
Abstract
This study combines field measurements and ODEON simulations to explore the acoustic adaptation mechanism of the Zhaomutang theatre in northeastern Jiangxi during opera performances and family sacrifices. The theatre’s spatial sequence (stage, front patio, Xiangtang, rear patio, and Qintang) creates a progressive sound field through volume control and material reflection, and coordinates sound energy gain, early reflection, and reverberation attenuation. During the performance, the stage and auditorium obtain moderate reverberation and lateral reflection, ensuring the fullness of the Gan opera singing and speech intelligibility. During the sacrifice, the Qintang and rear patio achieve semantic focus by shortening the sound propagation path and concentrating early sound energy. At the same time, the peripheral space still maintains fundamental speech intelligibility and ritual atmosphere. This reveals how traditional architecture dynamically adjusts multifunctional acoustics through spatial sequence and material differentiation, thus filling the gap in the study of multi-scene acoustics of ancestral temple theatres.
Similar content being viewed by others


Introduction
As one of the important carriers of Chinese civilization, traditional Chinese opera integrates a variety of art forms such as vocal music, dance, martial arts, and instrumental music, and has continued its vitality for hundreds of years in the unique opera architectural space. Unlike the proscenium stage or modern multifunctional theatre in the West, the performance space of traditional Chinese opera presents significant regional diversity and functional complexity1. Many such spaces exist, including temporary open-air stages, hall-style theatres with gates, stages, and courtyards connected, and multifunctional complex spaces inside an ancestral temple that can hold sacrificial rituals and opera performances. In these different types of theatres, the layout, material properties, and spatial scale of the building directly affect the artistic expression of the opera performance and the realization of the sacrificial ritual function by regulating key acoustic parameters such as the reflection path of sound energy, reverberation time, and speech intelligibility2.
In recent years, with the joint promotion of the protection of intangible cultural heritage and the integrated development of cultural tourism, the acoustic research of traditional opera venues has gradually become a hot spot in architecture, acoustics, and cultural heritage3,4,5. This type of research is dedicated to revealing the acoustic laws of historical buildings and provides a scientific basis for the digital protection, restoration, and adaptive transformation of cultural heritage6,7,8,9,10. Internationally, a relatively complete system has been formed for the acoustic research of historical performance spaces11,12,13. Researchers have revealed the relationship between theatre geometry and material acoustic properties through pulse response measurement, scaled model testing, and numerical simulation. For example, the Epidaurus Theatre balances reverberation time and speech clarity without sound reinforcement. Its semi-circular stepped stone stands and precise reflection design meet the acoustic requirements of speeches and choruses14. The Bayreuth Festspielhaus adopts a fan-shaped floor plan and a sunken orchestra pit, which improves the expressiveness of Wagner’s operas by optimizing the surround feeling of the sound field15. Research on Japanese Kabuki theatres shows that their smaller space volume, wooden ceilings, and tatami seating design achieve a compromise between speech clarity and musical expressiveness by enhancing early reflected sound energy16. At the same time, Pérez-Aguilar et al.17 analyzed the historical evolution of the acoustic performance of the Banda Primitiva de Llíria theatre in Spain and revealed the long-term impact of architectural renovation on the characteristics of the sound field; Bevilacqua’s team18,19,20 used digital reconstruction technology to systematically compare the acoustic differences between the Teatro Pompei and the Teatro San Carlo in Naples in opera, speech and concert scenes. These studies provide valuable references for historical theatres’ protection and functional adaptation. However, most focus on typical theatres in a single cultural context, and the research on the dynamic regulation mechanism of acoustics in multifunctional coupled spaces is still insufficient.
In response to this international trend, China’s acoustic research on traditional opera architecture has also experienced a transition from qualitative description to quantitative analysis. In the early stages of domestic research, scholars focused on the opera stages of well-known operas such as Peking Opera and Kunqu Opera. They explored the laws of direct sound propagation in semi-enclosed or courtyard-style venues21,22,23. With the maturity of field measurement and simulation technology, the acoustic characteristics of regional opera stages such as Jin Opera, Yue Opera, and Gan Opera have also gradually entered the vision research field24,25,26,27,28. As the research deepens, scholars have gradually realized that traditional Chinese operas are often “one space, multiple scenes”: many historical theatres are not only the stage for opera performances, but also the core venues for activities such as family sacrifices, festivals, and gatherings. This multifunctional characteristic puts higher requirements on acoustic design: sacrificial rituals require high speech intelligibility and short reverberation time29,30; while opera performances rely on moderate reverberation support and music clarity. However, most of the current literature is based on a single static scene, has not yet quantified the changes in the sound field parameters of the same building under different usage modes, and lacks a systematic explanation of the subspace coupling mechanism. This gap limits the scientific decision-making of revitalizing and utilizing traditional operas.
Studying ancestral temple theatres in northeastern Jiangxi is important in this context. As the third batch of national intangible cultural heritage operas, Gan Opera has unique requirements for the acoustic environment of the performance space due to its numerous roles, rich vocal cavities, and flexible accompaniment31. In addition, Leping City’s “ancient stage construction skills” were included in the fourth batch of national intangible cultural heritage. The layout of the ancestral temple theatre is very different from that of the guild hall-style and temple-style theatres32. Zhaomutang was built in the Ming Dynasty and is one of the most well-preserved prototypes of the “stage built into the ancestral temple” in northeastern Jiangxi. Its architecture adopts a vertical “three-entry” spatial sequence. A complex acoustic coupling pattern is formed by raising the stage, setting wooden beams, and adopting a hip roof33. This spatial structure serves the performance of Gan opera and meets the needs of family sacrifices. Its acoustic performance provides a typical example of the “multi-scene sound field reconstruction” of traditional theatres.
Given the above research gaps and the prototype value of Zhaomutang, this study proposes the following research questions: (1) Can the ancestral temple theatre achieve a dynamic balance between the acoustic needs of opera performances and sacrificial rituals through spatial sequence and material configuration? (2) How will the acoustic coupling relationship between each subspace affect the spatial distribution and dynamic changes of sound field parameters? To this end, this study uses the Zhaomutang theatre as a typical case. It combines on-site impulse response measurement with ODEON acoustic simulation to clarify the sound field distribution characteristics of the ancestral temple theatre in the dual scenes of opera performance and sacrifice. It reveals the regulatory mechanism of spatial coupling on acoustic performance. The results of this study not only fill the gap in the study of the multifunctional acoustic adaptability of traditional ancestral temple theatres but also provide a generalizable paradigm for the revitalization and utilization of historical spaces around the world.
Methods
Introduction and measurement of Zhaomutang theatre
Zhaomutang theatre is located in Yongshan Town, Leping City, Jiangxi Province. It is a provincial cultural relic protection unit. It was first built in the middle of the Ming Dynasty and was renovated during the Qing Dynasty and the Republic of China. According to local chronicles, the northeastern Jiangxi region has always been important to ancestor worship. When families hold major ceremonies or spring and autumn sacrifices in the ancestral temple, they often perform local operas such as Gan Opera to “entertain their ancestors with drama” to enhance the solemnity of the ceremony and the effect of entertaining the gods34. Under the influence of this tradition, many ancestral temples added a stage based on the original sacrificial space, gradually forming an architectural pattern of integrating ancestral temples and stages35. As an early example of ancestral temple theatres in northeastern Jiangxi, Zhaomutang’s architectural space form is closely arranged around balancing the dual needs of opera performances and sacrificial rituals.
The overall spatial sequence of Zhaomutang is a vertical “three-entry” layout, which is composed of five core divisions: stage, front patio, Xiangtang, rear patio, and Qintang. The stage is located at the southernmost end, with a height of about 2.8 m. The overhead space at the bottom also serves as the entrance to the building, facing the front patio and the Xiangtang. The top of the front patio is open and of moderate size. It can be used as a gathering area for some audiences during opera performances and as a crowd dispersal during sacrificial ceremonies. The Xiangtang is the largest and has the highest clearance. Compared with the front patio, it is slightly elevated. It is the main viewing space for large-scale family sacrificial ceremonies and performances, and occupies the core position of the entire functional system. The rear patio area is compact and mainly used for transitional family rituals or small-scale gathering activities. The Qintang has the highest terrain. Due to its relatively limited internal space and clearance, it is often used to store ancestral tablets and hold family sacrifice ceremonies. The Zhaomutang connects the stage, the Xiangtang, and the Qintang in series through the central axis, and connects them with the side corridors and the patio. This layout fits the local folk tradition of “entertaining ancestors with drama”. It shows the uniqueness and plasticity of the ancestral temple theatre layout in terms of acoustic transmission and visual organization.
Zhaomutang adopts a hybrid structural system of wooden beams and masonry bases regarding building materials and structure. The column grid, brackets, and beams are mainly made of wood, and the overall load-bearing structure is completed by mortise and tenon joints; the exterior walls and some load-bearing walls are mostly built with blue bricks, and the stone base further enhances the stability and moisture-proof performance of the building. The roof is a multi-slope hip roof style, covered with blue tiles, and the brackets and eaves retain rich wood carvings, reflecting the regional characteristics of the traditional ancestral temple architecture in northeast Jiangxi in terms of structure and aesthetics. The ground of the front and rear patios and corridors is mainly paved with stone slabs or bricks to adapt to high-frequency use and traffic; the stage area is paved with wooden floors and guardrails to meet the needs of actors’ performances and safety protection. Figure 1 shows the aerial photos of Zhaomutang and photos of the interior space; Fig. 2 and Table 1 give the specific dimensions of each subspace based on the laser ranging results, providing a geometric basis for subsequent acoustic measurement and simulation analysis.

a Aerial view; b stage; c front patio; d Xiantang; e rear patio and Qintang.

a plan view; b section view.
Acoustic parameter determination
The Zhaomutang has the dual functions of opera performance and family sacrifice. Its spatial acoustic performance must achieve a dynamic balance between the two types of activities with completely different perceptual goals. Opera performances focus on the extension of singing and the richness of timbre, clear lines, self-auditory feedback of actors, and the audience’s sense of encirclement and immersion. Therefore, it is necessary to comprehensively consider indicators such as early decay time (EDT), reverberation time (T30), definition (D50), clarity (C80), sound strength (G), and lateral sound energy factor (LF80) to achieve a balanced compromise between clarity, fullness, and spatial sense. Family sacrifices prioritize ensuring semantic intelligibility and precise recitation rhythm, focusing on four parameters: EDT, T30, D50, and speech transmission index (STI) to evaluate the degree of support for the space for recitation intelligibility and speech focusing effect.
(1) EDT measures the degree of enhancement of early reflected sound in a space. It is the time for an impulse response to decay from 0 dB to –10 dB and then linearly extrapolated to –60 dB. In an opera performance environment, a longer EDT helps to enhance the fullness of the sound, but a longer EDT may make the lyrics unclear. Studies have shown that the EDT of a traditional opera stage is usually maintained between 0.8 and 1.3 s, which can be considered both speech intelligibility and the sense of envelopment of the singing36. Since speech intelligibility is more important than spatial perception for sacrificial ceremonies, EDT should be controlled in the range of 0.6 to 1.0 s to ensure that the ritual recitation can be clearly understood29.
(2) T30 represents the duration of sound in an indoor space. The T30 value is usually obtained by measuring the time it takes for an impulse response to decay from –5 dB to –35 dB and then linearly extrapolating to –60 dB. The requirements for reverberation time in opera performances are relatively loose, and 0.8–1.4 s is generally considered the ideal range, which helps to enhance the fullness and continuity of the sound while ensuring the intelligibility of the lyrics25. Since speech intelligibility is more important than reverberation effect for family sacrificial scenes, T30 should be controlled at 0.6–1.0 s to reduce the adverse effects of excessive reverberation on speech intelligibility30.
(3) D50 measures the proportion of sound energy arriving within 50 ms of the total sound energy. Its mathematical expression is:
P(t) represents the instantaneous sound pressure of the impulse response at the measurement point. The higher the D50 value, the higher the speech intelligibility. Studies have shown that in opera performances, D50 should be kept between 0.45 and 0.65, which can ensure the intelligibility of the lyrics without excessively weakening the contribution of reverberation to the musical expression36. The D50 value should be higher for family sacrificial activities to ensure the intelligibility of ritual speech transmission. It is generally recommended to be no less than 0.5030.
(4) C80 measures the ratio of the sound energy arriving within the first 80 ms to the energy arriving thereafter. The calculation formula is:
When the C80 value is higher, the sound performance is clearer; when the C80 value is lower, the reverberation is stronger. In the opera performance scene, C80 should be controlled at 2–8 dB to ensure the clarity of the actors’ singing while maintaining moderate reverberation support37.
(5) G is used to measure the sound energy gain of the indoor space to the sound source. It is defined as:
P10(t) is the instantaneous sound pressure of the impulse response at a distance of 10 m from the sound source in the free field. Opera performances require a higher G value to enhance the voice intensity of the actors. Generally, a G value of 4–10 dB is ideal to ensure that the audience can get enough volume support25.
(6) LF80 evaluates the spatial envelopment and apparent sound source width potential. It is defined as the ratio of the lateral reflected sound energy to the total sound energy in the first 80 ms:
PL(t) represents the instantaneous sound pressure of the hall impulse response measured by an 8-shaped directional microphone. The higher the LF80 value, the stronger the sense of spatial envelopment the audience feels. Opera performances require an appropriate LF80 value to enhance the sense of presence and space on the stage.
(7) STI directly reflects the intelligibility of sentences and the clarity of syllable boundaries. Its value range is 0–1. The higher the value, the better the language intelligibility38. For family sacrifice scenes, STI should not be less than 0.50 to ensure the speech content is clearly understood.
Acoustic parameter measurement
In order to calibrate the simulation model and verify the simulation accuracy, before the acoustic simulation analysis, this study conducted on-site measurements of the acoustic parameters of the Zhaomutang in the empty field during performances by the ISO 3382-1:2009 standard. The measurements were performed using the 1002 Building Acoustics Measurement System (AHAI, Hangzhou, Zhejiang, China), including the ISV 1101 Acoustic Measurement Analyzer, the AWA 14425 Free-Field Measurement Microphone, the 2032 A Dodecahedron Loudspeaker, the 2044 A Power Amplifier, a Tablet Computer, and a Wireless Router. In the experiment, a pink noise signal was used to excite the loudspeaker, and the signal was collected through the microphone. After A/D conversion, it was imported into DIRAC (Brüel & Kjær, Hørsholm, Denmark) for sound quality parameter analysis. In order to reduce the impact of environmental noise on the measurement, all measurements were scheduled to be carried out from 11 pm to early morning. Before the measurement, the 1002 system was used to monitor the background noise level. The background noise levels in the 125–4000 Hz six octave bands were 27.7 dB, 26.5 dB, 22.1 dB, 24.3 dB, 21.6 dB, and 18.4 dB, respectively.
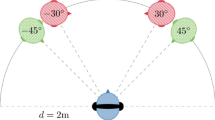
Figure 3 shows a photo of the on-site measurement, and the arrangement of the sound source and measurement points is shown in Fig. 5. The sound source was set at the centre of the stage to simulate the location of the primary sound source during an actual opera performance. A total of 28 measurement points were arranged in the auditorium, covering the front patio (F1–F8), Xiangtang (X1–X12), rear patio (R1–R4), and Qintang (Q1–Q4). The measurement of each measurement point was repeated 3 times, and the average value was taken as the result to reduce accidental errors and ensure the repeatability and accuracy of the results.

a Experimental arrangement at the stage; b experimental arrangement at the auditorium.
Simulation model validation and optimization
In this study, ODEON (v 18.10) acoustic simulation software was used to simulate the empty field acoustic characteristics of Zhaomutang to verify the reliability of the simulation results and optimize the model parameters. First, the three-dimensional model of the Zhaomutang theatre was constructed using SketchUp (v 2022) software (see Fig. 5), then imported into ODEON for acoustic calculation. The sound absorption coefficient and scattering coefficient of the model boundary material (see Table 4) refer to the existing literature data to ensure the accuracy of the model parameters. The simulation parameter settings follow the software requirements: the maximum number of reflections of the sound line is set to be higher than the number required for accurate calculation, the impulse response length is set to be long enough to ensure that the sound energy is completely attenuated, and the accuracy of the internal edge length of the model is set to 0.1 m. The simulation uses a point sound source (S1), the position of the receiving point is consistent with the actual measurement point, and the environmental conditions are set to be the same as the actual measurement environment (temperature 26 °C, humidity 78%).
The accuracy of the simulation model is verified by comparing it with the measured data, and the just noticeable difference (JND) is used to evaluate the simulation deviation. According to the ISO 3382–1:2009 standard, the JND values of various acoustic parameters are shown in Table 239. When the difference between the simulated and measured values is less than 1 JND, the simulation accuracy can be considered high40. Table 3 shows the difference between the simulated value and the measured value of each acoustic parameter of the auditorium (average value of each measuring point). In general, the difference between the simulated value and the measured value of each parameter of the auditorium is within a reasonable range.
Figure 4 compares the difference between the measured and simulated values of each receiving point: the scattered points represent the single point deviation, and the box plot shows the difference distribution statistics. Except for a few measuring points (such as F3, F4, F6, F7, F8, and R2, R3, R4) whose deviations in individual parameters exceed 1 JND, the differences of most measuring points are controlled within 1 JND. Except for F7 and F8, the maximum EDT deviation of the remaining measuring points does not exceed 1.5 JND; only a few measuring points of D50, C80, and G are higher than 2 JND. The front and rear patios, where errors are relatively concentrated, have small spatial scales and open tops, which causes the coupled acoustic field to fluctuate violently with frequency. At the same time, high-frequency scattering and diffraction effects are simplified in the model, so the simulation results in the high-frequency band tend to be low. Overall, after scattering coefficient correction and mesh refinement, the ODEON model is consistent with the measured results, providing a reliable simulation basis for the subsequent quantitative analysis of the acoustic characteristics of Zhaomutang.

Differences between simulated and measured values of acoustic parameters at each receiving point.
Sound field simulation settings
This study simulates and analyzes the sound field characteristics of Zhaomutang in opera performance and family sacrifice to quantitatively evaluate the sound quality parameter performance under different space utilization modes. As shown in Fig. 5, in the performance state, the sound source is set at S1, simulating the position of the actor standing in the centre of the stage to make a sound; the receiving points are arranged to cover the stage, front patio, Xiangtang, rear patio and Qintang to comprehensively analyse the propagation characteristics of sound in each space during the performance. In the sacrifice state, the sound source is set at S2, corresponding to the position where the host stands in the centre of the Qintang. The acoustic performance of the stage area is not considered in the sacrifice scene, and the arrangement of the receiving points in the remaining spaces is consistent with the opera performance state.

a Plan layout; b three-dimensional model.
Regarding the arrangement of measuring points, a total of 6 receiving points is set in the stage area to analyse the self-listening effect of the actors at different performance positions. 28 receiving points are set in the auditorium, distributed in each main subspace, to evaluate the impact of direct sound, early reflection sound, and spatial coupling on the audience’s auditory experience. Since the front patio is open and large, the measuring point arrangement considers the axial propagation characteristics from the stage to each point. It pays attention to the sound energy attenuation in the lateral area. As the main viewing and performance space, the Xiangtang has significant acoustic coupling with the front patio, so more receiving points are arranged in this area to obtain more detailed reflection path and reverberation characteristic data. The spatial scale of the rear patio and the Qintang is small, so the density of measurement points is reduced, but it still covers its main viewing and performance area.
In terms of simulation settings, the sound source height is set to 1.6 m, simulating the mouth height of the actors and the host of the sacrifice; the receiving point height is set to 1.2 m, corresponding to the ear height of the audience and the participants. In the grid response calculation, the receiving point spacing is set to 1.0 m to improve the spatial resolution and ensure data accuracy. The acoustic parameters23,24,41,42 of the model boundary material is detailed in Table 4, and the remaining simulation parameters are consistent with the settings in Section 2.4.
Results
Acoustic characteristics of performance state
Zhaomutang’s stage and auditorium present a clearly hierarchical and mutually coupled acoustic pattern during the performance. The simulation results shown in Fig. 6 use the frequency band as the horizontal axis, take the average value of each measurement point as the broken line, and the error bar represents the standard deviation (the same below), which intuitively reveals the characteristics of the progressive change of sound energy along the depth space sequence. First, from the perspective of time domain response, the EDT and T30 of the stage are controlled at 0.6–0.7 s and 0.6–0.8 s, respectively, while the auditorium is slightly higher, at 0.8–1.1 s and 0.8–1.0 s; the curve of the low-frequency band (125 Hz and 250 Hz) is slightly raised, reflecting the retention effect of wood and masonry materials on low-frequency sound energy. This numerical range continues the traditional demand for tail tone support in opera performances, and avoids the high reverberation range caused by syllable overlap due to exceeding 1.2 s.

a EDT; b T30; c D50; d C80; e G; f LF80.
In terms of early sound energy distribution, the D50 in the stage is 0.65–0.75, and the C80 is 6–8 dB, both significantly higher than the D50 (0.50–0.60) and C80 (3–5 dB) in the auditorium. D50 exceeding 0.50 indicates that at least half of the total sound energy arrives within 50 ms, which can suppress the temporal masking effect; while C80 exceeding 3 dB indicates that the early sound energy ratio is moderately high, which can significantly enhance the penetration of music and singing. The higher D50 and C80 combination in the stage not only strengthens the actor’s self-auditory feedback but also reduces the masking of the singing by the instrument; the D50 and C80 in the auditorium are in the ideal overlapping area of speech intelligibility and music clarity, providing a clear and lingering listening experience.
The gradient change of G value along the space highlights the layout intention of each viewing and performance functional area: the G value of the stage is as high as 16–17 dB, which is more than 10 dB higher than the 4–6 dB in the auditorium, far exceeding the just noticeable difference of loudness (JND = 1 dB). From the perspective of psychoacoustics, the actors are in a significant sound energy gain area and can clearly hear their own and their companions’ voices, which is conducive to maintaining pitch and rhythm; while the auditorium is in a loudness balance area to avoid the accumulation of low-frequency sound energy and the decrease in clarity. LF80 also presents a similar gradient: the LF80 in the auditorium is controlled between 0.20–0.25, which is in the appropriate range for generating a sense of spatial envelopment and apparent sound source width; the higher LF80 (0.25–0.30) in the stage provides the actors with stronger lateral early reflections, strengthens the compactness of the ensemble and the accuracy of spatial positioning, and is conducive to the coordination of multiple voice chambers and percussion instruments.
To further reveal the acoustic characteristics of each subspace in the auditorium, this study conducted a simulation analysis of the front patio, Xiangtang, rear patio, and Qintang in six octave bands (see Fig. 7). The results show that the front patio and Xiangtang are generally higher than the rear patio and Qintang in terms of D50, C80, G, and LF80, which clarifies the functional positioning of the front patio and Xiangtang as the main viewing area. In contrast, the rear patio and Qintang gradually reduce their early sound energy and lateral reflections as the propagation path is extended and the coupling boundaries increase, and the clarity and sense of envelopment decay in a step-by-step manner. This is consistent with the feedback from the actual viewing experience, that is, “the sound image in the back row is slightly narrowed, but the speech is still understandable.” The three-dimensional sound field distribution shown in Fig. 8 further reflects this gradient: D50 and C80 are significantly higher in the corridor areas on both sides than in the central axis area, indicating that the areas on both sides have obtained more sufficient early reflected sound energy. This is mainly because the clear height of the two sides is low, which can receive strong top reflections, while the side walls and beams provide more lateral reflected sound energy; LF80 reaches its highest point in the corridor space on both sides of the front patio, and the central open area is relatively low, so that the audience can get a sense of envelopment while maintaining the concentration of sound and image.

a EDT; b T30; c D50; d C80; e G; f LF80.

a EDT; b T30; c D50; d C80; e G; f LF80.
Overall, Zhaomutang achieves a layered configuration of acoustic performance by vertically connecting the spatial sequence of “stage, front patio, Xiangtang, rear patio, and Qintang”. More importantly, this acoustic strategy does not pursue the optimality of a single indicator, but makes each indicator form a multi-target feasible domain within the sensitive range of psychoacoustics. Specifically, by constructing the sound energy and early reflection gradients of “local peak (stage), medium platform (front patio and Xiangtang), and far attenuation (rear patio and Qintang)”, “actor enhancement (higher G and LF80), audience balance (medium G and LF80), overall moderate extension (appropriate T30 and EDT), and dual clarity of speech and singing (coordination of D50 and C80)” are unified into a multi-objective feasible domain.
Acoustic characteristics of sacrificial state
When the sacrificial ceremony is in progress, the primary sound source moves from the stage to the central axis of the Qintang, and the sound field pattern changes accordingly. The simulation results (Fig. 9) show that the EDT and T30 of the auditorium remain at 0.7–1.0 s in the frequency band of 125–4000 Hz; the low frequency 125 Hz is slightly higher, while the mid- and high-frequency bands are relatively stable. This shows that the larger indoor volume of the theatre has a significant delay effect on low-frequency sound waves. In contrast, the sound energy distribution is relatively uniform at higher frequencies, and the reverberation time tends to be stable. D50 generally falls between 0.55 and 0.70, indicating that the auditorium has good speech intelligibility in the sacrificial mode.

a EDT; bT30; c D50.
The comparison of the simulation results of each subspace (Fig. 10) reveals the influence of spatial form on the sound field characteristics. The EDT and T30 of the front patio and the Xiangtang are generally higher than those of the rear patio and the Qintang, mainly because the front patio and the Xiangtang are relatively open, with fewer sound wave reflection paths, resulting in a relatively longer reverberation time. In contrast, the rear patio and Qintang spaces are more closed, the sound energy decays faster, and the reverberation time is significantly shortened. This feature is conducive to improving speech recognition and meets the acoustic requirements of the ancestral temple building in the sacrificial function. The most significant change in the sacrificial sound field is the substantial increase in the early sound energy ratio: the D50 of the Qintang and rear patio reaches 0.75–0.85 and 0.65–0.75 respectively, which can fully support the slow and solemn reading of sacrificial texts; although the D50 of the Xiangtang and front patio is only 0.45–0.65, it can also ensure the basic understanding of the semantics by the external listeners. The three-dimensional sound field distribution diagram (Fig. 11) further shows that the D50 shows an obvious “high inside and low outside” gradient along the spatial axis, which is consistent with the ritual order of “emphasis on rituals inside and allow for external listening” in ancestral temple buildings.

a EDT; bT30; (c) D50.

a EDT; bT30; c D50; d STI.
The simulation results of STI further verify the above semantic focus pattern. The average STI values of the Qintang and rear patio reached 0.66 and 0.55, respectively, corresponding to the “Good” and “Fair” levels under the IEC 60268-16 standard. In contrast, the STI values of the Xiangtang and front patio dropped to 0.43 and 0.35, only reaching a basically understandable level. This means that the content of the priest’s recitation can be clearly understood mainly within the Qintang and rear patio. However, the peripheral audience can perceive the rhythm and tone of the recitation; they need to rely on visual cues and environmental atmosphere to assist in understanding its semantics. Combined with the D50 index, the improvement of STI is mainly due to the shortening of the propagation path and the concentration of early sound energy, rather than simply reducing reverberation.
A comprehensive analysis of the above results shows that there are three characteristics of the sacrificial sound field: first, the sound source moves forward to the Qintang and the smaller volume of the Qintang greatly increases the proportion of early sound energy, forming a core area with clear speech; second, the deep courtyard structure has a layered retention effect on low-frequency reverberation and an active release of high-frequency sound energy, which not only retains the solemn atmosphere of the ceremony but also avoids the masking caused by too long tail sounds; third, the axial gradient formed by D50 and STI creates a clear auditory hierarchy for the participants, realizing the functional zoning of straightforward recitation in the core of the Qintang and peripheral listening in the periphery, without the need for electroacoustic equipment.
Discussion
This study, using the Zhaomutang in Leping City, northeastern Jiangxi Province, as a case study, systematically reveals the acoustic adaptation mechanisms of ancestral temple theatres in the dual contexts of opera performances and family sacrifices through a combination of on-site impulse response measurements, ODEON 3D sound field simulation, and JND threshold verification. A reproducible evaluation paradigm was established. Key findings and discussions are as follows:
Zhaomutang and classical theatres worldwide exhibit significant commonalities in acoustic organization: the sound field is constructed around the energy matching of direct sound, early reflections, and late reverberation. The ancient Greek theatre of Epidaurus, with its semi-circular stands and stone steps, facilitates the progressive progression of direct sound and early reflections along the theatre’s axis. With its sunken orchestra pit and fan-shaped floor plan, the Bayreuth Festival theatre creates a uniform, enveloping feeling for the main auditorium. Japanese Kabuki theatres utilize flower paths and side aisles around the stage to enhance localized acoustic energy, enabling actors to hear each other. Zhaomutang achieves the same acoustical objectives through its unique vertical three-entry layout: the high G (16–17 dB) and LF80 (0.25–0.30) in the stage area provide strong self-auditory feedback for the performers; the moderate G (4–10 dB) and LF80 (0.20–0.27) in the front patio and Xiangtang balance clarity and envelopment; and the acoustic attenuation in the rear patio and Qintang effectively prevents excessive reverberation. The significance of this case lies in its use of the spatial layering of traditional Chinese patios and the complementary nature of wood and stone materials, achieving core acoustic effects similar to those of stone or concrete theatres without relying on modern acoustic structures.
Zhaomutang’s core value lies in its passive and dynamic balance between the distinct acoustic requirements of opera performances and sacrificial rituals through spatial sequence and material configuration. The depth sequence of “stage, front patio, Xiangtang, rear patio, and Qintang” during an opera performance creates a sound energy gradient from strong to weak. The stage area’s high sound gains and abundant lateral reflections ensure auditory feedback for the actors. The front patio and Xiangtang maintain moderate reverberation, sound energy intensity, and a sense of spatial enclosure, ensuring the richness of Gan Opera singing and the speech intelligibility. The rear patio and Qintang act as energy decay zones, suppressing the accumulation of tail sounds. When the scene switches to sacrificial mode and the sound source moves to the central axis of the Qintang, the shortened propagation path and increased local spatial enclosure significantly concentrate the early sound energy. The D50 and STI of the Qintang and rear patio increase significantly, forming a core area with highly focused semantics. The Xiangtang and front patio are transition zones, maintaining fundamental language intelligibility while diffusing the ritual atmosphere. This aligns with the ritual order of “emphasizing ritual within and allowing external audiences.” This passive strategy, which relies entirely on sound source displacement, spatial volume hierarchy, material reflective gradients, and open interfaces to achieve acoustic state switching, provides a model for revitalizing historical buildings today, striving for energy conservation and low carbon.
The “measurement, simulation, and verification” closed-loop approach established in this study provides a scalable framework for acoustic research in complex historical spaces. Simulation results identified key factors supporting Zhaomutang’s existing acoustic performance: the open courtyard design suppresses low-frequency retention, the differential reflection between the timber structure and brick walls regulates the proportion of early acoustic energy, and details such as the carved brackets and woodwork enhance mid- and high-frequency diffusion. Based on this, quantitatively guided, reversible micro-interventions can be implemented to address specific needs. Removable sound-absorbing curtains could be hung in the Xiantang, reducing T30 by ~0.10 s and increasing D50 by approximately 0.05 to improve the intelligibility of sacrificial speech. To enhance the musical effect of the rear seats during opera performances, lightweight, removable reflective partitions could be added between the Xiantang and the rear courtyard, projected to increase high-frequency C80 and G by approximately 0.3 dB and 0.4 dB, respectively. Such measures adhere to the international principle of “minimal intervention and reversible operation” in cultural heritage conservation and do not affect the main structure.
This study also has certain limitations: the scattering effects of decorative components such as brackets and wood carvings were simplified in the modeling as homogeneous scattering coefficients, which may lead to an underestimation of the diffusion characteristics of high-frequency sound energy; and the study focuses solely on the Zhaomutang case. Future work requires conducting comparative studies across multiple cases, combining subjective listening evaluations with reversible acoustic intervention experiments, and developing a comprehensive evaluation system that integrates objective acoustic parameters and subjective perceptions to promote refined and intelligent cultural heritage acoustic management.
Data availability
All data generated or analysed during this study are included in this published article.
References
Hu, Q., Yang, P., Ma, J., Wang, M. & He, X. The spatial differentiation characteristics and influencing mechanisms of intangible cultural heritage in China. Heliyon 10, e38689 (2024).
Zhu, J., Kang, J., Ma, H. & Wang, C. Grounded theory-based subjective evaluation of traditional Chinese performance buildings. Appl. Acoust. 168, 107417 (2020).
Mu, J., Wang, T. & Zhang, Z. Research on the acoustic environment of heritage. Build.: A Syst. Rev. Build. 12, 1963 (2022).
Cairoli, M. Identification of a new acoustic sound field trend in modern catholic churches. Appl. Acoust. 168, 107426 (2020).
Autio, H. et al. Historically based room acoustic analysis and auralization of a church in the 1470s. Appl. Sci.11, 1586 (2021).
Zhu, X., Oberman, T. & Aletta, F. Defining acoustical heritage: a qualitative approach based on expert interviews. Appl. Acoust. 216, 109754 (2024).
Katz, B. F. G., Murphy, D. & Farina, A. Exploring cultural heritage through acoustic digital reconstructions. Phys. Today 73, 32–37 (2020).
Mao, L., Ma, J., Zhang, X., Liu, B. & Niu, J. Comparison and simulation-based analysis of the sound field of Dong drum tower buildings. npj Herit. Sci. 11, 213 (2023).
Alvarez-Morales, L., Santos Da Rosa, N., Benítez-Aragón, D., Lazarich, M. & Díaz-Andreu, M. Recovering the intangible acoustic heritage of rock art sites: El Tajo de las Figuras as a case study. in 2023 Immersive and 3D Audio: from Architecture to Automotive, 2023 Sep 5–7, University of Bologna, Italy (IEEE, 2023).
Zhang, D., Shan, Y., Chen, X. & Wang, Z. Soundscape in religious historical buildings: a review. npj Herit. Sci. 12, 45 (2024).
Martín-Castizo, M., Girón, S. & Galindo, M. Acoustic ambience and simulation of the Bullring of Ronda (Spain). Buildings 14, 298 (2024).
Bevilacqua, A. & Fuchs, W. Digital soundscape of the Roman Theatre of Gubbio: acoustic response from its original shape. Appl. Sci. 13, 12097 (2023).
Bevilacqua, A. & Tronchin, L. Investigations on the acoustic response of two heritage buildings designed by Galli Bibiena and disappeared from history in the 18th century: The Nancy and Tajo opera theatres. J. Cult. Herit. 70, 302–311 (2024).
Psarras, S. et al. Measurements and analysis of the Epidaurus ancient theatre acoustics. Acta Acust. U. Ac 99, 30–39 (2013).
D’Orazio, D., De Cesaris, S., Morandi, F. & Garai, M. The aesthetics of the Bayreuth Festspielhaus explained by means of acoustic measurements and simulations. J. Cult. Herit. 34, 151–158 (2018).
Büttner, C., Yabushita, M., Parejo, A. S., Morishita, Y. & Weinzierl, S. The acoustics of Kabuki theaters. Acta Acust. U. Ac 105, 1105–1113 (2019).
Pérez-Aguilar, B., Quintana-Gallardo, A., Gasent-Blesa, J. & Guillén-Guillamón, I. The acoustic and cultural heritage of the Banda Primitiva de Llíria theater: objective and subjective evaluation. Buildings 14, 2329 (2024).
Tronchin, L., Yan, R. & Bevilacqua, A. The only architectural testimony of an 18th century Italian Gordonia-Style Miniature Theatre: an acoustic survey of the Monte Castello di Vibio Theatre. Appl. Sci.13, 2210 (2023).
Bevilacqua, A. & Iannace, G. Acoustic study of the Roman theatre of Pompeii: Comparison between existing condition and future installation of two parametric acoustic shells. J. Acoust. Soc. Am. 154, 2211–2226 (2023).
Bevilacqua, A. & Iannace, G. From discoveries of 1990s measurements to acoustic simulations of three sceneries carried out inside the San Carlo Theatre of Naples. J. Acoust. Soc. Am. 154, 66–80 (2023).
Wang, J. Introduction of Chinese traditional theatrical buildings part A: history. J. Tongji Univ. Nat. Sci. 2, 27–34 (2002).
Wang, J. & Mo, F. Quantitative analyses of the acoustic effect of the pavilion stage in traditional Chinese theatres. Appl. Acoust. 32, 290–294 (2013).
Wang, J. Acoustics of traditional Chinese courtyard theatrical buildings. Act. Acust. 40, 317–330 (2015).
Zhang, D., Feng, Y., Zhang, M. & Kang, J. Sound field of a traditional Chinese Palace courtyard theatre. Build. Environ. 230, 109741 (2023).
Wen, M., Ma, H., Yang, J. & Yang, L. Main acoustic attributes and optimal values of acoustic parameters in Peking opera theaters. Build. Environ. 217, 109041 (2022).
Zhao, Y., Liu, D. & Wu, S. The acoustics of the traditional theater in South China: The case of Wanfu theatre. in 2011 International Conference on Electric Technology and Civil Engineering, 2011 Apr 22–24, Lushan, China (IEEE, 2011).
Yang, Y., Gao, C. & Ding, H. A preliminary study on the classification of pre-modern Shanxi opera stages based on their acoustic characteristics. Hist. Stud. Nat. Sci. 35, 175–190 (2016).
Wang, Y., Mao, W. & Zhang, H. Acoustics of traditional courtyard theatre of Yue opera. Huazhong Arch. 42, 56–61 (2024).
Abdullah, A. H. & Zulkefli, Z. A. A study of the acoustics and speech intelligibility quality of mosques in Malaysia. Appl. Mech. Mat. vol. 564, pp. 129–134 (Trans Tech Publications Ltd, 2014).
Kitapci, K. & Çelik Başok, G. The acoustic characterization of worship ambiance and speech intelligibility in wooden hypostyle structures: the case of the Aslanhane Mosque. Acoust. Aust. 49, 425–440 (2021).
Kong, Q. An analysis of the band evolution and accompanying characteristics of Tanqu in Gan opera. Chin. Theatre 04, 83–84 (2022).
Yang, L. Research on performance form of Gan Opera and ancient stage in Le ping. Art. Des. 08, 92–93 (2013).
Cai, R. Entertainment and worship within one temple: Research on Zhaomu ancestry temple with theatre in Leping, Jiangxi province. Huazhong Arch. 34, 174–178 (2016).
Xu, J. & Zhang, X. The study of Leping ancient stage from the perspective of folk belief. Art. Des. 01, 83–85 (2015).
Zhang, J. A discussion on strategies for protecting and inheriting traditional construction skills of Leping ancient stage. Sichuan Drama 01, 155–157 (2020).
Mo, F. & Wang, J. Why the conventional RT is not applicable for testing the acoustical quality of unroofed theatres. J. Acoust. Soc. Am. 131, 3492–3492 (2012).
Beranek, L. In Concert Halls and Opera Houses 2nd edn 561–562 (Springer New York, 2004).
Standardization, I. O. f. & Technical Committee ISO/TC 159/SC 5, Ergonomics—Assessment of speech communication. (ISO, 2003).
Standardization, I. O. f. & Technical Committee ISO/TC 43/SC 2, acoustics—measurement of room acoustic parameters—part 1: performance spaces. (ISO, 2009).
Martellotta, F. The just noticeable difference of center time and clarity index in large reverberant spaces. J. Acoust. Soc. Am. 128, 654–663 (2010).
Zhang, D., Kong, C., Zhang, M. & Meng, Q. Courtyard sound field characteristics by bell sounds in Han Chinese Buddhist temples. Appl. Sci. 10, 1279 (2020).
Wu, S. in Architectural acoustics design principles 2nd edn 217–219 (China Architecture & Building Press, 2019).
Acknowledgements
This study was funded by the Jiangxi Province Social Science Fund Project (Grant No. 25YS25), the Academic Research Project of Social Science Academic Societies of National Social Science Foundation of China (Grant No. 24SGC090), the Jiangxi Province Culture, Art and Science Planning General Project (Grant No. YG2022105), and the Nanchang University Doctoral Research Start-up Fund (Grant No. 28770675). The funder played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
W.X. was involved in conceptualization, project administration, supervision, and writing—review and editing. K.M. was involved in methodology and investigation. J.L. was in charge of data curation. X.W. was in charge of writing—original draft preparation. H.L. was in charge of visualization. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xiong, W., Ma, K., Liu, J. et al. Acoustic adaptation mechanism of a traditional ancestral temple theatre in northeast Jiangxi. npj Herit. Sci. 13, 446 (2025). https://doi.org/10.1038/s40494-025-02025-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02025-x
