Swin-Transformer, which can quantify crack widths less than 0.2 mm.
The Google Brain team developed a series of Deeplab models17,18,19,20, among which DeeplabV3 + adopts the encoder-decoder architecture, introduces the atrous spatial pyramid pooling, and expands the receptive field through parallel or series dilated convolutions with different dilation rate, effectively reducing detail loss and further improving model accuracy. Fu et al.21 proposed a bridge crack semantic segmentation algorithm based on an improved DeeplabV3 + network, which changed the ASPP module in the original network from a parallel structure of each branch to a dense connection form, effectively improving the mIoU of the model. Zhang et al.22 proposed the FDA-Deeplab model, which introduced dual attention mechanism, integrated high-level and low-level features, and used the sample difficulty weight adjustment factor to solve the problem of sample imbalance. Jia et al.23 built a semantic segmentation network model based on DeeplabV3 + and ResNet50, optimized the probability threshold of pixel categories, and improved the pixel level detection accuracy. Although these methods have improved the segmentation accuracy, existing models still have problems such as local detail loss, large number of parameters, and slow inference speed. Moreover, most algorithms are aimed at the identification and extraction of a single disease, and there is relatively little research on the identification of multiple diseases. In practical situations, a bridge usually exhibits multiple diseases simultaneously, and different diseases with similar characteristics can interfere with each other during the identification process, increasing the difficulty of detection.
In response to the above issues, this paper proposed a lightweight semantic segmentation method for concrete bridge surface diseases based on improved DeeplabV3+. Firstly, the original backbone network was replaced with an improved MobileNetV324, which replaced the attention module, optimized the time-consuming layer, accelerated training speed, reduced parameter size, and achieved lightweight requirements. Secondly, the CSF-ASPP module was designed, which achieved cross scale fusion through cascading, added a convolution branch, modified the dilation rate, and replaced traditional convolutions with depthwise over-parameterized convolutionals (DO-Convs)25, this enhancement significantly improves the model’s multi-scale feature extraction ability, detection ability for small area diseases, and anti-interference ability. Finally, the focal loss function26 was adopted to solve the category imbalance problem by paying more attention to difficult samples. The improved model has better real-time performance and higher accuracy, reduces the performance requirements of edge artificial intelligence devices, is suitable for complex diseases segmentation environments, and can provide reliable support for subsequent quantitative analysis. It has broad potential and prospects for application in embedded devices, mobile devices, and real-time systems.
Research method
Method overview
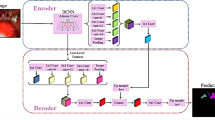
The network structure of the improved DeeplabV3 + proposed in this paper is shown in Fig. 1. The improved MobileNetV3 is used as the backbone network to extract the low-level and high-level features of input image, and high-level features are passed into the CSF-ASPP module. The CSF-ASPP module processes the high-level features in parallel using six ways, including 1 × 1 convolution for feature extraction, four 3 × 3 DO-Convs with dilation rate of 4, 8, 12, 16 for cross pixel feature extraction, and image pooling. The input of the DO-Conv layers is the concatenation of the feature layer output by the dilated convolution in the upper layer of each branch and the feature layer output by the backbone network the channel dimension. Six processing methods are used to obtain six corresponding feature layers, which are stacked and adjusted for channel number using 1 × 1 convolution to obtain a high-level feature layer. After upsampling the high-level feature layer, it is fused with the low-level feature layer that has been adjusted using 1 × 1 convolution to change the number of channel, resulting in a feature layer that contains both low-level features and high-level features of the input image. Then, 3 × 3 convolution is used for feature extraction, and the result is adjusted to the same size as the input image by upsampling before outputting. Additionally, the focal loss function is used to calculate the prediction error and adjust the network parameters.

Improved DeeplabV3 + network structure.
Replace the backbone network
Due to the large number of parameters in the backbone network Xception27 of DeeplabV3 + model, applying the model to the semantic segmentation task of bridge surface diseases requires a large overall computational load and is time-consuming. Therefore, we adopt the lightweight MobileNetV3 network as the backbone network. MobileNetV3 uses the depthwise separable convolution of MobileNetV128 and the inverted residual structure with linear bottleneck of MobileNetV229. Based on this, the h-swish function is used instead of the swish activation function, and the attention module SENet is added.
The swish activation function can effectively improve the accuracy of the network, but it requires a large amount of computation and is not suitable for lightweight networks. The h-swish function has a similar effect to the swish activation function, but with much lower computational complexity. Therefore, MobileNetV3 uses the h-swish function with simple differentiation to replace the swish activation function. The computation formulas for the swish and h-swish activation functions are shown in Eqs. (1 and 2), respectively.
MobileNetV3 adopts the channel attention module SENet, which performs global average pooling on the input feature layer and performs two fully connected operations. Then, the normalized weights are multiplied element-wise with the original input feature layer for the generalization model. The structure of SENet is shown in Fig. 2a. The ECA-Net module30 is improved from two aspects: avoiding dimensionality reduction and cross channel information exchange. The fully connected layers of SENet are removed to avoid the impact of dimensionality reduction on the prediction results. The structure of ECA-Net is shown in Fig. 2b. Therefore, we replaced the SENet module with the ECA-Net module and truncated the time-consuming layers in the backbone network to significantly reduce model parameters and computational complexity, making it possible to significantly reduce the training and prediction time required in bridge surface disease segmentation tasks. Table 1 shows the structure of the improved MobileNetV3 model.

Comparison of SENet and ECA-Net structures.
CSF-ASPP module
The structure of the original ASPP module is shown in Fig. 3a, its larger dilation rate convolution kernel is beneficial for extracting information on larger areas of diseases. However, in practical engineering, the surface diseases of concrete bridges often have smaller areas, which can easily lead to the loss of detailed and spatial information during feature extraction. In addition, the mutual interference between multiple diseases can lead to insufficient context information mining in the deep layers of the network. In response to the above issues, we made improvements to the ASPP module, and the improved CSF-ASPP module structure is shown in Fig. 3b.

Comparison of ASPP module before and after improvement.
We added the dilated convolution branch 5, and modified the dilation rate of the original dilated convolutions from 6, 12, 18 to 4, 8, 12, 16. The modified module has more convolutional kernels of different scale, which can extract more features of different scales, thereby enhancing the model’s ability to identify and extract diseases of different sizes. At the same time, in order to solve the interference problem between multiple diseases, we borrowed the idea of DenseNet31 model structure, redesigned the relationship between each branch, implemented branch cascading, enhanced the complementarity between multi-scale features, and improved the anti-interference ability of the model. Finally, we used depthwise over-parameterized convolutional instead of the original module’s 3 × 3 standard convolution. DO-Conv adds an additional depthwise convolution to the existing convolutional layers, improving the model’s feature representation ability. DO-Conv can be converted into traditional convolution operations, so replacing traditional convolutions in a model with DO-Convs does not increase computational requirements. DO-Conv combines ordinary convolution and depthwise convolution through kernel combination, as illustrated in Fig. 4.

DO-Conv kernel combination.
In Fig. 4, \(\:{\varvec{D}}^{\text{T}}\) is the transpose of \(\:\varvec{D}\) in the feature crosses of DO-Conv; \(\:\varvec{P}\) is a two-dimensional tensor, whose shape is determined by the size and stride of the convolution kernel; \(\:\varvec{W}\) is the three-dimensional weight; \(\:{C}_{\text{i}\text{n}}\) is the number of input channels, \(\:{C}_{\text{o}\text{u}\text{t}}\) is the number of output channels, the size of the convolution kernel is \(\:M\times\:N\), \(\:{D}_{\text{m}\text{u}\text{l}}\) is the depth multiplier, and each input channel is converted to \(\:{D}_{\text{m}\text{u}\text{l}}\) dimensional features. \(\:\circ\:\) represents depthwise convolution, \(\:\ast\:\) represents standard convolution. Compared to traditional convolution, DO-Conv uses more parameters for training without increasing the computational complexity of network inference, which not only accelerates convergence speed but also improves network performance. The computational cost of the forward propagation of the DO-Conv kernel combination method is shown in Eq. (3).
Loss function
The original DeeplabV3 + network model uses the cross-entropy loss function to calculate prediction errors, performs backpropagation, adjusts network parameters, and the formula for calculating the cross-entropy loss function is shown in Eq. (4).
In the formula: \(\:N\) is the total number of pixels; \(\:c\) is a semantic segmentation category; \(\:K\) is the total number of semantic segmentation categories; \(\:{y}_{i,c}\) is signum function, which takes 1 if the true class of pixel \(i\) belongs to \(c,\), and 0 if not; \({p}_{i,c}\) is the predicted probability that pixel \(\:i\) belongs to category \(\:c\).
In the actual bridge detection, there are various types and shapes of surface diseases, and the disease area is far less than the non disease area. Therefore, most of the pixels in the dataset of surface diseases in concrete bridges belong to the background category, while the pixels of surface diseases are very rare. This extreme imbalance of samples leads to the model tending to optimize the predictive performance of the majority class, while neglecting the identification of minority classes. Using the cross-entropy loss function cannot effectively balance the learning of fewer class samples. The focus loss function26 introduces a moderation factor to reduce the loss contribution of easy to classify samples, thereby placing more training focus on difficult to classify samples, aiming to increase the model’s attention to difficult to classify or minority class samples. The calculation formula for the focus loss function is shown in Eq. (5).
In the formula: \(\:{p}_{t}\) is the predicted probability of the true category of the sample; \({\alpha}_{t}\) is a balance factor used to adjust the loss of the model on each category; \(\gamma\) is an adjustable focus parameter that makes the model to focus more on difficult to classify samples and improve its generalization ability.
By paying more attention to difficult to identify samples, focus loss function can effectively solve the imbalance of disease types in the data. Especially when there are few disease samples, it can ensure the model’s ability to identify these minority classes (diseases), reduce the model’s bias towards the majority class (normal area), and make the model more adaptable and robust in complex backgrounds, thereby improving the overall performance of bridge disease segmentation. Therefore, we replaced the loss function of the model with the focus loss function to solve the problem of sample imbalance.
Experimental results and analysis
Dataset of concrete bridge surface diseases
The dataset of surface diseases in concrete bridges comes from RGB visible light images of bridge diseases manually captured by a traffic inspection company. In order to ensure the diversity and generalization of data, bridge disease images are collected from different bridge inspection personnel without fixed shooting conditions, such as focal length, object distance, shooting equipment, etc., and there is no fixed resolution size for disease images. The principle of filtering images is that the disease area is clear and the image resolution is high. In addition, these images also contain different lighting conditions and shooting angles, which can ensure the adaptability of the model to different complex environments. Finally, 420 images of common bridge surface diseases including spalling, exposed reinforcement rebar, efflorescence, and crack were manually selected, and the pixel level labeling of the surface disease areas was carried out using the software Labelme. Examples of concrete bridge surface disease images and their corresponding labels are shown in Fig. 5.

Examples of concrete bridge surface disease images and their corresponding labels.
We used built-in modules in Python to expand images, mainly using geometric transformation and color space transformation. The former includes vertical flip, rotation (90°,180°, − 90°), and the latter includes contrast enhancement and brightness enhancement. Finally, 2520 subgraphs with six times the original dataset were obtained based on the above six expansion methods, and the dataset was divided into training set and verification set in an 8:2 ratio.
Experimental environment and parameter setting
The experiments used 64-bit Windows10 operating system, Intel i9-14900 K CPU, NVIDIA RTX4080 GPU with 24GB memory. The model framework was built based on Pytorch1.11, and the GPU running platform was NVIDIA CUDA11.3. The input image size was set to 512 × 512, the batch size was set to 10, and the learning rate range was set to [0.00001,0.001]. The optimizer used momentum stochastic gradient descent (MSGD). The momentum parameter was set to 0.9, the weight decay was set to 0.001, the cosine annealing strategy was chosen as the learning rate decay method, and the training epoch was set to 150.
Evaluation metrics
In the experiments, we used intersection over union (IoU), mean intersection over union (mIoU), pixel accuracy (PA), mean pixel accuracy (mPA), parameters, and frame per second (FPS) as evaluation metrics.
IoU is the ratio of the intersection and union of two sets of true and predicted labels for a specific category, and mIoU is the average IoU of all categories. The mathematical expressions for IoU and mIoU are shown in Eqs. (6 and 7).
In the formula, \(\:{p}_{ij}\) represents the number of pixels where the real label is \(\:i\) and the predicted category is \(\:j\), \(\:k\) represents the largest number of valid category labels, and \(\:k+1\) represents the total number of categories.
PA is the proportion of correctly predicted pixels for a certain category to the total number of pixels in that category, and mPA is the average value of PA for all categories. The mathematical expressions for PA and mPA are shown in Eqs. (8 and 9).
Comparison of training processes
To visually compare the performance of DeeplabV3 + and the improved DeeplabV3+, we present the changes in loss values and mIoU values during the training process for both models in Fig. 6. As shown in Fig. 6, it can be observed that the training loss of the improved model decreases significantly faster than the original model in the initial stage, and stabilizes within fewer epochs. The overall loss value is also significantly lower than that of the original model. At the 150th epoch, the improved model recorded a loss of 0.032, compared to 0.074 for the original model. In addition, the improved model achieved higher mIoU values in the early stages of training and demonstrated higher and more stable segmentation accuracy with less fluctuation in subsequent epochs. The improved model achieved the mIoU of 75.24% at the 150th epoch, while the original model was only 71.51%. This indicates that the improved DeeplabV3 + exhibits better convergence performance on the concrete bridge surface disease dataset, and has better ability to capture multi-scale information and detailed features.

Model training process curve.
Backbone network comparison experiments
In order to test the impact of different backbone networks on the performance of DeeplabV3 + and the effectiveness of the improvement of MobileNetV3 proposed in this paper, we selected Xception network27, EfficientNet V2 network32, Resnet101 network33, MobileNetV3 network24, and improved MobileNetV3 network as backbone networks respectively, and performed comparative experiments under the same environmental parameters. The experimental results are shown in Table 2.
As can be seen from Table 2, when the improved MobileNetV3 was used as the backbone network, all four evaluation metrics improved compared with other backbone networks. Compared to Resnet101 and MobileNetV3, the mIoU increased by 5.87% and 2.31%, respectively, and the mPA increased by 9.50% and 5.62%, respectively. Additionally, the number of parameters is the lowest and the FPS is the highest. Compared with the backbone network Xception and Efficientnet V2, the mIoU and mPA of the improved MobileNetV3 were also slightly improved, and the parameter sizes were reduced by 90.44% and 88.02%, respectively. By synthesizing the four evaluation metrics, the improved MobileNetV3 can significantly reduce the number of network parameters while ensuring the segmentation performance of the model, effectively achieving the lightweight of the model.
Comparative experiments of CSF-ASPP module optimization
The CSF-ASPP module was optimized based on the ASPP structure, achieving optimal performance by designing cascade structure, using DO-Conv, increasing the number of branches, and adjusting the dilation rate. To verify the improved performance, the CSF-ASPP module comparative experiments were conducted using the improved MobileNetV3 as the backbone network. The experimental results are shown in Table 3.
According to Table 3, when using the cascaded structure, both mIoU and mPA were higher than the original ASPP structure, and the performance was optimal when the convolution type was DO-Conv, the number of branches was 4, and the dilation rate was (4, 8, 12, 16), with the mIoU and mPA reaching 74.60% and 83.99%, respectively. Compared with the original ASPP module, the CSF-ASPP module improved the mIoU and mPA by 2.81% and 3.15% respectively, proving that the CSF-ASPP module has better performance in semantic segmentation of concrete bridge surface diseases than the original ASPP module.
Ablation experiments
In order to further verify the effectiveness of the improved MobileNetV3 module, CSF-ASPP module, and focus loss function in segmenting four types of diseases including spalling, exposed reinforcement rebar, efflorescence, and crack, DeeplabV3 + was defined as the baseline method and ablation experiments were conducted. The experimental results are shown in Table 4.
By analyzing Table 4, it can be seen that compared to the baseline method, using the improved MobileNetV3 as the backbone network can significantly improve the model inference speed and to some extent enhance accuracy. After introducing the CSF-ASPP module, the inference speed slightly decreased, but the segmentation accuracy for each diseases was significantly improved. Among them, the segmentation accuracy for efflorescence was improved the most, with the IoU and PA increasing by 6.36% and 8.10%, respectively. This is because the CSF-ASPP module endows the model with stronger multi-scale feature extraction and interference resistance capabilities, notably enhancing the segmentation accuracy for diseases with blurred edges such as efflorescence. After replacing the loss function with the focus loss function, the mIoU and mPA increased by 0.64% and 0.69% respectively, with minimal impact on inference speed. In summary, the comprehensive performance of the model with three improvements is the best, and the inference speed is greatly improved while the accuracy is also significantly improved.
Comparative experiments of different semantic segmentation models
To verify the effectiveness of the improved DeeplabV3+, comparative experiments were conducted with U-Net34, HRNet35, PSPNet36, SETR37, SegFormer38, Mask2Former39, PIDNet40, and DeeplabV3+20. The comparison results are shown in Table 5.
From Table 5, it can be seen that although our method is slightly inferior to PSPNet in terms of parameters and FPS evaluation metrics, it performs the best in both mIoU and mPA evaluation metrics, at 75.24% and 84.68%, respectively. Compared with the baseline method DeeplabV3+, our method improved the mIoU and mPA by 3.73% and 4.21% respectively, reduced the parameter size by 90.33%, and increased the FPS by 36.22. The improved model ensures the smaller number of parameters and faster inference speed while improving segmentation accuracy, resulting in the best overall performance. In order to more intuitively show the differences in the segmentation effects of different methods on the surface diseases of concrete bridges, we selected six representative images for comparative experiments and visualized them, as shown in Fig. 7. Figure 7a are the disease images, 7b are the label images, and 7c–k are the semantic segmentation results obtained using U-Net, HRNet, PSPNet, SETR, SegFormer, Mask2Former, PIDNet, DeeplabV3+, and our method, respectively.


Visual comparison of segmentation results.
From Fig. 7, it can be seen that after training, the improved DeeplabV3 + produces segmentation results that are closer to the true values of the labels, and can more accurately and correctly segment and classify the surface disease of concrete bridges. The edge pixel detail detection is better than other models, and the segmentation outline is clear and obvious, with strong robustness.
Conclusion
In order to achieve high-precision and lightweight identification of surface diseases in concrete bridges, this paper proposed a lightweight semantic segmentation method for concrete bridge surface diseases based on improved DeeplabV3+. Firstly, replaced the original backbone network with the lightweight MobileNetV3, then used the ECA-Net module to replace the SENet module in the MobileNetV3 network, and deleted the time-consuming layers in the network, significantly reducing the model parameters. Next, designed the CSF-ASPP module by adding a convolutional branch and cascading adjacent branches to expand the receptive field and enhance pixel connectivity. Then, set the dilation rate to [4,8,12,16] and replaced Convs with DO-Convs to improve model performance. Finally, replaced the cross entropy loss function with the focus loss function to enhance training on the small number of samples. Experimental results indicate that the improved DeeplabV3 + outperforms the baseline method in segmentation accuracy for four types of concrete bridge surface diseases including spalling, exposed reinforcement rebar, efflorescence, and crack, with mIoU and mPA reaching 75.24% and 84.68%, respectively, outperforming other semantic segmentation models. The model has a parameter count of 6.97 × 106 and achieves an FPS of 52.64. Compared with the baseline method, the improved DeeplabV3 + shows increases of 3.73% and 4.21% in mIoU and mPA, reduces the parameter count by 90.33%, and increases the FPS by 36.22, thereby enabling efficient and rapid detection of concrete bridge surface diseases with a relatively small model size.
The dataset used in this study comes from images collected by a single traffic inspection company during the actual bridge inspection process. The disease samples are concentrated in temperate monsoon climate regions and lack images of diseases in extreme environments such as tropical and cold zones (such as peeling caused by freeze-thaw cycles and accelerated rebar corrosion in high temperature and high humidity areas). These images may have certain limitations in covering larger areas and richer scenes, which may affect the model’s generalization ability to bridges with significantly different environmental conditions or building materials.
In future research, we plan to collaborate with more bridge inspection agencies to collect more image data from different regions and bridges, and implement an active learning framework. This will further enrich the diversity and representativeness of the dataset, enabling better adaptation to the various complex environments encountered in practical engineering applications. Furthermore, we are considering deploying the proposed model to concrete bridge inspection drones. A multi-scale inference strategy will be implemented to dynamically adjust input resolution based on disease density, thereby reducing redundant computational overhead and balancing speed with accuracy. Leveraging drone metadata and Structure-from-Motion (SfM) techniques, we will achieve precise spatial calibration to convert segmentation masks into quantitative parameters (such as crack width and spalling area). This pipeline will provide scientific metrics for bridge maintenance decision-making, ensuring structural reliability and long-term durability.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Statistical Bulletin on the development of transportation industry in 2023. China Commun. News 2024-06-18, 002 .
Perry, B. J., Guo, Y., Atadero, R. & van de Lindt, J. W. Streamlined bridge inspection system utilizing unmanned aerial vehicles (UAVs) and machine learning. Measurement 164, 108048 (2020).
Liu, Y. F., Nie, X., Fan, J. S. & Liu, X. G. Image-based crack assessment of Bridge piers using unmanned aerial vehicles and three-dimensional scene reconstruction. Comput.-Aided Civ. Infrastruct. Eng. 35 (5), 511–529 (2020).
Humpe, A. Bridge inspection with an off-the-shelf 360° camera drone. Drones 4 (4), 67 (2020).
Wang, H. F. et al. Measurement for cracks at the bottom of bridges based on tethered creeping unmanned aerial vehicle. Autom. Constr. 119, 103330 (2020).
Jiang, S. & Zhang, J. Real-time crack assessment using deep neural networks with wall-climbing unmanned aerial system. Comput.-Aided Civ. Infrastruct. Eng. 35 (6), 549–564 (2020).
Morgenthal, G. et al. Framework for automated UAS-based structural condition assessment of bridges. Autom. Constr. 97, 77–95 (2019).
Peng, X., Zhong, X., Zhao, C., Chen, Y. F. & Zhang, T. The feasibility assessment study of bridge crack width recognition in images based on special inspection UAV. Adv. Civ. Eng 2020 8811649 (2020).
Lin, J. J., Ibrahim, A., Sarwade, S. & Golparvar-Fard, M. Bridge inspection with aerial robots: Automating the entire pipeline of visual data capture, 3D mapping, defect detection, analysis, and reporting. J. Comput. Civil Eng. 35 (2), 04020064 (2021).
Lin, T. Y. et al. Feature pyramid networks for object detection. In 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 936–944 (2017).
Yang, J. X., Li, H., Huang, D. & Jiang, S. X. Concrete bridge damage detection based on transfer learning with small training samples. In 7th International Conference on Systems and Informatics (ICSAI). 1–6 (2021).
Mu, Z. H. et al. Adaptive cropping shallow attention network for defect detection of bridge girder steel using unmanned aerial vehicle images. J. Zhejiang Univ.-Sci. A. 24 (3), 243–256 (2023).
Wan, H. F. et al. A novel transformer model for surface damage detection and cognition of concrete bridges. Expert Syst. Appl. 213, 119019 (2023).
Rubio, J. J. et al. Multi-class structural damage segmentation using fully convolutional networks. Comput. Ind. 112, 103121 (2019).
Li, H. T. et al. SCCDNet: A pixel-level crack segmentation network. Appl. Sci.-Basel. 11 (11), 5074 (2021).
Ding, W., Yang, H., Yu, K. & Shu, J. P. Crack detection and quantification for concrete structures using UAV and transformer. Autom. Constr. 152, 104929 (2023).
Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K. & Yuille, A. L. Semantic image segmentation with deep convolutional Nets and fully connected CRFs. arXiv:1412.7062 (2014).
Chen, L. C. et al. Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 40 (4), 834–848 (2018).
Chen, L. C., Papandreou, G., Schroff, F. & Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv:1706.05587 (2017).
Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In 15th European Conference on Computer Vision (ECCV) 11211, 833–851 (2018).
Fu, H. X., Meng, D., Li, W. H. & Wang, Y. C. Bridge crack semantic segmentation based on improved Deeplabv3+. J. Mar. Sci. Eng. 9 (6), 671 (2021).
Zhang, X. G., Ding, L. Z., Liu, Y. F., Zheng, Z. H. & Wang, Q. FDA-DeepLab semantic segmentation network based on dual attention module. J. Southeast. Univ. (Natural Sci. Edition). 52 (6), 1145–1151 (2022). (in Chinese).
Jia, X. J., Wang, Y. X. & Wang, Z. Fatigue crack detection based on semantic segmentation using DeepLabV3 + for steel girder bridges. Appl. Sciences-Basel. 14 (18), 8132 (2024).
Howard, A. et al. Searching for MobileNetV3. In IEEE/CVF International Conference on Computer Vision (ICCV). 1314–1324 (2019).
Cao, J. M. et al. DO-Conv: Depthwise over-parameterized convolutional layer. IEEE Trans. Image Process. 31, 3726–3736 (2022).
Lin, T. Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In IEEE International Conference on Computer Vision (ICCV). 2999–3007 (2017).
Chollet, F. Xception deep learning with depthwise separable convolutions. In 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1800–1807 (2017).
Howard, A. G. et al. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861 (2017).
Sandler, M. et al. MobileNetV2: Inverted residuals and linear bottlenecks. In 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4510–4520 (2018).
Wang, Q. L. et al. ECA-Net: Efficient channel attention for deep convolutional neural networks. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11531–11539 (2020).
Huang, G., Liu, Z., Laurens, V. D. M. & Weinberger, K. Q. Densely connected convolutional networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2261–2269 (2016).
Tan, M. X. & Le, Q. V. EfficientNetV2: Smaller models and faster training. In International Conference on Machine Learning (ICML) 139, 7102–7110 (2021).
He, K. M., Zhang, X. Y., Ren, S. Q. & Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778 (2016). (2016).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional networks for biomedical image segmentation.arXiv:1505.04597 (2015).
Sun, K. et al. High-resolution representations for labeling pixels and regions. arXiv:1904.04514 (2019).
Zhao, H. S. et al. Pyramid scene parsing network. In 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6230–6239 (2017).
Zheng, S. et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6877–6886 (2021).
Xie, E. et al. SegFormer: Simple and efficient design for semantic segmentation with transformers. In 35th Annual Conference on Neural Information Processing Systems (NeurIPS) 34, (2021).
Cheng, B. et al. Masked-attention mask transformer for universal image segmentation. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1280–1289 (2022).
Xu, J., Xiong, Z. & Bhattacharyya, S. P. PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 19529–19539 (2023).
Funding
This research was funded by the Shandong Housing and Urban-Rural Development Science and Technology Program (Grant No. 2022-K7-6).
Author information
Authors and Affiliations
Contributions
Conceptualization, methodology, validation, visualization, writing – original draft, Z.Y.; Conceptualization, methodology, writing – review & editing, C.D.; Data curation, methodology, investigation, X.Z.; Formal analysis, software, visualization, Y.L.; Project administration, resources, supervision, H.L. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, Z., Dai, C., Zeng, X. et al. A lightweight semantic segmentation method for concrete bridge surface diseases based on improved DeeplabV3+. Sci Rep 15, 10348 (2025). https://doi.org/10.1038/s41598-025-95518-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-95518-5
