
Abstract
In the era of rapid societal modernization, the issue of crime stands as an intrinsic facet, demanding our attention and consideration. As our communities evolve and adopt technological advancements, the dynamic landscape of criminal activities becomes an essential aspect that requires careful examination and proactive approaches for public safety application. In this paper, we proposed a collaborative approach to detect crime patterns and criminal emotions with the aim of enhancing judiciary decision-making. For the same, we utilized two standard datasets - a crime dataset comprised of different features of crime. Further, the emotion dataset has 135 classes of emotion that help the AI model to efficiently find criminal emotions. We adopted a convolutional neural network (CNN) to get first trained on crime datasets to bifurcate crime and non-crime images. Once the crime is detected, criminal faces are extracted using the region of interest and stored in a directory. Different CNN architectures, such as LeNet-5, VGGNet, RestNet-50, and basic CNN, are used to detect different emotions of the face. The trained CNN models are used to detect criminal emotion and enhance judiciary decision-making. The proposed framework is evaluated with different evaluation metrics, such as training accuracy, loss, optimizer performance, precision-recall curve, model complexity, training time, and inference time. In crime detection, the CNN model achieves a remarkable accuracy of 92.45% and in criminal emotion detection, LeNet-5 outperforms other CNN architectures by offering an accuracy of 98.6%.
Similar content being viewed by others
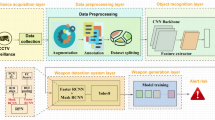

Introduction
Emotion detection from facial expressions has gained significant attention in recent years due to its potential applications in fields such as healthcare, education, and security1,2. The pervasive sense of fear and insecurity experienced by individuals underscores the pressing need to proactively prevent potential threats. Many heinous acts that pose a danger to public safety frequently involve portable weapons such as firearms, blades, handguns, and similar implements3,4,5. Emotions play a significant role in human behaviour, particularly in the context of criminal activities4 and safeguarding public safety applications. Detecting and understanding the emotions exhibited by individuals involved in criminal behaviour can provide valuable insights for law enforcement agencies and contribute to the prevention and investigation of crimes. In interpersonal relationships, facial expressions play an expressive and communicative role. Facial expression recognition (FER) is important because it may be used to infer a person’s mood or mental state from their expressions. Its applications go beyond merely understanding human behaviours, seeing someone’s mood, or judging someone’s mental state6. The ability to automatically recognize emotions from facial expressions can provide valuable insights into human behaviour and enhance human-computer interaction7.
Computer vision is a transformative technology that offers valuable insights from images8. Its applications span various domains, including photography, design, marketing, and even healthcare with X-rays and CT scans9. In photography, computer vision automates image tagging and enhances image quality, while in design, it aids designers in layout recommendations and colour palette extraction10. However, automation and intelligence are crucial for computer vision to be truly effective and valuable. Without them, human intervention becomes necessary, leading to time-consuming and labour-intensive processes11.
Advanced machine learning models such as deep neural networks are commonly used to achieve high levels of accuracy in facial expression detection12. Deep learning models, particularly Convolutional Neural Networks (CNNs), have achieved high accuracy in facial emotion detection. However, in the context of criminal facial expression detection, additional challenges and complexities, such as emotions manifesting in a diverse spectrum ranging from subtle indicators to overt expressions, need to be addressed to improve public safety applications13. Facial expression recognition technology holds diverse applications. It can identify potential health issues by detecting changes in facial expressions, enabling early interventions in healthcare14. In law enforcement, it analyses criminal facial expressions and improvises the judiciary decisions15. The automotive industry benefits from improved safety through fatigue and distraction detection in drivers, reducing accident risks16. Furthermore, in education and training, personalized learning experiences are facilitated by analyzing students’ expressions to gauge engagement and adapt the learning environment accordingly.
Recently, CNNs have been extensively studied for facial emotion detection. Researchers have proposed novel models incorporating spatial-temporal feature learning to improve emotion recognition17,18. However, relying solely on a limited set of basic emotions may not be sufficient for accurate results. A more comprehensive approach is needed to accurately recognize and classify diverse emotions, especially when fine distinctions are necessary. In the criminal context, AI-based facial emotion detection is an innovative approach to identifying and analysing emotions displayed by individuals, particularly in relation to criminal activities19. There exist various CNN architectures, each with its distinctive design and capabilities20,21,22 to detect emotion in different environments. The evaluation will encompass metrics such as accuracy, computational cost, and training time, employing a publicly available dataset tailored for criminal face expression analysis. This research endeavour endeavours to identify the most effective CNN architecture for criminal face expression detection, thereby shedding light on its potential applications in diverse fields, including law enforcement, forensic psychology, and security systems. Existing research predominantly focuses on criminal detection through AI models, yet there remains a critical gap as these endeavours often neglect the underlying emotional context associated with criminal behaviour.
To overcome this problem, we proposed an AI-based criminal and emotion detection framework for public safety applications. In the experiment, we employed two sets of data: one related to crime detection and the other focused on criminal emotions. The preprocessing of images is crucial in the context of crime detection, involving actions such as rescaling, adjusting shear range and zoom range, and incorporating horizontal flips. Two sets of CNN architecture are deployed to get trained on crime data and emotion data, offering noteworthy accuracy in detecting crime and criminal emotion in public safety applications. The proposed framework is evaluated by considering different evaluation metrics, such as training accuracy, loss, optimizer performance, and inference time.
Research contributions
The research contributions of the article are as follows.
-
We proposed an AI-based criminal and emotion detection framework to not only identify criminal activities but also uncover the emotions driving them, enhancing public safety efforts. By combining criminal and emotion detection, our proposed work goes beyond traditional approaches, providing a deeper understanding of the reasons behind unlawful actions.
-
We used two standard datasets, i.e., the criminal dataset comprised of criminal activities and 135 class-based emotion dataset comprised of 135 classes of emotions to train AI models. The trained AI models efficiently classify the criminal activities and subsequently classify their emotions while performing the crime. We employed different CNN architectures and compared them by considering statistical measures.
-
The proposed framework is evaluated by considering different evaluation metrics, such as training accuracy, training loss, optimizer performance, and inference time comparison.
Article layout
The rest of the paper is structured as follows. Section 2 discusses the existing state-of-the-art (SOTA) approaches. Section 3 presents the system model and problem formulation of the proposed scheme. Section 4 presents the proposed scheme and provides the details of the data preprocessing and CNN architecture. Section 5 presents the performance evaluation of the proposed scheme. Finally, section 6 concludes the article with the future scope of the work.
State-of-the-art works
This section discusses varied solutions proposed by researchers across the globe for enhancing public safety applications using AI techniques. In that regard, Xiao et al.16 discusses a deep learning model called FERDERnet that is designed for on-road driver facial expression recognition. The model uses transfer learning with fine-tuning and augmentation-based re-sampling to improve performance. Experiments show that FERDERnet outperforms other deep networks, achieving accuracy improvements of 3% to 8%. This success is attributed to the fine-tuning strategy and augmentation-based re-sampling, which enabled the model to learn from insufficient and imbalanced data. Removing the augmentation-based re-sampling module significantly decreased the classification accuracy of the model. Saeed et al.6 proposed an algorithm called FD-CNN for automatic facial expression recognition using eight expressions from the CK+ dataset. The algorithm consists of preprocessing, feature extraction, and classification using a convolutional neural network. The obtained accuracy of FD-CNN is better than the state-of-the-art, and its performance is validated through 10-fold cross-validation, achieving precision, recall, and F1 scores of 94.09%, 78.22%, and 84.07%, respectively.
Further, Ansari and Gunjan in30 proposed a network that adds dropout layers to the ResNet50 architecture, resulting in improved results compared to other networks. The proposed model achieved a training accuracy of 75% and a test accuracy of 55%. Future work suggests collecting more images for the FER2013 dataset to balance the emotions and ensure an equal number of images in each emotion class with more pose variety. Alternatively, Akhand et al.31 proposed an efficient DCNN using transfer learning with a pipeline tuning strategy for facial emotion recognition. The proposed method shows high recognition accuracy on well-known emotion datasets, but there is still room for improvement with hyperparameter fine-tuning and special attention to profile views. The proposed method has the potential for real-life industry applications, such as monitoring patients in hospitals or surveillance security. The idea of facial emotion recognition may be extended to cover emerging industrial applications, such as emotion recognition from speech or body movements. Sadr et al. in2 proposed the integration of CNN, LSTM, XGB, and KNN to leverage both deep learning and traditional machine learning. You can adopt a similar approach by combining CNN with LSTM or other models (e.g., SVM or Random Forest) to enhance the accuracy of emotion detection in criminal behavior.
Similarly, Chen et al.32 proposed a new facial expression recognition approach focusing on a more detailed and comprehensive representation of emotions. While most FER research focuses on a limited set of basic emotions, this study aims to capture the entire range of emotional concepts in a semantic-rich way. To achieve this, the authors construct a novel dataset with 135 emotion categories and propose a baseline approach for emotion recognition using fuzzy relationships to guide the network training process. The results of their evaluations suggest that this approach has benefits over previous methods for FER and highlight the need for more dedicated methods and larger datasets to further advance our understanding and analysis of fine-grained facial emotions.
Mehendale33 proposed FERC technique is a novel approach for facial emotion recognition using convolutional neural networks. It consists of a two-part CNN that removes the background from the picture and extracts the facial feature vector. FERC uses an expressional vector (EV) to identify five different types of regular facial expressions and achieves an accuracy of 96% with a length of 24 EV. The two-level CNN approach and novel background removal procedure improve accuracy and differentiate it from other commonly used strategies with single-level CNNs.
Li et al.34 proposed an improved facial expression recognition system using a deep residual network based on the ResNet-50 architecture. The proposed method achieved good accuracy and recognition effect on a validation dataset. The paper also mentions that future research will focus on collecting more emotional images to optimize and propose better algorithms for training hyperparameters of neural networks. The researchers also plan to explore ways to improve the accuracy of facial expression recognition based on deep residual networks. Overall, the paragraph highlights the current state of the art in facial expression recognition using deep learning techniques, with a focus on improving accuracy and performance through algorithmic and data optimization35.
The authors in25 presented a golden jackal optimized-based neural network to classify criminal activities based on their location, time, and suspicious activities. They utilized two open-source datasets, where criminal photo sketches are used to train neural networks to give similarity measures against a forensic image dataset. Further,26 extract crime-related activities from the dark and anonymous web using crawler, manual annotation tools, natural language processing, and data structuring. This unstructured data helps to train a knowledge discovery module to identify crime patterns in judicial investments.
Next,27 introduces crime detection and hotspot detection, an advanced AI framework that leverages police data and feature engineering to accurately detect and visualize crime hotspots. Further,36 examines the transformative impact of AI in corporate compliance and crime prevention, focusing on its role in detecting financial fraud, insider trading, and regulatory non-compliance through advanced data analytics. It also highlights ethical and privacy concerns, emphasizing the need for international cooperation and legal reforms to ensure AI applications in combating corporate crime. Mukta et al. in28 presents a real-time crime detection/monitoring system that integrates CCTV surveillance with AI models to detect crimes through weapon detection, violence detection, and face recognition. Their results show notable accuracy, that is, achieving over 80% accuracy in weapon detection, 95% in violence detection, and 97% in face recognition. Table 1 shows the comparative analysis of the proposed work with existing state-of-the-art works.
Motivation
Prior works in crime detection have primarily focused on isolated tasks such as weapon recognition, violence detection, or facial emotion analysis27,28,36. However, they often lack a comprehensive two-stage approach that integrates both real-time crime scene identification and post-crime emotional analysis. Unlike these existing models, the proposed framework uniquely combines crime activity detection (e.g., weapons, violence) with a second stage of criminal emotion recognition during court hearings, offering a more holistic perspective. This two-stage integration not only enhances the accuracy of crime identification but also provides valuable insights into the intent and emotional state of the suspect, which can support judicial decision-making and rehabilitation recommendations37. While activity-based crime detection leverages object and action recognition to identify potential threats, it lacks deeper insights into the psychological state of the perpetrator. Prior works on crime detection and facial emotion analysis have largely been distinct and independent from each other24. Crime detection models predominantly rely on activity recognition techniques, utilizing object detection and action classification to identify potential threats such as weapons, violent movements, or suspicious behaviors30. These approaches are effective in recognizing crime-related activities in real time but fail to capture the emotional and psychological state of the individuals involved.
Motivated by this, we developed a two-stage framework that addresses both aspects. The first stage focuses on real-time crime detection through the identification of weapons and violent actions using different AI models. The second stage goes beyond surface-level analysis by incorporating facial emotion recognition during court proceedings to understand the psychological and emotional state of the accused. This holistic approach enables a more comprehensive understanding of criminal behavior and supports informed legal decision-making, distinguishing our work from previous studies.
System flow model and problem formulation
System flow model
This section discusses the system model for detecting crime and identifying criminal facial emotions. The scheme utilizes a classification model for this purpose, and the proposed system design is shown in Fig. 1. The scheme considers the entity \(C_u\) for different criminals. Let’s say that there are n criminals in a given area, and we define the set of all criminals as \({[c_1,c_2,...,c_n]}\). Additionally, we define the set of criminal activities as \(C_r={[cr_1,cr_2,...,cr_m]}\), where m is the total number of criminal activities that we are interested in detecting.
For the experiment, we utilized two datasets, i.e., crime detection and criminal emotion datasets denoted as \(D_E\) in CSV file format. Image preprocessing in crime detection is essential for rescaling, shear range, zoom range, and horizontal flip. Also, facial emotion detection is essential for standardizing and enhancing the quality of input images, reducing noise and variations, and improving the accuracy and efficiency of subsequent analysis and emotion recognition algorithms. In the stage of data splitting, the dataset is divided into two subsets: a training set and a validation set. The training set is used to train the CNN model, while the validation set helps evaluate the model’s performance during training. This split ensures that the model generalizes well and avoids overfitting. After data splitting, the training data moves to CNN Architecture, which refers to the specific structure and layers of the CNN model, such as convolutional layers, pooling layers, and fully connected layers. The CNN architecture enables the model to extract relevant features from facial images. Finally, we perform the inference on different images based on the training dataset and analyze the output.

Proposed framework.
Table 2 shows all the symbols and their actual meaning in the proposed framework.
Problem formulation
We represent the criminal face emotion detection framework as a function F that takes an input image I and returns a set of classified emotions \(E={[e_1,e_2,...,e_m]}\) for each criminal in the image. For the proposed framework, we perform the training on different emotion classes and images from \(D_E\). The main aim of the proposed work is to enhance the detection rate of the utilized AI model (M) by employing indispensable characteristics of AI techniques.
where, \(\mathcal {O}\) is the objective function of the proposed work, where we want to maximize the accuracy of the AI model (M) in detecting the crime and criminal emotions.
The proposed scheme
Crime Detection
In this section, we discuss the crime detection approach based on the proposed CNN model. The CNN is designed to automatically extract relevant features from input data, eliminating the need for manual feature engineering and enhancing classification accuracy38,39. The model is trained on a diverse crime dataset that includes images, video frames, or other sensory inputs labeled as either crime or no-crime activities. The ultimate goal of this crime detection model is to provide an intelligent surveillance system that assists law enforcement agencies by reducing manual monitoring efforts and enabling quicker response times in identifying and addressing potential threats.
Data layer
For crime detection, the crime is defined as \(\alpha\). There are two different classes in the crime dataset. The non-crime class images are denoted as \(N_P\), and the criminal class images are denoted as \(A_P\).
For crime detection,
We organize the sample images for both classes, normal and crime, by storing them in labelled folders based on the individuals involved. All images for a particular person are grouped in a folder named after that person, while all images related to criminal activities are grouped within a designated folder labelled ’criminal.’ This structured organization simplifies the training process, allowing for efficient processing of both classes during model training and analysis. The filename and directory name operations are as follows:
where, \(\Omega\) represents the set of all file paths generated by the code, D represents the set of directory names in the file system, and F represents the set of filenames present in each directory. This formula represents the set \(\Omega\), which contains tuples (dirname, filename) where the directory name dirname belongs to the set D, and the filename belongs to the set F.
Crime dataset
For crime detection, we used the crime dataset, which contains the training and testing for crime detection. The crime dataset includes a training set with 334 criminal images and 263 person images. The testing set consists of 35 person images and 38 criminal images. This dataset provides an opportunity to analyze and identify visual patterns associated with criminal activities. Based on these data, we process the images to detect normal person activities and criminal activities.
CNN for crime detection
Prior to commencing the model training for crime detection, we conduct essential preprocessing steps that encompass rescaling, applying shear and zoom transformations, and enabling horizontal flips. It’s important to note that these preprocessing procedures are consistently applied to both the training and testing images, ensuring that the same transformations are employed on the dataset during both the training and evaluation stages. For rescaling, the pixel values of the images are divided by 255 to normalize them in the range [0, 1].
For the shear range, random shearing transformations are applied to introduce geometric distortions.
For zoom range, random zooming transformations are applied to allow the model to learn features at different scales.
For horizontal flips, random horizontal flips are applied to increase the diversity of the training data.
We also realized that the dataset images predominantly contain dark and low-contrast areas, which is typical in surveillance footage and crime scene images captured under poor lighting conditions. To ensure better classification and feature extraction, we applied preprocessing techniques such as image normalization (scaling pixel values between 0 and 1) to standardize brightness levels, adaptive histogram equalization (CLAHE) to enhance contrast in low-light images, and Gaussian blurring to reduce noise and improve edge detection. These preprocessing steps help our CNN model to effectively differentiate between actual crime objects and does not misclassify objects due to lighting variations. By improving contrast and normalizing pixel intensity, the model becomes more robust in detecting guns and crime-related objects.
After preprocessing, the images are ready to get trained by the CNN model. Eq. (11) represents a CNN operation, where the input \(X\) is passed through two Conv2D layers with filters \(F_1\) and \(F_2\) and kernel sizes \(K_1\) and \(K_2\) respectively. The ReLU activation function is applied after the first Conv2D operation, and the final output is obtained by adding the bias terms \(B_1\) and \(B_2\) to the result of the second Conv2D operation. The operation like:
Next, a targeted approach is initiated to extract pertinent information. Specifically, identified crime images are systematically saved to a dedicated directory. This process involves isolating frames or snapshots that capture crucial moments during the criminal activity. Subsequently, sophisticated computer vision techniques are employed to pinpoint and focus on the region of interest, specifically the criminal face, within these saved images. This meticulous extraction process ensures that relevant facial expressions and emotions exhibited during the commission of the crime are preserved for subsequent analysis, i.e., criminal emotion detection. Additionally, Algorithm 1 shows the sequential flow of the CNN algorithm in detecting crime in public safety applications.

CNN algorithm for crime detection.
Criminal emotion detection
In this section, we discuss the emotions of the criminal at the time of crime activity by adopting the essential benefits of AI models. Here, we summarize the dataset utilized while detecting criminal emotions, dataset preprocessing, and AI training. A detailed description of each phase is as follows.
Data layer
The data layer defines the criminal entity as \(C_u\) with different criminal activities \(C_r\). The different classes of emotions are defined as E. For this research, we consider the CSV file as input with 135 emotion classes. The input data is denoted as \(I_s\) containing URL denoted as \(U_l\) and the emotion labels \(Em_l\) with description d. For emotion detection,
For each row ith in the dataframe (i = 1 to N), perform the following steps: First, we retrieve the image from the URL. Let us consider the URL as \(U_l\) for i to be the URL corresponding to the row i in the dataframe. The \(Ui_o\) function is used to open and download the image. This process is called retrieving the images, and it is denoted as \(U_{ret}\).
Eq. (13) represents the action of opening and downloading an image from a URL. The variable \(U_i\) corresponds to the URL associated with the ith row in the dataframe, and \(Ui_o\) represents the function or operation of opening and downloading the image from that URL.
Criminal emotion dataset
The proposed work uses 135-class emotional facial expression dataset from standard IEEE DataPort dataset repository. The dataset is a collection of 696,168 facial images of 135 different subjects representing various emotions. Researchers from the University of Geneva and the University of Grenoble in Switzerland created it32,32. Traditional facial emotion recognition (FER) models often categorize expressions into basic emotions such as happiness, anger, and surprise. However, real-world criminal psychology involves a complex spectrum of emotions, which can provide deeper insights into guilt, remorse, deception, and intent. It consists of a balanced distribution of facial expressions across various demographics, ethnicities, and age groups, ensuring high generalizability and fairness in emotion recognition models. The dataset narrow downs the facial expression, such as outrage is further narrowed down to ferocity, dislike, grumpiness, fury, hysteria, loathing, rage, rejection, and revulsion, where each subcategory has a different facial expression.
The dataset is a large-scale facial emotion recognition dataset consisting of 696,168 labeled facial images across 135 distinct emotion categories, with each category containing between 994 and 12,794 images. The dataset is structured into three subsets: a training set with 556,803 images, a validation set with 69,560 images, and a testing set with 69,805 images, following standard machine learning practices to ensure effective generalization. Provided in JSON format, each image sample includes a filename, download URL, linguistic description, and an annotated emotion label, making it highly organized and accessible for AI training. By leveraging this fine-grained dataset, the model can detect subtle facial cues associated with emotions such as guilt, anxiety, regret, or defiance, which are crucial in legal investigations and judicial decision-making. During court hearings, where criminals often attempt to mask their true emotions, the AI model can analyze microexpressions and emotional inconsistencies that human observers might miss. For example, distinguishing between remorseful sadness and manipulative sorrow could aid judges in assessing the defendant’s true emotional state and intent.
This annotated dataset plays a crucial role in training the AI model to accurately classify a wide range of facial expressions, spanning 135 distinct emotion categories. Once an AI model is trained it can be deployed in law enforcement agencies, assisting in interrogations, court hearings, and forensic psychology assessments to identify the true emotional state of a suspect. This capability allows authorities to analyze non-verbal cues that may reveal a suspect’s real motive, intent, or psychological condition, enhancing investigative accuracy and judicial decision-making. Moreover, by integrating real-time facial emotion recognition into surveillance and security systems, the model can help detect suspicious behavior, providing an early warning system for potential criminal activities.
CNN for crime emotion detection
To represent the process of sending the image to the CNN model for a computer vision task and the preprocessing step denoted as \(P_d\), we can use the following mathematical equation:
Here, \(I_{img}\) represents the input image, and \(P_d(I_{img})\) represents the preprocessed image obtained after applying the preprocessing step denoted as \(P_d\). The preprocessed image is then fed into the CNN model for further processing and analysis in the computer vision task. The \(P_d(I_{img})\) function resizes the image in \(48\times 48\) pixel and also normalizes the image by dividing 255.0, which scales them in between 0 and 1. The resized image has a corresponding label, and it is converted in one hot encode.
where, the function \(P_d(I_{\text {img}})\) denotes the preprocessing operation, and \(\text {resize}(I_{\text {img}}, 48\times 48)\) represents the resizing of the image to a size of \(48\times 48\) pixels. The division by 255.0 is used to normalize the pixel values of the resized image, scaling them between 0 and 1. The resulting preprocessed image \(P_d(I_{\text {img}})\) is obtained by applying these operations to \(I_{\text {img}}\). In the preprocessing step, the mapping between labels and integers using dictionaries label_to_int and int_to_label in mathematical equations. For mapping labels to integers, let L denote the set of labels and N denote the number of unique labels. For each label l in L we have,
For mapping integers to labels such as, for each integer i in the range [0, N-1], we have,
After all processes, the input image is passed to the AI model for training. The CNN has the ability to process the image and get the required output. In CNN, there are different layers with unique operations, such as
-
Convolutional Layer 1 & 2:
$$\begin{aligned} C_1 = \text {ReLU}(\text {Conv2D}(F_1, K_1)(I_{\text {img}}))\end{aligned}$$(18)$$\begin{aligned} C_2 = \text {ReLU}(\text {Conv2D}(F_2, K_2)(C_1)) \end{aligned}$$(19)where, \(C_1\) and \(C_2\) represents the output feature maps, \(F_1\) and \(F_2\)represents the filters, \(K_1\) and \(K_2\) represents the kernel size, and \(I_{\text {img}}\) represents the input image. where \(C_2\) represents the output feature maps, \(F_2\) represents the filters, represents the kernel size, and \(C_1\) represents the input feature maps.
-
Maxpooling, Dropout, and Flatten layer
$$\begin{aligned} P = \text {MaxPooling2D}(C_2)\end{aligned}$$(20)$$\begin{aligned} D_1 = \text {Dropout}(P)\end{aligned}$$(21)$$\begin{aligned} F = \text {Flatten}(D_1) \end{aligned}$$(22)The above-mentioned equation (Eq. (20)) represents common operations in CNNs for feature extraction and dimensionality reduction. MaxPooling2D (P) reduces spatial dimensions by selecting maximum values in regions, preserving important features while reducing complexity. Dropout (\(D_1\)) randomly sets units to zero, preventing overfitting and promoting generalization. Flatten (F) converts the feature map into a 1D vector. These operations aid in extracting relevant features, reducing dimensionality, and enhancing generalization in the CNN model. The sequence of operations ensures efficient feature representation for accurate predictions.
-
Dense Layer 1:
$$\begin{aligned} D_2 = \text {ReLU}(\text {Dense}(N_1)(F)) \end{aligned}$$(23)where, \(D_2\) represents the output after applying a dense layer with ReLU activation, and \(N_1\) represents the number of neurons.
-
Dropout Layer 2:
$$\begin{aligned} D_3 = \text {Dropout}(D_2) \end{aligned}$$(24)where, \(D_3\) represents the output after applying dropout to the dense layer.
-
Dense Layer 2 (Final Layer):
$$\begin{aligned} O = \text {Softmax}(\text {Dense}(N_2)(D_3)) \end{aligned}$$(25)where, O represents the final output after applying a dense layer with softmax activation, and \(N_2\) represents the number of neurons in the final layer.
Algorithm 2 shows the step-by-step flow of the criminal emotion detection using LeNet-5 AI model.

LeNet-5 algorithm for criminal emotion detection.
Results and discussion
In this section, we discuss the performance analysis of the proposed framework by considering different evaluation metrics, such as training accuracy, loss, inference time, and optimizer performance.
Experimental tools and setup
The proposed framework is developed on Google Colab, a cloud-based platform that provides free access to GPU, TPU, and other computing resources to perform machine learning and deep learning tasks. Using Google Colab is an excellent way to perform computationally intensive tasks that may be too expensive to run on a personal computer. With the NVIDIA Tesla T4 GPU support available in Colab, deep learning tasks can be performed at a much faster rate and in a parallel manner. For image processing tasks, several Python libraries are available that can be used in conjunction with the Google Colab platform. Pandas is a popular library used for machine learning tasks, and it provides several functions that can be used to manipulate and analyze data. Numpy is another library that is widely used for scientific computing tasks, and it provides support for linear algebra, Fourier transforms, and matrices. Matplotlib is another popular Python library that is used for data visualization tasks. It provides several functions that can be used to create different types of charts and graphs to analyze and present data. Further, the proposed work is implemented on a system that has specifications, such as 16GB of RAM, to ensure smooth multitasking and efficient processing of data. Processor - quad-core Intel Core i7 processor clocked at 3.5GHz, providing the necessary processing power for the tasks at hand. It includes a 512GB solid-state drive (SSD) for fast data access and storage.
Further, we used Keras, a high-level deep-learning Application programming interface (API) that is written in Python. It provides several pre-built functions that can be used to develop deep learning models quickly and efficiently. CV2 is another library that is widely used for computer vision tasks, such as image classification, object detection, and image segmentation. It provides several functions that can be used to perform various image-processing tasks, such as image resizing, cropping, and filtering. Additionally, urllib is a library that is used for working with URLs, which can be used to access images from the internet for processing.
Simulation parameters
To predict the better output, the parameters perform an important role. We perform the experiment on different parameters like epochs, batch size, validation set, and optimizer. For crime detection, we perform training on 32 epochs and 10 batch sizes with 16 training steps per epoch with the use of the Adam optimizer. For criminal emotion detection, we use RMSprop optimizer based on the comparison of optimizer shown in Fig. 8. Also, we select the 264 epochs and 128 batch sizes for better outcomes on large datasets. We also compare the different CNN models with the same parameter to perform a comparative analysis for better accuracy. Tables 3 and 4 show all the implementation parameters and configurations employed in our proposed framework.

Crime detection (a) accuracy plot, (b) loss plot, comparison of (c) training and validation accuracy, (d) training and validation loss.
Performance analysis of the crime detection
The crime detection results using CNN are presented in Fig. 2a,b. Figure 2a illustrates the relationship between the number of epochs and the accuracy achieved by the AI model to detect crime in public safety applications. Over the course of 32 epochs, the model achieved an accuracy of 92.45%. This observation indicates the outperformance of the CNN model to learn intricate patterns and nuances associated with crime detection over successive epochs. The upward trajectory in accuracy underscores the effectiveness of the AI training, suggesting that the model continued to enhance its discriminatory capabilities with each epoch.
Figure 2c,d shows the accuracy and loss curves from the CNN-based crime detection model indicate a steady improvement in learning patterns from the dataset, which consists of images containing guns and crime scenes. Initially, the training loss starts around 0.8 while the validation loss is slightly higher at 0.75, reflecting the model’s struggle in the early stages. However, by epoch 5, training loss drops to 0.5 and validation loss follows at 0.6, indicating that the model is effectively distinguishing between crime and non-crime images. By epoch 10, training loss stabilizes around 0.33, while validation loss remains close at 0.4, showing minimal overfitting. Similarly, accuracy improves from 85.36% to 91.49% for training and 83.65% to 91.38% for validation, confirming that the model is generalizing well. The close alignment of validation and training accuracy suggests the CNN is successfully identifying weapons, human postures, and crime-related activities in images. This is crucial for crime detection, as the model can be deployed in surveillance systems, security checkpoints, and forensic analysis to automatically flag suspicious activities. Minor fluctuations in validation accuracy after epoch 7 suggest dataset variations. Overall, the model effectively learns crime-related features and helps automate crime detection, reducing manual monitoring efforts and improving security measures.

(a) ROC curve and (b) precision-recall curve.
Additionally, we also used ROC and precision-recall curve to further evaluate our proposed framework. In that view, Fig. 3a shows the ROC curve that evaluates the trade-off between true positive rate (TPR) and false positive rate (FPR), with an AUC (Area Under Curve) of 0.93, indicating strong classification performance. A high AUC score suggests that the model effectively differentiates between crime and non-crime images. Fig. 3b depicts the precision-recall curve that assesses the balance between precision (correct crime detections) and recall (ability to detect all crimes). The curve demonstrates a consistent upward trend, meaning the model maintains high recall while minimizing false positives. This is crucial in crime detection, as a high recall ensures that dangerous objects like guns are rarely missed, while high precision minimizes unnecessary false alarms.

(a) Crime image pixel intensity distribution (b) CNN model weight distribution.
Figure 4a shows how pixel values are distributed across the image dataset, ranging from 0 to 1 (after normalization). The histogram exhibits a higher concentration in lower pixel intensity ranges, indicating that many images contain dark or low-contrast areas, which are common in surveillance footage and crime scenes captured under poor lighting conditions. A well-spread distribution ensures that the CNN effectively learns to differentiate between shadows, objects, and real threats, rather than being biased toward brightly lit regions.
Figure 4b provides insights into how the CNN model has learned during training. Model training shows that the weights are centered around zero, with a near-symmetrical distribution extending from -0.3 to 0.4. This distribution suggests that the network has effectively learned meaningful feature representations without excessive bias towards certain weights, preventing overfitting. If the weights were skewed towards extreme values, it could indicate unstable training or overfitting. A balanced weight distribution as shown in Fig. 4b ensures the model generalizes well when detecting guns, weapons, and crime-related actions in images. Further, Fig. 2b displays the relationship between the epochs and the loss incurred by the AI model. The model recorded a loss of 20%. These figures provide a clear visualization of the performance of the crime detection model in public safety applications. The rationale behind the outperformance of the CNN model is that, due to the efficient capture of local features through convolutional operations, it can identify specific patterns and details relevant to criminal detection, contributing to a more focused and accurate AI model.
Performance analysis of the criminal emotion detection
The experiment demonstrates similar image processing and prediction tasks but differs in terms of the data sources. The first section retrieves images and their labels from a CSV file, while the second section processes images directly from a directory. The code showcases how to utilize a model to make predictions on images and visualize the results using Matplotlib. Figure 5 shows the example comparison image to identify the actual and model-predicted output. From Fig. 5, we can analyze that the AI model correctly predicts the emotion of the person, i.e., actual = adoration and predicted = adoration. Similarly, AI has been misclassified in Fig. 5 where actual=adoration but model predicted = affection; however, we wanted to mention that affection is a subcategory of adoration. So even though it is misclassified, the predicted still lies in the same emotion category. This shows the outperformance of the CNN model in bifurcating the emotions of the criminal. It is to be noted that the authors used a standard emotion dataset to train our AI models; eventually, the trained model helps in criminal emotion detection.

Emotion class prediction.
Figures 6 and 7, shows the graph comparing the performance of the accuracy and loss of different CNN architectures, respectively, including CNN, ResNet, LeNet-5, and VGGNet, reveals some interesting insights. The graph shows that the LeNet-5 achieves better accuracy, i.e., 99.6% compared to the existing AI models. The reason behind the outperformance of LeNet-5 is its hyperparameter tuning, such as kernel size, pooling, and stride. Furthermore, small implementation details, such as the choice of optimizer, learning rate, and weight initialization, significantly improve the performance of the LeNet model. Additionally, CNN is near to achieving higher accuracy, i.e., 99.4% with the other CNN architectures, by a significant margin in terms of accuracy. This is due to the innovative use of residual connections, which enables the training of very deep neural networks without encountering the vanishing gradient problem. Additionally, Table 5 displays the different statistical measures, such as accuracy, loss, precision, recall, F1 score, and training time of different CNN architectures employed in the proposed work.

Accuracy comparison between different AI models.

Loss comparison between different AI models.

Optimizer comparison graph.

(a) Inference time comparison of all CNN models and (b) inference time comparison with the number of images used in LeNet 5 model training.
Moreover, optimizers are a crucial component of neural network training as they play a key role in updating the model’s weights during the backpropagation process. Among the commonly used optimizers, Adam, RMSprop, and stochastic gradient descent (SGD) are often compared to each other in terms of accuracy performance. The optimizer comparison graph (as shown in Fig. 8) reveals that RMSprop outperforms SGD, making it a popular choice for many deep-learning tasks. RMSprop is an adaptive learning rate optimizer that scales the learning rate using a moving average of the squared gradients. This makes it highly effective in situations where the data has sparse gradients or non-stationary distributions. In fact, studies have shown that RMSprop can outperform other optimization methods, especially when working with deep neural networks. Compared to traditional optimization methods, RMSprop generally requires less fine-tuning of its hyperparameters and converges faster, making it an attractive choice for the proposed work. For the same, Table 6 displays the optimizer performance of all the optimizers used in the LeNet-5 model.
In addition to the accuracy and loss plot, we also analyze the performance of the proposed framework by utilizing the inference time parameter. Based on the inference time graph for different CNN architectures, it is evident that LeNet-5 has the least inference time among the considered models, which includes CNN, ResNet, LeNet-5, and VGGNet, as shown in Fig. 9a,b . LeNet-5 has a relatively small number of layers and parameters compared to the other models, making it computationally less expensive and faster in inference time.
Further, Table 7 provides a comparative analysis of different CNN architectures in the context of criminal emotion detection, focusing on accuracy, false positive/negative rates, model complexity, and computational efficiency. Among the architectures, LeNet-5 outperforms others with an accuracy of 98.6%, a low false positive rate (0.6%) and false negative rate (0.9%), and minimal computational requirements (only 0.06M parameters, 7.78 minutes training time, and 5 ms inference time). This makes LeNet-5 highly efficient for real-time applications, such as detecting subtle criminal emotions in court hearings or forensic investigations. While VGGNet (97.5%) and CNN (96.4%) also show strong performance, they require significantly higher training time and computational resources, making them less practical for large-scale deployments. On the other hand, ResNet-50 performs the worst (69.41%), with high false positive (8.2%) and false negative (10.5%) rates, suggesting it struggles with complex facial emotion classifications. Given that criminal facial expressions involve microexpressions and subtle emotional cues, LeNet-5’s lower complexity and high accuracy make it ideal for real-time crime detection applications, where both speed and precision are critical.
Conclusion and future works
In this paper, we proposed an AI-based crime and emotion detection framework for public safety applications. In the proposed framework, we used two standard datasets, i.e., the crime detection dataset and the criminal emotion dataset, which comprises of 135 unique facial emotions. These datasets are first preprocessed using rescaling, shear and zoom transformation, horizontal flips, and normalization. Then, different CNN architectures are used to train on both datasets. In the first module, CNN efficiently detects criminal patterns at the crime scene. Later, in the second module, different CNN architectures, such as Basic CNN, ResNet-50, LeNet-5, and VGGNet, are used to classify the criminal emotions at the time of the crime. The outcomes generated by this AI-driven analysis are then seamlessly communicated to judicial authorities. This integration provides valuable insights to enhance the overall performance of public safety applications. Crucially, it empowers the judiciary to make informed decisions based on the nuanced emotional context surrounding the crime, marking a significant stride towards a more comprehensive and insightful approach to criminal justice. The proposed framework shows significant results in terms of criminal detection using CNN, where an accuracy of 92.45% is achieved. Further, in emotion detection, LeNet-5 outperforms other existing AI models in terms of accuracy, i.e., 99.6%. Furthermore, we also considered other evaluation metrics, such as optimizer performance, inference time, and training loss comparison.
In future works, we will adopt the essential benefits of federated learning that offers decentralized training to improve public safety applications. Furthermore, we will focus on expanding the dataset by incorporating real-world surveillance footage and crime scene images captured under diverse conditions, including low-light environments, occlusions, and motion blur. This will ensure the model learns to recognize weapons, suspicious activities, and emotional cues in uncontrolled settings. We also intend to extend the facial expression dataset by including diverse ethnicities and demographic groups. We will explore transfer learning techniques and cross-cultural emotion mapping, allowing the model to adapt to different sociocultural contexts dynamically in the proposed framework.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Hassouneh, A., Mutawa, A. & Murugappan, M. Development of a real-time emotion recognition system using facial expressions and eeg based on machine learning and deep neural network methods. Inform. Med. Unlock. 20, 100372 (2020).
Sadr, H., Salari, A., Ashoobi, M. T. & Nazari, M. Cardiovascular disease diagnosis: A holistic approach using the integration of machine learning and deep learning models. Eur. J. Med. Res. 29(1), 455 (2024).
Rathod, T. et al. Blockchain-driven intelligent scheme for iot-based public safety system beyond 5g networks. Sensors 23(2), 969 (2023).
Patel, D. et al. Blockcrime: Blockchain and deep learning-based collaborative intelligence framework to detect malicious activities for public safety. Mathematics 10(17), 173915 (2022).
Saberi, Z. A., Sadr, H. & Yamaghani, M. R. An intelligent diagnosis system for predicting coronary heart disease. in 2024 10th International Conference on Artificial Intelligence and Robotics (QICAR) 131–137 (2024).
Saeed, S. et al. Automated facial expression recognition framework using deep learning. J. Healthc. Eng. 2022(1), 5707930 (2022).
Liu, L., Jiang, R., Huo, J. & Chen, J. Self-difference convolutional neural network for facial expression recognition. Sensors 21(6), 2250 (2021).
Dong, C.-Z. & Catbas, F. N. A review of computer vision-based structural health monitoring at local and global levels. Struct. Health Monit. 20(2), 692–743 (2021).
Ritter, F. et al. Medical image analysis. IEEE Pulse 2(6), 60–70 (2011).
Zschech, P., Walk, J., Heinrich, K., Vössing, M. & Kühl, N. A picture is worth a collaboration: Accumulating design knowledge for computer-vision-based hybrid intelligence systems. arXiv preprint arXiv:2104.11600 (2021).
Kakani, V., Nguyen, V. H., Kumar, B. P., Kim, H. & Pasupuleti, V. R. A critical review on computer vision and artificial intelligence in food industry. J. Agric. Food Res. 2, 100033 (2020).
Patel, Y. et al. An improved dense cnn architecture for deepfake image detection. IEEE Access 11, 22081–22095 (2023).
Patel, N. et al. Convolutional neural network and unmanned aerial vehicle-based public safety framework for human life protection. Int. J. Commun. Syst. 81, e5545 (2025).
Hasnul, M. A., Aziz, N. A. A., Alelyani, S., Mohana, M. & Aziz, A. A. Electrocardiogram-based emotion recognition systems and their applications in healthcare-a review. Sensors 21(15), 5015 (2021).
Mushtaq, N., Ali, K., Moetesum, M. & Siddiqi, I. Impact of demographics on automated criminal tendency detection from facial images. in 2022 International Conference on Frontiers of Information Technology (FIT) 88–93 (2022).
Xiao, H. et al. On-road driver emotion recognition using facial expression. Appl. Sci. 12(2), 807 (2022).
Podoletz, L. We have to talk about emotional ai and crime. AI Soc. 38, 1–16 (2022).
Mungra, D., Agrawal, A., Sharma, P., Tanwar, S. & Obaidat, M. S. Pratit: A cnn-based emotion recognition system using histogram equalization and data augmentation. Multimed. Tools Appl. 79, 2285–2307 (2020).
Jin, Z., Zhang, X., Wang, J., Xu, X. & Xiao, J. Fine-grained facial expression recognition in multiple smiles. Electronics 12(5), 1089 (2023).
Alzubaidi, L. et al. Review of deep learning: Concepts, cnn architectures, challenges, applications, future directions. J. Big Data 8, 1–74 (2021).
Saleem, M. A. et al. Comparative analysis of recent architecture of convolutional neural network. Math. Probl. Eng. 2022(1), 7313612 (2022).
Yadav, H. et al. Cnn and bidirectional gru-based heartbeat sound classification architecture for elderly people. Mathematics 11(6), 1365 (2023).
Tasci, G. et al. Zipper pattern: An investigation into psychotic criminal detection using eeg signals. Diagnostics 15(2), 154 (2025).
Aas, A. et al. Efficient and sustainable video surveillance using cnn-lstm model for suspicious activity detection. VFAST Trans. Softw. Eng. 13(1), 60–71 (2025).
Natarajan, R., Mahadev, N., Gupta, S. K. & Alfurhood, B. S. An investigation of crime detection using artificial intelligence and face sketch synthesis. J. Appl. Secur. Res. 19(4), 542–559 (2024).
Fernandez-Basso, C., Gutiérrez-Batista, K., Gómez-Romero, J., Ruiz, M. D. & Martin-Bautista, M. J. An ai knowledge-based system for police assistance in crime investigation. Expert Syst. 42(1), e13524 (2025).
Ahmad, R. et al. Chart: Intelligent crime hotspot detection and real-time tracking using machine learning. Comput. Mater. Continua 81(3), 4171–4194 (2024).
Mukto, M. M. et al. Design of a real-time crime monitoring system using deep learning techniques. Intell. Syst. Appl. 21, 200311 (2024).
Rajawat, A. S. et al. Fusion fuzzy logic and deep learning for depression detection using facial expressions. Procedia Comput. Sci. 218, 2795–2805 (2023).
Gaddam, D. K. R., Ansari, M. D., Vuppala, S., Gunjan, V. K. & Sati, M. M. Human facial emotion detection using deep learning. in ICDSMLA 2020: Proceedings of the 2nd International Conference on Data Science, Machine Learning and Applications 1417–1427 (Springer, 2022).
Akhand, M., Roy, S., Siddique, N., Kamal, M. A. S. & Shimamura, T. Facial emotion recognition using transfer learning in the deep cnn. Electronics 10(9), 1036 (2021).
Chen, K., Yang, X., Fan, C., Zhang, W. & Ding, Y. Semantic-rich facial emotional expression recognition. IEEE Trans. Affect. Comput. 13(4), 1906–1916 (2022).
Mehendale, N. Facial emotion recognition using convolutional neural networks (ferc). SN Appl. Sci. 2(3), 446 (2020).
Li, B. & Lima, D. Facial expression recognition via resnet-50. Int. J. Cognit. Comput. Eng. 2, 57–64 (2021).
Wang, M., Yao, R. & Rezaee, K. Mu-net-optlstm: Two-stream spatial-temporal feature extraction and classification architecture for automatic monitoring of crowded art museums (Tsinghua Science and Technology, 2024).
Garcia-Segura, L. A. The role of artificial intelligence in preventing corporate crime. J. Econ. Criminol. 5, 100091 (2024).
Reddy, P. V., Sanku, S., Akhilsai, T. & Gayatri, A. Cnn based criminal face identification system using video surveillance. Available at SSRN 5077518 (2024).
Khodaverdian, Z., Sadr, H. & Edalatpanah, S. A. A shallow deep neural network for selection of migration candidate virtual machines to reduce energy consumption. in 2021 7th International Conference on Web Research (ICWR) 191–196 (2021).
Nazari, M., Moayed Rezaie, S., Yaseri, F., Sadr, H. & Nazari, E. Design and analysis of a telemonitoring system for high-risk pregnant women in need of special care or attention. BMC Pregnancy Childbirth 24(1), 817 (2024).
Funding
This work was funded by the Researchers Supporting Project Number (RSP2025R509), King Saud University, Riyadh, Saudi Arabia and partially funded by the Kore University of Enna, 94100, Enna, Italy.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Raval, J., Jadav, N.K., Tanwar, S. et al. Criminal emotion detection framework using convolutional neural network for public safety. Sci Rep 15, 15279 (2025). https://doi.org/10.1038/s41598-025-97879-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-97879-3
