
Abstract
We use three-dimensional culture systems of human pluripotent stem cells for differentiation into pituitary organoids. Three-dimensional culture is inherently characterized by its ability to induce heterogeneous cell populations, making it difficult to maintain constant differentiation efficiency. That is why the culture process involves empirical aspects. In this study, we use deep-learning technology to create a model that can predict from images of organoids whether differentiation is progressing appropriately. Our models using EfficientNetV2-S or Vision Transformer, employing VENUS-coupled RAX expression, predictively class bright-field images of organoids into three categories with 70% accuracy, superior to expert-observer predictions. Furthermore, the model obtained by ensemble learning with the two algorithms can predict RAX expression in cells without RAX::VENUS, suggesting that our model can be deployed in clinical applications such as transplantation.
Similar content being viewed by others
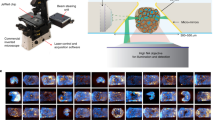


Introduction
The pituitary gland, the center of hormone secretion, contributes to metabolism, reproduction, and homeostasis by receiving signals from the hypothalamus and secreting various hormones. Many genes are associated with pituitary development, and pituitary dysfunction can be caused by various genetic defects1,2. The hypothalamic-pituitary-adrenal system is responsible for responding to stresses such as infection, hypotension, and surgery. Deficiency in this system can cause fatigue, anorexia, and other problems that can be life-threatening3. The standard treatment for adrenocorticotropic hormone (ACTH) deficiency is steroid replacement, but its use does not eliminate the risk of acute adrenal insufficiency and death4,5,6. Pituitary regenerative medicine may be able to reduce such risk.
We have succeeded in generating pituitary organoids from human pluripotent stem cells7,8,9. Hypothalamic-pituitary development is based on their interaction: For example, pituitary formation requires signals such as fibroblast growth factor (FGF) and bone morphogenic protein (BMP) from the hypothalamus10,11. We generated functional pituitary gland tissue by co-inducing hypothalamus and pituitary in an embryonic stem cell (ESC) / induced pluripotent stem cell (iPSC) aggregate using a three-dimensional culture method (serum-free floating culture of embryoid body-like aggregates with quick aggregation: SFEBq method)12. Transplantation of hypothalamic-pituitary organoids under the renal capsule of pituitary-insufficient mice improved pituitary function and reduced mortality, suggesting the possibility of clinical application7,8. However, differentiating various cell types simultaneously, intrinsic to three-dimensional culture, leads to heterogeneity in the induced-cell population and complicates maintaining constant differentiation efficiency. Our method allows the operator to remove cell aggregates that have clearly differentiated off-target, but the choice is empirical, depending on operator skill. While in knock-in cell lines the direction of differentiation can be confirmed using fluorescent proteins linked to gene expression, such genetic modifications would preclude clinical use.
In recent years, with the development of advanced graphics processing units (GPUs), availability of big data, and evolution of learning algorithms, deep-learning technology has advanced rapidly, with application in various fields13. In image recognition, since AlexNet won the 2012 ILSVRC competition with an error rate >10% better than other models14, convolutional neural networks (CNNs) with convolutional layers for feature extraction have become mainstream and various models have been developed15,16,17. CNNs have achieved classification performance comparable to that of experts in interpretation of two-dimensional images, such as those generated by chest radiography and retinal optical coherence tomography18, and some studies have reported deep learning models for organoid analysis19,20. Vision Transformer, which deploys self-attention and has been successful in natural language processing, has also been applied to image classification21,22. Vision Transformer does not rely on a convolutional layer and, when trained with sufficient data, outperforms CNNs at a lower computational cost than those of previous methods22.
In this study, we developed a model for predicting gene expression associated with future ACTH secretory function from images of hypothalamic-pituitary organoids in the differentiation process by combining a fluorescent protein knock-in cell line with recently developed architectures and methods. We also tested whether the model could predict cell line behaviors without fluorescent protein knock-in.
Results
High or low RAX expression in differentiating aggregates foreshadows subsequent pituitary differentiation
Pituitary development requires interaction with the hypothalamus in vivo10,11. We have reproduced this developmental process in vitro by producing a hypothalamic-pituitary complex using pluripotent stem cells and have successfully induced a functional pituitary (Fig. 1a). To investigate the differentiation of precursor-cell aggregates into the hypothalamic-pituitary complex, we focused on RAX. This transcription factor is expressed first in the developing anterior neural region and later in the retina, hypothalamus, pineal gland, and other tissues or organs23. Given the reciprocal interaction between the hypothalamus and pituitary in development, the induction of both structures is likely to be satisfactory in aggregates that express RAX well. Conversely, in those that do not express RAX well, the pituitary would likely develop poorly (Fig. 1b).

a Schema of hypothalamic-pituitary interactions in vivo and in vitro. CK, cytokeratin. b Well-formed aggregates and poorly-formed aggregates. The RAX::VENUS cell line was used to confirm the quality of the aggregates. Scale bar = 500 μm. c Immunostaining of hESC aggregates at day 100 for ACTH (white) and LHX3 (red), markers of pituitary differentiation. For RAX::VENUS, spontaneous luminescence of the VENUS protein was imaged without staining. Scale bar = 100 μm. d Culture protocol for hypothalamic-pituitary organoid induction. Aggregates not expressing RAX at day 30 will not secrete ACTH after prolonged cultivation. e Aggregates with large and small RAX expression area groups show differences in ACTH secretion at day 100. Values shown on the graphs represent the means ± SEM, n = 9 independent experiments. *p < 0.05.
In our protocol, aggregates are transferred from 96-well plates to 10 cm dishes at day 30 of differentiation. Aggregates further cultured express ACTH, as demonstrated by immunostaining at day 100 (Fig. 1c, d). When aggregates with high and low RAX expression were cultured separately at 10 aggregates/10 ml from day 30, ACTH secretory capacity and the number of ACTH-positive cells at day 100 differed significantly (p = 0.03 and p = 0.004) between them (Fig. 1e, Supplementary Fig. 1). ACTH secretion from aggregates in the high RAX expression group was sufficient for transplantation experiments, as shown in previous studies8,24. We thus considered RAX expression at day 30 to be a marker for subsequent pituitary differentiation to determine whether differentiation was progressing as desired.
Datasets and models
We differentiated RAX::VENUS knock-in human ESCs (VA22-N37 /RIKEN RBC) to confirm RAX expression. In this study, we performed multiclass classification according to the area expressing RAX::VENUS at day 30 of differentiation. While it is difficult for experts to predict the gene expression of organoids in detail, multiclass classification allowed comparison between experts and models. Since a certain level of RAX expression is considered necessary for future ACTH secretory capacity, we defined category C as those with a RAX::VENUS positive area of less than 40%. Category C included all aggregates in the low RAX expression group. The remaining groups were divided into categories A and B, because more detailed prediction of high and low RAX could facilitate regression analysis in the future. We created the categories A (70 < %RAX), B (40 ≤ %RAX < 70), and C (%RAX < 40) and collected 500 bright-field images of aggregates in each category (Fig. 2a). The mean percentage of area marking for RAX::VENUS was 79.5% for A, 56.3% for B, and 21.6% for C (Fig. 2b). In each category we randomly designated respectively 400 and 100 images as training and test data. We performed multiclass classification of A, B, and C using EfficientNetV2-S25 and Vision Transformer22, released by Google LLC (Mountain View, CA) in 2021 and 2020 respectively. EfficientNetV2-S is an architecture with CNN structure, balancing depth, width, and resolution, leading to better performance with fewer parameters. Vision Transformer is a model that uses Transformer, used in the field of natural language processing, for image classification; with the Attention mechanism, the dependency of components can be captured better. As optimization methods, we used AdamW26 for EfficientNetV2-S and Adam27 for Vision Transformer, optimizers often used in each architecture. After respectively 100 and 20 epochs of training in each fold, we found no further improvement in accuracy and cross-entropy loss. For each architecture, we created 5 trained models using cross-validation. We saved the weights of the epochs with the lowest cross-entropy loss for each validation and used the average of the 5 trained model outputs for prediction (Fig. 2c).

a Categories grouped by RAX area percentage. b Distribution of images according to RAX area percentage. c Schema of the model.
Model performance
The accuracies of multiclass classification among A, B, and C were 67.3% for EfficientNetV2-S, 65.7% for Vision Transformer, and 70.0% for an ensemble model that used the average of the model outputs obtained from EfficientNetV2-S and Vision Transformer (Fig3a). In addition, we focused on category C to permit the removal of aggregates that are not successfully in the process of differentiation into the hypothalamic-pituitary complex at day 30. For category C, EfficiencyNetV2-S had a high sensitivity of 83.0% (95% confidence interval 74.2%–89.8%), specificity of 89.0% (95% confidence interval 83.8%–93.0%), and an F-value of 81.0%, while these values for Vision Transformer were respectively 77.0% (95% confidence interval 67.5%–84.8%), 93.0% (95% confidence interval 88.5%-96.1%), and 80.6%. The ensemble model showed a sensitivity of 82.0% (95% confidence interval 73.1%–89.0%), a specificity of 89.5% (95% confidence interval 84.4%–93.4%), and an F-value of 80.8%. We further evaluated the performance of the models in discriminating each category from the others by constructing receiver operating characteristic (ROC) curves and found that the area under the ROC curve was 86.5% for A, 72.4% for B, and 93.6% for C in EfficientNetV2-S, 87.5% for A, 73.6% for B, and 93.1% for C in Vision Transformer, and 87.8% for A, 74.5% for B, and 94.1% for C in the ensemble of the two models (Fig. 3b).

a Confusion matrix of EfficientNetV2-S, Vision Transformer, and the ensemble model. Cells filled with darker colors have many images distributed in them. b Receiver operating characteristic (ROC) curve for each category.
Comparison with expert performance
Using the test dataset of 300 bright-field images, we compared the classification performance of this deep-learning model with that of human experts. Three experts involved in cell culture in our laboratory for more than a year were instructed to predict the percentage of cultured-aggregate area expressing RAX using only the bright-field images. The accuracy of the experts varied from 46.7% to 60.0%, independent of years of experience (Fig. 4a). In discriminating C, in which RAX was poorly expressed, from A and B, expert-analysis sensitivity ranged from 56.0% to 73.0% and specificity from 84.0% to 86.0%. When sensitivity and specificity of expert predictions were plotted on the ROC curves of EfficientNetV2-S, Vision Transformer, and the ensemble of both models, all data for experts lay under the curve (Fig. 4b), indicating that the deep-learning models outperformed all experts in respect of both sensitivity and specificity (Fig. 4c).

a Confusion matrix of human experts. Cells filled with darker colors have many images distributed in them. b Receiver operating characteristic (ROC) curve for category C with human expert performance. All the models outperformed the experts. c Sensitivity and specificity of the models and of human experts. There were no significant differences among the models. All models were superior to experts in sensitivity. There were no significant differences between the human experts and the models in specificity. Values shown on the graphs represent the means ± 95%Cis, *p < 0.05, **p < 0.01, ***p < 0.001. Eff, EfficientNetV2-S; Vit, Vision Transformer; Ens, Ensemble Model; Exp1, Expert 1; Exp2, Expert 2; Exp3, Expert 3.
Model Visualization
To identify the regions that contributed most to neural network decisions, we used the Grad-CAM28 method for EfficientNetV2-S and the Deep ViT Features29 method for Vision Transformer to provide a visual description of the 300-test data. We identified the regions of the aggregates on which EfficientNetV2-S focused attention by outputting a heat map with Grad-CAM. In EfficientNetV2-S, 96.3% of the images of aggregates with predicted labels of A involved the periphery of the aggregates. In addition, EfficientNetV2-S often focused on cystic regions in images of poorly formed aggregates, and 76.8% of all images with cysts were focused on the cystic area (Fig. 5a). For Vision Transformer, we used Deep ViT Features to perform principal component analysis (PCA) and to visualize the informative components. The dense key features of the last transformation block of the ViT were processed with PCA. Principal component (PC) 1 reflected the structures of the 96-well plate used in this study. PC2 reflected the parenchymal parts of the aggregates. PC3 reflected the periphery of the aggregates and some cysts. PC4 reflected the center of the aggregates. (Fig. 5b).

a Representative examples of the heatmaps of EfficientNetV2-S generated by Grad-CAM and a tabulation of where attention was focused. EfficientNetV2-S focuses on specific areas such as the periphery and cysts, just as did the experts. b Representative examples of the results of principal component analysis of Vision Transformer using Deep ViT Features. Merge images were generated with PC2, PC3, and PC4, which are thought to be involved in the classification of aggregates. PC1 principal component 1, PC2 principal component 2, PC3 principal component 3, PC4 principal component 4.
Prediction of differentiation of organoids without RAX::VENUS
Using RAX::VENUS knock-in cells (and thus observing RAX expression during differentiation) permits aggregate quality assessment. However, modifying RAX::VENUS impedes its clinical application, such as in transplantation. To address this, we investigated whether our model could be applied to KhES-1 cells (RIKEN RBC), without the use of RAX::VENUS, to assess aggregate quality in a similar manner.
We classified KhES-1 cells at day 30 of differentiation using the ensemble model of EfficientNetV2-S and Vision Transformer trained on VA22-N37 cells (with RAX::VENUS). To boost accuracy, 1350 of the 1500 images obtained from VA22N37 were used for training, and no images from KhES-1 were used. The model’s accuracy was 72.0% (Fig. 6a). When the model was applied to aggregate images obtained from KhES-1, 937 aggregate images were classified into 633 category A, 209 category B, and 95 category C (Fig. 6b). Among the aggregates obtained from KhES-1 cells, on immunostaining those that the model classified as A showed more RAX expression and those classified as C showed less RAX expression (Fig. 6c). Furthermore, when aggregates in each category were divided into 10 aggregates/10 ml individually and cultured, ACTH secretory capacity from highest to lowest matched categories A, B, and C in that order. At day 100 those classified as A had significantly higher ACTH secretory capacity than those classified as C (n = 9, p = 0.004) (Fig. 6d). The aggregates classified as A by the model were not cystic even at day 100.

a Confusion matrix of the ensemble model trained using 1350 images. b Schematic of model diversion. Prediction of categories by applying the trained model to aggregates derived from KhES-1. c Immunostaining of aggregates derived from KhES-1 on day30. Left: Predicted by the model as A. Right: Predicted to be C. Scale bar, 500 μm. d Comparison of ACTH secretory capacity at day 100 among three categories. Those predicted to be A had significantly higher ACTH secretory capacity. Values shown on the graphs represent the means ± SEM, n = 9 independent experiments. **p < 0.01.
Analysis of classified aggregates
We confirmed the differences in the molecular basis of the KhES-1 aggregates, as classified by the model, using relevant markers. Specifically, we confirmed the gene expression of the day 30 aggregates, which were classified as category A and category C, through immunostaining. This involved staining central nervous system markers (CDH2 and SOX1), hypothalamic markers (RAX, NKX2.1, and PAX6), and an oral ectoderm marker (PITX1), all of which are expected to be expressed in hypothalamic-pituitary organoids at day 30. Our findings revealed that RAX, a marker used for prediction, and central nervous system markers CDH2 and SOX1 were significantly more expressed in aggregates predicted to be category A, while other hypothalamic (NKX2.1 and PAX6) and pituitary markers showed no significant difference in their expression levels (Fig. 7).

Rate of immunostaining positive cells in each aggregate. Values shown on the graphs represent the means ± SEM, n = 3 independent experiments. *p < 0.05, ∗∗p < 0.01.
Discussion
Regenerative medicine has developed rapidly in recent years; to culture various types of tissue from pluripotent stem cells is now possible. Techniques are highly specialized and depend on operator skill. In this study, we developed a model to predict transcription factor expression from images of human pluripotent stem cells undergoing differentiation. By combining released-to-date new methods, swapping training and validation data, repeating the training process, and effectively using limited amounts of data, we tried to enhance the model’s performance. Our model could classify organoids undergoing differentiation into the hypothalamic-pituitary complex into three categories according to their RAX transcription factor expression area. Classification proved highly accurate. The model could determine the quality of organoids without fluorescent protein knock-in, permitting organoid selection for transplantation. In addition, in sorting out poorly formed aggregates, an essential step in aggregate culture, the model’s accuracy, sensitivity, specificity, and area under the ROC curve were better than those of experts who have been involved in cell culture for years, suggesting that deep learning is effective even in highly specialized fields such as cell culture. To the best of our knowledge, this is the first deep learning model to predict eventual differentiation from aggregates in the process of differentiation. Predictions during this process allow for earlier classification and the conservation of reagents and human resources.
The trained model also misclassified fewer aggregates than did experts between categories A (high RAX area percentage) and C (low RAX area percentage; 2.5% of all A and C images for EfficientNetV2-S, 1% for Vision Transformer, 1.5% for ensemble, and 7.5% for experts). This means that our trained model can predict RAX area more accurately than can experts. Increasing the number of images or developing a new architecture may enable more detailed categorization or regression analysis. Models that classify by expression of other genes are awaited; combinations of models may permit greater accuracy in assessing aggregate developmental quality.
We applied Grad-CAM and Deep ViT Features to identify the most critical regions for the model’s use in classification. We found that EfficientNetV2-S recognized the edges of the aggregates and the presence of cysts as particularly critical regions. In hypothalamic-pituitary complex aggregates, oral ectoderm surrounds hypothalamic neuroepithelium, often a point of interest for expert discrimination. The presence or absence of cysts is also easily recognized and focused on by experts. EfficientNetV2-S was found to discriminate among aggregates by examining the same areas as those used by experts. On the other hand, as revealed by PCA, Vision Transformer identified the well of the plate and the parenchymal part of the aggregates as critical areas. Vision Transformer then focused on multiple areas such as the edges, cysts, and centers of the aggregates. This seemed to be consistent with the process used by experts to obtain an overall image. Vision Transformer can capture global features from lower layers than CNN30, and the perspective of Vision Transformer differs from those of conventional CNN models. These features may contribute to differences between areas on which the models focus. To find and classify morphological differences using deep learning, as in our model, can provide evidence that the expression of particular genes influences tissue morphogenesis. Reciprocal prediction – of gene expression from images of developing tissues in vivo – also may prove feasible.
As mentioned earlier, the differences in classification decisions made by EfficientNetV2-S and Vision Transformer were substantial. These differences were also evident in the categorization of specific images. For example, of the 100 VA22-N37 test images that were labeled “C”, 9 images were classed as C only by EfficientNetV2-S and 3 were classed as C only by Vision Transformer. When classifying images of KhES-1 aggregates, in which RAX::VENUS was not knocked in, neither EfficientNetV2-S nor Vision Transformer alone was able to detect all aggregates that later exhibited low ACTH secretion; however, the ensemble of both models was able to detect many more poor-quality aggregates. The recognition characteristics of Vision Transformer and conventional CNNs have their own advantages and disadvantages31,32. It is thought that combining these characteristics will lead to improved performance. Indeed, in several image classification studies, the ensemble learning of Vision Transformer and CNN has outperformed other models33,34. This suggests that combining both models may lead to more accurate classification when sorting aggregates is readily inferred.
Applying the model trained using the hypothalamic-pituitary complex images of VA22-N37 to similar images of KhES-1 at day 30, classification into three categories was possible: A, with high RAX expression; B, with intermediate RAX expression; and C, with low RAX expression. Although absolute differences in quality and ACTH secretion capacity existed among the cell lines derived from particular aggregates, ACTH secretion capacity follows the descending order of A, B, C. Those classified as A had significantly higher secretion capacity than those classified as C (p = 0.004), suggesting that the same model can be used to predict quality of derivatives of KhES-1 aggregates. To assess the quality of organoids in which fluorescent proteins are not knocked-in is difficult. However, in such cases it may be effective to train a model in a culture system of cells with fluorescent proteins and then adapt it to a culture system of cells without fluorescent proteins, as was done in this study. Although it is necessary to establish a cell line with fluorescent protein knock-in, this method could be applied to other culture systems. For example, in the case of brain tissue, FOXG1, a telencephalic marker, could be used as a guide for telencephalic differentiation35,36. Foxg1KO mPSCs are reportedly inhibited from differentiating into dorsal telencephalon37. A model predicting telencephalic differentiation could be developed by predicting FOXG1 expression in aggregates. In addition, it may be possible to determine the quality of organoids at a later stage, immediately before transplantation, by creating a model that predicts outcomes using markers expressed at that later stage.
To confirm the molecular basis for the differences at the sites of interest identified by the model visualization, we confirmed gene expression in the predicted aggregates. We found that RAX and the CNS markers required for RAX expression (CDH2 and SOX 1) were highly expressed in the aggregates predicted to be A, while there were no differences in the expression of other hypothalamic markers (NKX2.1, PAX6) and oral ectoderm markers (PITX1). This suggests that RAX expression is the factor that produces morphological differences independent of other gene expression. Our model specifically predicted RAX expression, suggesting that it could be combined with models that specifically predict other gene expression for more accurate prediction.
In summary, we have developed a model that predicts the area of RAX expression in the hypothalamic-pituitary complex and the quality of in-culture aggregates more accurately than experts. The same method can be applied to culture systems of cells in which fluorescent proteins are not knocked-in, which is expected to contribute to improved quality and to reduce costs in clinical applications in the future.
Methods
Human ES cells (hESCs) and initial culture techniques
We used hESCs according to the hESC research guidelines of the Japanese government (Nagoya University ES-0001). For the experiments shown, we used the KhES-1 cell line (HES0001; RIKEN) and the VA22-N37 (HES0652; RIKEN) cell line, which is a RAX::VENUS reporter hESC line established from KhES-1, a biological replicate38. Undifferentiated hESCs were maintained on a feeder layer of mouse embryonic fibroblasts inactivated by mitomycin C treatment in DMEM/F-12 (Sigma) supplemented with 20% (vol/vol) KSR (Invitrogen), 2 mM glutamine, 0.1 mM nonessential amino acids (Invitrogen), 5 ng/mL recombinant human basic FGF (Wako), and 0.1 mM 2-mercaptoethanol under 2% CO2. For passaging, hESC colonies were detached and recovered en bloc from culture dishes by treatment with 0.25% (w/v) trypsin and 1 mg/mL collagenase IV in phosphate-buffered saline (PBS) containing 20% (v/v) KSR and 1 mM CaCl2 at 37 °C for 10 min. Detached hESC clumps were broken into smaller pieces using a pipette. Passages were performed at a 1:5 split ratio every four days.
Differentiation culture of hESCs
For SFEBq culture, hESCs were dissociated into single cells using TrypLE Express (Invitrogen) containing 0.05 mg/mL DNase I (USA), and 10 µM Y-27632. They quickly aggregated in low-cell-adhesion 96-well plates with V-bottomed conical wells (Sumilon PrimeSurface plate; Sumitomo Bakelite) in differentiation medium (10,000 cells per well, 100 µL) containing 20 µM Y-27632. Differentiation medium (gfCDM) was supplemented with 5% KSR. The gfCDM comprised Iscove’s modified Dulbecco medium/Ham’s F12 1:1, 1% chemically defined lipid concentrate, monothioglycerol (450 µM), and 5 mg/mL purified bovine serum albumin (>99% purified by crystallization; Sigma). SFEBq culture was initiated on day zero. Next, 100 µL of gfCDM per well was added to each well on day 3. From days 6 to 30, half of the medium was replaced every three days. SAG (Enzo Life Sciences) and recombinant human BMP4 (R&D Systems) were added to the culture medium to reach 2 and 5 nM, respectively, from day 6. BMP4 concentrations were diluted by half-volume changes in BMP4-free medium every third day after day 18. From day 18, the aggregates were cultured under high-O2 conditions (40%), till day 30.
Immunohistochemical studies
Organoids were fixed in 4% paraformaldehyde for 5–20 min. They were immersed in 20% sucrose and embedded in optimal cutting temperature compound (4583; Sakura Finetek, Tokyo, Japan). They were cryostat-sectioned at 10 µm; sections were picked up on glass slides. Immunostaining was performed as described below. The sections were washed three times (15 min per wash) in 0.3% Triton X-100/PBS for permeabilization and then washed with PBS three times (15 min per wash). Subsequently, the sections were incubated in 2% (w/v) dry skimmed milk/PBS for 1 h at room temperature (RT) for blocking. The sections were incubated overnight at 4 °C with primary antibodies diluted in 2% dry skimmed milk/PBS. The next day, the sections were washed three times (15 min per wash) with 0.05% Tween 20/PBS and incubated with secondary antibodies diluted in 2% dry skimmed milk/PBS for 2 h at RT. Next, 4,6-diamidino-2-phenylindole (DAPI; D523; Dojindo, Kumamoto, Japan) was added to visualize cell nuclei. The sections were then washed three times (15 min per wash) in 0.05% Tween 20/PBS and mounted in Slow Fade™ Diamond (S36972; Thermo Fisher Scientific). The primary antibodies used in this study are listed in Supplementary Table 1.
Imaging
Bright-field and fluorescent images of live organoids were captured at 4× magnification using an All-in-One Fluorescence Microscope BZ-X710 (KEYENCE). Exposure times were fixed at 1/3.5 s for bright-field images and 1.2 s for fluorescence images. The image was adjusted so that the center of the well was in the center of the image, and the Z-axis was fixed for continuous imaging.
Image Labeling
Before training, each bright-field image was labeled according to the percentage of aggregate area that expressed RAX. To measure the area of the aggregates in the blight-field image, the outer edges of the aggregates were identified using the Magnetic Lasso tool in PhotoShop. To measure the area expressing RAX::VENUS, the range of luminance above 45 in the fluorescent image was selected using ImageJ39, and the area was measured. Images were labeled as category A (70 < %RAX), category B (40 ≤ %RAX < 70), and category C (%RAX < 40), and 500 images were collected for each category.
Model Training Methods
Two different deep learning models, EfficientNetV2-S and Vision Transformer, were pre-trained on the ImageNet dataset and were trained on our image dataset of aggregates by fine tuning. The image size of the raw data was 1920 × 1440 pixels, which was reshaped to 224 × 224 pixels before input to the models. 1500 images of aggregates were split into a training data set, a validation data set (1200 images), and a test data set (300 images). The data were divided into categories A, B, and C in a 1:1:1 ratio. The 1200 images were divided into 5 folds and the model was trained by 5-fold cross-validation. For each fold, 100 epochs were trained on EfficientNetV2-S and 20 epochs on Vision Transformer. The weights with the lowest loss for each validation were saved. The average of the output of the prediction probabilities of the 5 models obtained by the 5-fold cross-validation was calculated as the final prediction probability for the test data set. The model output was the probability of each of the 3 categories of RAX area fraction. Cross-entropy was used as the loss function. The optimizers were adamW (Learning rate =0.001, Weight decay = 0.01) for EfficientNetV2-S and Adam (Learning rate = 3 × 10−5, Weight decay = 0.7) for Vision Transformer. GridMasko40 (p = 0.7) and AugMix41 (p = 0.7) were used as data augmentation for ViT. GridMask (p = 0.7), horizontal flip (p = 0.5) and vertical flip (p = 0.5) were used for EfficientNetV2-S model. All data augmentation methods were applied to the input images during the training of the model. Each data augmentation method is employed with a probability p. GridMask is an information dropping technique that improves the generalization performance of the model by masking the input image with periodically arranged black squares. AugMix is a method that randomly samples a variety of data augmentation methods and mixes them to produce a very diverse set of augmented images. A custom-built PC with a CPU (EPYC 7543, Advanced Micro Devices, Santa Clara, CA) and GPU (A100, 80 GB, NVIDIA Corporation, Santa Clara, CA) was used for all calculations using deep learning. Ubuntu 20.04 LTS was installed as the operating system. PyTorch 1.10.1+cu111, Torchvision 0.11.2+cu111 (https://github.com/pytorch/vision) was used to build the deep learning models.
Analysis of ACTH secretion
On day 30, after imaging, aggregates were transferred to low-cell-adhesion 6-Well Clear Flat Bottom Ultra-Low Attachment Multiple Well Plates (Corning; Product Number 3471) according to RAX expression area or to the results of model predictions. Ten aggregates per well were cultured in 2 ml gfCDM supplemented with 10% KSR and 2 µM SAG. Thereafter, half of the medium was replaced every 3 days. The concentration of KSR was increased to final 20% (vol/vol) from day 50. On day 100, after incubation for 3–4 days, culture supernatants were collected and cryopreserved at −150 °C. ACTH concentrations in supernatants were determined using an electrochemiluminescence immunoassay (ECLIA) method employed clinically in Japan (SRL; code:05055 5, https://test-directory-en.srl.info/akiruno_en/test/detail/050550300).
Statistics and Reproducibility
Statistical analyses were performed with R version 4.2.2. ACTH concentration was represented as mean ± standard error of the mean (SEM). Two-group comparisons were performed using the two-tailed unpaired t-test. McNemar’s test was used to compare the sensitivity and specificity of each. Significance was set at P < 0.05. We have described the exact n values for each experiment in the figure legends. The VA22N37 and KhES-1 datasets used in this study contained 1500 and 937 images, respectively. The sample size for each experiment was explained in the Methods section and figure legend.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Source data to reproduce figures is available on Figshare (https://doi.org/10.6084/m9.figshare.24616506)42 along with the datasets used to train and evaluate the models.
Code availability
All source code has been deposited at GitHub (https://github.com/Niioka-Group/Organoid-Classifier) with a DOI of https://zenodo.org/records/1392312143.
References
Kelberman, D., Rizzoti, K., Lovell-Badge, R., Robinson, I. & Dattani, M. T. Genetic regulation of pituitary gland development in human and mouse. Endocr. Rev. 30, 790–829 (2009).
Romero, C. J., Nesi-Franca, S. & Radovick, S. The molecular basis of hypopituitarism. Trends Endocrinol. Metab. 20, 506–516 (2009).
Oelkers, W. Adrenal insufficiency. N. Engl. J. Med. 335, 1206–1212 (1996).
Hahner, S. et al. High incidence of adrenal crisis in educated patients with chronic adrenal insufficiency: A prospective study. J. Clin. Endocrinol. Metab. 100, 407–416 (2015).
Burman, P. et al. Deaths among adult patients with hypopituitarism: hypocortisolism during acute stress, and de novo malignant brain tumors contribute to an increased mortality. J. Clin. Endocrinol. Metab. 98, 1466–1475 (2013).
Sherlock, M. et al. Mortality in patients with pituitary disease. Endocr. Rev. 31, 301–342 (2010).
Suga, H. et al. Self-formation of functional adenohypophysis in three-dimensional culture. Nature 480, 57–U215 (2011).
Ozone, C. et al. Functional anterior pituitary generated in self-organizing culture of human embryonic stem cells. Nat. Commun. 7, 100351 (2016).
Kasai, T. et al. Hypothalamic contribution to pituitary functions is recapitulated in vitro using 3D-cultured human iPS cells. Cell Rep. 30, 18–24.e5 (2020).
Takuma, N. et al. Formation of Rathke’s pouch requires dual induction from the diencephalon. Development 125, 4835–4840 (1998).
Potok, BrinkmelerM. L., Davis, M. A. & Camper, S. W. SA. TCF4 deficiency expands ventral diencephalon signaling and increases induction of pituitary progenitors. Developmental Biol. 311, 396–407 (2007).
Watanabe, K. et al. Directed differentiation of telencephalic precursors from embryonic stem cells. Nat. Neurosci. 8, 288–296 (2005).
Shen, D. G., Wu, G. R. & Suk, H. I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 19, 221–248 (2017).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Commun. Acm 60, 84–90 (2017).
Simonyan, K., Zisserman, A. Very deep convolutionalnetworks for large-scale image recognition. In: 3rd International Conference on Learning Representations, 1–14 (2015).
Szegedy, C. et al. Going deeper with convolutions. In: IEEE conference on computervision and pattern recognition, 1–9 (2015).
He, K., Zhang, X., Ren, S., Sun, J. Deep residual learning for image recognition. In: IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Kermany, D. S. et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 172, 1122–1131 (2018).
Park, K. et al. Deep learning predicts the differentiation of kidney organoids derived from human induced pluripotent stem cells. Kidney Res Clin. Pr. 42, 75–85 (2023).
Lim, M. H. et al. Deep learning model for predicting airway organoid differentiation. Tissue Eng. Regen. Med. 20, 1109–1117 (2023).
Vaswani, A. et al. Attention is all you need. Adv. Neural Info. Proc. Syst. 30, 5998–6008 (2017).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, 45–67 (2021).
Muranishi, Y., Terada, K. & Furukawa, T. An essential role for Rax in retina and neuroendocrine system development. Dev. Growth Differ. 54, 341–348 (2012).
Taga, S. et al. Generation and purification of ACTH-secreting hPSC-derived pituitary cells for effective transplantation. Stem Cell Rep. 18, 1657–1671 (2023).
Tan, M. X. & Le, Q. V. EfficientNetV2: Smaller models and faster training. In: International Conference on Machine Learning (2021).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. Preprint at https://ui.adsabs.harvard.edu/abs/2017arXiv171105101L (2017).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In: 3rd International Conferenceon Learning Representations, 1–15 (2015).
Selvaraju, R. R. et al. Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Computer Vis. 128, 336–359 (2020).
Amir, S., Gandelsman, Y., Bagon, S. & Dekel, T. Deep ViT features as dense visual descriptors.quantifying attention flow in transformers. Preprint at https://ui.adsabs.harvard.edu/abs/2021arXiv211205814A (2021).
Raghu, M., Unterthiner, T., Kornblith, S., Zhang, C. Y. & Dosovitskiy, A. Do vision transformers see like convolutional neural networks? In Advances in Neural Information Processing Systems 34 (Neurips 2021) (NIPS, 2021).
Tuli, S., Dasgupta, I., Grant, E. & Griffiths, T. L. Are convolutional neural networks or transformers more like human vision? Preprint at https://ui.adsabs.harvard.edu/abs/2021arXiv210507197T (2021).
Zhong, Y. & Deng, W. Face transformer for recognition. Preprint at https://ui.adsabs.harvard.edu/abs/2021arXiv210314803Z (2021).
Jiang, Z. C., Dong, Z. X., Wang, L. Y. & Jiang, W. P. Method for diagnosis of acute lymphoblastic leukemia based on ViT-CNN ensemble model. Comput. Intell. Neurosci. 2021, 1–12 (2021).
Tian G. et al. A deep ensemble learning-based automated detection of COVID-19 using lung CT images and Vision Transformer and ConvNeXt. Front. Microbiol. 13, 1024104 (2022).
Eiraku, M. et al. Self-organized formation of polarized cortical tissues from ESCs and its active manipulation by extrinsic signals. Cell Stem Cell 3, 519–532 (2008).
Kadoshima, T. et al. Self-organization of axial polarity, inside-out layer pattern, and species-specific progenitor dynamics in human ES cell-derived neocortex. Proc. Natl Acad. Sci. USA 110, 20284–20289 (2013).
Mall, E. M., Herrmann, D. & Niemann, H. Murine pluripotent stem cells with a homozygous knockout of Foxg1 show reduced differentiation towards cortical progenitors in vitro. Stem Cell Rep. 25, 50–60 (2017).
Nakano, T. et al. Self-Formation of Optic Cups and Storable Stratified Neural Retina from Human ESCs. Cell Stem Cell 10, 771–785 (2012).
Schneider, C. A., Rasband, W. S. & Eliceiri, K. W. NIH Image to ImageJ: 25 years of image analysis. Nat. Methods 9, 671–675 (2012).
Chen P., Liu S., Zhao H., Jia J. GridMask data augmentation. Preprint at https://ui.adsabs.harvard.edu/abs/2020arXiv200104086C (2020).
Hendrycks, D. et al. AugMix: A simple data processing method to improve robustness and uncertainty. Preprint at https://ui.adsabs.harvard.edu/abs/2019arXiv191202781H (2019).
Asano, T. et al. Human Pluripotent Stem Cell Culture Outcome Predicted by Deep Learning data sets. figshare https://doi.org/10.6084/m9.figshare.24616506 (2023).
Niioka-Group, Murasso, Abe, M. Niioka-Group/Organoid-Classifier. Zenodo https://doi.org/10.5281/zenodo.13923121 (2024).
Acknowledgements
We are grateful to Keigou Tsutsui and Akiko Tsuzuki for technical support; to all members of the Arima laboratory for valuable discussions; and to Dr. A S Knisely for comments on the manuscript. This research was supported by the following projects: AMED (JP23ek0109524, Japan), the JST FOREST Program (JPMJFR200N, Japan), Grant-in-Aid for Scientific Research (C) (JP23K08005, Japan), the Harmonic Ito Foundation, and Nagoya University Hospital Funding for Clinical Research.
Author information
Authors and Affiliations
Contributions
T.A., H.S., H.N., H.Y., and H.A. designed the study and wrote the manuscript. T.A., M.Sa., M.So., T.Miwata, and H.S. performed the experiments with technical help and advice from S.T., T.S., S.H., S.M., M.A., Y.Y.,T.Miyata, T.K., M. Su., T.O., D.H., S.I, and Y.B.
Corresponding authors
Ethics declarations
Competing interests
The authors declare the following competing interests: Sumitomo Pharma employs S.T. The authors are co-inventors on patent applications.
Peer review
Peer review information
Communications Biology thanks the anonymous reviewers for their contribution to the peer review of this work. Primary Handling Editors: Mo Li and Dario Ummarino.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Asano, T., Suga, H., Niioka, H. et al. A deep learning approach to predict differentiation outcomes in hypothalamic-pituitary organoids. Commun Biol 7, 1468 (2024). https://doi.org/10.1038/s42003-024-07109-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42003-024-07109-1
