
Abstract
Accurately and efficiently diagnosing Post-Acute Sequelae of COVID-19 (PASC) remains challenging due to its myriad symptoms that evolve over long- and variable-time intervals. To address this issue, we developed a hybrid natural language processing pipeline that integrates rule-based named entity recognition with BERT-based assertion detection modules for PASC-symptom extraction and assertion detection from clinical notes. We developed a comprehensive PASC lexicon with clinical specialists. From 11 health systems of the RECOVER initiative network across the U.S., we curated 160 intake progress notes for model development and evaluation, and collected 47,654 progress notes for a population-level prevalence study. We achieved an average F1 score of 0.82 in one-site internal validation and 0.76 in 10-site external validation for assertion detection. Our pipeline processed each note at 2.448 ± 0.812 seconds on average. Spearman correlation tests showed ⍴ > 0.83 for positive mentions and ⍴ > 0.72 for negative ones, both with P < 0.0001. These demonstrate the effectiveness and efficiency of our models and its potential for improving PASC diagnosis.
Similar content being viewed by others

Introduction
Post-acute sequelae of coronavirus disease 2019 (PASC), or Long COVID, is an often debilitating and complex infection-associated chronic condition (IACC) that occurs after SARS-CoV-2 infection and is present for at least 3 months beyond the acute phase of the infection1,2. PASC has affected tremendous individuals globally2,3,4,5, with over 200 distinct symptoms reported across multiple organ systems, emphasizing its complexity and multifaceted nature5,6,7. Currently, diagnosing, treating, and caring for patients with PASC remains challenging due to its myriad symptoms that evolve over long- and variable-time intervals1,5,8,9. The accurate characterization and identification of PASC patients are critical for effectively managing this evolving public health issue, such as accurate diagnosis, stratification of risk among patients, evaluation of the impact of therapeutics and immunizations, and ensuring diverse recruitment for clinical research studies1,5.
Electronic health records (EHRs) have been widely used in clinical practice and AI in healthcare research. Currently, EHR analyzes regarding PASC predominantly rely on structured data, such as billing diagnoses commonly recorded as ICD-10 codes. Yet, existing diagnostic codes for PASC (i.e., U09.9) have been shown to lack the requisite sensitivity and specificity for an accurate PASC diagnosis10,11,12,13,14. Additionally, findings reveal demographic biases among patients coded with U09.9, showing a higher prevalence in women, White, non-Hispanic individuals, and those from areas of lower poverty and higher education14,15. Structured billing diagnoses have limitations in assessing the true frequency of conditions associated with PASC, such as Postural Orthostatic Tachycardia Syndrome (POTS), which is diagnosed in 2–14% of individuals after a COVID-19 infection16. POTS did not have a specific ICD-10 code until October 1, 2022. Additionally, its primary symptoms—palpitations and dizziness—may be documented in clinical notes but often go unrecognized as part of the syndrome by clinicians, leading to underreporting in billing data. Comparable challenges are also found in diagnosing Myalgic Encephalomyelitis/Chronic Fatigue Syndrome (ME/CFS) when relying solely on structured data17,18,19. These biases and limitations complicate our understanding and management of PASC and highlight the need for improved diagnostic approaches.
Unstructured narratives, found in EHR notes, contain detailed accounts of a patient’s clinical history, symptoms, and the effects of those symptoms on physical and cognitive functioning. Previous studies have applied NLP to detect acute COVID symptoms within free-form text notes20,21,22,23. Studies on acute COVID-19 symptom extraction have achieved promising results24. However, due to the inherent difference between PASC and COVID-19, such NLP approaches are not directly transferable21,23,24. Other research has concentrated on identifying PASC symptoms without assertion detection. The PASCLex study by Wang et al. 25 developed a lexicon of symptoms and synonyms, employing a rule-based approach to search for symptoms within clinical notes.
To address the challenges of identifying PASC and build on previous research to improve diagnostic methods, we developed a hybrid NLP pipeline that integrates rule-based and deep-learning approaches. This hybrid pipeline not only detects relevant symptoms in clinical notes but also accurately determines their assertion status—whether a symptom is truly present or non-present. Our approach was implemented within data from the RECOVER Initiative, which provides access to large, diverse COVID-19 and PASC patient populations with electronic health records (EHR) data from a network of large health systems across the United States. One of the key features of our pipeline is a comprehensive PASC lexicon, developed in collaboration with clinicians, consisting of 25 symptom categories and 798 Unified Medical Language System (UMLS) concepts for precise symptom identification. Additionally, we designed a BERT-based module specifically to assess symptom assertions, distinguishing between symptoms that are present or non-present (including absent, uncertain, or other possible statuses, as detailed in the Methods). To ensure our approach extracts PASC symptoms from unstructured clinical notes robustly and efficiently, we curated 60 progress notes from New York-Presbyterian/Weill Cornell Medicine (WCM) for model development and internal validation, and 100 progress notes from 10 additional sites for external validation. To strengthen our evaluation in comparison with large language models, we developed a prompt and applied GPT-4 for symptom extraction with assertion detection on a 20-note subset of the WCM internal validation notes. Furthermore, we analyzed 47,654 clinical notes from 11 health systems to conduct a population-level prevalence study, aiming to improve the understanding of PASC-symptom mentioning patterns and refine disease characterization. Leveraging the RECOVER26 datasets, our approach addresses key limitations of prior research by incorporating a large, diverse population and validating performance across multiple sites, which helps account for variations in clinical language and documentation styles.
Results
PASC Lexicon
The PASC lexicon is an ontology graph consisting of 25 symptom categories, 798 finer-grained UMLS concepts, and their synonyms (Fig. 1). The complete symptom lexicon is available in Supplementary File 1.

PASC Lexicon with Examples of Representative Symptoms.
The 25 categories, together with the initial symptom lexicon, were identified by physicians (led by CF). The categories and lexicon were then manually mapped and consolidated using UMLS and SNOMED CT. To make the lexicon comprehensive, we included all synonyms from the UMLS concepts and the lexicon extracted from PASCLex25. We further leveraged the Broader-Narrower relationship (hierarchies between concepts) and included all children of a concept in the initial lexicon.
A Hybrid NLP Pipeline for PASC Symptom Extraction
We developed MedText, a hybrid NLP pipeline that integrates both rule-based modules and deep learning models at different stages (Fig. 2). At a high level, MedText employs a text preprocessing module to split the clinical notes into sections and sentences. It then uses the PASC lexicon and a rule-based NER module to extract PASC symptoms from clinical notes. Finally, a BERT-based assertion detection module is employed to determine whether the extracted symptom is positive or not (e.g., “there is no diarrhea”).

The architecture of the NLP pipeline.
Quantitative Results for Assertion Detection
In this study, we used three popular domain-specific pretrained BERT models, BioBERT, ClinicalBERT, and BiomedBERT27,28,29, to develop the assertion detection module in MedText. All BERT models were fine-tuned using the combination of the WCM Training Set and public i2b2 2010 assertion dataset30 (See Methods).
We evaluated the performance of assertion detection using the clinical notes in the WCM Internal Validation and Multi-site External Validation sets. Performance was measured regarding precision, recall, and F1-score (the harmonic mean of the precision and recall) across all the symptoms in these two datasets.
Figure 3 presents a comparative performance analysis on the WCM Internal Validation dataset. Among the three models, the BiomedBERT consistently shows superior performance across all metrics, particularly in an average recall of 0.75 ± 0.040 (95% CI: 0.676–0.834) and an average F1 score of 0.82 ± 0.028 (95% CI: 0.766–0.876).

Boxplots for the performance metrics—(a) Precision, (b) Recall, and (c) F1-score. ns not significant; **P ≤ 0.01; ***P ≤ 0.001; ****P ≤ 0.0001.
Figure 4 presents a comparative performance analysis on the Multi-site External Validation dataset. The precision, recall, and F1 scores show no significant differences across the models (i.e., P > 0.05 in t-tests). BiomedBERT achieved an average recall of 0.775 (95% CI: 0.726–0.825) and an average F1 score of 0.745 [95% CI: 0.697–0.796]) and ClinicalBERT (recall of 0.775 [95% CI: 0.713–0.838]) and F1 of 0.730 [95% CI: 0.649–0.812]), lower than BioBERT (recall of 0.792 [95% CI: 0.715–0.868] and F1 of 0.782 [95% CI: 0.716–0.848]). The average precision of BiomedBERT (0.737 [95% CI: 0.646–0.829]) is not significantly different from BioBERT (0.792 [95% CI: 0.704–0.880]), but is higher than ClinicalBERT (0.710 [95% CI: 0.598–0.822]).

Radar Chart for the performance metrics—(a) precision, (b) recall, and (c) F1-score—of the three fine-tuned MedText-BERT pipeline variants on the 100-note non-WCM multi-site external validation set. The metrics are computed for the positive (i.e., “Present”) symptom mentions. The BERT-based models trained/fine-tuned in different scenarios for assertion detection are: BioBERT fine-tuned, BiomedBERT fine-tuned, BiomedBERT benchmark, and ClinicalBERT fine-tuned from left to right in each subfigure. a Seattle - Seattle Children’s; (b) Monte - Montefiore Medical Center; (c) CHOP - The Children’s Hospital of Philadelphia; (d) OCHIN - Oregon Community Health Information Network; (e) Missouri - University of Missouri; (f) CCHMC - Cincinnati Children’s Hospital Medical Center; (g) Nemours - Nemours Children’s Health; (g) MCW - Medical College of Wisconsin; (i) Nationwide - Nationwide Children’s Hospital; (j) UTSW - UT Southwestern Medical Center.
Frequency Analysis of PASC Symptoms in The Population-Level Prevalence Study
Based on the WCM Internal Validation and Multi-site External Validation results, the BiomedBERT model was selected for a population-level prevalence study.
Figure 5A summarizes the positive (i.e., “positive”) mentions and negative (i.e., “non-positive”) mentions of 25 PASC categories identified by MedText on the Population-level Prevalence Study dataset. Among all the 11 sites, the Positive mention of “pain” is the leading symptom mentioned. Other leading symptom categories include headache, digestive issues, depression, anxiety, respiratory symptoms, and fatigue, in potentially varying orders across different sites.

A Frequency analysis of positive (“present”) in red and negative (“non-present”) in blue symptom category occurrences in different sites. B Spearman correlation coefficients between the positive (i.e., “present”) symptom mentioning patterns of sites and the overall dataset. C Spearman correlation coefficients between the negative (i.e., “non-present”) symptom-mentioning patterns of sites and the overall dataset. (a) Seattle Children’s, (b) Montefiore Medical Center, (c) The Children’s Hospital of Philadelphia, (d) Oregon Community Health Information Network, (e) University of Missouri, (f) Cincinnati Children’s Hospital Medical Center, (g) Nemours Children’s Health System, (h) Medical College of Wisconsin, (i) Nationwide Children’s Hospital, (j) UT Southwestern Medical Center, (k) Weill Cornell Medicine, (l) Total.
Figure 5B, C further compare the symptom-mentioning patterns in terms of the relative frequency of the symptom categories in different sites through the Spearman correlation test. In particular, the lowest Spearman correlation coefficient for the positive symptom-mentioning patterns between any two sites and the entire dataset exceeds 0.83, while for negative symptom-mentioning patterns, it is above 0.72. In the Spearman correlation test, any pair of sites or between any site and the overall dataset showed P < 0.0001.
Figure 6 shows the Spearman correlation coefficients for the positive mentions between each pair of the 25 symptom categories and the total number of symptom mentions.

Spearman correlation coefficients between the positive (i.e., “Present”) symptom-mentioning patterns of symptom categories. The total count of positive symptom mentions for each symptom category is to the right of the correlation diagram.
Processing Time
We deployed MedText on an AWS Sagemaker platform with a Tesla T4 GPU configuration, achieving efficient processing of the large-scale clinical notes datasets. Overall, MedText processed each note at an average of 2.448 ± 0.812 s across the 11 sites. Figure 7 shows the module-wise summary of the mean and standard deviation of runtime in seconds in the population-level prevalence study across 11 sites.

The mean (shown by the values on each bar) and standard deviation of the runtime of each MedText module in MedText computed for the mean runtime per note across the 11 sites.
Comparison between Rule-Based Module and GPT-4 for Symptom Extraction
To strengthen our evaluation, we conducted an experiment comparing our rule-based NER module with a large language model, GPT-4, for PASC-related symptom extraction (see Methods). Using a random sample of 20 intake notes from the WCM internal validation set, we applied GPT-4 (API version: 2024-05-01-preview) with a prompt specifying the 25 predefined symptom categories. GPT-4 generated 189 symptom mentions, which ZB manually reviewed to assess correctness—specifically, whether each mention existed in the note and corresponded to a valid symptom or synonym. This review identified 9 incorrect mentions, yielding a precision of 95.24% for GPT-4-based NER.
To estimate recall of the NER module in our hybrid NLP pipeline, we constructed a proxy ground truth by taking the union of all verified correct mentions identified by GPT-4 (180) and our rule-based NER module (640) on these 20 notes. This union set contains 706 verified correct mentions. Based on this reference set, the rule-based module achieved a recall of 90.65%.
In addition, our prompt also required GPT-4 to generate assertion labels. These assertion detection results produced by GPT-4 were manually reviewed for correctness, which achieved a weighted F1 score of 97.78% and a balanced accuracy of 97.72% on the 180 correctly recognized symptom mentions.
Discussion
In this study, we developed a hybrid NLP pipeline combining rule-based and deep learning techniques, leveraging state-of-the-art techniques31,32,33 for clinical text preprocessing and symptom extraction. Our pipeline not only identified relevant symptoms of PASC but also accurately evaluated whether the symptoms are truly present or absent. This pipeline includes a PASC lexicon we developed with clinical specialists, with 25 symptom categories and 798 finer-grained UMLS concepts and synonyms. We adapted a BERT-based module for symptom assertion detection. For model training and evaluation, we curated 160 progress notes from 11 health systems as part of the RECOVER initiative network across the U.S. Experiments on the WCM Internal Validation set and the Multi-site External Validation set show that BiomedBERT achieved the overall best performance in assertion detection. Our model showed high precision and recall, achieving an average F1 score of 0.82 in internal validation at one site and 0.76 in external validation across 10 sites for assertion detection, showing good generalizability across sites. Additionally, we collected 47,654 progress notes for a population-level prevalence study on PASC symptom-mention patterns. Our pipeline processed each note at an average speed of 2.448 ± 0.812 seconds. Spearman correlation tests showed ⍴ > 0.83 for positive mentions and ⍴ > 0.72 for negative mentions, both with P < 0.0001. These results demonstrate that our pipeline effectively, consistently, and efficiently captures PASC symptoms across multiple health systems. Our population-level prevalence study provided novel insights and may advance the understanding of the symptom-mentioning patterns related to PASC, shedding light on a more comprehensive understanding of PASC for future research and clinical practice.
The hybrid NLP pipeline we developed is tailored explicitly to PASC, while previous research has explored assertion detection in different clinical contexts, e.g., the BERT-based34 and prompt-based35. In particular, BERT-based models applied to Chia36 achieved an F1 score of ~0.77 for “Present” and a micro-averaged F1 score of ~0.72. Although these models claimed over 0.9 in both the F-1 score for “Present” and the micro-averaged F1 score evaluated on conventional benchmarking datasets, i2b2 201030, BioScope37, MIMIC-III38, and NegEx39, none of them have addressed the unique challenges posed by PASC-related narratives. Our model’s performance on the curated RECOVER datasets achieved an average F1 score of 0.82 in internal validation and 0.76 in 10-site external validation via BiomedBERT. This demonstrates that domain-specific models remain necessary compared to general-domain language models, given the nascent and rapidly evolving nature of PASC-related medical narratives. The lack of standardized terminology25, coupled with the limited availability of annotated training data40 and the heterogeneous symptomatology of PASC41, presents different challenges that are not as prevalent in more established clinical note datasets for NLP tasks. Comparative analyzes of holistic processing speeds across different NLP pipelines with BERT-based modules for unstructured clinical notes are not extensively documented in the literature, and the differences between datasets and experimental setups can undermine fair comparison. Nonetheless, our model offers a competitive runtime of ~2.5 seconds per note compared to LESA-BERT, a model originally designed for patient message triage, which required approximately 212.6 seconds to process its test set on a CPU with a batch size of 1. Its distilled versions, such as Distil-LESA-BERT-6 and Distil-LESA-BERT-3, showed inference times of 79.8 seconds and 40.8 seconds, respectively42. This demonstrates the efficiency of our pipeline.
We conducted error analysis during multi-site external validation and identified site-specific performance limitations, revealing potential causes that may affect model effectiveness. First, inconsistent manual annotations, e.g., “as needed” cases, led to varied interpretations of symptoms as rigorously “positive”, “hypothetical” in EHR was identified as “non-positive”; while phrases containing “history of”, symptoms were often misclassified as “positive”. Second, sentences listing multiple symptoms after the negation phrase “negative for” posed challenges. Excessive spacing in these instances caused the model to misinterpret the context, leading to symptoms frequently misclassified as “positive”, likely due to their distance from the negation keyword. Third, symptoms that were excluded from the performance evaluation, e.g., due to unresolved mismatches, could affect the NLP pipeline’s overall performance. Hopefully, these findings may provide clues for those working toward enhancing their model’s ability to address more intricate textual contexts or classify temporal context.
To date, we have not found any study reported applying Large Language Models (LLMs) (e.g., general-purpose models ChatGPT43,44, Gemini44,45, and open-source, medical domain-specific models OpenBioLLM-70B46 and Llama-3-8B-UltraMedical47) on PASC-related symptom extraction with assertion detection. To strengthen our evaluation, we randomly selected 20 notes from the 30-note WCM internal validation subset and applied GPT-4 to perform both NER and assertion detection, and compared with the rule-based NER module in symptom extraction. Without specifying PASC-specific lexicon, GPT-4 was able to achieve better performance in assertion detection on the 180 manually verified correctly identified symptoms, with a weighted F1 score of 97.78%. However, it also missed a notable amount of symptom/synonym-related tokens compared to the 640 correct symptom mentions by our rule-based NER module on the same 20 notes.
Our study has limitations: (i) Our current performance evaluation focused on the positive or negative mentions of symptoms already identified in the MedText pipeline. However, whether all possible symptoms are captured remains unclear. (ii) We excluded 18 symptom mentions from the performance evaluation due to unresolved mismatches that may affect the results of symptom extraction. (iii) Our primary goal in this work is to develop a generalizable NLP pipeline for extracting PASC-relevant symptoms from clinical narratives, with intake notes serving as an initial use case. While the intake notes are often the earliest comprehensive documentation of a patient’s initial concerns, they may overrepresent acute or prominent symptoms, potentially biasing the extracted distributions. To address these limitations, we will enhance our pipeline in the future via: (i) expanding the annotated datasets in collaboration with clinicians to annotate all possible symptoms given a note, (ii) integrating structured EHR data and COVID-related symptoms extracted from unstructured clinical notes, (iii) evaluating how different note types contribute to identifying high-risk patients and explore how the extracted outputs could be integrated into clinical workflows, for example, by flagging patients for specialist referral or follow-up care. Since our pipeline itself is not restricted to intake notes, it can be directly applied to other types of notes.
All the above demonstrate that our hybrid NLP pipeline, namely MedText, can extract symptoms effectively, efficiently, and robustly. Our MedText may contribute to (i) unlocking rich clinical information from narrative clinical notes, (ii) assisting clinicians in diagnosing PASC efficiently and precisely, (iii) supporting predictive modeling and risk assessment about PASC, (iv) facilitating the PASC clinical decision support system, and (v) adapting our pipeline for exact symptoms of other diseases may enable large-scale research and public health insights. However, MedText may not capture all nuanced clinical details, highlighting the importance of clinical review to ensure accuracy and completeness in symptom identification.
Methods
Ethics Oversight
Institute Review Board (IRB) approval was obtained under Biomedical Research Alliance of New York (BRANY) protocol #21-08-508. As part of the Biomedical Research Alliance of New York (BRANY IRB) process, the protocol has been reviewed in accordance with the institutional guidelines. The Biomedical Research Alliance of New York (BRANY) waived the need for consent and HIPAA authorization. IRB oversight was provided by the Biomedical Research Alliance of New York, protocol # 21-08-508-380. The study was performed in accordance with the Declaration of Helsinki.
Study cohort
We collected 47,814 clinical notes from 11 sites within the RECOVER network: Weill Cornell Medicine (WCM), Medical College of Wisconsin, Cincinnati Children’s Hospital Medical Center, The Children’s Hospital of Philadelphia, University of Missouri, Nationwide Children’s Hospital, Nemours Children’s Health System, Oregon Community Health Information Network, Seattle Children’s, UT Southwestern Medical Center, and Montefiore Medical Center. The data follow the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM), with the Institutional Review Board (IRB) approval obtained under Biomedical Research Alliance of New York (BRANY) protocol #21-08-508.
Curating Data for PASC Symptom Review and NLP Pipeline Evaluation
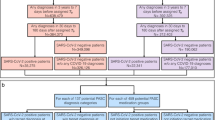
For pipeline development and validation, we sampled 60 ambulatory patients from WCM and 100 from 10 other sites in the RECOVER network (10 patients/site) (Table 1). Then, we extracted each patient’s intake progress notes for human annotators. Here, we hypothesize that the intake notes contain the most detailed list of problems for each patient. The 60 WCM notes form the Model Development Dataset, in which 30 were used as the WCM Training set, and the other 30 as the WCM Internal Validation set. The 100 notes from 10 other sites form the Multi-site External Validation set (Fig. 8). We also integrated the publicly available 2010 i2b2 assertion dataset35 with the WCM training set for model fine-tuning.

Data construction workflow.
For annotation, we designed a qualified review pipeline to generate manual annotations for symptom mentions. We first applied MedText to extract symptoms from the notes. Then, we used Screen-Tool, an open-source R software developed by TB, to determine the assertion status for each symptom mention (e.g., Fig. 9). Screen-Tool displays each extracted symptom highlighted in its context (the passage it belongs to), along with the symptom category identified by MedText as its concept. The annotators are required to determine whether this token is “related” or “unrelated” to this concept, as well as which of the five statuses it belongs to: “present”, “absent”, “hypothetical”, “past”, or “other”. For performance validation of assertion detection, these statuses are eventually mapped into a binary status: positive vs. non-positive. Specifically, “present” mentions are mapped to positive, while all the other statuses of mentions are deemed Negative.

Screen_Tool is an open-source R-based software for manual annotation of symptom mention.
Two annotators (ZB and ZX) independently reviewed and annotated each mention of extracted symptoms. We used Cohen’s Kappa (CK) metric to measure inter-rater agreement (IRA). This process achieved a value of 0.98 on the WCM annotated subset (i.e., including both the WCM training and WCM internal validation sets), and 0.99 on the multi-site external validation set. All mentions that had disagreements between the two annotators or were unrelated were removed from the dataset. Specifically, 24 out of 2301 mentions (<1.05%) were removed from the WCM annotated subset, and 18 out of 1886 (<0.5%) were removed from the multi-site external validation set. Among the 4187 mentions extracted from 160 annotated notes, 12 were ‘unrelated’ NER results where the trigger token did not match a recognized symptom or synonym. This yields an overall NER precision of 99.7%, with 99.5% (11 unrelated) on the WCM subset and 99.9% (1 unrelated) on the multi-site external validation set.
Constructing PASC Lexicon
We first compiled an initial symptom lexicon with 25 categories for PASC-related terms, based on input from subject matter experts (SMEs) and a literature review6. PASC symptoms were defined as patient characteristics occurring in the post-acute COVID-19 period. Next, we searched the symptoms in the UMLS Metathesaurus® (version 2023AB) in the English language, with vocabulary sources of “SNOMEDCT_US” and “MeSH”. We included concepts that can be strictly matched in UMLS, together with their children (narrow concepts). To make the lexicon comprehensive, we included all synonyms from the UMLS concepts and the lexicon extracted from PASCLex25. This process yielded a hierarchical knowledge graph comprising terms and keywords that define 798 symptom sub-concepts and synonyms, organized into 25 categories (Supplementary File 2).
Developing a Hybrid NLP Pipeline for PASC Symptom Extraction
We developed a hybrid NLP pipeline that combines rule-based and deep-learning modules to mine PASC symptoms. At a high level, MedText employs a text preprocessing module to split the clinical notes into sections and sentences. It then uses a rule-based NER module that utilizes a clinician-curated PASC lexicon to extract PASC symptoms from clinical notes. It then employs a BERT-based assertion detection module to assess if the extracted symptom is absent (e.g., “there is no diarrhea”) (Fig. 2).
MedText48 is an open-source clinical text analysis system developed with Python. It offers an easy-to-use text analysis pipeline, including de-identification, section segmentation, sentence split, NER, constituency parsing, dependency parsing, and assertion detection. For this study, we utilized modules ranging from section segmentation and sentence split to NER and assertion detection (Fig. 2).
The section split module divides the report into sections. This rule-based module uses a list of section titles to divide the notes. We used rules from medspacy, which were adapted from SecTag and expanded through practice49. The sentence split module splits the report into sentences using NLTK50. The NER module recognizes mention spans of a particular entity type (e.g., PASC symptoms) from the reports. Technically, it uses a rule-based method via SpaCy’s PhraseMatcher to efficiently match large terminology lists. Here, the NER step identifies and clarifies concepts of interest according to the 798 symptoms and their synonyms in the PASC lexicon. The assertion detection module determines the status of the recognized concept based on its context within the sentence35, as detailed below in the assertion detection module development.
Additionally, MedText features a flexible modular design, provides a hybrid text processing schema, and supports raw text processing and local processing. It also adopts BioC51 as the unified interface, and standardizes the input/output into a structured representation compatible with the OMOP CDM. This allows us to deploy MedText and validate its performance across multiple, disparate data sources. In this study, we deployed MedText on an AWS Sagemaker platform with a Tesla T4 GPU configuration and 15 GiB of CPU memory.
Developing the Assertion Detection Module
In this study, we used three popular domain-specific pretrained BERT models, BioBERT, ClinicalBERT, and BiomedBERT27,28,29, to develop classifiers for the assertion detection step in the MedText pipeline after extracting symptom mentions. Detailed descriptions of these pretrained BERT models and their hyperparameter settings are provided in the Table 2.
To construct training sets for model development, we utilized a publicly available 2010 i2b2 assertion dataset of clinical notes30,35, which consists of 4359 sentences and 7073 labels collected from three sites: Partners Healthcare, Beth Israel Deaconess Medical Center, and the University of Pittsburgh Medical Center30,35, and the WCM Model Training set to construct training sets for model development. In particular, 3055 sentences and 4243 mentions from the public i2b2 2010 assertion dataset30,35 merged with the 30-note WCM Model Training set were used as the training set for fine-tuning the BERT-based assertion detection models. This integrated dataset is referred to as the i2b2&WCM-merged training set. To evaluate the effectiveness of our fine-tuning approach, we conducted comparative analyzes among BiomedBERT29, BioBERT27, and ClinicalBERT28 - all of which were trained on the i2b2&WCM-merged training set. We used the WCM internal validation set (30 notes, 350 sentences and 953 mentions) for model selection and the 10-site multi-site external validation set (100 notes, 1,113 sentences and 1886 mentions) for performance evaluation (Table 1). This direct comparison offered insights into the relative strengths of each model in handling biomedical text. The multi-category prediction task of multiple possible assertion statuses from the original BERT models was revised into a binary prediction task. Specifically, only the “present” status is mapped to present with a label of 1. In contrast, all other possible statuses, including “absent”, “hypothetical”, and any form of “uncertain”, are mapped to negative with a label of 0.
Evaluation Plan
We explored three different models of assertion detection in the MedText pipeline and considered two different application scenarios: the numerical performance evaluation using the smaller datasets with manually annotated ground-truth labels (i.e., the Internal Validation set, and the Multi-site External Validation set) and the population-level prevalence study using approximately 5000 clinical notes from each site from the 11 sites of RECOVER network (i.e., the population statistics set). The patient demographics (race, ethnicity, age, and sex) across the 11 RECOVER sites in the population-level prevalence study are summarized in Table 3.
In the numerical performance evaluation, each model was assessed using precision, recall, and F1 score. For each trained and fine-tuned model, bootstrapping was applied in 100 iterations on the WCM Internal Validation set. The performance of these models was evaluated using the same metrics, along with their mean values, standard deviation, and 95% confidence intervals.
On the prevalence of PASC-related symptoms at the population level, we analyzed symptom mentions identified by the optimal configuration of our NLP pipeline across 11 RECOVER sites. Using the MedText pipeline, we analyzed 47,654 notes from these sites as a Population-level Prevalence Study dataset (Fig. 8). Specifically, this dataset included 5000 intake progress notes from unique patients per site, except for three sites: Nationwide had 3680 notes, Nemours had 2132, and Seattle had 1842. We then applied the Spearman rank correlation test to compare symptom-mentioning patterns across sites. We conducted pairwise Spearman tests between the sites and symptom categories, for positive and negative mentions, respectively. For between-site analysis, the symptom mentions over the 25 symptom categories of each site form the symptom-mentioning vector for this site. For between-site analysis, the symptom-mentions across the 11 sites of each symptom category form the symptom-mentioning vector of this symptom category.
Symptom Extraction and Assertion Detection Using Large Language Model: GPT-4
To compare our hybrid NLP pipeline with large language models for PASC symptom extraction and assertion detection, we conducted an experiment using GPT-4 (API version: 2024-05-01-preview). We randomly selected 20 intake notes from the subset used for WCM internal validation. GPT-4 was prompted with only the 25 predefined PASC symptom categories and instructed to extract all symptom mentions along with their assertion status (i.e., positive or negative). The model was allowed to rely on its internal knowledge to recognize synonymous expressions without being provided explicit lexicons. The specific prompt is provided in Supplementary File 3.
Each output mention was manually reviewed (by ZB) to determine whether the identified phrase existed in the original note and correctly matched a symptom or its synonym. To create a proxy ground truth for recall estimation, we took the union of all verified correct mentions extracted by either GPT-4 or the rule-based NER pipeline. Using this set, we evaluated recall for the rule-based method and precision for GPT-4. The assertion labels assigned by GPT-4 were also manually reviewed for correctness.
Data availability
Data utilized for this study was obtained from the PCORnet-RECOVER Amazon Warehouse Services (AWS) enclave which comprises 40 participating sites from PCORnet. Please send all data questions or access requests to the corresponding author, who will direct them accordingly.
References
National Academies of Sciences, Engineering, and Medicine; Health and Medicine Division; Board on Global Health; Board on Health Sciences Policy; Committee on Examining the Working Definition for Long COVID. A Long COVID Definition: A Chronic, Systemic Disease State with Profound Consequences. (National Academies Press (US), Washington (DC), (2024).
Thaweethai, T. et al. Development of a definition of postacute sequelae of SARS-CoV-2 infection. JAMA 329, 1934–1946 (2023).
Ford, N. D. et al. Long COVID and significant activity limitation among adults, by age - United States, June 1-13, 2022, to June 7-19, 2023. MMWR Morb. Mortal. Wkly. Rep. 72, 866–870 (2023).
Ballering, A. V., van Zon, S. K. R., Olde Hartman, T. C., Rosmalen, J. G. M. & Lifelines Corona Research Initiative Persistence of somatic symptoms after COVID-19 in the Netherlands: an observational cohort study. Lancet 400, 452–461 (2022).
Davis, H. E., McCorkell, L., Vogel, J. M. & Topol, E. J. Long COVID: major findings, mechanisms and recommendations. Nat. Rev. Microbiol. 21, 133–146 (2023).
Michelen, M. et al. Characterising long COVID: a living systematic review. BMJ Glob. Health 6, e005427 (2021).
Parums, D. V. Editorial: Post-acute sequelae of SARS-CoV-2 infection (PASC). Updated terminology for the long-term effects of COVID-19. Med. Sci. Monit. 29, e941595 (2023).
McCaddon, A. & Regland, B. COVID-19: A methyl-group assault?. Med. Hypotheses 149, 110543 (2021).
Miller, M. Poll: Doctors feel unprepared to treat Long COVID. de Beaumont Foundation https://debeaumont.org/news/2023/long-covid-poll/ (2023).
O’Hare, A. M. et al. Complexity and challenges of the clinical diagnosis and management of long COVID. JAMA Netw. Open 5, e2240332 (2022).
Pfaff, E. R. et al. Coding long COVID: characterizing a new disease through an ICD-10 lens. BMC Med 21, 58 (2023).
Duerlund, L. S., Shakar, S., Nielsen, H. & Bodilsen, J. Positive predictive value of the ICD-10 diagnosis code for long-COVID. Clin. Epidemiol. 14, 141–148 (2022).
Ioannou, G. N. et al. Rates and factors associated with documentation of diagnostic codes for long COVID in the national Veterans Affairs health care system. JAMA Netw. Open 5, e2224359 (2022).
Zhang, H. G. et al. Potential pitfalls in the use of real-world data for studying long COVID. Nat. Med. 29, 1040–1043 (2023).
Azhir, A. et al. Precision phenotyping for curating research cohorts of patients with unexplained post-acute sequelae of COVID-19. Med (N. Y.) 100532 (2024).
Ormiston, C. K., Świątkiewicz, I. & Taub, P. R. Postural orthostatic tachycardia syndrome as a sequela of COVID-19. Heart Rhythm 19, 1880–1889 (2022).
Madhavan, S. et al. Use of electronic health records to support a public health response to the COVID-19 pandemic in the United States: a perspective from 15 academic medical centers. J. Am. Med. Inform. Assoc. 28, 393–401 (2021).
Unger, E. R. et al. Myalgic encephalomyelitis/chronic fatigue syndrome after SARS-CoV-2 infection. JAMA Netw. Open 7, e2423555 (2024).
Dehlia, A. & Guthridge, M. A. The persistence of myalgic encephalomyelitis/chronic fatigue syndrome (ME/CFS) after SARS-CoV-2 infection: A systematic review and meta-analysis. J. Infect. 89, 106297 (2024).
Palmer, P. M., Padilla, A. H. & MacWhinney, B. The development and implementation of A data repository for swallow studies. Dysphagia 39, 476–483 (2024).
McMurry, A. J. et al. Moving biosurveillance beyond coded data using AI for symptom detection from physician notes: Retrospective cohort study. J. Med. Internet Res. 26, e53367 (2024).
Liu, F. et al. A medical multimodal large language model for future pandemics. NPJ Digit. Med. 6, 226 (2023).
Hurley, D. J., Neary, S. & O’Neill, E. Virtual triaging in an eye emergency department during the COVID-19 pandemic. Ir. J. Med. Sci. 192, 1953–1957 (2023).
Canales, L. et al. Assessing the performance of clinical natural language processing systems: Development of an evaluation methodology. JMIR Med. Inform. 9, e20492 (2021).
Wang, L. et al. PASCLex: A comprehensive post-acute sequelae of COVID-19 (PASC) symptom lexicon derived from electronic health record clinical notes. J. Biomed. Inform. 125, 103951 (2022).
RECOVER: Researching COVID to Enhance Recovery. RECOVER: Researching COVID to Enhance Recovery https://recovercovid.org/.
Lee, J. et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36, 1234–1240 (2020).
Huang, K., Altosaar, J. & Ranganath, R. ClinicalBERT: Modeling clinical notes and predicting hospital readmission. arXiv [cs.CL] (2019).
Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. 3, 1–23 (2022).
Uzuner, Ö, South, B. R., Shen, S. & DuVall, S. L. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J. Am. Med. Inform. Assoc. 18, 552–556 (2011).
Medtext. BioNLP Lab at Weill Cornell Medicine, GitHub, https://github.com/bionlplab/medtext.
Wang, S. et al. Radiology text analysis system (RadText): Architecture and evaluation. IEEE Int. Conf. Healthc. Inform. 2022, 288–296 (2022).
Pipeline - medtext 1.0 documentation. https://medtext.readthedocs.io/en/latest/pipeline/index.html.
van Aken, B. et al. Assertion detection in clinical notes: Medical language models to the rescue? In Proceedings of the Second Workshop on Natural Language Processing for Medical Conversations (Association for Computational Linguistics, Stroudsburg, PA, USA, https://doi.org/10.18653/v1/2021.nlpmc-1.5 (2021).
Wang, S. et al. Trustworthy assertion classification through prompting. J. Biomed. Inform. 132, 104139 (2022).
Kury, F. et al. Chia, a large annotated corpus of clinical trial eligibility criteria. Sci. Data 7, 281 (2020).
Szarvas, G., Vincze, V., Farkas, R. & Csirik, J. The BioScope corpus. In Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing - BioNLP ’08 (Association for Computational Linguistics, Morristown, NJ, USA, https://doi.org/10.3115/1572306.1572314 (2008).
Johnson, A. E. W. et al. MIMIC-III, a freely accessible critical care database. Sci. Data 3, 160035 (2016).
Harkema, H., Dowling, J. N., Thornblade, T. & Chapman, W. W. ConText: an algorithm for determining negation, experiencer, and temporal status from clinical reports. J. Biomed. Inform. 42, 839–851 (2009).
Wen, A. et al. A case demonstration of the Open Health Natural Language Processing Toolkit from the national COVID-19 cohort collaborative and the researching COVID to enhance recovery programs for a natural language processing system for COVID-19 or postacute sequelae of SARS CoV-2 infection: Algorithm development and validation. JMIR Med. Inform. 12, e49997 (2024).
Fritsche, L. G., Jin, W., Admon, A. J. & Mukherjee, B. Characterizing and predicting post-acute sequelae of SARS CoV-2 infection (PASC) in a large academic medical center in the US. J. Clin. Med. 12, (2023).
Si, S. et al. Students need more Attention: BERT-based AttentionModel for small data with application to AutomaticPatient message triage. MLHC abs/2006.11991, 436–456 (07–08 Aug 2020).
ChatGPT. https://chat.openai.com.
Hirosawa, T. et al. Diagnostic performance of generative artificial intelligences for a series of complex case reports. Digit. Health 10, 20552076241265216 (2024).
Gemini - chat to supercharge your ideas. Gemini https://gemini.google.com/.
aaditya/Llama3-OpenBioLLM-70B · Hugging Face. https://huggingface.co/aaditya/Llama3-OpenBioLLM-70B.
TsinghuaC3I/Llama-3-8B-UltraMedical · Hugging Face. https://huggingface.co/TsinghuaC3I/Llama-3-8B-UltraMedical.
Medtext documentation — medtext 1.0 documentation. https://medtext.readthedocs.io/en/latest/index.html.
SecTag -- tagging clinical note section headers. https://www.vumc.org/cpm/cpm-blog/sectag-tagging-clinical-note-section-headers.
NLTK :: nltk.tokenize package. https://www.nltk.org/api/nltk.tokenize.html.
Comeau, D. C. et al. BioC: a minimalist approach to interoperability for biomedical text processing. Database (Oxford) 2013, bat064 (2013).
Acknowledgements
This study is part of the NIH Researching COVID to Enhance Recovery (RECOVER) Initiative, which seeks to understand, treat, and prevent the post-acute sequelae of SARS-CoV-2 infection (PASC). This research was funded by the National Institutes of Health (NIH) Agreement OTA OT2HL161847 as part of the Researching COVID to Enhance Recovery (RECOVER) research program. We acknowledge the following RECOVER-EHR Consortium Members: PCORnet Core Contributors: Louisiana Public Health Institute: Thomas W. Carton, PI, Anna Legrand, Elizabeth Nauman. Weill Cornell Medicine: Rainu Kaushal, PI, Mark Weiner, PI, Sajjad Abedian, Dominique Brown, Christopher Cameron, Thomas Campion, Andrea Cohen, Marietou Dione, Rosie Ferris, Wilson Jacobs, Michael Koropsak, Alexandra LaMar, Colby Lewis V., Dmitry Morozyuk, Peter Morrisey, Duncan Orlander, Jyotishman Pathak, Mahfuza Sabiha, Edward J. Schenck, Catherine Sinfield, Stephenson Strobel, Zoe Verzani, Fei Wang, Zhenxing Xu, Chengxi Zang, Yongkang Zhang. Children’s Hospital of Philadelphia: L. Charles Bailey, mPI, Christopher B. Forrest, mPI, Rodrigo Azuero-Dajud, Andrew Samuel Boss, Morgan Botdorf, Colleen Byrne, Peter Camacho, Abigail Case, Kimberley Dickinson, Susan Hague, Jonathan Harvell, Miranda Higginbotham, Kathryn Hirabayshi, Sandra Ilunga, Rochelle Jordan, Aqsa Khan, Vitaly Lorman, Nicole Marchesani, Sahal Master, Jill McDonald, Nhat Nguyen, Hanieh Razzaghi, Qiwei Shen, Alexander Shorrock, Levon H. Utidjian, Kaleigh Wieand. PCORnet Data Contributors: Albert Einstein College of Medicine: Parsa Mirhaji, PI, Selvin Soby | Cincinnati Children's Hospital Medical Center: Nathan M. Pajor, PI, Jyothi Priya Alekapatti Nandagopal | Children's Hospital of Philadelphia: L. Charles Bailey, mPI, Christopher B. Forrest, mPI | Medical College of Wisconsin: Reza Shaker, PI, Bradley W. Taylor, PI, Alex Stoddard | Nationwide Children's Hospital: Kelly Kelleher, PI | Nemours/Alfred I. duPont Hospital for Children: H. Timothy Bunnell, PI, Daniel Eckrich | OCHIN, Inc.: Marion Ruth Sills, PI | Seattle Children's Hospital: Dimitri A. Christakis, PI, Daksha Ranade | University of Missouri School of Medicine: Abu Saleh Mohammad Mosa, PI, Xing Song | University of Texas Southwestern Medical Center: Lindsay G. Cowell, PI | Weill Cornell Medicine: Rainu Kaushal, mPI, Thomas Campion. Authorship has been determined according to ICMJE recommendations. We would like to thank the National Community Engagement Group (NCEG); all patients, caregivers, and community representatives; and all participants enrolled in the RECOVER Initiative. We would like to thank the patient representative, Elizabeth Noriega, for her contributions to this manuscript. This content is solely the responsibility of the authors and does not necessarily represent the official views of the RECOVER Program, the NIH, or other funders.
Author information
Authors and Affiliations
Contributions
All authors have read and approved the manuscript. Z.B.: Investigation, Writing, Formal analysis, Methodology; Z.X.: Investigation, Writing, Formal analysis; C.S.: Investigation, Writing; C.Z.: Investigation, Writing; H.T.B.: Investigation, Writing; C.S.: Investigation, Writing; J.R.: Investigation, Writing; A.T.M: Investigation, Writing; C.C.B.: Investigation, Writing; M.W.: Investigation, Writing; T.R.C.: Investigation, Writing; T.C.: Investigation, Writing; C.B.F.: Investigation, Writing; R.K.: Investigation, Writing, Funding acquisition, Resources; F.W.: Investigation, Writing, Supervision; Y.P.: Investigation, Writing, Supervision, Conceptualization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bai, Z., Xu, Z., Sun, C. et al. Extracting post-acute sequelae of SARS-CoV-2 infection symptoms from clinical notes via hybrid natural language processing. npj Health Syst. 2, 31 (2025). https://doi.org/10.1038/s44401-025-00033-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s44401-025-00033-4
