
Abstract
Tamil is the oldest language spoken in Tamil Nadu, India, with inscriptions dating back to the third century BCE found in caves, temples, and archaeological sites. The style and content of these inscriptions have evolved over time, reflecting changes in society, governance, and language usage. They provide valuable insights into rulers, dynasties, administrative systems, religious practices, and societal norms of their era. However, the diverse fonts and styles of these inscriptions necessitate an efficient method for alphabet and word recognition. Existing algorithms primarily recognize Tamil words and characters from the nineteenth century and do not address the language and styles used in the third century. This study proposes a novel DR-LIFT framework specifically designed for recognizing Tamil inscriptions from this earlier period, overcoming the limitations of current methods. The dataset used consists of third-century Tamil inscriptions. The algorithms within the DR-LIFT method specifically designed to detect text with intricate features such as curves, loops, and lines, significantly enhancing detection accuracy. The proposed framework achieves impressive outcomes, with a recognition accuracy of 99% and a recognition rate of 98.8%.
Similar content being viewed by others


Introduction
In the word, each country has their heritage, monuments and culture. India is a prosperous country with splendid temples, monuments and many historical buildings. Tamil is one of the oldest languages, and many ancient temples are enriched with stone inscriptions. The kings of the ancient period desired to be famous for many years, and they craved inscriptions about their victory in wars and poems in praise of them. Information on these inscriptions plays a vital role and acts as an excellent source for the upcoming generation to learn about the lifestyle of earlier kings and people's cultures [1]. As these inscriptions have such tremendous historical information, preserving them and identifying their modern meaning is essential. Tamil inscriptions are essential sources for researchers, historians, archaeologists, linguists, and epigraphists, helping them to reconstruct the past and understand the cultural heritage of Tamil-speaking regions. These inscriptions are historical records written in Tamil on various surfaces such as stone, metal, pottery, and temple walls. The inscription language used in the third century is Brahmi and Vattezhuthu style and alphabets. The poems reflect the richness of the language, cultural and regional heritage. These stone inscriptions are preserved and have immense historical importance. Among many languages spoken worldwide, Tamil is one of the oldest classical languages, survived for a long time [2]. Inscriptions are for many years; they may get spoiled due to natural calamities, and the details may get lost during cleaning. Therefore, deciphering these inscriptions and preserving them is necessary. Character inscriptions on stones are called epigraphy. Palaeography refers to the study of ancient inscriptions.
Subject matter experts in literature, language, grammar and dialectology are able to understand these inscriptions. Researchers in the Archaeological Department of Tamil Nadu try to understand the inscriptions in Devanagari scripts. Tamil language alphabet consists of twelve vowels (uir ezhuthukal), eighteen consonants (mei ezhuthukal) and one special letter called the aautha ezhuthu. In combination with these vowels and consonants, two hundred and sixteen letters called uir-mei ezhuthukal are obtained, which brings up two hundred and forty-seven letters in Tamil. Many researchers proposed various algorithms for recognizing Tamil letters from stone inscriptions, which they consider to be few characters. Recognizing Tamil characters despite their curves, letter variations, curves, and strokes is challenging and needs preprocessing. It involves segmentation of the letters, extraction of the main features and classification of letters [3]. Research on character recognition is being continued using various methods and algorithms. However, there are challenges due to distortion, illumination, identical background and foreground or lack of clarity in stone inscriptions [4]. The historical monuments and temples have stone inscriptions, and deciphering them requires preprocessing, segmentation, feature extraction and binarization. Text detection, recognition, and labelling help transition ancient to modern Tamil characters, which has many challenges during implementation. The challenges are identifying text in captured images, recognizing characters from inscribed images, and labelling them with their corresponding new Tamil characters.
The significance of text detection is underscored in this study, which involves pinpointing the regions or areas containing text within images, effectively distinguishing text from the background after elimination of elimination of background information. The text within the images exhibits colour and texture variations due to variations in brightness and illumination complexities such as non-alignment, multi-orientation, and curved text. The text recognition model is crucial for identifying unlined, curved, and diverse text shapes within images of temple walls. Deep learning neural networks-based recognition algorithms successfully identify text in images of natural stone slabs. Three Neural Network architectures were used, namely, (i) Feedforward NN, (ii) Convolutional NN, and (iii) Recurrent NN. Semi-supervised learning methods trained using annotated data for evolution from the ancient to the modern Tamil alphabet. The network is biased in discerning hidden similarities among neighbouring nodes in the graph, enabling it to assign accurate labels to previously unlabeled data.
The proposed DR-LIFT method uses two types of Tamil inscriptions: Vattezhuthu and Tamil-Brahmi. The dataset used in the proposed method is our own dataset, which consists of stone inscription images of the early third century. Preprocessing is performed using DnCNN for denoising. The Segmentation-based approach incorporates the Differentiate Binarization (DB) module, exhibits superior performance improvements compared to traditional models and streamlines the post-processing phase of text detection. Notably, DBNet [5] achieves higher accuracy in text detection when combined with the ResNet-18. The Fourier Contour Embedding (FCENet) [6] model simplifies post-processing through the utilization of Inverse Fourier Transformation (IVT) and Non-maximum Suppression (NMS), integrated with a backbone and a feature pyramid network (FPN). This model enhances the efficiency of text detection. Textsnake [7] method accurately extracted the curved text from images. Fully Convolutional Network (FCN) and TextSnake identified curved text through the analysis of the text centre line (TC) and Text Region (TR).
The curved text is effectively addressed through deep learning neural networks, with particular success seen in attention-based image text recognizers. An exemplary model in this category is the Show, Attend, and Read (SAR) [8] system, which utilizes a thirty-one layer ResNet and a Long Short Term Memory (LSTM) architecture for encoding and decoding. The SAR model includes a 2-dimensional attention module. This combination achieves better performance in recognizing curved and unaligned text. Similarly, the Multi-Aspect Non-Local Network for Scene Text Recognition (MASTER) [9] method recognizes text through a self-attention-based approach. MASTER learns spatial distortion and employs a memory-cached mechanism, leading to superior performance in handling both regular and irregular text. The Autonomous, Bidirectional, and Iterative Language Modeling (ABINet) [10] model adopts a unique strategy incorporating block gradient flow, Bidirectional Cloze Network (BCN), and iteration correction on noisy inputs. ABINet stands out as a self-based training method, capable of learning from unlabeled images and demonstrates superior performance in recognition of text from images. Neural Graph Machine (NGM) is a semi-supervised learning label propagation technique on constructed graphs applied to various neural network architectures such as FNN, CNN, and RNN [11, 12].
The proposed method is focused on inscriptions from the 3rd-century Tamil language, where researchers did not analyze and study the 3rd-century Tamil word, alphabet, and sentence recognition (Ref: www.worldcat.org). Table 1 gives descriptions of the research on other inscriptions.
Problem statement
The recognition of Tamil inscriptions from ancient texts presents significant challenges due to the complexity and variability of the characters involved. These inscriptions, found in historical artefacts and temple epigraphy, are crucial for understanding Tamil culture, heritage, and language evolution. Researchers encounter several challenges when attempting to recognize characters from stone inscriptions. The primary difficulties lie in accurately differentiating the text from the background stone surface, as the contrast between the two can be minimal, especially in cases where the inscription has weathered over time. The Tamil script, characterized by loops, curves, circles, and dots, presents significant challenges in accurately identifying the characters within images or input data. This script comprises numerous characters, each with distinct features that must be efficiently extracted to enhance the accuracy of character recognition. Deciphering ancient Tamil texts is labour-intensive and prone to human error, leading to delays in interpretation and analysis and complicating the development of robust machine-learning models capable of accurately recognizing and transcribing these characters into modern Tamil scripts. To address these challenges, advanced techniques are used to automate the recognition process with high accuracy.
Contributions
Considering the above problems and challenges, the contributions of the DR-LIFT methods are:
-
(i)
To implement the Detection, Recognition, and Labelling Interpreter Framework of Text (DR-LIFT) to effectively convert ancient third-century inscriptions into contemporary Tamil scripts, specifically the nineteenth-century variant.
-
(ii)
To propose a hybridization of deep learning architectures for efficient text classification of 3rd-century alphabets. Existing articles implemented various methods to detect the alphabet or word. The proposed DR-LIFT method recognizes alphabets, words and labelling (i.e., sentences) and converts the inscription to modern Tamil letters. Moreover, proposed algorithms provide the complete sentence meaning.
-
(iii)
To propose three novel neural networks—ABINET, MASTER, and SAR for text recognition. The outputs from these networks are combined with the GNN labelling framework to improve recognition performance and ensure accurate labelling of detected text.
-
(iv)
To implement Feedforward Neural Networks (FNN), Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN) within a Graph Neural Machine (NGM) framework enhanced by graph augmentation techniques.
Literature review
The article by Manigandan et al. [13] focuses on recognizing diverse Tamil characters from the 9th to 12th centuries. The authors employed Optical Character Recognition (OCR). The authors implemented Natural Language Processing (NLP) techniques and converted the input text into modern Tamil. Initially, in the segmentation process, the conversion of colour images into grayscale and binary images based on a threshold value is performed. Features such as bends, loops, and curls are extracted from segmented images using each character's Scale Invariant Feature Transform (SIFT) algorithm and precise character identification. Support Vector Machine (SVM) classifier classifies and constructs characters based on extracted vectors. The developed system addresses significant challenges in interpreting inscription images. The research by Giridhar et al. [14] explicitly targets the enhancement of optical character recognition (OCR) techniques for the earlier Tamil inscriptions used between the seventh and twelfth centuries. The authors used the Otsu threshold method for image binarization, defined a 2D CNN, classified the text and understood the ancient Tamil letters. Python's py-tesseract library is used to implement the OCR techniques. The system achieves a combined efficiency of 77.7 per cent based on the evaluation. RajaKumar et al. [15] proposed an artificial immune-based algorithm that enhanced the character recognition rates and reduced the training time for ancient Tamil character recognition, drawing inspiration from immune biological principles. Simulations demonstrate that this method exhibits swifter speed. Performance comparison also shows higher accuracy of the author’s method than traditional methods of NN. The preprocessing stages used in ancient Tamil character recognition include normalization, segmentation, and filtering. Rajan et al. [16] focus on providing a character recognition technique for inscription recognition through various classification techniques. The contour let transform is used for the identification of the characters from the input image. The above method provides a solution to overcome existing challenges through a 3D approach and yields more accurate results. The automated approach effectively solves the problems of the laborious and time-consuming traditional method of manually extracting content from stone inscriptions. Durga Devi et al. [17] added artificial neural networks (ANN) and identified ancient Tamil characters. The system utilizes binarised character images as input and preprocessed digitally acquired images of eleventh-century stone inscriptions. Qualitative and quantitative features are then extracted and classified into the images through ANN.
Heenkenda et al. [18] reviewed the manual and computational approaches for the identification of ancient inscriptions. The advent of technology and the limitations of manual methods have prompted the adoption of automated systems, making computational archaeology pivotal in the present era. Despite ongoing research in this domain, it remains a substantial challenge, necessitating more accurate and efficient methods. Chandure [19] enhanced the analysis of Ashoka-period Tamilian non-Hellenic inscriptions through 3D digital representation. Non-Hellenic inscriptions in the Brahmi alphabet express a non-Brahmi language spoken by Tamilians in the 3rd century BC. Dhivya [20] focused on recognizing Tamil language characters in stone-based images. These ancient inscriptions provide insights into the significance of historical languages. Researchers encounter several challenges during the identification of characters within stone inscriptions, such as distinguishing foreground pixels from background stone images, addressing perspective distortion, managing variations in light illumination, and coping with text shape and size variations. Shukla et al. [21] reviewed historical Tamil writings and analyzed the techniques that extract ancient letters and convert them to current Tamil characters that are used nowadays. Identification of the oldest Tamil symbols is significant and difficult. Magrnina [22] identify the ancient Tamil characters from the ninth to the twelfth century, using Optical Character Recognition (OCR) techniques. OCR converts pictures that contain text into a machine-readable form, comprised of different methods such as segmenting the input text, preprocessing and text recognition. Deep Learning (DL), specifically Convolution Neural Network (CNN), are used in training seventy-three class character recognition problems. Using the ReLU activation function, CNN excels in feature extraction and achieves segmentation and better recognition rates. Bhuvaneswari et al. [23] addresses the challenge of recognizing ancient Tamil characters from stone inscriptions using OCR. A dataset of 9th-12th century Tamil characters was developed, and an 18-layer CNN model was trained for feature extraction with ReLU activation, achieving high segmentation and recognition rates by mapping ancient to modern characters, highlighting advancements in historical text recognition using deep learning.
The recognition of ancient Tamil inscriptions, particularly those dating from the 3rd century BC to the 12th century AD, needed to be included in existing methodologies. The lack of comprehensive and annotated datasets specifically tailored for ancient Tamil scripts hampers the development of robust recognition models. Existing studies focus on modern Tamil scripts or specific character sets, neglecting the broader context of ancient inscriptions which are inscribed in stones and walls that require specialized approaches for accurate recognition and translation.
Author | Language | Problem | Algorithm | Limitations |
|---|---|---|---|---|
Manigandan et al. [13] | Tamil | To convert ancient Tamil to modern Tamil | Uses SIFT for feature extraction and SVM for classification | Achieve lower accuracy across varied character sets |
Giridhar et al. [14] | Tamil | Character recognition of 7th –12th -century Tamil inscriptions | Otsu thresholding and 2D CNN. Py-tesseract for classification | Performance limited by the model’s adaptability to highly varied ancient characters |
RajaKumar et al. [15] | Tamil | Eighth century Tamil consonants recognition | SVM Classifier | Constrained by limited character variability |
Rajan et al. [16] | Tamil | Identification of ancient Tamil letters and its characters | Contour-let transform method and Neural Network | Requires extensive preprocessing steps that could be optimized for efficiency |
Durga Devi et al. [17] | Tamil | Recognition and Classification of Tamil Stone Inscription | ANN | Model accuracy is sensitive to image quality; feature extraction could be enhanced |
Heenkenda et al. [18] | Multiple languages | Review of manual vs. computational techniques for ancient inscription identification | YOLO and RNN performs better than others | Highlighted need for more accurate and efficient systems to replace manual approaches |
Chandure et al. [19] | MODI lipi | Handwritten Modi character recognition | Transfer Learning, DCNN, SVM | Needs high computation, rely on pre-trained network that are not specialized for MODI lipi |
Dhivya et al. [20] | Tamil | Review of Ancient Tamil Character recognition | Deep learning algorithms and NN works better for inscription recognition | Existing articles struggles to recognize inscription text shape and size variation due to irregular stone surfaces |
Shukla et al. [21] | Tamil | Review of Identification of Early Tamil Extracts Actors Through Historical Writing | Methods like CRAFT works better for curved text detection | There are difficulties in recognizing and translating older symbols effectively |
Magrnina [22] | Tamil | Ancient Tamil Character Recognition from Epigraphical Inscriptions | CNNs for Tamil character recognition; ReLU activation for segmentation and recognition | Training an 18-layer CNN model for 73 classes requires substantial computational resources and can be time-consuming |
Bhuvaneswari et al. [23] | Tamil | Ancient Tamil Character Recognition in Stone Inscriptions | A deep learning approach to recognize and analyze Tamil ancient inscriptions | CNNs struggle with degraded inscriptions and requires a large, well-labeled dataset which is challenging in ancient scripts |
Methodology
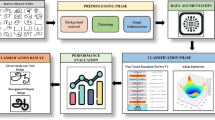
The framework of the DR-LIFT method is shown in Figure 1. The input Tamil inscriptions, such as Vattezhuthu and Brahmi, are captured using a smartphone camera using the MIT APP inverter. The captured images are de-noised using the DnCNN model to remove the noise from the inscriptions. The initial process is the alphabet detection, which uses three NN models such as DBNet, FCENet and TextSnake. The above three methods are used for the identification of the alphabet. Once the alphabets are recognized, the next step is the identification of the works from the inscriptions. Recognition is done using the proposed methods such as ABINet, MASTER and SAR. Finally, the Tamil words are labelled with the proposed methods such as Graph Neural Networks (GNN). Three types of GNNs are proposed for labelling such as FNN, RNN, and CNN. Once labelling is done, the interpretation of modern Tamil characters and the corresponding words is done. Figure 2 illustrates the workflow of the proposed method and shows the pipelining between the alphabet detection, word recognition, and labelling stages. It demonstrates how the ancient Tamil stone inscriptions in Brahmi and Vattezhuthu scripts are recognized and converted into modern Tamil words using the proposed DR-LIFT method.

Workflow of the proposed DR-LIFT framework of third century Tamil inscription in Brahmi and Vattezhuthu styles

Pipelining of the overall architecture of the proposed system
Figure 2 shows the pipelining between the alphabet detection, word recognition, and sentence labelling processes. It shows what input and output go into and out of each recognition process.
Dataset description
In the proposed DR-LIFT method, our dataset is used, and the description of the dataset is given in Table 2. Figure 3 shows some of the sample images of early Tamil inscriptions on stone, temples and walls of the 3rd century. The images in the dataset are de-noised using the DnCNN algorithm. Denoising Convolutional Neural Network (DnCNN) overcomes occlusion and weathering effects by effectively removing noise and enhancing the clarity of the input images. This network is trained to distinguish between the noise and the underlying patterns or features in an image. When applied to ancient inscriptions, DnCNN can filter out the distortions caused by occlusion (such as overlapping objects) and weathering (like erosion or fading), thereby revealing the original text or features more clearly.

Sample Stone Inscriptions Images of both Tamil Vattezhuthu Tamil Brahmi
Identification of stone inscriptions
DBNet
Figure 4 depicts the model of the proposed DR-LIFT for the identification of Tamil stone inscriptions, which is the backbone and initial process applied to the input Tamil inscription image. DBNet (Differentiable Binarization Network) enhances text recognition by applying a differentiable binarization module, which enables precise text boundary detection even in complex backgrounds. Its end-to-end optimization of both segmentation and binarization improves accuracy and efficiency, making it particularly effective for detecting irregular and small text in natural scenes compared to traditional methods. The up-sampling of the features in the image is done with an identical scale and divided into a feature map 'F'. This feature map predicts the probability (P) and the threshold map (T). From 'P' and 'F', we can find the value of the binary map \(\widehat{B}\)(approximate), which is computed. During training, supervision is applied over the three maps such as ‘P’, ‘T’ and \(\widehat{B}\), in which P and \(\widehat{B}\) share identical supervision. The bounding box is found during the inference period from \(\widehat{B}\) and P using the box formulation. The dataset was pre-trained for 100,000 iterations, and the models were fine-tuned using the test data for 1,000 epochs. The training batch size is set to 15, with an initial learning rate of 0.0006. A weight decay of 0.0001 is applied, and momentum is set to 0.9. The proposed DR-LIFT method employs a polynomial learning rate, where the learning rate at any given iteration is calculated as follows:\(Learning Rate=0.0006 {\left(1-\frac{iterations}{ max\_itertions}\right)}^{0.9}\). In this equation, max_iterations refers to the maximum number of iterations allowed [5] to avoid overfitting. In the proposed DBNet method, the initial process is character identification and binarization, which extracts the individual letters from the given image. In DBNet, the Differential Binarization (DB) method is used, and the approximate binary map \(\widehat{B}\) is computed as in Eq. (1).
where 'T' is the adaptive threshold and 'k' is the amplifying factor. The empirical value of 'k' is assigned as fifty. This binary function is differentiable; optimization is used during the segmentation network while training. The DB method can differentiate the text from its background and isolate the instances of the text that are packed closely.

Working process of DB Net
Threshold Map (T) Creation
The threshold map highlights the border of the text without supervision. It creates a 'T' map using border-like supervision and leads to better results. This threshold map is used as a threshold for the binarization process. Figure 5a–d shows the threshold map of the segmented characters.

Threshold map of the stone inscription a segmented character, b probability map, c supervised threshold map and d enhanced character
FCENet
The second proposed method for recognizing stone inscriptions is the Fourier Contour Embedding Net (FCENet), adapted from [6]. FCENet removes the noise in the stone inscriptions as it converts the text contours into the frequency domain using the Fourier series, enabling the network to focus on the most significant components while filtering out noise. By operating in the frequency domain, FCENet effectively distinguishes between genuine text contours and noise, even when the input text is occluded or affected by weathering.
Figure 6 shows the workflow of the FCENet method. From the input image, feature extraction is done in the backbone, which holds the ResNet 50 along with DCN and FPN and is given as input to the shared head for text detection. The classification branch in the shared head predicts the text region heatmap and the text centre region heatmap, and then pixel-wise multiplications result in the classification score map. The regression branch carries out the prediction of Fourier vectors that reconstruct the text contours through the IFT. The final text detection is formed through non-maximum suppression, abbreviated as NMS. Predictions are made on P3, P4, and P5 feature maps. Both branches have three (3 × 3) convolution layers and one (1 × 1) convolution layer. The classification branch predicts every mask of text areas and, finds the text centre region and performs better. The Fourier vector in the regression branch regresses every pixel in the text. Text instances with different scales are handled by the features P3 to P5. The size of the scales are small (P3), medium (P4) and significant texts (P5). The final detected results are obtained through the reconstruction of the Fourier domain using IFT and non-maximum suppression. FCENet stands out in text recognition by directly modeling arbitrary-shaped text contours using Fourier transformation, enabling more accurate detection of complex, curved texts. Additionally, its contour-based representation improves precision in detecting irregular text boundaries, outperforming conventional rectangular or quadrilateral bounding box methods commonly used in other text recognition models.

FCENet architecture
TextSnake (TS)
TextSnake provides a more flexible way of text representation that can predict curves. Figure 7 shows the character recognition method with TextSnake. From the inscription in Fig. 7 (a), an individual character is segmented, and the recognition process continues along the centre. TS can adapt according to the text, and changes can be made instantly using bending, rotation, or scaling. Figure 7 is specifically shown for Vattezhuthu, and the same process is used for the Brahmi inscription. The blue circles inside the red text region are each created with the centre line along the symmetric axis with radius R and an orientation of θ. Traditional methods use rectangles or quadrangles for text representation in which irregular shapes in text instances cannot be described. Meanwhile, Consider any sample text k, which contains more than one character; k can be represented as a list, say, M(k), where M(k) is an ordered list. M(k) = {A(0),A(1),…..,A(i),…A(n)}. In the list M(k), A(i) denotes the disk in its position, and n denotes the total count of available disks. Every disk A holds a set of geometrical attributes, for example, A = (c, r, θ). ‘c' indicates the centre, 'r' is the radius and 'θ' is the orientation of A. The text k gets reconstructed by calculating the union of all the disks in the ordered list M(k).

a depicts the segmentation of the characters, and b shows the disks and their centre point. c shows the text region as an ordered list, as depicted by the red line
Words recognition
Once the characters are identified, the next step is recognizing words. Three models are proposed in this study such as, (i) ABINet, (ii) MASTER and (iii) SAR. These methods are end-to-end text recognition methods and attention mechanisms, which can recognize stone inscriptions without clear word boundaries and spacing [8,9,10]. Bounding boxes will segment the letters and words, and recognition accuracy is in the range of 85–90%
ABINet
The main principle behind ABINet is the concept of Autonomous-Bidirectional-Iterative (ABI) [10]. The autonomous model blocks gradient flow between the vision and language models, ensuring that language modelling is enforced explicitly. To overcome the challenge of recognizing words in Tamil inscriptions without explicit spacing, the ABINet model, and specifically its Bidirectional Cloze Network (BCN) component, proves to be highly effective. The iterative correction method for the language model effectively mitigates the impact of noisy input. By incorporating sophisticated language modelling techniques, this model functions independently, enabling the separation of visual and language models, which improves text recognition accuracy, especially in difficult conditions such as low-quality images or texts with unclear word boundaries. There are two models in ABINet: (i) The vision model (VM) and (ii) The Language Model (LM). The VM has two main blocks: the backbone network and an attention module. The vision model comprises a backbone network and a positional attention module. In this method, ResNet is utilized for the feature extraction and Transformer units for the sequence modelling network. Figure 8 shows the structure of the ABINet architecture. Given an image x, the representation of feature extraction is given in Eq. (2).

Structure of the ABINet Model
In the above equation, H and W are the size of x, and the feature dimension is denoted by C. The position attention modules copy the features into character probabilities simultaneously as per Eq. (3).
Specifically, \(Q\epsilon {\mathbb{R}}^{TXC}\) denotes the positional encodings of the order of character, and the character sequence length is denoted by T.
The Language Model (LM) has the following properties:
-
1.
Treating the LM as an independent spelling rectification model, which accepts inputs in vectors and allocates anticipated letters.
-
2.
Blocking Gradient Flow (BGF) is performed at the input stage.
-
3.
Text data is used to train the LM.
Adopting the self-governing strategy enables the ABINet to be partitioned into meaningful and understandable units. The LM, the probability is considered to be the input, becomes consumable (allowing direct substitution with a more robust model) and flexible. Notably, the BGF inherently ensures the model learns linguistic knowledge, a significant departure from implicit modelling where the exact nature of the learned information is unknown. In the bi-directional representation, let M = (m1,m2,…mn) represent a string of text, where n represents the length of the text. The variable c denotes the class number, and the bidirectional model's conditional probability for Mi is denoted by \(P({m}_{i}|{m}_{n},\dots {m}_{i+1},{m}_{i-1},\dots .,{m}_{1})\), and the unidirectional model's conditional probability is denoted by \(P({m}_{i}|{m}_{i-1},\dots {m}_{1})\). The bidirectional representation is specified as \({H}_{m}=\left(n-1\right)\text{log}c\), and the unidirectional information is represented as \(\frac{1}{n}\sum_{i=1}^{n}\left(i-1\right)\text{log}c=\frac{1}{2}{H}_{m}\). The traditional ensemble models incorporate two unidirectional models, which have a unidirectional representation, capture only \(\frac{1}{2}{H}_{m}\) information, and reduce the model's ability to extract features. The LM removes the noise inputs, which improves the prediction of letters due to its iterative principle. Parallel prediction transformers include noise data from the input image, usually estimated characters obtained from visual predictions. The proposed DR-LIFT method removes the input noise by applying an iterative language model. In the iterative language model, various assignments of the variable m are done for multiple iterations of the LM, which leads to an accurate vision prediction.
MASTER
The MASTER model comprises two essential packages: (i) Multi-Aspect Global Context Attention (GC Attention)—based encoder and (ii) Transformer-based decoder. Rather than using one attention function, multiple attention functions are used, which are referred to as Multi-Aspect attention (MAGC). The encoder in the proposed model encodes the input image and creates a feature tensor. The primary role of this MASTER model is the MAGC encoding. Figure 9 depicts the structure of the MASTER model, which includes the MAGC attention-based encoder for representing the features and a decoder model. The feature map is denoted by C x H x W, which denotes the channel number, height, and width. The variable h represents the number of Multi aspects of Context, r is the bottleneck ratio, and C/r is the dimension of the bottleneck. The element-wise addition is indicated by \(\oplus and\otimes\), which denotes the matrix multiplication. The above model has the MAGC, a residual block (RB), max pooling and a convolution block. Inside the residual block, the projection shortcut is used in case of variable input, and for identical input, the identity shortcut is used. Next to the RB, the MAGC attention is induced and learns about the additional features. The size of the convolutional kernel is (3 × 3). A 1 × 2 max pooling layer is implemented in addition to the existing 2 × 2 max pooling layers and obtained the additional information, which recognizes the narrow and irregularly shaped characters. In the second part of the MASTER architecture, there is a decoder, which consists of a mass of basic blocks, which contains three core modules: (i) Multi-Head Attention, (ii) Masked Multi-Head Attention, and (iii) Feed Forward Network. A SoftMax and a 1 × 1 convolution operation is performed in the Global Context Block, where the feature map is converted.

The MASTER model
Show, attend and read (SAR)
In the SAR method, the input image is given to a ResNet, which consists of thirty-one layers that yield a two-dimensional feature map. Next, LSTM encodes the obtained 2D feature map. This encoding is done for every column; the last hidden state is considered a feature. A second LSTM model is used to decode the feature in order to get a series of characters. For every iteration during decoding, a weighted sum of two-dimensional features is computed by the attention module, depending on the current hidden state of the LSTM decoder. Figure 10 shows the SAR model’s structure. ResNet CNN comprises thirty-one layers: the convolution layer, max pool layer, and residual block. For the residual block, an identity shortcut is used; if the input and output dimensions are identical, a projection shortcut is used for varying input and output dimensions. ResNet CNN comprises thirty-one layers: the convolution layer, max pool layer, and residual block. For the residual block, an identity shortcut is used; if the input and output dimensions are identical, a projection shortcut is used for varying input and output dimensions. SAR model uses an encoder-decoder model, which is based on two-dimensional attention for processing texts that have irregular shapes. The encoder in the SAR model consists of two LSTM layers with five hundred and twelve hidden states. At this stage, the hidden state value is updated. After the terminating condition is satisfied, the final hidden state in the second layer is declared as the holistic feature for the given input image, and the same is valid for decoding.

Structure of the SAR model. The glimpses in the figure indicate the weighted sum of local features
The decoder is a two-layered LSTM model with an identical number of hidden layers as the encoder; there is no parameter sharing between the two. The initial input given to the decoder is the feature obtained from the decoder, and the process starts with the "START" token in the next step and continues until the LSTM layer receives the "END" token. At each step after the START token, the LSTM is fed with the output obtained in the previous step. In the training phase, the LSTM in the decoder is modified to match the ground truth character set. The final processing is the 2D attention module. Compared to the existing two-dimensional attention modules, where each location is treated independently, the proposed SAR method includes the 2D spatial relationships, which are easily achieved by the addition of multiple convolution operations. Table 3 gives the advantages of the deep learning methods ABINet, MASTER, and SAR proposed in the DRLIFT framework for word recognition.
Labelling using graph neural network (GNN)
Graphs are usually used for identification of the relationship between nodes, and depending on the weights, two nodes are connected with an edge. Neural Network (NN) architecture is one of the modern tools used in prediction, problem-solving and computer vision. The label propagation method is used to understand the relationship between data. The combination of NN and graphs is termed a Graph Neural Network (GNN) method that works on deep neural networks with graph data structure. The neural network architectures are trained using supervised learning to learn the identical hidden representation for the nearest nodes. This process is called a Neural Graph Machine (NGM). In the proposed DR-LIFT method, three NN models are implemented for labelling. The NGM technique works iteratively and refines the labels of the nodes by adding identical information from the neighbouring nodes and propagating these tables to the next similar node. In the DR-LIFT method, the final step is graph labelling, which is used for the identification of the group of words that forms a sentence. The three NN methods listed below identify the words and output the meaning of the inscription in the modern Tamil language.
Feedforward neural networks (FNN)
An FNN comprises more than one layer and consists of neurons connected. In this NN, the previous layer's output is fed as input to the next layer, and hence, they are stacked. The FNN has an input layer, multiple hidden layers, and an output layer. The central processing occurs in the hidden layer, and every node of this layer has a sum dependent on the input from the earlier layer. FFN can have many hidden layers. Alternatively, specific features serve as inputs. The parameters and their values that are used in the FNN are shown in Table 4. The FNN is used as a graph neural network to find Tamil inscriptions in modern Tamil. While the previous processes recognize the character and then the words, FNN implements the GNN and gives the output of the entire text. The Graph neural network model is trained using the labelled dataset, which is divided into training, validation, and test sets.
Recurrent neural network (RNN)
In a Recurrent Neural Network (RNN), the output of the previous node is given as input to the next node. In NNs, the output and input layers or nodes are usually independent. The RNN layer remembers the previous words. The hidden layer remembers the information that is in a sequence, known as a memory state. The FNNs forward all the information, and there is no looping in them.
where ht,\({h}_{t-1}\), \({x}_{t}\) denote the current state, the previous state and the input state, respectively. \({W}_{hh}\) is the weight of the recurrent neuron and the input neuron is indicated by\({W}_{xh}\). Similarly, in Eq. (3) \({y}_{t}\) indicates the output state and the output with weight is denoted by\({W}_{hy}\). The structure of the RNN architecture is shown in Fig. 11.

Working of CNN
Convolution neural network (CNN)
CNN has been implemented in pattern recognition and is also used in the image recognition process by applying deep learning techniques to carry out generative and descriptive tasks with the help of computer vision and NLP techniques. CNN work is based on neurons, which boosts image processing, and the layers in neurons pave the way to consider the entire image and avoid piece-wise image processing. The convolution layers carry out feature extraction from the input images and form a feature map of neurons. Figure 12 shows the structure of CNN.

Recurrent neural network
Results and discussions
This section evaluates the proposed DR-LIFT method based on various performance metrics depicted in the following tables and graphs. The evaluation of the DR-LIFT method based on character recognition is depicted in Fig. 13, and it is clear that DR-LIFT is superior to other methods. Figure 14 shows the character recognition rate of other methods, such as CNN with three feature point selection models [24], ResNet [25], End-to-End Deep Learning methods [26], and in [27], multiple methods have been used for character recognition. The figure shows that the proposed DR-LIFT method performs better than other methods.

Performance metrics comparison of the proposed method with other methods for character recognition

Character recognition rate comparison
Figure 15 displays the proposed system's cross-validation accuracy results with other methods, such as a Deep Neural Network [3], CNN [28], Modified Adaptive Back Propagation Network (MABP) [29], Support Vector Machine (SVM) [30], three-layer CNN (TCNN) [31], and Self-Adaptive Lion Optimization Algorithm with Transfer Learning (SALOA-TL) [2]. Figure 16 compares the word detection accuracy with other models [5, 32,33,34].

Cross-validation comparison of the test results

Word detection comparison of the proposed method and other methods
Figure 17 displays the character recognition rate of other methods and the DR-LIFT model, in which the latter performs well. Similarly, Fig. 18 shows the character recognition rate and character accuracy of the following methods such as Tesseract Engine [35], Fuzzy Rules [36], CNN + ADAM [37], DCNN [38], Grad-CAM [39], CAPNet [40] are compared. The proposed DR-LIFT method outperforms other methods in both cases. Table 5 lists the character recognition accuracy comparison of the proposed method in character recognition with methods such as K-Nearest Neighbor (KNN), CNN with ADAM optimizer, Support Vector Machine and Generative Adversarial Network (GAN). ML methods achieve a maximum of 90% accuracy, the proposed DR-LIFT method achieves about 99% character recognition accuracy.

Performance metrics comparison of character recognition

Performance comparison of other architectures with the proposed system for character recognition
Table 6 compares the execution time (s) and accuracy (%) of the SLOA-TL [2] method, which uses five pre-trained deep learning models such as Inception V3 [42], Xception [43], VGG19, VGG16 [44] and ResNet50, with the proposed DR-LIFT method over different epochs. The models mentioned above, and the proposed DR-LIFT method are evaluated after running the model for 30 iterations each for 25 epochs to achieve better accuracy. The SLOA-TL and the pre-trained models do not include advanced attention mechanisms, which are critical for handling challenging text patterns, such as those in inscriptions where characters are unclear or connected. The proposed DR-LIFT method uses ABINet such mechanisms, enabling it to focus on key regions of the image, improving both speed and accuracy.
In Table 7, all the methods proposed in the DR-LIFT model are evaluated, and the best combination of methods for inscription recognition is determined. This accuracy comparison is done for Brahmi and Vattezhuthu inscriptions. As a result of this evaluation, DB Net and ABINet perform better for Brahmi inscription recognition. FCENet and ABINet show higher accuracy in recognizing Vattezhuthu inscriptions.
DB Net and ABINet perform well for Bhrami inscriptions of the third century, and FCENet and ABINet show higher recognition accuracy for Vattezhuthu. Table 8 shows the recognition accuracy achieved by the alphabet and word recognition methods of the proposed DR-LIFT method for the seventh and ninth centuries. Other methods, such as MASTER and SAR, perform better for other Tamil texts of different centuries, and accuracy for Tamil inscriptions of the seventh and ninth centuries is included in the table.
Table 9 shows the efficiency of the proposed DR-LIFT method compared to existing methods. The existing models primarily focus on recognizing individual characters rather than entire words or sentences. In contrast, the proposed DR-LIFT method utilizes hybrid deep learning techniques to recognize stone inscriptions from the early third century and convert them into modern Tamil. The following table presents some previous articles that have addressed character or word recognition.
Table 10 gives the proposed DR-LIFT model’s effectiveness based on memory and execution time. DB Net excels in character recognition with a fast execution time of 30 ms and low memory usage (100–200 MB). DB Net is optimized for quick character detection, using streamlined architectures that minimize processing overhead. ABINet offers quick execution (28 ms) by using advanced language modelling techniques while maintaining moderate memory usage (200–250 MB). RNNs, although memory-efficient for sentence recognition, tend to have longer execution times (50 ms) due to their sequential processing nature. In contrast, CNNs provide a balanced approach to sentence recognition, with faster execution (43 ms) and moderate memory usage, benefiting from their ability to parallelize computations effectively.
Figure 19 and Fig. 20 summarize the performance of various text detection methods, highlighting their execution times and memory requirements. TextBox + + balances performance with an execution time of 95 ms and 400 MB of memory, benefiting from comprehensive feature extraction. RRD has a slightly slower execution time of 98 ms and higher memory usage at 650 MB, reflecting its complex architecture. In contrast, CRAFT excels with a faster execution time of 60 ms and 390 MB of memory due to its focus on character region awareness. FCN shows an execution time of 90 ms and uses about 560 MB, influenced by its pixel-wise prediction architecture. Finally, the proposed DR-LIFT method outperforms the others with an execution time of just 30 ms and a memory requirement of only 200 MB, which uses hybrid algorithms with advanced attention mechanisms that enhance efficiency for real-time applications.

Memory consumption comparison

Execution time comparison
Table 11 compares recognition methods and their accuracy across different ancient scripts. For Oracle Bone script, R-GNN gives Top-1 accuracy of 88% and Pseudo Category Labels achieved 98% accuracy, indicating a significant improvement with advanced labeling techniques. Ancient Greek script saw high accuracy at 95% using Meta Processing, which suggests effective adaptation for structured text. Egyptian Hieroglyphs achieved the highest accuracy at 97% using CNN-Glyphnet, highlighting CNN’s strength in handling complex symbol structures. The proposed DR-LIFT framework works well for Bhrami and Vattezhuthu inscriptions on palm leaves and paintings with higher accuracy.
Finally, Fig. 21 shows the output displayed on the mobile phone for the input text. The proposed model's results were checked with Tamil language professors of Aalim Muhammed Salegh College of Engineering. Conceptual accuracy was checked with Tamil professor 'https://www.aalimec.ac.in/wp-content/uploads/2024/04/DR.-TITUS-SMITH-T.pdf’.

Results of the DR-Lift method displayed on Mobile Phone
Discussion
The result section ensures the superiority of the proposed DRLIFT method thorough the comparison of various performance metrics of existing methods and the proposed method. In the proposed DRLIFT method, character recognition is done through DB Net, FCENet and TextSnake. The existing methods need to identify the input text in better lighting conditions or when images are not visible clearly. Figure 13 though 15compares the evaluation metrics of the existing methods and the character recognition rate. DB Net adaptively binarizes the images based on their content, which is particularly useful for handling variations in lighting conditions, image quality, and backgrounds commonly encountered in real-world scenarios. This adaptability improves the robustness of the system in different environments. Traditional character recognition algorithms need special processing for feature extraction; in contrast, FCENet directly learns to map input images (characters) to embedding or feature representations without the need for manual feature extraction. This process leads to a reduction in computation time. The third method used for character recognition is TextSnake. While the traditional methods focus on horizontal or fixed-shaped text detection, TextSnake can handle text in arbitrary shapes, including curved, oriented, or irregularly arranged text. This capability is especially useful for text appearing in natural scenes, signs, or images with non-standard text orientations. Figures 16 through 19 compare the performance metrics, such as sensitivity, accuracy, and specificity of the proposed DR-LIFT method, with the existing traditional methods.
Traditional methods find it difficult to handle images that have low resolution, noise, or distortions, specific fonts and styles and this leads to misinterpretations, especially in ambiguous cases where complex backgrounds or overlapping with other elements in the image are challenging for isolation and recognition more accurately. The proposed DR-LIFT method uses ABINet, Master, and SAR methods for word recognition. ABINet effectively recognizes characters and words even in complex backgrounds or noisy images. MASTER implements a multi-aspect learning approach that allows the model to capture stroke patterns, which improves the recognition rate effectively. Similarly, the SAR model attends to the most informative regions, learning complex patterns and adapting to diverse real-world conditions. The three models proposed for word recognition are specifically designed for scene text recognition. Finally, Table 7 shows the overall comparison of the methods used in this proposed DR-LIFT method. Among the proposed methods, the integration of DB Net and ABINet gives higher accuracy for Bhrami inscriptions, and FCENet integrated with ABINet performs better for Vattezhuthu inscriptions.
Conclusion
In this study, the Brahmi and Vattezhuthu Tamil inscriptions of the third century are converted into modern Tamil using hybrid architectures. The images of the inscription are captured on a mobile phone, and after executing the DR-LIFT method, the corresponding modern Tamil text is displayed on the mobile phone using the Matlab mobile app. Other researches use laboratory material to convert the inscription to modern Tamil, whereas in the proposed DR-LIFT method the conversion can be done in the mobile itself. The study divides the entire process into the following three sections: (i) identification of individual characters, (ii) Formation of words from the recognized characters, and (iii) Displaying the entire sentence or text, which is captured on screen and identified words. The proposed system uses DB Net, FCENet and Text Snake architectures for character recognition and ABINet, MASTER and SAR for word formation and three Graph Neural Network methods, such as CNN, FNN and RNN for final word recognition. The data set used for this study is our created data set, which contains Brahmi and Vattezhuthu forms of Tamil inscriptions of the early centuries. Tests were conducted on contemporary Tamil datasets, comparing the outcomes against alternative character recognition techniques. The findings indicate that the proposed DR-LIFT method consistently outperforms other existing methods. A comparative study among the proposed methods is done to determine whether the text gives better accuracy values. As specified in Table 7, DB Net and ABINet perform better for character recognition, and FCENet and ABINet yield higher accuracy in word recognition. The efficiency of the proposed method is compared with other text recognition methods based on memory requirements and execution time. The proposed DR-LIFT method performs better in both cases compared to existing algorithms. The limitation of the proposed DR-LIFT method is that it cannot recognize paintings and can only recognize stone inscriptions, and in future, the presented work may be enhanced to recognize ancient texts in paintings.
Data availability
No datasets were generated or analysed during the current study.
References:
Kaur S, Sagar BB. Brahmi character recognition based on SVM (support vector machine) classifier using image gradient features. J Discr Math Sci Cryptogr. 2019;22(8):1365–81.
Priya RD, Karthikeyan S, Indra J, Kirubashankar S, Abraham A, Gabralla LA, Nandhagopal SM. Self-adaptive hybridized lion optimization algorithm with transfer learning for ancient tamil character recognition in stone inscriptions. IEEE Access. 2023.
Prabavathi R. Prehistoric stone image Tamil character recognition using optimized deep neural network using Zernike moments and simplex method. TURCOMAT. 2021;12(11):5983–91.
Deepa J, Arvind B, Bharanidharan G, Dinesh S. An empirical analysis on recognition of ancient tamil inscriptions using machine learning. In: 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT) (Vol. 5), IEEE. 2024, pp. 1739–1744.
Liao M, Wan Z, Yao C, Chen K, Bai X. Real-time scene text detection with differentiable binarization. In: Proceedings of the AAAI conference on artificial intelligence (Vol. 34, No. 07), 2020, pp. 11474–11481.
Zhu Y, Chen J, Liang L, Kuang Z, Jin L, Zhang W. Fourier contour embedding for arbitrary-shaped text detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2021, pp. 3123–3131.
Long S, Ruan J, Zhang W, He X, Wu W, Yao C. Textsnake: a flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 20–36.
Li H, Wang P, Shen C, Zhang G. Show, attend and read: A simple and strong baseline for irregular text recognition. In: Proceedings of the AAAI conference on artificial intelligence (Vol. 33, No. 01), 2019, pp. 8610–8617.
Lu N, Yu W, Qi X, Chen Y, Gong P, Xiao R, Bai X. Master: multi-aspect non-local network for scene text recognition. Pattern Recogn. 2021;117: 107980.
Fang S, Xie H, Wang Y, Mao Z, Zhang Y. Read like humans: autonomous, bidirectional and iterative language modelling for scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, pp. 7098–7107.
Song Z, Yang X, Xu Z, King I. Graph-based semi-supervised learning: a comprehensive review. IEEE Trans Neural Netw Learn Syst. 2022;34(11):8174–94.
Bui, T. D., Ravi, S., & Ramavajjala, V. (2018, February). Neural graph learning: Training neural networks using graphs. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (pp. 64–71).
Manigandan, T. V. V. D. V. N. B., Vidhya, V., Dhanalakshmi, V., & Nirmala, B. (2017, August). Tamil character recognition from ancient epigraphical inscription using OCR and NLP. In 2017 international conference on energy, communication, data analytics and soft computing (ICECDS) (pp. 1008–1011). IEEE.
Giridhar, L., Dharani, A., & Guruviah, V. (2019). A novel approach to OCR using image recognition-based classification for ancient Tamil inscriptions in temples. arXiv preprint. arXiv preprint arXiv:1907.04917.
Rajakumar S, Bharathi VS. Eighth century Tamil consonants recognition from stone inscriptions. In: 2012 International conference on recent trends in information technology IEEE, 2012. pp. 40–43.
Rajan P, Sridhar S. Identification of ancient Tamil letters and its characters: automatic date fixation based on contour-let technique. In: Proceedings of the 1st International Conference on Graphics and Signal Processing 2017, pp. 40–43.
Durga Devi K, Uma Maheswari P. Recognition and classification of stone inscription character using artificial neural network. In: Artificial Intelligence and Technologies: Select Proceedings of ICRTAC-AIT 2020 Singapore: Springer Singapore.2021, pp. 253–261.
Heenkenda HMSCR, Fernando TGI. Approaches used to recognize and decipher ancient inscriptions: a review. Vidyodaya J Sci, 2020;23(02).
Chandure S, Inamdar V. Handwritten Modi character recognition using transfer learning with discriminant feature analysis. IETE J Res. 2023;69(5):2584–94.
Dhivya S, Beulah JR. Ancient Tamil character recognition from stone inscriptions–a theoretical analysis. In: 2022 2nd Asian Conference on Innovation in Technology (ASIANCON) IEEE. 2022, pp. 1–8.
Shukla A, Solanki V. A review mostly on identification of early tamil extracts actors through historical writing. In: 2022 11th International Conference on System Modeling & Advancement in Research Trends (SMART) IEEE, 2022, pp. 169–173.
Magrina MM. Convolution neural network based ancient Tamil character recognition from epigraphical inscriptions. IRJET. 2020;7(04):6130–43.
Bhuvaneswari S, Kathiravan K. Enhancing epigraphy: a deep learning approach to recognize and analyze Tamil ancient inscriptions. Neural Comput Appl. 2024. https://doi.org/10.1007/s00521-024-10137-x.
Kaliappan AV, Chapman D. Hybrid classification for handwritten character recognition of a subset of the tamil alphabet. In: 2020 6th IEEE Congress on Information Science and Technology (CiSt), IEEE 2021, pp. 167–172.
Zhao X, Zhou P, Xu K, Xiao L. An improved character recognition framework for containers based on DETR algorithm. Sensors. 2021;21(13):4612. https://doi.org/10.3390/s21134612.
Narang SR, Kumar M, Jindal MK. DeepNetDevanagari: a deep learning model for Devanagari ancient character recognition. Multimedia Tools Appl. 2021;80:20671–86.
Uddin I, Ramli DA, Khan A, Bangash JI, Fayyaz N, Khan A, Kundi M. Benchmark Pashto handwritten character dataset and Pashto object character recognition (OCR) using deep neural network with rule activation function. Complexity. 2021;2021(1):6669672. https://doi.org/10.1155/2021/6669672.
Karunarathne KGND, Liyanage KV, Ruwanmini DAS, Dias GKA, Nandasara ST. Recognizing ancient Sinhala inscription characters using neural network technologies. Int J Sci Eng Appl Sci. 2017;3(1):12.
Bhuvneswari G, Manikandan G. Recognition of ancient stone inscription characters using histogram of oriented gradients. In: Proceedings of International Conference on Recent Trends in Computing, Communication & Networking Technologies (ICRTCCNT). 2019.
Ajmire PE. Handwritten Devanagari vowel recognition using artificial neural network. Int J Adv Res Comput Sci. 2017;8(7):1059–62.
Chadha S, Mittal S, Singhal V. Ancient text character recognition using deep learning. Int J Eng Res Technol. 2020;3(9):2177–84.
Deng D, Liu H, Li X, Cai D. Pixellink: detecting scene text via instance segmentation. In: Proceedings of the AAAI conference on artificial intelligence (Vol. 32, No. 1). 2018. https://doi.org/10.1609/aaai.v32i1.12269
Baek Y, Lee B, Han D, Yun S, Lee H. Character region awareness for text detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2019, pp. 9365–9374.
Wang L, Yao X, Song C. Text detection method based on HDBNet in natural scenes. J Eng. 2023;2023(1): e12212.
Liyanage C, Nadungodage T, Weerasinghe R. Developing a commercial grade Tamil OCR for recognizing font and size independent text. In: 2015 Fifteenth International Conference on Advances in ICT for Emerging Regions (ICTer), IEEE. 2015, pp. 130–134.
Vellingiriraj EK, Balasubramanie P. A multimodal framework for the recognition of ancient Tamil handwritten characters in palm manuscript using Boolean bitmap pattern of image zoning. International Forum for Information Technology in Tamil. 2019.
Iyswarya R, Deepak S, Jagathratchagan P, Kailash J. Handwritten Tamil character recognition using convolution neural network by Adam optimizer. Int J Adv Res Sci Commun Technol. 2021;6(1):40–5. https://doi.org/10.48175/ijarsct-1356.
Sornam M, Vishnu Priya C. Deep convolutional neural network for handwritten tamil character recognition using principal component analysis. In: Smart and Innovative Trends in Next Generation Computing Technologies: Third International Conference, NGCT 2017, Dehradun, India, October 30–31, 2017, Revised Selected Papers, Part I 3 (pp. 778–787). Springer Singapore. 2018.
Tanvir Rouf Shawon M, Tanvir R, Rabiul Alam MG. Bengali handwritten digit recognition using CNN with explainable AI. arXiv e-prints, arXiv-2212. 2022.
Moudgil A, Singh S, Gautam V, Rani S, Shah SH. Handwritten Devanagari manuscript characters recognition using capsnet. Int J Cognit Comput Eng. 2023;4:47–54.
Krithiga R, Varsini SR, Joshua RG, Kumar CO. Ancient character recognition: a comprehensive review. IEEE Access. 2023. https://doi.org/10.1109/ACCESS.2023.3341352.
Liao M, Shi B, Bai X. Textboxes++: a single-shot oriented scene text detector. IEEE Trans Image Process. 2018;27(8):3676–90.
Liao M, Zhu Z, Shi B, Xia GS, Bai X. Rotation-sensitive regression for oriented scene text detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition 2018, pp. 5909–5918.
Zhang Z, Zhang C, Shen W, Yao C, Liu W, Bai X. Multi-oriented text detection with fully convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition 2016, pp. 4159–4167.
Athisayamani S, Singh AR, Athithan T. Recognition of ancient Tamil palm leaf vowel characters in historical documents using B-spline curve recognition. Procedia Comp Sci. 2020;171:2302–9.
Yuan J, Chen S, Mo B, Ma Y, Zheng W, Zhang C. R-GNN: recurrent graph neural networks for font classification of oracle bone inscriptions. Heritage Science. 2024;12(1):30.
Papadaki AI, Agrafiotis P, Georgopoulos A, Prignitz S. Accurate 3D scanning of damaged ancient Greek inscriptions for revealing weathered letters. Int Arch Photogramm Remote Sens Spat Inf Sci. 2015;40:237–43.
Barucci A, Cucci C, Franci M, Loschiavo M, Argenti F. A deep learning approach to ancient Egyptian hieroglyphs classification. IEEE Access. 2021;9:123438–47.
Fu X, Zhou R, Yang X, Li C. Detecting oracle bone inscriptions via pseudo-category labels. Herit Sci. 2024;12(1):107.
Funding
Open access funding provided by SRM Institute of Science and Technology for SRMIST – Medical & Health Sciences. The authors receives no funding for this paper.
Author information
Authors and Affiliations
Contributions
BM: Conceptualization, Data curation, Formal analysis, Investigation, Methodology and Writing. BM and PV: Project administration, Figures, Writing—original draft; PV: Supervision,and Review.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Murugan, B., Visalakshi, P. Ancient Tamil inscription recognition using detect, recognize and labelling, interpreter framework of text method. Herit Sci 12, 430 (2024). https://doi.org/10.1186/s40494-024-01522-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1186/s40494-024-01522-9
Keywords
This article is cited by
-
Deep inception neural network with residual connections for Tamil handwritten character recognition
Scientific Reports (2026)
