
Abstract
During the Qing Dynasty in China, Fujian, the region with the highest forest coverage in the country, experienced frequent commercial transactions of forestland. Throughout these transactions, local residents produced many valuable folk historical documents. These documents, represented by transaction agreements, not only record the aesthetic sophistication of society’s approach to important information in land transactions but also reflect this through their layout design. This study uses surviving Qing Dynasty rural mountain and forestland transaction agreements from Yongtai County in Fujian as sample references. Modern Machine Learning-related research methods explore the layout design preferences of these historical documents. Research reveals that the layout design of forestland transaction agreements varied across different historical periods of the Qing Dynasty and among various clans. These hidden layout features may indirectly reveal the historical reasons behind cultural sophistication differences and provide practical reference value for modern graphic layout design and historical document restoration.
Similar content being viewed by others
Introduction
In China, the Fujian region is renowned for its extensive mountainous forest coverage1,2, making commercial transactions involving forested land very frequent3. During the process of forestland transactions, local residents have left behind many valuable folk historical documents, with contractual documents being particularly important. This unique set of conditions has resulted in a significantly higher volume of forestland contract documents preserved in Fujian than in other regions of China, with a pronounced local character4. In the late Ming Dynasty, agreement transactions in Fujian were very frequent, and property rights were highly complex. To avoid disputes, new and old landlords had to resign agreements to confirm their respective rights. Moreover, since forestland often lacks clear physical boundaries5, agreements have become an essential tool for recording boundary references during use and leasing transactions6. Historical records indicate that from the Qing Dynasty onwards, contractual documents became fundamental to legal proceedings and had a significant impact on official determinations of rights. Consequently, during the Qing Dynasty, the extraordinary importance attached to contractual documents has resulted in a remarkably substantial volume of private contracts in Fujian7.
These forestland transaction agreements not only record significant historical and social information but also possess considerable social value through their layout design, making them worthy of in-depth exploration8. Scholars may examine the economic development, modes of production and daily life, class relations, and cultural evolution of the period through the contractual formats of the time9. Although Ming and Qing dynasty private land contracts lacked standardised formal requirements and appear stylistically similar overall, layout variations still exist across different periods and regions. These visual variations may stem from factors such as the parties involved, transactional customs, time periods, and local cultural influences10. While these layout characteristics are directly shaped by the written content11, the sociological insights revealed by these patterns of variation remain a subject worthy of in-depth investigation.
Furthermore, previous studies on layout patterns have focused predominantly on select historical texts12,13, leaving a significant gap in the research on the layout of folk documents. While scholarly research on the layout of classic books from the Song and Yuan dynasties is quite advanced14, the study of layout patterns in folk agreements from the Ming and Qing dynasties remains largely unexplored, with a lack of historical and cultural research based on layout patterns. In particular, the unique blessings found in the agreements from the Fujian region warrant further investigation into their layout patterns. Moreover, in past studies of layout design, the methodologies employed by scholars have tended to focus on traditional approaches such as textual analysis and qualitative description15,16,17, with a relative lack of quantitative analysis underpinned by substantial data. This may also introduce certain limitations in terms of research findings and persuasiveness.
In recent years, with the rapid advancement of social science research methods, Machine Learning has been widely applied in sociological research and has helped uncover many potentially significant scientific discoveries18,19,20. Machine Learning not only provides researchers with information on the importance ranking of explanatory variables but also allows for predictive assessment of the method’s accuracy21, making it a crucial tool in modern scientific research22. In previous studies, British scholars have used this method to investigate archaeological burial topics in Birmingham's Camp Hill Hexagon Park and the Shelford Abbey23.
Therefore, this study aims to use the Machine Learning method to analyse the layout of Qing Dynasty forestland transaction agreements from Yongtai County in Fujian, China, with the goal of revealing social and cultural features not revealed by previous scholars. This research could provide methodological references for scholars in the fields of design and history and has practical applications. Design scholars can derive new insights for modern graphic design by summarising layout design, whereas historians can estimate and reconstruct missing historical data through these layouts. Specifically, the contributions of this study are as follows: (1) Protective organisation and classification of existing forestland transaction agreements in Fujian; (2) Systematic exploration of layout design features in forestland transaction agreements; (3) Restoration and information inference of incomplete agreements via advanced modern Machine Learning methods.
Methods
Theoretical foundations
According to the theory of textual criticism concerning ancient books24, the stylistic characteristics of ancient texts exhibit distinct features across different eras, regions, or groups of authors, with layout styles serving as a key representative of such characteristics. For instance, previous research, including case studies by scholars such as Cui et al.25, has demonstrated that the layout styles of ancient texts display pronounced characteristic patterns across different periods. Consequently, as a type of ancient text, forestland transaction contracts can be analysed through the lens of textual edition studies. This suggests that forestland transaction contracts from Yongtai County, Fujian Province, would inevitably exhibit layout style variations corresponding to different eras, regions, or groups of authors. Therefore, by conducting information statistics on the research subjects and employing cutting-edge Machine Learning methods to explore data patterns, it is theoretically possible to comprehensively analyse the layout characteristics of forestland contracts and their influencing factors.
Methodologically, Machine Learning offers distinct complementary advantages over traditional statistical analysis in examining sociological patterns. While statistical analysis is extensively employed in sociology to capture phenomenological regularities26, its predictive accuracy remains limited despite effectively quantifying variable influences27. Conversely, Machine Learning methodologies exhibit distinct advantages for the practical predictive function sought in this study—namely, inferring missing historical information. Consequently, within contemporary sociological predictive research, Machine Learning approaches have been extensively applied to practical forecasting28.
Research subjects
Based on the aforementioned theoretical foundation and the research objectives outlined in the introduction, this study selected four villages within Yongtai County, China: Zhufeng Village, Nanshan Village (now integrated with Xiaoyang Village, hence treated as a single geographical unit in this research and collectively referred to as the Nanshan-Xiaoyang area), and Duitou Village and Gaifeng Village (Fig. 1) as the study areas29. A total of 182 existing forestland transaction agreements from this region were selected as the primary research subjects. The impact of various factors on these agreements is analysed from the following aspects: (1) Agreement Type Influence: Given the diversity of Qing Dynasty forestland transaction agreements in Yongtai County, this study focuses on two main types of agreements—selling agreements and additional agreements—to analyse the impact of agreement type on layout differences. (2) Clan Culture Influence: The agreement samples are categorised according to the originating clan to explore possible aesthetic preferences related to layout within different clans and the potential influence of clan culture on agreement layouts. (3) Historical period influence: Considering the nearly three-century rule of the Qing Dynasty in China, this study selects agreement samples from various representative periods of the Qing era to investigate how period differences affect agreement layouts.(4) Geographical Region Influence: This study examines the differences in contract formats across four regions: Zhufeng Village, Nanshan Village (Xiaoyang Village), Duitou Village, and Gaifeng Village.

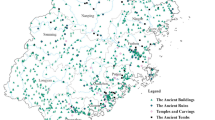
Geographical spatial location of the sample sources for the agreement research.
Research framework
To clarify the design details of this study, the overall research steps are presented in Fig. 2. Specifically, the study is conducted in three steps.

Content composition and the corresponding process of the study.
First, information extraction and coding are performed on the collected agreement samples. The coding process employed a method where three coders worked independently. To ensure the validity and consistency of the coding results, a Kappa consistency test was also conducted on the coding outcomes. During this coding process, the extracted information includes layout information and characteristic information of the agreement samples. The layout information of agreements encompasses three dimensions: baseline characteristics, overall characteristics. Therefore, with regard to contractual layout information, this study has established three categories of dependent variables. Meanwhile, the characteristic information of agreements includes three aspects: intrinsic characteristics, temporality, and regionality. Intrinsic characteristics are further divided into agreement type and clan affiliation at the time of signing, while temporality is subdivided into imperial reign and specific year of the reign. Therefore, with regard to the characteristic information of the contract, this study has established five independent variables.
Subsequently, the organised layout information and feature information undergo a Machine Learning + SHAP method analysis to assess the significance and directionality of correlations between these two sets of data. This analytical process first requires training the Machine Learning model using a subset of research samples. In selecting the Machine Learning model, this study conducts a comparative analysis of different model types to determine which model type offers optimal predictive interpretability. Subsequently, high-performing Machine Learning models were selected to evaluate the specific potential impact of various feature information (independent variables) on layout information (dependent variable). This analytical process can be understood as comprising two stages: first, using Machine Learning tools to assess the importance of different contract feature variables in influencing layout information variables; then, employing the SHAP tool to calculate the positive or negative directionality of the influence exerted by different contract feature variables on layout feature variables.
Finally, regarding the potential causal relationships between independent and dependent variables, this study integrates historical records and prior research conclusions to propose causal inferences. Furthermore, the Machine Learning model trained during this research demonstrates its practical application in reconstructing missing information within contractual documents, addressing real-world data gaps in actual scenarios.
Research variables
On the basis of the aforementioned research subjects and framework, this study sets the following variables (Table 1). Dependent Variables: As mentioned earlier, to comprehensively reflect the layout patterns, three sets of layout variables were established from three distinct evaluation perspectives, allowing for a quantitative description of the layout characteristics of the agreements. Explanatory Variables: These include agreement-specific variables (SEL, CLA), time-related variables (REI, YEA), and regional variables (STO). In Yongtai County, Fujian, China, forestland transaction agreements primarily include two types: selling agreements and supplementary agreements. Due to the differing clan cultures associated with each signing clan, variations in expression habits often arise30. This phenomenon has already been confirmed in the characteristics of past genealogical documents31. Therefore, this study distinguishes the agreements by using two intrinsic variables: agreement type (SEL) and clan affiliation (CLA). Similarly, recognising that different historical periods and regions may significantly influence cultural expressions in society32, this study incorporates temporal variables (REI and YEA) and a regional variable (STO) to capture the spatial and temporal effects on the layout of agreements33. Given that in China's Qing Dynasty, new decrees were often issued upon each emperor's accession, with their impact gradually diminishing over the course of the emperor's reign34, this study adopts a more precise set of temporal variables to reflect these nuances.
In general, the content of an agreement consists of four main parts: text, date, signatures, and blessings (Fig. 3). The section enclosed in the black frame represents the main text of the agreement, the red frame indicates the date, the yellow frame represents the signatures, and the green frame represents blessings. To comprehensively describe the layout patterns of the agreements, this study explores potential layout patterns for each of these four main components across three sets of layout variables (Table 2) and establishes dependent variables related to three types of layout characteristics. Specifically, the three sets of dependent layout variables represent baseline characteristics (Fig. 4A), overall characteristics (Fig. 4B), and inclination characteristics (Fig. 4C) within the layout. Figure 4 uses seals or signatures as representatives of the agreement components to illustrate the meanings of various layout characteristics. Baseline characteristics are defined as the ratio of the distance from the agreement component to the edge of the paper relative to the corresponding edge length of the paper. In Fig. 4A, baseline characteristics reflect the relative distances from the edges of the signature area to the edges of the agreement paper. Overall characteristics are defined as the ratio of the area occupied by the component to the total area of the agreement paper, as shown in Fig. 4B, which depicts the size relationship between the signature area and the total agreement paper area. Inclination characteristics are defined as the ratio of the area of the component within each quadrant to the area of that respective quadrant (Fig. 4C), illustrating the general positional bias of the signature area across the agreement paper layout. By establishing benchmark characteristics, holistic characteristics, and propensity characteristics, this study comprehensively defines the length relationships, area relationships, and distribution relationships within contract layouts to ensure the capture of patterns in contract layout features.

Content composition of common agreement samples.

Definition criteria in the process of setting the dependent variables (layout variables) in the study. A Baseline characteristics: relative distance to paper edges. B Overall characteristics: area ratio of component to paper. C Inclination characteristics: quadrant area distribution ratio.
Machine learning
Machine Learning constitutes a class of technologies whereby algorithm-driven computers autonomously learn latent patterns from data, iteratively optimise model parameters, and achieve predictions on unseen data or uncover hidden patterns. Its core advantage lies in its ability to automatically identify complex relationships between variables based on data characteristics without requiring manually predefined causal rules, finding extensive application across diverse research scenarios, including classification, regression, and forecasting35.
In this study, analysing the layout patterns of Qing Dynasty Fujian forestland contracts, Machine Learning demonstrated exceptional adaptability: On the one hand, it aligns perfectly with the characteristics of historical documents – diverse information types and limited sample sizes – enabling direct analysis without complex preprocessing of contract-related information. This facilitates efficient extraction of intrinsic patterns in layout design, particularly excelling at capturing non-linear relationships between layout features and influencing factors. It overcomes the limitations of traditional qualitative descriptions reliant on subjective judgement and linear models struggling to accommodate complex associations. On the other hand, it concurrently assesses the significance of influencing factors, clearly identifying core elements critical to layout patterns and providing quantitative support for research conclusions.
Extreme Gradient Boosting (XGBoost) is a highly efficient ensemble learning algorithm based on the gradient boosting framework. Its core principle involves iteratively training multiple weak learners (typically regression trees), optimising each round using residual information from the preceding round to progressively enhance overall predictive accuracy. Compared to traditional gradient boosting methods, XGBoost incorporates a regularisation term within its objective function. This aids in controlling model complexity and mitigating overfitting risks, while simultaneously enhancing computational efficiency through parallel processing and sparse feature optimisation mechanisms, significantly accelerating training speed36.
This approach proves particularly adept at handling high-dimensional, non-linear, and complex variable interaction scenarios. Consequently, within contract layout pattern modelling, it strikes a balance between precision and robustness, providing robust support for identifying key influencing factors and characterising intricate associative structures. To validate the model’s applicability and fitting quality, we conducted substitution tests on its common variants, ensuring it represents the most accurate and suitable model.
XGBoost constitutes an efficient implementation of gradient boosting, whose objective function comprises both training error and a regularisation term. Specifically:
Here, \({\mathcal{L}}(\varnothing )\) denotes the loss function,\({\hat{y}}_{i}\) represents the predicted value,\({{\rm{y}}}_{{\rm{i}}}\) signifies the true value, and \(\Omega ({f}_{k})\) refers to the regularisation term of the tree model, employed to constrain complexity, Each regression tree \({f}_{k}\) is defined as:
Here,\(q(x)\) denotes the sample, \(q:{{\mathbb{R}}}^{d}\to T\) represents the leaf node index to which it is assigned, \(T\) is the number of leaf nodes, \(w\) is the leaf node weight. The regularisation term is:
Here, γ controls the penalty on the number of leaves, whilst λgoverns the L2 regularisation of leaf weights.
During the t-th iteration, XGBoost employs a second-order Taylor expansion to approximate the objective function:
Here:
Representing first-order and second-order gradients, respectively. For a given tree structure, the optimal leaf weight can be analytically determined as:
and obtain the corresponding optimal objective function:
Thus, XGBoost employs a greedy algorithm to select the optimal partition in each iteration, progressively stacking weak learners to enhance overall predictive performance. Furthermore, we utilise Optuna as the automated hyperparameter optimisation framework during model computation. Optuna treats hyperparameter tuning as a black-box optimisation problem, aiming to discover the optimal combination within the given hyperparameter space to minimise the loss function on the validation set.
In this study, 80% of the research samples (146 entries) were employed for training the XGBoost model, whilst the remaining 20% (36 entries) were utilised to evaluate the model’s predictive accuracy.
SHAP model
Additionally, this study employs the SHAP (SHapley Additive exPlanations) method to conduct interpretability analysis on Machine Learning model predictions37. Drawing upon the Shapley value concept from cooperative game theory, SHAP treats the model’s prediction as a payoff and distributes this prediction fairly across each feature, thereby quantifying each feature’s contribution to the prediction.
Compared to traditional feature importance ranking methods, SHAP offers the advantage of unified global-local interpretation: on the one hand, it reveals the relative contributions of various layout features and influencing factors within the model at an aggregate level, clarifying which variables play a decisive role in contract layout formation; On the other hand, it generates localised explanations for individual samples, demonstrating how various features interact within specific contract texts to influence final classification or prediction outcomes. This facilitates a progressive understanding from “macro-level patterns” to “case-specific mechanisms”. Within this study’s context, SHAP’s application not only visually presents the weighting and causal pathways of layout components but also effectively mitigates the interpretability shortcomings inherent in “black-box models”. For instance, researchers can clearly discern whether certain features exert positive or negative effects when predicting different dependent variables, and further contextualise these effects by interpreting the underlying institutional logic and writing conventions within historical frameworks. By integrating model fitting outcomes with SHAP explanations, this approach safeguards the predictive accuracy of Machine Learning methods while ensuring research conclusions possess traceability and interpretability. This provides robust theoretical grounding for the quantitative analysis of historical documents.
Results
Model determination
Prior to conducting formal analysis, we performed Pearson correlation analyses on all explanatory variables and compared each dependent variable. The results of the Pearson analysis are presented in Fig. 5. All explanatory variables exhibit coefficients less than or equal to 0.6, indicating no multicollinearity issues among them. Consequently, the data presents no risk of redundancy and possesses statistical significance, rendering it suitable for further analysis. Among the analysed dependent variables, the findings concerning LR(T-L), AR(S), and ARQ(B-II) demonstrate significant research value. Specifically, calculations using XGBoost reveal that the regression models for these three dependent variables achieve an R-squared value of 0.675 and a Mean Squared Error (MSE) of 0.006357. This demonstrates that these variables possess not only theoretical academic value but also statistical significance. Moreover, during computation, we incorporated the Optuna hyperparameter tuning model, which automatically identifies optimal parameter settings (Table 3), including n_estimators, max_depth, learning_rate, subsample, and colsample_bytree. By configuring these optimal parameters, the model’s accuracy is substantially enhanced.

Autocorrelation characteristics among the explanatory variables.
Concurrently, within this study, we systematically compared the performance of several mainstream regression models (Table 4) across different dependent variables, including XGBoost(XGB), Random Forest (RF), and LightGBM (LGBM). We combined this with permutation testing to calculate empirical p-values, thereby assessing the statistical significance and robustness of the models’ predictive outcomes. The permutation test generates a null distribution of performance by randomly shuffling the order of independent variables and repeating the modelling process. This approach ensures results reflect model fitting quality while avoiding spurious correlations arising from chance or data structure biases, thereby providing robust statistical grounds for model selection. Results indicate that for the “signature area ratio,” XGBoost achieved optimal performance among all candidate models, with an empirical p-value of 0.196. This outperforms Random Forest (p = 0.748), LightGBM (p = 0.982), and multiple linear regression (p = 0.668), indicating its superiority in capturing the underlying relationship between the dependent and independent variables. For “Text Left-to-Right Ratio”, XGBoost again demonstrated the best performance (p = 0.088), more effectively capturing the structural information between input and output variables compared to other models. For “proportion of green area in the second quadrant”, multiple tree-based models, including XGBoost (e.g., Random Forest), achieved highly significant results (p = 0), while LightGBM also demonstrated strong statistical significance (p = 0.012). Among these models, XGBoost demonstrated superior robustness and consistency, maintaining highly significant results across multiple replicate experiments, indicating strong generalisation capability and reliability. The comparative findings collectively indicate that XGBoost delivers relatively superior performance and robustness when modelling multiple dependent variables. Consequently, XGBoost was selected as the primary analytical tool for subsequent variable relationship interpretation and mechanism exploration. This choice is grounded not only in the model’s predictive efficacy but also in the statistical significance evidence provided by replacement tests, thereby ensuring the scientific rigour and reliability of the research conclusions. Furthermore, across the different models, the regression with variable ARQ(B-II) as the dependent variable demonstrated stronger explanatory and predictive power than the models with the other two dependent variables. This suggested that the layout feature represented by ARQ(B-II) might best reflect the unique influences stemming from the historical period and regional cultural differences.
Importance of explanatory variables
Following the construction of the optimal XGBoost model, the study subjected the sample data to analysis using the SHAP tool. Results indicated that YEA was the most significant explanatory variable in both the LR (T-L) and AR (S) experimental groups. However, in the ARQ (B-II) experimental group, STO emerged as the most important explanatory variable. Within the XGBoost-SHAP model, significant differences in explanatory variable importance were observed across all three experimental groups: LR (T-L), AR (S), and ARQ (B-II) (Fig. 6). Specifically, in both the LR (T-L) and AR (S) experimental groups, YEA was the most important explanatory variable (with the highest importance proportion), at 32.0% and 32.2% respectively, indicating YEA’s significant influence on these two groups. Within the LR (T-L) experimental group, CLA emerged as the second most important variable after YEA, achieving an importance ratio of 21.5%, indicating CLA’s relatively strong influence in this group. In the AR (S) experimental group, REI ranked as the second most important variable after YEA, with an importance ratio of 26.5%, signifying REI’s relatively high impact within this group. Other explanatory variables, such as STO and SEL, exhibited comparatively lower significance. Within the ARQ (B-II) experimental group, STO emerged as the most significant explanatory variable, accounting for 48.6% of the importance proportion – substantially exceeding that of other explanatory variables.

Importance ranking results of the impact of explanatory variables on the dependent variables.
Non-linear effects of key variables
Subsequently, the study visualised the impact trends of significant explanatory variables, selecting those with an influence greater than 20% for representative analysis. The visualisation results are presented in Fig. 7, where the horizontal axis represents the explanatory variable’s numerical value, the vertical axis denotes the SHAP value, and the red line indicates the fitted curve, which intuitively reflects the trend of change. For explanatory variables with importance exceeding 20%, their specific influence tendencies on the dependent variable are as follows: (1) Within the LR(T-L) group, YEA data points exhibit considerable dispersion. The overall trend initially declines, reaching a minimum near YEA = 20, before rising between 20 and 30, indicating a positive influence. This suggests that the accession year of Qing Dynasty emperors exerts a discernible effect on the left-side space proportion within the main text layout; The SHAP values for the CLA variable exhibit significant variation with CLA changes, suggesting distinct layout characteristics among different clans. (2) Within the AR(S) group, YEA data points similarly exhibit no discernible monotonic distribution trend. No consistent pattern of SHAP values rising or falling with increasing YEA is observed. YEA = 20 again serves as a watershed: values between 0 and 20 indicate a positive influence, while those above 20 suggest a slightly negative impact. SHAP values differ across CLA clans’ codes, with certain clans (e.g., codes 2 and 10) exhibiting markedly higher or lower SHAP values than others, reflecting varying degrees of influence on AR(S). Additionally, SHAP values fluctuate considerably with REL values: positive effects occur at REL = 1 or 3, but a pronounced decline and negative effect emerge at REL = 4. (3) Within ARQ (B-II), SHAP values for STO remained largely consistent at levels 1–3. However, when STO = 4, SHAP values markedly increased, exerting a strong positive influence on outcomes. This finding indicates that layout characteristics across different regions exhibit both similarities and distinct differences.

Trend characteristics of the non-linear impact of explanatory variables on the dependent variables in the experimental groups.
Summary
Following the aforementioned analysis, this study concludes that Year (YEA) and Clan (CLA) constitute core variables influencing the dependent variables LR (T-L) and AR (S), whilst Region (STO) is the core variable affecting ARQ (B-II). Furthermore, the dependent variable AR (S) is also influenced by the Emperor’s Reign Title (REI). Specifically, for the dependent variables LR (T-L) and AR (S), the independent variable Emperor’s Year (YEA) exhibits differing influence tendencies depending on its value, with a turning point in the degree of influence occurring when YEA is approximately equal to 20. Similarly, for the dependent variables LR (T-L) and AR (S), the independent variable clan (CLA) exhibits differing positive or negative influence tendencies depending on its value. Moreover, distinct imperial reign periods (REI) exerted markedly divergent effects on the dependent variable AR(S). For the dependent variable ARQ(B-II), when the region (STO) was set to 4, a distinct negative tendency emerged, differing significantly from other value scenarios.
Discussion
Based on the analytical findings, the study concludes that as the reign of an emperor extended, the left margin of the contract text exhibited an overall tendency to shift towards the right. Furthermore, around the 20th year of each emperor’s accession, this trend demonstrated a certain degree of fluctuation. This phenomenon will be examined in the present study through the lens of two distinct characteristics: the “overall trend” and the “20-year fluctuation”.
Regarding the tendency for the left margin of the text to shift towards the right as the reign of the monarch extended, this study posits that the following reasons may be at play. First, the amount of information required in the agreement has increased over time. This could be due to the stability of social development in Yongtai County of Fujian after the Qianlong period of the Qing Dynasty. As economic transactions in the market became more complex, agreements required longer text explanations or larger written content to address potential legal loopholes, which in turn reduced the left baseline of the main text. Additionally, societal development has increased the diversity of needs, necessitating more textual content for detailed explanations, which ultimately contributes to the rightward shift of the text of agreement38. Secondly, with the development of social productivity, the production cost of paper for agreements has decreased, leading people to no longer need to compress the content to avoid running out of paper space39. In the early Qing Dynasty, continuous warfare across China left the paper production industry in many regions underdeveloped, causing people to be particularly frugal with paper use40. This resulted in a tendency for agreement signatories to align content and spacing towards the right (since the text of Chinese agreements is read from right to left). However, by the middle to late Qing Dynasty, the paper production industry had become more established, and the cost of paper had decreased41. According to the Guangxu Bingxu edition of Records of Fujian’s Unique Products: “Paper produced in each county fetched hundreds of thousands of taels annually at market.” and as recorded in the Comprehensive Examination of Imperial Dynasty Documents: Fujian Province annually contributed one million sheets of tribute paper. These accounts reflect the flourishing state of Fujian’s papermaking industry during the Qing Dynasty, characterised by massive production volumes and affordable prices. As a result, the need for tightly aligning content to the right may have diminished, allowing for a gradual shift of the left margin of the text toward the left (Fig. 8). Additionally, the increase in social stability further promoted cultural development, leading to changes in aesthetic standards42. In the early Qing Dynasty, owing to a lack of experience, the primary purpose of drafting agreements was to facilitate social transactions without considering the added value of neatness and readability43. However, as time progressed, to increase the readability of the text, people began to carefully adjust the layout of the agreement's content, increasing both the horizontal and vertical spacing of the text (the main text of Chinese agreements is written vertically from right to left, top to bottom, with columns arranged in vertical alignment). This inadvertently extended the length of the text. Furthermore, expanding the spacing between lines and characters not only reflects a clearer presentation of information but also indicates a shift in aesthetic understanding. Just as newspapers such as the 19th New York World (under Joseph Pulitzer) and the New York Journal-American (under William Randolph Hearst) experimented with layout innovations to attract readers, agreement drafters also began to adjust layouts to improve the reading experience (Illustrations and advertisements)44. Although there are diverse aesthetic preferences among individuals in society, there seems to be a common preference for increased line and character spacing in agreements. This expansion of text spacing appears to resonate with the appreciation of grandeur in Eastern culture.

Differences in the baseline distance of the left margin of the main text of agreements concluded at different times, but with the same other characteristics.
Regarding the phenomenon of the “twenty-year fluctuation,” this study posits that its causes may be closely linked to the stability of societal development. The reign periods of the emperors covered in this research sample, with the exception of the relatively lengthy Qianlong era, were predominantly brief, concentrated within a span of approximately twenty years. Consequently, for the three emperors whose reigns lasted between twenty and thirty years, the twenty-year mark coincided precisely with the watershed of their political stability. The fluctuating social environment precipitated shifts in numerous social customs and productive forces, consequently diminishing the margin space on the left side of the text. Historical records indicate that the twentieth years of the reigns of the Jiaqing, Daoguang, and Guangxu emperors respectively witnessed the White Lotus Rebellion, the Opium War, and the Great Drought of the Guangxu era. These turbulent events severely disrupted social stability and productivity. Faced with relatively scarce resources, it is highly probable that people minimised margins in writing to conserve paper materials or maximised the description of transaction details to mitigate disputes during periods of social upheaval. The greater margins observed on the left side of texts from the period over thirty years into the reign, however, likely stem from data fitting effects arising from the relative social stability of the Qianlong era.
The changes observed in the left margin of the text of the agreement are likely closely related to the cultural rules of different local clans. During the Qing Dynasty in Fujian, clan ideology was deeply ingrained in the local populace, serving as a crucial link in maintaining social structure and order45. Therefore, the clan system held significant importance in the social life of Fujian. Taking the Ke and Xie clans, which have the largest number of agreement samples, as examples, we observe that in the historical context of Yongtai, Fujian, large and influential clans like these had their own organisational structures and norms. These clans are typically established and adhere to strict document content regulations, which not only reflect the transmission of clan culture but also serve as a means to uphold clan orders and demonstrate their meticulousness and authority46. As a result, clans such as the Ke and Xie may have established specific compositional standards for the main text of agreements to ensure that each agreement was accurately conveyed. These paradigmatic written conventions indirectly streamline text length and, compared to other clans, create greater margins on the left side of the main text. Through these distinctive writing norms, clans showcased the rigour and standardisation of their internal governance to the outside world, thereby reinforcing and enhancing their social status and influence. Additionally, beyond the influence of clan norms on the content of the text, the art of calligraphy is also closely linked to the cultural level of the agreement signatories47. Typically, a signatory’s cultural literacy is directly related to the economic foundation of their clan48. Therefore, clans with different economic backgrounds often exhibit distinct layouts in the calligraphic expressions of their signatories49. Specifically, these differences in artistic expression can be reflected in aspects such as size, style, and spacing within the text. Consequently, the accumulation of these artistic expression differences indirectly leads to variations in the positioning of the left margin of the text across different clans.
The observed increase in the proportion of the agreement’s signature area with the progression of imperial reigns (dynasties) and years(time) is closely related to the standardisation and refinement of agreement practices. As indicated in the correlation analysis results, with the progression of imperial reigns and years, the proportion of the signature area within agreements shows a slight upward trend. Although this upward trend is less pronounced for imperial reigns compared to specific years (possibly related to the introduction of new policies and social regulations by each new emperor in China's feudal period), the shared expression of both factors suggests that a larger signature area proportion may facilitate social interactions. During the Qing Dynasty, agreements were indispensable legal instruments in social and economic activities and were crucial for maintaining social order and ensuring fair transactions50. The signature section, as a critical component of the agreements, represents not only the personal will and commitment of the signatories but also a key element for the enforcement of legal validity. To enhance the rigour and fairness of agreements, the Qing Dynasty government might have required that the signature section clearly record the specific roles of all parties involved in the agreement, including witnesses, introducers, and signatories6. The more refined and clear division of these social roles invisibly increases the amount of recorded information in the signature section, thereby increasing its formatting area proportion. In addition to the official requirements of the Qing government, the spontaneous demand from the public for greater rigour in transaction agreements may also have contributed to the increased proportion of the signature section51. This is reflected in the number of social roles involved in the agreement process. Observations of agreement samples from the Qing Dynasty reveal that early forestland transaction agreements often had only one witness or sometimes none at all52. However, by the middle to late Qing Dynasty, the number of witnesses in the signature section frequently exceeded one and, in some cases, reached three. This shift may be attributed to disputes arising from insufficient witnesses in early Qing transactions. Despite the presence of transaction introducers, signatories, and written information, such disputes cannot be fully avoided. As a result, to ensure fairness and objectivity, parties involved in transactions began to voluntarily invite more witnesses to participate in the agreement process53,54. Consequently, the increased number of witnesses naturally led to a larger proportion of the paper used for the signature section.
Research suggests that variations in the Signature Layout produced by different clans may be closely correlated with the cultural practices and customary conventions of local clans. As previously noted, given the potent legal efficacy of the signature section, differing levels of legal awareness among clans may have led to distinct cognitive disparities. These differences subsequently manifested as pronounced clan-specific variations in the layout of the signature section. Taking the “Ke” and “Xie” clans as representative examples, despite both being influential local clans, their customary practices in the signature section exhibit marked differences. This divergence may be understood in terms of both the number of signatories involved and the conventions governing the expression of signatures (Fig. 9). Specifically, members of the Ke clan tended to favour greater participation in contract formation alongside clearer articulation of terms, thereby enhancing the instrument’s credibility and legal efficacy. By contrast, the Xie clan members, when concluding contracts, often placed greater emphasis on the social status of participants rather than their sheer number. However, whether through the number of participants or the social standing of those involved, the fundamental purpose of ensuring contractual credibility is to better facilitate the fulfilment of the agreement. This has further shaped the cultural practices of each clan. Consequently, differing clan cultural practices result in variations in the content of the signature section, which in turn influences the final layout characteristics.

Differences in the area ratio of the signature area of agreements concluded by different clans (CLA) but with the same other characteristics.
Regarding blessings, their layout design principles are closely tied to regional characteristics, seemingly illustrating how geographical spatial differentiation among villages also gives rise to distinct cultural customs. Compared to the other three villages, Gaifeng Village is situated on a mountainous plain traversed by a main thoroughfare, thereby enjoying a more favourable foundation for economic development than the other three areas. Consequently, the more prominent and grand layout characteristics evident in the blessings of this area may be somewhat related to its economic foundation. Social development experience suggests that regions with a stronger economic base often enjoy greater assurance in cultural and educational standards, which in turn indirectly influences people’s cultural refinement and cognitive levels. Analysing the research samples specifically, it was discovered that in the forestland contracts established in this village, the blessing “Great Prosperity” was more frequently used than in the other three villages, where phrases like “Prosperity” or “Contract” were more common (Fig. 10). Moreover, the proportion of individual characters was also relatively larger. These characteristics may well be the accompanying products of the region’s economic development advantage.

Differences in the area ratio (ARQ) of the blessings (B) area in the second quadrant (II) of agreements concluded in different regions (STO) but with the same other characteristics.
This study systematically analysed the influencing factors and operational mechanisms of three core characteristics in forestland contract formats, utilising XGBoost and SHAP tools to examine 182 extant contracts from Yongtai County, Fujian Province, during the Qing Dynasty. The following specific findings were obtained. (1) Different layout characteristics of forestland contracts are influenced by distinct dominant factors. The proportion of left-margin space in the main text (LR(T-L)) and the proportion of seal area relative to total area (AR(S)) are primarily affected by historical period (YEA, REI) and clan affiliation (CLA). Among these, YEA exhibits the highest importance (32.2% and 32%). The proportion of area occupied by blessings in the second quadrant (ARQ(B-II)) is predominantly influenced by the region (STO) as the primary factor (accounting for 48.6% of importance). (2) Different historical periods fostered layout diversity. Regarding the proportion of left-hand margin space, temporal influence exhibits a “long-term trend coupled with phased fluctuations”. Overall, as reign lengths increased, text margins gradually narrowed while seal areas expanded, reflecting a shift from compact utility to standardised legibility. Secondly, during periods of social upheaval or change (such as the White Lotus Rebellion, Opium Wars, or droughts), the proportion of left-margin space underwent significant fluctuations and turning points. (3) Clan differences foster layout diversity. Documents from large clans exhibit relatively systematic conventions, featuring ample margins and prominent seals. Moreover, cultural and economic foundations across clans influence writing styles and layout details. (4) Regional variations produced layout diversity, most notably in blessings. For instance, in economically prosperous or culturally advanced villages, contract blessings featured bold calligraphy and relatively rich content, whereas in culturally less developed or geographically remote villages, such phrases were sparse and stylistically plain.
Consequently, the layout of Qing-era Fujian forestland contracts was not randomly generated but resulted from the combined influence of institutional constraints, economic foundations, cultural traditions, and technical conditions. Its evolutionary patterns essentially constitute a direct reflection of socio-economic and cultural transformations within Qing-era folk society onto documentary carriers, offering a fresh micro-level perspective for understanding the operational logic of Ming-Qing period folk society.
This study provided a new approach for interdisciplinary research, particularly in the effective application of Machine Learning models, especially XGBoost algorithms, within traditional fields of the humanities and social sciences, such as the study of agreement layout design. By employing data analysis methods, the research has successfully resolved complex and less intuitively observable patterns within the sociological domain. Specifically, converting the intricate object of the agreement layout into quantifiable data has unveiled its underlying processes of change, thereby validating the significant value of scientific data methods in addressing such issues. This study not only provided an innovative paradigm for interdisciplinary research across fields such as statistics, computer science, and the humanities and social sciences but also created new opportunities for deep integration and collaboration between different disciplines. Through this research, significant progress could be made in fostering communication between various fields, advancing the progress of interdisciplinary studies.
Research can predict the placement of missing elements in historical and design fields through methods such as data analysis and visualisation analysis. Specifically, when dealing with fragmentary agreement, deep exploration and analysis of the inherent layouts within the existing layout information can lead to approximate predictions of the positions and content of missing parts (such as dates, signatures, and key text elements). This study uses an example of an agreement with a missing blessing in the second quadrant (Fig. 11) to illustrate the practical application and effectiveness of this method. The research selected an agreement with partially missing blessings in the second quadrant and uses the undamaged content information from the agreement layout (such as year, surname, dynasty, geographical location, and agreement type) as explanatory variables for the model. These data were input into the previously constructed ARQ(B-II) XGBoost-SHAP model for predictive analysis, yielding an estimate of the proportion of the blessings area in the second quadrant. Subsequently, based on this proportion, the specific size of the blessing area was inferred. On the basis of the estimated area of the blessings, the study then infers their content composition. In agreements from Yongtai County, Fujian, blessings ending with “progress” include “great progress” and “progress”. By estimating the area of the blessings in the sample agreement, the study can confirm that the phrase does not include the character “great”. In this specific case, the information captured from the example includes the explanatory variable data: SEL = 1, CLA = 1, REI = 2, YEA = 47, and STO = 1. After these data are input into the model, the calculated result is ARQ (B-Ⅱ) = 0.1035786. The estimation indicates that, on the basis of the spacing of the characters in the existing blessings, the agreement’s blessings are most likely “progress”, as there is insufficient space for a third character.

Prediction of missing information of blessings (B) in damaged agreements.
A limitation of this study is the limited number of data samples, which may result in less stable analysis outcomes. Since the data significantly impact the accuracy of model predictions, a limited sample size can constrain the training process of the model and, consequently, affect the precision of the predictions55. To improve the accuracy and stability of predictions, future research should aim to expand the sample size or enhance the functionality of methods such as the Machine Learning algorithm. Moreover, this study was limited to three tree-based models (XGBoost, Random Forest, and LightGBM) and did not include traditional models (e.g., SVM) or deep learning models (e.g., CNN), which may have resulted in the absence of comprehensive benchmarking for model performance. Furthermore, as a pioneering attempt in this research direction, the study focused on only three particularly distinctive dependent variables, leaving numerous other layout features—such as line spacing, text alignment, and seal positioning—still largely unexplored.
Additionally, there may be inaccuracies or incompleteness in the discussion of potential causes. Although this study provides a thorough discussion of possible reasons, the formation and preservation of historical documents is a complex and multidimensional process involving numerous factors that are not fully understood. For example, writing practices of specific historical periods, the social context of agreement signing, and variations in preservation environments may all impact the formation and preservation status of agreement layouts.
Data availability
The datasets generated and analysed during the current study are available from the corresponding author.
Code availability
Not applicable.
References
Ying, Z. et al. Plantation development: economic analysis of forest management in Fujian Province, China. For. Policy Econ. 12, 223–230 (2010).
Ye, H. D. et al. Study on the geographical spatial characteristics of forest health resorts in Fujian Province, China. Sustainability 16, 3547 (2024).
Zheng, Z. M. Forestry economy and mountain society in the Ming and Qing Dynasties: a study of contract documents from Yongtai, Fujian. Acad. Mon. 52, 148–158 (2020).
Yan, X. T. A review of the collation and research on contract documents of the Ming and Qing Dynasties since the 20th century. Chi Zi 03, 31 (2015).
Dong, G. L., Liu, Z. H., Niu, Y. Z. & Jiang, W. Y. Identification of land use conflicts in Shandong Province from an ecological security perspective. Land 11, 2196 (2022).
Long, D. G. The diversification of land transactions in the Qing Dynasty. Front. Hist. China 4, 183–220 (2009).
Su, Y. G. Discovering the Chinese common law: the formation of the loan contract in the Qing Dynasty. Front. Law China 10, 365–398 (2015).
Zhang, J. L. Looking at land transactions in Fujian region during the Qing Dynasty from contract documents. China Story 01, 55–58 (2025).
Wang, G. Y. & Pan, W. J. An analysis of the form and characteristics of land contract documents in Northeast China in modern times. Agric. Archaeol. 03, 90–96 (2024).
Sugawara, J. Tradition and adoption: elements and composition of land-related contractual documents in provincial Xinjiang (1884-1955). In Studies on Xinjiang Historical Sources in 17-20th Centuries (eds Millward, J. A. et al.) 120–139 (The Toyo Bunko, 2010).
Li, R. Y. Making Texts in Villages: Textual Production in Rural China During the Ming-Qing Period. Doctoral dissertation, Harvard University (2014).
Zhao, P. H., Wang, W. L., Cai, Z. Q., Zhang, G. W. & Lu, Y. Q. Accurate fine-grained layout analysis for the historical Tibetan document based on the instance segmentation. IEEE Access 9, 154435–154447 (2021).
Garz, A., Sablatnig, R. & Diem, M. Layout analysis for historical manuscripts using sift features. In 2011 International Conference on Document Analysis and Recognition 508–512 (IEEE, 2011).
Dong, C. L. On the layout design of block-printed books in the Song Dynasty. China Publ. J. 20, 47–49 (2013).
Weng, H. T. Re-application of ancient literature in the view of localization of Chinese management. In Proceedings of the International Forum on Chinese Management Research II. 48–51 (Scientific Research Publishing Inc., Lanzhou, China, 2010).
Xu, J. & Chen, H. X. A study on land transaction contract documents in Northern China during the Qing Dynasty and the Republic of China: focusing on Right Karaqin Banner. Liaoning Ethn. Stud. 03, 96–101 (2024).
Xu, J. L. “Min Contracts” in folk contracts of the Ming Dynasty. Zhongzhou Acad. J. 06, 123–131 (2021).
Molina, M. & Garip, F. Machine learning for sociology. Annu. Rev. Sociol. 45, 27–45 (2019).
Brand, J. E., Zhou, X. & Xie, Y. Recent developments in causal inference and machine learning. Annu. Rev. Sociol. 49, 81–110 (2023).
Heiberger, R. H. Applying machine learning in sociology: how to predict gender and reveal research preferences. Kölner Z. Soziol. Sozialpsychol. 74, 383–406 (2022).
Jafarigol, E. et al. Religious affiliation in the twenty-first century: a machine learning perspective on the World Value Survey. Society 60, 733–749 (2023).
Matsuki, K., Kuperman, V. & Van Dyke, J. A. The random forests statistical technique: an examination of its value for the study of reading. Sci. Stud. Read. 20, 20–33 (2016).
Brooke, C. & Clutterbuck, B. Mapping heterogeneous buried archaeological features using multisensor data from unmanned aerial vehicles. Remote Sens. 12, 41 (2020).
Shi, Y. L. & Men, F. C. The research content of ancient book bibliography. Libr. Theory Pract. 04, 57–59 (2008).
Cui, Y., Yao, S. J., Wu, J. P. & Lv, M. H. Linking past insights with contemporary understanding: an ontological and knowledge graph approach to the transmission of ancient Chinese classics. Herit. Sci. 12, 382 (2024).
Motiwalla, L., Deokar, A. V., Sarnikar, S. & Dimoka, A. Leveraging data analytics for behavioral research. Inf. Syst. Front. 21, 735–742 (2019).
Hofman, J. M., Sharma, A. & Watts, D. J. Prediction and explanation in social systems. Science 355, 486–488 (2017).
Kyriazos, T. & Poga, M. Application of machine learning models in social sciences: managing nonlinear relationships. Encyclopedia 4, 1790–1805 (2024).
Shu, M. R. et al. Topical reviews of research on resilience to natural environment in Fujian traditional dwellings of China. Environ. Res. Commun. 6, 052001 (2024).
Ran, T. T. Pursuit of communality: land contracts and local societies in Shicang villages in southern Zhejiang Province in the Qing Dynasty. J. Shanghai Jiaotong Univ. 19, 77–85 (2011).
Li, F. F. & Li, J. J. Study on the characteristics of genealogy contract documents in Qing Dynasty. J. Innov. Soc. Sci. Res. 8, 93–94 (2021).
Fu, J. J. & Mao, H. S. Study on the spatiotemporal distribution patterns and influencing factors of cultural heritage: a case study of Fujian Province. Herit. Sci. 12, 324 (2024).
Chen, K. D. et al. Temporal and spatial differences in contract culture during the Qing Dynasty. npj Herit. Sci. 13, 166 (2025).
Wang, H. F. Opening the sea” or “closing the sea”: evolution of China’s maritime frontier policy in the 18th century. Lantai World 3, 21–22 (2013).
Sarker, I. H. Machine learning: algorithms, real-world applications and research directions. SN Comput. Sci. 2, 160 (2021).
Chen, T. Q. & Guestrin, C. XGBoost: a scalable tree boosting system. In Proc. 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 (Association for Computing Machinery, San Francisco, California, USA, 2016).
Nohara, Y., Matsumoto, K., Soejima, H. & Nakashima, N. Explanation of machine learning models using improved Shapley additive explanation. In Proc. 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics 546 (Association for Computing Machinery, Niagara Falls, NY, USA,2019).
Chen, X. M., Dong, Q. & Liu, X. Y. Graphic reconstructing and application research of traditional auspicious pattern in the customization for haute couture. Adv. Mater. Res. 1048, 341–344 (2014).
Shi, J. L. & Li, T. Technical investigation of 15th and 19th century Chinese paper currencies: fiber use and pigment identification. J. Raman Spectrosc. 44, 892–898 (2013).
Yu, T. Y. The formation and development of early industrialized society in Jiangnan in Ming-Qing period. J. Hist. Sci. 11, 53–61 (2007).
Drège, J. P. A Short History of Paper in Imperial China (De Gruyter, 2024).
Varnum, M. E. W. & Grossmann, I. Cultural change: the how and the why. Perspect. Psychol. Sci. 12, 956–972 (2017).
Yang, H. The impact of intensive farming on land tenure: evidence from Confucius’ manors (1759-1901). China Econ. Rev. 30, 279–289 (2014).
Steele, J. E. The 19th century world versus the Sun: promoting consumption (rather than the working man). Journalism 67, 592–600 (1990).
Zheng, Z. M. Family lineage organization and social change in Ming and Qing Fujian (Univ. Hawaii Press, 2001).
Freedman, M. Chinese Lineage and Society: Fukien and Kwantung (Routledge, 2021).
Kao, H. S. R., Xu, M. & Kao, T. T. Calligraphy, psychology and the Confucian literati personality. Psychol. Dev. Soc. 33, 54–72 (2021).
Granovetter, M. The forms of capital. In The Sociology of Economic Life (ed. Bourdieu, P.) 78–92 (Routledge, 2011).
Smith, R. J. The Qing Dynasty and Traditional Chinese Culture (Bloomsbury Publishing PLC, 2015).
Dykstra, M. Cross-jurisdictional trade and contract enforcement in Qing China. Int. J. Asian Stud. 16, 99–115 (2019).
Huang, P. C. C. Code, Custom, and Legal Practice in China: the Qing and The Republic Compared (Stanford Univ. Press, 2001).
Long, D. G.& Chi, X. The transformation of farmland rights transactions from the Song Dynasty to the Qing Dynasty: a study centering on the nature and rights of dian farmland. In The Institutions of Land Property Rights in China: Transformation and Development, 1560–1950 (eds Long, D. G. & Chi, X.) 99–143 (Springer, 2024).
Hsu, E. Cutting in the middleman: learning from ancient Chinese contract negotiation. Int. Negot. 1, 1–27 (2022).
Gipouloux, F. The figure of the intermediary: brokers, merchant manufacturers and guilds. In Elusive Capital (eds. Gipouloux, F.) 68–94 (Edward Elgar Publishing, 2022).
Chen, S., Ogawa, Y., Zhao, C. & Sekimoto, Y. Enhanced large-scale building extraction evaluation: developing a two-level framework using proxy data and building matching. Eur. J. Remote Sens. 57, 2374844 (2024).
Acknowledgements
We express our gratitude to The Educational Science Planning Project of Fujian Province (Exploration and Analysis of the Industry-Education Integration-Based Design Talent Cultivation Model in Higher Education Institutions under the Context of the Rural Revitalization Strategy, Grant No. 111423025) and The Youth Project of Fujian Provincial Social Science Fund (Contextual Linkages of Contractual Cultural Genes in Min-Tai (Fujian-Taiwan) Folk Traditional Documents, Grant No. FJ2024C162) for their support of this study.
Author information
Authors and Affiliations
Contributions
K.C. conceived and designed the study, acquired funding, and developed the methodology; B.L. established the study framework, performed initial drafting, and conducted primary data analysis; H.S. created visualisations, executed formal statistical analysis, and critically revised the manuscript; W.L. managed data curation, implemented validation protocols, and led secondary revisions; Z.L. coordinated resources collection and contributed to critical review; Y.H.provided investigative support and processed partial datasets; M.X. performed final proofreading.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, K., Liang, B., Sun, H. et al. Applying machine learning to analyse the layouts of Qing Dynasty forestland agreements in Fujian. npj Herit. Sci. 13, 644 (2025). https://doi.org/10.1038/s40494-025-02227-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02227-3
