
Abstract
Argyrophilic grain (AG) is a common neurodegenerative accumulation of 4 repeat tau in dendritic spine. Dementia with grain (DG) is defined as AGs with a sole pathological basis for cognitive decline. As with other multifactorial diseases, DG could result from interactions of environmental and genetic factors. However, the genetic basis of DG is largely unknown. To clarify the genetic architecture of DG pathogenesis, we conducted a genome-wide association study (GWAS) with 214 DG cases versus 12,405 controls. We have identified a candidate locus associated with the risk of DG, the SVIL locus on chromosome 10, with genome-wide significance (rs11595141, P = 4.86 \(\times\) 10–8) in the GWAS. Transcriptome-wide association analysis using summary statistics for DG-GWAS identified DAPK2 (PTWAS = 3.68 \(\times\) 10–5) as a novel candidate causal gene for DG pathogenesis in the brain frontal cortex. The genetic association analysis for the APOE locus revealed that the APOE allele did not affect DG pathogenesis. We also identified new variants in the MAPT encoding tau protein that could potentially affect DG pathology. This is the first GWAS for DG, and our genetic findings provide biological and clinical insights into the pathogenesis of DG.
Similar content being viewed by others
Introduction
Argyrophilic grain (AG) is an age-associated neurodegenerative accumulation of four repeat (R) tau in dendritic spine, characterized by spindle- or comma-shaped structure detected by Gallyas silver stain [1] and anti-4 repeat tau isomorphic specific antibody (RD4) [2]. AGs started to accumulate in the ambient gyrus (Saito Stage 1), spread to the medial temporal lobe (Stage II), and extended to the frontal lobe (Stage III), causing cognitive decline. Dementia with grain (DG) is defined as AGs as a sole morphological basis for cognitive decline [3]. The diagnosis of DG was based on Gallyas stain and RD4 immunostain, as well as western blot and immune-electron microscopy, confirmed by cryo-electron microscopy (cryo-EM). In contrast, Alzheimer’s disease (AD) related pathologies, neurofibrillary tangles (NFTs) and neuropil threads were cofilament of 3 R and 4 R tau [4] and distinct from AGs.
Corticobasal degeneration (CBD) and progressive supranuclear palsy (PSP) are other neurodegenerative disorders with abnormal aggregates of 4 R tau [5, 6]. The CBD pathology presents tau inclusions in neurons and glia with tau astrocytic plaques, and extensive thread-like pathology in both gray and white matter [6]. PSP is a tauopathy with abnormal accumulation of tau protein within neurons as neurofibrillary tangles (NFTs), primarily in the basal ganglia, diencephalon, and brainstem with neuronal loss in globus pallidus, subthalamic nucleus, and substantia nigra. Abnormal tau also accumulates within oligodendroglia and astrocytes [5]. Both CBD and PSP are sporadic disorders, with few reports of familial cases [7, 8]. Genetic association studies have identified the H1 haplotype of MAPT locus at chromosome 17q21 as a major genetic risk factor for CBD and PSP [9]. However, almost the entire Japanese population only has the H1 haplotype [10]. Furthermore, recent GWAS with Caucasian subjects have identified the MOBP locus as the common risk factor for CBD and PSP [11, 12]. These data suggest overlaps in genetic architecture across different tauopathies. On the other hand, the genetic basis for DG is so far not well understood.
In this study, we aimed to identify the genetic components of DG using GWAS in the Japanese population. We conducted the expression quantitative trait locus (eQTL) analysis and transcriptome-wide association analysis (TWAS) and investigated the possible mechanisms of DG pathogenesis by functional annotation using GWAS data. In addition, we compared the frequencies of genetic variants for APOE, the strong genetic risk factor for AD, and MAPT, which encodes the protein tau, between DG, AD, and cognitively normal (CN) subjects.
Materials and methods
Subjects and DNA samples
All 16,634 genomic DNA samples and the corresponding clinical data were recruited from the National Center for Geriatrics and Gerontology (NCGG) Biobank and Brain Bank for Aging Research, Tokyo Metropolitan Institute for Geriatrics and Gerontology (TMIG), Japan. This included 214 samples from patients with autopsy-confirmed DG, 12,405 control samples from cognitively normal (CN) subjects and non-carrier control subjects (12,307 CN and 98 non-AGs, respectively), and 4015 samples from patients with AD (included possible- and proxy-AD) and mild cognitive impairment (MCI), all of whom were Japanese. 214 DG cases and 98 non-AGs from TMIG were performed to detect AGs by autopsy brains using the Gallyas-Braak method and RD4 immunohistochemistry. The distribution of AGs followed a stereotypic regional pattern and could be classified into Saito’s stages [3]. DG cases were categorized above Stage 2. Non-AG subjects were categorized as Stage 0: No grains are detected. We referred to the age at the time of initial diagnosis for NCGG samples and at the time of death because of autopsy for TMIG samples. Among DG patients, the median age was 83.7 years (67-104 years), and 46.2% were female. The CN subjects from NCGG Biobank had subjective cognitive complaints but normal cognition on the neuropsychological assessment with a comprehensive neuropsychological test, and Mini-Mental State Examination score >23 (average: 27.8 ± 1.9). Among control subjects, the average age was 83.7 years (24-96 years), and 54.8% were female. The patients with AD were diagnosed with probable or possible AD and MCI using the criteria of the National Institute on Aging Alzheimer’s Association workgroups [13, 14]. Among AD patients, the average age was 78.1 years (43-98 years), and 61.7% were female. Genomic DNA from NCGG biobank was extracted from peripheral blood leukocytes by standard protocols using a Maxwell RSC Instrument and a Maxwell RSC Buffy Coat DNA Kit (Promega, Madison, WI, USA). Genomic DNA from TMIG was extracted from the renal cortex using a standard phenol-chloroform procedure and kept at -80°C until use. All subjects provided written informed consent. This study was approved by the ethics committee of the NCGG and TMIG and conducted in accordance with the Declaration of Helsinki.
Genotyping and quality control for GWAS
Genome-wide genotyping data for the 12,405 CN were downloaded from NCGG biobank. Genome-wide genotyping of all subjects was performed using the Infinium Asian Screening Array (Illumina, San Diego, CA, USA). We created a reference panel for imputation with high accuracy using the 1000 Genomes Project Phase 3 (1KGP 3 [May 2013 n = 2504]), and 3181 Japanese whole-genome sequence data from NCGG. We performed SNP imputation with minimac4 using the Japanese reference panel above. We used variants with an INFO score \(\ge \,\)0.7 in the association analysis. We first applied quality control (QC) filters to the subjects using PLINK 1.9[15]:(1) sex inconsistencies (--check-sex), (2) kinship coefficient (--genome 0.25), (3) genotype missingness (--mind 0.05), and (4) exclusion of outliers from the clusters of East Asian populations in a principal component analysis that was conducted together with 1000 Genomes Phase 3 data. We next applied QC filters to the variants: (1) genotyping efficiency or call rate (--geno 0.02), (2) minor allele frequency (MAF) (--maf 0.01), (3) Hardy–Weinberg equilibrium (--hwe 0.001), and (4) Strand orientation (--snps-only).
GWAS
Logistic regression analysis adjusted for sex and age was performed using PLINK 1.9 (--logistic, --covar) [15]. Heritability, genetic correlation, and linkage disequilibrium (LD)-score regression were evaluated using LDSC (v1.0.1) [16,17,18]. All variants were annotated using ANNOVER (avsnp150) [19]. Regional association plots were generated using LocusZoom (http://locuszoom.org). To check for the secondary association signals, we conducted conditional analyses for the loci of interest by performing logistic regression on each lead variant. To check the consistency of imputed genotypes for the lead variants of interest, we used multiplex PCR-invader assay (Third Wave Technologies, Madison, WI, USA) [20] by using a QuantStudio 7 Flex Real-Time PCR System (Thermo Fisher Scientific, Waltham, MA, USA) and sequencing. The genomic inflation factor lambda and LD score regression intercept were computed with LDSC v1.0.1 software using the ‘baselineLD’, in which LD scores built from the 1000 Genomes phase 3. The analysis was restricted to Hap Map3 variants and excluded multiallelic variants and variants without an rsID, and also excluded variants in MHC region on chromosome 6.
Genotyping accuracy
We evaluated the genotyping accuracy for the imputed SNPs using the following methods. For DG-GWAS, the accuracy of lead SNPs was validated by the PCR-invader assay [20].
Genetic heritability
To estimate SNP heritability in DG subjects, we performed LD score regression [17, 18]. We used LD scores from East Asian populations in the 1000 Genomes dataset suitable for general LD score analyses (LD score regression intercept, heritability) [17].
Genetic correlation
To analyze the genetic correlation between DG-GWAS and Japanese GWAS for different phenotypes, we used LDSC [16, 17]. We obtained summary statistics of Japanese GWAS data from the BioBank Japan (BBJ) database (PheWeb.jp) [21, 22]. Since PheWeb.jp (https://pheweb.jp) provides more than 220 phenotype summary statistics, we could not download all of them due to limited capacity. As DG is related to neurodegeneration, we first selected brain-related diseases (brain tumor, cerebral aneurysm, intracerebral hemorrhage, and ischemic stroke). We then included disorders (depression, epilepsy, Hashimoto’s disease, pulse pressure, myocardial infarction, type 1 diabetes, type 2 diabetes, and AID disease) that are associated with increased risk of dementia and memory impairment. Phenotypes such as BMI, gastric cancer, nephrotic syndrome, and systemic lupus erythematosus were excluded as they are not directly related to dementia, but rather to sarcopenia, which itself is linked to dementia. Therefore, sarcopenia-related phenotypes were also included. All GWAS summary statistics data were formatted for LD score regression filtering to HapMap3 SNPs. We used LD score files for East Asians produced by LDSC.
Transcriptome-wide association study (TWAS)
To estimate the association between predicted gene expression levels and GWAS summary statistics, we conducted a TWAS using Functional Summary-based Imputation (FUSION) [23]. We used precomputed prediction models of gene expression in brain tissues (amygdala, anterior, caudate, cerebellar, cerebellum, cortex, frontal, hippocampus, hypothalamus, nucleus, putamen, spinal cord, and substantia) with the expression weight data in the GTEx v8 expression model from FUSION site (http://gusevlab.org/projects/fusion/), LD score files for East Asian produced by LDSC, and the summary statistics of DG-GWAS. We set the Bonferroni significance level, taking into account the number of genes available for each tissue.
Association analysis for MAPT and APOE loci
Genotyping data in the MAPT (chr17:42,971,748-45,105,700) and APOE (chr19:44,409,011-46,412,650) loci for 4,015 AD subjects were downloaded from NCGG biobank. We performed logistic regression analysis on the MAPT and APOE loci to compare DG versus controls as well as DG versus AD, adjusting for age and sex using PLINK 1.9 (--logistic, --covar). Regional association plots were generated using LocusZoom (http://locuszoom.org).
Results
DG-GWAS
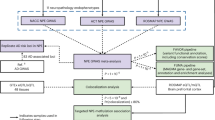
We illustrated the workflow of this study in Fig. 1. We conducted a DG-GWAS (214 DG cases and 12,405 control subjects, Supplementary Table S1) from the NCGG and TMIG biobanks. We selected control subjects with normal cognitive (MMSE > 23) from NCGG biobank, because DG was progressive neuronal loss with dementia [24]. We used 7,203,241 variants in the autosomes that passed QC filters. The genomic inflation factor (λGC) was 1.02; the LD-score regression indicated that the inflation was primarily due to polygenic effects (LD-score regression intercept = 1.01). The estimated SNP heritability (h2) for observed score was 3.4% (standard error of the mean = 3.5%). The DG-GWAS identified a genome-wide significance (GWS) locus (P < 5.0\(\times\)10–8) and twelve suggestive loci (P < 1.0\(\times\)10–6) (Fig. 2a, b, and Supplementary Table S2). Among them, the three lead variants (rs147403806, rs140769784, and rs72732628) were directly determined by ASA genotyping. As the genotypes for the ten other lead variants were determined by imputation analysis, we examined the accuracy of the imputed genotyping data for the variants by using the PCR-invader assay and a subset of the DNA samples used in GWAS and evaluated the concordance rate (Number of mismatching genotypes/Number of subjects) of the imputed variants (Supplementary Table S3). The INFO scores for three variants exhibited above 0.7 (rs527654945, 0.89; rs78182510, 0.77; and rs141081800, 0.95); however, they showed low concordance (rs527654945, 94.57%; rs78182510, 94.58%; and rs141081800, 98.22%), and we excluded these from further analysis.

The workflow of this study

GWAS for DG. a A Manhattan plot of the DG-GWAS. b Quantile–quantile plot of the DG-GWAS Pvalues. The blue line shows the GWAS significance threshold (P = 5.0\(\times\)10–8). The red line shows the suggestive threshold (P = 1.0\(\times\)10–6)
A GWS locus with lead SNP rs11595141 (P = 4.86\(\times\)10–8) was located closest to the SVIL gene (Table 1, Supplementary Fig. S1h). The nine remaining loci were NBAS, SLC9A9, TET2, SYNPO2, CALN1, PGM5, PLPPR1, WDR72, and FAM207A regions (Table 1, Supplementary Fig. S1a–g, i, j). All loci have no reports for genetic associations of dementia and related disorders (GWAS Catalog; https://www.ebi.ac.uk/gwas/). To verify the secondary association signals at these three DG-associated loci, we used the lead variants with 10 candidate loci in conditional analyses. No secondary independent association signals were detected in any of these loci (Supplementary Fig. S3).
The expression quantitative trait (eQTL) analysis
We also evaluated the cis-eQTL for the 10 lead variants associated with DG and gene expression data for brain tissue obtained from the GTEx database [25]. We found RP11-88I18.3 and TMEM252 gene expressions associated with the rs7019089 variant on PGM5 locus in the brain cerebellum (Supplementary Table S4). To further identify gene expressions associated with candidate DG risk variants, we also conducted AlphaGenome [26], a recently developed Artificial intelligence tool to explore genomic functions such as eQTLs, and obtained genes associated with candidate DG risk variants. The top 10 data for down- and up-regulated genes are shown in Supplementary Table S5.
Brain tissue-specific TWAS
To further annotate the candidate causal genes associated with DG, we conducted TWAS using the results of DG-GWAS in 13 brain tissues. In the brain frontal cortex, the DAPK2 gene on chromosome 15 reached Bonferroni-corrected significance (Z score = 4.13, PBon = 3.68 \(\times\)10–5). The regional association plots for the DAPK2 locus in DG-GWAS are shown in the supplementary Fig. S1k. The variants in the DAPK2 locus showed suggestive significance (Top lead variant (rs59606483) showed P = 3.66 \(\times\)10–5).
Genetic correlations across different diseases and traits
We investigated the genetic overlap between our GWAS data and phenotypes from other GWAS by using GWAS summary statistics from the BBJ database [21, 22]. Among the 20 phenotypes analyzed (BMI, brain tumor, cerebral aneurysm, depression, epilepsy, gastric cancer, Hashimoto’s disease, intracerebral hemorrhage, ischemic stroke, myocardial infarction, neuropathic bladder, nephrotic syndrome, osteoporosis, pulse pressure, periodontal disease, systemic lupus erythematosus, type 1 diabetes, type 2 diabetes, and AID disease; Supplementary Fig. S2), we found a significant correlation for pulse pressure (P = 0.018).
APOE and MAPT locus
APOE has three major allelic characters ε2, ε3, and ε4 [27]. These alleles are determined by two variants (rs7412 and rs429358). The ε4 allele of APOE is a strong genetic risk factor for the onset of AD [28]. For DG with APOE ε4, the pathology was reported to be a progressive disorder with AD [29]. In contrast, APOE ε2 seems to confer a protective effect against AD [30]. For DG, APOE ε2 has been demonstrated to increase the risk for the onset [31]. In this context, we assessed the impact of APOE alleles on the onset of DG with Japanese subjects. We first investigated the association of DG with the two variants (rs7412 and rs429358) in DG-GWAS and followed by the association between DG and the two variants with AD as controls (Table 2, Fig. 3a, b). The logistic regression analysis of the rs429358 variant for DG with AD as the control group showed a strong association with statistical significance (P = 6.\(25\times\)10–9), and the rs7412 variant had no significance (P = 0.28). However, DG-GWAS showed no association with rs7412 and rs429358 (P = 0.41). The frequencies of APOE ε4 alleles in DG, CN, and AD were 6.07, 9.77, and 22.27%, respectively (Table 3). APOE ε4 carriers had a higher AD risk than DG (DG-AD; PFisher < 2.2\(\,\times\)10–16, Odd Ratio (OR) = 0.21 (4.84 for AD cases versus DG), and DG versus CN; PFisher = 0.0097, OR = 0.58). We observed that the frequencies of APOE ε2 alleles for DG, AD, and CN were 4.67, 2.85, and 4.51, respectively (Table 3). The frequency of APOE ε2 carriers for DG showed statistical differences in the frequency of APOE ε2 carriers for AD (PFisher = 0.035, OR = 1.70), and no statistical differences for CN carriers (PFisher = 0.72, OR = 1.07).

Regional association plot for APOE and MAPT for DG vs CN and DG vs AD. Regional association plot for (a) DG vs CN, b DG vs AD in APOE on chromosome 19, c DG vs CN, and d DG vs AD in MAPT on chromosome 17
AGs are associated with neurofibrillary lesions enriched in 4-repeat (4 R) tauopathy [2]. We considered that the variants in the microtubule-associated protein tau gene (MAPT) on chr17p21, which encodes tau proteins, were associated with the risk of DG and also differentiated from AD. Then, we investigated the association for MAPT variants in our DG-GWAS and the association between DG and the variants with AD as controls. As shown in regional association plots for MAPT locus in the GWAS and in the association analysis with DG using AD as controls (Fig. 3c, d), we did not find the variants to reach suggestive significance (P < 1.0\(\times\)10–6). However, we confirmed that the rs9896485 variant in the MAPT was nominally associated with DG with protective effects (OR < 0.7) in the DG and in the association analysis with DG using AD as controls (P = 6.99\(\times\)10–5 for DG, and P = 8.38\(\times\)10–4 with AD as controls, respectively) (Table 2).
Discussion
We performed DG-GWAS in Japanese subjects for the first time and identified one novel GWS locus on chromosome 10 and nine suggestive loci (Table 1). The lead variant identified as the GWS locus, rs11595141, was closest to the SVIL gene. According to eQTL analysis from GTEx database [25], this lead variant is associated with decreased SVIL gene expression in the thyroid, although the relation to DG pathogenesis is unknown. SVIL encodes supervillin, a large eukaryotic protein from the villin/gelsolin superfamily of actin-binding proteins involved in many cellular processes [32]. There is no direct evidence to date on genes in the locus associated with neurodegenerative disorders. However, the SVIL locus was recently identified as a novel hypertrophic cardiomyopathy (HCM) risk locus [33]. Moreover, recent reports have shown that the subjects with HCM demonstrated an increased risk of dementia, mainly AD rather than other dementias [34]. In the genetic correlation analysis using the summary statistics of our DG-GWAS, we found a genetic correlation between pulse pressure and DG. These findings possibly suggest that the neurodegenerative disorder risks, including DG, may be associated with heart diseases, although no information regarding heart disease in DG patients was available in this study.
One of the suggestive loci identified in the GWAS is located downstream of the PLPPR1 gene. This locus was reported to be associated with the age at diagnosis of Parkinson’s disease (PD), a common neurodegenerative disease with complex clinical features [35]. PLPPR1 encodes a member of a brain-specific gene family that modulates neuronal plasticity during development, aging, and after brain injury [36, 37]. A previous study reported that PLPPR1 enhances axonal growth, improves motor behavior, and facilitates functional recovery after neuronal injury using mouse models [36, 37]. The PD-associated locus included missense variants with a predicted destabilizing effect on PLPPR1, and the other variants interact with both enhancers and promoters of PLPPR1 in addition to some other brain-expressed genes [35].
Another suggestive locus identified in the GWAS is located downstream of the NBAS gene. The top lead variant at this locus, rs187486988, is unique to East Asian (Table 1). NBAS encodes a NBAS subunit of NRZ tethering complex, which is involved in Golgi-to-ER retrograde transport [38]. However, no report of the relation between DG and NBAS was available.
By TWAS using the summary statistics of the GWAS, we identified an association between DG and DAPK2 in Brain_Frontal_Cortex_BA9. The regional plot for the DAPK2 locus in the GWAS showed a possible association with DG (Supplementary Fig. S1k). DAPK2 encodes one of the proteins for the death-associated protein kinase (DAPK) family, consisting of Ser/Thr protein kinases that control various cellular processes [39]. DAPK2 is involved in apoptosis, autophagy, granulocyte differentiation, and motility regulation [39, 40]. DAPK1 is a well-known molecule in the DAPK family, and interacts with Pin1/PINN-1 [41], which regulates dendritic protein synthesis [42] and is implicated in a variety of neurological diseases, including Alzheimer’s disease [43]. PINN-1 has been shown to regulate neuronal cytoskeleton and Tau protein phosphorylation and modulate neurodegeneration [44, 45]. Functional genetic variants (rs4877365 and rs4878104) of the DAPK1 gene have been associated with AD and frontotemporal dementia (FTD) [43, 46]. In our DG-GWAS, two functional variants in the DAPK1 gene showed no association with DG (P > 0.1). DAPK2 is highly homologous to DAPK1 in the catalytic domains, showing 80% identity at the amino acid level [39, 43]. While the association between DAPK1 function and neurological disorders is relatively well-known, that of DAPK2 is poorly understood.
Finally, by focusing on genetic variants of the APOE and MAPT genes, we examined the differences in the genetic architecture between DG and AD. We did not find any association between APOE ε4 carriers and DG risk. Whereas the previous report indicated that the APOE ε2 allele was protective for DG risk [31], our study did not replicate this finding. The MAPT locus represents two known haplotypes, H1 and H2. H1 haplotype is associated with the risk of AD, CBD, and PSP [11, 12, 47]. The H1 sub-haplotype (consisted from rs1467967, rs242557, rs3785883, rs2471738, rs8070723 and rs7521) [48] was not associated with our GWAS (P > 0.05). Our GWAS findings suggested that the MAPT H1/H2 alleles are unlikely to be the risk factor for DG. On the other hand, we have identified a novel variant (rs9896485) in the MAPT locus associated with a protective effect for DG with possible statistical significance. It is also known that the MOPB locus is the common risk locus for CBD and PSP [11, 12], however, there was no association at the GWAS (P > 0.1).
However, the present study has some limitations. Statistical power was insufficient to detect the variants with a lower odds ratio (<1.5) in the sample size of our population. Thus, the analyses with additional sample sizes and replication analyses with the other Asian cohorts may provide further insights into the genetic architecture of DG.
Our first GWAS for DG, followed by TWAS and related analysis in the Japanese population, has successfully revealed a novel genetic architecture of DG. We believe that the findings of genetic factors contributing to pathogenesis will provide novel biological and clinical insights and facilitate the medical and pharmaceutical investigations for developing early prediction, preventive measures, and treatment for serious common diseases.
Data availability
The datasets used or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Braak H, Braak E. Argyrophilic grain disease: Frequency of occurrence in different age categories and neuropathological diagnostic criteria. J Neural Transm Springe. 1998;105:801–19. https://doi.org/10.1007/s007020050096.
Togo T, Sahara N, Yen SH, Cookson N, Ishizawa T, Hutton M, et al. Argyrophilic grain disease is a sporadic 4-repeat tauopathy. J Neuropathol Exp Neurol Oxf Acad. 2002;61:547–56. https://doi.org/10.1093/jnen/61.6.547.
Saito Y, Ruberu NN, Sawabe M, Arai T, Tanaka N, Kakuta Y, et al. Staging of argyrophilic grains: An age-associated tauopathy. J Neuropathol Exp Neurol Oxf Acad. 2004;63:911–8. https://doi.org/10.1093/jnen/63.9.911.
Buée L, Bussière T, Buée-Scherrer V, Delacourte A, Hof PR. Tau protein isoforms, phosphorylation and role in neurodegenerative disorders. Brain Res Rev Elsevier. 2000;33:95–130. https://doi.org/10.1016/S0165-0173(00)00019-9.
Dickson DW, Rademakers R, Hutton ML. Progressive supranuclear palsy: pathology and genetics. Brain Pathol. 2007;17:74–82. https://doi.org/10.1111/j.1750-3639.2007.00054.x.
Dickson DW, Bergeron C, Chin SS, Duyckaerts C, Horoupian D, Ikeda K, et al. Office of rare diseases neuropathologic criteria for corticobasal degeneration. J Neuropathol Exp Neurol Oxf Academic. 2002;61:935–46. https://doi.org/10.1093/jnen/61.11.935.
Fujioka S, Sanchez Contreras MY, Strongosky AJ, Ogaki K, Whaley NR, Tacik PM, et al. Three sib-pairs of autopsy-confirmed progressive supranuclear palsy. Parkinsonism Relat Disord. Elsevier Ltd; 2015;21:101–5. https://doi.org/10.1016/j.parkreldis.2014.10.028.
Kouri N, Carlomagno Y, Baker M, Liesinger AM, Caselli RJ, Wszolek ZK, et al. Novel mutation in MAPT exon 13 (p.N410H) causes corticobasal degeneration. Acta Neuropathol. 2014;127:271–82. https://doi.org/10.1007/s00401-013-1193-7.
Houlden H, Baker M, Morris HR, MacDonald N, Pickering-Brown S, Adamson J, et al. Corticobasal degeneration and progressive supranuclear palsy share a common tau haplotype. Neurol Lippincott Williams Wilkins. 2001;56:1702–6. https://doi.org/10.1212/WNL.56.12.1702.
Evans W, Fung HC, Steele J, Eerola J, Tienari P, Pittman A, et al. The tau H2 haplotype is almost exclusively Caucasian in origin. Neurosci Lett Elsevier. 2004;369:183–5. https://doi.org/10.1016/J.NEULET.2004.05.119.
Kouri N, Ross OA, Dombroski B, Younkin CS, Serie DJ, Soto-Ortolaza A, et al. Genome-wide association study of corticobasal degeneration identifies risk variants shared with progressive supranuclear palsy. Nat Commun Nat Publ Group. 2015;6:7247. https://doi.org/10.1038/ncomms8247.
Farrell K, Humphrey J, Chang T, Zhao Y, Leung YY, Kuksa PP, et al. Genetic, transcriptomic, histological, and biochemical analysis of progressive supranuclear palsy implicates glial activation and novel risk genes. Nat Commun Nat Res. 2024;15:7880. https://doi.org/10.1038/s41467-024-52025-x.
Albert MS, DeKosky ST, Dickson D, Dubois B, Feldman HH, Fox NC, et al. The diagnosis of mild cognitive impairment due to Alzheimer’s disease: Recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimer’s Dementia. 2011; https://doi.org/10.1016/j.jalz.2011.03.008.
McKhann GM, Knopman DS, Chertkow H, Hyman BT, Jack CR, Kawas CH, et al. The diagnosis of dementia due to Alzheimer’s disease: Recommendations from the National Institute on Aging-Alzheimer’s Association workgroups on diagnostic guidelines for Alzheimer’s disease. Alzheimer’s Dementia. 2011; https://doi.org/10.1016/j.jalz.2011.03.005.
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MAR, Bender D, et al. PLINK: A tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet Cell Press. 2007;81:559–75. https://doi.org/10.1086/519795.
Bulik-Sullivan B, Finucane HK, Anttila V, Gusev A, Day FR, Loh PR, et al. An atlas of genetic correlations across human diseases and traits. Nat Genet Nat Publ Group. 2015;47:1236–41. https://doi.org/10.1038/ng.3406.
Bulik-Sullivan B, Loh PR, Finucane HK, Ripke S, Yang J, Patterson N, et al. LD score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat Genet Nat Publ Group. 2015;47:291–5. https://doi.org/10.1038/ng.3211.
Finucane HK, Bulik-Sullivan B, Gusev A, Trynka G, Reshef Y, Loh PR, et al. Partitioning heritability by functional annotation using genome-wide association summary statistics. Nat Genet Nat Publ Group. 2015;47:1228–35. https://doi.org/10.1038/ng.3404.
Wang K, Li M, Hakonarson H. ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res Oxf Acad. 2010;38:e164–e164. https://doi.org/10.1093/NAR/GKQ603.
Ohnishi Y, Tanaka T, Ozaki K, Yamada R, Suzuki H, Nakamura Y, et al. A high-throughput SNP typing system for genome-wide association studies. J Hum Genet 2001 46:8 Nat Publ Group. 2001;46:471–7. https://doi.org/10.1007/s100380170047.
Sakaue S, Kanai M, Tanigawa Y, Karjalainen J, Kurki M, Koshiba S, et al. A cross-population atlas of genetic associations for 220 human phenotypes. Nat Genet Nat Publ Group. 2021;53:1415–24. https://doi.org/10.1038/s41588-021-00931-x.
Shirai Y, Nakanishi Y, Suzuki A, Konaka H, Nishikawa R, Sonehara K, et al. Multi-Trait and cross-population genome-wide association studies across autoimmune and allergic diseases identify shared and distinct genetic component. Ann Rheum Dis. BMJ Publishing Group Ltd; 2022;81:1301–12. https://doi.org/10.1136/annrheumdis-2022-222460.
Gusev A, Ko A, Shi H, Bhatia G, Chung W, Penninx BWJH, et al. Integrative approaches for large-scale transcriptome-wide association studies. Nat Genet Nat Publ Group. 2016;48:245–52. https://doi.org/10.1038/ng.3506.
Saito Y, Yamazaki M, Kanazawa I, Murayama S Severe involvement of the ambient gyrus in a case of dementia with argyrophilic grain disease. J Neurol Sci. Elsevier; 2002;196:71–5. https://doi.org/10.1016/S0022-510X(02)00027-8.
Coorens THH, Guillaumet-Adkins A, Kovner R, Linn RL, Roberts VHJ, Sule A, et al. The human and non-human primate developmental GTEx projects. Nat Nat Res. 2025;637:557–64. https://doi.org/10.1038/s41586-024-08244-9.
Avsec Ž, Latysheva N, Cheng J, Novati G, Taylor KR, Ward T, et al. AlphaGenome: advancing regulatory variant effect prediction with a unified DNA sequence model. bioRxiv [Internet]. Cold Spring Harbor Laboratory; 2025 [cited 2025 Aug 29];2025.06.25.661532. https://doi.org/10.1101/2025.06.25.661532.
Utermann G, Steinmetz A, Weber W Genetic control of human apolipoprotein E polymorphism: Comparison of one-and two-dimensional techniques of isoprotein analysis. Hum Genet. Springer-Verlag; 1982;60:344–51. https://doi.org/10.1007/BF00569216.
Liu CC, Kanekiyo T, Xu H, Bu G. Apolipoprotein e and Alzheimer disease: Risk, mechanisms and therapy. Nat Rev Neurol NIH Public Access. 2013;9:106–18. https://doi.org/10.1038/nrneurol.2012.263.
Tolnay M, Probst A, Monsch AU, Staehelin HB, Egensperger R Apolipoprotein E allele frequencies in argyrophilic grain disease. Acta Neuropathol. Springer; 1998;96:225–7. https://doi.org/10.1007/S004010050887/METRICS.
West HL, William Rebeck G, Hyman BT Frequency of the apolipoprotein E ε2 allele is diminished in sporadic Alzheimer disease. Neurosci Lett. Elsevier; 1994;175:46–8. https://doi.org/10.1016/0304-3940(94)91074-X.
Ghebremedhin E, Schultz C, Botez G, Rüb U, Sassin I, Braak E, et al. Argyrophilic grain disease is associated with apolipoprotein E ε2 allele. Acta Neuropathol. Springer; 1998;96:222–4. https://doi.org/10.1007/S004010050886/METRICS.
Pestonjamasp KN, Pope RK, Wulfkuhle JD, Luna EJ. Supervillin (p205): A novel membrane-associated, F-actin-binding protein in the villin/gelsolin superfamily. J Cell Biol. 1997;139:1255–69. https://doi.org/10.1083/jcb.139.5.1255.
Tadros R, Zheng SL, Grace C, Jorda P, Francis C, Jurgens SJ, et al. Large scale genome-wide association analyses identify novel genetic loci and mechanisms in hypertrophic cardiomyopathy. Eur Heart J. 2023;44:2023.01.28.23285147. https://doi.org/10.1093/eurheartj/ehad655.3197.
Kumar P, Dezso Z, MacKenzie C, Oestreicher J, Agoulnik S, Byrne M, et al. Circulating miRNA Biomarkers for Alzheimer’s Disease. PLoS One. 2013;8. https://doi.org/10.1371/journal.pone.0069807.
Wallen ZD, Chen H, Hill-Burns EM, Factor SA, Zabetian CP, Payami H. Plasticity-related gene 3 (LPPR1. and age at diagnosis of Parkinson disease. Neurol Genet Ovid Technol (Wolters Kluwer Health). 2018;4:e271. https://doi.org/10.1212/nxg.0000000000000271.
Broggini T, Schnell L, Ghoochani A, Mateos JM, Buchfelder M, Wiendieck K, et al. Plasticity Related Gene 3 (PRG3) overcomes myelin-associated growth inhibition and promotes functional recovery after spinal cord injury. Aging Impact J LLC. 2016;8:2463–87. https://doi.org/10.18632/aging.101066.
Fink KL, López-Giráldez F, Kim IJ, Strittmatter SM, Cafferty WBJ Identification of Intrinsic Axon Growth Modulators for Intact CNS Neurons after Injury. Cell Rep. Elsevier B.V.; 2017;18:2687–701. https://doi.org/10.1016/j.celrep.2017.02.058.
Tagaya M, Arasaki K, Inoue H, Kimura H. Moonlighting functions of the NRZ (mammalian Dsl1) complex. Front Cell Dev Biol Front Media SA. 2014;2:92095. https://doi.org/10.3389/FCELL.2014.00025/XML/NLM.
Shiloh R, Bialik S, Kimchi A The DAPK family: A structure-function analysis. Apoptosis. Springer; 2014;19:286–97. https://doi.org/10.1007/s10495-013-0924-5.
Geering B, Stoeckle C, Rožman S, Oberson K, Benarafa C, Simon H-U DAPK2 positively regulates motility of neutrophils and eosinophils in response to intermediary chemoattractants. J Leukoc Biol. Oxford Academic; 2013;95:293–303. https://doi.org/10.1189/jlb.0813462.
Del Rosario JS, Feldmann KG, Ahmed T, Amjad U, Ko BK, An JH, et al. Death Associated Protein Kinase (DAPK) -mediated neurodegenerative mechanisms in nematode excitotoxicity. BMC Neurosci BioMed Cent Ltd. 2015;16:25. https://doi.org/10.1186/s12868-015-0158-2.
Westmark PR, Westmark CJ, Wang SQ, Levenson J, O’Riordan KJ, Burger C, et al. Pin1 and PKMζ sequentially control dendritic protein synthesis. Sci Signal. American Association for the Advancement of Science; 2010;3. https://doi.org/10.1126/scisignal.2000451.
Zhang T, Kim BM, Lee TH. Death-associated protein kinase 1 as a therapeutic target for Alzheimer’s disease. Transl Neurodegener BioMed Cent. 2024;13:1–26. https://doi.org/10.1186/s40035-023-00395-5.
Lu KP, Zhou XZ. The prolyl isomerase PIN1: A pivotal new twist in phosphorylation signalling and disease. Nat Rev Mol Cell Biol Nat Publ Group. 2007;8:904–16. https://doi.org/10.1038/nrm2261.
Pastorino L, Sun A, Lu PJ, Xiao ZZ, Balastik M, Finn G, et al. The prolyl isomerase Pin1 regulates amyloid precursor protein processing and amyloid-β production. Nat Nat Publ Group. 2006;440:528–34. https://doi.org/10.1038/nature04543.
Tedde A, Piaceri I, Bagnoli S, Lucenteforte E, Piacentini S, Sorbi S, et al. DAPK1 is associated with FTD and not with Alzheimer’s disease. J Alzheimer’s Dis IOS Press. 2012;32:13–7. https://doi.org/10.3233/JAD-2012-120556.
Sánchez-Juan P, Moreno S, de Rojas I, Hernández I, Valero S, Alegret M, et al. The MAPT H1 haplotype is a risk factor for Alzheimer’s disease in APOE ε4 Non-carriers. Front Aging Neurosci. Frontiers Media SA; 2019;11:327. https://doi.org/10.3389/fnagi.2019.00327.
Heckman MG, Kasanuki K, Brennan RR, Labbé C, Vargas ER, Soto AI, et al. Association of MAPT H1 subhaplotypes with neuropathology of lewy body disease. Mov Disord. John Wiley and Sons Inc.; 2019;34:1325. https://doi.org/10.1002/MDS.27773.
Acknowledgements
We gratefully acknowledge the work of the past and present members of the Medical Genome Center and NCGG Biobank. We also thank the past and present staff of the Department of Pathology, Neuropathology, Bioresource Center, Brain Bank for Aging Research, Tokyo Metropolitan Institute for Geriatrics and Gerontology for technical assistance.
Funding
This work was supported partly by grants from The Japan Foundation for Aging and Health (to SN); grants from AMED (grant numbers JP18kk0205009 to SN; JP21dk0207045, and JP23dk0207060 to SN and KO, JP24wm0425019 and JP24dk0207074h0001 to YS and SM); Research Funding for Longevity Sciences from the National Center for Geriatrics and Gerontology (24-15 to KO and 24-11 and 23-7 to DS); JSPS KAKENHI (grant number 23K21306 to DS, and JP 22H04923 (CoBiA) to YS and SM); and a grant from the Japanese Ministry of Health, Labor, and Welfare for Research on Dementia (to KO). Research Funding for Integrated Research Initiative for Living Well with Dementia (IRIDE) from Tokyo Metropolitan Institute for Geriatrics and Gerontology (to SN, YS, and SM). This work was also supported by grants from MHLW Research on rare and intractable diseases Program Grant Number JPMH23FC1008 (to YS).
Author information
Authors and Affiliations
Contributions
RM performed the core experiments and analyzed the data. RM and KO wrote the manuscript. DS, AI, and MA contributed to data acquisition and analyses. YS, SM, and TA recruited and prepared for TMIG samples. KO, YS, and SN designed the study. KT supervised the study. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
Ethics approval was obtained from both the ethics review board at the National Center for Geriatrics and Gerontology and Tokyo Metropolitan Institute for Geriatrics and Gerontology. All subjects provided written informed consent.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mitsumori, R., Ozaki, K., Saito, Y. et al. Genome and transcriptome-wide association studies identify multiple novel loci for dementia with grain in Japanese. J Hum Genet (2025). https://doi.org/10.1038/s10038-025-01438-7
Received:
Revised:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s10038-025-01438-7
