
Abstract
EEG is widely applied in emotion recognition, brain disease detection, and other fields due to its high temporal resolution and non-invasiveness. However, artifact removal remains a crucial issue in EEG signal processing. Recently, with the rapid development of deep learning, there has been a significant transformation in the methods of EEG artifact removal. Nonetheless, existing research still exhibits some limitations: (1) insufficient capability to remove unknown artifacts; (2) inability to adapt to tasks where artifact removal needs to be applied to the overall input of multi-channel EEG data. Therefore, this study proposes CLEnet by integrating dual-scale CNN (Convolutional Neural Networks) and LSTM (Long Short-Term Memory), and incorporating an improved EMA-1D (One-Dimensional Efficient Multi-Scale Attention Mechanism). CLEnet can extract the morphological features and temporal features of EEG, thereby separating EEG from artifacts. We conducted experiments on three datasets, and the results showed that CLEnet performed best. Specifically, in the task of removing artifacts from multi-channel EEG data containing unknown artifacts, CLEnet shows improvements of 2.45% and 2.65% in SNR(signal-to-noise ratio) and CC(average correlation coefficient). Moreover, RRMSEt(relative root mean square error in the temporal domain) and RRMSEf (relative root mean square error in the frequency domain) decrease by 6.94% and 3.30%.
Similar content being viewed by others
Electroencephalography (EEG) is a non-invasive technique and used to detect and record human brain electrical activity by placing electrodes on the scalp. EEG measures and records the electrical activity of neurons in the brain1, aiding doctors and researchers in understanding the functionality and activity of the brain under different conditions. Due to its advantages of high temporal resolution, portability, and non-invasiveness2, EEG is widely utilized in various fields such as monitoring sleep quality3, recognizing emotions4, detecting Alzheimer’s disease5,6,7,8,9,10, and detecting epilepsy11. However, EEG is a nonlinear, non-stationary, and easily interfered-with signal, which leads to EEG recordings being typically composed of electric signals generated by neuronal activity, other electrophysiological signals from the human body12 (such as Electrooculography (EOG), Electromyography (EMG), Electrocardiography (ECG)), and non-physiological signals (such as spatial electromagnetic noise)13. The presence of these uncertain artifacts and noise significantly reduces the quality of EEG recordings, posing challenges for accurate data analysis and impeding the development of EEG-related research and applications. Therefore, finding effective methods to remove these artifacts and noise while preserving EEG genuine information as much as possible holds paramount theoretical and practical significance.
Non-physiological noise can be removed by methods such as replacing the collection electrodes and using notch filters. In contrast, physiological artifacts such as EMG and EOG are difficult to remove using the aforementioned simple methods due to the irregularity of their movements and the overlap in frequency bands with common rhythmic EEG signals. Therefore, it is necessary to employ suitable artifacts removal algorithms to eliminate physiological artifacts from the collected EEG data. Existing methods for removing physiological artifacts include regression14, filtering15, wavelet transform decomposition16, blind source separation (BSS)17, and hybrid methods18,19. Regression methods primarily rely on setting a reference channel and using linear transformation to subtract the estimated artifact from the contaminated EEG, thus obtaining artifact-free EEG. However, the performance of regression methods for artifact removal significantly decreases in the absence of a reference signal. Additionally, a reference signal requires a separate channel for recording, which increases the operational difficulty and cost of EEG acquisition. The widely used filtering methods currently have certain limitations in practical applications. These methods typically require strict conditions to be met and have relatively limited applicability. Due to the significant overlap in the frequency spectra between physiological artifacts such as EMG and EOG and the effective components of EEG, it’s difficult to effectively separate these artifact components. BSS methods include principal component analysis (PCA)20, independent component analysis (ICA)21, empirical mode decomposition (EMD)22, canonical correlation analysis (CCA)23, and others. These methods map the signals contaminated by artifacts into another new data space through certain transformations. Then, they remove the components corresponding to artifacts using established criteria or manual intervention and reconstruct the remaining components to obtain artifact-free EEG. While BSS methods exhibit significant effectiveness in artifact removal, and combining multiple BSS algorithms can further enhance performance, they also have notable limitations. These limitations include the requirement for a large number of channels, sufficient prior knowledge, and manual selection for component rejection.
In recent years, with the improvement of hardware computing capabilities, increased availability of computational resources, enhanced processing power for big data, and the design of novel network architectures, deep learning (DL) has seen rapid development. Significant breakthroughs have been made in the performance of DL neural network models. As a result, DL has been applied across various domains to address different technical challenges, such as images24,26,27,28 and natural language processing25,29,30. Neural networks can learn deep-level features of EEG, enabling various tasks such as classification and reconstruction. Therefore, there has been a shift towards using DL-based methods for EEG artifact removal. Sun et al.13 proposed a one-dimensional residual convolutional neural network(1D-ResCNN) that utilizes three convolutional kernels of different scales to extract features from artifact-contaminated EEG data and reconstructs artifact-free EEG using features from three scales. Zhang et al.31 introduced a semi-synthetic benchmark dataset for removing EMG and EOG artifacts. They employed four different network architectures: fully connected network (FC), simple convolutional neural network without residual connections (SimpleCNN), complex convolutional neural network with residual connections and multiple branches (ComplexCNN), and recurrent neural network (RNN) for artifacts removal. They found that FC and RNN were suitable for removing EMG, while SimpleCNN and ComplexCNN were more effective in removing EOG. Therefore, Zhang et al. later designed a novel convolutional neural network (NovelCNN)32 specifically for removing EMG artifacts. Pu et al.33 utilized a Transformer-based neural network named EEGDNet to focus on local and non-local features at the same time for artifact removal. Since real EEG data is closely related to brain activity and exhibits strong temporal dependencies. So, DuoCL34, based on CNN and LSTM, was designed. DuoCL can effectively capture the temporal features of EEG to better separate artifact-free EEG from artifacts.
The methods based on DL have overcome the limitations of traditional approaches, such as the need for setting reference channels or manual inspection, thereby achieving automated artifact removal. However, the network structures of the aforementioned methods are often tailored to specific artifacts. For instance, NovelCNN based on CNN excels in removing EMG artifacts32, while EEGDNet based on the Transformer demonstrates outstanding performance in removing EOG artifacts, but may exhibit significant deviations when applied to other types of artifacts33. Due to DuoCL separation of attention between temporal and morphological features, the original temporal features may be disrupted during the process of extracting morphological features, which leads a decrease in the efficiency of LSTM in extracting temporal features34. Additionally, the aforementioned networks are designed for tasks involving single-channel EEG inputs, overlooking the inter-channel correlations of EEG signals. Consequently, they perform poorly in artifact removal tasks involving multi-channel EEG inputs. In summary, network structures capable of removing various types of artifacts and performing artifacts removal on multi-channel EEG have broader prospects for development.
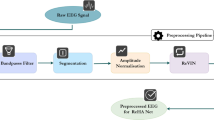
In this study, we combine CNN, LSTM, and an improved version of EMA-1D to design a dual-branch neural network model called CLEnet. Inspired by the Efficient Multi-Scale Attention (EMA)35 applied to two-dimensional images, EMA-1D is designed to capture pixel-level relationships through cross-dimensional interactions. CLEnet achieves artifact removal in an end-to-end manner, with the overall process (Section III) divided into three stages: (1) Morphological feature extraction and temporal feature enhancement. CLEnet employs two convolutional kernels of different scales to identify and extract morphological features at different scales, with the main network architecture consisting of stacked CNN. We embed EMA-1D into the CNN to maximize the extraction of genuine EEG morphological features while preserving and enhancing the temporal features of EEG; (2) Temporal feature extraction. The features extracted in the first stage are dimensionally reduced using fully connected layers to remove redundant information. Subsequently, LSTM is employed to preserve the temporal features of genuine EEG; (3) EEG reconstruction. The fused and enhanced features are flattened, and fully connected layers are used to reconstruct them into artifact-free EEG. The entire process trains CLEnet in a supervised manner, utilizing mean squared error(MSE) as the loss function.
The study utilized three EEG datasets. Dataset I: A semi-synthetic dataset formed by combining single-channel EEG, EMG, and EOG provided by EEGdenoiseNet31 in a specific manner. Dataset II: A semi-synthetic dataset created by combining ECG data obtained from the MIT-BIH Arrhythmia Database36,37 with single-channel EEG provided by EEGdenoiseNet31, following the same method as Dataset I. Dataset III: The dataset consist of real 32-channel EEG data collected from healthy university students performing a 2-back task by our team. Since the proportion of common artifacts such as EMG and EOG relative to the original signal is unknown, and physiological artifacts such as vascular pulsation and swallowing may also be present, the artifacts in this dataset are referred to as unknown artifacts. The three datasets were used for training and evaluation of CLEnet (Section IV-C). The research findings indicate: (1) Compared to mainstream models (1D-ResCNN, NovelCNN, DuoCL), CLEnet effectively eliminates EMG, EOG, and mixed artifacts (EMG + EOG). In the task of removing mixed artifacts (EMG + EOG), CLEnet achieved the highest signal-to-noise ratio(SNR: 11.498dB) and average correlation coefficient(CC: 0.925), as well as the lowest root mean square error in the temporal domain(RRMSEt: 0.300) and frequency domain (RRMSEf: 0.319); (2) CLEnet demonstrated superiority over mainstream models in the task of ECG artifact removal. Compared to DuoCL, CLEnet model, CLEnet showed a 5.13% increase in SNR, a 0.75% increase in CC, an 8.08% decrease in RRMSEt, and a 5.76% decrease in RRMSEf; (3) In experiments conducted on the team-collected dataset, CLEnet outperformed other models in the task of multi-channel EEG artifact removal, including EMG, EOG, and unknown artifacts. Compared to DuoCL, the SNR and CC of CLEnet increased by 2.45% and 2.65%, respectively, while RRMSEt and RRMSEf decreased by 6.94% and 3.30%, respectively. Furthermore, we conducted ablation experiments by removing the EMA-1D module from CLEnet, and observed a significant decrease in model performance, thus confirming the effectiveness of the EMA-1D module.
The main contributions of this study are as follows: (1) Dataset Contribution: Our team has collected a 32-channel EEG dataset containing unknown artifacts, establishing a benchmark experimental resource for advancing research on multi-channel EEG artifact removal. This dataset specifically addresses complex scenarios involving unknown noise sources, providing a foundation for developing and validating artifact removal algorithms under realistic conditions; (2) Methodology Innovation: We propose CLEnet, a novel deep learning framework designed to automatically remove diverse EEG artifacts, including unknown and hybrid artifacts, from both single- and multi-channel EEG. CLEnet model exhibits superior performance compared to mainstream artifact removal methods, particularly in adaptability (handling variable noise types) and reconstruction accuracy (preserving neural signal integrity). This aligns with recent advances in EEG feature extraction and temporal dynamics modeling; (3) Technical Advantage: CLEnet uniquely integrates advanced feature extraction modules to capture morphological characteristics of EEG signals while preserving temporal dynamics. This dual emphasis enables robust reconstruction of artifact-free EEG signals without compromising critical neurophysiological information.
Related works
CNN
CNN is a deep learning model widely used in the field of computer vision, which effectively processes and extracts image features by simulating the visual system of living organisms. The core component of CNN is the convolutional layer. In the convolutional layer, a set of convolutional kernels (also known as filters) is defined to perform convolution operations on input images, capturing local features within the images. Moreover, convolutional kernels possess translational invariance, meaning they can detect the same features at different positions within an image. By combining multiple convolutional kernels, CNN can learn rich feature representations.
Leveraging the powerful feature extraction capability of CNN, we designed two separate branches of convolutional layers to extract morphological features of different scales from EEG data in this study.
EMA
In 2023, Yang et al.35 proposed EMA for various images processing tasks. EMA not only reduces computational costs but also surpasses previous attention mechanisms in tasks such as images classification and object detection.
EMA adopts a parallel subnet structure, employing convolutional kernels of different sizes at various scales to gather spatial information across multiple scales. Subsequently, EMA utilizes Cross-spatial learning to effectively model global information encoding and long-range dependencies, thereby forming a more robust structure capable of handling short-term and long-term dependencies. Finally, it generates two spatial attention weight values to combine with input features, capturing pixel-level pairwise relationships and highlighting the global context of all pixels.
As EMA can attend to both short-term and long-term dependencies of pixels along the channel dimension, this study improves it to EMA-1D. The aim is using a small number of parameters to preserve and enhance the temporal features of one-dimensional signals such as EEG while extracting their morphological features. Additionally, EMA-1D can focus on inter-channel correlations, allowing effective features extraction even in tasks for multi-channel EEG inputs.
LSTM
LSTM exhibits remarkable performance in handling sequential data and time-series tasks which is a special type of recurrent neural network (RNN). Compared to traditional RNN, LSTM introduces gate mechanisms. Through carefully designed gate units, LSTM addresses the issues of vanishing and exploding gradients in traditional RNN.
The core idea of LSTM is selectively forgetting and memorizing information through gate units, thereby better capturing and utilizing long-term dependencies in sequential data. It consists of three key gate units: the Forget Gate, the Input Gate, and the Output Gate. The Forget Gate determines which information from the previous time step memory state needs to be forgotten. The Input Gate controls how the current time step input information updates the memory state. The Output Gate determines the importance of the current time step memory state for output. These gate units adaptively adjust the selective memorization and forgotten of information using learnable weights and activation functions.
Due to the temporal nature of EEG signals and the powerful temporal features extraction capabilities of LSTM, this study applies LSTM after CNN and EMA-1D to achieve high-quality reconstruction of EEG signals.
Proposed method
This section primarily describes that we proposed the overall architecture of CLEnet. Firstly, we elaborate on the EMA-1D module, followed by an explanation of the three stages of CLEnet. Finally, we describe the selection of our loss function and the training process of the entire network model.
Efficient multi-scale attention-1D
EMA-1D is an efficient multiscale attention module optimized for one-dimensional bioelectrical signals, such as EEG. Its core improvement lies in addressing the limitations of EMA in EEG processing through structural reorganization and dimensional adaptation. By adapting dimensions, streamlining the structure, and optimizing computational efficiency, EMA-1D resolves the issues of dimensional mismatch and parameter redundancy in EEG processing, providing a more suitable solution for extracting and reconstructing EEG features. The specific structure of the EMA-1D module is illustrated in Fig. 1., where \(\:C\) represents the number of EEG channels, \(\:T\) represents the number of EEG time points, and \(\:G\) represents the number of groups.
Feature grouping
The design of the feature grouping mechanism in EMA-1D aims to address two critical issues in traditional attention models for EEG processing: insufficient feature representation fidelity and computational redundancy, through structured feature partitioning and computational optimization35. The original input data has a shape of \(\:C\times\:T\). After channel grouping, the data shape changes to \(\:C//G\times\:T\) (where “\(\://\)” indicates discarding the remainder and returning the largest integer not greater than the quotient). The grouping strategy compels the model to focus on local feature interactions within specific channels of each subgroup, avoiding feature confusion caused by global channel fusion, thereby enhancing the representation capability for local regions of interest (e.g., specific frequency bands or spatial patterns) in EEG signals. By mapping the subgroups divided along the channel dimension to the batch dimension, the design leverages the invariance property of convolutional operations with respect to the batch dimension, enabling parallel feature processing without dimensionality reduction. This approach preserves the integrity of the original channel information while reducing computational complexity, significantly decreasing memory usage and computational overhead.
Dual parallel structure
The original EMA module employs a two-dimensional three-branch structure (horizontal pooling, vertical pooling, and 3 × 3 convolution), which relies on the spatial characteristics of images and is difficult to directly apply to EEG signals (one-dimensional time series)35. To address this, the original horizontal and vertical pooling branches are merged into a 1 × 1 temporal pooling branch, which performs global average pooling along the time axis \(\:T\) to generate a feature map of shape \(\:C//G\times\:1\). This branch utilizes one-dimensional convolution to fuse channel information and generates attention weights through a Sigmoid function. This enhancement improves the ability to capture time-dependent features in EEG signals while reducing redundant parameters. Additionally, the two-dimensional convolution kernels are ineffective in modeling the local multiscale features of time series in EEG. Therefore, the original 3 × 3 two-dimensional convolution is replaced with a one-dimensional convolution with a kernel size of 3, which directly operates on the time dimension to focus on local feature interactions between adjacent time points. By combining this with the global dependency modeling of the temporal pooling branch, the module achieves a synergistic enhancement of local details and long-term temporal patterns.
Cross-spatial learning
The cross-spatial learning mechanism of EMA-1D addresses the critical issues of local-global feature imbalance and spatial location information loss in EEG signal processing through multi-stage feature fusion and spatial information collaborative modeling35. Its workflow and core functions are as follows: After channel fusion of the features extracted by the temporal pooling branch, the data is first normalized using Batch Normalization to eliminate inter-channel distribution differences and enhance training stability. Subsequently, global average pooling and Softmax activation are applied along the time dimension \(\:T\) for the left and right branches, respectively, to extract global spatial dependencies across time steps, generating encoding vectors of dimension \(\:C//G\times\:1\). The two encoding vectors are reshaped into \(\:1\times\:C//G\) vectors and then multiplied with the feature vectors that were not globally pooled along the time dimension using matrix multiplication, producing two \(\:1\times\:T\) feature vectors. This design models long-range spatial contextual relationships through matrix multiplication while retaining high-resolution features to capture fine-grained spatial location information. Finally, the feature maps output by the two branches are aggregated via weighted summation, enhancing local spatial sensitivity while preserving global context, ultimately producing a spatial feature representation that combines broad scope with high precision.
Finally, the Sigmoid activation function transforms the feature maps into attention weights and embeds them into the grouped input, reshaping the data to \(\:C\times\:T\) to maintain consistency with the input data. The original input and final output data shapes are consistent, ensuring the generality of the EMA-1D module without compromising its effectiveness.

Structure of the EMA-1D.
CLEnet
The main architecture of CLEnet is composed of CNN, LSTM, and EMA-1D, and its name is derived from the initials of these three core modules. The CLEnet mode The CLEnet model achieves the reconstruction of artifact-free EEG signals through three stages: (1) morphological feature extraction and temporal feature enhancement, (2) temporal feature extraction, and (3) EEG reconstruction.
In the first stage, the model extracts multi-scale morphological features from artifact-contaminated EEG signals and repairs the temporal dependency features disrupted by local convolutional operations through a temporal feature enhancement module. Specifically, a dual-branch CNN is employed to extract morphological features from the input EEG signals, capturing local features such as waveform contours, spikes, and spindles, followed by embedding the EMA-1D module to enhance the temporal features disrupted by the CNN, thereby providing high-quality input for the second stage. In the second stage, the model utilizes LSTM to further extract temporal features from the EEG signals, enhancing the capability to model long-term temporal patterns and compensating for the limitation of CNN in extracting temporal features. In the third stage, the morphological and temporal features extracted from the first two stages are aggregated through weighted summation, and a fully connected layer is used to reconstruct artifact-free EEG signals with the same length as the original input, ensuring temporal alignment between the reconstructed signals and the input signals. At the same time, the loss function is used to optimize the reconstruction accuracy and detail fidelity, and finally output high-quality artifact-free EEG signals to achieve the purpose of artifact removal.
The key to reconstructing artifact-free EEG lies in the stage of morphological feature extraction and temporal feature enhancement. Since many artifacts overlap with artifact-free EEG in frequency or other aspects, morphological feature become crucial for artifact removal. To effectively extract the morphological features of artifact-free EEG signals, we employ CNN to perform local feature extraction from artifact-contaminated EEG signals. CNN utilizes one-dimensional convolutional kernels to perform sliding window operations on time series data, with each kernel focusing on detecting local waveform patterns within specific time scales through weight sharing and local connectivity mechanisms. By stacking multiple convolutional layers, hierarchical feature abstraction is achieved: the lower layers extract basic waveform features, while the higher layers combine these features to identify complex morphological patterns, thereby enabling precise extraction of multi-scale morphological features from EEG signals24.
To extract accurate and effective feature information, we designed a small module consisting of two convolutional layers, one EMA-1D layer, and one 1D average pooling layer, as depicted in Fig. 2. In this module, the two convolutional layers with equal numbers of kernels were used to extract the morphological feature of EEG. The EMA-1D layer was embedded after the extraction of morphological feature to protect and enhance temporal feature and focus on inter-channel relationships. Although CNN can effectively capture local features, their localized window operations may indirectly disrupt the potential temporal features in EEG signals. To address this issue, we embed the EMA-1D module after morphological feature extraction. EMA-1D achieves multi-scale temporal feature capture through its dual-branch parallel structure: the left branch generates dynamic attention weights through global average pooling and Sigmoid activation, enhancing the modeling capability of long-range temporal dependencies; the right branch employs a one-dimensional convolution with a kernel size of 3 to focus on local multi-scale features of adjacent time points, thereby achieving synergistic enhancement of local details and long-term temporal patterns35. Additionally, the cross-spatial learning mechanism of EMA-1D dynamically integrates global contextual modeling with local spatial sensitivity, producing spatial feature representations that combine broad scope with high precision. By embedding the EMA-1D module after the CNN, it not only repairs the temporal features disrupted by the CNN but also optimizes inter-channel relationship modeling through a grouping strategy. The 1D average pooling layer downsampled the feature information to reduce computational complexity. This small module was repeated five times, with the number of kernels sequentially set to 16, 32, 128, 256, and 512. In the final small module, the 1D average pooling layer was replaced with a dropout layer to prevent overfitting during training.
Due to its inherent feature, EEG exhibits different morphological features at different observation scales. Traditional end-to-end deep neural network models fail to fully capture these morphological feature38 because they cannot adapt to changes at different scales. When constructing neural network models, depth, width, and filter size are all key factors. Although increasing network depth is a common method to enhance the feature processing capability of convolutional neural networks, simply deepening the network does not effectively extract diverse morphological feature at different scales.
Multi-branch CNN achieves the co-expansion of feature representation diversity and model capacity through parallel architecture design, constructing differentiated computational paths. Compared to traditional single-branch networks, its multi-scale feature extraction mechanism significantly enhances the modeling capability for complex data27,39,40. Inspired by this, CLEnet adopts a dual-branch structure: first, each branch employs an independent computational strategy, with Branch 1 using a convolution kernel of size 3 to capture high-frequency transient artifacts, and Branch 2 using a convolution kernel of size 7 to model low-frequency rhythmic signals, while balancing parameter efficiency and feature diversity through grouped convolutions to enhance the ability to distinguish between artifacts and target signals; second, the branches dynamically fuse features through weighted summation, while leveraging feature reuse mechanisms to associate low-level waveform features with high-level rhythmic patterns, improving the efficiency of cross-temporal information integration; finally, the dual-branch structure disperses gradient flow through differentiated paths, alleviating the vanishing gradient problem, accelerating model convergence, and ensuring generalization ability in various artifact scenarios through lightweight design.

Structure of the CLEnet Model.
In the stage of temporal feature extraction, as shown in Fig. 2., the model first utilizes two fully connected layers to enhance and downsample the feature information extracted in the first stage, which contains both temporal and morphological features. Then, the feature vector is reshaped, and an LSTM layer is applied to it.
LSTM leverages memory cells and gate mechanisms to retain historical information over extended periods, selectively forgetting or preserving this information to capture both long-term and short-term variations in EEG signals. EEG signals exhibit oscillatory activities such as alpha, beta, theta, and gamma waves, which are characterized by pronounced temporal dependencies. LSTM is adept at extracting the dynamic features inherent in these oscillatory patterns. Furthermore, through its non-linear modeling capabilities, LSTM can identify abrupt changes or specific patterns associated with particular events within EEG signals. Despite the presence of artifacts in EEG data, LSTM effectively suppresses noise through dynamic modeling and memory mechanisms, thereby extracting more stable features and enhancing the accuracy of subsequent reconstruction processes34.
The feature vector after reshaping is denoted as \(\:X=({x}_{1},{x}_{2},\dots\:,{x}_{N})\). The feature extraction process of LSTM is defined as:
where \(\:h\) and \(\:c\) represent the hidden unit and memory unit in LSTM respectively; \(\:T=N\).
The general computation process of LSTM is as follows:
where \(\:W\) represents the weight matrix, \(\:b\) represents the bias vector. \(\:f\) denotes the forget gate vector in LSTM, \(\:i\) represents the input gate vector, \(\:\stackrel{\sim}{C}\) represents the vector of updated cell candidate values, and \(\:C\) represents the updated cell state.
The final input vector sequence of LSTM is denoted as \(\:O=({o}_{1},{o}_{2},\dots\:,{o}_{T})\), where the calculation formula for \(\:{o}_{t}\) is:
After the temporal feature extraction stage, we obtained two types of feature vectors with lengths of (512 × 1), which include both the morphological feature of the original pure EEG and its temporal feature.
The final EEG reconstruction stage consists of a Concatenate layer, a Flatten layer, and a Dense layer. We concatenated and flattened the previously obtained set of feature vectors into a vector of length 1024. Then, we use a fully connected layer to output reconstructed EEG with the same shape as the original input EEG.
Regardless of whether the input is single-channel EEG or multi-channel EEG signals, they are first divided into two independent processing branches upon entering the CLEnet model. In each branch, for single-channel EEG signals, the model uses the CNN to expand the channel dimension; for multi-channel EEG signals, the CNN not only extracts the morphological features of the signals but also captures the relationships between channels. After the first two stages of processing, the model has extracted morphological and temporal features, respectively. In the EEG signal reconstruction phase, single-channel EEG signals directly generate an output vector of the same length as the original signal through a fully connected layer. For multi-channel EEG signals, the fully connected layer first outputs a vector with a length equal to the product of the original signal’s time points and the number of channels. Subsequently, through reshaping, the output vector from the fully connected layer is reorganized into a signal with the same shape as the original multi-channel EEG signal, thereby achieving accurate EEG signal reconstruction.
The overall architecture of CLEnet network model is illustrated in Fig. 2. The dual-branch architecture enables more effective attention to different scales of morphological feature information compared to a single branch. The inclusion of the EMA-1D module allows the model to extract morphological feature without losing focus on temporal feature and inter-channel relationships. The use of LSTM is to further extract temporal feature, ultimately obtaining deep mixed features containing both morphological and temporal features. With these features, we can achieve the reconstruction of pure EEG with minimal information loss.
Learning process
The training process of the entire model is essentially the process of separating the real EEG from the original input EEG. We assume a vector \(\:x\), which represents the contaminated EEG data conforming to the distribution \(\:P\left(x\right)\), with dimensions \(\:{R}^{1\times\:T}\). The vector \(\:y\) represents the pure EEG data conforming to the distribution \(\:P\left(y\right)\), with dimensions \(\:{R}^{1\times\:T}\). Here, \(\:T\) represents the length of the sample, which is the length of a single segment of the original or real EEG. Our goal is to design a function \(\:f\left(\varTheta\:\right)\) that can project \(\:x\) onto another vector \(\:{y}_{r}\). We aim to optimize the function \(\:f\left(\varTheta\:\right)\) such that the projected vector \(\:{y}_{r}\) conforms to the distribution \(\:P\left({y}_{r}\right)\):
The objective of this process is to make \(\:P\left({y}_{r}\right)\) as close as possible to the target distribution \(\:P\left(y\right)\), where \(\:\varTheta\:\) represents the parameters that need to be learned. By minimizing the difference between \(\:P\left({y}_{r}\right)\) and \(\:P\left(y\right)\), we achieve the reconstruction and optimization of the original EEG data.
We paired the contaminated EEG data with the clean EEG data and input them into the network model for training. The training objective is to generate reconstructed EEG data that is closest to the clean EEG. To adapt to the training process, we choose MSE as the loss function. It measures the error between the original EEG data and the reconstructed EEG data at each data point, helping us assess the accuracy and quality of the reconstruction process for each data point. The formula for MSE is:
where \(\:n\) represents the number of time points in each EEG segment. We adopted the Adam optimizer for model training, following the approach of DuoCL, with a learning rate of 0.0001 and momentum parameters \(\:{\beta\:}_{1}\) and \(\:{\beta\:}_{2}\) set to 0.5 and 0.9, respectively. To accommodate the hardware configuration (RTX 4070 Ti GPU with 12GB VRAM), we optimized the batch size during the training process: a batch size of 512 was used for single-channel EEG data, while a batch size of 32 was applied for multi-channel EEG data. This configuration ensures efficient model execution while mitigating the risk of VRAM overflow. Furthermore, the training epochs were uniformly set to 200 to fully optimize model performance and achieve the best training outcomes. Based on calculations, the model achieves a FLOPs of 0.129 GFLOPs for a single forward pass, with a batch computation reaching 65.997 GFLOPs.
Results and discussions
To train and validate CLEnet model, we utilized two publicly available single-channel semi-simulated datasets and one proprietary multi-channel EEG dataset. The evaluation includes: (1) Comparing CLEnet with mainstream models to validate its effectiveness in removing EMG, EOG, and mixed artifacts (EMG + EOG) from single-channel EEG; (2) Comparing CLEnet with mainstream models to test its performance in removing ECG from single-channel EEG; (3) Comparing CLEnet with mainstream models and conducting ablation experiments to test its ability to remove unknown artifacts from multi-channel EEG.
Performance metrics
To comprehensively assess the performance of CLEnet, we focused on subjective evaluation and objective evaluation. Subjective evaluation involves visual inspection to judge the performance of CLEnet model. Objective evaluation involves quantitative analysis of the performance of model using objective metrics such as loss, SNR, RRMSEt, RRMSEf, and CC.
The loss (refer to formula 9) denotes MSE, which measures the difference between the EEG after artifact removal and the pure EEG, indicating the degree of fit between the two signals. The size of SNR (refer to formula 10) is related to the quality of the EEG after artifact removal. A larger SNR indicates better quality of the reconstructed signal. RRMSEt (refer to formula 11) represents the loss of temporal information in the reconstructed EEG, while RRMSEf (refer to formula 12) represents the loss of energy in the frequency domain. Smaller values of both losses indicate better performance of the model. CC (refer to formula 13) reflects the model impact on the nonlinear features of the reconstructed EEG. A larger CC implies a smaller influence, hence a higher value is desirable.
Where PSD stands for the Power Spectral Density of the input signal.
In the equation, the functions Cov and Var represent the covariance and variance of the signal, respectively.
Datasets
Ethics statement: The private data used in this study have been approved by the Ethics Committee of the Affiliated Hospital of Xuzhou Medical University (Approval No.: AF-35/06.2), in line with the relevant provisions of the Declaration of Helsinki. All subjects involved in this study signed a general informed consent form, and the confidentiality of the subject’s basic information was guaranteed.
Semi-simulated data
-
EEGdenoiseNet31: The dataset consists of 4514 segments of pure EEG, 5598 segments of EMG, and 3400 segments of EOG. Each segment has a duration of 2 s and has been resampled at 256 Hz, resulting in a length of 512 for each signal. Additionally, all segments are single-channel. We utilized the method from EEGdenoiseNet31 to mix EEG with EMG and EOG, separately (resulting in 4514 pairs of EEG-EMG and 3400 pairs of EEG-EOG), and creating single-artifact single-channel semi-synthetic datasets. Furthermore, we combined EEG with both EMG and EOG simultaneously (resulting in 3400 pairs of EEG with mixed artifacts - EMG + EOG), generating a multi-artifact single-channel semi-synthetic dataset. The process of dataset generation is as follows:
where \(\:{\upgamma\:}\) is generated based on different SNR values, ranging from − 5 dB to 5 dB. The calculation for SNR is as follows:
-
MIT-BIH arrhythmia dataset36,37: The dataset provides ECG signals, with each segment lasting for 30 min and sampled at 360 Hz. To align the ECG with EEG signals as used in EEGdenoiseNet31, we applied bandpass filtering to the ECG signals from 0.1 Hz to 45 Hz and resampled them to 256 Hz. Subsequently, the ECG signals were segmented into 2 s intervals, resulting in a total of 3600 segments. Finally, 3600 pairs of clean ECG and EEG were combined using formulas (14) and (15) to generate a single-channel semi-simulated dataset containing ECG.
Private data
To evaluate the ability of CLEnet model to remove unknown artifacts in multi-channel EEG input, we collected task-related EEG data from 11 healthy young university students. The gender ratio of the participants was 4: 7 (male: female), with an average age of 21.6 years. EEG data were recorded at a sampling rate of 1 kHz using 32 channels. During the data collection process, participants were instructed to perform a 2-back task as illustrated in Fig. 3. Each stimulus was presented for 300 ms, followed by a 3000 ms interval of a blank screen. Participants were required to judge whether two consecutive stimuli were identical, for example, determining if the second and fourth stimuli were the same. This process was repeated 64 times. A correct response was labeled as 1, while an incorrect response was labeled as 0. However, For the obtained EEG dataset contaminated artifacts, we are unable to quantify the SNR of common artifacts such as EMG and EOG relative to the EEG signals. Additionally, we cannot determine the exact number of artifact types introduced during the acquisition process or confirm the presence of physiological artifacts such as vascular pulsation and swallowing. Therefore, the artifacts are referred to as unknown artifacts, which the CLEnet model aims to address.

Possible stimuli in the 2-back experiment.
The collected EEG data were uniformly preprocessed as follows: first, irrelevant electrode channels were removed, resulting in 30 channels. A reference was then established using whole-brain averaging. Subsequently, bandpass filtering was applied to the EEG signals from 0.1 to 40 Hz, with additional notch filtering from 48 Hz to 52 Hz to effectively eliminate powerline interference. Segmentation was performed based on task labels 1 and 0, extracting segments of 1000 ms before and 3000 ms after each label. Each participant obtained 64 segments of EEG data, totaling 436 segments across all 11 participants after removing poor-quality or unusable segments. (ICA was applied, followed by expert inspection to remove artifact components, resulting in clean EEG data. The preprocessed EEG data, both before and after artifact removal, were paired to form a multi-channel dataset containing unknown artifacts. To adapt the data for model input and increase the dataset size, a sliding window technique was employed, resulting in a total of 47960 pairs of EEG data.
For the three datasets mentioned above, we partitioned them into training, testing, and validation sets using an 8:1:1 ratio.
Performance evaluation
We compared CLEnet with existing state-of-the-art models in experimental tests to evaluate its ability to reconstruct clean EEG from contaminated EEG. The compared models include 1D-ResCNN, NovelCNN, and DuoCL. They are all deep learning-based methods designed for single-channel EEG artifact removal. Among them, NovelCNN has the highest number of parameters.
Performance evaluation on EEGdenoiseNet
In comparison experiments with EEGdenoiseNet31, we tested the ability of CLEnet model to remove EMG, EOG, and mixed artifacts from single-channel EEG. To qualitatively analyze the results, we presented both time-domain and frequency-domain outcomes in the following figures. Specifically, for the case of SNR = 0 dB, contaminated EEG, clean EEG, and reconstructed EEG by the model are selected for observation and comparison. Figures 4, 5 and 6. show examples of time-domain results for EEG contaminated by EMG, EOG, and mixed artifacts, respectively. Frequency-domain results are illustrated in Figs 7, 8 and 9. In the time-domain results, the gray dashed line represents the contaminated EEG, while the orange and green lines denote the clean EEG and reconstructed EEG, respectively. The content enclosed in the red dashed box on the left side of each figure is magnified and displayed in the corresponding box on the right side. A closer proximity of the green line to the orange line indicates better reconstruction results and stronger artifact removal capability.

Example of time-domain waveform results for removing EMG artifacts. (a) 1D-ResCNN, (b) NovelCNN, (c) DuoCL, (d) CLEnet.

Example of time-domain waveform results for removing EOG artifacts. (a) 1D-ResCNN, (b) NovelCNN, (c) DuoCL, (d) CLEnet.

Example of time-domain waveform results for removing mixed artifacts (EMG + EOG). (a) 1D-ResCNN, (b) NovelCNN, (c) DuoCL, (d) CLEnet.
By observing the time-domain results, we found that:
-
In the EEG reconstruction experiment contaminated by EMG artifacts, the following observations were made: 1D-ResCNN performed the worst and exhibited significant signal bias. NovelCNN accurately reconstructed low-frequency and high-amplitude waveforms but suffered from severe loss of high-frequency components. DuoCL outperformed NovelCNN overall but exhibited relatively large peak amplitude overflow compared to CLEnet. CLEnet demonstrated the most outstanding performance, nearly eliminating all artifacts and reconstructing waveform details more effectively.
-
In EEG reconstruction experiments contaminated by EOG artifacts, relative to EEG contaminated by EMG and mixed artifacts, overall waveform changes were smaller. In the removal of EOG artifacts experiment, DuoCL reconstructed the overall waveform details closer to the clean EEG, with less waveform loss compared to the other three models. However, DuoCL did not accurately reconstruct peaks within the range of -1 to 1 compared to CLEnet. 1D-ResCNN and NovelCNN exhibited overall poorer performance.
-
Reconstructing clean EEG from EEG contaminated by mixed artifacts posed the greatest challenge. 1D-ResCNN and NovelCNN performed worse than DuoCL and CLEnet. In the low-frequency domain, DuoCL outperformed CLEnet with less amplitude overflow. However, CLEnet exhibited more accurate control over waveform details in the high-frequency domain. Overall, CLEnet demonstrated superior performance compared to the other models.

The PSD results after removing artifacts from EEG contaminated EMG.

The PSD results after removing artifacts from EEG contaminated EOG.

The PSD results after removing artifacts from EEG contaminated mixed artifacts (EMG + EOG).
Figures 7, 8 and 9. show examples of frequency domain reconstruction results. The black dashed line represents the PSD of clean EEG, the red dashed line represents the PSD of EEG reconstructed by CLEnet, the blue dashed line represents the PSD of EEG reconstructed by DuoCL, the orange dashed line represents the PSD of EEG reconstructed by NovelCNN, and the green dashed line represents the PSD of EEG reconstructed by 1D-ResCNN. The observations are as follows:
-
1D-ResCNN exhibited the poorest performance across all results, displaying significant discrepancies from the ground truth. Although all signals were filtered up to 80 Hz, the reconstructed results by 1D-ResCNN still contained frequency components beyond 80 Hz. Moreover, the reconstruction outcomes by 1D-ResCNN exhibited substantial loss of frequency information, with a significant proportion of distorted frequency bands, particularly noticeable in the EEG reconstruction experiments contaminated by EMG and mixed artifacts.
-
Although NovelCNN was capable of identifying non-existent frequency components, its performance was poor in the EEG reconstruction experiment contaminated by EOG. The overall PSD of the reconstructed EEG by NovelCNN was lower than that of the ground truth EEG, indicating that a single convolutional kernel may not accurately capture the frequency components. In the other two experiments as well, NovelCNN exhibited significant drawbacks, with the reconstructed results of PSD peaks differing substantially from reality.
-
Overall, DuoCL and CLEnet outperformed the first two models. In the EEG reconstruction experiment contaminated by EOG, DuoCL performed better than CLEnet, whereas in the experiment involving EMG artifacts, CLEnet achieved superior results. Specifically, in the denoising experiment for EEG contaminated by EMG and mixed artifacts, CLEnet’s reconstructed results exhibited more accurate details and closer proximity to the ground truth.
We presented the results obtained for all methods at SNRs ranging from − 5dB to 5dB in Table 1. In the EEG reconstruction experiment contaminated by EMG and mixed artifacts, CLEnet achieved the lowest average loss, highest average SNR, lowest average RRMSEt and RRMSEf, indicating minimal loss in both time and frequency domains. Moreover, it exhibited the highest data quality, as evidenced by the highest average CC value, suggesting the preservation of nonlinear characteristics and almost all information from the clean EEG while removing all artifacts. Conversely, in the EEG reconstruction experiment contaminated by EOG, DuoCL achieved the best results.
Performance evaluation on MIT-BIH arrhythmia dataset
The experimental results of the four models on the MIT-BIH arrhythmia dataset36,37 were shown in Table 2; Fig. 10. Table 2 reveals the average denoising capabilities of the four models for ECG artifacts at different signal-to-noise ratios (SNR). The results indicate that CLEnet achieved the best performance, followed by DuoCL. CLEnet outperformed DuoCL with an average loss increase of 7.46%, an average SNR improvement of 5.13%, an average CC increase of 0.75%, an average decrease of 8.08% in RRMSEt, and an average decrease of 5.76% in RRMSEf.
Figure 10. shows examples of time-domain and power spectral density (PSD) results reconstructed from EEG contaminated by ECG artifacts. Overall, the time-domain reconstruction outperforms the frequency-domain reconstruction. In the time domain, EEG waveforms reconstructed by 1D-ResCNN and NovelCNN exhibited severe distortions, while DuoCL and CLEnet demonstrated higher fidelity to the clean EEG details. However, upon closer examination of the content enclosed within the red dashed-line circles, CLEnet exhibited more accurate control over the precise peak amplitudes, resulting in a closer match to the clean EEG. In the frequency domain, 1D-ResCNN exhibited similar issues as in previous experiments by reconstructing filtered frequency components. While the frequency components in the reconstruction by NovelCNN were roughly restored, the overall curve was shifted downward compared to the real results. DuoCL and CLEnet exhibited more accurate extraction of frequency components. Comparatively, CLEnet losed less frequency information in the reconstruction, leading to more accurate extremum values and superior performance, as evident within the red dashed-line circles. Therefore, in the removal of ECG artifacts, CLEnet demonstrated stronger capabilities.

The time-domain and PSD results after removing artifacts from EEG contaminated ECG. (a) 1D-ResCNN, (b) NovelCNN, (c) DuoCL, (d) CLEnet.
Performance evaluation on private data
In this 30-channel dataset, besides EOG, EMG, and ECG, there may also be unknown artifacts present. To validate CLEnet capability to remove multiple artifacts from multi-channel EEG in real-world scenarios, we conducted experiments on this real dataset. We adapted the model architecture to accommodate multi-channel input and adjusted the dropout rate of the dropout layer in CLEnet to 0.1 for the experiments. The experiments not only compared the performance of CLEnet with 1D-ResCNN, NovelCNN, and DuoCL to determine if CLEnet outperformed existing models, but also conducted ablation experiments to verify the effectiveness of the EMA-1D module. The experimental results are shown in Table 3:
Compared to the existing three models, CLEnet exhibited the best performance, with an increase of 2.45% and 2.65% in average SNR and average CC, respectively. Additionally, compared to the performance of DuoCL, the average loss, RRMSEt and RRMSEf decreased by 3.17%, 6.94% and 3.30%, respectively. CLEnet demonstrated the ability to effectively combine channel correlations to reconstruct clean EEG in the task of artifact removal from multi-channel EEG. This indicated that CLEnet can effectively extract inter-channel correlations from multi-channel EEG inputs containing unknown artifacts, and integrate them with morphological and temporal features to reconstruct high-quality clean EEG. Furthermore, removing the EMA-1D module from CLEnet resulted in a significant decrease in performance, indicating the effectiveness of the EMA-1D module in artifact removal from multi-channel EEG. The EMA-1D module is crucial for CLEnet to outperform existing models overall. We selected the two channels FP1 and FP2 that are most affected by artifacts among the 30 channels and displayed them before and after artifact removal, as shown in Fig. 11.

Examples of artifact removal and reconstruction results for FP1 and FP2 channels.
Discussions
This study demonstrated that the proposed CLEnet model performed well in handling various types of artifacts across three datasets. It exhibited good performance not only in removing individual types of artifacts but also in tasks involving mixed or unknown artifacts. Regardless of the degree of signal contamination, CLEnet improved the quality of reconstructed signals.

Example feature graphs for CNN, EMA-1D, and LSTM.
To assess the feature extraction capability of the model, this study randomly selected EEG signals contaminated with EMG as input to the trained model. A comparative visualization analysis was performed on the feature maps extracted by the first layer of CNN, EMA-1D, and LSTM. It is noteworthy that only one feature map extracted by CNN and EMA-1D is displayed. All feature maps are shown in Fig. 12., where the vertical axis represents amplitude and the horizontal axis corresponds to time points. The CNN layer with a kernel size of 3 effectively captured detailed signal features, while the CNN layer with a kernel size of 7 extracted global characteristics that demonstrated higher morphological similarity to clean EEG signals. The integration of the EMA-1D module substantially reduced the amplitude of feature maps, demonstrating its unique advantage in suppressing high-frequency noise. The LSTM layer further enhanced the temporal consistency of signal reconstruction by capturing temporal dependencies. The reconstructed EEG signals output by the model exhibited close morphological alignment with the original clean EEG signals in the time-domain waveform, comprehensively validating the effectiveness of the proposed architecture in noise suppression and signal reconstruction.
However, in cases of severe EEG signal contamination, even with quality improvement through CLEnet reconstruction, the resulting signals may still be unusable for subsequent analysis. Therefore, heavily contaminated EEG signals should be discarded. A complete EEG artifact removal process requires a network model that can both reconstruct signals to improve quality and remove bad segments.
Furthermore, there exists spatial correlation between channels in multi-channel EEG, and each channel may contain different types of artifacts. This necessitates the model to fully consider the spatial correlation between channels, and based on this correlation, to remove different artifacts while reconstructing the EEG signal for each channel. Therefore, we fine-tuned the CLEnet model structure to accommodate multi-channel EEG inputs, and the results demonstrated that CLEnet can accurately extract spatial correlations and reconstruct the signal.
However, we observed that in the task of removing EOG artifacts, the performance of CLEnet was not superior to DuoCL. Improving CLEnet’s ability to remove EOG artifacts remains a challenging task to tackle. Additionally, the performance of all four models in the frequency domain reconstruction was inferior to that in the time domain reconstruction. This suggests that in artifact removal tasks, we can consider feeding both frequency domain and time domain information to the model for learning, which may lead to a better result.
Conclusion
EEG artifact removal remains a critical preprocessing challenge in neuroscience and medical applications. This study proposes CLEnet, a deep learning model based on convolutional operations and a novel attention mechanism, designed to reconstruct high-quality neural activity information from EEG signals contaminated by complex artifacts. The CLEnet architecture comprises three stages: (1) a morphological feature extraction module utilizing dual-scale convolution to capture local distinctions between artifacts and neural signals through multi-scale perception; (2) a temporal feature enhancement module integrating the EMA-1D attention mechanism and LSTM networks to synchronously reinforce the temporal dynamics of signals; and (3) a feature fusion and reconstruction module that employs fully connected layers for end-to-end reconstruction of artifact-free EEG signals. Innovatively, CLEnet decouples morphological features (e.g., waveform structures of artifacts) from temporal features (e.g., phase continuity of neural oscillations), thereby maximizing the preservation of neurophysiological information while eliminating noise.
To validate the model’s performance, experiments were conducted on semi-simulated datasets (containing EMG, ECG, and mixed artifacts) and a real 32-channel EEG dataset (containing unknown artifacts), with comparisons against mainstream methods such as 1D-ResCNN and NovelCNN. The results demonstrate that: (1) CLEnet achieves superior performance in both single and multi-channel scenarios, significantly outperforming baseline models in SNR, CC, RRMSEt and RRMSEf; (2) the model exhibits remarkable robustness against mixed and unknown artifacts (e.g., physiological noise from swallowing and vascular pulsation), highlighting its adaptability to complex real-world scenarios; (3) although its performance in EOG artifact removal is slightly inferior, the modular architecture provides extensibility for future optimizations in frequency-domain feature extraction.
The core contributions of this study are threefold: Dataset-wise, we established the first 32-channel EEG benchmark dataset containing unknown artifacts, offering realistic noise scenarios for multi-channel artifact removal research. Methodologically, the proposed CLEnet framework pioneers the synergistic optimization of morphological and temporal features, improving artifact removal accuracy for unknown and mixed artifacts while preserving neural signal integrity. Technically, the fusion mechanism of EMA-1D and dual-scale convolution breaks the dependency of traditional models on predefined artifact types, laying the foundation for EEG decoding in dynamic noise environments. Future work will focus on enhancing frequency-domain features and integrating cross-modal attention mechanisms to further improve the model’s generalization capability for non-stationary artifacts.
Data availability
The EEGdenoiseNet dataset used in this study is publicly available and can be downloaded from the website https://gin.g-node.org/NCClab/EEGdenoiseNet. The MIT-BIH arrhythmia dataset used in this study is publicly available and can be downloaded from the website https://physionet.org/content/mitdb/1.0.0/. The private datasets used in this study are available upon reasonable request by contacting the corresponding author X. Z.
References
Wolpaw, J. R., McFarland, D. J., Neat, G. W. & Forneris, C. A. An EEG-based brain-computer interface for cursor control. Electroencephalogr. Clin. Neurophysiol. 78 (3), 252–259. https://doi.org/10.1016/0013-4694(91)90040-B (1991).
Borhani, S. et al. Optimizing prediction model for a noninvasive brain–computer interface platform using channel selection, classification, and regression. IEEE J. Biomed. Health Inf. 23 (6), 2475–2482. https://doi.org/10.1109/JBHI.2019.2892379 (2019).
Tripathy, R. K. & Acharya, U. R. Use of features from RR-time series and EEG signals for automated classification of sleep stages in deep neural network framework. Biocybern Biomed. Eng. 38 (4), 890–902. https://doi.org/10.1016/j.bbe.2018.05.005 (2018).
Li, C. et al. Emotion recognition from EEG based on multi-task learning with capsule network and attention mechanism. Comput. Biol. Med. 143, 105303. https://doi.org/10.1016/j.compbiomed.2022.105303 (2022).
Xia, W., Zhang, R., Zhang, X. & Usman, M. A novel method for diagnosing Alzheimer’s disease using deep pyramid CNN based on EEG signals. Heliyon 9 (4), e14858. https://doi.org/10.1016/j.heliyon.2023.e14858 (2023).
Puri, D. V., Kachare, P. H. & Nalbalwar, S. L. Metaheuristic optimized time–frequency features for enhancing Alzheimer’s disease identification. Biomed. Signal Process. Control. 94, 106244. https://doi.org/10.1016/j.bspc.2024.106244 (2024).
Puri, D. V., Gawande, J. P., Kachare, P. H. & Al-Shourbaji, I. Optimal time-frequency localized wavelet filters for identification of Alzheimer’s disease from EEG signals. Cogn. Neurodyn. 19 (1), 12. https://doi.org/10.1007/s11571-024-10198-7 (2025).
Puri, D. V., Nalbalwar, S. L. & Ingle, P. P. EEG-based systematic explainable Alzheimer’s disease and mild cognitive impairment identification using novel rational dyadic biorthogonal wavelet filter banks. Circuits Syst. Signal. Process. 43 (3), 1792–1822. https://doi.org/10.1007/s00034-023-02540-x (2024).
Kachare, P. H., Sangle, S. B., Puri, D. V., Khubrani, M. M. & Al-Shourbaji, I. STEADYNet: Spatiotemporal EEG analysis for dementia detection using convolutional neural network. Cogn. Neurodyn. 18 (5), 3195–3208. https://doi.org/10.1007/s11571-024-10153-6 (2024).
Puri, D. V. et al. Leadnet: detection of Alzheimer’s disease using Spatiotemporal Eeg analysis and low-complexity Cnn. IEEE Access. https://doi.org/10.1109/ACCESS.2024.3435768 (2024).
Puri, D., Chudiwal, R. & Kachare, P. Detection of Epilepsy using Wavelet Packet Sub-bands from EEG Signals. In International Conference on Computing in Engineering & Technology (pp. 302–310). Singapore: Springer Nature Singapore. (2022)., February https://doi.org/10.1007/978-981-19-2719-5_28
Rashmi, C. R. & Shantala, C. P. EEG artifacts detection and removal techniques for brain computer interface applications: a systematic review. Int. J. Adv. Technol. Eng. Explor. 9 (88), 354–383. https://doi.org/10.19101/IJATEE.2021.874883 (2021).
Sun, W., Su, Y., Wu, X. & Wu, X. A novel end-to-end 1D-ResCNN model to remove artifact from EEG signals. Neurocomputing 404, 108–121. https://doi.org/10.1016/j.neucom.2020.04.029 (2020).
Goncharova, I. I., McFarland, D. J., Vaughan, T. M. & Wolpaw, J. R. EMG contamination of EEG: spectral and topographical characteristics. Clin. Neurophysiol. 114 (9), 1580–1593. https://doi.org/10.1016/S1388-2457(03)00093-2 (2003).
Narasimhan, S. V. & Dutt, D. N. Application of LMS adaptive predictive filtering for muscle artifact (noise) cancellation from EEG signals. Comput. Electr. Eng. 22 (1), 13–30. https://doi.org/10.1016/0045-7906(95)00030-5 (1996).
Islam, M. K., Rastegarnia, A. & Yang, Z. A wavelet-based artifact reduction from scalp EEG for epileptic seizure detection. IEEE J. Biomed. Health Inf. 20 (5), 1321–1332. https://doi.org/10.1109/JBHI.2015.2457093 (2015).
Jung, T. P. et al. Removing electroencephalographic artifacts by blind source separation. Psychophysiology 37 (2), 163–178. https://doi.org/10.1111/1469-8986.3720163 (2000).
Klados, M. A., Papadelis, C., Braun, C. & Bamidis, P. D. REG-ICA: a hybrid methodology combining blind source separation and regression techniques for the rejection of ocular artifacts. Biomed. Signal. Process. Control. 6 (3), 291–300. https://doi.org/10.1016/j.bspc.2011.02.001 (2011).
Yedurkar, D. P. & Metkar, S. P. Multiresolution approach for artifacts removal and localization of seizure onset zone in epileptic EEG signal. Biomed. Signal. Process. Control. 57, 101794. https://doi.org/10.1016/j.bspc.2019.101794 (2020).
Souza Filho, J. B., Van, L. D., Jung, T. P. & Diniz, P. S. Online component analysis, architectures and applications. Found. Trends® Signal. Process. 16 (3–4), 224–429. https://doi.org/10.1561/2000000112 (2022).
Nam, H., Yim, T. G., Han, S. K., Oh, J. B. & Lee, S. K. Independent component analysis of ictal EEG in medial Temporal lobe epilepsy. Epilepsia 43 (2), 160–164. https://doi.org/10.1046/j.1528-1157.2002.23501.x (2002).
Wang, G., Teng, C., Li, K., Zhang, Z. & Yan, X. The removal of EOG artifacts from EEG signals using independent component analysis and multivariate empirical mode decomposition. IEEE J. Biomed. Health Inf. 20 (5), 1301–1308. https://doi.org/10.1109/JBHI.2015.2450196 (2015).
De Clercq, W., Vergult, A., Vanrumste, B., Van Paesschen, W. & Van Huffel, S. Canonical correlation analysis applied to remove muscle artifacts from the electroencephalogram. IEEE Trans. Biomed. Eng. 53 (12), 2583–2587. https://doi.org/10.1109/TBME.2006.879459 (2006).
Shafiq, M. & Gu, Z. Deep residual learning for image recognition: A survey. Appl. Sci. 12 (18), 8972. https://doi.org/10.3390/app12188972 (2022).
Lauriola, I., Lavelli, A. & Aiolli, F. An introduction to deep learning in natural Language processing: models, techniques, and tools. Neurocomputing 470, 443–456. https://doi.org/10.1016/j.neucom.2021.05.103 (2022).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Communications of the ACM 60(6), 84–90. https://doi.org/10.1145/3065386 (2017).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. IEEE, Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition(CVPR) 2818–2826. (2016). https://doi.org/10.1109/CVPR.2016.308
Kaur, N., Jindal, N. & Singh, K. A deep learning framework for copy-move forgery detection in digital images. Multimedia Tools Appl. 82 (12), 17741–17768. https://doi.org/10.1007/s11042-022-14016-2 (2023).
Qazi, E. U. H., Zia, T. & Almorjan, A. Deep learning-based digital image forgery detection system. Appl. Sci. 12 (6), 2851. https://doi.org/10.3390/app12062851 (2022).
Zhou, H., Peng, J., Liao, C. & Li, J. Application of deep learning model based on image definition in real-time digital image fusion. J. Real-Time Image Proc. 17 (3), 643–654. https://doi.org/10.1007/s11554-020-00956-1 (2020).
Zhang, H. et al. EEGdenoiseNet: A benchmark dataset for deep learning solutions of EEG denoising. J. Neural Eng. 18 (5), 056057. https://doi.org/10.1088/1741-2552/ac2bf8 (2021).
Zhang, H., Wei, C., Zhao, M., Liu, Q. & Wu, H. IEEE. A novel convolutional neural network model to remove muscle artifacts from EEG. In ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 1265–1269. (2021). https://doi.org/10.1109/ICASSP39728.2021.9414228
Pu, X. et al. EEGDnet: fusing non-local and local self-similarity for EEG signal denoising with transformer. Comput. Biol. Med. 151, 106248. https://doi.org/10.1016/j.compbiomed.2022.106248 (2022).
Gao, T., Chen, D., Tang, Y., Ming, Z. & Li, X. EEG reconstruction with a dual-scale CNN-LSTM model for deep artifact removal. IEEE J. Biomed. Health Inf. 27 (3), 1283–1294. https://doi.org/10.1109/JBHI.2022.3227320 (2022).
Ouyang, D. et al. IEEE,. Efficient multi-scale attention module with cross-spatial learning. In ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 1–5. (2023). https://doi.org/10.1109/ICASSP49357.2023.10096516
Goldberger, A. L. et al. PhysioBank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals. Circulation 101 (23), e215–e220. https://doi.org/10.1161/01.CIR.101.23.e215 (2000).
Moody, G. B. & Mark, R. G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 20 (3), 45–50. https://doi.org/10.1109/51.932724 (2001).
He, K., Zhang, X., Ren, S. & Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37 (9), 1904–1916. https://doi.org/10.1109/TPAMI.2015.2389824 (2015).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1492–1500). (2017). https://doi.org/10.1109/CVPR.2017.634
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700–4708). (2017). https://doi.org/10.1109/CVPR.2017.243
Funding
This research was supported by the Unveiling & Leading Project of XZHMU (Grant No. JBGS202204), and by the Scientific Research Foundation for Excellent Talents of Xuzhou Medical University (D2023031 and D2019032), and by the National Key Research and Development Project (2000YFC2006601), and by the Jinhua Major Key Science and Technology Plan Project (2023-3-093).
Author information
Authors and Affiliations
Contributions
R. J. and S. T. contributed to this paper to the same extent and are co-first authors. R. J. and S. T. proposed the idea, conducted experiments, and wrote the first draft of the article. Y. Z. and W. Z. provided the dataset. H. H. and H. W. processed the data. R. Z. and J. W. gave theoretical guidance. X. Z. and S. L. reviewed the article and made the necessary modifications. All authors discussed the results and contributed to the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jiang, R., Tong, S., Wu, J. et al. A novel EEG artifact removal algorithm based on an advanced attention mechanism. Sci Rep 15, 19419 (2025). https://doi.org/10.1038/s41598-025-98653-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-98653-1
