
Abstract
This study systematically compares the performance of two widely used proteomics software packages, FragPipe (FP) and Proteome Discoverer (PD), in the identification of proteinaceous binders in painted artifacts. While both tools deliver comparable performance in terms of protein identification numbers and accuracy, FP demonstrates a marked advantage in computational efficiency, completing database searches within one minute and achieving a 95.7–96.9% reduction in processing time relative to PD. Conversely, PD exhibits strengths in the nuanced analysis of specific proteins, particularly in complex matrices such as egg white glue and mixed adhesive formulations. As an open-source software freely available for non-commercial use, FP affords both high efficiency and robust accuracy in the analytical characterization of polychrome binders, whereas PD offers complementary value through its enhanced capacity for the detection of low-abundance proteins. These findings advance proteomics in archaeology and heritage conservation, optimizing protein identification strategies for ancient painted artifacts.
Similar content being viewed by others
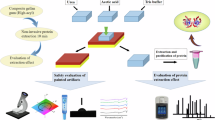


Introduction
Proteomics, an advanced analytical methodology integrating chromatography with mass spectrometry, facilitates the systematic investigation of the structure, composition, and function of proteins within complex biological matrices. Since its pioneering introduction to the field of cultural heritage science in 2006, proteomics has proven to be a powerful tool for the identification of proteinaceous materials in artworks and archaeological artifacts1,2,3,4,5,6,7,8,9,10. Beyond the characterization of individual proteins, proteomic approaches have opened new avenues for the study of ancient proteomes and metaproteomes, offering molecular-level insights into past organisms and their associated communities preserved within archaeological contexts11.
Painted artifacts—including murals, architectural polychromy, pottery, and ornamental objects—constitute vital material evidence of the evolution of artistic practices and technological innovation in antiquity. Proteinaceous binders such as animal glue, milk, and egg were extensively employed in traditional painting techniques, reflecting both regional material preferences and the transmission of artisanal knowledge across generations12,13,14,15,16. The advent of proteomic methodologies now enables the molecular analysis of these ancient biomolecules, offering new perspectives on the production technologies and aesthetic traditions of past societies. For instance, proteomic analysis of a 49,000-year-old ochre-stained stone slab from the Sibudu site in South Africa revealed residues of casein, providing the earliest known evidence of milk use in paint preparation13. Likewise, the identification of ovalbumin in Italian Renaissance frescoes has substantiated the continuity of tempera painting traditions within ecclesiastical art17, while the detection of bovine collagen in Qing dynasty tian-tsui headdress offers compelling insights into the binder formulations employed in traditional Chinese craftsmanship18.
Accurate identification of proteinaceous binders in painted artifacts not only deepens our understanding of ancient artistic practices but also informs strategies for cultural heritage preservation and sheds light on historical economies, animal resource management, and environmental adaptation7,19. However, the proteomic analysis of archaeological proteins presents significant challenges. Over time, proteins undergo degradation into fragmented and chemically modified peptides, resulting in discontinuous sequences and diminished confidence in identifications. Furthermore, exogenous proteins introduced through burial environments or handling can obscure authentic signals, necessitating rigorous data discrimination protocols during analysis20.
Within these constraints, the selection of database search tools and the optimization of search parameters become critical determinants of analytical success. Accurate peptide-spectrum matching, judicious database selection, and meticulous manual validation are essential for enhancing the reliability of identifications. Among the commonly employed search engines, Proteome Discoverer (PD), developed by Thermo Fisher Scientific Inc., is widely recognized for its stability, integrated data-processing workflows, and broad compatibility with quantitative strategies21,22,23,24. Notably, PD remains one of the most prevalent platforms in the field of paleoproteomics4,6,25,26,27. Nevertheless, its high licensing costs and comparatively slow search speeds may constrain its utility in large-scale or time-sensitive investigations28.
By contrast, FragPipe (FP), an open-source platform freely available for non-commercial applications and developed by the Nesvizhskii Lab, integrates the MSFragger search engine to deliver rapid and high-accuracy peptide identifications29. Recent studies have demonstrated FP’s robust performance across diverse experimental conditions29,30,31, with particular efficacy in the analysis of ancient proteins32,33,34.
Against this backdrop, the present study undertakes a systematic comparison of PD and FP within the context of painted artifact proteomics. Utilizing high-performance liquid chromatography coupled with tandem mass spectrometry (HPLC-MS/MS), we generated protein profiles from simulated samples and assessed the two platforms across key performance metrics, including search speed, protein identification counts, and identification accuracy. The results offer an empirical foundation for the selection and optimization of proteomic data analysis workflows in the study of cultural heritage.
Methods
Materials
Ferric oxide was purchased from Shanghai MacLean Biochemical Technology Co., Ltd. (China). Guanidine hydrochloride was obtained from Sinopharm Chemical Reagent Co., Ltd. (China). Dithiothreitol (DTT), iodoacetamide (IAA), urea, water, formic acid (FA), acetonitrile (ACN), trifluoroacetic acid (TFA), sequencing-grade trypsin, and ammonium bicarbonate (AMBIC) were sourced from Sigma-Aldrich (USA), all of analytical grade. Cowhide glue granules (No. 63020) and egg white powder (No. 63250) were acquired from Kremer Pigmente GmbH (Germany), while whole milk powder was provided by Bright Dairy & Food Co., Ltd. (China).
Specimen preparation
To evaluate the performance of different proteomic software in identifying a range of proteinaceous binders, test specimens were prepared using four representative binder types commonly encountered in painted artifacts: cowhide glue, milk, egg white, and a composite binder comprising equal proportions of the three.
The preparation procedure was as follows: each binder was dissolved in distilled water at 40 °C using a constant-temperature water bath (HH-8, Shanghai Lichen Instrument Technology Co., Ltd., China) to achieve a final concentration of 80 mg/mL35,36. Ferric oxide, a pigment frequently employed in traditional polychrome painting37,38 was then incorporated at a pigment-to-binder mass ratio of 1:2, following established protocols and corroborated by preliminary experiments19,36,39. Subsequently, 100 μL aliquots of the resulting mixtures were deposited onto polytetrafluoroethylene plates and allowed to dry under ambient conditions.
To simulate the effects of natural aging, the dried specimens were subjected to thermal aging in a blast oven (DHG-9070A, Shanghai Yiheng Technology Instrument Co., Ltd., China) at 100 °C for 100 h, with reference to and slight modifications from established methodologies in relevant literature40,41,42.
Protein extraction
Aged specimens were carefully scraped from the polytetrafluoroethylene plates and incubated with 3 mL of 1.89 M guanidine hydrochloride. The suspensions were subjected to ultrasonic treatment in a sonicator bath (KM-300DE, Kunshan Meimei Ultrasonic Instrument Co., Ltd.) at 210 W and 57 °C for 5 h. Upon completion of sonication, the samples were cooled to room temperature, centrifuged at 8000 rpm for 10 min at 25 °C, and the resulting supernatants were collected for further processing39.
A 300 μL aliquot of each supernatant was transferred into a 5 kDa molecular weight cut-off dialysis device (MD10, Hunan Yibo Biotechnology Co., Ltd., China) and dialyzed against 500 mL of deionized water. The dialysate was refreshed at intervals of 4, 8, 14, and 22 h to ensure thorough desalting. Following dialysis, the solutions were vacuum-concentrated using a centrifugal concentrator (Concentrator plus, Eppendorf CE, Germany), and the resulting residues were reconstituted in 10 μL of deionized water for subsequent analysis.
LC-MS/MS analysis
Protein solutions were first dissolved in 8 M urea, reduced with 5 mM DTT at 50 °C for 30 min, and subsequently alkylated with 15 mM IAA in the dark at room temperature for 30 min. The buffer was then exchanged to 50 mM AMBIC (pH 8.0) using a 5 kDa molecular weight cut-off dialysis device. Proteins were digested overnight at 37 °C with sequencing-grade trypsin at a trypsin-to-protein ratio of 1:20 (w/w, pH 8.0). The resulting peptide solution was acidified to pH 2 using FA to a final concentration of 1%, desalted with C18 ZipTips (Thermo Fisher Scientific Inc., USA), and vacuum-dried prior to analysis.
Peptide samples were analyzed using an EASY-nLC 1200 system coupled to an Orbitrap Fusion Lumos mass spectrometer equipped with an EASY-IC ion source (Thermo Fisher Scientific Inc., USA). Injection blanks were included before and after each sample analysis to minimize possible sample carryover between runs. Peptides were reconstituted in 10 μL of 0.1% formic acid and automatically loaded onto a homemade C18 analytical column (35 cm × 75 μm i.d., 2.5 μm, 100 Å) operated at room temperature. Chromatographic separation was achieved over a 120-min linear gradient of 3–35% acetonitrile in 0.1% formic acid, at a constant flow rate of 300 nL/min.
Following chromatographic separation, peptides were ionized via nanoelectrospray ionization and introduced into the mass spectrometer operating in data-dependent acquisition (DDA) mode with a 2-s cycle time between master scans, using the Orbitrap mass analyzer. Full MS scans were acquired at a resolution of 60,000 with the following parameters: AGC target = 4 × 105, m/z range = 350–1500, and maximum injection time = 50 ms. MS/MS scans were triggered on precursors with charge states +2 to +7 and intensities >20,000, employing higher-energy collisional dissociation (HCD), with quadrupole isolation (1.6 m/z), resolution of 15,000, AGC target = 50,000, and maximum injection time = 22 ms. A dynamic exclusion window of 30 s was applied.
Database search and software configuration
Database searches were conducted against UniProt datasets (retrieved on November 19, 2024), specifically targeting Laurasiatheria (Swiss-Prot) and Galloanserae (Swiss-Prot), with the inclusion of contaminant entries from The GPM CRAP database (https://www.thegpm.org/crap/). All analyses were performed on 64-bit Windows 10 operating systems.
For FP (v22.0) utilizing MSFragger (v4.1) as the search engine, the following parameters were applied:
Enzyme: Trypsin; Missed cleavages: 3; Fixed modification: Carbamidomethylation (C); Variable modifications: Oxidation (M), Acetylation (Protein N-terminus); Maximum variable modifications per peptide: 3; Precursor mass tolerance: 10 ppm; Fragment mass tolerance: 0.02 Da; Peptide length: 6–50 amino acids; Peptide mass range: 350–5000 Da.
For PD (v2.5.0.400) employing Sequest HT (v2.0.0.24) as the search engine, the parameters were as follows:
Enzyme: Trypsin; Missed cleavages: 3; Static modification: Carbamidomethylation (C); Dynamic modifications: Oxidation (M), Acetylation (Protein N-terminus); Maximum equal modifications per peptide: 3; Precursor mass tolerance: 10 ppm; Fragment mass tolerance: 0.02 Da; Peptide length: 6–50 amino acids; Precursor mass range: 350–5000 Da. False discovery rate (FDR) thresholds were set at 0.01 (strict) and 0.05 (relaxed).
For subsequent analysis, protein datasets were curated to exclude exogenous contaminants, notably human keratins and porcine trypsin, from the output of both software platforms. In accordance with the characteristic compositions of each proteinaceous binder, representative target proteins were selected for focused analysis: (1) Cowhide glue: Given that collagen constitutes approximately 85–90% of dermal proteins43, collagen was designated as the primary marker for evaluation. (2) Milk glue: The principal constituents include alpha-S1-casein (33.6% w/w), beta-casein (27.2%), alpha-S2-casein (10.1%), kappa-casein (8.4%), beta-lactoglobulin (8.3%), and alpha-lactoglobulin (2.4%)44. These proteins were selected as definitive targets. (3) Egg white glue. Major components include ovalbumin (54%), ovotransferrin (12%), ovomucoid (11%), ovomucin (3.5%), and lysozyme (3.4%)44, which were similarly designated as target proteins. (4) Mixed glue: Target proteins included the combined characteristic proteins of cowhide glue, milk glue, and egg white glue as outlined above.
The specific target proteins corresponding to each binder type are detailed in Table 1. Definitions of key metrics are as follows: Species identification rate of proteins = Number of proteins from a given species/Total number of proteins. Species identification accuracy of proteins = Number of proteins with correct species identification/Total number of proteins. Species identification rate of target proteins = Number of target proteins from a given species/Total number of target proteins. Species identification accuracy of target proteins = Number of target proteins with correct species identification/Total number of target proteins.
Results
Cowhide glue
The database search times for cowhide glue are presented in Fig. 1a. FP completed the search within 1 min, whereas PD required 32 min. In terms of protein identification, FP identified 77 proteins and 8 target proteins, while PD identified 72 proteins and the same 8 target proteins (Fig. 1b). Notably, 47 proteins (Fig. 1c) and 6 target proteins (Fig. 1d) were commonly identified by both software platforms. Compared to PD, FP achieved equivalent performance in target protein identification, reduced search time by 96.9%, and increased the total number of identified proteins by 6.9%.

a Database search time; b Numbers of identified proteins and target proteins; c Venn diagram of proteins; d Venn diagram of target proteins.
As illustrated in Fig. 2a, the 77 proteins identified by FP originated from 14 species, with Bos taurus constituting the majority (49.4%), followed by Sus scrofa (15.6%), Gallus gallus (13%), and Canis lupus familiaris (5.2%). The overall species identification accuracy of FP for cowhide glue was 49.4%, with an additional 33.7% from Laurasiatheria and 16.9% from Galloanserae. In comparison, Fig. 2b shows that the 72 proteins identified by PD were distributed across 13 species. While Bos taurus remained dominant (51.4%), the proportion of Gallus gallus increased markedly to 26.4%. PD achieved a 51.4% identification accuracy, with the remainder comprising 18% Laurasiatheria (e.g., Sus scrofa, Ovis aries) and 30.6% Galloanserae (including Gallus gallus, Anas platyrhynchos, and related taxa). Comparative analysis reveals that although FP identified a greater total number of proteins, PD exhibited a 4% higher species identification accuracy. It is important to note that this experiment lacked negative controls, and the detection of Galloanserae-derived proteins in both PD and FP indicates potential risks of cross-contamination.

a Species identification rate of proteins for FP; b Species identification rate of proteins for PD; c Species identification rate of target proteins for FP; d Species identification rate of target proteins for PD; e Peptide identification counts of Bos taurus target proteins (collagen alpha-1(I) chain, collagen alpha-1(III) chain, collagen alpha-2(I) chain) by FP and PD.
As shown in Fig. 2c, the target proteins identified by FP were derived from six species, with Bos taurus accounting for 37.5%, followed by equal contributions (12.5% each) from Tapirus terrestris, Canis lupus familiaris, Equus sp., Hippopotamus amphibius, and Gallus gallus. For PD (Fig. 2d), target proteins originated from five species, with Bos taurus maintaining the same 37.5% proportion as in FP, while Gallus gallus increased to 25%; the remaining collagen proteins were attributed to Laurasiatheria.
Further analysis focused on target proteins correctly assigned to Bos taurus by both platforms. As depicted in Fig. 2e, both FP and PD identified collagen alpha-1(I) chain, collagen alpha-1(III) chain, and collagen alpha-2(I) chain. Notably, FP achieved increases of 25%, 66.7%, and 23.8% in peptide identification counts for these proteins, respectively, compared to PD. Overall, FP outperformed PD in peptide identification for target proteins, yielding a 31.9% increase in peptide counts.
In summary, FP demonstrated superior performance over PD in the proteomic analysis of cowhide glue, achieving a 96.9% reduction in database search time and a 6.9% increase in total protein identifications, with comparable performance in target protein identification. Although PD exhibited marginally higher overall species identification accuracy (4%), both platforms were equivalent in correctly identifying the principal collagen types within the target protein set. Critically, FP achieved a notable advantage in the number of peptides identified for target proteins of correct species origin, with an improvement of 31.9% over PD.
Milk glue
For milk glue, FP required only 1 min for database searching, whereas PD took 29 min (Fig. 3a). In terms of protein identification, FP identified 125 proteins, including 15 target proteins, while PD identified 110 proteins with 12 target proteins (Fig. 3b). Among these, 79 proteins (Fig. 3c) and 11 target proteins (Fig. 3d) were commonly identified by both platforms. Relative to PD, FP exhibited a 96.6% reduction in search time, alongside increases of 13.6% and 25% in the total numbers of identified proteins and target proteins, respectively.

a Database search time; b Numbers of identified proteins and target proteins; c Venn diagram of proteins; d Venn diagram of target proteins.
As shown in Fig. 4a, the 125 proteins identified by FP originated from 21 species, with Bos taurus being the predominant source (56%), followed by Ovis aries (7.2%), Gallus gallus (7.2%), Sus scrofa (5.6%), among others. The overall species identification accuracy of FP was 56%, with the remaining 44% derived from Laurasiatheria and Galloanserae. In contrast, Fig. 4b shows that the 110 proteins identified by PD were distributed across 18 species, with Bos taurus again predominant (60%), followed by Gallus gallus (6.4%) and Canis lupus familiaris (5.5%). PD achieved a 60% species identification accuracy, with approximately 33% of proteins originating from other mammalian species. Although FP identified 15 more proteins than PD, PD demonstrated a 7.1% higher protein species identification accuracy.

a Species identification rate of proteins for FP; b Species identification rate of proteins for PD; c Species identification rate of target proteins for FP; d Species identification rate of target proteins for PD; e Peptide identification counts of Bos taurus target proteins (alpha-S1-casein, beta-casein, alpha-S2-casein, kappa-casein and beta-lactoglobulin) by FP and PD.
As illustrated in Fig. 4c, the 15 target proteins identified by FP were derived from eight species, with Bos taurus accounting for 33.3%, and the remainder from Bubalus bubalis (20%), Ovis aries (13.3%), Capra hircus (6.7%), and others. In comparison, Fig. 4d shows that the 12 target proteins identified by PD originated from six species, with Bos taurus contributing 41.7%, followed by Bubalus bubalis (25%), and the remainder classified under Laurasiatheria. Notably, PD’s species identification accuracy for target proteins exceeded that of FP by 25.2%.
Further analysis focused on target proteins correctly classified as Bos taurus. As shown in Fig. 4e, both FP and PD successfully identified alpha-S1-casein, beta-casein, alpha-S2-casein, kappa-casein, and beta-lactoglobulin, while alpha-lactoglobulin was undetected in either case. This absence likely reflects the naturally low abundance of alpha-lactoglobulin in milk44 and its susceptibility to degradation during aging. Regarding peptide identifications, FP demonstrated a slight advantage for alpha-S2-casein and kappa-casein, whereas PD showed marginally higher counts for beta-casein and beta-lactoglobulin. Nevertheless, both FP and PD achieved a total of 76 peptide identifications across all target proteins.
In summary, FP demonstrated a significant advantage over PD in database search efficiency for milk glue, achieving a 96.6% reduction in search time. FP also achieved 13.6% and 25% increases in the numbers of total proteins and target proteins identified, respectively. However, PD exhibited superior accuracy in species identification, with improvements of 7.1% and 25.2% in the accuracy rates for total proteins and target proteins, respectively, compared to FP. Importantly, both platforms performed comparably in terms of the number of peptide identifications for target proteins correctly assigned to Bos taurus.
Egg white glue
In the proteomic analysis of egg white glue, FP exhibited a substantially shorter database search time of 1 min, compared to 23 min for PD (Fig. 5a). Regarding protein identification, FP identified 70 proteins, including 25 target proteins, while PD identified 69 proteins, with 24 target proteins (Fig. 5b). Further analysis revealed 49 overlapping proteins (Fig. 5c) and 14 overlapping target proteins (Fig. 5d) between the two platforms. Overall, FP achieved a 95.7% reduction in database search time relative to PD, alongside increases of 1.4% and 4.2% in total protein and target protein identifications, respectively.

a Database search time; b Numbers of identified proteins and target proteins; c Venn diagram of proteins; d Venn diagram of target proteins.
As shown in Fig. 6a, the 70 proteins identified by FP originated from 25 species, with Gallus gallus as the predominant contributor (42.9%), followed by Bos taurus (15.7%) and Coturnix japonica (4.3%). The species identification accuracy of FP was 42.9%, with the remaining 57.1% of proteins attributed to Laurasiatheria and other Galloanserae species. In comparison, Fig. 6b shows that PD identified 69 proteins from 22 species, with Gallus gallus again comprising the largest proportion (43.5%), followed by Bos taurus (20.3%). PD attained a 43.5% species identification accuracy, with approximately 29% derived from other Galloanserae species (e.g., Anas platyrhynchos, Anser anser anser, Callipepla californica), and the remainder from mammals. Consistent with previous results for cowhide glue and milk glue, although FP identified one additional protein compared to PD, PD exhibited a 1.4% improvement in species identification accuracy.

a Species identification rate of proteins for FP; b Species identification rate of proteins for PD; c Species identification rate of target proteins for FP; d Species identification rate of target proteins for PD; e Peptide identification counts of Gallus gallus target proteins (ovalbumin, ovalbumin-related protein X (Fragment), ovalbumin-related protein Y, ovotransferrin, ovomucoid and lysozyme C) by FP and PD.
As illustrated in Fig. 6c, the 25 target proteins identified by FP originated from 18 species, with Gallus gallus accounting for 20%, and the remaining proteins derived from other Galloanserae species such as Coturnix japonica (8%), Meleagris gallopavo (8%), and Ortalis vetula (8%). In contrast, Fig. 6d shows that PD identified 24 target proteins from 16 species, with 25% originating from Gallus gallus, followed by Anas platyrhynchos, Callipepla californica, and Meleagris gallopavo (each 8.3%). In terms of species identification accuracy for target proteins, PD again outperformed FP, showing a 25% improvement, consistent with findings for milk glue.
Further analysis focused on target proteins correctly assigned to Gallus gallus by both platforms. As shown in Fig. 6e, FP and PD both successfully identified ovalbumin, ovalbumin-related protein X (Fragment), ovalbumin-related protein Y, ovotransferrin, and ovomucoid. Notably, however, lysozyme C was additionally identified by PD. Although FP also detected lysozyme C among target proteins, it erroneously assigned this protein to other Galloanserae species. PD’s integration of the Sequest HT search engine with Percolator post-processing significantly enhanced its species identification accuracy for egg white glue target proteins, yielding a 25% improvement over FP, and correctly attributing lysozyme C to Gallus gallus. Regarding peptide identifications, while FP failed to identify peptides attributable to Gallus gallus lysozyme C, FP achieved a 13.7% higher total peptide count for Gallus gallus target proteins compared to PD.
In summary, FP demonstrated a 95.7% reduction in database search time for egg white glue compared to PD, alongside 1.4% and 4.2% increases in total protein and target protein identifications, respectively. However, PD exhibited superior taxonomic accuracy, with 1.4% and 25% improvements in species identification accuracy for total proteins and target proteins, respectively. Furthermore, although FP identified 13.7% more peptides overall for Gallus gallus target proteins, PD uniquely identified 12 additional lysozyme C peptides, demonstrating enhanced sensitivity for the accurate identification of low-abundance proteins.
Mixed glue
The database search times for mixed glue are presented in Fig. 7a. FP required only 1 min to complete the search, whereas PD required 28 min. Regarding protein identification, FP identified 58 proteins, including 31 target proteins, while PD detected 68 proteins, of which 35 were target proteins (Fig. 7b). Further analysis revealed that 45 proteins (Fig. 7c) and 24 target proteins (Fig. 7d) were commonly identified by both platforms. Overall, FP achieved a 96.4% reduction in search time relative to PD; however, PD exhibited superior performance in protein identification, detecting 17.2% more total proteins and 12.9% more target proteins.

a Database search time; b Numbers of identified proteins and target proteins; c Venn diagram of proteins; d Venn diagram of target proteins.
As shown in Fig. 8a, FP identified 58 proteins from 20 species, with Gallus gallus and Bos taurus accounting for 32.8% and 29.3%, respectively. Other species included Anas platyrhynchos, Canis lupus familiaris, Coturnix japonica, and Ovis aries (each 3.4%). The overall species identification accuracy of FP was 62.1% (the combined proportion of Bos taurus and Gallus gallus), with the remaining 37.9% derived from Laurasiatheria and other Galloanserae species. In comparison, Fig. 8b shows that PD identified 68 proteins across 24 species, with Bos taurus (30.9%) and Gallus gallus (26.5%) as the predominant species, alongside a wider taxonomic range including Anas platyrhynchos, Bos mutus grunniens, and Canis lupus familiaris. Although PD identified more proteins, FP exhibited an 8.2% higher species identification accuracy.

a Species identification rate of proteins for FP; b Species identification rate of proteins for PD; c Species identification rate of target proteins for FP; d Species identification rate of target proteins for PD; e Peptide identification counts of Bos taurus target proteins (collagen alpha-1(I) chain, collagen alpha-1(III) chain, collagen alpha-1(XI) chain, collagen alpha-2(I) chain, alpha-S1-casein, beta-casein, alpha-S2-casein, kappa-casein, beta-lactoglobulin) by FP and PD. f Peptide identification counts of Gallus gallus target proteins (ovalbumin, ovalbumin-related protein X (Fragment), ovalbumin-related protein Y, ovotransferrin, ovomucoid, lysozyme C, collagen alpha-2(I) chain) by FP and PD.
As illustrated in Fig. 8c, FP’s 31 target proteins originated from 17 species, with Bos taurus accounting for 25.8% and Gallus gallus for 22.6%. The overall species identification accuracy for FP target proteins was 48.4%. In contrast, Fig. 8d shows that PD identified 35 target proteins from 18 species, with Bos taurus (25.7%) and Gallus gallus (20%) predominating, yielding a target protein species identification accuracy of 45.7%. FP thus showed a 5.9% improvement over PD in target protein species identification accuracy.
Further analysis focused on Bos taurus and Gallus gallus target proteins identified by both software platforms. As shown in Fig. 8e, both FP and PD successfully identified cowhide glue proteins from Bos taurus, including collagen alpha-1(I) chain, collagen alpha-1(III) chain, collagen alpha-2(I) chain, and milk glue proteins such as alpha-S1-casein, beta-casein, alpha-S2-casein, kappa-casein, and beta-lactoglobulin. Both platforms identified 100 peptides for Bos taurus target proteins; however, PD uniquely detected collagen alpha-1(XI) chain (peptide GPQGPAGR), which FP did not. As shown in Fig. 8f, both FP and PD identified Gallus gallus target proteins, including ovalbumin, ovalbumin-related protein X (Fragment), ovalbumin-related protein Y, ovotransferrin, ovomucoid, lysozyme C, and collagen alpha-2(I) chain. FP demonstrated a 7.8% increase in the total number of peptides identified for Gallus gallus target proteins compared to PD.
In summary, for mixed glue analysis, FP achieved a 96.4% reduction in database search time relative to PD. Conversely, PD outperformed FP in protein identification, detecting 17.2% more total proteins and 12.9% more target proteins. However, FP demonstrated superior performance in species identification accuracy, with 8.2% and 5.9% higher accuracy rates for total proteins and target proteins, respectively. Regarding peptide counts correctly assigned to Bos taurus and Gallus gallus target proteins, FP achieved 4.4% more peptides overall, though PD uniquely identified collagen alpha-1(XI) chain from Bos taurus, which was absent in FP’s results.
A one-way ANOVA was performed to assess differences between software platforms across multiple key parameters (Table 2). The independent variable was the software (FP or PD), and the dependent variables were drawn from analyses of cowhide glue, milk glue, egg white glue, and mixed glue. Results revealed a highly significant difference in database search time between FP and PD (p < 0.00001). However, differences in the numbers of identified proteins, target proteins, and species identification accuracy did not reach statistical significance.
Discussion
Proteinaceous binders, functioning as both pigment dispersants and fixatives, play an indispensable role in the creation and long-term preservation of painted artifacts45. Detailed compositional analyses of these materials not only illuminate the evolution of ancient painting techniques but also provide crucial insights into past modes of animal resource utilization, social exchange, and cultural integration. Among these binders, egg white, collagen, and milk casein represent the most prevalent components identified in ancient artworks44. Importantly, historical evidence indicates that artisans frequently employed combinations of these materials to enhance pigment cohesion and adhesion. For example, studies have documented the coexistence of animal glue with egg white or milk, as well as ternary mixtures of animal glue, egg, and milk in the polychromy of the Terracotta Warriors from the Qin Dynasty (246–208 BCE)45. Similar binder mixtures have also been reported in late 15th-century Italian murals46 and 18th-century Bolivian murals47. Drawing upon this body of literature, the present study prepared mixed glue specimens to simulate the complex binder systems historically employed in painted artifacts, thereby enabling a robust evaluation of proteomics search engines in deciphering such multifaceted materials.
Our results demonstrate that both FP and PD reliably identified proteins attributable to their source species in cowhide glue, milk glue, egg white glue, and mixed glues, confirming their suitability for the proteomic analysis of ancient proteinaceous binders. In terms of database search efficiency, FP exhibited a marked advantage, completing searches within 1 min, representing a 95.7–96.9% reduction in search time relative to PD (p < 0.00001, Table 2). This superiority is principally attributable to FP’s MSFragger engine, which pre-generates a non-redundant peptide segment index through fragment-ion indexing and conducts direct global matching against experimental spectra. By contrast, PD’s conventional pipeline, sequentially digesting protein databases into peptide candidates and matching each individually, introduces substantial computational overhead29. FP’s optimization effectively mitigates the efficiency bottleneck associated with traditional Sequest HT-based searches29.
Although no statistically significant differences were observed between the two platforms in the total number of identified proteins, the number of target proteins, or species identification accuracy (Table 2), certain performance biases were evident depending on the binder type. For example, in the case of egg white glue, PD uniquely identified lysozyme C correctly attributed to Gallus gallus, while in mixed glue samples, PD additionally detected collagen alpha-1(XI) chain assigned to Bos taurus, proteins that FP failed to identify. These results suggest that PD offers superior accuracy for the detection of low-abundance proteins in complex matrices.
The performance divergence between FP and PD stems primarily from their underlying algorithms. PD’s Sequest HT search engine utilizes cross-correlation (XCorr) scoring to match experimental spectra against theoretical predictions, with DeltaCn (ΔCn) further refining candidate selection48,49,50,51,52. This method appears particularly sensitive to low-abundance ions, enhancing PD’s capacity to detect proteins such as lysozyme C. Similar conclusions have been drawn from comparative evaluations of search engines for single-cell proteomics, where Sequest HT consistently outperformed MSFragger in identifying low-abundance proteins53. Moreover, PD employs Percolator for post-processing, leveraging semi-supervised machine learning to rescore peptide-spectrum matches (PSMs), refine statistical validation, and optimize FDR control54. In contrast, FP’s MSFragger relies on the Hyperscore algorithm for initial PSM scoring29, followed by Percolator for validation and preliminary FDR control, with final protein inference performed via ProteinProphet and FDR filtration by Philosopher’s custom algorithm28,55.
It is worth noting that both platforms employ Percolator for post-processing, utilizing semi-supervised learning and support vector machines (SVMs) to enhance the confidence of peptide identifications54. Compared to static search procedures and fully supervised post-processing, this semi-supervised strategy yields superior performance in protein species identification accuracy54, aligning with the observed absence of significant differences between FP and PD in this regard. Additionally, both platforms identified uncommon or unexpected species, such as Meleagris gallopavo, Aix sponsa, and Anas platyrhynchos, a likely artifact of sample aging, where fragmented peptide sequences lead to database misassignments.
Beyond performance, FP offers a significant cost advantage. As a freely available platform for academic and non-commercial use, FP circumvents the substantial licensing fees associated with commercial software like PD, rendering it particularly attractive for large-scale proteomic investigations where computational efficiency is paramount.
In summary, the comparative evaluation reveals no significant differences between FP and PD in terms of total protein identifications, target protein identifications, or species identification accuracy. Nevertheless, FP demonstrates a clear advantage in search speed, outperforming PD by 95.7–96.9%. Notably, PD exhibited superior sensitivity for specific low-abundance proteins, as evidenced by its unique identification of lysozyme C and collagen alpha-1(XI) chain in egg white glue and mixed glue, respectively. Taken together, FP, with its high efficiency and stable species identification accuracy, adequately meets the analytical requirements for routine characterization of polychrome binders in heritage studies. Meanwhile, PD retains value for supplementary analyses where the detection of low-abundance target proteins is a priority.
Accordingly, the selective or combined use of FP and PD, tailored to sample complexity and research objectives, offers an optimized strategy balancing computational efficiency and analytical depth in the proteomic investigation of artifact binders. These findings provide valuable guidance for the further refinement and application of proteomics tools in archaeology and cultural heritage conservation.
Data availability
The proteomics datasets underpinning the findings of this study have been deposited in the Mendeley Data repository and are accessible via https://doi.org/10.17632/2bb42dwxnp.1.
References
Tokarski, C., Martin, E., Rolando, C. & Cren-Olive, C. Identification of proteins in Renaissance paintings by proteomics. Anal. Chem. 78, 1494–1502 (2006).
Zhu, Z. et al. Accurate identification of the pastry contained in a ceramic pot excavated from Jurou Li’s grave from the Jin Dynasty (1115–1234 CE) in Xi’an, Shaanxi, China. Archaeometry 62, 130–140 (2020).
Zhu, Z., Yu, C., Miao, Y., Lu, Z. & Yang, J. Mass spectrometry identification of the liquor contained in the plum vase excavated from Jurou Li’s Grave of the Jin Dynasty (1115–1234 CE) in Xi’an, Shannxi, China. Herit. Sci. 6, 45 (2018).
Zhu, Z. et al. Biomass spectrometry identification of the fibre material in the pall imprint excavated from Grave M1, Peng-state Cemetery, Shanxi, China. Archaeometry 56, 681–688 (2014).
Pires, E., Carvalho, L. D. C., Shimada, I. & McCullagh, J. Human blood and bird egg proteins identified in red paint covering a 1000-year-old gold mask from Peru. J. Proteome Res. 20, 5212–5217 (2021).
Du, J. et al. Exploring purification methods to improve retrieval of collagenous binder residues from archeological murals. J. Cult. Herit. 62, 134–142 (2023).
Tang, L. et al. Paleoproteomic evidence reveals dairying supported prehistoric occupation of the highland Tibetan Plateau. Sci. Adv. 9, eadf0345 (2023).
Gilbert, C. et al. Species identification of ivory and bone museum objects using minimally invasive proteomics. Sci. Adv. 10, eadi9028 (2024).
Pozzi, F., Arslanoglu, J., Galluzzi, F., Tokarski, C. & Snyder, R. Mixing, dipping, and fixing: the experimental drawing techniques of Thomas Gainsborough. Herit. Sci. 8, 85 (2020).
Lanigan, L. T. et al. Multi-protease analysis of Pleistocene bone proteomes. J. Proteom. 228, 103889 (2020).
Hendy, J. et al. A guide to ancient protein studies. Nat. Ecol. Evol. 2, 791–799 (2018).
Rigante, E. C. L., Calvano, C. D., Ventura, G. & Cataldi, T. R. I. Look but don’t touch: non-invasive chemical analysis of organic paint binders - a review. Anal. Chim. Acta 1335, 343251 (2025).
Villa, P. et al. A milk and ochre paint mixture used 49,000 years ago at Sibudu, South Africa. PLoS One 10, e0131273 (2015).
Bhattacharya, S. et al. GC/MS and proteomics to unravel the painting history of the lost Giant Buddhas of Bāmiyān (Afghanistan). PLoS One 12, e0172990 (2017).
Zhu, Z. et al. Multi-analytical study on the Tara Thangka at Daxingshan Temple in Xi’an, Shaanxi, China. Stud. Conserv. 68, 602–613 (2023).
Orsini, S., Parlanti, F. & Bonaduce, I. Analytical pyrolysis of proteins in samples from artistic and archaeological objects. J. Anal. Appl. Pyrol. 124, 643–657 (2017).
Vinciguerra, R. et al. Deglycosylation step to improve the identification of egg proteins in art samples. Anal. Chem. 87, 10178–10182 (2015).
Zhu, Z., Tan, P., Yang, J., Ge, H. & Liu, L. Mass spectrometric identification of adhesive utilized in a Tian-tsui tiara of the mid-Qing Dynasty (1776–1839 CE) in the collection of the Tang Clan Folk Museum. Stud. Conserv. 64, 187–192 (2019).
Du, J., Zhu, Z., Yang, J., Wang, J. & Jiang, X. A comparative study on the extraction effects of common agents on collagen-based binders in mural paintings. Herit. Sci. 9, 45 (2021).
Warinner, C., Korzow Richter, K. & Collins, M. J. Paleoproteomics. Chem. Rev. 122, 13401–13446 (2022).
Millioni, R. et al. High abundance proteins depletion vs low abundance proteins enrichment: comparison of methods to reduce the plasma proteome complexity. PLoS One 6, e19603 (2011).
Rinas, A., Espino, J. A. & Jones, L. M. An efficient quantitation strategy for hydroxyl radical-mediated protein footprinting using Proteome Discoverer. Anal. Bioanal. Chem. 408, 3021–3031 (2016).
Cominetti, O. et al. Proteomic biomarker discovery in 1000 human plasma samples with mass spectrometry. J. Proteome Res. 15, 389–399 (2016).
Orsburn, B. C. Proteome discoverer—a community enhanced data processing suite for protein informatics. Proteomes 9, 15 (2021).
Maixner, F. et al. Paleoproteomic study of the Iceman’s brain tissue. Cell. Mol. Life Sci. 70, 3709–3722 (2013).
Bray, F. et al. Robust high-throughput proteomics identification and deamidation quantitation of extinct species up to Pleistocene with ultrahigh-resolution MALDI-FTICR mass spectrometry. Anal. Chem. 95, 7422–7432 (2023).
Elnaggar, A. et al. Paleoproteomic profiling for identification of animal skin species in ancient Egyptian archaeological leather using liquid chromatography coupled with tandem mass spectrometry (LC-MS/MS). Herit. Sci. 10, 182 (2022).
He, T. et al. Comparative evaluation of Proteome Discoverer and FragPipe for the TMT-based proteome quantification. J. Proteome Res. 21, 3007–3015 (2022).
Kong, A. T., Leprevost, F. V., Avtonomov, D. M., Mellacheruvu, D. & Nesvizhskii, A. I. MSFragger: ultrafast and comprehensive peptide identification in mass spectrometry-based proteomics. Nat. Methods 14, 513–520 (2017).
Yu, F. et al. Analysis of DIA proteomics data using MSFragger-DIA and FragPipe computational platform. Nat. Commun. 14, 4154 (2023).
Hsiao, Y. et al. Analysis and visualization of quantitative proteomics data using FragPipe-Analyst. J. Proteome Res. 23, 4303–4315 (2024).
Ma, M. et al. Forager-farmer transition at the crossroads of East and Southeast Asia 4900 years ago. Sci. Bull. 69, 103–113 (2024).
Cleland, T. P., McGuire, S. A., Beatrice, J. S., Moran, K. S. & France, C. A. A modified version of the sample preparation by Easy extraction and Digestion(-free) protocol for enamel-based sex estimation in archaeological remains. J. Archaeol. Sci. 168, 106006 (2024).
Blacka, C. et al. Rapid proteomic amelogenin sex estimation of human and cattle remains using untargeted Evosep-timsTOF mass spectrometry. Rapid Commun. Mass Spectrom. 39, e10022 (2025).
Li, A. Simulated experiment research on making process of cementation materials of wall paintings of Mogao Grottoes (Northwest University, 2017).
Dong, J. et al. Novel non-invasive method for extracting proteinaceous binders from panel paintings. J. Cult. Herit. 67, 92–100 (2024).
Zhang, Y., Wang, J., Liu, H., Wang, X. & Zhang, S. Integrated analysis of pigments on murals and sculptures in Mogao Grottoes. Anal. Lett. 48, 2400–2413 (2015).
He, L. et al. Polychromic structures and pigments in Guangyuan Thousand-Buddha Grotto of the Tang Dynasty (China). J. Archaeol. Sci. 39, 1809–1820 (2012).
Zhu, Z. et al. Optimization of GuHCl extraction protocol on collagen-based binders in murals by response surface methodology. J. Cult. Herit. 56, 56–64 (2022).
Axelsson, K. M., Larsen, R., Sommer, D. V. P. & Melin, R. Degradation of collagen in parchment under the influence of heat-induced oxidation: preliminary study of changes at macroscopic, microscopic, and molecular levels. Stud. Conserv. 61, 46–57 (2016).
Miao, B., Zhao, Z., Guo, P., Li, H. & Wang, Y. Cleaning iron rust compounds from cotton textiles: application to Qing Dynasty armor. Herit. Sci. 11, 56 (2023).
Dong, J. et al. Enhanced non-invasive extraction of proteinaceous binders from painted artifacts using composite gellan gum. npj Herit. Sci. 13, 286 (2025).
Tobin, D. J. Biochemistry of human skin—our brain on the outside. Chem. Soc. Rev. 35, 52–67 (2006).
Orsini, S., Yadav, A., Dilillo, M., McDonnell, L. A. & Bonaduce, I. Characterization of degraded proteins in paintings using bottom-up proteomic approaches: new strategies for protein digestion and analysis of data. Anal. Chem. 90, 6403–6408 (2018).
Yang, L., Huang, J., Sheng, M., Wang, L. & Wei, Y. Analysis of binding media of polychrome terracotta and horses of Qin Shihuang by gas chromatography-mass spectrometry. Chin. J. Anal. Chem. 47, 695–701 (2019).
van der Werf, I. D., Calvano, C. D., Palmisano, F. & Sabbatini, L. A simple protocol for matrix assisted laser desorption ionization - time of flight - mass spectrometry (MALDI-TOF-MS) analysis of lipids and proteins in single microsamples of paintings. Anal. Chim. Acta 718, 1–10 (2012).
Levy, I. K. et al. Investigation of proteins in samples of a mid-18th century colonial mural painting by MALDI-TOF/MS and LC-ESI/MS (Orbitrap). Microchem. J. 143, 457–466 (2018).
Keller, A., Nesvizhskii, A. I., Kolker, E. & Aebersold, R. Empirical statistical model to estimate the accuracy of peptide identifications made by MS/MS and database search. Anal. Chem. 74, 5383–5392 (2002).
Nesvizhskii, A. I. A survey of computational methods and error rate estimation procedures for peptide and protein identification in shotgun proteomics. J. Proteom. 73, 2092–2123 (2010).
MacCoss, M. J., Wu, C. C. & Yates, J. R. Probability-based validation of protein identifications using a modified SEQUEST algorithm. Anal. Chem. 74, 5593–5599 (2002).
Anderson, D., Li, W., Payan, D. G. & Noble, W. S. A new algorithm for the evaluation of shotgun peptide sequencing in proteomics: support vector machine classification of peptide MS/MS spectra and SEQUEST scores. J. Proteome Res. 2, 137–146 (2003).
Eng, J. K., McCormack, A. L. & Yates, J. R. An approach to correlate tandem mass spectral data of peptides with amino acid sequences in a protein database. J. Am. Soc. Mass Spectrom. 5, 976–989 (1994).
Peng, J. et al. Comparison of database searching programs for the analysis of single-cell proteomics data. J. Proteome Res. 22, 1298–1308 (2023).
Kall, L., Canterbury, J. D., Weston, J., Noble, W. S. & MacCoss, M. J. Semi-supervised learning for peptide identification from shotgun proteomics datasets. Nat. Methods 4, 923–925 (2007).
da Veiga Leprevost, F. et al. Philosopher: a versatile toolkit for shotgun proteomics data analysis. Nat. Methods 17, 869–870 (2020).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Project No. 42307551), and the Youth Open Project of the Emperor Qinshihuang's Mausoleum Site Museum (Project No. Qkfkt202412), the National Cultural Heritage Administration Revolution Relics Research Project (Project No. 2024-307), the Open Research Project of Key Scientific Research Base of Paper Cultural Relics - NCHA (Project No. 2024-0628). The authors are grateful to Ms. Ying Huang from the School of History and Cultural Heritage, Xiamen University for technical support.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
The manuscript was written with contributions from all authors. All authors have given approval to the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
Z.Z. serves as an Associate Editor for npj Heritage Science. This role, however, did not influence the consideration or peer review process of this manuscript. Rigorous editorial measures were implemented to ensure an impartial review, thereby preserving the integrity of the peer review process. The other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dong, J., Zhu, Z., Li, X. et al. Comparative analysis and optimization of proteomic information mining approaches for proteinaceous binders in painted artifacts. npj Herit. Sci. 13, 422 (2025). https://doi.org/10.1038/s40494-025-02002-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02002-4
