
Abstract
This paper presents a comprehensive experimental validation of machine learning for contamination classification of polluted high voltage insulators using leakage current. A meticulous dataset of leakage current for porcelain insulators with varying pollution levels was developed under controlled laboratory conditions. Critical parameters of temperature and varying humidity were also included in the dataset to reflect the impact of environmental conditions and bring the dataset close to real world scenarios. The dataset generated was preprocessed and critical features were extracted from time, frequency, and time-frequency domains. Four distinct machine learning models, encompassing decision trees and neural networks, were trained and evaluated on this dataset. The Bayesian optimization technique was used to optimize the parameters of Machine Learning Models. The models demonstrated exceptional performance, with accuracies consistently exceeding 98 %. Notably, the decision tree-based models exhibited significantly faster training and optimization times compared to their neural network counterparts. This study underscores the effectiveness of machine learning in improving the reliability of insulator maintenance and monitoring systems, paving the way for more robust predictive maintenance strategies.
Similar content being viewed by others
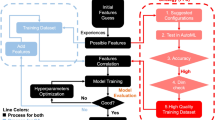


Introduction
High voltage porcelain insulators are crucial components in power transmission and distribution systems, serving to support and electrically isolate conductors while preventing unwanted current flow to the ground. However, their performance can be significantly affected by environmental pollution resulting in their contamination, which poses a continuous challenge in maintaining the reliability and efficiency of power networks.
Contamination of high voltage insulators (HVI) occurs when pollutants such as dust, salt, industrial emissions, and other particles accumulate on their surfaces. This contamination is caused from various sources, including coastal environments, industrial regions, agricultural activities, and desert areas1. Depending on the environmental conditions and the nature of the contaminants, the severity of the contamination can vary, leading to different operational challenges. The presence of contaminants on insulator surfaces can drastically alter their electrical properties. During periods of high humidity or rainfall, these contaminants can become conductive, forming a thin layer of electrolyte that facilitates the flow of leakage current along the insulator surface. Fig. 1 shows leakage current flow over a typical High Voltage Insulator. This phenomenon can lead to several adverse effects1,2.

Leakage Current Flow over Moist Contaminated Insulator.
The adverse effects faced by HVI include: Increased Leakage Currents: Contaminated insulators exhibit higher leakage currents, which can result in power losses and reduced system efficiency3; Flashovers: The presence of contaminants can lower the insulator’s surface resistance, increasing the likelihood of flashovers, where the insulator fails to prevent the current from arcing to the ground or across phases. Flashovers can cause power outages and equipment damage3; and Accelerated Aging and Degradation: Continuous exposure to contamination and subsequent leakage currents can accelerate the aging process of insulators, leading to mechanical and electrical degradation over time4,5.
To ensure the reliability of power systems, it is essential to monitor and classify the level of contamination on insulators. Contamination levels are generally categorized into three classes3: (1) Highly Contaminated: Insulators in this category experience significant deposition of pollutants, leading to high leakage currents and frequent flashovers; (2) Moderately Contaminated: Insulators with moderate contamination exhibit noticeable but not severe accumulation of pollutants, resulting in moderate leakage currents; and (3) Low Contamination: Insulators with low contamination have minimal pollutant deposits, maintaining their electrical performance with low leakage currents.
Classifying the contamination levels of HVI is critical for maintaining the reliability and safety of power systems. Accurate classification allows for timely and targeted maintenance, thereby preventing unexpected failures and prolonging the lifespan of the insulators. Several advanced methods have been developed to monitor and classify contamination levels, including machine learning algorithms, signal processing techniques, and visual inspections3.
The application of machine learning techniques offer a promising approach for the automatic classification of insulator contamination levels with higher accuracy and efficiency due to its ability to analyze complex, multidimensional data like leakage current signals influenced by environmental factors such as temperature and humidity. These models excel at capturing subtle patterns and nonlinear relationships in data, enabling robust performance across varying conditions. By automating contamination classification, machine learning enhances the efficiency, reliability, and scalability of predictive maintenance systems for high-voltage insulators.
By analyzing data such as leakage current, visual imagery, and environmental conditions, machine learning models can effectively identify patterns and predict contamination levels6,7. This automated approach improves the precision of contamination assessment, reduces the need for labor-intensive manual inspection, and significantly lowers the risk of power system failures. However, their exists a crucial gap in literature which substantiate the application of Machine Learning techniques for HVI contamination classification with realistic experimental data. The question that needs to be investigated is whether Machine Learning techniques, despite their outstanding performance in different applications, will still be effective in classifying HVI contamination on the basis of leakage current? Furthermore, key implementation challenges must also be identified.
In this research work, a dataset was generated through intensive experimentation for three contamination classes of the insulators representing high, moderate, and low contamination levels. We have applied multiple machine learning techniques on the dataset of contaminated porcelain HVI and analyzed their performance.
The following aspects are covered in this research paper:
-
1.
Preparation of artificially polluted insulators divided into three contamination classes indicating High, Moderate and Low contamination.
-
2.
An explicit dataset of leakage current for porcelain insulators with varying pollution levels was developed under controlled laboratory conditions. Critical parameters of temperature and varying humidity were also included in the dataset to reflect the impact of environmental conditions and bring the dataset close to real world scenarios.
-
3.
The dataset generated was preprocessed and features were extracted from time, frequency, and time-frequency domains. The extracted features were ranked and most important features identified.
-
4.
Four distinct machine learning models, encompassing decision trees and neural networks, were trained and evaluated on this dataset. The Bayesian optimization technique was used to optimize the parameters of Machine Learning Models
-
5.
Detailed discussion on the performance and accuracies of the Machine Learning Model.
This research paper is structured as follows. Section 2 presents a review of literature. Section 3 presents the experimental method and data collection. Section 4 and Section 5 presents the preprocessing and feature extraction of the leakage current data respectively. In section 6 we have discussed the machine learning techniques that were applied in this work. Section 7 contains the results and discussions. In section 8, we have presented our conclusions.
Background and related work
High-Voltage Insulators in the outdoor environment are prone to get contaminated by environmental pollution which can severely compromise their ability to provide insulation between High Voltage lines and metallic towers. HVIs are mostly exposed and operate in open air environmental conditions. During their operation, they are always prone to contamination. This is due to deposition of dust, soot, and salts from the environment. Therefore, the contamination assessment of High Voltage Insulators (HVIs) is a critical concern for maintenance departments. Over the years, several techniques have been developed to evaluate contamination levels and facilitate preventive maintenance. Major techniques proposed in the literature during the last decade are mentioned in this Section. The techniques mentioned in Table 1 and also shown in Fig. 2 are specifically designed to asses contamination of HVIs being used in OHTL. However, these techniques can also be used for assessment of High Voltage Bushings and electro-mechanical disconnectors in the power grid.
Acoustic and ultrasonic-based methods offer non-invasive monitoring with reasonable prediction accuracy. These techniques typically involve acoustic emission (AE) monitoring, wavelet transform, multi-resolution analysis (MRA) feature extraction, and support vector regression (SVR) stacking, utilizing piezoelectric sensors to capture relevant data8,9. A significant advantage of these methods is their immunity to electromagnetic interference, making them particularly useful in environments where other methods may struggle. However, their effectiveness is contingent on the quality of AE sensors, which are often expensive and require high precision10. Additionally, these methods are sensitive to ambient noise, which can compromise detection accuracy. Any degradation in signal quality can lead to incorrect assessments11.
Electromagnetic (EM) and Radio Frequency (RF) based methods assess contamination by analyzing the wideband electromagnetic radiation signature of insulators. These techniques involve collecting and analyzing EM and RF data, focusing on statistical measures and frequency spectrum analysis12. The primary advantage of these methods is their non-invasive nature, allowing remote monitoring with high sensitivity, especially within the 30 MHz to 130 MHz frequency range13. However, the high cost and specialization of the required equipment limit their accessibility. Moreover, these methods are highly sensitive to environmental noise, necessitating extensive data filtering to ensure accuracy. The effectiveness of EM and RF-based techniques is often restricted to specific types of insulators, limiting their general applicability.
Recent advancements in image-based contamination assessment of HVIs have shown significant potential in improving maintenance practices. Techniques using deep learning networks such as YOLO, RetinaNet, and customized Convolutional Neural Networks (CNNs) have achieved high accuracy in contamination detection7,14,15. These methods, which often involve capturing image data via UAVs, offer real-time, non-destructive testing. However, they are constrained by the need for high-quality images and significant computational resources. Sensitivity to ambient conditions, such as lighting, also presents a challenge.
Advanced techniques using hyperspectral, ultraviolet (UV), and infrared (IR) imaging have emerged for non-contact detection of contamination on HVIs, achieving recognition rates up to 96.67%16,17. These methods employ deep learning models like CNNs and ResNet, along with traditional machine learning techniques such as Multiple Linear Regression (MLR) and Random Forests (RF). However, the need for specialized equipment and the computational demands of these methods limit their widespread adoption. Sensitivity to environmental conditions remains a significant challenge18,19,20.
Partial Discharge (PD) based methods are gaining attention for their ability to detect early-stage degradation in HVIs, particularly in polluted environments. These methods utilize Ultra High Frequency (UHF) measurements combined with deep learning techniques to identify critical contamination levels that could lead to insulator failure21,22. Despite the advantages of real-time capabilities and portability, PD-based methods are sensitive to environmental factors like electromagnetic interference and require precise calibration for accurate results.
The most commonly used existing technqiues for HVI contamination level assesment are summarized in Table 1 along with their key strengths and weaknesses. Despite each technique having certain strengths, as shown in Table 1, these techniques suffer from numerous critical problems. These problems include their dependence on specialized equipment, high sensitivity to environmental noise, huge computational burden, lacking environmental adaptability and also sensitivities to non-uniform pollution. Leakage current based machine learning techniques have proven to be practical and widely applicable, making them a preferred choice for monitoring HVI. These techniques have clear advantage of High Accuracy (up to 96.82%); Real-Time Monitoring capability; Abilitity to operate in various environmental conditions; Robust Classification of contamination levels; relatively Low Computational Burden; no requirement of highly specialized sensors; and lastly no sensitivity to non uniform pollution levels. Leakage current-based machine learning methods remain a cornerstone for assessing HVI contamination due to their practicality and effectiveness across various environmental conditions. These methods involve analyzing the effects of environmental factors, such as humidity, on leakage current parameters2,23,24.
However, most of the leakage current based machine learning techniques presented in literature have been trained on very limited and straightforward datasets which do not reflect the kind of conditions that are expected in real-world scenarios. These methods face challenges related to computational complexity and the need for extensive data collection for proper training of machine learning models1,25,26,27. Experimental validation of these machine learning techniques on realistic datasets is lacking and this is the critical gap hindering the advancement of adaptability of these technique for HVI contaimantion assessment.
In the proposed research work, multiple machine learning techniques, including both the Decision Tree based and Neural Network based techniques have been analyzed on realistic leakage current datasets containing leakage current and environmental data for three different classes of contaminated insulators. The overall performance and accuracies of the machine learning models have been identified for HVI contamination level classification.
Fig. 2 summarizes the strengths and weaknesses of existing HVI contamination assessment techniques.

Major High Voltage Insulator contamination approaches with their strengths and weaknesses.
Machine learning techniques
The machine learning models chosen for this study are Extreme Gradient Boosting (XGBoost) and Light Gradient Boosting Machine (LightGBM) for the decision tree-based category, and Deep Neural Network (DNN) and TabNET for the neural network-based category. XGBoost and LightGBM, as gradient boosting frameworks, offer exceptional performance and scalability. XGBoost incorporates advanced regularization techniques, parallel processing, and second-order gradient optimization, enabling it to efficiently handle large datasets with sparse or missing values. LightGBM, with its Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB) techniques, provides faster training, efficient memory usage, and seamless handling of high-dimensional and categorical data. These features give XGBoost and LightGBM a significant edge in terms of speed, efficiency, and robustness, which are crucial for managing large-scale contamination datasets.
DNN and TabNet, on the other hand, excel in modeling complex patterns and relationships within data. DNNs can learn intricate, non-linear representations through their deep architecture, making them highly versatile and effective for capturing contamination patterns that require hierarchical feature extraction. TabNet, specifically designed for tabular data, employs a novel attention mechanism to focus on the most relevant features, ensuring both accuracy and interpretability. Additionally, TabNet is robust against noise and overfitting, making it ideal for sensitive datasets.
XGBoost (extreme gradient boosting)
XGBoost is a highly efficient and scalable implementation of the gradient boosting algorithm, designed for performance and speed. It builds upon the traditional gradient boosting framework by introducing several enhancements that make it particularly effective for machine learning tasks 60. One of the key improvements is its regularization techniques, which help control overfitting, a common issue in machine learning models. XGBoost does this by incorporating a more regularized objective function that penalizes the complexity of the model, which leads to better generalization on unseen data.
In addition to its robust regularization methods, XGBoost offers a variety of hyperparameters that significantly influence model performance. The most critical hyperparameters include:
-
1.
max_depth: This parameter defines the maximum depth of a tree. Increasing it can lead to a more complex model that may overfit the training data.
-
2.
min_child_weight: This parameter specifies the minimum sum of instance weights needed in a child node. Higher values can help prevent overfitting.
-
3.
subsample: This is the subsample ratio of the training instances. Lower values can reduce overfitting by introducing randomness into the training process.
-
4.
colsample_bytree: This parameter controls the subsample ratio of columns when constructing each tree, with lower values also helping to mitigate overfitting.
-
5.
learning_rate (or eta): This parameter determines the step size at each iteration while moving toward a minimum of the loss function. Lower values make the model more robust to overfitting.
These hyperparameters are crucial as they allow for fine-tuning of the model to adapt to specific datasets and tasks. By carefully adjusting these parameters, practitioners can enhance XGBoost’s ability to learn meaningful patterns while avoiding overfitting.
Additionally, XGBoost supports regularization techniques such as L1 (Lasso) and L2 (Ridge) regularization, controlled by the alpha and lambda hyperparameters, respectively. These techniques further assist in managing model complexity and improving generalization.
XGBoost supports parallel processing, which allows it to train models faster than many other implementations of gradient boosting. It also employs a novel tree boosting method that performs second-order gradient optimization (using the Hessian), enabling it to handle sparse data more efficiently. This makes XGBoost a popular choice for large-scale data and competitions, where high performance is crucial. Additionally, it provides features like early stopping, cross-validation, and built-in support for handling missing values, further enhancing its robustness and ease of use. All these features make it a suitable machine learning technique for contamination assessment through leakage current data.
LightGBM (light gradient boosting machine)
LightGBM (Light Gradient Boosting Machine) is another gradient boosting framework, specifically designed for high efficiency and scalability. It utilizes tree-based learning algorithms but is distinguished by its ability to handle very large datasets with speed and precision 61. LightGBM achieves its superior training speed by employing a technique called Gradient-based One-Side Sampling (GOSS), which focuses on the data instances with larger gradients while downsampling those with smaller gradients. This ensures that the model remains accurate while significantly reducing the amount of computation required.
Furthermore, LightGBM uses an exclusive feature bundling (EFB) technique that allows it to handle high-dimensional data more efficiently by bundling mutually exclusive features into a single feature, reducing memory consumption and speeding up training. LightGBM is also designed to be distributed, meaning it can be easily scaled across multiple machines, making it particularly well-suited for massive datasets. It supports various loss functions, boosting types, and offers built-in mechanisms to handle categorical features without the need for one-hot encoding, making it both versatile and powerful. Keeping these features in mind, we have selected this machine learning technique for contamination classification of HVI.
The key hyperparameters for LightGBM include:
-
1.
num_leaves: This parameter defines the maximum number of leaves in one tree. Increasing this value can improve accuracy but may lead to overfitting.
-
2.
max_depth: This parameter specifies the maximum depth of a tree. Limiting the depth can help prevent overfitting.
-
3.
min_data_in_leaf: This parameter sets the minimum number of data points required in a leaf. Higher values can help reduce overfitting.
-
4.
bagging_fraction: This controls the fraction of data used for each iteration. Lower values can introduce randomness and help avoid overfitting.
-
5.
feature_fraction: This parameter determines the fraction of features to be randomly selected for each tree. It helps in reducing overfitting by introducing randomness.
-
6.
learning_rate: This parameter determines the step size at each iteration while moving toward a minimum of the loss function. Smaller values make the model more robust to overfitting.
Deep neural network
DNNs are a sophisticated and widely used class of neural network architectures that consist of multiple layers of interconnected neurons, allowing them to learn complex patterns and representations in data 62. The core of a DNN is its fully connected layers, where every neuron in one layer is connected to every neuron in the subsequent layer. This structure enables the network to process and transform data through a series of linear and non-linear operations, capturing intricate relationships within the data. The network begins with an input layer, where raw data is fed into the model, and progresses through several hidden layers, each of which refines and abstracts the input data into more meaningful representations. The output layer then produces the final predictions or classifications based on these learned representations.
A key strength of DNNs lies in their ability to model non-linear relationships, thanks to the non-linear activation functions applied after each linear transformation within the hidden layers. These networks can have many hidden layers, hence the term “deep,” which allows them to learn very detailed and hierarchical features in the data. DNNs are versatile and have been successfully applied across various fields, including image and speech recognition, natural language processing, and even structured tabular data. Their deep structure enables them to perform exceptionally well on complex tasks, often outperforming traditional machine learning models when large amounts of labeled data are available for training. However, they also require significant computational resources and can be prone to overfitting, necessitating careful regularization and optimization techniques during training. DNNs, due to their versatility and effectiveness, have been selected for classifying HVI on the basis of their contamination.
The key hyperparameters for DNNs include:
-
1.
Number of Hidden Layers: This defines how many hidden layers are included in the network. More layers can capture more complex patterns but may also lead to overfitting.
-
2.
Number of Neurons per Hidden Layer: This specifies how many neurons are present in each hidden layer. A larger number can increase model capacity but may also cause overfitting.
-
3.
Activation Functions: Common choices include ReLU (Rectified Linear Unit) for hidden layers and Sigmoid or Softmax for output layers, depending on the type of prediction task.
-
4.
Dropout Rate: This regularization technique randomly drops a fraction of neurons during training to prevent overfitting. Typical values range from 20% to 50%.
-
5.
Learning Rate: This parameter controls how quickly the model updates its weights during training. A smaller learning rate can lead to more stable convergence.
-
6.
Batch Size: This defines the number of training samples utilized in one iteration. Common values include 32, 64, or 128.
-
7.
Number of Epochs: This is the total number of times the entire training dataset is passed through the network during training.
TabNet
TabNet is a deep learning model specifically designed for tabular data, a type of data that is often structured in rows and columns, such as spreadsheets or databases. Unlike many deep learning models that excel with unstructured data like images or text, TabNet is tailored to the unique challenges of tabular datasets 63. It leverages a novel sequential attention mechanism that allows the model to focus on the most salient features during training, which enhances both accuracy and interpretability.
The attention mechanism in TabNet is inspired by neural attention models but is adapted for tabular data. It selectively attends to different features at each decision step, creating a form of feature selection that is interpretable and effective. This makes TabNet not only powerful in terms of predictive performance but also valuable in scenarios where understanding the model’s decisions is crucial, such as in healthcare or finance. Additionally, TabNet’s architecture is designed to be robust against overfitting and noise, making it suitable for both large-scale datasets and smaller, more sensitive datasets.
The key hyperparameters for TabNet include:
-
1.
Feature Dimensions / Output Dimensions: Typically set between 32 to 512; often recommended to be equal.
-
2.
Number of Steps: Ranges from 2 (simple model) to 9 (very complex model), determining how many decision steps are used.
-
3.
Relaxation Factor: Varies from 1 (enforces strict feature usage) to 3 (relaxes restrictions), controlling how features are utilized across steps.
-
4.
Sparsity Coefficient: Ranges from 0 (no regularization) to 0.1 (strong regularization), influencing feature selection sparsity.
These models were chosen due to their proven effectiveness and efficiency in handling complex classification tasks. The decision tree-based models (XGBoost and LightGBM) are known for their speed and performance, while the neural network-based models (DNN and TabNET) offer robustness and flexibility in capturing intricate patterns in the data. The combination of these models ensures a comprehensive evaluation of the dataset, leveraging the strengths of both decision trees and neural networks. Fig. 3 shows the four machine learning techniques which were compared in the proposed research work. To ensure a fair comparison between these models, the hyper parameters were optimized using Bayesian Optimization.
Bayesian optimization
Bayesian optimization is a powerful technique for optimizing hyperparameters in machine learning models, particularly when dealing with complex and expensive-to-evaluate functions. This method employs a probabilistic model, typically a Gaussian process, to approximate the objective function and guide the search for optimal parameters. By strategically selecting points in the parameter space to evaluate, Bayesian optimization minimizes the number of evaluations required to identify the best-performing model configuration. In this study, we employed Bayesian optimization specifically to fine-tune the hyperparameters of four distinct machine learning models: XGBoost, LightGBM, Deep Neural Network, and TabNet. This approach ensures that each model is optimized under comparable conditions, facilitating a fair assessment of their performance. Each model was trained for up to 1000 epochs with an early stopping criterion based on validation loss improvement. This rigorous optimization process systematically explores the hyperparameter space, enhancing the reliability of performance metrics and allowing for an equitable comparison among the models64,65.

Selected machine learning models for classification.
The Table. 2 presents a comparison of different classification models based on the number of parameters and the model size. DenseNet has the highest number of parameters (268.8k) and occupies the largest model size (1.03 MB), reflecting its complex architecture, which includes numerous layers and parameters designed for deep learning tasks. On the other hand, TabNet, XGBoost, and LightGBM are more lightweight models, with fewer parameters and smaller sizes, making them more efficient in terms of storage. XGBoost and LightGBM, with parameter counts of 10.01k and 8.04k, respectively, are particularly compact, with sizes of only 0.0381 MB and 0.0305 MB. Decision tree-based models like XGBoost and LightGBM typically train faster because they use simple decision rules and work by recursively splitting the data based on feature values. These models also benefit from faster inference times due to their shallow tree structures, which can be constructed quickly compared to the deep layers in neural networks like DenseNet. The reduced complexity of tree-based models allows them to process and learn from data more efficiently, which is why they often outperform more complex models in terms of training speed.
Experimental methodology and data collection
A series of experiments were designed to generate realistic leakage current data under controlled laboratory conditions. Insulator samples with varying degrees of contamination were prepared to simulate different levels of environmental pollution. These samples were subjected to high voltage stress while being exposed to clean fog to emulate high humidity conditions. During these experiments, data on leakage current, temperature, and humidity were recorded using specialized sensitive sensors able to operate under high voltage conditions. An advanced data acquisition (DAQ) system with high sampling rates and dynamic ranges was also assembled in-house to carryout experimentation under high EMI conditions.
One significant challenge encountered during the data collection process was the presence of electromagnetic interference (EMI). A 60 Hz component originating from electrical sources in the lab can be clearly observed to be superimposed on the underlying temperature and humidity signals. This noise had to be carefully filtered out to ensure the integrity of the data. Following the noise removal, portions of the leakage current data were selected to create uniform size datasets.
Artificially polluted samples of ceramic insulators were prepared in the laboratory. These samples were then subjected to high voltages in a controlled environment, with clean fog introduced to simulate natural moisture conditions. The test setup is shown in Fig. 4.
Polluted insulator samples
Ceramic insulators were artificially polluted in a laboratory setting using a contaminant solution composed of varying proportions of salt and kaolin, as outlined in Table 3. Three distinct solutions were prepared to represent different pollution classes-high, medium, and low contamination levels-characterized by their Equivalent Salt Deposit Density (ESDD) and Non-Soluble Deposit Density (NSDD), while maintaining conductivity within the parameters discussed in66.
Additionally, three insulator samples with varying number of discs, were contaminated using each pollution class, as illustrated in Fig. 4 . Class 0 represents High Contamination level, Class 1 Medium Contamination level, and Class 2 low Contamination levelClass 0 represents a High Contamination level typically observed in coastal or desert regions with low rainfall or areas with significant industrial activity. Class 1 signifies Medium Contamination, commonly found in locations distant from direct pollution sources. Finally, Class 2 is considered a Low Contamination level, characteristic of regions with very clean air and ample rainfall. This methodology ensures that the results are relevant for assessing performance under various environmental conditions.

Samples of porcelain insulators with creepage distance 30 mm/kV (a) (d) 1 disc, (b) (e) 2 disc, (c) (e) 3 disc.
Experimental setup
Polluted insulators are suspended inside a fog chamber, as depicted in Fig. 5 and subjected to their nominal line-to-ground voltage (\(U_N\)), as shown in Fig. 6. (\(U_N\)) is 30 kV, 60 kV and 90 kV for a single disc, two disc and three disc insulators respectively Initially, both the insulators and the fog chamber are dry. Five minutes after the application of the nominal voltage , the steam generators are activated. The steam humidifies the insulator surface, causing the salts to dissolve and form electrolytes. Consequently, leakage current begins to flow on the insulator surface. In all the experiments the relative humidity varies from 55% to 100% to emulate different service environments of HVIs.
A total of nine experiments were conducted using three different string configurations: one, two, and three discs; each with three different contamination levels representing pollution classes. Each experiment was allowed to continue for up to 30 minutes, unless a flashover occurred earlier.
The specification of components used in experimental setup are shown in Table. 4

Experimental setup for testing contaminated insulators in a fog chamber. The system records leakage current, temperature, and humidity data using a data acquisition system.

Experimental scheme showing application of HV and Clean Fog.
Results
The experimental results for a single disc polluted with Solution A are illustrated in Fig. 7. Initially, the relative humidity in the fog chamber is relatively low, as shown in Fig. 7 (c), which results in leakage currents measuring only a few milliamperes. As the relative humidity increases and condensation begins to form on the insulator surface, dry band arcing occurs, manifesting as pulses in the leakage current. Notably, from 620 seconds onward, these leakage current pulses increase significantly in both frequency and magnitude, as depicted in Fig. 7(a). Additionally, Fig. 7(b) illustrates the trend in environmental temperature during this period.
In Fig. 8, a section of the results in Fig. 7 have been zoomed. Closer examination in Figs. 8(b) and 8(c) reveals a prominent 60 Hz signal superimposed on the underlying temperature and humidity signals. In the temperature graph, a clear spike coincides with the leakage current pulse shown in Figs. 8(a), suggesting that electromagnetic interference (EMI) is influencing these measurements. Similarly, the humidity graph in Fig. 8(c) shows a 60 Hz wave overlaying the baseline humidity signal, indicating that EMI is affecting sensor readings.

Experimental Results for 1 disc porcelain insulators contaminated with Sol. A (a) Leakage Current, (b) Temperature, (c) Relative Humidity.
Preprocessing of results
The raw results collected from DAQ and presented in Fig. 7 cannot be used directly for training of machine learning models. Therefore the data must be cleaned and converted into appropriate datasets which are suitable to be used for training and validation of machine learning models.
Data cleaning
As observed in the previous sections, the leakage current, temperature and relative humidity signals contain superimposed noise that needs to be removed to ensure data integrity. To address this issue, a low pass filter has been used to remove high frequency noise from the leakage current signal as shown in Fig. 8 (a). Conversely, the temperature and humidity signal has a high amplitude of low frequency noise superimposed with a low amplitude of high frequency component. The moving average filter was applied to these signals. This filtering technique effectively reduces interference and recovers the true temperature and relative humidity signals, as demonstrated in Fig. 8 (b) and (c).

Comparison of Raw and Pre-processed data after filtration (a) Leakage Current, (b) Temperature, (c) Relative Humidity.
Dataset preparation for machine learning models
All experiments were planned to continue for 30 minutes, however it was observed that flashover occurred quite early in most cases. This can be attributed to varying contamination and string lengths. The length of each experiment is summarized in Table. 5. It can be seen that the quickest flashover was in the case of Class 1-2D i.e., two-disc string polluted with solution belonging to Class 1. The reason behind this phenomena might be due to existing entrapped steam in the Steam Chamber because of which the insulator was not sufficiently dry at the start of the experiment.
To train machine learning models such as neural networks, a large amount of labeled training data is required67,68. The leakage current, humidity and temperature data will serve as input, whereas the pollution class will be the output. The dimensions of each training dataset must be similar for effective training of the model. Moreover, to avoid bias, similar number of training datasets will be collected for each experiment. A period of 300 seconds was selected from each experiment as shown in Table. 5. The datasets were prepared by selecting data from the beginning of experiment, having low relative humidity, and data from the end of the experiment, where relative humidity is high and the leakage current also shows an increasing trend. Each dataset represents a pollution class and string length, and it is composed of 300 seconds of data with sampling rate of 25000 samples per second (300 x 25000 = 7.5 Million measured values ). Each dataset is further split into 300 sub-datasets which will be further used for feature extraction and machine learning training. A total of nine experiments were performed considering three pollution classes and three string lengths as shown in Table 5. Therefore, a total of 2700 training/validation/testing data examples have been prepared which is a sufficient quantity for effective training and validation of neural networks.
Feature extraction and selection
Feature extraction transforms raw leakage current data into informative attributes that capture the underlying patterns and relationships. This section focuses on the extraction and evaluation of features from preprocessed leakage current signals to enhance the training and performance of deep learning models for condition monitoring of high voltage insulators.
We employed a comprehensive approach to feature extraction, including time-domain, frequency-domain, and time-frequency (wavelet) domain features. Time-domain features capture statistical properties of the signal, frequency-domain features provide insights into the spectral characteristics, and wavelet domain features reveal time-frequency localized information. To determine the most significant features, we utilize Random Forest and permutation importance techniques69,70, which highlight features such as temperature, relative humidity, peak-to-peak values, wavelet energy, and spectral centroid71,72. By analyzing the correlation between these features and their ability to differentiate between various contamination levels, we aim to identify the most relevant attributes for training deep learning models.
Feature extraction
To capture the complex behavior of leakage currents, we extract features from three different domains: time, frequency, and time-frequency. Time-domain features provide statistical information about the leakage current signal by capturing the overall behavior and variations in the signal amplitude over time, reflecting the insulator’s condition influenced by contamination and environmental changes73. Frequency-domain features are derived from the spectral analysis of the leakage current signal and are crucial for understanding the distribution of the signal’s power across different frequency components. They help identify periodicities, harmonics, and noise characteristics that may indicate the presence and severity of contamination on the insulator surface74.
Time-frequency domain features capture localized time-frequency information. These features include wavelet mean, wavelet standard deviation, wavelet energy, and peak wavelet values. Time-frequency features are important because they provide a more detailed analysis of transient events and non-stationary behavior in the leakage current signal, which are often associated with dynamic changes in contamination and environmental conditions. Temperature and relative humidity significantly influence leakage current behavior by affecting insulator surface conductivity75. Using average values for these environmental factors simplifies the model without losing important information, as these variables typically change gradually over time. Averages effectively capture the overall trend and typical conditions during the data recording period, which is crucial for long-term monitoring. The list of extracted features from leakage current are present in Table. 6 and they enhances the deep learning model’s ability to accurately predict the condition of high voltage insulators.76
We employed permutation importance and random forest to rank the features as per there importances77. The comparison of feature ranking is shown in Fig.9. The detailed exploration of features is discussed in78.

Feature ranking based on (a) Random Forest, (b) Permutation based.
The comparison of top 10 features identified by both methods are shown in Table. 7. The ranking reveals a high degree of agreement between the two methods, with 8 out of 10 features appearing in both lists. This consistency underscores their significance in accurately predicting the condition of high voltage insulators. Notably, temp and r_humid rank highest in both methods, highlighting their critical role.
Feature analysis play a critical role of in the development of efficient and generalized neural networks for condition monitoring of HVI79. By identifying and evaluating key features through methods such as Random Forest and Permutation Importance, we effectively reduced the dimensionality of the dataset. This not only streamlines the model training process but also enhances the model’s ability to generalize across various contamination and environmental conditions. The scatter matrix plot further validated the relevance of the selected features, illustrating their distinct relationships and class separation capabilities. Overall, our approach demonstrates that careful feature analysis and selection are pivotal in creating robust machine learning models that are both efficient and capable of delivering reliable predictive performance in real-world applications.
Results and discussion
A dataset comprising a total of 2700 examples, with 900 examples from each pollution class, was systematically divided into training (60 %), validation (20 %), and test (20 %) subsets. Each subset maintained an equal representation from the three pollution classes to ensure balanced and unbiased model evaluation. Given the efficiency of decision trees and neural networks in handling classification problems as highlighted in Section 2, two models from each of these categories were selected for this study, as illustrated in Fig. 3.
The parameters of each of these models were optimized using Bayesian optimization, a method well-suited for efficiently navigating complex parameter spaces. Bayesian optimization was conducted to identify the optimal set of parameters for each model80. For each set of parameters, the machine learning algorithms were trained for up to 1000 epochs, with an early stopping criterion: training was halted if the validation loss did not improve for 50 consecutive epochs. The best-performing models, determined by this rigorous optimization process, are presented as outputs. Their respective training and validation loss curves are depicted in Fig. 10.

Training process of four classification models (a) XGBoost, (b) LightGBM, (c) DNN, (d) TabNet.
All models demonstrated convergence and delivered robust performance across both the validation and testing datasets. The detailed performance metrics for validation and testing of these models are presented in Tables 8 and 9, respectively.
Table 8 summarizes the performance metrics for the validation dataset, highlighting the accuracies, precision, recall, and F1-scores for each model and pollution class. The decision tree-based models, XGBoost and LightGBM, achieved validation accuracies of 98.703% and 98.518%, respectively. In comparison, the neural network-based models, DenseNet and TabNet, both attained superior validation accuracies of 99.629%. Notably, precision and recall metrics for Class 0 and Class 1 (representing high and moderate contamination levels respectively) indicated slight misclassifications, whereas Class 2 (representing low contamination level) exhibited perfect precision and recall across all models, underscoring their efficacy in identifying this class.
Table 9 provides an overview of the performance metrics for the testing dataset. Here, LightGBM led the decision tree-based models with a testing accuracy of 99.259%, while XGBoost achieved 98.888%. Among the neural network-based models, DenseNet recorded a testing accuracy of 98.703%, and TabNet matched XGBoost with 98.888%. Similar to the validation results, Class 2 maintained perfect precision, recall, and F1-scores for all models during testing. The metrics for Class 0 and Class 1 demonstrated high performance, though minor deviations in precision and recall were observed, reflecting the complexity in distinguishing between these pollution levels.
These results underscore the effectiveness of the employed machine learning models in classifying high voltage insulator pollution levels, with all models achieving high accuracy and demonstrating strong generalization capabilities across both validation and testing phases. As the temperature and humidity data along with the leakage current are used to train the Machine learning models, these models can cater for different environmental conditions and effectively identify the contamination levels of insulators. This information is highly valuable for the maintenance department which can schedule the insulator cleaning accordingly.
The confusion matrices for the validation and test datasets are depicted in Fig. 11 and Fig. 12, respectively. These figures illustrate the performance of the machine learning models in terms of correctly and incorrectly classified instances across the three pollution classes (Class 0, Class 1, and Class 2).
In Fig. 11, which shows the confusion matrices for the validation dataset, all models exhibit high classification accuracy, with the majority of instances correctly identified. The XGBoost model (Fig. 11(a)) shows slight misclassifications between Class 0 and Class 1, while LightGBM (Fig. 11(b)) demonstrates similar misclassification patterns. The DenseNet model (Fig. 11(c)) exhibits minimal misclassifications, indicating its robustness in handling the validation data. The TabNet model (Fig. 11(d)) shows near-perfect classification performance, with only a few instances of misclassification between Class 0 and Class 1.

Confusion Matrix on validation data sets for (a) XGBoost, (b) LightGBM, (c) DNN, (d) TabNet.
Fig. 12 presents the confusion matrices for the test dataset, where the models maintain their high performance. The XGBoost model (Fig. 12(a)) and LightGBM (Fig. 12(b)) continue to show minor misclassifications between Class 0 and Class 1. DenseNet (Fig. 12(c)) and TabNet (Fig. 12(d)) again display strong performance with minimal misclassification errors. The consistency in performance between the validation and test datasets underscores the reliability and generalization capability of the trained models.

Confusion Matrix on test data sets for (a) XGBoost, (b) LightGBM, (c) DNN, (d) TabNet.
These confusion matrices highlight the effectiveness of the employed machine learning models in accurately classifying high voltage insulator pollution levels. The minor misclassifications observed are primarily between Class 0 and Class 1, reflecting the complexity in distinguishing between these pollution levels. Overall, the models demonstrate excellent performance, with DenseNet and TabNet showing particularly strong results.
During the validation and testing process, few examples were misclassified by each model. Fig. 13 (a) illustrates the number of misclassified examples for each model during both validation and testing phases. The bar chart reveals that LightGBM had the highest number of misclassified examples during validation, while DNN and TabNet had the fewest. On the other hand DNN shows highest number of misclassified examples during testing, whereas Light GBM showed the least misclassified examples.
Fig. 13 (b) provides a pie chart indicating the distribution of misclassified examples across different classes. It is evident that the majority of misclassified examples belong to Class 0, accounting for 57.1% of the total misclassifications. Class 1 follows with 42.9%, while Class 2 remarkably had no misclassified examples. This distribution underscores the challenge in distinguishing between Class 0 and Class 1, whereas Class 2 was consistently correctly classified by all models.

Misclassified examples during validation and testing (a) For different Models, (b) By classes.
The charts in Fig. 14 illustrate the indices and counts of misclassified examples for each machine learning model during both validation and testing phases. Fig. 14 (a) shows the misclassifications during the validation phase, while Fig. 14 (b) depicts the misclassifications during the testing phase.
In Fig. 14 (a), the bar chart presents the indices of misclassified examples and the frequency of misclassifications by each model (XGBoost, LightGBM, DenseNet, and TabNet). It is evident that certain examples were consistently misclassified across multiple models, indicating potential areas where the models struggled to distinguish correctly. For instance, examples at indices 117 and 124 were misclassified by all four models, suggesting a particular challenge in accurately predicting these instances.
Fig. 14 (b) provides a similar analysis for the testing phase, revealing that specific indices, such as 115 and 537, were frequently misclassified by several models. This consistency in misclassification patterns between validation and testing phases indicates that these examples possess inherent complexities that the models find difficult to classify correctly.
The presence of common misclassified indices across different models and phases underscores the need for further investigation into these specific instances. Addressing these challenging examples may involve additional feature engineering, data augmentation, or model enhancements to improve overall classification performance.

Frequency of misclassification of various examples (a) During Validation, (b) During Testing.
Conclusion
A meticulous dataset of leakage current for high voltage porcelain insulators with varying pollution levels was developed which reflected real world scenarios. The dataset generated was preprocessed and critical features were extracted from time, frequency, and time-frequency domains. Four distinct machine learning models, encompassing decision trees and neural networks, were trained and evaluated on this dataset. The models demonstrated excellent performance, with accuracies consistently exceeding 98 %. Notably, the decision tree-based models exhibited significantly faster training and optimization times compared to their neural network counterparts. Despite the high overall accuracy, few misclassifications were primarily observed between Class 0 (High) and Class 1 (Moderate) pollution levels, highlighting potential areas for further investigation and enhancement. As the temperature and humidity data along with the leakage current were used to train the Machine learning models, these models can cater for different environmental conditions and effectively identify the contamination levels of insulators. This study successfully presented the experimental validation of machine learning in classification of contaminated high voltage insulators which can significantly improve the maintenance of high voltage assets through out the power system.
Building on the success of contamination classification, future work can focus on leveraging machine learning models to predict flashover events based on leakage current and environmental data. By analyzing patterns that precede flashovers, such as abrupt changes in current waveform characteristics or environmental conditions, these models can provide early warnings and enable proactive interventions. This has the potential to significantly enhance grid reliability by preventing outages, reducing equipment damage, and optimizing maintenance schedules. Integrating flashover prediction with real-time monitoring systems would represent a transformative step toward fully autonomous, intelligent high-voltage asset management.
Data availability
Data used in this research can be made available upon request. The request can be made to corresponding author at umeramir.khan@kfupm.edu.sa.
References
Sopelsa Neto, N. F., Stefenon, S. F., Meyer, L. H., Ovejero, R. G. & Leithardt, V. R. Q. Fault prediction based on leakage current in contaminated insulators using enhanced time series forecasting models. Sensors 22, 6121 (2022).
Bagaskara, A. et al. Environmental effects on parameters of leakage current equivalent circuits of outdoor insulators. Emerging Science Journal 8, 310–325 (2024).
Maraaba, L. et al. Contamination level monitoring techniques for high-voltage insulators: a review. Energies 15, 7656 (2022).
Ridhwan, M., Lumba, L. S. & Suwarno, S. Effects of uv radiation and contaminant on the properties of polymeric insulator. In 2021 3rd International Conference on High Voltage Engineering and Power Systems (ICHVEPS), 085–090 (IEEE, 2021).
Manjang, S., Musaruddin, M., & Kitta, I. et al. Study of leakage current characteristics of high voltage insulators ageing after dry season in polluted environmental conditions. In 2021 3rd International Conference on High Voltage Engineering and Power Systems (ICHVEPS), 074–078 (IEEE, 2021).
Liu, X., Liu, Y., Yang, L., An, Y. & Lv, S. Pollution level detection of silicone rubber insulators based on deep extreme learning machine. In Ninth International Symposium on Sensors, Mechatronics, and Automation System (ISSMAS 2023), vol. 12981, 513–517 (SPIE, 2024).
Abilgazym, A., Zollanvari, A. & Bagheri, M. High-voltage insulator surface pollution classification using insulator type-specific cnns. In 2023 IEEE International Conference on Environment and Electrical Engineering and 2023 IEEE Industrial and Commercial Power Systems Europe, 1–6 (IEEE, 2023).
Stefenon, S. F. et al. Hybrid wavelet stacking ensemble model for insulators contamination forecasting. IEEE Access 9, 66387–66397 (2021).
Pei, C., Shu, N., Li, L., Wang, D. & Li, Z. An acoustic emission method for on-line monitoring the contamination-causing flashover of insulator. In 2008 International Conference on Electrical Machines and Systems, 817–822 (IEEE, 2008).
Al-geelani, N. A., Piah, M. A. M. & Abdul-Malek, Z. Identification of acoustic signals of corona discharges under different contamination levels using wavelet transform. Electrical Engineering 100, 1059–1067 (2018).
Pei, C., Shu, N., Li, L., Li, Z. & Peng, H. On-line monitoring of insulator contamination causing flashover based on acoustic emission. In 2008 Third International Conference on Electric Utility Deregulation and Restructuring and Power Technologies, 1667–1671 (IEEE, 2008).
Moura, E. P., Albert, B. B. & Fontgalland, G. Statistical classification of contamination in glass insulators by reading its spectrum. International Journal of Applied Electromagnetics and Mechanics 45, 589–595 (2014).
Azordegan, E. & Kordi, B. Remote assessment of high voltage insulators using wideband electromagnetic radiation signature. IEEE Transactions on Dielectrics and Electrical Insulation 23, 1467–1474 (2016).
Ebadollahi, S., Gill, B., Khosravani, H. & Pour, F. M. Assessing the contamination intensity of porcelain insulators using deep learning networks by uav. In 2024 IEEE 14th Annual Computing and Communication Workshop and Conference (CCWC), 0111–0118 (IEEE, 2024).
Roy, S. S., Paramane, A., Singh, J., Chatterjee, S. & Das, A. K. Accurate sensing of insulator surface contamination using customized convolutional neural network. IEEE Sensors Letters 7, 1–4 (2022).
Zha, H. et al. The characteristic analysis of esdd and nsdd detection of composite insulators based on hyperspectral technology. IEEE Transactions on Instrumentation and Measurement 72, 1–8 (2023).
Slama, M. E. A., Krzma, A., Albano, M. & Haddad, A. M. Experimental study and modeling of the effect of esdd/nsdd on ac flashover of sir outdoor insulators. Energies 15, 3782 (2022).
Xia, C. et al. Acquisition and analysis of hyperspectral data for surface contamination level of insulating materials. Measurement 173, 108560 (2021).
Jin, L. & Zhang, D. Contamination grades recognition of ceramic insulators using fused features of infrared and ultraviolet images. Energies 8, 837–858 (2015).
Yan, S. J., Duan, W. S., Shan, H. T. & Tong, M. S. Insulator contamination measurement based on infrared thermal and visible image information fusion. In 2019 PhotonIcs & Electromagnetics Research Symposium-Spring (PIERS-Spring), 1006–1011 (IEEE, 2019).
Orellana, L., Ardila-Rey, J., Avaria, G. & Davis, S. Danger assessment of the partial discharges temporal evolution on a polluted insulator using uhf measurement and deep learning. Engineering Applications of Artificial Intelligence 124, 106573 (2023).
Petri, Ld. P. S. et al. A portable system for the evaluation of the degree of pollution of transmission line insulators. Energies 13, 6625 (2020).
de Santos, H. & Sanz-Bobi, M. Á. A machine learning approach for condition monitoring of high voltage insulators in polluted environments. Electric Power Systems Research 220, 109340 (2023).
Nath, S., Chakraorty, B., Deb, S., Das, R. & Maur, S. Effect of humidity on overhead line insulator based on boundary frequency obtained from leakage current analysis. In 2023 IEEE 3rd Applied Signal Processing Conference (ASPCON), 321–324 (IEEE, 2023).
Zhang, J. et al. An insulator pollution degree detection method based on crisscross optimization algorithm with blending ensemble learning. In 2022 4th International Conference on Electrical Engineering and Control Technologies (CEECT), 83–87 (IEEE, 2022).
Ghiasi, Z., Faghihi, F. & Shayegani-Akmal, A. A. Artificial neural network approach for prediction of leakage current of polymeric insulator under non-uniform fan-shaped contamination. Electric Power Systems Research 209, 107920 (2022).
Dey, U., Chandra, M. & Das, S. Insulator contamination diagnosis using unsupervised machine learning. In 2022 3rd International Conference for Emerging Technology (INCET), 1–6 (IEEE, 2022).
Tao, X. et al. Detection of power line insulator defects using aerial images analyzed with convolutional neural networks. IEEE transactions on systems, man, and cybernetics: systems 50, 1486–1498 (2018).
Stefenon, S. F. et al. Classification of insulators using neural network based on computer vision. IET Generation, Transmission & Distribution 16, 1096–1107 (2022).
Corso, M. P. et al. Classification of contaminated insulators using k-nearest neighbors based on computer vision. Computers 10, 112 (2021).
Chen, T., Li, F., Wei, Z. & Li, Z. Contamination identification and classification on composite insulator by visible light images. In 2020 IEEE international conference on high voltage engineering and application (ICHVE), 1–4 (IEEE, 2020).
Maraaba, L., Alhamouz, Z. & Alduwaish, H. A neural network-based estimation of the level of contamination on high-voltage porcelain and glass insulators. Electrical Engineering 100, 1545–1554 (2018).
Pernebayeva, D., Bagheri, M. & James, A. High voltage insulator surface evaluation using image processing. In 2017 International Symposium on Electrical Insulating Materials (ISEIM), vol. 2, 520–523 (IEEE, 2017).
Tian, Z., Jin, L., Peng, C., Duan, W. & Gao, K. Discrimination of transmission line insulator contamination grades using visible light images. In 2016 IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), 1–5 (IEEE, 2016).
Al-Hamouz, Z. M. & Maraaba, L. S. Contamination level estimation method for high voltage insulators (2016). US Patent 9,384,560.
Maraaba, L., Al-Hamouz, Z. & Al-Duwaish, H. Prediction of the levels of contamination of hv insulators using image linear algebraic features and neural networks. Arabian Journal for Science and Engineering 40, 2609–2617 (2015).
Tian, Z. et al. Discrimination of insulator contamination grades using information fusion of multi-light images. In 2015 IEEE 11th International Conference on the Properties and Applications of Dielectric Materials (ICPADM), 967–970 (IEEE, 2015).
Maraaba, L., Al-Hamouz, Z. & Al-Duwaish, H. Estimation of high voltage insulator contamination using a combined image processing and artificial neural networks. In 2014 IEEE 8th International Power Engineering and Optimization Conference (PEOCO2014), 214–219 (IEEE, 2014).
Al-Duwaish, H. N., Al-Hamouz, Z. M., Mousa, W. A., Al-Absi, M. A. & Zummo, S. A. Contamination monitoring of high voltage insulators (2013). US Patent 8,400,504.
He, H. et al. A contactless insulator contamination levels detecting method based on infrared images features and rbfnn. IEEE Transactions on Industry Applications 55, 2455–2463 (2018).
Liu, Y. et al. Insulator contamination diagnosis method based on deep learning convolutional neural network. In 2021 3rd Asia Energy and Electrical Engineering Symposium (AEEES), 184–188 (IEEE, 2021).
Zhang, D. & Chen, S. Intelligent recognition of insulator contamination grade based on the deep learning of ultraviolet discharge image information. Energies 13, 5221 (2020).
Cao, B. et al. Assessment of insulator pollution degree based on contamination moisture with temperature change. IEEE Sensors Journal 22, 21172–21178 (2022).
Wang, Y.-C., Lin, Y.-T., Chang, H.-C. & Kuo, C.-C. Contamination assessment of insulators using microsystem technology with fuzzy-based approach. Microsystem Technologies 27, 1759–1772 (2021).
Salem, A. A. et al. The leakage current components as a diagnostic tool to estimate contamination level on high voltage insulators. IEEE Access 8, 92514–92528 (2020).
Ma, X. et al. Study on characteristic parameters and influencing factors of leakage current of polluted porcelain insulators. In 2020 IEEE International Conference on High Voltage Engineering and Application (ICHVE), 1–4 (IEEE, 2020).
Deb, S. et al. Estimation of contamination level of overhead insulators based on surface leakage current employing detrended fluctuation analysis. IEEE Transactions on Industrial Electronics 67, 5729–5736 (2019).
Sit, K., Chakraborty, A., Dalai, S., Chatterjee, B. & Pradhan, A. K. Mathematical morphology aided random forest classifier based high voltage porcelain insulator contamination level classification. In 2020 IEEE Region 10 Symposium (TENSYMP), 98–101 (IEEE, 2020).
Abouzeid, A. K., El-Hag, A. & Assaleh, K. Equivalent salt deposit density prediction of silicone rubber insulators under simulated pollution conditions. Electric Power Components and Systems 46, 1123–1133 (2018).
Chakraborty, S., Podder, S., Deb, S. & Nath, S. Qualitative analysis of contamination severity between nacl and cuso 4 for outdoor insulator. In 2018 IEEE Applied Signal Processing Conference (ASPCON), 342–345 (IEEE, 2018).
Deb, S., Choudhury, N. R., Ghosh, R., Chatterjee, B. & Dalai, S. Short time modified hilbert transform-aided sparse representation for sensing of overhead line insulator contamination. IEEE Sensors Journal 18, 8125–8132 (2018).
Jin, L., Xu, Z. & Zhang, S. A pre-warning method of contamination flashover based on the leakage current of insulators in dry condition. In 2017 International Symposium on Electrical Insulating Materials (ISEIM), vol. 2, 757–760 (IEEE, 2017).
Banik, A., Dalai, S. & Chatterjee, B. Autocorrelation aided rough set based contamination level prediction of high voltage insulator at different environmental condition. IEEE Transactions on Dielectrics and Electrical Insulation 23, 2883–2891 (2016).
Zhao, S., Jiang, X. & Xie, Y. Evaluating the contamination level of polluted insulators based on the characteristics of leakage current. International Transactions on Electrical Energy Systems 25, 2109–2123 (2015).
Patil, R. S., Patil, N. N. & Patil, P. S. An evaluation of techniques for monitoring the high voltage insulator pollution. International Journal of Applied Electromagnetics and Mechanics .
Amini, M. A. & Sedighi, A. R. A new procedure for determination of insulators contamination in electrical distribution networks. International Journal of Electrical Power & Energy Systems 61, 380–385 (2014).
Li, J., Sima, W., Sun, C. & Sebo, S. A. Use of leakage currents of insulators to determine the stage characteristics of the flashover process and contamination level prediction. IEEE Transactions on Dielectrics and Electrical Insulation 17, 490–501 (2010).
Yandong, H., Zhiguo, C. & Chenglin, W. Assessment of surface contamination of high voltage insulator based on evidence theory. In 2009 International Forum on Information Technology and Applications, vol. 3, 185–188 (IEEE, 2009).
Jiao, S., Liu, D., Xie, G. & Deng, Y. Assessment of contamination condition of insulator based on pso-svm. In 2009 4th IEEE Conference on Industrial Electronics and Applications, 358–362 (IEEE, 2009).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 785–794 (2016).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems 30 (2017).
Tang, J., Deng, C. & Huang, G.-B. Extreme learning machine for multilayer perceptron. IEEE transactions on neural networks and learning systems 27, 809–821 (2015).
Arik, S. Ö. & Pfister, T. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI conference on artificial intelligence 35, 6679–6687 (2021).
Onorato, G. Bayesian optimization for hyperparameters tuning in neural networks. arXiv preprint arXiv:2410.21886 (2024).
Franceschi, L. et al. Hyperparameter optimization in machine learning. arXiv preprint arXiv:2410.22854 (2024).
Commission, I. E. et al. Artificial pollution tests on high voltage insulators to be used on ac systems,(2nd edn). IEC Publication 507 (2014).
Data labeling. 233–268, https://doi.org/10.1007/978-1-4842-8170-3_7 (Apress eBooks, 2022).
Shanu, A. Classification methods for labelled data in machine learning. 99–107, https://doi.org/10.1007/978-981-19-1618-2_10 (Lecture notes in mechanical engineering, 2022).
Ramosaj, B. & Pauly, M. Consistent and unbiased variable selection under indepedent features using random forest permutation importance. Bernoulli 29, https://doi.org/10.3150/22-bej1534 (2023).
Gómez-Ramírez, J., Avila-Villanueva, M. & Fernández-Blázquez, M. Á. Selecting the most important self-assessed features for predicting conversion to mild cognitive impairment with random forest and permutation-based methods. Scientific reports 10, 20630 (2020).
Rajbahadur, G. K., Wang, S., Oliva, G. A., Kamei, Y. & Hassan, A. E. The impact of feature importance methods on the interpretation of defect classifiers. IEEE Transactions on Software Engineering 48, 2245–2261. https://doi.org/10.1109/TSE.2021.3056941 (2022).
Horel, E. Towards Explainable AI: Feature Significance and Importance for Machine Learning Models (Stanford University, 2020).
Chen, J. et al. Leakage current data cleaning method based on multidimensional harmonic feature fusion. In Ninth International Symposium on Sensors, Mechatronics, and Automation System (ISSMAS 2023), vol. 12981, 865–876 (SPIE, 2024).
Das, R. et al. Time-frequency representation aided deep transfer learning approach for localization and identification of single and multiple partial discharge events. In 2022 IEEE 6th International Conference on Condition Assessment Techniques in Electrical Systems (CATCON), 161–165 (IEEE, 2022).
Mohammadnabi, S. & Rahmani, K. Influence of humidity and contamination on the leakage current of 230-kv composite insulator. Electric Power Systems Research 194, 107083 (2021).
Vargic, R. On selected properties of time-frequency analysis. In 2023 International Symposium ELMAR, 201–206 (IEEE, 2023).
Yuan, X., Liu, S., Feng, W. & Dauphin, G. Feature importance ranking of random forest-based end-to-end learning algorithm. Remote Sensing 15, 5203 (2023).
Khan, U. A., Asif, M., Jung, J., Alhems, L. & Lee, B.-W. Feature extraction techniques from contaminated-insulator leakage current data for deep learning applications in condition monitoring of high voltage insulators. In 2024 10th International Conference on Condition Monitoring and Diagnosis (CMD), 608–611 (IEEE, 2024).
Musolf, A. M., Holzinger, E. R., Malley, J. D. & Bailey-Wilson, J. E. What makes a good prediction? feature importance and beginning to open the black box of machine learning in genetics. Human Genetics 141, 1515–1528 (2022).
Mitra, P. & Biessmann, F. Automated computational energy minimization of ml algorithms using constrained bayesian optimization. arXiv preprint arXiv:2407.05788 (2024).
Acknowledgements
The author would like to acknowledge the support provided by the Deanship of Research Oversight and Coordination (DROC) at King Fahd University of Petroleum and Minerals (KFUPM) for funding this work through project No. EC231015.
Author information
Authors and Affiliations
Contributions
U.A.K. Supervision, Conceptualization, Writing Original Draft; M.A. Methodology, Investigation, Software; M.H.Z. Validation, Visualization, Data Curation; and L.A. Funding Acquisition, and Resources. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Khan, U.A., Asif, M., Zafar, M.H. et al. Experimental validation of machine learning for contamination classification of polluted high voltage insulators using leakage current. Sci Rep 15, 13246 (2025). https://doi.org/10.1038/s41598-025-97646-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-97646-4
