
Abstract
Chinese possesses the essential attributes of unique character composition structure and the nested nature of medical entities, which causes many challenges for Chinese Electronic Health Records (EHRs) in medical named entity recognition tasks, such as scarce annotated data, strong tokenization ambiguity, and blurred entity boundaries. This increases the difficulty of extracting medical named entity categories. The paper proposes an effective Chinese clinical named entity recognition model that integrates BERT and adversarial enhancement in a dual channel architecture to address this issue. Firstly, the model integrates various advanced technologies, such as Bidirectional Long Short-Term Memory networks (BiLSTM), Iterative Deep Convolutional Neural Networks (IDCNN), and Conditional Random Fields (CRF), to improve the accuracy of named entity recognition. Secondly, the paper collected texts from medical record websites and utilized the YEDDA tool for professional annotation and processing of these texts, ultimately forming a more comprehensive target dataset. This process ensures that the model is exposed to representative Chinese clinical data during training, thereby improving recognition performance.Finally, experimental results indicate that the BPBIC model achieved a precision of 93.80%, a recall of 94.44%, and an F1 score of 94.12% on the augmented dataset CCKS2019 (CCKS2019+). Moreover, through knowledge graph analysis of medical entities extracted from single and multiple disease EHRs, the model assists doctors in achieving rapid and accurate diagnoses, thereby enhancing the efficiency of healthcare professionals.
Similar content being viewed by others

Introduction
Medical informatization is an inevitable direction for the modern, scientific, and standardized development of hospitals in the future. However, it requires a large amount of patients’ EHRs as data support. Unfortunately, most of the patients’ clinical treatment information is stored in an unstructured text format, which poses significant challenges for information extraction in this field. Effectively mining data and recognizing entities in unstructured medical information is a crucial problem that needs to be addressed for the advancement of medical information technology. Figure 1 depicts the process of extracting two entities, “直肠癌” and “腹腔镜直肠癌根治术”, from the diagnostic information of the medical record text provided by the CCKS2019 dataset.

Example of extracting entities from an EHR.
The NER task is a subtask within the field of information extraction1 that involves identifying entities with specific meanings in unstructured text within a particular domain. NER is a foundational method in natural language processing (NLP) tasks, first proposed by Grishman et al. at the Sixth Conference on Information Understanding (MUC-6)2 in 1996. This research primarily focused on identifying proper names such as names of people, places, organizations, and more.
Early NER initially relied on a rule-based approach, where experts were responsible for designing rules for lexicon and syntactic vocabulary patterns within a specific domain. Examples of such systems include LaSIE-II3 and NetOwl4. Rule-based NER systems can achieve satisfactory results when the lexicon size is limited. However, they often exhibit high precision but low recall due to domain-specific rules and incomplete lexicons. Additionally, domain-based rules are not universally applicable, and adapting rules to new domains can be both expensive and time-consuming1. In contrast, traditional machine learning methods5 such as Markov models6, decision trees, maximum entropy model, support vector machine, and CRF7 utilize domain-based rules in their models.
With the widespread application of deep learning methods to NER tasks, the efficiency of NER has significantly improved, particularly with the use of BiLSTM8 and IDCNN9. In recent years, several pre-trained language models have emerged, creating a significant impact in the field of NLP, notably bidirectional encoder representations from transformers (BERT)10, which has achieved superior performance in NER tasks. However, it is worth noting that most researchers have primarily focused on entity extraction from English documents. Extracting target entities from Chinese text is undeniably a complex and challenging task due to boundary uncertainty and the intricacies of the Chinese language structure. Furthermore, medical entity recognition involves an in-depth exploration of natural language processing in the medical domain. Chinese medical text information extraction encounters several significant challenges11,12,13. Firstly, there is a lack of uniform naming standards as different doctors may refer to the same entity differently. Secondly, medical texts often contain writing errors, abbreviations, and aliases. Lastly, the field of medicine continuously introduces new medical entities as it evolves.
To address these challenges, some researchers have begun using recurrent neural networks (RNN) and convolutional neural networks (CNN) for Chinese NER tasks14,15. RNN can be seen as multiple instances of the same network, where each neural network module passes information to the next module. On the other hand, CNN has the advantage of efficiently computing and extracting local features, making it well-suited for entity extraction tasks. However, the final result is significantly influenced by the last unit of the RNN. CNNs suffer from information loss after convolution and are unable to encode positional information. With the emergence of RNN and CNN variants, BiLSTM addresses the drawbacks of RNN and its bidirectionality allows for a focus on the global information of the sentence. IDCNN achieves the same results as CNN but with fewer parameters. BERT, a bidirectional transformer structure, has strong information memory and extraction capabilities. It generates word embeddings containing word-level features through whole-word masking during training. Introducing small perturbations generated by the adversarial algorithm during BERT’s pre-training can improve the model’s robustness.
In this paper, the model utilizes BERT-PGD as an embedding layer to capture rich semantic information. By combining BiLSTM and IDCNN networks, the model effectively incorporates both global and local information. Furthermore, the paper employ CRF for sequence decoding to obtain the globally optimal solution for entity labelling. The original dataset used in this study is provided by the China Conference on Knowledge Graph and Semantic Computing 2019 (CCKS2019). Experimental results demonstrate that the model significantly enhances entity recognition. The following provides an overview of the main contributions of this paper:
(1) This paper proposes a model (BPBIC) integrating Adversarial Training and Feature Enhancement for Chinese Medical Named Entity Recognition. The BPBIC model effectively identifies entities in Chinese EHRs by combining the local and global information extraction capabilities of BiLSTM and IDCNN.
(2) Data augmentation was performed on the original dataset CCKS2019 by annotating medical records obtained from medical websites, ensuring a richer and more diverse data source. This allowed for the evaluation of the BPBIC model’s generalization ability across different datasets.
(3) The Neo4J was used to construct a knowledge graph of Chinese electronic health records, which was visualized on the GraphXR platform, significantly improving doctors’ understanding of patients’ basic conditions and assisting in clinical decision-making.
Related work
CRF application in NER
Chinese EHR is an unstructured text, and researchers are increasingly focusing on how to extract valuable information from this type of text. In a study by Richa Sharma et al.16, they developed a Hindi NER system using MuRIL with conditional random field (CRF). The model was fine-tuned on the ICON 2013 Hindi NER dataset. Another study by Wei Li et al.17 combined active learning and deep learning approaches for NER. They utilized CRF to decode probability distributions into corresponding entity labels. These studies successfully extracted accurate information from unstructured text, demonstrating the effectiveness and feasibility of CRF in NER.
Deep learning-based NER
Combination of deep learning and CRF
In recent years, NER based on deep learning has become increasingly popular as a mainstream method. Wang et al.18 proposed a method that combines conditional random fields and deep learning models to address the issue of high redundancy and low efficiency in big data. Teng et al.19 also proposed a method to tackle the same problem. They addressed the problem of not considering label sequences in the output of long and short-term memory neural network models by combining them with conditional random fields, resulting in improved prediction results for entity recognition. Yu et al.20 introduced an IDCNN-CRF based entity recognition method that enhances the prediction speed compared to traditional methods. This study21 proposes the ELMo-Grid-LSTM-CRF model, which effectively combines contextualized character representations with a CRF layer to enhance the performance of Chinese Clinical Named Entity Recognition, demonstrating the advantages of this method in utilizing EMR information.
Application of BERT model
In 2018, Jacob Devlin et al.10 proposed a new language model called BERT. BERT incorporates contextual information into word embeddings through an attention mechanism and ensures the integrity of sentence context using a bidirectional Transformer. Before the advent of BERT, language models like Word2Vec22, Glove23, ELMO24, and GPT25 performed well in NLP tasks, but still had certain limitations. Word2Vec and Glove were able to map words to a low-dimensional vector space and utilize contextual words to represent static vectors. However, they had the drawback of not accurately identifying polysemous words that appear in the text. ELMO employs two bi-layer BiLSTMs for feature extraction and fuses semantic information through feature splicing. While the BiLSTM improves the representation of hidden information at the end of sentences, it does not fully address the issue of long-term dependencies. The effectiveness of BERT pre-training model has been demonstrated in the field of NLP, particularly when used in conjunction with classical models like BiLSTM and IDCNN, leading to significant improvements in entity recognition. Lung-Hao Lee et al.26 utilized BERT for character embedding and combined it with a BiLSTM-CRF model to address the complex idiosyncrasies of Chinese text. The ROCLING-2022 shared task27 focused on NER for healthcare in China and summarized the results of a competition involving seven teams. The most commonly used neural network architecture in this task was BiLSTM-CRF, demonstrating its generality and feasibility in Chinese NER. This study28 proposes a medical named entity recognition model based on BERT that integrates Glyph and dictionary information, significantly improving performance by incorporating a CNN structure and the Soft-Lexicon method.
Self attention model
Chaofan Li29 proposed a multi-head self-attention model that combines BiLSTM-CRF to extract multi-level and more specific text features, thereby addressing the issue of long-range dependency loss. Additionally, Xiaojing Du30 developed a model using multilevel CNN and attention mechanism to overcome the limitations of long short-term memory networks (LSTM) in fully utilizing GPU parallelism and capturing contextual information. This study31 proposes a multi-level semantic fusion network for Chinese medical named entity recognition, significantly enhancing the model’s contextual representations by integrating information from morphological, character, lexical, and syntactic levels.
Data augmentation and generalization ability evaluation
The RG-FLAT-CRF model proposed by Jiakang Li32 performed well on the CCKS 2019 dataset, emphasizing the importance of integrating word features and character features to ensure the richness and diversity of the data sources. Bin Ji et al.33 tackled the issue of high dependency between entities and the limited and sparse target scene dataset. They employed a collaborative approach of multiple neural networks and incorporated non-target scene data to address the problem of inconsistent data distribution. Pin Ni et al.34 introduced a method called stacked residual gated recursive unit convolutional neural network (StaResGRU-CNN), which utilizes pre-trained language modeling (PLM) for biomedical text prediction. By incorporating prior knowledge through transfer learning, they developed a Chinese medical prediction model that includes comprehensive downstream task evaluation, resulting in improved evaluation results.
Similarly, Peng Chen et al.35 proposed a hybrid neural network based on medical MC-BERT to extract textual local features and multilevel sequence interaction information, thereby enhancing the effectiveness of entity recognition. Xiaojing Du et al.36 considered NER to be a task of labeling sequences or detecting spanning boundaries. They proposed a multi-task learning and multi-policy approach based on MRC and demonstrated the effectiveness of the model on two different datasets. Liu Pan et al.37 provided a summary of recent advancements in Chinese medical NER. Their study was conducted using the dataset from the Chinese conference on knowledge graph and semantic computing. However, the availability of Chinese NER corpus is limited due to privacy and property protection concerns. Therefore, it is necessary for NLP researchers to obtain richer data.
Applications of generative models
The problem of insufficient data has been partially addressed by the emergence of text generation models such as SeqGAN38, LeakGAN39, and CatGAN40. However, the accuracy of the generated data did not meet expectations. The resistance to interference of these models is considered a measure of their merit. Ian J. Goodfellow41 first proposed the FGM, a neural network that is susceptible to interference due to its linear properties. Adversarial training has been used to improve the generalization ability of the model and reduce output errors. Aleksander Madry42 focused on enhancing the model’s resistance to various adversarial attacks through adversarial training (PGD) from the perspective of robust optimization.
Materials and methods
In this paper, we propose BPBIC as an improvement to the baseline model BiLSTM-CRF. The goal is to enhance the model’s anti-jamming and generalization abilities, as well as leverage both long and short distance information.
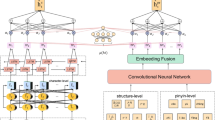
This section presents the BPBIC framework, illustrated in Fig. 2. BPBIC consists of four main layers: the input layer, neural network layer, CRF layer, and output layer. The input layer transmits data to the neural network layer. Initially, the BERT layer processes medical data by performing word splitting, masking, and labelling to generate vectorized text. Subsequently, the PGD backpropagates the vectorized text and updates the gradient to obtain new word vectors. These updated word vectors are then passed to the BiLSTM layer and IDCNN layer respectively. The BiLSTM layer extracts global information features, while the IDCNN layer extracts local information features. Moreover, the location sequence features of BERT can enhance the association strength between words. Finally, the fused neural network outputs are connected and fed back to the CRF layer for sequence labelling, resulting in the output of entity prediction labels.

Diagram of data enhancement method and BPBIC model.
BPBIC modelling algorithm:

BPBIC model.
This paper aims to address the issue of insufficient data by crawling text data from medical records on medical records (www.bingliwang.com). The crawled text was then annotated by experts using the YEDDA annotation tool43 to augment the dataset. Figure 2 provides an illustration of the data e nhancement method and the BPBIC model diagram used in this study.
Confrontation pre-training layer
Word embeddings play a crucial role in annotating text sequences and can be utilized to represent words with similar meanings in a sentence. These vectorized representations can then be used as input to a neural network. BERT is currently the most dominant language model in NLP and utilizes the bi-directional encoder part of Transformer. It does not rely on a temporal loop structure but instead relies on positional encoding to capture spatio-temporal correlation information in sequential data. Transformer is a deep network based on the self-attention model, which adjusts the connections between words in the same sentence to acquire word features. Additionally, it incorporates context into word embeddings through the use of multiple heads of attention. The formula for multi-head attention is as follows:
Where \(\:\text{Q}\), \(\:\text{K}\) and \(\:\text{V}\) are word vector matrices, \(\:{\text{d}}_{\text{k}}\) is embedding dimension, \(\:{\text{Q}\text{W}}_{\text{j}}^{\text{Q}}\),\(\:{\text{K}\text{W}}_{\text{j}}^{\text{K}}\) and \(\:{\text{V}\text{W}}_{\text{j}}^{\text{V}}\)denote the weight matrix of the \(\:\text{j}\)th head, \(\:\text{m}\) denotes the number of heads, and \(\:{\text{W}}^{\text{O}}\) is the additional weight matrix. Finally all the matrices are concatenated to obtain the result of multi-head attention calculation for the \(\:\text{j}\)th character.
In this study, the main task of BERT is to train the model to predict masked words by randomly masking some words and to make inferences using the positional information of the words. BERT uses a [CLS] tagging symbol at the beginning of each input sentence to represent the features of the entire sequence of inputs. In this paper, we also employ this representation in the downstream target task. A [SEP] symbol is used to separate two sentences. BERT is capable of learning the features of different word contexts by extracting temporal features from the position vectors and representing multisemantic words with different vectors. Figure 3a illustrates the process of sentence feature extraction by BERT.

(a) BERT feature extraction process: step.1 Segmentation of sentences; step.2 Full word mask; step.3 Add special tokens, [CLS] for sentence beginnings, [SEP] for separating sentences; step.4 Output embedding; step.5 Transformer feature extraction. (b). Embedded representation of BERT10.
BERT constructs the input representation of the token by using three embedding layers. The encoder layer of BERT receives the sum of the final embedding, token, segmentation, and positional embedding. The formula for this process is as follows.
The structure of the BERT embedding is illustrated in Fig. 3b. The [CLS] token is employed to indicate that the sentence is used for classification, while [SEP] is utilized to separate different sentences. The first layer of token embedding utilizes word piece tokenization to convert each segmentation token into a 768-dimensional vector. The second layer of segmentation embedding generates fixed tokens to determine the sentence to which the token belongs. The positional embedding encodes the positions of the vectors based on the respective word positions in the sentence.
Confrontation training
Adversarial training is a noise-injection training method aimed at enhancing the robustness and generalization capability of models under conditions of insufficient or corrupted data. Its format is as follows:
where \(\:D\) represents the training set, \(\:x\) represents the input samples, \(\:y\) represents the labels, \(\:\theta\:\) makes the model parameters, \(\:L\left(x,y;\theta\:\right)\) denotes the entire loss of a single sample, \(\:\varDelta\:x\) is the antagonistic perturbation, and \(\:\varOmega\:\) represents the perturbation space.
Adversarial training was initially applied in the field of image processing. Since text inputs are represented as one-hot vectors, the Euclidean distance remains constant, making it impossible to directly perturb the original data. Therefore, this study introduces adversarial training at the embedding layer to achieve perturbation and improve model performance. This research employs PGD adversarial training, and the training process is as follows:
-
(1)
Compute the loss of the input sample \(\:x\). Backpropagate to get the gradient and back up.
-
(2)
For each step t:
-
①
Calculate \(\:\varDelta\:x\) from the gradient of the embedding matrix and add it to the current embedding, which is equivalent to \(\:x+\varDelta\:x\)
-
②
If t is not the last step:
The gradient goes to 0. The forward and backward propagation is computed and the gradient is obtained based on \(\:x+\varDelta\:x\) of (1).
-
③
if t is the last step:
Recover the gradient to (1), compute the final \(\:x+\varDelta\:x\) and accumulate the gradient on (1).
-
①
-
(3)
Restore embedding to the value of (1).
-
(4)
Update the parameters according to the gradient of ③.
-
(5)
Repeat the process until the training is complete.
Against pre-training algorithm (BERT-PGD):

The adversarial pretraining algorithm.
BiLSTM layer
LSTM addresses the vanishing gradient problem in RNNs through the use of forgetting gates, input gates, and output gates. LSTM retains the memory cell \(\:{c}_{t-1}\) and directly passes it to the next time step, enhancing the word dependencies in NER tasks. However, LSTM may not fully capture the contextual information of sentences, which is why BiLSTM is introduced.

(a). Structure of LSTM. (b). Structure of BiLSTM.
BiLSTM combines two LSTMs, using concatenated sentence vectors \(\:{h}_{t}=\left[\overrightarrow{{h}_{t}}\:,\:\overleftarrow{{h}_{t}}\right]\) to ensure that the model contains both forward and backward information of the sentence.
Figure 4a,b illustrate the structure of the LSTM model and BiLSTM model, respectively.
The sequence \(X = \left\{ {X_{1} ,X_{2} ,X_{3} ,...,X_{{T - 1}} ,X_{T} } \right\}\)is input to the forward LSTM to obtain the forward sentence feature vector \(\:\overrightarrow{{\text{h}}_{\text{t}}}\):
The backward sentence feature vector \(\:\overleftarrow{{\text{h}}_{\text{t}}}\:\)is obtained from the backward LSTM:
Splice the two feature vectors \(\:\text{Y}\):
i.e.
The required contextual information is contained in \(\:\text{Y}\). The BiLSTM is calculated as follows:
Where \(\:{z}_{t}\) denotes the addition of moment \(\:\text{t}\), \(\:{c}_{t}\) denotes the update state of the memory cell at moment \(\:\text{t}\), \(\:{i}_{t}\), \(\:{o}_{t}\), and \(\:{f}_{t}\) are the output results of the input gate, output gate, and forgetting gate at moment \(\:\text{t}\), \(\:{\upsigma\:}\) denotes the activation function, \(\:\text{W}\) denotes the weight matrix, and \(\:\text{b}\) denotes the bias vector. In Eq. (11), \(\:{\text{h}}_{\text{t}}\) denotes the final output result of the whole LSTM, and in Eq. (12), \(\:{\text{h}}_{\text{t}}\) denotes the final output result of BiLSTM.
IDCNN layer
Normal CNN typically use convolutional kernels at successive positions of the input matrix. However, a dilated convolutional neural network (DCNN) enhances this process by increasing the dilation width. This means that when applied to the input matrix, the DCNN automatically skips input data in the expansion width, while keeping the size of the convolution kernel the same. Consequently, the convolutional kernel is able to gather data from a wider input matrix. As the number of layers increases, the dilation width also increases exponentially. While the number of parameters increases linearly with the number of layers, the receptive field expands exponentially, allowing for a quicker coverage of the entire data. You can refer to the extended convolutional neural network model in Fig. 5a,b,c.

(a) is the extended convolution with dilation width (1) (b) is the extended convolution with expansion width (2) (c) is the extended convolution with expansion width 3
The extended convolutional neural network is formulated as follows:
When α = 1, the extended convolutional network is equivalent to the traditional convolutional neural network. However, when α > 1, the extended convolutional network’s sensory field expands to capture more semantic information. The superposition of the extended convolutional neural network can capture chapter text features, but its large number of parameters makes model convergence difficult. By iterating the extended convolutional neural network, it is observed that the IDCNN can achieve the superposition effect of the extended convolutional neural network without adding extra parameters. The model stacks four extended convolutional blocks of the same size, each with an extended width of 1, 1, and 2. The global feature vector output from the BiLSTM layer is then fed into the IDCNN layer for convolution to extract local information features and finally output the feature vector.
CRFs layer
CRF is utilized for qualifying and predicting the final reasonable sequence labelled output. It effectively learns the potential relationships between sequences and eliminates the labelled sequences that do not comply with the syntactic rules of the sentence. This results in the generation of the best-labelled sequence as the output. Let’s consider the input sentence as \(X = \left\{ {x_{1} ,x_{2} ,x_{3} ,...,x_{{n - 1}} ,x_{n} } \right\}\) and the output tag sequence as \(y = \left\{ {y_{1} ,y_{2} ,y_{3} ,...,y_{{n - 1}} ,y_{n} } \right\}\). The labelling process of CRF can be summarized as follows:
In Eq. (14), A represents the transfer matrix, \(\:{\text{P}}_{\text{i},\text{j}}\) represents the probability matrix of generated labels, and \(\:{\text{A}}_{{\text{y}}_{\text{i}},{\text{y}}_{\text{i}+1}}\) represents the transfer score from label \(\:\text{i}\) to label \(\:\text{i}+1\). After processing all the sentences, the resulting output sequence follows the probability distribution as follows:
In Eq. (15), \(\:{\text{Y}}_{\text{w}}\) represents all possible instances in which the sequence label appears in the sentence. The loss function is defined as follows:
Finally, the global optimal solution of the objective is obtained by Viterbi decoding:
Experimental details
Datasets
This paper evaluates the performance of the model using the CCKS2019 dataset and the IMCS21 Chinese medical Q&A dataset[41]. The CCKS2019 dataset consists of six types of entities, which include diseases and diagnoses, imaging tests, laboratory tests, surgeries, drugs, and anatomical sites. The training and test sets of the CCKS2019 dataset contain 1000 and 379 records, respectively. Additionally, an augmented version of the CCKS2019 dataset, denoted as CCKS2019+, increases the number of records to 2000 and 679. On the other hand, the IMCS21 dataset, collected by Wei Chen et al[41], comprises medical records of 10 pediatric diseases, such as Bronchitis, fever and diarrhea, upper respiratory tract infection, indigestion, cold, cough, jaundice, constipation, and bronchopneumonia. The corpus of the IMCS21 dataset contains a total of 4116 annotated samples and 164,731 dialogues.
Data expansion process and results
This paper follows the annotation format of the CCKS2019 dataset and extracts the following entities from the crawled text data: diseases and diagnoses, imaging tests, laboratory tests, surgeries, medications, and anatomical sites. In the annotation process, this paper follows the following rules:
-
(1)
De-privatise the dataset before performing the annotation.
-
(2)
The labelling of entities cannot overlap and there can only be one entity type within the same string.
-
(3)
The labelling of entities cannot be nested and one entity cannot contain another.
-
(4)
Try to avoid punctuation within the entity.
-
(5)
If entity modifier symbols exist, such as “?“, “+”, “-“, etc., they may be labelled.
The main common encoding types in NER are BIO encoding and BIOES encoding. This paper chooses BIO encoding to be consistent with the CCKS2019 dataset encoding format. In the BIO encoding format, B- denotes the start of the entity, I- denotes the part of the entity other than the start, and O- denotes the non-entity part.
Jie Yang22 proposed YEDDA, a lightweight, efficient, and comprehensive open-source tool for text spanning annotation. This tool offers a systematic solution for text spanning annotation. An example of processing a piece of text data using the YEDDA annotation platform is shown in Fig. 6.

Example of medical text labelled using YEDDA.
A total of 1300 medical records were annotated in this study. Table 1 presents the distribution of the number of each type of entity in the CCKS2019 dataset, the number of each type of entity expansion, and the number of each type of entity in the CCKS2019 + dataset.
The CCKS2019 dataset will be divided into training set and test set according to 8:2. Table 2 gives the distribution of various types of entities in the CCKS2019 dataset training and test sets.
Model parameter setting
The experiments were conducted on a GPU server. Table 4 presents the optimal hyperparameter settings for the model, while Table 5 provides details of the experimental environment. This study primarily utilized python version 3.8, keras 2.6.0, tensorflow 2.6.0, and other required libraries to implement the models described in this paper. During the training process, the parameters were optimized using the Adam optimizer, and an early stop method strategy was employed to prevent model overfitting. The early stop was set to 5, meaning that if the model did not improve after 5 training sessions, the training process would be halted. After conducting several experiments, the optimal hyperparameters for the BPBIC model were determined as follows: embedding dimension of 128, hidden dimension of 128, maximum sequence length of 256, batch size of 32, dropout rate of 0.3, learning rate of 1e-3, and epoch of 60. The embedding dimension reduces the dimensionality of sparse matrices. Hidden dimensionality abstracts the features of the input data into another dimensional space, showing more abstracted features for better linear division. Maximum sequence length refers to the maximum input length accepted by the transformer. Batch size indicates the number of batch samples. Dropout layer helps mitigate the overfitting effect of the deep neural network, and it is set to 0.3 in this paper. Learning rate determines the magnitude of weight updates in the optimization algorithm. Adam is used as the optimization algorithm in this paper, with a learning rate of 1e-3. The number of iterations refers to the number of times the entire training set is used for training the neural network. Figure 7 illustrates the training performance of the BPBIC model on the CCKS2019 dataset.

Training performance of the BPBIC model on the CCKS2019 dataset. (a) Average training loss iteration. (b) Average training accuracy iterations. (c) Iteration of average F1 Score on the validation set.
Evaluation of indicators
Precision, recall, and F1 Score are commonly used as evaluation metrics in NER tasks. Precision measures the accuracy of the model by indicating the number of correctly labeled predicted entities, which is the ratio of the number of correctly identified positive samples to the total number of samples classified as positive. Recall, on the other hand, measures the ability of the model to predict actual positive samples by indicating the number of correctly predicted entities. F1 Score is a weighted average that balances the relationship between precision and recall. It provides a single metric to evaluate the model’s performance.
Where TP (True Positives) means that positive samples are correctly classified as positive samples, TN (True Negatives) means that negative samples are correctly classified as negative samples, FP (False Positives) means that negative samples are incorrectly classified as positive samples and FN (False Negatives) means that positive samples are incorrectly classified as negative samples.
Experimental results and analyses
Medical entity recognition experimental results
In this study, the BiLSTM-CRF baseline model is improved. The predicted results of the improved model are given in Table 6.
To evaluate the performance of the BPBIC model, we conducted an experiment using the CCKS2019 dataset. We compared the results of the BPBIC model with those of nine other Chinese medical NER models. Additionally, we compared the results of the augmented CCKS2019 + dataset with the original CCKS2019 dataset to assess the effectiveness of the augmented dataset. Each model was tested five times in the same experimental environment, and the best results were selected.
To further validate the generalisation ability of the model, this study used the IMCS21 dataset to input the BPBIC model and compared its prediction results with those of the Lattice LSTM model, BERT-CRF model, ERNIE model, FLAT model, LEBERT model, MC-BERT model and ERNIE-Health model44 are compared. Figure 8 demonstrates the results of precision, recall and F1 Score comparison for each model.

Comparison of prediction results of BPBIC model, Lattice LSTM model, BERT-CRF model, ERNIE model, FLAT model, LEBERT model, MC-BERT model, ERNIE-Health model.
Analysis of medical entity recognitio MRC-based medical NER with multi-task learning and mult N experiment results
This study presents the development of an NLP algorithm aimed at extracting clinically useful information from free text in Chinese EHRs. The algorithm demonstrates high performance in terms of precision, recall, and F1 Score when analyzing various medical information documents.
Training analysis
The training results of the BPBIC model on the CCKS2019 dataset are presented in Fig. 7. The training curves in Figs. 7a,b demonstrate that the training error loss stabilizes gradually after 25 rounds of iterations. The model achieves its highest training accuracy (98.04%) in the 36th round and maintains stability thereafter. Figure 7c illustrates the average F1 Score of the validation set, which gradually increases and stabilizes at around 92% during training. The growth of the F1 Score stops at round 51.
Analysis of model ablation experiments
By combining BiLSTM and IDCNN with CRF for sequence decoding, the precision, recall, and F1 Score are improved by 2.95%, 2.25%, and 2.61%, respectively, compared to the BiLSTM-CRF model. This improvement can be attributed to the enhanced access to local information features in the sentence through the fusion of IDCNN. The introduction of BERT further enhances all metrics, with a 6–9% improvement. After incorporating BERT, the precision, recall, and f1 score of the baseline model BiLSTM-CRF improve by 8.57%, 8.44%, and 8.51%, respectively. Similarly, the BiLSTM-IDCNN-CRF model shows improvements of 5.64%, 6.62%, and 6.14% in precision, recall, and f1 score, respectively, after combining with BERT.
In order to enhance the robustness and generalization of the model, this paper incorporates the PGD adversarial training algorithm after the BERT layer. The experimental results in Table 6 demonstrate that the model achieves an improvement of 0.29%, 0.66%, and 0.47% in precision, recall, and F1 Score, respectively, after the implementation of PGD adversarial training.
Comparison of predictions from different models
In this paper, we compare the prediction results of the BPBIC model with existing state-of-the-art models. The comparison is detailed in Table 7. Literature23 combines a multi-head self-attention model with BiLSTM-CRF to integrate character and word vectors. The model achieves a precision, recall, and F1 Score of 83.79, 82.12, and 82.95%, respectively. However, it struggles to identify the ‘Sur’ entity clearly. Literature [28], on the other hand, builds upon the BiLSTM-CRF model by incorporating a joint multilevel CNN to capture short- and long-term contextual information. It also uses an attention mechanism to focus on global contextual information. The precision, recall, and F1 Score of this model are 83.07%, 87.29%, and 85.13%, respectively. However, it is not effective in detecting ‘Ins’ entities. In our study, we achieved a precision, recall, and F1 Score of 91.57, 91.97, and 91.77%, respectively. The prediction results of our paper not only surpass these classical models but also outperform the known state-of-the-art models.
The prediction results of the augmented dataset in this study under different models are detailed in Table 8. By comparing Tables 7 and 8, it can be observed that the augmented dataset shows a 2–3% improvement in effectiveness for each model. These experimental results provide evidence for the reliability of the augmented data used in this study.
Comparison of IMCS21 dataset in different model prediction results
In a comparative study41, various models such as Lattice LSTM, BERT-CRF, ERNIE, FLAT, LEBERT, MC-BERT, and ERNIE-Health were evaluated for their prediction performance. The research employed the IMCS21 dataset to train the BPBIC model, and the prediction results are depicted in Fig. 8. The findings demonstrate that the BPBIC model surpasses the ERNIE-Health model41 in terms of accuracy (2.29% improvement) and F1 score (1.01% improvement) on the IMCS21 dataset.
The precision, recall, and F1 Score of the experimental results are closely related to the evaluated values of different entities. Therefore, it is crucial to consider the details of the precision, recall, and F1 Score for each entity in the dataset when evaluating the model’s performance. Figures 9 and 10, and 11 present the evaluated values of each entity in the BPBIC model for the three datasets: CCKS2019, CCKS2019+, and IMCS21, respectively.

CCKS2019 dataset assessed values for each entity.

CCKS2019 + dataset assessed values for each entity.
Figures 9 and 10, and 11 illustrate the variations in entity recognition performance across different datasets. From Fig. 9, it is evident that the metrics for ‘Dsa’, ‘Chk’, and ‘Ana’ are all approximately 90%, while the metrics for ‘Sur’ and ‘Med’ are above 92%, with ‘Sur’ reaching over 96%. However, the metrics for ‘Ins’ are only around 80%. Nevertheless, Fig. 10 shows that all the indicators for ‘Ins’ have been improved to varying degrees. This paper argues that the low assessment indicators of ‘Ins’ entities in the CCKS2019 dataset can be attributed to the uneven distribution of this entity type in the dataset. Figure 10 illustrates that while the accuracy rate of ‘Ins’ is 89.98%, the indicators for other entities surpass 91%. Notably, the three indicators for ‘Dsa’ exceed 92%, while ‘Sur’, ‘Med’, and ‘Ana’ all have indicators above 91%. Moreover, ‘Sur’, ‘Med’, and ‘Ana’ consistently exceed 93% for all indicators. Particularly, ‘Med’ achieves over 96% for all indicators. Comparing with Fig. 9, the precision rate, recall rate, and recall rate for the four entity types, ‘Dsa’, ‘Ins’, ‘Med’, and ‘Ana’, all exceed 93%. Dsa, Ins, Med, and Ana all showed improvements in terms of precision, recall, and F1 Score. Dsa increased by 2.92%, 0.73%, and 1.39%; Ins increased by 7.39%, 17.92%, and 12.54%.

Evaluated values for each entity in the IMCS21 dataset.
Med increased by 2.14%, 3.76%, and 2.98%; and Ana increased by 1.51%, 0.47%, and 0.99%. Among them, Ins showed the largest increase in all indicators. The issue of uneven distribution of entities was addressed by expanding the dataset. The precision rate of ‘Chk’ decreased by 2.70%, while the recall rate and F1 Score increased by 4.02% and 0.79%, respectively. The three indexes of Sur decreased by 1.37%, 0.53%, and 0.93%. There are two possible reasons for this result. The first reason is a labelling error, e.g., “在**全麻行直肠癌根治术(DIXON术)[O O O O O O B-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur ]” is mislabelled as “在**全麻行直肠癌根治术,(DIXON术) [O O O O O B-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur I-Sur ]”. The second reason is that the CCKS2019 + dataset includes a mix of Chinese and English when labelling ‘Sur’ entities, which leads to unclear recognition of word boundaries by the model. Consequently, the expected experimental results are not achieved for the two types of entities, ‘Chk’ and ‘Sur’. Overall, the gap between the indicators of entities is within 3%, and the indicators for various types of entities are well-balanced. Figure 11 presents the evaluation results of the BPBIC model on the short sentence dataset IMCS21. The results indicate that all three indicators for ‘Sym’ are above 91%, and the indicators for ‘Dru’ and ‘Exam’ are above 80%. As for ‘Dry’, its precision rate, recall rate, and F1 Score reached 80.02%, 77.70%, and 77.73% respectively. However, the indicators for ‘Ope’ are only around 50%. This paper suggests that the unsatisfactory prediction is due to the small training sample size of the ‘Ope’ entity.
In a recent study by Jia Ke45, the RoFormerV2-BiLSTM-CRF fusion model was employed to address the issues of word unstructuredness, unclear boundaries, and word polysemy in Chinese EHRs. RoFormerV2 eliminates bias terms from RoFormer, enhancing the training speed, and utilizes a pre-trained model with an updated residuals module to ensure model convergence in backpropagation. This study compares the precision, recall, and F1 Score of Word2Vec-BiLSTM-CRF, RoFormerV2-BiLSTM-CRF, and BPBIC. The line graphs depicting the comparative precision, recall, and F1 Score of Word2Vec-BiLSTM-CRF, RoFormerV2-BiLSTM-CRF, and BPBIC can be found in Fig. 12.

Comparison of precision, recall, and F1 Score of Word2Verc-BiLSTM-CRF, RoFormerV2-BiLSTM-CRF, and BPBIC Fold Plot.
The experimental results indicate that both BPBIC and RoFormerV2-BiLSTM-CRF models outperform Word2Vec-BiLSTM-CRF in terms of all entity types. Specifically, RoFormerV2-BiLSTM-CRF achieves higher recall scores than the BPBIC model by 2.24% and 1.19% for the ‘Chk’ and ‘Med’ entities, respectively. This improvement in recall scores for ‘Med’ entities can be attributed to the presence of entities with ambiguous boundaries, such as “腹盆CT” and “AVASTIN”. However, when it comes to overall performance, BPBIC outperforms both Word2Vec-BiLSTM-CRF and RoFormerV2-BiLSTM-CRF models, except for the boundary recognition of ‘Chk’ and ‘Med’ entities where RoFormerV2-BiLSTM-CRF surpasses BPBIC.
Medical knowledge graph analysis
Knowledge graph for single patient EHRs
The construction of a knowledge graph relies on the triad of ‘entity-relationship-entity’. In this study, we utilized Neo4J software to extract information from the CCKS2019 dataset and created a patient-centric knowledge graph. The version of Neo4j we used in this paper is 5.8.0. The code can be accessed at https://github.com/Zhanxxu/BPBIC.git. Figure 13 illustrates an example of constructing a knowledge graph for a single patient’s EHR. The knowledge graph is centered around the patient and directly relates to six healthcare entities: “疾病和诊断”, “检查”, “检验”, “药物”, “手术” and “解剖部位”. These entities are medical entities identified from the EHR, and the relationships between them are depicted by the connected edges in the knowledge graph.

Example of a single patient EHR knowledge graph.
-
(1)
‘Medical_Entity’: this is the direct relationship between the patient and the medical entity (grey circle) and includes “疾病和诊断”、“解剖部位” and “检查”, etc.
-
(2)
‘Belong_To’: this is the relationship between entity-specific properties and entities, such as “伯尔定-Belong_To-药物”,“子宫-Belong_To-解剖部位”.
-
(3)
‘Result’: this is the result pointed to by the specific performance of the checking entity (red circle) and the specific performance of the testing entity, which is the result entity after the patient has done the checking, such as “CT-Result-CT示: ……”.
-
(4)
‘Treatment’: this is the relationship between a drug-specific entity (green circle) and a disease-specific entity (purple circle), for example: “伯尔定-Treatment-颗粒细胞瘤”、“泰素-Treatment-颗粒细胞瘤”.
-
(5)
‘Early_Symptom’: this is the relationship between the symptom (yellow circle) and the specific disease, for example : “颗粒细胞瘤-Early_Symptom-腹胀”.
-
(6)
‘Inferred_Diagnosis’: this is the relationship between the test result (orange circle) and the disease, such as “CT示: -Inferred_Diagnosis-颗粒细胞瘤”.
Knowledge mapping of multi-patient EHRs
The results of multiple EHRs and their entity identification are imported into Neo4J. After visualizing the data using GraphXR, we can observe an example of the multi-patient EHR knowledge graph shown in Fig. 14a. In this graph, patients, entities, and entity-specific properties are represented as nodes. By selecting the ‘Patient’ node, users can access basic information about the patient, such as their name, symptoms, disease, diagnosis, and general conditions since discharge. The ‘Neighbours’ option allows users to explore the entities connected to the patient node. This comprehensive graph provides insights into the patient’s disease progression, treatments, and other relevant information by establishing relationships between semantic entities.

(a) Example of knowledge graph for multi-patient EHRs. (b). The process of finding relevant nodes in the knowledge graph.
After establishing the knowledge graph, the required relationships can be found within it. The process begins by starting from the patient node and identifying the relationship with the anatomical site node. From there, the relationship between the specific performance nodes can be determined through the anatomical site node. Figure 14(b) visually represents this process in a multi-patient knowledge graph, with the relevant paths highlighted in bold lines.
Conclusion
This paper introduces the BPBIC model, a hybrid neural network that utilizes adversarial BERT. The model employs Chinese pre-trained BERT to represent text word vectors and utilizes the positional coding layer of BERT to obtain contextual embeddings for each character. Additionally, perturbations are incorporated into the Embedding layer to enhance the model’s robustness and generalization. The BPBIC model combines BiLSTM and IDCNN models to capture both global and local features of the sentence. Finally, the model utilizes CRF in the last layer to obtain the optimal solution for sequence decoding. This study demonstrates the effectiveness of the method in Chinese medical entity extraction by analyzing the prediction results. To address the issues of a small dataset and uneven distribution of entities, experts were consulted to annotate the crawled medical text data and expand the CCKS2019 dataset. The results indicate that the CCKS2019 + dataset has improved evaluation metrics for each model. Additionally, this paper applies the BPBIC model to the entity recognition task on different datasets and analyzes its effect on each entity metric. Furthermore, a medical knowledge graph was constructed and analyzed. In future research, efforts will be made to train more comprehensive pre-trained models for Chinese medical texts, aiming to further enhance the recognition ability of BPBIC on entity recognition tasks and construct more comprehensive knowledge graphs.
Data availability
The source code and dataset for BPBIC can be accessed at: https://github.com/Zhanxxu/BPBIC.git. For any reasonable questions or requests, please contact the corresponding author. Corresponding author. E-mail address: t20050514@csuft.edu.cn (S. Che).
References
Zhao, S., Luo, R., Cai & Zhiping survey of Chinese named entity recognition. J. Front. Comput. Sci. Technol. 16 (2), 296–304 (2022).
Grishman, R. & Beth, M. Sundheim. Message understanding conference-6: A brief history. COLING 1996 volume 1: The 16th international conference on computational linguistics. (1996).
Humphreys, K. et al. UNIVERLSaSITIEY-IOI FSYSSHTEEFMFIAELSDU:SDEEDSCFORRIPTMIUOCN-7OF THE.
Description of. the NetOwlTM extractor system as used for MUC-7.
Li, J. et al. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 34 (1), 50–70 (2020).
Eddy, S. R. Hidden Markov models. Curr. Opin. Struct. Biol. 6 (3), 361–365 (1996).
Lafferty, J., McCallum, A. & Pereira, F. Conditional random fields: probabilistic models for segmenting and labeling sequence data. Icml 1 (2), 3 (2001).
Jozefowicz, R., Zaremba, W. & Sutskever, I. An empirical exploration of recurrent network architectures. International conference on machine learning. PMLR, : 2342–2350. (2015).
Yu, F. & Koltun, V. Multi-scale context aggregation by dilated convolutions. Preprint https://arXiv.org/1511.07122. (2015).
Devlin, J. et al. Pre-training of deep bidirectional transformers for language understanding. Proceedings of the conference of the North American chapter of the association for computational linguistics: human language technologies, 1 (2019).
Ji, B. et al. A hybrid approach for named entity recognition in Chinese electronic medical record. BMC Med. Inf. Decis. Mak. 19, 149–158 (2019).
Li, L. et al. Biomedical named entity recognition based on extended recurrent neural networks. IEEE International Conference on bioinformatics and biomedicine (BIBM). IEEE, 2015: 649–652. (2015).
Xie, Y., Li, A. & Zhong, C. Research on effects of pre-trained language models in medical named entity recognition. Proceedings of the 2021 9th International Conference on Information Technology: IoT and Smart City. 148–153. (2021).
Habibi, M. et al. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics 33 (14), i37–i48 (2017).
Wu, Y. et al. Named entity recognition in Chinese clinical text using deep neural network. MEDINFO 2015: eHealth-enabled Health. IOS Press, : 624–628. (2015).
Sharma, R., Morwal, S. & Agarwal, B. Named entity recognition using neural Language model and CRF for Hindi Language. Comput. Speech Lang. 74, 101356 (2022).
Li, W. et al. UD_BBC: named entity recognition in social network combined BERT-BiLSTM-CRF with active learning. Eng. Appl. Artif. Intell. 116, 105460 (2022).
Wang, Y. et al. An improved entity recognition approach to cyber-social knowledge provision of intellectual property using a CRF-LSTM model. Pattern Recognit. Lett. 163, 145–151 (2022).
Teng, L. et al. Khmer named entity recognition based on LSTM-CRF model. Wireless Technology, Intelligent Network Technologies, Smart Services and Applications: Proceedings of 4th International Conference on Wireless Communications and Applications (ICWCA 2020). Springer Singapore, 175–187. (2022).
Yu, B. & Wei, J. IDCNN-CRF-based domain named entity recognition method. IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT). IEEE, 2020: 542–546. (2020).
Li, Y. et al. Chinese clinical named entity recognition in electronic medical records: development of a lattice long short-term memory model with contextualized character representations. JMIR Med. Inf. 8 (9), e19848 (2020).
Mikolov, T. et al. Efficient Estimation of word representations in vector space. Preprint https://arXiv.org/1301.3781 (2013).
Pennington, J., Socher, R., Manning, C. D. & Glove Global vectors for word representation. Proceedings of the conference on empirical methods in natural language processing (EMNLP). 2014: 1532–1543. (2014).
Peters, M. et al. Deep Contextualized Word Representations. Proc 2018 Conf North Am Chapter Assoc Comput Linguist Hum Lang Technol Vol 1 Long Pap [Internet]. New Orleans, Louisiana: Association for Computational Linguistics; [cited 2023 Aug 21] . 2227–37. (2018). Available from: http://aclweb.org/anthology/N18-1202
Radford, A. et al. Improving language understanding by generative pre-training.[EB/OL]. (2018).
Lee, L. H., Lu, C. H., Lin, T. M. & NCUEE-NLP at SemEval-2022 Task 11: Chinese named entity recognition using the BERT-BiLSTM-CRF model. Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval- 2022: 1597–1602. (2022).
Lee, L. H. et al. ROCLING. Overview of the ROCLING 2022 shared task for Chinese healthcare named entity recognition. Proceedings of the 34th Conference on Computational Linguistics and Speech Processing 2022 363–368. (2022).
Zhong, S. & Yu, Q. Improving Chinese medical named entity recognition using glyph and lexicon. Proceedings of the AEIM 75–80. (2021).
Li, C. & Ma, K. Entity recognition of Chinese medical text based on multi-head self-attention combined with BILSTM-CRF. Math. Biosci. Eng. 19 (3), 2206–2218 (2022).
Kong, J. et al. Incorporating multi-level CNN and attention mechanism for Chinese clinical named entity recognition. J. Biomed. Inform. 116, 103737 (2021).
Shi, J. et al. Multi-level semantic fusion network for Chinese medical named entity recognition. J. Biomed. Inform. 133, 104144 (2022).
Li, J. et al. An RG-FLAT-CRF model for named entity recognition of Chinese electronic clinical records. Electronics 11 (8), 1282 (2022).
Ji, B. et al. Research on Chinese medical named entity recognition based on collaborative Cooperation of multiple neural network models. J. Biomed. Inform. 104, 103395 (2020).
Ni, P. et al. StaResGRU-CNN with CMedLMs: A stacked residual GRU-CNN with pre-trained biomedical Language models for predictive intelligence. Appl. Soft Comput. 113, 107975 (2021).
Chen, P. et al. Named entity recognition of Chinese electronic medical records based on a hybrid neural network and medical MC-BERT. BMC Med. Inf. Decis. Mak. 22 (1), 315 (2022).
Du, X., Jia, Y. & Zan, H. MRC-based medical NER with multi-task learning and multi-strategies. China National Conference on Chinese Computational Linguistics. Cham: Springer International Publishing, : 149–162. (2022).
Liu, P. et al. Chinese named entity recognition: the state of the art[J]. Neurocomputing 473, 37–53 (2022).
Yu, L. et al. Seqgan: Sequence generative adversarial nets with policy gradient. Proceedings of the AAAI conference on artificial intelligence 31 (1). (2017).
Guo, J. et al. Long text generation via adversarial training with leaked information. Proceedings of the AAAI conference on artificial intelligence 32 (1). (2018).
Liu, Z., Wang, J., Liang, Z. & Catgan Category-aware generative adversarial networks with hierarchical evolutionary learning for category text generation. Proceedings of the AAAI Conference on Artificial Intelligence 34 (05) 8425–8432. (2020).
Goodfellow, I. J., Shlens, J. & Szegedy, C. Explaining and Harnessing adversarial examples. Preprint at https://arXiv.org/1412.6572 (2014).
Mądry, A. et al. Towards deep learning models resistant to adversarial attacks. Stat, 1050(9). (2017).
Yang, J. et al. YEDDA: A lightweight collaborative text span annotation tool. Preprint at https://arXiv.org/1711.03759 (2017).
Chen, W. et al. A benchmark for automatic medical consultation system: frameworks, tasks and datasets. Bioinformatics 39 (1), btac817 (2023).
Ke, J. et al. Medical entity recognition and knowledge map relationship analysis of Chinese EMRs based on improved BiLSTM-CRF. Comput. Electr. Eng. 108, 108709 (2023).
Acknowledgements
This work was supported by the TAPU Research Fund (Grant No. 2024-1128-01-HNTP01).
Author information
Authors and Affiliations
Contributions
Xu Zhang: Conceptualization, Methodology, Writing - original draft, Software. Youchen Kao: Revise manuscript, methodology, writing, software. Shengbing Che: Conceptualization, Methodology, Writing – review & editing, Funding acquisition, Supervision. Juan Yan: Data curation, Formal analysis. Sha Zhou: Project administration, Methodology, Investigation. Shenyi Guo: Visualization, Methodology. Wanqin Wang: Visualization, Writing - original draft.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Word interpretation
‘Dsa’ denotes “疾病和诊断”, ‘Chk’ denotes “影像检查”, ‘Ins’ denotes “实验室检验”, ‘Sur’ denotes ““手术”, ‘Med’ means “药物”, ‘Ana’ means “解剖部位”, ‘Sym’ for “症状”, ‘Dru’ for “药品名称”, ‘Dry’ for “药物类别”, ‘Exam’ for “检查”, ‘Ope’ means “操作”.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, X., Kao, Y., Che, S. et al. Chinese medical named entity recognition integrating adversarial training and feature enhancement. Sci Rep 15, 14844 (2025). https://doi.org/10.1038/s41598-025-98465-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-98465-3
