
Abstract
Low-carbon innovation, as a key driving force for achieving the “dual carbon” goals, is crucial for promoting the process of environmental sustainability and accelerating the development of a green economy. Based on panel data from 288 prefecture-level cities in China from 2011 to 2022, a benchmark regression model, mediating effect model and threshold regression model were constructed to systematically examine the effects of data elements on the quality and number of regional low-carbon innovation. The results reveal that: (1) Data elements can promote the increases in the number and quality of regional low-carbon innovation, and this conclusion remains valid after a series of robustness tests. (2) Data elements can directly promote the quality and number of regional low-carbon innovation, and indirectly affect the quality and number of low-carbon innovation through integrating data elements and technology elements, data elements and labor elements, and data elements and capital elements. (3) According to the threshold effect test, data elements have different threshold effects on low-carbon innovation. Specifically, data elements can play a stronger positive role at higher integration levels of data and technology elements, data and labor elements, and data and capital elements. These research conclusions have important implications for leveraging the role of data elements and accelerating the realization of low-carbon innovation-driven development.
Similar content being viewed by others
Introduction
Climate change has emerged as a critical issue of global concern for the international community amidst the escalating global environmental crisis. Data publicly disclosed by the International Energy Agency indicates that global energy-related CO₂ emissions are set to hit a historical high of 37.4 billion tons in 2023. This marks a 1.1% rise from 2022, with an extra 410 million tons of emissions addedFootnote 1. The continuous growth of greenhouse gas emissions leads to the intensification of global warming, which then triggers a series of chain reactions (Shivanna 2022). The extreme floods in Dubai in April 2024, the highest temperature in New Delhi, India, reached 52.3 °C at the end of May, the highest temperature in Phoenix, western United States, reached 50 °C at the beginning of July, and the number of fires in the Amazon forest reached a record high. These extreme disasters have had important impacts on industrial production and people’s lives that cannot be ignored. In this context, nations across the globe have actively heeded the appeal of the international community. For instance, Japan and the United States have committed to reaching net-zero carbon emissions by 2050. As the world’s largest energy consumer and CO2 emitter, China has integrated environmental protection into its national development plan and has committed to achieving carbon neutrality and a carbon peak by 2030 and 2060, respectively (Hu et al. 2023). China’s development of a policy framework, implementation approach, and institutional innovation while advancing the “dual carbon” goal holds significant importance for achieving China’s low-carbon transition and provides a practical example for global climate governance. First, through the construction of photovoltaic power stations, water-saving irrigation systems, and other technologies to empower Africa’s “Great Green Wall” program, China has successfully built an ecological barrier on the southern edge of the Sahara, restored 18 million hectares of previously degraded land, and increased the vegetation coverage rate of Mali and other countries by 12% to 15%. Second, the digital technology-driven “ant forest” model has been transplanted across the country. The Philippine GCash platform visualized users’ carbon footprints through blockchain technology and attracted more than 700,000 users to participate in the initial launch. It plans to plant 365,000 trees in the Philippines every year to help local ecological restoration. Third, China has selected suitable species for Kazakhstan and helped build Astana’s ecological barrier. Presently, China has built a plant germplasm resource nursery covering 2.3 hectares, introduced 32 species and 15,600 plants, and completed the construction of a 20-hectare demonstration shelterbelt. These practices have proven that China’s climate actions have a paradigm-shifting innovation value in restructuring the global climate governance system.
Nowadays, low-carbon development has gradually become a prominent feature of China’s move towards high-quality development and low-carbon innovation (innovation) has progressively emerged as a crucial driving force for China’s sustainable development (Wang et al. 2021). As stated in the Global Innovation Index 2023 report issued by the World Intellectual Property Organization (WIPO), China ranks 12th globally in innovation, performing better than expected at its level of development, and has the highest number of international patent applications worldwide. Furthermore, the data indicate that, between 2016 and 2022, China’s green and low-carbon patent grants grew by 9.3% yearlyFootnote 2, while outside China, other nations displayed reduced growth patterns. China is now a key participant in the advancement of low-carbon and green technologies worldwide. However, China’s patent industrialization rate is only about 30%, significantly lower than those in the United States, the United Kingdom and other developed countries, and the issue of insufficient breakthrough technological innovations persists, both in terms of quantity and quality. Therefore, how to promote innovation has emerged as a significant subject in both theoretical and physical studies.
Following the agricultural and industrial economies, the digital economy has emerged as a novel economic paradigm. The core of this transformation lies in data elements (data), which drive the digitization of all factors and harbor immense value (Xu et al. 2022). As a new production factor, data needs to integrate with traditional production factors like technology, labor, and capital to promote economic and social development. Additionally, they can encourage the best possible distribution of other innovation components, lead to significant adjustments in innovation techniques, and provide a powerful boost to economic innovation and growth. Presently, the literature on data focuses primarily on pollution emission (Gao et al. 2024) and economic benefit (Yin et al. 2022), with few scholars examining the effects of data on innovation (Chen 2022). In 2023, the Data Elements ‘×’ Three-year Action Plan (2024-2026)Footnote 3 was jointly issued by the National Data Bureau and 17 other Chinese departments conducted a detailed work deployment on the data multiplication effect, which coincides with the comprehensive allocation requirements of production elements required to improve the level of innovation. By promoting the combination of data with traditional production elements, such as labor and capital, we will foster new models, emerging industries, and novel business models, and accelerate the level of innovation. Through real-time collection of energy usage and carbon output data of the entire production process, combined with machine learning algorithms, technological improvement bottlenecks can be accurately identified, which can improve the intensity and reliability of innovation technology and reduce environmental pollution (Jaf et al. 2023). Additionally, cross-domain data fusion may launch new low-carbon technology, such as the coupling of meteorological data and power grid scheduling data, which can subsequently decrease the error rates of wind power prediction models and enhance the efficiency of clean energy utilization (Hu et al. 2021). Given this, the process of improving the level of regional innovation and increasing data on China’s actual economy will likely be a successful strategy for increasing innovation levels. The contemporary advantages offered by the digital era must be swiftly harnessed by China, driving both enhanced optimization of production factor allocation and a systemic empowerment of innovation capacities. Thus, a query that merits consideration is: Can data promote the growth of the quality and number of innovation simultaneously? If the response is affirmative, what is the transmission mechanism through which data enables the quality and number of innovation? At the same time, considering the heterogeneity of different Chinese regions, do data have unique effects and characteristics on the quality and number of innovation in different regions? An in-depth exploration of data that enables innovation is necessary. Additionally, identifying data in this process that plays specific roles in formulating appropriate development policies is needed.
This paper deviates from prior research by offering the following three incremental contributions. First, the projection pursuit method is utilized to determine a data index, and the quality and number of innovation are incorporated within the same analytical framework to explore the impacts of data on the quality and quantity of regional innovation. It also extends the research domain of digital empowerment and innovation. At the same time, it deepens the understanding of the inherent law of the impact of data on the quality and number of innovation and provides a reference basis for improving the level of innovation through data. Second, from the economic perspective, the entry of data into the production process will change the composition and interrelationship of production functions. In this paper, data are integrated with technology elements, labor elements and capital elements, respectively, and the integration level of measurement technology, labor and capital of the coupling coordination degree model is utilized as the intermediary variable to analyse the indirect influence mechanism of data enabling innovation from three integration aspects. Third, based on China’s typical regional heterogeneity, data and innovation are included in the same framework, and the nonlinear effects of data on innovation are further analyzed. This yields a conceptual foundation for the advancement of data and the formulation of innovation policies, and also responds to the theoretical requirements of promoting innovation according to local conditions.
The remainder of the paper is structured as follows. The literature on data and innovation is reviewed in the second section. The paper’s theoretical examination and investigation hypothesis are expounded upon in the third section. Model building, variable measurement and data sources are introduced in the fourth section. The fifth section provides a thorough review of the paper’s empirical findings and conducts the robustness test. Finally, we conclude this paper, make some policy suggestions, and discuss shortcomings and prospects.
Literature review
Relevant research on data elements
Presently, academic circles primarily study the connotation characteristics, influencing elements, and the influencing effect of data. Regarding connotation characteristics, data, as an emerging form of production element, has characteristics including externality (Jones and Tonetti 2020), heterogeneity, partial exclusivity (Gaessler and Wagner 2022), and non-consumption (Sheng et al. 2024). Through the effective use of data, enterprises can achieve data accumulation and optimize internal processes (Wang et al. 2024), such that data is crucial to the intelligent information technology application process (Li et al. 2022). Prior studies have found that organizational culture, leadership support, technological progress, financial assistance, and reserves of digital talent mediate the efficacy of data (Liu et al. 2022). Regarding impacts, previous research has indicated that data components constitute a pivotal element in influencing innovation (Xiao 2024; Zhong and Zhang 2024), total element productivity (Huang and Chen 2024; Ren et al. 2024), urban green innovation (Zhang and Hua 2025) and pollution reduction (Gao et al. 2024), and all have positive promoting effects.
Relevant research on low-carbon innovation
innovation has become the fundamental driving force for climate change mitigation and sustainable development attainment (Pettifor and Wilson 2020; Lyu et al. 2024). Recent decades have witnessed a surge in scholarly focus on innovation studies across multiple disciplines. Academic circles have gradually increased research on innovation, which can be divided into connotation and impact research. Presently, scholars have not yet reached a unanimous consensus on the deeper meaning of innovation, but the prevailing perspective is that it represents a model defined by characteristics such as low energy consumption, minimal pollution, reduced emissions, high efficiency, and significant benefits. This model can achieve energy conservation, emission cuts, and mitigation of adverse environmental effects via technological advancements (Wang et al. 2022). Additionally, many international scholars, especially in Spain (Tirado-Herrero and Fuller 2021), Poland (Świadek et al. 2021), Korea (Kim 2022), Pakistan (Yuning et al. 2024), China (Pan et al. 2022; Hunjra et al. 2024) and other countries have conducted in-depth exploration of innovation and confirmed the positive effects of low-carbon city pilot policies, digital technology, and big data integrated pilot area policies on innovation. To enhance the readability of this paper and make it easier for scholars to recognize and contrast the presented studies, this paper systematically reviews and consolidates research on the effects of innovation, while also incorporating a literature review table, shown in Table 1.
It is noteworthy that innovation, green innovation and carbon-neutral technology innovation all play important roles in the field of environmental protection and sustainable development, and aim to reduce adverse environmental effects and promote the sustainable development of the economy and society (Song and Yu 2018), but with different emphases. innovation aims to be innovative by using low-carbon levels in product technologies, product concepts, or business operation models while using low-carbon value network innovation to deliver value to customers. Green innovation refers to innovation in a broad sense. When compared with other innovation activities, green innovation is marked by high investment, high risk, long cycles and strong environmental externality (Huang et al. 2019). It encompasses a broader range of areas, including energy saving, prevention of pollution, waste reuse, and other environmental protection-related domains (Arici and Uysal 2022). Carbon-neutral technology innovation serves as a pivotal breakthrough in achieving the “dual carbon” objectives. This innovation encompasses a system of technologies, including energy conservation and efficiency enhancement, low-carbon solutions, renewable energy production, alternative combustion methods, as well as negative carbon approaches like carbon capture and storage (Liu et al. 2023).
2.3 Relevant research on the impact of the digital economy on low-carbon transition
As an emerging economic form, the digital economy is crucial for advancing low-carbon sustainable development (Song et al. 2024). With the vigorous development of the digital economy, the enabling role of the digital economy has gradually attracted the attention of scholars. Most previous studies have explored the intricate connection between the digital economy and the low-carbon transition from two perspectives: the direct and indirect effects of the digital economy. Existing studies have selected different regions, such as BRICS, as research samples to demonstrate the positive effects of the digital economy on low-carbon transition (Sohail 2023). The sharing and transparency of the digital economy improve the precision of business forecasts, help to realize product value, and decrease energy losses resulting from imbalanced resource allocation in the microeconomic context, thereby facilitating the transition to a low-carbon economy (Ma et al. 2024). Additionally, some scholars consider green innovation to be a crucial element influencing the low-carbon transformation within the digital economy (Ma et al. 2022; Yang et al. 2023). In addition to green innovation, academic investigations have focused on analyzing the digital economy’s transitional mechanisms toward low-carbon development, incorporating critical examinations of innovation factor mobility and related determinants (Wang et al. 2022), labor productivity, industrial structure (Liu et al. 2024) and environmental governance (Zhang et al. 2022; Du and Xiao 2024). The following areas of study on data and innovation still require development, according to the analysis of the body of extant literature: first, in the current research, few scholars have conducted a comprehensive quantitative investigation on the quality and number of innovation. Second, when analyzing indirect effects, most of the existing studies used a single variable to analyze intermediary variables, ignoring the linkage effect between data and other production elements. Third, existing studies cannot integrate data and innovation to investigate the nonlinear effect between the two, using the same framework.
Theoretical analysis and research hypothesis
Direct conduction mechanism and research hypothesis
In general, data are information that can be recorded, shown, and kept in the form of data and that humans can use, communicate, and analyze. The productivity attributes of data and the unique support of digital technology make data conform to the characteristics of key production elements. Data factionalization and value encourage the growth of the digital economy before offering more informational assistance for innovation through data collection, integration and analysis, to promote the development and application of innovation.
(1) The effect of data on the quality of regional innovation
Different from the simple accumulation of innovation numbers, innovation quality emphasizes the intrinsic value attribute of innovation achievements, including qualitative elements such as originality, breakthrough, adaptability and sustainable impact. Data, as a knowledge carrier, accelerates the process of explicit tacit knowledge, transforms the practical experience into shareable knowledge assets through high-precision modeling, and improves the knowledge density and practicability of innovation. “Metcalfe’s Law” points out that the value of a network is equal to the square of the number of nodes in the network. With the continuous development of networking platforms, the expansion of network value is promoted and a positive feedback cycle is generated (Wang et al. 2024), the knowledge flow path is optimized and an efficient knowledge-sharing network is built between enterprises, universities and research institutes, providing comprehensive support for innovation decision-making. It ensures that the carbon benefit and economic benefits of the technical solution are optimized and that the innovation quality is strictly controlled. Furthermore, digital technology facilitates the advancement of innovation technology through knowledge spillovers, facilitating conventional industries to participate in clean energy generation (Tan et al. 2023). Furthermore, digital technologies can be leveraged by both public and private sectors to implement comprehensive environmental monitoring frameworks, making the formulation of emission reduction strategies more precise and scientific and directly promoting the quality of innovation.
(2) The effect of data on the number of regional innovation
Based on the “Endogenous Growth Theory”, data play a central role in driving the number of regional innovation (Liu et al. 2019). On the one hand, from the viewpoint of knowledge accumulation, the continuous accumulation and effective integration of data, as a key production element, provides a valuable information cornerstone for innovation (Chen et al. 2023). Enterprises and scientific research institutions can use these data to deeply analyze environmental and energy issues and explore new low-carbon technology pathways and innovation points, such as accurately positioning emission reduction technology needs through big data analysis. On the other hand, human capital serves as a crucial factor that affects regional green technology innovation and carbon emissions (Wu et al. 2024). Highly skilled scientific professionals are capable of creating new low-carbon technologies, enhancing energy efficiency, and decreasing carbon emissions (Zhang et al. 2024). The need for efficient data processing and applications has spawned the cultivation and gathering of relevant professionals, which both improves the innovation capacity in the region and attracts more external talent inflow to jointly devote themselves to innovation research. This interaction between human capital accumulation and knowledge accumulation has formed a virtuous cycle, further encouraging the enhancement in the number of regional innovation.
In conclusion, this paper proposes the following research hypothesis:
Research hypothesis 1a: data improve the quality of regional innovation.
Research hypothesis 1b: data improve the number of regional innovation.
Indirect conduction mechanism and research hypothesis
data have borderless and full coverage. In the context of digital economic expansion, the integration degree between different data and between data and other traditional elements is constantly increasing. data are different from general production elements, and their multi-dimensional characteristics determine that data can take into account the needs of different types of production elements in the process of integrating into economic activities. The marketization of data can effectively exert its “multiplier effect” and effectively facilitate the advancement of innovation activities by expanding the application scenarios and functional changes of innovation elements (Wu et al. 2023). data are deeply integrated with technology, labor and capital elements to better demonstrate their resource allocation capabilities, value exploration and value-added capabilities (Liu et al. 2024). Consequently, this paper examines the mediating effect of the integration level of data elements and technology elements (\({\rm{data}}\times {\rm{tec}}\)), the integration level of data elements and labor elements (\({\rm{data}}\times {\rm{lab}}\)), the integration level of data elements and capital elements (\({\rm{data}}\times {\rm{cap}}\)) in the process of data enabling the quality and number of innovation.
(1) Analysis of the mediating effect of the level of \({\rm{data}}\times {\rm{tec}}\)
\({\rm{Data}}\times {\rm{tec}}\) can improve technology integration capabilities, effectively provide multidimensional support, and inject new impetus into innovation. On the one hand, enterprises accumulate user data for data analysis through multilateral platforms, which can reduce business operating costs and improve the vitality of innovation. Digital platforms, artificial intelligence and big data can mine patterns in large-scale data to provide data support for innovation, and data sensing technology can be combined with the establishment of real-time monitoring systems, through the real-time feedback of data, timely adjustment of innovation solutions, and improved efficiency. On the other hand, \({\rm{data}}\times {\rm{tec}}\) can create an open digital technology innovation ecosystem, promote cooperation and exchanges in different fields, and facilitate the transnational convergence and accelerated deployment of innovations.
(2) Analysis of the mediating effect of the level of \({\rm{data}}\times {\rm{lab}}\)
As a key production element, data can improve industrial agglomeration ability and enable innovation through integration with labor elements, thus promoting sustainable economic and social development (Zhang et al. 2022). On the one hand, \({\rm{data}}\times {\rm{lab}}\) promotes the accurate application of data, and the workforce can help interpret the data through its expertise and experience. \({\rm{data}}\times {\rm{lab}}\) makes data interpretation more comprehensive and accurate, and guides the decision-making of innovation. On the other hand, \({\rm{data}}\times {\rm{lab}}\) promotes the optimization of intelligent production. The participation of the labor force makes the application of data-driven technology closer to the actual production, and more intelligent use of data technology serves enterprise production activities, thereby improving resource utilization and reducing environmental impact.
(3) Analysis of the mediating effect of the level of \({\rm{data}}\times {\rm{cap}}\)
\({\rm{data}}\times {\rm{cap}}\) can not only improve the quality and number of innovation, but also establish a solid foundation for the sustainable development of the low-carbon economy. On the one hand, the \({\rm{data}}\times {\rm{cap}}\) can bring more capital space. Enterprise projects can use capital elements to improve corporate environmental performance (Cao et al. 2021), enhance the inclusiveness of enterprises in the green economy, promote low-carbon technology innovation (Ren et al. 2022), better demonstrate the potential and value of data in projects to investors and increase investment attractiveness. On the other hand, \({\rm{data}}\times {\rm{cap}}\) can assist businesses in making more effective investment decisions. Through the support of capital, investment in innovation has increased. By utilizing technologies like artificial intelligence and data, enterprises can screen and identify innovation projects quickly and assess the potential risks and returns of the projects, thereby reducing decision-making costs and time-related costs and improving investment efficiency and success rate.
In conclusion, the research hypothesis 2 is presented here: data can indirectly affect the multiplication of numbers and the increasing quality of innovation through the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\).
Nonlinear conduction mechanism and research hypothesis
Within the framework of data application, data are likely to have nonlinear effects on the quality and number of innovation, that is, as the overall levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\), the ability of data to drive the quality and number of innovation may change, revealing nonlinear characteristics. (1) When the level of \({\rm{data}}\times {\rm{tec}}\) increases, the efficiency of data driving innovation may also increase. With the continuous integration of data and technology elements, more innovation potential can be released. For example, overlaying existing manufacturing practices with networked and intelligent capabilities can help improve manufacturing flexibility and precision, and improve the efficiency of innovation (Yu et al. 2021). (2) With higher-level \({\rm{data}}\times {\rm{lab}}\), human-machine collaboration becomes more compact and efficient. Through collaboration with data processing technology, the labor force can quickly acquire and analyze data, reduce the time cost of decision-making, better play the role of data in innovation, and promote the rapid implementation of innovation projects. (3) The higher level of \({\rm{data}}\times {\rm{cap}}\) will promote innovation. Capital injection can encourage more innovation, enable enterprises to better demonstrate the underlying value and return of innovation projects, attract more capital investment, and accelerate the development of innovation.
In conclusion, research hypothesis 3 is presented: data have different threshold effects on innovation. data can play a stronger positive role at higher integration levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\).
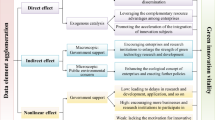
Figure 1 shows the theoretical framework of this paper.

Theoretical framework diagram.
Model building and variables measurement
Model construction
This paper uses the benchmark regression model, mediating effect model and threshold regression model to investigate the complex impact of data on urban innovation, to test the three presented hypotheses. Two-way fixed effects consider both the individual and the time fixed effect, effectively controlling the heterogeneous effects of both the individual and time, thus more accurately estimating the causal relationship between variables (Mummolo and Peterson 2018; Breuer and Dehaan 2024). In this paper, data index was introduced to analyze the innovation of 288 cities, and the benchmark regression model was built as shown in Eq. (1):
where, \({{\rm{innovation}}}_{{\rm{it}}}\) means the \({\rm{low}}-{\rm{carbon\; innovation}}\) level of the i city in the t year, followed by the innovation level including quality (\({{\rm{giq}}}_{{\rm{it}}}\)) and number (\({{\rm{gin}}}_{{\rm{it}}}\)). \({{\rm{\alpha }}}_{0}\) means the intercept term. \({{\rm{\alpha }}}_{1}\) means the parameter to be estimated, and \({{\rm{\alpha }}}_{{\rm{n}}}\) means the parameter vector to be estimated. \({{\rm{d}}{\rm{ata}}}_{{\rm{it}}}\) means the \({\rm{data\; elements}}\) of i city in the t year. \({{\rm{X}}}_{{\rm{it}}}\) means the control variables in the model, and includes four types of variables: industrial structure (\({{\rm{estate}}}_{{\rm{it}}}\)), industrial development level (\({{\rm{industry}}}_{{\rm{it}}}\)), financial development level (\({{\rm{finance}}}_{{\rm{it}}}\)) and foreign investment (\({{\rm{investment}}}_{{\rm{it}}}\)). \({{\rm{\lambda }}}_{{\rm{i}}}\) means unobservable individual fixed effects, and \({{\rm{u}}}_{{\rm{t}}}\) means unobservable time fixed effects. \({{\rm{\varepsilon }}}_{{\rm{it}}}\) is a random interference item.
A variable is considered a mediating variable when it plays a role in affecting the independent variable on the dependent variable. By examining the role of mediating variables, the specific mechanism of how the explanatory variable affects the explained variable is revealed (Xian et al. 2024). Mediation analysis contributes to more precise dependent variable forecasting while strengthening theoretical explanatory capacity. Furthermore, this paper introduces three mediating variables: the integration level of data and technology elements (\({{\rm{data}}}_{{\rm{it}}}\times {{\rm{tec}}}_{{\rm{it}}}\)), the integration level of data and labor elements (\({{\rm{data}}}_{{\rm{it}}}\times {{\rm{lab}}}_{{\rm{it}}}\)) and the integration level of data and capital elements (\({{\rm{data}}}_{{\rm{it}}}\times {{\rm{cap}}}_{{\rm{it}}}\)). It investigates the indirect influence mechanism of data supporting innovation using the following model.
In the above formula, \({{\rm{mediation}}}_{{\rm{it}}}\) represents the mediating variables. \({{\rm{\beta }}}_{0}\) and \({{\rm{\omega }}}_{0}\) represent the intercept item. \({{\rm{\beta }}}_{1}\), \({{\rm{\omega }}}_{1}\) and \({{\rm{\omega }}}_{2}\) indicate the parameter to be estimated, and \({{\rm{\beta }}}_{{\rm{n}}}\) and \({{\rm{\omega }}}_{{\rm{n}}}\) indicate the parameter vector to be estimated.
Additionally, the nonlinear relationship between data and innovation is tested by adopting the threshold regression model. Through threshold regression analysis, researchers can effectively model non-linear dependencies between regressors and outcome variables, while simultaneously determining critical threshold points and statistically validating their significance (Wang 2015). Relative to alternative modeling approaches, the static threshold regression framework demonstrates superior characteristics, including structural simplicity, broad data compatibility, and robust performance. These methodological merits justify its application in examining the nonlinear association between data elements and low-carbon innovation in the current study. Taking the levels of \({{\rm{data}}}_{{\rm{it}}}\times {{\rm{tec}}}_{{\rm{it}}}\), \({{\rm{data}}}_{{\rm{it}}}\times {{\rm{lab}}}_{{\rm{it}}}\), \({{\rm{data}}}_{{\rm{it}}}\times {{\rm{cap}}}_{{\rm{it}}}\) as threshold variables, this paper establishes models as shown in Eqs. (4) and (5):
where, \({{\rm{\mu }}}_{{\rm{i}}}\) represents the intercept term. \({{\rm{\theta }}}_{1}\), \({{\rm{\theta }}}_{2}\), \({{\rm{\theta }}}_{3}\) indicates the parameter to be estimated, and \({{\rm{\theta }}}_{{\rm{n}}}\) indicates the parameter vector to be estimated. \({{\rm{threshold}}}_{{\rm{it}}}\) represents the value of the threshold variable for t year of i city. γ represents the threshold value of the single threshold model, and \({{\rm{\gamma }}}_{1}\), \({{\rm{\gamma }}}_{2}\) respectively represents the first threshold value and the second threshold value of the double threshold model. \({\rm{I}}({{\bullet}})\) indicates an indicative function, taking the value 1 if the corresponding condition is true, otherwise 0. Figure 2 shows the block diagram of variable action mechanisms in this paper.

Block diagram of variable action mechanisms.
Measurement of variables
Explained variable
low-carbon innovation (innovation). The quantity of patents is a very trustworthy indicator that can more accurately reflect the degree of innovation because of the objectivity of patent grant criteria as well as benefiting from the availability of pertinent data. Meanwhile, the quantity of patents granted is a more accurate indicator of the degree of innovation than the number of patent applications. Therefore, this paper adopts a similar approach to that used by Wang and Li (2022), Zhu and Bai (2024), and Han et al. (2024), quantifying green innovation based on the count of green inventions patent applications, and utilizing the count of granted green patents as a measure of innovation. Specifically, the number of green utility model patents granted represents the number of innovation (gin), and the number of green invention patents granted, which suggests more innovation and novelty than green utility model patents, represents the quality of innovation (giq). Considering that innovation is a cumulative process, its cumulative results profoundly affect regional economic development and environmental sustainability. Therefore, to accurately measure and characterize the level of regional innovation, this paper utilizes the perpetual inventory method to deal with patent grant inventory and to reflect the continuous accumulation effect of innovation.
Core explanatory variable
data elements (data). To improve the level of data requires the popularization and improvement of infrastructure. Therefore, this paper expresses the level of data from the level of digital infrastructure. It uses the internet penetration rate, the proportion of internet-related employees, the level of internet output, and the number of mobile internet users. Specific measurements are shown in Table 2. Since this index of data is multidimensional, to effectively synthesize different measure indexes, the improved projection pursuit method, which is based on an accelerated genetic algorithm, is used to measure the index of data. Notably, the method has good robustness and strong anti-interference (Bickel et al. 2018). Through real-coded accelerated genetic computation, the optimization domain is substantially enlarged and premature convergence is systematically avoided, which collectively contributes to obtaining scientifically sound and stable solutions (Pei et al. 2023).
Mediating variables and threshold variables
In this paper, the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\), and \({\rm{data}}\times {\rm{cap}}\) are taken as the mediating variables and threshold variables to explore the mediating effect and the nonlinear effect of data in the process of innovation. In this paper, variables are measured in two steps: one is the single elements measure, that is, the measure of technology elements, labor elements and capital elements, and the other is the measurement of the level of elements integration.
For the single elements measurement, the measurement methods of technology elements, labor elements, capital elements are as follows: (1) technology elements: This paper uses scientific expenditure to represent technology elements. (2) labor elements: Education level is a significant factor promoting the continuous increase of labor level. This paper is measured by the number of employees in the education industry. (3) capital elements: This paper uses fixed assets to express capital elements.
The coupling coordination model serves as an effective analytical framework for quantifying integration levels among system elements. This methodology specifically evaluates synergistic development states, where the coupling degree quantitatively captures bidirectional interactions and mutual influences between paired systems. Therefore, the coupling coordination model is used to study the integration of data with technology elements, labor elements and capital elements. This paper utilized Eqs. (6) through (9) to calculate the coupling degree:
where, \({{\rm{U}}}_{1}\) is the data elements and \({{\rm{U}}}_{{\rm{i}}}\) is other production elements (i is technology elements, labor elements and capital elements). The range standardization approach is used in this paper to conduct dimensionless processing of indicators. technology elements, labor elements and capital elements are all positive indicators, as shown in formula (9). C denotes the coupling degree. T is the integrated coordination index, and both a and b indicate specific gravity. In this paper, \({\rm{a}}={\rm{b}}=0.5\) is used, which means that data are considered equally important as other elements. D refers to the coupling coordination degree of data with technology elements, labor elements and capital elements, namely, the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\), \({\rm{data}}\times {\rm{cap}}\), the value of which is [0,1]. Higher integration levels and better coordination between data and other elements are indicated by larger values. Here the smaller the value is, the worse the coupling state between data and other element systems, and the lower the integration level. According to formulas (6) through (9), the data are calculated, and the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\), and \({\rm{data}}\times {\rm{cap}}\) are finally obtained.
Control variables
This paper draws on past studies and selects four variables, namely industrial structure (estate), industrial development level (industry), financial development level (finance) and foreign investment (investment). (1) estate is closely related to innovation. Referring to the method of Shen and Li (2020), the ratio of the gross product of the tertiary industries to the gross product of the secondary industries is adopted to measure. (2) industry. It is measured by the number of industrial enterprises above the designated size. (3) finance. This study uses the ratio of loans outstanding by financial institutions to GDP to measure. (4) investment. This paper uses the ratio of foreign investment to GDP to measure investment.
Data sources
This paper utilizes 288 cities in China from 2011 to 2022 for research. The data selected for each variable are from the China City Statistical Yearbook, National Bureau of Statistics, China National Intellectual Property Administration, and provincial statistical yearbooks. Due to the limitation of data availability and continuity, there was a lot of missing data in Hong Kong, Macao, Taiwan, Tibet and other provinces, as well as Sansha, Danzhou, Hami, Turpan, and other cities, so the elimination process was done. For cities with less data missing, this paper uses linear interpolation to fill in the missing values to maintain data continuity. Meanwhile, to eliminate the problems of price fluctuation and control estimation bias, the relevant variables involved in the paper are logged and correspondingly deflated.
Empirical results and analysis
Data elements feature analysis
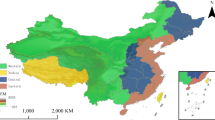
Figure 3 and Fig. 4 further show the spatial distribution of data from 288 cities in the base period and at the end of the study through geographical maps. Here, the darker the color, the higher the development level of data (non-colored areas indicate missing data and are not samples of this paper). Through our observation, we found that the data index showed an upward trend during 2011–2022. In general, the data show an “eastern-central-western” gradient distribution. In the eastern region, including coastal cities such as Shanghai, Shenzhen, and Hangzhou, the darker color indicates that the development level of data is higher, and these regions have stronger comprehensive advantages in the economic foundation, technology innovation, and talent reserve, thus promoting the development of data. Hohhot, Baoji, Kaifeng, and other cities in the central region have a relatively moderate level of data development. These regions have also made some progress in digitization, but a certain gap remains compared with the East, which may be related to geographical location, economic level, and scientific and technological innovation resources. In the western region, including Jiayuguan, Karamay, Jinchang and other places, data’s development level is low. However, as state support for the central and western regions continues to increase and the regional coordinated development strategy is implemented more thoroughly, the potential for future data-related development in these regions is enormous, and it is anticipated that they will close the gap with the eastern region.

Spatial distribution of data elements index for each city in 2011.

Spatial distribution of data elements index for each city in 2022.
Collinearity test
Considering that there may be multicollinearity between multiple variables, a collinearity test is performed on the variables before baseline regression analysis. This paper utilizes the variance inflation factor (VIF) to determine whether multicollinearity exists between variables by comparing statistics and critical values. Table 3 shows the VIF test results. 3.32 is the maximum VIF value, which is significantly lower than 10, so the multicollinearity of the variable is not an issue.
Analysis of benchmark regression results
This paper employs a two-way fixed effects model to analyze the impact of data on the quality and number of innovation. The regression results concerning the role of data in fostering innovation are summarized in Table 4. Columns (1) and (3) present the estimated outcomes without the inclusion of control variables, while columns (2) and (4) showcase the estimated results after incorporating control variables into the analysis. The results suggest that the effect of data on innovation is consistently positive, regardless of the inclusion of control variables. This indicates that data plays a crucial role in enhancing both the quality and quantity of regional innovation. This verifies research hypothesis 1. With the inclusion of control variables, for each 1 unit rise in the data index, both the quality and quantity of innovation are anticipated to increase by 0.683 and 2.663 units, respectively. The paper posits that data fragmentation and value orientation could stimulate the advancement of the digital economy. This, in turn, may facilitate innovation development by enhancing information support through data gathering, consolidation, and analysis, thereby fostering innovation development and implementation.
In terms of control variables, for every 1 unit increase in estate, the quality of innovation will increase by 0.004 units and is not significant, and the number of innovation will decrease significantly by 0.042 units. The paper suggests that the optimization and advancement of the estate contribute to the efficient utilization of resources and technological advancement. While this optimization stimulates the growth of certain high-tech sectors, thereby enhancing the quality of innovation, the impact may not be sufficiently pronounced due to factors like technological maturity and market demand. The adjustment of estate may also lead to the reduction of traditional high-carbon industries, thus significantly reducing the number of innovation. This paper suggests that for every 1% rise in the industry, there is a marginal decrease of 0.001% in the quality of innovation and a minor increase of 0.022% in the number of innovation, with no statistically significant effect. The paper argues that enhancements in the industry typically coincide with increased resource inputs, bolstering of the technological foundation, stimulation of market demand, and policy backing (Liu et al. 2022). Together, these jointly promote the application and effect of data in innovation. Perhaps because the promotion effect is mostly exploratory innovation, so the effect is not significant. Meanwhile, this role may drive more resources to mature processes, putting pressure on the improvement of the quality of innovation. The influence coefficients of finance on the quality and number of innovation are 0.001 and 0.003, and the effect is not significant. This result indicates that finance can have a promoting effect on innovation, but the positive impact is not significant. This paper holds that the improvement of finance generally increases the financing and investment channels needed for innovation, improves the application of fintech and data analysis technologies, and promotes the formulation of relevant policies and standards, thus creating a more favorable environment for data to play a part in innovation. This view has also been demonstrated by Acheampong (2019), Lv and Li (2021). However, innovation inherently possesses traits of high risk and prolonged cycles, which may lead to more funding for short-term effective projects, and insufficient investment in long-term high-quality innovation, resulting in insignificant effects. The influence coefficient of investment on the quality and number of innovation is positive, and the influence on the quality of innovation is significant, but the influence on the number of innovation is not significant. This may be because investment brings advanced technology and management experience, and these advanced elements, combined with local innovation resources, greatly promote the R&D of low-carbon technology, and then significantly improve the quality of innovation. However, while investment has also broadened financing channels and increased funding for innovation, the number of innovation has failed to grow significantly due to possible uncertainties in market acceptance and commercialization processes.
Endogeneity test
The omission of crucial variables or the potential bidirectional causal relationship between data and innovation can result in endogeneity issues. This paper utilized total postal business volume (iv) as an instrumental variable for the endogeneity test. The total postal business volume, serving as an indicator to gauge the progress of the communication industry, satisfies the criteria for choosing instrumental variables to establish correlations. Therefore, the two-stage least squares method (2SLS) and the dynamic panel model difference GMM were used to estimate the model at the same time. The test results are shown in Table 5.
The two-stage least squares regression results from columns (1) and (4) indicate that the first-stage regression demonstrated a significant correlation between the iv and data, thereby confirming the hypothesis of instrumental variable correlation. In the second-stage regression, the coefficients of the data were found to be significantly positive at a 1% level of significance, and the Kleibergen-Paap rk LM statistic was significant at a 1% level as well. These results suggest that the chosen instrumental variable was successfully identified. Additionally, the Kleibergen-Paap rk Wald F statistic surpasses the 10% critical value of 16.38, passing the weak instrumental variable test. In columns (3) and (6) of the difference GMM model results, the AR test reveals that the first-order sequences of the model exhibit correlation, while the second-order sequences do not, suggesting that the error terms of the original model do not display significant serial correlation. Simultaneously, the Hansen test value exceeding 0.05 suggests that the overidentification constraint is effective. These tests collectively indicate that difference GMM estimations can be reliably conducted. Notably, both model types, post-addressing the endogeneity issue, reveal that data exert a significantly positive influence on the quality and number of innovation, thereby further substantiating hypothesis 1.
Analysis of mediating effect
The test findings of the mediating effect of data enabling the quality and number of innovation are displayed in Table 6. Based on the influence coefficient and the significance level of the core explanatory variable and mediating variables within the model, it can be inferred that through the influence of the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\), data all have an indirect effect on innovation, providing evidence for hypothesis 2.
Specifically, columns (1) to (3), (4) to (6), and (7) to (9) are the model estimation results of the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\) as the mediating variables, respectively. It can be seen that under the influence of the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\), the indirect influence of data on the quality of regional innovation (-0.731*0.968, -0.536*0.913, -0.662*0.976) is inverse to the direct influence (1.391, 1.172, 1.330). The indirect influence of data on the number of regional innovation (-2.541*0.968, -1.865*0.913, -2.454*0.976) is also opposite to the direct effect (5.123, 4.365, 5.059). It shows that the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\) play a ‘masking effect’ between data and innovation. This paper holds that the reasons lie in that, on the one hand, although data directly promotes innovation, \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\) may face technical bottlenecks, talent shortage and resource misallocation in the integration process. These can limit the positive effects of the integration level on innovation. On the other hand, the integration process may also lead to negative effects such as resource dispersion and innovation direction deviation from low-carbon goals, thus obscuring the direct active influence of data on innovation to some degree. Therefore, the government must further optimize the integration mechanism and enhance the level of integration to give full play to the role of data in promoting innovation.
Nonlinear effect analysis
In this paper, the threshold regression model estimation method is used to test whether the nonlinear effect exists, determine its specific threshold value, and estimate the parameter values under different threshold intervals. As shown in Tables 7 and 8, in the process of enabling the quality of innovation with data, there is only a single threshold for the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\). Notably, they pass the significance test, with threshold values of 1.5556, 1.5884 and 1.7084, respectively. In the process of enabling the number of innovation with data, there is a double threshold for the level of \({\rm{data}}\times {\rm{tec}}\), with the threshold values of 0.7668 and 0.9343, and there is a single threshold each for the levels of \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\), these threshold values are 1.5884 and 1.7084, respectively. This analysis reveals that data exhibit a nonlinear impact on both the quality and number of innovation within the constraints of three threshold variables: the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\). This finding confirms hypothesis 3.
Secondly, the least square likelihood ratio statistic LR is used to identify the threshold, and the estimated result of the threshold and the corresponding 95% confidence interval can be observed. The likelihood ratio function diagram of the data on the quality and number of innovation is depicted in Figs. 5 and 6, respectively. The LR value of the likelihood ratio statistical test is zero when the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\) are taken when the threshold variable value reaches the threshold value.

a The levels of data×tec is threshold variable. b The levels of data×lab is threshold variable. c The levels of data×cap is threshold variable.

d The levels of data×tec is threshold variable. e The levels of data×lab is threshold variable. f The levels of data×cap is threshold variable.
The threshold regression results of the innovation by data are presented in Table 9. Columns (1) to (3) represent the results of data on the quality of innovation, and columns (4) to (6) represent the results of data on the number of innovation. Results show that whether data enable the quality or number of innovation, data have an active and significant influence on \({\rm{innovation}}\), and with the increasing value of the threshold variables, its impact shows a trend of ‘marginal increase’. As for data enabling the quality and number of innovation, this paper believes that the explanation is that the integration of data with technology elements, labor elements and capital elements provides more comprehensive information support, helping enterprises to make more precise decisions. Specifically, the integration of data and various elements enables enterprises to better manage labor and capital, reduce costs, improve efficiency, and provide broader possibilities for innovation. Through the deep integration of various elements, data can observably improve the refinement level of ecological environment governance, effectively promote multi-field collaborative governance, and provide solid technical support for the construction of a harmonious and symbiotic ecological civilization and society. Therefore, the improvement of the integration level significantly increases the effect of innovation, resulting in an increasing trend of the impact coefficient.
In general, under the constraint of the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\) as the threshold variables, there is a significantly nonlinear effect between data and the quality and number of innovation, which further confirms hypothesis 3.
Robustness test
To test the robustness of the results, this paper tested the results by using three methods: one-stage delay in explained variables, reduction of control variables, and increase of control variables. First, considering the time lag of innovation, this paper takes the innovation index with a lag of one year to make a regression. The results are consistent with benchmark regression results. Columns (1) and (2) display the findings in Table 10. Secondly, this work conducted a robustness test by decreasing the control variables. After excluding the control variable of investment, the regression analysis of data enabling innovation is conducted. The results of this analysis are displayed in columns (3) and (4) and are consistent with benchmark regression results. They demonstrate that data continues to have a significant active influence on innovation. Finally, the test is carried out by increasing the control variable of human capital (human). In this research, the logarithm of the total number of students in regular colleges and universities is chosen as a proxy for human. The impact coefficient and significance level of this explanatory variable in the findings mirror those of the previous tests, displaying notable consistency and robustness. These results are detailed in columns (5) and (6) of Table 10.
Discussion
In summary, this paper examines the effects of data on the number and quality improvement of innovation and finds that they are not only robust in China but also have wide applicability in the world. Future studies can further explore the specific practices and experiences of different countries and regions in using data to promote innovation and provide more useful references for global green and low-carbon development. Through empirical testing, this paper reveals the influencing mechanism of data on innovation, and draws the following conclusions.
(1) The influence of data on the universality of innovation
This paper finds that the data are conducive to the simultaneous improvement of the quality and number of regional innovation. In the Chinese context, the quality and number of innovation increase by 0.683 and 2.663 units for every 1 unit increase in the data. This conclusion is not only robust in China, as the growth logic and mechanisms associated with it are applicable elsewhere. As a strategic production element, the market-based allocation and value transformation mechanism of data continues to empower low-carbon technology research and development and industrial transformation decision-making through global data resource mining, intelligent modeling and scenario-based applications (Yin et al. 2022). This mechanism has universal rules that are applicable globally. For example, the Singaporean government demonstrates proactive leadership in smart city implementation, leveraging big data technologies to refine municipal administration and maximize resource utilization rates, which is in line with the logic of data promoting innovation presented in this paper. In Europe, with the publication of the European Data Strategy, the EU is working to build a native data market and promote the application of data in innovation. Therefore, the effect of data in facilitating innovation is also progressing in other regions and is worth examining.
(2) data indirectly affect the global perspective of innovation through levels of integration
data not only have a direct driving effect on regional innovation but also indirectly promotes it through multiple integration paths such as technology, labor, and capital linkage. With the progress of digitization, \({\rm{d}}{\rm{ata}}\times {\rm{tec}}\) is accelerating the reconstruction of the global industrial chain, and the deep collaboration between AI and the industrial internet is driving disruptive technological paradigm shifts in fields such as clean energy and intelligent manufacturing (Wang et al. 2022). In 2024, ExxonMobil launched the world’s largest Carbon Capture, Utilization and Storage (CCUS) project, covering an industrial cluster in Texas with an annual capture of 2.2 million tons of CO2. \({\rm{d}}{\rm{ata}}\times {\rm{lab}}\) significantly improves production efficiency and resource allocation accuracy through intelligent collaboration and promotes collaborative innovation of transnational industrial chains, and increases global green transformation and digital competitiveness (Jun and Qiu 2022). Take Denmark as an example, a country in the wind power industry that uses data to train its labor force and improve the professional skills of workers in the domain of clean energy. Thus, its labor force can better adapt to the new requirements of innovation and development. capital elements provide pivotal financial support for innovation. Under the trend of \({\rm{d}}{\rm{ata}}\times {\rm{cap}}\), capital prefers innovation projects with data advantages and technical potential, which effectively stimulates the level of innovation. In the field of solar energy, the German government and financial institutions have actively invested capital to build solar data monitoring and analysis systems. Through in-depth data analysis, the power demand and efficiency of various regions and industries are accurately identified, resources are rationally allocated, distribution plans are optimized, and low-carbon development.
(3) Regional heterogeneity and the threshold effect of data on innovation
This paper finds that data have significant threshold characteristics in driving the efficiency of innovation, and its nonlinear mechanism results from the integration of three elements. In terms of \({\rm{d}}{\rm{ata}}\times {\rm{tec}}\), when the level of collaboration between data and technology elements breaks through the critical threshold, the clean transformation rate of the technology research and development path is significantly improved. In the \({\rm{d}}{\rm{ata}}\times {\rm{lab}}\) aspect, when the structural adaptation of data-enabled human capital reaches a certain interval, the energy efficiency optimization of production processes accelerates. In terms of the \({\rm{d}}{\rm{ata}}\times {\rm{cap}}\), after the deep fusion of data and green capital crosses the critical point, the return on investment of environmental governance qualitatively increases.
The paper further reveals that data play a key enabling role in green and low-carbon transitions, which fully confirms the research conclusion of data enabling green development proposed by Tan and Cao (2023), which used BRICS countries as research samples. Through comprehensive resource convergence, data analytics can substantially improve the exactitude of environmental management systems, thereby facilitating the development of an integrated socio-ecological paradigm characterized by sustainability and harmony. With the growing integration of elements, the effectiveness of innovation has also been significantly enhanced. This change not only highlights the importance of data in green and low-carbon development but also highlights the direction that will lead to solving the ‘data gap’ problem of regional green transformation.
Conclusion and prospect
Conclusion
This paper employs the projection pursuit method to calculate data using data of 288 cities from 2011 to 2022. It then introduces the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\), and \({\rm{data}}\times {\rm{cap}}\) into the complex relationship between data and innovation using the benchmark regression model, mediating effect model, and threshold regression model. It utilizes estate, industry, finance and investment as control variables. Through theoretical analysis and empirical tests, the influence mechanism of data on the quality and number of innovation is revealed, and three proposed hypotheses are verified. The following are the outcomes. (1) The data can promote increases in the quality and number of regional innovation, and following robustness tests, this conclusion remains valid. (2) data can not only directly promote the quality and number of regional innovation, but also indirectly affect the quality and number of innovation through \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\). (3) Based on regional heterogeneity, data have different threshold effects on innovation. data play a stronger positive role at higher levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\) and \({\rm{data}}\times {\rm{cap}}\).
Policy recommendations
Although focused primarily on China, the data revealed in this paper have a wide range of practical implications for the mechanism of innovation. In the current context, countries are actively exploring innovation paths to achieve environmental protection. Given China’s status as one of the biggest developing nations globally, its practices and experiences in the realm of innovation are poised to offer valuable insights for other countries. Building upon the research findings outlined above, this report puts forth the recommendations to enhance both the quality and number of regional innovation:
(1) Maximize the utility of data-driven effects while ensuring effective convergence of multifactorial elements. This study found that data can significantly improve regional innovation, and when data are integrated with technology elements, labor elements and capital elements, the positive effects are greater. As digital transformation accelerates around the world, data has become an important driver of innovation and economic growth. First, governments of all countries should get more involved in the work of international organizations and learn from one another’s practical experiences to enhance coordination among countries. Second, the government ought to spend more on digital infrastructure, create a reliable data platform, and encourage the sharing of data. Train data analysis personnel and enhance the application efficiency of data in innovation. Finally, to promote the effective integration of data and other production elements, all elements can coordinate and supervise one another, forming a robust development environment, strengthening data-driven innovation projects, and promoting low-carbon industries’ sustainable development.
(2) Optimize estate and raise industry. This study found that compared with other variables, estate has a more pronounced role in advancing the quality of regional innovation, and industry has a stronger role in accelerating the number of innovation. To promote the development of regional innovation, we should pay close attention to optimizing the estate, increasing support for high-tech industries and green industries, and increasing their proportion in the regional economy, to strengthen the promoting role of industrial structure on the quality of innovation.
(3) Enhance the level of \({\rm{data}}\times {\rm{tec}}\). This study found that when the level of \({\rm{data}}\times {\rm{tec}}\) is employed as the mediating variable, the indirect effect on the quality and number of innovation is the greatest. Therefore, the government should foster the profound integration of data and technology by building a data-sharing platform, encouraging enterprises and scientific research institutions to strengthen data exchange and cooperation, and promoting the innovative application of \({\rm{data}}\times {\rm{tec}}\) in the domain of low-carbon. It has also increased investments in the R&D of \({\rm{data}}\times {\rm{tec}}\), cultivated cross-border interdisciplinary talents, provided strong support for deep \({\rm{data}}\times {\rm{tec}}\) and comprehensively enhanced innovation.
It is noteworthy that due to the economic, social, and cultural differences in countries and regions, countries should make appropriate adjustments and optimize relevant policies according to their actual local conditions. In the future, we look forward to conducting cross-border and cross-cultural comparative studies to more fully reveal the path to innovation.
Deficiency and prospect
While this paper provides partial insights into the impact of data on innovation, some limitations persist. (1) This paper utilizes Chinese urban panel data as the sample. Although it can provide some references for effectively exerting the effect of data and improving the level of innovation, it fails to conduct a global comparative analysis based on other countries due to data availability and other reasons. Therefore, we expect to expand the research objectives to other countries such as the United States in future studies and to conduct more extensive analysis and provide important reference values for global data to enable innovation. (2) As the data in this paper are all from public sources such as the China City Statistical Yearbook, the latest data available is for 2022 since the 2023 data have not been released. In the upcoming study, we propose to harness recent data for a more extensive examination of the connection between data and innovation, aiming for a more comprehensive analysis. (3) Although this paper utilizes the levels of \({\rm{data}}\times {\rm{tec}}\), \({\rm{data}}\times {\rm{lab}}\), and \({\rm{data}}\times {\rm{cap}}\) as the mediating variables and threshold variables, it explores the mediating and nonlinear effects of data in the course of influencing innovation. However, when data affect the process of innovation, other factors may affect the direction of action between the two. Therefore, in future studies, we will try to include other factors for empirical analysis and to further elucidate the mechanism ‘black box’ of data enabling innovation.
Data Availability
The data in this manuscript is from 2011 to 2022 and includes 9 variables, including one independent variable, one dependent variable, three mediating variables and threshold variables, and 4 control variables. The data for all variables is analyzable. The disclosure of the materials analyzed during the current study is subject to restrictions under an ongoing project. The corresponding author is willing to share the datasets upon any reasonable request under necessary confidentiality agreements.
References
Arici HE, Uysal M (2022) Leadership, green innovation, and green creativity: A systematic review. Serv Industries J 42(5-6):280–320
Bickel PJ, Kur G, Nadler B (2018) Projection pursuit in high dimensions. Proc Natl Acad Sci 115(37):9151–9156
Breuer M, DeHaan ED (2024) Using and interpreting fixed effects models. J Account Res 62(4):1183–1226
Cao SP, Nie L, Sun HP (2021) Digital finance, green technological innovation and energy-environmental performance: Evidence from China’s regional economies. J Clean Prod 327:129458
Chen P (2022) Is the digital economy driving clean energy development? - New evidence from 276 cities in China. J Clean Prod 372:133783
Chen L, Lu YQ, Meng Y et al. (2023) Research on the nexus between the digital economy and carbon emissions-Evidence at China’s province level. J Clean Prod 413:137484
Du DL, Xiao JJ (2024) Enhancing the resilience of regional digital innovation ecosystems: a pathway analysis from the lens of resource orchestration theory. Ann Regional Sci 73(4):1811–1838
Gaessler F, Wagner S (2022) Patents, data exclusivity, and the development of new drugs. Rev Econ Stat 104(3):571–586
Gao J, Zhang B, Zhang G et al. (2024) Innovative development of China’ energy models in digital economy era. Bull Chin Acad Sci (Chin Version) 39(8):1336–1347
Gao M, Wei H, Li L et al. (2024) How data factor flow affects corporate pollution reduction: The environmental effects of digital empowerment. J Clean Prod 478:143946
Huang Z, Liao G, Li Z (2019) Loaning scale and government subsidy for promoting green innovation. Technol Forecast Soc Change 144:148–156
Hu S, Xiang Y, Zhang HC et al. (2021) Hybrid forecasting method for wind power integrating spatial correlation and corrected numerical weather prediction. Appl Energy 293:116951
Hu F, Qiu L, Xiang Y et al. (2023) Spatial network and driving factors of low-carbon patent applications in China from a public health perspective. Front Public Health 11:1121860
Han DR, Wu HS, Lu K (2024) The effect of data element agglomeration on green innovation vitality in China. Humanities Soc Sci Commun 11(1):1–10
Huang P, Chen X (2024) The impact of data factor-driven industry on the green total factor productivity: evidence from the China. Sci Rep. 14(1):25377
Hunjra AI, Zhao S, Goodell JW et al. (2024) Digital economy policy and corporate low-carbon innovation: Evidence from a quasi-natural experiment in China. Financ Res Lett 60:104910
Jones CI, Tonetti C (2020) Nonrivalry and the economics of data. Am Economic Rev 110(9):2819–2858
Jun L, Qiu HT (2022) The Spatial Effect of Urban Digital Economy on the Green Development of Manufacturing Industry. Economic Geogr 42(12):13–22
Jaf DKI, Abdulrahman PI, Mohammed AS et al. (2023) Machine learning techniques and multi-scale models to evaluate the impact of silicon dioxide (SiO2) and calcium oxide (CaO) in fly ash on the compressive strength of green concrete. Constr Build Mater 400:132604
Kim YJ (2022) The countervailing effects of stocks of knowledge on low-carbon innovation through international collaboration. Energy Policy 170:113217
Liu SM, Zhang SJ, Zhu HD (2019) Study on the measurement and high-qualitity economy development effect of national innovation driving force. J Quant Technol Econ 36:3–23
Lv Z, Li SS (2021) How financial development affects CO2 emissions: a spatial econometric analysis. J Environ Manag 277:111397
Li R, Rao J, Wan LY (2022) The digital economy, enterprise digital transformation, and enterprise innovation. Manag Decis Econ 43(7):2875–2886
Liu QL, Trevisan AH, Yang MY et al. (2022) A framework of digital technologies for the circular economy: Digital functions and mechanisms. Bus strategy Environ 31(5):2171–2192
Liu Y, Yang Y, Li H et al. (2022) Digital economy development, industrial structure upgrading and green total factor productivity: Empirical evidence from China’s cities. Int J Environ Res Public Health 19(4):2414
Liu M, Xu X, Chu H et al. (2023) Research on the pathway of digital technology to drive China’s energy sector to achieve its carbon neutrality goal. Environ Sci Pollut Res 30(58):122663–122676
Lyu Y, Bai Y, Zhang J (2024) Digital transformation and enterprise low-carbon innovation: A new perspective from innovation motivation. J Environ Manag 365:121663
Liu M, Li S, Li Y et al. (2024) Evaluating the synergistic effects of digital economy and government governance on urban low-carbon transition. Sustain Cities Soc 105:105337
Liu Y, Xie YX, Zhong KY (2024) Impact of digital economy on urban sustainable development: Evidence from Chinese cities. Sustain Dev 32(1):307–324
Mummolo J, Peterson E (2018) Improving the interpretation of fixed effects regression results. Political Sci Res Methods 6(4):829–835
Ma Q, Tariq M, Mahmood H et al. (2022) The nexus between digital economy and carbon dioxide emissions in China: The moderating role of investments in research and development. Technol Soc 68:101910
Ma S, Gao Y, Li H (2024) Digital economic, resource curse and the development of low-carbon transformation. Resour Policy 91:104931
Pettifor H, Wilson C (2020) Low carbon innovations for mobility, food, homes and energy: a synthesis of consumer attributes. Renew Sustain Energy Rev 130:109954
Pan A, Zhang W, Shi X et al. (2022) Climate policy and low-carbon innovation: Evidence from low-carbon city pilots in China. Energy Econ 112:106129
Pei W, Hao L, Fu Q et al. (2023) Study on agricultural drought risk assessment based on information entropy and a cluster projection pursuit model. Water Resour Manag 37(2):619–638
Ren SM, Li LQ, Han YQ (2022) The emerging driving force of inclusive green growth: Does digital economy agglomeration work? Bus Strategy Environ 31(4):1656–1678
Ren Y, Zhang J, Wang X (2024) How does data factor utilization stimulate corporate total factor productivity: A discussion of the productivity paradox. Int Rev Econ Financ 96:103681
Song W, Yu H (2018) Green innovation strategy and green innovation: The roles of green creativity and green organizational identity. Corp Soc Responsib Environ Manag 25(2):135–150
Shen B, Li X (2020) Financial development, industrial structure upgrading and energy efficiency improvement. Inq into Economic Issues 12:131–138
Świadek A, Gorączkowska J, Godzisz K (2021) Conditions driving low-carbon innovation in a medium-sized European country that is catching up–case study of Poland. Energies 14(7):1997
Shivanna KR (2022) Climate change and its impact on biodiversity and human welfare. Proc Indian Natl Sci Acad 88(2):160–171
Sohail MT (2023) Green development in BRICS: unraveling the effects of environmental technology, R&D spending, and green investment in the context of COP21. Environ Sci Pollut Res 30(57):120000–120009
Sheng Z, Zhu C, Chen M (2024) Exploring the Impact of the Digital Economy on Green Total Factor Productivity—Evidence from Chinese. Cities. Sustainability 16(7):2734
Song Y, Sun X, Cai X et al. (2024) Impacts of the digital economy on urban low-carbon sustainable development. Front Energy Res 12:1425313
Tirado-Herrero S, Fuller S (2021) De-centering transitions: Low-carbon innovation from the peripheries. Environ Innov Societal Transit 41:113–115
Tan LS, Yang ZD, Irfan M (2023) Toward low-carbon sustainable development: Exploring the impact of digital economy development and industrial restructuring. Bus Strategy Environ 33(3):2159–2172
Tan W, Cao T (2023) Can green technology reduce carbon dioxide emissions? Evidence from G7 and BRICS countries. Heliyon 9(5):e15683
Wang YA, Fang XL, Yin SW et al. (2021) Low-carbon development quality of cities in China: Evaluation and obstacle analysis. Sustain Cities Soc 64:102553
Wang FZ, Liu XL, Zhang L et al. (2022) Does digitalization promote green technology innovation of resource-based enterprises. Stud Sci Sci 40(2):332–344
Wang L, Chen L, Li Y (2022) Digital economy and urban low-carbon sustainable development: the role of innovation factor mobility in China. Environ Sci Pollut Res 29(32):48539–48557
Wang T, Song Z, Zhou J et al. (2022) Low-carbon transition and green innovation: evidence from pilot cities in China. Sustainability 14(12):7264
Wang Y, Li M (2022) Credit policy and its heterogeneous effects on green innovations. J Financial Stab 58:100961
Wu T, Peng ZH, Yi Y et al. (2023) The synergistic effect of digital economy and manufacturing structure upgrading on carbon emissions reduction: Evidence from China. Environ Sci Pollut Res 30(37):87981–87997
Wang FT, Wang H, Xiong LC (2024) Does the digital economy exhibit multiplier effects? A case study on the optimization of agricultural production structure in rural digital economy. Int J Agric Sustainability 22(1):2386821
Wang H, Peng G, Du H et al. (2024) Effective approach toward low-carbon development: Digital economy development enhances carbon efficiency in cities. J Clean Prod 470:143292
Wu K, Geng YR, Guo T (2024) The impact of green technology innovation on carbon emissions from the perspective of urban agglomeration: The moderating effect of human capitals. J Nat Resour 39:2121–2139
Xu S, Yang C, Huang Z et al. (2022) Interaction between digital economy and environmental pollution: New evidence from a spatial perspective. Int J Environ Res Public Health 19(9):5074
Xian G, Chai Y, Gong Y et al. (2024) The relationship between healthy lifestyles and cognitive function in Chinese older adults: the mediating effect of depressive symptoms. BMC geriatrics 24(1):299
Yu Y, Zhang JZ, Cao Y et al. (2021) Intelligent transformation of the manufacturing industry for Industry 4.0: Seizing financial benefits from supply chain relationship capital through enterprise green management. Technol Forecast Soc Change 172:120999
Yin XM, Lin ZY, Chen J et al. (2022) Research on the dynamic value creation process of data element. Stud Sci Sci 40(2):220–229
Yang G, Xiang X, Deng F et al. (2023) Towards high-quality development: How does digital economy impact low-carbon inclusive development? Mechanism and path. Environ Sci Pollut Res 30(14):41700–41725
Yuning M, Taozhen H, Saleem N et al. (2024) Institutional pressure and low carbon innovation policy: the role of EMS, environmental interpretations and governance heterogeneity. Front Environ Sci 12:1385062
Zhang J, Lyu Y, Li Y et al. (2022) Digital economy: An innovation driving factor for low-carbon development. Environ Impact Assess Rev 96:106821
Zhang WX, Wang B, Wang J (2022) How does industrial agglomeration affect urban land use efficiency? A spatial analysis of Chinese cities. Land Use Policy 119:106178
Zhang KY, Wen YF, Wu YX (2024) How digital innovation ecosystems facilitate low-carbon transformation of the economy based on a dynamic qualitative comparative analysis. Sustainability 16(22):9962
Zhong C, Zhang C (2024) Can data elements enhance urban innovation? Evidence from China. China Economic Rev 88:102307
Zhu D, Bai XY (2024) Will capital market liberalization promote corporate green innovation? Foreign Econ Manag 46(3):122–135
Zhang H, Hua W (2025) Digital Economy, Environmental Regulation and Urban Green Development-A Study Based on 282 Prefecture-Level Cities in China. Pol J Environ Stud 34(1):431–446
Acknowledgements
We are very grateful to all those who have helped with the article.
Author information
Authors and Affiliations
Contributions
Dongri Han conceptualized and supervised the research. Ke Lu contributed to data analysis and original writing. Peisen Liu was responsible for methodological and manuscript revisions.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Not applicable. This article does not contain any studies with human participants performed by any of the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Han, D., Lu, K. & Liu, P. Multiplication of number and quality rise: data elements enable low-carbon innovation. Humanit Soc Sci Commun 12, 810 (2025). https://doi.org/10.1057/s41599-025-05194-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1057/s41599-025-05194-z
