
Abstract
The analysis and protection of grotto sculptures face growing urgency due to climate-driven deterioration and a shortage of domain experts. Here we present ChronoStyleNet (CSN) the world’s first domain-specific multimodal large model purpose-built for sculptural heritage. CSN is trained on 295 expert-annotated statues from the Feilai Peak Grottoes (covering 49% of the West Lake region and 13% of Zhejiang grotto sculptures) and 2.46 GB of archaeological literature. It achieves precise performance through targeted fine-tuning and structured prompting under limited data conditions. Evaluated on 22 Yuan-dynasty samples, CSN outperformed five mainstream multimodal large language systems within a six-dimensional ontology-aligned framework. This work establishes a scalable benchmark for domain-adaptive AI in cultural heritage, offering replicable methodology for other endangered monuments worldwide. CSN demonstrates that domain-adapted multimodal AI can deliver high-precision interpretation even with scarce data, providing new tools for digital preservation and scholarly research. It highlights AI’s potential to bridge expertise gaps and reshape conservation practices in vulnerable heritage contexts.
Similar content being viewed by others
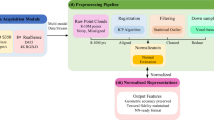

Introduction
The preservation of cultural heritage is facing mounting global challenges. Climate change, environmental degradation, and the destruction of heritage assets have led to the irreversible loss of historical and cultural knowledge. Among these, grotto sculptures stand out as vital material embodiments of religious art, encapsulating the social, cultural, and technological transformations across different historical periods. However, as outdoor stone carvings, they are particularly vulnerable to environmental factors such as weathering, erosion, and human impact.
Within this context, the Feilai Peak Grottoes in Hangzhou represent a major heritage site in the Jiangnan region, preserving a rich corpus of carvings that embody both regional traditions and evolving temporal styles. During the Yuan dynasty, Feilai Peak witnessed the emergence of a highly distinctive Sino-Tibetan syncretic style, characterized by a fusion of Han Chinese and Tibetan Buddhist artistic elements1,2. Sculptures from this period exhibit remarkable diversity in facial modeling, attire detailing, and religious iconography. This creates a complex and heterogeneous stylistic landscape that requires both precise visual analysis and deep cultural understanding for accurate interpretation.
This highly diverse and structurally complex sculptural corpus provides a challenging testing ground for AI in tasks of stylistic recognition and cultural semantic interpretation. However, accurately parsing and understanding these features remains a significant challenge3,4. Traditional approaches to stylistic and chronological classification of grotto sculptures rely heavily on the expertise of trained archaeologists and art historians, who integrate visual analysis, textual interpretation, and comparative stylistics5. However, this manual process faces growing limitations when applied to increasingly large and diverse image datasets. On the one hand, there is a growing shortage of domain experts: the field is experiencing a pronounced generational gap, with aging scholars and limited successor capacity, which has slowed documentation and interpretation efforts6. This expertise gap is compounded by the scarcity of annotated data, as high-quality documentation of irreplaceable heritage requires specialized skills and ethical considerations that limit large-scale data collection. On the other hand, many grotto sites—particularly in climatically sensitive regions like southern China—are experiencing accelerated deterioration due to weathering and environmental change7,8,9,10, placing urgent demands on timely documentation, analysis, and preservation. These challenges highlight the need for a novel approach that can scale with limited expert resources, leveraging sparse annotations and domain knowledge to address both data scarcity and interpretive complexity.
The rapid advancement of artificial intelligence is profoundly reshaping multiple academic fields, including cultural heritage research, historical artifact analysis, and digital preservation11,12,13,14,15. High-quality data collection and secure preservation are foundational to heritage digitization efforts, with existing studies primarily focusing on large-scale data mining16,17, knowledge graph construction15,18,19,20, and three-dimensional reconstruction techniques21,22,23,24. While traditional AI models, such as convolutional neural networks (CNNs), have achieved notable success in tasks such as image classification and feature extraction25,26,27,28, their inherent “black-box” nature limits scalability, interpretability, and adaptability to domain-specific knowledge3,4,29.
In recent years, multimodal large models (MLLMs) have been increasingly applied to cultural heritage analysis due to their ability to process and reason over both visual and textual inputs30,31,32,33. However, general-purpose MLLMs often lack nuanced understanding of archaeological terminology and historical context34,35. As task complexity grows36,37, conventional human supervision also faces challenges, as annotators find it increasingly difficult to reliably validate the accuracy of model outputs38,39,40,41. Meanwhile, MLLMs have begun to be employed as automated evaluation tools to support quality assessment of model-generated content42,43.
Despite these advancements, existing research largely emphasizes the development and transferability testing of general-purpose technologies, with limited attention paid to domain-specific adaptation. In particular, the analysis of grotto sculptures from the Jiangnan region—artifacts characterized by complex regional cultural features—remains underexplored. To address the unique demands of such regionally contextualized heritage, it is crucial to develop multimodal recognition and evaluation systems that are both culturally adaptive and aligned with rigorous academic standards44.
To address these challenges in grotto sculpture analysis, this research introduces ChronoStyleNet (CSN), a domain-adaptive multimodal generative framework for sculptural heritage. Built upon an instruction-tuned multimodal large language model architecture45,46,47,48, CSN uniquely integrates structured knowledge distillation to overcome limitations of traditional approaches. Specifically, the model encodes archaeological reasoning—such as chain-of-thought style analysis—into prompt templates, enabling it to simulate expert decision-making processes (e.g., linking “the right-exposed kasaya” features to Tibetan Vajrayana influences). To our knowledge, this is the world’s first domain-specific multimodal large model purpose-built for sculptural heritage, establishing both a benchmark dataset and a replicable methodological template for other endangered monuments worldwide.
CSN is trained on a curated dataset of 295 expert-annotated sculptures from Hangzhou’s Feilai Peak Grottoes (representing 49% of West Lake region carvings and 13% of Zhejiang’s known statues), supplemented by a 2.46 GB domain knowledge base including The Complete Collection of Chinese Grotto Sculpture, Chinese Grotto Temples1,2,10,49, and 233 research papers—covering a wide range of dynasties, regions, iconographic systems, and scholarly perspectives on Chinese Buddhist art. This hybrid training strategy—fusing visual features (via frontal/lateral photographs) with textual semantics (e.g., historical context from local gazetteers)-enables cross-modal association learning, allowing CSN to achieve robust performance with minimal labeled data. Unlike general-purpose MLLMs, CSN’s architecture prioritizes low-resource adaptability: its structured prompting mechanism and fine-tuning on archaeologically meaningful features (e.g., facial modeling, ritual gestures) preserve expert-level interpretive logic while reducing dependency on massive annotations. This design makes CSN particularly suitable for heritage sites with limited documentation resources, where traditional expert-driven methods are impractical.
To evaluate its effectiveness, we construct a six-dimensional evaluation system aligned with expert archaeological practice, covering: (1) historical period identification, (2) stylistic classification, (3) visual detail description, (4) terminological accuracy, (5) cultural interpretation, and (6) linguistic coherence. We then test ChronoStyleNet on a sample of 22 Yuan-dynasty grotto sculptures and compare its outputs with those of five leading mainstream multimodal large language systems with visual input capabilities—GPT-4o, Claude 3.5, Gemini 1.5 Pro, LLaMA 3.3 70B, and Grok Beta. Scoring is conducted using GPT-4o under blind conditions, with expert moderation for validation. Quantitative performance is supplemented with qualitative case analysis to examine models’ strengths and failure modes in detail. The full experimental framework of ChronoStyleNet is summarized in Fig. 1.

This figure presents ChronoStyleNet, a domain-adaptive multimodal framework for analyzing grotto sculptures. The workflow integrates targeted data collection and preprocessing, prompt-based task execution, and a structured six-dimensional evaluation system aligned with archaeological ontologies. It emphasizes the model’s ability to conduct detailed stylistic and cultural analysis under data-constrained conditions. Experiment design includes Yuan-dynasty samples and comparisons with baseline models.
Here we show that ChronoStyleNet outperforms general-purpose models in both recognition and interpretive accuracy for heritage sculpture analysis, demonstrating the value of domain-adapted MLLMs in supporting digital preservation, expert collaboration, and public education in low-resource archaeological contexts.
Methods
Data collection and preprocessing
This study curated a dataset of 345 grotto sculptures from the Feilai Peak site in Hangzhou. From this set, 295 well-preserved sculptures were selected based on visual completeness and historical clarity. These samples represent approximately 49% of all documented statues in the West Lake region and 13% of the known grotto sculptures in Zhejiang Province. It is important to note that at least 40% of Zhejiang’s grotto sculptures are unsuitable for data annotation. In many cases, key features—such as the heads—have been destroyed and later reconstructed in modern times, as seen in the Shiwudong Cave in Hangzhou, which contains around 500 such statues. In other cases, the statues are so small that they lack discernible facial or bodily features, as exemplified by the Great Buddha Temple in Xinchang, which includes over 1000 miniature figures. Each piece was systematically documented with one frontal and two lateral photographs. Attributes including name, period, inscription, facial structure, hairstyle, costume, posture, gesture, pedestal, halo, and body-head proportions were annotated using an archaeological ontology schema. A sample annotation format is illustrated in Supplementary Table 1.
We preprocessed images via normalization and quality filtering. Complementary textual materials—such as Buddhist terminology dictionaries, local gazetteers, and image-term alignment samples—were added to enhance domain specificity. A mixed data strategy balanced general image-text pairs with domain-specific content. Structured prompt templates were introduced to guide the model through archaeological reasoning tasks.
Model architecture
ChronoStyleNet (CSN) is built upon the llava-onevision-qwen2-7b50 architecture, a MLLM that integrates Qwen2 as the language backbone and supports high-resolution image input up to 2306 × 2306 pixels. Among the tested open-source MLLMs (llava-v1.5, llava-next, llava-onevision), the Qwen2-based variant exhibited the most robust Chinese-language understanding, making it a suitable foundation for this domain-specific task.
CSN was fine-tuned using 19,708 instruction–response pairs, including 10,731 general-domain samples and 8977 domain-specific samples related to heritage and Buddhist statuary. General instructions were curated from 13 open-source datasets and filtered for quality. Domain-specific data were generated using structured expert annotations combined with prompt-based synthesis using Qwen2-VL-72B.
All images were standardized via center-cropping and resizing, converted to RGB, and normalized using ImageNet statistics. Data augmentation techniques included random rotation, horizontal flipping, and perspective distortion.
Six-dimensional evaluation framework
To assess the archaeological applicability of CSN, we designed a six-dimensional evaluation framework that covers both visual recognition and cultural reasoning51, including:
Historical period identification: Accuracy of dynastic attribution
Stylistic classification: Ability to differentiate between regional and religious stylistic systems
Visual detail description: Precision in describing facial, attire, iconography, and pose features
Terminological accuracy: Consistency with archaeological and art-historical vocabulary
Cultural interpretation: Depth of understanding regarding religious or symbolic meaning
Linguistic coherence: Clarity, structure, and logical reasoning in textual output
This framework serves both as an internal performance benchmark and a comparative standard against general-purpose MLLMs in cultural heritage tasks.
Test sample construction
This study focuses on Yuan dynasty sculpture samples based on both historical significance and practical accessibility. Feilai Peak, located in Hangzhou, houses the largest and best-preserved collection of Yuan-period sculptures, notable for their fusion of Han Chinese and Tibetan Buddhist artistic traditions. In addition to its historical value, the sculptures are generally well preserved, with critical visual features such as dress, posture, and halos remaining largely intact. Many works are securely dated through local gazetteers, stone inscriptions, and archaeological research. Moreover, our research team is based in Hangzhou, enabling consistent on-site documentation and high-resolution image capture, thereby ensuring both the feasibility and completeness of the dataset. We selected 22 Yuan dynasty sculptures as evaluation samples, based on two criteria:
-
(1)
strong representativeness of the stylistic and iconographic diversity of Yuan-period Feilai Peak artifacts;
-
(2)
clear and uncontested period attributions supported by inscriptions and literature.
Samples were divided into:
In-domain group (18): Statues from Feilai Peak covered in training data.
Out-of-domain group (4): Statues from Baocheng Temple, a site in Hangzhou not included in the training set but sharing stylistic traits with the in-domain samples.
Stylistic similarity between the Baocheng Temple samples and the Feilai Peak corpus was determined based on expert assessment of religious figure types, drapery carving techniques, and facial modeling styles. Both sites are located within the same historical-cultural region, and reflect the institutional spread of Tibetan Buddhism in the Jiangnan area during the Yuan dynasty. Despite differences in iconographic themes, the Baocheng sculptures are stylistically complementary to those at Feilai Peak. For example, the Mahākāla statue(a fierce guardian deity in Esoteric Buddhism, often regarded as a wrathful form of Avalokiteshvara) at Baocheng Temple, which bears a clear Yuan inscription, shares key iconographic motifs with wrathful deities at Feilai Peak—such as fierce expressions, flaming aureoles, bone ornaments, and trampling poses. These visual parallels reflect a localized reinterpretation of tantric sculpture rituals under state-sponsored Buddhism, highlighting an integrated visual and cognitive framework for Yuan-era esoteric imagery in Jiangnan. This setup enables testing both recognition accuracy and cross-domain generalization. Detailed annotations of all samples, including domain classification and descriptive metadata, are provided in Supplementary Table 2.
Baseline models and evaluation targets
To benchmark CSN, we selected five widely adopted multimodal-capable mainstream large language systems as comparative baselines: GPT-4o, Claude 3.5, Gemini 1.5 Pro, LLaMA 3.3 70B, and Grok Beta. These models represent current multimodal capabilities and were evaluated on the same 22 samples under controlled blind conditions. Each received identical image inputs and standardized prompts. This ensured evaluation fairness by avoiding prompt engineering differences or model-specific bias. GPT-4o, Claude 3.5, Gemini 1.5 Pro, and Grok 3 were accessed via their respective official APIs. LLaMA 3.3 70B (Meta) was accessed through the Monica platform, which enables multimodal querying via an integrated vision module. The specific versions were as follows, with model characteristics and performance summarized in Table 1.
GPT-4o (OpenAI): Version gpt-4o, released November 20, 2024
Claude 3.5 Sonnet (Anthropic): Version Claude 3.5 Sonnet, released June 21, 2024
Gemini 1.5 Pro Experimental (Google): Version gemini-1.5-pro-exp-03-25, released March 25, 2025
LLaMA 3.3 70B (Meta): Version LLaMA-3.3-Nemotron-70B-Select, initially released December 6, 2024, last updated March 18, 2025 (accessed via Monica API)
Grok 3 Beta (xAI): Version Grok 3 Beta, released February 17, 2025
Scoring protocol
Evaluation was conducted using GPT-4o as a neutral scorer following a standardized multi-step process:
Reference creation: Target answers for each statue were written by domain experts. Throughout the processes of image annotation and evaluation, we collaborated closely with specialists in Buddhist grotto sculpture. Detailed expert evaluation descriptions can be found in Supplementary Table 2.
Output normalization: All model responses anonymized and uniformly formatted.
Automated scoring: GPT-4o compared model outputs to references across six dimensions and provided justifications43. Prompt structure and representative annotated scoring outputs can be found in Supplementary Note 1.
Expert calibration: Final scores were refined based on expert feedback to ensure the validity of the evaluation. An independent panel of cave-temple specialists, unaffiliated with the authors, rigorously assessed the model’s identification performance. Figure 2 illustrates the full evaluation workflow.

a We first input the task instructions and six-dimensional evaluation criteria into GPT-4o, guiding it to assess model-generated answers across six dimensions. b A multimodal large language model (MLLM) receives the image and prompt, generates an answer, which is then compared against a reference answer curated by domain experts. c GPT-4o produces dimension-wise scores, which are subsequently reviewed and refined through expert validation. d Finally, we visualize the validated scores across all dimensions and compute an overall score to reflect the model’s performance.
Statistical information
Both quantitative and qualitative analyses were conducted. To evaluate model performance across six expert-defined evaluation dimensions, independent samples two-tailed t-tests were used to compare ChronoStyleNet against each baseline model (GPT-4o, Claude 3.5, Gemini 1.5 Pro, LLaMA 3.3 70B, Grok Beta). For each comparison, Levene’s Test was applied to determine variance equality. If the assumption of equal variances was violated (p < 0.05), Welch’s t-test results were reported. The corresponding t-values, degrees of freedom, p-values, and Levene’s F-values for homogeneity of variance are provided in Supplementary Table 3. To assess the generalization capacity of ChronoStyleNet, an independent samples two-tailed t-test was conducted to compare its performance on in-domain (n = 18) and out-of-domain (n = 4) samples. The corresponding t-values, degrees of freedom, and p-values are provided in Supplementary Table 4. In all figures, error bars represent standard deviation (SD). Each model was evaluated across 22 test samples, with scoring conducted independently across six evaluation dimensions. All statistical analyses were performed using IBM SPSS Statistics 27.0 and GraphPad Prism 10.2.
Qualitative review examined reasoning logic, term usage, and symbolic interpretation. Error analysis focused on typical failures in period judgment, reasoning logic, and the precision of domain-specific knowledge usage. This helped define the current model’s limits and informed future optimization directions.
Results
ChronoStyleNet performance across six evaluation dimensions
This study evaluates the performance of ChronoStyleNet (CSN) against five mainstream multimodal systems (GPT-4o, Claude 3.5, Gemini 1.5 Pro, LLaMA 3.3 70B, and Grok Beta) using 22 Yuan Dynasty grotto statues as test samples. To aid understanding of ChronoStyleNet’s performance, Fig. 3 illustrates its overall architecture, highlighting key modules from data preprocessing to multimodal integration. The evaluation framework focuses on six key dimensions: historical period identification, style classification, descriptive details, terminology standardization, cultural interpretation, and linguistic logic. Figure 4 presents a streamlined visualization of this six-dimensional evaluation framework, highlighting scoring dimensions and their interrelations. the full scoring rubric is detailed in Supplementary Table 5. The output performance of sample tasks was systematically tested, with scoring conducted by GPT-4o as a neutral scorer under blind conditions using identical inputs and uniform instructions. This minimized the influence of cue words, information leakage, and human bias. The results were further refined with expert reviews to ensure fairness. Complete per-sample evaluation scores for each model across the six dimensions are available in Supplementary Table 6.

ChronoStyleNet integrates data preparation, preprocessing, Qwen2-based feature extraction, multimodal fusion, and temporal reasoning, with instruction-tuned training and outputs for digital archiving, interpretation, and engagement.

a Radar chart illustrating the six evaluation dimensions used to assess model performance: period accuracy, style granularity, detail richness, term consistency, cultural depth, and logic & coherence. b Heatmap showing the pairwise correlation coefficients among the six evaluation dimensions, indicating their interrelationships. c Workflow schematic summarizing the development and validation process of the evaluation framework, integrating Buddhist art and archaeological ontology with expert validation and cultural heritage goals. d Scoring evolution pathway, depicting the progressive levels of classification accuracy and interpretive depth from basic identification to scholarly innovation.
Among the six score items, CSN ranked first in the mean scores across five dimensions, showing a significant overall advantage (see Supplementary Table 3 for full test statistics). It performed well in the dimensions of historical period identification accuracy (3.95 points) and logical-contextual coherence (4.18 points), scoring much higher than all other models. CSN was able to extract precise temporal features that aligned with Yuan-dynasty characteristics—such as Vajrayana elements and regional facial modeling—thus enabling accurate dynastic classification. In contrast, general-purpose multimodal large language models tended to produce broader stylistic descriptions lacking specific cultural markers, often leading to vague or incorrect period attribution. This is reflected in their tendency to classify many Yuan samples as Tang dynasty (Fig. 6b), a pattern likely influenced by the dominance of Tang-era material in their training corpus and their limited integration of domain-specific chronology and symbolic reasoning.
CSN also significantly outperforms the other models in terms of terminological normativity (3.14 points) and depth of cultural interpretation (2.77 points), reflecting its stronger academic normativity and interpretive ability in terms of accurate use of domain terminology and comprehension and expression of cultural contextual information. CSN is capable of articulating how dynastic periods, regional styles, and religious influences interact—particularly the syncretic fusion of Han Chinese and Tibetan elements in Yuan-dynasty grotto art—thereby demonstrating more advanced cultural reasoning and academic expressiveness.
In terms of richness of descriptive details, CSN scores (2.50) are slightly lower than GPT-4o (2.73) and Claude 3.5 (3.00), ranking fourth among the models. This suggests that while CSN demonstrates a strong ability to identify critical stylistic cues for accurate period classification, it tends to terminate its descriptive output once sufficient evidence for dynastic attribution has been established. In contrast, general-purpose models often provide more exhaustive—but less targeted—descriptions. This difference reflects a trade-off between precision and verbosity: CSN prioritizes diagnostic features relevant to archaeological reasoning, whereas baseline models emphasize broader scene rendering. Consequently, there remains room for CSN to enhance its descriptive depth and contextual supplementation without compromising its accuracy.
To visualize model performance, we present a comparative summary in Fig. 5, which illustrates multi-dimensional evaluation outcomes.

a Average scores across six evaluation dimensions for CSN and five baseline multimodal large language models (GPT-4o, Claude 3.5, Gemini 1.5 Pro, LLaMA 3.3 70B, and Grok Beta), presented as mean (left), standard deviation (middle), and median (right) across dimensions. b Distribution of evaluation scores for each model across all dimensions, visualized using violin plots. c Comparison of CSN’s mean scores to the best-performing baseline model for each dimension. Asterisks indicate statistical significance (*p < 0.05, **p < 0.01, ***p < 0.001; two-tailed t-test).
Deviation is generally higher than other models (e.g., 1.43 on historical period recognition accuracy), indicating that its generation results fluctuate from case to case. This may be related to the fact that its generation strategy is more oriented towards diversity and exploration. In contrast, models such as Claude 3.5, which had a standard deviation of 0, were stable but performed more stereotypically in terms of output content. The Tukey HSD post-hoc test of the CSN against the other models with the highest scores in each of the six scoring dimensions showed the following results:
In six dimensions (historical period identification, style categorization, terminology specification, cultural interpretation, logical coherence, and overall evaluation), the CSN scored significantly higher than the other models (p < 0.001), which showed a clear advantage.
Only in the dimension of “richness of descriptive details”, Claude 3.5 scored the highest, and the difference with CSN was significant (p = 0.012), which showed the relative advantage of the Claude model in describing details.
Overall, CSN demonstrated leadership in knowledge accuracy, logic, terminology standardization, and cultural understanding, making it one of the most comprehensive models in the current test, and only slightly inferior to Claude 3.5 and GPT-4o in detail depiction.
In-domain and out-of-domain generalizations
This experiment focuses on the recognition and analysis of Yuan dynasty grotto statues, aiming to explore the understanding and judgment ability of CSN when dealing with grotto statues with distinctive regional characteristics. Based on the accumulated features of the Yuan dynasty statues of Feilai Peak in the previous training set, this round of experiment is especially set to compare the “in-domain” and “out-of-domain” samples:
In-domain samples (18 statues): from the Feilai Peak area in the training set, with highly consistent styles. Out-of-domain samples (4 statues): from other grottoes in Hangzhou, which were not involved in the training but have similar styles.
Figure 6 integrates visual heatmaps, category flow diagrams, and scoring comparisons to highlight CSN’s marked advantage in accurately analyzing in-domain samples, while also exposing performance gaps on out-of-domain tasks. From the statistical results (Fig. 6c), it can be seen that CSN scores significantly higher on the all dimensions of “in-domain” than “out-of-domain”, which shows a stronger adaptability and expressive ability to the geographical nature of the information in the domain, and the generalization ability of the model needs to be further improved. A full breakdown of generalization scores on in-domain and out-of-domain samples is provided in Supplementary Table 4.

a Heatmaps of evaluation scores across six dimensions (period accuracy, style granularity, detail richness, term consistency, cultural depth, and logic and coherence) for each model (CSN, GPT-4o, Claude 3.5, Gemini 1.5 Pro, LLaMA 3.3 70B, Grok Beta). Darker shades indicate higher scores. b Sankey diagram visualizing model-predicted dynastic categories for the Yuan dynasty samples. Lines represent the proportion of samples classified into each dynasty category by each model. c Comparison of CSN’s performance on in-domain (n = 18) versus out-of-domain (n = 4) samples. Scores are reported as means ± SD across six dimensions (*p < 0.05, **p < 0.01, ***p < 0.001; two-tailed t-test). d Case-wise comparison of expert references, CSN interpretations, and baseline model outputs for three Yuan-dynasty Buddhist statues.
In contrast, other mainstream models such as GPT-4o and Claude 3.5 are more homogeneous and neutral in their overall scores. This homogeneity is reflected in the relatively uniform and low variance in heatmap shading across models (Fig. 6a), indicating limited differentiation in evaluation scores across samples. For example, GPT-4o demonstrates consistent scores on dimensions such as logic & coherence and term consistency, as evidenced by solid color blocks without gradation. However, this consistency also highlights GPT-4o’s limited ability to capture nuanced regional differences and complex stylistic variations in out-of-domain samples.
Error analysis and interpretability findings
In order to further reveal the boundaries and limitations of the CSN model’s ability in the Buddhist statue recognition task, typical misjudgments and omissions are selected for analysis, focusing on the models’ deficiencies in stylistic judgments, terminology use, symbolic interpretation and logical expression.
In terms of overall performance, the CSN is able to determine the Yuan Dynasty style of the statues in most cases, but its specific analysis often appears to be based on unclear and ambiguous expressions, and lacks clear and characteristic supporting details. When identifying Yuan dynasty Buddhist statues, the model mostly uses general expressions such as “complex decoration” and “delicate carving” as the basis for judgment, but fails to point out key artistic features such as “the five-leafed crown” and “royal ease pose (lalitasana)”. In Sample 01 Vairocana (a central figure in Esoteric Buddhism, representing the universal Buddha), the model correctly attributes the statue to the Yuan period but omits doctrinally significant elements such as “the five-Buddha crown” and “turning-the-wheel mudrā”, which are essential for identifying Vairocana’s religious identity. This tendency of generalization weakens the persuasiveness and professionalism of the model judgment.
In terms of language expression, the CSN had problems with unclear logical chains and jumps in reasoning. For example, some of the responses contained assertions such as “It can be seen from the complex decoration that this is the style of the Yuan Dynasty”, failing to establish a reasonable reasoning process from visual details to style judgment and then to period attribution. This makes the output of the model formally complete, but lacking in academic verifiability and rigor.
The interpretation of symbolism is another challenge of the model. In the face of Tibetan Buddhist statues with strong religious connotations, the CSN often fails to accurately recognize their symbolic systems or misunderstands their religious functions. In Sample 05 Zambala (a tantric wealth deity in Tibetan Buddhism), although the model correctly identifies the dynasty, it fails to recognize core tantric symbols such as the jewel-spitting mongoose or the deity’s ritual association with abundance, thereby overlooking the statue’s esoteric religious role. In Sample 22 Mahākāla, the model completely ignores its typical identity as a protector deity, failing to mention its visual features such as stepping on people, embracing skulls, and flaming patterns, and even misinterpreting the “wrathful” shape as a symbol of “wisdom and enlightenment”, which is completely out of the cultural context of the Buddhist Tantric statue system. These issues are illustrated in Fig. 6d, which presents a comparative visualization of expert interpretations, CSN outputs, and baseline models’ responses across three Yuan-dynasty Buddhist statues.
Summary of evaluation outcomes
Through the comprehensive analysis of the CSN model’s recognition performance and multi-dimensional evaluation results on 22 groups of Yuan dynasty grotto statues, it can be seen that the model has a good performance in the areas of “historical period recognition”, “terminology standardization”, “cultural interpretation” and “linguistic interpretation”. Its overall score is ahead of other mainstream models, showing strong professional expression ability and adaptability to regional contexts. Within the coverage of the training corpus, CSN is able to accurately grasp the style of Yuan dynasty statues, and complete the task of style categorization and expression in a more standardized language.
However, the model still has systematic limitations in several key aspects. Firstly, CSN performs significantly better on “in-domain” samples than “out-of-domain” samples, which shows that its recognition ability is strongly dependent on the training context, and it is still difficult to cope with the task of migrating the recognition of unfamiliar styles and rare subjects, and its generalization ability is insufficient. Secondly, its scores on the “richness of descriptive details” dimension are low, and the standard deviation of the scores on each dimension is generally high, reflecting that its output still needs to be optimized in terms of consistency and completeness of details.
Discussion
This study proposes and evaluates ChronoStyleNet, a domain-specific multimodal model designed for stylistic identification and semantic interpretation of grotto sculptures, with a focus on Yuan-dynasty artworks from Feilai Peak, Hangzhou. Aligning with the trend of applying MLLMs to cultural heritage research, we construct a six-dimensional evaluation system incorporating expert-level archaeological criteria. Comparative testing with five general-purpose multimodal-capable systems reveals that CSN outperforms them in dimensions such as historical period recognition, cultural interpretation, and terminological precision.
ChronoStyleNet serves as an assistive tool for large-scale grotto image processing, style recognition, and scholarly description generation. Its structured prompt design and feedback loop allow for programmable expression of expert knowledge and continuous optimization during deployment. Importantly, CSN’s modular architecture and prompt-based design offer the potential to extend the model to other religious traditions or regional sculptural systems. With minimal architectural changes, the model can be transferred to new iconographic corpora through targeted prompt calibration and transfer learning. While the framework is broadly adaptable, certain iconographic systems may benefit from targeted adjustments to align with distinct symbolic logics. With its reusable scoring criteria and modular supervision interface, CSN also lowers the barrier for non-specialist users, offering educational applicability under guided use. As human–AI interaction increases, the model’s descriptive and interpretive capabilities will likely evolve through expert feedback and iterative refinement. This work highlights the potential of AI to bridge expertise gaps in endangered sites globally, redefining best practices for digital conservation and setting a new state of the art for heritage informatics.
However, the model faces multiple limitations that inform directions for future development. First, its current training scope is limited to sculptures from Feilai Peak. While this site offers strong preservation and clear stylistic features, broader coverage across regions and dynasties is needed to improve generalizability. We propose a three-phase data expansion plan: first extending to other major grottoes within Zhejiang, then to Jiangnan sites, and ultimately toward a balanced national-scale dataset. Future iterations will incorporate additional images per object, including multi-angle and close-up perspectives, to support more comprehensive spatial understanding and visual detail recognition.
CSN still struggles to capture the symbolic and ritual significance embedded in visual details. To improve this, we will introduce structured symbolic annotations informed by expert knowledge, linking elements such as gestures, ornaments, and deity forms to their religious functions. These annotations will support a stepwise training process—from visual recognition to symbolic inference and final interpretation. In parallel, we plan to incorporate religious ontologies and knowledge graphs to help the model reason across deity hierarchies and symbolic systems. In terms of output expressivity, CSN sometimes produces less detailed descriptions than baseline model. This may reflect a trade-off between clarity and richness. To address this, we will explore multi-stage generation and reinforcement-based strategies that allow for more elaborate yet accurate outputs. Prompt design will also be improved by embedding symbolic cues to make responses more specific and culturally grounded.
These findings suggest that while ChronoStyleNet has demonstrated its feasibility and utility, its output should remain subject to professional review in high-stakes applications such as digital conservation or public exhibitions. Future development may include integrating real-time environmental sensing for deterioration monitoring, extending the model’s utility in risk-aware heritage management. In public-facing applications, CSN can serve as the backbone for interactive tools such as AR-guided tours or semantic visualization interfaces. By bridging the gap between expert knowledge and lay perception, CSN provides a framework that facilitates the translational application of grotto art in public education and cultural communication.
Dataset Documentation
The dataset covers 49% of the qualified sculptural samples from the West Lake region, based on a total of 596 grotto sculptures across 24 cave sites. Sculptures from Shiwudong (Stone House Cave), amounting to approximately 500 entries, were excluded from the count due to their modern reconstructions and lack of historical authenticity.
Data availability
The expert-annotated sculpture dataset (295 statues from Feilai Peak Grottoes) and the test dataset (22 Yuan-dynasty sculptures) generated and analyzed during the current study are not publicly available at this time due to the sensitive nature of ongoing research and agreements with heritage authorities for the protection of cultural site data. However, these datasets, along with a detailed list of sources for the 2.46 GB archaeological literature corpus, are available from the corresponding author (Wei Ren, wei.ren1012@foxmail.com) on reasonable request, subject to appropriate ethical considerations and data sharing agreements.
Code availability
The custom code for the ChronoStyleNet (CSN) model, including scripts for data processing, model training (based on the llava-onevision-qwen2-7b framework), and evaluation, are currently under active development and refinement as part of ongoing research. The code is not yet publicly archived but is available from the corresponding author (Wei Ren, wei.ren1012@foxmail.com) on reasonable request for research and verification purposes, subject to a material transfer agreement or appropriate licensing to protect intellectual property. All training and evaluation code will be released in a public GitHub repository within six months of the paper’s acceptance. The repository link will be provided upon publication.
References
Lai, T. Han-Tibetan Treasures: a Study of the Feilai Peak Cave Statues in Hangzhou. (Cultural Relics Publishing House, 2015).
Shao, Q. (Ed.) Hangzhou Grottoes (Shanghai Jiao Tong University Press, 2023).
Grilli, E., Özdemir, E. & Remondino, F. Application of machine and deep learning strategies for the classification of heritage point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. XLII-4/W18, 447–454 (2019).
Cintas, C. et al. Automatic feature extraction and classification of Iberian ceramics based on deep convolutional networks. J. Cult. Herit. 41, 106–112 (2020).
Howard, A. F., Wu, H., Li, S. & Yang, H. Chinese Sculpture (Yale University Press, 2006).
Croce, V. et al. Semi-automatic classification of digital heritage on the aïoli open source 2D/3D annotation platform via machine learning and deep learning. J. Cult. Herit. 62, 187–197 (2023).
Wang, K., Xu, G., Li, S. & Ge, C. Geo-environmental characteristics of weathering deterioration of red sandstone relics: a case study in tongtianyan grottoes, southern China. Bull. Eng. Geol. Environ. 77, 1515–1527 (2018).
Zhang, J. et al. Surface weathering characteristics and degree of niche of sakyamuni entering nirvana at dazu rock carvings, China. Bull. Eng. Geol. Environ. 78, 3891–3899 (2019).
Sesana, E., Gagnon, A. S., Ciantelli, C., Cassar, J. & Hughes, J. J. Climate change impacts on cultural heritage: a literature review. WIREs Clim. Change 12, e710 (2021).
Su, B. Studies on Chinese Grotto Temples (SDX Joint Publishing Company, 2019).
Yu, T. et al. Artificial intelligence for dunhuang cultural heritage protection: The project and the dataset. Int. J. Comput. Vis. 130, 2646–2673 (2022).
Anichini, F. et al. Developing the ArchAIDE application: a digital workflow for identifying, organising and sharing archaeological pottery using automated image recognition. Internet Archaeol. https://doi.org/10.11141/ia.52.7 (2020).
Chen, H. et al. DualAST: dual style-learning networks for artistic style transfer. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 872–881. https://doi.org/10.1109/CVPR46437.2021.00093 (IEEE, 2021).
Gîrbacia, F. An analysis of research trends for using artificial intelligence in cultural heritage. Electronics 13, 3738 (2024).
Chapinal-Heras, D. & Díaz-Sánchez, C. A review of AI applications in human sciences research. Digit. Appl. Archaeol. Cult. Herit. 30, e00288 (2023).
Windhager, F. et al. Visualization of cultural heritage collection data: State of the art and future challenges. IEEE Trans. Vis. Comput. Graph. 25, 2311–2330 (2019).
Li, M., Wang, Y. & Xu, Y.-Q. Computing for Chinese cultural heritage. Vis. Inform. 6, 1–13 (2022).
Marsili, G. & Orlandi, L. M. Digital humanities and cultural heritage preservation: the case of the BYZART (byzantine art and archaeology on europeana) project. Stud. Digit.Herit. 3, 2, https://doi.org/10.14434/sdh.v3i2.27721 (2019).
Marchand, E. et al. Extraction of a Knowledge Graph from French cultural heritage documents.In Proc. ADBIS, TPDL and EDA 2020 Common Workshops and Doctoral Consortium, 23–35 https://doi.org/10.1007/978-3-030-55814-7_2 (Springer International Publishing, 2020).
Yang, S. & Hou, M. Knowledge graph representation method for semantic 3D modeling of Chinese grottoes. Herit. Sci. 11, 266 (2023).
Spallone, R. et al. 3D modelling and virtual reality for museum heritage presentation: Contextualisation of sculpture from the tang era. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. XLVIII-2-W4-2024, 413–420 (2024).
Skublewska-Paszkowska, M., Milosz, M., Powroznik, P. & Lukasik, E. 3D technologies for intangible cultural heritage preservation—literature review for selected databases. Herit. Sci. 10, 3 (2022).
De Luca, L. 3D modelling and semantic enrichment in cultural heritage. in Photogrammetric Week ’13 (eds. Fritsch D.). https://hal.science/hal-02892090 (2013).
Grilli, E., Dininno, D., Marsicano, L., Petrucci, G. & Remondino, F. Supervised segmentation of 3D cultural heritage. in Proc. 3rd Digital Heritage International Congress (DigitalHERITAGE) held jointly with 2018 24th International Conference on Virtual Systems & Multimedia (VSMM 2018), 1–8. https://doi.org/10.1109/DigitalHeritage.2018.8810107 (IEEE, 2018).
Bi, X., Sun, Z. & Chen, Z. A novel unsupervised contrastive learning framework for ancient Yi script character dataset construction. Npj Herit. Sci. 13, 39 (2025).
Yu, T. et al. End-to-end partial convolutions neural networks for dunhuang grottoes wall-painting restoration. in Proc. IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 1447–1455. https://doi.org/10.1109/ICCVW.2019.00182. (IEEE, 2019).
Li, Y. et al. Universal style transfer via feature transforms. Adv. Neural Inf. Process. Syst. 30, https://proceedings.neurips.cc/paper/2017/hash/49182f81e6a13cf5eaa496d51fea6406-Abstract.html (2017).
Marafini, F. A proposal of classification for machine-learning vibration-based damage identification methods. 593–598. https://doi.org/10.21741/9781644902431-96 (2023).
Tan, X., Wu, X. & Yang, C. Visual cultural symbol recognition based on muti-feature extracting. In Proc. 8th International Symposium on Computational Intelligence and Design (ISCID), 306–310. https://doi.org/10.1109/ISCID.2015.304 (IEEE, 2015).
Zhu, D. et al. XunZi-MLLM: A multimodal large language model for ancient text and image recognition. Digit. Scholarsh. Humanit. fqaf026. https://doi.org/10.1093/llc/fqaf026 (2025).
Rachabatuni, P. K., Principi, F., Mazzanti, P. & Bertini, M. Context-aware chatbot using MLLMs for Cultural Heritage. In Proc. ACM Multimedia Systems Conference 2024 on ZZZ, 459–463. https://doi.org/10.1145/3625468.3652193 (ACM, 2024).
Zhang, C. et al. Can MLLMs understand the deep implication behind Chinese images? In Proc. 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 700, 14369–14402. https://doi.org/10.18653/v1/2025.acl-long. (Association for Computational Linguistics, Vienna, Austria, 2025).
Liu, S. et al. CultureVLM: Characterizing and improving cultural understanding of vision-language models for over 100 countries. Preprint at https://doi.org/10.48550/arXiv.2501.01282 (2025).
Zhou, Z., Xi, Y., Xing, S. & Chen, Y. Cultural bias mitigation in vision-language models for digital heritage documentation: a comparative analysis of debiasing techniques. Artif. Intell. Mach. Learn. Rev. 5, 28–40 (2024).
Zhong, T. et al. Opportunities and challenges of large language models for low-resource languages in humanities research. Preprint at. https://doi.org/10.48550/arXiv.2412.04497 (2024).
Urailertprasert, N., Limkonchotiwat, P., Suwajanakorn, S. & Nutanong, S. SEA-VQA: Southeast Asian cultural context dataset for visual question answering. In Proc. 3rd Workshop on Advances in Language and Vision Research (ALVR), 173–185. https://doi.org/10.18653/v1/2024.alvr-1.15 (Association for Computational Linguistics, 2024).
Luo, Y., Tang, J., Huang, C., Hao, F. & Lian, Z. CalliReader: contextualizing chinese calligraphy via an embedding-aligned vision-language model. Preprint at https://doi.org/10.48550/arXiv.2503.06472 (2025).
Rein, D. et al. GPQA: a graduate-level Google-proof Q&A benchmark. First Conference on Language Modeling. https://openreview.net/forum?id=Ti67584b98 (ICLR, 2024).
Pavlova, V. & Makhlouf, M. Building an efficient multilingual non-profit IR System for the Islamic domain leveraging multiprocessing design in rust. In Proc. 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track 73, 981–990, https://doi.org/10.18653/v1/2024.emnlp-industry. (Association for Computational Linguistics, Miami, Florida, US, 2024).
Alrefaie, M. T., Salem, F., Morsy, N. E., Samir, N., & Gaber, M. M. The Dynamics of Meaning Through Time: Assessment of Large Language Models. arXiv. https://doi.org/10.48550/arXiv.2501.05552 (2025).
Chartier, M., Dakkoune, N., Bourgeois, G. & Jean, S. HiBenchLLM: historical inquiry benchmarking for large language models. Data Knowl. Eng. 156, 102383 (2025).
Liu, Y.et al. G-eval: NLG evaluation using GPT-4 with better human alignment. In Proc. 2023 Conference on Empirical Methods in Natural Language Processing 153, 2511–2522 https://doi.org/10.18653/v1/2023.emnlp-main. (Assoclation for Computational Linguistics, Singapore, 2023).
Sottana, A., Liang, B., Zou, K. & Yuan, Z. Evaluation metrics in the era of GPT-4: reliably evaluating large language models on sequence to sequence tasks. In Proc. 2023 Conference on Empirical Methods in Natural Language Processing 543, 8776–8788 https://doi.org/10.18653/v1/2023.emnlp-main. (Association for Computational Linguistics, Singapore, 2023).
Akbulut, C. et al. Century: a framework and dataset for evaluating historical contextualisation of sensitive images. In Proc. 13th International Conference on Learning Representations (2025).
Yu, T. et al. Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants. Preprint at https://doi.org/10.48550/arXiv.2310.00653 (2023).
Li, F. et al. LLaVA-NeXT-interleave: tackling multi-image, video, and 3D in large multimodal models. Preprint at https://doi.org/10.48550/arXiv.2407.07895 (2024).
Dong, X. et al. InternLM-XComposer2: mastering free-form text-image composition and comprehension in vision-language large model. Preprint at https://doi.org/10.48550/arXiv.2401.16420 (2024).
Liu, H., Li, C., Wu, Q. & Lee, Y. J. Visual Instruction Tuning. In Proc. 37th International Conference on Neural Information Processing Systems 1–25 (Curran Associates Inc., New Orleans, LA, USA, 2023).
Zhejiang Provincial Institute of Cultural Relics and Archaeology & Institute for Cultural Heritage, Zhejiang University. Collected Studies on the Archaeology of Zhejiang Grottoes: Volume I & II. (Zhejiang Ancient Books Publishing House, 2024).
LMMs-Lab. LLaVA-OneVision-Qwen2-7B Model Card. https://huggingface.co/lmms-lab/llava-onevision-qwen2-7b-ov (2024).
Tibaut, A. & Guerra de Oliveira, S. A framework for the evaluation of the cultural heritage information ontology. Appl. Sci. 12, 795 (2022).
OpenAI. GPT-4o Technical Report. https://openai.com/gpt-4o (2024).
Anthropic. Claude 3.5 Sonnet Model Card. https://www.anthropic.com/index/claude-3-5 (2024).
DeepMind, G. Gemini 1.5 Pro Experimental Release Notes. https://deepmind.google/technologies/gemini (2025).
AI, M. LLaMA-3.3-Nemotron-70B-Select Release Notes. https://ai.meta.com/llama (2024).
xAI. Grok 3 Beta Overview. https://x.ai/blog/grok (2025).
Acknowledgements
This research was funded by the Natural Science Foundation of Zhejiang Province (Y22D010489; “3D identification and classification of Buddhist sculptures based on the ResNet model”), the Philosophy and Social Sciences Planning Project of Zhejiang Province—Rare & Under-studied Disciplines Programme (23LMJX15YB; “AI-based cataloguing of figural sculptures from Zhejiang’s grotto temples and rock carvings”), the second cohort of “14th Five-Year Plan” Provincial Graduate-level Teaching Reform Projects, Zhejiang (JGCG2024479; “Construction and sharing of a graduate educational resource bank built on large-scale digital models of grotto sculptures”), and the 2022 Spring Breeze (Chunhui) Collaborative Research Project of the Ministry of Education (HZKY202220194; “Digital restoration of overseas-lost grotto sculptures using artificial intelligence”). We also acknowledge the advanced computing resources provided by the Supercomputing Center of Hangzhou City University. The authors are grateful to Kui Su, Jun Lu, Yio Zhang, Bing Yang and Yi Ding for their valuable assistance with high-performance computing.
Author information
Authors and Affiliations
Contributions
J.X. collected and organized the dataset, assisted in model fine-tuning, conducted experiments, analyzed results, created visualizations, and finished the manuscript. D.L. and L.Z. contributed to data collection and organization, and assisted in model tuning. X.Q. provided suggestions for research design and offered critical feedback. H.D.S. and W.R. designed the visual prompt tuning strategy and provided technical consultation. Y.R.H. organized data and provided feedback during model training. Z.K.Y. contributed to data collection. Z.X., R.Y., J.T.Y., J.W., W.C., and J.X. participated in the review of the manuscript. X.P.Z. was responsible for data labeling and annotation correction. C.Y. collected part of the data on grotto cultural relics and statues. W.Z. constructed and repeatedly revised the theoretical framework for research on cultural relic models. B.B.Z. contributed to the review of the manuscript. W.R. supervised the project, proposed the ChronoStyleNet framework, and provided key guidance on the overall direction. All authors contributed to the interpretation of results and provided substantial feedback on the analysis and manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xing, J., Ren, W., Lei, D. et al. Multimodal AI for Yuan Buddhist sculpture chronology and style. npj Herit. Sci. 13, 443 (2025). https://doi.org/10.1038/s40494-025-01994-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-01994-3
