
Abstract
Accurate multistep-ahead carbon price forecasting is crucial for ensuring the smooth operation of the carbon market, as it provides policy-makers with invaluable insights into future price trends. However, current state-of-the-art carbon price forecasting models, which are trained primarily via the mean squared error loss function, struggle to deliver precise and timely forecasts. To bridge this gap, this study introduces a hybrid multistep-ahead carbon price forecasting model that incorporates a training objective that encompasses both shape and temporal criteria. Specifically, this training objective includes two components: one aimed at accurate shape detection, which effectively captures the overall pattern of price movements, and the other focused on temporal variation identification, which excels in capturing changes over time. By integrating these components, the proposed model significantly reduces the loss associated with time delays while also improving forecasting shape coincidence. To validate the superiority of the proposed model, three-step-ahead, four-step-ahead, and five-step-ahead forecasting were conducted on two datasets from the European Union Emissions Trading System. The results show that the proposed model possesses a remarkable ability to capture abrupt changes in nonstationary carbon price data and achieves superior forecasting accuracy compared with other benchmark models, thus demonstrating its potential for practical applications in the carbon markets.
Similar content being viewed by others

Introduction
The heavy reliance of industrial production on fossil fuels has led to significant emissions of greenhouse gases, such as carbon dioxide, into the atmosphere; this, in turn, has contributed to global warming, provoked natural disasters, and given rise to a range of related issues (Zeng et al., 2024a). The European Union, in an effort to reduce rising greenhouse gas emissions, developed the European Union Emissions Trading Scheme (EU ETS), which is the largest carbon emissions trading market globally and has made notable advancements in the reduction of carbon emissions worldwide (Atsalakis, 2016).
In the EU ETS, the carbon price serves as a significant incentive for reducing emissions and advancing low-carbon technologies. In light of the pivotal role of the carbon price, policy-makers, investors, and market participants are actively seeking methods for accurately forecasting carbon prices over multiple steps to ensure the smooth operation of the carbon market and maximize investment portfolio benefits (Gao and Shao, 2022).
To date, the methods applied in the field of carbon price multistep forecasting can be broadly categorized into three primary groups, namely, econometric methods, artificial intelligence methods, and hybrid methods, as detailed in Table 1.
-
(1)
Econometric methods
Econometric methods are highly attractive in various areas of time series forecasting due to their high interpretability and computational efficiency. These methods are also widely adopted in the field of carbon price forecasting. Among them, the ARIMA, exponential smoothing, and GARCH methods are the most commonly used methods and play important roles in analyzing and forecasting carbon price trends. For example, Liu and Huang (2021) utilized a GARCH model to forecast the daily closing prices of EUA option contracts, with the experimental results showing a high degree of alignment between the forecasted and actual prices. Sheng et al. (2020) employed an ARIMA model to forecast EUA futures prices, and their experimental results indicated that the ARIMA model exhibited exemplary forecasting performance. However, notably, econometric methods that rely solely on linear assumptions may have limitations in fully capturing the inherent nonlinear characteristics of carbon price data (Hartvig et al. 2023).
-
(2)
Artificial intelligence methods
Artificial intelligence (AI) methods, which primarily utilize machine learning and deep learning algorithms, have been employed in a diverse range of time series forecasting domains (Kara, 2022; Lei et al., 2023). For example, Guo et al. (2023) applied machine learning techniques to forecast Chinese crude oil futures prices, thus contributing to the development of the emerging crude oil futures market and energy price risk management. During the same period, Shahzad et al. (2024) used AI to analyze the interactions among energy commodity futures, oil price futures, and carbon emission futures. Sarwar et al. (2024) used machine learning to develop an electricity price forecasting model that provided policy-makers with valuable insights into the factors that influence electricity consumption. Building on this foundation, Loizidis et al. (2024) introduced a novel approach that combines an extreme learning machine with bootstrap intervals and applied it to electricity market price forecasting. In addition, Zhang et al. (2024) applied deep learning algorithms to wind speed forecasting, thus providing a reliable tool for smart grid planning.
In contrast to econometric methods, AI methods do not necessitate a predefined functional form and are capable of learning complex patterns in data, with excellent ability to map nonlinear relationships (Sun and Huang, 2020). For example, Zhang et al. (2017) employed multioutput support vector regression to forecast the interval values of carbon futures prices, and the constructed model demonstrated superior forecasting performance compared with Holt’s exponential smoothing method. Later, Han et al. (2019) used a BP neural network to forecast weekly carbon prices in China’s Shenzhen carbon market, with consideration of the effects of energy, economy, weather conditions, and environmental factors on carbon price fluctuations. Additionally, Zhang and Xia (2022) utilized an LSTM model to extract information from online news data and Google trends to forecast future carbon prices. The experimental results indicated that the LSTM model exhibited superior forecasting accuracy and robustness compared with traditional econometric models. However, a single AI model may be overly reliant on specific features of in-sample data, which could lead to poor performance on out-of-sample data. Consequently, achieving optimal forecasting performance with a single AI model in the context of nonlinear and nonstationary carbon price data is challenging (Iwabuchi et al., 2022).
-
(3)
Hybrid methods
The advantage of hybrid methods over econometric and AI methods lies in their capacity to leverage the strengths of multiple techniques, thereby enhancing the accuracy and stability of forecasting. Currently, hybrid methods are the most prevalent approaches in the field of carbon price forecasting and consist primarily of various combinations of data decomposition algorithms, forecasting algorithms, and optimization algorithms. Specifically, decomposition algorithms decompose raw carbon price data into distinct components (submodes), where each component corresponds to variations at different frequency bands. Following this, a forecasting model is employed to forecast the future trajectory of each submode. Ultimately, the forecasting results for each submode are aggregated linearly or nonlinearly to yield the final forecasts. For example, Hao et al. (2020) utilized ICEEMDAN and WRELM to forecast carbon prices, and this hybrid model exhibited notable forecasting capabilities. Nadirgil (2023) initially decomposed carbon price data via CEEMDAN and VMD and subsequently utilized a BP neural network optimized by a GA algorithm to forecast the submodes. The experimental results demonstrated that the decomposition and optimization algorithms significantly improved the forecasting performance of the model. Additionally, Liu et al. (2024) combined BEMD, MVMD, and an improved MLP to construct a quadratic decomposition integrated framework for forecasting carbon prices in China’s Hubei and Guangdong carbon markets. The experimental results showed that the quadratic decomposition strategy increased the accuracy of the model’s forecasts. Specifically, the “quadratic decomposition strategy” refers to a method where the decomposition algorithm is first applied to split raw time series data into multiple submodes with distinct fluctuation frequencies, and decomposition is subsequently reapplied to specific submodes to further uncover hidden features within the original time series. The “divide-and-conquer” forecasting strategy not only captures more data features but also mitigates the adverse effects of noise (Niu et al., 2022; Zhou et al., 2022). However, existing hybrid models, which are often trained with the mean-squared error loss function, have a limited ability to promptly and accurately forecast abrupt changes in carbon price data caused by economic, political, environmental, and other uncertainties.
A review of the literature on carbon price forecasting reveals that there is still room for further development in enhancing the performance of forecasting models from the perspective of loss functions. The most commonly used loss function, the mean-squared error (MSE), evaluates the model’s performance by calculating the Euclidean distance between the true and forecasted values of the carbon price series. However, the MSE fails to consider the relationship between the true and forecasted carbon price series in terms of their shape and temporal patterns. As a result, models trained with the MSE loss function often struggle to produce satisfactory results when forecasting abrupt changes in nonstationary carbon price data. To address this gap, this paper proposes a novel hybrid model for multistep carbon price forecasting that is trained with both shape and temporal criteria. Furthermore, the experimental results confirmed that, compared with other advanced models, the proposed model exhibited superior performance in the multistep forecasting of carbon prices.
The principal contributions of this study are as follows. First, this paper introduces distortion loss incorporating shape and temporal criteria (DILATE), which is a novel training objective for carbon price multistep forecasting that explicitly penalizes shape distortion and time delay in forecasting models. The proposed model, which uses the DILATE loss function, has significant advantages in that it swiftly and accurately responds to the volatility and nonstationarity of carbon price data, which has practical implications for advanced scheduling in the carbon market. Second, this paper presents an adaptive decomposition of carbon price data through the construction of a hybrid forecasting model that incorporates the successive variational mode decomposition algorithm. The successive variational mode decomposition algorithm eliminates the requirement for predetermined submode counts, thereby greatly reducing the experimental costs and time. Finally, this study also develops an evaluation system that incorporates shape and temporal criteria, which enables a comprehensive comparison of the proposed model’s performance against that of other models, thereby offering a new perspective on enhancing the performance of carbon price multistep forecasting models.
The remainder of this paper is organized as follows: The “Methodology” section introduces the research methodology. The “Working framework for this study” section outlines the study’s framework. The “Analysis of the experimental results” section presents comparative experiments between the proposed model and other advanced time series forecasting models. The “Discussion” section presents experiments on the sensitivity of the loss function and the convergence of the optimization algorithm. Finally, the “Conclusions” section summarizes the findings and contributions of the study.
Methodology
This section introduces the decomposition algorithm, the forecasting model, the loss function, and the optimization algorithm employed in this study.
Successive variational mode decomposition
In 2020, Nazari and Sakhaei (2020) proposed the successive variational mode decomposition (SVMD) algorithm; its most notable feature is that it eliminates the need to predetermine the number of intrinsic mode functions (IMFs, i.e., submodes), which enables the continuous extraction of components. This is particularly important for processing complex time series, where predetermining the number of IMFs often results in under- or overdecomposition (Yang et al., 2023a). Additionally, the algorithm has two main advantages: low computational complexity and robustness to variations in the initial center frequencies of IMFs. Therefore, we employ the SVMD algorithm for adaptive decomposition of carbon price data in this study. The mathematical implementation process is summarized as follows.
The objective of the SVMD algorithm is to decompose a time series into several IMFs while ensuring that their frequency components exhibit a progressive variation. Given a time series denoted as \(f(t)\), the decomposition result can be expressed mathematically as follows:
where \({u}_{L}(t)\) represents the L-th extracted IMF, \(\sum _{i=1:L-1}{u}_{i}(t)\) denotes the sum of the previously extracted L − 1 IMFs, and \({f}_{u}(t)\) corresponds to the residual component.
To ensure that the decomposed IMFs exhibit the desired properties, each IMF must satisfy the following three constraints.
First, each IMF must minimize a specified constraint to ensure that its frequency components remain tightly concentrated around their central frequency.
where \({\omega }_{L}\) represents the central frequency of the L-th IMF, \(\delta (t)\) is the impulse function, and \(*\) denotes the convolution operator.
Second, when extracting \({u}_{L}(t)\), the following constraint criterion is established to minimize the spectral overlap between \({u}_{L}(t)\) and other components:
where \({\beta }_{L}(t)\) is the impulse response of the filter \({\hat{\beta }}_{L}\left(\omega \right)=\frac{1}{{\alpha (\omega -{\omega }_{L})}^{2}}\) and where \(\alpha\) is a balancing parameter.
Third, to avoid duplication between \({u}_{L}(t)\) and the previously extracted L-1 IMFs, \({u}_{L}(t)\) must satisfy the following condition:
where \(\hat{{\beta }_{i}}(\omega )\) denotes the filter with frequency response \(\omega\) and where \({\beta }_{i}(t)\) represents the impulse response of \(\hat{{\beta }_{i}}(\omega )\).
Consequently, during the SVMD process, each time an IMF is extracted from the time series \(f(t)\), the variational objective \(\min \left\{\alpha {J}_{1}+{J}_{2}+{J}_{3}\right\}\) (where \(\alpha\) is a balancing factor) must be minimized to adjust the frequency and amplitude of the IMF. Through iterative optimization, each IMF gradually adapts to distinct features of the time series until the series is fully decomposed into multiple IMFs.
Long short-term memory network
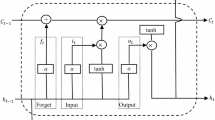
The long short-term memory (LSTM) network is a prevalent deep learning model designed specifically for processing sequence data (Hochreiter and Schmidhuber, 1997; Li et al., 2021). The gating mechanism embedded within the LSTM network effectively mitigates the issues of gradient explosion and vanishing and enhances the model’s ability to capture temporal dependencies within sequences (Qin et al., 2024; Zeng et al., 2024b). Figure 1 illustrates the LSTM network structure, and the primary computational process can be delineated as follows:

This figure illustrates the process by which data flows through an LSTM network. Upon examining the magnified view of an LSTM cell, it becomes apparent that each cell incorporates innovative gating mechanisms: forgetting gates, input gates, and output gates. These mechanisms enable the LSTM network to effectively capture the temporal dependencies within sequence data.
First, the formula for the forget gates of LSTM is as follows:
where \(\sigma (\cdot )\) denotes the sigmoid activation function, \({W}_{f}\) is the weight of the forget gates, \({h}_{t-1}\) denotes the hidden state of the previous time step, \({x}_{t}\) is the input at time \(t\), and \({b}_{f}\) represents the bias of the forget gates.
Second, the candidate values of the memory cells and the input gates are computed as follows:
where \({i}_{t}\) denotes the computational result of the input gates, \({W}_{i}\) is the weight of the input gates, \({b}_{i}\) indicates the bias of the input gates, and \({\widetilde{C}}_{t}\) is the candidate value of the memory cell.
Subsequently, LSTM combines the forget gates, the input gates, the previous-layer memory cell values, and the memory cell candidates to update the current cell state:
where \({C}_{t-1}\) denotes the previous-layer memory cell value.
Ultimately, the output gates of LSTM are implemented as follows:
where \({W}_{O}\) denotes the weight of the output gates and where \({b}_{O}\) is the bias of the output gates.
Distortion loss incorporating shape and temporal criteria
To better address the problem of multistep forecasting for nonstationary time series, Le Guen and Thome (2022) proposed an innovative loss function for training deep neural networks, called distortion loss incorporating shape and temporal criteria (DILATE). The concept is illustrated in Fig. 2. The DILATE function integrates two components: dynamic time warping (DTW) and the time distortion index (TDI). It explicitly calculates shape distortion (by aligning the real and forecasted trajectories and computing the shortest distance between them) and time delay (by measuring the deviation between the shortest path of the aligned trajectories and the diagonal line). Therefore, compared with models optimized via the mean-squared error (MSE) loss function, models trained with the DILATE function exhibit greater sensitivity to sudden changes in the time series.

This figure illustrates the implementation of two loss functions: mean-squared error (MSE) and distortion loss incorporating shape and temporal criteria (DILATE). The left side of the figure corresponds to the MSE loss function, which is frequently employed in the training of multistep carbon price forecasting models. Conversely, the right side of the figure depicts the training objective of a novel multistep carbon price forecasting model that utilizes the DILATE loss function.
The DILATE function has two components: shape distortion and time delay. First, the DTW algorithm is employed to measure the shape similarity between the ground-truth future trajectory of a time series and the model’s forecasted trajectory. Given a ground-truth time series trajectory \({\boldsymbol{x}}={x}_{1},{x}_{2},\cdots ,{x}_{n}\) and a forecasted trajectory \({\boldsymbol{y}}={y}_{1},{y}_{2},\cdots ,{y}_{n}\), a distance matrix \({\bf{D}}({\boldsymbol{x}},{\boldsymbol{y}})\) of size \(n\times n\) is constructed to quantify pairwise discrepancies between their temporal points.
where \(\Delta ({\boldsymbol{x}},{\boldsymbol{y}})\) is the distance matrix between \({\boldsymbol{x}}\) and \({\boldsymbol{y}}\) and where \(\delta ({x}_{i},{y}_{j})\) represents the Euclidean distance between \({x}_{i}\) and \({y}_{j}\).
The goal of the DTW algorithm is to find the optimal path \({P}_{{best}}\) in the distance matrix \({\bf{D}}({\boldsymbol{x}},{\boldsymbol{y}})\) that minimizes the cost from the element \((\mathrm{1,1})\) to \((n,n)\).
where \({P}_{n,n}\subset \left\{\mathrm{0,1}\right\}\) denotes all possible paths from element \((\mathrm{1,1})\) to element \((n,n)\) in the distance matrix.
Based on the distance matrix \({\bf{D}}({\boldsymbol{x}},{\boldsymbol{y}})\) and the optimal path \({P}_{{best}}\), the DTW algorithm calculates the shape distortion between the actual future trajectory \({\boldsymbol{x}}\) and the model’s forecasted trajectory \({\boldsymbol{y}}\) as follows:
However, the DTW algorithm is nondifferentiable; hence, it cannot be used directly in the training process of deep neural networks. To address this issue, Cuturi and Blondel (2017) proposed soft-DTW, in which the standard \(\min\) function has been replaced with a smooth operator, thereby transforming discrete, nondifferentiable DTW into continuous and differentiable soft-DTW. The computation formula for soft-DTW is as follows:
where \(\gamma\) represents the smooth operator, \(\Delta ({\boldsymbol{x}},{\boldsymbol{y}})\) is the distance matrix between \({\boldsymbol{x}}\) and \({\boldsymbol{y}}\), and \(\langle \cdot ,\cdot \rangle\) denotes the inner product operation.
Next, the TDI is defined to calculate the time delay between the actual future trajectory and the model’s forecasted trajectory. Essentially, it measures the Euclidean distance (namely, the deviation) between the optimal path \({P}_{{best}}\) and the diagonal of \({\bf{D}}({\boldsymbol{x}},{\boldsymbol{y}})\).
where \(\Omega\) is an \(n\times n\) matrix used to penalize the elements on the optimal path \({P}_{{best}}\) where \(i\ne j\).
However, \({TDI}({\boldsymbol{x}},{\boldsymbol{y}})\) is also nondifferentiable. To apply it in the backpropagation process of neural network training, \({P}_{{best}}={\nabla }_{\Delta }{DTW}({\boldsymbol{x}},{\boldsymbol{y}})\) is used to define a smooth approximation of the optimal path \({P}_{{best}}\).
Based on this smooth optimal path \({P}_{{best}}^{\gamma }\), the differentiable form of the TDI is defined as follows:
Finally, by linearly combining the shape distortion calculated by the DTW algorithm and the time delay defined by the TDI, the complete DILATE can be obtained.
where \(\alpha\) is a parameter that balances the shape distortion term and the time delay term.
Adaptive moment estimation algorithm
The Adam algorithm is an adaptive optimization algorithm proposed by Kingma and Ba (2014); it adjusts the learning rate based on historical gradient information to increase the convergence speed and generalization ability of the model. The Adam algorithm combines the advantages of RMSProp, AdaGrad, and AdaDelta, and its relatively low computational requirements make it excel in training deep neural networks on large-scale datasets (Khan et al., 2020; Zhang et al., 2020). The parameter update rules for the Adam algorithm are as follows:
where \({\varphi }_{t}\) denotes the gradient of the parameter \({\tau }_{t}\), \({\alpha }_{1}\) and \({\alpha }_{2}\) are the attenuation coefficients, \({\hat{k}}_{t}\) and \({\hat{z}}_{t}\) denotes the bias-corrected moving averages of the gradient, \({\tau }_{t+1}\) is the updated parameter, and \(\beta\) denotes the learning rate.
Working framework for this study
Proposed model
This paper introduces a novel multistep forecasting model for carbon prices, with a focus on the design of the loss function. The proposed model comprises three key modules: data decomposition, forecasting, and optimization.
-
(1)
Data decomposition module
In this study, the SVMD algorithm was employed to decompose raw carbon price data into a series of submodes characterized by distinct frequencies. This operation mitigated the adverse effects of noise inherent in the raw data, which could have compromised the accuracy of the subsequent forecasting module. Data preprocessing was performed through train‒test splitting to prevent data leakage and ensure experimental validity. Furthermore, this study applied min–max normalization to the data to accelerate the convergence of the forecasting model.
-
(2)
Forecasting module
When making multistep forecasts of the future, conventional loss functions frequently struggle to capture subtle fluctuations in nonstationary carbon prices precisely. To address this challenge, the study utilized the LSTM model trained with the DILATE function as a predictor for each submode. The DILATE function incorporates two criteria, shape distortion and time delay, thus enabling the LSTM model to better capture the dynamics of the submode sequences during training. The experimental results show that the DILATE function significantly enhances the predictor’s performance in forecasting real-world carbon price data, which often exhibit nonstationary characteristics and significant sudden variations.
-
(3)
Optimization module
In the optimization module, the Adam optimizer was employed to update the network parameters of the LSTM model that is based on the DILATE function. Adam computes adaptive learning rates independently for each parameter, thereby eliminating the need for manual adjustment of learning rate magnitudes. This feature facilitates rapid convergence and reduces training time, thus making Adam a widely adopted optimization method for deep learning models.
Working framework for this study
The overall framework and workflow of this study are illustrated in Fig. 3.

This figure depicts the specific workflow of this study in detail. Initially, the first module outlines the steps involved in data acquisition and preprocessing. Subsequently, the second module delineates the construction of the forecasting model, along with the computation of forecasting errors based on shape and temporal criteria. The third module showcases the optimization process for the learnable parameters within the model. Finally, the fourth module enumerates the evaluation system and the statistical tests conducted to assess the model’s forecasting performance.
Analysis of the experimental results
Data description
Daily closing carbon futures prices sourced from the EU ETS were selected for this study, with the aim of comparing the forecasting performance of the proposed model against that of state-of-the-art models. Both datasets originated from the Intercontinental Exchange and are accessible on the website https://cn.investing.com. Dataset 1 encompasses the period from January 2, 2017, to December 30, 2020, whereas Dataset 2 spans from January 4, 2016, to December 31, 2019. Each dataset comprises 1026 observations, with 80% allocated to the training set and 20% reserved for testing. Table 2 presents detailed statistical characteristics for both datasets. The p-values from the Augmented Dickey‒Fuller test and Jarque‒Bera test, which are presented in Table 2, indicate that both datasets exhibit nonstationarity characteristics and deviate from a normal distribution. Figure 4 illustrates the trends observed in the carbon price data utilized in this study. The subsequent experiments were conducted via MATLAB R2020a and PyTorch 1.13.1 on a Windows 11 system with an AMD Ryzen 5 5600U processor, a 2.30 GHz Radeon graphics card and 16 GB of RAM.

This figure shows the carbon price data used in this study: a line graph on the left illustrates the temporal trends of both datasets, while a bar plot on the right presents their distributions.
Experimental parameter settings
This study employed a trial-and-error approach to determine the hyperparameters for various forecasting models. Specifically, the maximum alpha parameter of the SVMD algorithm was set to 200. The alpha and gamma values for the DILATE function were set to 0.4 and 0.25, respectively. In both the proposed model and other baseline models, the LSTM network comprised one hidden layer with 128 units. The learning rate of the Adam optimizer was set to 0.0001, with batch sizes of 20 and 500 iterations. Additionally, the baseline CNN (MSE) model contained two convolutional layers with 60 and 80 channels. The baseline MLP (MSE) model had one hidden layer with 128 units.
Evaluation indicators
Prior studies have widely adopted various metrics, including the MAPE, RMSE, MAE, and UI, to evaluate the forecasting performance of models (He et al., 2024; He and Wang, 2021; Sun et al., 2023a; Wang et al., 2022a; Wang et al., 2023; Yang et al., 2023a; Yang et al., 2023b; Zhu et al., 2024). Building upon this existing research, this study developed an evaluation system that comprised four indicators: the DTW, TDI, MSE, and MAPE. This system was designed to assess differences between the proposed model and comparative models in terms of forecasting accuracy, shape distortion, and time delay. Specifically, the DTW and TDI were used to evaluate the ability of the proposed model to capture sudden changes in data and minimize temporal delays in its forecasts. The detailed calculation formulas for each of these evaluation indicators are provided in Table 3.
Comparative experiments
To validate the superiority of the proposed model in the task of multistep forecasting of carbon prices, three sets of comparative experiments were designed.
-
(1)
Benchmarking against typical time series forecasting models
In the first comparative experiment, three well-established predictors—MLP (MSE), CNN (MSE), and LSTM (MSE)—were selected as benchmark models. These predictors have demonstrated remarkable performance in the field of time series forecasting and are widely utilized. Table 4 presents the detailed evaluation metrics, and Fig. 5 depicts the upward trends in the forecasting accuracy and shape similarity observed for the benchmark models and the proposed model. These results underscore the effectiveness of the proposed model in enhancing carbon price multistep forecasting performance.
Table 4 The final forecasted scores of different models for the original time series. Fig. 5: Three-dimensional polyline filled charts for evaluation indicators. 
This figure offers a three-dimensional visualization of the evaluation results for the forecasting model, intuitively highlighting the proposed model’s superiority compared to other models. The experimental outcomes for Dataset 1 are denoted by black circles, while the results for Dataset 2 are signified by red circles.
Furthermore, to emphasize the superiority of the proposed model, performance gains over the worst-performing benchmark model, CNN (MSE), were calculated and are presented in Table 5. Specifically, on Dataset 1, the proposed model exhibited improvements of 29.42%, 30.84%, and 27.42% in the DTW indicator in 3–5-step-ahead forecasts, respectively, and it achieved enhancements of 52.90%, 54.66%, and 57.20% in the MSE indicator. Similarly, on Dataset 2, the proposed model outperformed CNN (MSE) by 47.40%, 48.86%, and 43.95% in terms of the DTW indicator and by 74.70%, 73.34%, and 70.25% in terms of the MSE indicator within the same forecast horizons. The proposed model demonstrated outstanding performance in the task of multistep carbon price forecasting, as evidenced by these results.
Table 5 The improvement percentages of the proposed model. -
(2)
Advantages of the SVMD algorithm
The SVMD algorithm stands out for its ability to decompose data without needing the number of submodes to be predefined. In this study, the SVMD algorithm decomposed raw carbon price data into three frequency-distinct submodes, namely, IMF 1, IMF 2, and IMF 3, as shown in Fig. 6. The frequency of fluctuations decreased sequentially from IMF 1 to IMF 3. IMF 1 represents the high-frequency component, which captures short-term fluctuations in the original data, whereas IMF 3 represents the low-frequency component, which reflects its long-term trend. To validate the effectiveness of the SVMD algorithm in removing noise from the original data, this section comparatively evaluates the forecasting performance of single models and hybrid models: LSTM (MSE) and SVMD-LSTM (MSE), and LSTM (DILATE) and SVMD-LSTM (DILATE).
Fig. 6: The results of the successive variational mode decomposition algorithm. 
The figure illustrates the outcomes of applying the successive variational mode decomposition algorithm to raw carbon price data. This algorithm breaks down the unprocessed data into multiple modal components, each highlighting unique aspects of the carbon price data at different frequencies or time scales.
On both Dataset 1 and Dataset 2, the models with the SVMD algorithm achieved lower values of the DTW, MSE, and MAPE than the models without the SVMD algorithm did. This finding fully confirms that the SVMD algorithm significantly enhances the forecasting accuracy and shape similarity of the model. Specifically, for the MSE indicator, the models that incorporate the SVMD algorithm achieved average improvements of 46.99%, 45.96%, and 43.28% over the models without the SVMD algorithm in the 3–5-step-ahead forecasts, respectively. Moreover, for the DTW indicator, the models with the SVMD algorithm achieved average improvements of 25.95%, 27.59%, and 24.74% over those without the SVMD algorithm for forecasts ranging from 3 to 5 steps ahead, respectively. Comparing the hybrid model and the single model, the analysis results show that decomposition algorithms play a critical role in improving the performance of the forecasting models. Therefore, the use of decomposition algorithms for data preprocessing is important for reducing the negative effect of noise on carbon price forecasting.
-
(3)
Advantages of the DILATE function
In comparative Experiment 3, both the LSTM and SVMD-LSTM models were trained via both the MSE loss and DILATE functions. The superiority of the DILATE function in enhancing forecasting accuracy, reducing shape distortion, and minimizing time delay was demonstrated by comparing the evaluation indicators of the DILATE-based model with those of the MSE-based model.
Specifically, in all the experiments except for the 5-step-ahead forecasting on Dataset 2, the models trained with the DILATE function achieved smaller values of the DTW and TDI than those trained with the MSE loss function did. This underscores the finding that the DILATE function, which explicitly incorporates shape and temporal criteria, significantly improves the models’ performance in forecasting sudden changes in data. The mean improvements for the models trained with the DILATE function, compared with those trained with the MSE loss function, were as follows: the DTW for 3-step forecasting improved by 0.70%, that for 4-step forecasting improved by 0.83%, and that for 5-step forecasting improved by 0.31%; the TDI for 3-step forecasting improved by 9.13%, that for 4-step forecasting improved by 10.77%, and that for 5-step forecasting improved by 11.60%.
Furthermore, as noted in Table 4, the DILATE-based models outperformed the MSE-based models in terms of the MSE and MAPE values in eight out of twelve experiments. Therefore, compared with models typically trained with the MSE loss function, models trained with the DILATE function exhibit superior forecasting accuracy. Consequently, the analysis of the results from comparative Experiment 3 supports the conclusion that the DILATE function outperforms the MSE loss function in enhancing the forecasting accuracy and reducing shape distortion and time delay in model forecasting.
-
(4)
Superiority of the proposed model
Table 4 clearly shows that the proposed model outperformed all the benchmark models by achieving the lowest DTW values across all the experiments, as well as the lowest MSE and MAPE values in three out of the six experiments. In the remaining three experiments, the proposed model secured the second-best MSE and MAPE values and was narrowly outperformed only by SVMD-LSTM (MSE). Figures 7 and 8 further elaborate on these findings by presenting scatter density plots that highlight the model’s forecasting results and box-line scatter violin plots that illustrate the distribution of the forecasting errors, respectively. Figure 7 shows the relationship between the true values and the forecasted values of the different models in the form of a density scatter plot and regression analysis. As shown in Fig. 7, the regression line achieved by the proposed model is closer to the 1:1 line than those of the other benchmark models. Moreover, the forecasting interval of the proposed model is narrower. Figure 8 shows the absolute error distributions of different forecasting models under different forecasting scenarios. Figure 8 shows that the absolute error distribution of the proposed model is more concentrated, less dispersed, and closer to the low-error region than those of the other benchmark models are. These visualizations demonstrate that the proposed model generated forecasted values closest to the true values and achieved the lowest forecasting error. However, the hybrid model did not perform as well as the single model in terms of the TDI metric in nearly all the experiments. Consequently, exploring methods for minimizing the forecasting time delay in hybrid models would be advantageous.
Fig. 7: The scatter density plots of forecasting results. 
This figure illustrates the scatter density of the forecasting results for the proposed model and the comparison model, specifically for the five-step-ahead forecasts for Dataset 2. Corresponding images for other experiments are included in the Appendix.
Fig. 8: The box-line scatter violin plots of forecasting error. 
This figure visualizes the distribution of forecasting errors for both the proposed model and the comparison model across multiple experiments. The scatter plots display the actual absolute error values, while the box-and-whisker plots and violin plots offer a comprehensive depiction of the distribution of these absolute error values. a Absolute error of the 3-step-ahead forecasting of dataset 1 yielded by the MLP (MSE), CNN (MSE), LSTM (MSE), LSTM (DILATE), SVMD-LSTM (MSE), and the proposed model; b absolute error of the 3-step-ahead forecasting of dataset 2 yielded by the MLP (MSE), CNN (MSE), LSTM (MSE), LSTM (DILATE), SVMD-LSTM (MSE), and the proposed model; c absolute error of the 4-step-ahead forecasting of dataset 1 yielded by the MLP (MSE), CNN (MSE), LSTM (MSE), LSTM (DILATE), SVMD-LSTM (MSE), and the proposed model; d absolute error of the 4-step-ahead forecasting of dataset 2 yielded by the MLP (MSE), CNN (MSE), LSTM (MSE), LSTM (DILATE), SVMD-LSTM (MSE), and the proposed model; e absolute error of the 5-step-ahead forecasting of dataset 1 yielded by the MLP (MSE), CNN (MSE), LSTM (MSE), LSTM (DILATE), SVMD-LSTM (MSE), and the proposed model; f absolute error of the 5-step-ahead forecasting of dataset 2 yielded by the MLP (MSE), CNN (MSE), LSTM (MSE), LSTM (DILATE), SVMD-LSTM (MSE), and the proposed model.




Diebold–Mariano test
The Diebold‒Mariano test is a statistical hypothesis test used to compare the forecasting accuracies of two forecasting models (Diebold and Mariano, 2002; Tian et al., 2025). The test is based on the difference between the forecasting error series of the two models. Specifically, for two different forecasting models, the first step is to calculate their respective forecasting error series (i.e., the differences between the actual and forecasted values). Afterwards, a hypothesis test is performed based on the mean and variance of the difference between the forecasting error series of the two models. Typically, the null hypothesis is that there is no significant difference in the forecasting accuracies of the two models, whereas the alternative hypothesis is that there is a significant difference in the forecasting accuracies of the two models. If the p-value of the Diebold‒Mariano test is less than the set level of significance, the null hypothesis is rejected, thus indicating that there is a significant difference in the forecasting accuracies of the two models. Conversely, if the p-value is greater than the significance level, the null hypothesis cannot be rejected, which implies that there is no significant difference in the forecasting accuracy of the two models.
To further validate the effectiveness of the proposed model, the Diebold‒Mariano test was conducted as reported in this section, and the corresponding p-values are presented in Table 6. Table 6 indicates that the proposed model outperformed the MLP (MSE), CNN (MSE), LSTM (MSE), and LSTM (DILATE) models in all the experiments at the 1% significance level. In two of the six experiments, the forecasting performance of the proposed model was superior to that of the SVMD-LSTM (MSE) model at the 5% significance level. In three of the six experiments, no statistically significant difference was found between the forecasting errors of the proposed model and those of the SVMD-LSTM (MSE) model. The results of the Diebold‒Mariano test provide compelling evidence that the proposed model outperforms the benchmark models in terms of forecasting ability.
Cross-validation for results evaluation
The traditional approach of merely partitioning the dataset into training and test sets may yield unreliable model evaluation results; this is because the specificity of the samples may not comprehensively represent the overall data characteristics. In contrast, cross-validation leverages a larger amount of data for model performance assessment (Hyndman and Athanasopoulos, 2021). In this way, it offers more dependable evaluation outcomes than a single-split method does. Consequently, to precisely gauge the forecasting performance of the proposed model and the comparison models under diverse data distributions, this section presents detailed cross-validation experiments. Specifically, a time window was employed to divide each of the two datasets used in this study into three subsets. The training-set segments of each subset were subsequently utilized to train the proposed model and other comparison models. The forecasting performance of these models was then evaluated on the test-set segments of each subset. Finally, the average of the model’s forecasting performance across all subsets was computed.
Table 7 presents the results of cross-validation, including the MSE and MAPE evaluation metrics. From Table 7, in four-sixths of the cross-validation scenarios, the proposed model consistently resulted in the lowest MSE and MAPE values compared with the other competing models. In the remaining two-sixths of the cross-validation cases, the proposed model ranked second in terms of forecasting performance, with SVMD-LSTM (MSE) outperforming it. This indicates that the proposed model demonstrates greater adaptability and generalizability to different data features and distributions than the other models do.
Discussion
This section delves into the computational complexity of the proposed model, the sensitivity of the DILATE function, and the convergence of the Adam optimizer. In addition, it analyses the connection between this study and previous research in the field of carbon pricing and summarizes the limitations of this study. Finally, practical application problems of the proposed model are discussed.
Computational complexity of the proposed model
To provide a more comprehensive analysis of the performance of the proposed model, this section discusses the computational complexity of the proposed model from both theoretical and numerical perspectives. First, we use Big O notation to analyze the growth trend of the time complexity of the proposed model with increasing input data size from a theoretical perspective. Assuming that the batch size is \(B\), the length of the input sequence is \({IL}\), the number of LSTM hidden cells is \(H\), and the length of the output sequence is \({OL}\), the time complexity of the proposed model consists of two main parts: the complexity of the forwards propagation of the LSTM model and the complexity of the computation of the DILATE function. The time complexity of the forwards propagation of the LSTM model is \(O\left(B\times {IL}\times H\right)\), whereas the time complexity of the computation of the DILATE function is \(O\left(B\times {{OL}}^{2}\right)\). Therefore, the overall theoretical time complexity of the proposed model is the sum of these two components: \(O\left(B\times {IL}\times H+B\times {{OL}}^{2}\right)\).
The computational complexities of the proposed model and baseline models were subsequently compared via three quantitative metrics: computational effort, number of parameters, and actual runtime. Table 8 lists the comparison results when performing three-step-ahead forecasting on Dataset 1. Table 8 shows that the proposed model had the longest actual runtime, which indicates that the proposed model requires more computational and storage resources than the baseline models do. However, given the rapid development of computing power, this does not fundamentally hinder the practical application of the proposed model. Notably, Table 8 also shows that the proposed model required the same number of computations and used the same number of parameters as the SVMD-LSTM (MSE) baseline model did, despite the difference in runtime; this is because the difference between these two models lies only in their loss functions, which are not involved in the forwards propagation process. Therefore, modifying the loss function usually does not affect the number of parameters or the theoretical computational effort of the model.
Sensitivity of the DILATE function
The DILATE function contains two pivotal parameters: alpha and gamma. Alpha serves as a balancing factor between the shape distortion term and the time delay term, whereas gamma functions as a smoothing operator for the minimum function. To gain deeper insights into the implications of different parameter configurations on both the training process and the ultimate performance of the proposed model, sensitivity experiments were conducted on the DILATE function, with a specific focus on alpha and gamma, across datasets with diverse characteristics. The results of these experiments are depicted in Fig. 9.

Sensitivity of the DILATE loss function.
Specifically, when forecasting IMF 1 across all datasets, regardless of the value of alpha, the DILATE of the proposed model decreased notably when gamma was within the range of 0.1 to 0.4 and achieved its lowest point at approximately gamma = 0.25. Similarly, when forecasting IMF 2 for all datasets, the model’s performance was influenced by both alpha and gamma in a manner akin to that in IMF 1 forecasting. However, for IMF 2, the robustness of the proposed model to variations in alpha was reduced significantly compared with that for IMF 1. For IMF 3, which had the lowest fluctuation frequency, changes in alpha and gamma produced distinctly different effects on the model’s forecasting performance compared with those observed for IMF 1 and IMF 2. Notably, the DILATE of the proposed model reached its minimum when alpha was between 0 and 0.3, irrespective of the gamma value.
Consequently, when forecasting submodal sequences at high and medium frequencies, the proposed model exhibited considerable sensitivity to the value of gamma. Conversely, when forecasting submodal sequences at low frequencies, the model demonstrated a significant sensitivity to the value of alpha. Ultimately, the proposed model attained remarkable robustness across datasets with varying characteristics when alpha was set to 0.4 and gamma was set to 0.25.
Convergence of the Adam optimizer
This section presents a comparative analysis of the convergence speeds of the Adam optimizer against those of Adagrad, SGD, ASGD, and Adadelta. The aim is to validate Adam’s superior performance in terms of convergence. The results when the MSE is used as the benchmark for comparison are presented in Fig. 10. In Fig. 10, each curve represents the average iteration error obtained from ten experiments, while the corresponding color bars depict the range of iteration errors across these same experiments. As illustrated in Fig. 10, Adam demonstrated a significant advantage in terms of convergence speed compared with Adagrad, SGD, ASGD, and Adadelta on both Datasets 1 and 2. Additionally, Adam resulted in the narrowest color bands, which indicates its high stability.

This figure showcases the convergence performance of the Adam optimizer on Datasets 1 and 2, comparing it with the SGD, ASGD, Adagrad, and Adadelta optimizers. The curves depicted represent the average iteration loss for each optimizer, calculated over ten repetitions. The color bands accompanying the curves illustrate the range of iteration error fluctuations for each optimizer across these repetitions.
Correlations between this study and previous studies
This study developed a hybrid multistep carbon price forecasting model based on the loss function perspective. By analyzing the experimental results of the proposed model and several baseline models, conclusions that are consistent and inconsistent with existing research in the field of carbon price forecasting can be drawn. (1) Consistency: This study revealed that, consistent with previous studies, the decomposition-integration framework has a powerful ability to increase the accuracy of carbon price forecasting. By applying data decomposition techniques, the influence of noise in the raw data on the forecasting model can be significantly reduced. (2) Inconsistency: In this study, the DILATE function was adopted as the training objective of the proposed model. Compared with the MSE loss function, which was commonly used in previous studies, the DILATE function demonstrates superior performance in both shape and temporal forecasting. Furthermore, it has an excellent ability to increase the forecasting accuracy of the model.
In conclusion, the forecasting model proposed in this study improves existing methodologies in the field of multistep-ahead carbon price forecasting from a loss function perspective. The aim is to explore a more powerful tool for multistep-ahead carbon price forecasting. The DILATE function introduced in this paper does not focus only on the simple Euclidean distance between the real carbon price series and the forecasted carbon price series. Instead, the DILATE function explicitly penalizes shape distortions and time delays between the true and forecast carbon price series. The experimental results demonstrate that the model trained with the DILATE function has greater sensitivity and accuracy in forecasting sudden changes in the carbon price series than does the model trained with the MSE loss function.
Limitations of this study
In this section, several limitations of the study are summarized as follows: (1) The forecasting models of the LSTM type exhibit superior performance compared to those of the SVMD-LSTM type in terms of the TDI indicator. This experimental outcome highlights the need for further research to minimize the time delay associated with the decomposition-integration model. (2) In the “Analysis of the experimental results” section, the experimental results indicate that the proposed model offers a significant advantage over the SVMD-LSTM (MSE) in capturing abrupt changes in the data and reducing forecasting time delays. However, it only demonstrates a marginal improvement in the MSE and MAPE indicators. Therefore, enhancing the forecasting accuracy of models utilizing the DILATE loss function represents a promising direction for future research.
Practical applications of the proposed model
To strengthen the relevance of the proposed model to the real world, this section analyses how the proposed model can be applied to real-world scenarios and what the practical implications are from the perspectives of different stakeholders in the carbon market. Specifically, the proposed model can help governments better understand the price fluctuations and supply-demand relationship in the carbon market, so that they can formulate more reasonable carbon reduction policies. Enterprises can use the proposed model to provide data on future carbon prices for adjusting production strategies and investment decisions. For example, enterprises can increase production when the proposed model forecasts a low-carbon price in the future, and reduce production when the proposed model forecasts a high-carbon price in the future, so as to maximize economic benefits. In addition, the proposed model can also provide investors with a scientific basis for investment. Based on the future trend of carbon price forecasted by the proposed model, investors can better position the carbon assets, choose the appropriate investment timing and price level, and reduce the investment risk.
In conclusion, by efficiently forecasting multistep-ahead carbon price, the proposed model can provide accurate reference for governments, enterprises, and investors to help them make more informed decisions. However, the proposed model still needs to be continuously researched and improved to solve its limitations and further improve the performance of multistep-ahead carbon price forecasting.
Conclusion
In this study, a hybrid multistep-ahead carbon price forecasting model is introduced, grounded in the perspective of loss functions. Initially, raw carbon price data is adaptively decomposed into a series of submodes with varying frequencies using the successive variational mode decomposition algorithm. Subsequently, each submode is independently forecasted using an LSTM model trained on a distortion loss function that incorporates both shape and temporal criteria. The Adam optimizer is utilized to iteratively refine the critical parameters of the forecasting model. Ultimately, the forecasting results of each submode are ensembled to obtain the final forecast for the original time series.
To substantiate the effectiveness of the proposed model, a series of detailed comparative experiments were conducted, involving five baseline models. The specific conclusions derived from these experiments can be summarized as follows: (1) The decomposition-integration framework significantly improves multistep-ahead carbon price forecasting accuracy compared to a standalone model. (2) The distortion loss function, incorporating shape and temporal criteria as a novel training objective for multistep-ahead carbon price forecasting, enhances the model’s ability to promptly and accurately forecast sudden fluctuations in nonstationary carbon price data. Additionally, it demonstrates superior performance in enhancing the overall forecasting accuracy of the models.
In conclusion, the model proposed in this study not only achieves high-precision multistep-ahead carbon price forecasts, but also demonstrates superior sensitivity in capturing sudden fluctuations in carbon price data, thus enabling policy-makers and carbon market participants to gain deep insights into the future trajectory of carbon prices. This data-driven intelligence provides stakeholders with a reliable basis for strategic decision-making and operational planning under changing market conditions.
Data availability
The datasets analyzed during the current study are available in the GitHub repository, https://github.com/yuanchen286/EU-ETS. These datasets were derived from the following public domain resources: https://cn.investing.com.
References
Adekoya OB (2021) Predicting carbon allowance prices with energy prices: a new approach. J Clean Prod 282:124519
Atsalakis GS (2016) Using computational intelligence to forecast carbon prices. Appl Soft Comput 43:107–116
Böhm L, Kolb S, Plankenbühler T et al. (2023) Short-term natural gas and carbon price forecasting using artificial neural networks. Energies 16:6643
Byun SJ, Cho H (2013) Forecasting carbon futures volatility using GARCH models with energy volatilities. Energy Econ 40:207–221
Cuturi M, Blondel M (2017) Soft-dtw: a differentiable loss function for time-series. Int Conf Mach Learn 2017:894–903
Diebold FX, Mariano RS (2002) Comparing predictive accuracy. J Bus Econ Stat 20:134–144
Gao F, Shao X (2022) A novel interval decomposition ensemble model for interval carbon price forecasting. Energy 243:123006
Guo L, Huang X, Li Y et al. (2023) Forecasting crude oil futures price using machine learning methods: evidence from China. Energy Econ 127:107089
Han M, Ding L, Zhao X et al. (2019) Forecasting carbon prices in the Shenzhen market, China: the role of mixed-frequency factors. Energy 171:69–76
Hao Y, Tian C, Wu C (2020) Modelling of carbon price in two real carbon trading markets. J Clean Prod 244:118556
Hartvig ÁD, Pap Á, Pálos P (2023) EU climate change news index: Forecasting EU ETS prices with online news. Financ Res Lett 54:103720
He Y, Wang Y (2021) Short-term wind power prediction based on EEMD-LASSO-QRNN model. Appl Soft Comput 105:107288
He Y, Zhu J, Wang S (2024) A novel neural network-based multiobjective evolution lower upper bound estimation method for electricity load interval forecast. IEEE Trans Syst Man Cybern Syst 54:3069–3083
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9:1735–1780
Hyndman RJ, Athanasopoulos G (2021) Forecasting: principles and practice, 3rd edition. Monash University, Australia
Iwabuchi K, Kato K, Watari D et al. (2022) Flexible electricity price forecasting by switching mother wavelets based on wavelet transform and long short-term memory. Energy AI 10:100192
Kara A (2022) A deep learning framework with convolutional long short‐term memory for influenza‐like illness trend estimation. Concurrency Comput Pract Exp 34:e6988
Khan AH, Cao X, Li S et al. (2020) BAS-ADAM: An ADAM based approach to improve the performance of beetle antennae search optimizer. IEEE/CAA J Autom Sin 7:461–471
Kingma DP, Ba J (2015) Adam: A Method for Stochastic Optimization. Paper presented at the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9
Le Guen V, Thome N (2022) Deep time series forecasting with shape and temporal criteria. IEEE Trans Pattern Anal Mach Intell 45:342–355
Lei T, Li RYM, Jotikastira N et al. (2023) Prediction for the inventory management chaotic complexity system based on the deep neural network algorithm. Complexity 2023:9369888
Li N, Li RYM, Pu R (2021) What is in a name? A modern interpretation from housing price in Hong Kong. Pac Rim Prop Res J 27:55–74
Liu S, Xie G, Wang Z et al. (2024) A secondary decomposition-ensemble framework for interval carbon price forecasting. Appl Energy 359:122613
Liu Z, Huang S (2021) Carbon option price forecasting based on modified fractional Brownian motion optimized by GARCH model in carbon emission trading. North Am J Econ Financ 55:101307
Loizidis S, Kyprianou A, Georghiou GE (2024) Electricity market price forecasting using ELM and Bootstrap analysis: A case study of the German and Finnish Day-Ahead markets. Appl Energy 363:123058
Nadirgil O (2023) Carbon price prediction using multiple hybrid machine learning models optimized by genetic algorithm. J Environ Manag 342:118061
Nazari M, Sakhaei SM (2020) Successive variational mode decomposition. Signal Process 174:107610
Niu X, Wang J, Zhang L (2022) Carbon price forecasting system based on error correction and divide-conquer strategies. Appl Soft Comput 118:107935
Qin C, Qin D, Jiang Q et al. (2024) Forecasting carbon price with attention mechanism and bidirectional long short-term memory network. Energy 299:131410
Sarwar S, Aziz G, Tiwari AK (2024) Implication of machine learning techniques to forecast the electricity price and carbon emission: Evidence from a hot region. Geosci Front 15:101647
Shahzad U, Sengupta T, Rao A et al. (2024) RETRACTED ARTICLE: Forecasting carbon emissions future prices using the machine learning methods. Ann Oper Res 337:11–11
Sheng C, Wang G, Geng Y et al. (2020) The correlation analysis of futures pricing mechanism in China’s carbon financial market. Sustainability 12:7317
Stübinger J, Walter D (2022) Using multi-dimensional dynamic time warping to identify time-varying lead-lag relationships. Sensors 22:6884
Sun S, Du Z, Jin K et al. (2023a) Spatiotemporal wind power forecasting approach based on multi-factor extraction method and an indirect strategy. Appl Energy 350:121749
Sun S, Hu M, Wang S et al. (2023b) How to capture tourists’ search behavior in tourism forecasts? A two-stage feature selection approach. Expert Syst Appl 213:118895
Sun S, Wang S, Wei Y et al. (2018) A clustering-based nonlinear ensemble approach for exchange rates forecasting. IEEE Trans Syst, Man, Cybern: Syst 50:2284–2292
Sun W, Huang C (2020) A carbon price prediction model based on secondary decomposition algorithm and optimized back propagation neural network. J Clean Prod 243:118671
Tian C, Niu T, Li T (2025) Developing an interpretable wind power forecasting system using a transformer network and transfer learning. Energy Convers Manag 323:119155
Vallance L, Charbonnier B, Paul N et al. (2017) Towards a standardized procedure to assess solar forecast accuracy: A new ramp and time alignment metric. Sol Energy 150:408–422
Wang M, Zhu M, Tian L (2022a) A novel framework for carbon price forecasting with uncertainties. Energy Econ 112:106162
Wang P, Liu J, Tao Z et al. (2022b) A novel carbon price combination forecasting approach based on multi-source information fusion and hybrid multi-scale decomposition. Eng Appl Artif Intell 114:105172
Wang P, Tao Z, Liu J et al. (2023) Improving the forecasting accuracy of interval-valued carbon price from a novel multi-scale framework with outliers detection: An improved interval-valued time series analysis mode. Energy Econ 118:106502
Yang D, Li Y, Guo J et al. (2023b) Regional tourism demand forecasting with spatiotemporal interactions: a multivariate decomposition deep learning model. Asia Pac J Tour Res 28:625–646
Yang S, Yang W, Wang X et al. (2023a) A novel selective ensemble system for wind speed forecasting: from a new perspective of multiple predictors for subseries. Energy Convers Manag 294:117590
Zeng L, Hu H, Tang H et al. (2024b) Carbon emission price point-interval forecasting based on multivariate variational mode decomposition and attention-LSTM model. Appl Soft Comput 157:111543
Zeng L, Li RYM, Zeng H et al. (2024a) Perception of sponge city for achieving circularity goal and hedge against climate change: a study on Weibo. Int J Clim Change Strateg Manag 16:362–384
Zhang F, Xia Y (2022) Carbon price prediction models based on online news information analytics. Financ Res Lett 46:102809
Zhang H, Wang J, Qian Y et al. (2024) Point and interval wind speed forecasting of multivariate time series based on dual-layer LSTM. Energy 294:130875
Zhang L, Zhang J, Xiong T et al. (2017) Interval forecasting of carbon futures prices using a novel hybrid approach with exogenous variables. Discret Dyn Nat Soc 2017:5730295
Zhang M, Zhou Y, Quan W et al. (2020) Online learning for IoT optimization: a Frank–Wolfe Adam-based algorithm. IEEE Internet Things J 7:8228–8237
Zhou F, Huang Z, Zhang C (2022) Carbon price forecasting based on CEEMDAN and LSTM. Appl Energy 311:118601
Zhu J, He Y, Yang X et al. (2024) Ultra-short-term wind power probabilistic forecasting based on an evolutionary non-crossing multi-output quantile regression deep neural network. Energy Convers Manag 301:118062
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 72301255), Key R&D and Promotion Project in Henan Province (Key Technology Projects: No. 232102241019), Henan Philosophy and Social Science Program (No. 2023CJJ183), China Postdoctoral Science Foundation (No. 2021M702935), Zhongyuan Talent Project (Yucai Project) (No. 244200510047), Major Project of Basic Research on Philosophy and Social Sciences in Colleges and Universities of Henan Province (No. 2022-JCZD-21), National Natural Science Foundation of China (Grant No. 72301157&72101138), Henan Philosophy and Social Science Program (No. 2023BJJ083), Key R&D and Promotion Project in Henan Province (Soft Science Projects: No. 242400411089 and Key Technology Projects: No. 242102320060), National Social Science Fund of China (No. 24BGL289), and Postdoctoral Research Program of Henan Province (No. 202103033).
Author information
Authors and Affiliations
Contributions
TN: conceptualization, funding acquisition, methodology. YC: software, writing—original draft, visualization. TL: data curation, investigation. SLS: investigation. WGZ: literature review, data analysis. MJC: literature review, data analysis, visualization. JKW: literature review, visualization. SYH: data curation, writing—review & editing, visualization. JJL: data analysis, visualization, investigation. YKZ: data analysis, funding acquisition, methodology.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
It does not apply to this article as it does not contain any studies with human participants.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Niu, T., Chen, Y., Li, T. et al. Paying attention to distortion: improving the accuracy of multistep-ahead carbon price forecasting with shape and temporal criteria. Humanit Soc Sci Commun 12, 807 (2025). https://doi.org/10.1057/s41599-025-05110-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1057/s41599-025-05110-5
